
Abstract
In this paper we examine the fundamental issues associated with the cycling of data assimilation and prediction in the case where observations are received after a delay, but we seek to assimilate them immediately on receipt, or within a short time of receipt. We obtain the optimal solution to this problem in the linear and non-linear cases, and explore its relation to simplified strategies which are adaptations of contemporary methods for large-scale data assimilation. We also discuss the challenges facing such cycling in large-scale numerical weather prediction.
Keywords:
1. Introduction
In the traditional cycling of forecasts and data assimilation (DA) for numerical weather prediction, the DA step for the global model has occurred every 6 or 12 hours. This was appropriate for an era when data was concentrated at the main synoptic times, and the limited area models (LAMs) for which the global model provides boundary conditions were cycled every 6 hours. However, in recent years data has become dominated by sources which are essentially continuous in time, and centres such as the Met Office will soon cycle their highest resolution LAM every hour.
By increasing the frequency of global analyses (e.g. to every hour) global forecasts can be based on more recent data, which is not only desirable in itself but provides timely lateral boundary conditions (LBCs) for high resolution LAMs. In one study of the Met Office’s 1.5 km LAM covering the British Isles (Tang et al., Citation2013) it was found that replacing 3-hour and 6-hour old LBCs by 3-hour and fresh LBCs improved the UK index (a basket of scores measuring forecast skill) by 1.5% (Bruce Macpherson, pers comm). Furthermore, by having more frequent analyses the analysis increments will be smaller, which will improve the validity of the linear approximations in DA schemes. More frequent analyses may also improve the affordability of DA methods as the computational load is distributed more evenly in time.
We will see that, because of the delay in receiving some data, to ensure that all the data which are received are also assimilated, the assimilation windows will need to overlap. We obtain the optimal solution to this problem, which involves manipulating simultaneously all the states in the window and their joint errors. We explore the relation between the optimal solution and simplified methods which are closer to current methods for large-scale DA.
We show that the current use of largely climatological prior error covariances may pose a challenge for high frequency cycling, and discuss how this may be overcome.
2. ‘Traditional’ vs. ‘Rapid Update’ cycling
An immediate issue is that observations are not received instantaneously. For example, by 09Z on 18 June 2015 the Met Office had received over 80 million observations valid between 09Z on 15 June and 03Z on 18 June 2015, including around 0.8 million surface, 2.1 million aircraft and sonde, 12.4 million satwind and 14 million ATOVS observations. The delay between validity time and receipt for these observation types is recorded in Fig. . We see that to receive 95% of aircraft and sonde, surface, ATOVS and satwind observation took respectively 0.6, 1.5, 3.4 and 4.1 hours.
Figure 1. Delay in receiving various observation types in the Met Office observation processing system, for observations valid between 9Z on 15 June 2015 and 3Z on 18 June 2015.
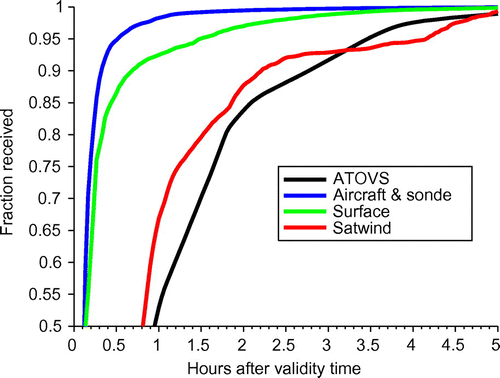
This presents a quandary for traditional cycling which aims to produce an analysis every 6 (at some centres every 12) hours. For definiteness consider 4D-Var (e.g. Li and Navon, Citation2001) with a 6-hour window [T-3,T+3], which generates an analysis at T-3 (in this discussion the units are hours).
One could perform the analysis at T+3 using all observations available by T+3, which would minimise the time delay to produce the analysis, but observations received after T+3 would not be assimilated. Alternatively, one could perform the analysis at T+7, by which time (in view of Fig. ) almost all the observations valid in the window have been received, but the analysis is onlyavailable 4 hours after the end of the window and 10 hours after its beginning. To generate an estimate of state at T+7 we could run a 10-hour forecast from the analysis, but compared with the estimate of state at T-3 this will be degraded by model error.
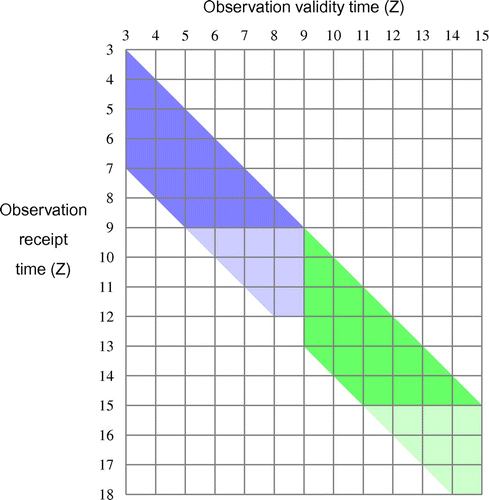
Centres such as the Met Office mitigate these issues by performing each analysis twice, a ‘late cut-off’ analysis currently at about , and an ‘early cut-off’ analysis at about T+3. This is illustrated somewhat schematically in Fig. , which shows two adjacent non-overlapping windows [3Z,9Z) and [9Z,15Z) (where [
,
) denotes the time interval
). For example, at 8Z we receive observations valid between 4Z and 8Z. Considering the window [3Z,9Z), for the ‘early cut-off’ run we perform the data assimilation at 9Z and use the observations in the dark blue region, and for the ‘late cut-off’ run perform it at about 12Z and use virtually all observations ever valid in the window (combined light and dark blue region).
Figure 2. Cycling with non-overlapping windows as used at the Met Office. Observations in the dark blue (dark green) region are assimilated for an ‘early cut-off’ run at 9Z (15Z). The extra observations in the lightly shaded regions are assimilated for ‘late cut-off’ runs at 12Z and 18Z.
In principle the late cut-off analysis could make use of the early cut-off one to reduce its work load, as is done in the ‘quasi-continuous’ approach of Järvinen et al. (Citation1996) and Veerse and Thèpaut (Citation1998), but at the Met Office the late cut-off analyses start again from scratch, making no use of the work done for the early cut-off analysis.
Having both early and late cut-off analyses goes some way to mitigating the shortcomings of 6-hourly cycling. However, the analyses are still 6 hours apart, which makes them insufficiently timely for some purposes, notably (considering the comments in Section 1) the LBCs for hourly LAM analyses; the analysis increment is much larger than would be the case with an hourly update, so nonlinearity can be a significant problem, especially for the linear model in 4D-Var; and the approach is inefficient insofar as the early cut-off analyses are not used as part of a cycle.
In Fig. we illustrate how we would like to deal with the same case: each hour we assimilate all observations received in the last hour, e.g. at 12Z we assimilate the observations received between 11Z and 12Z (green region); these are valid between 7Z and 12Z. In principle we do not re-assimilate the observations valid between 7Z and 12Z received at earlier times (blue, red yellow and cyan regions in Fig. ) as the information from these observations has been transferred to previous analyses and thereby to the background for this cycle.
Figure 3. Rapid update cycling with overlapping windows. Observations are assimilated within one hour of receipt.
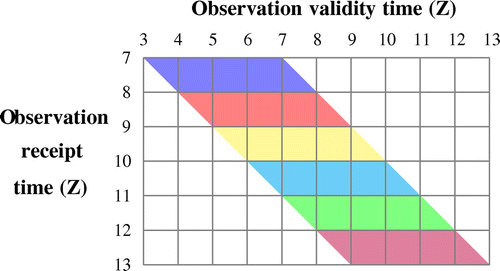
In the context of global NWP, which provides among other outputs LBCs for hourly cycling of LAMs, an hourly update cycle is natural, but in principle the updates could be as short as one model time step. For the purposes of this paper we will refer to any cycling where observations are assimilated as soon as they are received, or as in Fig. within some short time of receipt, as rapid update cycling (RUC).
We should note that the term ‘Rapid Update Cycle’ has been employed in the past to denote specific rapidly cycled NWP systems, for example by the National Centres for Environmental Prediction in the USA. In that case it referred to an operational regional forecast-analysis system over North America, where data was assimilated by 3D-Var (originally optimal interpolation) using non-overlapping windows of length one hour (Benjamin et al., Citation2004b; Benjamin et al., Citation2004a).
3. Optimal RUC
To examine the rapid update cycling problem further we will idealise it slightly by supposing that observations are valid at exact multiples of a time increment (as opposed to continuously in time), and become available after delays of
. We will suppose that observations received at time
are
(1)
Superscripts denote when the observations are received and subscripts their validity time, the longest delay being .
The first problem is to develop an optimal method for assimilating observations as soon as they are available. At time we seek to estimate
, given observations (Equation1
(1) ) and our previous estimate of
.
We will suppose that for we have observation operators
such that
(2)
and for each i a model (3)
where the distributions of the errors ,
are supposed known.
3.1. Notation and problem formulation
The optimal method is obtained by formulating the problem in such a way that standard estimation theory can be applied.
We will use the convention that the underlined vector denotes the concatenation of the
vectors
:
(4)
and similarly the underlined matrix is formed from matrices
of compatible size:
For example, if are vectors of length n and
are matrices of size
, then
,
are of size respectively
and
.
Define to be the observations received at time
, so
(5)
We seek the conditional expectations of and
given observations received up to time
(6)
Note that, given , and assuming
has zero mean, the best estimate of
before observations received at
are assimilated is
(7)
If we now define(8)
Then we may write (Equation2(2) ) and (Equation3
(3) ) as respectively
(9)
which are in the standard form for observation and signal map equations in estimation theory (e.g. Jazwinski, Citation1970).
3.2. Linear Gaussian case
It is illuminating to first work out the details in the simplest case, where in (Equation2(2) ) and (Equation3
(3) ) the observation operators
and model
are linear and the errors
are zero-mean, Gaussian and uncorrelated.
In this case(10)
where
for some matrices (where
denotes normally distributed with mean
and variance
), and setting
(11)
and(12) (Equation9
(9) ,Equation10
(10) ) become
(13)
with
and the problem of finding the conditional expectations (Equation6(6) ) of
and
given observations received up to time k, which may be denoted
,
, is solved by a standard Kalman Filter, as in Table .
Table 1. Optimal filtering with overlapping windows in linear-Gaussian case.
The basic objects manipulated are whole windows of states and observations and the covariances of the errors in these objects. The symbols in Table are whole-window analogues of their usual values, e.g. and
are
prior and posterior error covariance matrices of the estimated
. In special circumstances simplification is possible. For example, if new observations only occur in the final time slot, i.e. if the only observations which become available at k are
and there are no observations
, it is straightforward to show that (15)–(19) simplifies to a conventional Kalman smoother.
For linear the algorithm (15)–(19) finds
if the errors
are zero-mean, Gaussian and uncorrelated. As noted in Anderson and Moore (Citation1979), if we restrict attention to analysis-prediction equations of form (16) and (18) then we may drop the Gaussian assumption on
, merely requiring them to be zero-mean and uncorrelated, and (15)–(19) still minimises the expected error variance.
3.3. Variational equivalent of analysis step in linear Gaussian case
For large-scale data assimilation variational methods are almost universally used, so it is of interest to cast the optimal RUC analysis step (16) in variational form. Define(14)
(20)
(21)
where is the bottom right
submatrix of
. Then the analysis step (16) is equivalent to
(22)
where minimises
(23)
This is proved in Appendix 1. The term (Equation20
(20) ) constrains the N states in the intersection between the old and new windows by the inverse of the ‘background error covariance matrix’
. This ‘big B’ of size
is formed by taking the analysis error covariance from the previous stage and shearing off the oldest row and column.
3.4. General (nonlinear, non-Gaussian) case
We saw in Section 3.1 how the problem of assimilating data immediately it becomes available can be cast into a standard signal model/observation model form (Equation9(9) ) and (Equation10
(10) ), to which we can then apply well-established theory, e.g. Jazwinski (Citation1970). In particular, given (Equation9
(9) ) and (Equation10
(10) ) we can compute (sequentially in k) the conditional pdfs
and
. The novel feature for us is that
and
in (Equation9
(9) ) and (Equation10
(10) ) have a special structure which leads to significant simplifications, in particular enabling us to express these pdfs in terms of the original (as opposed to block) variables.
In general, given the prior pdf and the conditional pdf of the observations given the state
, Bayes’ theorem tells us that the posterior pdf
is
(24)
where the normalisation is
(25)
and the domain of integration . We will suppose the basic process satisfies the Markov property
which implies the same for underlined states
. Given
(the posterior pdf at
) and
, the Chapman-Kolmogorov equation then gives us for the prior pdf
(26)
We could cycle (Equation27(27) ) and (Equation25
(25) ) to obtain the posterior pdf for every k. However, as mentioned there are simplifications arising in this case.
By virtue of the fact that in (Equation8(8) ) the ith sub-vector of
depends only on
,
, the conditional pdf of the observations given the state, factors into
(27)
Additionally, the transition pdf may be written
(28)
Combined with (Equation27(27) ) this gives
(29)
We may cycle (Equation30(30) ) and (Equation25
(25) ), (Equation28
(28) ) to obtain the posterior pdf for every k. For example, if the observation operators
and model
are linear, and the errors
,
are Gaussian, then one may check that (Equation30
(30) ), (Equation25
(25) ) and (Equation28
(28) ) imply that the posterior pdf
where are given by (Equation20
(20) )–(Equation22
(22) ).
4. Example
We illustrate some of the foregoing with a small example, in which the model is the 40-dimensional chaotic model proposed by Lorenz (Citation1996):(30)
with ,
, where [i] denotes
. This system is integrated using fourth order Runge–Kutta with a time step of 0.05/6 during which time errors grow at a rate corresponding to order one hour in an atmospheric system. We therefore refer to time step k as time k. The truth is obtained by integrating (Equation31
(31) ) and to each component of x adding Gaussian model error every time step with variance
.
We suppose that at time k eight observations have just become available, at:
points ,
,
and
, valid at time
point , valid at time
point , valid at time
point , valid at time
point , valid at time
In this example we suppose there are no ‘instantaneously available’ observations (i.e. available at time k and also valid at k). Each observation has Gaussian error with variance where
. Every grid point is observed every 5 time steps and the observation network repeats itself exactly every 10 time steps. The system is well-observed and for the values of
used here the departure from linearity small enough that the foregoing linear theory can be well applied to the linearised model.
4.1. Non-overlapping windows with different lags
Consider first traditional non-overlapping window strategies. Suppose we have a 6-hour cycle with 6-hour windows. For the window we wish to assimilate observations valid in
. For non-overlapping windows we use an optimalFootnote1 smoother, i.e. 4D-Var (Li and Navon, Citation2001) with model error correctly accounted for and correct cycling of background error covariances. For the window
this produces analyses
.
As discussed in Section 2, the number of observations which are valid in the window and available for the analysis increases the longer the interval of time between the end of the window and when the analysis is performed, which we term the lag. For the present example the number of observations available at each time in the window if the analysis is performed at is shown in Table .
Table 2. Number of observations valid at times , available for analyses performed at
.
Taking for example the lag=2 case, at times k and the most recently available analyses are those in the window
with last analysis at
, while at
the most recently available analysis is at
. Table shows the validity time of the most recent analysis available at times
for lags of 0, 2 and 4 hours.
Table 3. Validity time of the most recent analysis available at times for lags of 0, 2 and 4 hours.
Fig. shows the RMS forecast error (using and averaged over 2000 cycles) in forecasts valid at times
taken from the latest available analysis using lag=0 (in black), lag=2 (in blue) and lag=4 (in green). Fig. illustrates a point about non-overlapping windows made in Section 2 above, that we choose between a short lag between observations and when the analysis is performed, giving timely analyses but not using all the observations, or a longer lag using more observations, but which at any given time requires longer forecasts which will be more degraded by model error.
Figure 4. RMS forecast error from most recent available analysis at times 0–5 hours into the next window following an assimilation window , for lags 0 (black), 2 (blue) and 4 (green). Dashed lines denote RMS error at times before the analysis is performed. Also shown in red is the RMS error in the optimal RUC analysis using the data available at each time. In this example
.
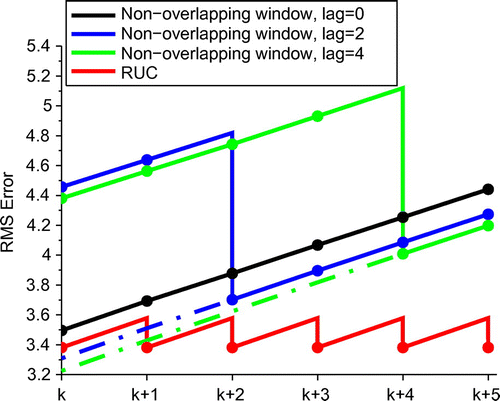
For the lag=2 and lag=4 cases we also show (dashed lines) the RMS forecast error for times between the end of the analysis window and the time the analysis is performed.
4.2. Optimal RUC
Since in our example the longest delay in receipt of observations is 5 h, for the optimal RUC method of Section 3 we have . At time j this produces analyses
.
A comparison of the observation usage of non-overlapping windows and optimal RUC was illustrated in Figs. and . In optimal RUC all observations are used, as soon as they are received.
The red curve in Fig. shows the RMS error in the RUC analysis at for
. From the foregoing we know this will always be less than the RMS error at j using any available analysis using a non-overlapping window with any lag. Note however that this error can be greater than that from the lagged analyses run at a later time, eg, in this example for the lag-2 and lag-4 analyses at time k. This is because the lagged analyses are using observations not available at time k.
5. Suboptimal methods for RUC
In Section 3 above we derived the optimal solution to the problem of assimilating data as soon as it becomes available, and saw that if the maximum delay is N and the state is described by n variables that this involved manipulating vectors of size and their error covariances of size
.
If observation and model errors are uncorrelated in time then optimal data assimilation methods for non-overlapping windows only involve vectors and matrices of size n and .
For large-scale systems manipulating vectors of size -pagination and more particularly matrices of size
may not be manageable. Furthermore, NWP centres already have methods implemented for non-overlapping windows (we will refer to these as ‘traditional methods’) and will naturally seek ways of adapting these to the RUC problem. Hence a topic of practical importance is the relationship between the optimal solution to RUC and traditional methods applied to RUC.
For simplicity we restrict attention to the case of linear forecast and observation operators whereas in Section 3.2 the errors are Gaussian and uncorrelated. We will designate the optimal solution for RUC in this case (i.e. Table ) as Method 0. We will develop suboptimal methods for RUC based on traditional methods for non-overlapping windows, with Method 3 a ‘naive’ application of such a method to RUC, and Methods 2 and 1 adaptations of this which are progressively closer to the optimal solution. We will then examine the relation between the four methods.
5.1. ‘Traditional’ methods as suboptimal methods for RUC
Suppose that at time k we have prior estimates(31)
and we have just received observations
A natural extension of the 4D-Var method (e.g. Li and Navon (Citation2001)) as used for non-overlapping windows is to form analyses at (32)
where
minimises(33) B in (Equation34
(34) ) is the error covariance of
, if this is known, or some approximation otherwise; we return to this point below. All our suboptimal methods 1–3 use (Equation33
(33) ) and (Equation34
(34) ) for the analysis. There are many different ways of forming new priors
. A non-exhaustive selection of possibilities is:
Method 3: The most similar to traditional 4D-Var, in which the only state saved from the above analyses is the first one (i.e. at the beginning of the window). Denoting the model evolution from
to j by
this gives us priors
(34) Method 2: Slightly better is to save and use the second analysed state, i.e. at time
, which will be at the beginning of the next window, giving us priors
(35) Method 1: Finally, we could follow the optimal solution and save and use all the analysed states, giving us priors
(36)
The number of prior states which are simply analysis states from the previous cycle is therefore 0, 1 and N for Methods 3, 2 and 1, respectively. The four RUC methods (with the optimal one of Section 3.2 labelled ‘Method 0’) are summarised in Table . The formation of backgrounds is shown in more detail for in Table .
Table 4. Summary of methods 0,1,2,3.
Table 5. The background states for the analysis at given the analysed states available from
, illustrated with
for Methods 0,1,2,3. After the analysis at
we have analyses
,
and
. The backgrounds
,
and
at
are formed from these analyses as shown in the table.
5.2. Covariance of analysis and background errors in methods 1–3
To compare the various methods we will need the covariance of their errors. We may write (Equation33(33) ) and (Equation34
(34) ) as
(37)
where(38)
(39)
(40)
where we use the notation to denote the i, j
submatrix of
. Denoting the truth by
and
it follows that for all Methods 1–3 the analysis error covariance is, from (Equation38
(38) )
(41)
We note this depends both on and (via
and
) the prescribed B.
The background error covariance depends on which method is used. For method
we may write
(42)
where as specified in (Equation12
(12) ) and
are illustrated for
in Table . Since the error in
using method
is
(43)
where we can express
in terms of
,
, model error covariance and the cross-covariance of analysis error
and model error
:
(44)
Table 6. Values of , for
, following Table .
In order to cycle Methods 1–3 we need to specify B in (Equation34(34) ). For the rest of this section, for the purposes of comparing the four methods, we will suppose that in Methods 1–3 we use
, which can be obtained from (Equation45
(45) ) (as above, underlined subscripts refer to submatrices, so
is the top left
submatrix of
). It can be shown that for methods 1 and 2 that
.
5.3. Relation between methods 0 and 1
An important comparison is between optimal Method 0 and suboptimal Method 1. They share the same background step (Equation43(43) ) with the same
. In both cases the analysis step may be written in the form (Equation38
(38) ), though whereas in Method 0 the gain
uses true , i.e. the covariance of the error in
, for Method 1 the gain
is
where is defined in (Equation40
(40) ). Because of the similarity in the structures of Methods 0 and 1 there is a simple and strong relation between their errors. If the sequence of background error covariances using Methods 0 and 1 are designated respectively
and
, and we start from the same prior error covariance
, then for all
the difference
is positive semi-definite, usually written
This is proved in Appendix 2.
5.4. Relation between methods in limit 
We have four RUC methods, the optimal and three suboptimal ones. We can cycle each as described above, for the suboptimal methods using (Section 5.2).
A limiting case which exhibits some of the differences between them, in particular how information is saved from previous cycles, is obtained by letting model error covariance for all k.
For simplicity suppose and
and
are independent of k. If
then after N cycles for method 0, one cycle for Methods 1 and 2, and immediately for Method 3, all knowledge of the initial background state
and its error covariance is lost. In Table we show the analysed state
produced by the four methods for any
if model error is infinite, and the corresponding background error and analysis error covariances.
Table 7. ,
and
for different methods in limit
, for
.
The optimal Method 0 retains all the observation information ever received; at time the estimate of state at any time between j and
is simply the average of all the observations ever received valid at that time. At the other extreme, Method 3 ‘forgets’ all the observation information from previous cycles: at time
the estimate of state at any time between j and
is just the value of the observation valid at that time and received at time
. Methods 1 and 2 retain observation information from the previous cycle only at the initial time. These different behaviours are reflected in the analysis error covariances shown in Table .
Comparing Methods 1 and 2, while in the limit Method 1 analyses are no better than those of Method 2, we note in Table that it has better backgrounds than Method 2.
5.5. Relation between methods in the limit
Suppose that for all k, and we are given an estimate
of
with error covariance
. Estimate the remaining states in the window
by
If for all k then Methods 1–3 simplify to their ‘strong constraint’ forms, in which (Equation34
(34) ) simplifies to
(45)
Crucially, in the limit Methods 0–3 coincide, so in particular Methods 1–3 are now optimal. This is proved in Appendix 3. In the absence of model error the ‘suboptimal’ methods all coincide with each other, and in fact are in this case optimal.
5.6. Comparison of methods 0–3 for the example of Section 4
We may apply linearised versions of Methods 0–3 to our nonlinear chaotic example of Section 4. In an attempt to mitigate the effects of linearisation error one can formulate outer loop-style iterations for these strategies, which may be worth implementing in more non-linear systems (for the examples here they made negligible difference). Alternatively one could use the ‘best linear approximation’ (Payne, Citation2013).
In our example of Section 4, at time k observations have just become available which are valid at so
. The optimal Method 0 and suboptimal Methods 1–3 all provide analyses
. (Since in our example no observations are instantaneously available,
is here a forecast from
).
Figure 5. RMS error in analysis at , various RUC strategies using all observations available at time k,
(upper set) and
(lower set).
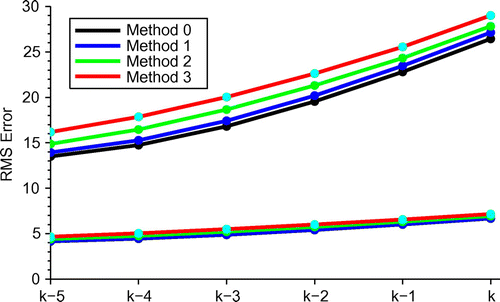
Each strategy is cycled 10,000 times and the first hundred cycles disregarded. Figure shows the RMS error in the analyses at , for the optimal Method 0 (black), and suboptimal Methods 1 (blue), 2 (green) and 3 (red), for
and 0.455 (upper and lower set respectively).
As expected from the foregoing, the errors are ordered
Furthermore, the analyses and therefore their errors converge as .
6. Impact of climatological background error covariances
A significant difference between the methods of the preceding sections and those used for large scale systems is that in the latter the prior error covariance (usually denoted B) is not cycled, but is either constant or is a convex combination of a constant and an estimate of cycled B (see (Equation47(47) ) below).
It is important to note that insofar as B is fixed it is advantageous to assimilate data as far as possible simultaneously in larger units rather than split it up into smaller volumes and assimilate it in smaller units. Intuitively, by assimilating many observations simultaneously the deficiencies of the fixed B are reduced.
Illustrating this point is complicated by the fact that increasing observation batch size tends to involve making other changes which themselves have an impact. If we compare cycling using non-overlapping windows with RUC then at no instant in time are the two methodologies assimilating the same observations (see Section 2). If we use 4D-Var to compare cycling with windows of length 1 (assimilating one observation every time step) with windows of length 2 (two observations every two time steps) then the latter has the advantage of covariances evolved through the window, which is a different point to the one being made.
If we compare assimilating two observations simultaneously every time step with assimilating one after the other, in the latter case we have to decide what B to use for the second observation. In Appendix 4 we show that if in a scalar system we assimilate two observations every cycle, and have a choice between assimilating them
| (a) | simultaneously using a fixed background error covariance B, or | ||||
| (b) | separately, the first with fixed background error covariance | ||||
We may contrast this result concerning the use of fixed background covariances with the fact that, if B is chosen optimally every cycle, and and
are chosen optimally every cycle, the two strategies will produce identical (and optimal) results.
This means that if B is fixed then, in this respect, RUC is at a disadvantage compared with conventional cycling as now there are more cycles with fewer observations used every cycle. In practice this effect may be dwarfed by the advantages of RUC as discussed in Section 2. If not, the obvious remedy is to improve the cycling of the background error covariances.
As noted above, the effect is due to using a fixed B, and is removed if B is cycled properly. This is unattainable in current large-scale NWP, but centres such as the Met Office already employ a ‘hybrid’ B (Clayton et al., Citation2013)(46)
where is fixed but
is an estimate (from an ensemble) of the true prior error covariance, with
. For best performance
as ensemble size increases, with the fixed part having no weight in the limit of an infinitely large ensemble.
There are other possible ways of introducing adaptivity into B, such as the ‘ensemble-variation integrated localised’ method (Auligné et al., Citation2016) and the so-called variational Kalman filters (Auvinen et al., Citation2010). In the latter the limited-memory quasi-Newton method is used to build a low-storage approximation to the Hessian of the analysis cost function, which therefore approximates the inverse of the analysis error covariance matrix, and can also be used to evolve the covariance forward to approximate B at the next analysis time.
7. Concluding remarks
Rapid update cycling (RUC) is the process by which we assimilate observations into a model as soon as they become available, or more practically, within some (short) time interval . We have seen that if the greatest delay in receiving observations is
then the optimal solution to RUC at time k involves manipulating the
vectors
formed from
and the moments of the errors in
, such as their
error covariances.
Compared with ‘traditional’ cycling RUC makes more timely use of observations, which is particularly important for the provision of LBCs for LAMs. Another advantage of RUC is that the increments are smaller and hence linearisation error is reduced.
We have purposely concentrated on fundamental topics and avoided such practically important matters as efficiency and cost. The fact that for each analysis observation volumes and increments are smaller, and we always have a recent one available, suggest that it should be possible to reduce the cost per analysis.Footnote2 On contemporary HPCs where the increased power comes through higher numbers of processors rather than increased clock speeds this is more important than the total cost per day.Footnote3
We may adapt ‘traditional’ methods designed for non-overlapping windows to RUC. These methods are suboptimal, but in all cases considered in this paper (Methods 1,2 and 3 in Section 4) they coincide with the optimal solution in the limit where model error vanishes.
Assimilating observations in smaller batches can be disadvantageous if climatological background error variances are used. This potentially poses a challenge for RUC, which could perhaps be met by improved cycling of error covariances.
Acknowledgements
The author thanks Mike Cullen and Andrew Lorenc for useful discussions on this topic, and the referees appointed by Tellus for their comments.
Notes
No potential conflict of interest was reported by the author.
1 Optimal except that we ignore linearisation error, which is small for our example.
2 Note also that there is scope for preconditioning using the work already done for recent analyses. This preconditioning could be based on Hessian eigenvectors (Fisher and Courtier, Citation1995), or on the vectors approximating the Hessian in the limited memory quasi-Newton method (Courtier et al., Citation1998).
3 We have also noted that the window length of RUC is determined by the longest delay in receiving observations, which in the operational example in Section 1 implies a window of 4 hours compared with the current 6 hours.
Related Research Data
References
- Anderson, B. and Moore, J. 1979. Optimal Filtering Prentice-Hall, Englewood Cliffs, NJ . 357 pp.
- Auligné, T., Ménétrier, B., Lorenc, A. C. and Buehner, M. 2016. Ensemble-variational integrated localized data assimilation. Mon. Weather Rev. 144, 3677–3696. DOI:10.1175/mwr-d-15-0252.1.
- Auvinen, H., Bardsley, J. M., Haario, H. and Kauranne, T. 2010. The Variational Kalman filter and an efficient implementation using limited memory BFGS. Int. J. Numer. Methods Fluids 64, 314–335. DOI:10.1002/fld.2153.
- Benjamin, S. G., Dévényi, D., Weygandt, S. S., Brundage, K. J., Brown, J. M., and co-authors. 2004a. An hourly assimilation-forecast cycle: the RUC. Mon. Weather Rev. 132, 495–518. DOI:10.1175/1520-0493.
- Benjamin, S. G., Grell, G. A., Brown, J. M., Smirnova, T. G. and Bleck, R. 2004b. Mesoscale weather prediction with the RUC hybrid isentropic terrain-following coordinate model. Mon. Weather Rev. 132, 473–494. DOI:10.1175/1520-0493.
- Boyd, S. and Vandenberghe, L. 2004. Convex Optimization Cambridge University Press, New York, NY . 716 pp.
- Clayton, A. M., Lorenc, A. C. and Barker, D. M. 2013. Operational implementation of a hybrid ensemble/4D-Var global data assimilation system at the Met Office. Q. J. R. Meteorol. Soc. 139, 1445–1461. DOI:10.1002/qj.2054.
- Courtier, P., Andersson, E., Heckley, W., Vasiljevic, D., Hamrud, M., and co-authors. 1998. The ECMWF implementation of three-dimensional variational assimilation (3D-Var). I: formulation. Q. J. R. Meteorol. Soc. 124, 1783–1807. DOI:10.1002/qj.49712455002.
- Fisher, M. and Courtier, P. 1995. Estimating the covariance matrices of analysis and forecast error in variational data assimilation. Tech. Memo. 220, 28. ECMWF, Shinfield Park, Reading, UK.
- Gallier, J. 2010. The Schur complement and symmetric positive semidefinite (and definite) matrices. Penn Eng. Online at: www.cis.upenn.edu/~jean/schur-comp.pdf
- Järvinen, H., Thèpaut, J.-N. and Courtier, P. 1996. Quasi-continuous variational data assimilation. Q. J. R. Meteorol. Soc. 122, 515–534. DOI:10.1002/qj.49712253011.
- Jazwinski, A. H. 1970. Stochastic Processes and Filtering Theory Academic Press, New York . 376 pp.
- Li, Z. and Navon, I. M. 2001. Optimality of variational data assimilation and its relationship with the Kalman filter and smoother. Q. J. R. Meteorol. Soc. 127, 661–683. DOI:10.1002/qj.49712757220.
- Lorenz, E. 1996. Predictability -- a problem partly solved. Proceedings, Seminar on Predictability Vol. 1, ECMWF, Reading, UK, pp. 1–18.
- Payne, T. J. 2013. The linearisation of maps in data assimilation. Tellus A: Dyn. Meteorol. Oceanogr. 65, DOI:10.3402/tellusa.v65i0.18840.
- Tang, Y., Lean, H. W. and Bornemann, J. 2013. The benefits of the Met Office variable resolution NWP model for forecasting convection. Met. Apps 20, 417–426. DOI:10.1002/met.1300.
- Veerse, F. and Thèpaut, J.-N. 1998. Multiple-truncation incremental approach for four-dimensional variational data assimilation. Q. J. R. Meteorol. Soc. 124, 1889–1908. DOI:10.1002/qj.49712455006.
Appendix 1
Proof of variational form of optimal solution given in Section 3.3
Continuing with the notation of Section 3.3 we readily obtain identities (EquationA1(A1) )–(EquationA3
(A3) ) below:
| (i) |
| ||||
| (ii) | By elementary algebra | ||||
| (iii) | From the definition of | ||||
Appendix 2
Proof of theorem of Section 5.3
If the sequence of background error covariances using Methods 0 and 1 are designated, respectively, and
, and we start from the same prior error covariance
, then for all
Proof For simplicity we shall suppose that both
and
are non-singular and that
, so denoting Method 1 quantities with tildes we have
and
. Hence from (17) and (Equation42
(42) ) we have
(A5)
and therefore(B1)
Now consider the matrix(B2)
Since is the sum of two positive semi-definite matrices it is positive semi-definite. Note also that since
is positive definite that
is invertible, so its Moore–Penrose inverse is its usual matrix inverse.
The term in square brackets in (EquationB2(B2) ) is the Schur complement of
in
so by Theorem 4.3 of Gallier (Citation2010) is positive semi-definite. Therefore if
then
is the sum of two positive semi-definite matrices, so is positive semi-definite. We conclude that if
then
. Since both methods satisfy (Equation43
(43) ) with the same
, both satisfy the same relation
Therefore implies
and the claim follows.
Appendix 3
Proof of equivalence of methods 0–3 if
Set to be the first n columns of the
matrix
, i.e.
Because it follows from (Equation40
(40) ) that
(B3)
We suppose inductively that for some Method 0 and Methods 1–3 have the same
and that
(C1)
This is true for by construction. For all methods we therefore have
Using the ‘Kalman identity’(C2)
it follows from (17), (Equation42(42) ) that for all methods
(C3)
and therefore from (16), (Equation38(38) ) that in all cases
(C4)
Recall that the superscript in
in (Equation43
(43) ) denotes the method used, with
as defined for the optimal solution in (Equation12
(12) ). For all
-pagination
Let denote the vector in square brackets in (EquationC5
(C5) ) and
the matrix in square brackets in (EquationC3
(C3) EquationC4
(C4) ). It follows from (18), (19) and (Equation43
(43) ), (Equation45
(45) ) that both for Method 0 and for Methods
we have
(C5) (where
is the first
sub-vector of
). Therefore the inductive hypothesis holds for
, and therefore for all k.
Appendix 4
4D-Var with a fixed background error covariance: impact of observation batch size
Suppose we have a linear system, observations in some time interval [0, T] and all errors are Gaussian. If we assimilate the observations using an optimal method, such as 4D-Var with correctly cycled prior and posterior error covariances, using m assimilation windows
then the estimate of state at time T is independent of m and of how we choose
However, if instead of properly cycling the error covariances the background error covariances are fixed, it is often advantageous to assimilate data in larger batches.
We illustrate this by considering a case where x is a scalar quantity, which evolves in time according to
for some constant (which is supposed known, so there is no model error) with
. At each time i we wish to assimilate an observation
with error variance
and an observation
with error variance
. To make the problem analytically tractable we will suppose that
are drawn (independently of i) from
, where for any i
with probability
.
We compare two assimilation strategies using 4D-Var with a non-cycled background:
Simultaneous (batch size of 2): at each time i we assimilate and
simultaneously using fixed background error covariance b, i.e.
where
minimises
Sequential (batch size of 1): at each time i we assimilate
using fixed background error covariance
to give intermediate analysis
, then assimilate observation
using fixed background error variance
to give final analysis
, i.e.
,
, where
minimise
(C6)
Table D1. Parameters for Equation (EquationD1(D1) ).
We will show the following: we can choose b so that, however and
are chosen, the mean square error using the simultaneous method is lower than that using the sequential method (and strictly lower if
and
).
Proof (summary)
| (1) | Denoting | ||||
| (2) | It follows from (EquationD1 | ||||
| (3) | Lemma. If | ||||
where the inequality is strict if and
.
This Lemma proves the claim, and is itself proved in (3a)–(3d).
| (3a) | Given constants | ||||
| (3b) | Consider the 1-parameter family of functions | ||||
| (3c) | We may also check that we have | ||||
| (3d) | We have found a value | ||||
At any extremum of Equation (EquationD11
(D11) ) must hold, and in particular for every
-pagination
The denominator is positive for all points in , therefore at any extremum in
Inserting this requirement with into the expressions for
in (EquationD5
(D5) ) it follows we would need
(D20)
which for is only possible if
.