
ABSTRACT
Building upon our experience implementing a mixed method study combining historical and topic modeling techniques to explore how institutional voids are resolved and their relationship to formal/informal markets, we describe the promise of Topic Modeling techniques for historical studies. Recent advancements – particularly improvements in artificial intelligence and machine learning techniques – have enabled the use of off-the-shelf AI to analyze and process large quantities of data. These techniques reduce research biases and some of the costs previously associated with computational text analysis techniques (i.e. corpus processing time and computational power). We highlight the usefulness of three text analysis techniques – structural topic modeling (STM), dynamic topic modeling (DTM), and word embeddings – and demonstrate their ability to support the generation of novel interpretations. Finally, we emphasize the continuing importance of the author in every step of the research process, especially for abstracting from AI outputs, evaluating competing explanations, inferring meaning, and building theory.
Philosophers of science have discussed three logical forms of inference: deduction, induction, and abduction (Minnameier Citation2010). Due to the nature of their research, historians have traditionally followed the abductive methodology, defined as ‘the process of generating and revising models, hypotheses and data analyses in response to surprising findings’ (Heckman and Singer Citation2017, 298). These same authors describe the abductive approach as follows:
The abductive model for learning from data follows more closely the methods of Sherlock Holmes than those of textbook econometrics. The Sherlock Holmes approach uses many different kinds of clues of varying trustworthiness, weights them, puts them together, and tells a plausible story of the ensemble
When using abduction, researchers engage in an ‘inference to the best explanation (IBE) approach’ (Pillai, Goldfarb, and Kirsch Citation2021), whereby the best explanation is selected from among the ‘lot’ of all possible explanations. Recent years have seen an increase in the number of articles using this methodology (Golden-Biddle Citation2020; Sharkey, Pontikes, and Hsu Citation2022; Shah et al. Citation2021; Kim, Agarwal, and Goldfarb Citation2022; Choudhury, Khanna, and Sevcenko Citation2022), coinciding with increasing interest in the use of historical and qualitative research methods to explain ‘surprising findings (Agarwal, Kim, and Moeen Citation2021; Pillai, Goldfarb, and Kirsch Citation2020; Heckman and Singer Citation2017).’
Although future scholars may be able to study broader sets of material artifacts, today, the primary source of archival content remains documents composed of text (i.e., e-mails – as shown in see, Kirsch et al. (Citation2023), see in this special issue – letters, news, or laws, to name just a few), we can paraphrase the quote above as follows: ‘Historians use many different kinds of textual documents (clues) of varying trustworthiness, weigh them, put them together, and tell a plausible story.’ Although historians have long relied upon a wide range of tools to generate interpretations of texts, with the rise of digital media, the scale of the analytic and interpretive challenge has become more daunting. The number of documents and text created daily is increasing; many conversations are later translated to text to be preserved for prosperity (i.e. company meetings, memos, or speeches by corporate leaders). The World Economic Forum estimated that by 2025, 463 exabytes of data would be created each day – the equivalent of 212 million DVDs per day (Desjardins Citation2019). As the production of text increases, we can ask: How will historians in the future analyze the enormous amount of textual data that is being generated? How will we be able to ‘put them together’? How will we be able to find patterns in the noise? How will we ‘connect the dots’? Some of these larger questions are beyond the scope of the current essay, but fortunately, some techniques are already available to support historical inference.
We explore these issues as follows: In the next section, we introduce topic modeling. This machine-learning (ML) technique detects patterns of word co-occurrence and identifies and clusters latent topics (word groups) that best describe a given set of documents. In the third section, we present three text analysis techniques that may be particularly useful for historians seeking to interpret large text corpora: structural topic modeling (STM), dynamic topic modeling (DTM), and word embedding. In the fourth section, we return to the role and impact of the researcher when using automated text analysis techniques. In the fifth section, we describe our experience implementing a mixed method study combining historical and topic modeling techniques to explore how institutional voids are resolved and their relationship to formal/informal markets (Villamor, Prieto-Nañez, and Kirsch Citation2022). In the final section, we discuss the implications of topic modeling for historical research.
Topic modeling
Topic modeling is a text analysis technique that uses statistical methods to discover or identify latent patterns or clusters of co-occurrences of words (topics) within a collection of documents (called a corpus) (Grimmer and Stewart Citation2013; Blei, Ng, and Jordan Citation2003; for a deeper understanding of topic modeling and the existing algorithms, see Churchill and Singh Citation2022). This technique is particularly useful for historians seeking to grapple with issues and questions that span longer time periods and have generated large-scale text corpora. In such cases, using ML and artificial intelligence to analyze text can open new avenues of inquiry.
Topic models follow a ‘bag of words’ approach, in which the order of words and grammar are ignored (Blei, Ng, and Jordan Citation2003), and topics are identified based on word co-occurrences and frequencies but without reference to context (i.e. the algorithm does not know what a given word means). The standard outputs of a topic model are (1) topics or word constellations, which describe clusters of terms that occur together, (2) topic loading per document, which is a matrix representing the weight of each topic for each document, and (3) a term loadings matrix, which represents the weight of each word by topic. In other words, one can think of topic modeling as a machine learning technique that helps the researcher identify and visualize latent structures in a text corpus, and the topic model produces a type of index that describes the contents of a corpus and points the reader to particular documents that reflect the categorized content.
Scholars may choose among multiple topic model algorithms – including Latent Dirichlet Allocation (LDA), the most commonly used (Blei, Ng, and Jordan Citation2003), correlated topic models (Lafferty et al. Citation2005), or hierarchical topic models (Griffiths et al. Citation2003), to name a few (for a review, see Churchill and Singh Citation2022). Each of these methodologies enables efficient processing of a given corpus while at the same time preserving the essential statistical relationships between words, which is particularly useful for tasks such as classification, novelty detection, summarization, or similarity analysis (Blei, Ng, and Jordan Citation2003). Moreover, any topic modeling algorithm allows the researcher to discover topics from the data rather than pre-specify or assume them – a property usually referred to as unsupervised – hence potentially reducing researchers’ biases. However, even unsupervised algorithms may still be subject to bias. As we will discuss below, research design decisions such as choosing the documents that are included in the corpus, deciding the parameters of the model, selecting the appropriate number of topics, or interpreting the results have important consequences for the outcome of any algorithmic process. We believe that topic models represent a promising tool that uses computational optimization to aid researchers in ‘summarizing’ large collections of texts, thereby aiding the discovery process.
Visualization plays an important role in such discovery. The graphical output of an LDA topic model – the most common algorithm used – displays the topics (and the top word frequencies in each topic) extracted from the corpus (see ). However, the output of a topic model requires interpretation by the researcher, including basic sensemaking and, significantly, labeling of topics. The topic model identifies the words that constitute the topics but does not ascribe meaning to those word configurations.
Figure 1. Sample output of an LDA topic model, illustrating the graphical output of an LDA topic model with ten topics from Villamor, Prieto-Nañez, and Kirsch (Citation2022). The output displays the topics (circles), how prevalent the topics are in the corpus (circle size), how similar topics are (how close the circles are), and the top words of each topic (list of words to the right). LDA-vis generates a two-dimensional visualization of all of the topics and the frequency (left part of the image) of the key terms in each topic (right part of the image). The axes of the inter-topic distance map have no meaning and are not interpretable. The two axes are generated through a Multi-Dimensional Scaling (MDS) process, a dimensionality-reduction technique that compresses data but identifies the two principal dimensions of a topic model but maintains as much information about topic distances. The distance between bubbles (topics) in the scatter plot is an approximation of the semantic relationships between topics distribution (i.e. the more similar the topics are, the closer they appear). The size of the bubbles represents the percentage of the words in the corpus that the topic contains (i.e. smaller bubbles are more specific/specialized topics, as they contain a lower number of different terms, and bigger bubbles are more general topics).
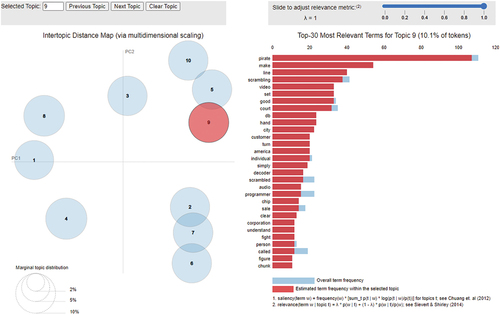
Using topic modeling can be particularly useful for historians for a number of reasons. First, the capabilities of an algorithm complement the skills of the researcher. Algorithms are well suited to (and efficient at) finding patterns among large texts while ignoring the context. In contrast, researchers excel in deeply understanding the context and phenomena they study while often struggling to identify systematic patterns in large text collections. Due to their contextual knowledge, historians will be particularly well suited to interpret the outputs of topic models and generate possible explanations for the connections among and between topics. In other words, when presented with – output of a basic LDA-vis topic model – historians’ contextual knowledge can help explain the bubbles, the distances and overlaps between them, and the relationships among the words that make up the topics. To summarize, while topic modeling is good at providing historians with the pieces of the puzzle – the ‘dots’ – historians are good at ‘connecting the dots’ and ‘putting the pieces together.’
Second, as the availability of text corpora increases, so does the ‘noise’ or information overload, which increases the cognitive burden upon human analysts seeking patterns in texts. By allowing the topic model to lighten the cognitive burden, historians can increase the size, number, and variety of textual inputs to historical research, potentially broadening the scope of adduced explanations (either by increasing generalizability or allowing analysis across longer temporal windows). Moreover, as explained below, some topic modeling algorithms allow the inclusion of metadata as covariates, increasing the researcher’s ability to compare different datasets over time.
Third, allowing an algorithm to identify latent topics might lead to some ‘surprising’ findings. For instance, an unexpected topic might emerge; some topics might appear closer to each other in a visualization than would have been expected. These observations might trigger additional questions and stimulate the researcher to search more deeply into those relationships that did not meet expectations, thereby refining research questions while simultaneously increasing the reliability of the study.
Finally, because scholarly discourse seeks to disambiguate among competing explanations, topic modeling may allow greater transparency and replicability. Replication is relatively rare in history, but in principle, scholars could easily share the outputs of topic models in fora that would allow multiple and iterative interpretations to emerge. And even in the absence of direct comparison, a well-specified topic model – when running on the same corpus and using the same model parameters – should generate the same output. Hence, a given topic model output might become a ‘common ground’ upon which historians might build inferences over time.
In sum, topic modeling works well when a scholar is trying to identify latent patterns in large, text-based datasets. However, when seeking to understand the mechanisms operating within real, historical contexts, other methodologies will still be necessary.
Structural Topic Modeling (STM)
For historians and other scholars seeking to understand change over time, a basic LDA topic model does not include a temporal dimension. The entire corpus of documents is treated as occurring in a single time period. Because many scholars, and especially historians, are interested in understanding how topics or concepts emerge, their prevalence over time, their relationships with other topics, and, in general, their evolution over time, structural topic modeling may be a better starting point. A structural topic model (STM) (Aranda et al. Citation2021; Chen et al. Citation2020; Sharma, Rana, and Nunkoo Citation2021; Lindstedt Citation2019; Roberts et al. Citation2014; Roberts, Stewart, and Airoldi Citation2016) has two features that place it at an advantage over other types of topic models: the mixed-membership model and the use of document metadata covariates. In mixed-membership models (the most commonly known of which is Latent Dirichlet allocation or LDA), documents in the corpus can be assigned to multiple topics. As such, documents are represented as a mixture of topics (as a vector of proportions that describes what fraction of the words belong to each topic; see Gerlach, Peixoto, and Altmann Citation2018).
Even more important, however, STM allows the scholar to incorporate ‘metadata into the topic modeling framework’ analysis (Roberts, Stewart, and Airoldi Citation2016, 9). In other words, STM allows the study of the relationships between topics and some metadata associated with the document. STM can take advantage of any conserved metadata field (such as location or type of source), but for historians, the most important metadata field will often be the date on which the given text was created. Where date is known and conserved across multiple documents in a corpus, STM can generate covariates that track topic prevalence over the range of that variable, in other words, track change over time (Roberts et al. Citation2014).Footnote1 STM uses these covariates in generating the topics ex-ante. Therefore, it uses temporal or other metadata as inputs into the modeling process. Although it is not entirely clear their impact on the output (i.e. identification of the actual topics), by introducing these covariates, structural topic models allow the topic-specific distribution of words to vary by covariate (Grimmer, Roberts, and Stewart Citation2022).
Examples of covariates introduced in these models include time (Blei and Lafferty Citation2006), geography (Eisenstein et al. Citation2010), ideological affiliation (Ahmed and Xing Citation2010), or even an arbitrary categorical covariate (Eisenstein et al. Citation2010; Roberts et al. Citation2014). includes two sample implementations of STM (Chen et al. Citation2020; Villamor, Prieto-Nañez, and Kirsch Citation2022). For historians, this feature means that structural topic models can account for the time at which the document was created and hence offer insights into how topic relevance evolves over time.
Figure 2. Sample structural Topic Modeling output, illustrating how topics’ prevalence varied based on a set of multiple covariates. Panel a shows how topics’ prevalence varies by time in Villamor, Prieto-Nañez, and Kirsch (Citation2022), and Panel B, shows how topics’ prevalence varies by location as presented by Chen et al. (Citation2020)Footnote5.
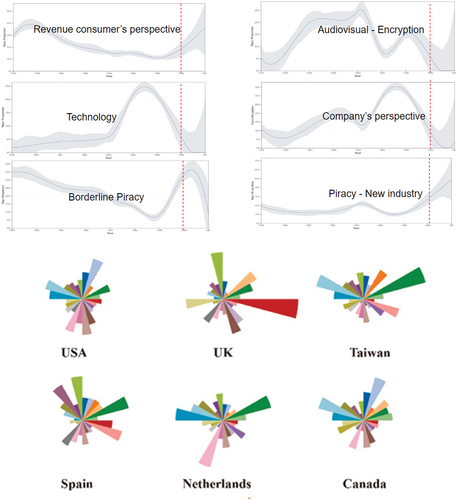
Both LDA and STM are based on word co-occurrence within the corpus and therefore have a ‘static’ view of the topics, meaning that one critical underlying assumption is that each topic is defined by a fixed vocabulary within the corpus. In other words, the topics (and the words in each topic) are inferred from the whole set of documents included in the corpus. Topics are the same for all the documents in the corpus, independent of the metadata of each document. STM shows the change in the prevalence of the same topic over time but cannot show how meaning itself changes over time.
Dynamic Topic Modeling (DTM)
To understand how the content of topics evolves – rather than simply topic prevalence – researchers have used dynamic topic models (or DTM, see Lafferty et al. Citation2005; also see for a comparison between STM and DTM). As one of the papers that introduced this type of model explains: ‘Under this model, articles are grouped by year, and each year’s articles arise from a set of topics that have evolved from the last year’s topics (p. 113).’ Rather than assuming that the documents in a corpus are equivalent for purposes of topic identification (as is the case of STM), DTM models are based on the belief that the sequencing of documents in a corpus reflects an evolving set of topics and that topics in one time period (t + 1) are associated with the topics from the previous time period (t) in measurable, predictable ways.
Table 1. This table summarizes some of the key differences between structural topic modeling and dynamic topic modeling approaches.
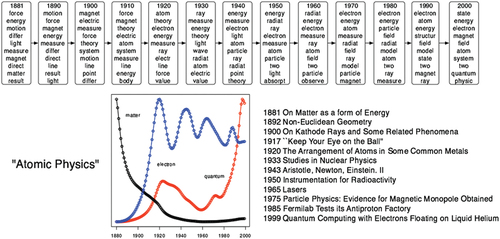
DTM estimates topics in a chosen period and, holding these topics constant, estimates these same topics in subsequent periods, allowing for variation in (1) the words contained in the topic and (2) changes in word prevalence in each period. DTM, therefore, captures change within each topic in addition to the emergence or prevalence/obsolesce of a topic. This method allows us to see what words and concepts dominate given topics in different periods and which topics dominate documents (see ). This methodology can be particularly useful for historians aiming to understand how a concept evolves over long periods.
Figure 3. Dynamic topic modeling output representation as presented in Lafferty et al. (Citation2005). DTM enables researchers to understand how topics evolve over time by showing how the words contained within a given topic change over timeFootnote6.
Word embedding
Another text analysis technique we also considered is Word Embedding. Researchers seeking to understand how the meaning of specific words relates to their use in a given corpus have used word embedding models (Selva Birunda and Kanniga Devi Citation2021). Word embedding is a technique used to capture word meaning and to study language evolution. This technique builds on the assumption that ‘similar words appear in similar contexts’ but recognizes that the meanings of words change over time. Given a corpus, word embeddings generate vector representations of the words and represent them in an n-dimensional space, in which words with similar meanings (and words that co-occur together) are closer together (Selva Birunda and Kanniga Devi Citation2021). Three major word embedding techniques have been developed: traditional word embedding, static word embedding, and contextualized word embedding (for a better understanding of each of them, see Selva Birunda and Kanniga Devi Citation2021).
To understand how meanings evolve, researchers have used temporal word embeddings, also known as dynamic word embeddings (Yao et al. Citation2018).Footnote2 This method allows researchers to generate different vectors for each word by time interval. Hence, this approach tries to capture how the meaning of a word changes over time (Hamilton, Leskovec, and Jurafsky Citation2016).
However, as with the other techniques discussed in this article, the outputs of a word embedding model are sensitive to research design (i.e. choices of specific algorithms and associated parameters). Also, it is worth highlighting two caveats that are particularly relevant to historians: First, word embedding techniques capture the bias of their context, thereby increasing the relevance and impact of the research design choices made when building the corpus. Second, similarly to DTM, the outputs of word embedding are sensitive to the researcher’s choice of comparison set and/or the period against which to benchmark.
Automated text analysis techniques and the researcher’s role
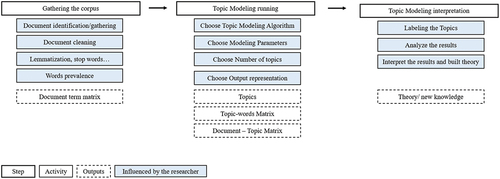
As has been previously suggested, machine learning techniques for text analysis, particularly topic models, have many advantages for analyzing large quantities of data. However, even though all of the methods discussed above are ‘unsupervised’ models, each depends upon important decisions on the part of the researcher or research team. The outputs of topic models are sensitive to inputs, choice of algorithm, and other parameters. Researchers should be aware of these research design choices and how they can influence outputs (Hannigan et al. Citation2019). identifies some of the multiple steps in the research process where researchers make research design decisions that influence the outputs of a topic model. Some of these decisions include: choosing the documents included in the corpus (Di Carlo, Bianchi, and Palmonari Citation2019), deciding whether and how to clean the data (Hannigan and Casasnovas Citation2020), selecting the best topic model or word embedding algorithm (Wang et al. Citation2019; Lai et al. Citation2016; Churchill and Singh Citation2022), choosing the model parameters (i.e. when using DTM, choosing the initial period; when using STM, choosing the appropriate metadata variables and whether these variables are prevalence or content covariates), deciding the correct number of topics within a corpusFootnote3 (Arun et al. Citation2010), labeling the topics (Grimmer et al. 20202), validating the results (Krippendorff Citation1980), and, finally and arguably most importantly, interpreting the results. Consequently, using machine learning techniques in historical corpora does not mean that the role and judgment of the researcher are undermined. In fact, we believe the opposite is true.
Figure 4. This figure represents the process of a topic model, showing the three main steps in the process (gathering the corpus, running the topic modeling, and interpreting the topic model), as well as the multiple actions included in each step. Moreover, the figure also highlights in blue the steps in which the researchers’ choices and decisions influence the output of the topic model. The Appendix Table below explains the impact of the researcher’s choices in more detail.
Because topics are rendered based on word co-occurrences and frequencies but ignoring context, to properly interpret topic modeling results, infer meaning from the output, and build theory, researchers need to have a deep understanding of the text included in the corpus, the phenomenon, and context being studied, and the choice of methodology. As Hannigan et al. (Citation2019) explain, ‘Topic modeling relies on interpretation and language-oriented rules but is also unique in its emphasis on the role of human researchers in generating and interpreting specific groups of topics based on the social contexts in which they are embedded (p. 587).’
Implementing these techniques to understand historical forces in management research
This final section describes an example of how we are using STM in our own work (Villamor, Prieto-Nañez, and Kirsch Citation2022). In 1974, the first commercial American broadcast satellite was launched into orbit above North America. Soon thereafter, the expected ecosystem within the United States developed. However, the satellite’s signal was not geographically constrained to U.S. territory. Hence, residents in multiple countries in the hemisphere – especially countries relatively close to the U.S. mainland – were also able to take advantage of the fact that the satellite signal was ‘out there.’ A small, transnational, unintended ecosystem emerged around the satellite television industry, offering entrepreneurial and business opportunities in these unregulated markets. In other words, entrepreneurs and amateurs filled the void. During these early years, satellite dishes encountered no barriers to use, and there were no regulations concerning the building and installation of dishes on private property. Satellite entrepreneurs, both within and outside the US, operated in a gray market. However, over time, concerns about piracy and signal theft arose, and the ‘satellite entrepreneurs’ were labeled as ‘pirates.’ Multiple stakeholders proposed solutions to resolve or fill the institutional void according to their perspectives and interests. By 1986, the scrambler, a new technology that prevented nonpaying-consumers from using the signal, was introduced. The introduction of these encrypting mechanisms formalized the distinction between legal and illegal activities.
Because this context represents a specific instance of the emergence and resolution of an institutional void wherein different stakeholders shaped the institutionalization process by supporting different conceptualizations of piracy and building on the uniqueness of this phenomenon (in which an exogenous shock – the launch of the satellite – created the institutional void), we proposed a process model for the creation and resolution of institutional voids, their relationship to stakeholders’ views of piracy, and their activities aiming to resolve the void.
As we sought to identify each stakeholder’s view and how these stakeholders saw themselves and debated with others, we realized that some form of text analysis was probably appropriate (and available) for our context and our research question. Therefore, we began exploring possible text analysis techniques while at the same time building the relevant text corpus. To capture each stakeholder’s view, we gathered documents representing each stakeholder’s view of the issue at particular points in time. Supported by deep historical knowledge on the part of one of the authors and a research question that centered around understanding each stakeholders view, we assembled a complex corpus containing documents that represent the perspectives of most of the key stakeholders participating in the ecosystem (i.e. satellite entrepreneurs, lobbyists representing the broadcasting industry, media from the US, the Caribbean, and Latin America, legal information about policy hearings and copyright law, etc.).
Early in the research process, we concluded that topic modeling would allow us to incorporate information from a larger number of sources and perspectives. Moreover, because unsupervised topic models can reduce researcher biases, starting with an agnostic approach to the content of the conversation in the satellite television ecosystem and using machines to identify the key topics in the conversations could increase our confidence in the existence of the observed phenomena and the conclusions drawn. However, perhaps not surprisingly, based upon the foregoing descriptions of competing text analysis tools, a key question we faced was: given the variety of topic models, which one should we use? Because of our interest in understanding the conversation between stakeholders, the topics they were talking about, when topics emerged and became ‘hot topics,’ and when they disappeared, we concluded that STM was the best approach. Using STM (Roberts et al. Citation2014, Citation2014) not only allowed us to identify the latent topics in our data but also enabled us to see the changing relevance of these topics over time and to compare the prevalence of the topics by year and across stakeholders.
Further, when running the STM, we faced three decisions: which metadata to include, whether to include it as topic prevalence, topic content, or both; and choosing the number of topics. Because we were interested in understanding the conversation between stakeholders and its evolution over time, we decided to include year and stakeholders as metadata variables (from each document, we include the year the document was created and which stakeholders’ perspective it represents: entrepreneurs, American companies, Caribbean countries, newspapers). Concerning the second question, we decided to include the metadata as prevalence covariates.Footnote4 Metadata for topic prevalence permits the metadata to affect the frequency with which a topic is discussed. Covariates of topic content allow the metadata to affect the word rate use within a given topic, that is, how a particular topic is discussed. Finally, concerning the third decision: choosing the number of topics, we decided to follow the topic coherence (Röder et al. Citation2015) and topic exclusivity (Roberts et al. Citation2014) criteria. We ran multiple STM models, specifying a diverse number of topics (we ran eight different STM models: one STM with three topics, one with four topics, one with five topics, and so on.) For each of these models, we computed coherence and exclusivity measures. Then, we plotted these measures (coherence and exclusivity scores) in a graph and identified the two alternative STMs that maximized both criteria (the STM with six topics led to an exclusivity score of 9.2 and a coherence score of −82, while the STM with seven topics had a higher exclusivity score − 9.4 – and a lower coherence score of −85). We then analyzed and compared the results of these two models (STM models with 6 and 7 topics) and, based on our historical and contextual knowledge, decided to choose STM with six topics as the best model.
The last step of the process included labeling the topics and interpreting the results. These two steps were also supported by the team’s historical and contextual knowledge of the phenomenon. Using STM enabled us to understand how topics evolve over time – it was particularly useful to see how topic prevalence changed over time and when they peaked – as well as how different stakeholders engage and drive the conversation. Moreover, the model outputs helped us verify that the textual patterns aligned with the proposed stages of our process model.
In sum, the topic modeling output helped us to verify the existence and relevance of the phenomenon we were studying, provided novel and interesting insights into how stakeholders influence and relate to each other (i.e. why some topics peaked twice), and visualized the hidden structure and ideas that existed in the corpus by stakeholder.
Conclusion
Topic modeling has already influenced the management field by allowing researchers to detect novelty and emergence, develop inductive classification systems, explore relationships between businesses and customers, analyze frames, and understand cultural dynamics (Hannigan et al. Citation2019). We applied these tools to a historical case study, the institutional void created by the launch of the first television satellite and reactions thereto. Thinking more generally, where else might business historians benefit from the use of topic modeling?
First and foremost, topic modeling is now available to the average researcher, allowing her to work with larger datasets, thereby potentially increasing the span and scope of any single study. For instance, recent advances have enabled the use of text analysis techniques with multiple languages that even use different alphabets, facilitating intercultural comparison of similar phenomena between different geographies. Further, because topic modeling identifies latent topics, the use of topic modeling can support better abductive reasoning by highlighting surprises in a corpus, allowing researchers to explore more diverse research questions. The use of STM, for instance, allows researchers to see new patterns of cultural and conceptual diffusion over time, space and other structural variables (such as type of stakeholder, etc.). On the other hand, DTM can help historians study how those same concepts emerge and evolve, enabling comparisons between perspectives, views, and geographies. Finally, word embedding can reveal how the concepts themselves change over time. Importantly, because these tools are now easily available, each researcher can implement and link these tools to their own fields of expertise. With further advances likely to support exploration and analysis in non-text corpora, future historians will also be able to extract and interpret latent relationships among images and video.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Notes on contributors
Marta Villamor Martin
Marta Villamor Martin is a Ph.D. student in Strategic Management & Entrepreneurship at the Management and Organizations Department at the University of Maryland's Robert H. Smith School of Business. Her research interests include industry evolution, entrepreneurship, and innovation.
David A. Kirsch
David A. Kirsch is Associate Professor at the Robert H. Smith School of Business and the College of Information Studies (i-School) at the University of Maryland, College Park. His research focuses on the intersection of problems of innovation and entrepreneurship, technological and business failure, and industry emergence and evolution.
Fabian Prieto-Nañez
Fabian Prieto-Ñañez is an assistant professor in the Department of Science, Technology, and Society at Virginia Tech University. His research focuses on the histories of technologies in the Global South through the lens of media devices and infrastructures and piracy, informality, and illegality in the use of early satellite dishes in the Caribbean.
Notes
1. Metadata covariates for topical prevalence allows the observed metadata to affect the frequency with which a topic is discussed. Covariates in topical content allow the observed metadata to affect the word rate use within a given topic – that is, how a particular topic is discussed. STM model allows including topic prevalence, topic content and both types of covariates simultaneously (Roberts et al. Citation2014).
2. Some example of a word meaning change is apple (which was traditionally only associated with fruits) or Amazon (traditionally associated with the rainforest in Brazil), which is now also associated with technology companies.
3. There are multiple approaches for deciding the appropriate number of topics, which include using perplexity or topic coherence (Röder, Both, and Hinneburg, 2015), the exclusivity of topics (Roberts et al. Citation2014), based on corpus and document size (Citation2020). However, in the end, it is a researcher’s decision.
4. We are using an abductive methodology. As such, we aim to explore the results, including the metadata as both content and prevalence covariates. This will enable us to understand the robustness of our results and provide a more nuanced understanding of the phenomena.
5. For researchers interested in learning an example of how to use STM, including code, see Github page; https://github.com/timhannigan/STM_standard_r_setup. This code was created by Tim Hannigan, as part of a Workshop on structural topic modeling for the IDeaS 2021 conference (https://www.interpretivedatascience.com/).
6. For researchers interested in learning an example of how to use DTM, including code, see the Github page; https://github.com/blei-lab/dtm.
References
- Agarwal, R., S. Kim, and M. Moeen. 2021. “Leveraging Private Enterprise: Incubation of New Industries to Address the Public Sector’s Mission-Oriented Grand Challenges.” Strategy Science 6 (4): 385–411. doi:10.1287/stsc.2021.0137.
- Ahmed, A., and E. Xing. 2010. “Staying informed: supervised and semi-supervised multi-view topical analysis of ideological perspective.“ In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, October 1140–1150.
- Aranda, A. M., K. Sele, H. Etchanchu, J. Y. Guyt, and E. Vaara. 2021. “From Big Data to Rich Theory: Integrating Critical Discourse Analysis with Structural Topic Modeling.” European Management Review 18 (3): 197–214. doi:10.1111/emre.12452.
- Arun, R., V. Suresh, C. E. Veni Madhavan, and N. Murthy. (2010). “On Finding the Natural Number of Topics with Latent Dirichlet Allocation: Some Observations” Pacific-Asia Conference on Knowledge Discovery and Data Mining, 391–402. doi: 10.1007/978-3-642-13657-343
- Blei, D. M., and J. D. Lafferty. 2006. “Dynamic topic models.“ Proceedings of the 23rd international conference on Machine learning, Pittsburgh Pennsylvania USA, June 113–120.
- Blei, D. M., A. Y. Ng, and M. I. Jordan. 2003. “Latent Dirichlet Allocation.” Journal of Machine Learning Research 3: 993–1022.
- Chen, X., D. Zou, G. Cheng, and H. Xie. 2020. “Detecting Latent Topics and Trends in Educational Technologies Over Four Decades Using Structural Topic Modeling: A Retrospective of All Volumes of Computers & Education.” Computers & Education 151: 103855. doi:10.1016/j.compedu.2020.103855.
- Choudhury, P., T. Khanna, and V. Sevcenko. 2022. “Firm-Induced Migration Paths and Strategic Human-Capital Outcomes.” Management Science 69 (1): 419–445. doi:10.1287/mnsc.2022.4361.
- Churchill, R., and L. Singh. 2022. “The Evolution of Topic Modeling.” ACM Computing Surveys 54 (10s): 1–35. doi:10.1145/3507900.
- Desjardins, J. 2019, April 17 “How Much Data is Generated Each Day?” World Economic Forum https://www.weforum.org/agenda/2019/04/how-much-data-is-generated-each-day-cf4bddf29f/
- Di Carlo, V., F. Bianchi, and M. Palmonari. 2019. “Training Temporal Word Embeddings with a Compass.” Proceedings of the AAAI Conference on Artificial Intelligence 33 (1): 6326–6334. doi:10.1609/aaai.v33i01.33016326.
- Eisenstein, J., B. O’connor, N. A. Smith, and E. Xing. 2010. “A Latent Variable Model for Geographic Lexical Variation.“ Proceedings of the 2010 conference on empirical methods in natural language processing, Cambridge, MA, October 1277–1287. Association for Computational Linguistics.
- Gerlach, M., T. P. Peixoto, and E. G. Altmann. 2018. “A Network Approach to Topic Models.” Science Advances 4 (7): 1360. doi:10.1126/sciadv.aaq1360.
- Golden-Biddle, K. 2020. “Discovery as an Abductive Mechanism for Reorienting Habits Within Organizational Change.” Academy of Management Journal 63 (6): 1951–1975. doi:10.5465/amj.2017.1411.
- Greene, D., and J. P. Cross. 2017. “Exploring the Political Agenda of the European Parliament Using a Dynamic Topic Modeling Approach.” Political Analysis 25 (1): 77–94. doi:10.1017/pan.2016.7.
- Griffiths, T., M. Jordan, J. Tenenbaum, and D. Blei. 2003. “Hierarchical topic models and the nested Chinese restaurant process.“ Advances in Neural Information Processing Systems 16: 17–24.
- Grimmer, J., M. E. Roberts, and B. M. Stewart. 2022. Text as Data: A New Framework for Machine Learning and the Social Sciences. New Jersey: Princeton University Press.
- Grimmer, J., and B. M. Stewart. 2013. “Text as data: The promise and pitfalls of automatic content analysis methods for political texts.“ Political analysis 21(3): 267–297. doi:10.1093/pan/mps028.
- Hamilton, W. L., J. Leskovec, and D. Jurafsky. 2016. “Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change” Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 1489–150. 10.18653/v1/P16-1141
- Hannigan, T. R., and G. Casasnovas. 2020. “New Structuralism and Field Emergence: The Co-Constitution of Meanings and Actors in the Early Moments of Social Impact Investing.” In Macrofoundations: Exploring the Institutionally Situated Nature of Activity Emerald Publishing Limited. doi:10.1108/S0733-558X20200000068008.
- Hannigan, T. R., R. F. Haans, K. Vakili, H. Tchalian, V. L. Glaser, M. S. Wang, S. Kaplan, and P. D. Jennings. 2019. “Topic Modeling in Management Research: Rendering New Theory from Textual Data.” The Academy of Management Annals 13 (2): 586–632. doi:10.5465/annals.2017.0099.
- Heckman, J. J., and B. Singer. 2017. “Abducting Economics.” The American Economic Review 107 (5): 298–302. doi:10.1257/aer.p20171118.
- Kim, S., R. Agarwal, and B. Goldfarb. 2022. “Creating Competencies for Radical Technologies: Revisiting Incumbent-Entrant Dynamics in the Bionic Prosthetic Industry.” SSRN Electronic Journal. doi:10.2139/ssrn.4024471.
- Kirsch, D. A., S. Decker, A. Nix, S. Girish Jain, and Kuppili Venkata, S. 2023. “Using Born-Digital Archives for Business History: EMCODIST and the Case of E-Mail”. Management & Organizational History RMOR.
- Krippendorff, K. 1980. “Validity in content analysis.“ In Computerstrategien Für Die Kommunikationsanalyse, edited by E. Mochmann, 69–112. Frankfurt, Germany: Campus. http://repository.upenn.edu/asc_papers/291
- Lafferty, J., D. Blei, P. Verghese, and J. Malik. 2005. “Correlated Topic Models.” Advances in Neural Information Processing Systems 17: 18.
- Lai, S., K. Liu, S. He, and J. Zhao. 2016. “How to Generate a Good Word Embedding.” IEEE Intelligent Systems 31 (6): 5–14. doi:10.1109/MIS.2016.45.
- Lindstedt, N. C. 2019. “Structural Topic Modeling for Social Scientists: A Brief Case Study with Social Movement Studies Literature, 2005-2017.” Social Currents 6 (4): 307–318. doi:10.1177/2329496519846505.
- Minnameier, G. 2010. The Logicality of Abduction, Deduction, and Induction. In M. Bergman, S. Paavola, A.-V. Pietarinen, and H. Rydenfelt (edited by), Ideas in action: Proceedings of the Applying Peirce Conference (pp. 239–251). Helsinki, Finland: Nordic Pragmatism Network
- Pillai, S. D., B. Goldfarb, and D. A. Kirsch. 2020. “The Origins of Firm Strategy: Learning by Economic Experimentation and Strategic Pivots in the Early Automobile Industry.” Strategic Management Journal 41 (3): 369–399. doi:10.1002/smj.3102.
- Pillai, S. D., B. Goldfarb, and D. Kirsch. 2021. Using Historical Methods to Improve Abduction and Inference to the Best Explanation in Strategy. HBS Mimeo.
- Roberts, M. E., B. M. Stewart, and E. M. Airoldi. 2016. “A Model of Text for Experimentation in the Social Sciences.” Journal of the American Statistical Association 111 (515): 988–1003. doi:10.1080/01621459.2016.1141684.
- Roberts, M. E., B. M. Stewart, D. Tingley, C. Lucas, J. Leder‐luis, S. K. Gadarian, D. G. Rand, and D. G. Rand. 2014. “Structural Topic Models for Open‐ended Survey Responses.” American Journal of Political Science 58 (4): 1064–1082. doi:10.1111/ajps.12103.
- Röder, M., A. Both, and A. Hinneburg. 2015. “Exploring the space of topic coherence measures.“ In Proceedings of the eighth ACM international conference on Web search and data mining, February 399–408.
- Sbalchiero, S., and M. Eder. 2020. “Topic modeling, long texts and the best number of topics. Some Problems and solutions.“ Quality & Quantity 54: 1095–1108. doi:10.1007/s11135-020-00976-w
- Selva Birunda, S., and R. Kanniga Devi. 2021. “A Review on Word Embedding Techniques for Text Classification.” Innovative Data Communication Technologies and Application 267–281. doi:10.1007/978-981-15-9651-3_23.
- Sha, H., M. A. Hasan, G. Mohler, and P. J. Brantingham. 2020. “Dynamic Topic Modeling of the COVID-19 Twitter Narrative Among US Governors and Cabinet Executives.” arXiv preprint arXiv: 200411692. Preprint posted online April 19, 2020. https://arxiv.org/abs/2004.11692
- Shah, P. P., R. S. Peterson, S. L. Jones, and A. J. Ferguson. 2021. “Things are Not Always What They Seem: The Origins and Evolution of Intragroup Conflict.” Administrative Science Quarterly 66 (2): 426–474. doi:10.1177/0001839220965186.
- Sharkey, A., E. Pontikes, and G. Hsu. 2022. “The Impact of Mandated Pay Gap Transparency on Firms’ Reputations as Employers.” Administrative Science Quarterly 67 (4): 1136–1179. doi:10.1177/00018392221124614.
- Sharma, A., N. P. Rana, and R. Nunkoo. 2021. “Fifty Years of Information Management Research: A Conceptual Structure Analysis Using Structural Topic Modeling.” International Journal of Information Management 58: 102316. doi:10.1016/j.ijinfomgt.2021.102316.
- Villamor, M., F. Prieto-Nañez, and D. A. Kirsch. 2022. “The Story of an Institutional Void: Satellite Television Pirates of the Caribbean Basin” Working paper.
- Wang, B., A. Wang, F. Chen, Y. Wang, and C. C. J. Kuo. 2019. “Evaluating Word Embedding Models Methods and Experimental Results.” APSIPA Transactions on Signal and Information Processing 8 (1). doi:10.1017/ATSIP.2019.12.
- Yao, Z., Y. Sun, W. Ding, N. Rao, and H. Xiong. 2018. “Dynamic Word Embeddings for Evolving Semantic Discovery” In Proceedings of the eleventh ACM international conference on web search and data. doi: 10.1145/3159652.3159703