
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Detecting movement patterns with complicated spatial or temporal characteristics is a challenge. The past decade has witnessed the success of deep learning in processing image, voice and text data. However, its application in movement pattern detection is not fully exploited. To address the research gap, this paper develops a deep learning approach to detect regional dominant movement patterns (RDMP) in trajectory data. Specifically, a novel feature descriptor called directional flow image (DFI) is firstly proposed to store the local directional movement information in trajectory data. A DFI classification model called TRNet is designed based on convolutional neural network. The model is then trained with a synthetic trajectory dataset covering 11 classes of commonly encountered movement patterns in reality. Finally, a sliding window detector is built to detect RDMP at multiple scales and a clustering-based merging method is proposed to prune the redundant detection results. Training of TRNet on the synthetic dataset achieves considerably high accuracy. Experiments on a real-world taxi trajectory dataset further demonstrate the effectiveness and efficiency of the proposed approach in discovering complex movement patterns in trajectory data.
1. Introduction
With the rapid development of positioning technologies, large amounts of trajectory data have been collected by tracking a wide range of objects including pedestrian, hurricane, animal and vehicles. Movement patterns embedded in trajectory data can provide valuable information for the tracked objects and the context, which play an important role in many applications. For example, hotspot or point of interest can be discovered from clusters of GPS observations in floating car data (Guo et al. Citation2012, Wang et al. Citation2017b). Passenger-finding strategies can be also studied by analyzing the distribution of origin and destination in taxi trips (Li et al. Citation2011). Sequential patterns in trajectory data, which indicate a sequence of locations frequently visited by a certain number of objects, have been explored to study route choice (Yang and Gidfalvi Citation2018) and individual travel behavior (Ye et al. Citation2009).
A large diversity of movement patterns in trajectory data have been studied in the previous work, e.g. chasing (De Lucca Siqueira and Bogorny Citation2011), flock (Wachowicz et al. Citation2011), following (Li et al. Citation2013) and convergence (Laube et al. Citation2005). A more detailed review of movement patterns can refer to Laube et al. (Citation2005) and Dodge et al. (Citation2008). Due to the heterogeneous properties of these patterns, previous approaches are generally designed for the discovery of a limited number of patterns. With a low generalization capability, they cannot be easily extended to support more conceptual query of movement patterns, e.g. finding the places where counter-clockwise movement pattern occurs.
In the past decade, deep learning, as a class of machine learning methods based on artificial neural network, has been successfully applied in many fields such as computer vision (Krizhevsky et al. Citation2012, Karpathy et al. Citation2014), speech recognition (Graves et al. Citation2013) and natural language processing (Kim Citation2014). Various architectures of the neural network have been designed including convolutional neural network (CNN) (Lecun et al. Citation1998), recurrent neural network (Mikolov et al. Citation2010) and deep belief network (Hinton et al. Citation2006). Inspired by this breakthrough, several attempts have been made in the transportation domain to employ deep learning methods to exploit the value of big data. In Zhang et al. (Citation2017), a spatial-temporal deep residual network is designed to predict the inflow and outflow in each region of a city by treating the traffic in a whole city as an image. In Wang et al. (Citation2017a), context information is integrated with traffic data to predict supply and demand for car-hailing services. In Yao et al. (Citation2018), a Multi-View Spatial-Temporal Network is designed to capture spatial, temporal and semantic relations to predict traffic based on taxi request data. However, predicting traffic from point observations can be regarded as a regression problem, which contributes little to detecting movement patterns in trajectory data.
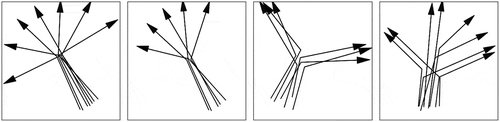
Conventional CNN models cannot be directly applied to movement pattern detection as the input of CNN is required to be a fixed tensor. A trajectory can contain a variable number of points, which belongs to vector data. Although vector data have been studied on the computer vision field, the efforts are mostly devoted to shape classification and matching (Belongie et al. Citation2002, Xu et al. Citation2009, Shu and Wu Citation2011, Wang et al. Citation2014), where a set of points describing the contour of an object is classified or matched. Compared with a set of point observations, a trajectory provides two additional pieces of information: direction and connectivity between points. These features can be crucial in distinguishing specific classes of patterns. An example is illustrated in where the four groups of trajectories follow a diverging pattern. It can be observed that both the number of trajectories in a group and the number of points within trajectory can be variable. A straightforward idea is to convert the trajectories into a density map and then classify the map with CNN. However, that approach is still problematic in handling direction information. If every trajectory is reversed in , the same density map is generated but a converging pattern will be followed.
Figure 1. Different kinds of diverge pattern.
To address the above problem, this paper proposes a novel feature descriptor for trajectory data and designs a CNN to classify movement patterns in trajectories. The approach discovers regions in space where a certain movement pattern is followed by the majority of trajectories, which is hence formulated as regional dominant movement pattern. That movement information can be applied in several areas, e.g. detecting hotspot or road intersections from GPS data, monitoring pedestrian movement for emergency purpose, studying the behavior of animals. The contributions of this paper are summarized as follows:
A novel feature descriptor is proposed for trajectory data as a direction flow image, which stores both position and direction information of a variable set of trajectories in a multi-spectral image.
A CNN-based model called TRNet is designed to classify regional dominant movement patterns in trajectories. A synthetic dataset is manually created by manually drawing trajectories to follow movement patterns commonly encountered in practice. Training of TRNet on the synthetic data achieves a considerably high accuracy.
A sliding window detector is designed to identify multiple RDMPs in a large collection of trajectories. A clustering-based merging method is further proposed to eliminate redundancy in the detection result.
Experiments on a real-world dataset demonstrate the efficiency and effectiveness of TRNet in complex movement patterns detection.
The remainder of this paper is organized as follows: Section 2 presents a review for movement pattern mining in trajectory data. The problem of RDMP detection is formulated in Section 3 and the proposed approach is described in Section 4. Section 5 presents experiments of TRNet on both synthetic and real-world datasets. Finally, a conclusion is drawn and future research directions are outlined in Section 6.
2. Related work
In the literature, many approaches have been proposed to detect various types of movement patterns in trajectory data. According to the form of the discovered patterns, they can be divided into two categories.
In the first category, patterns are extracted in the form of aggregated statistics in space, time or the attribute domain. In Cao et al. (Citation2005), spatiotemporal sequential patterns in trajectories are analyzed as a sequence of frequently traversed line segments. It requires generating representative line segments for trajectories, which can be computationally expensive. In Yang and Gidfalvi (Citation2018), that problem is avoided by directly taking map matched trajectories as input and contiguous sequential patterns are mined in the form of routes frequently traversed. However, the map matching step is still sensitive to errors in GPS data and it requires additional knowledge of the underlying road network. Similar in Bogorny et al. (Citation2009), semantic trajectories are generated first and movement patterns are mined as frequent itemsets, sequential pattern and association rules. However, sequential patterns are limited in discovering movement patterns with complex spatial characteristics such as convergence, clockwise and zigzag. In Demšar and Virrantaus (Citation2010), a space-time density cube is constructed to record the 3D kernel density around the polylines of trajectories, which enables visualization of spatio-temporal patterns. That approach is designed primarily for overcoming the cluttering of trajectories and it heavily depends on visual inspection to identify patterns.
In the second category, the movement pattern is identified as a certain set of trajectories or subtrajectories, which provides more details compared with the first category. In Laube et al. (Citation2005), Relative Motion (REMO) patterns are retrieved from geospatial lifelines of moving point objects (MPO) where a REMO matrix is constructed to store motion attributes (speed, azimuth) with rows representing objects and columns representing time steps. By detecting regions in the matrix with similar motion attributes, specific patterns including constancy, concurrence and trendsetter (a constancy linked to a concurrence) can be discovered. However, the approach only considers relative positions of objects and cannot handle spatial constraint properly. It may group objects which are far away into a single pattern. Moreover, REMO patterns are detected as connected components in the REMO matrix exhibiting similar motion attributes, which cannot be easily generalized to more sophisticated patterns such as zigzag.
In De Lucca Siqueira and Bogorny (Citation2011), the chasing pattern is studied as two trajectories keeping close to each other for a specific time period. It is detecting by evaluating each pair of trajectories to identify subtrajectories exhibiting a chasing behavior. A more complicated pattern called following is studied in Li et al. (Citation2013), which further considers the time lag between two trajectories. Detecting the following pattern is treated as a local sequence alignment problem and solved by detecting time intervals in which one trajectory is following another. Since both of these two approaches require pairwise comparison of trajectories, they are inefficient in mining large-scale dataset.
In Lee et al. (Citation2015), a unifying trajectory (UT) pattern is defined as a set of similar trajectory partitions with a reference line segment characterizing the overall movement. UT patterns are extracted in two steps: initial pattern discovery by performing subtrajectory clustering and granularity adjustment by constructing a pattern forest, which can still be computationally expensive.
In several recent studies, the pattern mining methods combine features from the two categories summarized above. In Endo et al. (Citation2016), movement features are extracted from a single trajectory as a grayscale image. A deep convolutional neural network is then trained to classify the transportation mode, which cannot support the analysis of collective movement. The approach developed in this paper follows the same procedure but more complex features and movement patterns are considered. In addition, a more challenging task is studied here including classification and pattern detection. In Yao et al. (Citation2017), a temporal sliding window is traversed along a trajectory to extract a sequence of movement behaviors including speed, duration and turning angle. Subsequently, an auto-encoder is trained to generate a fixed-length deep representation of the trajectory, based on which the trajectories are finally clustered. The method is still restricted in discovering more complicated movement patterns such as converging and diverging pattern. In Choi et al. (Citation2017), sequential pattern mining and clustering are performed to extract regions where a particular sequential pattern densely appears in space. That type of regional semantic trajectory pattern identifies regularities in the semantics of movement, which is different from the pattern studied in this paper.
As a summary, detecting sophisticated movement patterns with complex spatial characteristics in trajectory data is not fully exploited in the literature. The approach proposed in this paper belongs to the first category as the movement features are spatially aggregated into a multi-spectral image based on a grid partitioning of the space and regions where a specific pattern occurs are further detected. Considerably high accuracy is achieved in classifying sophisticated movement patterns. The approach can also be easily extended for detecting user-specified patterns by enlarging the training data.
3. Preliminaries and problem formulation
Let denote a trajectory that is defined as a sequence of
points as
where
stores the location
of the tracked object at the timestamp
.
The pattern studied in this paper is called the regional Dominant Movement Pattern (RDMP), which is defined as in a dominant trend or pattern followed by the majority of trajectories in a specific region. Given a trajectory set and grid partitions of the space
, the problem of RDMP detection is formulated as finding the regions in
where specific RDMP occurs. Formally, the result is exported as a set of regions
where
stores a polygon where that pattern occurs and
indicates the corresponding RDMP class.
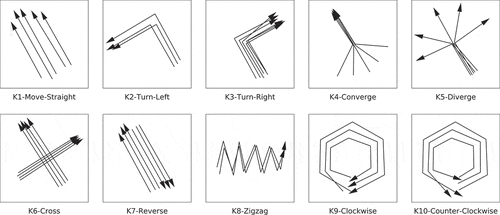
Based on the common movement patterns encountered in practice, 11 RDMP classes labeled from K1 to K11 are defined in this paper, including 10 regular classes: move straight, turn left, turn right, converge, diverge, cross, reverse, zigzag, clockwise, counter-clockwise and an 11th class called others. The last class covers all the other patterns that do not belong to K1-K10, e.g. background and noise. It is a common technique used in object detection to handle the case where the sliding window captures the background or part of a pattern (Ren et al. Citation2015). More details are described in Section 4.2. Several examples of movements in K1-K10 are displayed in . It is important to mark that these definitions are highly fuzzy and conceptual, where noise in observations and a small proportion of irregular movements are tolerated.
Figure 2. Example of 10 classes of regular regional dominant movement patterns. The caption indicates class index and name.
4. TRNet for RDMP detection
In this section, the directional flow image is introduced first, followed by synthetic data generation. After that, the architecture of TRNet and RDMP detection are presented.
4.1. Directional flow image
Inspired by the histogram of oriented gradients (HOG) descriptor (Dalal and Triggs Citation2005), the directional flow image (DFI) is designed to capture both the position and direction information in a set of trajectories. In this section, a formal definition of DFI is given first followed by a detailed description of the DFI construction algorithm.
Given a set of trajectories , a DFI is defined as a
-channel image with a height of
and width of
(in unit of pixels), where each pixel stores the directional flows into its neighboring pixels. Let
denote a pixel in DFI with a column index of
(
) and row index of
(
). An array of
values is stored at
written as:
The value stores the number of movements in
from the pixel
to its neighboring pixel
in the direction
. Nine neighbors of a grid (including itself) are considered thus
= 9. Given
and
, the direction
is calculated as:
where . () illustrates the mapping from direction
to the relative position of
with respect to
. Direction 5 represents moving from one pixel to itself, which is assumed to mark the endpoint of a trajectory. Therefore, channel 5 of DFI stores the frequency of endpoints in each pixel.
Figure 3. Illustration of DFI generation. (a) the number in a grid represents the direction of
with respect to
located at the centering grid (bold border); (b) selected pixel value of the DFI created from a single trajectory; (c) DFI of a K4-Converge pattern; (d) DFI of a K5-Diverge pattern. In (c) and (d), the nine channels of DFI are labeled from
to
.
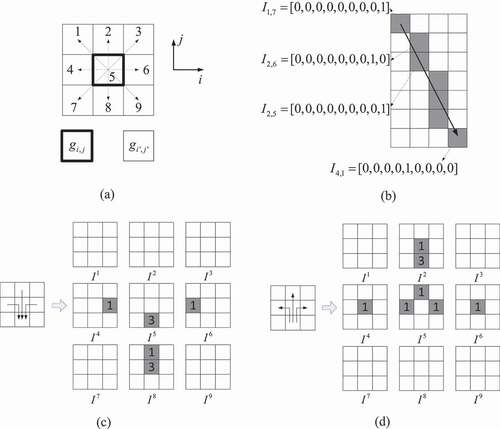
A concrete example is displayed in () where a DFI of shape is generated from a single trajectory. The trajectory is firstly rasterized as a sequence of grids using Bresenham’s algorithm (Bresenham Citation1965). In the first pixel
, the object firstly moves to its neighboring pixel
in direction 9 so that
. Subsequently, it moves from
to
in the direction 8, so that
. Finally, the object stops at the bottom right pixel, which is treated as moving from
to itself. Therefore, the value is stored as
.
Each channel of DFI actually stores the flows in direction
for
. Two examples of DFI generated from a trajectory set are further provided in (c, d) where the endpoints of the trajectories are stored in the channel
. It can be observed that the DFI generated from the converging and diverging trajectories are significantly different, which makes it possible to distinguish them.
As a DFI contains nine channels, it can be visualized as three RGB images with each consecutive three channels of a DFI rendered as the red, green and blue band of an RGB image, respectively. An example is illustrated in . Since most of the movement occurs in the direction 7, 8 and 9, the third RGB image shows more pixels in blue ( channel) and green color (
channel).
Figure 4. Visualization of DFI using three RGB images. Each consecutive three channels of DFI are rendered as the red, green and blue channel of one RGB file, respectively.

When constructing DFI from a trajectory set , the shape configuration of DFI needs to be determined first, which includes the coordinates of bottom left point of DFI denoted by
, the size of a single grid
(with equal width and height) and the width
and height
of DFI (in unit of grids). These parameters are determined based on user specification and the extent of input trajectory set
. Let
denote the minimum bounding rectangle (MBR) of
, the shape configuration of DFI can be determined in two modes: fixed grid and fixed shape.
● fixed grid: the grid size is specified by the user while
and
is calculated from the extent of
as:
where represents the mathematical floor function. An example is illustrated in ().
Figure 5. Illustration of computing the shape configuration of DFI from the minimum bounding rectangle (MBR) of trajectories: fixed grid mode (a) and fixed shape mode (b,c). The dotted line represents the MBR of a trajectory set.
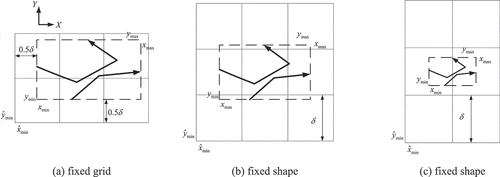
● fixed shape: the height and width
of the DFI are specified by the user while
and
is computed from the extent of
. Analogously, we have
Two examples of fixed shape mode are displayed in (,). The DFI generated from a specific set of trajectories can vary with the shape of DFI specified. The fixed shape mode is primarily used in the synthetic data generation procedure where the trajectories are assured to have a square extent. Consequently, DFIs can be generated in uniform and square shape, which facilitates the training of TRNet. On the other hand, the fixed grid mode is adopted when generating DFI for a real-world trajectory dataset, whose shape is not known in advance.
After the shape configuration of DFI is determined, a DFI can be constructed from following Algorithm 1. For each trajectory
in
, a sequence of grids
passed by
is obtained first by rasterizing
using Bresenham’s algorithm (Bresenham Citation1965). Subsequently,
is iterated where consecutive grids are examined with the directional flow information recorded in DFI. At the
th grid
, the object moves from
to the next grid
, the direction of movement
is calculated according to EquationEquation (2)
(2)
(2) and the channel
of the pixel corresponding to
in DFI is incremented as described by line 5 to 9 of Algorithm 5. For the last grid, only channel 5 is incremented. Finally, a DFI containing
channels with the shape of
is generated. The shape of DFI is written as
. In this paper,
is set as
and all the DFIs are created with a square shape where
. For simplicity, we directly refer to the shape of DFI as
where
is the number of pixels in both height and width.
Algorithm 1: Directional flow image construction algorithm
Input:
: a trajectory set
: shape configuration of DFI
Output
: a DFI of shape
1 = EmptyDFI(
)
2 for in
do
3 gridSeq = BresenhamRasterize()
4 N = gridSeq
5 for n in 1 to N-1 do
6 = gridSeq[
].x,
= gridSeq[
].y
7 = gridSeq[
].x,
= gridSeq[
].y
8
9
10 end
/*Update the pixel value of the last grid.
11 = gridSeq[N].x,
= gridSeq[N].y
12
13 end
14 return I
4.2. Synthetic data generation
The synthetic training data generation is divided into three steps. Firstly, trajectory seeds are drawn manually to follow these 10 RDMPs shown in . Each seed is a set of trajectories following a specific RDMP. The definition of RDMP is highly fuzzy and conceptual. During the drawing of trajectory seed, different types of variations in a trajectory set are considered including the number of points inside a trajectory and the size of a trajectory set, as shown in .
In practice, it is commonly required to detect RDMPs in a large set of trajectories, which could occur at multiple scales. A sliding window detection approach is adopted to address this problem by performing an exhaustive search in the space. More details are presented in Section 4.4. In that process, it is common to classify a DFI that differs significantly from those defined above. Therefore, an extra category labeled K11-Others is introduced to cover all other patterns that do not belong to the above 10 classes. Specifically, it contains two types of DFI: background and noisy. More details are presented below.
The background type corresponds to the case where only part of a trajectory set is covered by a window or the window is too large. Inspired by the anchor boxes used in Faster regional CNN (Ren et al. Citation2015), background DFI is generated by clipping a DFI in the K1-K10 category to generate a partially overlapped DFI. The clipping is controlled by the Intersection-over-Union (IoU) ratio. Let and
denote two boxes, their IoU ratio denoted by
is calculated as:
The clipping position can be set as either the margin or corner. Two examples are presented in (,) where the DFI is generated by clipping the trajectory set shown in . It could also happen that the area captured by the window is too large compared with the extent of a trajectory set. To take this factor into consideration, the extent of DFI can be enlarged under the control of . An example is illustrated in (). For generating a background DFI,
is empirically set as 0.3 for clipping along the margin and corner and 0.2 for enlarging the extent.
Figure 6. Illustration of generating background DFI in the K11-Others class by transforming the trajectory set in K5-Diverge class displayed in .
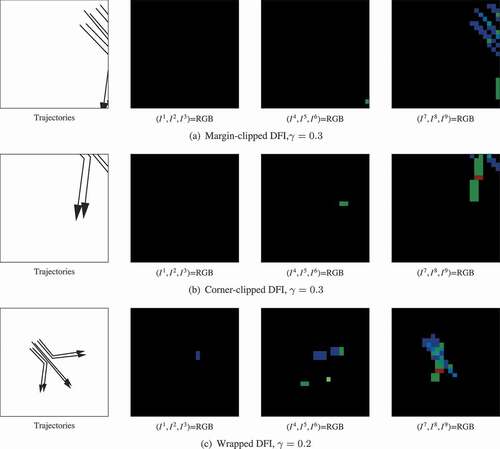
The noisy type of DFI covers some other regular movement patterns which are encountered in real-world data but not defined here, e.g. T pattern. To represent these cases, trajectories are also drawn to follow some regular patterns beyond K1 to K10. Some examples can be found in the last row of .
In the second step of synthetic data creation, data augmentation is performed by rotating these trajectory seeds to generates a larger number of trajectory sets. It is important to note that all the RDMP classes defined in this paper are rotation invariant. In other words, rotating by an arbitrary angle does not change the category. Based on that property, synthetic labeled trajectories can be easily augmented. A trajectory group is drawn manually according to the specified category and serves as a seed. That seed is then rotated multiple times by
to generate
samples belonging to that category. When drawing these seeds, variations are imposed primarily on the number of trajectories, proportions of individual branches and angles of movement to minimize the redundancy in the training data.
In the final step, DFIs are generated from the trajectory sets. To investigate the influence of DFI shape on the training of TRNet, three shapes of DFI are generated in this paper: and
. For a single shape, the constitution of the synthetic dataset is reported in . For each class in K1-K10, 34 trajectory seeds are manually drawn and they are rotated by 30 degrees for data augmentation. Regarding the K11 class, a larger number of DFIs are created as K11 is supposed to cover all the other cases beyond K1 to K10. For the noisy movement, 44 trajectory seeds are firstly drawn manually and 528 trajectory sets are generated after performing the same augmentation of rotation. Moreover, 4080 background DFIs are generated by randomly collecting samples from the DFIs in K1-K10 and performing the clip and extent enlargement operation. These background DFIs comprise an equal number (1360) of margin-clipped, corner-clipped and extent-enlarged DFI illustrated in . Finally, 8868 images are generated for a single DFI shape. Training of TRNet using the synthetic data is presented in Section 5.1.
Table 1. Synthetic data constitution for a particular shape of DFI.
4.3. Architecture design of TRNet
Inspired by LeNet that was originally designed for a handwritten digit recognition task (Lecun et al. Citation1998), TRNet is designed with several specific modifications described below.
In this paper, 11 classes of RDMP are considered where K11-Others is supposed to cover all the other cases beyond K1 to K10. Actually, there exists a hierarchical relationship where K1 to K10 constitute a regular class as a whole. That regular class together with K11-Others is supposed to fill the domain of DFI. To maximize the coverage of these relevant cases, many more samples are added to K11-Others than the remaining classes, as reported in . The imbalance of samples could cause a bias in training the classification model since more weight is put on the K11 class.
To alleviate this imbalance problem, TRNet is designed to contain two classifiers. The first one is a binary classifier, denoted by , which determines whether the DFI belongs to the regular class (K1-K10) or not (K11). When training
, all the samples in K1 to K10 are relabeled as 0 to denote the regular class and these samples in K11 are relabeled as 1. After aggregating all the samples from K1 to K10, the two classes have almost the same number of samples as reported in . The second classifier is called a regular one denoted by
, which only distinguishes DFI from K1 to K10.
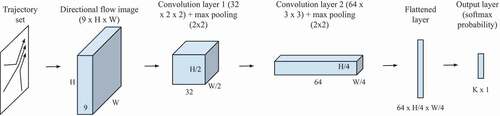
The two classifiers in TRNet are designed as two neural networks with the architecture shown in . Each network is created separately to take a DFI of shape as input. A convolution layer with 32 filters in size of
is added to extract features from the DFI. That convolution layer is then connected with a maximum pooling layer which reduces the size of the feature map by a factor of 2. A second group of convolution layer with 64 filters and maximum pooling layer is then appended to the network. The last pooling layer is then flattened and fully connected with a softmax probability layer of shape
, where
for the
and
for
. The output of the classifier is a vector with a length of
indicating the probability of the DFI in each class.
Figure 7. Architecture of classifiers in TRNet. For the binary classifier and for the normal classifier
.
When a new DFI is classified, its label is determined by and
collectively following Algorithm 2. Let
and
denote the class label and softmax probability return by
and
respectively. If the binary classifier
returns a label of 1 (corresponding to K11 class), and its probability
is higher than
, the DFI is predicted as K11 with a probability of
; otherwise, it is predicted to be class
with a probability of
.
Algorithm 2: Classify a DFI using the binary and regular classifier
Input:
: A DFI to be classified
: the binary and regular classifier
Output
,
: the class label (1 to 11) and its the probability
/*kb is 0 (regular) or 1 (others)*\
1 : =
.classify(I)
/*kr is in 1 or 10.*
2 : =
.classify(I)
3 if and
then
4 return 11,
5 else
6 return ,
7 end
The two classifiers are trained separately. The samples in K11 are only used for training of whereas the remaining samples are used in the training of both classifiers. For each classifier, the corresponding DFI samples are split into a training and a test subset. The former is used for training the model whereas the accuracy is reported on the latter. The loss function of TRNet is selected as a categorical cross-entropy measuring the difference between two distributions. It is calculated as:
where is the size of the training subset,
and
are the true and predicted probability of class
for the training sample
. In the training process,
is minimized using the ADADELTA gradient descent method (Zeiler Citation2012). The accuracy of the test subset is calculated as:
where is the true label of
th sample in the test dataset with the size of
,
is its predicted class and
is an indicator function that returns 1 if the condition
is true and 0 otherwise. The accuracy measures the generalization error of the trained model. In this paper, the DFI generation algorithm is implemented in C++ and TRNet is implemented in Python using the Keras libraryFootnote1.
4.4. RDMP detection with TRNet
The objective of RDMP detection is to find the regions for the occurrence of specific RDMPs. In practice, RDMPs could occur at multiple scales when the trajectory data covers a large area, e.g. a city. To discover RDMPs at multiple scales, TRNet is treated as a classifier and a classical sliding window detection method is employed to exhaustively search over sub-regions of the DFI. One problem remains to be addressed that conventional CNN model can only accept image with fixed shape as input but the sub-regions can have a variable extent.
One strategy is generating an extremely large DFI for the whole study area and classifying regions in different sizes using a more advanced CNN model that can take an image of variable shape as input. For instance, He et al. (Citation2015) designed a spatial pyramid pooling (SPP) layer to build a fixed-length vector from a variable shape of the convolutional feature map. With the SPP layer added, the CNN model still needs to be trained with images of different shapes. However, that approach is inappropriate for the RDMP detection as DFI shape can vary in a much broader range. Given a DFI generated with a grid size of 10 m, detecting RDMP in range of 100 m, 1k m and 10 km requires generating DFI of shape 10, 100 and 1000, respectively. The last size is too large to be used in the training procedure. As a consequence, the model could be problematic in detecting RDMPs in a 10 km range.
To address this problem, this paper adopts a different strategy. Instead of generating a single DFI and adopting advanced CNN models to handle DFI of variable shape, we generate a pyramid of DFIs at multiple scales with various grid sizes and apply the same conventional CNN model that takes DFI of a fixed shape as input. In the same example, we can train TRNet with DFIs of shape 10 and generate DFIs in a grid size of 10 m, 100 m and 1 km, respectively. The benefit is that the model can be trained in a memory-efficient way and RDMP can also be detected at multiple scales. The detailed approach is formally presented below.
Given a TRNet which takes input from DFI of shape and a user-specified range of region sizes (in meters) denoted by
, the RDMP detection procedure consists of the following steps:
Calculate a sequence of the grid sizes as
where
For each grid size
(a) Generate a single DFI for the whole trajectory set
(b) Slide a window over the DFI with stride of
(i). Normalize the extracted DFI and classify it with the TRNet;
(ii). Filter out if any of the two conditions are fulfilled: (a) the maximal softmax probability
where
is a user-specified threshold; (b) the DFI is classified as the K11-others category; otherwise export
to
;
(3) Merge the redundant boxes in
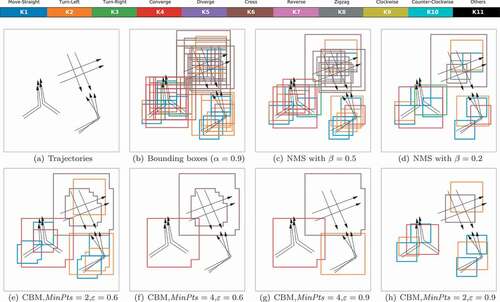
In sliding window detection, it is common to generate a large number of redundant boxes that actually identify the same object as shown in . That problem is commonly handled in the previous work with a procedure called non-maximum suppression (NMS), which was originally developed for eliminating unwanted responses in edge detector (Prince Citation2012).
Figure 8. Illustration of non-maximum suppression (NMS) and clustering-based merging (CBM). The detected window sizes are set as of
. The results of NMS and CBM are demonstrated in (c,d) and (e–h) respectively.
Let denote all the boxes classified as class
. The standard procedure of NMS is described below:
Select the box with the largest probability in
Remove all the boxes in
Export
An example of detecting RDMP in a region containing multiple RDMPs is demonstrated in . After filtered by , the detected boxes are shown in (). It demonstrates that TRNet is effective in classifying RDMP in trajectories using DFI. However, the boxes are heavily overlapped and contain a lot of redundancy. The results of NMS pruning are displayed in (,) where more boxes are pruned by a smaller
. However, the results are still problematic in several aspects. It cannot effectively prune the boxes in the same category but with a different size. NMS only considers the probability of prediction in pruning, which cannot eliminate these RDMPs that are part of others. In (), parts of a K2-Turn-Left pattern are detected as K1-Move-Straight.
Based on the above observation, a clustering-based merging (CBM) is developed in this paper to eliminate the redundant detection boxes in the following steps:
Cluster the boxes
It measures the spatial closeness between two boxes, which is in a range of [0,1]. The distance of two disjoint boxes is 1 and that of two identical boxes is 0.
(2) For each cluster, generate the cascaded union of the boxes as a polygon
As each polygon in is generated as a cascaded union of neighboring boxes in the same class, the restriction imposed by the square shape of the detection window can be partly relaxed.
The result of CBM is illustrated in (–). With too small , boxes in the same category but with different sizes cannot be clustered properly, as demonstrated by the K2 and K5 boxes in (,). When
is too small, some embedded RDMPs will form a cluster and cannot be pruned, as shown by the K1 boxes in (). However, setting a large
may prune the boxes that should have been kept. For example, the K2 box in (e) is pruned in (f) by setting a larger
. In (), it shows that with the proper setting of
and
, the redundancy in the detection results can be effectively eliminated. The result displayed in also implies that the selection of CBM parameters could be influenced by the spatial distribution of RDMPs. In practice, a small region could be selected to explore these parameters before applying them to the whole study area.
5. Experiments
5.1. Training of TRNet
The synthetic dataset is created to contain DFIs in three shapes ,
and
. According to the statistics shown in , 8868 images are generated for each shape. For the training of the binary classifier, all the samples are randomly split into a training subset 70% (6208 samples) and a test subset 30% (2660 samples). For the training of the regular 10-class classifier, the 4080 samples from K1 to K10 are used with the same split ratio of training (2856 samples) and test subset (1224 samples).
The accuracy and training time of different classifiers are reported in . To compare the training result without handling the class imbalance problem described in Section 4.3, another 11-class classifier is trained in the same architecture shown in with . It can be observed that the regular classifier achieves the highest accuracy close to 100% for all the three shapes of DFI. The accuracy of the binary classifier is significantly smaller than the regular one but much higher than the 11-class classifier. The reason could be that these 10 classes from K1 to K10 are highly distinguishable from each other so that they can be easily separated by the model. Although the binary classifier only needs to distinguish two classes, the diversity of its training samples substantially increases after adding samples in the K11 class. Consequently, it becomes difficult to train the binary classifier to learn these complex patterns and the case is even worse for the 11-class classifier. After combining the binary and regular classifier, the final accuracy is still higher than the 11-class one, which demonstrates the effectiveness of training two classifiers to address the class imbalance problem.
Table 2. Comparison of accuracy and training time for different classifiers. The training process contains 100 epochs.
Another interesting observation in is that a larger DFI shape tends to slightly decrease the accuracy of these classifiers. The reason can be explained in two ways. When the shape of DFI increases, its domain also becomes larger and it could be more difficult to learn these complex patterns. The features captured by DFI store more precise movement information at a microscopic scale, which could distract the model from learning these macroscopic patterns.
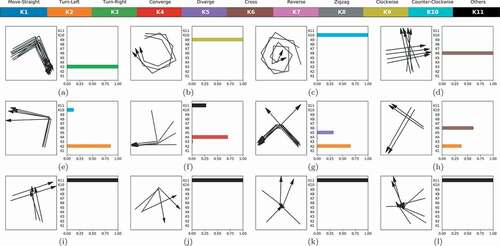
More concrete examples of the classification result are displayed in , where DFI is generated from the trajectories in a fixed shape of . It can be observed from the first row that TRNet can effectively classify the RDMP in a trajectory set, which is also robust to different kinds of noise and variations. When there exists a large deviation from a standard RDMP, the maximum softmax probability predicted by TRNet decreases, as shown in the second row of . Some patterns manually labeled as the category K11-Others can also be classified correctly, e.g. T pattern in (). In (), there exists a mixture of turning left and diverging pattern whereas the former is dominant. Consequently, the predicted probability of K2 is higher than K5.
Figure 9. Some classification results of TRNet with DFI generated in shape of . The trajectories are shown on the left side and the softmax probabilities are shown on the right.
5.2. Case study
After trained on the synthetic dataset, TRNet is evaluated on a public real-world taxi GPS dataset collected by DiDiChuXing, a taxi-requesting company in ChinaFootnote2. The data covers an area of shape 8.8 km 7.5 km in Chengdu, China. The GPS observations are collected every 3 s on average, where taxi order ID, vehicle ID, location and timestamp are recorded. The original data are collected for a 1-month period with 30 million observations per day on average. In this paper, only 1 day’s data (2016-11-01) are analyzed for demonstration purpose.
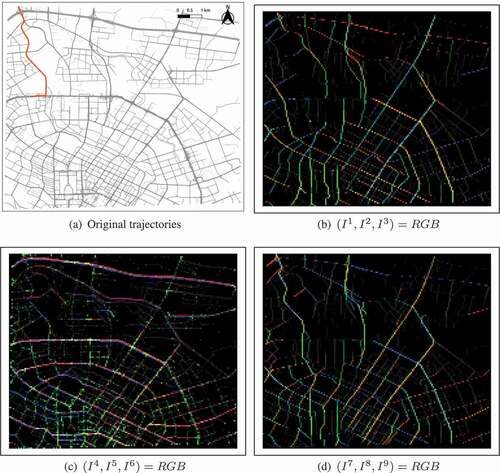
presents a map for the trajectories collected from 8:00 am to 9:00 am and the corresponding DFI. Some knowledge of the underlying movement can already be obtained from the visualization of DFI. It is reasonable to observe that most of the colors match with the direction of the underlying roads where the movement is constrained. For instance, the green color in () indicates a high value in the channel , which implies a high volume of flow in the north direction. Additionally, several roads in the northwestern direction are highlighted in (). In most of these places, green color can be observed in (), which corresponds to the channel
. It indicates that these roads also have a high volume in the southern direction. In (), the green color presents the distribution of the last point of these trajectories, namely, the destination of trips. However, visual inspection of DFI is still limited in discovering more complex movement patterns, where RDMP detection is needed.
Figure 10. DFI generated from real-world taxi trajectories. (a) Original trajectories collected from 8:00 to 9:00 am in Chengdu where a single trajectory is highlighted for illustration. (b–d) Visualization of DFI. The channels to
,
to
and
to
are rendered as an RGB image, respectively. The grid size is specified as 50 m.
5.2.1. RDMP detection results
According to the statistics reported in , TRNet with DFI shape of 10 is adopted for RDMP detection as it achieves the highest accuracy.
In the first experiment, sliding window detection is evaluated using trajectories collected from 8:00 to 8:05 am with the region size empirically set as . The result is displayed in . It can be observed that a large proportion of boxes are classified as K7-Reverse and K6-Cross. It can be explained by the fact that vehicle movement is primarily constrained to the road network which contains a lot of bidirectional roads and intersections. K2-Turn-Left and K5-Diverge are also frequently detected at some specific intersections. K8-Zigzag accounts for the smallest proportion as vehicles rarely move in that manner. Another interesting observation is that large boxes are concentrated on the class K6 and K7. The reason could be that a larger region tends to capture more objects, which is less likely to exhibit a dominant movement pattern. However, the high volume of flows at bidirectional roads and intersections could still be dominant.
Figure 11. Sensitivity analysis of sliding window detection results with respect to the probability threshold and stride ratio
. The trajectories are collected from 8:00 to 8:05 am. The other configurations are set as
. The three columns show RDMPs detected in K1-K5 (left), K7 (middle) and K6,K8-K10 (right).
![Figure 11. Sensitivity analysis of sliding window detection results with respect to the probability threshold α and stride ratio r. The trajectories are collected from 8:00 to 8:05 am. The other configurations are set as D=10,S=[250m,500m,1km,2.5km]. The three columns show RDMPs detected in K1-K5 (left), K7 (middle) and K6,K8-K10 (right).](/cms/asset/57120984-11b9-46fe-815f-417e192b8781/tgis_a_1700510_f0011_c.jpg)
The sensitivity of sliding window detection results with respect to the probability threshold and stride ratio
can be inspected by comparing these maps in . It is expected to detect more boxes with a smaller
. In addition, fewer boxes are detected with a larger
, where a smaller number of boxes are examined in the sliding window detection step. However, there are still many boxes that are only detected with
. That observation reveals a significant difference between RDMP detection and conventional object detection problems. RDMP detection is much more sensitive to the boundary of the sliding window as the movement recorded does not cover a continuous region in the space. Taking the trajectories displayed in () as an example, if the detection window is shifted a little towards the bottom then a K1-Move-Straight pattern will be detected. Therefore, it is more likely to miss some patterns with a larger stride ratio
.
The second experiment investigates the sensitivity of CBM with respect to configurations of and
. The other configurations are set as
and
. The result is depicted in . CBM can effectively eliminate the redundancy in the result of sliding window detection shown in . With a larger
, patterns spreading a wider region can be discovered. On the other hand, the region of a pattern can be more accurately identified with a smaller
. These maps also provide a clear view of the distribution of RDMPs. K1-Move-Straight patterns are majorly discovered at the roads with the flow in a single direction. K6-Cross and K7-Reverse are widely distributed in the area. K9-Clockwise and K10-Counter-Clockwise are discovered at these roads with a large curvature. K5-Diverge is concentrated on the southern region of the city where the road density is also higher.
Figure 12. Sensitivity analysis of clustering based merging (CBM) results with respect to configurations of and
. The trajectories are collected from 8:00 to 8:05 am. The other configurations are set as
. The three columns show RDMPs detected in K1-K5 (left), K7 (middle) and K6,K8-K10 (right).
![Figure 12. Sensitivity analysis of clustering based merging (CBM) results with respect to configurations of MinPts and ε. The trajectories are collected from 8:00 to 8:05 am. The other configurations are set as D=10,S=[250m,500m,1km,2.5km],α=0.9,r=0.2. The three columns show RDMPs detected in K1-K5 (left), K7 (middle) and K6,K8-K10 (right).](/cms/asset/b622dbfa-662b-4456-a982-ec4b9b611f17/tgis_a_1700510_f0012_c.jpg)
In the third experiment, temporal variations of RDMPs are explored by comparing RDMPs detected in a 30-min period in the morning, noon and afternoon. The configurations are set as and
. The result is demonstrated in . Several places with a stable movement pattern can be identified by comparing the maps in the left column. A K3-Turn-right pattern is detected at one intersection in the northern region of the city in all the three periods. In the northwestern region, a Y-shape intersection is detected as K5-Diverge pattern and another T-shape intersection as K4-Converge pattern. Several roads in the north-west direction in the western region are detected as K1-Move-Straight pattern. In the eastern region, the K4-Converge pattern is observed in the afternoon as opposed to K3-Turn-right in the noon and K1-Move-Straight in the morning. The maps in the middle column show that fewer K7-Reverse patterns are observed in the noon than the other two periods. Additionally, fewer K6-Cross patterns are observed in the noon and afternoon than the morning.
Figure 13. Comparison of RDMPs detected a 30-min time period in the morning (a), noon (b) and afternoon (c). The configurations are set as and
.
![Figure 13. Comparison of RDMPs detected a 30-min time period in the morning (a), noon (b) and afternoon (c). The configurations are set as D=10,S=[250m,500m,1km,2.5km],α=0.9,r=0.2,MinPts=4 and ε=0.6.](/cms/asset/853359dd-42ae-4ec2-b237-e423731ea5e5/tgis_a_1700510_f0013_c.jpg)
5.2.2. Performance analysis
The running time of some selected configurations of RDMP detection is reported in . As can be observed, the performance of RDMP detection substantially decreases with the increase of DFI shape and the reduction of stride ratio
. On the other hand, the size of trajectory set exhibits a relatively small effect on the total running time.
Table 3. Running time of RDMP detection. The detection configurations are set as . The symbol
represents DFI shape and
is the stride ratio used in sliding window detection.
The bottleneck of the RDMP detection program lies in the sliding window detection step, where subregions of the DFI are extracted and classified by TRNet. When the DFI shape increases from 10 to 50, the running time of the sliding window step increases by 9 times. The reason is that the image extracted for each subregion consumes much higher memory. Consequently, both retrieving subregions from a large DFI and classifying these images take a longer time. With a smaller
, a larger number of windows need to be examined, which also degrades the performance.
The impact of trajectory set size on the performance is relatively small because the shape of DFI is only determined by the extent of the trajectories. Although the running time of DFI generation linearly increases with
, it is still the smallest one among the three steps. The running time of CBS pruning is relatively consistent with respect to DFI shape and trajectory set size, which is primarily influenced by the number of RDMPs detected.
The above comparison further implies that the proposed method has a high scalability with respect to data volume. However, it may not be scale well to a large study area if many RDMPs occur on a small scale. In that case, the number of windows to be examined considerably increases. Addressing that type of scalability problem will be left as a future work.
6. Conclusions and future work
In this paper, a deep learning approach was proposed to find the regions where a specific RDMP occurs in a large collection of trajectories. A novel feature descriptor for a trajectory set was first proposed as a directional flow image, which stores the flow information from each pixel to its neighboring pixels. A classification model called TRNet was designed based on CNN, which contains a binary classifier for identifying the background and noisy RDMP and a 10-class classifier for distinguishing 10 commonly encountered RDMPs in the real world. A synthetic trajectory dataset was created by manually drawing trajectories to follow these RDMPs and training of TRNet achieved considerably high accuracy. Detecting RDMPs at multiple scales was solved by a sliding window detector and clustering-based merging suppression. Experiments on a real-world taxi trajectory dataset demonstrated that the proposed approach can effectively and efficiently detect a wide range of RDMPs in a large collection of trajectories. The approach also provided a guideline for applying deep learning approaches to movement pattern analysis.
Although only 11 classes of RDMP are considered in this paper, the proposed model can be easily extended to detect other types of patterns by enlarging the training dataset. Trajectory seeds in user-specified class (e.g. T pattern) can be added to retrain the model. Alternatively, the current classification scheme can be expanded by dividing one class into more specific classes. For instance, K1-Move-Straight samples can be relabeled as moving towards the north or south. It would also be possible to discover regular movement patterns by performing unsupervised learning such as clustering on the DFIs extracted from various time periods. However, some issues still exist in the performance and robustness to geometric transformations. We will leave these tasks as future work.
In addition to detecting other types of movement patterns, the proposed approach can be improved in several ways. First, the current approach can only find the regions where a specific pattern occurs whereas it remains unknown about which group of trajectories actually follows that pattern. One potential solution is to retrieve and analyze the trajectories passing through the detected regions, which will be explored in the future. Second, DFI is extracted as a nine-channel image, which can be highly sparse as the movement patterns, in reality, may only occupy a rather small subspace of the DFI domain. Reducing the dimension of DFI to save memory and improve performance is another research direction. Third, the current model can further be evaluated on other types of movement data such as the immigration track of animals.
Acknowledgments
The authors would like to acknowledge the editor and the anonymous three reviewers for their valuable suggestions. The first author is supported by the Chinese Scholarship Council. The project is also partly funded by the strategic project RENO financed by the Integrated Transport Research Lab (ITRL) at KTH.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data and codes availability statement
The data and codes that support the findings of this study are available in zenodo repository with the identifier doi:10.5281/zenodo.3530373.
Additional information
Notes on contributors
Can Yang
Can Yang is a Ph.D. student in the Department of Urban Planning and Environment at KTH, Royal Institute of Technology in Sweden. His research interests include spatio-temporal data mining, movement pattern analysis and map matching.
Győző Gidófalvi
Győző Gidófalvi is an associate professor in the Department of Urban Planning and Environment at KTH, Royal Institute of Technology in Sweden. His research interests include spatio-temporal data mining and analysis, location-based services, locations privacy and intelligent transportation systems.
Notes
2. The data can be downloaded at https://outreach.didichuxing.com/research/opendata/en/.
Related Research Data
References
- Belongie, S., Malik, J., and Puzicha, J., 2002. Shape matching and object recognition using shape contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24 (4), 509–522. doi:10.1109/34.993558
- Bogorny, V., Kuijpers, B., and Alvares, L.O., 2009. ST-DMQL: a semantic trajectory data mining query language. International Journal of Geographical Information Science, 23 (10), 1245–1276. doi:10.1080/13658810802231449
- Bresenham, J.E., 1965. Algorithm for computer control of a digital plotter. IBM Systems Journal, 4 (1), 25–30. doi:10.1147/sj.41.0025
- Cao, H., Mamoulis, N., and Cheung, D.W., 2005. Mining frequent spatio-temporal sequential patterns. In: Proceedings - IEEE international conference on data mining, ICDM, 82–89. doi:10.1016/j.chroma.2005.02.027
- Choi, D.W., Pei, J., and Heinis, T., 2017. Efficient mining of regional movement patterns in semantic trajectories. Proceedings of the VLDB Endowment, 10 (13), 2073–2084. doi:10.14778/3151106.3151111
- Dalal, N. and Triggs, B., 2005. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05) - Volume 1 - Volume 01, CVPR ’05. Washington, DC: IEEE Computer Society, 886–893. doi:10.1213/01.ANE.0000159168.69934.CC
- De Lucca Siqueira, F. and Bogorny, V., 2011. Discovering chasing behavior in moving object trajectories. Transactions in GIS, 15 (5), 667–688. doi:10.1111/tgis.2011.15.issue-5
- Demšar, U. and Virrantaus, K., 2010. Space–time density of trajectories: exploring spatio-temporal patterns in movement data. International Journal of Geographical Information Science, 24 (10), 1527–1542. doi:10.1080/13658816.2010.511223
- Dodge, S., Weibel, R., and Lautenschütz, A.K., 2008. Towards a taxonomy of movement patterns. Information Visualization, 7 (April), 240–252. doi:10.1057/PALGRAVE.IVS.9500182
- Endo, Y., et al. 2016. Classifying spatial trajectories using representation learning. International Journal of Data Science and Analytics, 2 (3), 107–117. doi:10.1007/s41060-016-0014-1
- Ester, M., et al., 1996. A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise. In: Proceedings of the second international conference on knowledge discovery and data mining, KDD’96. Portland: Oregon AAAI Press, 226–231.
- Graves, A., Mohamed, A.R., and Hinton, G., 2013. Speech recognition with deep recurrent neural networks. In: 2013 IEEE international conference on acoustics, speech and signal processing, May Vancouver, BC. Canada: IEEE, 6645–6649.
- Guo, D., et al., 2012. Discovering spatial patterns in origin-destination mobility data. Transactions in GIS, 16 (3), 411–429. doi:10.1111/tgis.2012.16.issue-3
- He, K., et al., 2015. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37 (9), 1904–1916. doi:10.1109/TPAMI.2015.2389824
- Hinton, G.E., Osindero, S., and Teh, Y.W., 2006. A fast learning algorithm for deep belief nets. Neural Computation, 18 (7), 1527–1554. doi:10.1162/neco.2006.18.7.1527
- Karpathy, A., et al., 2014. Large-scale video classification with convolutional neural networks. In: Proceedings of the 2014 IEEE conference on computer vision and pattern recognition, CVPR ’14. Washington, DC: IEEE Computer Society, 1725–1732. doi:10.1007/s00330-014-3197-7
- Kim, Y., 2014. Convolutional neural networks for sentence classification. CoRR, computing research repository, abs/1408.5882.
- Krizhevsky, A., Sutskever, I., and Hinton, G.E., 2012. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th international conference on neural information processing systems - Volume 1, NIPS’12. Lake Tahoe, Nevada: Curran Associates Inc, 1097–1105.
- Laube, P., Imfeld, S., and Weibel, R., 2005. Discovering relative motion patterns in groups of moving point objects. International Journal of Geographical Information Science, 19 (6), 639–668. doi:10.1080/13658810500105572
- Lecun, Y., et al., 1998. Gradient-based learning applied to document recognition. In: Proceedings of the IEEE, 2278–2324.
- Lee, J.G., Han, J., and Li, X., 2015. A unifying framework of mining trajectory patterns of various temporal tightness. IEEE Transactions on Knowledge and Data Engineering, 27 (6), 1478–1490. doi:10.1109/TKDE.2014.2377742
- Li, B., et al., 2011. Hunting or waiting? Discovering passenger-finding strategies from a large-scale real-world taxi dataset. In: 2011 IEEE international conference on pervasive computing and communications workshops (PERCOM Workshops), March, 63–68. doi:10.1016/j.tvjl.2010.05.029
- Li, Z., Wu, F., and Crofoot, M.C., 2013. Mining following relationships in movement data. In: 2013 IEEE 13th international conference on data mining (ICDM), 458–467.
- Mikolov, T., et al., 2010. Recurrent neural network based language model. In: Eleventh annual conference of the international speech communication association, Chiba, Japan.
- Prince, S.J.D., 2012. Computer vision: models, learning, and inference. 1st ed. New York, NY: Cambridge University Press.
- Ren, S., et al., 2015. Faster r-cnn: towards real-time object detection with region proposal networks. In: Advances in neural information processing systems, Montreal, Canada, 91–99.
- Shu, X. and Wu, X.J., 2011. A novel contour descriptor for 2D shape matching and its application to image retrieval. Image and Vision Computing, 29 (4), 286–294. doi:10.1016/j.imavis.2010.11.001
- Wachowicz, M., et al. 2011. Finding moving flock patterns among pedestrians through collective coherence. International Journal of Geographical Information Science, 25 (11), 1849–1864. doi:10.1080/13658816.2011.561209
- Wang, D., et al., 2017a. DeepSD: supply-demand prediction for online car-hailing services using deep neural networks. In: 2017 IEEE 33rd international conference on data engineering (ICDE), April, San Diego, California, 243–254.
- Wang, J., et al., 2017b. Automatic intersection and traffic rule detection by mining motor-vehicle GPS trajectories. Computers, Environment and Urban Systems, 64, 19–29. doi:10.1016/j.compenvurbsys.2016.12.006
- Wang, X., et al. 2014. Bag of contour fragments for robust shape classification. Pattern Recognition, 47 (6), 2116–2125. doi:10.1016/j.patcog.2013.12.008
- Xu, C., Liu, J., and Tang, X., 2009. 2D shape matching by contour flexibility. IEEE Transactions on Pattern Analysis and Machine Intelligence, 31 (1), 180–186. doi:10.1109/TPAMI.2008.199
- Yang, C. and Gidfalvi, G., 2018. Mining and visual exploration of closed contiguous sequential patterns in trajectories. International Journal of Geographical Information Science, 32 (7), 1282–1304. doi:10.1080/13658816.2017.1393542
- Yao, D., et al., 2017. Trajectory clustering via deep representation learning. In: 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, 3880–3887.
- Yao, H., et al., 2018. Deep multi-view spatial-temporal network for taxi demand prediction. In: AAAI conference on artificial intelligence, New Orleans, Louisiana.
- Ye, Y., et al., 2009. Mining individual life pattern based on location history. In: 2009 Tenth international conference on mobile data management: systems, services and middleware IEEE, Taipei, Taiwan, 1–10.
- Zeiler, M.D., 2012. ADADELTA: an adaptive learning rate method. CoRR, computing research repository, abs/1212.5701. doi:10.1094/PDIS-11-11-0999-PDN
- Zhang, J., Zheng, Y., and Qi, D., 2017. Deep spatio-temporal residual networks for citywide crowd flows prediction. In: AAAI conference on artificial intelligence, San Francisco, California, 1655–1661.