
Abstract
Eye-movement experiments suggest that the perceptual span during reading is larger than the fixated word, asymmetric around the fixation position, and shrinks in size contingent on the foveal processing load. We used the SWIFT model of eye-movement control during reading to test these hypotheses and their implications under the assumption of graded parallel processing of all words inside the perceptual span. Specifically, we simulated reading in the boundary paradigm and analysed the effects of denying the model to have valid preview of a parafoveal word n + 2 two words to the right of fixation. Optimizing the model parameters for the valid preview condition only, we obtained span parameters with remarkably realistic estimates conforming to the empirical findings on the size of the perceptual span. More importantly, the SWIFT model generated parafoveal processing up to word n + 2 without fitting the model to such preview effects. Our results suggest that asymmetry and dynamic modulation are plausible properties of the perceptual span in a parallel word-processing model such as SWIFT. Moreover, they seem to guide the flexible distribution of processing resources during reading between foveal and parafoveal words.
INTRODUCTION
The perceptual span during reading is substantially larger than the word that is currently fixated. English readers, for example, obtain information from about 3–4 letters to the left of fixation and up to 14–15 letters to the right (McConkie & Rayner, Citation1975, Citation1976; Rayner, Well, & Pollatsek, Citation1980). The larger extent into the direction of reading suggests that readers rely substantially on information ahead of the eyes in order to efficiently coordinate their eye movements with the ongoing word-recognition processes. Moreover, the size of the perceptual span seems to adjust to the processing difficulty of the fixated word. With a difficult word in foveal vision the perceptual span becomes smaller, allowing less preprocessing of the upcoming word in parafoveal vision (Henderson & Ferreira, Citation1990; Kennison & Clifton, Citation1995)—an effect recently implemented in a computational model (Schad & Engbert, Citation2012).
The boundary paradigm (Rayner, Citation1975; Rayner, McConkie, & Zola, Citation1980) is a powerful method to investigate the effect of parafoveal information on reading. While the reader's gaze is to the left of an invisible boundary located at the end of a given word n (word n is defined as the currently fixated word), the preview of the next word n + 1 to the right of the boundary is masked (e.g., with random letters forming a nonword). Immediately after the eyes have crossed the boundary the preview is replaced by the target word. Reading times of the target word are reliably longer for these invalid preview cases than when the reader previewed the identical target word on fixations also before the boundary. Consequently, this difference has been termed parafoveal preview benefit (see Hyönä, Citation2011; Schotter, Angele, & Rayner, Citation2012, for reviews). This definition is consistent with the notion that the perceptual span also contains parafoveal words that are preprocessed before they are fixated.
However, many questions regarding the perceptual span remain unresolved. One such issue relates to how the words falling into the perceptual span are processed during each fixation, and reading models differ fundamentally in their assumptions on this matter. SWIFT, as a fully implemented computational model of saccade generation during reading, postulates that attention is distributed across the full perceptual span, and all words inside the span are processed in parallel (Engbert, Longtin, & Kliegl, Citation2002; Richter, Engbert, & Kliegl, Citation2006; Schad & Engbert, Citation2012). While it is correct to say that SWIFT is a model of parallel processing, it is important to note that processing is not equally distributed over a large number of words. A more precise description of the SWIFT word processing mechanism is that word processing rates are dependent on word position within the perceptual span and on word length (Engbert, Nuthmann, Richter, & Kliegl, Citation2005), so that word processing is often limited to one or two words at a time (see Appendix C in Engbert et al., Citation2005). The assumption of graded parallel processing, however, is not undisputed as there are other models such as E-Z Reader implementing attention allocation in the form of a one-word spotlight that is sequentially shifted from word to word (Reichle, Citation2011; Reichle, Pollatsek, Fisher, & Rayner, Citation1998; see also Schotter, Reichle, & Rayner, this issue).
Research on eye-movement control during reading demonstrated that computational modelling is a useful scientific approach to directly test the plausibility of cognitive theories on the perceptual span during reading by means of systematic comparisons between experimental data and simulation studies. The full potential of theoretical models can only be realized, however, if they are used to make predictions on data that were not considered for model development and optimization or for parameter estimation. Following this approach, we used the SWIFT model to simulate reading in the boundary paradigm for preview of word n + 2, that is the word beyond the word to the right of the invisible boundary (Kliegl, Risse, & Laubrock, Citation2007; Risse & Kliegl, Citation2011), without fitting the model to the preview effects. We will explain the modelling approach in more detail below. In contrast to word n + 1, the next word n + 2 lies at the spatial limit of the perceptual span and parafoveal preprocessing should be attenuated due to decreasing visual acuity at such parafoveal distances. It its important to note, however, that models of saccade planning assume a perceptual component that typically extends to words n + 1 and n + 2 (Engbert & Krügel, Citation2010; Krügel & Engbert, Citation2010; Krügel, Vitu, & Engbert, Citation2012). The findings of word n + 2 preview in the boundary paradigm vary across experiments. While some studies did not find significant preview effects of word n + 2 (Rayner, Juhasz, & Brown, Citation2007; see also Angele, Slattery, Yang, Kliegl, & Rayner, Citation2008), other studies showed that, given a short two- or three-letter word n + 1, some information about the next word n + 2 can already be preprocessed during fixations on the preboundary word n if word n + 1 is subsequently skipped (Angele & Rayner, Citation2011; Kliegl et al., Citation2007; Risse & Kliegl, Citation2011, Citation2012; but see Radach, Inhoff, Glover, & Vorstius, Citation2013, for effects on word n + 2 even when word n + 1 was fixated). In fact, n + 2 preview effects occurred mainly on the word that was fixated first after the boundary (Kliegl et al., Citation2007; Risse & Kliegl, Citation2011, Citation2012). Thus, a computational model should account for nonlocal patterns of preview effects in the target region as they seem to reveal important spatiotemporal characteristics about the foveal and parafoveal integration-processes across the perceptual span during reading.
THE MODELLING APPROACH
Using a recently published version of the SWIFT model (Schad & Engbert, Citation2012; see also Engbert et al., Citation2005) we tested whether a model based on distributed attention across the perceptual span accounts for the specific pattern of n + 2 preview effects observed in the boundary paradigm. Following from the results reported above, our main questions concerned (1) whether the model generates an n + 2 preview benefit on word n + 2 after skipping word n + 1, (2) whether a preview benefit on word n + 2 is absent when word n + 1 was previously fixated, and (3) whether the model shows an effect of n + 2 preview on word n + 1 if it was fixated first. Moreover, it is often argued that parallel word processing naturally implies crosstalk between processing foveal and parafoveal words simultaneously, resulting in parafoveal-on-foveal effects of the not-yet-fixated word in fixation durations on the fixated word (Drieghe, Rayner, & Pollatsek, Citation2008; Schroyens, Vitu, Brysbaert, & d'Ydewalle, Citation1999; see also Trukenbrod & Engbert, Citation2012, for a scanning task). However, whether the nonlinear dynamics of the SWIFT model indeed generate such effects requires simulations if one wants to go beyond speculation. Here, we checked whether simulations with SWIFT also yield a parafoveal-on-foveal effect of previewing word n + 2 on word n. Experimental evidence for such a result is, however, mixed (i.e., parafoveal-on-foveal effects of word n + 2 were found only in Kliegl et al., Citation2007, and Risse & Kliegl, Citation2012, Experiment 1, but not Experiment 2).
A further goal was to use the SWIFT model and to test specific assumptions about the perceptual span during reading. To this end, we first fit the model parameters to the normal reading situation. In the boundary paradigm, normal reading occurs in the identical preview condition because in this condition preview is provided during all fixations. The best-fitting model parameters were then used to simulate reading in the invalid preview condition in which the target word n + 2 was not revealed until the eyes moved away from word n. Critically we did not optimize original or even additional model parameters to capture the preview effects in the boundary paradigm. Rather, we only assumed that the model deals with invalid cases, specifically the fact that there is a display change, in a principled way (described below). Using the parameter values fitted to reading with valid preview and the model's principled response to display changes, we explored how much of the preview effects are already inherent in the present version of the SWIFT model. These simulations were then compared with the experimental results, using a likelihood computation of the experimental data given the SWIFT model. In addition, we checked whether the model parameters stayed within a reasonable range given what we know about the perceptual span from experimental research. We also used the estimates of the model parameters as a source of information about how the model accounts for processing of parafoveal words. For this purpose, we investigated the range of certain span parameters and assessed their contribution to the processing of word n + 2 within the model.
The zoom lense model: SWIFT 3
To account for the reader's when- and where-decisions during reading, computational models of eye-movement control must provide an interface between cognitive and oculomotor processes. With respect to cognition, the SWIFT model represents sentence processing as a set of word-based lexical activations. This field of lexical activations (e.g., Erlhagen & Schöner, Citation2002) changes over time as a function of word processing. Word recognition is implemented as a two-stage process: A word is processed when its lexical activation increases from zero (i.e., no information about the word) to a maximum defining the word's difficulty and decreases from this maximum back to zero (i.e., full identification of the word). With respect to the oculomotor aspects of the model, SWIFT generates saccade programmes autonomously based on a random timer (similar to Findlay & Walker, Citation1999; see also Trukenbrod & Engbert, Citation2013). (All dynamical variables such as the random timer and the evolution of lexical activations of each word in the sentence were modelled as independent discrete random walk processes, see Nuthmann et al., Citation2010; Trukenbrod and Engbert, Citation2013. Parallel processing was approximated through randomly incrementing the random walks.) As illustrated in , word processing and oculomotor control are linked to each other via two routes: (1) The lexical activation of the fixated word in foveal vision can inhibit the initiation of the next saccade program by inhibiting the random timer. Thus, the activation of the fixated word influences the decision of when to move the eyes. (2) The lexical activations of all words in the sentence determine the probability with which each word is selected as the next saccade target. Thus, the lexical activation of all words influences the decision of where to move the eyes. Highly activated words are more likely to be fixated next whereas words with very low activation are likely to be skipped and not fixated at all. Accordingly, the lexical-activation field in SWIFT enables the full range of behaviours in the model. It allows forward saccades to the next word in sequence and word skipping as well as refixations and regressions back to earlier words. Simultaneously, it controls the processing-dependent prolongation of fixation durations through inhibition of the random timer according to the foveal activation state.
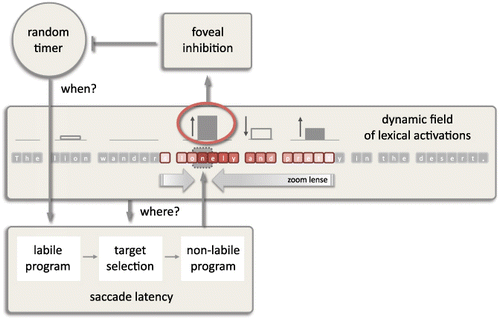
How much information is processed during each fixation and how fast it is processed is determined by the model's processing span. This can be regarded as the perceptual span of the model and defines the region of letters that contribute to the increase or decrease of lexical activation of the corresponding words. The processing span in the latest version of the SWIFT model (SWIFT 3; Schad & Engbert, Citation2012) is implemented as an inverse parabolic function that assigns a processing rate above zero to all letters falling below the curve. In agreement with a gradual reduction of visual acuity beyond the fovea, the processing rate decreases with increasing eccentricity from the fixation position. Moreover, this model also implemented the idea of an attentional zoom lense (e.g., Eriksen & St. James, Citation1986; LaBerge & Brown, Citation1989) such that the size of the processing span is modulated conditional on the foveal processing demand. As the lexical activation of the fixated word decreases, the right part of the span increases and more and more letters to the right of fixation fall inside the processing span. Such a dynamic span modulation conforms to findings of larger preview benefit in case of an easy compared to a difficult word before the boundary, that have been attributed to immediate adjustments of the perceptual span with local processing load (Henderson & Ferreira, Citation1990; Kennison & Clifton, Citation1995). A dynamic adjustment of the perceptual span has also been used as an explanation of various parafoveal-on-foveal effects observed with multivariate analyses of reading using corpus analyses (Kennedy & Pynte, Citation2005; Kliegl, Nuthmann, & Engbert, Citation2006). The zoom lense model has been developed and tested in the context of differences in reading normal and randomly shuffled text. In particular, it can account for a rather unintuitive finding of a reversal of the word frequency effect in shuffled text reading (Schad, Nuthmann, & Engbert, Citation2010; Schad & Engbert, Citation2012).
The processing span in the present SWIFT variant
The processing span in SWIFT is modelled in two parts, a left-side extension δL and a right-side extension δR. In order to investigate the characteristics of SWIFT's processing span, we estimated three parameters that could be interpreted as three independent properties of the processing span. The right side of the span is dynamically modulated as a function of the lexical activation ak(t) of the foveal word k at time t, i.e.,
Given the span extent δL to the left and δR to the right, the processing rate λ for a letter of eccentricity ε relative to the fixation position at zero was determined by an inverse-parabolic relation according to the equation,
Moreover, the processing span was normalized by , such that the total processing rate for all letters in the span was fixed at one. Note that this normalization has important implications. The broader the processing span, the smaller is the processing rate at the fixated position. This assumption relates to views of attention as a limited-capacity resource that can be allocated towards several processes simultaneously but at a cost of processing efficiency (Kahneman, Citation1973) and is also similar to the gradient shift hypothesis proposed by Inhoff, Eiter, and Radach (Citation2005). Schad and Engbert (Citation2012) showed with simulations that the reversed frequency effect observed in shuffled text reading (i.e., shorter rather than longer fixation durations on low-frequency compared to high-frequency words) was consistent with an increase in foveal processing efficiency when the processing span was small.
However, Schad and Engbert (Citation2012) estimated the actual processing span within a larger perceptual region. They assumed that there exists a fixed-extent region of preprocessing (15 letters to the right of fixation as motivated by findings on the perceptual span size) in which words are pre-activated slightly above zero. The model's processing span turned out to be substantially smaller than the total preprocessing region, rendering the processing span more comparable to the letter-identification span than the perceptual span (O'Regan, Citation1990; Underwood & McConkie, Citation1985). In order to test properties of the perceptual span instead, we implemented a model version in which words were not pre-activated until they fell into the processing span. This forced the model to select the absolute size of its processing span such that it allowed an efficient pre-activation of words to the right of fixation for becoming potential saccade targets and at the same time optimized the allocation of processing resources between foveal and parafoveal word processing. As a consequence, the best-fitting parameter values could be directly interpreted in analogy to properties of the perceptual span during reading. Estimating the modulation parameter δ1 as zero would lead to a model with a constant span independent of any ongoing processing activities in foveal vision. Additionally, estimating the asymmetry parameter δ2 as one would suggest an advantage for a symmetric rather than an asymmetric processing span with equal extent to the left and to the right of fixation. Thus, the best-fitting parameter values speak to important aspects of the processing span and inform us about what type of processing span is optimal in a model with parallel-distributed attention such as SWIFT.
Simulating the boundary paradigm
Simulation of reading in the boundary paradigm requires assumptions about how the model should behave when the boundary is crossed and the preview is replaced with the target word. It should be noted that these assumptions imply no changes to the SWIFT model architecture and are thus not counted as differences to SWIFT 3 as reported in Schad and Engbert (Citation2012). In order to simulate the occurrence of a display change in the invalid preview condition, we made the following assumptions.
Reset of lexical activation
As parafoveal preview benefit is interpreted as resulting from a head start of processing based on trans-saccadic integration of parafoveal information (Inhoff, Citation1990; Inhoff & Tousman, Citation1990; see also Inhoff & Radach, this volume), it is reasonable to assume that word recognition processes need to be restarted for the target word if it differs from its parafoveal preview (i.e., in case of invalid preview). Particularly when using random-letter nonwords for invalid previews as in the present study, there should not be much useful information to be integrated across saccades. We therefore reset the lexical activation of the target word n + 2 to zero when the model first fixated a word to the right of the boundary (i.e., to the right of word n; for similar assumptions see Kliegl & Engbert, Citation2003; Pollatsek, Reichle, & Rayner, Citation2006). The nonword preview of word n + 2 in the invalid preview condition was assigned to a processing maximum equal to the value A of the most difficult word in all experimental sentences accounting for the fact that nonwords are infrequent and therefore difficult to process.
Saccade cancellation
Moreover, the physical change of the display – although in principle occurring during a saccadic movement – might affect the oculomotor system and inhibit upcoming saccades (similar to Reingold & Stampe, Citation2004; Yang & McConkie, Citation2001). Thus, we assumed that with a probability of 0.25 an ongoing saccade program was cancelled when the model exceeded the boundary and when the saccade program was still in its early labile stage (see also Nuthmann, Smith, Engbert, & Henderson, Citation2010). We will report the simulation results (1) for a model with lexical reset only and (2) for a model with both lexical reset and saccade cancellation. For simulations with different parameter values for the activation reset and the saccade cancellation see in the Appendix.
Summary of model adaptations
In order to examine the perceptual span given parallel-distributed processing, we used SWIFT 3 as a starting model. With respect to the architecture of the model, we mainly changed two aspects compared to its predecessor. As the major goal was to estimate the full size of the model's perceptual span, the pre-activation of a constant 15-letter processing region was omitted. We expected that δR would now cover the full extent of parafoveal pre-activation necessary for the SWIFT model to show adequate eye-movement behaviour. Moreover, to test the importance of a constant left-side asymmetry of the perceptual span for a parallel-processing model like SWIFT an additional asymmetry parameter was inserted.
Further differences to SWIFT 3 were resulting from fixing parameter values rather than from changes in the model architecture. In order to reduce the total number of free parameters, we fixed several model parameters at values reported for SWIFT 3 in Schad and Engbert (Citation2012) for normal text reading (see for a complete overview). For example, parameters determining saccade programming such as the mean duration for the labile and nonlabile saccade-programming stages were taken from SWIFT 3 and thus did not differ between model variants. However, we fixed two further parameters to different values compared to SWIFT 3: (1) The global inhibition parameter (ppf) that slows down word processing to the right of fixation proportional to the residual activation of words to the left of fixation was set to zero and therefore rendered inactive. (2) The parameter for activation transfer across saccades (ι) were set to one (i.e., no activation reset) such that the full amount of parafoveally acquired information would be available in the next fixation. Both changes were made to enable substantial parafoveal preprocessing in the model and to allow processing to the right of fixation to be most effective on the model's dynamics.
TABLE 1 Summary of parameter values in the present SWIFT model
Other parameters were freely estimated for the present simulation but did not change the architecture of the model. Specifically, we fit all parameters that were associated with the model's processing span and those that were related to the lexical processing in the model. The latter was optimized for the present stimulus material because it differed from that used in Schad and Engbert (Citation2012). Finally, the present model was getting along without information about word predictability. Note that Schad and Engbert (Citation2012) showed that SWIFT 3 was able to perform adequately with the predictability parameter θ set to zero. Moreover, predictability as typically measured in the cloze task refers to the upcoming word's predictability (i.e., of word n + 1), which seems to be of lesser importance when the interest is in preprocessing of the preceding word n + 2. How well the present SWIFT model accounts for eye-movement statistics in reading (e.g., fixation durations and fixation probabilities for different word lengths and word frequencies) is summarized in in the Appendix.
RESULTS
Best-fitting model parameters
Parameters were estimated using a genetic algorithm procedure (see Mitchell, Citation1998). We ran seven independent parameter estimations and computed the means and standard errors for each of the nine free parameters. summarizes the results for both free and fixed parameter estimates and provides a comparison with the parameters of the zoom lense model (SWIFT 3) for normal text reading presented in Schad and Engbert (Citation2012). As a first result, the comparison of the best-fitting parameters showed that the constant span size was estimated to be much larger than in the normal text reading condition investigated by Schad and Engbert (Citation2012). This is mainly due to the fact that SWIFT 3 used a pre-activation zone of 15 letters to the right of fixation, while in the current version we neglected the pre-activation mechanism and limited processing to the span defined in Eqs. (1–3). As a result, the model needed an increased size of the constant span parameter to generate sufficient parafoveal information for the selection of saccade targets in the periphery. One implication of a larger constant span is that more letters to the right of fixation are preprocessed on any fixation, irrespective of the difficulty of the ongoing foveal processing. At the same time, due to the normalization of the inverse-parabolic processing span, foveal processing will always be slower than in a model consisting of a smaller span and the fixated word will be assigned to a smaller processing rate.
As a second result, the model showed, on top of that, some contribution of the dynamic span modulation relative to foveal processing. The processing span could increase up to five letters beyond the constant span size if the foveal processing demand dropped to zero during a fixation. Finally, the asymmetry parameter was estimated to be substantially smaller than one suggesting that even in its most focused state with minimum span size (i.e., in the case of highest lexical activation of the fixated word) the optimal processing span was asymmetric around the fixation position. Thus, even though the genetic algorithm was free to select between different processing span types, the parameter estimates suggest that the optimal processing span for the present SWIFT model consists of an asymmetric constant part and an additional processing-related modulation of the right side. More importantly, the estimates of the model's processing span were in a range that agrees well with what has been reported in studies investigating the perceptual span experimentally. We will discuss this in more detail below.
Simulated n + 2 preview effects in the boundary paradigm
The goal of this study was to simulate reading in the boundary paradigm using the SWIFT model and to compare the results with the experimentally observed n + 2 preview effects. Typically, experimental observations of n + 2 preview effects are aggregated condition means of fixation durations to approximate stable estimates of the fixation durations in the valid and invalid preview condition. However, one experiment represents only a single realization from the unknown distribution of true n + 2 preview effects. With a computational model, we can simulate many realizations and obtain a distribution of the means across different simulation runs. In order to compare the distribution of simulated results to the experimental outcome, we can then use likelihood computations to quantify how likely the experimental mean is given the SWIFT model. Therefore, we ran 100 independent simulations with 68 virtual subjects each reading 160 sentences, half of them with valid preview (i.e., the identical word) and the other half with invalid preview of word n + 2 (i.e., a random-letter nonword). The simulated data were then compared to the empirical data of 30 young adults from the study of Kliegl et al. (Citation2007) and 38 young adults from the study of Risse and Kliegl (Citation2011), all reading the same sentence material in the same experimental setup of the n + 2 boundary paradigm comparing valid identical previews with invalid nonword previews.
summarizes the present simulation results, and across rows shows the results for word n before the boundary, word n + 1 after the boundary, and the target word n + 2 after word n + 1 was previously fixated or skipped. The first two columns compare the simulation results (distributions) and experimental means (vertical lines) on the level of fixation durations (i.e., gaze durations) for the valid (green) and invalid (red) preview condition. Across columns, we successively test the assumptions with respect to the display change. The first column displays results from the model with lexical reset only (i.e., without saccade cancellation), the second column shows corresponding results from the model implementing both lexical reset and saccade cancellation after gaze-contingent display change. The right column illustrates the mean differences between the valid and invalid condition and therefore the size of the n + 2 preview effects on each word in the target region.
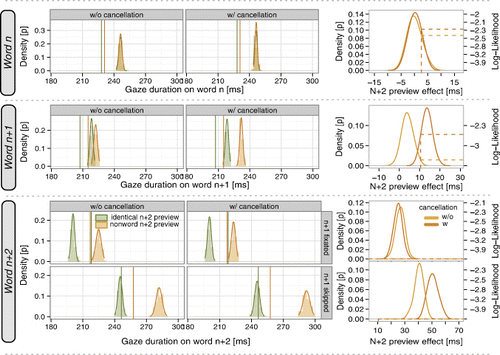
The results clearly show that the SWIFT model generates preview effects of word n + 2 in the boundary paradigm similar to what was observed in experiments. First, the model produced a differential effect on the target word n + 2 contingent on fixating or skipping word n + 1 (see bottom rows of panels of ): There was a substantial preview benefit on word n + 2 when word n + 1 was skipped and a weaker effect when word n + 1 was fixated. This result is in good qualitative agreement with the experimental results, but, quantitatively, the model clearly overestimated the magnitude of the preview benefit in both cases of skipping and fixating word n + 1 (i.e., the simulation distributions for valid and invalid preview are further apart than the difference between the two corresponding vertical lines indicating the experimental results).
Second, SWIFT also conformed well to the experimental results with respect to the parafoveal-on-foveal effect of word n + 2 (see top row of panels in ). There was almost no difference in fixation durations between the valid and invalid preview condition on word n before the boundary for both model variants with and without saccade cancellation. Note that the experimental results exhibit a trend in the direction of such a parafoveal-on-foveal effect which is small and not always significant (e.g., Risse & Kliegl, Citation2011).
Third, for fixations on word n + 1 after the boundary, SWIFT produced a small difference in fixation durations between the valid and invalid preview condition. This difference was substantially smaller in the model variant without saccade cancellation than the experimental effect. However, with the assumption that ongoing saccade programs are cancelled with some probability after a display change, the distribution of fixation durations for a nonword preview of word n + 2 shifted significantly to the right and resulted in a considerable increase in the n + 2 preview effect on word n + 1. Overall, both lexical reset and saccade cancellation were thus required for a recovery of the qualitative profile of the experimental effects.
This last result is an interesting finding because it suggests that nonlocal preview effects after crossing the boundary can be viewed as effects that are driven significantly by oculomotor inhibition due to the display change (O'Regan, Citation1990; Reingold & Stampe, Citation2004). However, in a recent study we found fixation duration differences between two display-change conditions when an easy preview changed to a difficult target word or vice versa (Risse & Kliegl, Citation2012). A difference between these two conditions suggests that such nonlocal n + 2 preview effects (i.e., on word n + 1 after the boundary) also involve higher-level cognitive processes and cannot be accounted for solely by low-level oculomotor inhibition. Moreover, saccade cancellation also increased fixation durations on word n + 2 if word n + 1 was skipped and thus contributed even more to the model's overestimation of preview benefit on word n + 2.
In summary, fitting the model to data from normal reading only (i.e., with a valid preview of word n + 2) and assuming a reset of lexical activation of word n + 2 after its replacement (i.e., after an invalid preview of word n + 2), the present version of the SWIFT model was able to account for effects observed from reading with invalid preview of word n + 2 in the boundary paradigm. In some cases, the observed experimental means differed considerably from the overall simulated mean fixation durations for the two preview conditions (e.g., on the preboundary word n) and their likelihoods were very small given the SWIFT model. Yet the differences between the preview conditions were captured quite well by the model. Most critically, without directly fitting the preview effects, SWIFT simulations yielded larger preview benefit on word n + 2 after skipping word n + 1. With the additional assumption of saccade cancellation due to the display change, they also showed an effect on word n + 1. However, the simulated n + 2 preview benefit overestimated the experimental results by far. The latter type of misfit may well be due to somewhat ad hoc assumptions about how the model was to respond to the display change specific for the boundary paradigm. We will return to this issue in the General Discussion.
Investigation of processing-span parameters
In this section, we report analyses on how the processing-span parameters account for parafoveal processing of word n + 2 and what they contribute to the n + 2 preview effects in the boundary paradigm. To this end, we focus on the preview benefit on word n + 2 in the simpler model without saccade cancellation after display changes, taking also into account whether word n + 1 was fixated or skipped. We carried out a parameter-range investigation (similar to a grid search) and computed the preview benefit for simulations with varying processing-span parameters (i.e., constant part δ0, dynamical part δ1, and asymmetry δ2 of the perceptual span), keeping all other parameters constant.
The most prominent result of these simulations was the difference in the evolution of preview benefit on word n + 2 after word n + 1 was fixated or skipped. Increasing the span parameters and thus the size of the processing span had a strong impact on the preview benefit after word n + 1 was skipped (see , right column). However, when word n + 1 was fixated, the preview benefit on word n + 2 was much weaker and started to increase with much greater span sizes. Note that the absolute right part of the span consists of both the constant span part δ0 and the dynamic part δ1 adding up to what is illustrated in the left column of . Interestingly, the single fixation durations (solid light-green lines) were much less affected by the processing span size than the gaze durations (solid dark-green lines) and showed a preview benefit maximally up to 15 ms at the largest span size.
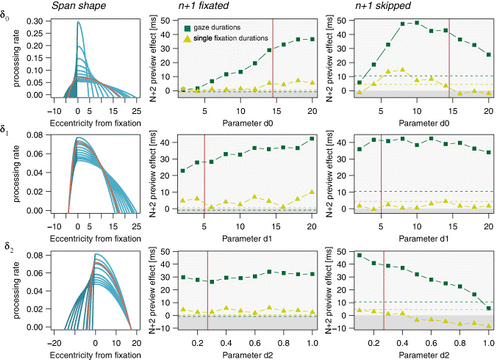
The most interesting result, in our opinion, can be traced back to varying the parameter of the constant part of the processing span (see , upper row). Increasing δ0 the parafoveal preview benefit first became increasingly large, reached asymptote, and then slowly decreased again. That more parafoveal preview is obtained when the span is larger seems trivial. But how can the preview benefit decrease again? The illustration of the processing span (see , left panel) suggests that with a large processing span, the SWIFT model assigns comparable processing rates to all words residing in the span. The processing rates for each word are low and indicate overall slow word-recognition at each location. In other words, lexical processing speed does not vary systematically between words, irrespective of whether they are in foveal or parafoveal vision. When activation of word n + 2 has been reset to zero after the display change and word n + 2 is then fixated, its activation will rise only slowly in foveal vision. In the case of identical preview, the activation of word n + 2 will continue to rise after its fixation, conserving the benefit from its prior preprocessing. However, as foveal processing speed is slow, lexical activation might not increase enough to exceed the processing maximum after which activation is decreasing again. As a consequence, word n + 2 may be activated higher after identical preview than after a nonword preview, and this may result in a higher likelihood to inhibit the next saccade programme and prolong n + 2 fixations in the case of valid preview rather than invalid preview.
In contrast, increasing the parameter value of the dynamic part δ1 of the processing span and thus the dynamic response of the processing span towards foveal processing difficulty lead only to moderate changes in the preview benefit on word n + 2 (see , middle row). Yet, although the parameter range tested here resulted in processing-span sizes that were even larger than those covered in the analysis of the constant span part, the according decrease in foveal processing efficiency did not affect the preview effect size as it did affect it when it was varied. This suggests that the dynamic increase of the span leads to a qualitatively different pattern of preview effects in the present model than a constant span of the same size. The fact that the span dilates and broadens only after foveal processing has reached the activation maximum and lexical activations are decreasing again seems to prevent preview benefit from turning into preview cost.
Finally, changing the asymmetry parameter δ2 had no strong effect on parafoveal preview benefit when word n + 1 was fixated (see , lower row). The span's proportion to the left side relative to the constant part of the right side did not contribute much to parafoveal processing of word n + 2. However, when word n + 1 was skipped, increasing the scaling parameter δ2 from 0.1 to 1.0 and thus increasing the left side of the processing span until it was equal to the right side in its most focused extent resulted in a constant decrease of preview benefit on word n + 2. As detailed above, a decrease in preview benefit is a result of the normalization of the processing span leading to a trade-off between foveal and parafoveal processing rates. Taken together, the present findings suggest that up to a certain span size the SWIFT model can compensate the decrease in foveal processing rate by increasing parafoveal processing rates. However, when the foveal processing rate falls below a critical value it results in decreasing preview effects of parafoveal processing.
DISCUSSION
In summary, we showed that the present version of the SWIFT model generates reliable preview benefit from word n + 2 in the boundary paradigm without directly fitting the model to such effects. To this end, we made the assumption that a display change causes a complete reset of lexical activation. With the additional assumption that display changes cause saccade cancellation with a 0.25 probability — a mechanism that has proven to be important also in other models to explain results from gaze-contingent experiments (Nuthmann et al., Citation2010) — SWIFT also produced a nonlocal preview effect of word n + 2 in fixation durations on word n + 1. Therefore, in its present version, the SWIFT model could account for a highly specific pattern of results in the n + 2 boundary experiments, that is, a larger preview benefit on the target word when the pretarget word n + 1 was skipped rather than fixated and an effect on word n + 1 if this was fixated first.
The role of the processing span parameters in the present SWIFT version
Many aspects of the results have already been discussed above. In the following, we want to focus on only a few issues most relevant to the present simulation approach. To investigate the role of the different processing-span parameters on parafoveal processing in the SWIFT model we defined the parameters such that they tested three independent properties of the processing span: a constant span part δ0, a dynamic adjustment into the direction of reading δ1, and an additional leftward asymmetry δ2. In principle, the current implementation allowed the possibility that the model required only a subset of these parameters to account for the reading data. If they were estimated to be 0 and/or 1, respectively, this would indicate, counter to our expectations, that there is no need to allow for a dynamic modulation of the perceptual span and/or that a symmetric processing span is sufficient when word-processing is parallel in a reading model such as SWIFT. The results suggested, however, that all three parameters contributed to an optimal model fit. A constant asymmetric processing span with a broader extent to the right than to the left (i.e., the combination of δ0 and δ2) was not sufficient for the SWIFT model to optimally account for the present eye-movement data under conditions of identical preview. Word processing benefited from a dynamic modulation of the processing span in response to foveal processing load, although this modulation might seem rather small in the present simulations (about five letters at its maximum). However, it was substantially larger than what was previously observed for normal text reading (Schad & Engbert, Citation2012).
Otherwise, there was a high consistency with the SWIFT 3 model. This is particularly striking as the parameters were estimated based on reading very different sentence material. In contrast to the sentence corpus used in Schad and Engbert (Citation2012), the experimental sentences used in the present study each involved a three-word target region with a short three-letter word n + 1 before a medium-length target word n + 2 (M = 5 letters). Thus, the likelihood of encountering three-letter words in the experimental sentences was artificially high due to requirements in the n + 2 boundary paradigm. Finding strong agreement in parameter estimates across reading material supports the validity and importance of the dynamic adjustment of SWIFT's processing span in accounting for eye movements during reading. In addition, the present simulation showed realistic values of parameter estimates of the processing span. In fact, the estimated parameters resulted in a processing span with a left extension of 3.9 letters and a maximum right extension of 19.5 letters (minimum 14.5 letters) and were thus very close to the experimental estimates of the perceptual span. Such coherence between estimated model parameters and experimentally observed measures of the perceptual span is an encouraging example of how eye-movement data may constrain parameters in computational modelling to reasonable values and increase our understanding of the complex theoretical concepts they are representing.
Overestimation of n + 2 preview benefit in the present SWIFT simulation
The present simulations were based on the idea to not fit the model to the preview effects in the boundary experiment but to examine whether a model optimized for the normal reading condition would succeed in showing preview effects even from word n + 2 at the spatial limits of the perceptual span. Qualitatively, the present SWIFT version captured well a complex pattern of local and nonlocal effects of previewing word n + 2 in the boundary paradigm. Yet not surprisingly, there were also a few noteworthy discrepancies, particularly on the quantitative level between the experimental and simulated preview effects. The size of the preview effects of word n + 2 were simulated reasonably well for fixations on word n and word n + 1 (given saccade cancellation). However, simulated preview effects on the target word n + 2 diverged seriously from the empirical observations. We propose two reasons.
This misfit may have been partially due to reading times on the preboundary word n that were overestimated by about 20 ms across all conditions. Overall however, the present simulations resulted in an adequate fit of fixation durations for different word lengths and word frequencies of the words used in the experimental sentences (see , Appendix). Thus, it seems unlikely that the misfit of fixation durations on the preboundary word may have been a result of the absence of predictability information in the present version of the SWIFT model or of the fixing of parameters. We suspect that it reflects word-specific biases in the present sentence material such as parafoveal-on-foveal differences from an upcoming three-letter content or function word at position n + 1. Such differences may currently not be adequately represented in the lexical activations of the SWIFT model and may originate from beyond linguistic word properties such as length and frequency.
In addition, the SWIFT model overestimated the fixation durations on the target word in case of invalid preview of word n + 2 and skipping word n + 1 by a similar magnitude of 20–30 ms compared to the experimentally observed viewing times. This overestimation in the model might be a consequence of how we simulated reading in the boundary paradigm with the SWIFT model. We implemented two assumptions: (1) We assumed that a display change of a nonword preview to the target word would reset the lexical activation of word n + 2 to zero. This assumption implies that no information about the parafoveal preview could be used on the next fixation after the boundary and word processing has to start completely from zero. However, even nonword previews share the word-length information with the target word. As the simulations in the Appendix (, upper row) show, resetting the activation of word n + 2 to zero may have overestimated the disadvantage of having preprocessed an invalid preview in parafoveal vision and thus inflated the nonword preview cost. (2) We assumed that saccade programmes were cancelled after a display change (i.e., in the nonword preview condition) with a probability of 0.25. Notwithstanding the fact that saccade cancellation led to a reasonable preview effect on word n + 1 when it was fixated first after the boundary, cancelling ongoing saccade programmes also increased fixation durations on word n + 2 when it was fixated first (see simulations in , lower row, Appendix). As a consequence, this also added to the already overestimated fixation durations on word n + 2 in case of a nonword preview.
Solutions for future simulations with the SWIFT model
Both the lexical activation reset and the saccade cancellation with a probability of 0.25 contributed to the overestimation of preview cost on word n + 2. Moreover, both parameters were fixed and chosen for considerations of plausibility. However, the results in the Appendix suggest that changing these values directly affects the size of the preview effects from word n + 2. One option for future simulations is, therefore, to estimate the optimal amount of rest activation that should be preserved after the boundary as well as the optimal probability of saccade programs that should be cancelled after a display change as two free parameters in the model. However, such a direct fit of preview benefit or preview cost is beyond the approach advocated here of exploring effects of parafoveal processing that are already inherent in the SWIFT model architecture without fitting the model to them.
Alternatively, one could design experiments to inform about how much activation is remaining after a display change and how many saccade cancellations seem reasonable. An index for differences in activation reset may be approximated from studies comparing preview benefit for different types of parafoveal previews (e.g., semantically anomalous, unpredictable, or visually dissimilar previews as in Drieghe, Rayner, & Pollatsek, Citation2005). We may also be able to obtain independent estimates of the probability of saccade cancellation from saccadic inhibition experiments as reported in Reingold and Stampe (Citation2004). Our prediction is that simulations using such experimental parameter values will result in a reduction of the preview benefit of word n + 2 and thus eliminate the overestimation of fixation durations after the display was changed.
Summary
The present simulations showed that parafoveal processing up to word n + 2 is inherent to a parallel model such as SWIFT without particularly fitting its parameters to the experimental preview effects. Moreover, based on the normal reading condition, the SWIFT model favoured a processing span that was both asymmetric around the fixation position and dynamically modulating its rightward extent with respect to the processing demand of the word in foveal vision. The estimated size of SWIFT's processing span was consistent with experimentally derived measures on the perceptual span during reading. Our simulation results confirm that computational models provide an intriguing and compelling way to test different conceptualizations of cognitive processes (i.e., related to different theoretical properties of the perceptual span) that are experimentally difficult to obtain.
Additional information
Funding
REFERENCES
- Angele, B., & Rayner, K. (2011). Parafoveal preprocessing of word n + 2 during reading: Do the preceding words matter? Journal of Experimental Psychology: Human Perception and Performance, 37, 1210–1220. doi:10.1037/a0023096
- Angele, B., Slattery, T., Yang, J., Kliegl, R., & Rayner, K. (2008). Parafoveal processing in reading: Manipulating n + 1 and n + 2 previews simultaneously. Visual Cognition, 16, 697–707. 10.1080/13506280802009704
- Drieghe, D., Rayner, K., & Pollatsek, A. (2005). Eye movements and word skipping during reading revisited. Journal of Experimental Psychology: Human Perception and Performance, 31, 954–969. doi:10.1037/0096-1523.31.5.954
- Drieghe, D., Rayner, K., & Pollatsek, A. (2008). Mislocated fixations can account for parafoveal-on-foveal effects in eye movements during reading. Quarterly Journal of Experimental Psychology, 61, 1239–1249. doi:10.1080/17470210701467953
- Engbert, R., & Krügel, A. (2010) Readers use Bayesian estimation for eye-movement control. Psychological Science, 21, 366–371. doi:10.1177/0956797610362060
- Engbert, R., Longtin, A., & Kliegl, R. (2002). A dynamical model of saccade generation in reading based on spatially distributed lexical processing. Vision Research, 42, 621–636. doi:10.1016/S0042-6989(01)00301-7
- Engbert, R., Nuthmann, A., Richter, E., & Kliegl, R. (2005). SWIFT: A dynamical model of saccade generation during reading. Psychological Review, 112, 777–813.10.1037/0033-295X.112.4.777
- Eriksen, C. W., & St. James, J. D. (1986). Visual attention within and around the field of focal attention – a zoom lense model. Perception and Psychophysics, 40(4), 225–240. doi:10.3758/BF03211502
- Erlhagen, W., & Schöner, G. (2002). Dynamic field theory of movements preparation. Psychological Review, 109, 545–572. doi:10.1037/0033-295X.109.3.545
- Findlay, J. M., & Walker, R. (1999). A model of saccade generation based on parallel processing and competitive inhibition. Behavioral and Brain Sciences, 22, 661–721.
- Henderson, J. M., & Ferreira, F. (1990). Effects of foveal processing difficulty on the perceptual span in reading: Implications for attention and eye movement control. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16, 417–429. doi:10.1037/0278-7393.16.3.417
- Hyönä, J. (2011). Foveal and parafoveal processing during reading. In: S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), Eye movements handbook (pp. 819–838). Oxford: Oxford University Press.
- Inhoff, A. W. (1990). Integrating information across eye fixations in reading. Acta Psychologica, 73, 281–297. doi:10.1016/0001-6918(90)90027-D
- Inhoff, A. W., Eiter, B. M., & Radach, R. (2005). The time course of linguistic information extraction from consecutive words during eye fixations in reading. Journal of Experimental Psychology: Human Perception and Performance, 31, 979–995.
- Inhoff, A. W., & Radach, R. (2014). Parafoveal preview benefits during silent and oral reading: Testing the parafoveal information extraction hypothesis. Visual Cognition, this issue.
- Inhoff, A. W., & Tousman, S. (1990). Lexical integration across eye fixations in reading. Psychological Research, 52, 330–337. doi:10.1007/BF00868065
- Kahneman, D. (1973). Attention and effort. Englewood Cliffs, NJ: Prentice-Hall.
- Kennedy, A., & Pynte, J. (2005). Parafoveal-on-foveal effects in normal reading. Vision Research, 45, 153–168. doi:10.1016/j.visres.2004.07.037
- Kennison, S. M., & Clifton, C. (1995). Determinants of parafoveal preview benefit in high and low working memory capacity readers: Implications for eye movement control. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 68–81. doi:10.1037/0278-7393.21.1.68
- Kliegl, R., & Engbert, R. (2003). SWIFT explorations. In J. Hyönä, R. Radach, & H. Deubel (Eds.), The mind's eye: Cognitive and applied aspects of eye movement research (pp. 103–117). Oxford, England: Elsevier.
- Kliegl, R., Nuthmann, A., & Engbert, R. (2006). Tracking the mind during reading: The influence of past, present, and future words on fixation durations. Journal of Experimental Psychology: General, 135, 12–35. doi:10.1037/0096-3445.135.1.12
- Kliegl, R., Risse, S., & Laubrock, J. (2007). Preview benefit and parafoveal-on-foveal effects from word n + 2. Journal of Experimental Psychology: Human Perception and Performance, 33, 1250–1255. doi:10.1037/0096-1523.33.5.1250
- Krügel, A., & Engbert, R. (2010) On the launch-site effect for skipped words during reading. Vision Research, 50, 1532–1539. doi:10.1016/j.visres.2010.05.009
- Krügel, A., Vitu, F., & Engbert, R. (2012). A single space makes a large difference: Fixation positions after skipping saccades. Attention, Perception, & Psychophysics, 74(8), 1556–1561. doi:10.3758/s13414-012-0365-1
- LaBerge, D., & Brown, V. (1989). Theory of attentional operations in shape identification. Psychological Review, 96(1), 101–124. doi:10.1037/0033-295X.96.1.101
- McConkie, G. W., & Rayner, K. (1975). The span of the effective stimulus during a fixation in reading. Perception & Psychophysics, 17, 578–586. doi:10.3758/BF03203972
- McConkie, G. W., & Rayner, K. (1976). Asymmetry of the perceptual span in reading. Bulletin of the Psychonomic Society, 8, 365–368. doi:10.3758/BF03335168
- Mitchell, M. (1998). An introduction togenetic algorithms. Cambridge, MA: MIT Press.
- Nuthmann, A., Smith, T. J., Engbert, R., & Henderson, J. M. (2010). CRISP: A computational model of fixation durations in scene viewing. Psychological Review, 117, 382–405. doi:10.1037/a0018924
- O'Regan, J. K. (1990). Eye movements and reading. In E. Kowler (Ed.), Eye movements and their role in visual and cognitive processes (pp. 395–453). Amsterdam, Netherlands: Elsevier.
- Pollatsek, A., Reichle, E. D., & Rayner, K. (2006). Tests of the E-Z Reader model: Exploring the interface between cognition and eye-movement control. Cognitive Psychology, 52, 1–56. doi:10.1016/j.cogpsych.2005.06.001
- Radach, R., Inhoff, A. W., Glover, L., & Vorstius, C. (2013). Contextual constraint and N + 2 preview effects in reading. Quarterly Journal of Experimental Psychology, 66, 619–633. doi:10.1080/17470218.2012.761256
- Rayner, K. (1975). The perceptual span and peripheral cues in reading. Cognitive Psychology, 7, 65–81. doi:10.1016/0010-0285(75)90005-5
- Rayner, K., Juhasz, B. J., & Brown, S. J. (2007). Do readers obtain preview benefit from word n + 2? A test of serial attention shift versus distributed lexical processing models of eye movement control in reading. Journal of Experimental Psychology: Human Perception and Performance, 33, 230–245. doi:10.1037/0096-1523.33.1.230
- Rayner, K., McConkie, G. W., & Zola, D. (1980). Integrating information across eye movements. Cognitive Psychology, 12, 206–226. doi:10.1016/0010-0285(80)90009-2
- Rayner, K., Well, A. D., & Pollatsek, A. (1980). Asymmetry of the effective visual field in reading. Perception & Psychophysics, 27, 537–544. doi:10.3758/BF03198682
- Reichle, E. D. (2011). Serial-attention models of reading. In: S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), Eye movements handbook (pp. 767–786). Oxford: Oxford University Press.
- Reichle, E. D., Pollatsek, A., Fisher, D. L., & Rayner, K. (1998). Toward a model of eye movement control in reading. Psychological Review, 105, 125–157. doi:10.1037/0033-295X.105.1.125
- Reingold, E. M., & Stampe, D. M. (2004). Saccadic inhibition in reading. Journal of Experimental Psychology: Human Perception and Performance, 30, 194–211. doi:10.1037/0096-1523.30.1.194
- Richter, E., Engbert, R., & Kliegl, R. (2006). Current advances in SWIFT. Cognitive Systems Research, 7, 23–33. doi:10.1016/j.cogsys.2005.07.003
- Risse, S., & Kliegl, R. (2011). Adult age differences in the perceptual span during reading. Psychology and Aging, 26, 451–460. doi:10.1037/a0021616
- Risse, S., & Kliegl, R. (2012). Evidence for delayed parafoveal-on-foveal effects from word n + 2 in reading. Journal of Experimental Psychology: Human Perception and Performance, 38, 1026–1042. doi:10.1037/a0027735
- Schad, D. J., & Engbert, R. (2012). The zoom lense of attention: Simulating shuffled versus normal text reading using the SWIFT model. Visual Cognition, 20(4–5), 391–421. doi:10.1080/13506285.2012.670143
- Schad, D., Nuthmann, A., & Engbert, R. (2010). Eye movements during reading of randomly shuffled texts. Vision Research, 50, 2600–2616. doi:10.1016/j.visres.2010.08.005
- Schotter, E. R., Angele, B., & Rayner, K. (2012). Parafoveal processing in reading. Attention, Perception, & Psychophysics, 74, 5–35. doi:10.3758/s13414-011-0219-2
- Schotter, E. R., Reichle, E., & Rayner, K. (2014). Re-thinking parafoveal processing in reading: Serial-attention models can explain semantic preview benefit and n + 2 preview effects. Visual Cognition, this volume.
- Schroyens, W., Vitu, F., Brysbaert, M., & d'Ydewalle, G. (1999). Eye movement control during reading: Foveal load and parafoveal processing. Quarterly Journal of Experimental Psychology, 52A, 1021–1046. doi:10.1080/713755859
- Trukenbrod, H. A., & Engbert, R. (2012). Eye movements in a sequential scanning task: Evidence for distributed processing. Journal of Vision, 12(1): 5, 1–12. doi:10.1167/12.1.5
- Trukenbrod, H. A., & Engbert, R. (2013). ICAT: A computational model for the adaptive control of fixation durations. Psychonomic Bulletin & Review (in press).
- Underwood, N. R., & McConkie, G. W. (1985). Perceptual span for letter distinctions during reading. Reading Research Quarterly, 20, 153–162. doi:10.2307/747752
- Yang, S.-N., & McConkie, G. W. (2001). Eye movements during reading: A theory of saccade initiation time. Vision Research, 41, 3567–3585. doi:10.1016/S0042-6989(01)00025-6
APPENDIX
Here we provide additional analyses and simulations with the SWIFT model that (1) illustrate the goodness-of-fit of the present model variant with respect to global and local reading statistics, and (2) test the assumptions we made regarding the model's response to display changes. Scripts for running simulations with the present SWIFT version and the R scripts to produce the Figures in this article are available at the Potsdam Mind Research Repository (http://read.psych.uni-potsdam.de/pmr2/).
SWIFT's performance: Fixation duration and fixation probability statistics
compares the experimental (exp: dotted lines) and simulated (sim: solid lines) fixation durations and fixation probabilities for different word-frequency classes (left panels) and different word lengths (right panels) across all words in sentences read in the condition with valid preview of word n + 2. This contains the subset of data to which the model was fit. The results show that although the model in its present version managed without predictability information (i.e., with θ set to zero) and also differed in some other aspects from the predecessor model SWIFT 3, e.g., the global inhibition (ppf) parameter was rendered inactive, the global reading statistics derived from the simulated eye movements were in overall good agreement with the experimental results.
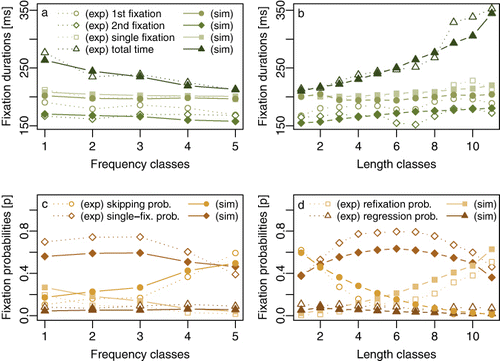
In particular, simulated fixation durations showed the expected decrease in fixation times when fixating words of higher frequency (i.e., words belonging to a higher frequency class) and increasing durations with increasing word length (i.e., words belonging to a higher length class). The relative decrease or increase was most pronounced for total reading times containing the durations of all fixations on a word including rereading, and this was so both for the simulated as well as the experimental data. However, while the SWIFT model captured the average durations of single fixations very well (i.e., cases in which a word was fixated only once during the first left-to-right reading of the sentence), it overestimated the duration of the first of multiple fixation cases substantially, specifically for words of the highest frequency class (10,000 or more occurrences per million) and of the two lowest length classes (2–4 letter words). This corresponds nicely with the fact that each sentence contained a three-letter word n + 1, of which half were very high-frequency function words that could even be repeated across sentences (e.g., “and” or “for”). As a consequence, readers might have shown an even stronger processing facilitation of these words reflected in even shorter fixation durations than could be explained purely on the basis of the frequency and length effects covered by the SWIFT model.
As can be seen in the bottom row of , the SWIFT model successfully reproduced highly specific word-length and word-frequency effects for different fixation probability measures. Although the probability of single fixations was generally underestimated by the model, it clearly showed the general trends in the data. Most noteworthy seems the inverted U-shaped relation between word length and single fixation probability showing the most single fixation cases for medium word lengths.
shows the comparison of the local reading statistics for the three words n, n + 1, and n + 2 in the target region. Also here, the simulated means for fixation durations and fixation probabilities were highly consistent with the empirical findings. The largest differences may be seen on word n + 2. Nevertheless, the SWIFT model seems to produce a similar ratio of skippings, single fixations, and refixation cases in the target region as obtained in the present n + 2-boundary experiments.
Display-change assumptions: Testing activation reset and saccade cancellation
TABLE A1 Experimental (exp) and simulated (sim) means for fixation duration and fixation probability measures on word n, n + 1, and n + 2 in the target region
Resetting the lexical activation of word n + 2 to zero after the display change implies the assumption that word-recognition processes have to restart from scratch when the target word replaces the nonword preview of word n + 2. However, it is likewise plausible that some low-level information can still be used after the display change (e.g., the word-length information) and some amount of lexical activation of word n + 2 may be preserved. Moreover, studies varying the degree of information overlap between preview and target have shown that different previews can lead to different amounts of preview benefit (e.g., Drieghe et al., Citation2005). (upper row) illustrates how the lexical reset affects the n + 2 preview effects in fixations after the boundary. As expected, the effect sizes increase the less activation is maintained after the display change. However, this relation is much stronger in gaze durations (dark green lines) and weaker in single fixation durations (light green lines), likely because higher activation of word n + 2 impacts stronger on the saccade-target selection (i.e., favouring refixations of word n + 2) and modulations of the single fixation duration due to foveal inhibition are more moderate.
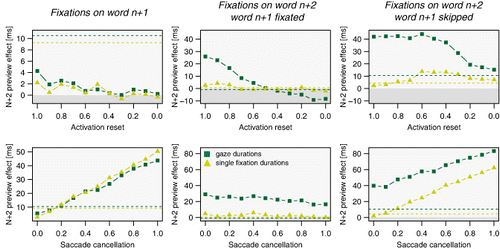
Increasing the number of saccade cancellations after a display change (while saccade programmes are still in their labile stage) shows a similar effect (see , bottom row). Preview effects of word n + 2 linearly increase with increasing number of cancelled saccades. In contrast to the activation reset, saccade cancellation influences gaze durations and single fixation durations alike. Additional saccade reprogramming costs are independent of the fixation type as saccades are cancelled with a certain unbiased probability determined only by the occurrence of a display change. As a consequence, they only affect the first fixation after crossing the boundary and do not influence the preview effects on word n + 2 when word n + 1 was previously fixated (see , bottom row right panel).