
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
To ameliorate the precision of clothing image classification, we proposed a clothing image classification method via the DenseNet201 network based on transfer learning and the optimized regularized random vector functional link (RVFL). First, the formula extracts weight’s parameters about DenseNet201 that is pre-trained on the ImageNet dataset for transfer learning, thereby obtaining an incipient network,after that trim this model parameters. The modified network is utilized to pick up the clothing image features output by the DenseNet201’s global average pooling layer. Second, regularization coefficient is introduced to control RVFL’s model complexity and solve the problem of over-fitting. Then, the generated solution vector of aquila optimizer (AO) is produced by marine predators algorithm (MPA). The input weights, biases of hidden layer and renormalization modulus of regularized RVFL are optimized using the improved AO algorithm. Finally, we use the optimized RVFL to assort abstracted fashion graphics traits. We use Accuracy, Macro-F1, Macro-R and Macro-P to assess the algorithm’s ability and compare this algorithm with ResNet50 network, ResNet101 network, DenseNet201 network, InceptionV3 network and different classifiers, which use DenseNet201 as the feature extractor to get the input. From the experimental results, this algorithm proposed has excellent classification power and generalization ability.
摘要
为了提高服装图像分类的精度,我们提出了一种基于密集度的服装图像分类方法DenseNet 201网络基于转移学习和优化的正则化随机向量函数链路(RVFL). 首先,公式提取关于密集网201的权重参数,该参数在ImageNet数据集上预训练用于转移学习,从而获得初始网络,然后修剪该模型参数. 修改后的网络用于拾取由DenseNet201的全局平均池层输出的服装图像特征. 其次,引入正则化系数来控制RVFL的模型复杂度,解决过拟合问题。然后,通过海洋捕食者算法(MPA)生成aquila优化器(AO)生成的解向量. 利用改进的AO算法优化了正则化RVFL的输入权重、隐层偏差和重正化模量. 最后,我们使用优化的RVFL来分类抽象的时尚图形特征. 我们使用Accuracy、Macro-F1、Macro-R和Macro-P来评估算法的能力,并将该算法与ResNet50网络、ResNet101网络、Density Net 201网络、InceptionV3网络和不同的分类器进行比较,这些分类器使用Density Net201作为特征提取器来获取输入. 实验结果表明,该算法具有良好的分类能力和泛化能力.
Introduction
In the near future, the internet is developing rapidly, clothing images on the Internet have also exploded. Whether these clothing images can be accurately and effectively classified is closely related to the interests of clothing e-commerce practitioners. The traditional clothing image classification is mainly done manually, which not only requires high labor costs but also cannot meet the requirements of classification accuracy because manual detection is easily affected by many subjective and objective factors. So, it is necessary to research an excellent garment classification algorithm to improve the classification performance and reduce the classification cost.
To research on a garment classification algorithm with superior performance, we need to pay attention to two aspects, one is to efficiently extract the traits of fashion graphics, and the other is to effectively classify the extracted clothing graphic traits. The ways of abstracting the traits of clothing images will be classified to conventional feature extraction ways and deep learning-based feature extraction methods. The conventional clothing graphic feature extraction method essentially extracts the color feature or texture feature of the clothing image. Color features describe the surface properties of clothing images or the corresponding clothing. Commonly used color trait abstraction ways with pigment moment (Weng et al. Citation2013), pigment histogram (Liu, Wei, and López-Rubio Citation2020) and pigment correlation (Moon Citation2007). The texture feature of the clothing image is a value calculated from the clothing image, which reflects the texture of the clothing, such as roughness, granularity, randomness, and normality. The commonly used texture feature extraction methods are histogram of oriented gradient (HOG) (Marek and Wojcikowski Citation2016), gray-level co-occurrence matrix (GLCM) (Chandy, Johnson, and Selvan Citation2014), local binary pattern (LBP) (Zhao Citation2021) et al. These traditional clothing image feature extraction methods have high requirements on clothing images and are likely influenced by elements like the graphic’s degree of angle, background, and deformation of the clothing image, so that this abstracted fashion graphic traits are not satisfied.
As computer deep learning’s fast advancement, researchers use a large number of data sets to train convolutional neural networks, so that the convolutional neural network can continuously study the deep traits of fashion graphics during training process and accomplish the abstraction and classification of fashion image features. At present, many scholars have applied convolutional neural network to the research of fashion graphic classification algorithm and have also obtained nice outcomes. Tan et al (Tan et al. Citation2020) ameliorated a network named Xception network then used this network to the fashion graphic classification algorithm. They improved the network’s nonlinearity and learning characteristics and innovated the L2 regularization approach is used to strengthen the network’s anti-interference capacity, thereby improving the network’s capacity to classify fashion graphics. Liu et al (Liu, Zhong, and Wang Citation2018) applied convolutional neural networks to classify images of female’s fashion. Liu et al (Liu, Luo, and Dong Citation2019) put forward a hierarchic classification mold on account of convolutional neural network (CNN), they executed the CNN using the VGG network as the underlying framework and were validated on the Fashion-MNIST dataset. Wang et al (Di Citation2020) used and contrasted the full connection neural network’s power, MobileNet V2, CNN and MobileNet V1 on the dress dataset about Fashion-MNIST and proved good ability of MobileNet V2. Kayyed et al (Kayed, Anter, and Mohamed Citation2020) put forward a fashion graphic classification model on account of the LeNet-5 structure for this dataset about Fashion-MNIST, obtained nice outcomes in addition. Yu et al (Yu et al. Citation2021) put forward an augmented capsule network with graphic traits and space fabric traits to deal with the subject that conventional neural networks unable to get the space fabric traits of fashion graphics. The network obtains the space structure traits of fashion graphics by enhancing the capsule network, and makes the extracted clothing features more robust through attention mechanism and a deeper network fabric, and reduces the computational load of the network through parameter optimization.
To effectively classify clothing image features, it is particularly important to select a suitable classifier. Using a neural network as a classifier to classify clothing image features is a good choice, however its arguments’ selection holds a great influence on the classification performance of the neural network, so to use the neural network as a classifier, it is necessary to hit appropriate arguments to increase its classification ability, swarm intelligence optimization algorithm can be considered as neural network’s parameter optimization method. The swarm intelligence optimization algorithm is a method to obtain the optimal solution of a problem, which is inspired by a great deal of appearance or math formula theory in nature. for instance, gray wolf optimizer (GWO) (Panda and Das Citation2019) is aroused by the leadership hierarchy and hunting behavior of gray wolves in nature, salp swarm algorithm (SSA) (Abualigah et al. Citation2019) imitates the salp swarming behavior when foraging and navigating in the ocean, and ant lion optimizer (ALO) (Mirjalili Citation2015) is on account the ant lions’ hunting mechanism in nature. The principles of these swarm intelligence optimization algorithms are casual and do not depend on gradient message, so they work well in solving nonlinear problems. RVFL (Scardapane et al. Citation2015) is a casual and high efficiency neural network. It generates the network’s hidden layer bias and input weight randomly and obtains the output weight by least square calculation or pseudo-inverse, which effectively overcomes the traditional gradient learning algorithm. Different from the extreme learning machine proposed by Huang (Huang et al. Citation2012), RVFL exists a plain connection between the output and the input node. This structure causes the input node to exist a greater influence on the algorithm’s ability, and generally has better performance in prediction or classification. But it is precisely because RVFL stochastic produces the network’s hidden layer biases and input weights, its classification result is tumultuous. Some scholars have applied the combination of intelligent optimization algorithm and neural network to the research work of clothing image classification algorithm. Hazarika et al (Hazarika and Deepak Citation2022a) create a random vector function link formula named 1-norm RVFL (1N RVFL). Newton technique is used to solve the external dual penalty problem of 1N RVFL, and the solution of 1N RVFL optimization problem is obtained. Li et al (Li, Shi, and Yang Citation2021) utilized the dragonfly algorithm to optimize the online sequence extreme learning machine’s hidden layer offset and the import weight. The validity of the model is verified by classifying the Fashion-MNIST dataset. Hazarika et al (Hazarika and Deepak Citation2022c) proposed a novel random vector functional link with ε-insensitive Huber loss function (ε-HRVFL) for medicinal record classification issues. Zhou et al (Zhou et al. Citation2021) proposed a fashion graphic classification algorithm with the combination of RVFL and convolutional neural network. The algorithm first uses a parallel convolutional neural network (PCNN) to abstract clothing graphic traits, then obtains the optimized RVFL classifier by using the RVFL’s hidden layer biases and the input weights majorized by grasshopper optimization algorithm (GOA), and classify the extracted features. Malik et al (Malik et al. Citation2022) created an extended feature RVFL (efRVFL), which analyzes the original feature space to generate an extended feature space, and then trains on it. They propose a set, which is about the extended feature RVFL (efRVFL). Different efRVFL basic models are trained in different feature spaces, so diversified and more accurate models can be generated. Hazarika et al (Hazarika and Deepak Citation2022b) proposed a nonlinear RVFL for estimating the daily suspended sediment load. The maximum overlapping discrete wavelet transform (MODWT) with boundary correction is applied to the model, which is used for SSL pre.
The RVFL neural network has a simple composition. The RVFL’s training is completed by calculating the weight of the output layer. The RVFL’s training time is much less than that of the neural network which needs gradient descent means to renew the network arguments in the past, and RVFL has a high classification performance. However, it is assumed that the hidden layer offsets and input layer weights are produced stochastically, which will cause network instability.
Inspired by the above literature, we proposed a fashion graphic classification algorithm via Densent201 and regularized random vector functional link (RRVFL) improved by MPA-AO algorithm. Unlike references (Li, Shi, and Yang Citation2021; Liu and Yang Citation2021) and (Li, Shi, and Yang Citation2021), which only optimizes the input layer weight and hidden layer offset, our method also optimizes the regularization factor. Follows are the capital innovations of this algorithm:
We migrate and learn from DenseNet201 network, which is more efficient in feature propagation and feature utilization, fine tune the model parameters, and then use its global average pooling layer to extract clothing image features.
We introduce regularization factor into RVFL to improve the generalization ability of RVFL and avoid overfitting. We use MPA algorithm to generate the initial search agent of AO algorithm, and use the optimized AO algorithm to improve the hidden layer deviation, input weight and regularization coefficient of RRVFL.
This RRVFL improved by the MPA-AO algorithm is applied to sort the extracted clothing image traits. This algorithm not only fully utilizes the function of convolutional neural network to voluntarily abstract clothing image traits, but also utilizes the optimized regularization RVFL to ameliorate the features classification’ accuracy.
Theoretical basis
DenseNet201 structure
DenseNet201, as a convolutional neural network with deeper layers, reduces the disappearance of gradients, improves the efficiency of feature propagation and feature utilization, and reduces the number of parameters of the network. The DenseNet201 network structure directly connects all layers, making the most complete transmission between layers can be achieved. The sub-modules of the DenseNet201 network are mainly dense block and transition layer, and the construction is displayed in .
Figure 1. Structure of dense block and transition layer.
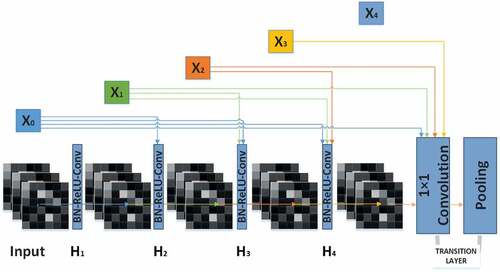
According to the DenseNet201 network structure, if it has layers in the DenseNet201 network, then there will be
connections. Each layer’s input derives from all the previous layers’ output. In ,
represents the import of the entire convolutional neural network. The input to
is
, the input to
is
and
, and so on. Therefore, compared with other traditional convolutional neural networks such as ResNet networks, which rely on the features output from the last layer of the network, DenseNet201 can fuse and utilize more low-level features, thereby improving the efficiency of feature propagation and feature utilization.
Regularized random vector functional link
As a type of single-hidden layer neural network, RVFL combines the hidden layer and the input layer to jointly influence the output layer. For a sample dataset with N inputs, the -th sample’s input is
, and the
-th sample’s output is
. The RVFL network, which hidden layer nodes is
can be represented by the following formula:
Among them, is the activation function,
is the input weight,
represents the hidden layer enhancement node’s bias, and
represents the outcome weight.
and
are commonly defined stochastically. EquationEquation (1)
(1)
(1) could be facilitated into a array and shown as:
Among them, represents the hidden layer enhancement node’s output,
represents the output weight, and
represents the output result, which is expanded as follows:
Contrasted with the conventional RVFL network, the regularized RVFL can better the network’s normalization capacity and can effectively prevent the overfitting problem of the model. A common practice is to find the minimum training error and output weights:
where the output error ,
is the regularization factor, which is used to trade off the effect between training error and model complexity. In order to find the minimum value of
, the closed-form solution of
can be obtained by fitting the grad of RVFL with respect to
to zero:
where, is an identity matrix of dimension
.
Aquila optimizer
AO [24] is a population-based optimization algorithm aroused by the deed of Skyhawks in capturing prey. There are four methods for the optimization process of the algorithm. The first search method is extended exploration, using high-altitude diving and vertical diving to search the space. First, Skyhawk searches for the best hunting area through high-altitude diving and vertical diving. The mathematical expression formula is:
where represents the solution for
loops emerged by the first hunt approach
.
represents the optimum key for
iterations, reflecting the approximate location of the prey.
is to dominate the expansion enquiry through the iterations’ number.
is the mean location of the immediate solution connected at the
-th loop,
is a stochastic figure in [0,1], and
and
represent the immediate and maximum loops.
here, represents the problem’s dimension and
represents the candidate solutions’ number.
The second step is to narrow the scope of exploration, that is, to explore in the divergent search space through the contour short-slip attack. The mathematical formula is shown as formula (10).
represents the key for t + 1 loops, which is produced by the second hunt step C.
is the dimensional space, and
represents the function of levy flight.
is a random solution of range
after t-th iterations.
The third step is to expand the development, that is, to explore within the convergent search space through a low-speed descent attack. The mathematical formula is expressed as shown in the following formula (11).
where represents the key for t + 1 iterations obtained by the third hunt approach,
and
are development tuning arguments fasten at 0.1,
represents the minimum limit of the given matter, and
is the maximum limit of the given problem.
The fourth step is to narrow the range, that is, to grab the prey by walking and diving, and its mathematical formula is shown in (12):
where represents the key for t + 1 iterations obtained by the fourth hunt approach.
is the quality function, which is applied to equipoise the hunt policy.
is the various motion of the AO tracing the quarry during the exploration period,
represents a dropping figure from 2 to 0, representing the flight slope of the AO tracking the quarry from the first location to the t-th location during the exploration period,
represents the immediate solution for t iterations.
Marine predators algorithm
MPA [25] is a novel metaheuristic optimization algorithm aroused by the predation strategies of predators in nature. The algorithm considers top predators to have the greatest search skills. The algorithm has a cream array and a quarry array, and the top predators constitute the elite matrix. The algorithm has three stages in the optimization process. The first phase is applied for the global hunt of the solution room. The second stage is to conduct local search around the best position after determining the best position, and the third stage is used to perform a local hunt for the best solution position at the moment in the solution room. And the algorithm can avoid falling into the local optimal trap as much as possible, so as to achieve better classification performance.
Clothing image classification network model
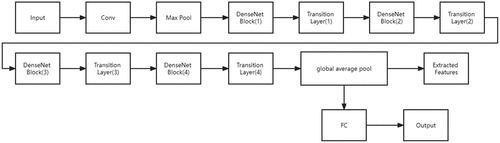
Since the DenseNet201 network structure can improve the efficiency of feature propagation and utilization, this paper selects the DenseNet201network as the feature extractor. First, we extract the weight arguments of the DenseNet201 pre-trained on the ImageNet dataset for transfer learning, after that train the incipient model obtained after transfer learning and fine-tune its parameters. Then extract the features of the output of its global average pooling layer, so that the feature extraction work for the clothing image dataset is completed. The network fabric of the DenseNet201 trait abstraction backbone is revealed in .
Figure 2. The structure of the Densenet201 feature extraction backbone.
The RVFL’s hidden layer offset and import weights are stochastic assigned and do not involve to be reset, while the output weights can be calculated analytically via an ordinary generalized inverse operation. So, when dealing with multi-classification problems, randomness greatly affects RVFL’s power. performance, and resulting lower precision, easy to fall into local optimum or overfitting and other hidden dangers. Considering the above problems, we first usher the regularization factor to solve the output weight of RVFL and solve the turbulence of the inverse matter on minimizing this error function, so as to control the model complexity of RVFL and resolve the matter of overfitting. After that, we use the MPA optimization algorithm to supply a group of suitable originating search agent for the AO algorithm to improve the influence of the initial population on the optimization and convergence effects of the AO algorithm. Finally, we use the AO algorithm improved by the MPA algorithm to ameliorate this hidden layer offset, input weights and regularization coefficients of the regularized RVFL to improve the stability and accuracy of its classification. Finally, the MARRVFL classifier model put forward in this paper is obtained.
The DFEB-MARRVFL clothing image classification algorithm put forward in this paper is obtained by combining the Densent201 feature extraction backbone (DFEB)and the MARRVFL classifier. is a flowchart of the algorithm.
Figure 3. Flowchart of the DFEB-MARRVFL algorithm.
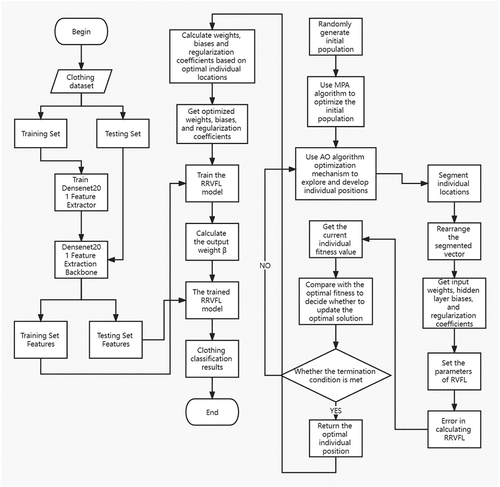
As shown in , DFEB-MARRVFL is mainly classified into three parts. The first part is the backbone of DenseNet201 feature extraction, which is mainly responsible for abstracting the traits of fashion graphic datasets. We divide the dataset into testing set and training set proportionally, use the training set to drill the DenseNet201feature extractor, and then use the trained trait extractor to abstract the test set’s traits, thus completing the first step of trait extraction. The second part is the MPA-AO optimization algorithm. The task of this part is to improve the hidden layer biases, input weights, and regularization coefficients of RRVFL to improve the instability of RRVFL caused by randomly generating parameters and improve RRVFL classification performance. First, we use the MPA algorithm to supply a group of suitable incipient search agent for the AO algorithm, so as to weaken the influence of the random generation of the incipient search agent on the optimization and convergence ability of the AO algorithm, and then use the optimization mechanism of the AO algorithm to affect the individuals in the population. The position is explored and developed, and the hidden layer bias input weight, regularization coefficient, and input weight of RRVFL are obtained by segmenting and rearranging the individual position, and the classification error of RRVFL is obtained as the fitness of the individual. The optimal fitness is compared to decide whether to update the optimal solution. If the algorithm does not reach the maximum number of iterations, it will continue to explore and develop, and if the most figure of loops is achieved, it will revert to the position of the optimal individual. The third part is the RRVFL classifier, the task of this part is to classify the features of the extracted clothing image dataset. First, we segment and rearrange the position of the optimal individual returned by the MPA-AO optimization algorithm to obtain the RRVFL’s hidden layer bias, the input weight, and regularization coefficient and use the extracted training set features to train RRVFL and calculate its output weight. Then, we use the classification function of RRVFL, the testing set features and the obtained output weights and input weights to calculate the test set features’ output. Finally, we compare the output matrix of the obtained testing set features with its real label matrix. If the outcome is not same as the tag, it is considered as a classification mistake. Finally, the figure of correctly classified samples is split by the figure of test set specimen to obtain the testing set classification degree of accuracy. shows the processing from the individual positions of the population to the RRVFL parameters.
Figure 4. Processing of individual locations to RRVFL parameters.
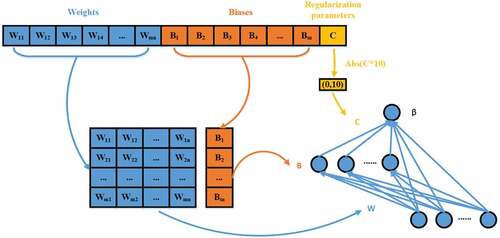
The position of the individual in the optimization algorithm is a row vector whose dimension is (hidden layer node×(input layer node+1)+1). In , is the RRVFL’s hidden layer nodes number, and
is the figure of hidden layer nodes of RRVFL. The figure of input layer nodes,
is the RRVFL’s input weight,
is the RRVFL’s hidden layer bias,
is the regularization factor of RRVFL,
is RRVFL’s output weight. As shown in , the first
particles at the individual position are divided into the input weight of RRVFL, and the matrix of
can be used as the input weight of RRVFL by rearranging it, and the next
particles are divided into the hidden layer partial weight of RRVFL. rearrange it into the column vector of
, which can be used as the RRVFL’s hidden layer bias, and the last remaining particle is the RRVFL’s regularization factor. Since the scope of particles is between [−1, 1], so use
to map the regularization factors to the (0,10) interval. RRVFL’s output weight
can be computed by processing the input weight of the RRVFL obtained by the individual position, the regularization factor and the hidden layer bias.
Experimental results and analysis
Experiment circumstances
The experimental system in this paper is windows10, the CPU processor of the experimental equipment is intel(R) Xeon(R) Bronze 3106, the memory is 64GB, and the GPU processor is NVIDIA GeForce RTX 2080Ti. The editing software is MATLAB 2018b.
Dataset selection
This paper uses the ACWS dataset, it was first proposed in the paper [22]. Pictures in the dataset are closely related to our lives. The dataset consists of 15 kinds of pictures such as Shorts, Top, Sweater, and Dress. This data set is used to prove the excellent performance of the model put forward in this paper. However, due to the large data set, full use will greatly increase the time and calculation cost. This paper selects 10 categories from them, namely Sweater, Shorts, Jumpsuit, Tee, Jacket, Skirt, Jeans, Dress, Blouse and Coat, of which 1000 images are selected for every class, and 10,000 fashion graphics are chosen regard as the test data set to verify the algorithm obtains the classification ability of fashion graphics, and divides the data set according to 7:3, that is, 7000 images are applied que the train set and 3000 images are applied que the testing set. presents an example of the categories of the ACWS dataset which is chosen by us.
Figure 5. Examples of ACWS dataset categories.

To prove the availability and generalization of the model, we also use the Fashion-MINIST dataset, which has 10 classes of graphics, namely: pullover, dress, shirt, sandal, ankle boot, sneaker, bag, coat, trouser, and t-shirt. The train dataset includes 6000 specimen per class, and the testing dataset contains 1000 specimens per class, so the train dataset owns 60,000 specimens and the testing dataset has 10,000 specimens. reveals a partial the Fashion-MNIST dataset’s case.
Figure 6. Example of Fashion-MNIST dataset.

Algorithm parameter settings
To achieve more excellent performance of the model, the selection of model parameters is particularly important. In this paper, ablation experiments are carried out for each parameter of the DFEB-MARRVFL algorithm, by using selected partial ACWS datasets to study the classification performance of the algorithm under different parameter values to select the most suitable parameters for subsequent experiments.
The effect of the activation function of RVFL
First of all, we need to research the influence of various activation functions of RVFL on the performance of the algorithm. In this paper, five activation functions are selected for ablation experiments, namely radbas function, tribas function, hardlim function, sine function and sigmoid function. 10 experiments were carried out under each activation function, and the average classification accuracy was taken for comparison. shows the experimental outcomes of the put forward model in this paper under every activation function. The 1 to 10 time represent the operation results of the 1st to 10th times, respectively. shows that if the activation function is the sigmoid function, the classification accuracy of the algorithm is very stable and its mean classification accuracy is the best. When we use the hardlim function as the activation function, the classification accuracy of the algorithm fluctuates slightly, and its average classification accuracy is slightly worse than the sigmoid function. When we use sine as the activation function, tribas and radbas, the algorithm fluctuates greatly, and the classification accuracy fluctuates around 10%–80%, which is very unstable, and the average classification accuracy is significantly poorer than that of the sigmoid function and the hardlim function. Therefore, we select the sigmoid function for RVFL for subsequent experiments.
Table 1. Classification results of the algorithm under different activation functions.
Effect of hidden layer nodes of RVFL on the model
As RVFL is a single hidden layer neural network, it is particularly important to choose the optimum hidden layer nodes’ figure to improve its classification performance. When the figure of selected nodes is too low, the classification performance may not meet the requirements. When the figure of chosen nodes is too strong, it will not only increase the amount of calculation but also overfitting risk. In this paper, 20 groups of hidden layer nodes of RVFL are selected for experiments. This hidden layer nodes’ quantity is in a range of [10, 200]. 10 points are added in each experiment, and under the value of each hidden layer nodes, 10 experiments were carried out to calculate the average classification accuracy to research the effect of hidden layer nodes’ figure on the performance of the model. The experimental outcomes are revealed in . The 1 to 10 T represent the operation results of the 1st to 10th times, respectively. Seen from that if the figure of hidden layer nodes is in the interval [10, 140], with the increase of hidden layer nodes’ figure, the classification ability of the model gradually increases, which means that in this interval, with the hidden layer nodes’ number increases, it will effectively ameliorate the classification the algorithm’s power. However, when the hidden layer nodes’ figure is in the interval [150–200], there is an overfitting phenomenon. The increase of hidden layer nodes’ figure does not improve the classification ability of the model. On the contrary, it decreases. Therefore, we select hidden layer nodes’ number as 140 for subsequent experiments.
Table 2. Classification results of the algorithm under different hidden layer nodes.
Influence of parameters of MPA-AO optimization algorithm on the proposed algorithm
The population size (search agent) and the maximum quantity of loops of MPA-AO algorithm will affect its optimization ability similarly. For studying these two parameters’ effect on the algorithm’s performance, this paper will conduct a combined experiment with these two parameters. Among them, the population size is selected 10 values: 5, 10, 15, 20, 25, 30, 35, 40, 45, 50. Select 10 values for the maximum number of iterations: 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, and combine the population number and the maximal quantity of loops for subsequent experimentation. The test outcomes are revealed in . intuitively reveals the change of the breakdown of the algorithm’s accuracy with the change of the search agent and the quantity of loops. It could be learned through the experimental results that if the quantity of loops is less, the algorithm’s classification accuracy is piecemeal wrong for the optimization algorithm doesn’t converge at this time. And when a high quantity of iterations, because the optimization algorithm has converged, so the accuracy is also relatively higher. The biggest difference between low iteration and high iteration is whether the algorithm can converge. If the quantity of loops is too less, the algorithm cannot converge. If the number of iterations is too high, the algorithm has already converged, and continuing the iteration will only waste resources. If the quantity of populations is 15 and the quantity of loops is 80, the classification accuracy of the algorithm reaches the optimum level. Subsequent increases in the quantity of search agent and the maximal quantity of loops does not effectively ameliorate the algorithm’s classification property, and increases the amount of computation and consumes more computing resources. Therefore, this paper selects the population number of MPA-AO optimization algorithm as 15, and the maximal quantity of loops as 80 for following experiments.
Figure 7. Classification accuracy of DFEB-MARRVFL under different search agents and maximum number of iterations.
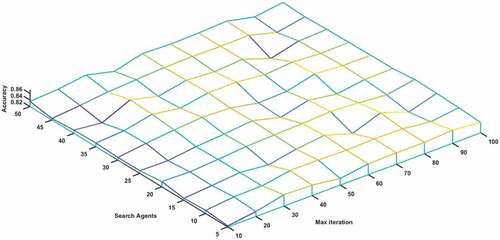
Table 3. Influence of population number and maximum number of iterations of MPA-AO algorithm on performance of the algorithm.
Experimental results and analysis
To bring the model’s results much convincing, this paper uses four evaluation indicators, Macro-P, Macro-R, Accuracy and Macro-F1, for assessing the algorithm’s power in this paper. Moreover, each algorithm in the subsequent experiments was run ten times to get the average figure to compare the experimental results. shows the settings of the final parameters of the algorithm.
Table 4. Settings of the final parameters of the algorithm.
To prove the improvement of the model’s classification ability in the paper contrasted with the traditional convolutional neural network, we selected the ResNet50 network, ResNet101 network, DenseNet201 network and InceptionV3 network based on transfer learning qua the targets of the distinction experiment. These networks are all obtained by performing transfer learning on the weight arguments of the network trimmed on the ImageNet dataset and fine-tuning its parameters. We compare every network model’s evaluation indicator and the algorithm in this paper, as shown in , and give the corresponding confusion matrix, as revealed in . See the experiment data, we can see that the evaluation indicators of ResNet50, ResNet101, and InceptionV3 are lower than the DFEB-MARRVFL algorithm proposed in this paper, and even lower than the DenseNet201 network structure, which verifies the traditional convolutional neural network mentioned above rely on the trait outcome by the last layer of the network. The DenseNet201 network structure can integrate and utilize more low-level features, thereby improving the efficiency of feature propagation and feature utilization. The evaluation indicators of the DFEB-MARRVFL algorithm are 14%–15% higher than DenseNet201, which proves the excellent classification performance of the MARRVFL classifier.
Figure 8. Confusion matrix for Resnet50, Resnet101, Densenet201, Inception V3 and DFEB-MARRVFL algorithms.

Table 5. Evaluation metrics of Resnet50, Resnet101, Densenet201, Inception V3 and DFEB-MARRVFL algorithms.
For improve the classification performance of the put forward DFEB-MARRVFL model and MARRVFL classifier additionally, we use different classifiers (RVFL, RRVFL, GWORRVFL, ALORRVFL, SSARRVFL, MPARRVFL, AORRVFL, AARRVFL, SARRVFL, GARRVFL) to classify the features extracted from the DFEB structure and compare the assessment indicators of every algorithm. The experiment result is revealed in . See this Table, we could know the property of using the primitive RVFL as the classifier is the lowest, and the performance of the RRVFL classifier that introduces the regularization mechanism to the RVFL owns a definite amelioration contrasted with the original RVFL. However, since it does not resolve the issue of randomly emanating hidden layer biases and import weights, its classification performance still falls short of the requirements. In the RRVFL classifier optimized by a single optimization algorithm, the GWO algorithm, ALO algorithm, SSA algorithm and MPA algorithm are not as good as the AO algorithm in their ability to ameliorate the arguments of RRVFL. Subsequently, we choose the GWO algorithm, ALO algorithm, SSA algorithm and MPA algorithm to supply the initial search agent for the AO algorithm and apply this optimized AO algorithm to improve the RRVFL’s arguments to get the corresponding GARRVFL, ALORRVFL, SARRVFL and MARRVFL classifiers. The experimental results show that the MARRVFL classifier performs the best. This fully demonstrates the excellent classification power of the MARRVFL classifier proposed in this paper.
Table 6. Evaluation metrics for DFEB-RVFL, DFEB-RRVFL, DFEB-GWORRVFL, DFEB-ALORRVFL, DFEB-SSARVFL, DFEB-MPARRVFL, DFEB-AORRVFL, DFEB-AARRVFL, DFEB-SARRVFL, DFEB-GARRVFL and DFEB-MARRVFL algorithms.
Analysis of stability and parameter optimization convergence
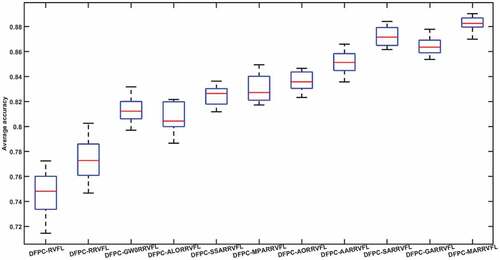
To prove the algorithm’s stability proposed by us, the model we proposed is contrasted with DFEB-RVFL, DFEB-RRVFL, DFEB-GWORRVFL, DFEB-ALORRVFL, DFEB-SSARVFL, DFEB-MPARRVFL, DFEB-AORRVFL, DFEB-AARRVFL, DFEB-SARRVFL and the DFEB-GARRVF algorithm. Each algorithm runs ten times, and a box plot is painted on the basis of the experimental results, revealed in . The line which color is red represents the data’s middle value. If this red line is lofty in the graph, the classification accuracy of this algorithm is higher. The blue box’s extent is the data’s scatter space. The less the distance between the quantiles, the more concentrated the position of the obtained classification outcomes, that is, the more stable the algorithm’s classification ability is. According to the experiment outcomes, the stabilization of the DFEB-RVFL and DFEB-RRVFL algorithms that are not improved through the optimization algorithm is the worst, because the problem of randomly generating hidden layer biases and input weights has not been solved. The stability of other algorithms that use optimization algorithms to optimize the parameters of RRVFL is improved compared with the first two. The DFEB-MARRVFL put forward by us has the smallest box and the best classification accuracy, which just proves its good stability and classification performance.
Figure 9. Box shapes for DFEB-RVFL, DFEB-RRVFL, DFEB-GWORRVFL, DFEB-ALORRVFL, DFEB-SSARVFL, DFEB-MPARRVFL, DFEB-AORRVFL, DFEB-AARRVFL, DFEB-SARRVFL, DFEB-GARRVFL and DFEB-MARRVFL algorithms picture.
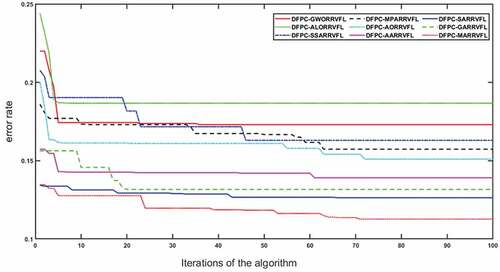
In order to evaluate the convergence speed and convergence the algorithm’s impression in parameter optimization, the algorithm proposed by us is contrasted with DFEB-GWORRVFL, DFEB-ALORRVFL, DFEB-SSARRVFL, DFEB-MPARRVFL, DFEB-AORRVFL, DFEB-AARRVFL, DFEB-SARRVFL and DFEB-GARRVFL algorithm, and the optimization and every algorithm’s convergence curves are drawn through the experiment outcomes. The experimental results are revealed in . It can be seen from the that DFEB-ALORRVFL converges quickly when optimizing parameters, and the convergence effect is very poor, mainly because it falls into a local optimal solution. Compared with other algorithms that use a single optimization algorithm for optimization, the DFEB-AORRVFL algorithm has the best convergence effect, followed by DFEB-MPARRVFL. The DFEB-MARRVFL put forward by us has the best convergence effect among the 9 algorithms, which indicates that the MPA-AO algorithm could better improve the input weights, hidden layer biases, and regularization coefficients of RRVFL.
Figure 10. Convergence curves of DFEB-GWORRVFL, DFEB-ALORRVFL, DFEB-SSARVFL, DFEB-MPARRVFL, DFEB-AORRVFL, DFEB-AARRVFL, DFEB-SARRVFL, DFEB-GARRVFL and DFEB-MARRVFL algorithms.
Algorithm effectiveness and generalization analysis
In the experiments in this chapter, we contrast the put forward algorithm with the GLCM-RVFL, LBP-HOG-SVM and InceptionV3-SRC algorithms, and we use the Fashion-MNIST dataset on the proposed algorithm and PCNN-GOARVFL proposed by Zhou [21] to prove the availability and generalization ability of our put forward algorithm. show the results of the experiments. It can be known from that these algorithms’ evaluation indicators using conventional trait abstraction approaches such as HOG, LBP and GLCM cannot meet the requirements, mainly because these feature extraction methods could merely abstract low-level traits of clothing graphics, which results the poor classification ability of the model. In contrast, the InceptionV3-SRC method using the InceptionV3 convolutional neural network to extract features has improved performance compared to the first two, but it is still 12–13% points poorer than the DFEB-MARRVFL model put forward by us. reveals the algorithm’s evaluation indicators put forward in this paper and the PCNN-GOARVFL algorithm on the Fashion-MNIST data set. It can be known from that the algorithm’s evaluation indicators proposed in this paper are 3–5% points better than the PCNN-GOARVFL algorithm, which indicating that it can effectively classify the Fashion-MNIST dataset, which proves the good generalization ability of the algorithm.
Table 7. Evaluation metrics for GLCM-RVFL, LBP-HOG-SVM, INCEPTIONV3-SRC and DFEB-MARRVFL algorithms.
Table 8. Evaluation metrics for PCNN-GOARVFL and DFEB-MARRVFL algorithms.
Conclusion
This paper proposed a fashion graphic classification algorithm with DenseNet201 network and improved regularized RVFL direction, we can draw the following conclusions:
The Densent201 trait extraction backbone based on transfer learning can better extract the traits of fashion graphics, improve the efficiency of feature propagation and utilization, and thus improve the classification ability of the algorithm for fashion graphics.
Innovating a regularization mechanism to RVFL can ameliorate the generalization capacity of the algorithm and improve the classification accuracy of RVFL. And compared with other optimization algorithms, the MPA algorithm is applied to provide the incipient search agent for the AO algorithm, and the RRVFL classifier optimized by the improved AO algorithm could attain a better convergence result in the process of optimizing the parameters, and improve the performance of the RRVFL classifier. The stability and classification performance of the algorithm are improved, and the issue of low and turbulent classification ability caused by RVFL stochastically arising hidden layer biases and import weights is resolved.
The DFEB-MARRVFL model put forward in this paper can improve the clothing image classification algorithm’s accuracy with effect. It owns excellent generalization capability, and the performance of the algorithm is more excellent than else fashion graphic classification algorithms.
Although the classification accuracy of DenseNet201 neural network is high, its huge number of parameters makes it impossible to ignore the delay in practical application. Next, we will look for and build a better neural network, so that we can have better classification performance while reducing model parameters.
Highlights
We extract the weight parameters of the Densenet201 network pre-trained on the ImageNet dataset for transfer learning, to obtain the initial network model and fine-tune the model parameters. The fine-tuned network model is then used as a feature extractor to extract the clothing image features output by the global average pooling layer of the Densenet201 network.
Aiming at the problem of low classification performance and instability of RVFL, we propose to introduce a regularization coefficient into the traditional RVFL, and solve the ill-posedness of the inverse problem by constraining the minimization of the empirical error function, which improves the generalization ability of RVFL and avoids overfitting. Then use the MPA optimization algorithm to provide a set of suitable initial populations for the AO algorithm, and use the optimized AO algorithm to optimize the input weights, hidden layer biases, and regularization coefficients of RRVFL, thus solving the problem of low classification performance and instability caused by RVFL randomly generating input weights and hidden layer biases.
The RRVFL optimized by the MPA-AO algorithm is used to classify the extracted clothing image features.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Abualigah, L., M. Shehab, M. Alshinwan, and H. Alabool. 2019. Salp swarm algorithm: A comprehensive survey. Neural Computing & Applications 32 (15):11195–20. doi:10.1007/s00521-019-04629-4.
- Chandy, D. A., J. S. Johnson, and S. E. Selvan. 2014. Texture feature extraction using gray level statistical matrix for content-based mammogram retrieval. Multimedia Tools and Applications 72 (2):2011–24. doi:10.1007/s11042-013-1511-z.
- Di, W. 2020. A comparative research on clothing images classification based on neural network models. Proceedings of 2020 IEEE 2nd International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Weihai, China, 495–99.
- Hazarika, B. B., and G. Deepak. 2022a. 1-Norm random vector functional link networks for classification problems. Complex & Intelligent Systems 8 (4):3505–21. doi:10.1007/s40747-022-00668-y.
- Hazarika, B. B., and G. Deepak. 2022b. Modwt—random vector functional link for river-suspended sediment load prediction. Arabian Journal of Geosciences 15 (10):1–14. doi:10.1007/s12517-022-10150-1.
- Hazarika, B. B., and G. Deepak. 2022c. Random vector functional link with ε-insensitive Huber loss function for biomedical data classification. Computer Methods and Programs in Biomedicine 215:106622. doi:10.1016/j.cmpb.2022.106622.
- Huang, G. B., H. M. Zhou, X. J. Ding, and R. Zhang. 2012. Extreme learning machine for regression and multiclass classification. Neurocomputing 70 (2):513–29. doi:10.1109/tsmcb.2011.2168604.
- Kayed, M., A. Anter, and H. Mohamed. 2020. Classification of garments from fashion MNIST dataset using CNN LeNet-5 architecture. Proceedings of 2020 International Conference on Innovative Trends in Communication and Computer Engineering (ITCE), Aswan, Egypt, 238–43.
- Li, J. Q., W. M. Shi, and H. D. Yang. 2021. Clothing image classification with a dragonfly algorithm optimized online sequential extreme learning machine. Fibres & Textiles in Eastern Europe 29 (3):90–95. doi:10.5604/01.3001.0014.7793.
- Li, J., W. Shi, and D. Yang. 2021. Color difference classification of dyed fabrics via a kernel extreme learning machine based on an im-proved grasshopper optimization algorithm. Color Research & Application 46 (2):388–401. doi:10.1002/col.22581.
- Li, J., W. Shi, and D. Yang. 2021. Fabric wrinkle evaluation model with regularized extreme learning machine based on improved Harris Hawks optimization. The Journal of the Textile Institute 113 (2):199–211. doi:10.1080/00405000.2020.1868672.
- Liu, Y. J., G. F. Luo, and F. Dong. 2019. Convolutional network model using hierarchical prediction and its application in clothing image classification. Proceedings of 2019 3rd International Conference on Data Science and Business Analytics (ICDSBA 2019), Istanbul, Turkey.
- Liu, G. H., Z. Wei, and E. López-Rubio. 2020. Image retrieval using the fused perceptual color histogram. Computational Intelligence and Neuroscience 2020 (9):1–10. doi:10.1155/2020/8876480.
- Liu, X. Q., and D. H. Yang. 2021. Color constancy computation for dyed fabrics via improved marine predators algorithm optimized random vector functional-link network. Color Research and Application 46 (5):1066–78. doi:10.1002/col.22653.
- Liu, Q. Q., Y. Q. Zhong, and X. Wang. 2018. Female apparel classification based on convolutional neural network. 11th International Symposium of Textile Bioengineering and Informatics (TBIS) 11 (4):575–81. doi:10.3993/jfbim00319.
- Malik, A. K., M. A. Ganaie, M. Tanveer, and P. N. Suganthan. 2022. Extended features based random vector functional link network for classification problem. IEEE Transactions on Computational Social Systems. doi:10.1109/TCSS.2022.3187461.
- Mirjalili, S. 2015. The ant lion optimizer. Advances in Engineering Software 83:80–98. doi:10.1016/j.advengsoft.2015.01.010.
- Moon, Y. S. 2007. Image retrieval using spatial color correlation and texture characteristics based on local fourier transform. Signal Processing 44 (1):10–16.
- Panda, M., and B. Das. 2019. Grey wolf optimizer and its applications: A survey. Proceedings of The Third International Conference on Microelectronics, Computing and Communication Systems, Jharkhand, India, 556:179–94.
- Scardapane, S., D. H. Wang, M. Panella, and A. Uncini. 2015. Distributed learning for random vector functional-link networks. Information Sciences 301:271–84. doi:10.1016/j.ins.2015.01.007.
- Tan, Z. Y., Y. P. Hu, D. J. Luo, M. Hu, and K. H. Liu. 2020. The clothing image classification algorithm based on the improved Xception model. International Journal of Computational Science and Engineering 23 (3):214–23. doi:10.1504/IJCSE.2020.111426.
- Weng, T. F., Y. L. Yuan, L. Shen, and Y. Zhao. 2013. Clothing image retrieval using color moment. 3rd International Conference on Computer Science and Network Technology (ICCSNT) 1016–20. doi:10.1109/ICCSNT.2013.6967276.
- Wojcikowski, M. 2016. Histogram of oriented gradients with cell average brightness for human detection. Metrology and Measurement Systems 23 (1):27–36. doi:10.1515/mms-2016-0012.
- Yu, F., C. H. Du, A. L. Hua, M. H. Jiang, X. Wei, T. Peng, and X. R. Hu. 2021. EnCaps: Clothing image classification based on enhanced capsule network. Applied Sciences-Basel 11 (22):11024. doi:10.3390/app112211024.
- Zhao, Q. 2021. Research on the application of local binary patterns based on color distance in image classification. Multimedia Tools and Applications 80 (18):27279–98. doi:10.1007/s11042-021-10996-9.
- Zhou, Z. Y., W. X. Deng, Y. M. Wang, and Z. F. Zhu. 2021. Classification of clothing images based on a parallel convolutional neural network and random vector functional link optimized by the grasshopper optimization algorithm. Textile Research Journal 92 (9–10):1415–28. doi:10.1177/00405175211059207.