
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Two simple models for the spread of heavy drinking among a network of individuals are re-introduced and analysed. We provide theorems on the spread of alcohol abuse for these models in cases involving simple connection schemes. Indicators for this spread that resemble the used in disease assessment are suggested and studied. We further provide computations with our models on general application networks and begin to study the reliability of the spread indicators.
1. Introduction
Over 22 million Americans suffer from substance abuse disorders, approximately 80% involve alcohol use disorder [Citation22]. Alcohol consumption and substance abuse are often closely tied to social behaviours. Particularly among teens and young adults, drinking is typically due to social motivations and peer influences have been shown to be predictive of substance abuse [Citation11–13]. The complexity and dynamic nature of social interactions highlight the potential usefulness of modelling and network- based approaches to understanding the interactions between behaviour patterns and alcohol use.
In the last decade there have been significant advances, mainly through the availability of vast amounts of data and fast computers, in our understanding of the structure of social networks (see [Citation2,Citation3,Citation8,Citation20,Citation25]). The first author developed an integro-differential equation model for the spread of alcohol abuse [Citation6] based on the network studies in [Citation5,Citation26]. In this report, we extend the research in these papers.
A wide range of mathematical modelling approaches have been used to examine social behaviour and alcohol use, including Markov models, differential equations, and individual-based networks [Citation1,Citation4,Citation7,Citation10,Citation16,Citation18,Citation19,Citation23,Citation24]. Several of these efforts have examined the spread of alcohol abuse between social contacts including the SIR/SIS models presented in [Citation4,Citation17,Citation21] as well as the data analysis in [Citation23] and the agent-based model in [Citation10].
In this paper we introduce two models based entirely on those in [Citation6] and originally [Citation5]. They each start from a network with N nodes which represent individuals. The first uses a cubic function to model the evolution of the drinking level index of individual i on step m:
(1)
(1)
is the list of nodes connected to i, its friends, and
is the number of indices listed in
.
is the resilience and measures the ith individual's resistance, with respect to drinking, from peer pressure. We think of the
as being a healthy individual with respect to drinking; they could be light drinkers or sober. While
is an individual who is generally considered unhealthy as far as his/her drinking. The connection weights are
for
indicating the strength of influence of person j on person i with
(2)
(2) so that
forms a σ-weighted average over the states
. Note that the weights
are not necessarily symmetric. We also have a step or iteration with ending time M so
. The parameter λ might be called a step size if we view (Equation1
(1)
(1) ) as a discretization of a differential equation (DE). We often think of
but always insist on
.
The inspiration for the cubic model comes primarily from viewing it as an approximation to a DE where 0 and 1 are stable steady states and the is unstable. Thus, when individual i's friends are heavy drinkers (
) this individual tends toward unhealthy alcohol consumption (
) and when the friends are healthier (
) individual i tends toward sobriety (
).
The second model we consider, referred to as the switch model, is
(3)
(3) where
is the Heaviside function,
To see that (Equation3
(3)
(3) ) provides a reasonable model, note that on the step from m to m+1, we have
Thus, if
, then
will be bigger than
and the opposite will occur if
, This approach was introduced in [Citation6] and, due to its similarity to certain neuronal network models, was especially easy to analyse.
Initial configurations at m=0 are provided for each of the schemes;
(4)
(4) We will prove in the next section that the
. The update formulas are set so the weighted influence of friends
when compared to the individual i 's resilience
will give an appropriate adjustment to their drinking level
. That is,
A common theme when examining transmission (whether behaviours, information or disease) is the evaluation of a bifurcation parameter, such as the basic reproduction number, which predicts whether the disease/information will spread or die out. Individual-based models often follow a natural threshold which suggests that it may be possible to find similarly predictable quantities in our case as well.
A focus of this paper is on the accuracy of the following quantities:
(5)
(5) SF stands for scale free. More precisely, does
or
provide a good predictor on the spread of unhealthy drinking? Here,
is a ratio of average of the individual's initial drinking levels with the average of the individual's resiliences. The number
takes into account the connection scheme and thus each individual's influence.
The outline of this paper is as follows. In Section 2 we show for each model that the for all i and m. We also prove theorems about the limiting behaviours in m for each model in the cases of all-to-all, star and leader-clique networks. In Section 3 we display our results on a variety of simulations where we look at generalizations of the simple networks studied in Section 2. We are focussed on the accuracy of
and
in this section. In Section 4 we experiment with our prediction scheme on two application networks. We will add some conclusions in Section 5.
2. Model properties and threshold criteria
In this section we establish some basic properties of the methods as well as theorems on the thresholds for the spread of heavy drinking on simple networks.
Theorem 2.1
For models (Equation1(1)
(1) ) and (Equation3
(3)
(3) ) with initial condition (Equation4
(4)
(4) ), the drinking levels
for
and
.
Proof.
For the Cubic Model (Equation1(1)
(1) ) we can rewrite the defining equation as
The proof is by induction, we assume that
for all i but m is fixed. From this we have,
. Recalling that
and that all the
give
and so,
(as well as being greater than or equal to
). Now, letting
we can show, using (Equation2
(2)
(2) ),
and then use the same proof to conclude that
and thus
. This verifies that
and finishes the analysis for the cubic model case (Equation1
(1)
(1) ).
For the switch model (Equation3(3)
(3) ); we again use induction and iterate from the mth time level with the assumption that
for all i but fixed m. Again, we will show this in the m+1 case. Since
and
it follows that, since all the terms on the right side of (Equation3
(3)
(3) ) are nonnegative,
. Now, since
and on the mth level
,
This shows that
for the switch model (Equation3
(3)
(3) ).
Analysis of simple networks: We now introduce a set of simple networks (Figure ) that we see as possible prototypes for more complex ones. We study theoretically an all-to-all network (Figure (A)) that we see as a place-holder for random networks. The star network (Figure (B)) provides some clues on the behaviour of scale-free systems and the leader-clique a further generalization of both the all-to-all and the star network. The idea of examining small networks is inspired by Golubitsky and Stewart [Citation9].
Figure 1. Simple networks. (A) All-to-All. (B) Star. (C) Leader Clique.
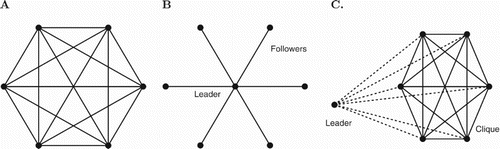
In the star network (Figure (B)) there is one leader or hub that is connected to each of the followers and thus has a significant influence. We see this as similar to a scale-free network where there tends to be a few nodes with high degrees of connectivity. We will see that it is important to take into account the numbers of connections in order to predict the spread of behaviour for both the star and eventually the scale-free networks.
In the leader clique network (Figure (C)), by varying the weight of the leader's connections to the follower clique members, we will be able to transition from an all-to-all situation to the star network.
All-to-all network: We now prove a theorem about the spread of heavy drinking in the simple case where the network is all-to-all as in Figure (A) with self-connections, uniform connection weights and uniform resiliences.
Theorem 2.2
Assume we have an all-to-all network and
Then, for the models (Equation1
(1)
(1) ) and (Equation3
(3)
(3) ) with initial condition (Equation4
(4)
(4) ),
Proof.
For the cubic model, we have from (Equation1(1)
(1) )
Note that since
for all i,
. When
we have
and thus the sequence
will be increasing in m for
. Since the sequence is bounded above by 1 it will converge to some limit between
and 1. But, since this sequence would increase beyond any limit in the open interval
, we have
for
. As in Theorem 2.1, letting
we can prove that
in the case when
.
For the switch model, we sum equation (Equation3(3)
(3) ) over all i, subtract r from each side and divide by N to find that
Thus, if
then
and, by induction,
for
. Knowing this guarantees that
for all m. So, letting
in (Equation3
(3)
(3) ) we have
where we computed the geometric series sum on the last step. So then, since
we have
In the case when
we can argue that
and thus
for
. Then, we have
finishing the proof for the switch model case.
Remark
Theorem 2.2 shows 's relation to 1 is an exact predictor of the spread of unhealthy drinking in the all-to-all network with self-connections, uniform connection weights and constant resilience.
Star network: We now analyse the situation in Figure (B) which provides a highly reduced example of a network with a connection scheme that, like a scale free network, has a small number of nodes which have significantly higher degrees than the other.
The star network in the case of the cubic model would be
(6)
(6)
(7)
(7) where the first equation is for a hub or super-connector with index H and the second is for each of the
follower nodes numbered 1 through
with constant resilience
.
The definition of the switch model on the star network is
(8)
(8)
(9)
(9) where, as with the cubic model, the first equation is for a hub or super-connector with index H and the second set of equations is for each of the
follower nodes numbered 1 through
. We are now in a position to prove a theorem about this reduced model. This result will show that if the hub is a heavy drinker with low resilience and the followers are, on average, moderate drinkers, then as time goes on, all the members of the network will become alcohol abusers.
Theorem 2.3
If drinking behaviour is governed by either the cubic or switch models above on the star network, and
then
Proof.
First, we show this for the cubic method. Averaging the second equation (Equation7(7)
(7) ) over i,
Since
,
which leads in turn, via Equation (Equation6
(6)
(6) ) and our assumption
, to
. By induction we can conclude that the sequences
and
are monotone increasing in m. Since
and
are each bounded above by 1, we conclude
and
as
( again, the conclusion that either
or
reaches any limit (in m) other than 1 leads to a contradiction). We can carry out the same analysis on each of the
's with
and finish the proof.
We now show this for the switch network; averaging over the follower nodes we have
Using an induction argument beginning with our assumptions at m=0, we have
so
and
so
. So, we now have
As in the previous proofs we have that
is an increasing sequence bounded by 1. Again, we can argue that its limit must be 1 by showing that any other limit between
and 1 would lead to a contradiction.
In the same way, we can prove
and then, since
is increasing we must have
as
.
Remark
Of course, the network structure is crucial here. Suppose and
. (So all v's
.) Further, add that
. Notations for averages for the entire star network are as follows:
So, we have
So, for large
we have
. But all v's
. These results show that
is not a good predictor of the emergence of heavy drinking in this (star) network.
At the same time, for this star network, we have
If we continue to suppose
,
and
large (So all v's
and
.), then
So
is consistent with the spread of heavy drinking in this situation.
Leader and clique network: We now consider a leader and clique model with the connection scheme as in Figure (C). Here, the network equations for the cubic model would look like the following:
The influence function
involves a weighted sum with parameter
;
For the switch model we have
Note that the connection weights are
(10)
(10) In this case we adjust the influence of the leader through the parameter
. If
is large, the leader has a strong influence and the network becomes somewhat similar to the star network except the leader is influenced only by himself. While if
then the leader's influence is the same as the other members of the clique and
is just the average over all the nodes including the leader
If, further,
then this is just the all-to-all network studied earlier.
Note that here our quantities and
may not good indicators of behaviour since we have manipulated the weights with this
parameter.
An interesting situation is where the leader is a heavy drinker with low resilience and either the clique has moderate drinkers or the leader has a significant influence ( large). The theorem below shows that all members will become alcohol abusers in these situations.
Theorem 2.4
If and
(11)
(11) then for either the cubic or switch models we have
Proof.
As in the other proofs, the key is to show that all members have an increasing drinking index. From the monotonicity and the fact that the limits must end up at a fixed point (in this case value 1) we can complete the proof. If then, with our assumption
,
So, we have
. Thus
and each of the
will be increasing sequences and they all must tend to 1.
If, instead, the clique members are healthy at the start so ; we need to consider
more carefully. Since
is positive, we use the right value in the ‘Max’ in Equation (Equation11
(11)
(11) ). So, we have
This statement shows the sequences will again be increasing and finishes the proof.
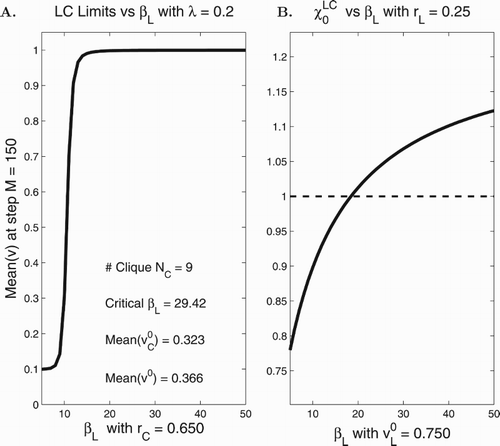
To investigate the leader clique network further, we carried out a simple computation with the cubic algorithm on the network in Figure (C) (with nodes instead of the 6 nodes displayed in Figure (C)) and the weighting scheme (Equation10
(10)
(10) ). For
values ranging from 5 to 50 we ran the cubic algorithm for M=150 steps with
,
,
,
and the
were chosen randomly on
and their mean was
. We examine the longer time behaviour of the average drinking level of the whole network (including the leader)
.
Figure (A) shows the final outcomes, as the leader's influence is increased in the case when the leader is already a heavy drinker (
) while all members of the clique are healthy (
). Of course, heavy drinking ensues as the leader's influence is increased.
Figure 2. Mean (A) and
(B) versus
from 5 to 50 across all simulations of the leader clique network with the cubic model. (The critical influence value given in (Equation11
(11)
(11) ) is
.)
If we knew the connections in our network (the knowledge we assume for and
) as well as the influence which includes the weights of the connections, we could compute the following parameter:
whose values, as they depend on
, are plotted in Figure (B). Observe that the point (in
) where
(where
) is an accurate predictor of the emergence of heavy drinking (Figure (B) – members
-index getting close to 1).
3. Simulations
In this section we extend the analysis developed in Theorems 2.2–2.3 to general graphs using computer experimentation. We have developed MATLAB codes that create either random or scale-free networks with N nodes and then implement either the cubic or switch network models for M steps.
For these simulations a symmetric adjacency matrix W was generated where each entry is 0 or 1 depending on whether there is a connection between nodes (individuals) i and j. Thus,
is just the nonzeroes in row i,
is the number of nonzeroes in that row and the
if
.
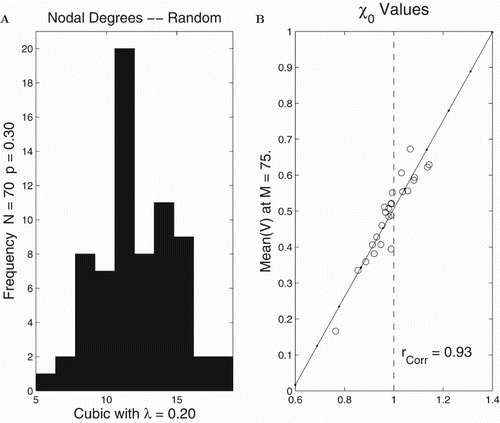
Figure has our results for many runs on a fixed random network with the cubic model in order to assess how well the -criterion derived in Theorem 2.2 predicts actual behaviour. The initial conditions and resiliences are randomly chosen for each run and uniformly distributed on
. We find that
is well correlated with the final averages for the index
at end step M in the case of this random network (correlation
).
Figure 3. Computational assessment of in the case of random networks with the cubic model. There were 25 runs on a fixed random network with N=70 nodes assembled with connection probability p=0.3 and the degree distribution in (A). The set of final means
at
steps versus
values on the horizontal axis are shown in (B). The
and
's were uniformly distributed. The least squares line
vs
is provided in (B) with correlation value r.
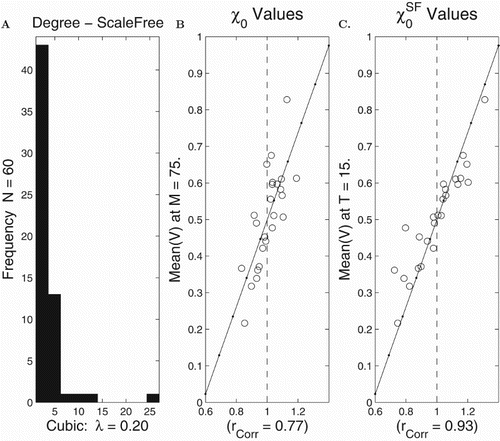
In Figure we display results from computer runs on a scale-free network with the cubic model. Here, we find that is not a good predictor of spread (correlation
). However, if we use
then we typically find a better correlation (
).
Figure 4. Computational assessment of and
in the case of scale-free networks with the cubic model. There were 25 runs on a scale-free network with the nodal connection distribution in (A) and N=70 nodes. The set of final means
at M=75 steps versus
are shown in (B) and versus
in (C). The
and
's were uniformly distributed. The least squares lines are provided in (B) and (C).
In Figure we continue the investigations whose results we showed in Figures and . In Figure (A), we show how the correlation between and spread is enhanced as more and more connections are added to the random network.
Figure 5. More on computations to assess and
. (A) Correlations of
and
for random networks with varying connection fractions P. (B) Histogram of outcomes for 15 correlation computations with
. (C) Histogram of outcomes for 15 correlation computations with
.
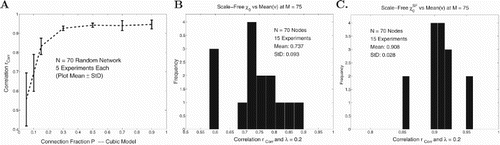
In Figures (B) and (C) we look at histograms of and
for scale-free networks that enhance the results observed in Figure . In each of these cases we did 15 experiments where each consisted of 25 runs on a particular fixed scale-free network. The results reinforced the predictability of
for such scale-free networks. Figure (B) has the correlation of
and
as 0.737, while Figure (C) has the correlation of
and
as 0.908.
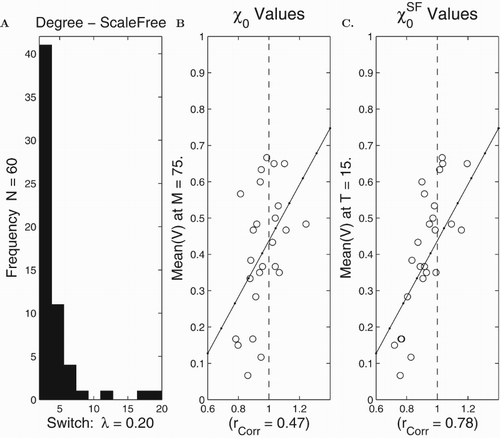
In Figure we display results from computer runs on a scale-free network with the switch model. Here, we find that is again not a good predictor of spread (correlation
). However, if we use
then we typically find a better correlation
. Unfortunately, the correlation between
is not as solid with the switch model as it was with the cubic.
Figure 6. Computational assessment of and
in the case of scale-free networks with the switch model. There were 25 runs on a scale-free network with the nodal connection distribution in (A) and N=70 nodes. The set of final means
at time T=15 are shown in (B) and (C). The
and
's were uniformly distributed. The least squares lines are provided in (B) and (C).
4. Applications – karate club and multiple clique networks
In this section we investigate the accuracy of and
for our cubic model on the spread of heavy drinking for two example networks.
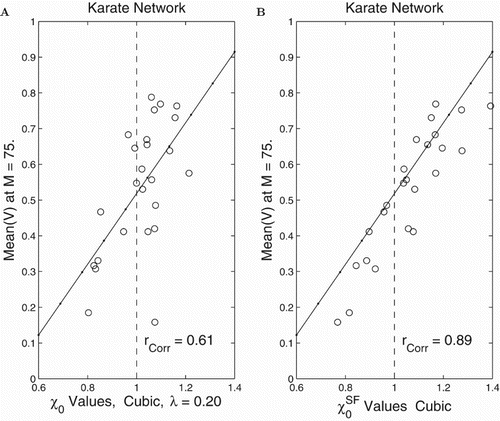
In the karate club [Citation27] there are two leaders who are not on friendly terms. In Figure we display the network and its degree distribution. In Figure we provide our results from applying our cubic model on this application network. The results in Figure where the correlation to is much better than to
was typical of our computations. The karate network has two hubs which suggest it is closer to a scale-free network than a random network. The computations show
is a better predictor of spread than
which is consistent with our new ideas. The correlation between predicted
values and outcomes was 0.89 while it was only 0.61 for
.
Figure 7. The karate club network. (A) Visualization of the nodes and connections. (B) The degree distribution – number of connections for each node.
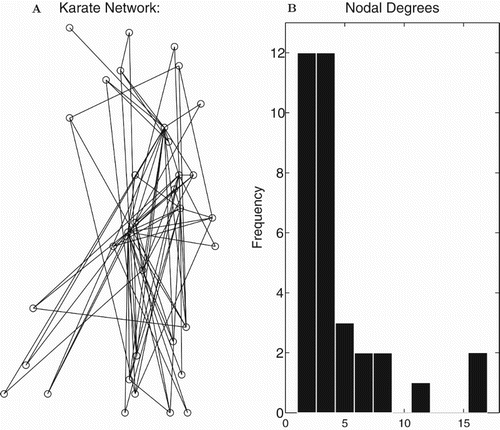
Figure 8. Computational assessment of and
(see (Equation5
(5)
(5) )) for the Cubic Model on the karate network. There were 25 simulations with sets of
's chosen randomly for each. Circles correspond to mean values
after 75 steps. Also shown are the least squares fit lines with horizontal coordinate
for (A) and
for (B).
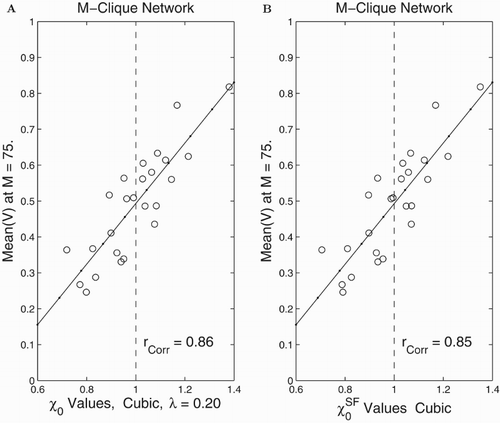
We also considered a multiple clique network as displayed in Figure (A). In this case there are several individuals who know members outside their own clique as well as others who only have friends (connections) within their clique. In our computations we found that both the and
quantities are good predictors for the multiple clique network (see Figures and ). Here, the correlation between final outcomes for drinking
and
was 0.86 and was 0.81 for
.
Figure 9. The multiple clique network. (A) Visualization of the nodes and connections. (B) The degree distribution – number of connections for each node.
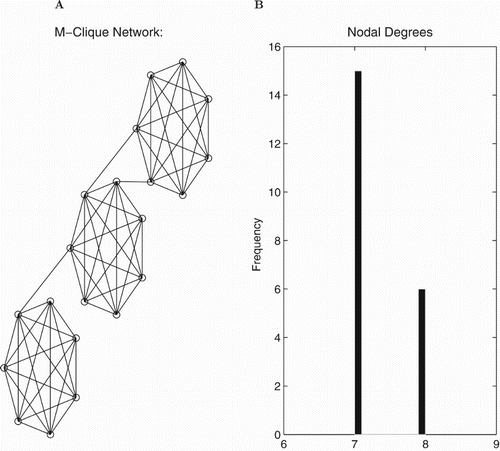
Figure 10. Computational assessment of and
(see (Equation5
(5)
(5) )) for the Cubic Model on the Multiple Clique Network. There were 25 simulations with
's chosen randomly for each. Circles correspond to mean values
after 75 steps. Also shown are the least squares fit lines with horizontal coordinate
for (A) and
for (B).
5. Discussion
In this paper we have examined two related simple difference models (cubic and switch) for the spread of alcohol abuse on networks. Each node or individual i in the network is identified by their drinking index at each time step m.
Inspired by the idea of reproduction number or in disease spread, we investigated three parameters
,
and
that depended on initial members drinking levels, resiliences and, for the latter two, connections and influence. We found that
was a good predictor of behaviour for the all-to-all and random networks. The
and
were better predictors for the behaviour of networks where the influence of individual nodes can be vastly different either through connections or weights.
In the future we intend to investigate treatment programmes such as alcoholics anonymous with our models. We find the question of finding optimum interventions for given networks and initial connection schemes very appealing and would look to [Citation14,Citation15] for inspiration.
Acknowledgments
The basic idea for this paper and specifically the cubic model was introduced in a Mathematical Problems in Industry workshop [Citation26]. The first author is grateful to Richard Braun for introducing him to their work. In this paper we have added scale-free networks, the switch model and analysis of specialized small networks (all-to-all, star and leader clique).
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- R. Bani, R. Hameed, S. Szymanowski, P. Greenwood, C. Kribs-Zaleta, and A. Mubayi, Influence of environmental factors on college alcohol drinking patterns, Math. Biosci. Eng. 10 (2013), pp. 1281–1300.
- A.-L. Barabasi, Linked, Perseus, 2002.
- A. Barrat, M. Barthelemy, and A. Vespignani, Dynamical Processes on Complex Networks, Cambridge University Press, Canmbridge, 2008.
- B. Benedict, Modeling alcoholism as a contagious disease: How ‘infected’ drinking buddies spread problem drinking, SIAM News 40 (2007), 3 pages.
- R.J. Braun, R.A. Wilson, J.A. Pelesko, J.R. Buchanan, and J.P. Gleeson, Applications of small world network theory in alcohol epidemiology, J. Alcohol Stud. 67 (2006), pp. 591–599.
- R. Braun, D.A French, Z. Teymuorglu, and T. Lewis, Continuum models of the spread of alcoholism, J. Integral Equations Appl. 22 (2010), pp. 441–462.
- A. Cintron-Arias, F. Sanchez, X. Wang, C. Castillo-Chavez, D.M. Gorman, and P.J. Gruenewald, The role of nonlinear relapse on contagion amongst drinking communities, in Mathematical and Statistical Estimation Approaches in Epidemiology, G. Chowel, J.M. Hayman, L.M.A. Bettencourt, and P.C. Castillo-Chavez, eds., 2009, Springer, New York, pp. 343–360.
- D. Easley and J. Kleinberg, Networks, Crowds and Markets, University Press, Cambridge, 2010.
- M. Golubitsky and I. Stewart, Nonlinear dynamics of networks: The groupoid formalism, Bull. Am. Math. Soc. 43 (2006), pp. 305–365.
- D.M. Gorman, J. Mezic, I. Mezic, and P.J. Gruenwald, Agent-based modeling of drinking behavior: A preliminary model and potential applications to theory and practice, Am. J. Public Health 96 (2006), pp. 2055–2060.
- D.B. Kandel, Drug and drinking behavior among youth, Ann. Rev. Sociol. 6 (1980), pp. 235–285.
- D.B. Kandel, On processes of peer influences in adolescent drug use: A developmental perspective, Adv. Alcohol Substance Abuse 3–4 (1985), pp. 139–162.
- E. Kuntsche, R. Knibbe, G. Gmel, and R. Engels, Why do young people drink? A review of drinking motives, Clin. Psychol. Rev. 25 (2005), pp. 841–861.
- R. Leander, S. Lenhardt, and V. Protopopescu, Using optimal control theory to identify network structures that foster synchrony, Phys. D 241 (2012), pp. 574–582.
- S. Lenhart and J.T. Workman, Optimal Control Applied to Biological Models, Chapman and Hall/CRC Press, Boca Raton, 2007.
- J.L. Manthey, A.Y. Aidoo, and K.Y. Ward, Campus drinking: An epidemiological model, J. Biol. Dyn. 2 (2008), pp. 346–356.
- A. Mubayi, P. Greenwood, C. Castillo-Chavez, P. Grunewald, and D.M. Gorman, The impact of relative residence times on the distribution of heavy drinkers in highly distinct environments, Socio-Econ. Plan. Sci. XX (2008), pp. 1–12.
- A. Mubayi, P. Greenwood, X. Wang, C. Castillo-Chavez, D.M. Gorman, P. Gruenewald, and R.F. Salt, Types of drinkers and drinking settings: An application of a mathematical model, Addiction 106 (2010), pp. 749–758.
- G. Mulone and B. Straughan, Modeling binge drinking, Int. J. Biomath. 5 (2012), pp. 57–70.
- M.E.J. Newman, The structure and function of complex networks, SIAM Rev. 45 (2003), pp. 167–256.
- J.S. Rasul, R.G. Rommel, G.M. Jacquez, B.G. Fitzpatrick, A.S. Ackleh, N. Simonsen, and R.A. Scribner, Heavy episodic drinking on college campuses: Does changing the drinking age make a difference?, J. Stud. Alcohol Drugs 72 (2011), pp. 15–23.
- Results from the 2012 National Survey on Drug Use and Health: Summary of National Findings, 2013.
- J.N. Rosenquist, J. Murabito, J.H. Fowler, and N. Christakis, The spread of alcohol consumption behavior in a large social network, Ann. Internal Med. 152 (2010), pp. 426–433.
- F. Sanchez, X. Wang, C. Castillo-Chavez, D.M. Gorman, and P.G. Gruenewald, Drinking as an epidemic: A simple mathematical model with recovery and relapse, in Guide to Evidence Based Relapse Prevention, K. Witkiewitz, G.A. Marlatt, eds., Academic Press, New York, 2007, pp. 353–368.
- S.H. Strogatz, Exploring complex networks, Nature 410 (2001), pp. 268–276.
- R.A. Wilson, J.R. Buchanon, J. Gleeson, and R. Braun, A network model of alcoholism and alcohol policy, Mathematical Problems in Industry Report (November 5, 2004).
- W.W. Zachary, An information flow model for conflict and fission in small groups, J. Anthropol. Res. 33 (1977), pp. 452–473.