
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A broad range of parameter estimation problems involve the collection of an excessively large number of observations N. Typically, each such observation involves excitation of the domain through injection of energy at some predefined sites and recording of the response of the domain at another set of locations. It has been observed that similar results can often be obtained by considering a far smaller number K of multiple linear superpositions of experiments with . This allows the construction of the solution to the inverse problem in time
instead of
. Given these considerations it should not be necessary to perform all the N experiments but only a much smaller number of K experiments with simultaneous sources in superpositions with certain weights. Devising such procedure would results in a drastic reduction in acquisition time. The question we attempt to rigorously investigate in this work is: what are the optimal weights? We formulate the problem as an optimal experimental design problem and show that by leveraging techniques from this field an answer is readily available. Designing optimal experiments requires some statistical framework and therefore the statistical framework that one chooses to work with plays a major role in the selection of the weights.
Keywords:
1 Introduction
We consider discrete parameter estimation problems with data vectors modelled as
1
1 where
is an
linear observation matrix that corresponds, for example, to the
th configuration of an experiment,
is the parameter vector to be recovered and
are zero-mean independent random vectors with covariance matrix
. In addition, we assume that there is a large set of observation matrices
, which is the case of interest in many geophysical and medical applications such as seismic and electromagnetic (EM) exploration, diffraction and electrical impedance tomography.[Citation1–Citation3]
The linear systems in (Equation11
1 ) can be aggregated into a single large system by defining
2
2 In the well-posed case where
has a stable inverse, the least-squares (maximum likelihood if
are Gaussian) estimate
of
is
3
3 When
does not have a stable inverse, a penalized least-squares estimate of the form
4
4 is often used. Here
is usually a symmetric positive semi-definite matrix and
is a positive regularization parameter. This choice will simplify analysis later on, although the proposed approach can be generalized for use of other regularizers of other functional forms.
We are particularly interested in large-scale problems where both the number of model parameters and the number of observations
are large. For instance, in an electromagnetic or a seismic survey, the number of a such observations,
, can be of the order of
or
. For such problems, solution of the system (Equation4
4
4 ) using direct methods is intractable computationally and instead iterative methods (typically, CGLS or LSQR [Citation4]) are employed. The main computational bottleneck associated with such solvers is the computation of matrix vector products: When
is very large, the computation of
times a vector can be prohibitively intensive by itself. We thus need to devise some data reduction methodology to make computations feasible.
For example, return to the well-posed case and assume the matrices come from a parameter estimation problem where the observed phenomena can be described by a set of differential equations that are linear w.r.t. the source term. Such operators can be written as
where
and
are sparse selection matrices related to the sensors and the sources, respectively, but
is a discretization of a partial differential equation on a mesh. Such problems arise in seismic and electromagnetic exploration as well as in impedance and diffraction tomography.[Citation1–Citation3] The least-squares estimate of the model
is
5
5 which requires multiple applications of
, thus, making the procedure computationally expensive. Alternatively, a far less-expensive procedure relies upon a recently developed data reduction technique based on the idea of ‘simultaneous sources’.[Citation5–Citation9] Here the estimate is based on a weighted combination of the form
. The basic idea is to exploit the savings achieved by simultaneously collecting the data.
For example, if each experiment corresponds to a different source in seismic or electromagnetic exploration, it can be rather expensive both in terms of time and cost to record many different experiments. If, on the other hand, it is possible to ‘shoot’ simultaneously with all the sources, then the recording time can be significantly shortened as a collection of simultaneous sources enables direct measurement of linear combinations of the data. That is, for a fixed one conducts an experiment that measures
directly. This acquisition strategy is of course far more efficient than the conventional process in which each data vector is measured independently while later on combining them with the weights
.
The linear system corresponding to is
6
6 where
and
. We assume the individual source noise levels
are known. The estimates (Equation3
3
3 ) and (Equation4
4
4 ) corresponding to
are
7
7 if
has a stable inverse, and
8
8 otherwise. Clearly, both solutions depend on
only through its unit-norm normalization
.
For example, let us return to the well-posed parameter estimation example with . The penalized least-squares estimate (Equation8
8
8 ) is
which requires much fewer applications of
than (Equation5
5
5 ). Of course, some information may be lost as
is not, in general, a sufficient statistic for
. We return to this point in Section 2.2 but it should be clear that some information might be sacrificed for the sake of computational or data collection savings.
Although the advantages of using simultaneous sources have been previously explored, the question of selecting appropriate weights has not received sufficient attention. We are aware of two main conducts that have been utilized so far. In [Citation10], the weights
are independent zero-mean random variables of variance one and are used to define the Hutchinson randomized trace estimator.[Citation11] More precisely, let
be the residual matrix defined as
Then,
where
denotes the Frobenius norm. If
are independent random weight vectors, then by the law of large numbers
as
. Therefore, the finite sum on the left-hand side can be used to approximate
. It is easy to see that the uniform distribution on
minimizes the variance of the trace estimator (see e.g. [Citation12]). Methods to select appropriate values of
are discussed in [Citation12].
In [Citation13] the Frobenius norm of the residual matrix is replaced by the squared 2-norm and is then chosen so that
The paper is structured as follows. In Section 2, we derive the mathematical framework. In Section 3, we discuss efficient numerical techniques for the solution of the weight design problem. In Section 4, we demonstrate the effectiveness of our approach by performing numerical experiments and finally, in Section 5 we summarize the study.
2 Optimal selection of weights
In this section, we consider statistical properties of the estimate to select optimal weights
. We also discuss methods to compensate for the information loss and to compare the loss achieved with different choices of weights
.
We begin our discussion with the well-posed problem and its solution (Equation77
7 ). As can be observed,
depends only on
; we may therefore assume that
. Since
is an unbiased estimator and
, it follows that its mean square error (
) is
To find an optimal
, in the sense of minimizing the
, we need to solve the constrained optimization problem
9
9 Before discussing properties of the solutions, we consider the ill-posed problem.
2.1 The ill-posed case
Other than recent numerous exceptions (see [Citation14–Citation19] and references therein), optimal experimental design of ill-posed problems has been somewhat an under-researched topic. In the case of ill-posed problems, the selection of optimal weights for (Equation88
8 ) is more difficult because this estimate is biased and its bias depends on the unknown
:
, where the inverse Fisher matrix is given by
(again, we may assume
). The
of
is then
10
10 As in the well-posed case, the goal would be to find weights
that minimize this
subject to the constraint
but this is not possible because
is unknown. We need information on
to control the
.
If is known to be in a convex set
, then we could consider a minmax approach where we minimize the worst
for
. A less pessimistic approach is to minimize an average
over
. Of course, other choices are possible and may be useful as long as their interpretation can be rationalized. In this note, we minimize a weighted average of the
. We model
as random and since
only depends linearly on
, it is enough to use prior second-order moment conditions. For example, if
and
, then the Bayes risk
under squared error loss of the frequentist estimate
defined by the fixed
is
and we solve the optimization problem
11
11 Finally, assume the distributions are Gaussian. That is, the conditional distribution of
given
is
and the prior distribution of
is
, with
. In this case, (Equation8
8
8 ) is the posterior mean (and a maximum a posteriori or MAP estimator) and the posterior covariance matrix is
. For each fixed
the Bayes risk of
is therefore
The corresponding optimization problem is
12
12
Remark
So far we have only considered linear/affine reconstructions of the model, which of course do not include many recovering techniques based, for example, on total variation or sparsity control. However, if the reason for choosing one of these nonlinear procedures is the belief that its optimal Bayes risk is smaller than that of the linear reconstruction, then the optimal Bayes risk of the latter provides an upper bound for the optimal Bayes risk of the nonlinear procedure. Furthermore, if the upper bound is not too conservative then minimizing the Bayesian risk for an affine estimator can be a useful guide for other reconstruction techniques.
2.2 Compensating for the information loss
As we have explained, some information may be lost with the reduction to . If the loss is unacceptable, we may compensate by using more than a single reduction as follows. Let
be the number of independent data reductions and
. Define
where the sequence
is assumed to be i.i.d.
. The
data reduction is
. We solve for
using the vector of
reductions
and matrix
defined as
The associated Bayes risk is
with
. The optimization problem is
13
13 There are some particular cases that may make this optimization easier and provide upper bounds for the optimal solution of (Equation13
13
13 ). These bounds can be useful when we study the loss as a function of
. One particular case consists of using prior information about the experiments to classify the matrices
into
groups whose members are similar on a realistic set of models
. For example
may include only
and
while
uses only
,
and
, etc. A second simplification consists of assuming
so that there is only one constraint but
independent experiments. The final and simplest approach is to find the optimal
in (Equation12
12
12 ) and then repeat the experiment
times. This leads to the risk
14
14
2.3 Quantifying the information loss
Although in general the optimization problem does not have a unique minimum, a local minimum may still provide a sufficient reduction of the risk achieved with the reduced data . This does not mean, however, that the data reduction is useful for much information may be lost. It is therefore important to assess whether the computational savings obtained through the data reduction justifies the information loss.
Figure 1. The loss as a function of the number of vectors.
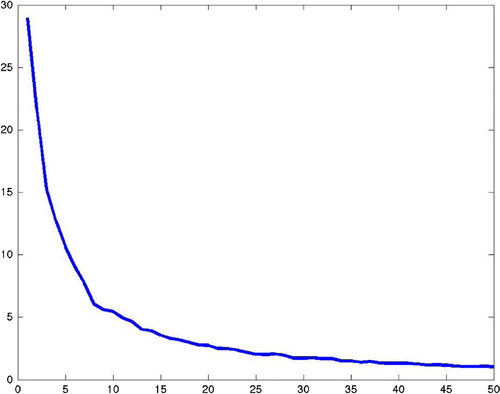
To assess the information loss of the data reduction, we compare its associated risk to that of the complete data. The Bayes risk of the complete (i.e. exhaustive acquisition) problem iswhile the risk associated with the reduced data
is
15
15 We quantify the information loss using the risk ratio
16
16 This loss indicates the degradation of the average recovery when using the reduction
instead of the full data. If the loss is much greater than
then using a single set of weights may lead to significant deterioration in the recovery. In this case one may want to use a number of weights as explained in Section 2.2. The loss is then
To determine an appropriate value of
, we may plot the loss as a function of
. The idea is to balance the trade-off between the cost of the experiment and the information loss. The following example illustrates this point.
Example 1
We generate random matrices
of sizes
and use
random unit vectors (not optimal)
. Figure shows a plot of
as a function of
. The curve has a classical L-shape and provides an upper bound for the optimal risks
. The figure shows that using less than
experiments will result in significant loss of information but using more than
may be a waste of resources. Thus, the loss curve is important if we would like to design an effective and yet efficient experiment.
2.4 Numerical properties of the design function
We now study properties of the weights selected in the fully Bayesian framework; that is, solutions of (Equation1212
12 ). First, note that neither the constraint
nor the objective functions
and
are convex and consequently there is no guarantee of a unique solution. In fact, if
is a solution of (Equation12
12
12 ), then so is
. And any permutation of an optimal sequence
is a solution of (Equation13
13
13 ).
Example 2
Consider the following simple well-posed case:
It is easy to see that for
,
and the optimal solutions of (Equation9
9
9 ) are
. That is, the optimal solution does not use the information provided by
. To see how much information is lost, we compare the risk of the full least-squares solution and the one based on
. The two optimal weights lead to the same estimate
with
. For the full least-squares solution, we have
and thus
with
. Hence, in this case the information lost by the reduction to
leads to a
that is twice as large as that of the full least-squares estimate. To compensate, we may conduct a single replication with the optimal
to match the
obtained without the data reduction.
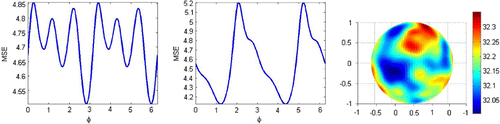
Example 3
Next, we consider the problem (Equation1212
12 ) for a the case
and
. The matrices
are random
matrices with i.i.d.
entries,
and
. We parameterize
in terms of the angle
by
for
and by spherical coordinates for
. In Figure , the value of the objective function for two random realizations of the matrices
and
is plotted, and one realization for
. The problem has multiple minima for the first instance, but a unique minimum for the second instance, as the two minima are equivalent. For the case
there are many more local minima at various places on the sphere. Local minima may not be too detrimental to our final goal. The value of
is not as important as long as we achieve a reduction of the risk. For the same reason, even if we do not have a global solution we may still find weights
that substantially decrease the risk one would have achieved by using other more naive choices.
Figure 2. The objective function as a function of for the weight
for two realizations of the matrices
and
from example
. We also show the case
.
3 Numerical solution
3.1 Direct approach
To solve the problem (Equation1212
12 ), we enforce the constraints by parameterizing
in terms of
spherical coordinate angles
on the unit
-sphere:
17
17 We then use the BFGS method to solve the minimization problem iteratively. This requires the computation of the derivatives of the objective function. Rewriting the objective function as
and setting
we have that
To evaluate the derivative of
we use implicit differentiation
We further define the matrices
which leads to the calculation
and finally
18
18 The gradient w.r.t. the angles
is then obtained by multiplication by the Jacobian of the transformation (Equation17
17
17 ). We have used the BFGS [Citation20] method to solve each optimization problem and we fix the termination tolerance of each problem, demanding that the norm of the gradient is reduced to
of its initial value. To address the problem of multiple minima, we repeat the optimization procedure for a number of random initial guesses for
and select the solution with the smallest value of the objective function. The method to solve the problem (Equation13
13
13 ) which involves multiple weights is completely analogous.
The techniques introduced in the previous sections work well for small-scale problems. However for large-scale problems, when is large the computation of the objective function and its derivatives can be rather expensive. Here, we can use a stochastic trace estimation [Citation11] and substitute the problem with
19a
19a v[ 2 v&#Xtop;(C(w)-1M mMC(w)-1)v
+ v&#Xtop; (A(w)&#Xtop;C(w)-2A(w)) v ]
s.t. w1 and19b
19b where the expectation value over random vectors
is approximated by sampling.
3.2 Heuristic weight selection
We can interpret minimization of (Equation1515
15 ) as maximizing the operator
. However, in practice it only needs to be maximized over a set of ‘relevant’ models
. Let us now make the bold step of maximizing over a single reference model
, which can be, for example, a constant background model or a more sophisticated prior. (Note that we cannot use the data to obtain
as we consider experimental design here.) We now obtain
Now
is just the reduced data that would result from the model
. Let us define and compute the
data matrix
as in (Equation2
2
2 ) but with
taken to be a row of
data (so
is
) and denote by
the
matrix of weights (with unit norm rows). We get
Let us now perform a singular value decomposition (SVD) upon
. We obtain
and the solution for
(under appropriate constraints) is the sub matrix of
corresponding to the truncated SVD, which is equivalent to obtaining the first
principal components from the data matrix
. For large-scale problems, the first
left eigen vectors and the corresponding eigen values can be estimated effectively through Lanczos iteration. In the following sections, we shall refer to this heuristic choice for
as the ‘SVD’ choice. This heuristic approach works almost as well as the more optimal
in the numerical examples below while avoiding the intricate and expensive optimization process associated with the optimal weights problem. A similar approach using the SVD for faster data processing rather than experimental design was proposed in [Citation21].
4 Numerical experiments
In this section, we test the methods developed on two-dimensional seismic tomography problems. First, we consider a simple toy model on a square domain to test and second we consider a more complicated reconstruction based on the Marmousi model.[Citation22]
We consider a rectangular domain with the top boundary
representing a ground-air interface while the remaining boundary
represents an artificial boundary of the model.
The acoustic pressure field is determined by the Helmholtz equation with appropriate boundary conditions:
20a
20a
20b
20b
20c
20c where
is the slowness, i.e.
with
the propagation velocity and
represents sources of angular frequency
. The Sommerfeld boundary condition (Equation20c
20c
20c ) prevents artificial reflections from the synthetic domain boundary
. We discretize (20) on a rectangular grid using a five-point stencil for the Laplacian which is sufficient for numerical experiments and obtain
where the Laplace operator
depends upon
and
through the Sommerfeld boundary condition. Note that
is a complex-valued vector.
Figure 3. Reconstructions with their corresponding relative error .
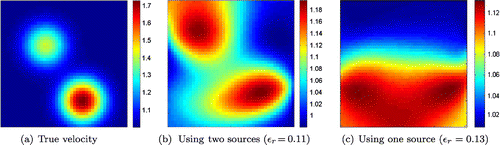
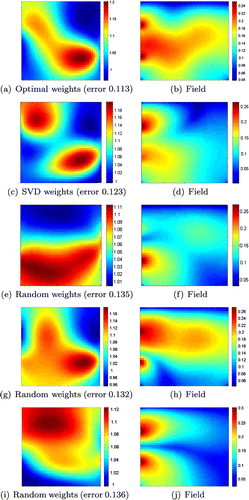
Figure 4. Reconstructions with a single combined source using various weight choices (left). On the right, the fields generated by the sources are displayed.
The inverse problem is to determine from measurements of
for several given sources
, where
labels the experiments which can involve several frequencies. We assume further that all experiments measure
at the same locations which are described by the linear sampling operator
, i.e. we measure
. The predicted data for a given slowness model
is
(suppressing implicit
dependence) and the least-squares error is
21
21 We add a Tikhonov regularization term to
and solve the inverse problem as
22
22 where
denotes the Laplacian weighted
norm.
We can apply the formalism developed above and consider instead of (Equation2121
21 )
23
23 for various choices of weights. The Bayes risk function (Equation13
13
13 ) is defined by linearization around a reference model
. Because we are dealing with complex variables, the weight vectors are now complex valued and satisfy
and there is an additional complex phase factor
for each component in (Equation17
17
17 ).
4.1 A simple toy model
For the first problem, we consider we take to be the square domain
which we discretize by a uniform
grid. Absorbing boundary conditions are assumed except at the top where we impose Dirichlet boundary conditions. Sources are placed on the left boundary and
uniformly spaced detectors are placed on the right. In Figure (a), we depict the synthetic velocity model which we use to compute simulated data to which we add
Gaussian noise. Sources of
(i.e. one wavelength in domain) are placed on the left in two configurations. First we consider
experiments with a source at
depth and at
depth. Second one source is placed in the middle. The inversion is performed as described in Section 3 and the regularization parameter
was chosen by the Morozov discrepancy principle.[Citation23] We solved the optimization problem (Equation22
22
22 ) using limited memory BFGS. We depict the resulting reconstructions in Figure (b) and (c) along with a relative error measure defined as follows:
24
24 It is clear that for
we capture the basic structure of the model, whereas
is insufficient.
Figure 5. Reconstructions of the Marmousi velocity model using only the low frequency data with all and with
simultaneous sources. We also indicate the relative reconstruction error
.
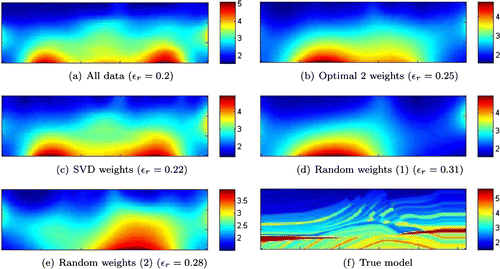
Figure 6. Fields for the simultaneous sources for the case
using the various weight selection methods. Notice how the good weights cover the domain more or less uniformly.
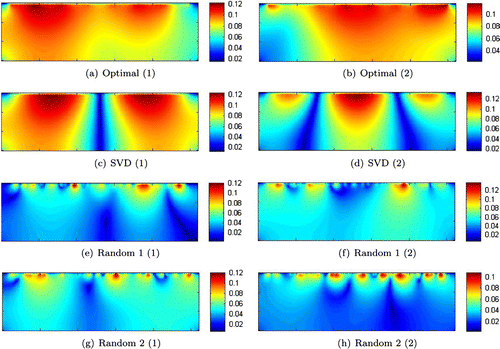
Figure 7. Reconstructions of the Marmousi velocity model using the protocol described. We compare the final result using all the data, and a simultaneous sources protocol with optimal, SVD and random weights.
Next we consider using a single simultaneous source by superposition of the two sources with a unit norm weight vector. In Figure , we show reconstructions using various methods for selection of the weights (left column). The right column shows the absolute value of the pressure field generated by the corresponding simultaneous source. We computed the optimal weight vector as described in Section 3 using
different random initial guesses for
, and selecting the one with lowest risk. Second, we used the method described in Section 3.2 and finally we generated three random phase weight vectors. It is evident that the optimal weights yield the best reconstruction both visually and in terms of relative error as defined in (Equation24
24
24 ). These optimal results were followed closely by those of the SVD method 3.2. The random weights offered a reasonable reconstruction in (g) but not in (e) and (i). By inspecting the fields in the rightmost column seems that the optimal choice has selected the source combination to provide the best possible domain coverage. The source of the SVD-based approach did so to a lesser extent and the random choices essentially cover the domain randomly, as expected.
4.2 Marmousi model
As a second numerical experiment, we consider the true velocity model depicted in Figure (f) of the Marmousi model. The domain is 3 km by 10 km and velocity is given in km units. We use a
grid for the discretization. Forty emitters are placed at uniform distances on the surface and
receivers are placed in between the emitters. We generate data for five distinct frequencies
(in Hz), with a total of
experiments. We note that the low frequencies are needed to avoid local minima, but are not quite realistic. We added
Gaussian noise to the synthetic data. Optimal weights were precomputed before the inversion by linearization around a constant
km
background model which was also used for the SVD method for selection weights.
First of all we present the reconstructions for a single frequency of Hz using all
experiments and with
weight vectors, each a combination of the
sources. For the latter we show the results for the optimal weights, SVD-based weight selection, and random phase weights in two realizations. It is clear from Figure that the random weight selection performs much worse that the other methods. In this case the SVD reconstruction is even better than using the optimal weights.
In Figure , we depict the resulting pressure field from the two simultaneous sources. We observe again that the optimal and SVD weights result in a more or less uniform and balanced coverage of the domain whereas the random choices do no share this virtue.
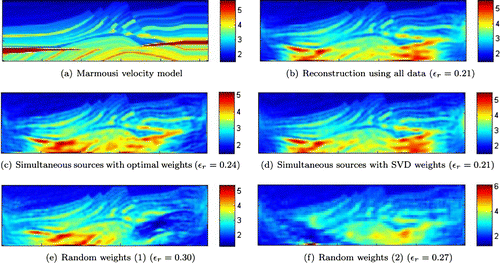
To obtain more accurate reconstructions, higher frequencies must be included. Because of the nonconvexity of the problem we perform a frequency continuation by which we first solve (to full convergence) for the lowest frequency, then use the result as initial guess for the next stage where we add an additional frequency, etc. Because accuracy of the reconstruction increases we can expect to require more simultaneous sources as well as more and more frequencies are included. In this example, we use simultaneous sources corresponding to frequencies
, again for the aforementioned three methods for weights selection. In Figure , we depict the resulted reconstructions. Remarkably, the reconstructions with the SVD or optimal weights are no worse visually than the reconstruction using all the data, whereas the random weights do not offer comparable results. We note that the advantage of using simultaneous sources decreases with higher frequencies.
5 Summary and conclusions
We have introduced a novel methodology for optimal experimental design of acquisitions involving simultaneous sources. Based on an optimal Bayesian risk statistical framework and the assumption of a linear inverse problem we have formulated an optimality criterion for selection of the weights in which individual observations should be combined. We derived a heuristic guess for the optimal weights based upon the SVD and we performed numerical experiments to test the efficacy of the method. In all cases, it was found that an informed choice of the weights generally outperforms a random weight choice. This is because our statistical framework incorporates information about the domain under consideration and the experimental setup.
Even though for most realistic applications the numerical models lead to nonlinear inverse problems, both weight selection based on a linearized version of the model was still found to perform quite well. Development of computationally viable optimal simultaneous source experimental design that accounts for the nonlinear nature of the observation model is a subject for future work.
In this study, Gaussian assumptions were taken for the noise model and Tikhonov regularization was considered for the ill-posed case. These choices are by no mean exclusive, and in principle, derivation of optimal experimental design for simultaneous sources can be performed for other alternative noise models as well as for other forms of regularization.
So far incorporation of constraints was not considered (other than such that can be introduced in the form of exact penalty). Future research would be to generalize the proposed formulation to account for such.
Additional information
Funding
References
- Arridge SR. Topical review: optical tomography in medical imaging. Inverse Probl. 1999;15:41–93.
- Casanova R, Silva A, Borges AR. A quantitative algorithm for parameter estimation in magnetic induction tomography. Meas. Sci. Technol. 2004;15:1412–1419.
- Dorn O. A shape reconstruction method for electromagnetic tomography using adjoint fields and level sets. Inverse Probl. 2000;16:1119–1156.
- Hansen PC. Rank-deficient and discrete ill-posed problems. Philadelphia: SIAM; 1997.
- Beasley CJ. A new look at marine simultaneous sources. Leading Edge. 2008;27:914–917.
- Romero LA, Ghiglia DC, Ober CC, Morton SA. Phase encoding of shot records in prestack migration. Geophysics. 2000;65:426–436.
- Herrmann FJ, Erlangga YA, Lin TTY. Compressive simultaneous full-waveform simulation. Geophysics. 2009;74:A35–A40.
- Morton SA, Ober CC. Faster shot-record depth migrations using phase encoding. Vol. 17, SEG technical program expanded abstracts. New Orleans, LA: SEG; 1998. p. 1131–1134.
- Romberg J, Neelamani R, Krohn C, Krebs J, Deffenbaugh M, Anderson J. Efficient seismic forward modeling and acquisition using simultaneous random sources and sparsity. Geophysics. 2010;75:WB15–WB27.
- Haber E, Chung M, Herrmann F. Solving PDE constrained optimization with multiple right hand sides. SIAM J. Optim. 2012;22:739–757.
- Hutchinson MF. A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines. J. Commun. Statist. Simul. 1990;19:433–450.
- Tenorio L, Andersson F, de Hoop M, Ma P. Data analysis tools for uncertainty quantification of inverse problems inverse problems. Inverse Probl. 2011;27:045001.
- Symes B. Source synthesis for waveform inversion. Denver: SEG Expanded Abstracts; 2010 p. 1018–1022.
- Haber E, Horesh L, Tenorio L. Numerical methods for experimental design of large-scale linear ill-posed inverse problems. Inverse Probl. 2008;24:055012.
- Coles DA, Morgan FD. A method of fast, sequential experimental design for linearized geophysical inverse problems. Geophys. J. Int. 2009;178:145–158.
- Horesh L, Haber E, Tenorio L. Book series on computational methods for large-scale inverse problems and quantification of uncertainty. Volume optimal experimental design for the large-scale nonlinear ill-posed problem of impedance imaging. Wiley; 2009.
- Maurer H, Curtis A, Boerner DE. Recent advances in optimized geophysical survey design. Geophysics. 2010;75:75A177–75A194.
- Haber E, Horesh L, Tenorio L. Numerical methods for the design of large-scale nonlinear discrete ill-posed inverse problems. Inverse Probl. 2010;26:025002.
- Lahmer T. Optimal experimental design for nonlinear ill-posed problems applied to gravity dams. Inverse Probl. 2011;27:125005.
- Nocedal J, Wright S. Numerical optimization. New York (NY): Springer; 1999.
- Habashy TM, Abubakar A, Belani A, Pan G, Schlumberger. Full-waveform seismic inversion using the source-receiver compression approach. In: 2010 SEG Annual Meeting; 2010 October 17–22; Vol. 3353; Denver, Colorado, USA: Society of Exploration Geophysicists; 2010.
- Bourgeois A, Bourget M, Lailly P, Poulet M, Ricarte P, Versteeg R. The Marmousi experience. Vol. 5–9, Chapter Marmousi data and model. Copenhagen: EAGE; 1991.
- Morozov VA. The discrepancy principle for solving operator equations by the regularization method. Zh. Vychisl. Mat. Mat. Fiz. 1968;8:295–309.