
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In the iterative solution of an ill-posed linear system , how to select a fast and easily established descent direction
to reduce the residual
is an important issue. A mathematical procedure to find a double optimal descent direction
in
, without inverting
, is developed in an
-dimensional Krylov subspace. The novelty is that we expand
in an affine Krylov subspace with undetermined coefficients, and then two optimization techniques are used to determine these coefficients in closed form, which can greatly accelerate the convergence speed in solving the ill-posed linear problems. The double optimal descent algorithm is proven to be absolutely convergent very fast, accurate and robust against noise, which is confirmed by numerical tests of several linear inverse problems, including the heat source identification problem, the backward heat conduction problem, the inverse Cauchy problem and the external force identification problem.
1 Introduction
In this paper, we develop a double optimal descent algorithm (DODA) in an affine Krylov subspace to iteratively solve the following linear equations system:1
1 where
is an unknown vector, to be determined from a given non-singular coefficient matrix
, and the input
. For the existence of the solution
, we suppose that
, and hence
has a full rank with
.
The linear inverse problems are sometimes obtained via an -dimensional discretization of a bounded linear operator equation under a noisy input. When
is severely ill conditioned and the data are corrupted by noise, we may encounter the problem that the numerical solution of Equation (Equation1
1
1 ) might deviate from the exact one to a great extent, and in general a generalized solution
is found, where
is a pseudo-inverse of
in the Penrose sense.
If we only know perturbed input data with
, and if the problem is ill posed, i.e. the
is not closed or equivalently
is unbounded, we have to solve Equation (Equation1
1
1 ) by a regularization method.
A measure of the ill-posedness of Equation (Equation11
1 ) can be performed by using the condition number of
[Citation1]:
2
2 where
denotes the Frobenius norm of
.
For every matrix norm , we have
, where
is a radius of the spectrum of
. The Householder theorem states that for every
and every matrix
, there exists a matrix norm
depending on
and
such that
. Anyway, the spectral condition number
can be used as an estimation of the condition number of
by
3
3 where
is the collection of all the eigenvalues of
. Turning back to the Frobenius norm, we have
4
4 In particular, when
is symmetric,
. Roughly speaking, the numerical solution of Equation (Equation1
1
1 ) may lose the accuracy of
decimal points when
.
Due to the ill-posedness of the problem, small errors in the data may lead to computed solution far off the correct one, rendering straightforward approaches to solve Equation (Equation11
1 ) useless. To overcome the sensitivity to noise, it is often using a regularization method to solve the ill-posed problem,[Citation2–Citation5] where a suitable regularization parameter is used to suppress the approximation error and propagated data error, ensuring stability of the solution
with respect to the perturbed data
.
The iterative algorithm for solving linear equations system can be derived from the discretization of a certain ordinary differential equations system.[Citation6] Particularly, some descent methods can be interpreted as the discretizations of gradient flows.[Citation7] For a large-scale linear equations system, the major choice is using an iterative algorithm, where an early stopping criterion is used to prevent the reconstruction of noisy component in the approximate solution, and which has the regularization effect. Recently, some useful and simple methods have been developed by the author for solving Equation (Equation11
1 ), like the optimally generalized regularization method,[Citation8] optimally scaled vector regularization method,[Citation9] adaptive Tikhonov regularization method,[Citation10] optimal preconditioner method,[Citation11] the globally optimal iterative method,[Citation12] as well as the optimal and globally optimal tri-vector iterative algorithms (OTVIA).[Citation13, Citation14]
There are a lot of numerical methods that converge significantly faster than the steepest descent method (SDM), and unlike the conjugate gradient method (CGM), they insist their search directions to be the gradient vector at each iteration.[Citation15] The SDM performs poorly, yielding the iteration counts that grow linearly with ,[Citation16] whose unwelcome slowness has to do with the choice of the gradient descent direction
and its original steplength
detected by the SDM. Liu [Citation13] has explored a variant of the SDM by feeding the concept of an optimal descent tri-vector to solve ill-posed linear equations system, which is an optimal combination of the steepest descent vector
, the residual vector
and a supplemental vector
, where not only the direction
but also the steplength are modified from a theoretical foundation of optimization being realized on an invariant manifold. This novel method outperformed better than the generalized minimal residual method (GMRES),[Citation17] the CGM, and other gradient descent variant methods. The concept of optimal vector driving algorithm was explored by Liu and Atluri [Citation18] for solving linear equations. The idea of using two optimizations in the solution of Equation (Equation1
1
1 ) in a Krylov subspace was proposed by Liu [Citation19]. Then, Liu [Citation20] used the scaling invariant property of the merit function for a maximal projection to derive a maximal projection solution of linear problem in an affine Krylov subspace, which is proven better than the least-square solution. As a continuation, we further explore the concept of double optimal iterative algorithm with an
-vector in a Krylov subspace as a descent direction to solve Equation (Equation1
1
1 ).
The remaining parts of this paper are arranged as follows. In Section 2, we review the invariant-manifold method. The Krylov subspace method used to derive an optimal descent direction is demonstrated in Section 3. In Section 4, we solve the optimal parameters appeared in the optimal descent direction by two optimization techniques, of which the doubly optimized solutions of these parameters are given in a closed-form type. Section 5 outlines the numerical procedures of the -vector DODA in terms of
weighting parameters which are optimized explicitly from two different merit functions, where the convergence of the DODA is proven. The numerical examples of linear inverse problems solved by the iterative algorithm of DODA are given in Section 6, where we compare the numerical performance of DODA with other several algorithms. Finally, the conclusions and discussions are drawn in Section 7.
2 Invariant manifold
For the linear equations system (Equation11
1 ), which is expressed to be
in terms of the residual vector:
5
5 we can introduce a scalar function:
6
6 where
is a monotonically increasing function of
,
is an initial value of
and
.
In order to keep the iterative orbit evolving on the manifold, Liu and Atluri [Citation18] have derived an iterative algorithm:
7
7 where
8
8
9
9
10
10 In the above,
11
11 is a relaxation parameter.
Because the convergence speed is closely correlated to by
12
12 where
13
13 the author has previously developed several optimal iterative algorithms basing on the minimization of
. On the other hand, the term
in Equation (Equation7
7
7 ) is a steplength. Liu [Citation21] has proposed a new algorithm to solve Equation (Equation1
1
1 ) by maximizing the steplength in a Krylov subspace.
3 The Krylov subspace method
There are several numerical solution methods of Equation (Equation11
1 ), which are originated from the idea of minimization. For the positive definite linear system, solving Equation (Equation1
1
1 ) by the SDM is equivalent to solve the following minimization problem [Citation22, Citation23]:
14
14 where
is a positive definite matrix.
Liu [Citation12–Citation14] has proposed new methods by minimizing the following merit function:15
15 to obtain a fast descent direction
, in terms of two or three vectors, for the iterative solution of Equation (Equation1
1
1 ). Because the above minimization is quite difficult when
is expressed as a linear combination of multi vectors, Liu [Citation24] has solved, instead of Equation (Equation15
15
15 ), the following minimization problem in a Krylov subspace:
16
16 In the solution of linear equations system, the Krylov subspace method is one of the most important classes of numerical methods, and the iterative algorithms that are applied to solve large-scale linear systems are mostly the preconditioned Krylov subspace methods.[Citation24–Citation29] In the past few decades, the Krylov subspace methods for solving Equation (Equation1
1
1 ) have been studied in depth since the appearance of pioneering work,[Citation30, Citation31] such as the minimum residual algorithm,[Citation32] the GMRES,[Citation17, Citation27] the quasi-minimal residual method,[Citation28] the biconjugate gradient method,[Citation33] the conjugate gradient squared method [Citation34] and the biconjugate gradient stabilized method.[Citation35] There are more discussions on the Krylov subspace methods in the review papers [Citation26, Citation36] and text books.[Citation37, Citation38] The most are paying more attention to the residual vector and its ‘optimality’ of some residual errors in the Krylov subspace to derive the ‘best approximation’.
It is known that for the iterative algorithm to solve linear equations system (Equation11
1 ), the best descent direction
is given by
.[Citation39] Then in order to find the best descent direction
, we require to solve the following linear problem:
17
17 Suppose that we have an
-dimensional Krylov subspace generated by the coefficient matrix
from the right-hand side vector
in Equation (Equation17
17
17 ):
18
18 Let
. The idea of GMRES is using the Galerkin method to search the solution
, such that the residual
is perpendicular to
.[Citation17] It can be shown that the solution
minimizes the residual [Citation37] in Equation (Equation16
16
16 ). It is known that the GMRES does not always perform well for ill-posed linear systems.[Citation40–Citation44] In order to solve ill-posed linear problems based on the GMRES, Calvetti et al. [Citation40] have proposed the range restriction GMRES (RRGMRES), which expands the solution in the following Krylov subspace:
19
19 This method restricts the Krylov subspace to generate an approximate solution in the range of the coefficient matrix
. Calvetti et al. [Citation40] confirmed that the RRGMRES performs well for ill-posed linear problems.
Let be the characteristic equation of the coefficient matrix
, which can be written as:
20
20 where
because we suppose that
is non-singular. The Cayley-Hamilton theorem [Citation45] asserts that
21
21 From the above equation, we can expand
by
22
22 and hence, the solution of Equation (Equation17
17
17 ) is given by
23
23 The above process to find the optimal descent direction of
is quite difficult to be realized in practice, since the coefficients
are hard to find when
is a quite large positive integer. Moreover, the computation of the higher order powers of
is very expensive. In order to have an effective iterative algorithm, the above series should be truncated properly. Hence, motivated by Equation (Equation23
23
23 ), we can suppose that
is expressed by
24
24 which is to be determined as an optimal combination of
and the
-vector
, when the coefficients
and
are optimized in Sections 4.2 and 4.3, respectively.
Now we describe how to set up the -vector
by the Krylov subspace method. Suppose that we have an
-dimensional Krylov subspace generated by the coefficient matrix
from the right-hand side vector
in Equation (Equation17
17
17 ):
25
25 Then, the Arnoldi process is used to normalize and orthogonalize the Krylov vectors
, such that the resultant vectors
satisfy
, where
is the Kronecker delta symbol.
Let26
26 be an
Krylov matrix with its
th column being the vector
. Because
are linearly independent vectors and
, the rank of
is
. Hence, Equation (Equation24
24
24 ) can be written as:
27
27 where
28
28 and
. The superscript
denotes the transpose.
Remark 1
The Krylov subspace method is an iterative method, of which the th step approximation to the solution of Equation (Equation1
1
1 ) is found in
. The approximation is of the form
, where
is a polynomial at most with
degree. Usually, the number
is smaller than the degree of the minimal polynomial of
, and indeed in the numerical algorithm we can choose
.
4 Doubly optimized descent direction of 
The most of the existent numerical methods to solve linear system (Equation11
1 ) in the Krylov subspace are paying attention to the minimizations of the residual norm or to the fulfilment of some Galerkin conditions. To the best knowledge of the author, there exists no numerical method to find the numerical solution of Equation (Equation1
1
1 ), simultaneously based on the two minimizations in Equations (Equation15
15
15 ) and (Equation16
16
16 ).
4.1 The first optimization
Let29
29 and we attempt to establish a merit function, such that its minimization leads to the best fit of
to
, because
is just the equation we use to find the best descent direction
.
We consider finding the best approximation of to
. The orthogonal projection of
to
is regarded as the approximation of
by
, whose error vector is written as:
30
30 where the brace denotes the inner product. The best approximation can be found with
minimizing the square norm of error vector:
31
31 or maximizing the square norm of the orthogonal projection of
to
, i.e.
32
32 Let us define the following merit function:
33
33 of which the inequality follows from the Cauchy-Schwarz inequality:
Let
be an
matrix:
34
34 where
is defined by Equation (Equation26
26
26 ). Then, with the aid of Equations (Equation27
27
27 ) and (Equation29
29
29 ) v can be written as:
35
35 where
36
36 Inserting Equation (Equation35
35
35 ) for
into Equation (Equation33
33
33 ), we encounter the following minimization problem:
37
37 where
38
38
39
39
40
40
41
41 in which
denotes the gradient with respect to
. Equation (Equation41
41
41 ) is obtained from Equation (Equation40
40
40 ) by taking the derivative of
with respect to
, which is given below by using the componential form:
42
42 where
is the
th component of
43
43 which is an
positive definite matrix. Because of
, from the last equation in the above we can deduce Equation (Equation41
41
41 ). Here, we have to emphasize that Equation (Equation42
42
42 ) minimization of
is fully equivalent to the minimization of
defined by Equation (Equation10
10
10 ), because
is a known vector.
By using44
44 we can derive the following equation to solve
:
45
45
4.2 A closed-form solution of
In view of Equation (Equation4343
43 ), Equations (Equation40
40
40 ) and (Equation41
41
41 ) can be written as:
46
46
47
47 Because
has a full column
, the positivity of
is guaranteed. From Equation (Equation45
45
45 ), we can observe that
is proportional to
, which is supposed to be
48
48 where
is a multiplier to be determined.
Then, by Equations (Equation3939
39 ), (Equation47
47
47 ) and (Equation48
48
48 ), we have
49
49 where
50
50 is an
positive definite matrix. Inserting Equation (Equation49
49
49 ) into Equations (Equation38
38
38 ) and (Equation46
46
46 ) we have
51
51
52
52 where
53
53 is an
positive semi-definite matrix.
Now, from Equations (Equation4848
48 ), (Equation51
51
51 ) and (Equation52
52
52 ), we can derive the following equation:
54
54 By cancelling the quadratic term
on both sides, we can obtain a linear equation, which renders a closed-form solution of
:
55
55 and from Equation (Equation49
49
49 ), we can obtain the closed-form solution of
:
56
56 Inserting the above
into Equation (Equation27
27
27 ), we can obtain
57
57 where
58
58
59
59 are, respectively, an
constant matrix and a constant scalar, both being fully determined by the coefficient matrix
and the right-hand side vector
in Equation (Equation17
17
17 ).
4.3 The second optimization to find
Upon letting60
60
in Equation (Equation57
57
57 ) can be expressed as
61
61 We can derive the closed-form solution of
by the second optimization of the second merit function:
62
62 where
63
63 Taking the derivative of Equation (Equation62
62
62 ) with respect to
and equating it to zero, we can obtain
64
64 Inserting it into Equation (Equation61
61
61 ) we arrive at
65
65 where
is defined by Equation (Equation60
60
60 ) and
is defined by Equation (Equation63
63
63 ).
4.4 The proof of
Inserting Equation (Equation3434
34 ) for
into the first
in Equation (Equation53
53
53 ) and comparing the resultant with Equation (Equation58
58
58 ), it immediately follows that
66
66 Then, by using Equations (Equation53
53
53 ) and (Equation50
50
50 ), we have
67
67 such that
is a projection operator. Indeed,
is a well-known result that
is an orthogonal projection operator.
In terms of ,
defined in Equation (Equation63
63
63 ) can be written as:
68
68 It follows that
69
69
70
70 where Equation (Equation67
67
67 ) was used in the first equation. With the aid of Equation (Equation59
59
59 ), Equation (Equation70
70
70 ) is further reduced to
71
71 Now, after inserting Equation (Equation71
71
71 ) into Equation (Equation64
64
64 ), we can obtain
72
72 however, in view of Equation (Equation69
69
69 ), the right-hand side is just equal to
. Hence, we have
73
73 As a consequence, we have a neater form of the doubly optimized descent direction of
, which is given by
74
74 where
75
75 Equation (Equation74
74
74 ) is better than Equation (Equation65
65
65 ), for saving computations.
Sometimes it is better to use the following normal equation:76
76 to find the best descent direction
, because the coefficient matrix
is now positive definite. The process to find the best direction
is the same, where we only need to replace
by
, and
by
.
5 A double optimal descent algorithm
5.1 The numerical algorithm
The numerical procedure of the DODA is described in this section. Before that we need to compute the inverse matrix in Equation (Equation50
50
50 ). The accuracy of this matrix is crucial for the DODA, and we can use the following matrix conjugate gradient method (MCGM) developed by Liu et al. [Citation46] to find the the inverse matrix
of
:
(i) Assume an initial .
(ii) Calculate and
.
(iii) For , we repeat the following iterations:
77
77 If
converges according to a given stopping criterion, such that,
78
78 then stop; otherwise, go to step (iii). In the above, the boldfaced capital letters denote
matrices, the norm
is the Frobenius norm and the inner product symbol
is used for matrices. Because for the inverse problems to be computed we will use rather small
, the inverse matrix
is easily computed by the above MCGM algorithm, which is convergent very fast.
Thus, we arrive at the following DODA:
| (i) | Select | ||||
| (ii) | For | ||||
Remark 2
Note that are constructed from the Krylov subspace method and following by the Arnoldi process to orthonormalize the Krylov vectors, the resultant optimal algorithm is the DODA with the Krylov subspace method. In the Krylov subspace method, the expansion matrix
is not fixed, and it can adjust its configuration at each iterative step to accelerate the convergence speed, which, however, leads to a consumption of computational time in the calculation of the inverse of
to obtain
,
and
at every iterative step.
5.2 The proof of the convergence of DODA
In this section, we prove that the algorithm DODA is convergent. From the second equality in Equation (Equation4848
48 ) by cancelling the common term
on both sides, we have
80
80 where
, by using Equations (Equation55
55
55 ) and (Equation36
36
36 ), can be written as
81
81 With the help of Equations (Equation59
59
59 ) and (Equation73
73
73 ), we have
82
82 hence, Equation (Equation80
80
80 ) becomes
83
83 In view of Equation (Equation83
83
83 ), the iterative algorithm (Equation79
79
79 ) reduces to
84
84 By using Equations (Equation8
8
8 ) and (Equation5
5
5 ), it follows that
85
85 Taking the square norms of both sides and using Equation (Equation83
83
83 ), we can derive
86
86 Because of
and
, it immediately leads to
87
87 which indicates that the algorithm DODA is absolutely convergent.
Remark 3
The present algorithm DODA can provide a fast reduction of the residual. Indeed for the DODA, from Equations (Equation2929
29 ), (Equation74
74
74 ), (Equation75
75
75 ) and (Equation66
66
66 ), we have
88
88 where
and Equation (Equation67
67
67 ) were used in the derivation of the second equation. In terms of the intersection angle
between
and
, we have
89
89 If
,
and the DODA with
converges with one step, due to
by Equation (Equation86
86
86 ). On the other hand, if we take
, then the DODA also converges with one step. We can see that if a suitable value of
is taken then the DODA can converge within
steps. Therefore, we have the following convergence criterion of the DODA. If
90
90 then the iterations in Equation (Equation79
79
79 ) terminate, where
.
6 Numerical examples
In order to evaluate the performance of the newly developed method of DODA, we test some linear inverse problems. Some numerical results are compared with that computed by the GMRES,[Citation17] RRGMRES,[Citation40] the OMVIA developed by Liu [Citation24], the OTVIA developed by Liu [Citation13] and a recent non-iterative algorithm based on the double optimal solution (DOS).[Citation19] The algorithm in [Citation19] is applied to solve linear problem by selecting a suitable value of for the dimension of the Krylov subspace.
In the comparison of numerical solution with exact solution, we use two criteria to measure the accuracy of numerical solution. First, the numerical error is defined to be the absolute value of the difference between numerical solution and exact solution. In addition to that, we also compare the root-mean-square error (RMSE), which is defined by91
91 where
and
are, respectively, the numerical solution and exact solution, and
is the total number of data points to be compared.
6.1 Example 1
Finding an -order polynomial function
to best match a continuous function
in the interval of
:
92
92 leads to a problem governed by Equation (Equation1
1
1 ). The coefficient matrix
is the
Hilbert matrix defined by
93
93
is composed of the
coefficients
appeared in
, and
94
94 is uniquely determined by the function
.
The Hilbert matrix is a notorious example of highly ill-conditioned matrices. Equation (Equation11
1 ) with the matrix
having a large condition number usually displays that an arbitrarily small perturbation of data on the right-hand side may lead to an arbitrarily large perturbation to the solution on the left-hand side.
In this example, we consider a highly ill-conditioned linear system (Equation11
1 ) with
given by Equation (Equation93
93
93 ). The ill-posedness of Equation (Equation1
1
1 ) increases fast with
. We consider an exact solution with
and
is given by
95
95 where
are random numbers between
.
It is known that the condition number of Hilbert matrix grows as when
is very large. For the case with
, the condition number is extremely huge up to the order of
. We solve this problem by using the DODA with the Krylov subspace method. Under a noise
, and for
and
, the DODA is convergent very fast only through three steps with the convergence criterion
, where the maximum error is
. It is very time saving because we only need to calculate the
matrix
three times, which is using the MCGM developed by Liu et al. [Citation46]. Under a convergence criterion
in Equation (Equation78
78
78 ), the process to find
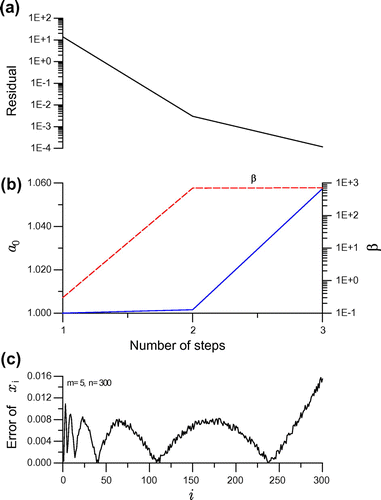
is convergent very fast with five or six iterations, although we do not show them at here. The numerical results are shown in Figure . It is interesting that even for a large value of
, we do not need a large value of
, of which merely
was used. Also we can observe that the accuracy does not lose although the ill-posedness of the linear Hilbert problem is highly increased for
.
Figure 1. For example 1 solved by the DODA with Krylov subspace, showing (a) residual, (b) and
and (c) numerical error.
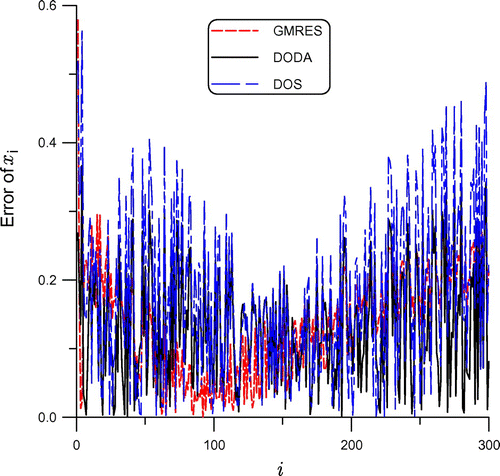
As mentioned, the algorithm in [Citation19] is applied to solve linear problem by selecting a suitable value of for the dimension of the Krylov subspace. This algorithm has been named the DOS. Under a large noise with
and for
, we take
and apply the GMRES, DODA and DOS to solve this problem, whose numerical errors are compared in Figure . The maximum error of DODA is
, while that for the GMRES is 0.579 and DOS is 0.566. The RMSE obtained by the DODA is 0.154, while that obtained by the GMRES is
, and that obtained by the DOS is 0.214. It can be seen that the DODA is slightly accurate than the GMRES and the DOS.
Figure 2. For example 1 under a large noise with , comparing numerical errors obtained by the DODA, DOS and GMRES.
6.2 Example 2
In this section, we apply the DODA to identify an unknown space-dependent heat source function for a one-dimensional heat conduction equation:
96
96
97
97
98
98 In order to identify
, we can impose an extra condition:
99
99 We propose a numerical differential method by letting
. Taking the differentials of Equations (Equation96
96
96 ), (Equation97
97
97 ) and (Equation99
99
99 ) with respect to
, and letting
, we can derive
100
100
101
101
102
102
103
103 This is an inverse heat conduction problem (IHCP) for
without using the initial condition.
Therefore, we can first solve the above IHCP for by using the method of fundamental solutions (MFS) to obtain a linear equations system, and then the method introduced in Section 5 is used to solve the resultant linear equations system; hence, we can construct
by
104
104 which automatically satisfies the initial condition in Equation (Equation98
98
98 ).
From Equation (Equation104104
104 ), it follows that
105
105 which together with
being inserted into Equation (Equation96
96
96 ) leads to
106
106 Inserting Equation (Equation100
100
100 ) for
into the above equation and integrating it, we can derive the following equation to recover
:
107
107 For the purpose of comparison, we consider the following exact solutions:
108
108 In Equation (Equation107
107
107 ), we disregard the ill-posedness of
, and suppose that the data
are given exactly. A random noise with an intensity
is added on the data
. Under the following parameters
and
, we solve this problem by the DODA with 200 steps. In Figure (a) and (b), we plot the residual,
and
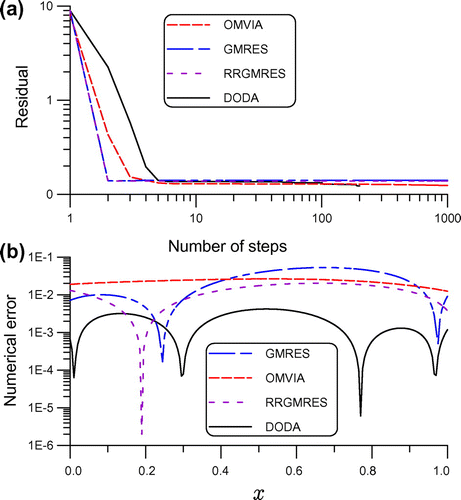
, and the numerical solution is compared with the exact solution in Figure (c). The numerical error is shown in Figure (b), whose maximum error is 0.00421. It can be seen that the present DODA can provide very accurate numerical result. This result is better than that calculated by Liu [Citation47] using the vector regularization iterative method, whose maximum error is 0.0086. Then under the same parameters as that used in the DODA, we apply the GMRES,[Citation17] the RRGMRES [Citation40] and the OMVIA [Citation24] to solve this problem. The residuals and numerical errors are compared in Figure . When the maximum error of GMRES is 0.053, the maximum error of RRGMRES is 0.02, and the maximum error of OMVIA is 0.0265. The maximum error of DODA as shown in the above is 0.00421, which is the best one among the four numerical methods. The RMSE of GMRES is
, the RMSE of RRGMRES is 0.014, the RMSE of OMVIA is 0.023 and the RMSE of DODA is 0.0024. It can be seen that the DODA is much accurate than other three numerical algorithms.
Figure 3. For example 2 solved by the DODA with Krylov subspace, showing (a) residual, (b) and
and (c) numerical error.
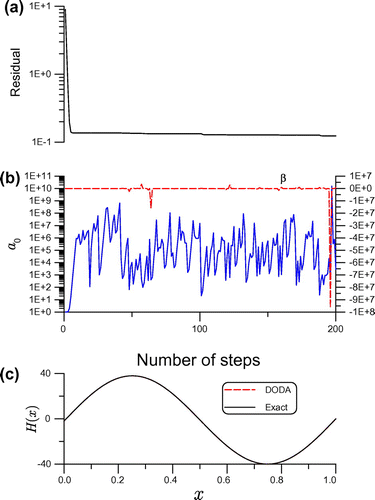
Figure 4. For example 2 solved by the DODA, GMRES, RRGMRES and OMVIA, comparing (a) residuals and (b) numerical errors.
6.3 Example 3
When the backward heat conduction problem (BHCP) is considered in a spatial interval of by subjecting to the boundary conditions at two ends of a slab:
109
109
110
110 we solve
under a final time condition:
111
111 The fundamental solution of Equation (Equation109
109
109 ) is given as follows:
112
112 where
is the Heaviside function.
The MFS has a serious drawback that the resulting linear equations system is always highly ill conditioned, when the number of source points is increased, or when the distances of source points are increased.
In the MFS, the solution of at the field point
can be expressed as a linear combination of the fundamental solutions
:
113
113 where
is the number of source points,
are unknown coefficients and
are source points being located in the complement
of
. For the heat conduction equation, we have the basis functions
114
114 It is known that the location of source points in the MFS has a great influence on the accuracy and stability. In a practical application of MFS to solve the BHCP, the source points are uniformly located on two vertical straight lines parallel to the
-axis, not over the final time, which was adopted by Hon and Li [Citation48] and Liu [Citation49], showing a large improvement than the line location of source points below the initial time. After imposing the boundary conditions and the final time condition to Equation (Equation113
113
113 ), we can obtain a linear equations system:
115
115 where
116
116 and
.
Since the BHCP is highly ill posed, the ill condition of the coefficient matrix in Equation (Equation115
115
115 ) is serious. To overcome the ill-posedness of Equation (Equation115
115
115 ), we can use the DODA to solve this problem. Here, we compare the numerical solution with an exact solution:
For the case with
, the value of final time data is in the order of
, which is small by comparing with the value of the initial temperature
to be retrieved, which is
. First we impose a relative random noise with an intensity
being imposed on the final time data. Under the following parameters
,
,
,
and
and
, we solve this problem by the DODA. With five steps the DODA is convergent. In Figure (a) and (b), we plot the residual,
and
, and the numerical solution is compared with the exact solution in Figure (c), whose maximum error is
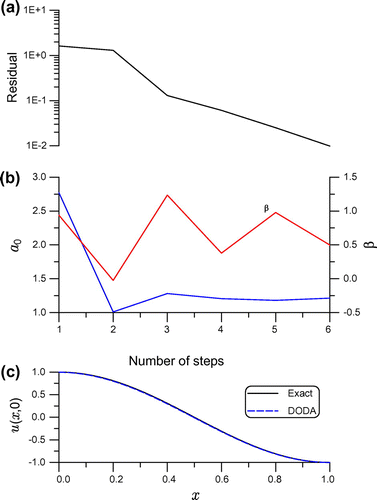
. It can be seen that the present DODA converges very fast and is very robust against noise, and we can provide a very accurate numerical result by using the DODA.
Figure 5. For example 3 solved by the DODA with Krylov subspace, showing (a) residual, (b) and
and (c) comparing numerical and exact solutions.
Then under the same parameters as that used in the DODA, we also apply the GMRES,[Citation17] the RRGMRES,[Citation40] the OMVIA [Citation24] and the OTVIA [Citation13] to solve this problem. The residuals and numerical errors are compared in Figure . The OMVIA is convergent with 142 steps and the maximum error is 0.041. The GMRES is convergent with 16 steps and the maximum error is 0.148. The RRGMRES is convergent with four steps and the maximum error is 0.0124. The OTVIA does not converge within 1000 steps and the maximum error is 0.0994. Then we apply the DOS with to solve this problem, whose numerical error as shown in Figure (b) with the maximum error being
is better than that of GMRES, OMVIA and OTVIA, but is worse than that of DODA. It can be seen that the DODA is the best one among the six numerical methods, which is convergent faster and accurate than other five algorithms DOS, GMRES, RRGMRES, OMVIA and OTVIA. The RMSE of GMRES is
, the RMSE of DOS is
, the RMSE of OMVIA is
and the RMSE of OTVIA is
. The RMSE of DODA is
, while that for the RRGMRES is
. For this ill-posed problem, the DODA is better than the RRGMRES.
Figure 6. For example 3 solved by the DODA, DOS, GMRES, RRGMRES, OMVIA and OTVIA, comparing (a) residuals and (b) numerical errors.
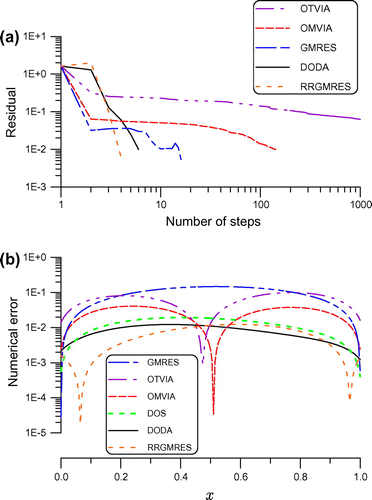
Figure 7. For example 4 solved by the DODA with Krylov subspace, showing (a) residual, (b) and
and (c) comparing numerical and exact solutions.
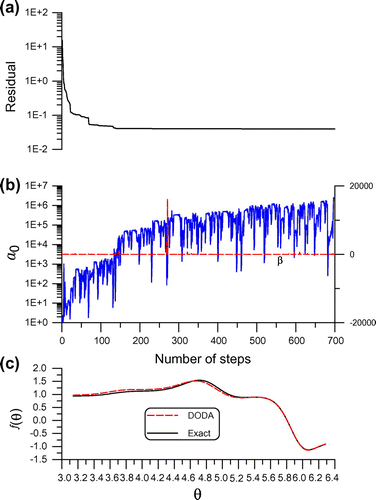
Figure 8. For example 4 solved by the DODA, DOS, GMRES, RRGMRES, OMVIA and OTVIA, comparing (a) residuals and (b) numerical errors.
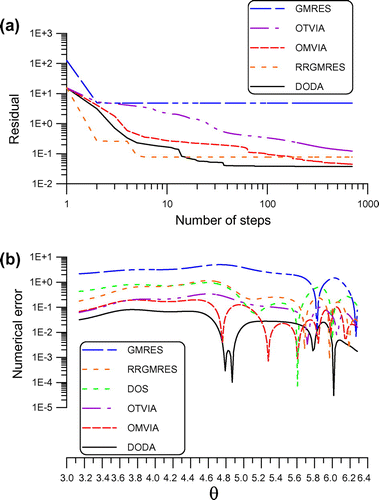
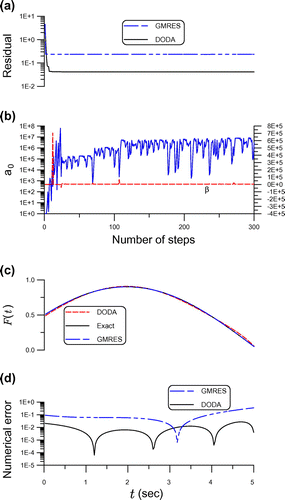
Figure 9. For example 5 solved by the DODA and GMRES, showing (a) residuals, (b) and
, (c) comparing numerical and exact solutions and (d) numerical errors.
6.4 Example 4
Let us consider the inverse Cauchy problem for the Laplace equation:117
117
118
118
119
119 where
and
are given function. The inverse Cauchy problem is specified as follows:
To seek an unknown boundary function on the part
of the boundary under Equations (Equation117
117
117 )–(Equation119
119
119 ) with the overspecified data being given on
.
It is well known that the MFS can be used to solve the Laplace equation when a fundamental solution is known. In the MFS, the solution of at the field point
can be expressed as a linear combination of fundamental solutions
:
120
120 For the Laplace equation (Equation117
117
117 ), we have the fundamental solutions:
121
121 In the practical application of MFS, by imposing the boundary conditions (Equation118
118
118 ) and (Equation119
119
119 ) at
points on Equation (Equation120
120
120 ), we can obtain a linear equations system:
122
122 where
123
123 in which
, and
124
124 The above
with an offset
can be used to locate the source points along a contour with a radius
.
For the purpose of comparison, we consider the following exact solution:125
125 defined in a domain with a complex amoeba-like irregular shape as a boundary:
126
126 After imposing the boundary conditions (Equation118
118
118 ) and (Equation119
119
119 ) at
points on Equation (Equation120
120
120 ), we can obtain a linear equations system. The noise being imposed on the measured data
and
is
.
We solve this problem by the DODA with and
. The descent direction
is solved from
. Through 700 steps the residual and the values of
and
are shown in Figure (a) and (b). The numerical solution and exact solution are compared in Figure (c), whose maximum error is smaller than 0.0884. It can be seen that the DODA can accurately recover the unknown boundary condition.
Then under the same parameters as that used in the DODA, we apply the GMRES,[Citation17] the RRGMRES,[Citation40] and the OMVIA [Citation24] to solve this problem. The residuals and numerical errors are compared in Figure . When the maximum error of GMRES is 5.02 (failure) and the maximum error of RRGMRES is 1.16, the maximum error of OMVIA is 0.197. The maximum error of DODA as shown in the above is much better than that calculated by Liu [Citation13] by using the OTVIA, of which the maximum error is 0.34. Then we apply the DOS with to solve this problem, whose numerical error as shown in Figure (b) with the maximum error being
is better than that of GMRES, but is worse than that of RRGMRES, OMVIA, OTVIA and DODA. The RMSE of GMRES is
, the RMSE of RRGMRES is
, the RMSE of DOS is
, the RMSE of OMVIA is
and the RMSE of OTVIA is
. The RMSE of DODA is
, which is better than other five algorithms. Again, it can be seen that the DODA is the best one among the six numerical methods, which is convergent faster and much more accurate than other five algorithms.
6.5 Example 5
Let us consider the following inverse problem to recover the external force for
127
127 In a time interval of
, the discretized data
are supposed to be measurable, which are subjected to the random noise with an intensity
. Usually, it is very difficult to recover the external force
from Equation (Equation127
127
127 ) by the direct differentials of the noisy data of displacements, because the differential is an ill-posed linear operator.
To approach this inverse problem by the polynomial interpolation, we begin with128
128 Now, the coefficient
is split into two coefficients
and
to absorb more interpolation points; in the meanwhile,
and
are introduced to reduce the condition number of the coefficient matrix. We suppose that
129
129 and
130
130 The problem domain is
, and the interpolating points are:
131
131 Substituting Equation (Equation129
129
129 ) into Equation (Equation128
128
128 ), we can obtain
132
132 where we let
. Here,
and
are unknown coefficients. In order to obtain them, we impose the following
interpolated conditions:
133
133 Thus, we obtain a linear equations system to determine
and
:
134
134 We note that the norm of the first column of the above coefficient matrix is
. According to the concept of equilibrated matrix,[Citation50] we can derive the optimal scales for the current interpolation with a half-order technique as
135
135
136
136 where
is a scaling factor.[Citation50] The improved method uses
-order polynomial to interpolate
data nodes, while regular method with a full-order can only interpolate
data points.
Now we fix (of the above
) and
and consider the exact solution to be
, which is obtained by inserting the exact value of
into Equation (Equation127
127
127 ). The parameters used are
, and
. When we use the DODA with
, we let it run 300 steps. The descent direction
is solved from
. The residual and the values of
and
are shown in Figure (a) and (b). The numerical solution and exact solution are compared in Figure (c), whose maximum error is smaller than 0.027. It can be seen that the DODA can accurately recover the unknown external force.
When we apply the GMRES to solve this problem, the parameter is changed to
, and the other parameters are unchanged. In Figure , we plot the results obtained by the GMRES with dashed-dotted lines, of which as shown in Figure (c) and (d) we can see that the GMRES is less accurate with the maximum error being 0.35. The RMSE obtained by the DODA is
, while that obtained by the GMRES is 0.117. It can be seen that the DODA is much accurate than the GMRES.
7 Conclusions and discussion
In the present paper, we have derived a double optimal algorithm, including an -vector optimal search direction in an
-dimensional affine Krylov subspace to solve a highly ill-posed linear system. This algorithm is a multi-vector DODA, of which the expansion coefficients in the descent direction are solved in closed-form through double optimizations of two basic merit functions to measure the distance between
and
. The DODA has a good computational efficiency and accuracy in solving the ill-posed linear equations system. Numerical tests on the linear inverse problems have confirmed the robustness of the DODA against noisy disturbance even with an intensity being large up to
. For the test examples, we found that the DODA can converge fast and stable with the iterations account smaller than the dimension of the considered problem. As the usual Krylov subspace method, the value of
cannot be too large; otherwise, many computational time is required to construct the Krylov matrix by the Arnoldi process at each iteration step. When
is large, the Krylov matrix will be highly ill conditioned for the ill-posed problem. The DODA is convergent faster than other numerical methods investigated in this paper, and indeed it can achieve smaller residual errors than the GMRES, the RRGMRES and the OMVIA under the same value of
. In the proof of the convergence of the DODA, we have derived an exact equation to estimate the difference of two consecutive square residual norms:
How to maximize the quantity in the square brackets, i.e.
might be an important issue, which will lead to a further study of the structure of the Krylov subspace resulting to the best configuration of the projection operator
. On the other hand, based on Theorem 5 in [Citation20], the square residual obtained by the DODA is smaller than that obtained by the algorithms based on the least square of residual with the following relation:
This fact revealed that the DODA is more efficient than other algorithms, and all numerical examples investigated in this paper by assessing the convergence speed, the maximum error, the absolute error and the RMSE confirmed the superiority of DODA.
Acknowledgments
The author highly appreciates the constructive comments from anonymous referees, which improve the quality of this paper. Highly appreciated are the project NSC-102-2221-E-002-125-MY3 and the 2011 Outstanding Research Award from the National Science Council of Taiwan, and the 2011 Taiwan Research Front Award from Thomson Reuters. It is also acknowledged that the author has been promoted as being a Lifetime Distinguished Professor of National Taiwan University since 2013.
References
- Stewart G. Introduction to matrix computations. New York (NY): Academic Press; 1973.
- Kunisch K, Zou J. Iterative choices of regularization parameters in linear inverse problems. Inverse Probl. 1998;14:1247–1264.
- Wang Y, Xiao T. Fast realization algorithms for determining regularization parameters in linear inverse problems. Inverse Probl. 2001;17:281–291.
- Xie J, Zou J. An improved model function method for choosing regularization parameters in linear inverse problems. Inverse Probl. 2002;18:631–643.
- Resmerita E. Regularization of ill-posed problems in Banach spaces: convergence rates. Inverse Probl. 2005;21:1303–1314.
- Chehab JP, Laminie J. Differential equations and solution of linear systems. Numer. Algorithms. 2005;40:103–124.
- Helmke U, Moore JB. Optimization and dynamical systems. Berlin: Springer; 1994.
- Liu CS. Optimally generalized regularization methods for solving linear inverse problems. CMC: Comput. Mater. Con. 2012;29:103–127.
- Liu CS. Scaled vector regularization method to solve ill-posed linear problems. Appl. Math. Comput. 2012;218:10602–10616.
- Liu CS. A dynamical Tikhonov regularization for solving ill-posed linear algebraic systems. Acta Appl. Math. 2012;123:285–307.
- Liu CS. An optimal preconditioner with an alternate relaxation parameter used to solve ill-posed linear problems. CMES: Comput. Model. Eng. Sci. 2013;92:241–269.
- Liu CS. A globally optimal iterative algorithm to solve an ill-posed linear system. CMES: Comput. Model. Eng. Sci. 2012;84:383–403.
- Liu CS. An optimal tri-vector iterative algorithm for solving ill-posed linear inverse problems. Inverse Probl. Sci. Eng. 2013;21:650–681.
- Liu CS. A globally optimal tri-vector method to solve an ill-posed linear system. J. Comput. Appl. Math. 2014;260:18–35.
- Barzilai J, Borwein JM. Two point step size gradient methods. IMA J. Numer. Anal. 1988;8:141–148.
- Akaike H. On a successive transformation of probability distribution and its application to the analysis of the optimum gradient method. Ann. Inst. Stat. Math. Tokyo. 1959;11:1–16.
- Saad Y, Schultz MH. GMRES: a generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM J. Sci. Stat. Comput. 1986;7:856–869.
- Liu CS, Atluri SN. An iterative method using an optimal descent vector, for solving an ill-conditioned system Bx = b, better and faster than the conjugate gradient method. CMES: Comput. Model. Eng. Sci. 2011;80:275–298.
- Liu CS. A doubly optimized solution of linear equations system expressed in an affine Krylov subspace. J. Comput. Appl. Math. 2014;260:375–394.
- Liu CS. Discussing a more fundamental concept than the minimal residual method for solving linear system in a Krylov subspace. J. Math. Res. 2013;5:58–70.
- Liu CS. An optimally generalized steepest-descent algorithm for solving ill-posed linear systems. J. Appl. Math. 2013; ID 154358, 15 p.
- Jacoby SLS, Kowalik JS, Pizzo JT. Iterative methods for nonlinear optimization problems. New Jersey (NJ): Prentice-Hall; 1972.
- Ostrowski AM. Solution of equations in Euclidean and Banach spaces. 3rd ed. New York (NY): Academic Press; 1973.
- Liu CS. An optimal multi-vector iterative algorithm in a Krylov subspace for solving the ill-posed linear inverse problems. CMC: Comput. Mater. Con. 2013;33:175–198.
- Dongarra J, Sullivan F. Guest editors’ introduction to the top 10 algorithms. Comput. Sci. Eng. 2000;2:22–23.
- Simoncini V, Szyld DB. Recent computational developments in Krylov subspace methods for linear systems. Numer. Linear Algebra Appl. 2007;14:1–59.
- Saad Y. Krylov subspace methods for solving large unsymmetric linear systems. Math. Comput. 1981;37:105–126.
- Freund RW, Nachtigal NM. QMR: a quasi-minimal residual method for non-Hermitian linear systems. Numer. Math. 1991;60:315–339.
- van Den Eshof J, Sleijpen GLG. Inexact Krylov subspace methods for linear systems. SIAM J. Matrix Anal. Appl. 2004;26:125–153.
- Hestenes MR, Stiefel EL. Methods of conjugate gradients for solving linear systems. J. Res. Nat. Bur. Stand. 1952;49:409–436.
- Lanczos C. Solution of systems of linear equations by minimized iterations. J. Res. Nat. Bur. Stand. 1952;49:33–53.
- Paige CC, Saunders MA. Solution of sparse indefinite systems of linear equations. SIAM J. Numer. Anal. 1975;12:617–629.
- Fletcher R. Conjugate gradient methods for indefinite systems. Lecture notes in Math. Vol. 506. Berlin: Springer-Verlag; 1976. p. 73–89.
- Sonneveld P. CGS: a fast Lanczos-type solver for nonsymmetric linear systems. SIAM J. Sci. Stat. Comput. 1989;10:36–52.
- van der Vorst HA. Bi-CGSTAB: a fast and smoothly converging variant of Bi-CG for the solution of nonsymmetric linear systems. SIAM J. Sci. Stat. Comput. 1992;13:631–644.
- Saad Y, van der Vorst HA. Iterative solution of linear systems in the 20th century. J. Comput. Appl. Math. 2000;123:1–33.
- Saad Y. Iterative methods for sparse linear systems. 2nd ed. Pennsylvania (PA): SIAM; 2003.
- van der Vorst HA. Iterative Krylov methods for large linear systems. New York (NY): Cambridge University Press; 2003.
- Liu CS. The concept of best vector used to solve ill-posed linear inverse problems. CMES: Comput. Model. Eng. Sci. 2012;83:499–525.
- Calvetti C, Lewis B, Reichel L. GMRES-type methods for inconsistent systems. Linear Algebra Appl. 2000;316:157–169.
- Kuroiwa N, Nodera T. A note on the GMRES method for linear discrete ill-posed problems. Adv. Appl. Math. Mech. 2009;1:816–829.
- Matinfar M, Zareamoghaddam H, Eslami M, Saeidy M. GMRES implementations and residual smoothing techniques for solving ill-posed linear systems. Comput. Math. Appl. 2012;63:1–13.
- Morikuni K, Reichel L, Hayami K. FGMRES for linear discrete ill-posed problems. Appl. Numer. Math. 2014;75:175–187.
- Yin JF, Hayami K. Preconditioned GMRES methods with incomplete Givens orthogonalization method for large sparse least-squares problems. J. Comput. Appl. Math. 2009;226:177–186.
- Horn RA, Johnson CR. Matrix analysis. New York (NY): Cambridge University Press; 1985.
- Liu CS, Hong HK, Atluri SN. Novel algorithms based on the conjugate gradient method for inverting ill-conditioned matrices, and a new regularization method to solve ill-posed linear systems. CMES: Comput. Model. Eng. Sci. 2010;60:279–308.
- Liu CS. A vector regularization method to solve linear inverse problems. Inverse Probl. Sci. Eng. 2013. dx.doi.org/10.1080/17415977.2013.823415.
- Hon YC, Li M. A discrepancy principle for the source points location in using the MFS for solving the BHCP. Int. J. Comput. Methods. 2009;6:181–197.
- Liu CS. The method of fundamental solutions for solving the backward heat conduction problem with conditioning by a new post-conditioner. Numer. Heat Transfer B: Fundam. 2011;60:57–72.
- Liu CS. A two-side equilibration method to reduce the condition number of an ill-posed linear system. CMES: Comput. Model. Eng. Sci. 2013;91:17–42.