
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We present two methodologies on the estimation of rating transition probabilities within Markov and non-Markov frameworks. We first estimate a continuous-time Markov chain using discrete (missing) data and derive a simpler expression for the Fisher information matrix, reducing the computational time needed for the Wald confidence interval by a factor of a half. We provide an efficient procedure for transferring such uncertainties from the generator matrix of the Markov chain to the corresponding rating migration probabilities and, crucially, default probabilities. For our second contribution, we assume access to the full (continuous) data set and propose a tractable and parsimonious self-exciting marked point processes model able to capture the non-Markovian effect of rating momentum. Compared to the Markov model, the non-Markov model yields higher probabilities of default in the investment grades, but also lower default probabilities in some speculative grades. Both findings agree with empirical observations and have clear practical implications. We use Moody's proprietary corporate credit rating data set. Parts of our implementation are available in the R package ctmcd.
2010 AMS Subject Classification:
1. Introduction
Credit risk modelling and financial regulations have received added attention from Mathematics and Economics disciplines since the 2008 financial crash. On January 1, 2018, and for purposes of risk assessment, the new guideline IFRS 9 took effect requiring the calculation of expected losses for the complete maturity of certain obligors' riskier contracts. Thereby, a cornerstone of credit risk modelling lies in the ability to accurately estimate probabilities of default over varying time horizons. This can be either done by considering market data (e.g. bond or credit default swap prices, as well as implied probabilities of default from equities, see Bielecki et al. Citation2011) or historical (default or rating) data. In this manuscript, we focus on the latter.
Remark 1.1
(Obtaining Default Probabilities: Risk-neutral vs real-world) It is important to note the distinction between these estimation methods. Using market data such as bond prices or credit default swaps to estimate default probabilities actually gives risk neutral default probabilities. Our approach uses observed data and therefore gives real-world (physical) default probabilities. Our results can be used without any adjustment in capital requirement calculations where real-world default probabilities are needed.
When estimating probabilities of default, it is typical that credit ratings are considered in the calculation, as they allow for more granularity. Ratings, as categorical solvency measures, might be issued by (external) rating agencies or be produced by the financial institutes themselves as part of the Pillar I internal ratings-based approach underpinning the Basel regulatory framework. Due to idiosyncratic company-level or general business-cycle changes, credit ratings vary over time, and this effect is referred to as a rating transition or rating migration. This dynamical movement is a stochastic process with a discrete state space in continuous-time. Here Markov chains are a simple, robust and tractable class to model the movement of such rating transitions. The specific models that can be used depend on the type of data available.
Most literature dealing with the modelling of credit rating transitions focuses on anonymous discrete-time data and often on an annual basis. This data is easier to use and less costly to obtain than the ‘full’ (continuous-time company specific rating transitions) data set. In the discretely observed data case, it is not possible to follow individual obligors over the different periods which forces one to treat all companies in the same rating as equivalent. Hence, one is naturally led to a Markov chain construct (continuous or discrete). Assuming a continuous-time Markov chain (CTMC) model that has been observed only at specific discrete points, obtaining the maximum likelihood estimator (MLE) and understanding the error of this estimate is a classical problem. Many works have investigated the estimation of Generator matrices or the (intermediate) Transition Probability Matrices (TPM), see Kalbfleisch and Lawless (Citation1985), Bladt and Sørensen (Citation2005, Citation2009), dos Reis and Smith (Citation2018) to mention a few and Pfeuffer (Citation2017) for an overview and algorithm implementation in the statistical language R.
Despite these works, the problem of how to conduct statistical inference in this context or, in particular, how to derive error estimates for discretely observed Markov processes, is still an issue. Since our inference is likelihood based, Wald confidence intervals (or Wald intervals) are the natural choice for error estimation. In Kalbfleisch and Lawless (Citation1985), the authors use numerical techniques to estimate the derivatives and use a so-called quasi-Newton method to obtain the MLE.Footnote† More recently, Bladt and Sørensen (Citation2005, Citation2009) consider the Expectation Maximization (EM) algorithm and a Markov chain Monte Carlo (MCMC) algorithm to obtain the MLE. In the case of the EM, the authors provide a numerical scheme based on a formula from Oakes (Citation1999) to obtain the error in the estimate. Following their approach dos Reis and Smith (Citation2018) give exact expressions for errors arising from the EM algorithm. Building on these, we transfer the errors in the estimation of the CTMC's generator matrix to the estimation errors of the rating transitions probabilities themselves. As far as we are aware, such estimations have not been considered, although, they are of significant practical importance. When complete continuous-time rating transition data is available, then the computation of point estimates and Wald intervals for the parameters of a CTMC is straightforward, see e.g. Lando and Skodeberg (Citation2002).
Concerning the second contribution of our manuscript, Lando and Skodeberg (Citation2002) show that rating transitions exhibit non-Markovian behaviours. In particular, an obligor that has been recently downgraded into a certain rating is more likely to be downgraded further than other obligors currently in that rating. Such an effect is referred to as (downward)-rating momentum. A similar effect may also appear in upgrades; however, it is not as apparent. Documented (non-Markovian) effects in rating transitions include rating drift (or momentum) in Altman and Kao (Citation1992) and Lando and Skodeberg (Citation2002), rating stickiness in McNeil et al. (Citation2005) and specific rating agencies' policies (see Carey and Hrycay Citation2001, Løffler Citation2005). Nickell et al. (Citation2000) highlight non-Markovian patterns in transition probabilities for ratings and discuss their dependence regarding underlying variables like industry, domicile and business cycle. However, of these effects rating momentum is the most important to capture and what we look to model here.
The rating momentum effect has a non-negligible bearing on the risk attributed to a portfolio as it makes defaults of investment grade bonds likelier than defaults that are estimated within the standard Markov framework. Couderc (Citation2008, p. 8) report on the temporal span of the rating drift (for a certain Standard & Poor's database) and its mean reversion. When looking to model over longer horizons, the non-Markov effects such as momentum become more pronounced, i.e. have a larger impact on transition probabilities. At a practical level, the IFRS9 regulation requires knowledge of risks on rating migrations over longer horizons where these effects can significantly change the results. When one can access the full data set (continuous-time observations), it is possible to construct tractable models that capture non-Markov effects and this is one of our contributions. The model we propose is able to capture the momentum behaviour, and we found that the purely Markov model underestimates default risk in investment grades but overestimates the risk in some speculative grades. We discuss this in more detail in Section 4.
For clarity, we summarize the contributions of our manuscript in the next two points.
In the CTMC setting with discretely observed data, we provide a new simpler closed-form expression for the Hessian of the likelihood function, enabling faster computation of confidence intervals via the Fisher information matrix (Wald intervals). We further provide expressions allowing one to transfer confidence intervals at the level of the generator matrix to the level of rating transitions and probabilities of default, where they can be easily interpreted. Recall that in the case of discrete anonymous data one is forced to adopt the Markov assumption.
In the setting of continuously observed data, we propose a tractable and parsimonious model that captures the non-Markovian phenomenon of rating momentum. We provide a calibration procedure and several comparative tests based on Moody's Corporate Credit Ratings data set (see Section 2). Most notable is the difference between empirical, Markov (CTMC) and non-Markov (our model) estimates of probabilities of default. We observe that in several cases the Markov model under- or overestimates the probabilities of default empirically observed while the non-Markov model provides better agreement.
Remark 1.2
(Software and R-code) The algorithms relating to Markov Chains (in Section 3) are part of the CRAN R-package ctmcd: Estimating the Parameters of a Continuous-Time Markov Chain from Discrete-Time Data (see Pfeuffer Citation2017)—https://CRAN.R-project.org/package=ctmcd
Potential Non-Markov Models with Application to Rating Momentum. Different models have been introduced in the past to incorporate non-Markov phenomena. We briefly overview some of these works here. Interested readers are encouraged to consult the reference herein.
Extended State Space and Mixture Models. Christensen et al. (Citation2004), attempt to take non-Markovian effects into account while preserving some Markovian structure. The idea is to extend the state space to include + and − states, referred to as excited states. For example, when a company downgrades from rating A to rating B, it is instead given the rating , which has a higher probability of further downgrades than B. Similarly, if the company transitions from B to A, it is instead rated
which has a smaller probability of downgrade than A. This construction allows us to maintain the Markov property; however, we must calibrate many more parameters and, in real-world data, we do not observe a company belonging to the excited or non-excited state. Moreover, when successive transitions occur, it is unknown whether the company was in the excited or non-excited state. Hence calibrating an intensity between excited and non-excited states seems impossible. One could navigate around this by assuming excited states do not jump to non excited states, but this is against empirical evidence of momentum reducing over time, see Couderc (Citation2008, p. 35) for example.
D'Amico et al. (Citation2016) apply a semi-Markov model to capture the observed effect that companies move through states not following an exponential distribution. However, they still rely on the Markov transition structure and hence they need to expand the state space in order to include momentum. Related to this approach is Frydman and Schuermann (Citation2008), where the authors cleverly use two different time homogeneous CTMC generator matrices, however, it does not capture momentum since the jump itself is Markov.
Hidden Markov Model (HMM). A different idea is to use a hidden Markov model (HMM) (see Cappé et al. Citation2005 for a complete account). The HMM approach to credit risk can be traced back to the work of R. Elliot, see overview in Korolkiewicz (Citation2012) and its references. Roughly, the approach considers two processes , the observed (published) credit rating Y and the ‘true’ credit rating X which is unobserved (or hidden). The paradigm is that the observed credit ratings are assumed to be ‘noisy’ observations of Y and not the true representation of the credit risk. The goal is then to use Y to make inference on X. In such a setup if one considers the noisy observation and the true rating as correlated, then rating momentum can be added into the model. Although this approach has some benefits, the work appears to be constrained to the discrete time case and, from the literature point of view, the approach remains unexplored.
Hazard Rates, Point Processes and self-exciting Marked Point Processes. Let us start by discussing Hazard rates. The main work in this area for credit ratings is given in Koopman et al. (Citation2008). An extensive work bringing hazard rate methodologies to the estimation of probabilities of default can be found in Couderc (Citation2008) (and references therein). The paradigm is that each company has a corresponding hazard rate (a parameter) and in this hazard rate one can encode various factors such as momentum for example. The issue with Koopman et al. (Citation2008)'s methodology is that they must calibrate parameters for each of the various transitions with the extra variables to obtain the probabilities of these transitions. This however, increases the model's complexity greatly. Our goal is to present a model as parsimonious as possible that captures rating momentum.
The approach we pursue relies on point processes that are dependent on their own history, so-called self-exciting processes (see Daley and Vere-Jones Citation2003, Citation2008). Point processes are generalizations of Markov processes and a natural choice for our model. One of the most satisfying aspects of using point processes is that one can capture rating momentum by adding only a small number of parameters (2 to 4 in our case). The most common example of a self-exciting process is the Hawkes process. These processes appear in other areas of mathematical finance, such as models for limit order books and are also used in high-frequency trading, see Bacry et al. (Citation2015). However, they have not been fully utilized in credit transitions. A Hawkes process can be thought of as a counting process (similar to a Poisson process) which in one dimension has an intensity of the form (see Dassios and Zhao Citation2013),
where N is a counting measure and denotes that an event has occurred (this will be a rating change in our case), μ is the baseline intensity and φ is the impact on the intensity and allows the intensity to depend on past events. By setting
the Hawkes process reduces to a Poisson process. A common choice for φ is the so-called exponential decay, namely
with
. Functions of this form are useful since the event's influence on the intensity weakens as time progresses, hence we can account for momentum reducing over time (agreeing with the findings of Couderc Citation2008).
Using a Hawkes process allows us to embed past dependence in the jump times, however, in this simplistic form it is not fit for our purposes since we require different changes to intensity dependent on whether it is an upgrade or a downgrade. Further, we require the baseline intensity μ, to depend on the current state. Such extended Hawkes processes are referred to as marked point processes, since to each event observed one assigns a mark to indicate the type of event, see Daley and Vere-Jones (Citation2003, Chapter 6.4). We discuss this further in Section 4.
This work is organized as follows. In Section 2 we overview the data paradigms and describe the data we work with. In Section 3 we establish our closed-form expression for the Wald confidence intervals for the underlying Transition Probability Matrix (TPM) in the Markov setting. Finally, in Section 4 we analyse Moody's corporate credit rating data set, we test for non-Markovianity and calibrate the proposed non-Markov model. We also give due attention and discuss the effect of adding momentum in the estimation of default probabilities. In order to help keep this work self contained we supplement the core ideas with further discussion in the Appendix.
2. Data description
To illustrate the statistical methods we develop in this manuscript, we use the proprietary Moody's corporate credit rating data set, which comprises continuous-time observations for 17,097 entities (companies) in the time interval Jan 1, 1987 to Dec 31, 2017. Through the remainder of the article we refer to this set as the ‘Moody's data set’. Some of the discrete data is available publicly, but the full data set is proprietary and must be purchased. Other works such as Christensen et al. (Citation2004) also use the full Moody's data set.
The rating categories in Moody's data set are depicted in decreasing order of rating quality as ‘Aaa’, ‘Aa1’, ‘Aa2’, ‘Aa3’, ‘A1’, ‘A2’, ‘A3’, ‘Baa1’, ‘Baa2’, ‘Baa3’, ‘Ba1’, ‘Ba2’, ‘Ba3’, ‘B1’, ‘B2’, ‘B3’, ‘Caa1’, ‘Caa2’, ‘Caa3’, ‘Ca’, ‘C’. We define ‘C’ as the default category. The refinements ‘1’, ‘2’ and ‘3’ shall be referred to as modifiers in the following. The ratings ‘Aaa’ to ‘Baa3’ are the so-called ‘Investment Grade’ block while the ratings ‘Ba1’ to ‘Ca’ form the ‘Speculative Grade’ block.
We employ a standard data aggregation arrangement where we aggregate all modifiers within their rating class. For instance, we group ‘Aa1’, ‘Aa2’, ‘Aa3’ as ‘Aa’ and so on to obtain the following categories in decreasing credit quality: ‘Aaa’, ‘Aa’, ‘A’, ‘Baa’, ‘Ba’, ‘B’, ‘Caa’, ‘Ca’ and ‘C’ (Default Category). We shall use the standard aggregation unless otherwise stated.
For clarification, unlike the Standard and Poor rating classes where ‘C’ is taken as the rating above default and ‘D’ is used as default, in the Moody's rating system, ‘C’ denotes default. We use the latter notation throughout our manuscript.
As described in the introduction there are two data paradigms, a discrete (missing) and a continuous (full) one. In Section 3 of the paper we construct annually discretized rating transition matrices from this data, and one is led to use a (CTMC) Markov model. In Section 4, we use the full data set and its richness allows us to expand the scope to non-Markov models.
3. Calculating Wald confidence intervals for discretely observed Markov processes
The working paradigm for this section is the discrete time data one and we work towards estimating the generator matrix of the underlying CTMC model. For this setting, it was shown in dos Reis and Smith (Citation2018) that the Expectation-Maximization (EM) algorithm is the strongest algorithm for the estimation of
(a description of the EM algorithm for this context is provided in Appendix 1). The EM is built to use likelihood-based inference which has the advantage that one can obtain errors for the estimate by taking derivatives, the so-called Wald confidence intervals. The goals of this section are to find expressions for these derivatives and then use them to obtain the corresponding intervals for the transition probabilities.
Our CTMC set up is similar to that of dos Reis and Smith (Citation2018). We understand companies' ratings as defined on a finite state space , where each state corresponds to a rating. We denote Aaa as rating 1 and C (default) as rating h. Let
be an h-by-h stochastic matrix, which will be the corresponding TPM (at, say, time t = 1) and
is an h-by-h generator matrix; we denote
,
and the intensity of state i by
where
. A standard assumption used in credit risk modelling is that the default state is an absorbing state, hence
. In the data, companies are observed to withdraw (e.g. via mergers or early payment) and we treat such a withdrawn rating as a censored result.
Regarding the CTMC's generator, we work with stable generator matrices, i.e. matrices that satisfy the following definition.
Definition 3.1
(Stable-Conservative infinitesimal Generator matrix of a CTMC) We say a matrix is a generator matrix if the following properties are satisfied for all
:
for
Our quantity of interest is the time varying transition probability matrix, , which is related to the generator matrix
via,
(1)
(1) We assume throughout that
is a valid generator matrix (in the sense of Definition 3.1), hence
is well defined. Considering the case where the CTMC is observed at times
and denote
for
and the transition matrix over that interval by
.
The likelihood of the discretely observed Markov process is given by,
(2)
(2) Although this is not the full likelihood of a CTMC, it is the likelihood based on the observable data, so in effect, the EM algorithm looks to find
to maximize (Equation2
(2)
(2) ). Therefore the Wald confidence intervals of
are based on this likelihood. One can construct confidence intervals for other algorithms such as the quasi-optimization of the generator (see Kreinin and Sidelnikova Citation2001) by bootstrapping, but these are computationally more expensive to calculate.
3.1. Direct differentiation for gradient and Hessian of the likelihood
The standard procedure to derive a confidence interval is to use the variance of the estimator (in our case, the negative inverse of the Hessian H of the likelihood L in (Equation2(2)
(2) )). Since the EM algorithm deals with a missing data likelihood, these derivatives are complex to calculate, however, Oakes (Citation1999, Section 2) derived a simpler formula for the Hessian. This formula was used by Bladt and Sørensen (Citation2009) and dos Reis and Smith (Citation2018) to obtain error estimates in this setting. A formula for obtaining the Hessian is useful, however, while the second derivative can inform us about errors at the level of the generator matrix, it does not shed light on how these errors propagate to the transition probabilities (see (Equation1
(1)
(1) )). For that we need to be able to take further derivatives.
Relying on first principles, it turns out that for this problem one can extract derivatives without the said formula in Oakes (Citation1999) and derive a new closed-form solution involving matrix exponentials for the gradient and the Hessian by direct differentiation.
Similar to the situation in dos Reis and Smith (Citation2018) the parameter space of is closed at zero and we can only differentiate in the interior of the space, hence we introduce the notion of allowed pairs. This concept allows one to incorporate absorbing states in the analysis.
Definition 3.2
(Allowed pairs)
Let , then we say that the pair
is allowed if
(not in the diagonal) and
is not converging to zero under the EM algorithm.
Essentially i, j is allowed if and thus in the interior of the parameter space of
. For ease of presentation we denote by
the matrix of allowed pairs of
, namely: for
the number of allowed pairs in the estimation of
we define the matrix
as the
-by-2-dimensional matrix which records the allowed pairs of
.
Let be an h-by-h matrix, α, β, s, r
and
be an h-dimensional column vector with 1 at entry r and zero elsewhere. Let us further denote
as the entries of matrix
and assume
, then using standard properties of derivatives and integrals of matrix exponentials (see Wilcox Citation1967, Van Loan Citation1978) it follows that,
(3)
(3) Using (Equation3
(3)
(3) ), we can directly calculate the first and second derivative of the likelihood function for a discretely observed Markov process. Let
and
be allowed pairs for the generator
, then the expressions for the gradient and Hessian of the logarithm of (Equation2
(2)
(2) ) are as follows: for the Gradient we have
while for the Hessian we have
whereas
These estimates are direct applications of the theory above and hence we omit the steps. Both the formula of dos Reis and Smith (Citation2018, p. 7) and this new one are exact expressions for the Hessian and thus for the Fisher information matrix. However, the new formula is of distinctly reduced complexity, which consequently leads to clearly shorter computing times. Since the Hessian is only defined for allowed pairs the matrix is dimension-wise smaller than
-by-
.
We compute the Wald confidence intervals as follows,
recall that
The ijth component of the Hessian is the differential
The Fisher information matrix is given by
The Wald
A 95% confidence interval for the generator matrix estimate based on Moody's discretely observed corporate rating data is illustrated in Table . To obtain the Wald confidence interval, the computation time was ≈1 s with the new expression compared to ≈2 s for the formula of dos Reis and Smith (Citation2018).
Table 1. Confidence Interval (at 95% confidence) for the entries of the Generator Matrix for Moody's Corporate Rating Discrete-Time Transition Matrix.
3.2. The Delta method—confidence intervals for probabilities
The object we are estimating is the generator matrix , thus the confidence intervals are based on the entries of this matrix. Although obtaining these confidence intervals are useful, from a practitioners standpoint it is more useful to know how this uncertainty propagates to the underlying TPM and the estimated probabilities of default. This is a classical problem in statistics where one wishes to consider how the confidence interval changes under a transformation (in this case (Equation1
(1)
(1) )), the standard method to do this is known as the Delta method, see Lehmann and Casella (Citation1998) for further information.
We construct confidence intervals for each individual element in using the set of allowed pairs (Definition 3.2). We consider the confidence interval for the transition probability
at time t as,
That is for a fixed t,
is a multivariate function of the allowed pairs,
, in
. This leads to the following result.
Theorem 3.3
Assume asymptotic normality holds for all allowed pairs, let denote the allowed pairs of
(our MLE estimate) and fix t. Then, for each i, j in the state space with
, the variance in
is given by,
(4)
(4) provided
, where
denotes the vector constructed by differentiating w.r.t. each element in
then evaluated at
, and
is the inverse Hessian matrix at the MLE. Moreover, for each
,
The proof of this result is given in Appendix 2. The assumption that is extremely mild and can be easily checked once the MLE estimate is found.
At this point, we take advantage of the fact that we have already derived a closed-form expression for the Hessian. Hence we can easily compute (Equation4(4)
(4) ), moreover, it is now straightforward to compute the confidence interval for the transition probabilities. This is an extremely useful result since it allows one to quantify the uncertainty at the level of the estimation of transition probabilities (instead of the generator matrix), and critically, uncertainties in the probability of default. Figures and show such intervals for probability of default estimates from Moody's corporate rating data 2016 and a time horizon of up to 10 years. One can see that this procedure easily allows one to quantify the error of probability of default predictions for arbitrary time horizons. This is especially interesting as this parameter is an important ingredient to the calculation of expected losses over lifetime in the IFRS 9 regulatory framework.
Figure 1. Confidence Intervals as maps of time for Discrete-Time Transitions into the Default Category C over 10 years- Moody's Corporate Rating Discrete-Time Transitions 2016.
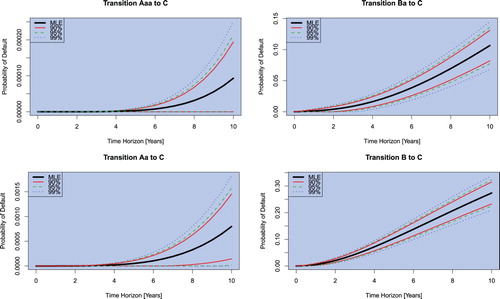
Figure 2. Confidence Intervals as maps of time for Discrete-Time Transitions into the Default Category C over 10 years- Moody's Corporate Rating Discrete-Time Transitions 2016.
3.3. Confidence intervals w.r.t. information
We benchmark our analysis against dos Reis and Smith (Citation2018, Section 4). We consider a true generator matrix (which is the MLE Markov generator described in Section 4.5) and from that simulate multiple years worth of data which is viewed as empirical data. We then introduce the EM algorithm to increasing amounts of data and assess how the estimate and errors change. By using a known generator, we additionally assess the accuracy of the estimate and error. From a computational point of view, matrix exponentials embed highly nonlinear dependencies in the elements of and
. Therefore, to understand the error we consider how both the error of
and
changes as the amount of information changes.
We consider the scenario of 250 obligors per rating and simulate 50 years worth of transitions (i.e. the number of companies that made each transition). We then apply the EM algorithm using 1 year worth of data then 2 years etc up to 50 years. In the case of a company defaulting we replace it with the rating they were pre-default. This implies that the amount of ‘information’ obtained from each year is similar. We plot the results in Figure .
Figure 3. Estimated value in some TPM entries and 95% confidence interval as the amount of data increases.
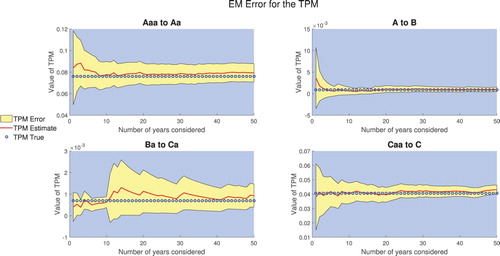
One observes that in most cases the errors in the TPM behave as expected. The surprising result is the Ba to Ca entry whose error increases. As alluded above, one can only understand the error in the TPM by understanding the underpinning error of the generator estimation. Although, in theory, the Ba to Ca transition depends on all entries in the generator we know that certain entries have a greater impact. We, therefore, look at the error in some important generator entries, Figure .
Figure 4. Estimated value in the generator and 95% confidence interval as the amount of data increases.
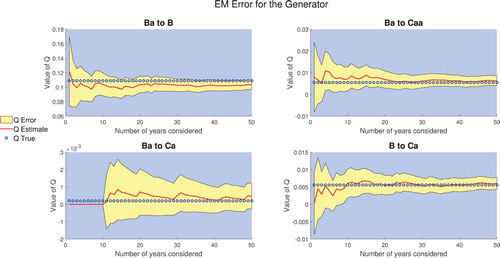
From Figure it is clear that the main contributor to the error is (unsurprisingly) the Ba to Ca entry. Initially, we need to wait for a transition from Ba to Ca to happen which increases the likelihood and hence the uncertainty surrounding the estimate. Moreover, it then takes several more years of data before the estimate becomes more stable. This uncertainty in the generator then propagates to uncertainty in the TPM entries, and one observes the extremely strong correlation between the TPM entry and the corresponding generator entry. Due to this, the error in the Ba to Ca transition probability is much larger than the other estimates, even after 50 years of observation. This behaviour in the CTMC modelling is not ideal (and the IFRS 9 regulation exacerbates the effect), but it shows some of the challenges in obtaining good estimates and errors for small probabilities (rare events), namely that the model is still sensitive to individual observations. One can use this to assess the sensitivity in the model, for example, adding one observation of a company defaulting and then recomputing the probabilities and their associated errors will provide an idea of the sensitivity.
4. Extending Markov processes to capture rating momentum
In this section, we work with the continuously observed data case and hence can broaden our scope of models (we are no longer restricted to Markov models). In the previous section, we highlighted many good features of the EM algorithm, in particular, that one could derive closed-form expressions for the errors. However, the EM algorithm does not generalize well as one quickly runs into difficulties when using models that have more complex likelihoods. This is the case when we generalize to point processes. Before detailing the model we are proposing let us start by showing that the data (see Section 3) contains non-Markov features.
4.1. Testing for non-Markovian phenomena
In Lando and Skodeberg (Citation2002)'s analysis of Standard and Poor's rating data set, the authors tested the presence of rating momentum. For consistency and completeness, we show that rating momentum behaviour is also present in Moody's data set.
The test follows a standard semi-parametric hazard model approach developed in Andersen et al. (Citation1991) (see also Andersen et al. Citation2012). The basic idea is to test whether the intensity (from leaving the state) is influenced by previous transitions, that is, we model the intensity for any given firm, n in state i as,
where q is an unspecified ‘baseline’ intensity,Footnote†
Z contains information relating to the firm and c is the coefficient we estimate. One important point here is that we are often dealing with censored observations (many firms stop being rated after a while), hence using hazard models is useful since we have access to the theory of partial likelihoods which can handle censored observations, see Cox and Oakes (Citation1984). One can then for example set the covariate Z as,
Hence in this setting the Markov assumption is equivalent to the null hypothesis c = 0. The general statistical framework including fitting c by maximizing the partial likelihood is covered in Andersen et al. (Citation1991) and Lando and Skodeberg (Citation2002, Appendix A), but we do not discuss these further here.
The result from this analysis can be seen in Table —we can see a statistically significant downward momentum effect (i.e. the null hypothesis is rejected on standard significance levels α of ,
or
) but no significant upward momentum behaviour in the Moody's data. These findings are consistent with those of Lando and Skodeberg (Citation2002).
Table 2. Likelihood ratio test for downward and upward momentum.
4.2. Our new model to capture rating momentum
As one can see from Table there is very strong evidence that downward momentum exists in the data. Let us now describe a tractable methodology, using marked point processes that can capture this effect. Readers unfamiliar with point processes can consult Appendix 3 for further details.
The likelihood of a single realization of a marked point process is given in Daley and Vere-Jones (Citation2003, p.251), namely,
(5)
(5) where we use the following notation,
is the set of times at which events occur,
is the intensity, k is the mark and f is the so-called mark's distribution. The subscript g is a common notation used to imply that this is the intensity of the ground process, i.e. we are only considering the events of interest. Setting
and
we recover the likelihood of a CTMC and hence one can see that these processes are generalizations of Markov processes.
To incorporate rating momentum into such models we draw inspiration from Hawkes processes and change the intensity of the model for appropriate rating changes. The basic idea is to start with a CTMC (with generator matrix ), which acts as a baseline intensity, then add a non-Markov component which is a self-excitation intensity decaying exponentially.Footnote† That is, any downgrade observed increases the intensity of then future downgrades for a certain while. We also introduce two types of momentum, one if the company downgrades from investment-grade (Baa and better) and another if the company downgrades from a speculative-grade (this modelling choice is further discussed in Section 4.4 and 4.5). Using the same notation as before, given the state space
such that state h (default) is absorbing, we model the intensity of the stochastic process X at time t as follows,
where m denotes investment or speculative downgrade,
is the set of downgrade times (of type m) prior to time t and
and
correspond to the intensity and memory of the ‘momentum’ in each case. One can note that the intensity of the stochastic process drops (returning to the baseline intensity) as more time elapses since the previous downgrade and this rate is controlled by
. In particular, this allows one to include empirically observed effects such as the momentum's influence reducing over time (see Couderc Citation2008).
In this set up we add only four parameters to the parameters of the CTMC case; the effectiveness of this parsimony is substantiated below (see Section 4.4). To the best of our knowledge, no other model we are aware of captures the momentum effect so simply. Further parameters and extensions can be introduced, nonetheless, we focus only on this model. Its analysis is found in Sections 4.3.1 and 4.5.
We work under the following modelling assumptions which, we believe to be sufficiently reasonable and keep the model parsimonious (most of these can be easily lifted and the model extended).
We only consider downward momentum. Since upward momentum is not as statistically significant (Table ) we do not consider it.
There are two types of momentum, investment and speculative.
Companies being downgraded from investment grades (numerically these are the ratings from 1 to
Finally (not easy to remove) no points occurred prior to time 0, the so-called edge effects. This essentially means that companies do not have momentum when they are initially rated.
Remark 4.1
(Prudent Estimation)
Since we only consider momentum as a purely negative effect, if we assume a company has no momentum when it initially does then we will obtain more conservative numbers for the downgrades. Therefore in calibration, if one does not use a full history of a company's rating change the model will be more prudent.
With these assumptions let us define the mark's distribution. We take the following marked distribution (for ,
is the time of the ith jump),
where we denote by
the time immediately prior to the ith jump and
is the number of states one can downgrade to i.e.
. Substituting the intensity and mark distribution into (Equation5
(5)
(5) ), yields the following expression for the likelihood,
(6)
(6)
Note that the likelihood is for the information regarding one company. We can construct the likelihood of multiple companies by taking the product, but it is worthwhile noting that this assumes independence among companies. This is unlikely to be true due to business cycles etc, however, these correlated systemic effects can be introduced into risk modelling using the methods from McNeil and Wendin (Citation2007). Hence, we concentrate purely on the idiosyncratic effect of rating momentum.
The integral involving the momentum (last integral in (Equation6(6)
(6) )) can be simplified, to
Unlike the CTMC case this likelihood is complex and there appears to be no real simplification, the main reason for this is the time and history dependence amongst jumps for which simplifications of the form
are no longer possible. We proceed forward by relying on Markov Chain Monte Carlo (MCMC) techniques to estimate the parameters.
4.3. An MCMC calibration algorithm for the model
In the CTMC setting as considered in Bladt and Sørensen (Citation2005, Citation2009) and dos Reis and Smith (Citation2018) the data augmentation step for the CTMC was costly making the algorithm extremely slow compared to other algorithms. In our setting, we have access to a complete data set and this expensive step is avoided. Moreover, the likelihood we deal with is complex and thus MCMC (see Gilks et al. Citation1995) is one of the few methods that can deliver reasonable estimations.
The basic set up of MCMC is to estimate the parameter(s) θ through its posterior distribution given some data D, typically denoted . In general, one cannot access this posterior distribution and direct Monte Carlo simulation is not possible as one does not know the normalizing constant. MCMC gets around this by observing through Bayes' formula that,
where L is the likelihood and
is the prior distribution of θ. It is then possible to sample from this distribution using the Metropolis-Hastings algorithm with some proposal distribution.
Let denote the set of all company transitions. We are interested in obtaining the joint distribution
where
is the matrix with the baseline intensities and jump probabilities (has the same form as a generator matrix of a CTMC) and
,
are the momentum parameters. Since we assume the prior distribution of
,
and
to be independent, Bayes' theorem implies that,
where L is the likelihood defined in (Equation6
(6)
(6) ). The full conditional distribution of each parameter is obtained by conditioning on knowledge of all other parameters.
For the priors, firstly for , we assume that the initial transitions carry no momentum hence we can set the prior as the CTMC maximum likelihood estimate (MLE) based on the initial transitions. We therefore set the prior as exponential with the mean being the MLE. For
and
, we use a Gamma random variable with a reasonable variance as the prior. This is to reflect that we have far less knowledge for these parameters but do not expect them to be either zero or too large.
The next issue we tackle is how to simulate from the full conditional distribution. Dealing with the parameters of the model first, their full conditional distributions are clearly not standard distributions so we use the single-component Metropolis-Hastings algorithm. As always with Metropolis-Hastings we need to define a good proposal function. In order to avoid a high number of rejections, we take our proposal as a Gamma random variable with mean as the current step and a small variance. In effect, this creates a random walk type sampling scheme that is always nonnegative. Therefore, if we denote the set of parameters by γ and the proposal distribution by ψ (which can depend on the current parameters), the nth step acceptance probability of a proposed point given the current
is given by,
where
denotes the set of parameters at the nth update not including the s parameter.
4.3.1. Model calibration
Now that we have the necessary tools, we can calibrate our model using Moody's data set. Running 11,000 MCMC iterations (taking 1000 burn in) we obtain the following results.Footnote† For the Markov style ‘base’ component,
and for the momentum parameters,
One interesting observation arising from calibration is the difference of momentum parameters across the investment and the speculative downgrades. There is apparently more momentum in the speculative downgrades than in the investment downgrades, namely, the momentum intensity is larger and lasts longer in speculative grades.Footnote†
This may seem counter-intuitive, however, setting a credit rating ultimately involves combining information from various sources and making a judgement on the exposure of that company (sovereign) to different risks. As discussed in Couderc (Citation2008, Chapter 5 and 6), there appears to be a noticeable difference on which information influences downgrades/defaults for investment-grade and speculative-grade obligors. This points towards an intrinsic difference between these classes of ratings and thus it is not too surprising that our momentum model also shows a difference. From a practical point of view, the model suggests that a downgrade in a speculative-grade company is more damming for future performance, the information that influences speculative-grade rating changes implies deeper issues within the company and hence higher chances of further downgrades/default.
4.4. Bayesian information criterion
Let us give some justification for the use of this model. We have argued that a point process style model is a strong choice and to keep the model as robust and simple as possible we added four extra ‘momentum parameters’ (with relation to the CTMC model). We believe four to be the optimal choice due to the fact that only adding two parameters does not yield as good a fit to the observed data and adding parameters to every rating does not seem appropriate, since we do not have enough transitions across all ratings to obtain a reliable fit. We therefore did not consider more momentum groups than investment and non-investment grade.
As we have access to a full data set, one can directly calculate the MLE for the generator matrix of the Markov model setting. Therefore we can test our momentum model against the purely Markov model.
The Markov model is a particular case of our momentum model, set and
a constant for
. Hence, a priori the non-Markov model stands to fit the data better (in the sense of achieving a likelihood at least as large). The question we look to answer is, are we actually capturing the data better or just overfitting? To do this we calculate the Bayesian Information Criterion (BIC), it is a common test used in statistics for model selection and is known to penalize model complexity more than other statistical tests, such as the Akaike information criterion (see Claeskens and Hjort Citation2008, Chapter 3). We believe this feature makes the BIC a good test to justify our more complex model. The BIC for a model M can be written as (some authors use the negative of this)
where n refers to the number of data points and
is the number of parameters in the model. From a given set of models, the model with the largest BIC is taken as the better one. Naturally, the indicator of how much ‘better’ one model is over another is the difference in the BIC, where a BIC difference strictly greater than 10 is taken as very strong evidence of the model superiority.
The result in Table gives us confidence that our non-Markov model captures reality better without overfitting and with sufficient parsimony with relation to the Markov (CTMC) one.
Table 3. The BIC difference between the non-Markov and Markov model on the Moody's dataset.
4.5. Examples and testing
Probabilities of default as maps of time: Markov vs. non-Markov. One important aspect of the non-Markov theory is how it impacts the estimates for the TPM and the transition probabilities.
Remark 4.2
(Obtaining transition probabilities and model simulation) In the standard Markov set up, the TPM is calculated using (Equation1(1)
(1) ). In the non-Markov set up we do not have such a simple relation, hence we are forced to use Monte Carlo techniques. In this case, we prescribe multiple companies in each rating at the start (we used a total of
) and simulate individual transitions according to the point process model. By recording the rating of each company at various points in time (see below) we can then build transition matrices over several time horizons in the same way one builds an empirical TPM.
The simulation of our momentum model is similar to that of a standard CTMC, i.e. based on the current state one simulates a ‘jump time’ then simulates the new state to jump into. The main difference here is the added complexity of the time and history dependence that exists in our momentum model. To simulate the jump time of a fixed company we use the standard accept/reject method introduced in Ogata (Citation1981, Algorithm 2) for varying intensities. For each accepted jump time, we then calculate the transition probabilities based on this time and simulate the jump to the next state. We then repeat this process for each company up until the time horizon required.
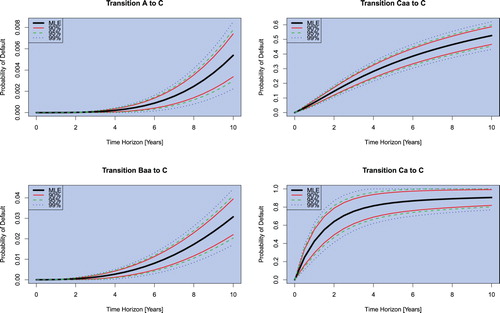
It is of particular interest to understand how the evolution in time of the probabilities of default change when using the CTMC Markovian and our non-Markovian model. Using the calibrated model, Figure details the probabilities of defaults for the various ratings as maps in time.
Figure 5. The probability of default given by each model for various ratings as a function of time.
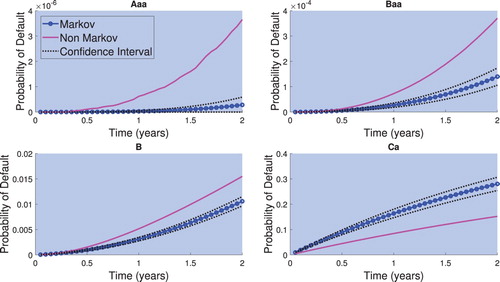
The first observation one can make from Figure is, the non-Markov model produces higher probabilities of default, except for the Ca rating (the non-Markov default probability is also lower for rating Caa). The reason for this is precisely the non-Markovianity in the data. In a Markov framework, all companies in the same rating are treated the same, consequently, it is unlikely that an investment-grade company will continue to downgrade quickly while the non-Markov model allows for this.
On the other hand, companies may enter rating Ca before defaulting, hence in the momentum model, some companies in this rating are carrying an extra term making default more likely. This implies we can account for a larger number of defaults while keeping the matrix Ca to C entry smaller. This is not the case in the Markov model and thus to produce enough defaults from Ca one makes the
matrix entry larger. Consequently, the Markov model overestimates the default probability for obligors initially rated Ca.
Probabilities of default: Empirical vs. Markov vs. non-Markov. To test how reliable these results are, we can compare one-year probabilities of default as estimated from each calibrated model compared to that we observe from the data. To do so, we fix some time horizon T (one-year here) and consider all companies that have either defaulted or not withdrawn by this period. We then build an empirical TPM over this horizon based on the company's rating at time zero and T. Concentrating solely on probabilities of default we obtain the results in Table .
Table 4. Comparing one-year probability of defaults of each model against the empirical observations. For reference we add explicitly the number of companies per rating at starting time t = 0 as in the Moody's data set.
The results in Table are interesting because they highlight stark differences in the models. Starting with the investment-grade, unfortunately, we do not have enough data to fully assess default probabilities at this level. The only grade for which a default within a year is observed is Baa and is higher than what both models predict. One reason the momentum model may not capture this probability as well is the way we have set up the momentum parameters, i.e. an investment and speculative set, and Baa is at the turning point. On the other hand, this number is estimated from a smaller number of defaults so is subject to a larger error. Comparing the Markov and non-Markov, it is unsurprising that our model makes investment-grade defaults more likely.
For the speculative-grades, one observes that Ca and Caa firms have lower one-year default probabilities in the non-Markov model and these estimates are closer to the empirical observations. This is exactly due to the reason mentioned previously, companies downgrading into Ca and Caa ‘poison’ the data in the Markov setting. Implying that in a Markov world a company initially rated Caa or Ca is viewed to be riskier than it actually is.
The difference between the models may have a large impact on a bank's capital requirements for regulation. Although the non-Markov model makes most ratings riskier than the Markov model, we feel it provides a more accurate reflection of default risk.
Remark 4.3
(Limitations from censored data) Unfortunately, in our study, we are limited to small-time horizons due to censored data. Namely, since the default is absorbing, as soon as a company defaults, we keep that information up to the terminal time. However, many companies are only rated over a few years before withdrawing and therefore if we look at empirical TPMs over longer horizons they are built with less (non-default) data. Since we do not want to use the Markov assumption, there does not appear to be a way to incorporate this lost data. Therefore we can only obtain ‘accurate’ numbers on short time scales.
5. Summary
In the first part of this paper we have shown how one can evaluate errors in the transition matrices of continuous-time Markov chains at the level of discretely observed data using new closed-form expressions. These results reduced the computation of confidence intervals to less than one half of the time needed by current approaches. Moreover, and of practical importance, by employing the Delta method, our results provide an intuitively interpretable understanding of uncertainty in the model output, the probabilities of default.
In the second part, we have shown the significance of being able to capture non-Markov effects in rating transitions. Comparing against empirical probabilities of default and the classical Markov chain model, one finds a tendency for the Markov chain model to overestimate on some speculative-grades and underestimate on investment-grades. We address this issue by providing a parsimonious model that better captures default probabilities (where empirically observed). Moreover, the non-Markov model points towards significantly higher probabilities of default for investment-grades, where such values are not empirically observed, thus making it more prudent. We believe that the model we present provides a more accurate view of reality and hence should be considered in credit risk modelling. These observations further highlight the importance of understanding so-called model risk and its potential impact in quantitative risk analysis in general.
Acknowledgements
The authors would like to thank Dr. R. P. Jena at Nomura Bank plc London, Prof. M. Fischer at Bayerische Landesbank Munich, also H. Thompson and M. Chen from the Zurich Insurance Group and Dr. M. de Carvalho at the University of Edinburgh for the helpful comments. The authors would like to thank two anonymous referees for their comments and suggestions to clarify the manuscript.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
† A quasi-Newton method (or scoring procedure) only requires one to estimate the first order derivative. More common approaches such as Newton-Raphson for finding the MLE would also require evaluation of the second derivative.
† Observe that we are not assuming that the baseline is time homogeneous in the test.
† This is a common and well-understood form to use in Hawkes processes, see Bacry et al. (Citation2015).
† The MCMC algorithm, written in MATLAB, took ≈8.5 h to run on a Intel Xeon E7-4660 v4 2.2 GHz processor.
† Note that both and
.
References
- Altman, E.I. and Kao, D.L., The implications of corporate bond ratings drift. Financ. Anal. J., 1992, 48, 64–75. doi: 10.2469/faj.v48.n3.64
- Andersen, P.K., Hansen, L.S. and Keiding, N., Non-and semi-parametric estimation of transition probabilities from censored observation of a non-homogeneous Markov process. Scand. J. Stat., 1991, 18, 153–167.
- Andersen, P.K., Borgan, O., Gill, R.D. and Keiding, N., Statistical Models Based on Counting Processes, 2012 (Springer-Verlag: New York).
- Bacry, E., Mastromatteo, I. and Muzy, J.F., Hawkes processes in finance. Market Microstruct. Liquidity, 2015, 1, 1550005.
- Bielecki, T.R., Crépey, S. and Herbertsson, A., Markov chain models of portfolio credit risk. In The Oxford Handbook of Credit Derivatives, edited by A. Lipton and A. Rennie, chap. 10, pp. 327–382, 2011 (Oxford University Press: Oxford).
- Bladt, M. and Sørensen, M., Statistical inference for discretely observed Markov jump processes. J. R. Stat. Soc. B (Stat. Methodol.), 2005, 67, 395–410. doi: 10.1111/j.1467-9868.2005.00508.x
- Bladt, M. and Sørensen, M., Efficient estimation of transition rates between credit ratings from observations at discrete time points. Quant. Finance, 2009, 9, 147–160. doi: 10.1080/14697680802624948
- Cappé, O., Moulines, E. and Rydén, T., Inference in Hidden Markov Models, Springer Series in Statistics, 2005 (Springer: New York). With Randal Douc's contributions to Chapter 9 and Christian P. Robert's to Chapters 6, 7 and 13, with Chapter 14 by Gersende Fort, Philippe Soulier and Moulines, and Chapter 15 by Stéphane Boucheron and Elisabeth Gassiat.
- Carey, M. and Hrycay, M., Parameterizing credit risk models with rating data. J. Bank. Financ., 2001, 25, 197–270. doi: 10.1016/S0378-4266(00)00124-2
- Christensen, J.H.E., Hansen, E. and Lando, D., Confidence sets for continuous-time rating transition probabilities. J. Bank. Financ., 2004, 28, 2575–2602. doi: 10.1016/j.jbankfin.2004.06.003
- Claeskens, G. and Hjort, N.L., Model Selection and Model Averaging, 2008 (Cambridge Books: Cambridge).
- Couderc, F., Credit risk and ratings: Understanding dynamics and relationships with macroeconomics. PhD Thesis, Ecole Polytechnique Fédérale de Lausanne, 2008.
- Cox, D.R. and Oakes, D., Analysis of Survival Data, 1984 (Routledge).
- Daley, D.J. and Vere-Jones, D., An Introduction to the Theory of Point Processes. Vol. I, Second edition, Probability and its Applications (New York), 2003 (Springer-Verlag: New York), Elementary theory and methods.
- Daley, D.J. and Vere-Jones, D., An Introduction to the Theory of Point Processes. Vol. II, Second edition, Probability and its Applications (New York), 2008 (Springer: New York), General theory and structure.
- D'Amico, G., Janssen, J. and Manca, R., Downward migration credit risk problem: A non-homogeneous backward semi-Markov reliability approach. J. Oper. Res. Soc., 2016, 67, 393–401. doi: 10.1057/jors.2015.35
- Dassios, A. and Zhao, H., Exact simulation of Hawkes process with exponentially decaying intensity. Electron. Commun. Prob., 2013, 18, 1–13. doi: 10.1214/ECP.v18-2717
- dos Reis, G. and Smith, G., Robust and consistent estimation of generators in credit risk. Quant. Finance, 2018, 18, 983–1001. doi: 10.1080/14697688.2017.1383627
- Frydman, H. and Schuermann, T., Credit rating dynamics and Markov mixture models. J. Bank. Financ., 2008, 32, 1062–1075. doi: 10.1016/j.jbankfin.2007.09.013
- Gilks, W.R., Richardson, S. and Spiegelhalter, D.J., Introducing Markov chain Monte Carlo. In Markov Chain Monte Carlo in Practice, edited by W.R. Gilks, S. Richardson, and D. Spiegelhalter, 1st edition, p. 19, 1995 (Chapman and Hall: New York).
- Inamura, Y., Estimating continuous time transition matrices from discretely observed data. Technical report, Citeseer, 2006.
- Kalbfleisch, J.D. and Lawless, J.F., The analysis of panel data under a Markov assumption. J. Am. Stat. Assoc., 1985, 80, 863–871. doi: 10.1080/01621459.1985.10478195
- Knight, K., Mathematical Statistics, Chapman & Hall/CRC Texts in Statistical Science Series, 2000 (Chapman & Hall/CRC: Boca Raton, FL).
- Koopman, S.J., Lucas, A. and Monteiro, A., The multi-state latent factor intensity model for credit rating transitions. J. Econom., 2008, 142, 399–424. doi: 10.1016/j.jeconom.2007.07.001
- Korolkiewicz, M.G.W., A dependent hidden Markov model of credit quality. Int. J. Stoch. Anal., 2012, 2012, Art. ID 719237, 13.
- Kreinin, A. and Sidelnikova, M., Regularization algorithms for transition matrices. Algo Res. Quart., 2001, 4, 23–40.
- Lando, D. and Skodeberg, T.M., Analyzing rating transitions and rating drift with continuous observations. J. Bank. Financ., 2002, 26, 423–444. doi: 10.1016/S0378-4266(01)00228-X
- Lehmann, E.L. and Casella, G., Theory of Point Estimation, Second, Springer Texts in Statistics, 1998 (Springer-Verlag: New York).
- Løffler, G., Avoiding the rating bounce: Why rating agencies are slow to react to new information. J. Econ. Behav. Organ., 2005, 56, 365–381. doi: 10.1016/j.jebo.2003.09.015
- McNeil, A.J. and Wendin, J.P., Bayesian inference for generalized linear mixed models of portfolio credit risk. J. Empir. Finance, 2007, 14, 131–149. doi: 10.1016/j.jempfin.2006.05.002
- McNeil, A.J., Frey, R. and Embrechts, P., Quantitative Risk Management: Concepts, Techniques and Tools, 2005 (Princeton: Oxford).
- Nickell, P., Perraudin, W. and Varotto, S., Stability of rating transitions. J. Bank. Financ., 2000, 24, 203–227. doi: 10.1016/S0378-4266(99)00057-6
- Oakes, D., Direct calculation of the information matrix via the EM. J. R. Stat. Soc. B (Stat. Methodol.), 1999, 61, 479–482. doi: 10.1111/1467-9868.00188
- Ogata, Y., On Lewis' simulation method for point processes. IEEE Trans. Inform. Theory, 1981, 27, 23–31. doi: 10.1109/TIT.1981.1056305
- Ogata, Y., Statistical models for earthquake occurrences and residual analysis for point processes. J. Am. Stat. Assoc., 1988, 83, 9–27. doi: 10.1080/01621459.1988.10478560
- Pfeuffer, M., ctmcd: An R package for estimating the parameters of a continuous-time Markov chain from discrete-time data. R. J., 2017, 9, 127–141. doi: 10.32614/RJ-2017-038
- Van Loan, C., Computing integrals involving the matrix exponential. IEEE Trans. Autom. Control, 1978, 23, 395–404. doi: 10.1109/TAC.1978.1101743
- Wilcox, R., Exponential operators and parameter differentiation in quantum physics. J. Math. Phys., 1967, 8, 962–982. doi: 10.1063/1.1705306
Appendix 1
Fundamentals of discretely observed Markov processes
The EM algorithm for this problem (See Section 3) is discussed in detail in Bladt and Sørensen (Citation2005) and dos Reis and Smith (Citation2018) and we encourage the reader to consult these texts for further information. For completeness, we present a brief review of the EM algorithm for the setting of continuous-time Markov chains.
For convergence of the EM algorithm, one works under the following assumption.
Assumption A.1
(Element constraint)
Similar to Bladt and Sørensen (Citation2005), we will use a manual space constraint to obtain the convergence. Take , such that for
,
. Moreover, we assume adjacent mixing, namely, for
,
and
.
We denote the space of generator matrices which satisfy this condition as .
This assumption is a trivial constraint when one works in credit risk as it requires that: (a) firms can be upgraded or downgraded by one rating which is clearly the case; and (b) that changes in ratings do not happen too fast which is also the practical case.
Let be a stochastic process over the finite state space
. Associated to
is, for i, j in the state space,
the number of jumps from i to j in the interval
and by
the holding time of state i in the interval
. The EM algorithm is then given by,
Take an initial intensity matrix
While the convergence criterion is not met and
E-step: calculate
M-step: set
Set
End while and return
By dos Reis and Smith (Citation2018, Theorem 2.10), provided the algorithm does not hit the boundary of , we obtain convergence (in distribution and parametric) to a stationary point. Typically the E-step in the EM algorithm needs to be calculated numerically, however dos Reis and Smith (Citation2018) following Van Loan (Citation1978) and Inamura (Citation2006) obtained the following result.
Proposition A.2
Let be the column vector of length h which is one at entry i and zero elsewhere, further let us define the
-by-
matrices
and
as,
Consider a CTMC X observed at n time points
; denote by
the state of the chain at time
, i.e.
. Then, the expected jumps and holding times across observations are,
When one only has access to an observed sequence of TPMs with equal observation length we obtain,
where
(the number of observations) and
is the TPM of the uth observation.
Roughly speaking, the above formula is taking each row in the TPM to contain equal amounts of information (observations). When one knows the number of transitions between the states , then
is replaced by
, where
is the number of observed transitions in observation u.
The M-step is just the ratio of these two quantities and thus the results yield closed-form expressions for the EM algorithm's steps making the algorithms much faster (see results in dos Reis and Smith Citation2018).
Appendix 2
Proof of Theorem 3.3
The proof relies on the multivariate delta method, see Lehmann and Casella (Citation1998, Theorem 8.16).
Proposition A.3
(Delta Method)
Let ,
, be n independent s-tuples of random variables with
and
. Let
denote the empirical mean,
, and suppose that h is a real-valued function of s arguments with continuous first partial derivatives. Then,
We now have the necessary material to prove our result.
Proof of Theorem 3.3.
The assumption of asymptotic normality implies the expectation and covariance assumption of Proposition A.3. Moreover, it follows from standard results in likelihood based inference that (see Knight Citation2000, Chapter 5.4).
For the partial derivatives of the probability matrix, it follows immediately by arguments in Section 3.1. Also note that this representation implies that the first partial derivatives of exist and are continuous.
To complete the proof, we need only to show that the RHS of (Equation4(4)
(4) ) is strictly positive. Firstly, at a maximum
is negative definite (hence
is also negative definite), therefore it is enough to have that
around the MLE. Observing the latter is one of the theorem's assumptions concludes the proof.
Appendix 3
Overview of point processes
Let us discuss how we look to embed history dependence into the model. We are interested in Hawkes processes (a specific type of self-exciting point process) which have intensities of the form
Hawkes processes are used to model many different phenomena, from earthquake occurrence to high frequency trading, see Ogata (Citation1988) and Bacry et al. (Citation2015). Setting
yields a constant intensity and this is equivalent to the Markov setting. However, φ allows us to vary the intensity with past events which is key for momentum since past downgrades influence future transitions. As described in the introduction, a Hawkes process is just a counting process (generalizing a Poisson process), hence it would imply that a rating transition had occurred and not which rating we have moved into. The latter being key, we consider processes which take values on some state space: such processes are known as marked point process (MPPs), see Daley and Vere-Jones (Citation2003, Section 6.4). MPPs are point processes on a product space
, that is, we return a set of values,
for
, where one thinks of
as the event time of the point process (with intensity λ) and
of the “mark” associated to the event. These notions are what we shall use, but in general
can be multidimensional e.g. to include spatial dependence. In our case we have
namely, it denotes the ratings which ensure our marked point process to be well defined.
The likelihood of a single realization of a MPP, is given in (Daley and Vere-Jones Citation2003, p. 251),
where we have the following notation,
is the set of events occur,
is the intensity and f is the so-called mark's distribution. The
symbolizes that the intensity and mark distribution depend on previous events. Namely, the intensity at time
,
depends on the previous events,
. Also note the distinction that
does not depend on the mark
, but the mark
is allowed to depend on time
. The subscript g is a common notation used to imply this is the ground process, which in our case is simply the timing of the upgrades/downgrades. By allowing the intensity and hence the number of jumps and the mark distribution to depend on previous events we can easily change the probability of upgrade/downgrade and thus embed rating momentum into the process. Further details on likelihoods of MPP can be found in Daley and Vere-Jones (Citation2003, Section 7.3).
One reason that we believe MPPs are a good choice for this particular problem is that one can view them as a natural generalization of CTMCs. This is apparent from the likelihood since, letting and
we recover the likelihood of a CTMC.