
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We formulate an optimal design problem for the selection of best states to observe and optimal sampling times for parameter estimation or inverse problems involving complex non-linear dynamical systems. An iterative algorithm for implementation of the resulting methodology is proposed. Its use and efficacy are illustrated on two applied problems of practical interest: (i) dynamic models of HIV progression and (ii) modelling of the Calvin cycle in plant metabolism and growth.
Introduction
In many scientific fields where mathematical modelling is utilized, mathematical models grow increasingly complex, containing possibly more state variables and parameters, over time as the underlying governing processes of a system are better understood and refinements in mechanisms are considered. Additionally, as technology invents and improves devices to measure physical and biological phenomena, new data become available to inform mathematical modelling efforts. The world is approaching an era in which the vast amounts of information available to researchers may be overwhelming or even counterproductive to efforts. We explore a framework based on the Fisher Information Matrix (FIM) for a system of ordinary differential equations (ODEs) to determine when an experimenter should take samples and what variables to measure when collecting information on a physical or biological process that is modelled by a dynamical system.
Inverse problem methodologies are discussed in [Citation1] in the context of dynamical system or mathematical model parameter estimation when a sufficient number of observations of one or more states (variables) are available. The choice of method depends on assumptions the modeller makes on the form of the error between the model and the observations (the statistical model). The most prevalent source of error is observation error, which is made when collecting data. (One can also consider model error, which originates from the differences between the model and the underlying process that the model describes. But this is often quite difficult to quantify.) Measurement error is most readily discussed in the context of statistical models. The three techniques commonly addressed are maximum likelihood estimators (MLE), used when the properties of the error distribution are known; ordinary least squares (OLS), for error with constant variance across observations; and generalized least squares (GLS), used when the variance of the data can be expressed as a non-constant function. Uncertainty quantification is also described for optimization problems of this type, namely in the form of observation error covariances, standard errors, residual plots, and sensitivity matrices. Techniques to approximate the variance of the error are also included in these discussions.
Experimental design using the FIM, which is based on sensitivity matrices, is described in [Citation2] for the case of scalar data. Sensitivity matrices are composed of functions that relate the change in a variable to the change in the parameter. The first order quantifications of these relations are called traditional sensitivity functions and are useful in suggesting when a variable should be sampled to get the most information for estimating a particular parameter, especially when the first order sensitivity functions are used in conjunction with the so-called second order sensitivity functions. This work also examines the usefulness of generalized sensitivity functions,[Citation3] which are calculated using the FIM, that are known to describe how information about the parameters is distributed across time for each variable. Both types of sensitivity functions are then used in numerical simulations to determine the optimal final time for an experiment of a process described by a logistic curve.
In [Citation4], the authors develop an experimental design theory using the FIM to identify optimal sampling times for experiments on physical processes (modelled by an ODE system) in which scalar or vector data will be taken. The experimental design technique developed is applied in numerical simulations to the logistic curve, a simple ODE model describing glucose regulation and a harmonic oscillator example.
In addition to when to take samples, the question of what variables to measure is also very important in designing effective experiments, especially when the number of state variables is large. Use of such a methodology to optimize what to measure would further reduce testing costs by eliminating extra experiments to measure variables neglected in previous trials. In [Citation5], the best set of variables for an ODE system modelling the Calvin cycle [Citation6] is identified using two methods. The first, an ad-hoc statistical method, determines which variables directly influence an output of interest at any one particular time. A model using a subset of variables is determined via multivariate linear regression, and the efficacy of the model is then measured using the Akaike Information Criterion. The variables that appear in the best models at the most time points are then identified as the most important to measure. Such a method does not utilize the information on the underlying time-varying processes given by the dynamical system model. Extension of the second method first suggested in [Citation5], based optimal design ideas, is the subject of our presentation here.
Building on the theory in [Citation4] and [Citation5], we formulate a previously unexplored optimal design problem to determine not only the optimal sampling variables out of a finite set of possible sampling variables but also the optimal sampling time distribution given a fixed final time. We compare the SE-optimal design introduced in [Citation2] and [Citation4] with the well-known methods of D-optimal and E-optimal design on a six-compartment HIV model [Citation7] and a thirty-one dimensional model of the Calvin Cycle.[Citation6] Such models where there may be a wide range of variables to possibly observe are not only ideal on which to test our proposed methodology, but also are widely encountered in applications.
Mathematical background
Mathematical and statistical models
We explore our experimental design questions using a mathematical model(1)
(1) where
is the vector of state variables of the system generated using a parameter vector
,
, that contains
initial values and
system parameters listed in
,
is a mapping
,
is the initial time, and
is the final time. We define an observation process
(2)
(2) where
is an observation operator that maps
, where
is the number of variables observed at a single sampling time. If we were able to observe all states, each measured by a different sampling technique, then
and
; however, this is most often not the case because of the impossibility of or the expense in measuring all state variables. In other cases (such as the HIV example below) we may be able to directly observe only combinations of the states.
In order to discuss the amount of uncertainty in parameter estimates, we formulate a statistical model [Citation1] of the form(3)
(3) where
is the hypothesized true value of the unknown parameters and
is a vector random process that represents observation error for the measured variables. We make the standard assumptions:
where
and
for
. Realizations of the statistical model (Equation3
(3)
(3) ) are written
When collecting experimental data, it is often difficult to take continuous measurements of the observed variables. Instead, we assume that we have
observations at times
,
,
. We then write the observation process (Equation2
(2)
(2) ) as
(4)
(4) the discrete statistical model as
(5)
(5) and a realization of the discrete statistical model as
If we were given
, we could solve (Equation1
(1)
(1) ) for
, a process known as solving the forward problem. Alternatively, if we had a set of data
,
, we could estimate
in a process known as solving the inverse problem. We will use this mathematical and statistical framework to develop a methodology to identify sampling variables that provide the most information pertinent to estimating a given set of parameters and the most informative times at which the samples should be taken.
Formulation of the optimal design problem
Several methods exist to solve the inverse problem. A major factor [Citation1] in determining which method to use is additional assumptions made about . It is common practice to make the assumption that realizations of
at particular time points are independent and identically distributed (i.i.d.). If, additionally, the distributions describing the behaviour of the components of
are known, then maximum likelihood methods may be used to find an estimate of
. On the other hand, if the distributions for
are not known but the variance
(also unknown) is assumed to vary over time, weighted least squares methods are often used. We propose an optimal design problem formulation using a generalized weighted least squares criterion.
Let denote the set of all bounded distributions on the interval
. We consider the generalized weighted least squares cost functional for systems with vector output
(6)
(6) where
is a general measure on the interval
. For a given continuous data set
, we search for a parameter
that minimizes
.
We next consider the case of observations collected at discrete times. If we choose a set of time points
,
, where
and take
(7)
(7) where
represents the Dirac delta distribution with atom at
, then the weighted least squares criterion (Equation6
(6)
(6) ) for a finite number of observations becomes
To select a useful distribution of time points and set of observation variables, we introduce the
by
sensitivity matrices
and the
by
sensitivity matrices
that are determined using the differential operator in row vector form
represented by
and the observation operator defined in (Equation2
(2)
(2) ),
(8)
(8) Using the sensitivity matrix
, we may formulate the Generalized Fisher Information Matrix (GFIM). Consider the set
of admissible observation maps and let
represent the set of all bounded distributions
on
. Then the GFIM may be written
(9)
(9) Taking
different sampling maps in
represented by the
-dimensional row vectors
,
, we construct the discrete distribution on
(10)
(10) where
represents the Dirac delta distribution with atom at
. Using
in (Equation10
(10)
(10) ), we obtain the GFIM for multiple discrete observation methods taken continuously over
,
(11)
(11) where
is the observation operator in (Equation2
(2)
(2) ) and (Equation4
(4)
(4) ) and
is the covariance matrix as described in (Equation3
(3)
(3) ). Applying the distribution
as described in (Equation7
(7)
(7) ) to the GFIM (Equation12
(12)
(12) ) for discrete observation operators measured continuously yields the discrete
FIM for discrete observation operators measured at discrete times
(12)
(12) This describes the amount of information about the
parameters of interest that is captured by the observed quantities described by the sampling maps
,
, listed in
, when they are measured at the time points in
.
The questions of determining the best (in some sense) and
are important questions in the optimal design of an experiment. Recall that the set of time points
has an associated distribution
, where
is the set of all bounded distributions on
. Similarly, the set of sampling maps
has an associated bounded distribution
. Define the space of bounded distributions
with elements
. Without loss of generality, assume that
is closed and bounded, and assume that there exists a functional
of the GFIM (Equation10
(10)
(10) ). Then the optimal design problem associated with
is selecting a distribution
such that
(13)
(13) where
depends continuously on the elements of
.
The Prohorov metric [Citation8] provides a general theoretical framework for the existence of and approximation in
(a general theoretical framework is developed in [Citation2, Citation9]). The application of the Prohorov metric to optimal design problems formulated as (Equation14
(14)
(14) ) is explained more fully in [Citation2]: briefly, define the Prohorov metric
on the space
, and consider the metric space
. Since
is compact,
is also compact. Additionally, by the properties of the Prohorov metric,
is complete and separable. Therefore, an optimal distribution
exists and may be approximated by a discrete distribution.
The formulation of the cost functional (Equation14(14)
(14) ) may take many forms. We focus on the use of traditional optimal design methods, D-optimal, E-optimal or SE-optimal design criteria, to determine the form of
. Each of these design criteria are functions of the inverse of the FIM (assumed hereafter to be invertible) defined in (Equation13
(13)
(13) ).
In D-optimal design, the cost functional is writtenBy minimizing
, we minimize the volume of the confidence interval ellipsoid describing the uncertainty in our parameter estimates. Since
is symmetric and positive semi-definite,
. Additionally, since
is assumed invertible,
, therefore,
.
In E-optimal design, the cost functional is is the largest eigenvalue of
, or equivalently
To obtain a smaller standard error, we must reduce the length of the principal axis of the confidence interval ellipsoid. Since an eigenvalue
solves
, an eigenvalue of
would mean
, or that
is not invertible. Since
is positive definite, all eigenvalues are therefore positive. Thus,
.
In SE-optimal design, is a sum of the elements on the diagonal of
weighted by the respective parameter values,[Citation2, Citation4] written
Thus in SE-optimal design, the goal is to minimize the sum of squared errors of the parameters normalized by the true parameter values. As the diagonal elements of
are all positive and all parameters are assumed non-zero in
,
.
In [Citation4], it is shown that the D-, E- and SE-optimal design criteria select different time grids and yield different standard errors. We expect that these design cost functionals will also choose different observation variables (maps) in order to minimize different dimensions of the confidence interval ellipsoid.
Algorithm and optimization constraints
In most optimal design problems, there is not a continuum of measurement possibilities that may be used; rather, there are possible observation maps
. Denote this set as
. While we may still use the Prohorov metric-based framework to guarantee existence and convergence of (Equation14
(14)
(14) ), we have a stronger result first proposed in [Citation5] that is useful in numerical implementation. Because
is finite, all probability distributions made from the elements of
have the form
for a fixed
. Moreover, the set of all distributions that use
sampling methods
is also finite. For a fixed distribution of time points
, we may compute using (Equation13
(13)
(13) ) the set of all possible FIM
that could be formulated from
. By the properties of matrix multiplication and addition, this set is also finite. Then the functional (Equation14
(14)
(14) ) applied to all
in the set produces a finite set contained in
. Because this set is finite, it is well ordered by the relation
and therefore has a minimal element. Thus for any distribution of time points
, we may find at least one solution
. Moreover,
may be determined by a search over all matrices
formed by
elements from
. Therefore, for a fixed
and
a global optimal set of
sampling methods may be determined.
Due to the computational demands of performing non-linear optimization for time points and
observation maps (for a total of
dimensions), and to the difference in techniques between searching for an optimal
in the finite set
and searching for an optimal distribution of
sampling times, we instead solve the coupled set of equations
(14)
(14) where
represents a set of
sampling maps and
,
, is an ordered set of
sampling times. These equations are solved iteratively as
(15)
(15) where
is the D-, E- or SE-optimal design criterion. We begin by solving for
where
is specified by the user. The system (Equation17
(17)
(17) )-(Equation18
(18)
(18) ) is solved until
or until
. For each iteration, (Equation17
(17)
(17) ) is solved using a global search over all possible
. Since the sensitivity equations cannot be easily solved for in the models chosen to illustrate our method, we use a modified version of tssolve.m by A. Attarian,[Citation10] which implements the myAD package developed by M. Fink.[Citation11]
Solving (Equation18(18)
(18) ) requires using a non-linear constrained iterative optimization algorithm. While MATLAB’s fmincon is a natural choice for such problems, as reported in [Citation4], it does not perform well in this situation. Instead, we use SolvOpt developed by A. Kuntsevich and F. Kappel [Citation12] (which utilizes a modified version of Shor’s
-algorithm) to search for an optimal distribution local to an initial uniformly spaced time point distribution. There exist many types of constraints that may be placed on this optimization. The four constraints used in [Citation4] are
Optimize all time points such that
. This method optimizes
The initial and final time points are fixed as
Optimize the time steps
Optimize the time steps
Standard errors
In order to compare the ability of different optimal design criteria to minimize uncertainty in parameter estimation, we compute the standard errors associated with these parameters. We begin by selecting an ODE system, a nominal set of parameters that we would estimate, the start and end times of the experiment
and
, the number
of sampling times
, and the number of observation maps we wish to use. After an optimal
and
are determined according to one of the three previously described optimal design methods, we compute the standard errors for the parameters in
. There are multiple techniques [Citation4] available to compute standard errors; here we choose to use asymptotic theory due to its ease of implementation.
Asymptotic theory for standard errors
If we assume that the covariance matrix is constant over time (
), then we may use an ordinary least squares (OLS) framework to estimate standard errors. Once an optimal
,
, and
are determined, we obtain data from an experiment or simulate data
as a realization of the random process
described in (Equation5
(5)
(5) ), and then we estimate the parameters in
by solving the inverse problem using the OLS criterion.[Citation1] The discrete OLS estimator is defined as
(16)
(16) where
is the set of all possible values of
, such that each element of the difference vector
is weighted using the variance of its corresponding sampling maps. One realization of this problem using data
,
, is written
(17)
(17) However, calculating
still requires the unknown
. If the number of parameters
of a system is sufficiently small and number of observations
large so that
, then we may calculate the bias adjusted estimate of the variances
(18)
(18) and find the estimate of
using
(19)
(19) Therefore, finding
when
is unknown requires solving the coupled system of equations (Equation21
(21)
(21) ) and (Equation22
(22)
(22) ).
We may utilize the asymptotic properties of the OLS minimizer (Equation19(19)
(19) ) to learn about the behaviour of the model (Equation1
(1)
(1) ) and (Equation3
(3)
(3) ). As the number of samples
,
has the following properties [Citation1, Citation13, Citation14]
where
(20)
(20) is the
covariance matrix, and
is the
matrix
(21)
(21) The approximation
to the covariance matrix
is
(22)
(22) We may use
to approximate the standard errors of each parameter in
. For the
th element of
, written
, the asymptotic standard error is
where
is the element in the
th row and
th column of
, and
is the corresponding element in
. Additionally, since the FIM is defined to be the inverse of the covariance matrix, we may approximate the FIM using (Equation25
(24)
(24) ) by
.
Example 1: HIV model
After validating code results for time point selection on simple models such as those in [Citation4], we examined the performance of both the time point and observable operator selection algorithms on the log-scaled version of the HIV model developed in [Citation15]. While the analytic solution of this system cannot easily be found, this model has been studied, improved and successfully fit to and indeed validated with several sets of longitudinal data using parameter estimation techniques.[Citation7, Citation16, Citation17] Additionally, the sampling or observation operators used to collect data in a clinical setting as well as the relative usefulness of these sampling techniques are known.[Citation7] The model includes uninfected and infected CD T-cells, called type 1 target cells (
and
, respectively), uninfected and infected macrophages (subsequently determined to more likely be resting or inactive CD
T-cells), called type 2 target cells (
and
), infectious free virus
, and immune response
produced by cytotoxic T-lymphocytes CD
. The HIV model with treatment function
is given by
(23)
(23) The log-scaled HIV model, which is used to alleviate difficulties due to the large differences in scales of the variables and the parameters, is
(24)
(24) where
,
,
,
,
and
.
In [Citation7] this model’s parameters are estimated for each of 45 different patients who were in a treatment programme for HIV at Massachusetts General Hospital (MGH). These individuals experienced interrupted treatment schedules, in which the patient did not take any medication for viral load control. Seven of these patients adhered to a structured treatment interruption schedule planned by the clinician. We use the parameters estimated to fit the data of one of these patients, Patient 4 in [Citation7], as our “true” parameters for this model. This patient was chosen because the patient continued treatment for an extended period of time (1919 days) and the corresponding data set contains 158 measurements of viral load and 107 measurements of CD4 cell count (
) that exhibit a response to interruption in treatment, and the estimated parameters yield a model exhibiting trends similar to that in the data.
Table 1 Values of parameters in the HIV model (26).
Sensitivity analysis performed in [Citation15] and parameter subset selection carried out in [Citation18] identified subsets of the 20 parameters and six initial conditions that would likely be reliably estimated when solving the corresponding inverse problems. Based on their results, we treat the subset of parameters as unknown and fix all other parameters. The values for the fixed parameters and
are computed in [Citation7] and given in Table . It is important to choose parameters to which the model is sensitive; a poor choice for the components of
will negatively affect sensitivity matrices and may lead to a near-singular FIM. Based on currently available measurement methods, we allow the possible types of observations including (1) infectious virus
, (2) immune response
, (3) total activated CD4 cells
and (4) type 2 (resting or unactivated) target cells
, each with an assumed error variance of
of the initial variable values given by
.
HIV observable selection results, times fixed
To simulate the experience of a clinician gathering data as a patient regularly returns for scheduled testing, we fix the sampling times and choose the optimal observables. We consider choices of sampling operators out of the four possible observables, all
of which will be measured at
evenly spaced times over 2000 days, corresponding to measurements every 40, 20, 10 and 5 days, respectively. The
optimal sampling maps are determined for each of the three optimal design criteria, and the asymptotic standard errors (ASE) are calculated after carrying out the corresponding inverse problem calcualtions.
Table 2 Number of observables, number of time points, observables selected by D-optimal cost functional, and the minimum and maximum standard error and associated parameter for the parameter subset in the HIV model (27).
Table 3 Number of observables, number of time points, observables selected by E-optimal cost functional, and the minimum and maximum standard error and associated parameter for the parameter subset in the HIV model (27).
Table 4 Number of observables, number of time points, observables selected by SE-optimal cost functional, and the minimum and maximum standard error and associated parameter for the parameter subset in the HIV model (27).
Tables , and display the optimal observation operators determined by the D-, E- and SE-optimal design cost functions, respectively, as well as the lowest and highest ASE. In all three optimal design criteria, there was a distinct best choice of observables (listed in Tables , and ) for each pair of and
. When only
observable could be measured, each design criterion consistently picked the same observable for all
; similarly, at
, both the D-optimal and SE-optimal design criteria were consistent in their selection over all
, and E-optimal only differed at
. Even at
, each optimal design method specified at least two of the same observables at all
.
The observables that were rated best changed between criteria, affirming the fact that each optimal design method minimizes different aspects of the standard error ellipsoid. At observable, D-optimal selects the CD4 cell count while E-optimal and SE-optimal choose the infectious virus count. As a result, the min(ASE) calculated for a parameter estimation problem using the D-optimal observables is approximately 1/3 lower than the min(ASE) of E- and SE-optimal for all tested time point distributions. Similarly, the max(ASE) calculated for E- and SE-optimal designed parameter estimation problems is approximately 1/3 lower than that of D-optimal. Thus at
, based on minimum and maximum asymptotic standard errors, there is no clear best choice of an optimal design cost function.
At allowed observables, both the D- and SE-optimal cost functions are minimized by an observation operator containing both activated CD4 cells (type 1 target cells) and type 2 target cells. The E-optimal cost function still favours infectious virus count in addition to type 2 target cells (at
) or type 1 target cells (at
). As a result, max(ASE) in the E-optimal design parameter estimation problem is
–
lower than that of D- or SE-optimal; however, the D- and SE-optimal designs reduce min(ASE) by
–
of the min(ASE) of E-optimal. Therefore at
, the E-optimal cost functional would be preferable if the largest ASE’s were to be reduced, but for the best overall improvement (as measured by percent reduction from the E-optimal ASE), D- and SE-optimal are recommended.
Table 5 Approximate asymptotic standard errors calculated by asymptotic theory (Equation25(24)
(24) ) using optimally spaced
time points under constraints C2 (left set of 3) and C3 (right set of 3) and optimally selected
observables for parameters of interest
of the HIV model (27). Smallest ASE per parameter is highlighted using bold font.
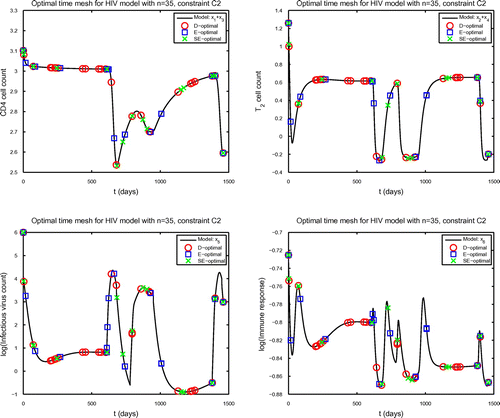
Fig. 1 Solution of (27) plotted using the observables log (upper left), log
(upper right),
(lower left) and
(lower right). Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x)
times under constraint C2.
When selecting observables, each of the three design criteria select many of the same observables. This is to be expected as
in this simulation. For
, both total CD4 cell count and immune response
are selected by all design criteria. The D-optimal criterion also chooses type 2 cell count, so the lack of information on virus count as measured by
leads to its high max(ASE),
. E-optimal (and at larger
, SE-optimal) choose to measure infectious virus count, reducing ASE
and thus reducing the max(ASE) by more than
. While at low
, E-optimal has the lowest min(ASE) and max(ASE), SE-optimal performs better at high
, so when selecting
observables, the number of time points
may affect which optimal design cost function performs best.
HIV observables and time point selection results
When taking samples on a uniform time grid, D-, E- and SE-optimal design criteria all choose observation operators that yield favourable ASE’s, with some criteria performing best under certain circumstances. For example, the SE-optimal observables at ,
yield the smallest standard errors; however, for all other values of
at
, E-optimal performs best. At
, E-optimal is a slightly weaker scheme. The examples in [Citation4] also reveal that D-, E- and SE-optimal designs are all competitive when only selecting time points for several different models. Now we wish to investigate the performance of these three criteria when selecting both an observation operator and a sampling time distribution using the algorithm described by Equations (Equation17
(17)
(17) ) and (Equation18
(18)
(18) ).
To maintain consistency across trials while slightly simplifying the parameter estimation problem, we allow the set of six parameters and three initial conditions ,
,
,
,
,
,
,
,
to be treated as unknowns and fix all other parameters. We again allow the possible observations of (1) infectious virus
, (2) immune response
, (3) CD4 cells
and (4) type 2 target cells
, each with an assumed error variance of
of the initial variable values given by
. To reflect the often limited resources of a clinical trial, we allow
observation maps to be included in the observation operators
and examine the distribution of time points if
or
samples (consisting of all observables in the observation operator) which may be taken from
through
. We begin all simulations with uniformly spaced sample times, and use either time grid constraint C2 or C3. Both constraints assume that samples are taken at
and
, so we in effect are optimizing the remaining 33 or 103 observation times.
When choosing observables and distributing
time points using constraint C2, the D-optimal cost function yields the lowest ASE for the parameters
,
,
,
,
,
), but the SE-optimals ASE are on the same order of magnitude (Table ). Both the D- and SE-optimal cost functions selected the same observables, and they both were minimized by similar distributions of time points (Figure ). The E-optimal design leads in the smallest ASE for
, with an ASE
that is half that of D-optimal and SE-optimal. E-optimal, however, trails D- and SE-optimal in the accuracy of an estimate for
, with an ASE
that is larger by one order of magnitude. The large difference in ASE’s for these two parameters may be related to the observables selected by each design criterion: E-optimal design chooses
(the variable most closely related to
) as an observable when D- and SE-optimal choose
(whose right hand side contains
). All three also chose
. The distribution of time points selected under each optimal design criterion focuses on regions very soon before or after a change in behaviour of the selected observables (Figure ). This may indicate that fewer sampling points may be needed for parameter estimates of similar accuracy. For the experimental design constraints of 35 time point allocated using constraint C2, the D-optimal cost functional is best for most parameters, but E-optimal is best for some parameters.
The ASE calculated for choosing observables and distributing
time points using constraint C3 are very similar (Table ), and the selected observables remain unchanged; however, the optimal distribution of time points under each design criterion (Figure ) is more uniform than when using constraint C2 (Figure ). For small
with
observables under constraint C3, D-optimal design is best for most parameters, but E-optimal is best for the remaining few. While the choice of a particular time point distribution constraint does not greatly impact the calculated ASEs for the paramters of interest, the constraint C3 yields a measurement schedule that may be more feasible for a patient to follow in that it does not call for as many days of multiple observations.
Fig. 2 Solution of (27) plotted using the observables log (upper left), log
(upper right),
(lower left) and
(lower right). Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x)
times under constraint C3.
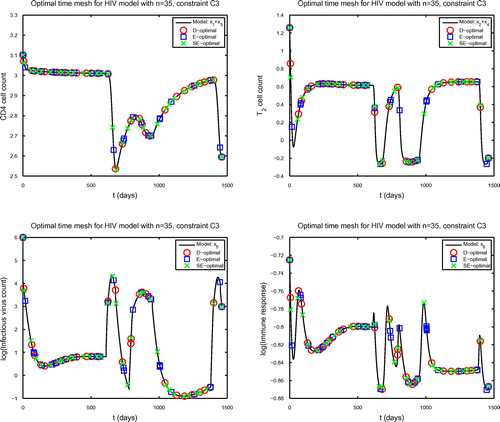
Table 6 Approximate asymptotic standard errors calculated by asymptotic theory (Equation25(24)
(24) ) using optimally spaced
time points under constraints C2 (left set of 3) and C3 (right set of 3) and optimally selected
observables for parameters of interest
of the HIV model (27). Smallest ASE per parameter is highlighted using bold font.
Fig. 3 Solution of (27) plotted using the observables log (upper left), log
(upper right),
(lower left) and
(lower right). Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x)
times under constraint C2.
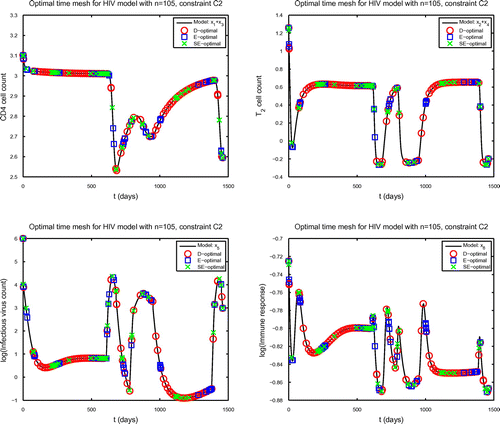
Choosing observables and distributing
time points using constraint C2 leads to a different pattern in which optimal design criterion is best for which parameter. For the more dense time point distribution, SE-optimal design is a much stronger candidate against D- and E-optimal (Table ). It yields the lowest ASE’s for
, while E-optimal is best for
and D-optimal is best for
. The D- and SE-optimal cost functions again choose the same observables of
and
, so their ASE’s for all parameters are similar. In this scenario, the E-optimal design has the largest percent reduction in ASE from those of D- and SE-optimal for the parameters
and
. E-optimal also changed its selected observables to
and
. The distribution of time points for the D-optimal design criteria appear very close to uniform (Figure ), and the distributions for E- and SE-optimal are clustered near local maxima, local minima, and other large changes in behaviour of the observables; however, even slight differences between the distributions of the E- and SE-optimal costs functions are visible. Consider the graph of infectious virus count in Figure . There is a cluster of SE-optimal times between
and
, but no E-optimal times occur during that interval. Very soon after, between
and
, there is a cluster of E-optimal times but no SE-optimal times. These clusters may indicate that either these periods in the patient’s treatment history are key to characterizing the parameters or that fewer time points may be adequate to obtain sufficiently accurate parameter estimates.
Fig. 4 Solution of (27) plotted using the observables log (upper left), log
(upper right),
(lower left) and
(lower right). Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x)
times under constraint C3.
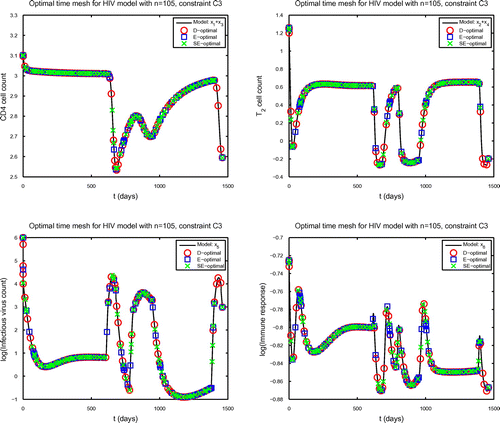
Table 7 Top: Optimal 5 observables chosen by each optimal design criterion when estimating the parameters of the model in [Citation6]. Bottom: Approximate asymptotic standard errors calculated using asymptotic theory (Equation25
(24)
(24) ) for each parameter in
using the optimal 5 observables with time point constraints of uniform spacing, constraint C2, and constraint C3. Smallest ASE for each parameter per time point constraint is highlighted in bold font.
The strength of SE-optimal design for large does not hold for time grid constraint C3 (Table ). E-optimal design provides the lowest ASE for the parameters
, D-optimal is best for
and the ASE calculated using the SE-optimal designed experiment is often the largest. The observables selected in this case are the same as the
, constraint C2 case. The optimal time point distributions determined under all three design criterion are near uniform (Figure ). Small differences between the distributions may be observed when the functions have a slope of high magnitude, indicating that the distributions are not exactly uniform. As the time point optimization routine is started with a uniform time point distribution, this may indicate that when samples are taken at many times during an experiment, a uniform distribution is somewhat near optimal for model (27) or, more significantly, that a uniform distribution is not an appropriate initial distribution to use to obtain the optimal time point distribution.
Between D- and E-optimal, there is no clear leader for optimal time point and observable selection in these examples for system (27). The SE-optimal criterion is useful in estimating some parameters under the constraint C2, and in most cases yields standard errors on the same order of magnitude of the leading optimal design criterion. The optimal design algorithm successfully identifies observables and a time distribution that optimizes an aspect of the Fisher Information Matrix as determined by the choice of optimal design cost functional; however, the time point distributions exhibit tendencies to cluster near times when the slopes of function solutions are changing. We proceed to examine the algorithm’s performance when presented with a system that allows many possible observables and does not require as many sampling times.
Example 2: Zhu’s Calvin Cycle model
The second model we use as an example is characteristic of the large differential equation systems that often appear in industrial problems. In [Citation6], Zhu et al., present an ODE model for the Calvin Cycle in fully grown spinach. The Calvin Cycle, part of the light-independent reactions in photosynthesis, plays an important role in plant carbon fixation, which leads to the growth of the plant. This model contains 165 parameters and initial conditions, 31 ODEs and 7 concentration balance laws and involves 38 state variables (metabolite concentrations in different parts of the cell) as well as a calculation for photosynthetic CO uptake rate. The metabolites used in the model are denoted by RuBP, PGA, DPGA, T3P, FBP, E4P, S7P, ATP, SBP, NADPH, HexP, PenP, NADHc, NADc, ADPc, ATPc, GLUc, KGc, ADP in photorespiration, ATP in photorespiration, GCEA, GCA, PGCA, GCAc, GOAc, SERc, GLYc, HPRc, GCEAc, T3Pc, FBPc, HexPc, F26BPc, UDPGc, UTPc, SUCP, SUCc and PGAc, and the parameters are mainly initial conditions, maximum reaction velocities and Michaelis–Menten constants for reaction substrates, products, activators and inhibitors. The ‘c’ following some metabolite names indicates that the model compartment corresponds to the metabolite concentration in cytosol; compartment names lacking a ‘c’ are the metabolite in the chloroplast stroma. The full system of equations and parameter values may be found in the appendices of [Citation6]. While the model has not been validated with data as completely as the family of HIV models discussed above, it is representative of the models used to describe plant enzyme kinetics and utilizes well-documented Michaelis–Menten enzyme kinetic model formulations.[Citation19]
Fig. 5 Solutions of selected state variables in the Zhu model [Citation6]. Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) sampling times under constraint C2 when sampling the optimal 5 observables to estimate
(Table ). Top left: Carbon uptake rate
; top right: ATP; bottom left: SUCc; bottom right: RuBP.
![Fig. 5 Solutions of selected state variables in the Zhu model [Citation6]. Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 sampling times under constraint C2 when sampling the optimal 5 observables to estimate θ→a (Table 7). Top left: Carbon uptake rate A(t); top right: ATP; bottom left: SUCc; bottom right: RuBP.](/cms/asset/20031c57-0a8c-4f7b-a7dc-7a69cc316960/gipe_a_797973_f0005_oc.gif)
Fig. 6 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) sampling times under constraint C3 when sampling the optimal 5 observables to estimate
(Table ). Top left: Carbon uptake rate
; top right: ATP; bottom left: SUCc; bottom right: RuBP.
![Fig. 6 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 sampling times under constraint C3 when sampling the optimal 5 observables to estimate θ→a (Table 7). Top left: Carbon uptake rate A(t); top right: ATP; bottom left: SUCc; bottom right: RuBP.](/cms/asset/b0784ac1-6c13-426a-b694-7a97ad42b719/gipe_a_797973_f0006_oc.gif)
In [Citation5], sets of the optimal 3, 5, 10 and 15 metabolites are identified as the most useful to measure in an experiment in order to estimate a subset of 6 parameters, = [KM
, KM
, KI
, KC, KM
, KM
]
with true values
= [0.0115, 0.0025, 0.00007, 0.0115, 0.15, 0.15]
, and a subset of 18 parameters,
=[RuBP
, SBP
, KM
, KM
, KI
, KE
, KM
, KM
, KI
, KE
, KM
, KM
, KI
, KC, KM
, KM
, V
, V
]
with true values
= [2, 0.3, 0.0115, 0.02, 0.075, 0.05, 0.05, 0.05, 0.4, 0.058, 0.02, 0.0025, 0.00007, 0.0115, 0.15, 0.15, 0.3242, 0.0168]
. The simulation was set in the framework of an experiment run for 3000 seconds over which 11 samples are taken at evenly spaced times for the optimization of estimates for
and 21 samples for estimation of
.
We use a similar set up for our simulations in order to judge the ability of the time and variable selections to minimize the asymptotic standard errors of both and
using
and
observables and
time points over the time interval
. Each metabolite is assigned a variance of
of its initial value, and to reduce computation time, all metabolites that do not change in concentration over time (
) are excluded from the search algorithm. As it is often possible to measure a particular metabolite’s concentration in plant tissue, we allow
to be composed of 28 vectors in
that are composed of a one in the element corresponding to the position of the differential equation describing the dynamics of the metabolite in the vector of model ODEs and zero elsewhere.
We compare the ASE calculated for evenly spaced measurements over the interval
against the optimally spaced
time points according to constraints C2 and C3 and plot the D-, E- and SE-optimal time point distributions on the solutions of selected compartments in the Zhu model of [Citation6]. The four compartments chosen for graphing are carbon uptake rate
(units
mol m
s
), which is a rate calculated from the output of the model that describes the plant’s efficiency in using the available environmental resources to develop; adenosine triphosphate (ATP) in chloroplast stroma, which is a well-known metabolite active in photosynthesis; sucrose, a sugar, in cytosol (SUCc); and Ribulose-1,5-bisphosphate (RuBP), a metabolite connected to the enzyme RuBisCO, which is essential to carbon fixation.
The simplest scenario we test is the selection of the optimal observables (metabolites) and
time points to use when estimating the six parameters in
. For all three optimal design methods, the optimal observables determined under the uniform grid were also determined to be optimal after the time point distribution is optimized under constraints C2 and C3. These observables are listed in the upper portion of Table . All three optimal design methods identify the observables PGA, SERc and F26BPc, indicating that these three metabolites may be central to accurate estimates of the parameters in
; moreover, the E-optimal and SE-optimal cost functions selected the same set of five observables.
The similarity in results, however, does not continue through the selected time point distributions. Under constraint C2 (Figure ), the D-optimal distribution is loosely clustered about the center of the time interval, the E-optimal time points are clustered about seconds, and SE-optimal chooses a small cluster of time points around the initial bump and allows a few samples after the function reaches a steady state. Using constraint C3 (Figure ), all three optimal design criteria chose a majority of their sampling times before
and allow only a few sampling times after the system reaches a steady state. The optimization of time point distributions yields improved asymptotic standard errors from those of the uniform distribution – sometimes by an order of magnitude or more. For all three time point constraints, D-optimal yields the smallest ASE’s for the most number of parameters, and SE-optimal yields the smallest ASE’s for the second most number of parameters. Both optimal design criteria perform better with the C3 optimal times than the C2 optimal times. Therefore, in this simple case, using either the D- or SE-optimal design criterion with time point distribution constraint C3 would yield the best results.
The next scenario is the selection of the optimal observables and
time points to use when estimating the six parameters in
. For all three optimal design methods, the optimal observables determined under the uniform grid were also determined to be optimal after the time point distribution is optimized under constraints C2 and C3. These observables are listed in the upper portion of Table reftab:zhusps106. Of the 28 possible observables, 20 were selected by at least one optimal design criterion, 8 of which (DPGA, T3P, E4P, S7P, ATP, GCA, SERc, T3Pc) were selected by two criteria and one, GOAc, was selected by all three. The effect of adding five observables does not have a large effect on the estimated ASE for the six parameters of interest. The ASE’s listed in Table reftab:zhusps106 for the
observable case are on the same order as those in Table for the
observable case for each time point constraint.
The optimal time point distributions also differ from those selected under the five observable case. Under constraint C2 (Figure ), the D-optimal distribution is loosely clustered near the boundaries of the time interval while the E- and SE-optimal time points are scattered over the whole interval. Using constraint C3 (Figure ), the D-optimal times are spread throughout the middle half of the time interval, E-optimal over the first half, and SE-optimal over the second half. While there are no easily discernible patterns between the distributions chosen under the C2 and C3 constraints, the optimization of time point distributions again yield improved asymptotic standard errors from those of a uniform time distribution. For all three time point constraints, D-optimal yields the smallest ASE’s for the most number of parameters, and SE-optimal yields the smallest ASE’s for the second most number of parameters. Other than for the parameters it estimates best, SE-optimal is often the worst criterion. The time point distribution under constraint C2 allows smaller ASE’s for the observable variables case. Therefore, using the D-optimal design criterion with time point distribution constraint C2 would yield the best results.
The addition of five observables for does not greatly impact most of the calculated ASE’s. For the time point constraints C2 and C3, all but one of the minimum ASE’s remain on the same order of magnitude, and some of the ASE’s increase when
observables are allowed from when
observables are allowed. This may indicate that for a small parameter set such as
, only a small amount of information is needed to obtain the best possible results; adding extra information (through additional observables) does not further improve the ASE’s.
Table 8 Top: Optimal 10 observables chosen by each optimal design criterion when estimating the parameters of the model in [Citation6]. Bottom: Approximate asymptotic standard errors calculated using asymptotic theory (Equation25
(24)
(24) ) for each parameter in
using the optimal 10 observables with time point constraints of uniform spacing, constraint C2 and constraint C3. Smallest ASE for each parameter per time point constraint is highlighted in bold font.
Fig. 7 Solutions of selected state variables in the Zhu model [Citation6]. Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) sampling times under constraint C2 when sampling the optimal 10 observables to estimate
(Table ). Top left: Carbon uptake rate
; top right: ATP; bottom left: SUCc; bottom right: RuBP.
![Fig. 7 Solutions of selected state variables in the Zhu model [Citation6]. Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 sampling times under constraint C2 when sampling the optimal 10 observables to estimate θ→a (Table 8). Top left: Carbon uptake rate A(t); top right: ATP; bottom left: SUCc; bottom right: RuBP.](/cms/asset/82d558d3-538c-4450-8dfe-9442f7b12fd5/gipe_a_797973_f0007_oc.gif)
Fig. 8 Solutions of selected state variables in the Zhu model [Citation6]. Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) sampling times under constraint C3 when sampling the optimal 10 observables to estimate
(Table ). Top left: Carbon uptake rate
; top right: ATP; bottom left: SUCc; bottom right: RuBP.
![Fig. 8 Solutions of selected state variables in the Zhu model [Citation6]. Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 sampling times under constraint C3 when sampling the optimal 10 observables to estimate θ→a (Table 8). Top left: Carbon uptake rate A(t); top right: ATP; bottom left: SUCc; bottom right: RuBP.](/cms/asset/90fea977-9764-46d6-836a-134fa4c1bacc/gipe_a_797973_f0008_oc.gif)
Now consider the parameter vector . We identify the optimal
observables and the optimal distribution of
time points using the D-, E-, and SE-optimal cost functionals. Three metabolites, RuBP, SBP and F26BPc, are selected by all three cost functionals, indicating that these three observables may be important to measure to accurately estimate a large number of the parameters in
. The inclusion of RuBP
and SBP
in
may also heavily influence the selection of observables. Many of the other metabolites selected by at least one of the cost functionals, namely, PGA, SERc and T3Pc, were also selected for
in the experimental setup of
observables and
time points, indicating that they are still relevant to some of the parameters in
.
Using the uniform time point distribution yields standard errors that are up to six order of magnitude larger than the parameter (KI = 0.00007) and are typically two or three orders of magnitude larger than the parameter value (Table ). Constraint C2 also leads to large standard errors when using the D- and E-optimal cost function. The E-optimal standard errors, in fact, do not change from those calculated using the uniform time point distribution, and as shown in Figure , the E-optimal time distribution under constraint C2 is uniform. The SE-optimal design criterion performs the best when using constraint C2 and produces much smaller standard errors, though the standard errors are still larger than the parameter values by orders of magnitude for most parameters. Both D- and SE-optimal perform favourably under constraint C3: the D-optimal, C3 design produces smaller ASE’s than the SE-optimal, C2 design, and the SE-optimal, C3 design yields the smallest ASE’s for almost all parameters. Under the constraint C3 and the SE-optimal cost functional, the calculated ASE’s are zero to one orders of magnitude larger than the parameter values.
The favourable performance of the SE-optimal design criterion under constraint C2 may be attributed to its selected time point distribution (Figure ). The SE-optimal distribution is the only one that places a large number of time points (5 out of 11) before the solution approaches a steady state at . The E-optimal design, as mentioned previously, selects the uniform distribution, and the D-optimal design suggests sampling after the solution has achieved a steady state. When using constraint C3, the E-optimal design selects a distribution that maintains the uniform spacing between points in the interior of the time interval (0,3000) (Figure ), again leading to poor ASE’s. Both the D- and SE-optimal designs place the majority of the 11 time points in the first one-third of the time interval, thus capturing more of the dynamical system’s behaviour before it achieves a steady state. These front-heavy distributions greatly reduce the estimated ASE’s from those calculated using a uniform time distribution.
Table 9 Top: Optimal 5 observables chosen by each optimal design criterion when estimating the parameters of the model in [Citation6]. Bottom: Approximate asymptotic standard errors calculated using asymptotic theory (Equation25
(24)
(24) ) for each parameter in
using the optimal 5 observables with time point constraints of uniform spacing, constraint C2 and constraint C3. Smallest ASE for each parameter per time point constraint is highlighted in bold font.
Fig. 9 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) sampling times under constraint C2 when sampling the optimal five observables to estimate
(Table ). Top left: Carbon uptake rate
; top right: ATP; bottom left: SUCc; bottom right: RuBP.
![Fig. 9 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 sampling times under constraint C2 when sampling the optimal five observables to estimate θ→c (Table 9). Top left: Carbon uptake rate A(t); top right: ATP; bottom left: SUCc; bottom right: RuBP.](/cms/asset/47ed942f-1368-489e-956c-35bc1d6213eb/gipe_a_797973_f0009_oc.gif)
Fig. 10 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) times under constraint C3 when sampling the optimal five observables to estimate
(Table ). Top left: Carbon uptake rate
; top right: ATP; Bottom Left: SUCc; bottom right: RuBP.
![Fig. 10 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 times under constraint C3 when sampling the optimal five observables to estimate θ→c (Table 9). Top left: Carbon uptake rate A(t); top right: ATP; Bottom Left: SUCc; bottom right: RuBP.](/cms/asset/74e4b1fc-7f85-44bf-9cf2-10fe45fcf0f6/gipe_a_797973_f0010_oc.gif)
The last case tested is designing experiments using each of the three cost functionals to estimate when allowed
observables and
time points. As in the case of only allowing five observables for estimation of
, the metabolites RuBP, SBP and F26BPc are selected by all three optimal design criteria. Additionally, PenP and SERc are selected by all three. A total of 15 different metabolites are chosen across the three optimal design criteria, of which only five are chosen by a single criterion and five selected by two criteria (Table ). The three optimal design criteria show more agreement on which 10 observables are important to
than which 10 are important to
(in that case, a total of 20 different metabolites are chosen). This indicates that the three design criterion agree upon observables that are central to understanding the behaviour of the model but also select observables that help minimize their associated cost functionals.
Similar to the five observable cases for , the ASE’s calculated when using a time point distribution optimized under the C2 or C3 constraints are smaller than those of the uniform time point distribution (though the difference is much less pronounced). While the ASE’s from the D- and SE-optimal criteria are typically smallest under the uniform time point distribution, the E-optimal designed experiment yields the smallest ASE’s for the most number of parameters under constraint C2 (Table ). The ASE’s for the D-optimal experiment under constraint C2 are typically larger than those for the D-optimal experiment with a uniform time distribution, and the SE-optimal ASE’s see only marginal improvements. For parameters when the E-optimal ASE’s are not as small as those for the D- and SE-optimal designs, the ASE’s are often still on the same order. These ASE’s are still orders of magnitude larger than the values of some parameters. The minimum ASE’s under constraint C3 are smaller than those under constraint C2 (and are notable improvements over those from the uniform time point distribution), but most are improved by only one order of magnitude or less. The D- and SE-optimal cost functions yield the smallest standard errors for more parameters under C3 than C2, as well.
The performance improvements seen in the D- and SE-optimal experimental designs from the C2-optimal time point distributions to the distributions optimal under constraint C3 can be easily explained. Under constraint C2, neither criterion produced clusters of time points (Figure ). The distributions generated by both criteria are more similar to the uniform distribution that was used as the initial seed for the time point distribution optimization than to the highly clustered distributions seen for other selections of and
(such as the one shown in Figure ). The D-optimal distribution only contains one time point before
, as well, thus ignoring the early dynamics of the system. The E-optimal time point distribution contains clusters at the very beginning (
) and very end (
) of the time interval as well as a loose cluster between
and
.
All three optimal design criteria produce non-uniform distributions under constraint C3 (Figure ). The time point distributions determined using the E- and SE-optimal cost functions place a majority of their time points before , capturing the dynamics early in the system solution. The D-optimal distribution also concentrates its sampling times before
, but does not as tightly cluster the time points. All three cost functionals under time point constraint C3 produce smaller ASE’s than those calculated with a uniform time point distribution (Table ). The distributions generated under both constraints C2 and C3 indicate that heavily weighting time periods when the system is changing its pattern of behaviour (such as transitioning from oscillations to a steady state) produce smaller standard errors than uniform or near-uniform distributions.
Table 10 Top: Optimal 10 observables chosen by each optimal design criterion when estimating the parameters of the model in [Citation6]. Bottom: Approximate asymptotic standard errors calculated using asymptotic theory (Equation25
(24)
(24) ) for each parameter in
using the optimal 10 observables with time point constraints of uniform spacing, constraint C2 and constraint C3. Smallest ASE for each parameter per time point constraint is highlighted in bold font.
Fig. 11 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) sampling times under constraint C2 when sampling the optimal 10 observables to estimate
(Table ). Top left: Carbon uptake rate
; top right: ATP; bottom left: SUCc; bottom right: RuBP.
![Fig. 11 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 sampling times under constraint C2 when sampling the optimal 10 observables to estimate θ→c (Table 10). Top left: Carbon uptake rate A(t); top right: ATP; bottom left: SUCc; bottom right: RuBP.](/cms/asset/7ee99972-25ee-4578-9b7e-8951c477116b/gipe_a_797973_f0011_oc.gif)
Fig. 12 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) times under constraint C3 when sampling the optimal 10 observables to estimate
(Table ). Top Left: Carbon uptake rate
; top right: ATP; bottom left: SUCc; bottom right: RuBP.
![Fig. 12 Solutions of selected state variables in the Zhu model.[Citation6] Plotted on top of each curve are the D-optimal (circle), E-optimal (square) and SE-optimal (x) n=11 times under constraint C3 when sampling the optimal 10 observables to estimate θ→c (Table 10). Top Left: Carbon uptake rate A(t); top right: ATP; bottom left: SUCc; bottom right: RuBP.](/cms/asset/0d539d08-abf6-41aa-ab9b-0e3622b27289/gipe_a_797973_f0012_oc.gif)
Our computations using the Zhu model of [Citation6] for the Calvin cycle indicate that both the selection of observables and the distribution of sampling times across the experiment affect the estimated asymptotic standard errors – sometimes by several orders of magnitude. While the ASE’s calculated for all exercises were often larger than the parameter values, this may be related to the model’s tendency to quickly reach a steady state.
Overall, the optimal design cost functions performed best under time point constraint C3, followed by C2 and finally the uniform distribution. While in some examples a particular cost functional would do particularly well (such as D-optimal in the , 10 observable case and SE-optimal in the
, 5 observable case), it is hard to determine apriori – or even using the results of a uniform time distribution – which cost functional will perform best for a particular set of parameters and observables. The reduction in ASE’s gained from adding additional observables is also difficult to predict. Adding five observables to better estimate
did not result in noticeably smaller estimated asymptotic standard errors as calculated by asymptotic theory. The improvement may be better quantified using a different method to calculate asymptotic standard errors such as Monte Carlo simulations or bootstrapping, but that is beyond the scope of this initial investigation.
Conclusion
Expanding the efforts reported in [Citation4] on time point distribution selection using the D-, E- and SE-optimal design criteria, we introduce a new methodology and algorithm for selecting both optimal observables and an optimal time point distribution. While the D- and E-optimal cost functions are well established in the literature, the SE-optimal design method is relatively new but competitive. We compare the abilities of these three design criteria to reduce the estimated asymptotic standard errors of selected subsets of parameters for two ordinary differential equation models representative of ODE systems used in industrial applications: the log-scaled HIV model (27) and the model of [Citation6] for the Calvin cycle. These examples suggest the strengths of each design method in selecting appropriate observable variables and sampling times.
Collecting patient data for the treatment of HIV is limited by the types and expenses of assays available. In efforts with experimental data,[Citation7] parameter estimation for the HIV model (27) has only been performed with one or two observed quantities. Our tests for determining the optimal sets of 1, 2 and 3 observables when data is collected at uniformly distributed times show that the SE-optimal design criterion performs very similarly to the D-optimal criterion; moreover, a small number of observables may be compensated for by allowing more sampling times. While only measuring one observable may not quite be adequate for accurate parameter estimates, taking either 201 or 401 measurements of two observables yielded similar standard errors when compared to an experiment in which three observables are sampled 51-101 times.
For the HIV model, we compared the performance of all three design criteria under time point distribution constraints C2 and C3. When determining the optimal distribution of 35 time points, D-optimal yields the smallest ASE’s for the most parameters, followed by E-optimal, for both time point constraints. When determining the optimal distribution of 105 time points, however, D-, E-, and SE-optimal each yield the smallest ASE’s for some of the parameters under C2, and both D- and E-optimal are strong performers under constraint C3. The SE-optimal standard errors, while not the lowest, are on the same order of magnitude as those of D- and E-optimal. Therefore for our selected parameter values, D- and E-optimal more reliably yield the smallest standard errors.
The Zhu model of [Citation6] is representative of experimental environments where a great number of state variables may possibly be measured but the costs of measurements limit the number of observed variables that may be sampled. We compared the estimated asymptotic standard errors calculated using the observables and time point distributions determined with the D-,E-, and SE-optimal design methods. For the small parameter subset , a small number of observables is sufficient to obtain as small ASE’s as possible - adding more observables does not improve the ASE’s generated for any of the design methods. Optimizing the time point distribution under either constraint C2 or C3 improves the ASE’s by up to two orders of magnitude. At both 5 and 10 observables, the D-optimal design provides the smallest ASE’s for the most parameters, followed by SE-optimal. The E-optimal standard errors, however, are often on the same order of magnitude, indicating that it is still competitive.
When testing the treatment of the larger parameter subset of the Zhu model by each of the three design methods, we found that while an excellent selection of observables and time points may still yield small standard errors (as with the SE-optimal design method with 5 observables under constraint C3), adding more information through more observables reduces the calculated ASE’s in the uniform time distribution. At 5 observables, the SE-optimal cost function performs the best and E-optimal time distribution optimization fails to venture far from the uniform grid initially used; at 10 observables, E-optimal performs best under constraint C2 and all three design criteria perform the best for different parameters under constraint C3. Thus for the Zhu model, it is difficult to predict which optimal design criterion will perform best in a particular case.
While the performance of each optimal design criteria is highly dependent upon the ODE system, parameter subset, number of observables allowed, number of time points allowed, and even constraints imposed on the time point distribution selection, the examples performed using the HIV model (27) and the Zhu model [Citation6] demonstrate that the D-, E-, and SE-optimal design methods are all competitive and useful. Moreover, in the Zhu model examples, selection of optimal time points can reduce the estimated asymptotic standard errors of parameters by several orders of magnitude, thus providing data that is more useful in a parameter estimation problem without taking more samples or measuring more observables. Thus the new methodology developed and illustrated here can be an important tool in designing experimental protocols for obtaining data to be used in estimating parameters in complex dynamic models.
Acknowledgments
This research was supported in part (HTB and KLR) by grant number R01AI07 1915-07 from the National Institute of Allergy and Infectious Diseases and in part (KLR) by Fellowships from the CRSC and CQSB. The authors are grateful to Dr. Laura Potter of Bioinformatics, Syngenta Biotechnology, Inc., Research Triangle Park, NC, for her numerous conversations on plant biology experimentation and for initially providing, among a number of other references, the reference [Citation6].
References
- Banks HT, Davidian M, Samuels JR, Sutton KL. Chapter 11, An inverse problem statistical methodology summary, CRSC Technical Report CRSC-TR08-01, NCSU, 2008. In: Chowell G, Hayman JM, Bettencourt LMA, Castillo-Chavez C, editors. Statistical estimation approaches in epidemiology. Berlin: Springer; 2009. p. 249–302.
- Banks HT, Dediu S, Ernstberger SL, Kappel F, Generalized sensitivities and optimal experimental design, CRSC-TR08-12; 2008, (Revised) 2009 [J. Inverse Ill-posed Probl. 2010;18:25–83].
- Thomaseth K, Cobelli C. Generalized sensitivity functions in physiological system identification. Ann. Biomed. Eng. 1999;27:607–616.
- Banks HT, Holm K, Kappel F. Comparison of optimal design methods in inverse problems, CRSC Technical Report CRSC-TR10-11, NCSU; 2010 [Inverse Probl. 2011;27:075002].
- Avery M, Banks HT, Basu K, Cheng Y, Eager E, Khasawinah S, Potter L, Rehm KL. Experimental design and inverse problems in plant biological modeling, CRSC Technical Report CRSC-TR11-12, NCSU; 2011 [J. Inverse and Ill-posed Problems, doi:10.1515/jiip-2012-0208].
- Zhu X-G, Sturler E, Long SP. Optimizing the distribution of resources between enzymes of carbon metabolism can dramatically increase photosynthetic rate: a numerical simulation using an evolutionary algorithm. Plant Physiol. 2007;145:513–526.
- Adams BM, Banks HT, Davidian M, Rosenberg ES. Model fitting and prediction with HIV treatment interruption data, CRSC Technical Report CRSC-TR05-40, NCSU; 2005 [Bull. Math. Biol. 2007;69:563–584].
- Prohorov YV. Convergence of random processes and limit theorems in probability theory. Theor. Prob. Appl. 1956;1:157–214.
- Banks HT, Bihari KL. Modeling and estimating uncertainty in parameter estimation, CRSC Technical Report CRSC-TR99-40, NCSU; 1999 [Inverse Problems. 2001;17:95–111].
- Attarian A. tssolve.m, Retrieved August 2011, from http://www4.ncsu.edu/arattari/.
- Fink M. myAD, Retrieved August 2011, from http://www.mathworks.com/matlabcentral/fileexchange/15235-automatic-differentiation-for-matlab.
- Kuntsevich A, Kappel F. SolvOpt, Retrieved July 2011, from http://www.kfunigraz.ac.at/imawww/kuntsevich/solvopt/.
- Davidian M, Giltinan D. Nonlinear models for repeated measurement data. London: Chapman & Hall; 1998.
- Seber GAF, Wild CJ. Nonlinear regression. New York: Wiley; 1989.
- Adams BM, Banks HT, Davidian M, Kwon H, Tran HT, Winfree SN, Rosenberg ES. HIV dynamics: modeling, data analysis, and optimal treatment protocols, CRSC Technical Report CRSC-TR04-05, NCSU; 2004 [J. Comput. Appl. Math. 2005;184:10–49].
- Adams BM. Non-parametric parameter estimation and clinical data fitting with a model of HIV infection [PhD Thesis]. NC State Univ.; 2005.
- Banks HT, Davidian M, Hu S, Kepler G, Rosenberg E. Modeling HIV, immune response and validation with clinical data, CRSC Technical Report CRSC-TR07-09, NCSU; 2007 [J. Biol. Dyn. 2008;2:357–385].
- Banks HT, Cintrón-Arias A, Kappel F. Parameter selection methods in inverse problem formulation, CRSC Technical Report CRSC-TR10-03, NCSU, revised November 2010. In: Mathematical model development and validation in physiology: application to the cardiovascular and respiratory systems. Lecture notes in mathematics. Mathematical biosciences subseries. Springer-Verlag; in press.
- Banks HT. Modeling and control in the biomedical sciences, Lecture notes in biomathematics, Vol. 6. Levin S, editor. Berlin: Springer-Verlag; 1975.