
ABSTRACT
This article presents an interpretation of the transformation of selection tests in our societies, such as competitive examinations, recruitment or competitive access to goods or services, based on the opposition between reality and world proposed by Luc Boltanski in On Critique. We would like to explore the change in the format of these selection tests. We argue that this change is made possible by a spectacular enlargement of the space for comparisons between candidates and by the implementation of machine learning techniques. But this shift is not the only and simple consequence of the introduction of the technological innovation brought by massive data and artificial intelligence. It finds justification in the institutions and organizations that order selection tests because this new test format claims to absorb the multiple criticisms that our societies constantly raise against the previous generations of tests. This is why we propose to interpret the attention and the development of these automated procedures as a technocratic response to the development of a critique of the categorical representation of society.
The proliferation of classification tests
Rather than juries, committees, judges, or recruiters, can we use calculation techniques to select the best candidates? Some proponents of algorithm decision systems consider human judgements to be so burdened by prejudices, false expectations, and confirmation biases that it is much wiser and fairer to trust a calculation (Kleinberg et al. Citation2018). On the other hand, a large body of literature is concerned that the implementation of decision automation may lead to systemic discrimination (Pasquale Citation2015; O’Neil Citation2017; Eubanks Citation2017; Noble Citation2018). While algorithmic calculations are increasingly used in widely different contexts (music recommendations, targeted advertising, information categorization, etc.), this question takes a very specific turn when calculations are introduced into highly particular spaces in our societies: the devices used to select and rank candidates to obtain a qualification or a rare resource. Following the terminology of Luc Boltanski and Laurent Thévenot (Citation1991), these selection situations constitute a particular form of reality tests (‘épreuve de réalité’). Backed by institutions or organizations granting them a certain degree of legitimacy, a disparate set of classification tests has become widespread in our societies with the development of procedures of individualization, auditing, and competitive comparison (Espeland and Sauder Citation2016; Power Citation1997). Some of these situations are extremely formalized and ritualized, whereas others are hidden in flows of requests and applications addressed to the government, companies, or a variety of other organizations. With the bureaucratization of society (Hibou Citation2012), we are filling out an increasing number of forms and files in order to access rights or resources.
The stability of these selection devices is still uncertain. The way that choices are made, the principles justifying them, are constantly used to fuel criticism that challenges tests. In this article, we offer a conceptual interpretation of the impact that machine learning techniques have on selection tests.Footnote1 The hypothesis that we wish to explore is that there is a displacement of the format of classification tests made possible by a spectacular expansion in the candidate comparison space and the implementation of machine learning techniques. However, this displacement is more than just a consequence of the introduction of technological innovation contributed by big data and artificial intelligence. Its justification is based on the claim that this new test format takes into account the multiple criticisms that our societies have constantly raised against previous generations of tests. This is why we propose to interpret the rise of these automated procedures as a technocratic response to the development of criticism of the categorical representation of society, which is itself developing as a result of the individualization and subjectification processes throughout our societies (Cardon Citation2019).
The conceptual framework outlined in this text links four parallel lines of analysis.Footnote2 The first is related to the transformation dynamics of selection tests in our societies. To shine light on it, we propose a primitive formalization of four types of selection test, which we call performance tests, form tests, file tests, and continuous tests (). The progressive algorithmization of these tests is based on an expansion in the space of the data used in decision making. This involves actors from increasingly diverse and distant spatialities and temporalities through successive linkages. To allay the criticism levelled at previous tests, the expansion of the comparison space allows candidates’ files to have a different form, by increasing the number of data points in the hopes of better conveying their singularities. The justifications provided to contain criticism increase in generality and are formalized through the implementation of a new test that groups these new entities together in the ‘technical folds’ (Latour Citation1999) formed by the computation of machine learning. These folds themselves then become standardized and integrated into a new comparison space. However, new criticism can rapidly emerge, once again leading to a dynamic of expansion of candidates’ comparison space (John-Mathews et al. Citation2023). This dynamic process of test displacement under the effect of criticism is applicable to many types of reality test (Boltanski and Chiapello Citation1999). In this article we will rather pay attention to ‘selection’ tests during which a device must choose and rank candidates within an initial population.
Figure 1. The displacement of reality test.

The second line of analysis in this article is related to the process of spatial–temporal expansion of the data space used to automate decisions (the comparison space). The development of algorithmic calculation and, more particularly, artificial intelligence, enables the emergence of a continuous expansion of devices allowing for the collection of data necessary for calculation (Crawford Citation2021). This process has two components: it is first and foremost spatial, spanning a network of sensors that increasingly continuously cling to people's life paths by means of various affordances; secondly, it is temporal, given that a new type of selection test has the particularity of being supported by the probability of the occurrence of a future event, to organize the contributions of past data. The displacement of selection tests thus constantly expands the comparison space, not only by increasing the number of variables and diversifying them, but also by re-agencing the temporal structure of the calculation around the optimization of a future objective.
The third line of analysis studied here looks at the change in calculation methods and, more specifically, the use of deep learning techniques to model an objective based on multidimensional data (Cardon, Cointet, and Mazières Citation2018). This displacement within statistical methods, that is the transition from simple machine learning models to complex deep learning techniques, is the instrument of the test displacement dynamic. By radically shifting calculation towards deep learning, it transforms the possibility of using initial variables to make sense of test decisions and explain them.
The fourth and more general line of analysis looks at the way of justifying (through principles) and legitimizing (through institutional stabilization authorities) the principles on which calculations base selection. The dynamic that this text seeks to highlight reveals a displacement in the legitimization method required if tests are to become widely accepted. Whereas traditional selection tests draw on government resources and a compromise between meritocracy and egalitarianism, the new tests that orient classifications use an increasing amount of data that is not certified by institutions; rather, this data is collected by private actors, and is therefore the responsibility of individuals and contingent on their behaviour. Hence, the justification of tests is based less on the preservation of the current state of society (maintaining equality in a population, distributing in accordance with categories recognized by all, rewarding merit) than on an undertaking to continuously transform society.
Reality and the world
The interpretation of this test displacement dynamic is based on the distinction between reality and the world as proposed by Luc Boltanski in On Critique (Citation2009). Reality refers to a social order that is constantly supported by institutions in order to produce qualifications and stable and shared representations of the social world. Reality endures because it is established by organized tests (competitions, recruitment, classifications, qualifications, wage scales, etc.) that are endorsed by institutions or quasi-institutions. Soundly anchored in an objectification framework produced by statistical instruments, reality tests define the categories and symbolic representations that allow us to say whether a result is fair or unfair: the competition allowed the best candidate to be selected; this individual has the qualities required to fill this position; this file meets the conditions for obtaining a loan, and so forth. It is also on the basis of these same categorical representations that the results of reality tests can be criticized. By drawing on other categories (such as sex, gender, education, etc.), it is possible to show that the reality tests results of as different as school examinations (Bourdieu and Passeron Citation1964) and access to kidney transplants (Baudelot et al. Citation2016) are unfair because they discriminate by favouring the upper classes. Our ordinary sense of justice is therefore based on a set of categories that are both descriptive and prescriptive, and which are endorsed by institutions and contribute to producing what Luc Boltanski calls reality (Boltanski and Thévenot Citation1983; Boltanski Citation2009).
However, the results of reality tests can be challenged from a broader perspective, which in this case shines light on the artificial and arbitrary dimension of the categories used to stabilize reality and our ordinary sense of fairness. Luc Boltanski uses the term world – ‘everything that is the case’ (Boltanski Citation2009; Susen Citation2014) – to describe the background world from which it is possible to condemn the artificiality of reality. Tests therefore appear unfair because they do not take into consideration the singularity of candidates’ profiles, because test criteria are imperfect, because other dimensions of the world should be included in the calculation, because the very meaning of tests is debatable, and so on. The criticism levelled at the results of reality tests can therefore be called meta-criticism – or existential criticism – insofar as it highlights the existence of a world containing facts that are denser and more diverse than the information used in the selection process. Nonetheless, the new types of selection tests being deployed today through artificial intelligence claim precisely to implement an expansion and singularization of information. Therefore, we also propose to interpret the displacement of a set of ideal-type characterizations of selection test formats as a particular policy aimed at assimilating criticism by claiming to expand points of access to the world.
1. Performance tests and form tests
In order to deploy this displacement dynamic, we need an initial situation. To characterize our societies’ forms of selection, we can consider two types of tests that constitute the two facets of organized modernity: performance tests and form tests. The former, which are competitive, place value on merit, while the latter, which are bureaucratic, place value on the rights of individuals in a given national space. The compromise between these two parallel tests is at the heart of the organizational forms of liberal democracies. Their claim is to encourage individual responsibility while ensuring collective solidarity.
1.1. Performance tests
Selection tests have a pure form: competition. Individuals are assembled for a test in which only the quality of their performance will be taken into consideration to make a decision: passing an exam, a driver's test, a song contest, a tennis match, and so forth. Performance in the situation is the only element that evaluators (exam graders, talent show juries, etc.) can take into consideration in the evaluation. Any element for evaluating a candidate that is not directly relevant for evaluating the performance must be excluded. Without other attributes, in the situation the candidate can only mobilize a set of incorporated qualities and resources, such as in the case of a sports competition, which constitutes the ‘purest’ form of performance test (Stark Citation2020).
To uphold these performance tests, highly formalized rules both in terms of the guaranteed equality of opportunities between candidates and of the independence of juries are necessary. This is why it is important for institutions to act as guarantors of the valid execution of the test. They must be recognized by the candidates, possess a sort of monopoly over the trophies offered to the winners, and ensure the durability and stability of the qualifications benefiting the selected candidates. In France, the baccalaureate examination organized by the French Ministry of Education tests the skills and knowledge of candidates exiting secondary school, and passing it is a condition for moving on to higher education. The institution organizes an identical test for everybody, without local arrangements, subject to anonymity, with identical exam subjects, and so forth. It must also ensure the strict control of juries so that they exercise their judgement on the sole basis of the criteria that the test seeks to evaluate. Performance tests are one of the most stable classification devices in our societies. The conditions that they must meet are then so demanding that they have to be separated from the course of regular social activities and adopt the form of a specific ritual (Bourdieu Citation1981).
1.2. Form tests: multiple criteria, one rule
In parallel, a second type of initial situation is found in the bureaucratic facet of performance tests: form tests. In organized bureaucracies, access to resources and certain statuses is indexed automatically, based on a number of criteria. In this case, it is necessary for applicants to belong to the categories defined to meet the conditions of the test. Access to welfare benefits, to a university, or to certain privileges (such as a disability card) is determined by simple criteria that are the result not only of previous tests but also, above all, of individuals’ belonging to stable categories: income, number of children, medical data, or marital status. The criteria mobilized by the institution are transformed into several variables-thresholds and the test is reduced to the application of formal decision rules. Unlike performance tests, candidates will not be called upon to perform, and an intermediary takes part in the decision-making process: the form. The form allows for the extraction of variables which will perform the costly process of translating candidates and their skills into justification of the priority assigned to them. Criteria-based assignment rules automatically translate candidates’ qualities into test results, and consequently also translate the rule into the principle justifying the categorization. Knowledge of criteria allows candidates to interpret both how and why they have been categorized in a given way; for example, it is apparent that it is relevant and fair to give priority to ‘single mothers’ in the waiting list for a place in a childcare centre.
1.3. The statistical stabilization of reality
As soon as a candidacy form is submitted to a selection test, the choice of the categories that it provides to selectors (or, as we will see later, the algorithm helping them to make a decision) can be discussed. The movement supporting the test displacement dynamic is fuelled by the development of increasingly harsh criticism of the imperfect and arbitrary nature of the categorical representation of society. The reality can constantly be challenged by highlighting the irreducible diversity of the world. However, it is necessary to emphasize in advance the cardinal role played by statistical objectification instruments in stabilizing reality (Boltanski Citation2012). The use of categories to describe individuals is based on the fact that it is possible to infer correlations between certain categories in the file and the manifestation of certain types of candidate qualities. The implementation of this ‘statistical reasoning style’ (Hacking Citation1994) is based on a set of presuppositions that was established and institutionalized during the remarkable deployment of the measurement of individuals starting in the mid-nineteenth century (Porter Citation1986; Gigerenzer et al. Citation1989), four features of which are relevant to mention here.
Statistics and democracy. The first is the close ties between the development of statistical knowledge and the formation of modern democracies. As Ian Hacking (Citation1990) points out, democratic and liberal societies affirming the autonomy of individuals are necessary for statistical knowledge to highlight the fact that despite being free, individuals’ behaviours obey globally consistent patterns. The probabilistic paradigm thus replaced the causality of natural laws by a technique for reducing uncertainty which, following a vast undertaking to categorize populations, allowed nations to develop techniques for understanding and governing populations (Desrosières Citation2000). The development of statistical knowledge thus allowed for the big picture of the nations spawned by the great revolutions of the eighteenth century, based on the equalization of individuals: all people are commensurable, and deviations rather than differences are what can be put into perspective. This statistical equalization introduced the idea of distribution and therefore the comparison of populations within a given set.
The homogenization of categories and nomenclatures. The second feature is that the development of statistical systems cannot be dissociated from an undertaking to categorize the social world. The ‘deluge of numbers’ that hit Western societies during the nineteenth century is the consequence of the immense work undertaken to record, measure, and quantify social activities (Porter Citation1995). Births, crimes, diseases, professional activities, moves, and so forth: in all of these domains, it was necessary to establish descriptive classes to categorize occurrences in large statistical portraits of populations. This process contributed to homogenizing nation states (Didier Citation2020; Scott Citation2008) by developing global nomenclatures that served to record, compare, and govern societies (Bowker and Star Citation1999). It is precisely because these categories break the social world down on the basis of common criteria that comparisons can be made and categories take on meaning in relation to one another. The statistical description of societies is therefore closely associated with the production of ‘conventions of equivalence’ that make society intelligible as a whole, greatly benefiting the emerging field of social science (Desrosières Citation2014).
Constant causes and the interpretability of society. The third feature highlighted by historians of statistics is that these portraits of society give shape to the statistical argument par excellence which consists in establishing correlations between categories. Quetelet's ‘frequentist’ statistics of ‘the average man’ generalizes the idea that social phenomena can be correlated with constant causes. Some types of behaviour or events can be interrelated through a convention of equivalence because they are determined by a ‘constant cause’ as opposed to an ‘accidental cause’, which can be correlated only with behaviours or singular events (Desrosières Citation2010). Both practically, through the maintenance of a codified system of regular recordings, and epistemologically, by distributing statistical events around average values, the ‘frequentist’ method of social statistics thus contributed to solidifying the constant relationships between certain types of categories and certain types of events. Embedded in regular and reliable institutional and technical devices, these relationships took on a certain externality, making them a solid support for establishing correlations with numerous social phenomena and for inferring a causal interpretation of them. For example, it would be argued that a candidate who has obtained a certain type of qualification is likely to perform better in a certain type of job. However, as we will see, it was a different model, that of the probability of causes, which the so-called ‘Bayesian’ techniques refused for a long time in statistical thinking proposed to reopen. They would do so by introducing the possibility that ‘accidental causes’ not distributed following a regular law might become the medium for statistical correlations of another type (McGrayne Citation2011).
Collective representation and reflexivity. Last of all, the system of categories serving to describe society has also become an instrument allowing ordinary people to decipher the social world. Gender, age, income level, profession, or education, but also a set of regular descriptors give a durable shape to society and assign individuals to categories representing them. Several surveys have shown the extent to which this categorical system constitutes a representation of society which is profoundly embedded in ordinary forms of perception (Boltanski and Thévenot Citation1983). It provides representations, points of comparison, and explanations that feed actors’ common sense. This capacity for understanding, comparing, and explaining the differences between categories of individuals is also at the heart of the formation of a series of expectations pertaining to the meaning of fairness (John-Mathews Citation2021, Citation2022). Ted Porter (Citation1995) highlighted the extent to which the development of statistical arguments at the end of the nineteenth century could be used as a weapon wielded by dominated groups in order to observe and criticize the social order by shining light on the fact that certain categories of individuals were systematically excluded from the results of reality tests. For injustice to become observable, it is simultaneously necessary for categories and a nomenclature to shine light on the unequal distribution of resources and opportunities (Bruno and Didier Citation2013; Desrosières Citation2014). Often criticized as instruments of bureaucratic rationalization, the critical dynamic of statistics was thus at the heart of the formation of social movements and their capacity to denounce inequalities (Boltanski Citation2014).
1.4. The shortcomings of performance and form tests
The performance-form compromise that has stabilized in organized liberal modernity (Wagner Citation2002) nonetheless appears to be hypocritical and rigid, faced with the diversification of practices and the subjectification of individual experiences. The basic formalism of these standard tests is systematically criticized due to its rigidity, its lack of understanding of context and, ultimately, its arbitrary nature. The competition form has been the subject of recurrent criticism, consisting in demystifying the supposed veil of ignorance that the performance places over the real diversity of candidates’ qualities. Already present in the 1970s in Pierre Bourdieu's work on school examinations (Bourdieu and Passeron Citation1964), criticism of the meritocracy of competitive exams is regularly brought into the public arena (Allouch Citation2017; Duru-Bellat Citation2012). Behind the fantasy of equality among candidates, the principles of performance tests impose an ideology (of merit, success, exploits, etc.) that alienates other ways of demonstrating candidates’ qualities.
Form tests are similarly the subject of recurrent criticism. Based on excessively large and impersonal statistical aggregates, form tests appear to be a bureaucratic solution that selects categories and not individuals. They are therefore criticized for producing injustices by eliminating certain singularities or focusing on categories that are no more than imperfect approximations of the principle that the test seeks to honour. For example, the selection policy implemented at Sciences Po to promote social diversity offers a specific path for accessing examinations to candidates graduating from secondary schools in geographic areas combining social and economic difficulties. This geographic criterion – the location of the secondary school – was retained to avoid the adoption of a policy of affirmative action based on parents’ social and economic situation. As a result, middle-class secondary school students who have nonetheless chosen to study at this type of secondary school can access Sciences Po's specific examination pathway by ‘usurping’ spots that were not intended for them. The choice of the categorical criterion – using the variable of a secondary school in a disadvantaged neighbourhood as a proxy for parents’ social position – thus appears to be an unstable convention that can be misused. The leeway existing between broad categories and the realities that they seek to describe always opens the possibility for criticism of tests.
A solution to better adjust the rule of the test to the diversity of cases therefore consists in expanding the number of criteria considered in the final decision. Faced with criticism for making excessively unequivocal selections in a space of comparison that is far too small, bureaucratic organizations have therefore tended to increase the number of criteria. They thus aim to integrate, into the definition of cases, elements regarding the candidates’ situation of which had previously been silenced or smothered by excessively generalized variables. This increase in the number of variables is intended to reduce the unfairness of interpreting candidates’ capabilities by means of a test. At the same time, it must still be based on a customized classification and qualification involving numerous intermediaries (statistics institutions, databases, surveying processes, etc.). Thus, when institutions increase the number of variables, decision-making rules become increasingly complex. The semantic relationship between criteria and the principle loses its immediacy. For example, let's suppose that in order to accept a childcare application form, the application must overall score more than 20 points, where 5 points are given per child, the mother's single status counts for 10 points, taxable income counts for 3 points, and so forth. The institution can no longer justify the legitimacy of the decision by directly invoking principles of fairness; rather, legitimacy is established through the calculation of the ‘number of points’ variable, which is supposed to convey the reality of the case. Through its variability, the variable is supposed to encompass and convey all of the potentialities of situations, and in so doing, to withstand the criticism that tests are contingent, unfair, and excessively costly. In bureaucratic situations, increasing the number of criteria contributes to making decisions opaque, thus encouraging criticism of favouritism, which undermines the stability of tests. Drowned in a set of threshold values, decisions lose their power and are interpreted as a game between strategist candidates and the bureaucratic work of organizations.
2. File tests
Despite the still numerous services that they continue to provide to governments and organizations, the performance/form test duo is poorly suited to the requirements of complex societies, and notably the increasingly competitive forms of access to statuses and resources. Performance tests place a veil of ignorance over a world of underlying forces by making the mechanisms that propagate inequalities invisible. Form tests are bureaucratic, reductive, easy to deceive, and excessively mechanical. As a result, the large majority of selection tests in our societies have now adopted a combination of performance and form, which can be called file tests: the candidate provides a series of documents to test administrators, and after the examination, some of them are required to perform before a jury. The establishment of a file has become standard practice whenever individuals must compete to access a resource, service, or qualification: calls for tenders, recruitment, university selection, access to a loan or an organ transplant, and so forth.
File tests incorporate prior information on candidates by considerably expanding the number of elements mobilized in the comparison space. They borrow from form tests the records of certain categorical properties of candidates while introducing a process – which accelerated considerably with the shift towards continuous tests – of expansion towards information that can no longer be transformed into criteria. Despite juries’ ceaseless efforts to adopt decision rules and categorize files in tables, the file's capacity to produce variables is exhausted and dissolves into a collection of disparate pieces of information that cannot systematically be compared on a file-to-file basis. For example, this is the case when candidates’ curriculum vitae include extracurricular dimensions, such as ‘hobbies’ or ‘travel’, or when selection files require candidates to add a cover letter when submitting their school reports. The expansion of the entities and events required in the comparison space comes at a price: the translation into variable becomes more confusing and muddled; weighting a priori appears more random and bureaucratic; and the rule itself becomes too time-consuming to establish. The broadening of the signals invited into the decision process therefore forces a loosening of the automatic relationship between criteria and the rule in exchange for a synthetic evaluation of a set of unstructured pieces of information. Committees and juries must tolerate the fact that their judgement of candidates is also based on an ‘impression’ which may be influenced by disparate entities in the file. This is why in recruitment tests in particular, file selection is accompanied by a performance test in the form of an interview or an audition in order to complete the decision.
2.1. Domesticating the variability of hypotheses
The use of computational techniques to assist the decisions of juries and committees in analysing files is not new, but today it constitutes one of the most anticipated promises of artificial intelligence. These methods have long been used, with the help of a computer script, to verify a form's compliance with deterministic decision rules. However, as for machine learning tools, they propose to provide a technological solution for juries’ confusion when dealing with the uncertainty of their judgements faced with files combining an increasingly large list of entities and events. Juries may feel helpless faced with the diversity of points of reference offered by files for orienting judgements around different principles. The quality of their decisions can much more easily be criticized (Tetlock Citation2005) on various grounds: they prioritized certain criteria over others; their social homogeneity hides structural biases; they were not attentive to the diversity of variables that could lead to other definitions of the optimal candidate; and so on. Faced with disparate and extensive files, the introduction of automated tools to assist in decision-making based on machine learning models proposes the replacement of unstable justification of judgements with statistical probability. These tools order variables when the candidate comparison space becomes less comprehensible. The introduction of a statistical score in file tests is carried out today in a very different way, depending on the domain. It sometimes adopts the form of no more than an additional piece of information in the file, such as in the case of the prediction of the likelihood of a repeat offence in American judges’ decisions to grant bail; or it can have a greater automaticity, such as to guide the police to places where crimes are more frequent (Brayne and Christin Citation2021). As draft legislation on AI use shows, the question of the automaticity of test results is one of regulators’ main points of intervention in seeking to ‘keep a human in the loop’ (Jobin, Ienca, and Vayena Citation2019).
The appearance of machine learning techniques in file tests also introduces a change in statistical culture that warrants some attention (Breiman Citation2001). One of the particularities of these methods is that they are unaware of the decision rule in advance; they learn from the data. To set up this type of model, it is necessary to train an algorithm with a dataset (training database) composed of both input data (files) and the output results of previous candidates (the successful and unsuccessful candidates). The model is then adjusted by trial and error to make the prediction error based on training as small as possible (Goodfellow, Bengio, and Courville Citation2016). If the model is learned based on the correspondence between input and output data, the decision rule can no longer be grounded on criteria-based justifications which are a priori stable and automatic. The model governing selection is a statistical approximation of the best way to compare file variables in relation to the given objective. A traditional way of presenting the operations governing the design of such a model consists in defining three separate spaces (Cournuéjols, Miclet, and Barra Citation2018; Mitchell Citation1997). Input data constitute the observed space, and the results of the calculation constitute the decision space. Between these two, the designer of the calculation must imagine a hypothesis space (sometimes also called the ‘constructed space’, ‘latent space’, or ‘version space’). The latter space does not exist and cannot be empirically observed; it is an imaginary space in which the designer projects the ideal variables that should preside over the algorithm's decision ().
Figure 2. Categorical machine learning and the hypothesis space.
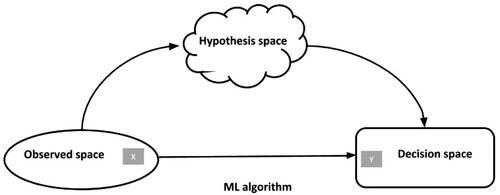
For example, in the case of recruitment, the designer of a hiring algorithm sets the goal of selecting intelligent, motivated, and competent candidates. However, these ideal variables – which establish the basis of the justification of the algorithmic decision – do not exist in the real data of the observed space. They relate to ideal qualities that the designer wants to be the basis of the decision. Because it is impossible to have objective data allowing one to unequivocally incorporate these principles, it is necessary, in the real data – i.e. in the observed space –, to find good approximations so that the decision can effectively be made on the basis of the qualities projected in the hypothesis space. This is the task entrusted to the learning algorithm: discovering, in the observed data, the model that best approximates the ideal variables of the decision. In traditional uses of machine learning methods, the designer is asked to verify the quality of the relationship between the observed space and the hypothesis space. They must be attentive to the choice of data used in the learning model. They can use an input variable to verify that the relevant variables as a function of the goal have not excessively deformed the results with respect to this control variable. This is how we can measure demographic bias, for instance if the selected goal has contributed to systematically excluding certain populations. In machine learning, the idea that the designer is capable, at the very least through approximation, of controlling the semantic link between the observed space and the hypothesis space has long constituted the base point of the possibility to assess their fairness.
2.2. Criticizing categories of reality from the world
This change in calculation method is the consequence of a constant increase in the size of candidates’ files. However, this increase in the number of data points also reflects the transformation of our societies’ relationship with forms of categorization of reality. With the individualization and complexification of social interdependencies, individuals’ criticism of the taxonomies into which they are categorized is being expressed more and more vehemently (Bruno, Didier, and Prévieux Citation2015). The regular patterns shown by social statistics no longer have an impact on our societies. They are often denounced as a set of hardened and abstract conventions that are incapable of conveying the complexification of social life and the singularities of individuals (Desrosières Citation2014). This movement is first and foremost evidenced in the effects of the criticism, developed in particular by the social sciences, aimed at revealing the constructed and artificial nature of statistical categorization (Boltanski Citation2014; Desrosières and Thévenot Citation1988). We are also witnessing a challenging of national indicators, such as the unemployment rate, consumer price index, or GDP, which are often identified as statistical constructions that can be manipulated according to the political constraints of the moment. The statistical pictures produced by government organizations are perceived as being reductive and have led, under the pressure of econometrics in particular, to profound transformations in statistical instruments that replace socio-professional categorization with continuous variables such as income (Pierru and Spire Citation2008; Angeletti Citation2011). The production of categories also encompasses worldviews originating in the history of power relations in our societies which hide structural asymmetries between groups, such as patriarchy, institutional racism, or the economization of the world (Eubanks Citation2017; Crawford and Calo Citation2016; Murphy Citation2017).
Social science's destabilization of broad statistical aggregates intersects with the development of increasingly harsh social criticism with respect to categorical representations of society, without the former being the cause of the latter. This criticism is based on our societies’ individualization logics and the imperative of singularization that is becoming an increasingly heavy burden for individuals (Martuccelli Citation2010). Individuals are expressing, more strongly than before, the desire for self-representation based on their chosen identities rather than being represented by the statistical categories assigned to them. At all crossroads of social life, people demand to not be reduced to the category that supposedly represents them. They refuse to allow themselves to be enclosed in the socio-professional categories that served to lay the foundations of a status-based society. Patients no longer wish to be reduced to their disease, customers to their purchases, tourists to their routes, militants to their organization, witnesses to silence, and so on. The classification systems which became normal categories for perceiving the social world no longer operate as interpretation instruments shared by all. This subjectivist critique of categorical assignment first and foremost rejects the homogenizing nature of excessively large categories that suppress intra-categorical variability. Under the effect of the developing role of economics and social science as expertise in public and private organizations, an immense undertaking of refinement and granularization has taken place, densifying and increasing the accuracy of the measurements of statistical devices. Society is no longer simply broken down into strata related to social status, but rather displays inequalities between genders, geographic origins, religions, life paths, etc. The multiplication of the principles used to differentiate individuals thus contributes to decreasing the centrality of the opposition between social classes. This enables the emergence of new dimensions of individuals that had not been registered in the traditional statistical system, such as personal biography, network of acquaintances, mobility, etc. The comprehensibility of social structure has thus become more complex due to the multiplicity of dimensions according to which individuals can be compared to one another.
However, criticism of the categorical representation of society also encompasses a more radically subjectivist dimension. These representations of the social world are also criticized for their normalizing effect and their inability to take into account the personal and experienced dimensions of the feeling of discrimination. The categorical objectification of individuals simply overlies a realist engineering of an increasingly denser world. Luc Boltanski's notion of world precisely refers to this set of traits, affects, or relationships with others and things that are not taken into account in the objectification techniques classically used during institutional reality tests. The world constantly spills over the limits of reality, defying the codification techniques, categorization rules, and decision rules of the social systems supporting it. The representation of the social world developed by pragmatic sociology, for example, is not composed of fixed entities that can be described by variables with monotonic causal relationships with one another. In contrast with the idea of a ‘general linear reality’ (Abbott Citation1988), many disciplines within sociology believe that the meaning of entities changes depending on the place, situation, or interactions. They also believe that they are very poorly depicted by the set categories of traditional statistical instruments. Deconstructed by social science, refused by individuals, imprecise for those producing them, and too rigid for comprehensive sociology, statistical categories are accused of poorly representing the singularity of individuals when subjected to tests.
3. Moving towards continuous tests
We posit that the development of criticism of the way that individuals and society are described by the metrologies of social statistics contributes to undermining the format of selection tests. It is in this sense that we interpret the currently embryonic displacement from file tests to continuous tests. Continuous tests are closely related to the rollout of artificial intelligence methods and deep learning techniques in particular, which offer an approach that is much more open to the variety and undecidability of the causes of individuals’ actions. To calculate society as accurately as possible, it is nonetheless relevant to change the nature of the data, the type of categorization used to order it, and the ‘constant causes’ method of statistical calculation. To do so, continuous tests very closely combine a spatial and temporal expansion of the candidate comparison space, a transformation of the calculation method underlying the decision, and a normative displacement of the way of justifying the test's principles.
3.1. The spatial expansion of the data space
While one of the responses to criticism of tests is to increase the number of data points in candidate files, the dynamic triggered by the digitalization of the calculation and of data is taking a new turn: the displacement of criteria with variables is being combined with a transformation of variables into traces. An example can serve to illustrate this new shift. Consider two databases used in the literature on loan allocation in the machine learning field. The first is the German loan database (Hofmann Citation1990). It contains data of 20 variables for 1000 former loan applicants. Each applicant was categorized as ‘good credit’ (700 cases) or ‘bad credit’ (300 cases). The majority of the variables are qualitative, such as civil status, gender, credit history, the purpose of the loan, or work, and can contain several encoded categories. For example, variables related to employment are encoded with 5 possible attributes: unemployed, non-qualified employee, qualified employee, manager, and highly qualified employee. This set of traditional data is characterized by the fact that it contains few variables, that each variable is subdivided into several modalities, and that these modalities provide a stable and homogenous description of each data point.
The second dataset is a typical example of the new type of databases that the digital revolution has made possible. Like the first, it was used to generate credit scores by Lu, Zhang, and Li (Citation2019) in an article that won the prize for best article at the ICIS 2019. The main feature of this dataset is that it is composed of a must larger number of data points and that the number of variables increased spectacularly. For each loan applicant, the platform collects personal data such as: (i) records of online purchases (in other words, the order time, product name, price, quantity, type of product, and information on the receiver); (ii) mobile telephone records (in other words, call history, mobile telephone use, detailed use of mobile applications, GPS mobility trajectories); and (iii) social media use (in other words, if the borrower has an account, (if so) all of the messages posted with time stamps and presence on social media, including number of fans, follows, comments received, and ‘likes’ received on weibo.com). Each variable is no longer broken down into a small number of modalities but rather into a series of granular pieces of information: shopping list, telephone calls, geolocated travel, behaviour on social media. The data are no longer aggregated as variables but rather resemble information flows that are as elementary as possible. The first dataset is composed of categorical entities, whereas the second is composed of granular flows of behavioural traces. The first seeks to convey, in the candidate comparison space, personal states that can be inferred to be related to a loan application; the second does not make this effort, considering that all information available represents something from the candidate's world, without, however, being able to relate it to the candidate's capacity to repay a loan (Poon Citation2007).
This initial data transformation process is at the heart of the promise of big data. By expanding the network of information, files adopt an unprecedented form and enable the establishment of continuous tests that are claimed to have far more affordances on a candidate's world. Instead of sampling interpretable variables, the calculator breaks down information into a set of flows that extend into the candidate's past as well as that of other candidates whose future is known. This process appears to be a way of addressing criticism of the conventional, rigid, and arbitrary nature of reality. It seeks to assimilate increasingly larger portions of individuals’ lives and behaviour, to espouse the world and ‘life itself’ (Rouvroy and Berns Citation2013; Lury and Day Citation2019). Continuous test databases record a priori a set of individuals’ behaviours, choices, and actions in order to insert them into a comparison space, the scope of which expands to candidates’ worlds without seeking to establish a relationship with the nature of the test. The data characterizing them no longer associate them with a candidate's identity but rather seek to record and transform something more continuous in their life path that could be liable to better orient the decisions of tests. This transformation in the format of data has been identified by many analyses. It establishes, alongside individuals, a ‘data double’ (Haggerty and Ericson Citation2017, 611; Lyon Citation2001), an ‘informational person’ (Koopman Citation2019), a ‘data dossier’ (Solove Citation2004), or a ‘doppelganger’ (Harcourt Citation2015) which constitutes a person's digital shadow by totalizing a fragmented set of behavioural information. In reality, these data are more difficult to unite in a single point or to articulate to one another, and as it is often much more difficult to extract relevant predictions than the privacy panic feeding much research in the domain could imagine (Salganik et al. Citation2020). It nevertheless constitutes a new identity production regime, a few features of which can be highlighted.
The first feature is that the candidates’ world can be introduced into the calculation only because a new sociotechnical network of affordances allows for samples of signals to be collected during the course of individuals’ lives. Pervasive, distributed, and increasingly discrete and opaque, the digital framework used to collect this information nonetheless remains fragmented and extremely specific to a particular type of activity (movement, using your debit card, surfing the web, etc.). Moreover it is largely controlled by the private operators of large digital services (Mau Citation2019). These traces come to exist only because a network of sensors has been implemented, in other words, a metrology for collecting and archiving these signals and the artefacts used to calculate them. The spread of these probe and sensor devices in our societies, the fact that they are spanning increasingly more numerous and varied territories are now interpreted as a tipping point towards a new form of capitalism (Zuboff Citation2019).
The second feature is related to the fact that this regime of knowledge on individuals can be described as ‘post-demographic’ (Rogers Citation2009). These data longer to seek to capture individuals in the traditional formats of social statistics (gender, age, education, profession, etc.). They define not a stable state of identity but rather an extensive and disconnected set of oscillating and partial micro-states describing a conduct, a location, a feeling, or an expression (Terranova Citation2004, 56). The granular fragmentation of these signals adopting the form of a trace that detaches a specific activity from an individual's course of action is often compared to the concept of ‘dividuals’ introduced by par Gilles Deleuze (Citation1992). This transition from variables to traces has significant consequences for the ways in which individuals are statistically associated with a whole. By virtue of the conventions of equivalency underpinning large-scale statistical categorizations, any categorical attribution can be related to a population of which the categorized individual is one case within a known distribution (Le Bras Citation2000). Categorical identification allows us to relate the results of a test to a more global distribution, and therefore to shine light on inequality or unfairness in test results. However, when an individual's trace is compared to a set of other traces which can no longer be compared with one another in terms of a given category, revealing unfairness becomes much more difficult. By eliminating the categorization of individuals, the test loses its reference population, which in turn makes it more difficult to show that the test results are unfair.
A third feature is related to the behavioural nature of these continuous signals, which seek to capture individuals in a way that is as close as possible to their living state and biology. This discards the possibility of individuals’ reflexive self-identification with the symbolic forms representing them. These new databases (purchasing behaviour, browsing history, behaviour on social media, location, sensor recordings while driving a vehicle, success or failure during a multiple-choice test on a MOOC video, etc.) do not record explicit performances carried out in specialized arenas but rather turn each course of action into a micro-performance. In this sense, it is not an exaggeration to consider social life, at any point at which it encounters a sensor, to be a theatre for testing individuals and an infra-political space that remains partially opaque and invisible. This continuous data produces statistical aggregates which, from the point of view of the people exploiting it, do not need to be closely articulated to large-scale categorizations of reality. As John Cheney-Lippold (Citation2017) demonstrates in his analysis of this ‘soft biopolitics’, they produce ‘measurable types’ which do not have symbolic referents in the categorical grammar of identities. Google is completely indifferent to whether a user identifies as ‘male’, ‘female’, or another non-binary label; all it needs is probabilities estimating the behaviour of this user as being 74% ‘female’. Through trial and error, the algorithm tests different trace aggregates in such a way as to get as close as possible to the goal. The calculation itself condenses aggregates of meaning that are interrelated by variable and changing predictive paths. Last of all, these paths between the observed space and the decision space move away from social actors’ definition of their identity and therefore lose intelligibility. The trajectory of the decision from the observed space to the decision space follows a series of changing branches, passing through aggregates of signals forming sorts of chimaera (patterns) to which is it is very difficult to assign meanings. Nonetheless, novel attempts do now exist in the XAI (explainable artificial intelligence) literature, to try to view these paths within the hidden layers of neural networks, such as the work of Chris Olah at OpenAI.Footnote3
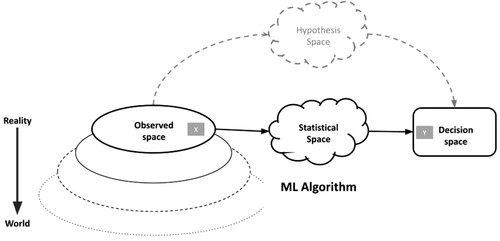
When the number of input variables increases significantly, when they adopt the form of unlabelled traces, it becomes impossible to project a hypothesis space and to comprehend the relationship between the observed space and the goal of the machine learning. In the displacement towards continuous tests (), the hypothesis space darkens until becoming a ‘black box’ that it is increasingly difficult to elucidate, even though a great deal of highly innovative IT and algorithm ethics research is seeking to overcome this difficulty (Olah, Mordvintsev, and Schubert Citation2017). The hypotheses that we can make regarding the variables that are important in choosing the right candidate are based no longer on input data but on the goal that serves to adjust the model. The hypothesis space, as both an ontological and normative externality, no longer provides affordances for meta-criticism. This displacement in the calculation architecture begs for a reformulation of the problematization of the ethical and technical implications of machine learning. Issues related to algorithm transparency and the explicability of results appear to be far less important than examining the paths followed by the calculation to optimize the target variable used to train the model (Amoore and Ethics Citation2020).Footnote4 Moreover, the target variable itself has been displaced over time.
Figure 3. The hypothesis space makes way to a statistical space.
3.2. Temporal expansion
The second direction that this expansion process follows is temporal. It is characterized by a reorganization of the temporalities of the calculation transporting the modelling of files towards a future prediction (Cevolini and Esposito Citation2020). The goal used to adjust the model is no longer immediately associated with the actual data of the file, but is projected at a future expectation which becomes increasingly more distant from the data gathered by the test. Consider another simple example. The most basic learning models set a temporal variable as their goal: namely, passing or failing. Candidates who will pass the test have been designated by a model that has learned to recognize them, based on a database composed of the files of previous winners. However, the hypotheses formed to justify the variable used as the goal of the learning never define present qualities exclusively, but also powers to act in the future. Successful candidates are chosen because they are assumed to have the skills that will allow them to execute a given type of performance in the future. Juries, judges, or recruiters constantly make these types of hypotheses during their deliberations, without having the possibility of objectifying them in the form of a numerical probability. The expansion of the comparison space enabled by quantification techniques promises to provide an estimate of this future probability using the traces of former test candidates. Their current performances become the goal for modelling the selection of new candidates. The data used to produce the learning model therefore incorporates information that goes beyond the temporal context of the test to evaluate future performances; For instance, the ranking of candidates for a heart transplant is henceforth guided by prediction of life expectancy in good health following the transplant (Hénin Citation2021); the hiring of salespeople at a company is guided by an estimate of its turnover five years from now; and the inspection of the technical systems of boats is determined by a prediction of having an accident at sea. Judicial risk evaluation instruments seek to estimate, prior to a trial, whether a defendant is a threat to public safety, or if he or she is at risk of repeat offending should bail be granted (Harcourt Citation2006). This projection of the calculation towards the anticipation of a future performance has the goal of pushing back the boundaries of the unknown by incorporating potentialities within a space that can be measured by probabilities.
3.3. The governmentality of the continuous
The continuous test format has been rapidly rolled out within digital bodies that possess the data adequate for operations of this type. It is involved in recommendation techniques, content filtering, targeted advertising, or the categorization of information on the Internet (Cardon Citation2015; Fourcade and Johns Citation2020), but has not yet deeply penetrated the selection tests of other social worlds. In the worlds of recruitment, the police force, the legal system, medicine, or education, numerous initiatives are underway to incorporate this new test format into devices which still predominantly employ file tests. The promises and fears aroused by this displacement towards continuous tests are however already at the heart of public debate and academic discussion. As a result, we would like to highlight four features of these tests, among many others.
The first feature of the deployment of continuous tests is related to the fact that optimizing models around a target variable contributes to linearizing choices around a single goal. In her distinction between ‘ordinal’ and ‘nominal’ forms of evaluation, Marion Fourcade (Citation2016) contrasts tests based on the quantified reduction of factors with a single magnitude, to those based on preserving the diversity of substantial categories. The optimization of file traces via a target goal as implemented by machine learning devices realigns the multiple paths of a calculation with a single dimension. The translation into an unequivocal categorization (a score accompanied by an estimation of error) of a comparison space, the dimensionality of which has nonetheless been considerably expanded, is both the greatest feat and the weakness of artificial intelligence techniques. However impressive this ability to order such a disparate and varied data space may seem, continuous tests are never able to allay criticism. Beyond questions regarding the opacity and explication of calculations, doubts around the fair treatment of the nominal diversity of candidates always reappear, as the intensity of the debate around algorithmic discrimination shows.
The second feature is related to the shift of the source of legitimacy of tests. Devices intended to rank, classify, and distribute opportunities within our societies constitute forms of power that must receive a certain form of legitimacy (the members of the society must consider a test's results to be ‘fair’). These devices constitute a form of domination, considering that tests contribute to creating asymmetries between those who pass them and those who fail. In his analysis, Luc Boltanski (Citation2009, 123–131) contrasts two forms of domination: simple domination and complex or managerial domination. Whereas simple domination seeks to confirm the legitimacy of reality tests by making corrections to the malfunctions highlighted by criticism, complex domination constitutes a new configuration of the exercise of power marked by a policy of constantly modifying reality tests in order to circumvent criticism. As he writes, this consists in ‘continuously altering the contours of reality as if to inscribe the world in it, as a site of constant change’ (ibid.: 123). Faced with criticism claiming that traditional statistical categories are a very poor representation of reality, the new algorithmic tests seek to reduce the randomness and inaccuracy of reality tests. This is done by continuously including more ‘world’ through new affordances responsible for summoning new states of people in order to incorporate them into the calculation. This never-ending expansion, in which the incessant promises of big data proponents are obvious, always has a certain aspect of pointlessness: ‘It is then the world itself that is the subject of debarment, and which, as it were, finds itself abolished’ (ibid.: 123). This attempt to assimilate the world into tests makes test design increasingly more dependent on scientific expertise. ‘In the political metaphysics underlying this form of domination, the world is precisely what we can now know through the powers of Science – that is to say, indivisible, the so-called natural sciences and the human or social sciences, which are increasingly closely combined with one another to the point of confusion’ (ibid.: 131). Only experts on this new type of data – promoted by the positivist undertaking to establish a science of social physics (Pentland Citation2014) – are capable of accessing the world and making it available to calculators. They therefore usurp for themselves the possibility of constantly reorganizing reality tests. These tests are justified, no longer on the basis of comprehensible principles, but rather on the idea that the observable data overlap and that they cover the world in the most adequate way possible. Complex domination therefore establishes a form of governmentality that is not based on the preservation of an established social. It instead turns change into a way of exercising domination led by the questioning of the categories established to the benefit of a more flexible, fluid, and reversible representation of the states of individuals (Boltanski Citation2008). By constantly and opaquely modifying the form, size, and manner in which the real is recorded, continuous tests can justify themselves only by setting the goal that they seek to optimize.
The third feature of the deployment of continuous tests is that they contribute to de-ritualizing the test form itself. Categorization and selection rituals assigning specific values to different individuals lose their particularity, becoming re-embedded in the course of ordinary life. Selection tests lose their prestige and their rareness as they are dispersed within a multitude of courses of action in which the states acquired during previous tests can constantly be called into question. The institutions endorsing tests delegate their authority to a set of scattered intermediaries. This proliferation of tests combining increasingly distant spatio-temporalities dilutes the pacifying and stabilizing role of institutions. Noortje Marres and David Stark (Citation2020) have shown that tests are no longer limited trials within a controlled environment for the purpose of determining a result that is as independent as possible from their context. Rather, it is now society itself that is constructed as a vast test environment in which individuals are incessantly put to the test.
A fourth feature of continuous tests is that they constantly modify the boundaries of reality by rigidifying it in such a way as to interconnect and centralize its different elements. The dispersion of tests along the continuum of social life contributes to modifying the behaviours of social actors, whose courses of action are constantly shaped and re-agenced by these micro-tests (Esposito and Stark Citation2019). Continuous tests modify the boundaries of reality because their output is itself incorporated, logged in such a way that it modifies another test in a different spatio-temporality. This process of modifying the social world through tests is particularly visible at digitalized companies. A company's different departments and units involved in deploying continuous tests are interconnected by means of an increasingly centralized information system. The rigidification of the processes used to collect, analyse, and provide feedback on data are also accompanied by a formalization of business processes which must now accommodate the technical constraints of the information systems that make them possible. Whereas continuous tests are often promoted for their flexibility and adaptability to the unique contexts that they are capable of assimilating, they are simultaneously centralizing and rigidifying because they need to shape the social world to exist.
4. Conclusion
We argue in this paper that the displacement of tests towards continuous tests characterizes selection situations as a transfer of legitimacy from the semantic production of institutions, to institutions’ constant adaptability to transformations of the world. The characterization of this displacement, which in this text is based on Luc Boltanski's concepts of reality and world, shows the relevance of highlighting the impact of AI in the format of tests.Footnote5 It does so by establishing a type of governmentality that seeks to circumvent criticism by ‘espousing’ the world. In this respect, continuous tests undoubtedly resemble new political technologies which, for governments and large organizations, pursue an ‘instrument-based governance’ dynamic (Le Galès Citation2016) already initiated with the practice of indicators, track records, benchmarking, and the influence of evaluation devices. Continuous tests mark the transition from a ‘government of the real’ (Berns Citation2015) to a way of governing based on the world by prioritizing effects over causes.
The boundaries of this new configuration call for a discussion that is outside of the scope of this article. However, we believe that it is important to maintain indeterminacy in evaluating the potential of these new types of tests. On the one hand, they can certainly be described as a new form of domination, as we have just done. The world that the new calculators claim to assimilate does not have a lot in common with the world as defined by Luc Boltanski. It is no more than an attempt to expand the network of data by assigning individuals to the fragmented traces of some of their behaviours, as opposed to assigning them to self-identification in categories. The discrepancy between the world of continuous tests and that from which subjectivities are constructed is sufficiently large for the potential for criticism not be stifled. However, other ways of evaluating these new devices must also be considered to explore the way in which the evaluation of individuals’ qualities is now increasingly dependent on socio-technical systems. From this point of view, a critical analysis opportunity for social science can be established, consisting of much more closely investigating how the calculations of neural networks work. Announcing the disappearance of the hypothesis space – as we have done – is simply a way of saying that a calculation's intelligibility has become so complex and strange that social science should abandon its goal of understanding forms of sociotechnical life. A more novel and ambitious approach would be to truly pay attention to the diversity of the proposals and paths traced by these new types of calculations within information spaces to which we are not accustomed. The questions raised by these types of calculators are closely related to the idea that they unequivocally reduce the future by shaping it to suit the interests of those who set their goals. However, we can also look at this question in another way, exploring the variety of ways of representing and constructing the world demonstrated by machine learning techniques (Amoore and Ethics Citation2020). In this sense, criticizing selection tests would consist, not simply in creating a discrepancy between reality and the world, but in shining light on the variety of possible worlds encompassed within continuous tests.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Dominique Cardon
Dominique Cardon is a professor of Sociology at Sciences Po. He's the director of the médialab of Science Po.
Jean-Marie John-Mathews
Jean-Marie John-Mathews is a researcher in AI Ethics at Institut Mines-Télécom Business School.
Notes
1 This theoretical contribution is inspired by our document-based survey of the various selection devices employed by the French government or companies.
2 For this survey, we organized discussion workshops dedicated to a particular algorithm with a researcher or a designer of the tool. This work has been conducted with Etalab, the French government task force for Open Data, and the médialab of Sciences Po (France). We explored the selection devices implemented by municipalities to obtain spots at childcare centres; the Parcours Sup system, which assigns secondary school students spots at higher education institutions in France; the Agence de biomédicine's Score Coeur device for assigning coronary artery bypass grafts; the system for automatically triggering audits for ships setting sail (Cib Nav); and the prediction of the evolution of job opportunities at Pôle emploi. Moreover, in another survey, we looked at the algorithmic devices implemented as a part of corporate recruitment procedures (John-Mathews, Cardon, and Balagué Citation2022).
4 Some research developing in the Fair ML community today is even looking at the possibility of criticism (algorithmic bias) through the implementation of a new meta-test conducted ex post and alongside the learning of models (John-Mathews, Cardon, and Balagué Citation2022). In this case, the machine test is ‘retranslated into a form test’ by means of quantification procedures (bias metrics, ‘explicability’, ‘privacy’, etc.) in order to make criticism possible a posteriori.
5 Further development of the claims presented in this paper would require more detailed empirical investigation. This will be carried out in future research works.
References
- Abbott, Andrew. 1988. Transcending general linear reality. Sociological Theory 6, no. 2: 169–86.
- Allouch, Annabelle. 2017. La société du concours. L’empire des classements scolaires. Paris: Seuil/République des idées.
- Amoore, Louise, and Cloud Ethics. 2020. Algorithms and the attribute of ourselves and others. Durham: Duke University Press.
- Angeletti, Thomas. 2011. Faire la réalité ou s'y faire? La modélisation et les déplacements de la politique économique au tournant des années 1970. Politix 24, no. 3: 47–72.
- Baudelot, Christian, Yvanie Caillé, Olivier Godechot, and Sylvie Mercier. 2016. Maladies rénales et inégalités sociales d’accès à la greffe en France. Population 71: 23–51.
- Berns, Thomas. 2015. Gouverner sans gouverner: une archéologie politique de la statistique. Paris: Presses universitaires de France.
- Boltanski, Luc. 2008. Rendre la réalité inacceptable. À propos de La production de l’idéologie dominante. Paris: Demopolis.
- Boltanski, Luc. 2009. De la critique. Précis de sociologie de l’émancipation. Paris: Gallimard. [On critique. A sociology of emancipation, Cambridge, Polity, 2011].
- Boltanski, Luc. 2012. Enigmes et complots. Une enquête à propos d’enquêtes. Paris: Gallimard. [Mysteries and conspiracies: Detective stories, spy novels and the making of modern societies, John Wiley & Sons, 2014].
- Boltanski, Luc. 2014. Quelle statistique pour quelle critique. In Statactivisme. Comment lutter avec des nombres, 33–50. Paris: La Découverte.
- Boltanski, L., and E. Chiapello. 1999. Le nouvel esprit du capitalisme (Vol. 10). Paris: Gallimard.
- Boltanski, Luc, and Laurent Thévenot. 1983. Finding one’s way in social space: A study based on games. Social Science Information 22, no. 4-5: 631–80.
- Boltanski, Luc, and Laurent Thévenot. 1991. De la justification: les économies de la grandeur. Paris: Gallimard. [On justification. Economies of worth. Princeton University Press, 2006].
- Bourdieu, Pierre. 1981. Épreuve scolaire et consécration sociale. Actes de la recherche en sciences sociales 39: 3–70.
- Bourdieu, Pierre, and Jean-Claude Passeron. 1964. Les héritiers: les étudiants et la culture, 183. Paris: Les Editions de minuit. Collection Grands documents, numéro 18.
- Bowker, Geoffrey C., and Susan Star. 1999. Sorting things out: Classification and its consequences. Cambridge: The MIT Press.
- Brayne, Sarah, and Angèle Christin. 2021. Technologies of crime prediction: The reception of algorithms in policing and criminal courts. Social Problems 68, no. 3: 608–24.
- Breiman, Leo. 2001. Statistical modeling: The two cultures. Statistical Science 16, no. 3: 199–309.
- Bruno, Isabelle, and Emmanuel Didier. 2013. Benchmarking. L’État sous pression statistique. Paris: Zones.
- Bruno, Isabelle, Emmanuel Didier, and Julien Prévieux, eds. 2015. Statactivisme: Comment lutter avec des nombres. Paris: Zones.
- Burrell, Jenna. 2016. How the machine ‘thinks’: Understanding opacity in machine learning algorithms. Big Data & Society 3, no. 1: 2053951715622512.
- Cardon, Dominique. 2015. À quoi rêvent les algorithmes. Nos vies à l’heure des big data. Paris: Seuil/République des idées.
- Cardon, Dominique. 2019. Society2Vec: From categorical prediction to behavioral traces. SASE Conference, New York, June 27–29.
- Cardon, Dominique, Jean-Philippe Cointet, and Antoine Mazières. 2018. Neurons spike back. The invention of inductives machines and the artificial intelligence controversy. Réseaux 5: 173–220.
- Cevolini, Alberto, and Elena Esposito. 2020. From pool to profile: Social consequences of algorithmic prediction in insurance. Big Data & Society 7, no. 2: 2053951720939228.
- Cheney-Lippold, John. 2011. A new algorithmic identity soft biopolitics and the modulation of control. Theory, Culture & Society 28: 164–81.
- Cheney-Lippold, John. 2017. We are data. Algorithms and the making of our digital selves. New York: New York University Press.
- Cournuéjols, Antoine, Laurent Miclet, and Vincent Barra. 2018. Apprentissage artificiel. Deep learning, concepts et algorithmes. Paris: Eyrolles.
- Crawford, Kate. 2021. The atlas of AI: Power, politics, and the planetary costs of artificial intelligence. Yale University Press.
- Crawford, Kate, and Ryan Calo. 2016. There is a blind spot in AI research. Nature, October 13.
- Deleuze, Gilles. 1992. Postscript on the societies of control, 1990. Cultural Theory: An Anthology, 139–42.
- Desrosières, Alain. 2000. La politique des grands nombres: histoire de la raison statistique. Paris: La découverte.
- Desrosières, Alain. 2001. Between metrological realism and conventions of equivalence: The ambiguities of quantitative sociology. Genèses 43, no. 2: 112–27.
- Desrosières, A. 2010. A politics of knowledge-tools: The case of statistics. In Between enlightenment and disaster: Dimensions of the political use of knowledge, 111–29. Brussels: Peter Lang.
- Desrosières, Alain. 2014. Prouver et gouverner. Une analyse politique des statistiques publiques. Paris: La découverte.
- Desrosières, Alain, and Laurent Thévenot. 1988. Les catégories socioprofessionnelles. Paris: La découverte.
- Didier, Emmanuel. 2020. America by the numbers: Quantification, democracy, and the birth of national statistics. Cambridge: MIT Press.
- Duru-Bellat, Marie. 2012. Le mérite contre la justice. Paris: Presses de Sciences Po.
- Espeland, Wendy, and Michael Sauder. 2016. Engines of anxiety. Academic rankings, reputation and accountability. New York: Russell Sage Foundation.
- Esposito, Elena, and David Stark. 2019. What’s observed in a rating? Rankings as orientation in the face of uncertainty. Theory, Culture & Society 36, no. 4: 3–26.
- Eubanks, Virginia. 2017. Automating inequality, how high-tech tools profile, police, and punish the poor. New York: St. Martin’s Press.
- Fourcade, Marion. 2016. Ordinalization: Lewis A. Coser memorial award for theoretical agenda setting. Sociological Theory 34, no. 3: 175–95.
- Fourcade, Marion, and Fleur Johns. 2020. Loops, ladders and links: The recursivity of social and machine learning. Theory and Society 49, no. 5: 803–32.
- Gigerenzer, Gerd, Zeno Swijtnik, Theodore Porter, Lorraine Daston, John Beatty, and Lorenz Krüger. 1989. The empire of chance. How probability changed science and everyday life. Cambridge: Cambridge University Press.
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep learning. Vol. 1, no. 2. Cambridge: MIT press.
- Hacking, Ian. 1990. The taming of chance. Cambridge: Cambridge University Press.
- Hacking, Ian. 1994. Styles of scientific thinking or reasoning: A new analytical tool for historians and philosophers of the sciences. Trends in the Historiography of Science 151, 31–48.
- Haggerty, Kevin D., and Richard V. Ericson. 2017. The surveillant assemblage. In Surveillance, crime and social control, 61–78.
- Harcourt, Bernard. 2006. Against prediction: Profiling, policing and punishing in an actuarial Age. Chicago, IL: University of Chicago Press.
- Harcourt, Bernard. 2015. Exposed. Desire and disobedience in the digital age. Cambridge: Harvard University Press.
- Hénin, Clément. 2021. Confier une décision vitale à une machine. Réseaux 1, no. 225: 187–213.
- Hibou, Béatrice. 2012. La bureaucratisation du monde à l’ère néolibérale. Paris: La découverte.
- Hofmann, H.J. 1990. Die Anwendung des CART-Verfahrens zur statistischen Bonitätsanalyse von Konsumentenkrediten. Zeitschrift fur Betriebswirtschaft 60: 941–62.
- Jobin, Anna, Marcello Ienca, and Effy Vayena. 2019. The global landscape of AI ethics guidelines. Nature Machine Intelligence 1, no. 9: 389–99.
- John-Mathews, Jean-Marie. 2021. Critical empirical study on black-box explanations in AI.
- John-Mathews, Jean-Marie. 2022. Some critical and ethical perspectives on the empirical turn of AI interpretability. Technological Forecasting and Social Change 174: 121209.
- John-Mathews, Jean-Marie, Dominique Cardon, and Christine Balagué. 2022. From reality to world. A critical perspective on AI fairness. Journal of Business Ethics 178, no. 4: 945–59.
- John-Mathews, Jean-Marie, Robin De Mourat, Donato Ricci, and Maxime Crépel. 2023. Re-enacting machine learning practices to enquire into the moral issues they pose. Convergence, p.13548565231174584.
- Kleinberg, Jon, Jens Ludwig, Sendhil Mullainathan, and Cass R. Sunstein. 2018. Discrimination in the age of algorithms. Journal of Legal Analysis 10: 113–74.
- Koopman, Colin. 2019. How We became our data. A genealogy of the informational person. Chicago, IL: The University of Chicago Press.
- Latour, Bruno. 1999. Pandora’s hope. Essays on the reality of social sciences. Cambridge: Harvard University Press.
- Le Bras, Hervé. 2000. Naissance de la mortalité. L'origine politique de la statistique et de la démographie. Média Diffusion.
- Le Galès, Patrick. 2016. Performance measurement as a policy instrument. Policy Studies 37, no. 6: 508–20.
- Lyon, David. 2001. Surveillance society: Monitoring everyday life. Berkshire: Open University Press.
- Lu, T., Y. Zhang, and B. Li. 2019. The value of alternative data in credit risk prediction: Evidence from a large field experiment. ICIS 2019 Conference, Munich, December.
- Lury, Celia, and Sophie Day. 2019. Algorithmic personalization as a mode of individuation. Theory, Culture & Society 36, no. 2: 17–37.
- Mackenzie, Adrian. 2017. Machine learners. Archaeology of a data practice. Cambridge: The MIT Press.
- Marres, Noortje, and David Stark. 2020. Put to the test: For a new sociology of testing. The British Journal of Sociology 71, no. 3: 423–43.
- Martuccelli, Danilo. 2010. La société singulariste. Paris: Armand Colin.
- Mau, Stefen. 2019. The metric society. On the quantification of the social. Cambridge: Polity Press.
- McGrayne, Sharon Bertsch. 2011. The theory that would not die. How Bayes’ rule cracked the enigma code, hunted down Russian submarines & emerged triumphant from two centuries of controversy. New Haven: Yale University Press.
- Mitchell, Tom. 1997. Machine learning. Boston: McGraw-Hill.
- Murphy, Michele. 2017. The economization of life. Durham: Duke University Press.
- Noble, Safiya Umoja. 2018. Algorithms of oppression: How search engines reinforce racism. New York: New York University Press.
- Olah, Chris, Alexander Mordvintsev, and Ludwig Schubert. 2017. Feature visualization. Distill 2, no. 11: e7.
- O'Neil, Cathy. 2017. Weapons of math destruction: How big data increases inequality and threatens democracy. Crown.
- Pasquale, Franck. 2015. The black box society. The secret algorithms that control money and information. Cambridge: Harvard University Press.
- Pentland, Alex. 2014. Social physics. How good ideas spread. The lessons from a new science. New York: The Penguin Press.
- Pierru, Emmanuel, and Alexis Spire. 2008. Le crépuscule des catégories socioprofessionnelles. Revue française de science politique 58, no. 3: 457–81.
- Poon, Martha. 2007. Scorecards as devices for consumer credit: The case of Fair, Isaac & Company incorporated. The Sociological Review 55, no. 2_suppl: 284–306.
- Porter, Theodore M. 1986. The rise of statistical thinking 1820-1900. Princeton: Princeton University Press.
- Porter, Theodore M. 1995. Trust in numbers. The pursuit of objectivity in science and public life. Princeton: Princeton University Press.
- Power, Michael. 1997. The audit society. Rituals of verification. London: Oxford University Press.
- Rogers, Richard. 2009. Post-demographic machines. Walled Garden 38, no. 2009: 29–39.
- Rouvroy, Antoinette, and Thomas Berns. 2013. Gouvernementalité algorithmique et perspectives d’émancipation. Réseaux 177, no. 1: 163–96. [Rouvroy, Antoinette, Thomas Berns. 2013. Algorithmic governmentality and prospects of emancipation. Disparateness as a precondition for individuation through relationships? Réseaux 177: 163–96].
- Salganik, Matthew J., I. Lundberg, Alexander T. Kindel, Caitlin E. Ahearn, Khaled Al-Ghoneim, Abdullah Almaatouq, Drew M. Altschul, et al. 2020. Measuring the predictability of life outcomes with a scientific mass collaboration. Proceedings of the National Academy of Sciences 117, no. 15: 8398–403.
- Scott, James C. 2008. Seeing like a state. New Haven and London: Yale University Press.
- Solove, Daniel. 2004. The digital person: Technology and privacy in the information age. New York: New York University Press.
- Stark, David, ed. 2020. The performance Complex. Valuations and competitions in social life. London: Oxford University Press.
- Supiot, Alain. 2018. La gouvernance par les nombres. Paris: Fayard.
- Susen, S. 2014. Is there such a thing as a ‘pragmatic sociology of critique’? Reflections on Luc Boltanski’s ‘on critique’. In The spirit of Luc Boltanski: Essays on the 'pragmatic sociology of critique', trans. Simon Susen, eds. S. Susen, and B.S. Turner, 173–210. London, UK: Anthem Press.
- Terranova, Tiziana. 2004. Network culture: Politics for the information Age. London: Pluto.
- Tetlock, Philip. 2005. Expert political judgement: How good is it? How can we know? Princeton: Princeton University Press.
- Wagner, Peter. 2002. A sociology of modernity: Liberty and discipline. London: Routledge.
- Zuboff, Shoshana. 2019. The age of surveillance capitalism. The future for a human future and the new frontier of power. New York: Public Affairs.