
ABSTRACT
This paper argues that methods used for the classification and measurement of online education are not neutral and objective, but involved in the creation of the educational realities they claim to measure. In particular, the paper draws on material semiotics to examine cluster analysis as a ‘performative device’ that, to a significant extent, creates the educational entities it claims to objectively represent through the emerging body of knowledge of Learning Analytics (LA). It also offers a more critical and political reading of the algorithmic assemblages of LA, of which cluster analysis is a part. Our argument is that if we want to understand how algorithmic processes and techniques like cluster analysis function as performative devices, then we need methodological sensibilities that consider critically both their political dimensions and their technical-mathematical mechanisms. The implications for critical research in educational technology are discussed.
Introduction
In this paper we confront the issue of the relevance of social science methods in educational research. In particular, we focus on the problem of researching algorithms – particularly those algorithms that enact new kinds of educational technologies like Learning Analytics (henceforth LA) – as an exemplar of the need for educational researchers to develop new methodological repertoires that can both (a) critically account for the social power of technical devices and artefacts, and (b) provide detailed analyses of the technical and mathematical mechanisms of such devices. Informed by recent methodological debates in sociology that engage with ‘the social life of methods’ (Savage Citation2013), our approach is to inquire into one specific method, that of cluster analysis, which underpins some of the operations performed by LA platforms. Our aim is to provide both a broad critical examination of the ‘algorithmic assemblage’ that constitutes LA – where we take an algorithmic assemblage to refer to the interlocking programming practices, assumptions, economic logics and functioning of algorithms themselves – and also a detailed ‘mechanological’ investigation of the technical and mathematical processes of cluster analysis as a specific algorithmic technique featured in LA.
By adopting a unified focus on the socio-political and the mechanological, we make an explicit commitment to symmetrical analysis (Latour Citation1996; Law Citation2009). That is, our argument assumes a level playing field or, in more philosophical terms, a condition of equal ontological standing between the world of human society and that of nonhuman ‘actants’: technologies, artefacts and machines. One of the most debated notions in contemporary social science, symmetry is in fact a useful methodological framing that invites social researchers to engage in a more detailed descriptive study of sociotechnical networks, viewed as heterogeneous systems where discourse and materiality are bound up with each other. As such, the careful analysis of the interactions within and across networks opens up a plurality of vantage points and leads to configurations of interlocking explanations and technical deconstructions that, potentially at least, surpass more ‘traditional’ analyses focusing on either the social or the material.
Although ambitious in scope, this unified viewpoint comes with an important clause: symmetrical analyses are at their best when they take into account the different degrees of granularity of sociomaterial networks and when, as a result, they engage in a careful work of foregrounding (Latour Citation1996). This is achievable through a case study approach whereby one element is closely examined while the others move into the background. Our mechanological analysis of cluster analysis broadly follows this template. Consequently, we acknowledge that ours is a partial description that focuses on one facet among many of the emerging sociomaterial networks of algorithmic education, whose intricacies cannot be comprehensively dissected in a single paper. We invite the reader to evaluate our central contention accordingly.
The contention is as follows: methods used for the classification and measurement of online education are partially involved in the creation of the realities they claim to measure. Hence these methods are partaking in an active generation of social realities. To substantiate our claim, we examine cluster analysis as one of the elements that constitute the LA assemblage: an array of networks of expert knowledge, technologies and algorithms. We claim that LA might be conceived as an ‘algorithmic assemblage’ in which methods (which include cluster analysis) are interwoven with expert knowledge, mathematical mechanisms, technical practices and political and economic objectives. As part of this assemblage, cluster analysis operates as a ‘performative device’ that translates clusters of digital data about learners into socially negotiated ‘materialisations’ (Latour and Woolgar Citation1986): phenomena that emerge when the social world is rendered traceable and visible.
About performativity and material semiotics
A central theme in our analysis is that of performativity: the notion that social practices, forms of knowledge, objects and analytic devices do not simply represent reality but are implicated in its reproduction. Performativity developed in the theoretical furrow of actor-network theory and its subsequent elaborations, gaining traction in economic sociology over the last decade as an attempt to describe how global market conditions are not only the result of structural factors, but also the product of the loose apparatus of economic theory, research and algorithmic financial innovations which actively intervene in the enactment (and legitimation) of a particular version of economic reality (MacKenzie Citation2004).
Our aim is to apply performativity as an explanatory framing to unpick recent developments in educational technology, arguing that the interaction between forms of educational expertise, interests and algorithmic techniques is leading to a new form of unquestioned educational consensus around educational data science. Our use of performativity follows John Law’s distinction between a more traditional actor-network approach (what he calls ‘actor-network theory 1990’) and the ‘diasporic’ developments after 1995 which can be better described as ‘material semiotics’ to reflect a higher degree of openness to theoretical contaminations (Law Citation2009). Therefore, ‘actor-network theory 1990’ established the foundations of a descriptive method that treats everything in the social world as the product of the relations within which human and nonhuman ‘actants’ are located. Material semiotics takes this powerful toolkit and, in a rather pragmatic fashion, opens it up to insights from other areas of social theory, in order to expand the explicatory range of claims. Hence, material semiotics is not afraid to mobilise the Foucauldian distinction between epistemes and dispositifs (Foucault Citation1979), with Ruppert, Law, and Savage (Citation2013) arguing that while an episteme is inherently discursive, a ‘dispositif’ (translated into English as ‘apparatus’) involves a more heterogeneous assemblage of material, institutional and behavioural elements, and as such it lends itself to the sort of empirical problems tackled by material semiotics. We will return to the notion of dispositif later. Similarly, Law (Citation2009, 151) describes how Bourdieu’s ideas about the reproductive power of social practices can be assimilated within material semiotics as they allow researchers to develop a richer descriptive picture of how social reality is ‘enacted into being’ (see also Callon Citation1998; Garcia-Parpet Citation2007).
Context: the relevance of methods in educational research
As social scientists, we are mindful of the importance of locating technologies and technology-mediated practices in contexts – within and across sociotechnical systems of people, instruments, economic interests and cultures. We are also aware that a large amount of research has been slow or reluctant to engage in the social scientific study of technologies in education (Selwyn Citation2010). However, embracing social science in educational research creates its own raft of complex challenges, as it requires an awareness of the ongoing ‘methodological crisis’. We refer in particular to recent debates about a perceived obsolescence of the ‘traditional’ research methods, and the related invitation to examine the large amounts of unsolicited data trails left behind by people as they go about their routine transactions mediated and recorded by digital devices (Ruppert, Law, and Savage Citation2013; Savage and Burrows Citation2007).
The entanglement of data and sociality is also very much evident in education. Indeed, the ways in which many aspects of education are now organised and managed depend to a large extent on methodological capacities in data collection, forms of calculation and the communication of findings derived from data. In this respect, the historical trajectory of the English school inspection regime since the early 1990s (Ozga Citation2009; Ozga, Segerholm, and Lawn Citation2015) represents valuable evidence of a trend whereby data are increasingly positioned in the educational discourse as a form of objective validation for a wide range of decisions. Not only did this trajectory reflect a shift in terms of ‘governing knowledge’ and a ‘recoding’ (Ozga Citation2016, 75) of inspection practices along quantitative lines; it was also accompanied by the entanglement of technical expertise, governance and commercial interests. For example, Ozga (Citation2016) describes the entry of external, for-profit agencies in the school inspection space and the rise of a ‘market logic’ focused on the negotiation of contracts and the provision of technical expertise, all framed by the unquestioned hegemony of performance data.
The rise of hybrid, public–private forms of data governance in education is also reflected in significant developments in the corporate ed-tech sector. For example, the commercial education publisher Pearson is increasingly moving towards ‘educational data science methods’ that depend on data collected from its online courses and e-textbooks, which it can then mine and analyse for patterns of learning, and is simultaneously positioning itself as an expert authority on the use of big data to inform evidence-based policy-making (Williamson Citation2016). Pearson is both seeking to reconfigure techniques of educational governance through the provision of digital tools, and to open up new global marketplaces for its software products and solutions.
These developments pose a problematic relation between policy, evidence and profit, as those private companies that provide the technical platforms and data science methodologies for the measurement and analysis of educational data are increasingly treated as authoritative sources of evidence and knowledge about education. Policy support for LA has been offered in relation to K-12 education in the US (Roberts-Mahoney, Means, and Garrison Citation2016), as well as in all three sectors of school, further education and higher education in the UK, as evidenced by the government-commissioned Educational Technology Action Group. Deep-rooted assumptions about education as human capital development and learning as skills development and behaviour change underpin the design of such technical platforms, and, as they are promoted through policy documents, assume significant status in the conceptualisation, measurement and reporting of learning. Data scientific modes of measurement and analysis are therefore being operationalised as objective ways of knowing, calculating about and intervening in educational practices and learning processes.
In fact, the overarching theme that emerges across these discussions is a need for educational research to engage in a more informed fashion with the assumptions that underpin instrumentalist readings of data and technology: how is knowledge in the ‘global education marketplace’ created, and how are technologies, devices and data involved in its legitimisation? The first step in answering these questions is to reject the view of methods and digital data analysis as ‘pure’ technical tools in the hands of objective agents, and subject those very tools to a more rigorous form of study: methods must become objects of inquiry. While this view is clearly informed by approaches in material semiotics, it also draws on Bowker and Star’s influential examination of how classificatory systems become embedded in institutional settings, acquiring taken-for-granted, almost invisible qualities and contributing to shape those very settings with significant implications for the people and the objects being classified (Bowker and Star Citation1999). The key aspect in this process is the political nature of classification procedures, which always serve more than one purpose or group.
Efforts have been made in the sociological and research methods literature to highlight the political and performative nature of data analysis tools – a notable example is the work of Uprichard, Burrows, and Byrne (Citation2008) on SPSS (the popular software package for data analysis), and a conceptually related discussion of how methods like cluster analysis ‘shape our knowledge about the world’ (Uprichard Citation2009, 139).
In a similar fashion, we contend that methods used for the classification and measurement of education are not neutral and objective but are, to varying degrees, involved in the creation of the educational realities they claim to measure. This process of sociomaterial co-construction is the result of ontological and epistemological negotiations taking place across heterogeneous networks of people, organisations, technologies and analytic techniques – negotiations in which methods operate as ‘inscription devices’ that turn sometimes nebulous and open-to-interpretation ‘learning phenomena’ into easily readable materialisations (Latour and Woolgar Citation1986).
These inscriptions are then treated as real and consequential through a process of legitimisation that draws on the established language of the learning sciences, while aligning perfectly with the logic of economic rationality and ‘accountability’ that pervades governance cultures in education (and beyond). The inscribed analytic outputs act therefore as ‘immutable mobiles’ (Latour Citation2005): entities that move across sociomaterial networks while holding their shape and function. Through these manoeuvres, data constructs tie into established centres of authority creating bonds that consolidate alliances, thus contributing to a convincing discourse of ‘shared interests’ between data science, governance and education.
The rest of the article is organised as follows. First, we introduce LA platforms as particular kinds of methodological devices and, taking up the lead from critical studies of the ‘social life of methods’, interrogate the algorithmic assemblage of actants, practices, knowledges and so on that enact LA methods. Second, we provide an in-depth examination of the specific algorithmic process of cluster analysis in the context of e-learning and Massively Open Online Courses (MOOCs), to indicate how its technical and mathematical mechanisms perform within LA platforms. This examination is preceded by a brief description of the methodological approach in sociomaterial studies. In the discussion, we contend that the relevance of social scientific educational research may depend on being both critical, and also more descriptive of the mechanisms that enact educational technologies.
Critiquing LA
LA has been described as the ‘measurement, collection, analysis, and reporting of data about learners and their contexts, for the purposes of understanding and optimizing learning and the environments in which it occurs’.Footnote1 A key concern in LA is the use of insights derived from data to generate ‘actionable intelligence’ to inform tailored instructional interventions (Campbell, De Blois, and Oblinger Citation2007; Clow Citation2013). Notably, LA has become a site of significant commercial, academic and political interest. The start-up company Knewton has become one of the world’s most successful LA platforms, providing back-end support to educational content produced by Pearson (the world’s largest educational publisher and e-learning provider) as well as many others. Knewton works by collecting a variety of different educational attainment data combined with psychometric information and social media traces to produce a kind of ‘cloud’ of data on each individual that can be used as a quantitative record for data mining. Its chief executive has claimed that the Knewton system is able to routinely capture millions of data points on millions of students, amassing one of the world’s most extensive data reservoirs – big educational data that can then be mined and analysed for insights on learning processes at a global scale (Berger Citation2013).
Beyond commercial appeal, LA is also developing as an academic field. According to Clow (Citation2013), LA is less a solid discipline than an eclectic ‘jackdaw’ approach that picks up methods from other areas, as long as they serve its overarching pragmatic aims. Such a stance is particularly interesting, as it presumes that methodologies are indeed ‘pure instruments’ which transfer from one field to another without bringing along a heavy baggage of epistemological and ontological assumptions. Nonetheless, the field is trying to establish a distinctive academic identity in relation to a range of contiguous approaches which use the same techniques but for different purposes. The area of algorithmic economics is, probably, where the most high-profile applications of these techniques beyond education can be found. See, for example, the work carried out at Microsoft research on computational methods to develop predictive models of consumer behaviour,Footnote2 or Amazon’s ability to approximate shipping information even before customers’ decisions are finalised (Spiegel et al. Citation2012).
Against this backdrop, LA has been termed part of an ‘emerging field of educational data science’ (Piety, Hickey, and Bishop Citation2014), which also includes business intelligence (rapidly becoming established in the HE sector), machine learning, web analytics and educational data mining (EDM). If we are interested in the social life of LA methods, then locating them within the expert field of educational data science is important in illuminating the history of their origins and the aspirations to which they are being put. Piety, Hickey, and Bishop (Citation2014, 4–5) describe the field as a ‘sociotechnical movement’ originating in the period 2004–2007 as techniques of EDM were first developed. It grew from 2009 onwards as educational data scientists formed a professional community with its own conferences, associations, methods and shared styles of thinking, and especially as policy-makers and funders began to see it as ‘the community dealing with “Big Data” in education’ (Piety, Hickey, and Bishop Citation2014, 3). Since then, commercial organisations and universities have begun turning their educational technology departments into educational data science labs. For example, various computer science/education research groups have emerged in the last several years at the intersection of academia and corporate ed-tech. Two of the most notable ones are the Stanford Lytics groupFootnote3 and Pearson’s own Centre for Digital Data, Analytics & Adaptive Learning.Footnote4
Viewed through the theoretical lens of material semiotics, these manoeuvres across academic groups, commercial companies and policy-makers can be explained as ‘ontological politics’ associated with the emergence and the stabilisation of sociomaterial networks (Law and Singleton Citation2005). These political negotiations include, for instance, the ‘problematisation’ (Latour Citation2005) of educational big data as a timely and urgent challenge, the involvement of individuals, the recruitment of technologies and analytic techniques, the forming of alliances and the kindling of interest and sponsorship in the academic and public discourse. Consider for example Barber’s call (Citation2014, 6), on behalf of the commercial educational publisher and software vendor Pearson, for ‘further research that brings together learning science and data science to create the new knowledge, processes, and systems this vision requires’. Likewise, Pea (Citation2014, 37) argues for the establishment of a new ‘specialized’ field combining the sciences of digital data and learning, and for the construction of a ‘big data infrastructure’ to model learning behaviour.
The formation of the learner as a data construct, however, is not unproblematic on either epistemological or ontological lines: it assumes that the learner can be perceived and understood scientifically as data, whilst also implying that the data construct itself is ontologically symmetrical with the person being represented. However, as with many other data-based methods and practices, the data actually construct a ‘data double’ that can only ever be regarded as a temporary approximation stitched together from available data points, a double that becomes ontologically problematic as it is then used as the basis for active intervention to reshape the embodied actions of the learner (Hope Citation2015). As Mayer-Schönberger and Cukier (Citation2014, 46) note, the ‘robotic algorithms’ of LA platforms are able to access spreadsheets of learner data, calculate odds and make probabilistic predictions, and automate decisions about pedagogical intervention in a few milliseconds, with ‘the risk that our predictions may, in the guise of tailoring education to individual learning, actually narrow a person’s educational opportunities to those predetermined by some algorithm’.
These brief notes on the social life of LA methods indicate that if we wish to conduct relevant social scientific research on such technological platforms, then we need to interrogate their underlying assumptions, the discourses used to support them, their imbrication in commercial and academic settings, the expert knowledges that underpin them, and even the economic and political contingencies of their production. In this sense, an LA platform like Knewton can be regarded as an algorithmic assemblage, the hybrid product of algorithmic forms of data analysis that can only function in relation to myriad other elements which are far from being harmoniously interrelated. Thus, Kitchin (Citation2014) demonstrates how algorithms need to be understood as ‘black boxes’ that are hidden inside intellectual property and impenetrable code; as ‘heterogeneous systems’ in which hundreds of sequenced operations are woven together in relation with datasets, companies, programmers, standards and laws; as ‘emergent’ and evolving systems that are constantly being refined, reworked and tweaked; and as complex, unpredictable and fragile systems that are sometimes miscoded, buggy and ‘out of control’. It is only through such algorithmic assemblages that any individual process can take place – and through which algorithms may then be perceived as performative devices. According to Mackenzie (Citation2006), for example, algorithms establish certain forms of ‘order’, ‘pattern’ and ‘coordination’ through processes of sorting, matching, swapping, structuring and grouping data, and Beer (Citation2013, 81) therefore argues that ‘algorithms are an integrated and irretractable part of everyday social processes’, with the potential ‘to reinforce, maintain or even reshape visions of the social world, knowledge and encounters with information’. The active and performative dimensions of algorithms are also part of the algorithmic assemblage – one that is, then, both socially produced, but also socially productive.
We have attempted so far to provide a sense of how LA platforms can be perceived as algorithmic assemblages, a complex network of human actors, expert knowledges, devices, practices and techniques, all framed by political and economic contexts and assumptions. In the remainder of the paper, we attend to one specific algorithmic process that is enacted within LA platforms, that of cluster analysis, and demonstrate how its operational properties, and the scientific history from which it emerges, function to constitute patterns in data. This analysis will be preceded by a more detailed description of our methodological approach.
Sociomaterial methods
Studying phenomena from a sociomaterial perspective requires a specific methodological approach. In the first place, an anti-essentialist position is needed to account for situations of uncertainty where human and nonhuman actants are equally implicated in the sociotechnical constitution of the world. We therefore assume that there are no essential, intrinsic qualities that define our objects of study, and we choose instead to describe the political interweaving of social and technological mediations that lead to ‘versions’ of reality, which remain relatively open and display varying degrees of fragility and instability (Latour Citation2005). This approach has already been used to describe the ontological politics that underpin the ‘MOOC phenomenon’ (Perrotta, Czerniewicz, and Beetham Citation2015). In that context, the analytic work focused on opening up the black-box of digitisation technology, to highlight the ontological alteration carried out through computation that created a sociotechnical interface between digital TV production and corporate e-learning, with the appropriation of the latter of digital playback affordances that allow forms of personalised, pick-and-mix cultural consumption.
In this paper we attempt a more detailed description of performativity – one that, as mentioned in the introduction, chooses to foreground certain aspects on nonhuman agency over others. This enables us to carry out an analysis that is at the same time sociological and ‘mechanological’. In this respect, ‘device’ is a useful framing that brings together the notion of sociotechnical assemblage, with its emphasis on symmetry between sociality and materiality, and Foucault’s notion of dispositif (Citation1980). According to Foucault, a dispositif is a ‘thoroughly heterogeneous ensemble’ (Foucault Citation1980, 194) consisting of a multidimensional configuration of discursive and non-discursive elements. Foucault introduced this notion as part of his analysis of the entanglement of power, religion and sexuality in Western society. For instance, the confessional, as featured in various Christian creeds, can be considered as a dispositif: a physical artefact and a discursive site where subjectivities, power relations and social practices are enacted (Agamben Citation2009).
Against this conceptual backdrop, the investigation of cluster analysis we propose here is articulated along three analytic axes: (a) a traditional sociological inquiry that examines the historical development of this method at the intersection of the social sciences and computer science; (b) the mediating role of epistemic groups that emerge as nodes or centres of expertise in the emerging LA network; (c) framing all of the above, a discussion of the performative power of cluster analysis as a set of mathematical operations that conflate two diametrically opposed functions: the discovery of ‘natural’ patterns and the imposition of ordering structures.
Analysing cluster analysis
One of the specific methods that enacts LA platforms is cluster analysis, which represents an excellent case study to illustrate the entanglement of social construction and ‘objective’ technical expertise. Although cluster analysis originated in anthropology and, most notably, psychology (Cattell Citation1945; Tryon Citation1939), it was never a particularly popular approach among social researchers, and it developed mostly outside of social science circles. Savage and Burrows (Citation2007) argue that social scientists looked with suspicion at the adoption of cluster analysis in market research since the 1970s, as it was perceived as a reductionist, overly descriptive technique that avoided the ‘hard’ questions (answerable through more traditional multivariate analyses), in favour of ‘visualisations’ that made statistical information accessible to a wide audience of corporate marketing departments. Dolnicar (Citation2003) also critiqued the problematic alignment between the operational properties of cluster analysis, in particular its approach to data-driven segmentation, and the requirements of market research executives, with their strong interest in overly homogenous, distinct groups of consumers amenable to marketing strategies such as diversification and penetration. This caused a tendency whereby segments and partitions were being constructed, according to Dolnicar (Citation2003, 12):
in a black-box manner. This is supported by the observation that most of the parameters of the partitioning algorithm applied are not critically questioned. Instead, pre-prepared algorithms are imposed on the available data, even if they are inappropriate for the data at hand.
Aside from market research, cluster analysis saw significant developments in computer science (e.g., Bonner Citation1964), reflecting a growing interest in using computational techniques to make sense of diverse types of scientific (e.g., epidemiologic) and industrial data. The rise of artificial intelligence also reflects the growing diffusion and sophistication of clustering algorithms, which allow computers to modify their behaviour and make ‘intelligent’ decisions on the basis of actual and predicted patterns in the data.
In essence, cluster analysis operates by partitioning a given data set into groups (clusters), in such a way that all the units in a cluster are more similar to each other than to units in other clusters. A simple way to observe similarity is by plotting a line graph showing relationships between scores. This simple technique, however, tends to ignore the actual ‘distance’ between scores or, in graphical terms, the degree of ‘elevation’ (Field Citation2000). This is well illustrated in , which shows that although two cases in a data set may superficially display similar patterns, we need more precise information about the actual distance between them.
Figure 1. The similarity between data points needs to take into account the distance between scores to lead to meaningful clusters-adapted from Field (Citation2000).
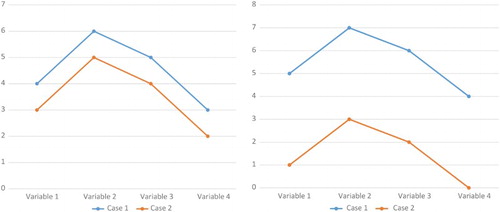
In cluster analysis the degree of similarity between data points is generally (but not exclusively) computed in terms of Euclidean distance, based on the assumption that measurements are at least on an interval scale. Cluster analysis is, in principle, an ‘unsupervised’ technique, which means that clustering should not occur on the basis of predefined classes that reflect expected or desirable relations amongst the data. In actuality, it is very hard to undertake clustering without some notion of the grouping criteria and without establishing a number of parameters, such as the number of clusters and their density. As a consequence, there always remains a degree of uncertainty as to whether the partitions reflect the overall structure of the data, or if the process has produced artificial groupings. Given the nature of clustering algorithms, results will always be obtained irrespective of the number of variables used and sample size. As notably observed by Aldenferder and Blashfield (Citation1984, 16): ‘Although the strategy of clustering may be structure-seeking, its operation is one that is structure-imposing’.
The challenge is compounded by the existence of a range of different algorithms, each with its specific properties and the potential to produce different outcomes. The choice of algorithms is partly dependent on the definition of a clustering criterion, which needs to account for the types of clusters which are expected to occur in the data set. The choice of such a criterion is important because different criteria may influence the partitions produced by the clustering process. This means that the parameters established at the outset only define one possible partitioning approach which is ‘good’ under specific assumptions, but not necessarily the ‘best fit’ for the data (Halkidi, Batistakis, and Vazirgiannis Citation2001). This degree of uncertainty is largely acknowledged in the cluster analysis literature, and underpins considerable research efforts that focused on the validation of clustering results (e.g., Rousseeuw Citation1987). As an algorithmic method, cluster analysis is therefore exploratory rather than confirmatory (Uprichard Citation2009) and, more importantly, it reflects specific inductive principles which are nothing more than the ‘mathematical formalisations of what researchers believe is the definition of a cluster’ (Estivill-Castro Citation2002, 65) – as such, ‘Clustering is in the eye of the beholder’ (Estivill-Castro Citation2002).
While some sociologists have already noted the epistemic and political ramifications of algorithms, they are still largely described as inert devices in the hands of human actors (Gillespie Citation2014). Conversely, we argue here that ‘epistemic politics’ are not second-order phenomena that emerge from the human usage of algorithms, but are the result of these machines’ very own operational properties, which endow them with distinct performative power. This is to say that, in the specific case of clustering algorithms, patterns are not just ‘found’ but, at the same time, actively constituted. The entanglement of finding and making is in fact observable at the level of the mathematical formalisations, which describe the operations that attempt to create clusters in a data set. Take, for example, the popular K-means clustering technique, which is described by the following equation:
In the equation, mi represents the centre of a cluster called Ci, while d(x,mi) is the Euclidean distance between a data point (called x) and the centre mi. Thus, the function E works by actively attempting to minimise each point’s distance from the centre of its cluster. The algorithm starts by establishing a number of clusters, each with its own centre; it then takes data points and assigns them to clusters using distance from the centres as a criterion. Centres are then recalculated and the process starts again until distance is minimised, so that stable results can be obtained. This means that the K-means algorithm has a tendency to be iterative, that is, the method is performed several times with different starting values, leading to a ‘best’ solution that, in mathematical terms, does not necessarily represent a ‘global optimum’ – a solution optimal among all possible alternatives – but a ‘local optimum’: a solution that is optimal only in relation to a range of several possible candidates (Steinley Citation2006).
Important implications begin to emerge from this discussion. Chief among these is the ontological indeterminacy of cluster analysis’ outputs and their relationship with the apparatus of sociotechnical and human factors that underpin the choice of a priori grouping criteria and attributes. While this choice is (possibly) less contentious in the case of biological variables (such as gene expression levels or tissue types) as evidenced in the growing application of cluster analysis in biomedical ‘big data’ research, it is rather problematic when based on social or educational attributes. We can accept that basic biomedical features are ‘essential’ in an Aristotelian sense, that is, that they reflect distinct characteristics and refer to discrete classes of phenomena. However, this view cannot be easily extended to socioeducational phenomena, which can be better described from a Wittgensteinian perspective, less concerned with how the world actually is than how it is represented symbolically, never in terms of distinct categories, but through overlapping and ‘polythetic’ relationships (Wittgenstein Citation1953). This is to say that, for the most part, learning environments and the relationships therein are not ‘naturally occurring’ but are the result of a complex interplay of choices and negotiations, many of which are contingent and draw on a broad palette of cultural factors. Several antecedent and concurrent factors (educational, technological, epistemological and so on) influence the range and types of attributes around which groupings may or may not form. This argument makes perfect sense from an educational design perspective, as it rests on the rather uncontentious assumption that learning is, to a degree at least, shaped by the pedagogic and epistemic conditions put in place and reinforced by instructional designers, teachers and learners.
However, the significance of these networked negotiations between agents – these ‘agencements’ (Callon Citation2007) to remain faithful to a sociomaterial terminology – is sometimes lost in the more instrumentalist readings of LA and EDM, even in otherwise theoretically informed accounts. The problem arises again from believing in the neutral and ‘pure’ nature of tools and methods of data analysis – a belief which inevitably leads to reifying the outputs of those analyses as equally neutral, objective and natural phenomena. This confusion is apparent, for instance, in Siemens (Citation2013, 7) when he suggests that the techniques shared by LA and EDM can be placed on a conceptual continuum (possibly borrowed from biomedical research) from basic to applied research. Forms of learning are thus ‘discovered’ in the same way as epidemiological subpopulations:
Through statistical analysis, neural networks, and so on, new data-based discoveries are made and insight is gained into learner behavior. This can be viewed as basic research where discovery occurs through models and algorithms. These discoveries then serve to lead into application.
By treating clusters of users (or any other analytic output) as essential entities, analysts run the risk of crystallising knowledge about those groups. As a result, deeply contextual knowledge about patterns of engagement with digital content in an online course – for example, about ‘completing’ modules by watching videos and performing assessments – turns into a factual, universal account of learning and accomplishment in online settings. The outputs of the analyses are no longer considered as contingent, but as totalising formulations of the social order of digital learning.
There are various examples in the LA and EDM literature which illustrate the range of antithetic and circumstantial criteria chosen for creating clusters: frequency of accessing course materials (Hung and Zhang Citation2008); choice of synchronous vs. asynchronous communication during online collaborative work (Serçe et al. Citation2011); strategies used by learners during one-on-one online mentoring (Del Valle and Duffy Citation2009). However, one case in particular exemplifies the issue being discussed here. A well-received paper by Kizilcec, Piech, and Schneider (Citation2013) uses cluster analysis to identify four prototypical trajectories of engagement in three MOOCs offered by Stanford University on the platform Coursera: Completing, Auditing, Disengaging and Sampling. The objective and ‘natural’ quality of the resulting clusters is then emphasised by virtue of their ‘making sense from an educational point of view’ (p. 172). The clusters are therefore construed as subpopulations of learners we could realistically expect to ‘discover’ across a range of diverse online learning contexts. The same clustering approach was used on a different community of learners in the competing, UK-based platform Futurelearn produced by the Open University (OU) (Ferguson and Clow Citation2015). In this replication, the authors found noticeably different patterns in their data. Whilst ‘Completing’ and ‘Sampling’ clusters were identified in line with the previous study, more nuanced forms of engagement also emerged: Strong Starters, Mid-way Dropouts, Nearly There, Late Completers and Keen Completers. Ferguson and Clow insightfully suggest that these differences can be explained in light of the different ‘social-constructivist pedagogy’ that (ostensibly, it should be added) underpins the Futurelearn MOOC platform (Laurillard Citation2009), which tries to incorporate not just content and assessment but also social interactions. The authors therefore cautiously conclude that
it is not possible to take a clustering approach from one learning context and apply it in another, even when the contexts are apparently similar. Convincing clusters of learners are most likely to emerge when the approach is informed by the texture of the learning context. (Ferguson and Clow Citation2015, 58)
Over and above the methodological implications, this unfolding academic discussion in the LA community is particularly interesting from a sociological perspective. The two papers in question point to the differences which are beginning to transpire in the LA epistemic network, with the emergence of centres of expertise that reflect different educational philosophies; one (Stanford’s) eager to develop a ‘data-driven science of learning’, or ‘educational data science’,Footnote5 that enthusiastically (and forcefully?) marries educational research and computer science; the other (the OU’s) showing a degree of intellectual alignment with the tradition of ‘socially sensitive’ British educational research, with its emphasis on conversations, dialogue and contexts (Crook Citation1996; Laurillard Citation2009; Wegerif Citation2007).
Conclusion
The examples discussed in the previous sections illustrate the interweaving of interests, choices and technical aspects that become visible when an ‘objective’ method like cluster analysis is examined from a sociomaterial angle. The paper’s aim has been to qualify the contention that this method (like similar ones) acts as a ‘performative device’, one with its own complex social life in commercial and academic settings, rooted in expert forms of knowledge, practices, and framed by economic and political contexts and contingencies. As suggested in the methodological section, ‘device’ should not be understood too literally as a reified artefact that produces certain outputs, but as a metonymic notion which helps us describe how an heterogeneous, networked configuration of expert knowledge, mathematical formalisations, educational philosophies and political-economic interests operates in a coherent way to produce the same social realities it claims to objectively ‘discover’. As such, our examination shows that such devices are not only engaged in the objective representation of the world, but also in its reproduction. This becomes particularly evident when the ‘objective’ representational discourse is mobilised by different groups within the network according to different assumptions, interests and agendas. In this sense, this paper explored the problem of expert knowledge defining its own uses and its own ontologies. The trend that we sought to challenge is the one in which data science is used to define ‘forms of learning’, only to assume in a circular way that the expert knowledge of data science is needed to support those same forms of learning. Descriptions of reality include forms of expert knowledge as their own referents – this creates a closed circuit whereby only the reality advocated by a network of experts is acceptable under the conditions defined by their own knowledge.
Following this, what are the implications for critical research in educational technology? In the first place, there is the suggestion that critically minded observers need not limit themselves to denouncing structural inequalities and ideological conflicts. Such a critical reading can be applied to the ways Knewton and other LA providers reinforce market-based solutions to education. At the opposite end of the ‘critical spectrum’ there is the opportunity to analyse in a more descriptive fashion how hegemonic discourses in education are given authority through techniques and devices. An example was provided here, meant to describe how the technical and the social become entangled to the point of being inseparable. The choice of cluster analysis was not coincidental either. This method is clearly assuming a certain symbolic quality due to its association with the growing importance of big data and the rise of artificial intelligence – two areas whose profound social, economic and cultural significance is reinforced in education by companies like Pearson, which has recently also supported research and development in the area of artificial intelligence in education, claiming that ‘artificial intelligence is increasingly present in tools such as adaptive curricula, online personalised tutors and teachable agents’, using ‘big data’ from massive populations of learners to gain insight into learning processes that might be coded into ‘smarter digital tools’ (Pearson College London Citation2015).
Above all, the analysis proposed here illustrates that sociotechnical networks, no matter how big and influential, are never monolithic entities where ‘pure’ instruments are in the hands of ‘pure’ agents; but are always open to negotiations and re-interpretations. This stance requires a commitment to the openness and indeterminacy of technologies, even data analysis tools, which entails challenging the equally essentialist notion that data analysis is intrinsically suspect and always leading to increased surveillance and less equitable forms of education. As noted by Savage (Citation2013), quantification is not necessarily bound to an instrumental worldview, except in the weakest meaning. Quantification and classification can also be part of empirical projects that seek to ‘array differences’ in the social world in less rationalistic ways, not only aiming to generalise and extrapolate, but also rendering specificity, particularity and the relative ‘thickness’ of human relations.
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes on contributors
Carlo Perrotta is Academic Fellow at the University of Leeds. He is interested in educational technology and his background is in social psychology, sociology and cultural theory. He has written reports, articles, and presented at international conferences a range of topics including creativity, Science, Technology, Engineering and Mathematics (STEM) education, digital identities, e-assessment and the factors influencing the educational benefits of Information and Communication Technology (ICT). He is currently exploring recent trends in ‘massively open’ education, mostly from a sociomaterial perspective.
Ben Williamson is a Lecturer in Education in the School of Social Sciences at the University of Stirling, having previously worked at the University of Exeter and Futurelab. Ben’s research focuses on education policy and educational technology from a critical, sociological perspective. He has led the ESRC-funded Code Acts in Education project (https://codeactsineducation.wordpress.com/) and is a contributor to the Digital Media and Learning Research Hub (http://dmlcentral.net/person/ben-williamson/).
Additional information
Funding
Notes
References
- Agamben, G. 2009. What is an Apparatus? Stanford, CA: Stanford University Press.
- Aldenferder, M. S., and R. K. Blashfield. 1984. Cluster Analysis. Beverly Hills, CA: Sage.
- Barber, M. 2014. “Foreward.” In Impacts of the Digital Ocean, edited by K. E. DiCerbo, and J. T. Behrens, V–VI. Austin, TX: Pearson.
- Beer, D. 2013. Popular Culture and New Media: The Politics of Circulation. London: Palgrave Macmillan.
- Berger, R. 2013. “Knewton CEO and Founder Jose Ferreira Talking about Knewton’s Big Step into Personalized Learning.” EdTech Review, October 23. http://bit.ly/1KTVuZc.
- Bonner, R. 1964. “On Some Clustering Techniques.” IBM Journal of Research and Development 8 (1): 22–32. doi: 10.1147/rd.81.0022
- Bowker, G., and S. L. Star. 1999. Sorting Things Out. Classification and its Consequences. Cambridge: MIT Press.
- Callon, M., ed. 1998. The Laws of the Markets. Oxford: Blackwell; Keele: The Sociological Review.
- Callon, M. 2007. “What Does it Mean to Say that Economics is Performative?” In Do Economists make Markets? On the Performativity of Economics, edited by D. MacKenzie, F. Muniesa, and L. Siu, 311–357. Princeton, NJ: Princeton University Press.
- Campbell, John P., Peter B. De Blois, and Diana G. Oblinger. 2007. “Academic Analytics: A New Tool for a New Era.” Educause Review 42 (4): 40–57.
- Cattell, R. B. 1945. “The Principal Trait Clusters for Describing Personality.” Personality Bulletin 42: 129–161.
- Clow, D. 2013. “An Overview of Learning Analytics.” Teaching in Higher Education 18 (6): 683–695. doi: 10.1080/13562517.2013.827653
- Crook, C. 1996. Computers and the Collaborative Experience of Learning. London: Routledge, Psychology Press.
- Del Valle, R., and Duffy, T. M. 2009. “Online Learning: Learner Characteristics and Their Approaches to Managing Learning.” Instructional Science 37 (2): 129–149. doi: 10.1007/s11251-007-9039-0
- Dolnicar, S. 2003. “Using Cluster Analysis for Market Segmentation-typical Misconceptions, Established Methodological Weaknesses and Some Recommendations for Improvement.” University of Wollongong Research Online. http://ro.uow.edu.au/commpapers/139.
- Estivill-Castro, V. 2002. “Why so Many Clustering Algorithms: A Position Paper.” ACM SIGKDD Explorations Newsletter 4 (1): 65–75. doi: 10.1145/568574.568575
- Ferguson, R., and D. Clow. 2015. “Examining Engagement: Analysing Learner Subpopulations in Massive Open Online Courses (MOOCs).” Proceedings of the Fifth International Conference on LA and Knowledge, ACM, 51–58, March 16–20.
- Field, A. 2000. “Cluster Analysis.” Postgraduate Statistics. http://www.statisticshell.com/docs/cluster.pdf.
- Foucault, M. 1979. Discipline and Punish: The Birth of the Prison. Harmondsworth: Penguin.
- Foucault, M. 1980. The Confession of the Flesh. Power/knowledge: Selected Interviews and Other Writings. New York: Pantheon Books.
- Garcia-Parpet, M.-F. 2007. “The Social Construction of a Perfect Market: The Strawberry Auction at Fontaines-en-Sologne.” In Do Economists Make Markets? On the Performativity of Economics, edited by D. MacKenzie, F. Muniesa, and L. Siu, 20–53. Princeton, NJ: Princeton University Press.
- Gillespie, T. 2014. “The Relevance of Algorithms.” In Media Technologies: Essays on Communication, Materiality, and Society, edited by T. Gillespie, P. J. Boczkowski, and K. A. Foot, 167–193. Cambridge, MA: MIT Press.
- Halkidi, M., Y. Batistakis, and M. Vazirgiannis. 2001. “On Clustering Validation Techniques.” Journal of Intelligent Information Systems 17 (2): 107–145. doi: 10.1023/A:1012801612483
- Hope, A. 2015. “Foucault’s Toolbox: Critical Insights for Education and Technology Researchers.” Learning, Media and Technology 40 (4): 536–549. doi:10.1080/17439884.2014.953546.
- Hung, J. L., and K. Zhang. 2008. “Revealing Online Learning Behaviors and Activity Patterns and Making Predictions with Data Mining Techniques in Online Teaching.” MERLOT Journal of Online Learning and Teaching 4 (4): 426–437.
- Kitchin, R. 2014. “Thinking Critically about and Researching Algorithms.” The Programmable City working paper 5. http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2515786.
- Kizilcec, R. F., C. Piech, and E. Schneider. 2013. “Deconstructing Disengagement: Analysing Learner Subpopulations in Massive Open Online Courses.” Proceedings of the Third International Conference on LA and Knowledge, Leuven, Belgium, ACM, 170–179, April 08–12.
- Latour, B. 1996. On Actor-network Theory: A Few Clarifications. Soziale Welt 47. Jahrg., H. 4, 369–381.
- Latour, B. 2005. Reassembling the Social: An Introduction to Actor-network-theory by Bruno Latour, Vol. 10. Oxford: Oxford University Press.
- Latour, B., and S. Woolgar. 1986. Laboratory Life: The Construction of Scientific Facts. Princeton, NJ: Princeton University Press.
- Laurillard, D. 2009. “The Pedagogical Challenges to Collaborative Technologies.” International Journal of Computer-Supported Collaborative Learning 4 (1): 5–20. doi: 10.1007/s11412-008-9056-2
- Law, J. 2009. “Actor-network Theory and Material Semiotics.” In The New Blackwell Companion to Social Theory, edited by B. S. Turner, 141–158. Oxford: Blackwell.
- Law, J., and V. Singleton. 2005. “Object Lessons.” Organization 12 (3): 331–355. doi: 10.1177/1350508405051270
- MacKenzie, D. 2004. “The Big, Bad Wolf and the Rational Market: Portfolio Insurance, the 1987 Crash and the Performativity of Economics.” Economy and Society 33 (3): 303–334. doi: 10.1080/0308514042000225680
- Mackenzie, A. 2006. Cutting Code: Software and Sociality. New York: Peter Lang.
- Mayer-Schönberger, V., and K. Cukier. 2014. Learning from Big Data: The Future of Education. New York: Houghton Mifflin Harcourt Publishing Co.
- Ozga, J. 2009. “Governing Education through Data in England: From Regulation to Self-evaluation.” Journal of Education Policy 24 (2): 149–162. doi: 10.1080/02680930902733121
- Ozga, J. 2016. “Trust in Numbers? Digital Education Governance and the Inspection Process.” European Educational Research Journal 15 (1): 69–81. doi: 10.1177/1474904115616629
- Ozga, J., C. Segerholm, and M. Lawn. 2015. “The History and Development of Inspectorates in England, Sweden and Scotland.” In Governing by Inspection, edited by S. Grek, and J. Lindgren, 68–74. London: Routledge.
- Pea, R. 2014. A Report on Building the Field of LA for Personalized Learning at Scale. Stanford, CA: Stanford University.
- Pearson College London. 2015. “Intelligence Unleashed: How Smarter Digital Tools can Improve Learning.” Pearson College London, September 7. https://www.pearsoncollegelondon.ac.uk/subjects/business-school/news/2015/09/intelligence-unleashed.html.
- Perrotta, C., L. Czerniewicz, and H. Beetham. 2015. “The Rise of the Video-recorder Teacher: The Sociomaterial Construction of an Educational Actor.” British Journal of Sociology of Education 1–17. doi:10.1080/01425692.2015.1044068.
- Piety, P. J., D. T. Hickey, and M. J. Bishop. 2014. “Educational Data Sciences – Framing Emergent Practices for Analytics of Learning, Organizations and Systems.” LAK ‘14, March 24–28, Indianapolis, IN, USA. http://bit.ly/1KTVZ5s.
- Roberts-Mahoney, H., A. J. Means, and M. J. Garrison. 2016. “Netflixing Human Capital Development: Personalized Learning Technology and the Corporatization of K-12 Education.” Journal of Education Policy. doi:10.1080/02680939.2015.1132774.
- Rousseeuw, P. J. 1987. “Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis.” Journal of Computational and Applied Mathematics 20: 53–65. doi: 10.1016/0377-0427(87)90125-7
- Ruppert, E., J. Law, and M. Savage. 2013. “Reassembling Social Science Methods: The Challenge of Digital Devices.” Theory, Culture & Society 30 (4): 22–46. doi: 10.1177/0263276413484941
- Savage, M. 2013. “The ‘Social Life of Methods’: A Critical Introduction.” Theory, Culture & Society 30 (4): 3–21. doi: 10.1177/0263276413486160
- Savage, M., and R. Burrows. 2007. “The Coming Crisis of Empirical Sociology.” Sociology 41 (5): 885–899. doi: 10.1177/0038038507080443
- Selwyn, N. 2010. “Looking Beyond Learning: Notes Towards the Critical Study of Educational Technology.” Journal of Computer Assisted Learning 26 (1): 65–73. doi: 10.1111/j.1365-2729.2009.00338.x
- Serçe, F. C., K. Swigger, F. N. Alpaslan, R. Brazile, G. Dafoulas, and V. Lopez. 2011. “Online Collaboration: Collaborative behavior Patterns and Factors Affecting Globally Distributed Team Performance.” Computers in Human Behavior 27 (1): 490–503. doi: 10.1016/j.chb.2010.09.017
- Siemens, G. 2013. “Learning Analytics: The Emergence of a Discipline.” American Behavioral Scientist 57 (10): 1380–1400. doi: 10.1177/0002764213498851
- Spiegel, J. R., M. T. McKenna, G. S. Lakshman, and P. G. Nordstrom, Amazon Technologies, Inc. 2012. Method and system for anticipatory package shipping. U.S. Patent 8,271,398.
- Steinley, D. 2006. “K-means Clustering: A Half-century Synthesis.” British Journal of Mathematical and Statistical Psychology 59 (1): 1–34. doi: 10.1348/000711005X48266
- Tryon, R. C. 1939. Cluster Analysis: Correlation Profile and Orthometric (Factor) Analysis for the Isolation of Unities in Mind and Personality. Ann Arbor, MI: Edwards Brothers.
- Uprichard, E. 2009. “Introducing Cluster Analysis: What it can Teach Us about the Case.” In Byrne and Ragin’s Sage Handbook of Case Based Methods, edited by D. Byrne, and C. C. Ragin, 132–147. London: Sage.
- Uprichard, E., R. Burrows, and D. Byrne. 2008. “SPSS as an ‘Inscription Device’: From Causality to Description?” The Sociological Review 56 (4): 606–622. doi: 10.1111/j.1467-954X.2008.00807.x
- Wegerif, R. 2007. Dialogic Education and Technology: Expanding the Space of Learning (Vol. 7). Berlin: Springer.
- Williamson, B. 2016. “Digital Methodologies of Education Governance: Pearson PLC and the Remediation of Methods.” European Educational Research Journal 15 (1): 34–53. doi: 10.1177/1474904115612485
- Wittgenstein, L. [1953] 2009. Philosophical Investigations. 4th ed. Oxford: Wiley Blackwell.