
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
A deterministic model proposed in previous literatures to approximate the well-known Richards model is investigated. However, the model assumption of small initial value for infection size is released in the current manuscript. Taking the advantage of the closed form of solutions, we establish the epidemic characteristics of disease transmission: the outbreak size, the peak size and the turning point for the cumulative infected cases. It is shown that the usual disease outbreak threshold condition (the basic reproduction number is greater than unity) fails to fully guarantee the existence of peaking time and turning point when the initial infection size is not relatively small. The epidemic characteristics not only depend on
but also on another index, the net reproduction number
.
1. Introduction
The Richards model [Citation14]
also known as the theta-logistic model [Citation15], was initially formulated as an extension to the logistic model in order to investigate the ecological population growth. Since last decade, it has been widely employed to fit epidemic data. Unlike models with several compartments commonly used to predict the disease spread, the Richards model considers only the cumulative infective population size with saturation in growth as the outbreak progresses, caused by decreases in recruitment because of attempts to avoid contacts (e.g. wearing facemask) and implementation of control measures. In this single equation,
represents the cumulative infected cases at moment t,
is the carrying capacity or total case number (maximum case number), r is the per-capita growth rate of the infected population and a is the exponent of deviation from the standard logistic curve which makes the model much more flexible: a>1 (or a<1) signifies that the cumulative number of infection grows faster (or slower) than that predicted by the logistic growth model. The solution to the Richards model can be explicitly expressed by
with
being the turning point defined as the time when the second derivative of
equals zero, or equivalently, when
takes the value
[Citation17]. For more details about the Richards model, we refer the reader to the study [Citation4].
Some epidemic pattern suggests a single S-shaped curve for the cumulative cases, which is consistent with the solution of the Richards model. Therefore, the Richards model is used to fit the single-phase severe acute respiratory syndrome (SARS) outbreaks in Hong Kong and Taiwan well [Citation10,Citation19]. Meanwhile, it is also employed to fit the 2005 dengue outbreak in Singapore to study the impact of intervention measures relating to the turning point [Citation11], the weekly reported dengue case data in Havana City to assess the contribution of hurricane to dengue transmission [Citation8] as well as H1N1 [Citation5,Citation9]. The Richards model gives a single S-shaped curve while some epidemic datasets share a multiphase outbreak pattern, such as dengue outbreaks in Taiwan [Citation6]. To fit these multiple-wave patterns, Hsieh and his collaborators proposed a multiphase Richards model [Citation7] and their method was successfully used to fit the multi-wave dengue outbreak in Taiwan [Citation6] and 2003 SARS outbreak in Toronto [Citation7].
This Richards model has made so many successful applications in real-time data fitting and predictions of infection dynamics, although several parameters (e.g. the exponential term) share no clear epidemiological explanation, which poses a puzzle to the community of theoretical epidemiology to find the intrinsic link between the Richards model and well-established deterministic epidemic models, such as the Kermack–McKendrick model. To approximate the Richard model, recently the authors in [Citation17] proposed the following model
(1)
(1) a modified version of the classical SIR model. The novelty of the model lies on the consideration of the ‘actually at risk’ total population
, which is defined as the eventually infected population, that is,
is the total number of ‘actually’ vulnerable individuals for the disease transmission at time t [Citation12],
is the actually at risk susceptibles that will be exposed to the pathogen during the entire epidemic under consideration (at ‘actual’ risk for infection) and
is the number of infected individuals. In their model, the frequency-dependent disease transmission term
is used, while δ is the removal rate, which refers to all removal forms from the infected individuals due to disease induced death or recovery. In [Citation17], this model is used to illustrate the epidemiological interpretations for parameters in the Richards model, especially the exponent a. The model (Equation1
(1)
(1) ) is also validated to the datasets for Canada 2009 H1N1 two-stage epidemic outbreak data, two-stage SARS outbreak data in Toronto, Singapore 2005 dengue data, and Taiwan 2003 SARS data and the results are compared with those obtained by the Richards model in terms the turning point and multiple waves/phases. The model (Equation1
(1)
(1) ) is also adopted to describe the transmission of avian influenza (H7N9) virus among birds [Citation12] and then extended to infer the dynamics of the cumulative number of infected humans due to infection transmitted by infected birds. Fitting the epidemic data for humans, the authors estimated the key parameters in the model system quantifying the bird and human components of an avian influenza epidemic. More recently, this model is used to fit the Ebola outbreak in west Africa [Citation18].
All these previous investigations provide important information on epidemic characteristics and suggestions on epidemic control, but most of them propose an implicit assumption that the disease is initialized by an infinitesimally small proportion of the population, that is, the initial value of infected individuals to the deterministic model is assumed to be very small, which is almost negligible compared to the initial number of susceptibles. However, this underlying assumption for the deterministic model may be unappropriate in some scenarios as argued in [Citation13]. For example, a discrete formulation for disease spread is vital at the initial contamination stage of an epidemic outbreak when the number of infectives is small [Citation16]. In this case, the randomness should be carefully accounted, which can be described by a stochastic process, such as the model in [Citation16] and references therein. In other words, the evolution of an epidemic outbreak in an isolated population can be split into two stages: a stochastic Markov process describing the initial contamination and a linked deterministic dynamical system with random initial conditions for the continued development of the outbreak [Citation16]. Motivated by this, we assume the initial distribution of infectives to be not negligible compared with the size of susceptibles. Another reason is related to a late surveillance programme which provides large initial infection value.
In this work, we are going to release the assumption of small initial number of infectious individuals and assume its size can be random. Under this released assumption, we will investigate the final size relationship of the epidemic and predict the real-time number and the peak time of infected individuals. In particular, we are going to figure out the time when the inflection of the cumulative case curve occurs (the turning point), i.e. the moment when a rapid increase in case numbers is replaced by a slower increase and this inflection point indicates the moment when the rate of increases in numbers of cumulative cases reaches its maximum. It is shown that the usual disease outbreak threshold condition (the basic reproduction number is greater than unity) fails to guarantee the existence of peaking time and turning point.
The remaining part of this paper starts from solving the model system to obtain a closed form of solutions, based on which the final size, peak time and turning point are discussed. The conclusion and discussion are given in the last section.
2. Theoretical analysis
We can rewrite the model system (Equation1(1)
(1) ) into
(2)
(2) with initial condition
,
, and
. To investigate the characteristics of the epidemic pattern, we start from solving the system directly to obtain a closed form of solutions in terms of the initial values as well as model parameters.
2.1. Explicit solutions
The first and last equations of (Equation2(2)
(2) ) give
which indicates
(3)
(3)
Now we solve the system for two different cases: and
.
When , the equality (Equation3
(3)
(3) ) implies
. Since
for all
, we have
(4)
(4) Therefore
and the last equation of (Equation2
(2)
(2) ) reads
, from which we obtain
Using the relationship (Equation4
(4)
(4) ), we can express the solution into
(5)
(5)
When , denote
, which is a constant determined by the initial value and intrinsic coefficients. Note that
when
while
when
. In this case, Equation (Equation3
(3)
(3) ) can be written as
(6)
(6)
Substituting Equation (Equation6(6)
(6) ) into
, we have
(7)
(7) and correspondingly, the N-equation in Equation (Equation2
(2)
(2) ) becomes
(8)
(8) Since
, Equation (Equation8
(8)
(8) ) takes the form of a Bernoulli equation (also in the form of Richards equation whose solution can be solved) and its solution can be explicitly obtained as
Since , we have
Hence, the solution for component
can be expressed as
(9)
(9) Taking differentiation of the above expression with respect to t, we get
However, on the other side
, therefore
(10)
(10) and the susceptible population size as follows:
(11)
(11) This solution for
can also be obtained directly from Equation (Equation3
(3)
(3) ).
It would also be interesting to apply the closed form for the number of infected individuals (Equation10(10)
(10) ) into various scenarios to predict the starting time and the duration of disease outbreak. For example, in order to predict the starting time, we just need to solve the equation for time t
to get a negative root, which is the starting time when only one individual got infected. Similarly, to predict the duration of the disease outbreak, which can be defined as the duration in which the number of daily infected cases
is greater than some threshold value ε, one may evaluate two roots of the equation
for time t and take the difference for two roots to infer the time duration of disease outbreak.
Note that the same closed form of solutions is obtained in [Citation12,Citation18] for the case when . In the following sections, we are going to use these explicit solutions to investigate various indices quantifying the epidemic characteristics.
2.2. Reproduction numbers
Before investigating the epidemic characteristics, we first introduce two indices, the basic reproduction number and the running reproduction number
at time t [Citation1,Citation12]. The basic reproduction number of model (Equation2
(2)
(2) ),
represents the number of secondary infections generated by an introduction of a primary infection into the total population previously unexposed to the disease. However, since at the starting point, the model is seeded with initial size of infection
, therefore, the running reproduction number
at time t [Citation1,Citation12] is given by
which measures the number of secondary infections caused by a single infected individual in the population at time t. Naturally, the current magnitude of the running reproduction number (i.e. whether or not it exceeds one) determines the increases or decreases in infection. It is easy to see that
is a static constant, solely dependent on the model parameters, while
is time-dependent, ‘running’ with disease spread. Moreover, the basic reproduction number
is always greater than the running reproduction number
. It would also be interesting to write down the net reproduction number [Citation2] as the running reproduction number at initial time when t=0:
(12)
(12) which will play an important role in the whole paper. Note that the net reproduction number is not equal to the basic reproduction number
as
is not negligible. The net reproduction number gives the average number of secondary infectious cases resulting from each case in a given population (with a proportion of infectious individuals).
From Equation (Equation12(12)
(12) ) we have
, then the parameter K defined in Section 2.1 can be rewritten as
(13)
(13) On the other hand, from Equation (Equation12
(12)
(12) ), we can also get
(14)
(14) Equalities (Equation13
(13)
(13) ) and (Equation14
(14)
(14) ) will be used in subsequent sections.
2.3. Outbreak size
During an epidemic outbreak, majority of people are keen to know ‘How big is an outbreak likely to be?’. One can infer the information related to this question from the outbreak size, which illustrates the cumulative number of infected population during the disease transmission, and mathematically, it is determined by the quantity
.
For the case when (the basic reproduction number
), we have
and
by (Equation5
(5)
(5) ) and therefore, the outbreak size is
.
For the case when (
), we have
and
from Equations (Equation10
(10)
(10) ) and (Equation11
(11)
(11) ) and the outbreak size is
where Equation (Equation13
(13)
(13) ) is used.
Similarly, when (
), we have
and
which gives the outbreak size
.
Summarizing the above argument, we have the following result about the outbreak size:
Proposition 2.1.
The outbreak size is either
when the basic reproduction number
which implies that every individual involved will get infected) or
when
which means some ‘actually’ vulnerable individuals can escape from infection due to the low transmissibility of the pathogen
.
2.4. Epidemic peak
Once outbreaks have begun, knowing their potential severity helps public health authorities to respond immediately and effectively. The epidemic peak [Citation3] indicates the largest number of diseased individuals in the population, that is, the maximum value of . It is particularly important to find out the time (peaking time
) such that the number of infected cases reaches maximum. In this subsection, we are going to find the peaking time
and the peak size at this moment.
Since when
(
), the number of infected cases always decreases and there is no peak for the infected individuals.
When (
), we can write the I-equation of Equation (Equation2
(2)
(2) ) into
where the equality
from Equations (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ) is used. Here, the function
satisfies
and
for all t>0. Hence if
(the net reproduction number
), then
for all t>0 and
. There is no peak for
for this case. However, if
(that is
), there exists a unique
such that
since
. In this case,
is the peak time when the infected population size attains its maximum value. The peak time can be obtained by solving
, which is
The population sizes are
,
and
from equalities (Equation11
(11)
(11) ), (Equation10
(10)
(10) ) and (Equation9
(9)
(9) ).
Applying Equations (Equation13(13)
(13) ) and (Equation14
(14)
(14) ), one obtains
(15) (p)
(15) (p)
From the above argument, we can claim that
Proposition 2.2.
The infected population size always decreases when however, when
the pattern of
evolution is dependent on the net reproduction number
If the net reproduction number
then
for all t>0 while when
there exists a peak time for the infected cases
such that
if
and
if
where the peak time and the size of each compartment at the time are given by Equation (Equation15
(15) (p)
(15) (p) ).
2.5. Turning point for the cumulative number of the infected cases
During an epidemic outbreak, the surveillance programme reports the daily/weekly newly infected cases, while the trend of the newly reported cases indicates whether the epidemic becomes worsening or improving. This trend can be traced by observing the rate of change of the cumulative cases. In particular, the time (the turning point ) is of interest when the inflection of the cumulative case curve occurs, i.e. the moment when a rapid increase in case numbers is replaced by a slower increase and this moment marks the key turning point when the spread of the disease starts to decline. Theoretically, this turning point
, defined as times at which the rate of accumulation changes from increasing to decreasing or vice versa, can be easily located by finding the inflection point of the epidemic curve.
Let be the cumulative number of reported cases at time t, then the growth rate of cumulative cases (i.e. the number of newly infected individuals at time t) is given by
and the rate of change of the newly infected cases is
.
If (
), then from Equation (Equation4
(4)
(4) ), we have
which shows the number of newly infected cases always decreases and there is no turning point.
If (
), from Equations (Equation6
(6)
(6) ) and (Equation7
(7)
(7) ), we have
and thus
Based on Equation (Equation9
(9)
(9) ), we can observe
Therefore, if
, or if
and
,
, which implies that there is no turning point. However, when
and
, then there exists a unique positive
such that
. Actually
can be solved from
which turns out to be
We can obtain the corresponding size for each compartment at the turning point from
Equations (Equation6
(6)
(6) ) and (Equation7
(7)
(7) ):
and
Furthermore, the newly infected cases on the turning point is
According to Equation (Equation14(14)
(14) ), when
(
), the condition
(
) is equivalent to
(
, respectively). Further, applying Equation (Equation13
(13)
(13) ), we have
(16) (t)
(16) (t)
Summarizing the above argument, we have the following results about the turning point:
Proposition 2.3.
When or when
and
there is no turning point, which implies that the growth rate of the cumulative cases decreases for all
When
there is a unique turning point at
. In this case, the growth rate of cumulative cases is increasing as
and decreasing as
. The turning point, the size of each compartment at the time, and the maximum rate of increase of cumulative cases are given by Equation (Equation16
(16) (t)
(16) (t) ).
3. Conclusion and discussion
In the study of epidemic outbreaks by means of mathematical models, most previous work has implicitly assumed that the disease is initialized by an infinitesimally small proportion of the population. In the current paper, we modify this assumption in order to account for an arbitrarily large initial proportion of infected individuals. By assuming the non-negligible amount of infection in the population that fed into the deterministic model, we revisit the model system proposed in [Citation17] (see also in [Citation12]). The model admits a closed form of solutions with explicit expressions, based on which we get the whole picture of the epidemic characteristics with respect to the model parameters and initial values for the system. In particular, we investigate the final and outbreak sizes of the epidemic, the peak time and turning point for an epidemic outbreak.
Many results of the current paper are investigated in terms of two indices: the basic reproduction number and the net reproduction number
(the running reproduction number
at initial time t=0). The net reproduction number
is smaller than the basic reproduction number
, and they are almost equal when the initial infection size
is very small compared to
. The
coordinate plane can be divided into five different regions (see Figure ) with one region (
) being not biologically feasible. Then the whole picture of the epidemic characteristics can be drawn for each region, as summarized in Table , which shows that the existence of the turning point implies the existence of the peak time, but the converse claim does not hold. Moreover, the usual condition that the basic reproduction number
can not guarantee the existence of peak time, neither the turning point when the initial infection size
is not negligible.
Figure 1. The regions in the plane with different epidemic characteristics.
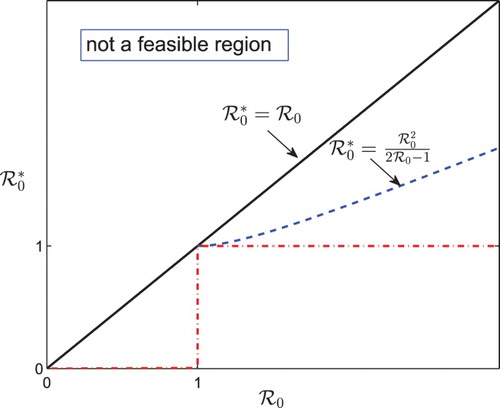
Table 1. Epidemic characteristics of Equation (Equation2 (2) (2) ) with respect to the reproduction numbers and . Note that is always less than based on (Equation12(12) (12) ), also shown in Figure .
(2) (2) ) with respect to the reproduction numbers and . Note that is always less than based on (Equation12(12) (12) ), also shown in Figure .
Peak time represents the moment when the infected incidence reaches its maximal value while the turning point quantifies the moment when the growth rate of cumulative cases attains its maximum. Therefore, it is reasonable to expect a time lag from turning point to peak time. Actually, when , from the expressions of
and
it follows that
Hence, the peak time always happens later than the turning point, and the time interval between turning point and peak time is independent of the initial susceptible and infected population sizes
and
(as well as the net reproduction number
). Due to the time lag between turning point and peak time, in some surveillance programmes for epidemic outbreaks, one cannot observe the turning point, or both the peak time and turning point.
On the other hand, direct calculation yields the ratio of the infected population sizes at these special moments
implying that the ratio of the peak value of infected cases and the size at the turning point is independent of the net reproduction number (as well as the initial condition). The following lemma shows that
for
.
Lemma 3.1.
Proof.
Denote then
and it suffices to prove that
for x>1. Direct calculation gives
, with
. Since
for x>1, it follows from
that
for x>1, that is,
for x>1. Further,
implies that
for x>1. The proof is complete.
Finally, it is interesting to highlight the novel conditions for the existence of peak time and turning point in the current paper. If the initial infection size is infinitesimally small relative to the size of susceptibles, the existence of peak time implies the existence of turning point for the number of cumulative cases, and vice versa. Moreover, they exist if and only if the basic reproduction number is greater than unity [Citation12,Citation17]. However, when the initial infection size is not negligible as assumed in the current paper, the existence of peak time (as well as the turning point) is not only dependent on the basic reproduction number
, but also on the net reproduction number
. Furthermore, the existence of turning point implies that of the peak time, but not vice versa.
Acknowledgements
The authors are grateful to the anonymous referees for their careful reading and helpful suggestions.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- F. Brauer, Compartmental models in epidemiology, in Mathematical Epidemiology, Lecture Notes in Mathematics, F. Brauer, P. van den Driessche and J. Wu, eds., Springer, Berlin, 2008, pp. 19–79.
- O. Diekmann, J.A.J. Metz, and J.A.P. Heesterbeek, The legacy of Kermack and McKendrick, in Epidemic Models: Their Structure and Relation to Data, Their Structure and Relation to Data, D. Mollison, ed., Cambridge University Press, Cambridge, 1995, pp. 95–115.
- Z. Feng, Final and peak epidemic sizes for SEIR models with quarantine and isolation, Math. Bios. Eng. 4 (2007), pp. 675–686. doi: 10.3934/mbe.2007.4.675
- Y.H. Hsieh, Richards model: A simple procedure for real-time prediction of outbreak severity, in Modeling and Dynamics of Infectious Diseases, Series in Contemporary Applied Mathematics (CAM), Z.Ma, J.Wu and Y. Zhou, eds., Higher Education Press, Beijing, 2009, pp. 216–236.
- Y. -H. Hsieh, Pandemic influenza A (H1N1) during winter influenza season in the southern hemisphere, Infl. Other Resp. Vir. 4 (2010), pp. 187–197. doi: 10.1111/j.1750-2659.2010.00147.x
- Y. -H. Hsieh and C.W.S. Chen, Turning points, reproduction number, and impact of climatological events for multi-wave dengue outbreaks, Trop. Med. Int. Health 14 (2009), pp. 628–638. doi: 10.1111/j.1365-3156.2009.02277.x
- Y. -H. Hsieh and Y. -S. Cheng, Real-time forecast of multiphase outbreak, Emerg. Infect. Dis. 12 (2006), pp. 122–127. doi: 10.3201/eid1201.050396
- Y. -H. Hsieh, H. dejjArazoza, and R. Lounes, Temporal trends and regional variability of 2001–2002 multiwave DENV-3 epidemic in Havana City: Did Hurricane Michelle contribute to its severity? Trop. Med. Int. Health. 18 (2013), pp. 830–838. doi: 10.1111/tmi.12105
- Y. -H. Hsieh, D.N. Fisman, and J. Wu, On epidemic modeling in real time: An application to the 2009 novel A (H1N1) influenza outbreak in Canada, BMC Res. Notes 3 (2010), p. 283. doi: 10.1186/1756-0500-3-283
- Y. -H. Hsieh, J. -Y. Lee, and H. -L. Chang, SARS epidemiology modeling, Emerg. Infect. Dis. 10 (2004), pp. 1165–1167. doi: 10.3201/eid1006.031023
- Y.H. Hsieh and S. Ma, Intervention measures, turning point, and reproduction number for dengue, Singapore, Am. J. Trop. Med. Hyg. 80 (2005), pp. 66–71.
- Y. -H. Hsieh, J. Wu, J. Fang, Y. Yang, and J. Lou, Quantification of bird-to-bird and bird-to-human infections during 2013 novel H7N9 avian influenza outbreak in China, PLoS ONE 9 (2014), p. e111834. doi: 10.1371/journal.pone.0111834
- J.C. Miller, Epidemics on networks with large initial conditions or changing structure, PLoS ONE 9 (2014), p. e101421. doi: 10.1371/journal.pone.0101421
- F.J. Richards, A flexible growth function for empirical use, J. Exp. Bot. 10 (1959), pp. 290–301. doi: 10.1093/jxb/10.2.290
- J.V. Ross, A note on density-dependence in population models, Ecol. Model. 220 (2009), pp. 3472–3474. doi: 10.1016/j.ecolmodel.2009.08.024
- I. Sazonov, M. Kelbert, and M.B. Gravenor, A two-stage model for the SIR outbreak: Accounting for the discrete and stochastic nature of the epidemic at the initial contamination stage, Math. Biosci. 234 (2011), pp. 108–117. doi: 10.1016/j.mbs.2011.09.002
- X.-S. Wang, J. Wu, and Y. Yang, Richards model revisited: Validation by and application to infection dynamics, J. Theor. Biol. 313 (2012), pp. 12–19. doi: 10.1016/j.jtbi.2012.07.024
- X.-S. Wang and L. Zhong, Ebola outbreak in West Africa: real-time estimation and multiple-wave prediction, Math. Bios. Eng. 12 (2015), pp. 1055–1063. doi: 10.3934/mbe.2015.12.1055
- G. Zhou and G. Yan, Severe acute respiratory syndrome epidemic in Asia, Emerg. Infect. Dis. 9 (2003), pp. 1608–1610.