
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Power generation comprises high environmental and ecological impacts. The global power industry is under pressure to develop more efficient ways to operate and reduce the impacts of inherent process variability. With the rapid development of technologies within the energy sector, large volumes of data are available due to in-time operational measurements. With increased computer processing capabilities, machine learning is applied to explore these in-time operational measurements for improved process understanding. This research paper investigates machine learning algorithms for energy efficiency improvement at coal-fired thermal power plants by conducting a systematic literature review. This research is essential since it provides guidelines for applying machine learning towards sustainable energy supply and improved decision-making. Subsequently, efficient processes result in the reduction of fuel usage, which results in lower emission levels for equivalent power generation capacity. Furthermore, this study contributes towards future research by providing valuable insights from academic and industry-related studies.
1. Introduction
The global power industry is under pressure to develop more efficient ways to operate and to reduce the impact of variable operations on market supply and the environment (Sleiti, Kapat, and Vesely Citation2022). Minimal attention was given to energy management during the early 1970s (Petrecca Citation2014). However, energy security was a big concern after the oil crisis, leading to more energy-efficient technologies and operations (Kaya and Keyes IV Citation1980). Studies published over the last few decades focused predominantly on energy management, emphasising the need for more effective ways to generate and use energy resources globally (Bunse et al. Citation2011; Narisco and Martins Citation2020; Schulze et al. Citation2016). This need originates from the challenges that emerge by balancing the use of valuable resources, the human population and providing proper living conditions (Narisco and Martins Citation2020).
Energy efficiency is the attempt to decrease the recourses used while considering resource depletion, monetary savings, environmental impacts, and resource security (Lovins Citation2017; Patterson Citation1996). Energy efficiency is considered one of the primary contributors to a sustainable society and is considered a critical aspect in all industries and countries. In South Africa, 2003 data indicate that the mining sector consumes more than 175 PJ of energy annually. Thus, it is identified as the highest consumer of electricity (Oladiran and Meyer Citation2007). These energy-intensive operations could be more sustainable, provided the government's regulations on carbon emissions (Awuah-Offei Citation2016).
Numerous initiatives have been launched globally over the last few years to highlight the importance of energy efficiency (Narisco and Martins Citation2020), including, but not limited to, climate and energy initiatives by the European environment agency (Climate & Energy Package Citation2020), and the energy star programme (Energy Star Overview Citation2016). Given this high electricity demand, the Chinese government and various other countries, including India (Mishra Citation2004) and Zimbabwe (Murehwa et al. Citation2012), focus explicitly on thermal power plants for electricity generation. A thermal plant consists of various boilers that feed into common steam receivers (Murehwa et al. Citation2012). These feed sources are mainly coal, oil, nuclear or gas. Most power plants use coal to generate electricity (Bi et al. Citation2014; Murehwa et al. Citation2012).
A coal-fired boiler converts water into steam (Jagarnath Citation2019). Two boilers exist in coal-fired thermal plants: the pulverised coal-fired boiler and the fluidised bed combustion boiler. In India, 70% of electricity is produced by coal-fired power plants, and in China, thermal power generation contributes 73.4% to the total capacity (Bi et al. Citation2014; Mishra Citation2004). Coal generally has a low calorific value and a high ash content (Mishra Citation2004). The problem is that the electricity generated from these thermal power plants produces greenhouse gases, including nitrogen oxides and carbon monoxide
(Bi et al. Citation2014). Therefore, the impact of power generation globally comprises high environmental and ecological risks.
From an engineering viewpoint, Haddadin et al. (Citation2023) indicated that a balance could be reached by maintaining the current structure while increasing the use of renewable energy within power plants. This prospect will provide a dual benefit for a cleaner environment amid a few changes to the power system’s components and framework (Haddadin et al. Citation2023). Despite the need to shift from coal to other renewable energy sources, the generation and production of electricity in coal-fired thermal power plants will continue for at least another twelve years (Zima et al. Citation2022). Coal-fired power plants generate 38% of electrical power worldwide (Kitto Citation1996). For this reason, the focus should be on technological improvements, behavioural changes and the price or policy tools to induce these changes towards optimal efficiency (Lovins Citation2017).
One operational objective of the coal-fired boiler is to reach optimal operating efficiency while considering reliability and cost (Rambalee et al. Citation2011). Various technologies have been implemented to optimise and stabilise these thermal plants. These technologies include model predictive control (MPC) and advanced process control (APC), which have been introduced to ensure stable control of the boiler and to balance the burner management system (Rambalee et al. Citation2011). These technologies contribute to reducing harmful emissions ( and
).
With the rapid development of these technologies, a large quantity of data has been captured (Sleiti, Kapat, and Vesely Citation2022). The volume of data is increasing in all sectors, which results in more opportunities for improved efficiency (Narisco and Martins Citation2020). However, the structure and volume of the datasets are becoming more complex and newer methods are required to deal with these complexities (Sleiti, Kapat, and Vesely Citation2022). Most enterprises focus on machine learning (ML) to explore and operate these volumes of data (Narisco and Martins Citation2020). Machine learning is a subset of artificial intelligence (AI) (Shinde and Shah Citation2018). Ayodele (Citation2010) stated that analysing machine learning algorithms is classified as computational learning theory. Subsequently, the learning is not considered consciousness learning but finding patterns in the data instead. Machine learning algorithms provide valuable insight into the difficulty of learning relationships in various environments (Ayodele Citation2010).
Machine learning techniques have been developed since the 1950s, and many advancements have been made within the last few decades. Prominent machine learning applications include the following industries: manufacturing (Wuest et al. Citation2016), retail (Jia, Zhao, and Tong Citation2013), finance (Goodell et al. Citation2021), and the energy sector (Nabavi et al. Citation2020). There has been an increase in academic papers on energy management and various new developments focusing specifically on machine learning and sustainability. However, Prashar (Citation2017) stated that there is still a lack of knowledge on implementing these concepts for energy efficiency.
For this reason, this research study aims to investigate machine learning applications at coal-fired thermal power plants for improved energy efficiency by conducting a systematic literature review. To achieve the aim, the following objectives have been formulated:
To provide an overview of the fundamentals of machine learning theory followed by an overview of how these techniques are currently applied for energy efficiency.
To investigate which machine learning techniques are applied at coal-fired thermal power plants for improved energy efficiency.
To investigate how these machine learning techniques are applied at coal-fired thermal power plants for improved energy efficiency.
To identify the current literature limitations and to provide valuable future research recommendations.
The research paper is outlined as follows. First, a detailed literature study on machine learning algorithms is provided in Section 2, specifically on supervised, unsupervised, semi-supervised and reinforcement learning. Section 3 outlines the search protocol developed for the systematic literature review and discusses the results in Section 4. Conclusions and future recommendations based on the results obtained in this study are provided in Sections 5 and 6, respectively.
2. Literature review: the application of machine learning for energy efficiency improvements
Artificial intelligence (AI), in general, impacts the energy sector since it can assist in the development of clean, cheap, and reliable energy (Makala and Bakovic Citation2020). Furthermore, AI eliminates energy waste and reduces energy costs by improving the planning, operations, and control of various power systems (Makala and Bakovic Citation2020). Machine learning is a subset of AI closely related to statistics (Ongsulee Citation2017). First, an overview of the fundamentals of machine learning is provided, followed by a few case studies on how some of these algorithms are applied for improved energy efficiency in the industry.
2.1. An overview of machine learning
Machine learning techniques are divided into supervised, unsupervised, semi-supervised, and reinforcement learning (Bhatt Citation2019). Supervised learning develops an artificial system that maps the relationships or the patterns between the input and the output variables (Liu Citation2011). Based on these findings, the system predicts outcomes based on new information by referring to the relationships and patterns identified during the learning process. Classification of the input data is determined if the output takes a finite set of discrete values. In contrast, regression of the input data is identified if the output takes continuous values. With supervised learning, the input-output relationships are based on specific parameters. These unknown parameters must first be determined by training the algorithms (Liu Citation2011). The structure of supervised learning is demonstrated in (Liu Citation2011):
Figure 1. Supervised learning algorithm (Liu Citation2011).
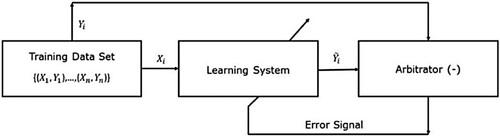
With supervised learning, the training data need to be labelled (Liu Citation2011). Labelled data are already tagged with the specific output (Javatpoint Citation2022). The training sample is identified as . The variable
is the system input, and
is the system's output.
The indices (i) is defined as the index of the training sample. First, is fed to the learning system, and an output
is generated. The output variable
is compared to the labelling
by an arbitrator. This arbitrator computes the difference between the
and
variables. The difference between the two variables, which is the error signal, is sent back to the learning system. The system evaluates the difference and adjusts the parameters accordingly to minimise the error signal, the difference between the
and
variables. The primary purpose of this learning process is to minimise the error signal of the training set, and to obtain the optimal set of learning system parameters (Liu Citation2011).
The objective of training the artificial system is to estimate the parameters based on known data, whereas testing aims to assess the predictions on unseen data. The data used in the training process are not used in the testing of the system. For this reason, it is not guaranteed that the system will perform the same in both instances. In addition, the training process is complex and lacks generalizability. Generalizability is defined when the system is trained to minimise training error and complexity (Liu Citation2011).
Supervised learning algorithms include, but are not limited to, linear classifiers such as the support vector machine, decision tree, and Bayesian networks (Ayodele Citation2010). Supervised learning can be used for discriminative pattern classification since the classes can be manipulated. However, with supervised learning, collecting and labelling unlabelled data is challenging. Various mistakes can occur, and it is time-consuming (Liu Citation2011). In the following sections, various machine learning algorithms are explained.
2.1.1. The support vector machine
A support vector machine is an algorithm that assigns labels to objects in the dataset (Boser, Guyon, and Vapnik Citation1992). The purpose is to find an optimal hyperplane within a specific N-dimensional space (Gandhi Citation2018). In this N-dimensional space, the data points are classified accordingly, as demonstrated in (Gandhi Citation2018).
Figure 2. The support vector machine: Potential hyperplane (Gandhi Citation2018).
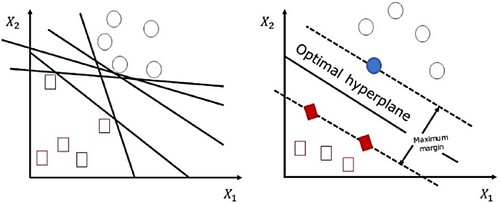
The hyperplanes in N-dimensional space separate two classes from each other. The primary goal is to select the hyperplane with the maximum margin. A maximum margin is defined as the maximum distance between the two classes.
Gandhi (Citation2018) stated that future data points could be classified with more confidence by maximising the distance. A hyperplane depends on the number of features. The hyperplane is a line if the support vector machine has two features. However, if the number of features is three, the hyperplane is two-dimensional. A support vector is a data point closest to the hyperplane. Subsequently, this vector influences the position and orientation of the hyperplane (Lovins Citation2017).
2.1.2. The decision tree
A decision tree is applied to solve classification and regression problems (Gupta Citation2017). An upside tree represents the decision-making process. The tree consists of internal nodes, which are split into branches. A decision is made at the end of each branch. A classification tree primarily aims to classify the data points according to the classes, whereas a regression tree predicts continuous values (Gupta Citation2017).
With a decision tree, all the features and attributes are considered in the decision-making process. The cost is linked to the accuracy of the prediction. For example, a function calculates how much accuracy each decision tree split will cost. The split with the least cost is selected. A cost function is typically used for both classification and regression problems. For regression, the following cost function is formulated:
(1)
(1) The average response of the training data of the group is considered the prediction for that group. The function is applied to all the data, and the cost is calculated accordingly. For classification, the following cost function is formulated:
(2)
(2) The variable
is the proportion within each class
. A perfect class purity is defined when the
value is either 1 or 0, meaning the group contains all inputs from a similar class. A minimum number of training inputs on each leaf can be defined for a decision tree. This will ensure that the tree stops splitting after reaching a specific number of splits. Subsequently, the parameter known as the maximum depth can also be set, which is defined as the length of the longest path from the tree's root to the leaf (Gupta Citation2017).
Other supervised machine learning techniques include the Bayesian network, Naive Bayes and the Gaussian Process (GP). The Bayesian network is a probabilistic model that mainly uses Bayesian inference to compute probabilities. The model consists of nodes and directed edges (Brownlee Citation2019). These models consider conditionally dependent and independent relationships between random data points. Like the rest of the algorithms discussed in this section, these models are also trained before predicting the probabilities of events.
The Naïve Bayes is defined as a probabilistic model based on the Bayes Theorem. The Naïve Bayes algorithm is mainly applied to solve classification problems. Bayes Theorem is defined as follows (Chauhan Citation2022):
(3)
(3) where P(A|B) is the probability of A occurring, given B has already occurred. P(B|A) is the probability of B occurring given A has already occurred. P(A) is defined as the probability of A occurring, and P(B) is the probability of B occurring.
The Gaussian Process (GP) is designed specifically to solve regression and probabilistic classification problems. These processes are versatile, so various kernels can be specified, and the prediction interpolates the observations. However, these processes lose efficiency in high-dimensional spaces (Yi Citation2022).
Unlike supervised learning, unsupervised learning algorithms do not use labelled data (Ayodele Citation2010). Unsupervised learning is complex since the hidden patterns and relationships between the data points are unknown. Unsupervised learning algorithms primarily aim to identify hidden patterns and group similarities (Javatpoint Citation2022).
The unsupervised learning algorithm mainly addresses three problems (IBM Cloud Education Citation2020b): clustering, association, and dimensionality reduction. Clustering is defined as a method that clusters or groups objects in one specific group that has similarities (Javatpoint Citation2022). An association rule is a method that identifies the relationships between various variables in a dataset (Javatpoint Citation2022). The size of the datasets used influences the performance. However, overfitting is a common challenge when working with large data sets. Dimension reduction is applied to reduce the number of features. This algorithm also preserves the integrity of the data while reducing the variables to a reasonable size (IBM Cloud Education Citation2020b).
Unsupervised learning algorithms can solve complex problems in a considerable amount of time. However, the output might not be as accurate as supervised learning since the data is not labelled, and no result is known in advance (javatpoint Citation2022). One of the most popular unsupervised learning algorithms is neural networks (NN). This algorithm is discussed in the following section.
2.1.3. Neural networks
Neural networks (NN) are also known as artificial neural networks (ANN) or simulated neural networks (SNN) (IBM Cloud Education Citation2020a). These networks are a subset of machine learning at the centre of deep learning. Neural networks consist of node layers (input, hidden, and output layers). The structure of a deep neural network is presented in (IBM Cloud Education Citation2020a).
Figure 3. The deep neural networks (IBM Cloud Education Citation2020a).
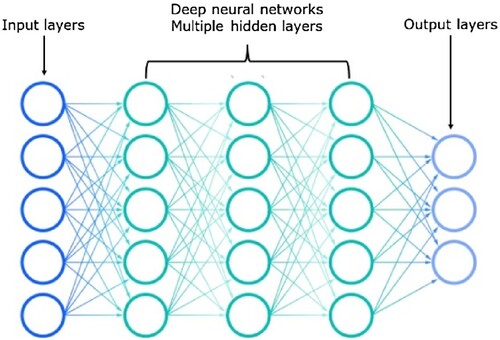
Each node or artificial neuron consists of a weight and threshold. As stated in Section 2.1, each algorithm must be trained to improve accuracy over time. Training of the algorithm contributes towards the accuracy of the prediction. Once properly trained, the algorithm can be employed as a powerful machine learning tool, specifically for image and speech recognition. A node is similar to a linear regression model, consisting mainly of data, weights, a threshold value, and an output. A node’s equation is defined as follows (IBM Cloud Education Citation2020a):
(4)
(4)
Weights are assigned to the node when the input layer is determined. The weight depends on the importance of the provided variable (IBM Cloud Education Citation2020a). An activation function is used to determine the output. An activation function is defined as follows (IBM Cloud Education Citation2020a):
(5)
(5) If the predicted output of a specific node is above the threshold value, the node is activated, and data is sent to the following layer of the entire network. Therefore, the output of one node becomes the input of another. A feedforward neural network is defined when data is passed from one node to another in the network (IBM Cloud Education Citation2020a).
There exist various types of artificial neural networks. Only the most common types are discussed in this paper. depicts the most basic neural network as demonstrated by Frank Rosenblatt in 1958 (Rosenblatt Citation1958):
Figure 4. The neural networks (Rosenblatt Citation1958).
Feedforward neural networks are also referred to as multi-layer perceptions (MLPs). They are comprised of sigmoid neurons and not perceptions since most real-world problems are non-linear. Convolutional neural networks (CNN) typically use principles from linear algebra, specifically matrix multiplication, to identify specific relationships in the data. Recurrent neural networks (RNN) consist of various feedback loops. Time-series data are used to make precise predictions (Rosenblatt Citation1958).
Johnson (Citation2022) stated that one of the most common ways to train neural networks is to use the backpropagation method. This method is applied by tuning the neural network weights by considering the error rate obtained from the previous epoch. As explained in Section 2.1, the primary purpose of training any machine learning algorithm is to reduce the error rate to deliver a more reliable model for accurate predictions. This approach is mostly followed in training neural networks since it is fast and easy to programme. There are no parameters to tune except the number of inputs, and it is considered flexible (Johnson Citation2022).
A study conducted by Smrekar et al. (Citation2009) employed machine learning by developing an artificial neural network (ANN) model that predicts steam properties from a coal-fired boiler. The authors considered three input parameters: steam pressure, temperature, and flow. The models developed in this study yielded high accuracy on both the training and testing data. Furthermore, the study demonstrated the usefulness of ANN modelling for coal-fired boilers. The authors stated that some boiler processes, such as pulverises and combustion, are challenging to develop physical models since the relations between these variables are not always known. For this reason, ANN models are applicable since these types of models can consider most things known and unknown (Smrekar et al. Citation2009).
Other unsupervised machine learning techniques include the K-Nearest Neighbor and the K-means clustering. The K-Nearest Neighbor is applied to solve both classification and regression problems. The K-Nearest Neighbor assumes that similar characteristics exist between data points near each other. The euclidean distance is used to calculate the distance between the data points (Harrison Citation2018).
The K-means clustering technique divides data points into K groups, where K is defined as the number of clusters (IBM Cloud Education Citation2020b). The number of clusters is based on the distance from each group's centroid. All points allocated near the centroid are clustered into one category. A small K-value indicates large groupings with less granularity, and a large K-value means smaller groupings with more granularity.
Semi-supervised learning is defined when the data is only half labelled (IBM Cloud Education Citation2020b). Subsequently, unsupervised and semi-supervised learning is mainly applied to prevent data from being incorrectly labelled.
2.1.4. Reinforcement learning
Supervised and reinforcement learning utilises a function that maps the dependency between the input and output data (Song et al. Citation2013). However, supervised learning provides a correct set of actions to obtain a specific output, whereas reinforcement learning uses rewards and punishments to obtain a particular result (Bhatt Citation2019).
Unsupervised learning and reinforcement learning's objectives are different. Unsupervised learning recognises the patterns between data points, whereas reinforcement learning identifies an action model. This action model aims to maximise the total cumulative rewards of the system. provides an overview of the action-reward feedback loop of reinforcement learning (Bhatt Citation2019):
Figure 5. Reinforcement learning algorithm (Bhatt Citation2019).
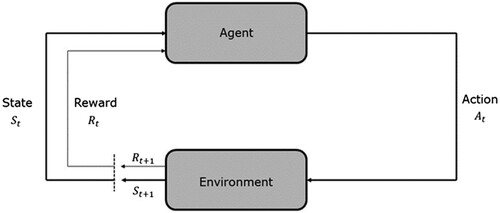
The state is defined as the agent's current state. The reward variable
indicates the feedback from the environment, and a policy refers to the method used to map the agent's actions (Bhatt Citation2019). The environment is defined as the space the agent operates in, and the value
is defined as the future reward the agents may receive if a specific action
is followed. The primary objective is to build an optimal policy while maximising the reward. In reinforcement learning, exploration and exploitation are prevalent definitions. A decision must be made where both are balanced (Bhatt Citation2019).
2.1.5. Errors and evaluation criteria
The performance of a machine learning model is analysed based on the prediction error against the validation dataset. This study presents and discusses the coefficient of determination , root-mean-square error (RMSE), normalised RMSE, mean absolute error (MAE) and mean absolute percentage error (MAPE). The values obtained from these performance metrics provide information on the machine learning model's robustness and effectiveness (Muhammad Ashraf et al. Citation2020).
Assume presents the sample size used as input,
and
denote the predicted values and the actual values, respectively. The maximum and minimum value of
are denoted by
and
, respectively. The coefficient of determination
is given in Equation (6).
(6)
(6)
Nagelkerke (Citation1991) indicated that the coefficient of determination estimates the percentage of variance explained in a given dataset. The root-mean-square error (RMSE) and the normalised RMSE are estimated as illustrated in Equations (7–8)
(7)
(7)
(8)
(8)
The root-mean-square error (RMSE) estimates the standard deviation of the residuals between the predicted values and the actual values of an observation (Otto Citation2019). Furthermore, the normalised RMSE (NRMSE) enables comparing various models with different scales (Otto Citation2019). The mean absolute error (MAE) and mean absolute percentage error (MAPE) are illustrated in Equations (9–10)
(9)
(9)
(10)
(10) The mean absolute error (MAE) presents the error obtained between the predicted values and the real values of the specific dataset (Qi et al. Citation2020). Furthermore, the mean absolute percentage error (MAPE) estimates the average magnitude of the error between the predicted value and the actual values of a specific dataset (De Myttenaere et al. Citation2016).
Baressi Šegota et al. (Citation2020) stated that the K-fold cross-validation is part of the training process of a machine learning model, specifically when the data sets used are small. First, the data is split into k splits, where (k−1) subsets of the dataset are used for training, and the remaining subset is used for testing. This process is repeated k times until all the splits have been used as the testing split precisely once. Subsequently, this allows the entire dataset to be used as a testing set systematically and provides more information on the model's performance (Baressi Šegota et al. Citation2020).
2.2. The application of machine learning for improved energy efficiency
Machine learning applications also include, but are not limited to, renewable energy predictions, fault detection and power quality monitoring. Renewable energy resources, including wind power, hydropower, and photovoltaic energy, have gained attention over the last few years and are considered alternative energy supply (Sogabe et al. Citation2018). The problem encountered with renewable energy resources is often a mismatch between the electricity supply and demand, resulting in instability and limited power output (Sogabe et al. Citation2018). Virtualitics (Citation2021) added that the power demand and generation must always be equivalent to prevent blackouts due to inefficient energy.
However, machine learning algorithms can predict the electricity required for any renewable source for a specific period to satisfy demand. Virtualitics (Citation2021) argued that these predictions and evaluations will contribute towards reducing harmful emissions by encouraging the use of reliable renewable energy sources as an alternative to coal or other non-renewable energy. Sogabe et al. (Citation2018) indicated that there is a need for a practical approach to address these types of issues. Khan and Khan (Citation2013) proposed smart grids due to their ability for intelligent, robust, and functional power grids. Sogabe et al. (Citation2018) applied two deep reinforcement learning techniques for smart grid optimisation. These techniques captured the supply and demand feature and selected the appropriate behaviour, maximising the reward of the deep reinforcement learning model (Sogabe et al. Citation2018). The beforementioned studies provide a general overview of how these algorithms can assist with better decision-making.
Despite using renewable energy sources, clean coal power plants are still one of the dominant choices for power generation by developing energy-efficient operations and ensuring carbon capture and storage (Haddadin et al. Citation2023). Haddad and Mohamed (Citation2022) stated that, with the newest advancements in clean coal technologies, it is essential to gain a fundamental and comprehensive understanding of these modelling philosophies. For this reason, this study focuses on machine learning applications at coal-fired thermal power plants for improved energy efficiency.
One of the leading causes of failure in a steam power plant is defined as boiler waterwall tube leakage (Khalid et al. Citation2020). In 2021, Khalid, Hwang, and Kim (Citation2021) stated that the primary reason for failure in thermal power plants is equipment, specifically boiler and turbine faults (Khalid, Hwang, and Kim Citation2021). Based on these two studies, the authors indicated that developing efficient fault-detection processes in power plants is required. These intelligent tube leak-detection systems can improve the efficiency and reliability of modern power plants (Khalid et al. Citation2020; Khalid, Hwang, and Kim Citation2021). Khalid, Hwang, and Kim (Citation2021) proposed a novel machine learning-based optimal sensor selection to analyse the turbine and boiler faults in the power plant. The results of this study demonstrated that the machine learning models’ computational efficiency was enhanced by reducing the number of sensors for both scenarios. Furthermore, the performance of these models was improved by up to 97% and 92.60% in the water wall tube leakage and the turbine motor fault, respectively (Khalid, Hwang, and Kim Citation2021).
Alvarez Quiñones, Lozano-Moncada, and Bravo Montenegro (Citation2023) proposed a methodology to schedule predictive maintenance of distribution transformers using machine learning. The authors focused explicitly on classification predictive modelling to obtain the minimal number of distribution transformers prone to fail. In conclusion, the machine learning methodology was implemented and saved 13% in corrective maintenance expenses in one specific year (Alvarez Quiñones, Lozano-Moncada, and Bravo Montenegro Citation2023).
In the study conducted by Haddadin et al. (Citation2023), the Elman neural network (ENN) and the generalised regression neural network (GRNN) were proposed for a cleaner coal-fired supercritical unit. These models obtained more accurate results than previously published models. Subsequently, the authors predicted the supercritical pressure, the production, and the steam temperature. It is important to note that these variables have been selected since they represent energy efficiency and cleaner production. The Mean Square Error was used as a performance metric to evaluate the models’ effectiveness and performance (Haddadin et al. Citation2023).
From these case studies, it is evident that the application of machine learning is extended to solve a wide range of problems in various areas, including renewable energy predictions, fault detection and optimal power generation in coal-fired thermal power plants. Furthermore, machine learning provides the ability to make more accurate decisions in real-time and deliver sustainable solutions (Ghosh Citation2017). To further extend the machine learning analysis, an in-depth investigation is conducted on the type of machine learning algorithms and how these algorithms were applied in coal-fired thermal power plants for improved energy efficiency from 2012 - 2022. First, the research method of the systematic literature review is outlined, followed by a discussion of the results.
3. A systematic literature review: the review protocol
The number of published papers in various research fields exponentially increases, resulting in information overload. Pejić-Bach and Cerpa (Citation2019) stated that there is a gap between the number of published articles and the time to review these studies. A systematic literature review addresses this gap by providing insight into only the relevant papers and their scientific development (Pejić-Bach and Cerpa Citation2019).
A systematic literature review is considered evidence-based research and originated in the medical industry (Kitchenham et al. Citation2009). Kitchenham et al. (Citation2009) defined the word evidence as a synthesis of the best quality studies in the academic literature of a particular topic or research field. A systematic literature review is different from a formal literature review since a methodologically rigorous method is followed to obtain research results (Kitchenham et al. Citation2009).
In this paper, a systematic literature review is conducted to investigate machine learning applications at coal-fired thermal power plants for improved energy efficiency. The systematic literature review conducted in this study is based on the guidelines proposed by Kitchenham et al. (Citation2009) and Kumar and Garg (Citation2020). Kitchenham et al. (Citation2009) conducted a systematic literature review to identify the status of Evidence-based Software Engineering (EBSE) papers since 2004, and Kumar and Garg (Citation2020) conducted a systematic literature review on context-based sentiment analysis in social multimedia.
Kitchenham et al. (Citation2009) method consists of seven stages, including the formulation of research questions, search process, inclusion and exclusion criteria, quality assessment, data collection, data analysis and deviations from the protocol. The review process by Kumar and Garg (Citation2020) was divided into six stages: formulating the research questions, search strategy, study selection, quality assessment, data extraction and data synthesis. The search protocol followed in this paper consists of five stages: Formulating the research questions, the search process, study selection: Inclusion and exclusion criteria, quality assessment, data extraction, and data synthesis.
3.1. Research question formulation
The following research questions were formulated to collect and collate research evidence from existing studies:
Research Question 1: Which machine learning algorithms were applied at coal-fired thermal power plants for improved energy efficiency?
Research Question 2: How were these machine learning algorithms applied at coal-fired thermal power plants for improved energy efficiency?
3.2. Search process
The search process consists of defining keywords in locating only the relevant studies. Scientific papers that contain all three keywords were selected:
Machine learning
Energy efficiency
Coal-fired thermal power plant
A manual search was conducted, and only published scientific journal articles were selected. The following databases were used to identify the relevant studies:
Science Direct
Scopus
Web of Science
IEEE Explore
Emerald Insight
3.3. Study selection: inclusion and exclusion criteria
The following studies were included in the search process:
Only published journal articles were included in the search process.
Journal articles containing the following three keywords: Machine learning, energy efficiency and coal-fired thermal power plant. These studies may include any review study or studies that refer to other studies containing the relevant keywords.
Journal articles that were published between 2012 and 2022.
The following studies were excluded from the search process:
Non-English articles
3.4. Quality assessment process
For the quality assessment, Kitchenham et al. (Citation2009) followed the database of abstracts of reviews of effects (DARE) criterion outlined by York University. This criterion is explicitly defined for studies that evaluate other studies that conducted a systematic literature review. The systematic literature review conducted in this study identified all types of studies. For this reason, quality assessment criteria are used as outlined by Albliwi et al. (Citation2014) and Mangaroo-Pillay and Coetzee (Citation2022). This assessment consists of four phases: Identification, screening, eligibility, and inclusion. Each phase is described in .
Table 1. The quality assessment process.
3.5. Data extraction
The data extracted from each study were the following:
The fundamentals of each study ().
The type of machine learning algorithm applied ().
The year of publication ().
The databases ().
Table 2. Systematic literature review results.
One researcher extracted the data, and the other checked the extraction. All three researchers evaluated the selected studies to ensure that the studies adhered to the quality assessment process.
3.6. Data analysis
Each study identified is summarised in to show:
The title of each study
The type of machine learning algorithm applied in coal-fired thermal power plants for energy efficiency.
Each database the study was published in.
The year of publication.
Reference.
4. Discussion of results
In this section, the results are discussed.
4.1. Search results
As indicated in Section 3, the review results are collected by the following information: Title, the type of machine learning model applied, published year, database, and reference. The studies identified were divided into three sections: Those that applied machine learning models, review papers and others. Others are defined as papers that did not apply machine learning models; however, the authors of these studies referred to other studies that contained the keywords used in this systematic literature review. Therefore, these studies were included in the search. All reviews and other studies are explained. The studies that applied machine learning models are further discussed in . For this reason, only an overview of the model type is provided in .
Table 3. Describes how machine learning models were applied in each study.
provides an overview of each study identified in the search by referring to the following: Title, type of machine learning model applied in each study, published year, database, and the reference. According to the search protocol developed, the studies were further analysed by addressing the two research questions.
4.1.1. Research question 1: which machine learning algorithms were applied in coal-fired thermal power plants for improved energy efficiency?
Fourteen studies contained all three keywords: Machine learning, energy efficiency and coal-fired thermal power plant. Two studies were identified in Science Direct, 11 in Scopus and one in IEEE Xplore. Seven of these studies were published in 2022, four in 2020, two in 2016 and one in 2015. These results are summarised in .
Figure 6. Search results: Publications per year and database.

demonstrates that most studies were identified in Scopus, and zero studies were identified in Web of Science and Emerald Insight. Furthermore, most studies were published recently, in 2022, and fewer studies were published before 2015. These results indicate the increased attention machine learning applications have gained over the last decade at coal-fired thermal power plants for improved energy efficiency. Various machine learning algorithms were developed and applied in the 14 studies identified. provides an outline of these types of algorithms.
Figure 7. The type of machine learning algorithms applied in each study.
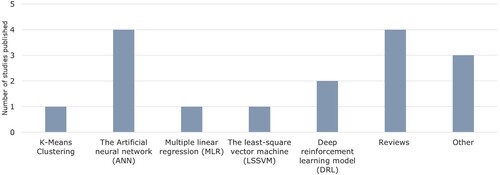
The types of machine learning algorithms developed in these studies were identified as follows:
K-Means clustering
The artificial neural networks (ANN)
Multiple linear regression (MLR)
The least-square vector machine (LSSVM)
Deep reinforcement learning (DRL) and deep learning.
Muhammad Ashraf et al. (Citation2020) applied three different machine learning algorithms. For this reason, 16 algorithms are identified in . These results showed that artificial neural networks were the most popular algorithm to solve the identified problems. The multi-layered perceptron (MLP) was mainly developed and applied within these.
Four studies conducted a review: Yu et al. (Citation2022), Wu et al. (Citation2022), Dhanalakshmi and Ayyanathan (Citation2022), and Babatunde (Citation2020). These reviews did not particularly apply or develop machine learning models but provided an overview of these algorithms. The ‘other’ studies identified in did not apply or develop machine learning models: Zima et al. (Citation2022), Variny and Kšiňanová (Citation2022), and (Nikula, Ruusunen, and Leiviskä Citation2016). However, the authors of these studies referred to other studies that contained the keywords used in this systematic literature review. Therefore, these studies were included in the search. From the studies identified, it is also important to note that no review, like the one conducted in this study, was identified. Research question two is addressed in the next section.
4.1.2. Research question 2: how were these machine learning algorithms applied in coal-fired thermal power plants for energy efficiency?
A further review of the seven studies provided insight into how these algorithms were applied in industry to address specific problems by focusing on the datasets, input parameters, training method and results. Furthermore, to provide a more comprehensive overview of the current literature, a detailed overview is provided of each study's contribution and potential future recommendations. A description of each is provided in .
provides an overview of how the different machine learning algorithms were applied in each study, followed by an overview of each study's contribution and future recommendations. The seven studies developed and implemented machine learning models in various forms. As discussed in Section 2, a specific process is followed in training supervised, unsupervised and reinforcement learning algorithms.
shows that four studies developed unsupervised learning algorithms, including artificial neural networks and the K-means clustering algorithm. One study applied one supervised algorithm (the least square vector machine), and two focused on deep learning or deep reinforcement learning.
There are similarities between the studies that applied unsupervised learning algorithms. Muhammad Ashraf et al. (Citation2020), Baressi Šegota et al. (Citation2020) and Rossi and Velázquez (Citation2015) used the backpropagation algorithm to train the artificial neural networks. Typical performance metrics used to determine the performance of the ANN included the following: The coefficient of determination, the root mean square error (RMSE), and the mean absolute error (MAE). Most other algorithms followed a similar approach, as explained in Section 2.
Multiple researchers emphasised the value of artificial neural networks. Artificial neural network models are flexible and can be applied to problems even if much of the information is unknown (Smrekar et al. Citation2009). These algorithms are designed to solve complex problems related explicitly to modelling, control and optimisation (Babatunde Citation2020). Furthermore, these algorithms can model complex non-linear relationships between inputs and outputs, which is much more challenging than traditional models (Chiroma and Abdulkareem Citation2016).
Wu et al. (Citation2022) highlighted that the articles identified in their review demonstrated the importance and the applicability of various machine learning algorithms, including decision trees, support vector machines (SVM), and artificial neural networks (ANN), specifically feedforward deep neural networks and recurrent neural networks. Another systematic review conducted by Dhanalakshmi and Ayyanathan (Citation2022) revealed that the artificial neural network (ANN) was mostly applied in the identified studies.
The type of machine learning model employed depends on the volume of data and the problem identified. However, as these different studies are evaluated, it is evident that there is a common thread across all these research studies identified from conducting the review. Specifically, most researchers suggested that artificial neural networks be used when working with large datasets and complex problems, especially those related to industrial processes and power plants.
Evidently, each study contributed to academia and industry by incorporating realistic and practical approaches. The studies by Sleiti, Kapat, and Vesely (Citation2022) and Wahyuningtyas and Asrol (Citation2022) indicated the importance of a decision support system for optimal decision-making. These studies illustrated that a data-driven approach alone is insufficient, and a tool is required to integrate it with system parameters for optimal decision-making. Furthermore, the importance of actual data is highlighted in by Sleiti, Kapat, and Vesely (Citation2022) and Wahyuningtyas and Asrol (Citation2022). Real data will improve decision-making and provide an accurate view of the system and its components, specifically when applying machine learning.
5. Summary and conclusions
This research paper investigated machine learning algorithms utilised for energy efficiency improvement at coal-fired thermal power plants by conducting a systematic literature review. Subsequently, this paper provided an overview of the identified relevant studies, focusing on the type of machine learning algorithms and the application thereof. This paper contributed towards research by providing guidelines for sustainable energy supply and improved decision-making towards more efficient processes. Efficient processes result in the reduction of fuel usage, which results in lower emission levels for equivalent power generation capacity. This research paper adds value to the industry and academia by identifying all scientific articles that applied machine learning algorithms in the power industry.
First, an overview of machine learning was provided, explicitly focused on supervised, unsupervised, semi-supervised and deep reinforcement learning algorithms. Second, a systematic literature review followed the same method as Kitchenham et al. (Citation2009). A search protocol was developed by formulating research questions, identifying keywords, databases, inclusion and exclusion criteria, and a quality assessment. From the search process, only 14 studies contained the three keywords. Two studies were identified in Science Direct, 11 in Scopus and one in IEEE Xplore. Seven of these studies were published in 2022, four in 2020, two in 2016 and one in 2015.
From the review, three studies mentioned machine learning: Zima et al. (Citation2022), Variny and Kšiňanová (Citation2022), and Nikula, Ruusunen, and Leiviskä (Citation2016), four conducted a review: Yu et al. (Citation2022), Wu et al. (Citation2022), Dhanalakshmi and Ayyanathan (Citation2022), and Babatunde (Citation2020), and seven applied machine learning at a coal-fired thermal power plant for energy efficiency (Baressi Šegota et al. Citation2020; Chiroma and Abdulkareem Citation2016; Fu et al. Citation2020; Rossi and Velázquez Citation2015; Sleiti, Kapat, and Vesely Citation2022; Wahyuningtyas and Asrol Citation2022). The seven studies applied different machine learning algorithms, including K-means clustering, multiple linear regression (MLR), the least-square vector machine (LSSVM), deep reinforcement learning (RL) and artificial neural networks (ANN). Typical performance metrics used to determine the performance of the ANN included the following: The coefficient of determination, the root mean square error (RMSE), and the mean absolute error (MAE).
Various researchers emphasised the value of artificial neural networks. Artificial neural network models are flexible and can be applied to problems even if all the information is unknown (Smrekar et al. Citation2009). The models can solve complex problems related explicitly to process modelling, control and optimisation. Furthermore, these algorithms can model complex non-linear relationships between inputs and outputs, which is much more challenging than traditional models (Chiroma and Abdulkareem Citation2016). The studies by Sleiti, Kapat, and Vesely (Citation2022) and Wahyuningtyas and Asrol (Citation2022) indicated the importance of a decision support system for optimal decision-making. These studies illustrate that a data-driven approach alone is insufficient, and a tool is required to integrate with system parameters for optimal decision-making. The results obtained from this study underline the significance of some applications of machine learning algorithms. For instance, the artificial neural network is famous for detecting non-linear patterns and predicting the behaviour of most industrial processes and power plants (Rossi and Velázquez Citation2015). The potential future recommendations are identified and explained in Section 6.
6. Limitations and future recommendations
One limitation identified from the systematic literature review conducted in this study is that the keywords are particular, resulting in fewer studies identified on the selected databases. For future research, it is recommended to broaden the search by removing the keyword: coal-fired thermal power plant. By eliminating this keyword, over 3000 studies are identified from Scopus. This will provide insight into how various machine learning algorithms are applied to solve related energy problems in other industries. For example, technologies may be investigated to improve asset failure prediction, resulting in optimised plant production and enhanced energy efficiency.
It is further recommended that a review is conducted that does not only focus on coal-fired thermal power plants but also on the application of machine learning for gas turbines and other fossil fuel plants, including gas-fired and oil-fired power plants. An extensive amount of research has been conducted on machine learning, and a comprehensive review that includes all power plants may further pave the way for future researchers and the industry.
The review showed that various supervised, unsupervised and reinforcement learning models are applied to solve industry-related problems. Based on the systematic literature review conducted and reported on in this paper, limited industry-related applications were identified for machine learning applications at coal-fired thermal power plants under investigation, especially to improve the operational efficiency of the status quo operations. Furthermore, Decision trees, Gaussian processes (GP), and the Naïve Bayes techniques were typically not found in the literature for the research question. It is, therefore, proposed that researchers investigate these techniques for the identified research question, i.e. the aim to improve energy efficiency at coal-fired thermal power plants while reducing fuel usage. Further research should also include comparing these identified techniques with that of an artificial neural network for energy-improved operations at coal-fired thermal power plants. It must be noted that coal-fired refers to coal being utilised within a boiler house to generate steam; therefore, emphasise must be placed on the coal-fired boiler.
Another limitation identified in the literature is applying the long short-term memory network (LSTM) technique. The LSTM has been developed and applied in various industries because it can process time series data (Pan et al. Citation2021). Furthermore, the LSTM can remember previous information and use this memory to calculate the current output (Pan et al. Citation2021).
For future research, it is recommended that this modelling technique is applied for optimal operational control of various units at coal-fired thermal power plants. Applying the LSTM may also contribute towards improving the energy efficiency of coal-fired boilers.
Furthermore, neural network predictive control (NNPC) is a model integrated with predictive control (MPC). One of the primary contributors of this model is its ability to be employed in real-time for simple controls and disturbance reduction (Megahed, Abdelkader, and Zakaria Citation2019). No such model has been identified in this review. For this reason, it may be valuable to investigate the application of such a model to enhance a power plant's automation and operational decision-making. It is recommended that the readers refer to for a more comprehensive overview of each study’s potential future research opportunities. These opportunities highlight the limitations of current literature and may be investigated for future research.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Albliwi, S., J. Antony, S. A. H. Lim, and T. van der Wiele. 2014. “Critical Failure Factors of Lean Six Sigma: A Systematic Literature Review.” International Journal of Quality & Reliability Management 31 (9): 1012–1030.
- Alvarez Quiñones, L. I., C. A. Lozano-Moncada, and D. A. Bravo Montenegro. 2023. “Machine Learning for Predictive Maintenance Scheduling of Distribution Transformers.” Journal of Quality in Maintenance Engineering 29 (1): 188–202. https://doi.org/10.1108/JQME-06-2021-0052
- Awuah-Offei, K. 2016. “Energy Efficiency in Mining: A Review with Emphasis on the Role of Operators in Loading and Hauling Operations.” Journal of Cleaner Production 117: 89–97. https://doi.org/10.1016/j.jclepro.2016.01.035
- Ayodele, T. O. 2010. Types of Machine Learning Algorithms. In www.intechopen.com. IntechOpen. https://www.intechopen.com/chapters/10694.
- Babatunde, D. E. 2020. Artificial Neural Network and Its Applications in the Energy Sector: An Overview. 670216917.
- Baressi Šegota, S., I. Lorencin, N. Anđelić, V. Mrzljak, and Z. Car. 2020. “Improvement of Marine Steam Turbine Conventional Exergy Analysis by Neural Network Application.” Journal of Marine Science and Engineering 8 (11): 884. https://doi.org/10.3390/jmse8110884
- Bhatt, S. 2019. Reinforcement Learning 101. [online] Medium. https://towardsdatascience.com/reinforcement-learning-101-e24b50e1d292.
- Bi, G. B., W. Song, P. Zhou, and L. Liang. 2014. “Does Environmental Regulation Affect Energy Efficiency in China's Thermal Power Generation? Empirical Evidence from a Slacks-Based DEA Model.” Energy Policy 66: 537–546. https://doi.org/10.1016/j.enpol.2013.10.056
- Boser, B. E., I. M. Guyon, and V. N. Vapnik. 1992. “A Training Algorithm for Optimal Margin Classifiers.” In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, 144–152, July.
- Brownlee, J. 2019. A Gentle Introduction to Bayesian Belief Networks. [online] Machine Learning Mastery. https://machinelearningmastery.com/introduction-to-bayesian-belief-networks/.
- Bunse, K., M. Vodicka, P. Schönsleben, M. Brülhart, and F. O. Ernst. 2011. “Integrating Energy Efficiency Performance in Production Management–gap Analysis Between Industrial Needs and Scientific Literature.” Journal of Cleaner Production 19 (6–7): 667–679. https://doi.org/10.1016/j.jclepro.2010.11.011
- Chauhan, N. 2022. Naïve Bayes Algorithm: Everything You Need to Know. [online] KDnuggets. https://www.kdnuggets.com/2020/06/naive-bayes-algorithm-everything.html.
- Chiroma, H., and S. Abdulkareem. 2016. “Neuro-genetic Model for Crude oil Price Prediction While Considering the Impact of Uncertainties.” International Journal of Oil, Gas and Coal Technology 12 (3): 302–333.
- Climate & energy package. 2020. Climate.ec.europa.eu. https://climate.ec.europa.eu/eu-action/climate-strategies-targets/2020-climate-energy-package_en.
- De Myttenaere, A., B. Golden, B. Le Grand, and F. Rossi. 2016. “Mean Absolute Percentage Error for Regression Models.” Neurocomputing 192: 38–48. https://doi.org/10.1016/j.neucom.2015.12.114
- Dhanalakshmi, J., and N. Ayyanathan. 2022. “A Systematic Review of Big Data in Energy Analytics Using Energy Computing Techniques.” Concurrency and Computation: Practice and Experience 34 (4): e6647. https://doi.org/10.1002/cpe.6647
- Energy Star Overview. 2016. Energystar.gov. https://www.energystar.gov/about.
- Fu, J., H. Xiao, H. Wang, and J. Zhou. 2020. “Control Strategy for Denitrification Efficiency of Coal-Fired Power Plant Based on Deep Reinforcement Learning.” IEEE Access 8: 65127–65136. https://doi.org/10.1109/ACCESS.2020.2985233
- Gandhi, R. 2018. Support Vector Machine — Introduction to Machine Learning Algorithms. Towards Data Science; Towards Data Science, June 7. https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47.
- Ghosh, P. 2017. The Value of Machine Learning: Benefits and Best Practices - Dataversity. Los Angeles, CA: Dataversity, June 8. https://www.dataversity.net/value-machine-learning-benefits-best-practices/
- Goodell, J. W., S. Kumar, W. M. Lim, and D. Pattnaik. 2021. “Artificial Intelligence and Machine Learning in Finance: Identifying Foundations, Themes, and Research Clusters from Bibliometric Analysis.” Journal of Behavioral and Experimental Finance 32: 100577. https://doi.org/10.1016/j.jbef.2021.100577.
- Gupta, P. 2017. Decision Trees in Machine Learning. [online] Towards Data Science. Available at: https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052.
- Haddad, A., and O. Mohamed. 2022. “Qualitative and Quantitative Comparison of Three Modeling Approaches for a Supercritical Once-Through Generation Unit.” International Journal of Energy Research 46 (14): 20780–20800. https://doi.org/10.1002/er.8330
- Haddadin, M., O. Mohamed, W. Abu Elhaija, and M. Matar. 2023. “Performance Prediction of a Clean Coal Power Plant via Machine Learning and Deep Learning Techniques.” Energy & Environment. 0958305X231160590.
- Harrison, O. 2018. Machine Learning Basics with the K-Nearest Neighbors Algorithm. [online] Medium. https://towardsdatascience.com/machine-learning-basics-with-the-k-nearest-neighbors-algorithm-6a6e71d01761.
- IBM Cloud Education. 2020a. What are Neural Networks? [online] www.ibm.com. Accessed 05 August 05, 2023. Available at: https://www.ibm.com/topics/neural-networks.
- IBM Cloud Education. 2020b. What is Unsupervised Learning? Www.ibm.com; IBM Cloud Education, September 21. https://www.ibm.com/cloud/learn/unsupervised-learning#:~:text=Unsupervised%20learning%2C%20also%20known%20as.
- Jagarnath Mahato. 2019. Jagarnath Mahato. [online] Coal Handling Plants. https://www.coalhandlingplants.com/boiler-in-thermal-power-plant/.
- javatpoint. 2022. “Supervised Machine Learning - Javatpoint.” Www.javatpoint.com, 2022, www.javatpoint.com/supervised-machine-learning.
- Jia, L., Q. Zhao, and L. Tong. 2013. Retail pricing for stochastic demand with unknown parameters: An online machine learning approach. In 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton) (pp. 1353-1358). IEEE. 2013, October.
- Johnson, D. 2022. Back Propagation Neural Network: Explained With Simple Example. [online] www.guru99.com. https://www.guru99.com/backpropogation-neural-network.html.
- Kaya, A., and M. A. Keyes IV. 1980. “Energy Management Technology in Pulp, Paper and Allied Industries.” IFAC Proceedings Volumes 13 (12): 609–622. https://doi.org/10.1016/S1474-6670(17)69499-0
- Khalid, S., H. Hwang, and H. S. Kim. 2021. “Real-world Data-Driven Machine-Learning-Based Optimal Sensor Selection Approach for Equipment Fault Detection in a Thermal Power Plant.” Mathematics 9 (21): 2814. https://doi.org/10.3390/math9212814
- Khalid, S., W. Lim, H. S. Kim, Y. T. Oh, B. D. Youn, H. S. Kim, and Y. C. Bae. 2020. “Intelligent Steam Power Plant Boiler Waterwall Tube Leakage Detection via Machine Learning-Based Optimal Sensor Selection.” Sensors 20 (21): 6356. https://doi.org/10.3390/s20216356
- Khan, R. H., and J. Y. Khan. 2013. “A Comprehensive Review of the Application Characteristics and Traffic Requirements of a Smart Grid Communications Network.” Computer Networks 57 (3): 825–845. https://doi.org/10.1016/j.comnet.2012.11.002
- Kitchenham, B., O. P. Brereton, D. Budgen, M. Turner, J. Bailey, and S. Linkman. 2009. “Systematic Literature Reviews in Software Engineering–a Systematic Literature Review.” Information and Software Technology 51 (1): 7–15. https://doi.org/10.1016/j.infsof.2008.09.009
- Kitto, J. B. 1996. “Developments in Pulverized Coal-Fired Boiler Technology.” In Missouri Valley Electric Association Engineering Conference, 1–11, April.
- Kumar, A., and G. Garg. 2020. “Systematic Literature Review on Context-Based Sentiment Analysis in Social Multimedia.” Multimedia Tools and Applications 79 (21–22): 15349–15380. https://doi.org/10.1007/s11042-019-7346-5
- Liu, B. 2011. “Supervised Learning.” In Web Data Mining, 63–132. Berlin, Heidelberg: Springer.
- Lovins, A. 2017. “Energy Efficiency.” Energy Economics 1: 234–258.
- Makala, B., and T. Bakovic. 2020. Artificial Intelligence in the Power Sector. EMCompass No. 81. Washington, DC: International Finance Corporation. https://openknowledge.worldbank.org/handle/10986/34303.
- Mangaroo-Pillay, M., and R. Coetzee. 2022. “Lean Frameworks: A Systematic Literature Review (SLR) Investigating Methods and Design Elements.” Journal of Industrial Engineering and Management 15 (2): 202–214. https://doi.org/10.3926/jiem.3677
- Megahed, T. F., S. M. Abdelkader, and A. Zakaria. 2019. “Energy Management in Zero-Energy Building Using Neural Network Predictive Control.” IEEE Internet of Things Journal 6 (3): 5336–5344. https://doi.org/10.1109/JIOT.2019.2900558
- Mishra, U. C. 2004. “Environmental Impact of Coal Industry and Thermal Power Plants in India.” Journal of Environmental Radioactivity 72 (1-2): 35–40. https://doi.org/10.1016/S0265-931X(03)00183-8
- Muhammad Ashraf, W., G. Moeen Uddin, A. Hassan Kamal, M. Haider Khan, A. A. Khan, H. Afroze Ahmad, F. Ahmed, et al. 2020. “Optimisation of a 660 MWe Supercritical Power Plant Performance—a Case of Industry 4.0 in the Data-Driven Operational Management. Part 2. Power Generation.” Energies 13 (21): 5619. https://doi.org/10.3390/en13215619
- Murehwa, G., D. Zimwara, W. Tumbudzuku, and S. Mhlanga. 2012. “Energy Efficiency Improvement in Thermal Power Plants.” International Journal of Innovative Technology and Exploring Engineering (IJITEE) 2 (1): 20–25.
- Nabavi, S. A., A. Aslani, M. A. Zaidan, M. Zandi, S. Mohammadi, and N. Hossein Motlagh. 2020. “Machine Learning Modeling for Energy Consumption of Residential and Commercial Sectors.” Energies 13 (19): 5171. https://doi.org/10.3390/en13195171
- Nagelkerke, N. J. 1991. “A Note on a General Definition of the Coefficient of Determination.” Biometrika 78 (3): 691–692. https://doi.org/10.1093/biomet/78.3.691
- Narciso, D. A., and F. G. Martins. 2020. “Application of Machine Learning Tools for Energy Efficiency in Industry: A Review.” Energy Reports 6: 1181–1199.
- Nikula, R. P., M. Ruusunen, and K. Leiviskä. 2016. “Data-driven Framework for Boiler Performance Monitoring.” Applied Energy 183: 1374–1388. https://doi.org/10.1016/j.apenergy.2016.09.072
- Oladiran, M. T., and J. P. Meyer. 2007. “Energy and Exergy Analyses of Energy Consumptions in the Industrial Sector in South Africa.” Applied Energy 84 (10): 1056–1067. https://doi.org/10.1016/j.apenergy.2007.02.004
- Ongsulee, P. 2017. “Artificial Intelligence, Machine Learning and Deep Learning.” In 2017 15th International Conference on ICT and Knowledge Engineering (ICT&KE), 1–6. IEEE. November.
- Otto, S. 2019. How to normalise the RMSE. Www.marinedatascience.co, January 7. https://www.marinedatascience.co/blog/2019/01/07/normalizing-the-rmse/.
- Pan, H., T. Su, X. Huang, and Z. Wang. 2021. “LSTM-based Soft Sensor Design for Oxygen Content of Flue gas in Coal-Fired Power Plant.” Transactions of the Institute of Measurement and Control 43 (1): 78–87. https://doi.org/10.1177/0142331220932390
- Patterson, M. G. 1996. “What is Energy Efficiency?: Concepts, Indicators and Methodological Issues.” Energy Policy 24 (5): 377–390. https://doi.org/10.1016/0301-4215(96)00017-1
- Pejić-Bach, M., and N. Cerpa. 2019. “Planning, Conducting and Communicating Systematic Literature Reviews.” Journal of Theoretical and Applied Electronic Commerce Research 14 (3): 1–4. https://doi.org/10.4067/S0718-18762019000300101
- Petrecca, G. 2014. “Energy Conversion and Management.” Cham, Switzerland, 101–103.
- Prashar, A. 2017. “Energy Efficiency Maturity (EEM) Assessment Framework for Energy-Intensive SMEs: Proposal and Evaluation.” Journal of Cleaner Production 166: 1187–1201. https://doi.org/10.1016/j.jclepro.2017.08.116
- Qi, J., J. Du, S. M. Siniscalchi, X. Ma, and C. H. Lee. 2020. “On Mean Absolute Error for Deep Neural Network Based Vector-to-Vector Regression.” IEEE Signal Processing Letters 27: 1485–1489. https://doi.org/10.1109/LSP.2020.3016837
- Rambalee, P., G. Gous, P. G. R. De Villiers, N. Mcculloch, and G. Humphries. 2011. Power Control: Advanced Process Control. Control Engineering, June 20. https://www.controleng.com/articles/power-control-advanced-process-control/
- Rosenblatt, F. 1958. “The Perceptron: A Probabilistic Model for Information Storage and Organisation in the Brain.” Psychological Review 65 (6): 386. https://doi.org/10.1037/h0042519
- Rossi, F., and D. Velázquez. 2015. “A Methodology for Energy Savings Verification in Industry with Application for a CHP (Combined Heat and Power) Plant.” Energy 89: 528–544. https://doi.org/10.1016/j.energy.2015.06.016
- Schulze, M., H. Nehler, M. Ottosson, and P. Thollander. 2016. “Energy Management in Industry–a Systematic Review of Previous Findings and an Integrative Conceptual Framework.” Journal of Cleaner Production 112: 3692–3708. https://doi.org/10.1016/j.jclepro.2015.06.060
- Shinde, P. P., and S. Shah. 2018. “A Review of Machine Learning and Deep Learning Applications.” In 2018 Fourth international conference on computing communication control and automation (ICCUBEA) (pp. 1–6). IEEE, August.
- Sleiti, A. K., J. S. Kapat, and L. Vesely. 2022. “Digital Twin in Energy Industry: Proposed Robust Digital Twin for Power Plant and Other Complex Capital-Intensive Large Engineering Systems.” Energy Reports 8: 3704–3726. https://doi.org/10.1016/j.egyr.2022.02.305
- Smrekar, J., M. Assadi, M. Fast, I. Kuštrin, S. De, 2009. “Development of Artificial Neural Network Model for a Coal-Fired Boiler Using Real Plant Data.” Energy 34 (2): 144–152.
- Sogabe, T., D. B. Malla, S. Takayama, S. Shin, K. Sakamoto, K. Yamaguchi, T. P. Singh, M. Sogabe, T. Hirata, and Y. Okada. 2018. Smart grid optimisation by deep reinforcement learning over discrete and continuous action space. In 2018 IEEE 7th World Conference on Photovoltaic Energy Conversion (WCPEC)(A Joint Conference of 45th IEEE PVSC, 28th PVSEC & 34th EU PVSEC) (pp. 3794-3796). IEEE, June.
- Song, M. L., L. Yang, J. Wu, and W. D. Lv. 2013. “Energy Saving in China: Analysis on the Energy Efficiency via Bootstrap-DEA Approach.” Energy Policy 57: 1–6. https://doi.org/10.1016/j.enpol.2012.11.001
- Variny, M., and M. Kšiňanová. 2022. “Repowering Industrial Combined Heat and Power Units: A Contribution to Cleaner Energy Production.” Polish Journal of Environmental Studies 31 (3): 2861–2879. https://doi.org/10.15244/pjoes/144096
- Virtualitics. 2021. Using Machine Learning in the Energy Sector. Blog.virtualitics.com, November 24. https://blog.virtualitics.com/using-machine-learning-in-the-energy-sector.
- Wahyuningtyas, D., and M. Asrol. 2022. “The Implementation of K-Means Clustering in Coal-Fired Power Plant Performance.” International Journal of Emerging Technology and Advanced Engineering 12 (3): 1–8. https://doi.org/10.46338/ijetae0322_01
- Wu, S. R., G. Shirkey, I. Celik, C. Shao, and J. Chen. 2022. “A Review on the Adoption of AI, BC, and IoT in Sustainability Research.” Sustainability 14 (13): 7851. https://doi.org/10.3390/su14137851
- Wuest, T., D. Weimer, C. Irgens, and K.-D. Thoben. 2016. “Machine Learning in Manufacturing: Advantages, Challenges, and Applications.” Production & Manufacturing Research, [Online] 4 (1): 23–45. https://doi.org/10.1080/21693277.2016.1192517.
- Yi, W. 2022. Understanding Gaussian Process, the Socratic Way. [online] Medium. https://towardsdatascience.com/understanding-gaussian-process-the-socratic-way-ba02369d804.
- Yu, W., P. Patros, B. Young, E. Klinac, and T. G. Walmsley. 2022. “Energy Digital Twin Technology for Industrial Energy Management: Classification, Challenges and Future.” Renewable and Sustainable Energy Reviews 161: 112407. https://doi.org/10.1016/j.rser.2022.112407
- Zima, W., J. Taler, S. Grądziel, M. Trojan, A. Cebula, P. Ocłoń, P. Dzierwa, et al. 2022. “Thermal Calculations of a Natural Circulation Power Boiler Operating Under a Wide Range of Loads.” Energy 261: 125357. https://doi.org/10.1016/j.energy.2022.125357
