
ABSTRACT
Research projects that actively involve ‘crowds’ or non-professional ‘citizen scientists’ are attracting growing attention. Such projects promise to increase scientific productivity while also connecting science with the general public. We make three contributions. First, we argue that the largely separate literatures on ‘Crowd Science’ and ‘Citizen Science’ investigate strongly overlapping sets of projects but take different disciplinary lenses. Closer integration can enrich research on Crowd and Citizen Science (CS). Second, we propose a framework to profile projects with respect to four types of crowd contributions: activities, knowledge, resources, and decisions. This framework also accommodates machines and algorithms, which increasingly complement or replace professional and non-professional researchers as a third actor. Finally, we outline a research agenda anchored on important underlying organisational challenges of CS projects. This agenda can advance our understanding of Crowd and Citizen Science, yield practical recommendations for project design, and contribute to the broader organisational literature.
1. Opening the boundaries of project participation
Science has for a long time been dominated by professional scientists who work individually or in well-defined teams, operating within a distinctive institutional setting (Shapin Citation2008; Dasgupta and David Citation1994; Strasser et al. Citation2019; Sauermann and Stephan Citation2013). More recently, projects have emerged in which the ‘lead investigators’ who organise and lead projects involve ‘crowds’ of individuals who self-select in response to open calls for participation. Notably, these crowds consist not only of professional scientists but also non-professional ‘citizens’. Rationales for involving crowds include higher scientific productivity resulting from additional labour inputs and diverse knowledge, but also the potential to bridge between science and the broader public (Bonney et al. Citation2014; Van Brussel and Huyse Citation2018). In addition to being extremely open with respect to participation, such projects also tend to be more open than traditional projects with respect to the transparency of research processes and the disclosure of intermediate results and data (Franzoni and Sauermann Citation2014). As such, Crowd Science and Citizen Science (collectively abbreviated as ‘CS’) fall within the realm of Open Innovation in Science (Beck et al. Citation2021). To illustrate, consider just three examples:
The online platform Zooniverse currently hosts over 80 research projects in the natural and medical sciences, as well as the humanities. Projects are led by professional scientists who ask the general public to help with data generation and analysis by classifying or transcribing images as well as sound and video files. The platform has a crowd of over 2.2 million volunteers who have contributed a large volume of labour to data-related tasks but who have also made important discoveries in the process (Simpson, Page, and De Roure Citation2014; Sauermann and Franzoni Citation2015). Among others, contributors have transcribed ancient papyri (Williams et al. Citation2014), have made accessible U.S. Supreme Court Judges’ conference notes for legal studies (Black and Johnson Citation2018), and have discovered new planets and other astronomical objects (Lintott et al. Citation2009). Projects have resulted in over 100 scientific publicationsFootnote1 and have made data publicly available for other researchers to build on.
Just One Giant Lab (JOGL) provides an open platform for crowds to tackle research and innovation challenges, especially related to sustainable development goals. In 2020, JOGL started the OpenCovid19 Initiative, which allows anyone to propose research projects, recruit contributors, and solicit financial as well as non-financial resources (Kokshagina Citationforthcoming; Santolini Citation2020). Crowd members who wish to join can use listings and filtering mechanisms to find projects that best match their skills and interests, and team members can interact with each other using a range of communication tools. As of April 2021, the Initiative is hosting 123 projects in areas such as tracing and predicting the spread of Covid, studying the pandemic’s socio-economic and environmental consequences, developing diagnostic tests, as well as investigating potential Covid treatments.Footnote2
The project CurieuzeNeuzen enlisted a crowd of over 2,000 citizens of the city of Antwerp to collect data on air quality and to participate in data analysis, interpretation, and the diffusion of results. The team of lead investigators was composed of volunteers and professional scientists, holding expertise in diverse areas such as scientific research, computer programming, and communication. The data produced by the project were used to investigate predictors of variation in nitrogen dioxide concentrations in cities and to validate and improve existing computer models. Project results were also used to inform policy debates and to advocate for stricter regulations regarding traffic and air pollution. A survey among participants suggested that the project increased their awareness of environmental problems as well as their intentions to take personal action to improve air quality (Van Brussel and Huyse Citation2018; Irwin Citation2018). The original CurieuzeNeuzen project has been replicated and expanded in other regions of Belgium, drawing tens of thousands of participants (Weichenthal et al. Citation2021).
Policymakers and funding agencies support Crowd and Citizen Science efforts, hoping that CS can accelerate scientific knowledge production and increase the societal impact of research (European Commission Citation2018; US Congress Citation2016). There is also a growing community of practitioners and scholars who study CS initiatives from within particular scientific domains such as biology or astronomy (Sullivan et al. Citation2009; Ponciano et al. Citation2014; European Citizen Science Association Citation2015; Petridis et al. Citation2017). However, not all observers are optimistic: Many professional scientists remain sceptical about involving non-professionals in research (Burgess et al. Citation2017), and many CS projects face challenges in attracting enough contributors, coordinating project work, ensuring the quality of processes and outputs, and reconciling scientific as well as non-scientific project goals (Sauermann et al. Citation2020; Aceves‐Bueno et al. Citation2017; Druschke and Seltzer Citation2012).
We believe that management and innovation scholars are uniquely equipped to advance research on Crowd and Citizen Science, both to understand this emerging organisational form and to improve project design for the benefit of science and society. At the same time, CS can serve as an intriguing research context to study more general questions. To stimulate and accelerate such work, this article makes three main contributions. First, we discuss similarities and differences between two streams of research that have investigated CS using the terminology of ‘Citizen Science’ and ‘Crowd Science’, respectively (Section 2). Our conclusion is that these streams study strongly overlapping sets of projects but use different disciplinary lenses. We suggest that integrating aspects of both streams may yield fruitful avenues for future research on CS. Second, scholars have proposed several taxonomies of CS projects, focusing on different and often disconnected dimensions. Although this diversity may be beneficial to satisfy different descriptive and analytical needs, it risks a fragmentation of research. We propose a multi-dimensional framework that is grounded in prior research on knowledge production and organisational theory and that highlights four fundamental types of contributions that can be made by the crowd (Section 3). We illustrate how this framework can be used to create descriptive ‘profiles’ of CS projects and discuss how it can be extended to account for the increasing role of machines as an additional actor (Section 4). Building on this framework, we outline in Section 5 an agenda for future research on CS that is anchored on four underlying organisational challenges: The division of tasks, the allocation of tasks to different actors, the provision of rewards to motivate contributions, and the provision of information to enable successful collaboration and decision making (Puranam, Alexy, and Reitzig Citation2014). Finally, we argue that CS is not only an interesting phenomenon in itself, but that the open and transparent nature of CS projects makes them an ideal context to study related phenomena such as the digital transformation of research and the role of large platforms, the increasing size and specialisation of scientific teams, crowdsourcing, co-creation, as well as the gig economy and online labour markets (Section 6).
2. Two complementary lenses: Citizen Science and Crowd Science
2.1. Citizen Science
In its most common use, the term Citizen Science refers to projects that involve non-professional ‘citizens’ directly in scientific research (Haklay et al. Citation2021). Such projects are often led by professional scientists but can also be organised entirely by citizens.Footnote3 Some of these projects have published case studies and reports on their activities, often in outlets specific to the scientific fields in which they operate (Bonney et al. Citation2009; ExCiteS Citation2019; Druschke and Seltzer Citation2012; Willett et al. Citation2013). Scholars in science and technology studies as well as the information sciences have also investigated such projects (Wiggins and Crowston Citation2011; Ceccaroni et al. Citation2019; Ottinger Citation2010).
The involvement of citizens in research has two historical origins (Strasser et al. Citation2019). One is the long tradition of ‘amateur naturalists’ and ‘gentleman scientists’ who pursued research often out of their own interest and curiosity prior to the professionalisation of science in the mid-19th century (Shapin Citation2008). A second important influence are radical science movements of the 1960s and 70s that were critical of academic and corporate science and often responded to perceived threats resulting from science and innovation such as nuclear war, air pollution, or pesticides. The primary goal of these movements was to advocate for a science that serves the interests of the citizens (Strasser et al. Citation2019; Irwin Citation2001). Mechanisms to accomplish this goal included protests, public deliberations and engagement exercises, but also efforts of citizens to produce their own knowledge without depending on the professional system.
Partly reflecting these different historical origins, there are different views regarding the nature and goals of Citizen Science (Woolley et al. Citation2016). While one main tradition of Citizen Science focuses on the potential of citizens to contribute to academic knowledge production through activities such as data collection and environmental monitoring (Bonney Citation1996), the second tradition focuses on opportunities to make science more responsive to the needs of citizens and to incorporate their local knowledge and personal experience (Irwin Citation1995). In recent work, these different streams have been synthesised into contrasting ideal-type views of CS: a ‘productivity view’ focusing on scientific output, and a ‘democratization view’ considering scientific but also non-scientific goals such as citizen empowerment, education, awareness, and advocacy (Sauermann et al. Citation2020).
Some Citizen Science practitioners and scholars continue to challenge the scientific establishment, including its professional norms and standards. Some projects also see their primary purpose in societal change, inclusiveness, or advocacy rather than the generation of scientific knowledge in the traditional sense (Ottinger Citation2010). However, ‘mainstream’ Citizen Science – as advocated and shaped by its large membership organisations in both Europe and the USA – considers the goal of knowledge production as essential (ECSA Citation2020; Turrini et al. Citation2018).
2.2. Crowd Science
The term Crowd Science refers to projects that involve larger ‘crowds’ of individuals in research. This term has emerged more recently and is used primarily in the fields of management and economics (Franzoni and Sauermann Citation2014; Scheliga et al. Citation2018; Lyons and Zhang Citation2019; West and Sims Citation2018). The focus of this work is on the fact that project participants come from outside a focal lab or research organisation and respond to open calls for contributions; relationships are governed by general participation rules rather than individual contracts. Whereas Citizen Science focuses on the fact that contributors are not professional scientists, this aspect is less central in Crowd Science: Although most Crowd Science projects engage with citizen crowds, crowds may also consist of professional scientists and other experts. Examples include Harvard Medical School’s effort to crowdsource research problems from within the university community (Guinan, Boudreau, and Lakhani Citation2013), as well as a series of Polymath projects that require high levels of training in mathematics (Polymath Citation2012). Discussions of Crowd Science typically start from the vantage point of professional scientists who enlist crowds to advance their research. As such, there has been little consideration of projects that are driven entirely by crowd members.
Research on Crowd Science draws heavily on the literature in ‘crowdsourcing’ (e.g. Tucci, Afuah, and Viscusi Citation2018; Jeppesen and Lakhani Citation2010; Poetz and Schreier Citation2012) to understand both benefits and challenges of involving crowds. Compared to (firm-sponsored) crowdsourcing, however, Crowd Science projects tend to be more transparent with respect to their internal processes and also often disclose intermediate and final results (Franzoni and Sauermann Citation2014). This openness provides opportunities for collaboration and knowledge spillovers but also creates challenges regarding incentives and appropriability (see also Dasgupta and David Citation1994). Crowd Science projects also typically do not pay crowd members for their work and do not use tournament-based financial prizes (Scheliga et al. Citation2018).Footnote4
Given their disciplinary backgrounds, scholars using the Crowd Science lens focus on potential benefits in terms of knowledge production. Although this also includes greater alignment between research and the needs of the broader public (Beck et al. Citation2020), this literature has paid little attention to non-scientific project outcomes such as citizen learning, empowerment, or advocacy. As such, it is much more aligned with the ‘productivity view’ of Citizen Science than with the ‘democratization view’ (see Section 2.1).
Most of the projects investigated in the Crowd Science literature operate online. For example, Zooniverse projects use a sophisticated internet platform to involve crowd members in the classification of digital objects such as images, videos, or audio files (Lyons, Zhang, and Rosenbloom Citation2019; Sauermann and Franzoni Citation2015). The Ludwig Boltzmann Gesellschaft has completed two projects to crowdsource research questions in mental health and traumatology, using the website ‘Tell Us!’ to solicit contributions from a broad range of individuals across time and space (Beck et al. Citation2020). Epidemium, a collaborative effort to advance cancer research using big data, brings together crowd members with cancer knowledge and data science expertise using an online platform that hosts open data sets and serves as a repository for crowd contributions (Benchoufi et al. Citation2017). Crowd Science researchers’ focus on online projects is not surprising given that internet-based technologies are often necessary to reach and organise large and diverse crowds (Brabham Citation2008; Scheliga et al. Citation2018). In contrast, Citizen Science research has studied a broader range of projects in both online and offline contexts. Even in the latter, however, technological tools and infrastructure are often critical. For example, smartphones with GPS technology and cameras have significantly increased the scale and data quality of projects in environmental monitoring (Haklay Citation2013). We will return to the important role of technology in Section 4 below.
2.3. Integration
The prior discussion suggests that there are a few types of projects that would fall within the dominant definition of one of the literatures but not the other: Researchers studying Crowd Science would have little to say about small-scale projects taking place offline and pursuing primarily non-scientific goals such as advocacy, while scholars of Citizen Science would consider projects out of scope that solicit contributions only from professional scientists (see ). Upon closer inspection, however, it becomes clear that Crowd Science and Citizen Science scholars study a strongly overlapping set of projects, with landmark examples such as Zooniverse, eBird, and Foldit figuring prominently in both literatures (e.g. Sauermann and Franzoni Citation2015; Raddick et al. Citation2013). Thus, in the large majority of cases, ‘Crowd Science’ and ‘Citizen Science’ do not refer to different types of projects. Rather, these terms reflect different disciplinary lenses used to study the same general phenomenon, focusing on different features to describe projects, highlighting different mechanisms when analysing how projects operate, and using different criteria when discussing project success.Footnote5
Figure 1. Large overlap between citizen science and crowd science projects.
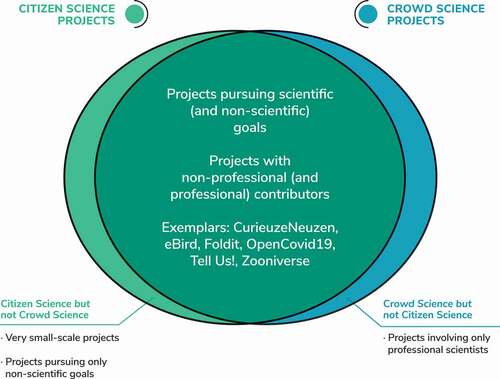
Going forward, we expect that both streams of literature will continue to evolve and make important contributions in their respective domains.Footnote6 At the same time, there are opportunities for complementarities and convergence. For example, Crowd Science research could consider a broader range of outcomes, including scientific outputs such as data and publications but also non-scientific outcomes such as citizen learning (Beck et al. Citation2021). Similarly, Citizen Science research will increasingly investigate large-scale online projects (Newman et al. Citation2012), and theories as well as empirical methods used by scholars of Crowd Science may prove useful in the future. We hope that our discussion in subsequent sections of this article may be valuable for both communities. Indeed, we will continue to draw on both literatures when reviewing prior work and making our conceptual arguments, referring to Crowd Science and Citizen Science collectively as ‘CS’.
In the next section, we review existing taxonomies of CS and propose a more flexible multi-dimensional approach to ‘profile’ projects. This approach is useful for general descriptive purposes, while focusing on dimensions that should resonate particularly with scholars in management, economics, as well as science and innovation studies.
3. A multi-dimensional framework to profile CS projects
3.1. Limitations of existing taxonomies
Scholars have proposed a variety of taxonomies of CS projects (see for examples). Many of these have emerged for descriptive purposes or as part of evaluation practices carried out by lead investigators and funding agencies (Strasser et al. Citation2019). As such, they emphasise selected dimensions that were salient in particular contexts. Some taxonomies – especially those tied to the ‘democratization view’ of CS – involve implicit hierarchies that ascribe a higher value to projects that involve citizens more extensively (Strasser et al. Citation2019; Arnstein Citation1969).
Table 1. Examples of existing CS project taxonomies
As shown in , many taxonomies consider different underlying dimensions jointly to define mutually exclusive types of projects. While this approach can yield intuitive categories, it makes it difficult to account for less common combinations of project characteristics and to accommodate novel types of projects. For example, one prominent taxonomy distinguishes
Contributory projects that are ‘designed by scientists and for which members of the public primarily contribute data’,
Collaborative projects that are ‘designed by scientists and members of the public contribute data but also help to refine project design, analyze data, and/or disseminate findings’, and
Co-created projects that are ‘designed by scientists and members of the public working together and for which at least some of the public participants are actively involved in most or all aspects of the research process’ (Shirk et al. Citation2012).
This taxonomy originated in a context where the crowd contributed primarily data, and it is unable to accommodate prominent projects such as Foldit (where crowds help solve problems) or Tell Us! (where crowds identify research questions but are not involved in other stages of the research).
In the following, we propose to ‘profile’ CS projects using a multi-dimensional framework. The goal is not to classify projects in the sense of a taxonomy, but to describe projects flexibly with respect to the contributions that are made by the crowd at different stages of the research process. The framework highlights four types of contributions that feature prominently in research on knowledge production and organisational theory. This, in turn, enables us to analyse CS more deeply as a novel form to organise scientific research (Puranam, Alexy, and Reitzig Citation2014) and points to promising avenues for future work especially by management and innovation scholars (Section 5).
3.2. Multi-dimensional framework
We start by conceptualising the research process as consisting of several different stages such as defining research questions, analysing data, and diffusing findings to the broader public (Beck et al. Citation2021; Shirk et al. Citation2012; Newman et al. Citation2012). These stages form the ‘backbone’ of our framework (visualised in ). Although we use a linear representation, this is clearly a simplification – research processes tend to be highly nonlinear and teams may iterate between stages. Moreover, not all projects involve all the activities depicted in and some projects may have additional stages. As such, analysts using the framework may modify the stages to ensure the inclusion of all relevant activities in a particular context and to achieve the appropriate balance between detail and parsimony. Journals and professional associations are currently going through a similar process in order to codify lists of research activities that can be used to define authorship and disclose author contributions (Sauermann and Haeussler Citation2017; CASRAI Citation2018).Footnote7
Building on this backbone, we can now characterise projects with respect to the contributions made by the crowd at each stage. In doing so, it is important to keep in mind that different projects can work with different crowds.Footnote8 For example, the crowd in the Zooniverse project Galaxy Zoo as well as in CurieuzeNeuzen included primarily regular citizens that were quite diverse with respect to the level of education, income, or demographic characteristics (Van Brussel and Huyse Citation2018; Raddick et al. Citation2013). In contrast, the crowd in a series of Polymath projects was much smaller, consisting of individuals with training in mathematics, including professionals as well as non-professionals (Franzoni and Sauermann Citation2014).Footnote9
Our framework has four key dimensions: (1) the particular activities carried out by the crowd, (2) the knowledge contributed when performing these activities, (3) other resources contributed, and (4) the decisions made. shows how mapping crowd contributions along these four dimensions leads to distinct ‘profiles’ of crowd involvement, using the examples of Galaxy Zoo (Panel A), CurieuzeNeuzen (Panel B), and Polymath (Panel C). We now discuss each dimension in more detail.
Activities. The first dimension captures the particular activities performed by the crowd. This dimension is important because research activities are the essential building blocks of the knowledge production process (Haeussler and Sauermann Citation2020; Shibayama, Baba, and Walsh Citation2015). Engaging in different types of activities also allows crowd members to accomplish non-scientific goals such as learning and advocacy (Druschke and Seltzer Citation2012). At an aggregate level, information about activities is already captured by the process stages that form the backbone of the framework (e.g. developing research questions or collecting data). As such, entries for this dimension can convey more specific details about the role crowd members play. If the project profile is to be used for analytical rather than descriptive purposes, entries can also capture theoretically relevant constructs, e.g. the size or complexity of individual tasks (see Section 5 on future research opportunities regarding task division).
In Galaxy Zoo, contributors’ main task is to classify images of galaxies using a simple series of questions. Some crowd members also discuss galaxies and help others with difficult cases in a forum.Footnote10 Both of these activities fit within the broader stage of ‘collect and process data’ (, Panel A). The project CurieuzeNeuzen involved crowd members in several different stages of the research. Most importantly, they physically collected air samples outside their home windows in different locations and also provided data on traffic intensity as well as the geometrical configuration of their streets. Crowd members also participated in a presentation of results and flagged results that stood out. Based on their understanding of the local conditions, residents from particular areas of the city engaged in the verification of results and contributed insights to explain unexpected or deviant findings. Participants also contributed to the diffusion of results, e.g. by displaying posters with project results at their houses for neighbours and those passing by. In the project Polymath, crowd members participate in essentially all stages: They propose and select problems to solve, design methods through ongoing discussions, collaboratively solve problems, and help write the papers under the collective pseudonym D.H.J. Polymath (e.g. Polymath Citation2012).
Knowledge. Although some activities are primarily physical in nature (e.g. collecting air samples in CurieuzeNeuzen), almost all activities require crowd members to contribute different types of knowledge. Indeed, knowledge is a key input examined by scholars studying science and innovation processes (Singh and Fleming Citation2010; Gruber, Harhoff, and Hoisl Citation2013; Von Hippel Citation1994) and also figures prominently in discussions of crowdsourcing (Afuah and Tucci Citation2012). Within this dimension, analysts can describe concretely what particular knowledge crowd members bring to bear. For analytical purposes, it will often be useful to consider different types of knowledge that are practically or theoretically relevant. One possible distinction is that between common knowledge held in the general population, specialised knowledge held by a smaller part of the population, and domain-specific expert knowledge gained through formal education or long-term practice (Franzoni and Sauermann Citation2014).
shows the respective entries for our example projects. In Galaxy Zoo, most crowd members use common knowledge to judge basic characteristics of galaxies such as their shape. Some crowd members use specialised knowledge gained through experience on the platform to manage discussions and to help others with difficult cases. In CurieuzeNeuzen, crowd members used common knowledge to set up measurement devices outside their windows as part of the ‘collect and process data’ stage. However, they used common as well as specialised knowledge (in this case, their understanding of the local environment) when identifying interesting patterns in the data and coming up with explanations for unexpected results. They also used specialised knowledge regarding the project process and results when helping diffuse results. In Polymath, contributions require specialised or even expert knowledge in mathematics. Some crowd members also contribute specialised knowledge regarding how complex discussions can be organised effectively and what technical tools might be helpful.Footnote11
Resources other than effort and knowledge. Studies of science and knowledge production highlight that research also requires other types of resources such as money, materials, and equipment (Stephan Citation2012; Furman and Stern Citation2011). Contributions of such resources tend to be less visible in prior taxonomies of CS projects (). However, they are central to some projects such as SETI@home, where citizens contribute primarily computing power. Similarly, a growing number of projects involve crowd members primarily as providers of financial resources – e.g. on the crowdfunding platform Experiment.com (Sauermann, Shafi, and Franzoni Citation2019; Franzoni, Sauermann, and Di Marco Citation2021). Finally, some projects such as American Gut ask crowd members to collect and contribute specimens such as stool and blood samples or personal data generated via automatic tracking devices (Wiggins and Wilbanks Citation2019; McDonald et al. Citation2018; Newman et al. Citation2012).Footnote12
Even if such resources are not the crowd’s primary contribution to a project, crowd members often have to provide resources in order to perform research activities. For example, online CS projects typically require access to computers and the internet, while offline projects often require means of transportation to perform data collection or attend meetings (Newman et al. Citation2012). The lack of access to resources or the associated costs may prevent some individuals to contribute their effort and knowledge, increasing inequality and selection biases in project participation (Franzen et al. Citation2021).
To illustrate this dimension, consider again the examples in . In Galaxy Zoo, the primary resource required from contributors (other than their effort and knowledge) is computer and internet access. In CurieuzeNeuzen, crowd members provided space in front of their windows to collect air samples and contributed their own transportation to pick up and drop off collection devices and attend project meetings. Crowd members also contributed a share of the project budget through crowdfunding (Irwin Citation2018). Contributors in Polymath require primarily computer and internet access to participate in online discussions. Although we described resources quite specifically in , broader categories (e.g. tangible vs. intangible, or low vs. high cost) can also be useful.
Decisions. The fourth dimension captures to what extent crowd members contribute by taking decisions in different stages of the research. Decision-making is a pervasive but also challenging aspect of scientific research, and the decisions that are made shape both the rate and the direction of output (Latour and Woolgar Citation1979; Stephan Citation2012). Not surprisingly, decision-making is also a key process studied in the general organisational literature (Puranam, Alexy, and Reitzig Citation2014). The analyst completing a project profile may choose to describe decisions made by crowd members in specific detail, but may also indicate more generally participants’ level of involvement in decision making, ranging from none to providing input and recommendations for lead investigators (‘consultation’) to having full control over particular aspects of the project (see Arnstein Citation1969). It can also be useful to distinguish what the decisions are about, e.g. about project content (e.g. what to do), project processes (how to do), or about concrete study objects (e.g. is the bird in this image of species A or species B).
Many projects grant few decision rights to the crowd, while others allow crowd members a significant degree of influence. Indeed, decision-making is at the centre of discussions around the normatively ‘right’ degree of crowd involvement and shapes the degree to which CS can ‘democratise’ science (Arnstein Citation1969; Haklay Citation2013; Strasser et al. Citation2019).Footnote13 This final dimension also reveals important connections to prior dimensions. For example, different types of activities (dimension 1) tend to involve different types of decisions, and different types of decisions likely require different kinds of knowledge (dimension 2).
shows the key decisions made by crowd members in our three example projects. In Galaxy Zoo, crowd members have little control over the project content or process. The main decisions they make are tied directly to the primary task – classifying galaxies by deciding between different options (e.g. smooth vs. spiral galaxy). Participants in CurieuzeNeuzen were involved in a somewhat broader range of decisions such as where to locate collection devices (within guidelines set by the lead investigators) or providing recommendations regarding which data patterns to highlight in reports. In contrast, Polymath projects give contributors many opportunities to make recommendations and decisions: The initial problem to be solved was defined by mathematician Timothy Gowers. For subsequent Polymath projects, other lead investigators and ultimately crowd members proposed several alternative problems. Contributors decided which problems to pursue through blog discussions and informal polls.Footnote14 Both the direction of the work and the problem-solving approach were deliberately kept open at the outset and emerged through collective decisions as participants collaborated over time.Footnote15
These four primary dimensions of our framework – activities, knowledge, resources, and decisions – focus on the contributions made by the crowd. In addition, we also capture in the Outcomes that resulted from these various contributions and the projects more generally (see our related discussion of project goals in Section 2). The primary outcomes of Galaxy Zoo and Polymath were scientific (e.g. peer-reviewed publications and/or data for future research use), although the projects also provided enjoyment and learning to participants (Raddick et al. Citation2013). CurieuzeNeuzen resulted in publications and valuable data but also yielded important non-scientific outcomes such as citizens’ learning about their local environments, changes in citizens’ traffic-related attitudes and behaviours, as well as policy influence (Van Brussel and Huyse Citation2018).
3.3. Discussion of the framework
Before we build on our framework to discuss new developments in CS (Section 4) and to identify opportunities for future research (Section 5), we highlight a few important points.
First, the primary purpose of the framework is to create a conceptual and visual space that allows analysts to map the contributions of crowds to a research project. The creation of a project ‘profile’ per se is purely descriptive and should not be confused with the assessment and evaluation of the observed level of crowd involvement. In particular, evaluators may disagree over whether a particular profile of crowd contributions should qualify as ‘active involvement’ in research, and whether a particular project deserves the label of Citizen Science or Crowd Science. This question is not inconsequential, given that several funding agencies have dedicated programmes to run (and study) CS projects, or that framing projects as CS may seem to fulfill requirements regarding ‘broader impacts’ (Davis and Laas Citation2014; SwafS Citation2017).
Perhaps the most contentious question in this respect is whether crowd contributions of resources alone – without contributions of effort or knowledge – qualify as ‘active involvement’ in research (Del Savio, Prainsack, and Buyx Citation2016; Haklay et al. Citation2020). One view is that crowd members who only provide access to computing power or money do not play an active role in the research, and that citizens who donate personal specimens or data should be seen as study subjects rather than investigators. Others argue that such resource contributions can be significant enough to justify the label of Citizen Science (ECSA Citation2020; Socientize Consortium Citation2013). We do not think there is a general answer to this question. Rather than focusing on terminology, evaluators should assess projects based on the profile of crowd contributions and the goal they wish to accomplish. For example, a funding agency seeking to help democratise science may place a high emphasis on the breadth of citizen involvement and on the level of decision rights granted to participants. As such, this agency may not want to support a project that only asks the crowd to provide access to computing power. Another agency focusing on research output might support such a project because it efficiently leverages idle resources available from the crowd. Both agencies will benefit from a thorough understanding of the particular nature of crowd involvement. As such, funding agencies and other evaluators could routinely ask applicants to submit a project profile of expected crowd contributions as well as scientific and non-scientific outcomes. In a similar vein, CS projects could publish such profiles to help potential crowd participants determine whether there is a match in terms of the required levels of commitment, knowledge, access to resources, and opportunities to participate in decision making, but also in terms of the scientific and non-scientific goals a project seeks to accomplish.
Second, although we used the framework to profile projects with respect to contributions of the crowd, it can also be used to identify the contributions of other types of ‘actors’. Most importantly, it can be used to map the contributions made by lead investigators, i.e. the individuals who organise and lead CS projects. These lead investigators are often professional scientists (e.g. the organisers of Zooniverse projects) but can also include citizens with relevant expertise in different domains (e.g. in CurieuzeNeuzen). Considering the resulting profiles jointly will then allow for an explicit comparison of the roles of lead investigators and crowds in different stages of the research process.
A third important point is that the crowd contributions or project outcomes that were initially planned may not be realised. For example, some projects plan for extensive crowd involvement but fail to attract enough contributors, while others realise that contributors lack the knowledge and time required to perform the assigned activities (Crowston, Mitchell, and Østerlund Citation2019). Similarly, the contributions of the crowd in a particular project may change, e.g. when some key contributors start with narrow tasks but take on additional responsibilities over time (Lintott et al. Citation2009). Learning due to extended project participation can also allow crowd members who started with common knowledge to contribute specialised expert knowledge later in a project’s life (Crowston et al. Citation2019; Ponti et al. Citation2018). If such nuances are important for the analyst, they can be captured by creating multiple profiles for a given project, reflecting planned versus realised crowd contributions or contributions at different points in time.
Finally, we recognise that our multi-dimensional framework is more complex than prior taxonomies of CS projects. We believe that this complexity is justified given the greater ability to represent crowd contributions in a nuanced manner, to avoid confounding different dimensions, and to create a space for unusual and novel types of projects. For example, our framework can easily accommodate the growing number of projects that involve crowds only in generating research questions (Guinan, Boudreau, and Lakhani Citation2013; Beck et al. Citation2020), while such projects do not fit in the popular taxonomy distinguishing contributory, collaborative, and co-created projects (see ). That being said, we limited the framework to four dimensions that are firmly grounded in theories of innovation and organisation and that are also practically relevant.Footnote16
4. From tool to third actor: the rise of machines
Technological advances have fuelled an increase in the scale and scope of CS projects by providing powerful tools and infrastructure (Newman et al. Citation2012). As noted earlier, for example, smartphones with GPS have improved citizens’ ability to collect high quality observational data, and online platforms provide the core infrastructure for large projects such as Foldit and eBird. Digital technologies and algorithms also help lead investigators to ‘manage’ crowds, keeping contributors engaged through gamification (Waldispühl et al. Citation2020), verifying the accuracy of contributors’ submissions (Sullivan et al. Citation2018), correcting for cognitive or behavioural biases of the crowd (Kamar, Kapoor, and Horvitz Citation2015), providing just-in-time training and support (Katrak-Adefowora, Blickley, and Zellmer Citation2020), or assigning contributors to tasks based on their levels of expertise and prior performance (Kamar, Hacker, and Horvitz Citation2012; Trouille, Lintott, and Fortson Citation2019).
In addition to serving as tools and infrastructure that enable CS projects, advanced technologies such as artificial intelligence (AI) and robots increasingly perform core research activities themselves (Franzen et al. Citation2021; Ceccaroni et al. Citation2019). As such, it is useful to consider ‘machines’ as distinct actors that make their own contributions, augmenting and sometimes substituting for crowds and lead investigators (Raisch and Krakowski Citation2021; Brynjolfsson and Mitchell Citation2017). In this section, we briefly discuss some of these developments, show how they can be captured in the framework developed in Section 3, and consider implications for the future of CS.
Many well-known CS projects – including those on the platform Zooniverse – ask crowd members to classify images, videos, and other objects (see , Panel A). Human classifiers were especially important early-on, when computers were unable to recognise even relatively simple patterns with sufficient quality (Hopkin Citation2007). But lead investigators seized opportunities to use crowd-generated data to train and improve algorithms (Ceccaroni et al. Citation2019; Rafner et al. Citation2021). Once crowds have generated training data, algorithms are often more efficient, which is particularly important given the increasing scale and speed at which new raw data become available in many fields (Kuminski and Shamir Citation2016; Walmsley et al. Citation2021). Indeed, some Zooniverse projects were retired from the platform once citizens had generated enough training data, allowing algorithms to perform the remaining work (Trouille, Lintott, and Fortson Citation2019).
Although automated classifications can be interpreted as the substitution of crowds by machines, the initial need for crowd-generated training data also indicates a complementarity between crowds and machines. More importantly, advanced CS projects have moved beyond static function allocation to either crowds or machines (De Winter and Dodou Citation2014) to create hybrid systems that ‘augment’ humans and exploit new types of complementarities (Rafner et al. Citation2021; Raisch and Krakowski Citation2021). For example, the project eBird distributes individual classification tasks intelligently between citizens, algorithms, and experts, allowing humans and machines to learn from each other and to improve the performance of the overall system (Kelling et al. Citation2012). Some Zooniverse projects optimise the activities of humans and machines dynamically – volunteers who perform above certain thresholds are moved up to higher ‘workflow levels’ where they work on objects that could not be classified reliably by entry-level volunteers or algorithms, using more flexible interfaces and even creating new classification categories (Trouille, Lintott, and Fortson Citation2019; Walmsley et al. Citation2021). Although large and well-funded platforms such as eBird and Zooniverse are at the forefront of developing such hybrid systems, efforts to integrate crowds and machines (‘human-in-the-loop’) are quite common in projects focusing on data collection and processing (Franzen et al. Citation2021; Gander, Ponti, and Seredko Citation2021).
The roles of crowds and machines are also shifting in problem solving activities. Several early CS projects recognised the advantages humans had in solving complex problems that were challenging for the computational approaches available at the time. The project Foldit, for example, achieved significant successes in protein structure prediction (Cooper et al. Citation2010). However, Foldit players and lead investigators soon started to incorporate creative solution approaches into algorithms, dramatically increasing the effectiveness of automated problem-solving (Franzoni and Sauermann Citation2014). Modern algorithms are very effective (Yang et al. Citation2020; Senior et al. Citation2020) and it is perhaps not surprising that Foldit has gradually moved from protein structure prediction to more challenging problems such as protein design.Footnote17 Similarly, the platform Science at Home initially used crowds to help solve problems in quantum physics (Jensen et al. Citation2021) but has now started to additionally investigate crowd members’ human problem solving as a core area of research – creating new ambiguities regarding the role of citizens as active participants in research vs. study subjects (see Section 3.3).Footnote18 Finally, problem solving using analogies has long been considered too difficult for algorithms but recent research demonstrates that hybrid systems combining crowds and machines can leverage the respective strengths of both actors (Kittur et al. Citation2019).
Although some research activities are increasingly carried out by algorithms rather than crowds or professional scientists, there are other areas where humans continue to have distinct advantages. One is the ability to recognise important problems and to formulate research questions that should be studied in the first place (Beck et al. Citation2020; Brynjolfsson and Mitchell Citation2017). Another advantage is that humans are better at noticing and dealing with unexpected objects or events, a skill that remains difficult for algorithms trained using existing data (Heaven Citation2019; Trouille, Lintott, and Fortson Citation2019).Footnote19 A final advantage is humans’ ability to operate flexibly in physical space. For example, the platform iNaturalist uses mostly algorithms to classify images for environmental monitoring, but it still requires human crowd members to explore their physical natural environments and to capture and upload images (Weinstein Citation2018; Green et al. Citation2020). That being said, technologies are also making inroads in these areas. For example, automated camera traps help monitor wildlife populations, wireless sensor networks collect and transmit data for environmental monitoring, and robotic systems can carry out monitoring of plant growth in community gardens (Joshi et al. Citation2018; Swanson et al. Citation2015; Newman et al. Citation2012). Perhaps most strikingly, researchers are working on ‘robot scientists’ that perform all activities of the research process, starting from the generation of research questions (AI-based, using libraries of existing research), to the execution of physical experiments using robots, to the codification of results that are then fed back into the algorithm to derive new hypotheses (Sparkes et al. Citation2010; Shi et al. Citation2021).
What might the increasing capabilities of new technologies imply for the future development of CS? First and foremost, many of these technologies will likely benefit projects by providing better tools and infrastructure that enable increased participation and higher performance – in terms of scientific output but also other project outcomes such as citizen learning (Newman et al. Citation2012; Green et al. Citation2020). Second, even when taking over core research tasks, new technologies may have positive effects if they free crowds from the need to perform repetitive tasks and enable them to focus on more interesting and intellectually challenging activities and objects (Franzen et al. Citation2021; Trouille, Lintott, and Fortson Citation2019). However, to the extent that such work is limited in volume, or requires additional knowledge and resources that pose barriers for crowd participants, there is a risk that CS becomes less inclusive by focusing primarily on expert volunteers (Raisch and Krakowski Citation2021; Brynjolfsson and Mitchell Citation2017). This may not be a concern from a ‘productivity’ perspective, but may limit CS’s potential to advance the non-scientific goals highlighted by the ‘democratization view’ (Section 2). Our conjecture is that there may be a divergence in the CS landscape: Some projects may pursue primarily productivity goals by complementing crowds with new technologies but also letting machines do the work if that is more efficient than relying on the crowd. Other projects may use technologies to broaden citizen participation and improve non-scientific outcomes such as learning and awareness – continuing to rely heavily on crowds even if that means tradeoffs in scientific efficiency. Either way, the goals of the lead investigators as well as the guidance provided by policy makers and funding agencies will play an important role in shaping the future development of CS projects in light of the increasing capabilities of machines.
Although we cannot tell how exactly the roles of crowds, lead investigators, and machines will develop in the future, the framework developed in Section 3 can help to study such developments. We already discussed how our framework can be applied to crowds as well as lead investigators (Section 3.3); it is a small step to also profile projects with respect to the involvement of machines. provides a stylised example: It shows for a hypothetical project how each of the three types of actors is involved in different stages of the research process (blue cells indicate active involvement of a particular actor in a particular stage). Such project profiles are useful for descriptive purposes but can also provide the starting point for researchers studying Crowd and Citizen Science. As such, we now turn to the final part of this article: Outlining an agenda for future research on CS, focusing on key organisational questions that result from the collaboration between lead investigators, crowds, and machines.
Figure 2. Conceptual framework and illustrative ‘profiles’ of crowd contributions for Galaxy Zoo (Panel A), CurieuzeNeuzen (Panel B), and Polymath projects (Panel C).
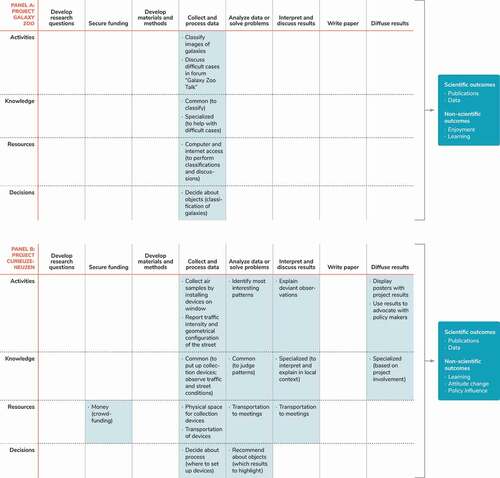
Figure 2. Continued.
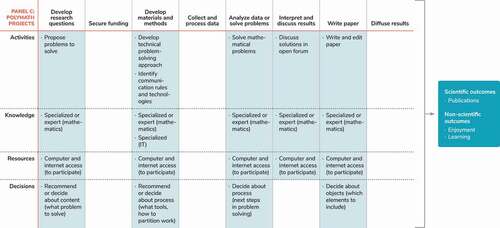
Figure 3. Profile of project contributions made by lead investigators, crowd, and machines .

5. CS as a ‘new form of organizing’: opportunities for future research
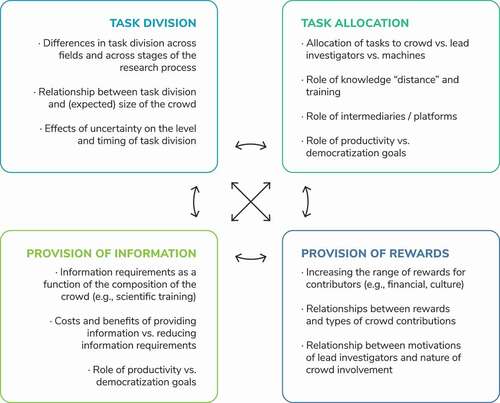
The descriptive framework developed in Sections 3 and 4 allows us to characterise CS projects comprehensively with respect to the activities, knowledge, resources, and decisions that are contributed by different actors – the crowd, lead investigators, as well as machines. To structure our discussion of future research opportunities, we additionally build on a second framework that enables a sharper focus on key organisational aspects that are underlying the observed CS project profiles. In particular, we conceptualise CS as a ‘new form of organizing’ scientific knowledge production that differs from traditional academic research with respect to four central aspects (Puranam, Alexy, and Reitzig Citation2014; Walsh and Lee Citation2015): The mapping of the overall project goal into component tasks (task division), the allocation of tasks to different actors (task allocation), mechanisms to motivate and incentivise contributions (provision of rewards), and mechanisms to supply contributors with the information required to perform their work and coordinate with each other (provision of information). We briefly discuss how CS differs from traditional research with respect to each of these organisational aspects,Footnote20 highlight specific research questions regarding each aspect, and show how the descriptive project profiles developed in Sections 3 and 4 can help study these organisational questions.
5.1. Task division
The first aspect of organising is that the overall project goals have to be mapped onto contributory tasks that can be performed by different actors. In traditional research projects, task division is often kept at a relatively high level of aggregation (e.g. broad research activities such as data collection versus data analysis), and these broader categories also serve to credit (and blame) professional contributors (CASRAI Citation2018). Depending on the size of the project, task division can be more or less formal and can emerge or change over the course of a project (see Haeussler and Sauermann Citation2020; Walsh and Lee Citation2015).
Task division at a high level of aggregation is still relevant in CS, especially as it relates to the division of labour between different types of actors such as crowds and lead investigators (as reflected in ). However, CS projects tend to go further by dividing tasks more finely within these broad categories in order to allow a large number of contributors to participate. Consider extreme examples such as Galaxy Zoo, which has broken the task ‘classify thousands of galaxies’ into thousands of micro-tasks that involve looking at a single galaxy and making a handful of simple classification decisions. Participants in the project Polymath work on larger sub-tasks, sometimes solving significant parts of the overall mathematical problem. However, considering that mathematics is a field where research has traditionally been done by individuals or very small teams (Wuchty, Jones, and Uzzi Citation2007), Polymath still involves a greater division of tasks than traditional projects. Another observation is that CS projects vary considerably with respect to the timing of task division. Large projects requiring common knowledge (e.g. Galaxy Zoo and CurieuzeNeuzen) often divide tasks ex ante, while smaller projects requiring specialised knowledge and longer-term involvement of crowd members tend to manage task division more flexibly (e.g. Polymath). Potential explanations are that large projects would face greater adjustment costs when changing task division, but also that their optimal task division may depend less on which particular crowd members join the project.
This discussion raises several interesting questions for future research: First, how does the level of task division depend on the nature of the overall problem (e.g. as reflected in differences across fields)? Relatedly, how does task division differ across activities within a project, e.g. data collection versus the formulation of research questions? Second, how does optimal task division depend on the size of the crowd? Finally, how do the level and timing of task division depend on uncertainty, both with respect to the research itself but also regarding the number and composition of crowd members who respond to the call for participation? Although motivated by the particular context of CS, questions such as these are quite general and are being tackled also in related contexts, most notably crowdsourcing (Afuah Citation2018) and traditional scientific teams (Haeussler and Sauermann Citation2020). As such, researchers can build on these existing literatures and may also be able to contribute insights back to those domains.
The multi-dimensional profiles developed in Sections 3 and 4 can serve as a starting point to investigate some of these questions empirically. For example, entries on the first dimension (activities) provide direct insights on the tasks performed by crowd members as well as by lead investigators and machines. When coded with respect to the ‘size’ of tasks (with smaller size indicating greater task division), the resulting data can be used to examine the relationships between task division and other interesting variables such as the scientific field and the number of crowd contributors.
5.2. Task allocation
After tasks have been divided, they need to be allocated to different contributors. In traditional research projects, tasks are typically assigned by lead investigators based on their understanding of team members’ interests and capabilities (Owen-Smith Citation2001; Freeman et al. Citation2001). In CS projects, individual contributors are not known ex ante and most participate only for a short time, making it difficult for lead investigators to learn about their skills (Sauermann and Franzoni Citation2015). As such, lead investigators typically broadcast an open call for contributions and crowd members self-select based on the perceived fit between their skills and interests on the one hand, and the tasks offered by the project on the other (see also Afuah Citation2018; Puranam, Alexy, and Reitzig Citation2014). However, some lead investigators also allocate tasks more explicitly based on contributors’ emerging track record, e.g. by promoting core contributors to deal with difficult cases (Trouille, Lintott, and Fortson Citation2019) or asking them to moderate a discussion forum (Rohden Citation2018).
Future research is needed on a first-order question: When and why do lead investigators assign activities to crowds in the first place – rather than to professional team members or machines? Following the literature on crowdsourcing and open innovation, one reason might be the crowd’s access to valuable knowledge. Among others, this might involve a greater diversity of knowledge inputs, specialised knowledge resulting from particular experiences (e.g. as patients), as well as knowledge of pre-existing problems and solutions (Beck et al. Citation2020; Afuah and Tucci Citation2012; Felin and Zenger Citation2014). A second reason is that CS contributors can contribute large volumes of effort that would be difficult or even impossible to mobilise within the traditional system (Sauermann and Franzoni Citation2015). The profiles developed in Section 3 can help us study when and why lead investigators allocate tasks to the crowd. For example, entries for the second and third dimensions in allow us to see what types of knowledge and other resources crowd members contribute. If the knowledge contributed is ‘common’, the primary rationale for allocating tasks to the crowd is likely related to effort and cost (e.g. image classification in Galaxy Zoo). If the knowledge contributed is ‘specialised’, lead investigators likely invite crowds also to access knowledge that may otherwise be difficult to get (e.g. residents’ knowledge about local conditions that helped interpret data in CurieuzeNeuzen). Indeed, explicitly comparing the profiles of contributions made by crowds vs. lead investigators vs. machines () may yield novel insights into the rationales for involving different types of actors, and into potential complementarities between the contributions these actors make at different stages of the research.Footnote21
A second area for future research on task allocation is the self-selection at the level of individual crowd members. In conventional crowdsourcing, organisations spend considerable time to clarify what particular inputs they are looking for, or what particular problems they are trying to solve (Lakhani Citation2011). Crowd members can then assess whether a particular project is a match for their own profile of skills or knowledge. While this idea should in principle also apply in the context of CS, self-selection may be difficult to the extent that there is a greater ‘distance’ between professional scientists and non-professional citizens with respect to knowledge about scientific processes and substance, making it difficult for citizens to see where they can best contribute (see Brossard, Lewenstein, and Bonney Citation2005; Bonney et al. Citation2016). As such, it would be interesting to study how citizens’ self-selection into CS projects depends on their levels of education, on the specific types of contributions requested (dimensions 1–4 of our framework), but also the outreach strategies used by lead investigators. Interestingly, while much of the current research on self-selection in crowdsourcing focuses on task characteristics and skill profiles in a static sense (Afuah Citation2018), many CS projects offer training opportunities and facilitate citizen involvement in order to overcome knowledge gaps (Druschke and Seltzer Citation2012; Van Brussel and Huyse Citation2018). Future research could study task allocation when projects can ‘upskill’ contributors, and whether self-selection matters not only with respect to current skills and knowledge but also the willingness to learn.
Finally, future research should study how intermediaries and new technologies can support projects with both task division and task allocation. For example, the Zooniverse platform offers sophisticated infrastructure to divide tasks and assign them to contributors using algorithms (see Section 4). Just One Giant Lab allows projects to post specific needs and enables volunteers to efficiently search for tasks that match their skills and interests (Kokshagina Citationforthcoming). The platform SciStarter uses AI to recommend new projects that are expected to be a good match based on crowd members’ characteristics, past project choices, as well as activity within projects (Zaken et al. Citation2021).
5.3. Provision of rewards
The third organisational challenge is to motivate contributors to perform their respective tasks (Puranam, Alexy, and Reitzig Citation2014). In traditional academic science, salient rewards include authorship and reputation among peers, which translate into other benefits such as job security (tenure) and income (Stephan Citation2012; Merton Citation1973). Curiosity and desires for social impact can also be important motivators (Cohen, Sauermann, and Stephan Citation2020).
CS projects typically do not provide any financial rewards for contributors (Sauermann and Franzoni Citation2015; Haklay et al. Citation2021). Given that crowd members are not socialised in the traditional institution of science and their number is large, there is also a limited role for authorship and peer recognition, although a few CS projects have granted authorship to individual crowd members or have recognised the crowd under a collective pseudonym (e.g. Polymath Citation2012; Khatib et al. Citation2011; Lintott et al. Citation2009). As such, CS projects appear to rely on a more limited range of motivators: One is crowd members’ intrinsic interest in particular topics such as astronomy or ornithology (Sauermann and Franzoni Citation2013). Another motivator is crowd members’ desire to contribute to science generally, or to help address grand challenges such as climate change and environmental pollution (Geoghegan et al. Citation2016). Some CS projects such as CurieuzeNeuzen or Tell Us! can have direct connections to contributors’ personal problems, offering opportunities for the ‘self-use’ of project outputs (e.g. learning about air quality in one’s own street) or promising longer-term personal benefits from scientific results (e.g. improved medical treatments). Finally, some projects motivate contributors through gamification (Khatib et al. Citation2011; Hamari, Koivisto, and Sarsa Citation2014) or by enabling personal interactions that create social rewards.
Future research could investigate if the range of rewards can be expanded. In particular, crowdsourcing projects in other domains typically rely on financial incentives, including effort-based pay but also sophisticated tournament mechanisms (Boudreau, Lacetera, and Lakhani Citation2011). Although there is a strong belief in the Citizen Science community that citizens should participate as unpaid ‘volunteers’ (perhaps to distinguish CS from commercial crowdsourcing), not paying contributors may result in systematic biases by excluding individuals who need to earn an income to support their livelihood (Haklay et al. Citation2021). As such, relying on unpaid volunteers may be particularly problematic for projects that seek to ‘democratise’ science by including citizens who are typically less represented in the scientific enterprise. A related important question – both from a functional and an ethical perspective – is whether and how crowd members should share in any economic payoffs that are generated by CS projects (Afuah Citation2018; Guerrini et al. Citation2018).Footnote22 Going beyond rewards in a narrow sense, prior research suggests that organisational culture and norms may also play an important role in motivating effort and in discouraging misconduct (Ouchi Citation1979; Rasmussen Citation2019). Whether and how project-level culture can ‘work’ in CS is a particularly interesting question given that projects such as Galaxy Zoo and Polymath operate for many years, but most contributors participate for only very short amounts of time (Sauermann and Franzoni Citation2015; Harrison and Carroll Citation1991).
Especially if the range of rewards can be expanded, future work should examine how the effectiveness of different reward mechanisms depends on the particular contributions that are requested from the crowd (dimensions 1–4 in ). Relatedly, we need to understand better how crowd members’ intrinsic rewards are shaped by task division and task allocation (see prior sections), and how new technologies can be employed to make CS projects more engaging and rewarding (Trouille, Lintott, and Fortson Citation2019; Hamari, Koivisto, and Sarsa Citation2014). However, our discussion in Section 4 suggests that machines may not only enhance crowd motivation but may also make it less important: Once the fixed costs of development have been incurred, machines often need little additional ‘reward’, providing an attractive outside option for lead investigators who find it difficult or costly to attract and retain crowd contributors (Hamid and Bonnie Citation2014). Thus, studying rewards for the crowd is not only interesting per se, but also has important implications for task allocation and the potential substitution between crowds and machines.
Finally, future research is needed on the rewards for lead investigators (Geoghegan et al. Citation2016). The question of motivation may be straightforward for citizen leaders who start projects addressing concrete local problems (e.g. CurieuzeNeuzen) or for professional scientists who can tap into the crowd to achieve vastly superior scientific performance (e.g. Galaxy Zoo). To understand the potential of CS beyond these more obvious cases, however, research is needed on the rewards that motivate a broader range of (potential) lead investigators. Among others, we need to understand how professional scientists assess the potential benefits (and costs) of using CS practices and how ‘accurate’ their estimates are. Research could also explore to what extent scientists value non-scientific in addition to scientific outcomes, and how such preferences differ across individuals and fields (Cohen, Sauermann, and Stephan Citation2020). Finally, it would be interesting to study how lead investigators’ different motivations predict which research activities they allocate to the crowd (dimension 1 in our framework), how much they involve the crowd in decision making (dimension 4), and whether they think of crowds and machines as complements or substitutes (Section 4).
5.4. Provision of information
The final organisational challenge is to supply contributors with the information they need to perform their tasks and coordinate with others. In traditional research, information is typically shared in team meetings or through individual interactions between the lead investigators and other team members (Owen-Smith Citation2001). Many CS projects also rely on meetings and physical co-location (e.g. CurieuzeNeuzen) as well as online discussion tools to share information (e.g. Polymath). Rather than providing information, however, other projects reduce the need for information by breaking activities into simple micro-tasks that require little information to perform, and by modularising tasks such that less coordination is needed between crowd members (e.g. Galaxy Zoo). Some projects also employ algorithms to coordinate crowd contributors without the need to actually share the necessary information with the individuals themselves (Kamar, Hacker, and Horvitz Citation2012; Trouille, Lintott, and Fortson Citation2019).
Existing research has studied the provision of information in traditional organisational contexts as well as in more novel contexts such as open source software development and distributed work (Dahlander and O’Mahony Citation2010; Shah Citation2006; Majchrzak, Malhotra, and Zaggl Citation2021; Okhuysen and Bechky Citation2009). Many of the insights from this work may generalise to CS as well. Nevertheless, information provision deserves more attention specifically in CS projects because contributors – especially non-professional citizens – may have a significantly larger information ‘deficit’ than the actors investigated in prior research. For example, while a distributed team of programmers working on open source software can rely on a shared understanding of how programming works, it will take more information to coordinate between a professional physicist and citizen scientists without training in physics. Especially given the short-term involvement of many contributors, this greater need for information may lead CS projects to primarily rely on modularisation as well as algorithms and project infrastructure, rather than trying to transfer information through training or direct communications. Future research could study such issues by relating the coordination mechanisms employed by projects to the levels of crowd involvement in research activities and decision making (dimensions 1 and 4), but also to the characteristics of the crowd. Similarly, the overlap in the activities performed by lead investigators and crowd members (visible in ) may shape coordination needs within and across groups of actors, and may be correlated with the use of different coordination mechanisms. Again, we suspect that the solutions that lead investigators employ to address this fourth organisational challenge depend heavily on the degree to which they pursue productivity versus democratisation goals.
summarises opportunities for future research on the four organisational aspects, while also highlighting important interdependencies. We believe that progress on this research agenda will help scholars better understand how Crowd and Citizen Science projects are currently organised but may also yield valuable recommendations for improving project design.
Figure 4. Opportunities for future research on key organisational aspects of Crowd and Citizen Science.
6. Summary and conclusion
Science is becoming increasingly open and collaborative (Beck et al. Citation2021). Although openness with respect to research outputs and data is now well established in many fields, an even more radical development is the opening of traditional organisational boundaries by involving crowds, including citizens who are not professional scientists. In this paper, we integrate and expand upon two related streams of research: Crowd Science and Citizen Science. Our discussion of differences and similarities (Section 2) concluded that the two streams study strongly overlapping sets of projects but do so focusing on different outcomes (related to ‘productivity’ vs. ‘democratisation’) and different defining mechanisms (e.g. self-selection in response to an open call vs. involvement of non-professionals). Although management and innovation scholars tend to follow the Crowd Science tradition, the two streams are complementary and can jointly advance our understanding of an important development in science.
In Section 3, we proposed a multi-dimensional framework that improves upon prior taxonomies of CS by providing a conceptual and visual space to flexibly characterise the different contributions made by the crowd. In Section 4, we additionally recognised the important role of technology, which is evolving from supporting infrastructure to an actor that takes over distinct roles in the research process. Our framework allows analysts to create comprehensive ‘profiles’ of the contributions that lead investigators, crowds, and machines make to particular projects. These profiles can serve both descriptive and analytical purposes and can be valuable for CS organisers as well as funding agencies seeking to assess the level and nature of crowd involvement. By highlighting empty cells in the profiles of current CS projects (see ), the framework may also reveal opportunities for a deeper integration of crowds into the research process.
The involvement of crowds in scientific research can yield significant benefits in terms of both productivity and democratisation, but it also poses important organisational challenges. Scholars with a background in management, economics, and innovation studies are well equipped to study these challenges and develop recommendations for lead investigators and policy makers. To stimulate such research, we conceptualised CS as a ‘new form of organizing’ (Puranam, Alexy, and Reitzig Citation2014) and derived pressing research questions related to task division, task allocation, provision of rewards, and provision of information (Section 5). This discussion can also be useful for CS practitioners and scholars in other fields by highlighting fundamental organisational issues that have been less explicit in prior work, and by linking to a rich body of research that can help understand and leverage organisational design parameters.
Although our focus has been on Crowd and Citizen Science as the phenomenon of interest, CS can also serve as an intriguing research context to examine a broad range of more general phenomena and research questions. We conclude by highlighting just a few of these opportunities. First, many CS projects are at the forefront of using digital technologies as enabling infrastructure but also to complement or replace human lead investigators and crowds (see Section 4). As such, CS may enable scholars to study the challenges and opportunities arising from digital transformation, including aspects such as virtual collaboration, gamification, and hybrid intelligence (Martins, Gilson, and Maynard Citation2004; Kittur et al. Citation2013; Hamari, Koivisto, and Sarsa Citation2014). Second, CS projects involve crowds of varying sizes and compositions, use crowds for a broad range of activities, and use many different mechanisms to organise distributed work (see ). Studying this heterogeneity may enable research in crowdsourcing to better understand the contingency factors involved in working with crowds, and to explore more extensive types of crowd involvement such as co-creation (Afuah Citation2018; Boudreau and Lakhani Citation2013; Poetz and Schreier Citation2012). Crowdsourcing scholars may also find it stimulating to study a context where crowds are not paid, raising a host of new challenges related to self-selection, motivation for sustained engagement, and goal (mis-)alignment. Third, although CS provides many benefits to participants and enables new types of research, some projects also raise concerns regarding the potential replacement of paid workers by unpaid crowds as well as the ethical treatment of contributors who volunteer to help create significant value (Hamid and Bonnie Citation2014). As such, scholars studying the gig economy and online labour markets may find CS interesting because it pushes the limits with respect to parameters such as the level of pay, the size of crowds, but also the scope and geographic distribution of projects and contributors (Kittur et al. Citation2013; Wood et al. Citation2019; Chen et al. Citation2019). Last but not least, studying CS may yield important insights into more general developments in science and innovation. For example, there is a clear trend towards larger teams and increasing specialisation in virtually all fields (Wuchty, Jones, and Uzzi Citation2007; Singh and Fleming Citation2010), raising new challenges regarding task allocation, coordination, and the sharing of rewards (Haeussler and Sauermann Citation2020; Teodoridis, Bikard, and Vakili Citation2019). Relatedly, growing team size and resource requirements in science may increase entry barriers for new Principal Investigators and create tensions between efficiency and diversity in research (Freeman et al. Citation2001; National Academies Citation2018). In many respects, large CS projects and global platforms such as Zooniverse, eBird, and ScienceAtHome represent extremes of these developments and may provide fruitful research settings for scholars interested in the future of the science and innovation enterprise.
An overarching appeal of Crowd and Citizen Science as a research setting is that projects are unusually open and transparent, allowing us to look deeply into their internal organisation and to measure typically unobserved processes and outcomes. The best way to start might be to just join one of the many projects inviting contributions in areas such as astronomy, biology, medicine, and even the social sciences.Footnote23
Acknowledgments
We thank Timothy Gowers (Polymath), Chris Lintott (Zooniverse), Filip Meysman (CurieuzeNeuzen), and Marc Santolini (OpenCovid19) for sharing insights on their projects and commenting on our article. We also thank Robin Brehm, Chris Hesselbein, Marisa Ponti, Julia Suess-Reyes, and Robbie Ward for extremely helpful feedback. We are grateful for funding from ESMT Berlin as well as the Austrian National Foundation for Research, Technology and Development, grant for Open Innovation in Science. All remaining errors are our own.
Notes
1 https:/www.zooniverse.org/about/publications; accessed 17 April 2021.
2 https://app.jogl.io/program/opencovid19; accessed 17 April 2021.
3 The literature struggles to clearly distinguish ‘professional scientists’ and ‘citizens’, e.g. because many Citizen Science participants have scientific training, including PhDs (Raddick et al. Citation2013). Some observers emphasise that such participants contribute outside of their roles as employees of scientific institutions, i.e. as private citizens (Strasser et al. Citation2019).
4 There is considerable heterogeneity across CS projects and the landscape is evolving. As such, our characterisation of Crowd and Citizen Science projects focuses on typical features as of the writing of this article.
5 Large-scale projects that produce high volumes of data by assigning micro-tasks to contributors may seem extremely effective from the ‘productivity’ perspective taken by Crowd Science scholars, but undesirable to Citizen Science advocates taking a ‘democratization view’. Indeed, large CS platforms have been described as ‘adding an army of unpaid volunteers to help in solving current scientific problems at a lower price’ or the ‘social dumping of paid professionals and “uberizing of research”’ (Strasser et al. Citation2019, p. 67).
6 Although many studies on CS are published in general outlets, there are now also dedicated journals including ‘Citizen Science Theory and Practice’ as well as the ‘International Journal of Crowd Science’.
7 Some of these lists also include activities broadly related to ‘management’, including funding acquisition and project administration. Although these activities alone do not officially qualify for authorship at many journals (ICMJE Citation2020), they are often the informal justification to include Principal Investigators on articles coming out of their labs (Stephan Citation2012).
8 We follow prior work by considering the crowd as an entity, ignoring the complication that projects can involve different crowd members in different ways. Of course, the analyst could account for such complexities by creating separate profiles for different groups (e.g. crowd members of type 1 vs. type 2).
9 The original Polymath project was started in 2009 by Timothy Gowers, followed by an ongoing series of additional projects with evolving project designs. Our discussion of Polymath draws on different sources about particular projects in the series as well as the current general Polymath rules (https://polymathprojects.org/general-polymath-rules/; accessed 17 April 2021).
10 Our description of example projects abstracts from uncommon and exceptional contributions. For example, one contributor to Galaxy Zoo made an unexpected discovery while classifying images and was subsequently involved in writing a paper on that discovery (see Lintott et al. Citation2009).
11 For example, a contributor moved part of the discussion to a completely different platform (GitHub) to facilitate computational aspects of the work (https://github.com/km-git-acc/dbn_upper_bound; accessed 17 April 2021).
12 For a discussion of ethical issues related to such projects, see Wiggins and Wilbanks (Citation2019).
13 Although not reflected in , crowd members always have at least one choice: Whether or not to contribute their effort, knowledge, and resources conditional upon being asked. Voluntary self-selection is a defining feature of CS and gives crowd members considerable power to shape the success (or failure) of projects.
14 https://gilkalai.wordpress.com/2021/01/29/possible-future-polymath-projects-2009-2021/; accessed 17 April 2021.
15 Gowers on the process for Polymath I: ‘I shall publish a large number of extra posts for the purposes of trying to organise the threads of the discussion. However, I will not try to guess in advance what any of these threads might be, so initially all these extra posts will be empty. Only when clearly defined subdiscussions emerge will I suggest that they continue on separate threads. This is because I want the whole process to be as democratic as possible: ideally it won’t always be me who decides that a subdiscussion is sufficiently “clearly defined” to deserve its own place’ https://gowers.wordpress.com/2009/01/30/background-to-a-polymath-project/; accessed 17 April 2021.
16 The dimensions in our framework can indirectly capture several of the aspects featured in prior taxonomies. For example, descriptions of crowd members’ activities and decisions yield a good impression of task structure and task interdependencies (Franzoni and Sauermann Citation2014), while the dimension of resource contributions can reflect the virtual vs. physical nature of projects (Wiggins and Crowston Citation2011). Other project characteristics are not captured but could be investigated as antecedents of the observed patterns of contributions. For example, the composition of the crowd in terms of expertise or socio-demographic background is an important characteristic that likely shapes what contributions crowd members are able and willing to make.
17 https://fold.it/portal/node/2,008,706; accessed 17 April 2021.
18 https://www.scienceathome.org/; accessed 17 April 2021.
19 Zooniverse’s Chris Lintott draws a more nuanced distinction to highlight the important role of volunteers for serendipitous discovery: ‘Machines are good at finding the unusual, but not working out which unusual things are interesting’ (email communication, 2 June 2021).
20 We largely abstract from differences across fields and take as the comparison ‘traditional’ lab-based academic research performed in teams of professional scientists, including PhD students and Postdocs (Stephan Citation2012; Walsh and Lee Citation2015; Shibayama, Baba, and Walsh Citation2015).
21 A similar approach has been taken in recent work studying the division of labour between lead investigators and staff in traditional research projects (Shibayama, Baba, and Walsh Citation2015). An interesting finding in that study is that task allocation may be inefficient from a pure productivity standpoint because labs also pursue other goals such as the education of junior members. There is an obvious parallel in the context of CS: Projects may assign tasks to crowd members not only in order to increase scientific productivity but also to accomplish other goals such as citizen awareness and learning (see also Section 4 on different scenarios regarding the replacement of crowds by machines).
22 Although many CS projects are too small or ‘basic’ to generate significant economic value, some projects have considerable commercial potential, even resulting in patent applications (Guerrini et al. Citation2018). These issues become even more salient considering that CS projects can also involve firms and industrial scientists (Franzoni and Sauermann Citation2014; Del Savio, Prainsack, and Buyx Citation2016).
23 Catalogues of projects include https://scistarter.org/, https://eu-citizen.science/projects, https://www.citizenscience.gov/catalogue/#, and https://www.buergerschaffenwissen.de/projekte. Accessed 17 April 2021.
References
- Aceves‐Bueno, E., A. S. Adeleye, M. Feraud, Y. Huang, M. Tao, Y. Yang, S. E. Anderson. et al. 2017. “The Accuracy of Citizen Science Data: A Quantitative Review.” The Bulletin of the Ecological Society of America 98 (4): 278–290. doi:https://doi.org/10.1002/bes2.1336.
- Afuah, A. 2018. “Crowdsourcing: A Primer and Research Framework.” In Creating & Capturing Value through Crowdsourcing, edited by C. L. Tucci, A. Afuah, and G. Viscusi. 11-38. Oxford, UK: Oxford University Press.
- Afuah, A., and C. L. Tucci. 2012. “Crowdsourcing as a Solution to Distant Search.” Academy of Management Review 37 (3): 355–375. doi:https://doi.org/10.5465/amr.2010.0146.
- Arnstein, S. R. 1969. “A Ladder of Citizen Participation.” Journal of the American Institute of Planners 35 (4): 216–224. doi:https://doi.org/10.1080/01944366908977225.
- Beck, S., C. Bergenholtz, M. Bogers, T.-M. Brasseur, M. L. Conradsen, D. Di Marco. et al. 2021. “The Open Innovation in Science Research Field: A Collaborative Conceptualisation Approach.” Industry and Innovation 1–50. https://www.tandfonline.com/doi/full/10.1080/13662716.2020.1792274
- Beck, S., T.-M. Brasseur, M. K. Poetz, and H. Sauermann. 2020. “What Is the Problem? Crowdsourcing Research Questions in Science.” Working Paper.
- Benchoufi, M., O. De Fresnoye, K. Levy-Heidmann, E. Mariani, and O. Tauvel-Mocquet. 2017. “Epidemium - White Paper.” Accessed September 12, 2021. https://www.roche.fr/fr/medias/presse/livre-blanc-epidemium.html
- Black, R. C., and T. R. Johnson. 2018. “Behind the Velvet Curtain: Understanding Supreme Court Conference Discussions through Justices’ Personal Conference Notes.” Journal of Appellate Practice and Process 19: 223.
- Bonney, R. 1996. “Citizen Science: A Lab Tradition.” Living Biard 15 (4): 7–15.
- Bonney, R., C. B. Cooper, J. Dickinson, S. Kelling, T. Phillips, K. V. Rosenberg, J. Shirk. 2009. “Citizen Science: A Developing Tool for Expanding Science Knowledge and Scientific Literacy.” BioScience 59 (11): 977–984. doi:https://doi.org/10.1525/bio.2009.59.11.9.
- Bonney, R., J. L. Shirk, T. B. Phillips, A. Wiggins, H. L. Ballard, A. J. Miller-Rushing, J. K. Parrish. et al. 2014. “Next Steps for Citizen Science.” Science 343 (6178): 1436–1437. doi:https://doi.org/10.1126/science.1251554.
- Bonney, R., T. B. Phillips, H. L. Ballard, and J. W. Enck. 2016. “Can Citizen Science Enhance Public Understanding of Science?” Public Understanding of Science 25 (1): 2–16. doi:https://doi.org/10.1177/0963662515607406.
- Boudreau, K. J., and K. R. Lakhani. 2013. “Using the Crowd as an Innovation Partner.” Harvard Business Review 91 (4): 60–140.
- Boudreau, K. J., N. Lacetera, and K. R. Lakhani. 2011. “Incentives and Problem Uncertainty in Innovation Contests: An Empirical Analysis.” Management Science 57 (5): 843–863. doi:https://doi.org/10.1287/mnsc.1110.1322.
- Brabham, D. C. 2008. “Crowdsourcing as a Model for Problem Solving: An Introduction and Cases.” Convergence: The International Journal of Research into New Media Technologies 14 (1): 75–90. doi:https://doi.org/10.1177/1354856507084420.
- Brossard, D., B. Lewenstein, and R. Bonney. 2005. “Scientific Knowledge and Attitude Change: The Impact of a Citizen Science Project.” International Journal of Science Education 27 (9): 1099–1121. doi:https://doi.org/10.1080/09500690500069483.
- Brynjolfsson, E., and T. Mitchell. 2017. “What Can Machine Learning Do? Workforce Implications.” Science 358 (6370): 1530–1534. doi:https://doi.org/10.1126/science.aap8062.
- Burgess, H., L. DeBey, H. Froehlich, N. Schmidt, E. Theobald, A. Ettinger, J. HilleRisLambers. et al. 2017. “The Science of Citizen Science: Exploring Barriers to Use as a Primary Research Tool”. Biological Conservation 208: 113–120. doi:https://doi.org/10.1016/j.biocon.2016.05.014.
- CASRAI. 2018. “Credit - Contributor Roles Taxonomy.” Accessed 12 September 2021. https://casrai.org/credit/
- Ceccaroni, L., J. Bibby, E. Roger, P. Flemons, K. Michael, L. Fagan. J. L. Oliver. 2019. “Opportunities and Risks for Citizen Science in the Age of Artificial Intelligence.” Citizen Science: Theory and Practice 4:1.
- Chen, M. K., P. E. Rossi, J. A. Chevalier, and E. Oehlsen. 2019. “The Value of Flexible Work: Evidence from Uber Drivers.” Journal of Political Economy 127 (6): 2735–2794. doi:https://doi.org/10.1086/702171.
- Cohen, W. M., H. Sauermann, and P. Stephan. 2020. “Not in the Job Description: The Commercial Activities of Academic Scientists and Engineers.” Management Science 66 (9): 4108–4117. doi:https://doi.org/10.1287/mnsc.2019.3535.
- Congress, U. S. 2016. “Crowdsourcing and Citizen Science Act.”
- Cooper, S., F. Khatib, A. Treuille, J. Barbero, J. Lee, M. Beenen, A. Leaver-Fay. et al. 2010. “Predicting Protein Structures with a Multiplayer Online Game.” Nature 466 (7307): 756–760. doi:https://doi.org/10.1038/nature09304.
- Crowston, K., C. Østerlund, T. K. Lee, C. Jackson, M. Harandi, S. Allen, S. Bahaadini. et al. 2019. “Knowledge Tracing to Model Learning in Online Citizen Science Projects.” IEEE Transactions on Learning Technologies 13 (1): 123–134. doi:https://doi.org/10.1109/TLT.2019.2936480.
- Crowston, K., E. Mitchell, and C. Østerlund. 2019. “Coordinating Advanced Crowd Work: Extending Citizen Science.” Citizen Science: Theory and Practice 4 (1): 1–2.
- Dahlander, L., and S. O’Mahony. 2010. “Progressing to the Center: Coordinating Project Work.” Organization Science 22 (4): 961–979. doi:https://doi.org/10.1287/orsc.1100.0571.
- Dasgupta, P., and P. A. David. 1994. “Toward a New Economics of Science.” Research Policy 23 (5): 487–521. doi:https://doi.org/10.1016/0048-7333(94)01002-1.
- Davis, M., and K. Laas. 2014. ““Broader Impacts” or “Responsible Research and Innovation”? A Comparison of Two Criteria for Funding Research in Science and Engineering.” Science and Engineering Ethics 20 (4): 963–983. doi:https://doi.org/10.1007/s11948-013-9480-1.
- De Winter, J. C., and D. Dodou. 2014. “Why the Fitts List Has Persisted Throughout the History of Function Allocation.” Cognition, Technology & Work 16 (1): 1–11. doi:https://doi.org/10.1007/s10111-011-0188-1.
- Del Savio, L., B. Prainsack, and A. Buyx. 2016. “Crowdsourcing the Human Gut. Is Crowdsourcing Also ‘Citizen Science’?” Journal of Science Communication 15 (3): 1–16. doi:https://doi.org/10.22323/2.15030203.
- Druschke, C. G., and C. E. Seltzer. 2012. “Failures of Engagement: Lessons Learned from a Citizen Science Pilot Study.” Applied Environmental Education & Communication 11 (3–4): 178–188. doi:https://doi.org/10.1080/1533015X.2012.777224.
- ECSA. 2020. “ECSA’s Characteristics of Citizen Science.”Accessed 12 September 2021. https://doi.org/http://doi.org/10.5281/zenodo.3758668.
- European Citizen Science Association. 2015. “ECSA Strategy.” Accessed 12 September 2021. https://ecsa.citizen-science.net/wp-content/uploads/2020/02/ecsa_strategy.pdf
- European Commission. 2016. “8 ambitions of the EU's open science policy.” Accessed 12 September 2021. https://ec.europa.eu/info/research-and-innovation/strategy/strategy-2020-2024/our-digital-future/open-science_en
- ExCiteS. 2019. “Citizen Science and Botanic Knowledge among Herders and Farmers in Kenya.” Accessed 12 September 2021. https://uclexcites.blog/2019/05/29/citizen-science-and-botanic-knowledge-among-herders-and-farmers-in-kenya/
- Felin, T., and T. R. Zenger. 2014. “Closed or Open Innovation? Problem Solving and the Governance Choice.” Research Policy 43 (5): 914–925. doi:https://doi.org/10.1016/j.respol.2013.09.006.
- Franzen, M., L. Kloetzer, M. Ponti, J. Trojan, and J. Vicens. 2021. “Machine Learning in Citizen Science: Promises and Implications.” In The Science of Citizen Science, edited by K. Vohland, A. Land-Zandstra, L. Ceccaroni, J. Rob Lemmens, P. M. Ponti, R. Samson, and K. Wagenknecht, 183–198, Cham, Switzerland: Springer.
- Franzoni, C., and H. Sauermann. 2014. “Crowd Science: The Organization of Scientific Research in Open Collaborative Projects.” Research Policy 43 (1): 1–20. doi:https://doi.org/10.1016/j.respol.2013.07.005.
- Franzoni, C., H. Sauermann, and D. Di Marco. 2021. “When Citizens Judge Science: Evaluations of Social Impact and Support for Research.” Working Paper.
- Freeman, R., E. Weinstein, E. Marincola, J. Rosenbaum, and F. Solomon. 2001. “Competition and Careers in Biosciences.” Science 294 (5550): 2293–2294. doi:https://doi.org/10.1126/science.1067477.
- Furman, J. L., and S. Stern. 2011. “Climbing Atop the Shoulders of Giants: The Impact of Institutions on Cumulative Research.” American Economic Review 101 (5): 1933–1963. doi:https://doi.org/10.1257/aer.101.5.1933.
- Gander, A. J., M. Ponti, and A. Seredko. 2021. “What Can Machine Learning Do? Implications for Citizen Scientists.” Zendo Working Paper.
- Geoghegan, H., A. Dyke, R. Pateman, S. West, and G. Everett. 2016. “Understanding Motivations for Citizen Science.” In UK Environmental Observation Framework. https://www.ukeof.org.uk/resources/citizen-science-resources/MotivationsforCSREPORTFINALMay2016.pdf
- Green, S. E., J. P. Rees, P. A. Stephens, R. A. Hill, and A. J. Giordano. 2020. “Innovations in Camera Trapping Technology and Approaches: The Integration of Citizen Science and Artificial Intelligence.” Animals 10 (1): 132. doi:https://doi.org/10.3390/ani10010132.
- Gruber, M., D. Harhoff, and K. Hoisl. 2013. “Knowledge Recombination across Technological Boundaries: Scientists Vs. Engineers.” Management Science 59 (4): 837–851. doi:https://doi.org/10.1287/mnsc.1120.1572.
- Guerrini, C. J., M. A. Majumder, M. J. Lewellyn, and A. L. McGuire. 2018. “Citizen Science, Public Policy.” Science 361 (6398): 134–136. doi:https://doi.org/10.1126/science.aar8379.
- Guinan, E., K. J. Boudreau, and K. R. Lakhani. 2013. “Experiments in Open Innovation at Harvard Medical School.” MIT Sloan Management Review 54 (3): 45–52.
- Haeussler, C., and H. Sauermann. 2020. “Division of Labor in Collaborative Knowledge Production: The Role of Team Size and Interdisciplinarity.” Research Policy 49 (6): 103987. doi:https://doi.org/10.1016/j.respol.2020.103987.
- Haklay, M. 2013. “Citizen Science and Volunteered Geographic Information: Overview and Typology of Participation.” In Crowdsourcing Geographic Knowledge, edited by D. Sui, S. Elwood, and M. Goodchild, 105–122, Dordrecht, Netherlands: Springer.
- Haklay, M., D. Fraisl, B. Greshake Tzovaras, S. Hecker, M. Gold, G. Hager, et al. 2021. “Contours of Citizen Science: A Vignette Study.” Accessed 12 September 2021. https://osf.io/preprints/socarxiv/6u2ky/.
- Haklay, M. M., D. Dörler, F. Heigl, M. Manzoni, S. Hecker, and K. Vohland. 2021. “What Is Citizen Science? The Challenges of Definition.” In The Science of Citizen Science, edited by K. Vohland, A. Land-Zandstra, L. Ceccaroni, J. Rob Lemmens, P. M. Ponti, R. Samson, and K. Wagenknecht, 13–33, Cham, Switzerland: Springer.
- Hamari, J., J. Koivisto, and H. Sarsa. 2014. Does Gamification Work? A Literature Review of Empirical Studies on Gamification. Paper presented at the System Sciences (HICSS), 2014 47th Hawaii International Conference on System Sciences, Waikoloa, Hawaii, USA.
- Hamid, E., and N. Bonnie. 2014. “Heteromation and Its (Dis)contents: The Invisible Division of Labor between Humans and Machines.” First Monday 19: 6. doi:https://doi.org/10.5210/fm.v19i6.5331.
- Harrison, J. R., and G. R. Carroll. 1991. “Keeping the Faith: A Model of Cultural Transmission in Formal Organizations.” Administrative Science Quarterly 36 (4): 552–582. doi:https://doi.org/10.2307/2393274.
- Heaven, D. 2019. “Why Deep-Learning Ais are so Easy to Fool.” Nature 574 (7777): 163–166. doi:https://doi.org/10.1038/d41586-019-03013-5.
- Hopkin, M. 2007. “See New Galaxies—without Leaving Your Chair.” Nature Publishing Group. Accessed 12 September 2021. https://www.nature.com/articles/news070709-7#article-info
- ICMJE. 2020. “Defining the Role of Authors and Contributors.” Accessed 12 September 2021. http://www.icmje.org/recommendations/browse/roles-and-responsibilities/defining-the-role-of-authors-and-contributors.html
- Irwin, A. 1995. “Citizen Science: A Study of People, Expertise and Sustainable Development.” London and New York: Routledge. https://www.routledge.com/Citizen-Science-A-Study-of-People-Expertise-and-Sustainable-Development/Irwin/p/book/9780415130103
- Irwin, A. 2001. “Constructing the Scientific Citizen: Science and Democracy in the Biosciences.” Public Understanding of Science 10 (1): 1–18. doi:https://doi.org/10.1088/0963-6625/10/1/301.
- Irwin, A. 2018. “Citizen Science Comes of Age.” Nature 562 (7728): 480–482. doi:https://doi.org/10.1038/d41586-018-07106-5.
- Jensen, J. H. M., M. Gajdacz, S. Z. Ahmed, J. H. Czarkowski, C. Weidner, J. Rafner, J. J. Sørensen. et al. 2021. “Crowdsourcing Human Common Sense for Quantum Control.” Physical Review Research 3 (1): 013057. doi:https://doi.org/10.1103/PhysRevResearch.3.013057.
- Jeppesen, L. B., and K. Lakhani. 2010. “Marginality and Problem-Solving Effectiveness in Broadcast Search.” Organization Science 21 (5): 1016–1033. doi:https://doi.org/10.1287/orsc.1090.0491.
- Joshi, S., N. Randall, S. Chiplunkar, T. Wattimena, and K. Stavrianakis. 2018. ‘We’-a Robotic System to Extend Social Impact of Community Gardens. Paper presented at the Companion of the 2018 ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA.
- Kamar, E., A. Kapoor, and E. Horvitz. 2015. Identifying and Accounting for Task-Dependent Bias in Crowdsourcing. Paper presented at the Third AAAI Conference on Human Computation and Crowdsourcing, San Diego, California, USA.
- Kamar, E., S. Hacker, and E. Horvitz. 2012. Combining Human and Machine Intelligence in Large-Scale Crowdsourcing. Paper presented at the 11th International Conference on Autonomous Agents and Multiagent Systems, Valencia, Spain.
- Katrak-Adefowora, R., J. L. Blickley, and A. J. Zellmer. 2020. “Just-in-Time Training Improves Accuracy of Citizen Scientist Wildlife Identifications from Camera Trap Photos.” Citizen Science: Theory and Practice 5: 1.
- Kelling, S., J. Gerbracht, D. Fink, C. Lagoze, W.-K. Wong, J. Yu, T. Damoulas, C. Gomes. 2012. Ebird: A Human/Computer Learning Network to Improve Biodiversity Conservation and Research. Paper presented at the Twenty-Fourth Innovative Applications of Artificial Intelligence Conference, Toronto, Ontario, Canada.
- Khatib, F., F. DiMaio, S. Cooper, M. Kazmierczyk, M. Gilski, S. Krzywda, H. Zabranska. et al. 2011. “Crystal Structure of a Monomeric Retroviral Protease Solved by Protein Folding Game Players”. Nature Structural & Molecular Biology 18(10): 1175–1177. doi:https://doi.org/10.1038/nsmb.2119.
- Kittur, A., J. V. Nickerson, M. Bernstein, E. Gerber, A. Shaw, J. Zimmerman, M. Lease, J. Horton. 2013. The Future of Crowd Work. Paper presented at the Proceedings of the 2013 conference on Computer supported cooperative work, San Antonio, Texas, USA.
- Kittur, A., L. Yu, T. Hope, J. Chan, H. Lifshitz-Assaf, K. Gilon, F. Ng. et al. 2019. “Scaling up Analogical Innovation with Crowds and AI.” Proceedings of the National Academy of Sciences 116 (6): 1870–1877. doi:https://doi.org/10.1073/pnas.1807185116.
- Kokshagina, O. forthcoming. “Open Covid‐19: Organizing an Extreme Crowdsourcing Campaign to Tackle Grand Challenges.” R&D Management.
- Kuminski, E., and L. Shamir. 2016. “A Computer-Generated Visual Morphology Catalog Of 3,000,000 SDSS Galaxies.” The Astrophysical Journal Supplement Series 223 (2): 20. doi:https://doi.org/10.3847/0067-0049/223/2/20.
- Lakhani, K. 2011. “Innocentive.Com.” HBS Case #608170. Cambridge, MA, USA: Harvard Business School Publishing.
- Latour, B., and S. Woolgar. 1979. Laboratory Life: The Social Construction of Scientific Facts. Beverly Hills: Sage.
- Lintott, C. J., K. Schawinski, W. Keel, H. Van Arkel, N. Bennert, E. Edmondson, D. Thomas. et al. 2009. “Galaxy Zoo: ‘Hanny’s Voorwerp’, a Quasar Light Echo?” Monthly Notices of the Royal Astronomical Society 399 (1): 129–140. doi:https://doi.org/10.1111/j.1365-2966.2009.15299.x.
- Lyons, E., and L. Zhang. 2019. “Trade-Offs in Motivating Volunteer Effort: Experimental Evidence on Voluntary Contributions to Science.” PLOS ONE 14 (11): 11. doi:https://doi.org/10.1371/journal.pone.0224946.
- Majchrzak, A., A. Malhotra, and M. A. Zaggl. 2021. “How Open Crowds Self-Organize.” Academy of Management Discoveries 7 (1): 104–129. doi:https://doi.org/10.5465/amd.2018.0087.
- Martins, L. L., L. L. Gilson, and M. T. Maynard. 2004. “Virtual Teams: What Do We Know and Where Do We Go from Here?” Journal of Management 30 (6): 805–835. doi:https://doi.org/10.1016/j.jm.2004.05.002.
- McDonald, D., E. Hyde, J. W. Debelius, J. T. Morton, A. Gonzalez, G. Ackermann, A. A. Aksenov. et al. 2018. “American Gut: An Open Platform for Citizen Science Microbiome Research.” Msystems 3 (3): e00031–18. doi:https://doi.org/10.1128/mSystems.00031-18.
- Merton, R. K. 1973. The Sociology of Science: Theoretical and Empirical Investigations. Chicago: University of Chicago Press.
- National Academies. 2018. “The Next Generation of Biomedical and Behavioral Sciences Researchers.” Washington, DC: The National Academies Press. doi:https://doi.org/10.17226/25008.
- Newman, G., A. Wiggins, A. Crall, E. Graham, S. Newman, and K. Crowston. 2012. “The Future of Citizen Science: Emerging Technologies and Shifting Paradigms.” Frontiers in Ecology and the Environment 10 (6): 298–304. doi:https://doi.org/10.1890/110294.
- Okhuysen, G. A., and B. A. Bechky. 2009. “Coordination in Organizations: An Integrative Perspective.” Academy of Management Annals 3 (1): 463–502. doi:https://doi.org/10.5465/19416520903047533.
- Ottinger, G. 2010. “Buckets of Resistance: Standards and the Effectiveness of Citizen Science.” Science, Technology, & Human Values 35 (2): 244–270. doi:https://doi.org/10.1177/0162243909337121.
- Ouchi, W. G. 1979. “A Conceptual Framework for the Design of Organizational Control Mechanisms.” Management Science 25 (9): 833–848. doi:https://doi.org/10.1287/mnsc.25.9.833.
- Owen-Smith, J. 2001. “Managing Laboratory Work through Skepticism: Processes of Evaluation and Control.” American Sociological Review 66 (3): 427–452. doi:https://doi.org/10.2307/3088887.
- Petridis, P., M. Fischer-Kowalski, S. J. Singh, and D. Noll. 2017. “The Role of Science in Sustainability Transitions: Citizen Science, Transformative Research, and Experiences from Samothraki Island, Greece.” Island Studies Journal 12 (1): 115–134. doi:https://doi.org/10.24043/isj.8.
- Poetz, M. K., and M. Schreier. 2012. “The Value of Crowdsourcing: Can Users Really Compete with Professionals in Generating New Product Ideas?” Journal of Product Innovation Management 29 (2): 245–256. doi:https://doi.org/10.1111/j.1540-5885.2011.00893.x.
- Polymath, D. H. J. 2012. “A New Proof of the Density Hales-Jewett Theorem.” Annals of Mathematics 175 (3): 1283–1327. doi:https://doi.org/10.4007/annals.2012.175.3.6.
- Ponciano, L., F. Brasileiro, R. Simpson, and A. Smith. 2014. “Volunteers‘ Engagement in Human Computation for Astronomy Projects.” Computing in Science & Engineering 16 (6): 52–59. doi:https://doi.org/10.1109/MCSE.2014.4.
- Ponti, M., I. Stankovic, W. Barendregt, B. Kestemont, and L. Bain. 2018. “Chefs Know More than Just Recipes: Professional Vision in a Citizen Science Game.” Human Computation 5: 1–12. doi:https://doi.org/10.15346/hc.v5i1.1.
- Puranam, P., O. Alexy, and M. Reitzig. 2014. “What’s “New” about New Forms of Organizing?” Academy of Management Review 39 (2): 162–180. doi:https://doi.org/10.5465/amr.2011.0436.
- Raddick, M. J., G. Bracey, P. L. Gay, C. Lintott, C. Cardamone, P. Murray, K. Schawinski, A. S. Szalay, J, Vandenberg. 2013. “Galaxy Zoo: Motivations of Citizen Scientists.” Astronomy Education Review 12:1.
- Rafner, J., M. Gajdacz, G. Kragh, A. Hjorth, A. Gander, B. Palfi. A. Berditchevskaia, et al. 2021. Revisiting Citizen Science through the Lens of Hybrid Intelligence. arXiv 2104.14961. https://arxiv.org/abs/2104.14961
- Raisch, S., and S. Krakowski. 2021. “Artificial Intelligence and Management: The Automation–Augmentation Paradox.” Academy of Management Review 46 (1): 192–210. doi:https://doi.org/10.5465/amr.2018.0072.
- Rasmussen, L. M. 2019. “Confronting Research Misconduct in Citizen Science.” Citizen Science: Theory and Practice 4 (1): 1–11.
- Rohden, F. 2018. “Support, Connect, and Organize. Exploring Moderator Roles in Citizen Science Discussion Forums.” Accessed 12 September 2021. https://gupea.ub.gu.se/bitstream/2077/57001/1/gupea_2077_57001_1.pdf
- Santolini, M. 2020. “Covid-19 the Rise of a Global Collective Intelligence.” Accessed 12 September 2021. https://theconversation.com/covid-19-the-rise-of-a-global-collective-intelligence-135738
- Sauermann, H., and C. Franzoni. 2013. “Participation Dynamics in Crowd-Based Knowledge Production: The Scope and Sustainability of Interest-Based Motivation.” SSRN Working Paper.
- Sauermann, H., and C. Franzoni. 2015. “Crowd Science User Contribution Patterns and Their Implications.” Proceedings of the National Academy of Sciences 112 (3): 679–684. doi:https://doi.org/10.1073/pnas.1408907112.
- Sauermann, H., and C. Haeussler. 2017. “Authorship and Contribution Disclosures.” Science Advances 3 (11): e1700404. doi:https://doi.org/10.1126/sciadv.1700404.
- Sauermann, H., K. Shafi, and C. Franzoni. 2019. “Crowdfunding Scientific Research: Descriptive Insights and Correlates of Funding Success.” Plos One14 (1): e0208384. doi:https://doi.org/10.1371/journal.pone.0208384.
- Sauermann, H., K. Vohland, V. Antoniou, B. Balaz, C. Goebel, K. Karatzas, P. Mooney. et al. 2020. “Citizen Science and Sustainability Transitions.” Research Policy 49 (5): 103978. doi:https://doi.org/10.1016/j.respol.2020.103978.
- Sauermann, H., and P. Stephan. 2013. “Conflicting Logics? A Multidimensional View of Industrial and Academic Science.” Organization Science 24 (3): 889–909. doi:https://doi.org/10.1287/orsc.1120.0769.
- Scheliga, K., S. Friesike, C. Puschmann, and B. Fecher. 2018. “Setting up Crowd Science Projects.” Public Understanding of Science 27 (5): 515–534. doi:https://doi.org/10.1177/0963662516678514.
- Senior, A. W., R. Evans, J. Jumper, J. Kirkpatrick, L. Sifre, T. Green, C. Qin. et al. 2020. “Improved Protein Structure Prediction Using Potentials from Deep Learning.” Nature 577 (7792): 706–710. doi:https://doi.org/10.1038/s41586-019-1923-7.
- Shah, S. K. 2006. “Motivation, Governance, and the Viability of Hybrid Forms in Open Source Software Development.” Management Science 52 (7): 1000–1014. doi:https://doi.org/10.1287/mnsc.1060.0553.
- Shapin, S. 2008. The Scientific Life: A Moral History of a Late Modern Vocation. Chicago, IL, USA: University of Chicago Press. https://press.uchicago.edu/ucp/books/book/chicago/S/bo5747715.html
- Shi, Y., P. L. Prieto, T. Zepel, S. Grunert, and J. E. Hein. 2021. “Automated Experimentation Powers Data Science in Chemistry.” Accounts of Chemical Research 54 (3): 546–555. doi:https://doi.org/10.1021/acs.accounts.0c00736.
- Shibayama, S., Y. Baba, and J. P. Walsh. 2015. “Organizational Design of University Laboratories: Task Allocation and Lab Performance in Japanese Bioscience Laboratories.” Research Policy 44 (3): 610–622. doi:https://doi.org/10.1016/j.respol.2014.12.003.
- Shirk, J. L., H. L. Ballard, C. C. Wilderman, T. Phillips, A. Wiggins, R. Jordan, E. McCallie. et al. 2012. “Public Participation in Scientific Research: A Framework for Deliberate Design.” Ecology and Society 17 (2): A29. Ddoi:https://doi.org/10.5751/ES-04705-170229.
- Simpson, R., K. R. Page, and D. De Roure. 2014. Zooniverse: Observing the World’s Largest Citizen Science Platform. Paper presented at the Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea.
- Singh, J., and L. Fleming. 2010. “Lone Inventors as Sources of Breakthroughs: Myth or Reality?” Management Science 56 (1): 41–56. doi:https://doi.org/10.1287/mnsc.1090.1072.
- Socientize Consortium. 2013. “Citizen Science for Europe. Towards a Better Society of Empowered Citizens and Enhanced Research.” Accessed 12 September 2021. https://ec.europa.eu/digital-single-market/en/news/green-paper-citizen-science-europe-towards-society-empowered-citizens-and-enhanced-research
- Sparkes, A., W. Aubrey, E. Byrne, A. Clare, M. N. Khan, M. Liakata, M. Markham. et al. 2010. “Towards Robot Scientists for Autonomous Scientific Discovery.” Automated Experimentation 2 (1): A1. doi:https://doi.org/10.1186/1759-4499-2-1.
- Stephan, P. 2012. How Economics Shapes Science. Cambridge, MA, USA: Harvard University Press.
- Strasser, B., J. Baudry, D. Mahr, G. Sanchez, and E. Tancoigne. 2019. ““Citizen Science”? Rethinking Science and Public Participation.” Science & Technology Studies 32: 52–76.
- Sullivan, B. L., C. L. Wood, M. J. Iliff, R. E. Bonney, D. Fink, and S. Kelling. 2009. “Ebird: A Citizen-Based Bird Observation Network in the Biological Sciences.” Biological Conservation 142 (10): 2282–2292. doi:https://doi.org/10.1016/j.biocon.2009.05.006.
- Sullivan, D. P., C. F. Winsnes, L. Åkesson, M. Hjelmare, M. Wiking, R. Schutten, L. Campbell. et al. 2018. “Deep Learning Is Combined with Massive-Scale Citizen Science to Improve Large-Scale Image Classification.” Nature Biotechnology 36 (9): 820–828. doi:https://doi.org/10.1038/nbt.4225.
- SwafS. 2017. Citizen Science Policies in the European Commission. Science with and for Society Policy Brief. Accessed 12 September 2021. https://www.sisnetwork.eu/media/sisnet/Policy_brief_Citizen_Science_SiSnet.pdf
- Swanson, A., M. Kosmala, C. Lintott, R. Simpson, A. Smith, and C. Packer. 2015. “Snapshot Serengeti, High-Frequency Annotated Camera Trap Images of 40 Mammalian Species in an African Savanna.” Scientific Data 2 (1): 1–14. doi:https://doi.org/10.1038/sdata.2015.26.
- Teodoridis, F., M. Bikard, and K. Vakili. 2019. “Creativity at the Knowledge Frontier: The Impact of Specialization in Fast- and Slow-paced Domains.” Administrative Science Quarterly 64 (4): 894–927. doi:https://doi.org/10.1177/0001839218793384.
- Trouille, L., C. J. Lintott, and L. F. Fortson. 2019. “Citizen Science Frontiers: Efficiency, Engagement, and Serendipitous Discovery with Human–Machine Systems.” Proceedings of the National Academy of Sciences 116 (6): 1902–1909. doi:https://doi.org/10.1073/pnas.1807190116.
- Tucci, C. L., A. Afuah, and G. Viscusi. 2018. Creating and Capturing Value through Crowdsourcing. Oxford, United Kingdom: Oxford University Press.
- Turrini, T., D. Dörler, A. Richter, F. Heigl, and A. Bonn. 2018. “The Threefold Potential of Environmental Citizen science - Generating Knowledge, Creating Learning Opportunities and Enabling Civic Participation.” Biological Conservation 225: 176–186. doi:https://doi.org/10.1016/j.biocon.2018.03.024.
- Van Brussel, S., and H. Huyse. 2018. “Citizen Science on Speed? Realising the Triple Objective of Scientific Rigour, Policy Influence and Deep Citizen Engagement in a Large-Scale Citizen Science Project on Ambient Air Quality in Antwerp.” Journal of Environmental Planning and Management 62 (3): 1–18.
- Von Hippel, E. 1994. ““Sticky Information” and the Locus of Problem Solving: Implications for Innovation.” Management Science 40 (4): 429–439. doi:https://doi.org/10.1287/mnsc.40.4.429.
- Waldispühl, J., A. Szantner, R. Knight, S. Caisse, and R. Pitchford. 2020. “Leveling up Citizen Science.” Nature Biotechnology 38 (10): 1124–1126. doi:https://doi.org/10.1038/s41587-020-0694-x.
- Walmsley, M., C. Lintott, T. Geron, S. Kruk, C. Krawczyk, K. W. Willett, S. Bamford, et al. 2021. Galaxy Zoo Decals: Detailed Visual Morphology Measurements from Volunteers and Deep Learning for 314,000 Galaxies. arXiv:2102.08414. https://arxiv.org/abs/2102.08414
- Walsh, J. P., and Y.-N. Lee. 2015. “The Bureaucratization of Science.” Research Policy 44 (8): 1584–1600. doi:https://doi.org/10.1016/j.respol.2015.04.010.
- Weichenthal, S., E. Dons, K. Y. Hong, P. O. Pinheiro, and F. J. Meysman. 2021. “Combining Citizen Science and Deep Learning for Large-Scale Estimation of Outdoor Nitrogen Dioxide Concentrations.” Environmental Research 196: 110389. doi:https://doi.org/10.1016/j.envres.2020.110389.
- Weinstein, B. G. 2018. “A Computer Vision for Animal Ecology.” Journal of Animal Ecology 87 (3): 533–545. doi:https://doi.org/10.1111/1365-2656.12780.
- West, J., and J. Sims. 2018. “How Firms Leverage Crowds and Communities for Open Innovation.” SSRN Working Paper.
- Wiggins, A., and J. Wilbanks. 2019. “The Rise of Citizen Science in Health and Biomedical Research.” The American Journal of Bioethics 19 (8): 3–14. doi:https://doi.org/10.1080/15265161.2019.1619859.
- Wiggins, A., and K. Crowston. 2011. From Conservation to Crowdsourcing: A Typology of Citizen Science. Paper presented at the 44th Hawaii International Conference on Systems Sciences (HICSS), Kauai, Hawaii, USA.
- Willett, K. W., C. J. Lintott, S. P. Bamford, K. L. Masters, B. D. Simmons, K. R. Casteels, E. M. Edmondson. et al. 2013. “Galaxy Zoo 2: Detailed Morphological Classifications for 304 122 Galaxies from the Sloan Digital Sky Survey.” Monthly Notices of the Royal Astronomical Society 435 (4): 2835–2860. doi:https://doi.org/10.1093/mnras/stt1458.
- Williams, A. C., J. F. Wallin, H. Yu, M. Perale, H. D. Carroll, A.-F. Lamblin, L. Fortson, D. Obbink, C. Lintott, James H. Brusuelas. 2014. A Computational Pipeline for Crowdsourced Transcriptions of Ancient Greek Papyrus Fragments. Paper presented at the 2014 IEEE International Conference on Big Data, Washington DC, USA.
- Wood, A. J., M. Graham, V. Lehdonvirta, and I. Hjorth. 2019. “Good Gig, Bad Gig: Autonomy and Algorithmic Control in the Global Gig Economy.” Work, Employment and Society 33 (1): 56–75. doi:https://doi.org/10.1177/0950017018785616.
- Woolley, J. P., M. L. McGowan, H. J. A. Teare, V. Coathup, J. R. Fishman, R. A. Settersten, S. Sterckx. et al. 2016. “Citizen Science or Scientific Citizenship? Disentangling the Uses of Public Engagement Rhetoric in National Research Initiatives.” BMC Medical Ethics 17 (1): 33. doi:https://doi.org/10.1186/s12910-016-0117-1.
- Wuchty, S., B. Jones, and B. Uzzi. 2007. “The Increasing Dominance of Teams in Production of Knowledge.” Science 316 (5827): 1036–1039. doi:https://doi.org/10.1126/science.1136099.
- Yang, J., I. Anishchenko, H. Park, Z. Peng, S. Ovchinnikov, and D. Baker. 2020. “Improved Protein Structure Prediction Using Predicted Interresidue Orientations.” Proceedings of the National Academy of Sciences 117 (3): 1496–1503. doi:https://doi.org/10.1073/pnas.1914677117.
- Zaken, D. B., K. Gal, G. Shani, A. Segal, and D. Cavalier. 2021. Intelligent Recommendations for Citizen Science. Paper presented at the AAAI-21 Conference on Artificial Intelligence. https://ojs.aaai.org/index.php/AAAI/article/view/17726