
Abstract
We present three statistical methods for causal analysis in life course research that are able to take into account the order of events and their possible causal relationship: a cross-lagged model, a latent growth model (LGM), and a synthesis of the two, an autoregressive latent trajectories model (ALT). We apply them to a highly relevant causality question in life course and health inequality research: does socioeconomic status (SES) affect health (social causation) or does health affect SES (health selection)? Using retrospective survey data from SHARELIFE covering life courses from childhood to old age, the cross-lagged model suggests an equal importance of social causation and health selection; the LGM stresses the effect of education on health growth; whereas the ALT model confirms no causality. We discuss examples, present short and non-technical introduction of each method, and illustrate them by highlighting their relative strengths for causal life course analysis.
Introduction
In recent decades there has been rapidly growing interest in research into how socioeconomic status (SES) and health are related over the life course. For example, illness and disability during childhood together with parental and adult social class influence health later in life (Blane, Netuveli, & Stone, Citation2007). This finding supports the view that biological and social factors in early life play an important role in development later in life. This field of enquiry is termed life course research, since it is concerned with development throughout life (Bartley, Citation2004; Blane et al., Citation2007; De Stavola et al., Citation2005; Kuh, Ben-Shlomo, Lynch, Hallqvist, & Power, Citation2003; Warren, Citation2009).
One interest of life course researchers is to make inferences of a causal nature, which requires us to move beyond the traditional approach simply describing the correlation of variables. In this paper we address social causation and health selection, where social causation suggests that SES affects the health status while health selection suggests that health status affects SES. To address such causal questions, we need a consistent sequence of observations that follow variations at the level of the individual, given that causality does not occur spontaneously but develops over time. Therefore, it is not sufficient to use cross-sectional data but longitudinal repeated measurement data is required, preferably from the early to the late stages of life. Three methods that are particularly suited to answering causal questions in life course research with longitudinal data are the focus of this paper: cross-lagged structural equation models, latent growth models, and autoregressive latent trajectories models as a combination of the first two. Cross-lagged structural equation model allows to use long time span information (for example distant age ranges) and can use different observed variables. Latent growth model (LGM) and autoregressive latent trajectories model (ALT) use the same observed variables over time, so that in many practical situations with limited data availability and comparability the time span tends to be shorter than for a cross-lagged model. We illustrate these methods in separate sections and consider their advantages and disadvantages. We also discuss them in comparison to other similar approaches. Our review is an illustration for researchers dealing with similar research questions or methods. In the end we provide a list of useful references.
The structure of this paper is as follows. In the next section we begin with structural equation model (SEM) as the foundation of all three methods, then we provide an overview of each method, underlying its rationale, key features and main uses, and briefly discuss an example of a real case of the application of these three models by referring to selected research papers. Then, we illustrate each one using empirical data and continue with a discussion of the merits of the methods and our conclusions.
Structural equation model
A SEM is a multivariate regression model that extends standard regression by allowing multiple outcomes, called ‘endogenous’ variables and unobserved ‘latent’ variables. For each endogenous variable there is a corresponding regression equation, which can depend on other endogenous variables, as well as on exogenous variables. Exogenous variables here refer to the predictor variables (covariates) that are not determined by any other variable in the model. A SEM combines the approach of confirmatory factor analysis for the measurement model and path analysis for the structural model. The measurement model describes how well the observed indicator variables serve as measurement instruments for the underlying latent variable, whereas the structural model describes the relationship among the latent variables, and both are denoted by path coefficients. This combination of the measurement model and the structural model is the core advantage of SEM: together, they simultaneously take into account the measurement errors, the multiple dependent variables of the model, and estimate direct, indirect and total effects (Acock, Citation2013; Bollen, Citation1989; Wang & Wang, Citation2012).
Cross-lagged structural equation model
A cross-lagged structural equation model (CL) takes into account the temporal order of longitudinal data by modelling a cross-lagged structure, where X at time t causes Y at time t + 1, or Y at time t causes X at time t + 1. Beside cross-lagged parameters, the temporal order is also shown by autoregressive parameters; that is, X at time t affects X at time t + 1, and likewise for Y. To describe graphically those associations we use single-headed arrows to define the causal relationships in the model. In addition, to define the covariances or correlations, and without causal interpretation, we use double-headed or bidirected arrows (Hox & Bechger, Citation1998).
The general model of a SEM can be expressed in three basic equations:
(1)
(2)
(3)
The first equation represents the structural model which establishes the relationship among the latent variables. The components of η are endogenous latent variables: ξ are exogenous latent ones, and both are a system of linear equations with B and ; ζ is a residual vector. Equations Equation2
(2) and Equation3
(3) represent measurement models which define the latent variables in terms of the observed variables. That is, Equation Equation2
(2) links the endogenous indicators, Y, to endogenous latent variables, η, and Equation Equation3
(3) links the exogenous indicators,X, to the exogenous latent variables
. In addition, both
and δ are the residuals (Bollen, Citation1989; Wang & Wang, Citation2012).
Having specified the model above, the next step is to find a unique solution for all the free parameters in the model. The model is said to be identified if the parameters in the system of equations in the model can be uniquely generated.
The model estimation for the structural parameters is derived from the covariance matrix of the observed variables, and the most widely used fitting function is maximum likelihood (ML). The procedure is to minimise the difference in the residuals between the sample variances/covariances and those estimated from the model. Note that maximum likelihood will work best when the variables are assumed to follow a Gaussian distribution and the sample size is large. There are other methods, such as ordinary least squares (OLS), 2 stage least squares and Bayesian methods, but these are beyond our scope. For detailed information on parameter fitting, refer to Bollen (Citation1989). A graphical representation of a cross-lagged structural equation model can be found in the Analytical Strategy section; see Figure (a) for an example. The latent variables are represented by ellipse shapes, and the observed variables are with rectangular shapes. The arrows from the latent variables to the observed variables represent measurement models while the arrows among the latent variables represent the structural relationships.
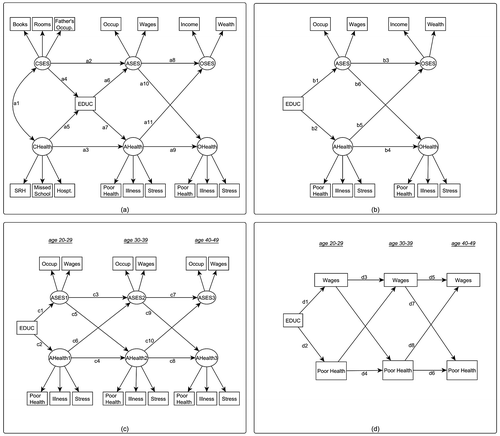
Figure 1. Four cross-lagged models, each with a specific time dimension and covariates. Model 1(a) describes the cross lagged model using the whole range of age, i.e. from childhood to old age. Model 1(b) reduces Model 1(a) by excluding childhood in order to have the same observation time. In Model 1(c) we only use the adult life indicators, i.e. the same measurements over 30 years. Model 1(d) extends Model 1(c) by using only one indicator for each SES and Health measurement.
If the variance/covariance matrix in the estimated model is not statistically different from the observed variance/covariance matrix, then the model fits the data well. We evaluate the adequacy of the model (i.e. the overall model fit)by means of goodness of fit statistics, of which there are many, such as χ2 (ideally the p-value is not significant), the comparative fit index (CFI)and the Tucker-Lewis index (TLI) (ideally both are >95%), the root mean square error of approximation (RMSEA) (ideally <0.05 and the 90% confidence of interval (CI) should be less than 0.08) and the standardised root mean square residual (SRMR) (ideally <0.05) (Browne & Cudeck, Citation1992; Byrne, Citation1998; Hu & Bentler, Citation1999; MacCallum, Browne, & Sugawara, Citation1996). We must emphasise that evaluation of the model is not purely a statistical matter. It should also be based on sound theory and empirical findings. If a model makes no substantive sense, it is not justified even if it statistically fits the data very well (Wang & Wang, Citation2012). Moreover, note that a good overall model fit is neither necessary nor sufficient for the identification of causal estimates.
Warren (Citation2009) is an example of how a CL can be applied to model the dynamics of the relationships between SES and health across the life course. He uses the Wisconsin Longitudinal Study, which includes information about individuals’ SES and health from childhood until late adult life. He imposes an indirect relationship through education between childhood SES and health later on and finds that higher childhood SES leads to greater educational achievement, better childhood health leads to better adult health and more educational achievement leads to better SES and better health. The hypothesis of social causation is strongly supported, while health selection is only indirectly supported through education.
Latent growth model
The main focus of a LGM is on changes or development over time. This requires that the subjects are followed over time with repeated measures of each variable of interest. The goal of this model is to make inferences about the features of growth trajectories, i.e. the initial levels of outcome measures and their rate of change. This leads us to more substantive questions concerning when or at what level the process begins and how it varies over time. In LGMs, the changes are represented by growth parameters or trajectories (which are specified as latent variables): the intercept, the initial value of the outcome measure, which is sometimes called a constant, because it is the standard from which change is measured, and the slope, which tells us how much the curve grows or the rate of outcome changes over time. In terms of causal analysis, the model can estimate the causal effect of the initial level on the rate of change.
LGMs assume that the subject’s growth trajectories vary randomly around the overall mean of growth trajectories (Bollen & Curran, Citation2006; Wang & Wang, Citation2012).
The trajectory equation for a simple LGM model is
(4)
where yit is the value of the trajectory variable y for the i-th case at time t, αi is the random intercept for case i, βi is the random slope for case i, and are random error terms.
The mean of the intercept, αi, and the mean of the slope, βi, are of interest, and can be modelled as follows:
(5)
(6)
where μα and μβ are the mean intercept and mean slope across all cases. Note also that and
are assumed to be uncorrelated with
.
The above equations can be combined as follows:(7)
The first term refers to fixed components, which represent the mean structure; and the second to random components, representing various sources of individual variability.
The identification, parameter estimation, and goodness of fit in a LGM are similar to those of the CL method. For example, the most common estimation method is ML. There are various types of ML estimators, for instance, robust ML (MLM) accounts for non-normality and ML with robust standard error (MLR) accounts for small sample size. For goodness of fit, the most commonly used indicators are CFI or TLI indices (Bollen & Curran, Citation2006).
A graphical representation of a LGM and details on how it can be applied to empirical life course analysis will be shown in the Analytical Strategy section; see Figure . Repeated measurements of SES and health are used to construct the trajectories and the causal analysis between SES and health is described by the cross-lagged path between the trajectories.
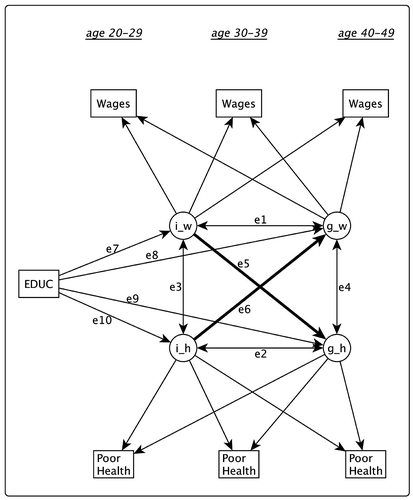
Figure 2. LGM model with education as the exogenous variable. The SES is represented by wages and health by percentage of years of poor health.
An example of a LGM in life course research is an empirical analysis of the direct relationship between changes in SES indicators and changes in morbidity over time (Hallerod & Gustafsson, Citation2011). The time-invariant covariates are age, sex, and social class, and the observed outcome measures are education, occupation, income, and morbidity. The authors find that each intercept has significant variance, indicating that the latent intercept factor significantly varies across individuals. Apart from education, the slopes and variances of occupation, income, and morbidity are significant, which indicates that the slope also varies across individuals. Furthermore, from the intercepts, women have slightly lower average education levels and there is an age difference that reflects the expansion of the education system in the 1980s. From the slopes, people who have a white collar father or a self-employed father, net of education, occupation and income intercepts, have slightly better career prospects.
ALT model
We have described above two methods to incorporate temporal order, at the level of time-specific influences, and at the level of latent trajectories. These two methods employ different approaches: cross-lagged models take into account the stability through autoregressive parameters, within each time-specific, while LGMs take into account the accumulation, or the whole range of observations over their trajectories. A combination of these two methods is called an ALT model (Bollen & Curran, Citation2006), and it can be created in two ways: either by adding the autoregressive parameters to the repeated and observed variables of a LGM, or by adding the trajectory parameters to a CL model.
By adding the autoregressive parameters we avoid the potential bias of independencies, i.e. we treat later observations as direct functions of earlier observations plus a time-specific error. Although ALT might in some specific cases be mathematically equivalent to a LGM, with autoregressive error structures it represents a more flexible and generic expression of that model (Hamaker, Citation2005; Morin, Maïano, Marsh, Janosz, & Nagengast, Citation2011).
The general ALT equation, with two variables, y and w, is as follows:(8)
(9)
where αyt is the fixed intercept at time t, is the autoregressive parameter,
is the residual, and the first observations yi1and wi1 are treated as predetermined (Bollen & Curran, Citation2006).
The identification, parameter estimations, and model evaluations are the same as in CL and LGM. A graphical representation of an ALT model can be found in the Analytical Strategy section: see Figure . It extends the LGM graphs by adding autoregression parameters for both SES and health. Although we could not find an example of ALT applied to our research question, this model has been used in psychological research (Morin et al., Citation2011). They studied the interplay between self-esteem and body image in adolescents. They found that self-esteem and body image levels remained high and stable over time, and the growth of self-esteem were positively influenced by the growth of body image.
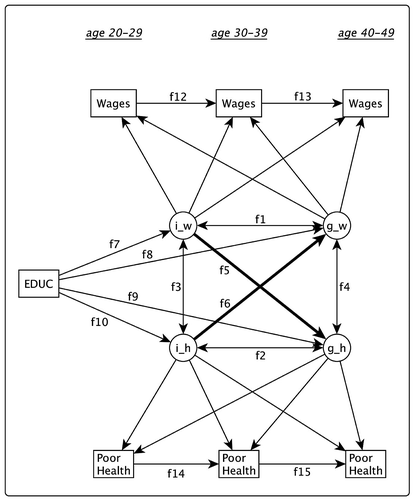
Figure 3. ALT model, similar to the LGM model in Figure , but with regressing later time-specific repeated measures on earlier measures of the same construct.
Data and methods
The data-set we use for these analyses is SHARELIFE, the third wave of data collection in 2008/2009 for Survey of Health, Aging and Retirement in Europe (SHARE) that collects micro-data on the health and SES of individuals over 50 years old across 15 European countries, covering the interplay between economic, health, and social factors in shaping older people’s living conditions (Borsch-Supan et al., Citation2013). SHARELIFE collected retrospective life course data on individuals and their spouses regarding their health and SES from childhood to old age. The data we use combine six European countries (Austria, Germany, The Netherlands, France, Switzerland, and Belgium), which are similar enough in terms of social model and welfare state for the data to be aggregated, particularly given that our analysis serves only for illustrative purposes (Pappadà, Citation2010). We only use males (N = 3812) because gender differences are beyond the scope of this study. We use these data and design to study our causality hypotheses: social causation (SC) and health selection (HS).
Analytical strategy
Figure shows four cross-lagged models with different age ranges and measurements. Figure (a) shows the CL model using the whole age range, i.e. from childhood to old age. We start by exploiting the full age ranges, because, by default, this is the preferable way to address causality in life course research (Heckman, Citation1981; Smith, Citation2009). We split the life course data into three time points: childhood (C), adult life (A), and old age (O). We define childhood as up to 15 years old, adult life as between 30 and 54 years old; and old age as above 55 years old, and we construct age-specific latent variables and measurement models. The information about childhood SES refers to when they were age 10, and consists of number of books in the household (the place where they lived), number of rooms per person, and father’s occupation (following ISCO skill levels 1–4). For SES in adult life we use two indicators: ISCO skill levels and monthly average wages weighted by PPP to 2006 German euros (Weiss, Citation2012), while for SES in old age we use monthly household net income and household wealth (net financial assets). The educational achievement of individuals is expressed in years of schooling. For health status during childhood (until age 15), the respondents were asked to self-rate their health in five categories, and then whether they missed school or were hospitalised for one month or more. For adult and old age health, we use three indicators: periods of stress, periods of illness, and periods of poor health. The variables contain the percentage of years in which a person reports experiencing one of the health conditions. Altogether, we have six latent variables, each with their observed variables or indicators. For simplicity, we do not draw the residuals. We allow CSES and CHealth to covary by adding a bidirected arrow between them. Education acts as a mediator of the effects between childhood and adult life (MacKinnon, Citation2008). This makes it possible to differentiate between direct effects, i.e. the effect of CSES on ASES and its indirect effect through education.
Figure (b) shows a similar cross-lagged design but without childhood information. It is a model nested within Figure (a) with exactly the same information on adult life and old age. We exclude the childhood information in this model to make it comparable to the age ranges of the subsequent models. In order to fully achieve this comparability, our next step is Figure (c), where we exclude old age and use the adult life indicators, observe them at ages 20–29, 30–39, and 40–49. In Figure (d), instead of measurement models we use single measured indicators of SES and health, namely average wages and the percentage of years in which a person reports experiencing poor health (years of poor health) along the same time dimension. While CL models allow both latent and measured variables, including the option that indicators of a concept such as SES might change between life stages, a LGM requires SES to be measured over time in exactly the same way. Thus, in order to compare a CL model and a LGM, we need to use wages as the indicator of SES for both models.
The causal hypotheses in Figures (a)–(d) are represented by the cross-lagged paths (arrows) between SES and health, which represent the changes in SES caused by changes in health, and vice versa. In addition, the autoregressive parameters, e.g. the pathway between ASES and OSES, show the steady-state relationship, i.e. how SES at one time point affects subsequent SES.
In Figure we are interested in how changes in both socioeconomic and health status influence each other at the level of trajectories. We replicate the data design and the measurements of Figure (d), but this time average wages and years of poor health are not directly associated, but through their intercepts and slopes. The trajectories in the LGM take into account the accumulative processes of the development of wages and health over time, i.e. over 30 years in our model. To estimate the changes in SES and health over the three time periods, we denote the intercept of average wages with i–w and its slope with g–w, and the health trajectories with i–h and g–h. To explain variation in the intercept and the slope, we include education as a time-invariant variable. The factor loadings of the intercepts are fixed at one, which means the intercept influences all measures across time equally, while the factor loadings for the slope are fixed at the amount of time elapsed since the first measurement. Assuming linear trajectories and equal time intervals between the observations, we set time scores at 0, 10, and 20 for the three time points respectively. The causal hypothesis in this model is through the intercept and the slope, i.e. the intercept of wages can affect the slope of health (SC), and the intercept of health can affect the slope of wages (HS).
Finally, Figure shows the ALT model, which extends Model 2 taking into account the stability of the development of average wages and years of poor health. This allows us to test the same hypotheses of causality as in Model 2 while taking into account the potential bias that can occur by ignoring the autoregressive paths between the average of wages or between years of poor health.
For all models, we include cohort as control variable (but we do not show it in the diagrams) and we use male samples only. All the analyses are done using Mplus version 7.3. We use full-information maximum likelihood for the parameter fitting to address the problem of missing data (Arbuckle, Citation1996; Little & Rubin, Citation2002).
Results
The distribution of the variables for the cross-lagged models can be seen in Table in the section ‘Variables for CL Models’. The subsequent parts show the characteristics of LGM and ALT models. From here onwards ‘Model 1a’ refers to ‘Figure a’, etc.
Table 1. Descriptive statistics of all variables in all models.
We begin with the results for Model 1a with the correlation of SES and health in childhood (see column ‘Model 1a’ in Table ). We find no substantive correlation (0.030) between childhood SES and health. Next, we move to the autoregressive parameters, where we find that for all time periods all parameters are statistically significant. Furthermore, CSES affects ASES not only through its autoregressive parameter (0.562), but also indirectly (mediated) through education (CSES to education = 0.520 and education to ASES = 0.354). We conclude that the direct effect of CSES on ASES is larger than the indirect one. For the causality hypotheses, described through the cross-lagged paths between SES and health from childhood to adult life we do not find them statistically significant, either indirectly via education or directly (direct paths not shown in the figure (a)). However, from adult life to old age both hypotheses are confirmed; i.e. for SC a one-standard-deviation improvement in SES in adult life is associated with a0.064 standard-deviation of less health problems in old age health. In other words, the better the job and wage in adult life, the fewer health problems in old age. In addition, or HS a one-standard-deviation increase in worse health is associated with a 0.049 standard-deviation deterioration in SES at older age, which means increasing health problems in adult life will reduce income and wealth in old age.
Table 2a. Parameter estimates (standardised) for all models. NS = not shown (in the figure); ASES1 = Adult SES at time 1, Wages P1 = Wages at time 1, etc.
In Model 1b, we find all the autoregressive parameters are statistically significant and the sizes are close to the ones in Model 1a. The effect of education on adult SES (0.630) stays statistically significant and becomes stronger in this model. It can be interpreted as one standard deviation of enhancement of education leading to a 0.630 standard-deviation improvement in adult SES. Regarding the causality hypotheses, both social causation and health selection are present and of about the same size. The estimated parameters in Model 1b do not differ much from Model 1a, which tells us that excluding childhood information from the same population and the same design can lead to similar results. We find that our model fits the data well (see Table for the goodness of fit of all models).
Table 2b. Various goodness of fit statistics for all models.
In Model 1c, we focus the observations on the adult life period only, and observe the events from age 20–29 to age 40–49. We find all autoregressive parameters statistically significant. The effect of education on SES at ages 20–29 is also statistically significant (0.477), which can be interpreted as a one-standard-deviation enhancement of education leading to a 0.477 improvement in SES at age 20–29. Regarding causality, SC is present (−0.028) at both age transitions, but the absolute sizes of the effect are less than in Model 1b and SC in the second age transition is at a lower level than in the previous transition. Compared to Model 1b, HS is no longer confirmed, as the coefficients are small.
In Model 1d, we use a single indicator for both SES and health and observe them at three time points. As in Model 1a and 1b, all the autoregressive parameters are statistically significant for both average wages and years of poor health. In addition, we also find that the effect of education on SES consistently remains significant, even though it is smaller (0.123). However, for no period do we find any statistically significant SC or HS between average wages and years of poor health.
Model 2 shows the LGM, and the distribution of the variables can be seen in the lower part of Table in the section ‘Variables for LGM and ALT’. The correlation between the intercept and the slope of average wages is statistically significant (−0.235), i.e. controlling for cohort and education those who started with higher wages experience a smaller increase over time. This can be interpreted as a ceiling effect: those whose ages are already high can increase their wages only by a limited amount. On the contrary, the correlation between the intercept and the slope of years of poor health is not statistically significant. Furthermore, neither the correlation of the two intercepts nor the correlation of the two slopes are statistically significant, indicating that the initial level of average wages is not correlated with initial health problems, and the rate of change of average wages is not correlated with the rate of change of years of poor health. Neither SC nor HS are statistically significant, i.e. neither the path from the intercept of average wages to the slope of years of poor health, nor from the intercept of years of poor health to the slope of average wages. However, education statistically significantly affects the intercept and growth of average wages (0.130 and 0.257) and the slope of years of poor health (−0.062). This means that education is an important factor for having a good starting salary and a better progression of it. Additionally, higher education leads to a less steep decline in health. The latter conclusion supports social causation, bearing in mind that education is one dimension of SES.
Model 3 shows the ALT Model, which is only slightly different from Model 2, i.e. we add the autoregressive parameter for average wages and years of poor health. We note three important changes. First, the correlation between the intercept and the slope of years of poor health is now statistically significant with a negative sign (−0.296), which can be interpreted as, controlling for cohort and education, those who initially have more health problems experience a less steep increase in accumulative years of poor health between ages 20 and 50. Second, the effect of education on the trajectories of years of poor health (−0.052) just loses its statistical significance, but its size is close to that in Model 2. Finally, we obtain a very well-fitting model. The correlations of the two trajectories are not statistically significant, neither between the intercepts nor between the slopes. We find none of the autoregressive parameters for either average wages or years of poor health statistically significant. Regarding the causality hypotheses, neither SC nor HS is confirmed.
Discussion
We have presented three statistical methods for causal analysis and their applications in the life course framework: a cross-lagged model, a LGM, and an ALT model. We have demonstrated how social causation and health selection can be addressed by each of the three models.
Applying a cross-lagged model, and looking at the long time span from childhood to old age and using different indicators for different ages, we find that both social causation and health selection are present, but only from adult life to old age. From childhood to adult life we only find statistically significant effects in the autoregressive parameters and in how education takes a role as a mediator between childhood and adult SES. The advantage of CL is that it allows different observed variables to be used as indicators for the underlying concept to be measured. This is not only important practically, because in a given data-set measures for SES are likely to differ between childhood, adult life and old age. It may also reflect theoretical reasons for changing indicators of SES or health from one age range to another, because different indicators may have different relative importance at different ages. Even though these variables may be measured with error, CL can handle this by imposing latent variables (measurement model). By comparing the SC and HS coefficients between different ages a CL model can reveal critical periods for the effect of certain factors. The steps from Model 1a to 1d illustrate that finding empirical support for causal hypotheses such as SC and HS in life course research heavily depends on the length of the periods observed (for instance age transitions) and the chosen indicators. In particular, limiting the focus to adult life only (Model 1c) decreases support for SC but almost erases support for HS, either because such effects take longer than 10 years, or they do not take place in adult life. Simplifying the measurement of SES and health in Model 1d deletes any support for our causal hypotheses, which suggest that either wages alone are not relevant for subsequent health changes or that a univariate measurement of health is less sensitive for our research question than the measurement models used in our Model 1a to 1c.
A LGM requires the use of the same variable for SES or health, measured over several occasions. It focuses on how the initial state of one variable affects the growth of another variable. For the same practical and theoretical reasons just mentioned, the time span for this model will in most cases be limited, because the same variables for SES or health for the whole life span might not be available or theoretically appropriate. Regarding our causality question, the only statistically significant result that we can interpret causally is the effect of education on the slope of years of poor health (SC). In principle, LGM focuses on the accumulative progression of SES and health over time. One disadvantage of LGM is the lack of autoregressive parameters, since it assumes that a later observation is independent of a previous one. This drawback of LGM is the main advantage of ALT. It is hard to deny that each observation will always depend on the previous one. Although our ALT model takes this into account, the results in terms of our causal question are similar to the LGM model.
To conclude, for causal analysis in a life course framework where we analyse long age ranges and have different observed variables for each time period, CL is more suitable. Instead, if the same variables are available over time then LGM or ALT would also be appropriate choices. Thus, the data available and the research question are central for the decision on the method, and we have provided examples to distinguish the characteristics of the different ones available. Any analysis of this kind should be based on a sound understanding of the mechanisms, their time line, and the operationalization of them, because results heavily depend on such choices.
We have also tried to approach the topic of our paper with simulated data. The general advantage of simulated data is that one can impose a certain constraint, for example a ratio between the coefficient of SC and the coefficient of HS in order to check if a method can reveal exactly this result. In principle this approach can increase the comparability of the results across methods and can improve the explanation of differences. In our particular simulation we faced the problem that it was impossible to simulate data not using a very specific complex model that, by this very nature, already favours one of the three models used to analyse the simulated data later on. Thus, we created three simulated datasets, each created by one of our three methods. Results show that within LGM and ALT it does not matter greatly which model is used to simulate or analyse the data, stressing the similarity of these two models. However, data created by a CL Model and analysed with LGM/ALT or vice versa produced results very different from the ones we imposed during the data simulation. The results are available as a supplementary material and the programmes are available from the authors upon request.
We acknowledge the debate about the limits of causal modelling, in particular in social research. It has been argued that complexity theory should be used to regard the social world holistically taking into account that it is unpredictable with multi-directional causality and feedback in unpredictable contexts, and with webs and networks of non-linear causality. ‘Causal modelling is necessary but unacceptably reductionist and over-simplistic, omitting the very details which must be included in understanding causality’ (Morrison, Citation2012). We can not discuss such fundamental criticism to causal modelling here, we admit that all our approaches are based on accepting such simplifications and claim that statistical causal modelling can be useful in many circumstances. Note that certain problems, which are not specific to causality or life course analysis, should also be considered, e.g. sample size and missing data (including attrition/drop outs). For categorical data and small sample sizes, the rapid development of bootstrap or Monte Carlo methods for computational issues (resampling) looks promising to handle estimation problems for non-normally distributed data, while for missing data we can use various multiple imputation methods (Efron & Tibshirani, Citation1994; Gilks, Richardson, & Spiegelhalter, Citation1996).
We mentioned earlier that there are other methods for dealing with time ordering and causal analysis: the graphical chain model (GCM) and latent transition analysis (LTA). The GCM makes use of the Markov properties of the repeated measurements, and thus it can draw conclusions about conditional independency structures of the variables of interest. In addition, it offers a relatively simple way to estimate direct and indirect effects, with a sequence of regression models using ML. The disadvantage of the GCM is that it cannot take measurement errors into account and it is not straightforward to incorporate latent variables. For exploratory purposes, and with its computational simplicity, this approach can be employed together with SEM in order to obtain a baseline model. LTA is a mixture model that identifies a priori unknown homogenous classes of individuals based on the measures of interest, and models the dynamics or changes in the categorical latent class (the transition) over time. LTA is similar to LGM, the difference being that LTA deals with categorical latent variables. Like the other methods, the estimation method of LTA uses ML or Bayesian methods.
Table summarises the methods we have discussed above and presents their distinguishing characteristics. We do not show ALT since it is a combination of CL and LGM. Each approach is prone to misspecification, so that to achieve robust conclusions in causal inference more than one approach should be adopted, with the results compared and inconsistencies investigated, thus carrying out sensitivity analysis in the broader sense (De Stavola et al., Citation2005).
Table 3. Summary of statistical methods in this review.
We provide below a selected bibliography that we consider useful for more in-depth study. An accessible introduction to SEM and CL is given in some useful handbooks (Bollen, Citation1989; Hox & Bechger, Citation1998; Jöreskog & Sörbom, Citation1996; Kline, Citation2011). They provide details of SEMs with a clear exposition of the technical issues. For LGM and ALT, we recommend Bollen and Curran (Citation2006), who focusses on the LGM and extend it to the ALT model. In addition, for the applications of LGM using Stata we recommend Acock (Citation2013). For the GCM, useful references are Whittaker (Citation1990) and Cox and Wermuth (Citation1996). They contrast path diagrams with conditional independence graphs. For LTA, we recommend Collins and Lanza (Citation2010) and Lanza, Patrick, and Maggs (Citation2010). Since longitudinal data is the main resource for causal life course analyses, a general reference for longitudinal data analysis is Diggle, Heagerty, Liang, and Zeger (Citation2002). In addition, for recent advances in the modelling of probability and causal analysis, we recommend Pearl (Citation2009).
Supplementary material
Supplementary material for this article can be accessed here http://dx.doi.org/10.1080/13645579.2015.1091641.
Notes on contributors
Eduwin Pakpahan is a research assistant at the Department of Political and Social Sciences at the European University Institute (EUI) in Florence. His background is in statistics and he is interested in the interplay between socioeconomic and public health research.
Rasmus Hoffmann is affiliated with the Department of Public Health at the Erasmus Medical Centre in Rotterdam and the Department of Political and Social Sciences at the European University Institute in Florence, where he leads a project on causality between socioeconomic status and health, funded by a starting grant of the European Research Council. His background is in sociology, demography, and public health.
Hannes Kröger is a research assistant at the Department of Political and Social Sciences at the European University Institute (EUI) in Florence. His background is in labour market and health sociology, and quantitative methodology in social sciences.
TSRM_1091641_simulation_design_and_results.pdf
Download PDF (255.2 KB)Acknowledgements
This paper uses data from SHARE wave 4 release 1.1.1, as of 28 March 2013 or SHARE wave 1 and 2 release 2.6.0, as of 29 November 2013 or SHARELIFE release 1, as of 24 November 2010. The SHARE data collection has been primarily funded by the European Commission through the fifth Framework Programme (project QLK6-CT-2001-00360 in the thematic programme Quality of Life), through the sixth Framework Programme (projects SHARE-I3, RII-CT-2006-062193, COMPARE, CIT5-CT-2005-028857, and SHARELIFE, CIT4-CT-2006-028812) and through the seventh Framework Programme (SHARE-PREP, N° 211909, SHARELEAP, N° 227822 and SHARE M4, N° 261982). Additional funding from the US National Institute on Aging (U01 AG09740-13S2, P01 AG005842, P01 AG08291, P30 AG12815, R21 AG025169, Y1-AG-4553-01, IAG BSR06-11 and OGHA 04-064) and the German Ministry of Education and Research as well as from various national sources is gratefully acknowledged (see www.share-project.org for a full list of funding institutions).
Funding
This work was financially supported by the European Research Council for the research project “SESandHealth” [grant number 313532].
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Acock, A. (2013). Discovering structural equation modeling using Stata. Texas: Stata Press.
- Arbuckle, J. L. (1996). Full information estimation in the presence of incomplete data. In G. A. Marcoulides & R. E. Schumacker (Eds.), Advanced Structural Equation Modeling (pp. 243–277). Mahwah, NJ: Lawrence Erlbaum.
- Bartley, M. (2004). Health inequality: An introduction to theories, concepts and methods. Cambridge: Polity Press.
- Blane, D., Netuveli, G., & Stone, J. (2007). The development of life course epidemiology. Revue d'Épidémiologie et de Santé Publique, 55, 31–38.10.1016/j.respe.2006.12.004
- Bollen, K. A. (1989). Structural equations with latent variables. Toronto: Wiley.10.1002/9781118619179
- Bollen, K. A., & Curran, P. J. (2006). Latent curve models: A structural equation perspective (Vol. 467). New Jersey, NJ: Wiley.
- Borsch-Supan, A., Brandt, M., Hunkler, C., Kneip, T., Korbmacher, J., Malter, F., … Team, S. C. C. (2013). Data resource profile: The Survey of Health, Ageing and Retirement in Europe (SHARE). International Journal of Epidemiology, 42, 992–1001.10.1093/ije/dyt088
- Browne, M. W., & Cudeck, R. (1992). Alternative ways of assessing model fit. Sociological Methods & Research, 21, 230–258.
- Byrne, B. M. (1998). Structural equation modeling with LISREL, PRELIS, and SIMPLIS: Basic concepts, applications, and programming. Mahwah, NJ: L. Erlbaum Associates.
- Collins, L. M., & Lanza, S. T. (2010). Latent class and latent transition analysis: With applications in the social, behavioral, and health sciences. New Jersey, NJ: Wiley.
- Cox, D. R., & Wermuth, N. (1996). Multivariate dependencies: Models, analysis, and interpretation. Boca Raton, FL: Chapman & Hall/CRC.
- De Stavola, B. L., Nitsch, D., dos Santos Silva, I., McCormack, V., Hardy, R., Mann, V., … Leon, D. A. (2005). Statistical issues in life course epidemiology. American Journal of Epidemiology, 163, 84–96.10.1093/aje/kwj003
- Diggle, P. J., Heagerty, P., Liang, K.-Y., & Zeger, S. L. (2002). Analysis of longitudinal data (2nd ed.). Oxford: Oxford University Press.
- Efron, B., & Tibshirani, R. J. (1994). An introduction to the bootstrap. Boca Raton, FL: CRC Press.
- Gilks, W. R., Richardson, S., & Spiegelhalter, D. J. (Eds.). (1996). Markov chain Monte Carlo in practice. Boca Raton, FL: Chapman&Hall/CRC.
- Hallerod, B., & Gustafsson, J. E. (2011). A longitudinal analysis of the relationship between changes in socio-economic status and changes in health. Social Science & Medicine, 72, 116–123.
- Hamaker, E. L. (2005). Conditions for the equivalence of the autoregressive latent trajectory model and a latent growth curve model with autoregressive disturbances. Sociological Methods & Research, 33, 404–416.
- Heckman, J. J. (1981). The incidental parameters problem and the problem of initial conditions in estimating a discrete time-discrete data stochastic process. In C. F. Manski & D. McFadden (Eds.), Structural analysis of discrete data and econometric applications (pp. 179–195). Cambridge, MA: MIT Press.
- Hox, J., & Bechger, T. (1998). An introduction to structural equation modelling. Family Science Review, 11, 354–373.
- Hu, L. T., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal, 6(1), 1–55.10.1080/10705519909540118
- Jöreskog, K. G., & Sörbom, D. (1996). LISREL 8: User’s reference guide. Lincolnwood, IL: Scientific Software International.
- Kline, R. B. (2011). Principles and practice of structural equation modeling (3rd ed.). New York, NY: The Guilford Press.
- Kuh, D., Ben-Shlomo, Y., Lynch, J., Hallqvist, J., & Power, C. (2003). Life course epidemiology. Journal of Epidemiology and Community Health, 57, 778–783.10.1136/jech.57.10.778
- Lanza, S. T., Patrick, M. E., & Maggs, J. L. (2010). Latent transition analysis: Benefits of a latent variable approach to modeling transitions in substance use. Journal of Drug Issues, 40, 93–120.10.1177/002204261004000106
- Little, R. J. A., & Rubin, D. B. (2002). Statistical analysis with missing data (2nd ed.). Hoboken, NJ: Wiley.10.1002/9781119013563
- MacCallum, R. C., Browne, M. W., & Sugawara, H. M. (1996). Power analysis and determination of sample size for covariance structure modeling. Psychological Methods, 1, 130–149.10.1037/1082-989X.1.2.130
- MacKinnon, D. P. (2008). Introduction to statistical mediation analysis. New York, NY: Routledge.
- Morin, A. J. S., Maïano, C., Marsh, H. W., Janosz, M., & Nagengast, B. (2011). The longitudinal interplay of adolescents’ self-esteem and body image: A conditional autoregressive latent trajectory analysis. Multivariate Behavioral Research, 46, 157–201.10.1080/00273171.2010.546731
- Morrison, K. (2012). Searching for causality in the wrong places. International Journal of Social Research Methodology, 15, 15–30.10.1080/13645579.2011.594293
- Pappadà, G. (2010). A comparative analysis of welfare systems and the health and social sector: Evidence from 16 European countries. European papers on the new welfare. Retrieved 21 June, 2015 from http://eng.newwelfare.org/2010/10/08/a-comparative-analysis-of-welfare-systems-and-the-health-and-social-sector-evidence-from-16-european-countries-2/
- Pearl, J. (2009). Causality: models, reasoning, and inference (2nd ed.). Cambridge: Cambridge University Press.10.1017/CBO9780511803161
- Smith, J. P. (2009). Reconstructing childhood health histories. Demography, 46, 387–403.10.1353/dem.0.0058
- Wang, J., & Wang, X. (2012). Structural Equation Modeling: Application Using Mplus. Chichester: Wiley.10.1002/9781118356258
- Warren, J. R. (2009). Socioeconomic status and health across the life course: A test of the social causation and health selection hypotheses. Social Forces, 87, 2125–2153.10.1353/sof.0.0219
- Weiss, C. T. (2012). Two measures of lifetime resources for Europe using SHARELIFE. SHARE Working Paper, 06-2012.
- Whittaker, J. (1990). Graphical models in applied multivariate statistics. Chichester: Wiley.