
ABSTRACT
Platformized cultural production is in flux. Artificial intelligence is often seen as a key driving force of this shift. This article examines the proliferation of AI-generated media to introduce a new concept to theorize cultural production: hyperproduction. This notion designates the penetration of cultural life with deep generative models. Juxtaposing two empirical use cases–autonomous vehicles and virtual influencers—the article problematises the convergence of simulation and reality through the lens of video game engines. Although those case studies seem to be at odds with each other, they illustrate the mechanisms of new profit models built on rent extraction. Consequently, far from ushering a Matrix-style simulation that cannot be theorized, hyperproduction remains not only grounded in, but also bounded by, reality: the reality of rentier capitalism.
1. Introduction: Mona Lisa's multiplicity
In November 2021, three months before the Russian invasion of Ukraine, Sber – a state-owned Russian banking and financial services company – announced the creation of ruDALL-E, the ‘world's first neural network capable of creating images based on text descriptions in Russian’ (Sber Citation2021a). What is noteworthy about the text-to-image model is not only its cost (developers claim the model required 23,000 GPU hours to train it based on 120 million image-text pairs) but that it is open to the public. Unlike its American counterpart DALL-E, a proprietary model presented by the Microsoft-backed research lab OpenAI in early 2021, a 1.3 billion parameters version of ruDALL-E is available under an open-source license. In addition to trying out the model using text queries (), anyone can download and modify its source code.
Figure 1. ‘Mona Lisa painted by van Gogh’. Generated by ruDALL-E (Citation2022).

In the following months, developers modified ruDALL-E in creative ways. In one instance, the deep neural network was fine-tuned on all official Pokémon images, resulting in a potent and accessible tool for bringing indefinite new Pokémon-inspired creatures into being (Woolf Citation2022). Another developer simplified the process of fine-tuning so that users can train the model on their own pictures within a few clicks on Google ColabFootnote1 – combined with an appeal to refrain from using their free software to create for-profit non-fungible tokens (NFTs) (Looking Glass Citation2021). As one artist, who trained the model on bird illustrations from old books in order to create synthetic birds, admitted: ‘I’m playing around with some silly toys here. I have no idea how this whole thing learns anything’ (Solis Citation2022). In other words, there is no need to comprehend the inner workings of neural networks for training text-to-image models.
Open-source models like ruDALL-E and Stable Diffusion illustrate that the creation of synthetic media has become easy, widely accessible, and fast. Synthetic media is an umbrella term for AI-generated images, videos, environments, audio, and text.Footnote2 But the automated production of synthetic media is by no means a new phenomenon. Indeed, modern computing is premised on enabling virtual realities. These realities have become all too real for some (Rothman Citation2018). Deep fakes – the use of face-swapping techniques to manipulate videos or images – are the most apparent controversy over synthetic media within both academic discourse and public debate. Yet amidst the spotlight on questions of misinformation and geopolitics, literature on the relationship between AI-generated synthetic media and social theory has been underrepresented. Irrespective of whether the synthetic Mona Lisas resemble Vincent van Gogh's style in a meaningful way, the visualization of this absurd potentiality symbolizes the research question of this article: How can the proliferation of AI-generated media be conceptualized?
One way to answer this question would be to resort to Baudrillard’s (Citation1994) idea of hyperreality: the ‘generation by models of a real without origin or reality.’ Rather than the capital/labour dichotomy that characterised earlier critiques of capitalism, Baudrillard famously argued, simulations, signals, and codes increasingly define social interactions and activities. Capital and labour are only two of a plethora of codes that mediate how people interact with one another and how they conduct their daily lives. In rendering intelligible the role of the media in the second half of the twentieth century through the lens of hyperreality, Baudrillard identified a ‘precedence of simulation over all that already existed as real’ (Hegarty Citation2004, 60). To summarise Baudrillard's claims, we are unable to distinguish reality from a simulation because simulations are omnipresent features of reality itself. This argument remains indispensable in an era of AI-generated media. But in the 1990s, Baudrillard could not have foreseen the rise of deep generative models as algorithmic driving forces of synthetic media production.
ruDALL-E is a clear example of such a deep generative model. It is a neural network architecture that was designed to recognise the ‘true data distribution of the training set so as to generate new data points with some variations’ (Pandey Citation2018). The 120 million labelled image-text pairs, which include the Mona Lisa and van Gogh's paintings, constitute ruDALL-E's training set. Therefore, it is paramount to begin with the premise that deep generative models, by design, ‘present us with a technically and historically predetermined space of visual possibilities’ (Offert Citation2021, 3). The outputs fabricated by deep generative models never come from scratch. Instead of giving rise to a Matrix-style simulation that escapes the grip of social theory, synthetic media remain not only grounded in but also bounded by reality.Footnote3 Surely, there is a reliance on inputs of real-world training data (Offert Citation2021). But beyond that algorithmic grounding in reality, deep generative models are also rooted in a specific political-economic reality.
This reality is best defined as rentier capitalism. For Christophers (Citation2020:, 1), rentier capitalism refers to a ‘system of economic production and reproduction in which incomes are dominated by rents and economic life is dominated by rentiers.’ The key idea is that economic actors are now more likely to make profits by monetizing their valuable assets instead of selling commodities. An asset is a type of property that can engender revenue streams by ‘turning things into resources which generate income without a sale’ (Birch Citation2015, 122). For example, the reason for releasing an open-source version of ruDALL-E is not the empowerment of creatives. Comparable to trial periods for streaming websites, the model is a sample of what is possible at a higher scale. Instead of 1.3 billion parameters, the commercial version of ruDALL-E contains 12 billion parameters. As a result of its increased size, Sber (Citation2021b) claims that this more sophisticated version ‘is suitable for creating commercial materials: illustrations for advertising, architectural and industrial design, and vector and stock images.’ This, of course, is a marketing pitch. Nonetheless, ruDALL-E exemplifies the transformation of a deep generative model into a proprietary infrastructure offering – a scarce asset whose intended reach goes beyond a singular industry or application domain to the metaverse.
In this article, we aim to problematize the political-economic grounding of deep generative models by introducing the idea of hyperproduction. This notion designates the penetration of cultural life with deep generative models. Given that the creation of AI-generated media has now become a matter of a few clicks, it is not fruitful to theorize their production process as a unidirectional chain of events, just like the production of a physical medium or a commodity. In its Glossary of Statistical Terms, the OECDFootnote4 (Citation2001) defines economic production as ‘an activity carried out under the control and responsibility of an institutional unit that uses inputs of labour, capital, and goods and services to produce outputs of goods or services.’ This definition shows that production is typically measured as a linear development of sequential transformation that is defined by inputs and outputs: two easily identifiable variables. Hyperproduction, by contrast, blurs the line between inputs and outputs as opposed categories to delineate the production process into a much more circular process.
Juxtaposing the logic of two empirical use cases of deep generative models – autonomous vehicles and virtual influencers – the article shows that far from reflecting a step-by-step process, hyperproduction is better understood as a circular dynamic. Autonomous vehicles, for example, are now trained in simulated environments powered by video game engines.Footnote5 Conversely, virtual influencers blur the analytical distinction between production inputs and production outputs by design: their success is defined by virtuous social media feedback loops. However, what unites both use cases is a profit model based on rent extraction. Although these use cases are embedded in very different industries, they show how two companies, Unity Technologies and Epic Games, consolidate a key part of the proprietary infrastructure needed for the industrial use of hyperproduction. The intensification of their economic and cultural power has important consequences across and beyond cultural industries.
To elucidate those consequences, the article begins with a brief media history of synthetic production. This contextual background serves to justify the article's focus on the combination between deep generative models and video game engines as driving forces of contemporary forms of synthetic media production. The article then situates hyperproduction as a distinct logic of rentier capitalism, before proceeding to the case study analysis. The discussion shows that two factors of asset specificity of video game engines are especially pertinent for hyperproduction: real-time physics and 3D graphics, and programmability and modularity. The article concludes by pointing out the implications of the burgeoning hyperproductive condition to the corporate-backed metaverse.
2. A brief media history of synthetic production
Hyperproduction is the product of a longstanding discursive aspiration and a material phenomenon for computing to be indistinguishable from reality (Gaboury Citation2021)–a history that includes early daemons and Joseph Weizenbaum's 1964 ELIZA programme. Weizenbaum famously warned about the ELIZA effect where humans demonstrate a willingness even a desire to believe in computers, in his case as compassionate listeners. Weizenbaum's warning about humanity's desire to be deceived is a central premise and anxiety about artificial intelligence. As Natale (Citation2021:, 56) puts it:
[Weizenbaum's] deep interest, on the contrary, in how the program would be interpreted and ‘read’ by users suggests that he aimed at the creation of an artifact that could produce a specific narrative about computers, AI, and the interaction between humans and machines. ELIZA, in this regard, was an artifact created to prove his point that AI should be understood as an effect of users’ tendency to project identity. In other words, ELIZA was a narrative about conversational programs as much as it was a conversational program itself.
From this brief history, we acknowledge the beginnings of the circular logic of synthetic media where digital and physical environments converge–an interaction that can be understood through the notion of the post-digital. Part of what the post-digital covers, according to Berry and Dieter (Citation2015:, 5), is a wide range of issues attached to the entanglements of media life after the digital, including a shift from an earlier moment driven by an almost obsessive fascination and enthusiasm with new media to a set of affectations that now includes unease, fatigue, boredom, and even disillusionment. The cultural perception that today's AI-generated media might be a little too real is certainly part of the structures of feeling associated with the post-digital. From this perspective, we are living in an already post-digital world defined by decades of laborious world-building through materialising computer modelling and computational imagination. This evolution might be characterised with what Hayles (Citation1999:, 8) defines as reflexivity: ‘the movement whereby that which has been used to generate a system is made, through a changed perspective, to become part of the system it generates.’ The very possibility of synthetic media representing productive force in the first place indicates a particular conjecture in post-digital societies (Berry and Dieter Citation2015).
The desire for this post-digital morass came in part from the autonomous possibilities of computers to produce more manageable, automated worlds. The very possibility of modern computing in part depends on American military subsidies that looked to the power of computing as new techniques for managing battlefields and wars. Gaboury's historical contribution, among many, lies in situating the beginnings of computer graphics at the University of Utah – an early node on the ARPANET and a major recipient of ARPA funding. As researchers at the University of Utah produced the first computer graphics in 1968, other ARPA worked with the CIA under the guidance of Secretary of Defence Robert McNamara to build a ‘digital hamlet intelligence system,’ the tempest to Utah's 3d teapot. The Hamlet Evaluation System (HES) produced monthly statistical reports on the status of ‘population control’ in the countryside, as well as state-of-the-art digital maps showing the status of hamlet control by either the Government of Vietnam or the National Liberation Front. By spring 1967, the HES was fully functional in the field and stayed operational – albeit with several upgrades – until 1973. The HES consumed ‘thousands of man-days of work by countless young army officers’ (Allen Citation2001, 224), making it one of the largest – and most labour-intensive – geographical information systems of its time (Allen Citation2001, 417). This virtual Vietnam was an important example of the promised computational imaginary of computing. These early forms of synthetic media demonstrate the investment in computing to better wage war – innovations that were privatised a decade or so later and put in corporate service and partially re-articulated as Silicon Valley innovation (Turner Citation2006).
The legacy of the US military's funding of synthetic media is directly applicable to this article's focus on how video game engines relate to hyperproduction. Game engines are in some way an accidental discovery as early game developers found new revenues streams by licensing out their internal engines to other developers. Epic Games, one of the oldest developers of game engines made famous by its success with Fortnite, co-developed this industry by licensing out its Unreal Engine. Unreal's licensing strategy acted as a breakdown between video games as an entertainment industry to video games becoming more integrated into wider circuits of cultural life. To further this link, the first game to use the Unreal Engine 2 was America's Army, quite literally what Dyer-Witheford and de Peuter (Citation2009) label as a ‘a game of empire.’ America's Army was a free-to-play online competitive shooter meant as a recruitment tool. That is the moment this article wishes to explore: the breakdown when a video game engine acts as a virtual reality that has as its object a kind of post-digital effect, of gamers becoming soldiers.
The success of Unreal's game engine has led the firm to invest heavily in the metaverse as its next business venture. Epic Games hopes that the game engine will become the foundational infrastructure for the metaverse. If game engines, or other digital creative tools like Photoshop, have always been productive, then the metaverse intensifies the convergence of physical and digital worlds. In coining a new term to grasp the integration of deep generative models into the circuits of media production, we are inspired by Johnson’s (Citation2017:, 225) argument that ‘a theory of media production enables us to understand not just distinct media institutions and industry sectors, but also how those forces figure into larger processes of communication, culture, and meaning creation.’ The political economy of communication, in other words, is not only an economic issue, and neither is the rise of hyperproduction. This history of synthetic production indicates the links between corporate discourses and material realities that drive both the speculative promise of hyperproduction and fund its actualization.
3. Reality engines: the industrial metaverse and rentier capitalism
I’m most excited by the potential of the ‘industrial metaverse’ where the goal doesn't have anything to do with social interaction; rather, it's about simulating experiences in the virtual world before moving into the physical world. […] The industrial metaverse can transform the way every physical asset – buildings, planes, robots, cars, etc. – on the planet is created, built, and operated.
The cross-industrial provision of video game engines and associated corporate imaginaries surrounding a future industrial metaverse neatly illustrate the ‘technological expansion and empowerment of rentier capitalism’ (Sadowski Citation2020, 3). Of course, the generation of rent through infrastructure offerings is by no means limited to video game engines. Similar to the provision of AI-as-a-service offerings and cloud computing infrastructure, video game engines were initially created to fulfil company-internal needs.Footnote6 Amazon's tremendously lucrative cloud computing subsidiary AWS, for instance, also sprung out of an internal tool to manage the increasing complexity of the company's own logistical network. In other words, the assetization of video game engines – the process of turning them into an infrastructure offering that is ‘owned or controlled, traded, and capitalized as a revenue stream’ (Birch and Muniesa Citation2020, 2) – does not seem to be novel. But why does hyperproduction nonetheless constitute a distinct manifestation of rentier capitalism?
3.1. Deep generative models and video game engines
The answer to this question lies in the computational features of deep generative models as the primary technical driving force of contemporary synthetic media generation. To recapitulate, the purpose of those models is to enable algorithms to recognise patterns in the data they are provided in order to produce new outputs (e.g. images) inferred from the training dataset. While there is a wide range of deep generative models, generative adversarial models (GANs) are their most well-known subtype.
The central logic of GANs, as introduced by Ian Goodfellow and his colleagues, might be imagined as a productive contest between two artificial neural networks. First, the generator network creates artificial outputs from random input, like public domain bird illustrations (). The second network, called the discriminator, is fed both synthetic and genuine bird illustrations and taught to distinguish between the two. The generator improves if the bogus nature of its outputs is recognised by the discriminator. If the latter is tricked by the generator into believing a synthetic bird illustration to be real, it is less likely to make the same mistake again.Footnote7 Before the discriminator network is finally discarded, ‘the interplay of these two networks, both of which want to outplay the respective other, leads to incremental improvements on both sides’ (Whittaker et al. Citation2020, 93). In Baudrillard (Citation1994, 2) terms, rather than attempting ‘to make the real, all of the real, coincide with their models of simulation’, GANs attempt to iteratively make their synthetic outputs coincide with their pre-defined models of the real.
Figure 2. Logic of generative adversarial networks. Adapted from Wikimedia Citation2022.
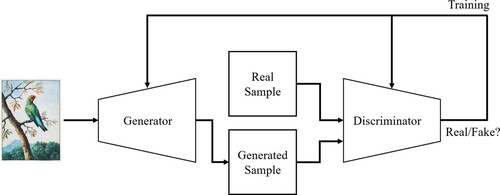
To facilitate this iterative process of synthetic media generation in complex use cases, game engines such as Unity and Unreal come into play. The creation of synthetic images from 2D public domain bird illustrations by using a GAN, for example, does not include the rendering of a bird's morphable physical structures. But in other situations, such a 3D modelling might be required – and video game engines are now widespread infrastructural tools to assist with synthesizing potent 3D models. In 2016, for example, Wood et al. (Citation2016, 1) presented UnityEyes, ‘a novel method to rapidly synthesize large amounts of variable eye region images as training data […] that can be used to estimate gaze in difficult in-the-wild scenarios.’ Put differently, the aim was to fabricate many realistic images of eyes that can be used to statistically predict where a real person is looking. The crux lies in the software used by Wood et al. (Citation2016, 5) to generate the 3D eyeball model for rendering one million synthetic eye images:
We used the Unity 5.24 game engine to render our eyeball and generative eye region model. Our contribution here is a massive speedup in rendering time compared to previous work. This allows us to easily generate datasets several orders of magnitude larger than before – an important factor in successfully training large-scale learning systems […]: a 200x speedup.
In this sense, Wood et al.'s (Citation2016) rationale for using Unity's engine rather than writing their own image rendering software reflects the economics of cloud computing infrastructure more broadly. Most notably, the authors refer to the vast increase of their dataset and the acceleration of rendering time. Such an expansion of resources is also a key reason for the creation of rentier relations in cloud computing, such as by using Amazon's SageMaker platform to simplify the development of machine learning models. As Srnicek (Citation2021:, 39) reminds us, ‘cloud computing is desirable for businesses because it enables the rapid expansion of resources, often at levels of technical expertise that are far beyond what the businesses themselves can provide.’ But the dominant proprietors of cloud computing infrastructure are not necessarily the dominant proprietors of hyperproduction.
Instead, some of the world's most powerful technology companies and their AI research laboratories rely on the provision of game engines by Unity Technologies and Epic Games as training grounds for machine learning. In 2018, Google's subsidiary DeepMind, for example, had signed a deal with Unity Technologies to use its engine ‘at a giant scale to train algorithms in physics-realistic environments’ (Captain Citation2018). Yet, both sides refrained from disclosing any details about the licensing costs. Along similar lines, although OpenAI built a simulation on top of the Unity game engine to train a real robotic hand how to solve the Rubik's Cube (Akkaya et al. Citation2019, 7), details about those rentier relations remain nebulous. In spite of this lack of data, the infrastructural role of game engines evokes Birch and Muniesa’s (Citation2020:, 6) point that ‘assets are often unique, meaning that their value derives from their asset specificity.’
The term asset specificity denotes ‘the degree to which the value of a specific or set of tangible or intangible assets is connected to their current use’ (Moles and Terry Citation1997). A high degree of specificity suggests that it is unlikely that an asset would be used for anything other than what it was initially intended for (e.g. the production of video games). Low asset specificity indicates that an asset has a wide range of potential applications. Game engines are examples of low asset specificity.
If even a behemoth such as Google resorts to the licensing of Unity's game engine, this is a clear sign that Unity's proprietary software architecture cannot be reproduced. Industry-leading game engines, in other words, have become scarce ‘infrastructure assets’ (Birch and Muniesa Citation2020, 13) whose reach is not limited to a particular purpose or clearly defined application domain. By infrastructure assets, we mean that their revenue streams underlie synthetic media production across industries. However, there is a relative absence of conceptual work on the assetization of video game engines. Although media scholars have emphasised their non-gaming industry deployment (Freedman Citation2018; Nicoll and Keogh Citation2019), such empirical use cases have not been analysed through the lens of emerging rentier relations or contextualized as a continuation of a much longer media history of synthetic production.
4. Hyperproduction, video game engines, and asset specificity
The remainder of this article argues that two factors of game engines’ asset specificity are especially pertinent for hyperproduction: real-time physics and 3D graphics, and programmability and modularity. Those factors constitute the low asset specificity of video game engines. Empirically, the article substantiates this argument by comparing two use cases: autonomous vehicles and virtual influencers. Juxtaposing the rationale for deploying video game engines across those use cases indicates that hyperproduction is not a unidirectional process that simply transforms inputs into outputs.
Although autonomous vehicles and virtual influencers initially seem to be at odds with each other, they congeal into a useful illustration of the circuitous nature of hyperproduction – a two-directional loop from simulation to reality (sim2real) and from reality to simulation (real2sim). Sim2real refers to the transfer of knowledge from the synthetic domain to the real domain (e.g. by training a self-driving car in simulation). By contrast, real2sim refers to the transfer of knowledge from the real domain to the synthetic domain (e.g. by creating a virtual influencer based on real-world data). The fact that those directions entail different techniques () stresses the need to take seriously the licensing strategies of Unity Technologies and Epic Games.
Table 1. Asset specificity of video game engines in two use cases of hyperproduction.
In terms of the sim2real and real2sim distinction, it is imperative to note that there is a stylistic rationale behind this structure. The boundary between simulation and reality is not fixed or clearly defined, as Baudrillard (Citation1994) lucidly reminds us. Even when it comes to technical dimensions, it is not possible to state whether a transfer happens from simulation to reality or from reality to simulation. When it comes autonomous vehicles, for example, there is a constant back-and-forth between data that is generated in synthetic environments and data that is generated in on physical streets, with real-world encounters. The same argument applies to the feedback loops of virtual influencers. Nevertheless, we hold that there is an immense value in crafting the article in this way: not as an example of a reductionist Cartesian dualism, but rather as a strategy to delineate a flexible and dynamic spectrum of empirical possibilities.
The following two sections begin by explaining the respective factor of game engines’ asset specificity on a general level. The sections then discuss its empirical manifestations by analyzing patterns and differences in light of the use cases. Finally, the article extrapolates those insights beyond those two use cases.
4.1. Real-time physics and 3D graphics
A key objective of Unity Technologies and Epic Games has long been the optimization of their video game engines to render 3D environments in real-time while ensuring the provision of realistic physics and graphics components. As Nicoll and Keogh (Citation2019:, 10) put it, game engines can automate ‘computational tasks such as rendering, physics, and artificial intelligence, thereby freeing up developers to focus on ‘higher-level’ aspects of the design process.’ This computation of physically accurate transformations of objects is highly relevant for improving a range of machine learning techniques, including deep generative models. To return to the above-mentioned example of UnityEyes, merely increasing the size of a dataset of synthetic eye images is not useful if the model trained on these images fails to recognise where a real person is looking. Along similar lines, if a robotic hand can only master a Rubik's Cube in a virtual simulation, but fails to do so in physical reality, such a result might be less headline-generating.
Nevertheless, demonstrations of the potency of deep generative models, such as OpenAI's robot hand, point to the strategic rationale behind the uptake of game engines as tools for synthetic media generation. In this regard, it is worth digging into the details of which computational techniques and logics underlie the use of simulations to fine-tune the parameters of deep generative models. Tobin (Citation2020), a former research scientist at OpenAI and involved in the company's robot hand work, articulates the advantages of resorting to simulated environments in the following way:
Unlike robotic data, simulated data is super cheap, basically zero marginal cost. It's very fast, you can run simulators faster than real-time. And it's scalable, right? You can have a simulation running on every corner of your data centre … It's safe, right? So, you can't actually damage something by running a simulation – at least not yet. And you get labels for free: because you design the world, you know where all the objects are. You aren't beholden to real-world probability distributions.
Given those affordances, Unity Technologies and Epic Games are in a powerful position vis-à-vis car manufacturers. When Unity (Citation2018) announced the creation of its automotive division, the firm counted ‘eight of the world's top 10 Automotive Original Equipment Manufacturers as customers, helping improve the way they design, build, service and sell automobiles.’ Epic Games (Citation2022a) boasts that ‘BMW, Ford, and Toyota are already harnessing the power of Unreal Engine to drive efficiencies and open up new creative avenues.’ While services include areas such as prototype visualization and assembly line training, the repurposing of game engines to train the neural networks of autonomous vehicles the most intriguing phenomenon for the purposes of this article. The higher the future demand for such simulations, the more rent can be generated by the two dominant providers of game engine technology. If they remain the proprietors of this technology, an expansion of their market power is a likely scenario.
On a technical level, the progress in transferring machine learning patterns from synthetic to real-world environments has been significant in recent years. Concerning autonomous vehicles, game engines facilitate the combination of two approaches. The first approach is domain randomization, a ‘technique for training models on simulated images that transfer to real images by randomising rendering in the simulator’ (Tobin et al. Citation2017, 23). The idea is that if there is sufficient variety in simulation, an AI model may perceive the real world as just another variation of it. OpenAI's robot hand, for example, relied on this approach. The second one is procedural generation, which we might imagine as the algorithmic, rather than manual, creation of content like roads and trees. Tesla (Citation2021), for example, never publicly disclosed that it relies on the provision of game engines by Epic Games or Unity Technologies for its endeavour to become the leading manufacturer of autonomous vehicles. Nonetheless, its demonstration of recent work with simulations at the firm's AI day provides useful hints:
Most of the data that we use to train [deep neural networks] is created procedurally using algorithms as opposed to artists making these simulation scenarios manually. The interactions between parameters such as curvature, varying trees, cones, poles, and cars with different velocities produce an endless stream of data […] We want to recreate any failures that happen to the autopilot in simulation so that we can hold autopilot to the same bar from then on. […] We have used 371 million simulated images with 480 million labels to train the neural networks of the car.
Consequently, the rationale for an uptake of game engines to render them is not the randomization of parameters but instead the tailoring of parameters such as facial expressions, clothing, and gestures to consumer demographics and psychographics. In other words, the point is not to collect synthetic data in a randomized simulation but to use real-world data to create synthetic personalities that do not have to be realistic at all. Their value is defined by follower count and lead generation. In 2022, Lil Miquela, at the time the world's most successful virtual influencer, for example, had more than 3 million followers on Instagram and more than 3.5 million followers on TikTok. In 2020, Lil Miquela earned an estimate of $11.7 million for her creators, a Los Angeles-based studio named Brud (Ong Citation2020). It is no secret that there are economic links between Brud and Epic Games. The music video of Lil Miquela's debut song, Hard Feelings, for example, was produced ‘using Unreal Engine, while virtual cameras were used to set up shots that had a grounding in reality but that were also impossible in the real world’ (Webster Citation2020). In the video, Lil Miquela performs acrobatic dance moves on the back of a lorry. After being chased by police cars, she ends up relaxing on the truck while it slowly disappears on the horizon amidst an endless field of flowers.
Virtual influencers like Lil Miquela illustrate that game engines are as integrated into the cultural life of hyperproduction as they are with its technical workings. The capability of game engines to fabricate hyper-realistic 3D worlds is as much a material force for computation (e.g. training neural networks) as it represents a cultural force for entertainment (e.g. rendering engaging music videos). How exactly does this circuit of transfer from the real domain to the synthetic domain and vice versa work in practice? To answer this question, we need to consider the programmability and modularity of video game engines as decisive factors of their low asset specificity.
4.2. Programmability and modularity
The term programmability refers to the fact that video game engines are ‘capable of being programmed’ (Chun Citation2008, 224) and can be used to create indefinite new digital objects, from synthetic eye images to a trailerless lorry traversing a red flower field. The term modularity means that the architecture of game engines is composed of two parts. First, there is a core with low variability (e.g. real-time 3D graphics). Second, there is a periphery with higher variability (e.g. sector-specific tools). Modularity, in other words, is a regime of high-level programming (McKelvey Citation2011; Russell Citation2012). For example, Unity Technologies and Epic Games offer tools for architectural design, whose functionality is different from tools for military simulations. But some functions, such as real-time physics, apply across the board. As Nicoll and Keogh write (Citation2019, 11), game engines are not ‘discrete, unchanging, or totally black-boxed objects, but rather modular toolsets that can be customized to facilitate a variety of different design methodologies and project types.’ This interplay between programmable and modular features transforms game engines into valuable infrastructure assets.
Naturally, much of the information about how those features manifest in the daily business of licensing out game engines is hermetically sealed by non-disclosure agreements and trade secrets. For example, the exact amount of how much Epic Games benefits from Lil Miquela's viral success is unlikely to come to light. But this does not mean that we cannot attempt to comprehend the empirical function of programmability and modularity. Compared with the prominence of Lil Miquela, the Instagram follower count of Maya – a virtual brand ambassador for Puma in the Southeast Asia region – is rather low. But unlike Lil Miquela's creators Brud, Maya's originators are surprisingly transparent about their strategy in extracting and analysing consumer data to fabricate her. Maya is the result of the combined effort of the work of multiple firms coordinated by UM Studios x Ensemble Worldwide, an agency based in Kuala Lumpur (Lim Citation2020). One of the companies that co-created Maya is the Singapore-based SoMin AI. On its website, SoMin AI does not only showcase its products to ‘supercharge and automate your digital ad performance’ but also technical demonstrations of what its data-driven virtual influencer production pipeline actually looks like.
SoMin AI ‘combines deep multi-view personality profiling framework and style generative adversarial networks facilitating the automatic creation of content that appeals to different human personality types’ (Farseev et al. Citation2021, 890). In other words, the company uses a person's social media content to infer their personality type and then creates tailored social media content based on the preferences of people with the same personality type. It utilises the Myers-Briggs Type Indicator, an instrument that was developed in the 1940s. These days, it is seen by most personality psychology experts as ‘little more than an elaborate Chinese fortune cookie’ (Hogan Citation2006, 28). SoMin AI eventually combines this automated personality type inference with retrieving the best-performing brand content among users with a similar Myers-Briggs personality type to train a deep generative model for producing content.
For example, in the case of Maya, the company ‘mapped millions of faces in SEA from multiple online sources’, including Instagram, and used this data to render ‘several face versions, the first building block to creating a virtual person’ (Lim Citation2020). Subsequently, other companies built on this groundwork and fabricated Maya's 3D face model () and refined her personality traits, which indicate a robotic passion for Puma products – the epitome of the post-digital (Berry and Dieter Citation2015).
Figure 3. Maya Gram (Citation2022), a virtual influencer for Puma in the SEA region.

Given her roots in the extraction of real-world user data, Maya is an apt example of the real2sim transfer in hyperproduction. Compared to other 3D animation software, Unity Technologies and Epic Games do not only promise to improve the rendering of virtual influencers like Maya but also the ease of fine-tuning details. In February 2021, Epic Games (Citation2021) announced MetaHuman Creator, a browser-based app that enables ‘creators of 3D content to slash the time it takes to build digital humans from weeks or months to less than an hour, while maintaining the highest level of quality.’ Similar to Google Colab, the platform used by artists to modify ruDALL-E, MetaHuman Creator runs in the cloud, so that its computational processes take place in data centres. After having created a character in the browser, users can then export it to Unreal Engine for animation and motion graphics. The crux is that characters developed with MetaHuman Creator are licenced for use only with Unreal Engine-based products.
Although the tool is free to use, it illustrates the consolidation of a proprietary ecosystem. As Birch and Muniesa (Citation2020:, 24) put it, ‘as content, in whatever form, has become almost costless to reproduce, companies and individuals have turned to IPRs [i.e. intellectual property rights] to secure their profits.’ For asset holders in the era of hyperproduction, the modular structure of video game engines is perfectly suited to prevent users from switching providers as they allow for the technical integration of trademarks. In the license agreement for MetaHuman Creator, Epic Games (Citation2022b) legally ensures that users are not allowed to ‘remove, disable, circumvent, or modify any proprietary notice or label’ included in the 3D characters. If the virtual influencer industry expands, game engine providers may thus siphon off profits from the likes of Lil Miquela (quite literally) as long as they underpinned their initial creation.
The case of autonomous vehicles underscores that the role of programmability and modularity is not limited to intangible outcomes. As tools to facilitate the sim2real transfer, car manufacturers leverage game engines in the pursuit of improved physical and tangible outcomes. Unity Technologies (2021: 11-13), for example, showcases its provision of game engine tools to Volkswagen Group of America. Although it is vital to be aware that such reports are designed to promote the product in question (i.e. Unity's game engine), we hold that they still entail insightful evidence:
We use image and ground-truth data generation in Unity to train neural networks for the implementation of autonomous driving components such as sensors, perception, prediction, and driving. […] For some projects with limited scope, we use synthetic data as a cheaper data-generation option, whereas projects with broader goals take advantage of a mixture of real-world and synthetic data. […] Unity's vast variety of assets makes it possible to design desired scenarios.
Another consequence of the programmability and modularity of game engines is the cultural habituation of firms in non-gaming industries into their modus operandi. Experience with game engines has even become a hiring criterium, both within the automotive sector and the influencer industry. For example, in a job advertisement for an ‘Autopilot Simulation Engineer’, Tesla (Citation2022) adds ‘experience working with Unreal Engine 4’ as the desired requirement. Along similar lines, Lil Miquela's creator studio Brud (Citation2022) looked for candidates that ‘work on character-driven projects and stories with the real-time production team in the Unreal Engine.’ This aspect illustrates Freedman’s (Citation2018:, 237) argument that the industrial migrations of game engines (across entertainment forms, 3D imaging, prototyping and manufacturing, scientific visualisation, architectural rendering, cross-platform mixed reality, and within the military) suggest they have broad power for organising the cultural field.’
To migrate into non-gaming industries, Unity Technologies and Epic Games use an economic strategy that they have in common with technology giants like Alphabet and Amazon: intrafirm cross-subsidization. This means that both firms strategically accept (temporary) losses in certain domains (e.g. high initial costs for setting up a tool such as MetaHumanCreator) in light of their skyrocketing profit margins in other business domains (e.g. micro-transactions in Fortnite). Such profits also facilitate the acquisition of start-ups. According to Crunchbase (Citation2022), Epic Games has made a total of 18 acquisitions, including a Serbian company that was instrumental in developing MetaHumanCreator. Unity Technologies has acquired 25 companies, most recently a Canadian company specialising in the production of digital humans. Although the analysis of how cross-subsidization and such mergers shape the trajectories of synthetic media and how such dynamics affect the political economy of platforms (Van Dijck, Poell, and De Waal Citation2018) is a task for future research, we can already see signs that economic power and cultural power go hand in hand in an era of hyperproduction.
5. Conclusion: the hyperproductive condition
This article argued that the penetration of cultural life with deep generative models is neither a temporary nor a coincidental phenomenon. We witness a transformation of the nature of platformized cultural production. Seen this way, the corporate imaginary of an ‘industrial metaverse’ (Lange Citation2022) is not a proposal to re-write reality, but rather a discursive attempt to push more production into a rentier relationship with proprietary reality engines. What is at the stake here is not the dissolution of reality and simulation in a philosophical sense but the intensification of rentier relations across cultural life. Hyperproduction, in this sense, can be seen as describing an ‘increased or excessive production’ (Collins Dictionary Citation2022) of dependencies between owners of valuable infrastructure assets and those who rely on them on a day-to-day basis. As a result of this, a primary conclusion is that economic actors that control the necessary hardware and software that is needed for hyperproduction, including Unity Technologies and Epic Games, are likely to expand their economic and cultural power as more industries will come to adopt deep generative models in their daily work. This conclusion entails a number of important empirical, political, and theoretical implications.
On an empirical level, the main conclusion is that the idea of hyperproduction can serve as an impetus for a wide range of future empirical case studies. We see a strong potential for linking political-economic approaches to platforms with social thought on rentiership in order to trace the evolution of AI-generated media. Such a cross-disciplinary approach would be well-placed to disentangle the tensions between discursive aspirations in the form of techno-optimistic imaginaries (e.g. the industrial metaverse), and material realities of uneven economic outcomes. For example, an object of study could be OpenAI's large-scale language model GPT-3, which the company offers on a subscription basis to users, similar to how cloud providers provide access to their computational resources. Although it remains to be seen whether and how GPT-3 or DALL-E will find their way into the daily business of media organisations, mapping this emerging ecosystem of services is an auspicious task.
While it is vital to be wary of the discursive strategies of industry actors aimed at attracting venture capital, we anticipate the emergence of creative manifestations of hyperproduction in the years to come. In this article, we discussed a certain facet of this development: the role of video game engines. The juxtaposition of autonomous vehicles and virtual influencers showed that although game engines are used in very different ways, two factors of asset specificity can be clearly identified: real-time physics and 3D graphics, and programmability and modularity. The rationale for deploying video game engines with respect to autonomous vehicles is the randomization of the parameters of synthetic worlds as a way to optimize artificial neural networks for their real-world use in cars. Conversely, the case of virtual influencers neatly illustrates the logical inversion of this process: the tailoring of influencers’ synthetic parameters and personality traits based on the real-world social media data of users. Taken together, those cases reflect prototypical examples of two inverted directions of hyperproduction: simulation to reality (sim2real) and reality to simulation (real2sim).
Against that backdrop, it is also conceivable that future use cases are positioned in between those paradigmatic examples. The importance of synthetic environments to fine-tune the parameters of artificial neural networks is likely to increase. Gartner (Citation2021b), a market research firm, predicts that by 2024, 60% of the data used for the development of AI will be synthetically generated. This means that in theory, firms can bypass the reliance on real-world data and circumvent data privacy regulations, such as the EU's General Data Protection Regulation (GDPR). The possibility of such modes of regulatory circumvention raises intriguing questions about future governance structures of AI-generated media, including but not limited to two challenges.
First, we agree with Steinhoff (Citation2022) in that it is pivotal to go beyond regulatory agendas that are purely derived from privacy-oriented conceptsFootnote8, like Zuboff's (2019) influential notion of surveillance capitalism. At its core, Zuboff's argument relies on the key premise that the extraction, accumulation, and analysis of real-world user data is the most important competitive advantage for technology companies. However, the ability of Unity Technologies and Epic Games to dominate the worldwide market for video game engine technology by setting up licencing strategies that result in a quasi-oligopolistic industry structure calls into question an exclusive focus on privacy and data. If more training data stems from synthetic sources, a focus on user data as a regulatory point of leverage is likely to be less impactful. In any case, there is an urgent need for more empirical evidence to grasp and problematise the potentially anti-competitive nature of rentiership (Birch Citation2020) when it comes to the provision of infrastructure assets such as video game engines. But if synthetic media is purely presented as a problem of misinformation within regulatory debates, such anti-competitive tendencies would remain unexplored and undiscovered.
Second, regulatory frameworks must consider the fact that the proliferation of AI-generated media is a cross-industrial phenomenon. At the time of finishing this article, most legislative frameworks and emerging policy proposals do not adequately account for the cross-sectoral role of synthetic media. The European Commission's Artificial Intelligence Act, for example, includes a provision to disclose the artificial nature of media content that resembles ‘existing persons, objects, places or other entities or events’ and would falsely appear to a person to be authentic’ (Veale and Borgesius Citation2021, 108). But this disclosure obligation legally falls on the users, not the providers, of synthetic media software. In other words, companies that provide the infrastructural tools without which certain forms of synthetic media would not exist in the first place, such as video game engines, would not be affected by this policy approach.
On the other hand, there are already examples of what provider-centric modes of synthetic media governance could look like. In 2022, the Cyberspace Administration of China unveiled a draft bill that aims to regulate deep synthesis services that are defined as ‘technologies using generative sequencing algorithms to make text, images, audio, video, virtual scenes, or other information’ (China Law Translate Citation2022). While it needs to be noted that this is not an example of democratic oversight, it still remains a useful example of oversight. What the draft bill shows is that, without some sort of conceptual abstraction, it is not possible to transform the elusive phenomenon of synthetic media into a regulatable set of practices, processes, and relations. In this case, the Cyberspace Administration uses an elaborate definition of deep synthesis services that takes into account the crucial technological role of generative sequencing algorithms – a different term for deep generative models. The model becomes a ‘regulatory object’ (Seyfert Citation2021) in its own right, rather than remaining a black-boxed entity. By establishing the legal category of ‘deep synthesis service providers’ (China Law Translate Citation2022), the proposed draft bill exhibits a neat infrastructural sensitivity.
Against this backdrop, we hope that the notion of hyperproduction to designate the penetration of cultural life with deep generative models will be a helpful reference point for scholars, regulators, activists, and other actors engaged in the emerging domain of synthetic media governance. We see abstraction as a prerequisite for effective regulation – not as the only requirement, but an important one. Without adequately representing the complexity of AI-generated media (i.e. by making it intelligible to a broader audience), its cross-sectoral role and implications will not find the appreciation that it requires, within both academic and policy circles. How can the design and governance structures of synthetic media be reimagined in ways that take seriously human rights, social justice, fair competition, and democratic values? Future research would be well-advised to explore this sweeping question, going beyond an analysis of the status quo to envision alternative trajectories of how synthetic modes of production could serve the common good, rather than undermining trust and solidarity. Even if those scenarios will not materialise, they could act as a normative benchmark of what should be done – and inform regulatory action in the here and now.
On a theoretical level, far from creating a multitude of simulated worlds that we cannot grasp with the toolkit of social theory, synthetic media remain firmly grounded in, and bounded by, reality. As a cultural phenomenon, hyperproduction calls into question established modes of thinking about what AI-generated media is and how it can (or should) be governed. For example, if deep fakes and geopolitical issues of misinformation remain the central point of reference that shapes our thinking of how AI impacts media production, the types of research questions and arguments that follow from this entry point would remain restricted by it. By contrast, a more imaginative and creative analytical repertoire to make sense of AI-generated media helps go beyond an excessive focus on media content (i.e. types of misinformation) in favour of a nuanced structural analysis of changes in media production. Deep fakes and text-image-models are merely the tip of a much bigger, and largely unexplored, iceberg: the integration of deep generative models into the ‘platform society’ (Van Dijck, Poell, and De Waal Citation2018).
This expanded perspective opens up fruitful new ways to analyse and theorise the cultural ramifications of AI's geographies of production. For as much attention has been given to the shipping container as both a physical and digital object that enables supply chain capitalism (Klose Citation2015; Tsing Citation2009), this article has unearthed another kind of imbrication of capitalism and worlding. Not only a continuation of a political economy over what companies control global operating systems (McKelvey Citation2018) but an attempt to shift the terrain of media production to reality itself (Braman, Citationforthcoming). Hyperproduction is also a possibility for production building on Rossiter’s (Citation2014) idea of ‘logistical worlds’ as it refers to the attempts of firms to create meta-logistical worlds upon a subscription basis to a new generation of downstream producers, competing on a level planning field between human and synthetic talent.
In appreciation of the circular nature of hyperproduction, it is worth returning to the article's beginning as it now comes to an end. As more digital content is produced on top of already-hyperproduced content (e.g. the fake Mona Lisas), a consequence of this development might be the homogenization and convergence of media production overall. The point of the Mona Lisa is that there is only one, not infinite AI-generated imitations. But if synthetic outputs soon become real enough to be seen as the training grounds for deep generative models, models that produce better synthetic media, that in turn transform into the new training grounds, hyperproduction would trigger an endless spiral that recycles archived content. While the cultural ramifications of such a spiral of synthetic media would not be dramatic in hermetically sealed environments such as the training of autonomous vehicles, they could potentially have detrimental effects on the deliberative and democratic conventions of mediated public spheres. After all, hyperproduction goes hand in hand with entirely new spaces for media production.
One such space is the ‘deep latent space’ (Offert Citation2021) of generative models like DALL-E and GPT-3. Latent space can be imagined as a ‘representation of compressed data in which similar data points are closer together in space’ (Tiu Citation2020). For example, a text-to-image model is able to generate visualisations of text queries such as ‘Mona Lisa painted by van Gogh’ because it first decomposes this natural language input into its constitutive elements: ‘Mona Lisa’ and ‘painted by van Gogh.’ It then relates those elements to structural similarities that it identified in the data it was trained on (which includes both the Mona Lisa as well as van Gogh's paintings). As Tiu (Citation2020) explains, ‘these similarities, usually imperceptible or obscured in higher-dimensional space, can be discovered once our data has been represented in the latent space.’ After having related the constitutive elements of text queries to representations of compressed training data, the model reconstructs the latent space representation into a 2D image that represents a morph between the Mona Lisa and van Gogh's paintings – not in the sense of an artistic morph, but in the sense of how the model interpreted the relation between data points within latent space. Every time this process takes place, a different outcome is generated. Paradoxically, every synthetic Mona Lisa is unique.Footnote9
With respect to this latter point, Baudrillard’s (Citation1994) work on hyperreality is helpful to problematise the role of deep generative models in shaping social, economic, and cultural life. But unlike the idea of hyperreality, hyperproduction is not meant to be a superstructure hovering above the capitalist system – it probes how capitalist systems co-constitute reality. Although we cannot foresee the future worlds of synthetic media, we can strive to develop a theoretical repertoire to imagine them.
Acknowledgements
The authors wish to thank Mark Graham for his comments on an early manuscript. The paper has also benefited from the conversations that the authors have engaged in as part of the Machine Agencies group, which is based in the Speculative Life Cluster at the Milieux Institute for Arts, Culture and Technology at Concordia University.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Fabian Ferrari
Fabian Ferrari is a doctoral candidate at the Oxford Internet Institute.
Fenwick McKelvey
Fenwick McKelvey is an Associate Professor in Information and Communication Technology Policy in the Department of Communication Studies at Concordia University. He is co-director of the Applied AI Institute and leads Machine Agencies at the Milieux Institute.
Notes
1 Google Colab is a cloud-based machine learning platform. It allows users to run python code in the browser, without having to use additional software. Google Colab also provides free access to computing resources, including graphics processing units (GPUs).
2 The article intentionally uses a broad understanding of synthetic media to cast a wide net of empirical phenomena and highlight their relevance for a theory of hyperproduction. This is a useful strategy to adequately answer the research question framing this article.
3 Herein lies our divergence from Baudrillard (Citation1994), who theorizes ‘the hyperreal as taking on a life of its own disconnected from the capitalist mode of production’ (Ryan Citation2007, 2).
4 We do not wish to imply that the ways in which states or quasi-state institutions such as the OECD define economic production is equivalent with actually-existing business practices. Rather, the point is to emphasize the relationship between inputs and outputs.
5 A video game engine is a software architecture that comprises required libraries and support tools, thereby partially automating laborious tasks faced by game designers. For example, in 2019, 53 percent of the top 1,000 games in Apple's App Store and Google Play were developed with Unity Engine, including Pokémon Go (Hollister Citation2020).
6 According to Unity's co-founder David Helgason, ‘we were going to be a game studio, but when we decided we'd be a technology company back in 2004, we basically wrote on the wall that we wanted democratise game development – to enable small studios with whatever high-end technology they felt was necessary for them’ (Cook Citation2012).
7 In this example, what classifies as the real sample consists of illustrations rather than images of birds – a playful demonstration that the meaning of real sample is context-dependent. Given that we focus on theorizing the role of deep generative models in giving rise to a distinct form of rentier capitalism, we intentionally use a simplified portrayal of GANs. Not all forms of synthetic media are generated by GANs.
8 Admittedly, this is not so much an ‘no, but’ argument but rather a ‘yes, and’ argument. Of course, data privacy regulations are highly important. However, there is a danger in using the extraction of user data as the one-and-only explanation of uneven power relations in the context of the political economy of artificial intelligence.
9 The fact that there is, in theory, an endless number of possibilities to create relations and links between data points in ever-more sophisticated forms of latent space is what makes models such as DALL-E and GPT-3 powerful in the first place. A homogenization of cultural production can co-exist with a heterogenization of synthetic media production.
References
- Akkaya, Ilge, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, et al. 2019. ‘Solving Rubik’s Cube with a Robot Hand’. ArXiv:1910.07113 [Cs, Stat], October. http://arxiv.org/abs/1910.07113.
- Allen, George W. 2001. None so blind: A personal failure account of the intelligence in Vietnam. Chicago: Ivan R. Dee Publishing.
- Baudrillard, Jean. 1994. Simulacra and simulation. Ann Arbor: University of Michigan Press.
- Berry, David M., and Michael Dieter. 2015. Postdigital aesthetics. London: Palgrave Macmillan.
- Birch, Kean. 2015. We have bever been neoliberal: A manifesto for a doomed youth. Winchester, UK Washington, USA: Zero Books.
- Birch, Kean. 2020. Techno science rent: Toward a theory of rentiership for techno scientific capitalism. Science, Technology, & Human Values 45, no. 1: 3–33.
- Birch, Kean, and Fabian Muniesa, eds. 2020. Assetization: Turning things into assets in technoscientific capitalism. Cambridge: MIT Press.
- Braman, Sandra. Forthcoming. Meta: A meditation on media economics. In The SAGE handbook of the digital media economy, eds. Terry Flew, Julian Thomas, and Jennifer Holt. Thousand Oaks, CA: Sage Publications.
- Brud. 2022. ‘Brud is seeking Sr Software Engineer (UE4/C++) & Sr Real-time Lighter (UE4)’. https://forums.unrealengine.com/t/brud-is-seeking-sr-software-engineer-ue4-c-sr-real-time-lighter-ue4/145442.
- Captain, Sean. 2018. How Google’s DeepMind will train its AI inside Unity’s video game worlds. FastCompany, 26.09.2018. https://www.fastcompany.com/90240010/deepminds-ai-will-learn-inside-unitys-video-game-worlds.
- China Law Translate. 2022. Provisions on the Administration of Deep Synthesis Internet Information Services (Draft for solicitation of comments). https://www.chinalawtranslate.com/deep-synthesis-draft/.
- Christophers, Brett. 2020. Rentier capitalism: Who owns the economy, and who pays for It. London: Verso.
- Chun, Wendy. 2008. Programmability. In Software studies: A lexicon, ed. Matthew Fuller, 224–229. Cambridge: MIT Press.
- Collins Dictionary. 2022. ‘Hyperproduction’. https://www.collinsdictionary.com/dictionary/english/hyperproduction.
- Cook, Dave. 2012. ‘Unity interview: engineering democracy’. VG247.com, 18.10.2012. https://www.vg247.com/unity-interview-engineering-democracy.
- Crunchbase. 2022. List of Epic Games’s 18 Acquisitions. https://www.crunchbase.com/search/acquisitions/field/organizations/num_acquisitions/epic-games-2.
- Dyer-Witheford, Nick, and Greig de Peuter. 2009. Games of empire: Global capitalism and video games. Minneapolis: University of Minnesota Press.
- Epic Games. 2021. ‘Announcing MetaHuman Creator: Fast, High-Fidelity Digital Humans in Unreal Engine’. Epic Games News, 10.02.2021. https://www.epicgames.com/site/en-US/news/announcing-metahuman-creator-fast-high-fidelity-digital-humans-in-unreal-engine.
- Epic Games. 2022a. ‘The Automotive Field Guide’. https://ue.unrealengine.com/ENT-1845-11-2020-Automotive-Field-Guide_LP-Automotive-Field-Guide.html.
- Epic Games. 2022b. ‘MetaHuman Creator End User License Agreement’. https://www.unrealengine.com/en-US/eula/mhc.
- Farseev, Aleksandr, Qi Yang, Andrey Filchenkov, Kirill Lepikhin, Yu-Yi Chu-Farseeva, and Daron-Benjamin Loo. 2021. SoMin. ai: Personality-driven content generation platform. Proceedings of the 14th ACM international conference on Web search and data mining: 890–893.
- Freedman, Eric. 2018. Software. In The craft of criticism: Critical media studies in practice, eds. Michael Kackman, and Mary Celeste Kearney, 318–330. New York: Routledge.
- Gaboury, Jacob. 2021. Image objects: An archaeology of computer graphics. Cambridge: The MIT Press.
- Gartner. 2021. ‘By 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated’. Gartner Blog, 24.07.2021. https://blogs.gartner.com/andrew_white/2021/07/24/by-2024-60-of-the-data-used-for-the-development-of-ai-and-analytics-projects-will-be-synthetically-generated/.
- Gram, Maya. 2022. Instagram Profile [@mayaaa.gram]. https://www.instagram.com/mayaaa.gram.
- Hayles, N. Katherine. 1999. How we became posthuman: Virtual bodies in cybernetics, literature, and informatics. Chicago, IL: University of Chicago Press.
- Hegarty, Paul. 2004. Jean baudrillard: Live theory. London/New York: Continuum.
- Hogan, Robert. 2006. Personality and the fate of organizations. London: Routledge.
- Hollister, Sean. 2020. ‘Unity’s IPO filing shows how big a threat it poses to Epic and the Unreal Engine’. The Verge, 24.08.2020. https://www.theverge.com/2020/8/24/21399611/unity-ipo-game-engine-unreal-competitor-epic-app-store-revenue-profit.
- The Influencer Marketing Factory. 2022. Virtual Influencers Survey, 29.03.2022. https://theinfluencermarketingfactory.com/virtual-influencers-survey-infographic.
- Johnson, Derek. 2017. Production. In Keywords for media studies, eds. Laurie Ouellette, and Jonathan Gray. New York: New York University Press.
- Klose, Alexander. 2015. The container principle: How a box changes the way we think. Cambridge: The MIT Press.
- Lange, Danny. 2022. ‘The industrial metaverse: Where simulation and reality meet’. VentureBeat, 26.01.2022. https://venturebeat.com/2022/01/26/the-industrial-metaverse-where-simulation-and-reality-meet/.
- Lim, Shawn. 2020. ‘Puma introduces a virtual influencer in South East Asia called Maya’. The Drum, 17.03.2020. https://www.thedrum.com/news/2020/03/17/puma-introduces-virtual-influencer-south-east-asia-called-maya.
- Looking Glass. 2021. Making ruDALL-E fine tuning quick and painless. Google Colab. https://colab.research.google.com/drive/15vFLeepkSTr1qd4xs31g9kMEiwkWP0sh#scrollTo=y-s9LfFBSyty.
- McKelvey, Fenwick. 2011. A programmable platform? Drupal, modularity, and the future of the Web. Fibreculture 18: 232–254.
- McKelvey, Fenwick. 2018. Internet daemons: Digital communications possessed. Minneapolis: University of Minnesota Press.
- Moles, Peter, and Nicholas Terry. 1997. Asset Specificity. In The handbook of international financial terms, eds. Peter Moles and Nicholas Terry. Oxford: Oxford University Press.
- Natale, Simone. 2021. Deceitful media: Artificial intelligence and social life after the turing test. Oxford: Oxford University Press.
- Nicoll, Benjamin, and Brendan Keogh. 2019. The unity game engine and the circuits of cultural software. Cham: Springer International Publishing.
- OECD. 2001. Economic Production. https://stats.oecd.org/glossary/detail.asp?ID=725.
- Offert, Fabian. 2021. Latent deep space: Generative adversarial networks (GANs) in the sciences. Media+Environment, December, doi:10.1525/001c.29905.
- Ong, Thuy. 2020. ‘Virtual Influencers Make Real Money While Covid Locks Down Human Stars’. Bloomberg, 29.10.2020. https://www.bloomberg.com/news/features/2020-10-29/lil-miquela-lol-s-seraphine-virtual-influencers-make-more-real-money-than-ever.
- Pandey, Prakash. 2018. ‘Deep Generative Models’. Towards Data Science, 31.01.2018. https://towardsdatascience.com/deep-generative-models-25ab2821afd3.
- Rossiter, Ned. 2014. Logistical worlds. Cultural Studies Review 20, no. 1: 53–76.
- Rothman, Joshua. 2018. ‘In the age of AI, is seeing still believing?’. The New Yorker, 12.11.2018. https://www.newyorker.com/magazine/2018/11/12/in-the-age-of-ai-is-seeing-still-believing.
- ruDALL-E. 2022. Write a text query and get an image generated by ruDALL-E. https://rudalle.ru/en/demo.
- Russell, Andrew L. 2012. Modularity: An interdisciplinary history of an ordering concept. Information & Culture: A Journal of History 47, no. 3: 257–287.
- Ryan, Michael T. 2007. Hyperreality. In The blackwell encyclopedia of sociology, ed. George Ritzer. Malden, MA: Wiley-Blackwell.
- Sadowski, Jathan. 2019. When data is capital: Datafication, accumulation, and extraction. Big Data & Society 6, no. 1: 1–12.
- Sadowski, Jathan. 2020. The internet of landlords: Digital platforms and new mechanisms of rentier capitalism. Antipode 52, no. 2: 562–580.
- Sber. 2021a. ‘Sber creates ruDALL-E, first multimodal neural network generating images based on Russian-language description’. Sberbank Press Release, 02.11.2021. https://www.sberbank.com/news-and-media/press-releases/article?newsID=dd220542-ab0b-4c3f-91d4-0e40dd33f0d4&blockID=7®ionID=77&lang=en&type=NEWS.
- Sber. 2021b. ‘ruDALL-E neural network by Sber for image generation based on Russian-language descriptions now available on ML Space platform’. Sberbank Press Release, 15.12.2021. https://www.sberbank.com/news-and-media/press-releases/article?newsID=a26a208d-6c72-4f8a-a3b7-aefe1112cbae&blockID=7®ionID=77&lang=en&type=NEWS.
- Seyfert, R. 2021. Algorithms as regulatory objects. Information, Communication & Society 25, no. 11: 1–17.
- Solis, Daniel. 2022. These birds do not exist. https://twitter.com/Daniel-Solis/status/1487913576929103884.
- Srnicek, Nick. 2021. Value, rent, and platform capitalism. In Work and labour relations in global platform capitalism, eds. Julieta Haidar, and Maarten Keune. Cheltenham: Edward Elgar.
- Steinhoff, James. 2022. Toward a political economy of synthetic data: A data-intensive capitalism that is not a surveillance capitalism? New Media & Society: 29–45.
- Tesla. 2021. AI Day. https://www.youtube.com/watch?v=j0z4FweCy4M.
- Tesla. 2022. Software Engineer, Autopilot Simulation. https://www.tesla.com/careers/search/job/software-engineerautopilotsimulation-101985.
- Tiu, Ekin. 2020. Understanding Latent Space in Machine Learning. Towards Data Science, 04.02.2020. https://towardsdatascience.com/understanding-latent-space-in-machine-learning-de5a7c687d8d.
- Tobin, Josh. 2020. ‘Lecture 22 Sim2Real and Domain Randomization – CS287-FA19 Advanced Robotics at UC Berkeley. Course Instructor: Pieter Abbeel’. YouTube, 20.02.2020. https://www.youtube.com/watch?v=ac_W9IgKX2c.
- Tobin, Josh, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. 2017. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real world. 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp. 23-30. IEEE.
- Tsing, Anna. 2009. Supply chains and the human condition. Rethinking Marxism 21, no. 2: 148–176.
- Turner, Fred. 2006. From counterculture to cyberculture. Chicago, IL: University of Chicago Press.
- Unity Technologies. 2018. ‘Unity Technologies Increases Commitment to Automotive with Dedicated Team’. Press Release, 17.03.2018. https://unity.com/our-company/newsroom/unity-technologies-increases-commitment-automotive-dedicated-team-industry.
- Van Dijck, José, Thomas Poell, and Martin De Waal. 2018. The platform society: Public values in a connective world. Oxford: Oxford University Press.
- Veale, Michael, and Frederik Zuiderveen Borgesius. 2021. Demystifying the draft EU Artificial Intelligence Act — analysing the good, the bad, and the unclear elements of the proposed approach. Computer Law Review International 22, no. 4: 97–112.
- Webster, Andrew. 2020. ‘Virtual artist Miquela debuted a music video at Lollapalooza’. The Verge, 31.03.2020. https://www.theverge.com/2020/7/31/21348119/miquela-hard-feelings-music-video-lollapalooza.
- Whittaker, Lucas, Tim C. Kietzmann, Jan Kietzmann, and Amir Dabirian. 2020. “All around me are synthetic faces”: The mad world of ai-generated media. IT Professional 22, no. 5: 90–99. doi:10.1109/MITP.2020.2985492.
- Wikimedia. 2022. GAN Architecture. https://commons.wikimedia.org/wiki/File:A-Standard-GAN-and-b-conditional-GAN-architecturpn.png.
- Wood, Erroll, Tadas Baltrušaitis, Louis-Philippe Morency, Peter Robinson, and Andreas Bulling. 2016. Learning an appearance-based gaze estimator from one million synthesised images. Proceedings of the ninth biennial ACM symposium on Eye tracking research & applications, pp. 131-138.
- Woolf, Max. 2022. ‘Make Your Own AI-Generated Pokémon’. Google Colab, 13.01.2022. https://colab.research.google.com/drive/1A3t2gQofQGeXo5z1BAr1zqYaqVg3czKd?usp=sharing.