
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Many forecasting studies compare the forecast accuracy of new methods or models against a benchmark model. Often, this benchmark is the random walk model. In this note, I argue that for various reasons an IMA(1,1) model is a better benchmark in many cases.
KEYWORDS:
JEL CLASSIFICATION:
I. Introduction
It is a common practice to compare the forecast performance of a new model or method with that of a benchmark model. This holds in particular in these days where many new and advanced econometric models are put forward, like various versions of dynamic factor models and where many studies emerge using novel machine learning methods, see Kim and Swanson (Citation2018) for a recent extensive survey and application.
Typically, one chooses as the benchmark for one-step-ahead forecasts a simple autoregressive time series model, and most often one seems to choose for a random walk model. When denotes a time series to be predicted, then the random walk forecast for
is
which is based on the random walk model
where is a mean-zero white noise process with variance
. One motivation to consider this model is of course that there is no parameter to estimate, and hence there is no effort involved to create this forecast.
In many situations, however, the random walk model rarely fits the actual data. For financial time series, one may perhaps encounter this model as it associates with asset price movements, but for many other time series like in macroeconomics or business, the random walk model does not provide a good fit. It is therefore that in this note I propose to replace the random walk benchmark model by another model, which has more face value for a wider range of economic variables. This new benchmark model is the Integrated Moving Average model of order (1,1) [with acronym: IMA(1,1)], which looks like
This IMA(1,1) basically is a random walk model with an additional-lagged error term . The
parameter, which can be positive or negative and which is usually bounded by −1 and 1, in this IMA(1,1) model can be estimated using Maximum Likelihood or Iterative Least Squares. As an example, Nelson and Plosser (Citation1982) and Rossana and Seater (Citation1995) find much empirical evidence of this model for a range of macroeconomic variables.
Writing
then the variance of ,
, is
using the methods outlined in Chapter 3 of Franses, van Dijk, and Opschoor (Citation2014), and the first-order autocovariance, , is
This makes that the first-order autocorrelation of ,
, is
When , then
, and when
, then
.
In this note, I will show that the IMA(1,1) model follows naturally in a variety of settings. First, there will be some theoretical arguments. Next, I provide two additional, empirics-based, arguments. The last section concludes.
II. How can an IMA(1,1) model arise?
This section shows that an IMA(1,1) can follow from temporal aggregation of a random walk process, that it can follow from a simple basic structural model, that it associates with a time series process which experiences permanent and immediate shocks, and that it can be viewed as a simple and sensible forecasting updating process associated with exponential smoothing.
Aggregation of a random walk
Suppose that there is a variable where
is of a higher frequency than t. For example,
amounts to months, where t can concern years. Suppose further that the variable at the higher frequency
obeys a random walk model, that is,
where is a mean-zero white noise process with some variance. Suppose that this high-frequency random walk is temporally aggregated to a variable with frequency t, and suppose that this aggregation involves m steps. So, aggregation from months to years implies that m = 12. Working (Citation1960) shows that such temporal aggregation results in the following model:
where the first-order autocorrelation of , say,
is the only non-zero valued autocorrelation, and this autocorrelation is
When ,
. When
,
. In other words, aggregation of a high-frequency random walk leads to an IMA(1,1) model with a positive valued
.
Basic structural model
Consider the basic structural time series model (Harvey Citation1989)
with
Writing the latter expression as
where L is the familiar lag operator, then we have
Multiplying both sides with and ordering the variables gives the joint expression for
:
Here the IMA(1,1) model in (1) appears with . The MA(1) parameter
is negative when
and it is positive when
. Note that when the error source in the two equations of the basic structural model is not the same
, that then still the IMA(1,1) model appears, see Harvey and Koopman (Citation2000).
Permanent and temporary shocks
Another but related way to arrive at an IMA(1,1) model is given by the following. Suppose that a time series can be decomposed into a part with permanent shocks and a part with only transitory shocks, like
As such, the white-noise shocks with variance
have a permanent effect, because of the
operator, and the white noise shocks
with variance
have a temporary (immediate) effect. Multiplying both sides with
results in
This is
with the variance of equal to
The first-order autocovariance is equal to
and hence
which is non-zero and negative because of the positive-valued variance .
Forecast updates
A final simple motivation to favour an IMA(1,1) model as a benchmark is because it can be written as a simple random walk forecast update but now where past forecast errors are accommodated, where still the prediction interval can simply be computed (Chatfield, Citation1993). Consider again
The one-step-ahead forecast is based on
The error term can be viewed as the forecast error from the previous forecast, that is
Hence,
There are now four possible cases in terms of forecast updates, and these depend on the sign of and on the sign of
. Note that the latter expression associates with a so-called simple exponential smoothing model (Chatfield et al. Citation2001).
III. Further arguments
Two further arguments which would make the IMA(1,1) model a better benchmark are the following. First, as Hyndman and Billah (Citation2003) show, the IMA(1,1) model has the same forecasting function as the so-called ‘Theta’ method, proposed in Assimakopoulos and Nikolopoulos (Citation2000). The Theta method is a simple benchmark that performs well in forecasting competitions like the M3 and M4, see Makridakis and Hibon (Citation2000), and Makridakis, Spiliotis, and Assimakopoulos (Citation2019), respectively.
Finally, an IMA(1,1) process can have autocorrelations that associate with long memory. At the same time, long memory associates with aggregation across time series variables (Granger Citation1980) and structural breaks (Granger and Hyung Citation2004). Consider again,
Using the lag operator, this can be written as
And hence
This can be written as
or
Put simpler, the approximate infinite autoregression reads as
with
Now consider the fractionally integrated model
with , see Granger and Joyeux (Citation1980). Franses, van Dijk and Opschoor (Citation2014, 91) show that this can be written again as an infinite autoregression
where now
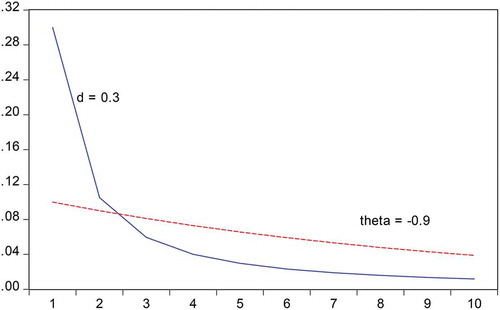
For particular values of and d, the patterns of the autoregressive parameters of the IMA(1,1) and the fractionally integrated process can look very similar. Consider for example which gives the first 10 autoregressive parameters, that is
to
for
and
.
Figure 1. The first 10 autoregressive parameters in an approximate autoregressive model, that is to
for
and
.
IV. Conclusion
In this note, I proposed to replace the random walk benchmark model in forecast evaluations by another model, which has more face value for many economic variables. This new benchmark model is the Integrated Moving Average model of order (1,1). I have put forward six arguments why this IMA(1,1) model is a suitable benchmark model in practice.
Disclosure statement
No potential conflict of interest was reported by the author.
References
- Assimakopoulos, V., and K. Nikolopoulos. 2000. “The Theta Model: A Decomposition Approach to Forecasting.” International Journal of Forecasting 16: 521–530. doi:10.1016/S0169-2070(00)00066-2.
- Chatfield, C. 1993. “Calculating Interval Forecasts (With discussion).” Journal of Business and Economic Statistics 11: 121–144.
- Chatfield, C., A. B. Koehler, J. K. Ord, and R. D. Snyder. 2001. “A New Look at Models for Exponential Smoothing.” The Statistician 50: 146–159.
- Franses, P. H., D. van Dijk, and A. Opschoor. 2014. Time Series Models for Business and Economic Forecasting. Cambridge UK: Cambridge University Press.
- Granger, C. W. J. 1980. “Long Memory Relationships and the Aggregation of Dynamic Models.” Journal of Econometrics 14: 227–238. doi:10.1016/0304-4076(80)90092-5.
- Granger, C. W. J., and N. Hyung. 2004. “Occasional Structural Breaks and Long Memory with an Application to the S&P 500 Absolute Stock Returns.” Journal of Empirical Finance 11: 399–421. doi:10.1016/j.jempfin.2003.03.001.
- Granger, C. W. J., and R. Joyeux. 1980. “An Introduction to Long-memory Time Series Models and Fractional Differencing.” Journal of Time Series Analysis 1: 15–39. doi:10.1111/j.1467-9892.1980.tb00297.x.
- Harvey, A. C. 1989. Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge UK: Cambridge University Press.
- Harvey, A. C., and S. J. Koopman. 2000. “Signal Extraction and the Formulation of Unobserved Components Models.” Econometrics Journal 3: 84–107. doi:10.1111/1368-423X.00040.
- Hyndman, R. J., and B. Billah. 2003. “Unmasking the Theta Method.” International Journal of Forecasting 19: 187–290. doi:10.1016/S0169-2070(01)00143-1.
- Kim, H. H., and N. R. Swanson. 2018. “Mining Big Data Using Parsimonious Factor, Machine Learning, Variable Selection and Shrinkage Methods.” International Journal of Forecasting 34: 339–354. doi:10.1016/j.ijforecast.2016.02.012.
- Makridakis, S., and M. Hibon. 2000. “The M3-competitions: Results, Conclusions and Implications.” International Journal of Forecasting 16: 451–476. doi:10.1016/S0169-2070(00)00057-1.
- Makridakis, S., E. Spiliotis, and V. Assimakopoulos. 2019. “The M4 Competition: 100,000 Time Series and 61 Forecasting Methods.” International Journal of Forecasting. in print. doi:10.1016/j.ijforecast.2019.04.14.
- Nelson, C. R., and C. I. Plosser. 1982. “Trends and Random Walks in Macroeconomic Time Series: Some Evidence and Implications.” Journal of Monetary Economics 10: 139–162. doi:10.1016/0304-3932(82)90012-5.
- Rossana, R., and J. Seater. 1995. “Temporal Aggregation and Economic Time Series.” Journal of Business and Economic Statistics 13: 441–451.
- Working, H. 1960. “Note on the Correlation of First Differences of Averages in a Random Chain.” Econometrica 28: 916–918. doi:10.2307/1907574.