
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Earth observations, especially satellite data, have produced a wealth of methods and results in meeting global challenges, often presented in unstructured texts such as papers or reports. Accurate extraction of satellite and instrument entities from these unstructured texts can help to link and reuse Earth observation resources. The direct use of an existing dictionary to extract satellite and instrument entities suffers from the problem of poor matching, which leads to low recall. In this study, we present a named entity recognition model to automatically extract satellite and instrument entities from unstructured texts. Due to the lack of manually labeled data, we apply distant supervision to automatically generate labeled training data. Accordingly, we fine-tune the pre-trained language model with early stopping and a weighted cross-entropy loss function. We propose the dictionary-based self-training method to correct the incomplete annotations caused by the distant supervision method. Experiments demonstrate that our method achieves significant improvements in both precision and recall compared to dictionary matching or standard adaptation of pre-trained language models.
1. Introduction
Earth observation (EO) plays a key role in meeting global challenges, including those identified by the UN Sustainable Development Goals, the Paris Agreement on climate change, and the Sendai Framework for Disaster Risk Reduction (Kavvada et al. Citation2020; Guo Citation2020; Guo et al. Citation2021; Chen and Sun Citation2022). EO data have been used to produce massive unstructured EO resources, such as scientific papers and reports, data description files, and code markdown files. However, transforming these resources to knowledge sharing requires urgent attention (Zhu Citation2019; Sun et al. Citation2019; Guo et al. Citation2020; Nativi et al. Citation2020). The Group on Earth Observations (GEO) recently proposed a goal to build a GEO Knowledge Hub (GKH) to link EO resources for effective sharing and reuse.
Remote sensing, as a major EO technical method, provides a large amount of raw data. Tracing back to the source, satellites and their onboarding instruments greatly determine EO capabilities (Wang and Yan Citation2020; Zhao et al. Citation2021). Over the years, the number of satellites sent to space has increased significantly. According to the Union of Concerned Scientists (UCS) Satellite Database, as of September 2021, there were more than 4,550 operational satellites in orbit, nearly a quarter of them performing EO missions with more than 1000 types of instruments. Satellites and their onboard instruments link EO resources in the knowledge production chain (Craglia et al. Citation2017; Sudmanns et al. Citation2020), in which the extraction of satellite and instrument entities from unstructured EO resources is a key step in tracking.
Exact string matching with an existing dictionary (e.g. the UCS Satellite Database) is the most straightforward way to extract satellite and instrument entities. However, this method has two problems. First, since the dictionary only includes official full names and abbreviations, entity recognition has a low recall. For example, ‘Landsat 9’ is also expressed as ‘Landsat-9’ and ‘Landsat9,’ and ‘Soil Moisture Active Passive’ as ‘Soil Moisture Active and Passive Observatory.’ Additionally, dictionary matching suffers from ambiguity, especially for short names. For example, ‘SSM’ can represent ‘SQUID Superconducting Magnetometers’ or ‘Surface Soil Moisture.’ In recent years, Named Entity Recognition (NER) has been widely used to detect various entity types.
Deep learning-based NER methods, such as convolutional neural networks (CNNs) (Collobert et al. Citation2011; Strubell et al. Citation2017), gated recurrent units (GRUs) (Yang, Salakhutdinov, and Cohen Citation2016), and bidirectional long short-term memory (BiLSTM) (Lin et al. Citation2017; Žukov-Gregorič, Bachrach, and Coope Citation2018; Mao et al. Citation2019), have achieved excellent performance in NER tasks. Vaswani et al. (Citation2017) proposed a transformer model that eschews recurrence and instead adopts an attention mechanism. With improved computing resources, pre-trained language models represented by BERT (Devlin et al. Citation2019) have achieved state-of-the-art results on various NLP tasks (Han et al. Citation2021). These models use a transformer architecture and are trained on massive open-domain data through an unsupervised method to learn rich linguistic knowledge. Downstream tasks merely require appropriate fine-tuning of the pre-trained language model. Benefiting from complex neural networks and nonlinear transformation, deep learning-based NER methods can automatically learn the implicit features of the input data, thereby reducing the heavy work of designing handcrafted features.
However, deep learning-based approaches require a large number of manually annotated sentences for model training. This is particularly challenging in the EO domain because the acquisition of domain-expert annotation is expensive and slow. One approach to alleviate this need is to use distant supervision to automatically generate labels (Fries et al. Citation2017; Giannakopoulos et al. Citation2017; Shang et al. Citation2018), using existing dictionaries (or knowledge bases) to label sentences to generate training data for NER tasks. However, most dictionaries have limited coverage of entities, which leads to incomplete and noisy annotations due to the ambiguity of entities.
In this paper, we apply the pre-trained language model and distant supervision to the EO domain to automatically extract satellite and instrument entities from unstructured texts. We compare and integrate publicly available satellite and instrument knowledge bases to form a comprehensive dictionary, based on which we propose a distance supervision algorithm that considers the accuracy and coverage of labeling and use it to generate training data on a large number of open-access geoscience texts. We fine-tune the RoBERTa model (Liu et al. Citation2019) on the training data to make full use of the rich linguistic knowledge learned by the model during pretraining. An early stopping strategy is used to alleviate incomplete and noisy annotations caused by distant supervision. A weighted cross-entropy loss function is used to overcome the class imbalance. Referring to the teacher-student framework in the open domain (Liang et al. Citation2020), we propose a dictionary-based self-training method. We iteratively generate new training data by comparing the similarity between the pseudo-labels of the training data predicted by the model and the official names in the dictionary, to correct incomplete annotations of the training data while generating as few wrong labels as possible. shows an example of extracting satellite and instrument entities deployed on the HuggingFace website.
Figure 1. Example of extracting satellite and instrument entities deployed on the HuggingFace website.
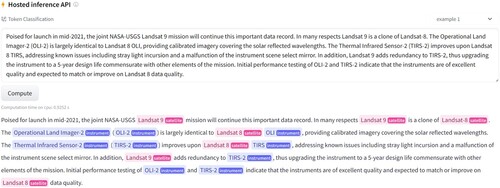
The rest of this paper is organized as follows. Section 2 presents existing work on the extraction of satellite and instrument entities, as well as distantly supervised NER studies. Section 3 introduces the training and test data. Section 4 introduces the dictionary-based self-training method using the pre-trained language model with distantly labeled data. Section 5 presents the experimental results of our approach and compares them with those of existing methods. Section 6 provides the conclusion.
2. Related work
On extracting satellite and instrument entities from unstructured texts, Duan et al. (Citation2018) combined rule-based and neural-network-based methods to automatically extract entities, such as satellites, instruments, variables, and datasets, from scientific papers. The Global Change Master Directory (GCMD) was utilized as an external dictionary to generate distinct labels based on the exact string matching. The Conditional Random Field (CRF) model was used to refine the results. One limitation of this study is that Earth observation satellites and instruments included in the GCMD dictionary are not complete, which will lead to incomplete annotations of the training set. Besides that, only one CRF layer was utilized, which has limited improvement in the performance of named entity recognition. Jafari et al. (Citation2020) present an end-to-end framework, named SatelliteNER, for extracting satellite entities. Since only the main word within the satellite name was kept (e.g. only Landsat was utilized for Landsat-7 and Landsat-8 satellites), different satellites within the same series were not distinguished. Another limitation is that the Spacy NER model could be influenced by the original entity labels (e.g. person, location). In addition, the test data are directly segmented from distantly supervised training data, which also suffer from incomplete and noisy annotations.
Our work is also related to the distantly supervised NER task. Distant supervision methods are proposed to alleviate human efforts in data annotation. SwellShark (Fries et al. Citation2017) utilized a collection of lexicons, ontologies, heuristic rules, and other forms of distant supervision to build biomedical NER taggers. It requires the involvement of domain experts to construct regular expressions over POS tags to match noun phrases. Distant-LSTM-CRF (Giannakopoulos et al. Citation2017) used a list of high-quality phrases and syntactic rules to generate distantly labeled data. This method focuses on token labeling with high precision to reduce incorrectly annotated entities, which leads to incomplete annotations as well. AutoNER (Shang et al. Citation2018) utilized dictionaries to generate pseudo entity labels by exact string matching. Considering the limited coverage of dictionaries, they identified high-quality phrases as entities of unknown type to extend the existing dictionaries. Their method achieves a high precision but still suffers from a relatively low recall. Liang et al. (Citation2020) proposed a two-stage training framework to learn named entity taggers from distant supervision in the open domain. They collected gazetteers from resources such as Wikidata to generate distant labels through POS tagging and hand-crafted rules. They firstly fine-tuned a pre-trained language model with distant labels, and then replaced the distant labels with the pseudo labels predicted by the model for further training.
Compared with these existing studies, this paper firstly acquired and fused multiple satellite and instrument repositories to form a more comprehensive dictionary. Distantly supervised training data were generated based on this dictionary and a test dataset was manually labeled. A self-training method based on an advanced pre-trained language model was then utilized to iteratively correct false-positive labels to further improve both the precision and the recall.
3. Data
We introduce the training and test datasets used in this paper. shows the framework for generating the training data.
Figure 2. Framework for generating the training dataset.
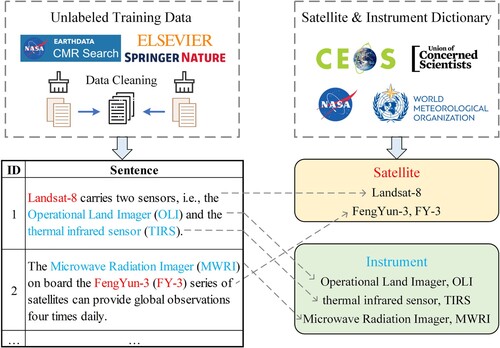
3.1. Earth observation capability dictionary
Several agencies and organizations have developed satellite databases for various purposes. UCS has produced a satellite database with open-source information on operational satellites since 2005 as a research tool for both specialists and non-specialists. As of October 2021, the open-source UCS database collects about 1028 Earth observation satellites in operation, covering civil, government, commercial, and military users. The Committee on Earth Observation Satellites (CEOS) builds databases of missions, instruments, measurements, and datasets, as the official consolidated statement of agency programs and plans, and therefore omits commercial satellite missions. The World Meteorological Organization (WMO) has a similar vision, focusing on atmospheric, ocean, and terrestrial observation tasks, and its satellite database contains 818 records with limited resources for commercial missions.
To provide a comprehensive and effective dictionary, we consider UCS, CEOS, and WMO as the databases to obtain civil, commercial, government, and military observation satellites and instruments. The mapping process is conducted based on satellites’ official full names, alternative names, and acronyms, resulting in 1530 satellite records and 1734 instrument records dating back to 1959. The satellite dictionary has 36 fields, including aspects of names, countries, agencies, purposes, users, orbits, mass, power, launches, and links. The instrument dictionary has eight fields, including names, agencies, types, and dates.
3.2. Raw data acquisition
NASA's Earth Observing System Data and Information System (EOSDIS) is used to archive and distribute Earth science data from multiple missions to users, and the Common Metadata Repository (CMR) catalogs all its data and service metadata records. We obtained 33,000 EOSDIS metadata records using the CMR search API and used the content of their abstract field as part of the raw training data.
The Elsevier research product API enables one to obtain article metadata and full-text content, such as abstracts indexed by Scopus, and journals published on the ScienceDirect full-text platform. The full text of open-access articles can be downloaded from Springer Nature API. We obtained the titles, abstracts, and full texts of 18,625 articles under the subject of Earth science through the API as another part of the raw training data.
3.3. Distant label generation
We use the IOB (inside, outside, beginning) format to tag tokens, where B-XXX indicates that the chunk where a token is located belongs to type XXX and the token is at the beginning of the chunk, I-XXX indicates that a token is inside a chunk belonging to type XXX, and O indicates that the token does not belong to a predefined entity.
Our principle of generating distant labels is to increase the coverage of predefined entities as much as possible while ensuring accuracy. To avoid ambiguity, we assume that when people refer to an abbreviation of an entity, they mention its full name at least once in the full text. We let the case-insensitive denote the set of full names in the dictionary; the case-sensitive denotes the set of short names in the dictionary. The tuple
denotes the name of an entity, where
is the short name for the entity, and
is the long name.
denotes the set of
corresponding to the
appearing in the full text.
is initialized to null and is case-insensitive.
is the set of all training data, where
denotes the full text of an article. The distant-label generation method adopted in this paper is summarized in .
Figure 3. Optimized dictionary matching method to generate distant labels. Full names of named entities are case-insensitive to improve coverage, and short names are case-sensitive to avoid ambiguity.
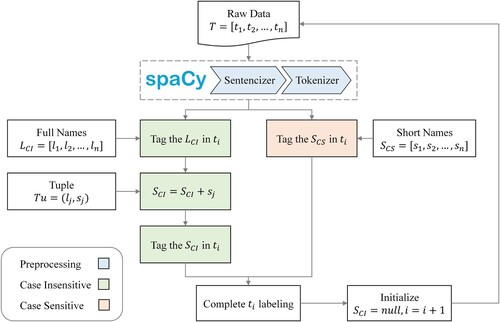
The original full-text is segmented into sentences, words, and punctuation marks via the spaCy package. Then we tag the named entities in
with the case-insensitive full name set
and case-sensitive short name set
. If
is matched, then
is added to
as
. The named entities in
are tagged with the case-insensitive
. At the end of
, we initialize
to null and start iteration
.
4. Methodology
shows the research framework of this study. We use the distantly labeled data to fine-tune the pretrained language model with early stopping, and dictionary-based self-training to correct incomplete annotations and further improve performance. For the loss function, we assign different weights according to entity types to solve the problem of data imbalance.
Figure 4. Overall fine-tuning and self-training procedures with BERT. The BERT model is fine-tuned to output pseudo-labels of training data. By judging the similarity between the pseudo-labels and the official names in the dictionary, new training labels are generated as the next input.
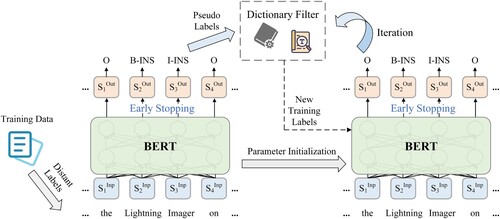
4.1. Fine-tuning the BERT model with distantly labeled data
We introduce the process of fine-tuning the BERT model. The inputs are processed using a pre-trained BERT tokenizer to split strings, convert tokens strings to IDs, and generate special tokens. The BERT tokenizer is based on WordPiece (Wu et al. Citation2016), which aims to balance the size of the dictionary and the number of out-of-vocabulary (OOV) words. This allows BERT to store only 30,000 words when processing English text, and few OOV words are encountered. The outputs of the BERT tokenizer are fed into the BERT layers to generate token, segment, and position embeddings. The sum of these embeddings is the input representation of a token. BERT can classify a pair of sentences. The segment embeddings layer distinguishes sentences in a pair. The input in the NER task is only one sentence (or paragraph), so segment embeddings are all 0. The position embeddings layer encodes the position information of a token in a sentence.
BERT is pre-trained through a masked language model (MLM) and next sentence prediction (NSP), which are unsupervised. The pre-trained BERT model learns rich semantic and syntactic knowledge through unsupervised training on a large text corpus, which enables it to effectively migrate to the target NER task. The large number of parameters gives the model a good fitting ability. For example, BERTBASE has 12 layers, 768 hidden dimensions, 12 attention heads, and 110 million parameters, and BERTLARGE has 24 layers, 1024 hidden dimensions, 16 attention heads, and 335 million parameters. The NER classifier layer uses the output embeddings of the BERT model to predict the type of each token.
4.2. Early stopping
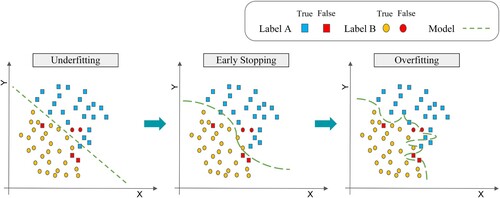
The number of parameters of the pre-trained language model enables it to fit the named entity recognition task of this paper. The distantly supervised training data suffer from the mislabeling and omission of named entities. The features of these false labels are harder to learn and require more iterations to fit. Early stopping is an important strategy to avoid overfitting. At first, the model has only semantic and syntactic knowledge learned from a large text corpus. Then we fine-tune the model on the training data. Training stops after iterating to a specified threshold. This prevents overfitting of the incomplete annotated labels while retaining knowledge learned during pre-training. shows the model’s ability to fit the data in the stages of underfitting, early stopping, and overfitting. Early stopping effectively improves generalization performance.
Figure 5. Evolution of underfitting, early stopping, and overfitting.
4.3. Weighted cross-entropy loss
In this paper, there is an imbalance in the number of instances from each class in the training data. The ratio of the number of instances of B-Satellite, I-Satellite, B-Instrument, I-Instrument, and O is approximately 2:1:2:1:60. Since the essence of model training is to minimize the loss function, the model tends to predict the token as the type with a higher number in the training data.
We use the weighted cross-entropy loss function to solve the problem of class imbalance, where and
respectively denote standard and weighted cross-entropy loss of a token; input
contains raw scores for each label;
(1)
(1) where
,
, and
is the number of classes to be classified; and
(2)
(2) where
is the predefined weight of each label. For an input sentence, the losses are averaged across all tokens. We use
to denote the weighted cross-entropy loss of the i-th token, and
is the weight of the true label. Thus the loss of the sentence is
(3)
(3) where
is the length of the input sentence.
4.4. Dictionary-based self-training
When using the dictionary to label the training data, we strive to label the named entities as accurately as possible. The resulting problem is that many named entities are incorrectly labeled as type O. We previously adopted the strategy of early stopping to prevent the model from overfitting these false-negative labels. We use dictionary-based self-training to further correct them.
We use to denote the NER model parameterized by
,
the initial pre-trained BERT parameters,
the probability that the
-th token belongs to the
-th class, and
the distantly labeled data, where
and
. Using the early stopping strategy for the first training, we can obtain the model.
(4)
(4) and use this to generate pseudo-labels
by
(5)
(5) We define
and initialize
. If
are in the form of (B-X, I-X) and
are all type O, then we need to judge whether
are false-negative labels based on the dictionary created above. The Jaccard index and cosine similarity are commonly used text similarity metrics. The Jaccard index is the ratio of common words to total unique words in both phrases,
(6)
(6) Cosine similarity evaluates the similarity of two vectors by calculating the cosine of the angle between them. The cosine similarity between two nonzero vectors is
(7)
(7) With cosine similarity, we need to convert phrases to vectors. One way is to use Word2Vec (Mikolov et al. Citation2013; Mikolov et al. Citation2013) to get word embeddings and take their average as the phrase vector. However, there are many proper nouns in satellite and instrument names that have no corresponding word vectors in Word2Vec. In addition, simply taking the average of word vectors ignores the semantic information of the words in a phrase. We use the SentenceTransformers framework (Reimers and Gurevych Citation2019) to calculate the cosine similarity between phrases, which takes into account the contextual information and reduces the number of OOV words. If
or
, then we update
by.
(8)
(8) where
are tuning thresholds, and use the new
to generate the model
to start the next iteration.
5. Results
5.1. Training, development, and test sets
We obtained 18,625 full-text articles in the Earth science domain, and 33,000 EOSDIS metadata records, totaling 3,762,506 sentences. We used the method shown in to label the named entities. Since there are very few sentences with annotated named entities, the model tends to fit O (non-entity) and ignore valid annotations. Therefore, we simplified the training data by keeping only sentences for which annotated named entities exist. The number of processed sentences was only approximately 1% of the original. In addition, since the metadata records of CMR are often highly similar between datasets of the same source, sentences in the training data are duplicated. We cleaned and deduplicated the training data, and finally obtained a total of 38,463 sentences, with a deduplication ratio of roughly 15%. The results are shown in . We randomly split 20% from the training set as the development set.
Table 1. Number of sentences, words, and tags at different stages of training data.
The training dataset can be noisy and may contain erroneous automatically annotated entities, so it is not suitable to split a portion from it as a test set. Therefore, we evaluated our methods on manually checked test sets. We obtained descriptions of 100 scientific data items in the EO domain from several data repositories (e.g. PANGAEA), for a total of 400 sentences. We manually annotated named entities on these sentences and generated two test sets: one full and one simplified. The full test set contained all 400 sentences, and the simplified test set contained 185 sentences with annotated named entities.
5.2. Ner performance comparison
We use precision, recall, and F1 score to evaluate NER tasks:
(9)
(9)
(10)
(10)
(11)
(11) where TP (true positive) means that the values of the actual and predicted class are both ‘yes,’ FP (false positive) means that the actual class is ‘no’ and the predicted class is ‘yes,’ and FN (false negative) means that the actual class is ‘yes’ and the predicted class is ‘no.’ We separately calculated metrics for the satellite and instrument and took the average value.
Based on the analysis performed on the development set, we chose the optimal class weights and early stopping thresholds. Since the number of entities of type O is approximately 60 times that of type Satellite or Instrument, we decayed the weight of type O by half each time until one-sixty-fourth. Training would stop if the development F1 did not improve in the last 5 rounds.
We experimented with eight NER methods, and the results are shown in . (1) The dictionary matching method uses the official names in the dictionary to directly detect named entities. Optimized dictionary matching is our proposed distant label generation method, as shown in ; (2) BiLSTM-CRF (Huang, Xu, and Yu Citation2015; Lample et al. Citation2016) learns the semantic information of the context through the bidirectional LSTM model, and uses CRF to predict the labels of tokens. We employ a two-layer Bi-LSTM to extract features for each token, which are used by a CRF layer for token-based classification. The embedding and hidden dimensions are set to 512; (3) BERT-base (Devlin et al. Citation2019) is our baseline model, with a total of 110 million parameters. DistilBERT-base (Sanh et al. Citation2020) is a distilled version of BERT-base, with six layers, 768 hidden dimensions, 12 attention heads, and 65 million parameters. Based on BERT-base, RoBERTa-base eliminates the next-sentence pretraining target and training with larger mini-batches. RoBERTa-large is an enlarged version of RoBERTa-base, with 355 million parameters. We compared the difference between the CRF loss and the weighted cross-entropy loss in optimizing pre-trained language models.
Table 2. Results of different NER methods: F1 (Precision/Recall).
Compared with the method of direct dictionary matching, this optimized dictionary matching method showed a significant improvement in precision, from 0.64–0.75, and the F1 score increased from 0.58–0.60. BiLSTM-CRF had no obvious improvement, which indicated that the dictionary we built already had a good ability to recognize satellite and instrument entities in unstructured text. The BERT model and its variants showed excellent performance in named entity recognition compared to the optimized dictionary matching method. The performance of the pre-trained language model also improved as the number of parameters increased. Compared with the CRF loss, the weighted cross-entropy loss decreased the precision while increasing the recall, resulting in only a small increase in the F1 score. In addition, the weighted cross-entropy loss required more training time due to the need to compare the performance of different class weights on the development set to select the optimal weights. We also evaluated the performance of the pre-trained language model on the raw dataset. But the model failed to converge. The reason could be that only 1% of the sentences in the raw dataset have entity labels, which makes the model unable to fit.
5.3. Performance evaluation of self-training
Based on the first stage of training, we conducted experiments of dictionary-based self-training. The threshold of the Jaccard index was set to 0.6, and the threshold
of cosine similarity to 0.75. We conducted six iterations of self-training, whose final results are shown in . Our method significantly improved the F1 score. Specifically, it mainly improved the recall of the CRF loss and the precision of the weighted cross-entropy loss. Through the self-training method, we iteratively corrected some of the false-negative labels in the O labels and effectively reduced the misfitting of the model.
Table 3. Results of dictionary-based self-training: F1 (Precision/Recall).
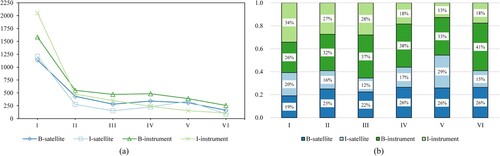
a shows the change in the number of O labels corrected to other labels at different stages of self-training for the RoBERTa-large model. In the first iteration, the number of corrected false-negative labels was the highest, and this number declined in subsequent iterations. Over six iterations, the number of B-satellite labels increased by 7.2%, I-satellite labels by 10.3%, B-instrument labels by 9.8%, and I-instrument labels by 15.6%. b shows the percentage of O labels corrected to other entity types after each iteration. The number of newly added Instrument entities was generally more than that of Satellite entities. We believe this is because the use of instrument names in the text is more diverse than that of satellite names. Therefore, the initial labeling of the Instrument with the dictionary had lower coverage.
Figure 6. (a) Number of O labels corrected to other labels at different stages of self-training; (b) Percentage of type O corrected to other entity types after each iteration.
5.4. Further discussion
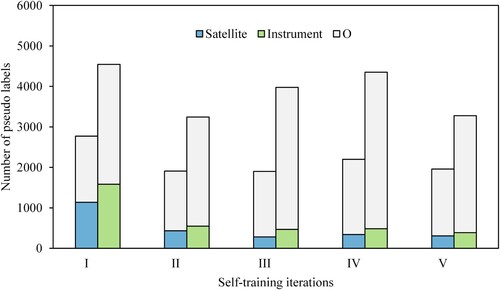
In the open domain, Liang et al. (Citation2020) directly used the pseudo-labels generated by the teacher model to train the student model. However, we built a relatively comprehensive satellite and instrument dictionary, and pseudo-labels can be filtered by comparing their similarity with the official names in the dictionary. This is equivalent to a significant manual effort by experienced Earth scientists to create handcrafted rules. shows the number of pseudo-labels generated in each self-training iteration, and the number of satellite and instrument labels after dictionary-based similarity matching. In the first self-training iteration, half of the pseudo-labels were judged to be true labels. After that, only about one-sixth of the pseudo-labels were retained each time. It can be seen that dictionary-based filtering effectively eliminates wrong labels.
Figure 7. Number of different entity types in pseudo-labels. Bar represents total number of satellite or instrument entities added in each iteration of self-training. Satellite or instrument segment in a bar represents the number of entities remaining after dictionary-based similarity matching.
6. Conclusions
In this paper, distantly supervised training data and the dictionary-based self-training method were utilized to automatically extract satellite and instrument entities. Major contributions are as follows.
We integrated satellite and instrument knowledge bases from different sources to form a comprehensive dictionary. Based on the dictionary and open-access geoscience texts, we constructed training data labeled with satellite and instrument entities, and manually annotated the test data for model evaluation;
We proposed a dictionary-based self-training method for augmenting distantly-supervised training data to improve entity recognition of satellites and instruments in unstructured text. We iteratively had the pre-trained language model label unlabeled data and matched these entities to the satellite and instrument dictionaries. Close matches were accepted as the true labels for the next iteration of training. Our method led to an improvement in both precision and recall.
The developed satellite and instrument NER model could help to link unstructured EO resources, thereby promoting the sharing and reuse of EO data, methods, and results. Although this paper focused on the EO domain, we believe that it could also apply to the implementation of NER tasks that lack manually labeled data in other domains. In the future, we will use our method to detect more named entities, such as essential variables and GCMD Keywords, thereby promoting more efficient sharing and reuse of unstructured EO resources. We plan to further facilitate knowledge sharing by expressing unstructured EO resources as RDF triples based on the semantic web and knowledge graph technologies.
Data availability statement
The experimental data and NER models are available on GitHub at https://github.com/THU-EarthInformationScienceLab/Satellite-Instrument-NER. The raw datasets, the dictionaries of satellites and instruments, and the training and test sets are in the data folder. The satellite and instrument NER models are available through the HuggingFace service.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Chen, Fang, and Zhongchang Sun. 2022. “Big Earth Data for Achieving the Sustainable Development Goals in the Belt and Road Region.” Big Earth Data 6 (1). Taylor & Francis, 1–2. doi:10.1080/20964471.2022.2033424.
- Collobert, Ronan, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. “Natural Language Processing (Almost) from Scratch.” The Journal of Machine Learning Research 12 (null): 2493–2537.
- Craglia, Max, Jiri Hradec, Stefano Nativi, and Mattia Santoro. 2017. “Exploring the Depths of the Global Earth Observation System of Systems.” Big Earth Data 1 (1–2): Taylor & Francis, 21–46. doi:10.1080/20964471.2017.1401284.
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. Minneapolis, Minnesota: Association for Computational Linguistics. doi:10.18653/v1/N19-1423.
- Duan, X., J. Zhang, R. Ramachandran, P. Gatlin, M. Maskey, J. J. Miller, K. Bugbee, and T. J. Lee. 2018. A Neural Network-Powered Cognitive Method of Identifying Semantic Entities in Earth Science Papers.” In 2018 IEEE International Conference on Cognitive Computing (ICCC), 9–16. doi:10.1109/ICCC.2018.00009.
- Fries, Jason A., Sen Wu, Alexander Ratner, and Christopher Ré. 2017. SwellShark: A Generative Model for Biomedical Named Entity Recognition without Labeled Data.” CoRR abs/1704.06360. http://arxiv.org/abs/1704.06360.
- Giannakopoulos, Athanasios, Claudiu Musat, Andreea Hossmann, and Michael Baeriswyl. 2017. “Unsupervised Aspect Term Extraction with B-LSTM & CRF Using Automatically Labelled Datasets.” In Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, 180–188. Copenhagen, Denmark: Association for Computational Linguistics. doi:10.18653/v1/w17-5224.
- Guo, Huadong. 2020. “Big Earth Data Facilitates Sustainable Development Goals.” Big Earth Data 4 (1): Taylor & Francis, 1–2. doi:10.1080/20964471.2020.1730568.
- Guo, Huadong, Dong Liang, Fang Chen, and Zeeshan Shirazi. 2021. “Innovative Approaches to the Sustainable Development Goals Using Big Earth Data.” Big Earth Data 5 (3): Taylor & Francis, 263–276. doi:10.1080/20964471.2021.1939989.
- Guo, Huadong, Stefano Nativi, Dong Liang, Max Craglia, Lizhe Wang, Sven Schade, Christina Corban, et al. 2020. “Big Earth Data Science: An Information Framework for a Sustainable Planet.” International Journal of Digital Earth 13 (7): Taylor & Francis, 743–767. doi:10.1080/17538947.2020.1743785.
- Han, Xu, Zhengyan Zhang, Ning Ding, Yuxian Gu, Xiao Liu, Yuqi Huo, Jiezhong Qiu, et al. 2021. Pre-Trained Models: Past, Present and Future.” AI Open, August. doi:10.1016/j.aiopen.2021.08.002.
- Huang, Zhiheng, Wei Xu, and Kai Yu. 2015. Bidirectional LSTM-CRF Models for Sequence Tagging.” ArXiv:1508.01991 [Cs], August. http://arxiv.org/abs/1508.01991.
- Jafari, Omid, Parth Nagarkar, Bhagwan Thatte, and Carl Ingram. 2020. SatelliteNER: An Effective Named Entity Recognition Model for the Satellite Domain.” In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2020, Volume 3: KMIS, Budapest, Hungary, November 2-4, 2020., 100–107. doi:10.5220/0010147401000107.
- Kavvada, Argyro, Graciela Metternicht, Flora Kerblat, Naledzani Mudau, Marie Haldorson, Sharthi Laldaparsad, Lawrence Friedl, Alex Held, and Emilio Chuvieco. 2020. “Towards Delivering on the Sustainable Development Goals Using Earth Observations.” Remote Sensing of Environment 247 (September): 111930. doi:10.1016/j.rse.2020.111930.
- Lample, Guillaume, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural Architectures for Named Entity Recognition.” In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 260–270. San Diego, California: Association for Computational Linguistics. doi:10.18653/v1/N16-1030.
- Liang, Chen, Yue Yu, Haoming Jiang, Siawpeng Er, Ruijia Wang, Tuo Zhao, and Chao Zhang. 2020. BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision.” In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 1054–1064. KDD ‘20. New York, NY, USA: Association for Computing Machinery. doi:10.1145/3394486.3403149.
- Lin, Bill Y., Frank Xu, Zhiyi Luo, and Kenny Zhu. 2017. “Multi-Channel BiLSTM-CRF Model for Emerging Named Entity Recognition in Social Media.” In Proceedings of the 3rd Workshop on Noisy User-Generated Text, 160–165. Copenhagen, Denmark: Association for Computational Linguistics. doi:10.18653/v1/W17-4421.
- Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “RoBERTa: A Robustly Optimized BERT Pretraining Approach.” ArXiv:1907.11692 [Cs], July. http://arxiv.org/abs/1907.11692.
- Mao, Huina, Gautam Thakur, Kevin Sparks, Jibonananda Sanyal, and Budhendra Bhaduri. 2019. “Mapping Near-Real-Time Power Outages from Social Media.” International Journal of Digital Earth 12 (11): 1285–1299. Taylor & Francis, doi:10.1080/17538947.2018.1535000.
- Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space.” ArXiv:1301.3781 [Cs], September. http://arxiv.org/abs/1301.3781.
- Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and Their Compositionality.” In Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2, 3111–3119. NIPS’13. Red Hook, NY, USA: Curran Associates Inc.
- Nativi, Stefano, Mattia Santoro, Gregory Giuliani, and Paolo Mazzetti. 2020. “Towards a Knowledge Base to Support Global Change Policy Goals.” International Journal of Digital Earth 13 (2): Taylor & Francis, 188–216. doi:10.1080/17538947.2018.1559367.
- Reimers, Nils, and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 3982–3992. Hong Kong, China: Association for Computational Linguistics. doi:10.18653/v1/D19-1410.
- Sanh, Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2020. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter.” ArXiv:1910.01108 [Cs], February. http://arxiv.org/abs/1910.01108.
- Shang, Jingbo, Liyuan Liu, Xiaotao Gu, Xiang Ren, Teng Ren, and Jiawei Han. 2018. Learning Named Entity Tagger Using Domain-Specific Dictionary.” In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2054–2064. Brussels, Belgium: Association for Computational Linguistics. doi:10.18653/v1/D18-1230.
- Strubell, Emma, Patrick Verga, David Belanger, and Andrew McCallum. 2017. Fast and Accurate Entity Recognition with Iterated Dilated Convolutions.” In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2670–2680. Copenhagen, Denmark: Association for Computational Linguistics. doi:10.18653/v1/D17-1283.
- Sudmanns, Martin, Dirk Tiede, Stefan Lang, Helena Bergstedt, Georg Trost, Hannah Augustin, Andrea Baraldi, and Thomas Blaschke. 2020. “Big Earth Data: Disruptive Changes in Earth Observation Data Management and Analysis?” International Journal of Digital Earth 13 (7): Taylor & Francis, 832–850. doi:10.1080/17538947.2019.1585976.
- Sun, Kai, Yunqiang Zhu, Peng Pan, Zhiwei Hou, Dongxu Wang, Weirong Li, and Jia Song. 2019. “Geospatial Data Ontology: The Semantic Foundation of Geospatial Data Integration and Sharing.” Big Earth Data 3 (3): Taylor & Francis, 269–296. doi:10.1080/20964471.2019.1661662.
- Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need.” In Proceedings of the 31st International Conference on Neural Information Processing Systems, 6000–6010. NIPS’17. Red Hook, NY, USA: Curran Associates Inc.
- Wang, Lizhe, and Jining Yan. 2020. “Stewardship and Analysis of Big Earth Observation Data.” Big Earth Data 4 (4): Taylor & Francis, 349–352. doi:10.1080/20964471.2020.1857055.
- Wu, Yonghui, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, et al. 2016. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.” ArXiv:1609.08144 [Cs], October. http://arxiv.org/abs/1609.08144.
- Yang, Zhilin, Ruslan Salakhutdinov, and William Cohen. 2016. “Multi-Task Cross-Lingual Sequence Tagging from Scratch.” ArXiv:1603.06270 [Cs], August. http://arxiv.org/abs/1603.06270.
- Zhao, Tianjie, Michael H. Cosh, Alexandre Roy, Xihan Mu, Yubao Qiu, and Jiancheng Shi. 2021. “Remote Sensing Experiments for Earth System Science.” International Journal of Digital Earth 14 (10): Taylor & Francis, 1237–1242. doi:10.1080/17538947.2021.1977473.
- Zhu, Yunqiang. 2019. “Geospatial Semantics, Ontology and Knowledge Graphs for Big Earth Data.” Big Earth Data 3 (3): Taylor & Francis, 187–190. doi:10.1080/20964471.2019.1652003.
- Žukov-Gregorič, Andrej, Yoram Bachrach, and Sam Coope. 2018. Named Entity Recognition With Parallel Recurrent Neural Networks.” In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 69–74. Melbourne, Australia: Association for Computational Linguistics. doi:10.18653/v1/P18-2012.