
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
An approach is developed to read and simulate experimental data using inverse problems. The idea is founded on a locally sequential refinement of the reconstruction. The regularization that occurs under a scheme of separate matching with observations is the basis for a numerical solution. The simultaneous identification of several unknowns using a set of mathematical models and functional representations of the desired quantities combines the simulation with inverse problem solutions. This unified approach is applied to the investigation of the enzyme kinetics. The object in question is simulated in the absence of information about the functional type of sought kinetic parameters, the noise structure and its level, and also details of observations. Nevertheless, the composition and volume of the samples under consideration prove to be sufficient not only for determining all of the kinetic parameters but also for clarifying the observation conditions. The obtained results demonstrate the effectiveness of the sequential regularized solutions to the inverse problems for the case of acting at once all the known features of ill-posed problems.
Nomenclature
| a | = | parameters of a mathematical model |
| = | regularized parameters without full matching with errors | |
| = | regularized parameters minimizing residuals with samples | |
| a(δ) | = | regularized parameters matching with consistency corridor |
| f | = | driving force |
| k-1, k1, k2 | = | kinetic parameters |
| m | = | sample volume |
| p | = | number of parameters |
| t | = | time |
| u | = | direct problem solution (state function) |
| = | actual state | |
| u(δ) | = | sample |
| C | = | intermediate complex |
| C* | = | invariant state |
| E | = | enzyme |
| E0 | = | initial value |
| I1,2 | = | invariants |
| KM | = | Michaelis constant |
| = | regularized estimate using the Michaelis–Menten function | |
| = | regularized estimate using the inverse problem solution | |
| = | mathematical operator depended on parameters | |
| N | = | number of approximation nodes |
| P | = | penalty function |
| P | = | product |
| S | = | substrate |
| S0 | = | initial value |
| S* | = | invariant state |
| S(δ) | = | sample |
| = | actual state | |
| Tm | = | final time of observations |
| Tobs | = | observation grid |
| = | regularized grid of observations without full matching with errors | |
| = | regularized grid of observations minimizing residuals with samples | |
| = | regularized grid matching with consistency corridor | |
| V | = | production rate |
| V(δ) | = | sample |
| = | actual state | |
| = | regularized state | |
| Vmax | = | maximum reaction rate |
| = | regularized estimate using the Michaelis–Menten function | |
| = | regularized estimate using the inverse problem solution | |
| = |
| |
| = | measure of solution complexity | |
| δ | = | upper bound of noise |
| = | noise | |
| γ | = | residuals of the observation matching equations |
| ρ | = | residuals with observations |
| τ | = | grid of sought quantity approximaxion |
| ν | = | absolute estimation error |
| χ | = | nodes of approximaxion |
| Π | = | penalty coefficient |
| X | = | vector of parametrization |
| Ω | = | stabilizer |
1. Introduction
The investigations of new objects and processes are characterized, as a rule, by the absence of essential information regarding their phenomenological properties. In such cases, the study can be accomplished using an inverse problem in which the unknown object properties are included in the composition of the desired solution. The uniqueness of the sought quantities’ reconstruction is established by obtaining additional observations and conditions toward a direct problem’s solution. The additional data should preserve the one-to-one correspondence between the sought quantities and samples.
Traditionally, an inverse problem formulation is considered to be an extension of a parental direct problem [Citation1–8]. However, methodologically, inverse problems can be used in more contexts than as a solution to a single problem. In [Citation9], the application of inverse problems in the form of a specific sequence was proposed to solve all of them with the same initial data. Accordingly, the experimental data can be simulated in the framework of not just a single inverse problem but also within a specific set of such formulations. Here, the simulation reflects the adequacy of the model in question as a discrepancy with an observation set and clearly shows the directions of further modelling, which should improve an obtained discrepancy with samples. The simulation with solutions to a series of inverse problems facilitates the object’s investigation in the absence of a significant amount of initial data on phenomenological properties, and when there exist definitional uncertainties.
In general, the requirement of solving a series of inverse problems extends the solution domain. The extension can occur at all levels of the simulation. As known, these levels include 1) a problem formulation, where a solution character is defined; 2) a functional representation, wherein an approximation of the desired functions is performed; and, of course, 3) calculations, wherein the final discrete form of the problem in question can be ill-conditioned or weakly sensitive to variations of unknowns.
As introduced by [Citation10], the primary requirement for solutions to ill-posed problems is the restriction of feasible states to boundaries that are consistent with errors in the initial data. This principle should also be used to formulate the sequence of regularized solutions to inverse problems. Correspondingly, the critical condition of the correct identification is the sequence formation that narrows down the choice of arbitrary elements at each simulation level. The approach for specifying such a sequence depends on the initial information, and different ideas can be suggested.
An inductive sequence of solutions to inverse problems can restrict numerical oscillations during the changes of the object model and during the transitions of its approximation. This idea was proposed in [Citation9]. The required sequence is performed as a transition from the simple model of an object to a more complex one while at the same time drawing on the previous identification. The initial choice of a simple model with its gradual complication together with the regularization of the solution at the calculation level facilitates the necessary restrictions of a solution domain.
A decomposition sequence of solutions to inverse problems also turns out to be an effective means of limiting feasible object states if there are far more uncertainties in the investigation of the object on the whole than in studying any part of it. The formulation of the inverse problems in the case of splitting a complicated object into components and studying only one of them was considered in [Citation11].
The present paper considers a case when an extension of a solution domain is associated with introducing a significant number of, for example, discretization nodes. This extension is typical for complicated functions. Their reconstruction within a single inverse problem solution requires a large number of measurements, which are often not possible to obtain. In this case, the sequential solutions to a series of inverse problems can also be useful. As in the above matters with induction and decomposition approaches, the necessary restrictions are implemented by the gradual transition from a simple form of an approximation to more complicated species. At the calculation level, the control of the variations of the sought solution is realized by the minimization of stabilizing functionals [Citation10]. In the end, the identification – in accordance with the principle ‘from simple to extended’, including the mandatory regularization – allows for a significant reduction of numerical instability when the mathematical formulation has uncertainties.
Thus, the same set of experimental data is proposed, associating with a set of inverse problems, functional representations, and numerical stabilization procedures. The developed approach will reveal the object’s properties, for which other known methods require postulating and introducing an essential volume of initial data. For all three simulation levels, which were mentioned earlier, the feasible states of an object will be restricted, and solutions to inverse problems will be matched with the noise of initial data. As a result, the structure, properties, and features of the object under study are identified in detail despite the existence of substantial uncertainties regarding initial information and sought quantities.
The idea of serial solutions to similar problems is widespread in both numerical mathematics and the theory of complex systems. Among the numerical methods, the relaxation method is commonly known [Citation12,Citation13]. Also, multigrid methods [Citation14] first compute an approximation on a coarser grid – usually the double spacing – and use that as a solution with interpolated values for the other grid points as the initial assignment. In mathematical programming [Citation15], a difficult problem is approximated by a simpler problem whose ‘relaxed’ solution provides information about the solution to the original problem. The proposed solutions to a series of inverse problems and a locally sequential refinement of a functional representation – together, they express a sequence of regularized solutions – are similar to the relaxation idea. Here, a simpler problem is an identification of a separate component of the sought quantity.
In [Citation16,Citation17], the sequential regularization method has been proposed. The technique is a functional iteration procedure for solving direct problems with isolated singularities. It has been introduced to improve a stiff numerical scheme of solutions to direct problems. Below the sequence of regularized solutions is used for other purposes. The first objective is solutions to a series of inverse problems to reconstruct unknowns in the framework of expansive uncertainties. The second objective is the extension of sought quantity approximation. Because of this, the object modification is controlled at each simulation level.
In the context of optimization theory, the most closely related field is that of robust optimization and robust control [Citation18,Citation19]. Commonly known that the optimization often has a high sensitivity to perturbations in the problem parameters. Robust optimization develops the idea that a solution should be constructed, satisfying any implementation of the uncertainty in a given set. The locally sequential refinement of the reconstruction initially involves filtration of uncertainties. The best choice of a regularized element is based on a stabilizer minimizing together with a sample matching when standard optimization methods are applied. Especially important for a satisfactory reconstruction is that the condition not to exceed the interval of concentration should be met. If the latter condition is introduced into robust optimization procedures, then the approaches will be close together. It may be noted that the local sequential refinement essentially proposed below offers a robust optimization for a solution to inverse problems without the postulation of the uncertainty kind.
Along with the regularization of inverse problems, machine learning is being widely developed to identify complicated objects [Citation20–22]. However, in the framework of machine learning, an object is not considered as a whole, and it is assumed that although identifying the complete object may not be possible, determining specific patterns or regularities can be useful. In contrast, the simulation with inverse problems is based on a sequence of transitions from a simpler to a more general object description, where patterns are not postulated and can be determined by solutions to inverse problems.
Other approaches can also be used to identify complex functions. Among them are neural networks [Citation23,Citation24], nonparametric regression and classification techniques [Citation25–28]. The main difference of these methods with the locally sequential refinement is the adaptive regularization of the sought quantity reconstruction. The approaches mentioned above do not have this feature. However, namely, this feature makes possible the transition from a strongly smoothed solution to its detailing.
Certainly, the essential requirement of the correct solution to the inverse problem is a performance of conditions ensuring the uniqueness of reconstruction and the identifiability of desired parameters. Justifying unambiguity requires considerable theoretical efforts [Citation1,Citation2,Citation5,Citation29,Citation30]. In this direction, the practical results can be achieved by excluding the manifestation of an invariant family in a solution to a direct problem [Citation31]. This idea is implemented below to prove the identifiability of parameters of enzyme kinetics.
The case study will be chosen to demonstrate how a traditional simulation methodology can be improved because, in terms of machine learning, the patterns of the object are obtained on the whole. Though the object in question is widely used in biosciences, at present, inverse problems regarding this object are not solved because there are essential numerical difficulties for the identification without the regularization [Citation32].
The paper is organized as follows. In Section 2, an abstract inverse problem is formulated to use a large class of mathematical models and to reconstruct different representations of unknowns in a series, taking into account the required changes in the simulation of the object. Section 3 describes how it should regularize the numerical solutions without a known regularization parameter, while at the same time, taking into account all features of simulation and observations. In Section 4, the locally sequential refinement of a functional representation is proposed to restrict local violations of a monotone behaviour occurring in desired quantities during the reconstruction. In Section 5, the mathematical model and features of the object under study are formulated. Section 6 is devoted to the identifiability of the kinetic parameters. The conditions of the simultaneous reconstruction of all the kinetic parameters of the model in question are defined. Section 7 formulates the solutions to the series of inverse problems and facilitates the identification of an extended number of unknowns within significant uncertainties in the source data. Section 8 describes the alternative solution to control the proposed approach. Section 9 demonstrates the approach application for processing the experimental data of enzyme kinetics. Section 10 summarizes the obtained results.
2. An abstract inverse problem
Consider a general formulation of an inverse problem, which can cover a range of simulation questions. A broad class of mathematical models, a set of desired quantities, and various representations of unknowns are involved in order to perform their modification, which is necessary during simulation procedures.
Let the model of the object in question be given in a domain space ![]()
(1)
(1)
where u is a direct problem solution that denotes an observable state function, f is a known external excitation (an abstract ‘driving force’), a=
, p ≥ 1 is the unknown object’s properties, and La denotes a continuous operator that acted in a Banach space and whose ranges of values are also a Banach space.
The existence of a unique element u for the given a and f is supposed everywhere below. It is also assumed that, generally, the operator does not need to have a continuous inverse operator
. Besides, it is assumed that the domain of Eq. (1) is not a compactum at
![]() . These conditions will play a key role, when quantities a =
. These conditions will play a key role, when quantities a = are estimated with general assumptions about their functional properties and when a broad class of mathematical models is involved [Citation10]. The condition of the parameter’s unidentifiable limits the number of unknown quantities. This condition for the superposition of the linear operators was obtained in [Citation31].
No restrictions are put on the form of the operator La. Any mathematical model can be used with both the lumped and the distributed parameters. Both analytical and numerical methods can be applied in solving the direct problem (1). The drawback in the latter case is the usual stumbling block for numerical analysis, that is, a loss of the generality power of the obtained results.
It is required that one seek the function u and its parameters a = , p ≥ 1 with a minimal estimation error
when a sample
is given to have a prototype
on the discrete set
(or the measurement points) from a known observation space, such as
(2)
(2)
(3)
(3)
where the approximately known element
deviates from the prototype
on each statistically independent m group by a known amount,
(4)
(4)
Here is any function, including random ones, with the known and limited measure (3) on each element of the observation set Ξ;
denote the noise internals of concentration; and m is the number of statistically independent elements of Ξ.
The prototype is the solution to Eq. (1) with an actual (‘true’) quantity
,
. The number m characterizes the sample size. For the present study, this number is not significant and has a minimum value satisfying the identifiability conditions [Citation31]. Such a sample is defined everywhere below as a sample of limited size.
Note that some features of the formulation (1) – (4) are essential for the developed approach.
The observation model (2), (3) conveys a broad class of noise sources and facilitates the study of many valuable cases of measurements. One of them is a sample with a bound volume, while the other is the nonzero level of the noise. It is also possible to account for the simulation and systematic measurement errors. Any hypothesis regarding the distribution of noise does not need to be introduced, and the expected value and covariance matrices are not specified. Only the measure (3) is considered to be known.
Eq. (2) expresses the direct measurements. If necessary, any other representation can also be contemplated, for instance, when the observations are a function of the state u (see Section 7). The norm of condition (4) is the standard estimator of the noise level. It is possible to use, for example, the rms norm or the absolute norm, which can be derived in any experiment. The selection determines the accuracy of the estimation. The choice of the norm of condition (4) was considered in [Citation33–35].
Condition (4), which is called the observation matching equations below, is one of the basic premises for determining the unknowns. It requires providing the proximity between the observed and the model-calculated
states by the noise level separately carried out for each given sample. If the desired quantities are the vector-functions (p > 1), then condition (4) requires the observations to be set as statistically independent groups.
3. Regularization under separate matching with observations
The critical roles of the sequential solutions to a series of inverse problems are the restriction of numerical variations in sought quantities and matching a solution with a measurement noise level. The latter should be less than the threshold level, which disturbs the parameter’s identifiability (for more details, see [Citation36]). At the calculation level, the methods that meet these requirements are called the regularized methods. The regularization principles were introduced and justified in [Citation10].
The choice of the regularization approach is defined by the simulation features of the problem in question. For further discussion, the following premises are essential.
The proposed simulation implies different types of inverse problems, including the coefficient inverse problem, the boundary inverse problem, and others. The regularization should be easily adapted for all.
The regularization should be sufficient for any model of an object.
Several model parameters or functions may be unknown, so the sought quantities are the vector-functions with which multiple samples of a state function should be associated.
The reconciliation with the observations should be separately carried out for each given sample, which contrasts the generalized matching condition
(5)
traditionally used in the regularization theory [Citation10]. Here, it is necessary to take into account that the condition (5) leads to a deliberately biased solution for a nonzero interval of concentration, δ ≠ 0, because of the primarily multipoint set
The values of
Features of a solution to a direct problem are considered to be known, and the regularization should be able to include this information into the reconstruction procedures.
Among the known approaches for solutions to ill-posed problems, such as the Tikhonov regularization [Citation10], Morozov discrepancy principle [Citation37], Ivanov quasi-solution [Citation38], and iterative regularization [Citation39,Citation40], all the requirements from a) – f) are met by the regularization scheme [Citation33]. This scheme is methodologically based on theory [Citation10] and, in particular, addresses the model identification and parameter estimation from the standpoint of the abstract inverse problem (1) – (4). This regularization is determined as the following formulation.
The reconstruction of unknown parameters a = of Eq. (1), using a noisy sample
with the known measure (3) and providing the necessary restriction and consistency, is reduced to the variational problem:
(6)
(6)
where Ω[a] denotes a continuous and nonnegative functional, the domain of which involves the sought parameters a.
The scheme (6) requires determining element a(δ), which minimizes the preset functional Ω when the direct problem solution u is matched with the noise level separately for each element of the observation set . This functional Ω is defined as a stabilizer because its minimization ensures the restriction of the solution domain. Also, the functional Ω is the complexity measure of the desired solution. Its inclusion in the minimization criterion facilitates choosing the best element a(δ) among all possible estimates in the sense of attaining a minimum of the complexity measure of the desired solution [Citation10]. Below, it will be shown how the stabilizer ensures the solution’s stability (see subsection 9.2).
As for the theoretical substantiation of the scheme (6), note that the inverse problem is reduced to the nonlinear programming problem. The substantiation of both the existence and the uniqueness of the solution to the abstract problem (6) has known difficulties. The uniqueness of the parameters’ reconstruction of the abstract operator La can be challenging to prove. At the same time, if the specific object is considered, then it is possible to obtain the particular conditions of solvability for the problem in question (see Section 6).
Concerning the regularization scheme (6), there are some noteworthy features.
The main difference between the scheme (6) and other known regularization approaches is the requirement to be partially fitted with the noise level for each element of the set . The scheme (6) has not the regularization parameter [Citation10] because the stabilizer Ω is directly minimized. Note as well that in [Citation33], the non-optimality of the traditional Tikhonov’s scheme with a regularization parameter was demonstrated when the desired solution was a vector function. The scheme with the regularization parameter cannot match the desired solution with the noise level separately for each element of the observation set. However, the Tikhonov’s scheme facilitates the dominant technique for investigating general mathematical properties of ill-posed problems. The scheme (6) is especially useful when the noise level has the nonzero and improvable value, and several unknown quantities are simultaneously estimated [Citation9,Citation11,Citation33–35].
This scheme (6) can be applied to solve a wide array of inverse problems. Its application does not depend on the kind of mathematical model used, which can be either a multidimensional or a nonlinear equation with both lumped and distributed parameters. Any required degree of regularization is realized according to the chosen approximation of the unknowns [Citation33–35]. Any quantitative and qualitative preliminary information of both the unknowns and the state function can be introduced into the reconstruction procedures. For example, it can be information about monotonous behaviour as a direct problem solution and as reconstructed functions. A variety of parameters of the object in question are supposed to be simultaneously estimated if the one-to-one correspondence between the direct problem solution and sought quantities is satisfied. It will be demonstrated below that the scheme (6) facilitates attracting the conditions of the unique solution to the inverse problem.
The application of the scheme (6) in practice is better suited for standard mathematical methods. A penalty function for a finite-dimensional basis is introduced as follows:
(7)
(7)
where
are the residuals of the observation matching equations, Πi denotes penalty coefficients, and N denotes the number of discretization nodes. The piecewise linear basis
is used in Section 9. The penalty function (7) reduces the variational problem (6) to the unconstrained programming problem for the parameterization vector
. Known algorithms and software can be used to determine its solution. For the simulation below, the algorithm of the coordinate descent will be used.
4. A locally sequential refinement of a reconstruction
The numerical oscillations can occur both in general and local kinds. For the first case, the solution at each point of its region can differ significantly from the solution at the neighbouring point. This case, which is known as high-frequency oscillations, is being intensively studied. Several regularized techniques are being proposed to restrict the oscillations in general [Citation2–8,Citation10,Citation16,Citation37–41]. For the second case, a local disturbance of a monotonous behaviour of desired quantities occurs. These kinds of the low-frequency oscillations are typical for a large volume of a discretization set (see Section 9). At present, insufficient attention is paid to the regularization of the low-frequency oscillations.
Having proposed the restriction of the desired solutions in general by the scheme (6), we will implement the relaxation rules for solutions to ill-posed problems. The reconstruction should be based on the elementary step, which consists of varying only one element of the set of unknowns, and the number of variable elements being chosen in a specific cyclic order. The restriction technique described below is the essential addition to the stabilizer’s implementation because local disturbances of a monotonous behaviour will be bounded for the cases, where the stabilizer cannot exclude the appearance of spikes.
It is well-known that for ill-posed problems, applying a general type of an initial approximant is incorrect because its domain will contain an unordered set of elements. Very often, a priori information on the functional type of sought quantities is absent. However, the specific features of the solution to the direct problem – the position of extremum, the inflection and intersection points, the monotonicity, and similar others – are known. This essential information can be implemented in the locally sequential refinement of the functional representations of the unknowns. Their steps are described below.
4.1. First step: the simpler approximation
Generally, the reconstruction should be started with the simpler approximation of the sought quantity, for example, with constant values. By this simplification, the discrepancy between the observation set and the direct solution
will significantly exceed the measurement noise level. However, this solution may already express the critical functional properties of the observed object state and – importantly – can show the areas in which the discrepancy with the observations is the highest. A difference between features of a solution and observed state functions reflects the zones of the unsatisfactory consistency with the experimental data.
For example, the displacement of a calculated position of some function feature from its observed place shows the presence of a simulation error. Also, the monotonous behaviour of both the desired quantities and direct problem solutions can be controlled effectively. In the case of interrelated processes, the control can be accomplished by checking positions, which express the inception of growth or drop of each interrelated part of a process (for more details, see subsection 9.2).
The question regarding the convergence of the approach described above is solved by controlling the level of the changes in the functions being identified. Any known norm, such as the root mean squares or the absolute deviation, can be used measuring changes of a new solution relative to its previous version. The stabilizing functional is the convenient target, which can be applied for such control.
4.2. Second step: the local refinement of a part of the desired quantity
Further reconstruction should be implemented as a local refinement. The specification of sought elements is performed only within a separate local zone when other elements of the vector of unknowns remain unchanged. The latter is taken from the previous solution.
The local refinement is performed for the parts with a weak discrepancy or a consistency violation between the functional properties of a direct problem solution and observations. For example, the previously introduced constants can be dissected into the parts according to the established zones of the poor discrepancies. After this, the transition from a piecewise constant function to a piecewise linear approximation can be performed together with the sequential solutions to the inverse problems for each step of the transformations. Any other approximants can be applied.
The criterion of satisfactory detailing is the determination of a smaller discrepancy for given samples, as well as the improvement of a certain degree of the sought solution complexity, which, for example, can be a stabilizer.
The refinement bounds are determined by both the complexity of the function being identified and the sample size. In particular, a variant that adds only one new node in the selected zone can be considered.
4.3. Third step: the refinement expansion
Each extension of the approximation requires the regularization. It should be implemented starting from the local zone and finishing on the whole range of observations. The necessary stabilization during the step-by-step reconstruction is described in Section 3.
Additionally, if it is required, any other ideas of restrictions, for example, the descriptive regularization [Citation41] can be applied. The scheme (6) can combine the stabilizer with the application of all of them. In such a combination, the stabilizer restricts the solution throughout the domain space, and the additional local regularization realizes the solution smoothing when the weak sensitivity generates the disturbance of the solution’s monotonicity in a local zone. These restrictions together provide the regularization of both the high- and low-frequency numerical oscillations.
As a result, the reconstruction during the sequential change from the refined zone to the whole area of the observation can match the current size of the parameterization set with the sample volume. The initially determined solution, which has the highest restrictions on the sought functions, is transformed from its neighbourhood and checked for its variations. The locally sequential refinement – and, at the same time, the regularized reconstruction from the neighborhood of the previously determined solution – should be performed until the required consistency with the given observations is reached, and the solution complexity will be minimized.
4.4. Fourth step: the refinement expansion
The proposed sequence of the transitions differs from the approximation extension, which is usually applied in theory. As a standard, the solution is sought in the entire function domain after the extension. Here — and this is imperative — the reconstruction is implemented for only a portion of a finite-dimensional basis of approximation, as defined by the worst residual. The next step of the extension is accomplished by using another weak discrepancy or by using the differences between the observed and calculated features of the solution to the direct problem. The scheme is analogous to the relaxation methods but differs from them by its implementation of a portion on a finite-dimensional basis.
The required minimum volume of the experimental data should reflect the basic functional properties of observed states, such as smoothness, non-negativity, monotonicity, convexity, and others. They are supposed to be known. These characteristics facilitate controlling the reconciliation with the observations at a qualitative level. It is desirable to observe these characteristics experimentally because the choice of the refinement zone is based on them.
At the quantitative level, determining the volume of the necessary information is the subject of a separate problem of the experimental design. The design method that takes into account the noise action and provides the necessary regularization is proposed in [Citation42].
The level of the changes in the identified functions has allowed controlling the convergence of the proposed approach. Any known norm, such as the root mean squares or the absolute deviation, can be used measuring changes of a new solution relative to its previous version. The stabilizer is a convenient target, which can be applied to such control.
The justification of the proposed method of a complex function reconstruction is based on the following conditions: i) the minimization of residuals chosen sequentially from the worst value to the general minimum magnitude, ii) the construction of the sought solution approximation according to the principle from the simple to the complex one, iii) the transition to the next simulation step from the vicinity of the previous solution, iv) the regularization of both the high- and low-frequency numerical oscillations, v) the control over the reduction of the selected complexity criterion of the solution, and vi) the obligatory fulfillment of the requirement of compliance with the specific features of observed states such as the maximum position, the inflection and intersection points, the regions of the solution monotonicity, and similar features.
Thus, the locally sequential refinement is the solution to a series of similar problems implemented the procedures for the isolation of problem singularities on each simulation level by the sequential regularized transactions from a partial to a general kind of a sought quantity approximation.
5. The object in question
Consider time-dependent kinetics of irreversible biomedical reactions. One of the most investigated processes in bioscience is a substrate transformation into a product under the catalytic influence of an enzyme [Citation43]. This kinetic is based on the so-called Henri-Michaelis–Menten scheme and is applied to a variety of spheres, including alveolar filtration of dust, the richness of species pools, filtering alcohol from the blood, and many others.
The choice of this object is made because, in bioscience, there are many investigations, where the commonly known Michaelis–Menten function gives essential simulation errors. At present, the change of the fitting function is accomplished as ‘a black box’ approximation without directly accounting any object features. In contrast, the developed simulation with inverse problems can directly account for any known, or observed object properties and substantiate the required modification of the fitting function. Especially emphasize that, namely, the correct reconstruction of sought parameters can reflect the actual functional kind of the observed discrete set.
It is necessary to keep in mind that there is no a priori information about the functional character of the parameters of enzyme kinetics. In general, they should be seen as time-dependent functions. However, at present, the mathematical simulation of enzyme kinetics has been made in the framework of the constant kinetic parameters. This simplification reflects the overall picture of the object’s dynamics. Nevertheless, from the viewpoint of mathematical modelling, this leads to an unsatisfactory discrepancy between the experimental data and state function calculated by the mathematical model. In particular, many experiments show a significant difference between the observed and model-calculated states obtained with the constant parameters. Processing of the experimental data in Section 9 confirms the existence of similar modelling errors. Thus, the determination of the nature of the parameters of enzyme kinetics is a critical point of the object simulation. The latter is the purpose of the present study.
5.1. The direct problem
According to the Henri-Michaelis–Menten scheme, the enzyme E reacts with the substrate S to form an intermediate complex C, which then, under the action of the enzyme, forms a product P and releases the enzyme. These objects are schematically represented as the reaction:
(8)
(8)
where k-1 and k1 are the microscopic rate parameters, and k2 is the catalytic parameter.
The mathematical model of the object (8) can be obtained by applying the law of mass action [Citation44]. As a result, the time evaluation of the object is entirely determined by a pair of coupled equations:
(9)
(9)
together with an uncoupled equation
(10)
(10)
having the initial conditions
(11)
(11)
The direct problem (9) – (11) is known as the Briggs–Haldane equations of enzyme kinetics [Citation45].
Additionally, basic Eqs. (9) – (11) obey two conservation laws:
(12)
(12)
These equations determine the necessary and sufficient set of the state functions S(t), C(t), E(t), P(t), which fully characterize the object in question. If the function P(t) is sought from Eq. (10), then the accuracy of the numerical solution to the direct problem is determined from Eq. (12).
Note that everywhere below, the dimensions of the kinetic parameters and the state functions S(t), C(t), E(t), P(t) are omitted in order not to overload the paper with information that is not used. Formally, this most straightforward procedure of the dimensionless is permissible because each parameter can be sorted with its identity dimension value, and the original equations will be transformed into a dimensionless form. Because of this, the focus is on the mathematical aspects of the reconstruction.
5.2. The features of the direct problem
The known solutions to the Briggs–Haldane equations described in [Citation46–48] have expressed the features of the enzyme kinetics. The typical behaviour of the state functions S(t), C(t), E(t), P(t) for the constant parameters are shown in .
Figure 1. Typical behaviour of the solutions to the direct problem (9) – (11).
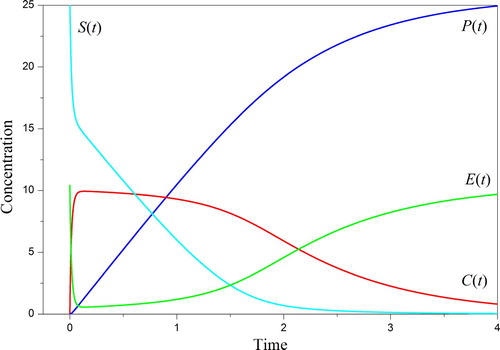
Note that there are three areas with the crucial significance, namely, i) the narrow interval at the initial stage, ii) the middle part with the slow varied function C(t), and iii) the final phase of the process. Below, it will be demonstrated that the observations in these areas ensure the best reconstruction. Consequently, the exclusion of observations in these areas excludes obtaining the necessary information about the peculiarities of solving the direct problem. This notation does not close the question of the optimal design and determining the best observations should be separately considered.
Traditionally, investigations of enzyme kinetics are based on the property of the direct problem (9) – (11), which is known as the quasi-steady-state approximation [Citation49] and is described, in detail, in the literature [Citation50–53]. The state is considered to be appropriate in cases, where the enzyme concentration is small compared with the substrate concentration. This ration of the components occurs when the enzyme is first mixed with a large amount of a substrate. There exists an initial period during which the complex concentration accumulates. The reaction quickly achieves a steady state in which complex C remains approximately constant over time. Then, from Eqs. (9) – (12), it follows (for example, see [Citation53]) that the production rate depends on the concentration of a substrate as the function
(13)
(13)
where
is the maximal reaction rate that can be attained when the substrate concentration is so large that the entire enzyme exists in form C, and
denotes the substrate concentration at the half-maximal rate. The hyperbola (13) is known as the Michaelis–Menten function.
In the characterization of an enzyme, it is essential to know the optimal concentration of substrates. This concentration relates to the values and
. Their estimations are easily realized from the observation fitting by the hyperbola (13) and using the nonlinear regression technique. The estimations come from the approximation by the Michaelis–Menten function have severe limitations.
The magnitude Vmax is the asymptote of the hyperbole (13) for S → ∞. Therefore, the function (13) does not reflect the properties of the direct problem solution, and
. The function (13) is obtained for the quasi-steady state so measurements on the entire observation space
are not considered. It is also necessary to take into account that the function (13) proposes the only usage of the constant parameters,
. Because of the hyperbolic nature of the function (13), the estimation of the parameters
is always biased relative to their actual values.
5.3. The inverse problem
The peculiars mentioned above are avoided by moving to the inverse problem. Their solutions will approximate the object in question more accurately than the hyperbole (13). The inverse problem is formulated as follows.
The existence, uniqueness and stability of the solutions to the Briggs–Haldane equations are supposed to be satisfied. For the object with the state function u = {S(t), C(t), P(t), E(t)}, two samples,
(14)
(14)
are known. The measurements are performed at the same observation time
. The parameters {
} should be estimated using the samples
and
. Their prototypes
and
are satisfied by Eqs. (9) – (11).
The identification of the kinetic parameters makes it possible to read the observations (14) and reveal all the features of the object (8) by reconstructing the functions S(t), C(t), E(t), P(t). The functional type will express the character of the microscopic rate, catalytic process, and production rate. By this, the simulation with inverse problems will give essential information regarding the enzyme kinetics and will answer the question about the adequate representation of its parameters.
5.4. The reconstruction features
To say anything in advance about the functional kind and character of kinetic parameters is impossible. They can be either constant quantities or variable functions. For Eqs. (9) – (11), it turns out to be characteristic that, even for small discrepancies between the functions S and V and their observations and
, there are significant variations of the desired quantities
, which are met by small changes of the direct problem solutions {S, V} (see subsection 9.2). This case requires a regularization, which will be accomplished by the scheme (6).
For the sake of definiteness in the framework of the present paper, the inverse problem is defined as the traditional formulation, where composition and the volume of initial data are enough to identify the model’s parameters in the framework of a single formulation. For estimating enzyme parameters, the traditional formulation was considered in [Citation24]. In the framework of its formulation, the features of the object were not determined.
At the same time, the experimental schemes, which are usually used for studying enzyme reactions, have several characteristic traits. They transform the traditional formulation of the inverse problem into the simulation by the solutions to a series of inverse problems (see Section 7). It is necessary to take into account the following features.
The nature of the information that usually comes from the enzyme experiments [Citation54] requires additional identification of the initial values . The extension of a number of the unknowns raises the question of invariant subset existence and necessitates determining the conditions that segregate the desired parameters from the invariant subset. The identifiability of the kinetic parameters is studied in Section 6.
The observation model (14) needs the values δ1,2, which express the within-sample scatter and determine the boundaries of the consistency corridor of the state functions with their observations. For the cases of experimental data considered below, the essential feature is the absence of any information about the noise. Nevertheless, the scheme (6) can reveal the approximate valuation of the boundaries of the consistency corridor. Their values are determined by a simple reception, which is described in Section 7.
Along with the above, it is necessary to take into account that descriptions of enzyme experiments, as a rule, do not contain information about the observation time Tobs. The absence is because of the existing practice of researches on enzyme reactions. If two samples {,
} are obtained, then the sample
is approximated by the function (13), and its parameters
and
are estimated. Because of this, no observation times Tobs are required. A similar approach is extensively applied in practice [Citation46]. Despite the widespread use of this approach, its application provides an estimate of only a limited number of process parameters and requires special experimental conditions for the implementation of a quasi-steady-state.
Thus, in contrast to the estimation of the function (13) parameters and
there is a statement regarding the inverse problem, which allows for the features of the enzyme kinetics to be identified. The inverse problem in question differs from the traditional formulation because of the lack of data on the initial conditions, the noise level, and the observation times. Nevertheless, the conjugacy of the functions S(t) and V(t) makes it possible to expand the composition of the unknowns and to reconstruct the observation time,
together with the parameters a = {k-1, k1, k2, S0, E0}. The upper bounds of the noise δ1,2 are estimated using the residuals of the observation matching equations.
Note that if kinetic models are more complex than (9) – (11) and there are possibly additional intermediate steps as well as no explicit relation between the functions V and S, then it will be necessary to obtain complete information on the observation conditions and also to require an experiment, where the identifiability conditions must be satisfied. The conditions for Eqs. (9) – (11) are determined below.
6. The identifiability of the kinetic parameters
The extension of a number of the unknowns necessitates substantiating the uniqueness of the simultaneous reconstruction of all the parameters a = {k-1, k1, k2, E0, S0}. If the class of the invariant solutions to the direct problem are determined and the conditions of their existence are revealed, then the criteria of the parameter identifiability are defined ex contario. Such approach effectiveness has been shown in [Citation31] to justify the identifiability even for the existence of invariant properties.
6.1. Propositions
Let us study the invariant properties of the direct problem (9) – (11) relatively its parameters. Suppose that for the solution {S*(t), C*(t), P*(t), E*(t)}∈ ![]() * there corresponds a subset of two different vectors,
* there corresponds a subset of two different vectors, and
, where
∈A*={a:
}. Any continuous functions k- 1(t), k1(t), k2(t) and constant E0, S0 = const > 0 are considered.
The transformation and the invariant family A* should be determined, which does not change the direct problem solution. Grounded in the conditions of the existence of family A*, the criteria for the identifiability of all the kinetic parameters will be gained.
6.2. Invariants of the Briggs–Haldane equations
Substituting the parameters and
in Eqs. (9) – (11) and subtracting these equations from each other, the conditions
,
are obtained. This result means that the solution u = {S, C, P, E} to the problem (9) – (11) is not invariant relative to the parameters k2 and S0. However, the functions {S, C} are invariant with respect to the parameters k-1, k1 and E0. For the latter case, the intermediate complex C depends on the substrate S as the function
(15)
(15)
where
and
(16)
(16)
are the invariants of Eqs. (9) – (11). The initial value C|t=0 imposes the condition
(17)
(17)
The existence of the invariants I1 and I2 indicates that any functions {S, C}, satisfied by Eq. (9), can be associated with the transformation
(18)
(18)
(19)
(19)
which preserves the solutions {S, C} over the domain of Eq. (9), and
![]() *≡
*≡ ![]() . Thus, for the general case, the reconstruction of the vector-function a = {k-1, k1, k2, S0, E0} is impossible.
. Thus, for the general case, the reconstruction of the vector-function a = {k-1, k1, k2, S0, E0} is impossible.
6.3. Identifiability criteria for the states with invariant properties
If the sought parameters are positively defined, k-1, k1, k2, E0, S0 > 0, then the additional conditions are obtained for invariants:
(20)
(20)
(21)
(21)
The transformation (19), taking into account (20), yields . Further, from (16), (17) and (19), it follows that
Then, taking into account (20) and (21), the condition is determined.
Therefore, in the vicinity of the initial stage of the enzyme process, t ∼ 0, the transformations (18) and (19) for the positively defined parameters will lead to an increase of any transformed coefficient regarding its parental value
and a decrease of any
relative to
. This condition expresses the criterion for choosing the desired elements from the invariant family (18) and (19) because, at the initial stage of the enzyme process, the parent parameter k-1 always has the minimum value while the parent parameter k1 always has the maximum value among all the elements of the invariant family.
In order to fully express the conditions of the invariant transformations (18), (19), it is necessary to determine the initial values and
. To do this, from (15), it is determined
On the other hand, from Eq. (9), it follows that
Finally
(22)
(22)
and
In the end, for any functions S and C satisfied by Eq. (9), it is possible to specify the new parameters (18), (19), which will not change the values of a pair {S, C} in the whole domain of Eq. (9). The invariant I1 is any function that satisfies conditions (17) and (20), and the invariant I2 is specified as the function I2 = S(I1/C – 1), which should have the initial condition (22). The invariant family does not exist for the constant parameters, {k-1, k1, k2, E0, S0 = const}, because of I1 ≡ 0 for any t.
As proved, the parameters S0 and k2 do not belong to the invariant subset. Further, if the sought parameters are positively defined, k-1, k1, k2, E0, S0 > 0, then the parental values k-1|t = 0 and E0 always have the minimum, and k1|t = 0 the maximum magnitudes among any other ones from the invariant subset. These conditions express the criteria of the unique estimation of the vector-function a = {k-1, k1, k2, E0, S0} as the parental element of the invariant family (18), (19). The relevant criteria should be involved in the reconstruction procedure.
6.4. Invariant property illustrations
Let us demonstrate the above-revealed character of the invariant transformation. Consider the parental parameters
(23)
(23)
Figures and show the various I1,2, for which the transformations (18), (19) save the functions S and C for . The transformed parameters are depicted in Figures and . They express the features of the invariant transformation regarding the minimum and maximum values of the parental parameters k-1 and k1.
Figure 2. Invariant I1 of the problem (9) – (11) with the parameters (23): 1 – ; 2 –
; 3 –
; 4 –
.
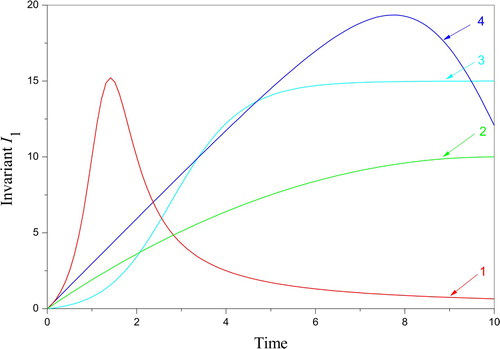
Figure 3. Invariant I2 = S(I1/C – 1) of the problem (9) – (11) with the parameters (23) and various I1: 1 – ; 2 –
; 3 –
; 4 –
.
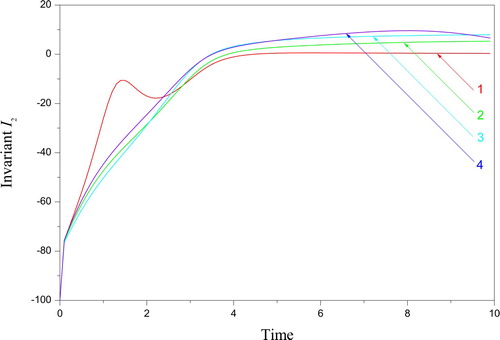
Figure 4. The parameters k-1 from the invariant subset (18): 1 – the parent function from (23), 2 – transformed by, 3 – transformed by
, 4 – transformed by
, 5 – transformed by
.
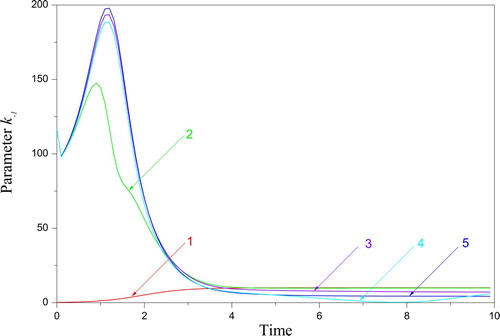
Figure 5. The parameters k1 from the invariant subset (19): 1 – the parent function from (23), 2 – transformed by , 3 – transformed by
, 4 – transformed by
, 5 – transformed by
.
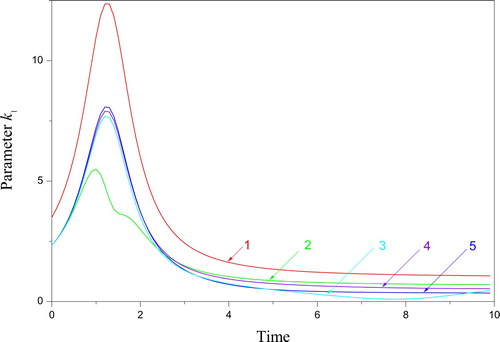
Thus, there are conditions of the unique estimation of the parameters a = {k-1, k1, k2, E0, S0} despite the existence of the invariant properties of the problem (9) – (11).
7. The inductive sequence of inverse problems
Now, the sequence of the subproblems identifying the extended complex of unknowns will be introduced. For the case discussed below, the sequence should implement the inductive principle ‘from a partial to a general’, because the volume of initial information is insufficient. In the framework of the formulations, the transitions will be performed by controlling the solution’s complexity measure.
7.1. First subproblem: entirely consistent with the sample
The reconstruction of the observation time should be started from the case when the state function S(t) is entirely consistent with the first sample,
, and the discrepancy with the second sample
is minimized regarding the desired parameters a = {k-1, k1, k2, S0, E0}. The regularized solution
and
is determined as the following subproblem:
(24)
(24)
where the state functions S and V are determined as the solution to the direct problem (9) – (11).
The solution to subproblem (24) is central to the running simulation because it defines the observation grid that is consistent with the experimental data as much as possible. The observation grid, in turn, entirely defines the further identification of the kinetic parameters. However, in subproblem (24), the measurement errors of the sample
are not taken into account and
are sought without any restrictions to the variations of the state functions.
Here, the determination of the element is considered as the initial approximation for the next subproblem. Its necessary restriction and reconciliation with the noise level will be fulfilled during the next steps in the framework of the second and third subproblems. The choice of the stabilizer Ω[a] is determined by the functional properties of desired quantities and is described in Section 9. The spherical norm of matching conditions in (24) is introduced to facilitate the convexity of the target function.
7.2. Second subproblem: the upper bound of the reconstruction error
Obtained the initial guess of the observation grid , the further estimation requires accounting the interval of concentration of the sample
. Because of the heterogeneity of the unknowns a and Tobs, this subproblem is divided into two parts. First, the vector
is sought for the given grid
. Accordingly, the constraints of the parameters k-1, k1, k2, S0, E0 are provided, and the discrepancy for each sample is minimized. Second, the grid
is reconstructed using the previous estimate
. The initial values
are taken from the solution to subproblem (24). The important advantage over the previous subproblem is the account of the difference between the model-calculated function and its observations,
. The difference has significance for nonzero measurement errors.
According to the scheme (6), the regularized reconstruction is reduced by the penalty function to the following sequentially solved extremal problems:
(25)
(25)
Here, the requirements for limiting the growth of the sought quantities
are accomplished because their stabilizers Ω[a] and Ω[Tobs] are minimized. The choice of the stabilizers is determined by the functional properties of desired quantities and is described in Section 9. The spherical norm of matching conditions in (25) is introduced to facilitate the convexity of the target function.
The solution to subproblem (25) gives the values of the worst residuals for each sample:
The obtained values of the residuals include the uncertainties of the simulation and the measurements. If the noise levels
are known, then it is possible separating the obtained residuals
on the simulation and the measurement errors and estimating the level of the simulation error ζ under the condition ζ = max{(ρS - δ1), (ρV - δ2)}. In the case of the unknown noise level
, the values
are introduced, for which all the residuals between the samples and the regularized solution to the next subproblem do not exceed
. Such a technique is an effective way to estimate the boundaries of the consistency corridor
.
It should be noted that the above-described technique does not make the lack of information about measurement errors an insignificant factor. The knowledge of the noise level remains an essential part of the inverse problem formulation.
7.3. Third subproblem: matching into the framework of the consistency corridor
Now, the regularization of the desired elements is being implemented for those values
starting from which the reconciliation with each of the samples (14) is satisfied and the stabilizers for both the observation grid Tobs and vector a = {k-1, k1, k2, S0, E0} are minimized. Mainly, this subproblem should impose the maximum functional limitations of the desired elements. The corresponding regularized solution
, consistent with the errors, is determined from the following extremal subproblems:
(26)
(26)
and
(27)
(27)
where the values
denote the boundaries of the consistency corridor. Their values may be less than the previously determined residuals
because in the framework of the solution to subproblems (26), (27) the simulation errors can be reduced. The initial values of the sought elements
are given from the solution to subproblem (25).
Unlike the previous subproblems, for the case (26), (27), the regularization of the sought quantities is executed within the setting of the consistency corridor. The introduction of the bounds allows for reaching the maximum restrictions of the sought quantities. The absolute norm of matching conditions in (26) and (27) is chosen to strengthen the limits in the final step of the sequential solutions.
An essential feature of the proposed sequence (24) – (27) is that the solutions are not sought for all the unknown functions but are sought sequentially from the restricted subset of the previous solution as described in Section 4. The gradual increase in the numbers of sought quantities combined with the local sequential refinement, as well as the regularization over all the unknowns, are the necessary conditions. Because of this, the passage from a particular to the more general representation occurs. Due to this, the acquisition of arbitrary elements, which could be satisfied by the observation matching equations, is eliminated. Excluding subproblems (24) and (25) and solving only subproblems (26) and (27) in the absence of a priori information on the sought properties will result in an arbitrary character of the estimation (see subsection 9.2).
Note that if the observation time Tobs and the measurement errors δ1,2 are specified, then the requirement to solve subproblems (24), (25), and (27) is excluded, and only subproblem (26) is required. As a result, the traditional inverse problem is formulated. The availability of the information on the observation time Tobs would improve the solution by eliminating the need for any additional regularization when the grid is sought. It is necessary to take into account that the regularization is an essential smoothing factor. The absence of information on the noise level also leads to an intense smoothing of the solution, mainly when the model-calculated states have achieved sufficient consistency with the observations.
Everywhere below, the Kutta-Merson method is used to solve the direct problem (9) – (11). Minimization is done by the coordinate descent method. Each search step is performed less than 1 s on a computer with CPU i7-6600U. The overall time of one search cycle for 200 approximation nodes requires about 3 min. The total time of minimization depends on the node number and does not exceed 1 h.
8. The estimation of the Michaelis–Menten function parameters
The application of the locally sequential refinement (Section 4) and the solutions to the series of the inverse problems (Section 7) can be compared with the parameter estimation of the function (13), which is the adequate process model for the case of quasi-steady-state observations (Section 5). For definiteness, the corresponding values and
will be named as the fiducial quantities henceforth. According to the scheme (6), their regularized estimates are the solution to the problem:
(28)
(28)
where
is the boundary of the consistency corridor. Its value is determined in the same way as the values
(Section 7). Interestingly, the value
expresses an upper boundary of the simulation error because the function (13) gives only the behavioral tendency of the observed state functions (see below).
The regularized estimates and
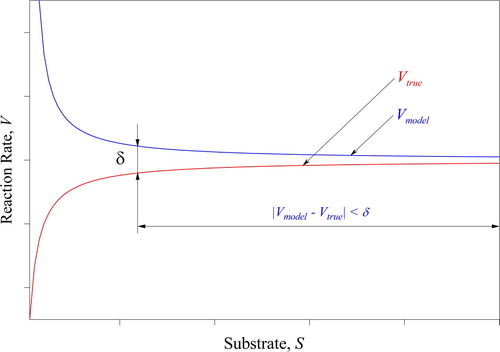
differ from those usually obtained in the enzyme kinetics [Citation54] by the nonlinear regression techniques. The formulation (28) performs the regularization according to the scheme (6), in which the stabilizer has the norm of Euclidean space, and reconciliation with observations is carried out under the absolute norm. The solution to the problem (28) satisfies the requirements of reducing both the influence of a weak sensitivity of state functions and the effect of measurement errors. Unable to cover this issue in detail, the existence of the weak sensitivity of a hyperbola is illustrated in . It demonstrates that there is an observation area in which two different hyperbolas (13) can be matched within a given internal scatter δ. Besides, the existence of significant errors of the estimation was demonstrated in [Citation32], where the least-squares are minimized. All these notes mean that the estimation of the function (13) should be regularized, which will be done here as the formulation (28).
Figure 6. The possibility of matching two different hyperbolas.
Because of the maximum rate can be directly determined from the problem (9) – (11), its comparison with the fiducial quantities – in the case of the quasi-steady-state – expresses the adequacy of the reconstruction of the desired vector
. The values estimated in this way are defined everywhere below as the control quantities,
and
.
For all the subproblems, the physically justified qualitative information will be used as follows:
the positive definiteness of the desired parameters, k-1, k1, k2, S0, E0 > 0;
the decreasing nature of the functions C and V in the domain
the process in the initial stage has a small region, where the maximum reaction rate
All these conditions can be easily implemented within the framework of problems (24) – (27) as the constraints of the minimization problem.
For all the solutions, the numerical control of the determination of the unique element Tobs is provided, which can be done by checking the monotone behaviour of the discrepancy . The uniqueness of the determination of the best element
is also verified numerically, where the stabilizer minimization and the locally sequential refinement are controlled for chasing the best solution (all details are described below).
9. Experimental data processing
Now, the simulation with the series of the inverse problems, including the locally sequential refinement will be implemented to process two experiments of enzyme kinetics. One of them has a weak dependence on time, and another has a significant dependence on time. All the numerical values will reflect the real values but will have the dimensionless forms according to the remark in Section 5.
The simulation will be divided into two parts of the parameter’s representations – the constant and variable quantities – and will have three steps for each part according to the series of subproblems (24) – (27). Because of this, the reconstruction will express how the simulation errors can be improved in the frame of the sequential regularization of the extension of the object structure.
9.1. Weak time-variable parameters
The case is characterized by the small number of nodes N, for which all features of sought quantities are expressed. The focus will be made on studying the adequate reconstruction of the observation time Tobs. The observation grid dependence over the residuals between the experimental data and model-calculated state is the primary purpose of this subsection. This dependence can express the numerical features of the proposed approach when the sought functions are practically constants.
Let us process the experimental data given in [Citation55]. The samples and
are represented in , Section 1. For this case, the fiducial quantities
,
= 0.077 and the boundary of the consistency corridor
= 0.008189 (Section 8) were determined per the solution to the problem (28) (see , Section 2). Below, the proposed sequence of the regularized solutions is described in detail.
Table 1. The reconstruction for the experimental data [Citation55].
9.1.1. The first part: constant parameters
Consider the identification of the constants, k-1, k1, k2, S0, E0 = const. Three steps of matching with the observations will be performed according to the serial solutions described in Section 7.
In the first step, requiring the entirely consistent solution to the sample , the solution to subproblem (24) with the stabilizer
(29)
(29)
is determined. As proved in Section 6, the constant parameters of the Eqs. (9) – (11) are uniquely estimated. By this, no actions are required to divide the invariant family (18), (19).
The reconstruction gives the following estimates:
k-1 = 0.09999, k1 = 1.12380, k2 = 0.17180, S0 = 4.17823, E0 = 3.27367 ( = 29.48).
The observation grid , which was reconstructed according to the given volume of the sample m = 9, as well as the residuals with the observations, are shown in , Section 3.1. The complete composition of the obtained solution is given in the Appendix, Section 1.1 (available in the electronic version of the paper because of the large amount of data). The criteria of the solution adequacy – the worst residuals – have the values
= 0.510−12,
= 0.0079787. The control quantities
= 0.4536 and
= 0.06961 were obtained. Their comparison with the values
and
shows satisfactory consistency.
In the second step, requiring the regularized minimization of the discrepancies with the samples and
, the solution to subproblem (25) with the stabilizers (29) and
(30)
(30)
is considered. This yields the following clarified parameters:
k-1 = 0.21789, k1 = 2.84887, k2 = 0.25702, S0 = 3.03913, E0 = 2.04971 ( = 21.67,
= 229.99).
The regularized observation grid and other results are given in the Appendix, Section 1.2. The worst residuals
= 0.005085,
= 0.004086 were obtained. The control quantities
= 0.4489 and
= 0.06539 were determined.
In the third and final step, which required matching into the framework of the consistency corridor, the solutions to subproblems (26) and (27) with the stabilizers (29) and (30) yielded the ultimate constant parameters:
(31)
(31)
The regularized observation grid is shown in , Section 3.2. The complete composition of the solution is given in Section 1.3 of the Appendix. The consistency corridors
and
were determined. The worst residuals
=
and
=
were obtained. The control quantities
= 0.4486 and
= 0.06525 were found.
Summarize the results of the reconstruction of the constant parameters.
The residuals, consistency corridors and stabilizers were minimized. It can be seen that all of the transitions under the proposed sequence of the inverse problems improved matching with the samples S(δ) and V(δ). The condition reflects the final solution’s improvement. The decrease in the worst residuals expresses the reduction of the simulation error. Such behaviour demonstrates that the proposed regularized solution to the inverse problem series improves the approximation of the experimental data and that the regularized parameters
and
are estimated more precisely than the traditional ones
and
. At the same time, the lowest values of the stabilizers,
and
indicate sufficient regularization. In contrast, the least-squares formulation (24) cannot ensure the minimum of the complexity measure.
Thus, it can be concluded that the obtained estimates of the constant parameters adequately characterize the process under study. Though, the next question is of undoubted interest. What will occur if the kinetic parameters are the time-dependent functions? The question is also motivated by the fact that the obtained residuals are higher than the values of observed states. This difference means that the simulation error has a significant value. The improvement of the simulation error requires the widening of the approximation.
9.1.2. The second part: the variable parameters and the local sequential refinement
Consider the identification of the sought parameters as the functions over time using the previously described samples. The piecewise linear functions
(32)
(32)
will approximate the desired quantities k-1(t), k1(t), k2(t). Here
is the approximation grid,
denotes the sought nodes of the parameters, and N is the number of the nodes.
The stabilizer is chosen according to the recommendations [Citation34,Citation35] and conclusions of Section 5 as a functional:
(33)
(33)
where Tm denotes the final time of the observation. The functional Ω3 expresses the conditions of the segregation of the sought parameters from the invariant subset (18), (19). Its minimization facilitates the unique reconstruction of the variable kinetics parameters (see Section 6).
The measure of the solution complexity
is introduced to control the reconstruction quality for all the cases considered below. The measure will express the solution deviations from the constant values.
For all the cases considered below the differences are not significant between the observation grid obtained in the framework of three solutions to the serial subproblems (24) – (27). Therefore, only the final results are represented.
The first step of the reconstruction is the identification of the node’s set , the volume of which has a small size, N ≤ m. The solutions to subproblems (26), (27) and the locally sequential refinement for partitioning the estimation interval with N = m, where m = 9, yielded the estimates S0 = 3.00293, E0 = 2.01037. The final observation grid
is presented in , Section 4.1. The identified approximation nodes
are given in the Appendix, Section 1.5. The measure
and the control quantities
= 0.45012,
= 0.06842 were obtained.
This step demonstrates that the residuals with the observations are improved, = 2.3910−5,
= 3.2210−5. However, the number of nodes N = 9 does not express satisfactory approximation. Because of this, the magnification of the number N should be continued.
The second step of the reconstruction is the sequential increase of node number N. The locally sequential refinement of the solutions to the subproblems (26), (27) was executed under the stabilizers (30) and (32). The consistency corridors = 3.2210−5 were found. The satisfactory approximation of the sought functions was started from the value N = 66 (, Section 4.2). The desired initial states S0 = 2.9913, E0 = 2.0066 were determined. The reconstructed nodes
are shown in the Appendix, Section 1.6. The measure
, the worst residuals
=
,
=
and the control quantities
= 0.45102,
were obtained.
Summarize the results of the reconstruction of the variable parameters k-1(t), k1(t), k2(t).
The serial regularized solutions depict decreasing the measure of the solution complexity, >
(). Such behaviour means that the stabilization of the desired solution is satisfactory. The values of the obtained residuals differ from the residuals of the previous case with the constant parameters (subsection 9.1.1). Their improvements are of more than two orders of magnitude. At the same time, the deviations of the variable parameters k-1(t), k1(t), k2(t) from the constants in (31) are not significant. The observation grid
and the initial states S0, E0, which were estimated for the piecewise linear approximation, differ insignificantly from the values, which were obtained for the constants (, Sections 3 and 4). The estimates
and
differ from the values
and
by about 4.85% and 11.18% consequently.
Table 2. The measure of the solution complexity and matching with the observations for the different number of nodes N, experimental data [Citation55], and subproblem (26), (27).
All the criteria of the adequate solution such as the absence of numerical oscillations in the general and local sense, the minimum of the residuals , and decreasing the complexity measure M are satisfied. It is remarkable for the proposed approach (Section 4), that the transition from the approximation nodes N = 6 to N = 66 has not changed the estimations significantly despite the limited size of the sample.
Thus, the proposed solutions to the series of the inverse problems (24) – (27) and the locally sequential refinement can satisfactorily reconstruct not only the unknown parameters but also the observation grid . The control and fiducial quantities obtained by the different methods are close to the estimates. The reconciliation confirms the reconstruction adequacy. This conclusion is also confirmed by the fact that the time-dependent parameters differ slightly from the previously reconstructed constant parameters. That is, having extended the approximation meaningfully, the estimates have not changed significantly. For enzyme kinetics, it is indicative that the transition to the variable kinetic parameters k-1(t), k1(t), k2(t) significantly improves the approximation of the observations
. The obtained results demonstrate the general character of the object under study.
9.2. Reconstruction of complex dependencies
Having obtained confirmation in the previous subsection that the observation grid was adequately reconstructed, we turn to the desired parameters k-1, k1, k2 with the strong dependence over time. The identification of the kinetic parameters is performed for the case of a large number of the nodes N, which is required to approximate the sought functions satisfactorily. Of course, such a case has significantly more uncertainties than the previous case. It is attractive to determine the best solution among others who are close in the residuals but differ significantly in nature.
Let us process the experimental data [Citation56]. The samples
It is indicative that the value
Table 3. The reconstruction for the experimental data [Citation56].
It is important to note that the experimental data [Citation56], unlike the previous ones, has the observations for the key areas of the state functions. Both the region of the maximum rate and the final stage of the process are these essential areas. The observations of the similar parts of the direct problem solution facilitate the complete control of the estimation adequacy. Ignoring observations in these areas will distort the process representation over the entire period of its existence. Consequently, the properties of the direct solution will be extensively used below.
9.2.1. The first part: constant parameters
Consider the reconstruction of the constants k-1, k1, k2, S0, E0 = const. Similar to subsection 9.1.1, three inverse problems (Section 7) will be solved.
In the first step, the solution to subproblem (24) with the stabilizer (29) yields the following sought parameters:
The results, which reflect the overall solution, are given in the Appendix, Section 2.1. The worst residuals = 0.4510−9 and
= 0.19057 were obtained. The control quantities
= 1.1875 and
= 5.3615 were determined. A comparison between the control and fiducial quantities shows poor consistency.
In the second step, solving subproblem (25) with the stabilizers (29) and (30) clarifies the parameters as follows:
All other estimates are shown in the Appendix, Section 2.2. The worst residuals = 0.0028 and
= 0.19073 were obtained. The control quantities
= 1.1875 and
= 5.3592 were gained.
In the third and final step, the solutions to problems (26) and (27) using the stabilizers (29) and (30) and the boundaries of the consistency corridor improve the estimation. The worst residuals have become smaller than in the previous step:
= 0.10004 and
= 0.18471. Finally, the constant parameters were estimated as follows:
Other obtained results are given in the Appendix, Section 2.3. The solution to the direct problem (9) – (11) yields the control quantities = 1.1683 and
= 5.1246.
All of the results of this part of the simulation demonstrate that in the framework of the constant kinetic parameters, the consistency with the observations remains weak, and the best residual differs slightly from the value
. From the adequacy viewpoint, it is critical that the behaviour of the identified function V(t) in the region with the maximum rate
differs meaningfully from the observations (see the Appendix, Sections 2.1–2.3).
Thus, the simulation of the kinetic process with the constant kinetic parameters is unsatisfactory.
9.2.2. The second part: the variable parameters and the local sequential refinement
The dependence of the sought parameters on time is considered as the primary condition to improve the simulation accuracy. The approximation will be sequentially extended from simple to complicated functional representations. The previously identified properties of the object in question are the basis of the required extension.
The first step of the simulation accounts for the existence of three areas of the worst reconciliation obtained in the previous subsection (see the Appendix, Section 2.3). According to these areas of unsatisfactory consistency, and following the recommendations of Section 4, the sought parameters k-1(t), k1(t), k2(t) were approximated by three piecewise constant functions, for which the variability intervals are 0 < t1 ≤ 50, 50 < t2 < 65, t3 ≥ 65. The stabilizer was as follows:
For this case of partitioning, the proposed sequence (24) – (27) facilitates identifying the parameters S0 = 68.86097, E0 = 1.63189. All other results are shown in , Section 3, and the Appendix, Section 2.4. The control quantities are = 1.2107 and
= 4.1539. The consistency corridors turn out to be
. The estimates express the improvement in the consistency, for which the worst residuals
= 0.00034,
= 0.12873 are obtained. Because of this, the approximation extension is the correct way to decrease the simulation error.
The second step is the approximant change to the piecewise linear functions (32). The initial number of the nodes was N = 6 (, Section 4). The other initial values were selected from the previous step. The stabilizers (33) and (30) were used. The solution convergence was controlled according to the level of the change in the complexity measure M ().
Table 4. The measure of the solution complexity and matching with the observations for the different number of nodes N, experimental data [Citation56], and subproblem (24).
The third step of the reconstruction is the sequential increase of node number N. The locally sequential refinement has played a crucial role in eliminating the loss of numerical stability during the identification. Namely, the principle of reconstructing only the parts of each desired function, and not immediately identifying them as a whole, ensures attracting a large number of the discretization nodes. By this and following the regularization principle, the solution was built as smooth as possible for each N. Here, the weak consistency with the samples is typical. Further, the residuals were minimized to determine the best consistency corridor. Finally, the particularization of the desired quantities was carried out into the framework of the consistency corridor.
For the experimental data under study, the node number of satisfactory approximation was started from the value N = 165. For this value, the consistency corridors = 0.05 and
= 0.03 were determined to identify the smoothest kinetic parameters (subsection 2.10 of the Appendix). Based on this solution, the reconstruction was accomplished to achieve minimal residuals with the samples (subsection 2.11 of the Appendix). The regularized reconstruction has reflected the pulsation character of the kinetic parameters. After this, the pulsation detailing was performed ( and subsection 2.12 of the Appendix). Compared to the previous reconstruction, the latter solution has improved the monotonous behaviour of C and V functions.
The final node number was N = 176. The minimal consistency corridors were determined. The initial states S0 = 70.101, E0 = 1.463 were identified. The control quantities
= 1.004,
= 4.4766 were found. The reconstructed grid
is given in , Section 4.5. The sought nodes
for the various N are presented in subsections 2.5–2.12 of the Appendix.
All the above-listed results express the unique and stable reconstruction of four functions k-1(t), k1(t), k2(t), Tobs, whose approximations required 539 nodes and for which only two samples with a total volume of 22 points were used.
9.2.3. The features of the reconstruction
In Figures , the changes of the functions k-1(t), k1(t), k2(t) are depicted during the locally sequential refinement. Their sequential transformations show that exchanging from the simple to the complex representations has a strictly defined final form (Figures ). The direct problem solution with identified parameters expresses all the features of the kinetic under study (Figures and ). The constants and the final representations of the kinetic parameters are the interrelated forms. The estimates are not arbitrary or random (compared to Figures and ) and do not contain oscillating components (compared to Figures and ).
Figure 7. The estimation of the parameter k-1 for the various nodes N (its value is indicated on the curves).
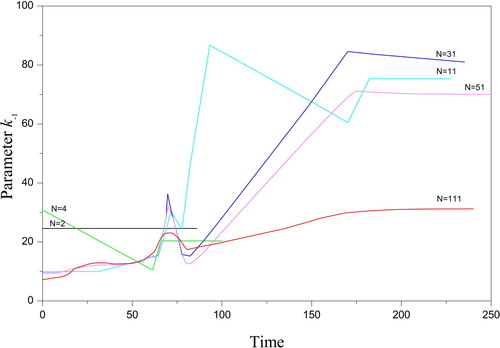
Figure 8. The estimation of the parameter k1 for the various nodes N (its value is indicated on the curves).
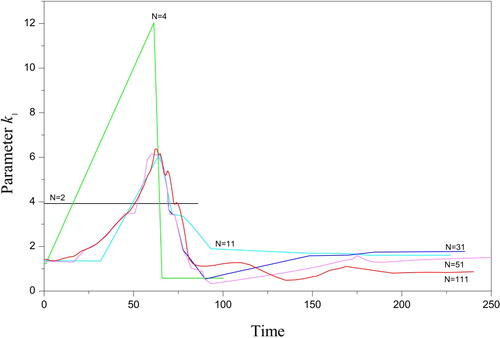
Figure 9. The estimation of the parameter k2 for the various nodes N (its value is indicated on the curves).
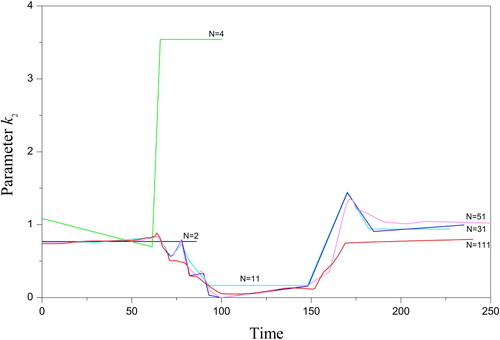
Figure 10. The reconstructed kinetic parameters, N = 176 (the experimental data [Citation56]): 1 – the parameter k-1, 2 – the parameter k1, 3 – the parameter k2.
![Figure 10. The reconstructed kinetic parameters, N = 176 (the experimental data [Citation56]): 1 – the parameter k-1, 2 – the parameter k1, 3 – the parameter k2.](/cms/asset/91d5f0ae-8587-4a0f-81b1-42769e438589/gipe_a_1782900_f0010_oc.jpg)
Figure 11. The reconstructed functions, N = 176 (the experimental data [Citation56]): 1 – C, 2 – V.
![Figure 11. The reconstructed functions, N = 176 (the experimental data [Citation56]): 1 – C, 2 – V.](/cms/asset/bdf932ba-b114-4548-8b58-10b397cb14c3/gipe_a_1782900_f0011_oc.jpg)
Figure 12. The dependence V(S): 1 – the experimental data [Citation56], 2 – the regularized solution, N = 176, 3 – the Michaelis-Menten function with the parameters and
.
![Figure 12. The dependence V(S): 1 – the experimental data [Citation56], 2 – the regularized solution, N = 176, 3 – the Michaelis-Menten function with the parameters Vmax(0) and KM(0).](/cms/asset/85e3883d-df1c-4844-b40d-080d5564d4ee/gipe_a_1782900_f0012_oc.jpg)
Figure 13. The exclusion of the locally sequential refinement from the sequence (24) – (27), N = 11.
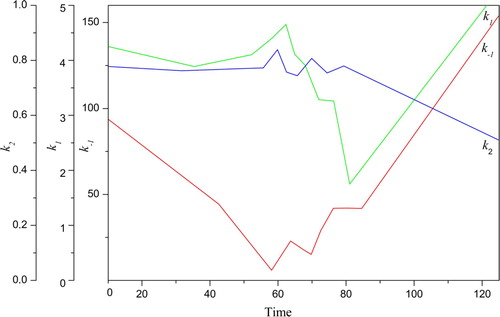
Figure 14. The local refinement without the regularization, N = 71.
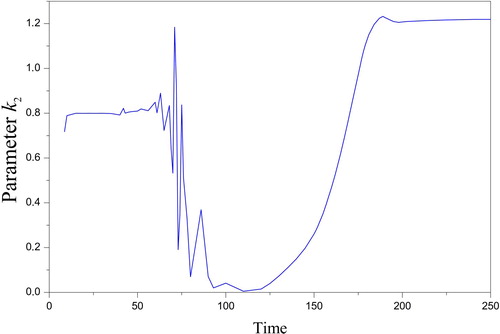
The essential part of the reconstruction was the control over the behavior of the direct problem solutions C(t) and V(t). It is supposed that the functions C(t) and V(t) should be increasing at the range , and should be decreasing at the range
. The local disturbances of the solution monotonicity have occurred during the increase of the nodes number N (). The control has determined the character and behaviour of the sought parameters significantly. In particular, the staircase character of the parameters k-1(t), k1(t), k2(t) at the initial stage was revealed precisely due to this control.
Figure 15. The magnification of nodes and the local violation of the function V monotonous: a) N = 95; b) N = 131; c) N = 161; d) N = 95; e) N = 131; f) N = 151.
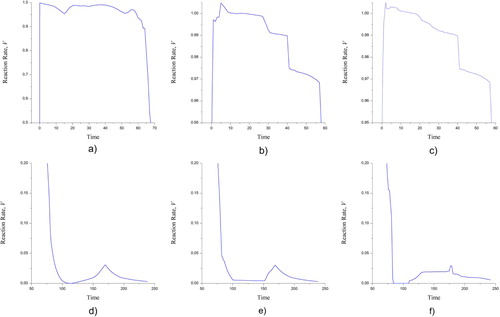
Especially underline that another essential part of the reconstruction stabilization was the third subproblem in the sequence of the solutions (Section 7). It facilitates matching into the framework of the consistency corridors. Satisfying the latter condition provides the effective restriction of numerical oscillations. The solution was determined on the boundaries of these corridors per the regularization feature [Citation42]. Because of this, only the minimization of residuals with samples, including its regularized formulation, for example (24), in principle, cannot give the satisfactory detailing of the sought functions (see subsubsection 9.2.4).
Also, note that even regularized estimates and
, described in subsection 5.2 as the commonly used enzyme model, cannot adequately reflect the area with the maximum reaction rate for the experimental data under the study. To explain the difference between the fiducial and control quantities, the dependence of V(S) should be considered. expresses the cause of the difference. It is the piecewise monotonic behavior of the function V(S). Fitting by the smooth hyperbola (13) gives rise to the insufficient approximation () and, consequently, the discrepancies with the observations have high values. All the obtained solutions highlight that the traditional approach gives rise to the overestimation,
. The comparison with the inverse problem solution, which was obtained in [Citation32] by the least-squares method, demonstrates the advantage of the mandatory regularization having the pinpoint accuracy of the regularized estimates
and
(see ).
A positive feature of the regularized reconstruction is a gradual decrease in the complexity measure (). Such behaviour indicates the regularity of functional expansion. The use of other starting values of sought quantities, as well as the forced change of any of them during the reconstruction, reduced the measure
only when the initial values
were excluded from the stabilizer (32). However, this exclusion gives rise to the intense smoothing of the solution.
9.2.4. The significance of the sequential refinement procedures
Let us demonstrate the significance of each option of the proposed sequence of regularized solutions.
For the first option – without the locally sequential reconstruction – only the problems (26) and (27) were solved at once for the whole nodes with the small discretization, N = 11. The results are presented in . As can be seen, the arbitrary forms of the sought functions were obtained. However, for this case, the solution regularization and matching with the observations were fulfilled, and the discrepancies with the observations were rather low,
These values demonstrate that the object in question has a typical feature of ill-posed problems. Here, the small discrepancies between the state functions and their observations correspond to the significant variations of the sought parameters. If the locally sequential refinement of the reconstruction is not performed, then the filtration of arbitrary elements is absent.
For the second option – without the general regularization – the solution to subproblem (24) with the refinement into the local interval 60 ≤ t ≤ 80 was determined, where the stabilizer Ω3[a] was not used, and the sought functions {k-1(t), k1(t), k2(t)}N=71 were estimated by the minimization of the least-squares. As can be seen in , the numerical instability occurs if the least-squares are minimized without the solution restriction. The stability absence demonstrates the principal role of the stabilizer and the local refinement.
9.2.5. The dependence on the noise level
In the case of unknown noise level, it is crucial to investigate its effect on the reconstruction. Here, two factors matter: i) the sensitivity of solving the direct problem to changes in the desired parameters, and ii) the numerical stability performed by the reconstruction method. If the analysis is limited to the particular cases, then numerical simulation of observations with increasing measurement errors is sufficient.
Let us carry out such modelling for the observations of the states S and V, which are determined from the solution to the direct problem (9) – (11) with the reference parameters {,
} reconstructed in subsection 9.2.2. The samples
and
will be simulated according to Eqs. (14), where
is the random functions with a normal distribution. The observations with 1%, 5% and 10% noise from the current value of the observed state and the volume m = 11 are shown in . For them, the approach described in Sections 4 and 7 was applied. The results are represented in .
Figure 16. The sample simulation with the noise level 1%, 5% and 10%.
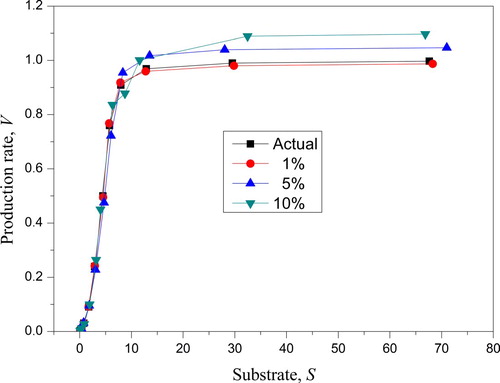
Figure 17. The reconstruction with the noise simulation: 1 – the actual parameter, 2 – the noise level 1%, 3 – the noise level 5%, 4 – the noise level 10%.
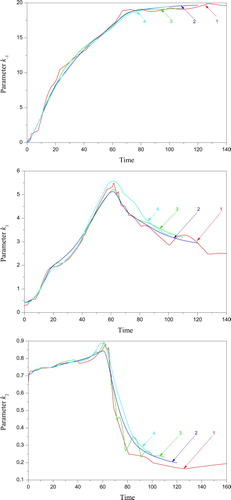
The reconstruction generally reflects the previously noted smoothing property of the solution when the consistency corridor is extended. For the noise 1% and 5%, the desired vector
was identified for arbitrarily given initial values both relative to the parameters
and the grid
. For the small noise, δ ≤1%, the reconstruction by the proposed approach gives the functions, which differs slightly from the reference quantities. For the noise 5% and 10%, the details of the reference functions are smoothed, but the general functional properties – the regions of the growth and decrease, minimum and maximum values – are saved. However, for the noise 10%, an arbitrary set of the initial grid
led to zero values of its nodes,
. The solution convergence was restored if the initial values of the sought grid
were chosen near the reference values. In practice, this means that for increased noise, the simultaneous identification of the parameters a and the nodes
had significant difficulties in meeting the convergence conditions. It will be executed when the nodes
are approximately known. Such a solution behaviour underlines the significance of both a level of noise and observation conditions in the problem formulation. It is also noteworthy that the reconstruction with increased noise leads to a highly biased estimate of the right boundary
of the observation interval.
Thus, the simulation with the series of the inverse problems, including the locally sequential refinement, was successfully applied in the case of acting at once all the known features of ill-posed problems such as nonuniqueness, nonstability, poor sensitivities, and noise action. If the sufficient domain restrictions are met, then the solution to the inverse problem can be determined within the framework of significant uncertainties. The simulation with inverse problems facilitates not only identifying all of the kinetic parameters but also clarifying the observation conditions.
10. Conclusions
The main results of the investigation are as follows.
Comprehensive information on an object’s properties can be extracted from a small sample.
If a sample has a limited size, then the basis of the stable identification of a large number of unknowns is the locally sequential refinement of the approximation of desired quantities. The locally sequential refinement requires the maximum restrictions of the feasible region in general.
The object in question has all the attributes of the ill-posed problem, namely, the violation of the one-to-one correspondence, the oscillations of the numerical calculations and the weak sensitivity to the local variation of the object’s states. However, the unique and stable solution was determined, and the reconstruction of the complicated dependencies using the small volume of observations was carried out.
The proposed regularization under separate matching with observations facilitates the stable estimation, adequate reconciliation with samples, and determination of the consistency corridor of the solutions with the given observations. The essential part of the reconstruction is adequate accounting for the multiple characters of samples as well as matching the solution with the noise level separately for each element of the observation set. The regularization of the complex functional dependencies without the locally sequential refinement gives rise to arbitrary solutions. The stabilizers were successfully used in fulfilling the solution restrictions throughout the variable domain space, and the locally sequential refinement showed the effectiveness in eliminating the local violations during the increase of the discretization nodes.
Any additional information, including the conditions of the unique solution to the inverse problem, can be involved in the regularization to facilitate the improvement of the estimation. The proposed regularization can take into account any changes during the simulation, such as the type of the approximation, the kind of the model used, the nature of the restrictions imposed and other changes.
The expansion of the desired solution with several unknowns leads to the formulation of the sequence of the inverse problems. Their choice should be based on the principle of ‘from simple to complex and extended’. The exclusion of restrictions from any level of the simulation leads to arbitrary solutions.
The effectiveness of the proposed approach was compared with the traditional processing of enzyme kinetics experiments. In one case, the satisfactory reconciliation was obtained, and in another, there was a significant difference with the results of the hyperbola’s estimation. The difference has appeared because the Michaelis–Menten function is not applicable to objects with variable kinetic parameters. For all the considered experimental data, the transition to the dependencies of kinetic parameters over time improved the consistency with the observations.
The solution to the inverse problem provides important additional information regarding the features of the enzyme kinetics. The pair were reconstructed more precisely than the ones obtained by the Michaelis–Menten function. For the inverse problem, the mandatory observations in the quasi-stationary region, which are required for the application of the Michaelis–Menten function, do not matter in principle. Moreover, the most preferred observations are fulfilled in the areas, where the reactions turn out to be essentially nonstationary. The obtained solutions express the necessary components of the experimental data, which can offer the best estimation of the kinetic parameters.
Further investigations will be directed to estimate the parameters of the Verhulst equation, commonly known in biomathematics. The simulation with inverse problems will facilitate revealing novel features of the growth processes.
Romanovski_GIPE_2019_0111_Appendix.docx
Download MS Word (232 KB)Acknowledgements
The author would like to thank the reviewers, whose attention and comments have substantially improved the presentation of the results and have supported the publication.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Lavrentiev MM, Romanov VG, Vasiliev VG. Multidimensional inverse problems for differential equations. New York: Springer-Verlag; 1970.
- Glasko VB. Inverse problems of mathematical physics. New York: American Institute of Physics; 1988.
- Groetsch CW. Inverse problems in the mathematical sciences. Braunschweig Wiesbaden: Vieweg; 1993.
- Engl HW, Hanke M, Neubauer A. Regularization of inverse problems. Dordrecht: Kluwer Academic Publishers; 2000.
- Tarantola A. Inverse problem theory and methods for model parameter estimation. Philadelphia: SIAM; 2005.
- Ramm A. Inverse problems. mathematical and analytical techniques with applications to engineering. Boston: Springer; 2005.
- Isakov V. Inverse problems for partial differential equations. 2nd ed New York: Springer; 2006.
- Kirsch A. An introduction to the mathematical theory of inverse problems. New York: Springer; 2011.
- Romanovskii MR. Solution of inverse problems with an unknown model of the process. J Eng Phys. 1983;45(3):1076–1082. doi: 10.1007/BF00826508
- Tikhonov AN, Arsenin V. Solutions of ill-posed problems. New York: Halsted Press; 1977.
- Romanovskii MR. Recreating the structure of an object as a whole by using the properties of one part. J Eng Phys. 1991;60(6):800–805. doi: 10.1007/BF00871524
- Shaw FS. An introduction to relaxation methods. New York: Dover Publications, Inc.; 1953.
- Ortega JM, Rheinboldt WC. Iterative solution of nonlinear equations in several variables. Philadelphia: SIAM; 2000.
- Trottenberg U, Oosterlee CW, Schüller A. Multigrid. London: Academic Press; 2001.
- Minoux M. Mathematical programming: theory and algorithms. New York: Wiley-Interscience Publication; 2008.
- Ascher UM, Lin P. Sequential regularization methods for higher index DAEs with constraint singularities: The linear index-2 case. SIAM J Numer Anal. 1995;33(5):1921–1940. doi: 10.1137/S0036142993253254
- Lin P. A sequential regularization method for time-dependent incompressible Navier-Stokes equations. SIAM J Numer Anal. 1996;34(3):1051–1071. doi: 10.1137/S0036142994270521
- Bertsimas D, Brown DB, Caramanis C. Theory and Applications of robust optimization. SIAM Rev. 2011;53(3):464–501. doi: 10.1137/080734510
- García J, Peña A. Robust optimization: Concepts and Applications. In: Nature-inspired methods for Stochastic, robust and dynamic optimization. Intechopen; 2018. DOI:10.5772/intechopen.75381
- Alpaydin E. Introduction to machine learning. Cambridge: The MIT Press; 2004.
- Shawe-Taylor J, Cristianini N. Kernel methods for pattern analysis. University Press: Cambridge; 2004.
- Mohri M, Rostamizadeh A, Talwalkar A. Foundations of machine learning. Cambridge: The MIT Press; 2012.
- Mishra A, Desai V. Drought forecasting using feed-forward recursive neural network. Ecol Modell. 2006;198(1):127–138. doi: 10.1016/j.ecolmodel.2006.04.017
- Kropat E, Meyer-Nieberg S, Weber GW. Singularly perturbed diffusion-advection-reaction processes on extremely large three-dimensional curvilinear networks with a periodic microstructure - efficient solution strategies based on homogenization theory. Num Algebra. Contr Opt. 2016;6(2):183–219.
- Weber GW, Batmaz I, Köksal G, et al. CMARS: A new contribution to nonparametric regression with multivariate adaptive regression splines supported by continuous optimization. Inverse Probl Sci Eng. 2012;20(3):371–400. doi: 10.1080/17415977.2011.624770
- Kuter S, Weber GW, Akyürek Z. A progressive approach for processing satellite data by operational research. Oper Res Int J. 2017;17:371–393. doi: 10.1007/s12351-016-0229-x
- Özmen A, Kropat E, Weber GW. Spline regression models for complex multi-modal regulatory networks. Optim Meth Software. 2014;29(3):515–534. doi: 10.1080/10556788.2013.821611
- Yerlikaya-Özkurt F, Taylan P. New computational methods for classification problems in the existence of outliers based on conic quadratic optimization. Comm Stat - Simul Comp. 2020;49(3):753–770. doi: 10.1080/03610918.2019.1661477
- Prilepko AI, Orlovsky DG, Vasin IA. Methods for solving inverse problems in mathematical physics. New York – Basel: Marcel Dekker, Inc.; 2000.
- Walter E, Pronzato L. Identification of parametric models: from experimental data. Berlin: Springer; 1997.
- Romanovski M. Upper bound of experiment informativeness. Inverse Probl Sci Eng. 2003;11(5):375–389. doi: 10.1080/1068276031000086769
- Stroberg W, Schnell S. On the estimation errors of KM and V from time-course experiments using the Michaelis–Menten equation. Biophys Chem. 2016;129(12):17–27. doi: 10.1016/j.bpc.2016.09.004
- Romanovskii MR. Regularization of inverse problem. High Temp. 1980;18(1):135–140.
- Romanovskii MR. Regularization of inverse problems by the scheme of partial matching with elements of a set of observations. J Eng Phys. 1982;42(1):92–98.
- Romanovskii MR. Regularization in the problem of determining external heat-transfer conditions. J Eng Phys. 1983;44(5):548–555. doi: 10.1007/BF00831944
- Romanovski M. Heat experiment design: factors of identification error reduction. Inverse Probl Sci Eng. 2006;14(2):129–152. doi: 10.1080/17415970500171118
- Morozov VA. Methods for solving incorrectly posed problems. New York: Springer-Verlag; 1984.
- Ivanov VK. On Ill-posed problems. Matem Sbornik. 1963;61(2):211–223.
- Gilyazov SF, Gol'dman NL. Regularization of ill-posed problems by iteration methods. Dordrecht: Springer; 2000.
- Bakushinsky AB, Kokurin M. Iterative methods for approximate solution of inverse problems. Dordrecht: Springer; 2004.
- Morozov VA, Gol'dman NL, Samarin MK. Descriptive regularization method and quality of approximate solutions. J Eng Phys. 1977;33(6):1117–1124. doi: 10.1007/BF00865394
- Romanovskii MR. Planning an experiment for mathematical model identification. J Eng Phys. 1990;58(6):800–807. doi: 10.1007/BF00872738
- Cornish-Bowden A. Fundamentals of enzyme kinetics. 4th ed London: Wiley-Blackwell; 2012.
- Murray JD. Mathematical biology. 3rd ed Berlin: Springer-Verlag; 2002.
- Palmer T, Bonner PL. Enzymes: biochemistry, biotechnology, clinical chemistry. 2nd ed Philadelphia: Woodhead Publishing Limited; 2007.
- Otten HA. Some remarks on the Michaelis-Menten kinetic equations. Math Biosciences. 1974;19(1-2):155–161. doi: 10.1016/0025-5564(74)90034-0
- Noethen L, Walcher S. Quasi-steady state in the Michaelis–Menten system. Nonlinear Analysis: Real World Applications. 2007;8:1512–1535. doi: 10.1016/j.nonrwa.2006.08.004
- Schnell S, Maini PK. Enzyme kinetics far from the standard quasi-steady-state and equilibrium approximations. Math Computer Modelling. 2002;35(1–2):137–144. doi: 10.1016/S0895-7177(01)00156-X
- Briggs GE, Haldane JBS. A note on the kinetics of enzyme action. Biochem J. 1925;19(2):338–339. doi: 10.1042/bj0190338
- Muller J, Kutler C. Methods and models in mathematical biology. Berlin: Springer; 2014.
- Segel LA, Edelstein-Keshet L. A primer on mathematical models in biology. Philadelphia: SIAM; 2013.
- Schwartz R. Biological modeling and simulation. London: MIT Press; 2008.
- Segel LA. On the validity of the steady-state assumption of enzyme kinetics. Bull Math Biol. 1988;50(6):579–593. doi: 10.1016/S0092-8240(88)80057-0
- Cornish-Bowden A. Analysis and interpretation of enzyme kinetic data. Perspectives in Science. 2014;1(1-6):121–125. doi: 10.1016/j.pisc.2014.02.010
- Hanes CS. The effect of starch concentration upon the velocity of hydrolysis by the amylase of germinated barley. Biochem J. 1932;26(5):1406–1421. doi: 10.1042/bj0261406
- Dette H, Melas VB, Wong WK. Optimal design for goodness-of-fit of the Michaelis–Menten enzyme kinetic function. J Am Stat Assoc. 2005;100(472):1370–1381. doi: 10.1198/016214505000000600