
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we discuss Bayesian model calibration and use adaptive Metropolis algorithms to construct densities for input parameters in a previously developed HIV model. To quantify the uncertainty in the parameters, we employ two MCMC algorithms: Delayed Rejection Adaptive Metropolis (DRAM) and Differential Evolution Adaptive Metropolis (DREAM). The densities obtained using these methods are compared to those obtained through direct evaluation of Bayes formula. We also employ uncertainties in input parameters and observation errors to construct prediction intervals for a model response. We verify the accuracy of the Metropolis algorithms by comparing chains, densities and correlations obtained using DRAM, DREAM and direct numerical evaluation of Bayes’ formula. We also perform similar analysis for credible and prediction intervals for responses.
1. Introduction
Uncertainty quantification plays an important role in the modelling of biological processes that involve complex phenomena. Input parameters are often correlated and cannot be directly measured from data, so these parameters must be estimated. Additionally, available data may be noisy due to measurement noise or limitations in sensor capabilities. The difficulty in parameter estimation can be exacerbated in biological applications since measurements are taken in groups rather than individual state variables as discussed in [Citation1]. For these reasons, it is essential to quantify uncertainties in the model response due to uncertainties in the parameters, errors in the measurement data and model discrepancy.
Development of models for viral infection processes is critical to understand the disease spread of HIV, and quantified uncertainties are required when constructing optimized treatment regimes. To illustrate these issues, we employ the HIV model(1)
(1)
developed in [Citation2,Citation3]. Here, and
represent the uninfected and infected type 1 target cells, respectively. Similarly,
and
represent uninfected and infected type 2 target cells. Note that
and
cells could represent, for instance, CD4 T-lymphocytes and macrophages. Here, V is the total number of infectious and non-infectious free viruses, and E represents the immune effector cells. Whereas, this model is quite simplified, it provides a framework to investigate control strategies for HIV [Citation2]. Studying the HIV infection dynamics using mathematical models can contribute to understanding of fundamental features of infection and to improved disease monitoring and treatment. Though we perform our verification using model (Equation1
(1)
(1) ), there are more comprehensive models such as the one found in [Citation4].
The description of the parameters in model (Equation1(1)
(1) ) are summarized in Table . Examples of parameters that can be measured are
, the death rate of infected cells, and c, the death rate of free virus. Values of parameters that can be directly measured are provided in [Citation5–Citation8]. On the other hand, immune response parameters such as
and
are not well known and must be inferred through a fit to data. The authors of [Citation9] determine the parameter values involved in their model by applying physical constraints and using the expressions for the steady states.
In this paper, we employ a Bayesian framework to infer probability density functions (pdf) for model parameters. We subsequently propagate these uncertainties through the model to construct credible and prediction intervals for a quantity of interest. We focus on the performance of two adaptive Metropolis algorithms – Delayed Rejection Adaptive Metropolis (DRAM) [Citation10] and DiffeRential Evolution Adaptive Metropolis (DREAM) [Citation11,Citation12] – due to their capability to infer highly correlated posterior densities.
We note that the use of DRAM and DREAM for dynamic models is well established. The contribution of this paper is to illustrate a framework for verifying the accuracy of these algorithms when inferring distributions for highly correlated parameters and constructing credible and prediction intervals for quantities of interest. We illustrate this verification process using two techniques. In the first, we employ energy statistics to test the null hypothesis that posterior samples, computed using DRAM and DREAM, are from the distributions obtained by directly approximating Bayes’ relation using quadrature techniques for a 3-parameter example. Secondly, we employ energy statistics to compare posterior samples from DRAM and DREAM for a moderate dimensional example having 12 parameters. For this case, we also verify the accuracy of both algorithms by comparing posterior means with the true parameters used to generate synthetic data. By establishing this verification procedure, we significantly extend initial analysis of the model using DRAM for a 6-parameter case as presented in [Citation13].
In Section 2, we summarize the process of model calibration using Bayesian inference. Synthetic measurement data are used to infer probability density functions (pdf) for the parameters in the model. We then discuss different algorithms that one can employ to compute the posterior distributions in Section 3. Once parameter densities are constructed, the uncertainties in the input parameters and observation errors are propagated through the model to construct uncertainty bounds. More specifically, credible and prediction intervals allow us to bound the model response distributions in terms of parameter uncertainties and the observations errors. The process of constructing these estimates is described in Section 4. Finally, in Section 5, we demonstrate the model calibration process and the construction of prediction intervals using DRAM and DREAM for the HIV model (Equation1(1)
(1) ). We verify the accuracy of the two methods by constructing densities for three parameters and comparing the results to densities that are computed by solving the Bayes’ formula directly. The accuracy of DRAM and DREAM is also verified by estimating the densities for a larger set of parameters, which vary greatly in their orders of magnitude.
Table 1. Parameters in the HIV model (Equation1(1)
(1) ).
2. Bayesian inference
In [Citation2], where the model (Equation1(1)
(1) ) is developed, the authors estimate parameter values using frequentist techniques. The authors use an iterative generalized least squares method and obtain uncertainty in the estimation process. Here, we perform Bayesian inference to estimate densities for model parameters. The Bayesian framework is also natural for uncertainty quantification since one can propagate the parameter densities through the model.
Bayesian techniques have been applied to models arising in bioscience, including an HIV model [Citation14]. In the field outside of HIV modelling, the importance of parameter estimation and uncertainty quantification of pharmacokinetics models is illustrated in [Citation15]. Smoothing using Gaussian processes on chemical reaction dynamics of producing nylon involving 6 to 24 parameters is discussed in [Citation16], and [Citation17] discusses accelerated sampling procedures of Bayesian inference with applications in systems biology and nonlinear dynamic systems. The estimation of rate constants for a continuous-time Markov ion channel model is discussed in [Citation18]. Other applications of Bayesian inference include deformable neuronanotomical atlases [Citation19] and several other models in Systems Biology Markup Language [Citation20].
For observations, we employ the statistical model
(2)
(2)
where and Q are random variables, respectively, denoting measurements at time
, observation errors, and parameters. The response of model (Equation1
(1)
(1) ) at time
is defined to be
.
For the comparisons between DRAM and DREAM, we employ synthetic data for which we specify the structure of the observation errors . We assume they are independent and identically distributed (iid) and
, where
is an unknown value that we infer. For measured data, the assumption of iid data is often violated, thus necessitating consideration of a statistical model
(3)
(3)
where is a model discrepancy term with hyperparameters
that are also inferred.
Let y be the realization of the random variable Y such that(4)
(4)
where f is the model response with realized parameters q evaluated at time for
and
is a realization of the observation error. We assume that models may have multiple responses. In a model with multiple responses, we let
be the number of responses. For example,
in model (Equation1
(1)
(1) ).
For the statistical model (Equation2(2)
(2) ), our objective is to construct the posterior density that best reflects the distribution of parameter values based on the sampled observations.
2.1. Bayesian estimation formula
The Bayesian estimation formula(5)
(5)
states that a posterior distribution is specified in terms of a likelihood function
and prior distribution
. Here, p is the dimension of input parameters. With the assumption that the model errors are iid and
, the likelihood for a model with a single response is given by
(6)
(6)
where(7)
(7)
We employ flat priors chosen to ensure that solutions to the model (Equation1(1)
(1) ) remain positive and well posed. For several parameters, such as
and
, we employ improper flat priors defined on
. We note that for such improper priors, one must employ likelihoods that ensure proper posteriors.
The likelihood function for a model with multiple responses and iid observation errors is given by(8)
(8)
where(9)
(9)
3. Posterior distributions
The goal for model calibration is to construct the posterior distribution for parameters q using (Equation5
(5)
(5) ). However, evaluation of the right-hand side of (Equation5
(5)
(5) ) and computation of marginal densities require multidimensional integration, where the dimension of integration depends on the number of input parameters to be estimated. When this dimension is high, it becomes impossible to compute the integral analytically, and even quadrature via Monte Carlo sampling becomes prohibitively expensive. To avoid approximating high-dimensional integrals, we employ sampling-based Markov Chain Monte Carlo (MCMC) methods. We employ two MCMC algorithms: Delayed Rejection Adaptive Metropolis (DRAM) and DiffeRential Evolution Adaptive Metropolis (DREAM). We also consider a direct method, where the integral is approximated using a numerical quadrature, to compute the posterior. For low-dimensional parameter spaces, comparison with these direct solutions provides a way to verify the accuracy of densities constructed using sampling-based Metropolis methods.
3.1. Direct method
We start by computing the density using the formula in (Equation5(5)
(5) ) with numerical approximation, which we term the direct method. We note that the likelihood functions that appear in the numerator and denominator of (Equation5
(5)
(5) ) can be very small. For the case of a flat prior, we avoid numerical evaluation of
by reformulating the posterior so that
(10a)
(10a)
Since the integral in (10b) cannot be computed analytically, we use a trapezoid rule with a uniform grid to approximate the integral. For one-dimensional integration with a uniform grid on with n grid points, we let
(11)
(11)
The one-dimensional trapezoid rule is then(12)
(12)
We employ a tensored trapezoid rule to approximate higher dimensional integrals. We verified the accuracy of these techniques by performing convergence tests with increasing values of n. The solution obtained in the direct method is regarded as the true solution when verifying the accuracy of sampling-based methods.
3.2. Delayed rejection adaptive metropolis (DRAM)
We first summarize DRAM as discussed in [Citation10] and detailed in [Citation13]. The adaptive Metropolis (AM) step allows the algorithm to update the chain covariance matrix as chain samples are accepted. This way, information learned about the posterior distribution through the accepted chain candidate is used to update the proposal. The sample covariance matrix, which determines the variance and correlation of the proposal distribution, is given by(13)
(13)
Here, is a design parameter that depends on the parameter dimension p. A common choice is
as detailed in [Citation10]. The term
ensures that
is positive definite with
. The covariance matrix is updated every
steps, often specified as
in practice. Also, the covariance is computed recursively to improve the efficiency so that
(14)
(14)
where the sample mean is also computed recursively(15)
(15)
Secondly, Delayed Rejection (DR) provides a mechanism for constructing alternative candidates when the current candidate is rejected. A second-stage candidate is chosen using the proposal function(16)
(16)
where is the notation for proposing
having started at
and rejected
, and
ensures that the second-stage proposal function is narrower than the original. The second-stage step improves the chance that the next candidate will be accepted and increases mixing. We take
and employ second-stage DR in our examples in Section 5, though different values of
and numbers of delayed rejection stages can be employed.
The DRAM algorithm with a flat prior is summarized in the following algorithm. To simplify notation, we suppress time dependence and multiple responses and consider the statistical model with realizations
for
.
| (1) | Set the design parameters | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (2) | Determine | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (3) | Set | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (4) | Compute the observation error variance estimate | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (5) | Construct the covariance estimate | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (6) | For
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (1) | Set the design parameter | ||||
| (2) | Sample | ||||
| (3) | Construct second-state candidate | ||||
| (4) | Sample | ||||
| (5) | Compute | ||||
| (6) | Compute | ||||
| (7) | If | ||||
Else | |||||
3.2.1. Chain mixing and convergence
There exist a variety of diagnostic tests to assess the mixing and convergence of chains.
To assess mixing, one often computes the acceptance ratio, which is defined as the percentage of accepted candidates. Whereas, the optimal value of acceptance ratio varies depending on the geometry of the posterior, values between 0.1 and 0.5 are often considered desirable. Alternatively, one can check the autocorrelation(17)
(17)
to establish that the chain is producing uncorrelated samples from the posterior.
Qualitative and quantitative convergence tests generally establish the lack of convergence rather than convergence. Qualitatively, one can visually examine chains to assess both mixing and convergence. However, a visually burned-in chain does not necessarily guarantee convergence since it may later jump – e.g., to another mode in a multi-modal distribution. Quantitatively, DRAM uses Geweke’s convergence diagnostics based on [Citation23]. This tests for equality of the mean of the first 10% and last 50% of the chain. However, Geweke diagnostics provide a necessary but not a sufficient condition for convergence. Hence the Geweke values indicate when the chain is not converged rather than when it is converged. Finally, one can run independent parallel chains with over-dispersed starting values, relative to the posterior distribution and monitor Gelman–Rubin convergence diagnostics. Due to its inherently parallel nature, we employ this strategy when monitoring the convergence of DREAM chains.
3.3. Differential evolution adaptive metropolis (DREAM)
The second MCMC method we employ is DREAM, which is developed in [Citation11,Citation24]. DREAM is an adaptive Metropolis algorithm, which can prove advantageous for problems having multimodal or heavy tailed posterior densities. Because it employs differential evolution to provide chain mixing, it can locate regions containing global minima more effectively than DRAM can with single chains.
The candidate parameters are proposed based on differential evolution(18)
(18)
where is the candidate point in chain i,
is the current population,
is the value of the jump size and d denotes the number of randomly sampled pairs. Furthermore, p is the number of parameters,
denotes the number of chains, and
satisfy
for
. Finally, we take
with
and
, where b and
are small compared to the width of the target distribution.
DREAM runs multiple chains simultaneously, and the chain values are used to adapt the proposal distribution, which in turn affects the mixing. The communication between chains occurs at given intervals, and the cost of communication between chains is much lower compared to the cost of model evaluations. Hence, the method is inherently parallel and can be advantageous for parameters having multimodal, heavy-tailed densities.
The algorithm, assuming a flat prior, is summarized as follows:
| (1) | Draw a current population | ||||
| (2) | Compute the likelihood | ||||
| (3) | Construct the candidate | ||||
| (4) | For | ||||
| (5) | Compute the likelihood | ||||
| (6) | If accepted, update the chain | ||||
| (7) | Remove potential outlier chains using the interquartile range statistics during the burn-in process as explained in the next subsection. | ||||
| (8) | Compute the Gelman and Rubin convergence diagnostic R [Citation25] for each dimension | ||||
| (9) | If | ||||
In the DREAM software, which can be requested at [Citation26], DREAM can accommodate both homoscedastic and heteroscedastic types of observation errors. For models with homoscedastic errors, the code can easily be modified to accommodate models with multiple responses, once one accommodates potentially differing error variances. Details regarding extensions to the basic DREAM algorithm to improve the search efficiency are provided in [Citation24].
3.3.1. Burn-in and convergence
The convergence of sequences of chain elements is monitored using R-statistics, which is a factor by which the scale of the sequences shrink to the posterior distribution as one takes more samples. As detailed in [Citation25], R-statistics uses the mean and variance between sequences as well as the variance of samples within a single sequence, referred to as ‘within sequence variance’. The R-statistics are quantitative and can be used to assess convergence without visually inspecting chains. It is important to note that the first assumption of R-statistics is that the seed values of the multiple chains be over-dispersed relative to the posterior distribution. The second assumption is that the chains are independent. Although the DREAM chains are not independent during burn-in due to crossover, the states of individual chains are independent after they become independent of initialization. More details can be found in [Citation11,Citation24].
To compute the R-statistic, take a sample of the last 50% of the chain values. Let be the number of samples and
be the number of chains. The steps for computing the factor are the following.
| (1) | Compute the sequence means. | ||||
| (2) | Compute the sample variance B of the sequence means. | ||||
| (3) | Compute the sample variance of each sequence. | ||||
| (4) | Compute the average of within sequences variances, W. | ||||
| (5) | Estimate the variance of posterior distribution by | ||||
| (6) | Compute the R-statistic | ||||
4. Credible and prediction intervals
4.1. Intervals computed using DRAM
To construct credible and prediction intervals using DRAM, N parameter values specified by the user are sampled and the model responses are computed at these parameter values. For example, the 95% credible interval for an expected response is constructed by sorting the computed responses and determining the upper 2.5% and 97.5% quartiles. To compute the 95% prediction interval, for future observations, the observation error is added to the computed responses before determining the 95% interval. The observation error is generated by a normally distributed random variable with mean 0 and variance . In DRAM, one has the option of inferring
based on the conjugacy between the prior and likelihood. If
is not inferred during model calibration, we use the OLS estimate of the observation error to construct the prediction intervals. Readers are directed to [Citation13] for more details regarding the computation and interpretation of credible and prediction intervals in the context of Bayesian inference.
4.2. Intervals computed using DREAM
In DREAM, the values from all of the chains are combined in a matrix so that the column contains all the chain values for the parameter
. The number of columns thus corresponds to the number of parameters that are estimated. The model response is computed for the last 25% of the values from each column. It is noted that 25% is chosen to ensure that the parameter values in the chains have converged. The generated responses are sorted, and the appropriate interval of the response is stored. For example, the responses at upper 2.5% and 97.5% are stored to compute the 95% credible interval. For prediction intervals, observation error is added to the response. The error is generated from a distribution
, where
(20)
(20)
and denotes the parameters determined through the ordinary least squares Step 2 in the DRAM algorithm. Once the noise is added to the model responses, they are sorted and the responses at the upper 2.5% and 97.5% are stored, for example, to construct the 95% prediction interval. Since the DREAM package does not come with the feature to update observation error, we added this feature using the prior conjugate in the similar manner it is implemented in DRAM. If the observation error is updated during the chain evolutions, sampled
values are used when constructing the prediction interval.
Table 2. Nominal parameter values.
5. Metropolis algorithm performance
We demonstrate here the performance of the two adaptive Metropolis methods for the HIV model (Equation1(1)
(1) ) for two cases. In the first, we consider three parameters
to permit verification of DRAM and DREAM through direct numerical approximation of (Equation5
(5)
(5) ). We also illustrate the construction of credible and prediction intervals for the model response and demonstrate that DRAM and DREAM provide comparable results. Secondly, we consider the construction of posterior densities for 12 parameters to illustrate the feasibility of DRAM and DREAM for a problem with moderate dimensionality.
To generate the synthetic data, we solve the model (Equation1(1)
(1) ) with the initial condition
(21)
(21)
for the states , and the parameter values summarized in Table , which are reported in [Citation3]. Once the solution to the model is computed, we add iid normally distributed observation errors. Here,
, where
(22)
(22)
For verification, we employ the direct method to compute the parameter densities for . In this example, we use a uniform grid with 101 grid points in each dimension. We restricted the region of integration to
for our computations to decrease the run time since the magnitude of the likelihood function outside the specified region is negligible. The accuracy of numerical approximation of the direct method is illustrated by a convergence test summarized in Table . The means and standard deviations of the three parameters remain unchanged between
and
quadrature points in the trapezoid rule (Equation12
(12)
(12) ). This indicates that the numerical approximation of integrals in (Equation5
(5)
(5) ) has converged and hence the direct method can provide a baseline for the verification of the sampling methods.
For the three parameter case, we first perform numerical experiments assuming that the observation error is fixed. In this case, we employed the OLS estimate of the observation error. The chains, marginal densities, correlations and prediction intervals are compared with this setting. We then perform additional experiments, where the observation error is updated as the chains evolve. For the second case, we compare the credible and prediction intervals of DRAM and DREAM. We do not include Direct here since we have not incorporated observation error. In principle, it is possible to do so by integrating with respect to the noise parameters. However, for the considered example with six responses, this would add six dimensions to the integration, which is infeasible.
Table 3. Mean and standard deviation of ,
and
using
quadrature points.
5.1. Three parameter case
5.1.1. Chains and marginal densities
Whereas DRAM and DREAM each have criteria to assess the convergence of parameters, the chains can also be used to examine the convergence visually for both DRAM and DREAM. It is noted that DRAM contains a single chain, from which means and variances of the parameters are computed. In Figure , we observe that the DRAM chains have visually converged in probability to a stationary distribution. On the other hand, DREAM is comprised of multiple chains, which evolve to fluctuate around the mean value as the iteration number increases. The initial iterations are plotted in Figure to illustrate the mixing between chains. The last 1000 iterations of five chains are plotted in Figure and we see that the chains have converged.
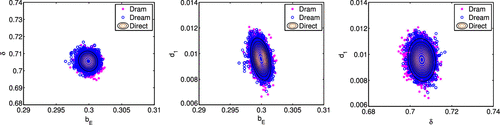
We see from the results summarized in Table that the means and the standard deviations for the three parameters are qualitatively comparable among the three methods. In Figure , we illustrate that the marginal densities obtained with the three methods are in agreement. The densities shown in Figure are obtained using a smoothed kernel density estimate (KDE). Typically, DREAM requires more KDE smoothing than DRAM. This is one aspect of DREAM that must be addressed by the users. In Figure , we show the contour plots of the marginal posterior distributions for each pair of parameters, computed with the Direct method, along with joint sample points produced by DRAM and DREAM. We note that qualitatively the variability and correlation are in agreement for the three methods.
Figure 1. DRAM chains for ,
and
.
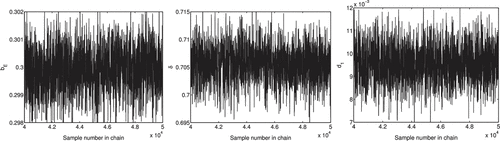
Figure 2. Initial DREAM chains for ,
and
.
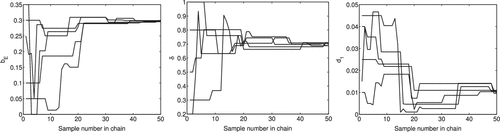
Figure 3. Burned-in DREAM chains for ,
and
.
Table 4. Mean and standard deviation for ,
and
.
Both the marginal densities and correlations appear to be qualitatively comparable, thus visually confirming the accuracy of the sampling-based Metropolis algorithms. Moreover, the scatter plots constructed using DRAM and DREAM coincide with the contour plots constructed using the Direct method. The contour plots represent the values of joint density functions. We note that the parameters and
are slightly negatively correlated, while
and
, as well as
and
, exhibit minimal correlation.
Figure 4. Marginal densities for ,
and
obtained using Direct evaluation, DRAM and DREAM.
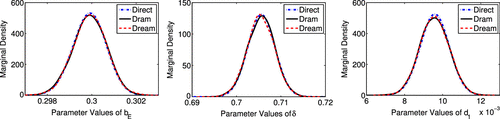
Figure 5. Contour plots from the Direct method plotted with joint sample points from DRAM and DREAM showing the correlations between ,
and
.
5.1.2. Energy statistics
Visual verification, based on the examination of Figure , is qualitative and subject to the degree to which smoothing is employed when constructing KDE. To quantify the hypothesis that DRAM and DREAM are sampling from the same distribution as the posterior distribution that is directly computed via the Direct method, we employ the energy statistics detailed in [Citation27,Citation28].
To determine whether two sets of samples are drawn from the same distribution, we let and
be independent random samples. To test the null hypothesis
, we compute the energy distance
(23)
(23)
and test statistics(24)
(24)
Here and
denote the distributions of X and Y and
is the Euclidean norm. By summing the absolute difference between samples from two distributions, the test statistics indicate the distance between two sets of samples. Smaller test values indicate that samples from two distributions are closer than those samples with larger test values, indicating greater consistency with
.
Suppose that two sets of samples X and Y are under consideration. Let be the test statistic of the pooled sample
, and
be the test statistic of the
permutation of the elements in W. Intuitively, the statistics of random permutations of a set [X , Y] should be identically distributed under the null hypothesis. For hypothesis testing, we compute the p-value
(25)
(25)
as detailed in [Citation29]. Here, R is the number of replicates, which is the number of times the test statistics are computed. The null hypothesis is rejected if the p-value is less than a specified significance level.
Table 5. Energy test performed for 3 parameters using samples via Direct, DRAM and DREAM.
To test the null hypothesis that DRAM and DREAM chains come from the same distribution as the samples from the Direct method, we use 2500 samples for each method with replicates. For the Direct samples, we obtain random samples using the inverse cumulative distribution functions. For DRAM and DREAM, we sampled every tenth value in a chain after burn-into ensure approximately uncorrelated samples. The test statistics and p-values for the energy test are summarized in Table .
For the significance level , the null hypothesis that the samples are from the same distribution is not rejected when the test is performed for individual parameters using Direct and DRAM, as well as Direct and DREAM. However, for both cases there is a p-value of 0.01 that is at the threshold for
. For the DRAM and DREAM comparison, we reject the null hypothesis for the individual parameter
.
For joint samples, the energy test indicates that samples from DRAM are from the true posterior distribution numerically approximated by Direct. However, we reject the null hypothesis that DREAM is sampling from the true distribution at the considered levels. This likely reflects the rougher DREAM chains observed in Figure . As future work, we will also investigate the degree to which DREAM can be further tuned to improve its efficiency and convergence to the posterior distribution. Similarly, we reject the null hypothesis that the joint samples from DRAM and DREAM are from the same distributions.
We emphasize that we performed these tests with the chain samples, rather than kernel density estimates, to avoid introducing an additional estimation procedure into the results.
5.1.3. Convergence diagnostics
In this section, we examine the convergence diagnostics for DRAM and DREAM. The default diagnostics used in DRAM are summarized in Table .
Table 6. Convergence diagnostics for DRAM.
We let denote the autocorrelation time, which is the ratio of covariance and variance of samples. The covariance is computed using samples that are 10 iterations apart, unless otherwise specified by a user. The autocorrelation time is used to establish that the samples are uncorrelated. More details are documented in [Citation22].
The Geweke diagnostic near 1 indicates that the mean from the first 10% and last 50% samples are very close. The acceptance ratio without the delayed rejection stage is 0.310 and the ratio combined with 2nd stage delayed rejection is 0.527.
On the other hand, we look at R-statistics and autocorrelation time for DREAM. The R values for all three parameters are below 1.2 after iterations. The acceptance ratio for DREAM is 0.343.
5.1.4. Prediction Intervals
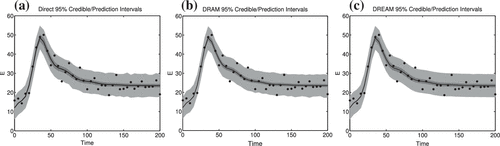
Finally, we consider the credible and prediction intervals shown in Figure . The inner intervals represent the credible intervals, which incorporate parameter uncertainties. The outer intervals in lighter grey represent the prediction intervals. The results obtained using Direct evaluation, DRAM and DREAM are nearly identical. One can observe that about 95 out of the 100 data points fall in the prediction intervals, suggesting that they have good frequentist coverage properties in this application.
Figure 6. Credible and prediction intervals for the response E using (a) Direct evaluation, (b) DRAM and (c) DREAM.
5.2. 12 Parameter case
Here we illustrate the performance of the DRAM and DREAM algorithms to infer parameter densities for a moderate number of parameters. We estimate the densities for . We note that the smallest and the largest parameter values among
, which are used to generate the synthetic data, are
e-7 and
1e+4, respectively. Hence the orders of magnitude among these parameters vary greatly.
We use the generated data to perform model calibration using DRAM and DREAM. We take a total of 1,000,000 chain evaluations including burn-in for DRAM. In DREAM, we set the maximum number of function evaluations to be 1,000,000 and use 10 chains. The prior for both DRAM and DREAM is a uniform distribution for
where
and
are summarized in Table .
Table 7. Lower and upper bounds for the prior distributions for
.
The estimated densities are plotted in Figure and the pairwise plots are shown in Figures and . The Direct method is not applicable in this case due to the larger dimension of input parameters. The mean values are summarized in Table , where the values listed as TRUE represent the parameter values used to generate the synthetic data. We note that the convergence of the posterior means to the TRUE values is an asymptotic result and may not be achieved for the limited considered data. As we will detail in later discussion, the discrepancy in is likely due to the fact the fact that it may not be identifiable in the sense that it is uniquely determined by the data.
Figure 7. Estimated densities for 12 parameters with DRAM (solid line) and DREAM (dashed line).
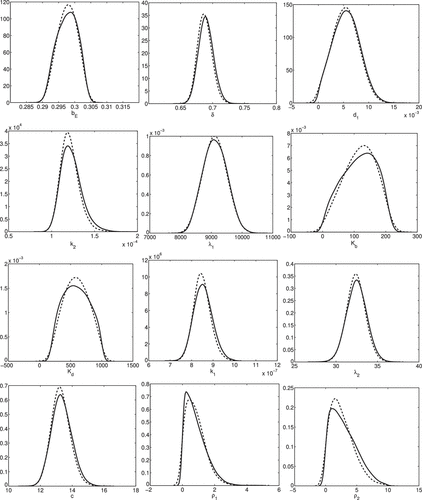
Figure 8. Parameter pairwise plots computed using DRAM.

Figure 9. Parameter pairwise plots computed using DREAM.

Table 8. Mean values obtained using DRAM and DREAM for 12 parameters.
The acceptance ratios for DRAM and DREAM are 0.201 and 0.147, respectively. The convergence diagnostics for DRAM are summarized in Table . Larger values of compared to the three parameter case indicate slower convergence for the 12 parameter case. The Geweke values near 1 for most parameters indicates that the means have remained the same over iterations. The R-statistics and autocorrelations are employed as convergence diagnostics for DREAM. R-statistics values are below the threshold after
iterations; however, the autocorrelation values are not near zero for some parameters. Again, the lack of samples from the analytically derived posterior indicates the necessity for performing a verification test through comparison of DRAM and DREAM.
Table 9. Convergence diagnostics with DRAM for 12 parameters.
Figures – indicate that the two methods qualitatively yield similar marginal densities and pairwise plots for all 12 parameters. To quantitatively ascertain whether DRAM and DREAM are sampling from the same posterior distribution, we compute the energy statistics (Equation24(24)
(24) ) detailed in Section 5.1.2. For this test, we use 2500 samples from each DRAM and DREAM and
replicates. Again, every tenth sample of a chain is recorded to obtain approximately uncorrelated samples.
The test statistics and p-values are presented in Table . We note here that whereas the smoothed KDE plots in Figure are qualitatively similar, the null hypothesis is rejected for all parameters except for and c at the
level. In the 12-parameter case, statistical tests indicate that the samples from DRAM and DREAM are not from the same distributions. This may be due, in part, to the property that DREAM chains are often rougher than DRAM chains due to the differential evolution component used to explore the posterior.
Table 10. Energy test performed for 12 parameters using DRAM and DREAM samples with the null hypothesis that DRAM and DREAM chains are drawn from the same distribution.
The mean values are also not in agreement among TRUE, DRAM and DREAM for some parameters. We note that convergence of the posterior means to the true values is expected in the asymptotic limit and discrepancies are likely due to the limited amount of data. In some cases, the disagreement may also be due to the observation errors. In the absence of observation errors, the mean values of DRAM and DREAM are much closer to the true values. The disagreement may also be caused by parameter non-identifiability issues. For example, single-valued correlated parameters may not be estimated uniquely. In our example, and
as well as
and c appear linearly correlated with nearly single-valued pairwise plots which could be a consequence of parameter non-identifiability or an inability of the available data to distinguish their effects. The posterior distributions for
and
are similar to the priors, thus indicating that the model and data are not informing the inference procedure for these parameters and hence they are likely not identifiable.
There are methods to eliminate parameter non-identifiability. Though they perform frequentist inference, the authors of [Citation30] present methods for detecting non-identifiable parameters prior to estimation. Also, issues with over-parameterization are discussed in [Citation18], where the ion channel model with superfluous states results in parameters that spread over a wide range of values, are multi-modal or are uniformly distributed. Detection of non-identifiable parameters results not only in accurate parameter estimation, but also reduction of parameter dimensions. An example is illustrated in [Citation31], which demonstrates the reduction of 61 model parameters to 26 parameters through successful isolation of non-identifiable parameters. Alternatively, one could perform parameter selection to eliminate non-identifiable parameters prior to model calibration. Some parameter selection techniques include variance-based methods and screening methods based on global sensitivity analysis. Details on this topic can be found in [Citation13] and the use of global sensitivity analysis to isolate influential parameters in an analogous HIV model is presented in [Citation32].
Alternatively, one can employ active subspace techniques to determine subspaces of identifiable parameters [Citation33–Citation35]. This approach has the advantage that it can accommodate linear combinations of parameters rather than focusing solely on parameter subsets as is the case for global sensitivity analysis and parameter subset selection algorithms.
6. Conclusions
We described Bayesian techniques for model calibration and used them to construct prediction intervals for the HIV model (Equation1(1)
(1) ). We first constructed posterior densities for three parameters using DRAM and DREAM. A single chain for each parameter evolves to the posterior distribution using delayed rejection and adaptation features in DRAM, whereas multiple chains are run to increase efficiency in DREAM.
We showed that DRAM and DREAM can be used to construct parameter densities even when individual parameters differ by many orders of magnitudes. One of the major differences between DRAM and DREAM is the single-chain in DRAM as opposed to the simultaneous multiple chains in DREAM. Running multiple chains of DRAM is an option for convergence assessment based on Gelman–Rubin diagnostics. In the case of the HIV model (Equation1(1)
(1) ), a single-chain DRAM is sufficient to efficiently sample from the posterior distribution.
To verify the accuracy of the DRAM and DREAM methods, we compared the posterior densities and pairwise plots obtained via DRAM and DREAM to the true values computed directly from (Equation5(5)
(5) ) for a three parameter case. Through the use of energy statistics, we showed that DRAM and DREAM are sampling from the true posterior density for the three parameter case. For a twelve parameter case, we showed that although DRAM and DREAM yielded qualitatively similar posterior densities, they differed somewhat for various parameters. This difference was quantitatively illustrated through the use of energy statistics. This may be due, in part, to the property that DREAM produces rougher chains due the differential evolution aspect of the algorithm. We note that the primary contribution of the paper is the illustration of this verification framework. As future work, we will also investigate the degree to which DREAM can be further tuned to improve its efficiency and convergence to the posterior distribution.
We also discussed credible and prediction intervals, which are constructed by propagating the input uncertainties through the model. The credible intervals quantify uncertainties in the model responses due to the parameter uncertainties, whereas the prediction intervals quantify uncertainties in the responses due to both the parameter uncertainties and the observation error. In the HIV example, credible and prediction intervals were constructed for the immune effector cells, E, using DRAM and DREAM as a part of a verification exercise.
The Metropolis methods discussed here can be used to perform parameter estimation and to obtain predictive estimates in other models, and can be extended to a larger number of parameters. These methods have been successfully applied to models involving gene transcription activity [Citation36,Citation37], cellular signaling pathways [Citation38], and an algae model [Citation31]. Moreover, the application of DRAM and DREAM to models with higher parameter dimensions has also been documented. Models with input parameter dimensions of 25, 50 and 100, are examined in [Citation11]. Also, a hydrology model in [Citation12], calibrated using DREAM, has 63 to 65 parameters. Recently, [Citation39] presented the use of MCMC methods, including DRAM and DREAM, as a part of uncertainty quantification for a groundwater flow problem, in addition to a 10-dimensional multimodal mathematical function and 100-dimensional Gaussian functions. In their examples, it is reported that DREAM is more efficient than DRAM. These applications indicate the efficiency of DRAM and DREAM in model calibration for models arising in bioscience with a wide range of parameter dimensions.
Acknowledgements
The authors thank Kayla Coleman for performing energy tests and providing insights regarding their interpretation. The authors also thank Tom Banks for input and discussion regarding the HIV model.
Additional information
Funding
Notes
No potential conflict of interest was reported by the authors.
References
- Gutenkunst RN , Casey FP , Waterfall JJ , et al . Extracting falsifiable predictions from sloppy models. Ann N Y Acad Sci. 2007;1115:203–211.
- Adams BM , Banks HT , Davidian M , et al . HIV dynamics: modeling, data analysis, and optimal treatment protocols. J Comput Appl Math. 2005;184:10–49.
- Adams BM , Banks HT , Davidian M , et al . Model fitting and prediction with HIV treatment interruption data. Bull Math Biol. 2007;69(2):563–584.
- Banks HT , Davidian M , Hu S , et al . Modeling HIV immune response and validation with clinical data. J Biol Dyn. 2008;2:357–385.
- Ferguson NM , deWolf F , Ghani AC , et al . Antigen-driven CD41 T cell and HIV-1 dynamics: residual viral replication under highly active antiretroviral therapy. Proc Nat Acad Sci USA. 1999;96(26):15167–16172.
- Mitter JE , Markowitz M , Ho DD , Perelson AS . Improved estimates for HIV-1 clearance rate and intracellular delay. AIDS. 1999;13(11):1415–1417.
- Perelson AS , Essunger P , Cao Y , Vesanen M , et al . Decay characteristics of HIV-1-infected compartments during combination therapy. Nature. 1996;378:188–191.
- Ramratnam B , Bonhoeffer S , Binley J , Hurley A , et al . Rapid production and clearance of HIV-1 and hepatitis C virus assessed by large volume plasma apheresis. Lancet. 1999;354:1782–1785.
- Callaway DS , Perelson AS . HIV-1 infection and low steady state viral loads. Bull Math Biol. 2002;64:29–64.
- Haario H , Laine M , Mira A , et al . DRAM: efficient adaptive MCMC. Stat Comput. 2006;16(4):339–354.
- Vrugt JA , ter Braak CJF , Clark MP , et al . Treatment of input uncertainty in hydrological modeling: doing hydrology backward with Markov chain Monte Carlo simulation. Water Res Resour. 2008;44(12):W00B09. DOI:10.1029/2007WR006720
- Vrugt JA , terBraak CJF , Gupta HV , et al . Equifinality of formal (DREAM) and informal (GLUE) Bayesian approaches in hydrologic modeling? Stoch Environ Res Risk Assess. 2008;23(7):1011-1026.
- Smith RC . Uncertainty quantification: Theory, implementation, and applications. Philadelphia (PA): SIAM; 2014.
- Huang Y , Liu D , Wu H . Hierarchical Bayesian methods for estimation of parameters in a longitudinal HIV dynamic system. Biometrics. 2006;62:413–423.
- Gelman A , Bois FY , Jian J . Physiological pharmacokinetic analysis using population modeling and informative prior distributions. J Am Stat Assoc. 1996;91:1400–1414.
- Campbell D , Steele RJ . Smooth functional tempering for nonlinear differential equation models. Stat Comput. 2001;22(2):429–433. DOI:10.1007/s11222-011-9234-3
- Calderhead B , Girolami M , Lawrence ND . Accelerating Bayesian inference over nonlinear differential equations with Gaussian processes. Adv Neural Inform Process Syst. 2009;21:217–224.
- Siekman I , Wagner LE II , Yule D , et al . MCMC Estimation of Markov Models for Ion Channels. Biophys J. 2001;100:1919–1929.
- Grenander U , Miller M . Representations of knowledge in complex systems. J R Stat Soc Ser B. 1994;56:549–603.
- Bois FY . GNU MCSim: Bayesian statistical inference for SBML-coded systems biology models. Bioinformatics. 2009;25(11):1453–1454.
- Laine M . Adaptive Markov Chain Monte Carlo methods. Finnish centre of excellence in inverse problems research. Available from: https://wiki.helsinki.fi/display/inverse/Adaptive+MCMC.
- Laine M . MCMC Toolbox for Matlab. Available from: http://helios.fmi.fi/lainema/mcmc/.
- Brooks SP , Roberts GO . Convergence assessment techniques for Markov chain Monte Carlo. Stat Comput. 1998;8(4):319–335.
- Vrugt JA , ter Braak CJF , Diks CFH , et al . Accelerating Markov chain Monte Carlo simulation by differential evolution with self-adaptive randomized subspace samplings. Int J Nonlinear Sci Numer Simul. 2009;10(3):273–290.
- Gelman A , Rubin DB . Inference from iterative simulation using multiple sequences. Stat Sci. 1992;7(4):457–472.
- Vrugt JA . Software: matlab packages. University of California Irvine. Available from: http://faculty.sites.uci.edu/jasper/sample/.
- Székely GJ , Rizzo ML . Testing for equal distributions in high dimensions. InterStat. 2004.
- Székely GJ , Rizzo ML . Energy statistics: a class of statistics based on distances. J Stat Plan Inference. 2013;143:1249–1272.
- Rizzo ML , Székely GJ . DISCO analysis: a nonparametric extension of analysis of variance. Ann Appl Stat. 2010;4(2):1034–1055.
- Raue A , Kreutz C , Maiwald T , et al . Structural and practical identifiability analysis of partially observed dynamical models by exploiting the profile likelihood. Bioinformatics. 2009;25:1923–1929.
- Haario H , Kalachev L , Laine M . Reduced models of algae growth. Bull Math Biol. 2009;71(7):1626–1648.
- Wentworth MT , Smith RC , Banks HT . Parameter selection and verification techniques based on global sensitivity analysis illustrated for an HIV model. SIAM/ASA J Uncert Quant. 2016;4(1):266–297.
- Bang Y , Abdel-Khalik HS , Hite JM . Hybrid reduced order modeling applied to nonlinear models. Int J Numer Methods Eng. 2012;91:929–949.
- Constantine PG . Active subspaces: emerging ideas for dimension reduction in parameter studies. Philadelphia (PA): SIAM Spotlights; 2015.
- Constantine PG , Dow E , Wang Q . Active subspace methods in theory and practice: applications to kriging surfaces. SIAM J Sci Comput. 2014;36(4):A1500–A1524.
- Barenco M , Tomescu D , Brewer D , et al . Ranked prediction of p53 targets using hidden variable dynamic modeling. Genome Biol. 2006;7(3):R25.
- Rogers S , Khanin R , Girolami M . Bayesian model-based inference of transcription factor activity. BMC Bioinform. 2007;8:S2.
- Klinke DJ . An empirical Bayesian approach for model-based inference of cellular signaling networks. BMC Bioinform. 2009;10:371.
- Lu D , Ye M , Hill MC , et al . A computer program for uncertainty analysis integrating regression and Bayesian methods. Environ Model Soft. 2014;60:45–56.