
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Qinghai-Tibet Plateau lakes are important carriers of water resources in the ‘Asian’s Water Tower’, and it is of great significance to grasp the spatial distribution of plateau lakes for the climate, ecological environment, and regional water cycle. However, the differences in spatial-spectral characteristics of various types of plateau lakes, and the complex background information of plateau both influence the extraction effect of lakes. Therefore, it is a great challenge to completely and effectively extract plateau lakes. In this study, we proposed a multiscale contextual information aggregation network, termed MSCANet, to automatically extract Plateau lake regions. It consists of three main components: a multiscale lake feature encoder, a feature decoder, and a Multicore Pyramid Pooling Module (MPPM). The multiscale lake feature encoder suppressed noise interference to capture multiscale spatial-spectral information from heterogeneous scenes. The MPPM module aggregated the contextual information of various lakes globally. We applied the MSCANet to the lake extraction of the Qinghai-Tibet Plateau based on Google data; additionally, comparative experiments showed that the MSCANet proposed had obvious improvement in lake detection accuracy and morphological integrity. Finally, we transferred the pre-trained optimal model to the Landsat-8 and Sentinel-2A dataset to verify the generalization of the MSCANet.
1. Introduction
The Qinghai-Tibet Plateau is situated in the middle and south of Asia and Europe, the origin of the main rivers in China and Southeast Asia, known as the ‘Asian’s Water Tower’. With a large number of lakes and a wide distribution, the Qinghai-Tibet Plateau ranks first among the five largest lake groups in China, and the area of lakes is more than half of the general area of lakes in China. Plateau lakes play an influential role in the terrestrial water cycle, participating in the natural water cycle, responding positively to climate fluctuations, and acting as a global climate indicator (Lu et al. Citation2020). Therefore, the complete extraction of Tibetan Plateau lakes is of great value in the national water cycle, climate and environment monitoring, as well as the protection of lake ecosystems. The Qinghai-Tibet Plateau has an alpine anoxic climate, with an average altitude of 4,000–5,000 meters and an average temperature below zero throughout the year. The plateau is predominantly mountainous with complex topography and landscape. In the process of extracting plateau lakes, the noise of snow, glaciers, and mountain ridges will interfere with the lake extraction results. In addition, there are many kinds of lakes with different geometric forms on the Qinghai-Tibet Plateau, including irregular saltwater lakes, freshwater lakes, and frozen lakes, resulting in a rich variety of spectral texture features on the surface of lakes. Such complex spectral-spatial features will increase the difficulty of complete and accurate lake extraction.
Conventional lake extraction methods mainly rely on the radiometric features of multispectral bands to retrieve lake information. For example, McFeeters (Citation1996) proposed the normalized difference water index (NDWI) to detect water bodies using near-infrared (NIR) and green bands. Xu (Citation2006) developed a modified NDWI (MNDWI) to extract water bodies using green and short-wave infrared (SWIR) bands while suppressing noise from aggregated background regions. However, due to the spatial and temporal variations in the spectral features of lakes, there is difficulty in determining the appropriate threshold value to effectively distinguish lakes from other features (Chen et al. Citation2020). Unlike traditional methods, deep learning has demonstrated effective and outstanding feature learning capabilities. Various researchers have focused on deep learning-based image segmentation and have successively proposed some classical segmentation models (Ge, Xie, and Meng Citation2022). In this regard, many models are adapted from fully connected networks (Shelhamer, Long, and Darrell Citation2017), and encoder-decoder networks are typical FCN-based pixel-level semantic segmentation algorithms, such as U-Net (Ronneberger, Fischer, and Brox Citation2015), PSPNet (Zhao et al. Citation2017), and SegNet (Badrinarayanan, Kendall, and Cipolla Citation2017). The encoder-decoder architecture can improve the inaccurate acquisition of the location of the target region features and the loss of details, mitigating the problem of rough boundaries of the extraction results. Given the excellent performance of codec networks, some researchers have applied them to lake extraction. For example, Mayer et al. (Citation2021) used a U-Net network to capture information on the largest freshwater lake in Southeast Asia, Tonle Sap Lake, from SAR images. Ge, Xie, and Meng (Citation2022) extracted some lakes within China by deepening the U-Net model. All of the above methods can better extract lakes, yet there is incompleteness in segmenting lakes, resulting in complex spatial environments. Therefore, to ensure the quality of lake segmentation, we used the encoder-decoder network model as the infrastructure for lake extraction. Based on this, we further improved the ability of the neural network to obtain the lake extent accurately and completely.
With the gradual improvement of equipment performance and the continuous development of neural networks, relevant experts and scholars have applied deep neural network algorithms to lake extraction research (Li et al. Citation2022). For example, Wang et al. (Citation2020c) proposed a neural network with a multidimensional densely connected convolutional neural network (DenseNet) as a feature extraction skeleton to fuse different levels of lake features and automatically extract the range area of Pyongyang Lake. Li et al. (Citation2021) proposed a fully convolutional neural network with improved densely connected blocks to predict lake information in high-resolution remote sensing images on the basis of the spectrum characteristics of Lakes. Duan and Hu (Citation2019) designed the multiscale feature supervised network, named MSR-Net, to refine the final extraction results of lake water bodies using multiscale information from different levels. Additionally, researchers have made corresponding progress in the extraction of lakes on the Tibetan Plateau. Li et al. (Citation2018) proposed an end-to-end fully convolutional neural network LaeNet to segment the lakes on the Tibetan Plateau and the boundary lines between the lakes and the background region from remote sensing images. Weng et al. (Citation2020) proposed an SR-SegNet model based on codec network architecture for retrieving lake-specific spatial resolution on the Tibetan Plateau. Qin et al. (Citation2020) designed a depth gradient network (UDGN) to improve the spatial resolution of the Tibetan Plateau lake region. However, due to the very different types of lakes on the Tibetan Plateau, the spatial-spectral features are rich and diverse. The above methods are not capable of extracting plateau lake features, which suffer from the loss of lake spatial information. Considering that plateau lake features change with the image scale (Duan and Hu Citation2019), only by combining features of different scales and using multiscale information can we better solve the problem of changes in the size and shape of plateau lakes and the loss of detailed information. To this end, researchers have explored some integration strategies to optimize the network structure using multiscale features of lakes on the Tibetan Plateau. Wang et al. (Citation2020a) proposed an end-to-end multiscale plateau lake extraction network model based on ResNet-101 and depth-separable convolution. However, this model is prone to noise in the extraction process for lakes with rich surface textures. Wang, Gao, and Zhang (Citation2021) proposed a plateau lake segmentation network HA-Net based on a mixed-scale attention model. However, this method can obtain better extraction results for lakes on the Tibetan Plateau. Because of the high interclass heterogeneity of Tibetan Plateau features, the extraction of lake results is interfered with by complex background information, such as snow, glaciers, and mountains, which have the problem of contextual information ambiguity.
To solve the problem of missing contextual information due to background noise interference in lakes. Kang et al. (Citation2021) capture contextual information at different scales by constructing a contextual feature extractor (CTE). Xia et al. (Citation2021) proposed a dense skip connection neural network based on multiscale feature integration and an attention mechanism, which uses connection operations to fully access contextual semantic information and extract a more suitable classification of advanced features. However, considering that the lakes on the Qinghai-Tibet Plateau have certain special characteristics compared with other lakes, the above methods cannot be universally applied to the extraction of plateau lakes. The special features of lakes on the Qinghai-Tibet Plateau are as follows: (1) Plateau lakes are composed of different types of lakes, such as brackish lakes, freshwater lakes, and frozen lakes, with complex and diverse spatial characteristics, resulting in large differences in types and spatial characteristics among lakes. (2) Plateau lakes are mainly distributed in the range of 4000–5000 m above sea level, with complex surroundings, mountains, and snow glaciers, and some of them have icing phenomena. These interference noises easily cause misjudgment and lead to the blurring of contextual information, which interferes with the final prediction effect of plateau lakes. Therefore, for the first challenge of complex spatial features, this study considered the multiscale characteristics of plateau lakes by employing filters of different scales to activate different perceptual fields on the lake feature map and capture the extent of lakes with different spatial patterns. For the second ambiguity problem, we suppressed the weights of irrelevant features by enhancing the weights of highland lake regions. Contextual information was fully exploited in the multiscale receiver domain. In addition, the useful global context was enhanced, and the ambiguity was suppressed using the skip connection operation to raise the expressiveness of the network model in the context of heterogeneity.
In this study, we proposed a multiscale contextual Information aggregation network (MSCANet) for automatically extracting the spatial extent of lakes on the Tibetan Plateau from complex backgrounds. First, based on the encoder network, we proposed a new multiscale lake feature encoder to obtain the spatial-spectral features of lakes on the Tibetan Plateau at different scales. By constructing the interdependence between different feature channels, we focused on the lakes local features and suppress interference from noise in neighboring mountains, snow, etc. Furthermore, before the high-level and low-level features of the lake were fused, the ability to accurately capture lake features is enhanced by aggregating global contextual information of different regions through a Multicore Pyramid Pooling Module (MPPM). Finally, MSCANet was used to improve the accuracy of lake pixels classification and achieve the complete extraction of lake regions on the Tibetan Plateau in a complex context.
Our main contributions are as follows:
In this study, we proposed a deep encoder-decoder network, MSCANet, that aggregates multiscale contextual semantic information for extracting lake regions on the Tibetan Plateau. An encoder-decoder structure was used to connect feature mappings from different levels to obtain more accurate spatial details of plateau lakes.
To completely extract the features of different Tibetan Plateau lakes under complex background noise interference, we designed a multiscale lake feature encoder, which was composed of a Multiscale Feature Integration Module (MSFI) and an Inverted Bottleneck Channel Attention Module (IBCE). It aims to fully utilize feature contextual information from different scale receptive domains and enhance the sensitivity of the model to multiscale spatial-spectral features of plateau lakes.
Introducing the Multicore Pyramid Pooling Module (MPPM), which used the pyramid structure to expand the receptive fields and aggregate the global contextual information of different regions. Context-rich semantic feature maps were generated to improve the robustness of plateau lake extraction in complex backgrounds.
2. Methodology
2.1. Algorithm design
In this study, a multiscale contextual information aggregation network MSCANet was conceived for extracting lakes on the Tibetan Plateau. The architecture used a typical encoder-decoder structure as the base network architecture. It introduces jump-connected cascading low-level features and corresponding high-level features of Tibetan Plateau lake images. The complex spectral texture details of lakes are propagated into high-level semantic features, which makes the overall network model continuously optimized during the training process (Lu et al. Citation2019). Additionally, the multiscale inverted bottleneck channel attention module and the multicore pyramid pooling module were incorporated to address the problem that the shadows of snow, glaciers, and mountains on the Tibetan Plateau were similar to the spatial features of lakes and interfere with the lake extraction results. Therefore, the performance of the network model in extracting lakes on the Tibetan Plateau is improved.
The MSCANet model architecture is shown in , which was composed of three parts: a multiscale lake feature encoder, a feature, a decoder, and a Multicore Pyramid Pool Module (MPPM). First, the spatial resolution of lake features on the Qinghai-Tibet Plateau was reduced by the multiscale lake feature encoder to obtain high-level multiscale lake spectral-spatial features. Specifically, the multiscale lake feature encoder was composed of four sets of Multiscale Feature Integration Modules (MSFI) and an Inverted Bottleneck Channel Attention Module (IBCE). In particular, MSFI can integrate global and local lake features and activate different scale perceptual fields on the lake feature map using multiscale filters to fully exploit the high-level and low-level features of Tibetan Plateau lakes to capture different ranges of lake areas on the corresponding feature images. The relationship between different channels of the multiscale lake feature map was then modeled by the IBCE to accurately extract the spectral features as well as the spatial features of the Tibetan Plateau lakes (Feng et al. Citation2019). This module facilitated the contextual information flow of the whole feature channel. It can automatically filter the lake locations that need attention in the feature map and reduce the loss of lake information in different channels of the feature map.
Figure 1. MSCANet network structure.
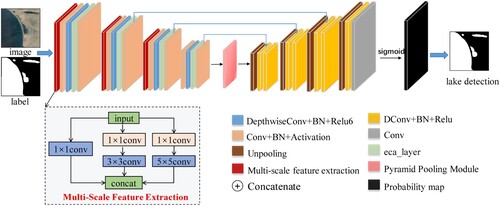
The details of the Multiscale Feature Integration Module (MSFI) are described in section 2.2, the Inverted Bottleneck Channel Attention Module (IBCE) in section 2.3, and the Multicore Pyramidal Pooling (MPPM) unit in section 2.4.
2.2. Multiscale feature integration module (MSFI)
The lakes on the Qinghai-Tibet Plateau have different morphologies and are disturbed by large amounts of snow, glaciers, ridges, and other noise. The existing methods cannot guarantee the correctness of lake pixels classification, especially for small lakes, and cannot extract the detailed part completely. The extraction of semantic and contextual information was enhanced because convolutional filters of different sizes can activate receptive fields of various sizes (Ma et al. Citation2019). Additionally, the multiscale receptive domain aggregated contextual information can not only adapt to the diverse shapes and sizes of lakes on the Tibetan Plateau and make full use of the multiscale features of lakes; it is also the key to distinguishing lakes from shadows (Kang et al. Citation2021). Therefore, this paper introduced the multiscale feature integration module (MSFI), which was used to encode multiscale spatial contexts and make the most of the spatial information of lakes on the Tibetan Plateau.
The multiscale feature extraction section of illustrates the architecture, with multiple parallel convolutional layers combined at different sizes. To obtain semantic information at different scales of the input lake images, three different sizes of convolution kernels were integrated into the first four stages of the encoder in this study: 1 × 1, 3 × 3, and 5 × 5. Due to the increase in computational burden caused by the increase in the number of convolution kernels, the convolution operation of 1 × 1 was augmented to minimize the number of feature dimensions before the 3 × 3 and 5 × 5 convolutions. Among them, the smaller-sized convolution kernels are suitable for mining the local location features of the lake; the larger-sized convolution kernels were suitable for extracting the global features of the lake (Gao et al. Citation2019; Ma et al. Citation2019). Since the local spatial information of the global contextual information of the lake features are weak, the local spatial information of the lake has strong location information but a weak contextual relationship (Sun et al. Citation2019). Therefore, by combining lake features at different scales and extracting both local spatial information and global contextual semantic information at different scales, the complete extraction of lake features while ensuring the capture of local detailed features ultimately improves the robustness of lakes feature extraction on the Qinghai-Tibet Plateau in complex contexts.
2.3. Invert bottleneck channel attention module (IBCE)
Currently, deep convolutional neural networks have been broadly used for lake water classification (Mayer et al. Citation2021; Li et al. Citation2022; Zhang et al. Citation2021c), and by deepening the network, certain progress has been made in promoting the accuracy of feature classification. However, He et al. (Citation2016) discovered that increasing the depth of the neural network does not certainly enhance the performance of the CNN. In contrast, the accuracy may degrade after reaching a saturation state. To avoid the degradation of the network, in this paper, an Inverted Bottleneck Channel Attention Module (IBCE) was constructed to build a lightly weighted deep neural network with reduced computational complexity. Additionally, the IBCE can fuse the inverted residual bottleneck unit and the attention mechanism-based channel weight sharing unit based on the relationship between different channels of lake features, enhancing the sensitivity of the network to the spatial-spectral features of the lake and suppressing the interference noise. Therefore, it can solve the problem of insufficient extraction of spatial information of plateau lake spectra in the complex noise background of remote sensing images (Zhang et al. Citation2021d) and improve the contextual information extraction ability.
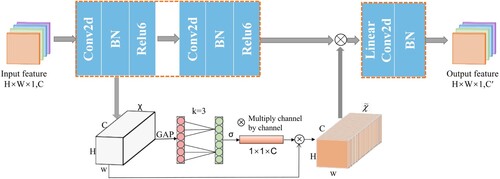
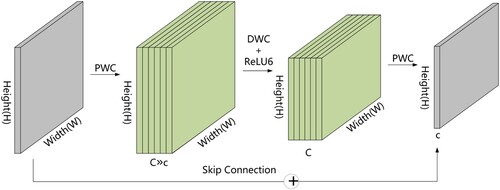
In this study, we extracted the unique spectral-spatial features of Tibetan Plateau lakes in remote sensing images by fusing IBCE modules to target the effective features in each layer. The input data were the lake images of the Tibetan Plateau, and the sum of the convolution kernel dot product was used on each remote sensing image to extract the spectral features of fixed pixel size. Then, the spatial features, such as lake texture, contour, and shape, on remote sensing images were obtained by sliding the window to cover the whole spatial dimension. The specific process is shown in . First, the input Tibetan Plateau lake feature map was expanded to a high-dimensional subspace by point-state convolution to increase the number of channels and improve the gradient propagation ability of the extended convolution layer. Additionally, the linear combination between the input channels was used to generate new features and enhance the ability to obtain spatial information about the lake. Second, a channel-by-channel convolution kernel of depth three was used to slide over different input channels separately to increase the acceptance domain of the feature channels, generating one output channel at a time. Since depthwise convolution provides as many filters as the number of channels in the input image, the generated output image retains the depth of the input image. Next, an attention mechanism was applied to the output features of the deep convolution, and the individual features of the output image are processed across channels interactively (Wang et al. Citation2020d). One-dimensional convolution was used to generate channel weight values, capturing information about the local dependencies between each channel and its adjacent channels. That is, valuable feature information was caught from the feature map by weighting each lake feature (see 2.3.2 for details of the process). All of them were completed, and then the individual channels were processed using point-state convolution to compress the output spatial dimension. In the process of compression, the linear bottleneck transformation preserved the complete feature information of the lake. This linear pointwise transformation with structure contributes to the information flow of the entire feature channel (Sandler et al. Citation2018). Finally, IBCE with a step size of two was used instead of convolution and pooling operations in the shrinkage path to compress the dimensions of the input lake feature map and achieve deep mining of the spatial-spectral features of the Tibetan Plateau lakes.
Figure 2. Schematic diagram of the attention module of the inverted bottleneck channel.
2.3.1 Invert residual bottleneck unit
Depthwise separable convolution is a vital part of the inverted residual bottleneck block (Kulkarni et al. Citation2021), which can improve the robustness of existing models as well as feature representation, making full use of the surrounding and spatial information of the Tibetan Plateau lakes. Depthwise separable convolution decomposes the traditional convolution operation into deep convolution and point convolution to extract features (Li, Zhang, and Lee Citation2019b). As in and , the depth convolution kernels are interconnected with each of the input channels to generate the number of feature maps that are equal to the input channels. The point convolution is a typical 1 × 1 convolution applied to merge information from several channels to strengthen the network's capability to represent lake features (Wang et al. Citation2020d). As shown in , the inverted residual bottleneck architecture leverages deep convolution and point convolution to generate a lightly weighted deep neural network.
Figure 3. Depthwise convolution.
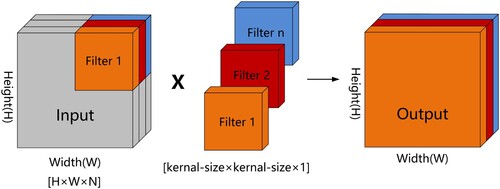
Figure 4. Pointwise convolution.
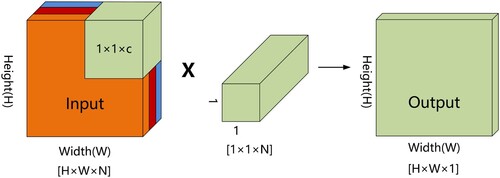
Figure 5. Inverted Residual Block.
The inverted residual bottleneck unit can effectively reduce the network model parameters as well as the complexity while improving the ability to obtain the spectral-spatial information of the feature images and ensuring a high degree of freedom of the model (Zhang et al. Citation2021b). Assuming that the input feature map size is pixels, the number of input channels is M, the convolutional kernel size is
pixels, and the output channel number is N, the mathematical expressions for the computation of the traditional convolution and the computation of the depthwise separable convolution are shown in EquationEquation (1)
(1)
(1) and EquationEquation (2)
(2)
(2) , respectively:
(1)
(1)
(2)
(2)
The amount of deep separable convolution and conventional convolution is shown in EquationEquation (3(3)
(3) ).
(3)
(3)
(4)
(4) According to EquationEquation (4)
(4)
(4) , the reduction in the computational complexity of the depthwise separable convolution is related to the number of output channels and the size of the convolution kernel used. For example, when the kernel size was 3
3, the depthwise separable convolution reduces the computation by approximately 8
9 times compared to the conventional convolution.
2.3.2 Channel weight-sharing unit based on the attention mechanism
To be able to ignore distracting information such as snow, glaciers, and ridges that are not related to lakes and focus only on important lake information, the spatial-spectral characteristics of lakes on the Tibetan Plateau can be extracted more accurately. In this study, we used the channel attention mechanism (Wang et al. Citation2020d) to strengthen the weights of lake regions and suppress the weights of irrelevant features. The output features of the deep convolutional layer were first pooled globally at the channel level without dimensionality reduction, as expressed by EquationEquation (5)(5)
(5) . Global average pooling was used to give each feature map a weight that can be learned to obtain a feature vector with a global perceptual field, which in turn leads to a lake aggregation feature.
(5)
(5) Suppose that the feature vector of the input feature after depth convolution processing is
, where W, H, and C represent the width, height, and channel size of the feature vector, respectively. Then, the interchannel weight was calculated by Formula (6),
(6)
(6)
We have modified Euations(8) and Equation(11). To clearly show the equations that need to be modified, we have marked (8) and (11) in red.
Among them, is the sigmoid activation function, such as the calculation Formula (7).
is the parameter matrix of learning channel attention, defined as Formula (8). It can be seen from Equation (8) that the weight calculation of
only considers the interaction between
and its
adjacent channels.
(7)
(7)
(8)
(8)
For all channels to share the same parameters, Equation (9) was used, where denotes the set with
of its neighboring channels.
(9)
(9)
In other words, the channel weight values can also be generated by performing a fast one-dimensional convolution () of size
to obtain the local dependency information between each channel and
adjacent channels, as shown in Eq. (10).
(10)
(10)
Among them, the interactive coverage (the kernel size of the one-dimensional convolution) was mainly determined adaptively using a function (11) related to the channel dimension,
(11)
(11) In Formula (11), C is the channel dimension. In this study, we set γ and b to 2 and 1, respectively. By mapping ψ, high-dimensional channels have longer-range interactions, while low-dimensional channels have shorter-range interactions by using nonlinear mapping, which ultimately uses attention to focus on important regions of the entire lake feature map (Wang et al. Citation2022).
2.4. Multi-core pyramid pooling module
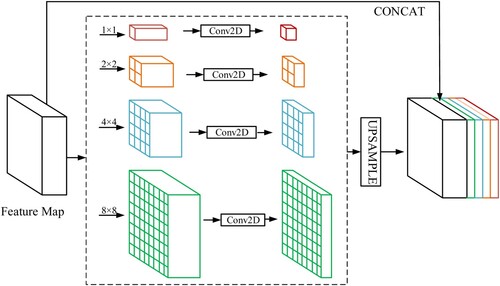
To further increase the receptive field of the neural network and improve the ability of lake feature learning, this study introduced the Multicore Pyramid Pooling Module MPPM (Zhao et al. Citation2017) to extract the deep and shallow context information from the multiscale features of the Qinghai-Tibet Plateau lakes against a complex background. By fusing this information to increase the utilization efficiency of global information, the lake detection model was more accurate. As shown in , the MPPM module uses four different size ranges of pooling operations to obtain lake features from different views according to the specific features of the Tibetan Plateau lakes. Four pooling operations with different kernel sizes are arranged in a pyramid to disperse the input lake feature maps into different regions, therefore outputting feature images with different sizes. Upsampling methods such as bilinear interpolation were used to scale the feature maps to the same size as the original input features, and then all the feature maps from the multicore pooling were fused using a connection, which in turn collected high semantic level Tibetan Plateau lake features from different views (Yu et al. Citation2021).
Figure 6. Multi-core Pyramid Pooling Unit (MPPM) network architecture.
3. Data and experiment
3.1. Dataset
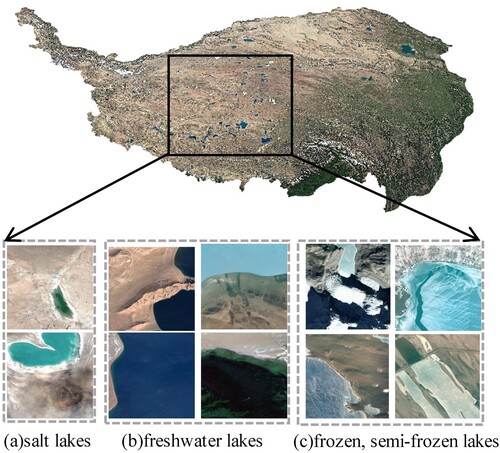
The Tibetan Plateau lake semantic dataset (Wang et al. Citation2020a), as shown in , contains visible spectra of Google Earth remote sensing images at 17 m spatial resolution. The Google Earth is a virtual earth software developed by Google that combines satellite imagery and aerial photography data. The lake dataset was taken at altitudes of 3,000–5,000 meters on the Tibetan Plateau. Lakes on the Tibetan Plateau can be divided into salt and freshwater lakes, where salt lakes have shorelines accompanied by salt belts. Freshwater lakes were characterized by a spectrum of white, light blue, dark blue, and black. Black lakes share shadows of mountains and clouds with similar features, while white lakes have similar features of snow. From the state of the lake, it can be classified as frozen, semi-frozen, and nonfrozen. The dataset had a total of 6774 images with a pixel size of 256 × 256, and the lakes are labeled using labelme. In this study, 6164 images were randomly selected for training and 610 images for testing according to the literature (Wang et al. Citation2020a).
Figure 7. The Tibetan Plateau lake semantic dataset.
3.2. Data preprocessing
We first apply grayscale stretching to the labeled images of the Tibetan Plateau lake semantic dataset (Wang et al. Citation2020d) to change the image contrast and emphasize the local features of the lake in the images. By grayscale mapping, the grayscale value in one segment of the original labels was mapped to another grayscale value, which in turn stretches or compresses the grayscale distribution range of the whole image. Different parameters were set to make the dark part of the image darker and the light part brighter, which finally achieved the enhancement of image contrast, selectively highlighting the target image and suppressing the background image. Increase the gray value distribution between the background and the lake to better separate the lake target from the background.
The remote sensing images with larger resolution cannot be fed directly into the classification network due to the limitation of computer resources, so the remote sensing images were segmented into nonoverlapping image blocks to train the model (Dong et al. Citation2021). It was feasible for our model to input images of arbitrary size during the prediction process. We unified all input images to 128 × 128 pixels to facilitate training and ensure sufficient training memory. In the process of training the model, the convergence of the network became hard, and the rate of training decreased as the depth of the network increased (Huang et al. Citation2019). To improve the accuracy and training efficiency of the network, we standardized the input images by normalizing the distribution of the input images to a normal distribution with mean 0 and variance 1. The calculation formula was as follows.
(12)
(12)
(13)
(13)
(14)
(14) where c, w, and h represent the channel, width, and height of the input image, respectively, and µ is the average value of the input image. As opposed to σ2, which was the variance of the input image. The input images and their normalized results were A and B, respectively.
3.3. Implementation detail
In this study, our experiment was designed and implemented based on the Keras deep learning framework, using Pycharm and Anaconda software to write the programs. The experimental environment was a Linux-based runtime environment with two 24-core Hygon C86 7165 24-core Processor CPUs. The GPU was powered by ASPEED Graphics Family 16Gb. Under this foundation, network training, testing, and validation were conducted using remote sensing image data to corroborate the outstanding advantages of the proposed network model oriented to remote sensing image lake extraction.
Lake extraction is a dichotomous classification problem in semantic segmentation. A sigmoid classifier was used at the end of the MSCANet to obtain the probability that each pixel belongs to a water body, and usually, such problems use a binary cross-entropy loss function.
(15)
(15) In the above equation,
is the true value of the ith pixel, which indicates the true probability that the pixel belongs to the water body or the background.
is the predicted value of the ith pixel, and
takes a value falling within (0,1).
tends to be closer to 1, indicating a higher probability of being a water body. The training process continuously adjusts the weight parameters of the network to minimize the loss. In the experiments, the adaptive moment estimation (Adam) optimizer (Kingma and Ba Citation2014) was used for training, setting the initial learning rate to 0.0001 and the number of iterations to 5000.
3.4. Evaluation metrics
In considering the quantitative evaluation of the extraction accuracy of water bodies, this study used the Precision, the Recall, the F1-score, the intersection over union (IOU), and the mean intersection over union (MIOU) (Wang et al. Citation2020a), as shown in Eqs. Equation(16)(16)
(16) –(20).
(16)
(16)
(17)
(17)
(18)
(18)
(19)
(19)
(20)
(20) where TP denotes the count of correctly extracted lake pixels, FP represents the number of incorrectly extracted lake pixels, FN indicates the amount of extracted missed lake pixels, and k denotes the number of categories (excluding the number of backgrounds).
4. Results and analysis
4.1. Extraction results of the Tibetan Plateau lake semantic dataset
To verify the effectiveness of the proposed MSCANet model for lake extraction in the Tibetan Plateau lake semantic dataset, we employed AMS-UNet (Lu et al. Citation2019), Unet(Ronneberger, Fischer, and Brox Citation2015), ResNet(He et al. Citation2016), ResUNet(Gao et al. Citation2019), FCN_VGG16(Li et al. Citation2019a), MSCENet(Kang et al. Citation2021), HR-Seg(Zhang et al. Citation2020) for comparison. The experimental results are shown in . Specifically, compared with AMS-UNet, MSCANet increased in F1, MIou values by 2.82%, 3.54%, respectively. Because IBCE module fully utilizes contextual information, it also has strong expressive power in heterogeneous contexts. The MSCANet showed an increase in F1, MIou values of 4.54%, 6.06%, respectively, compared with U-Net. This is because MSFI can capture lake information at different scales and get more comprehensive spatial information. In particular, the average growth rate of F1, MIou of MSCANet in comparison with ResNet, ResUNet was increased by 3.735%, 5.785% respectively. The reason lying in the fact is that the channel attention mechanism can focus on the local features of the lake and suppress the interference of the surrounding background noise. Furthermore, our method outperformed the FCN_VGG16 with growth of 2.22%, 3.88% in F1, MIou values, respectively. Thanks to the ability of MSFI to activate different receptive fields according to the filters of different scales, it has the ability to extract various spatial patterns of lakes. In comparison with MSCENet, our method MSCANet gained 1.12% and 1.14% in F1, MIou values respectively, which is due to the fact that IBCE helps to enhance the sensitivity of the network to the spatial spectral features of the lake and improve the ability of contextual information extraction. HR-Seg combined a high-resolution network (HRNet) as the underlying architecture with a contextual aggregation design at different levels to enhance the low-to-high feature information obtained from different branches, Compared to HR-Seg, MSCANet exhibits an improvement of 4.04% and 7.19% in F1, MIou values, as MPPM aggregates contextual information from different areas of the globe by expanding the receptive fields and channel attention mechanism can concentrate on the target lake areas.
Table 1. Experimental results of the Tibetan Plateau lake semantic dataset.
4.1.1. Analysis of the lakes spatial characteristics
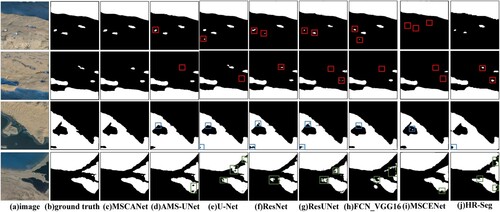
The MSCANet proposed in this study can effectively extract the spatial information of small lakes from remote sensing images, as in the first and second areas of , and the contours and shapes of small lakes very close to each other can be accurately obtained (red boxes). The (d) AMS-UNet, (f) ResNet, (g) ResUNet, (i) MSCENet, and (j) HR-Seg models in the first block cannot completely predict the small lake area. Especially (i) all small lakes are not predicted. (e) U-Net did not accurately identify the lake and mistakenly treated the land as a lake because U-Net only takes the image blocks as input and cannot handle the boundary regions of each image block; the second block area of all seven comparison networks had the problem of incomplete and accurate extraction of small lakes. In the third area, the MSCANet model can extract the lake area (blue box) accurately, avoiding the irregular form of the ground boundary, while the other comparison models misclassify the road detail part as the lake extent. In the fourth area, the MSCANet model can distinguish the narrow road between two lakes and ensure the accuracy and continuity of the overall contour of the extraction results, while (e) UNet and (j) HR-Seg could not specify the demarcation line of the two lakes. Meanwhile, (d) AMS-UNet extracted lakes show holes (green boxes) and (e) UNet, (f) ResNet, and (g) ResUNet all show misclassification. (h) FCN_VGG16 was a fully convolutional network-based lake extraction model, which can better extract large-area lakes with regular shapes. However, because the fully convolutional network cannot solve the problem of blurred class boundaries, it had a large deviation in predicting different classes for lakes with complex spatial shapes, such as region four incorrectly classifying most of the lakes on the right side as ground and misclassifying small detailed parts of the irregular ground as lake boundaries. (i) MSCENet was a multi-scale context extractor-based network architecture, as shown in , which had a serious problem of failing to identify small lakes, such as region one, two, and four. Simultaneously misjudgment cases existed, such as the land area in the middle of region three lakes. The reason for this is that the CTE module causes a loss of continuity of spatial features of different morphological water bodies in a complex background environment. (j) HR-Seg was a multi-scale contextual aggregation algorithm for semantic segmentation, and the approximate location of lakes could be predicted. However, it could not completely delineate the small lake area, and there was a problem of incomplete extraction compared to the label. Although (i) MSCENet and (j) HR-Seg are both multi-scale contextual semantic algorithms, however, they cannot be universally applied to plateau lakes’ spatial feature extraction accurately for the geographic environment of snow-covered, glacier-covered, and mountainous areas in the Tibetan Plateau. By comparing several common neural networks, it was proven that the MSCANet model can mine the spatial information of remote sensing images to achieve the correct classification of target pixels and complete extraction of the detailed parts of small lakes.
Figure 8. Lake localization for different segmentation models.
4.1.2. Analysis of the frozen lakes surface
For the frozen lake surface, the MSCANet also had good results. As shown in (d) AMS-UNet has holes in the first two frozen areas of the lake during extraction and then predicts disturbances similar to the lake spectrum as lakes in the third four areas. (e) U-Net identified a large number of shaded parts as lakes and completely cuts the boundary between lakes and land. (f) ResNet and (g) ResUNet were very poor at recognizing frozen lake surfaces and cannot extract frozen lake surfaces completely. The noise was obvious, and the extracted classification results were far from the image reality, which leads to the visual inability to obtain the boundary of the lake. (h) FCN_VGG16 had the problem of class boundary-blurring; for example, in the first two regions, although there was incomplete extraction, the situation of mistaking land for lakes was more serious. (i) The MSCENet resulted in wrong frozen lake surface extraction. (j)HR-Seg extraction of frozen lake surfaces had a large number of missing features, such as the first and second areas. The problem of misclassifying lakes surfaces were also more serious, such as the third and fourth areas. The overall effect of (c) MSCANet is shown in the third column of , which could extract particularly small frozen lakes and rarely mistook land shadows as lakes. But (c) MSCANet also existed a small part of frozen lake surface extraction incomplete and misclassification, such as the first area (red box), which is due to the fact that the ground is very similar to the frozen lake surface in appearance. On the whole, our proposed MSCANet had a large improvement compared to other models and obtained the most accurate segmentation results as possible.
Figure 9. Frozen lake localization for different segmentation models.

4.1.3. Analysis of the lakes texture and spectral features
Different kinds of objects may share the same spectrum, while one object may have distinct spectra (Wang et al. Citation2020b). Additionally, in Google's remote sensing images, the different seasons of shooting can likewise cause differences in the texture and spectral features of the lake. By observing the five different regions in , it can be found that the proposed method in this study can still extract the results more completely and accurately on lakes with different textures and spectral features. We successfully solved the problem that lakes with rich surface textures easily generate noise in the extraction process and have an insufficient ability to obtain spectral information from remote sensing images. In the first three areas, the lakes had a complex texture structure. (d) AMS-UNet. (f) ResNet. (g) ResUNet and (j) HR-Seg had a weak effect in extracting the lakes with a large difference in texture features (red box), and none of the lakes with complex texture features were captured completely. Additionally, the phenomenon of classifying the land context around the lake as a lake is more serious in the first region, such as (f) ResNet (g) ResUNet has more obvious noise (blue box). (i) MSCENet did not capture the small lake in the upper left corner of the first area at all. The lakes in the fourth and fifth blocks had different spectral characteristics. Specifically, the five comparison models in the fourth block have more or less incomplete extraction as well as incorrect extraction (blue box); the lake in the fifth block was spectrally black, (c) MSCANet can accurately extract the lake area, while (d) AMS-UNet, (e) U-Net, (f) ResNet, (g) ResUNet, and (j) HR-Seg regarded the black spectral features as land (green box), and most of the lake extent was not detected. In general, (g) ResNet had the worst result, and (h) FCN_VGG16 had a better extraction result compared with the other four comparison networks. Meanwhile, the proposed method (c) MSCANet can still well maintain the integrity, continuity, and the ability to accurately capture the detailed parts of the extraction results under the complex texture and spectral features.
Figure 10. Lake localization for different segmentation models.

4.2. Modeling generalization
The MSCANet network was trained using the Tibetan Plateau lake semantic dataset, and the optimal model training weights were saved (Wang et al. Citation2021). To validate the generalizability of the proposed Tibetan plateau lakes extraction model, MSCANet, on different scale remote sensing images. In this paper, Landsat-8 satellite images with 30 m resolution, Sentinel-2A satellite images with 10 m resolution, and Google Earth images with 8 m resolution were selected as data source. Meanwhile, we chose lakes with different types, states and spectral-spatial features on the Tibetan Plateau to verify the effectiveness of MSCANet.
4.2.1. Landsat-8 dataset
Considering the wide coverage of lakes on the Qinghai-Tibet Plateau. In this paper, NASA’s hyperspectral remote sensing satellite Landsat-8 images with 30 m resolution in 2020 were selected as the validation data source, thus encompassing a broader plateau lake area. We employed the GLC_FCS30-2020 land use label (Zhang et al. Citation2021a) and adjusted this multiclassification label into two categories: non-water bodies and water bodies. Eventually, in order to better authenticate the accuracy of different types of lakes extracted from the Tibetan Plateau. We divided the validation dataset into five major categories: small lakes, frozen lakes, background-disturbed lakes, freshwater lakes, and salt lakes. After the data augmentation process, the final sample sizes were determined: 120 small lakes, 123 frozen lakes, 150 background-disturbed lakes, 183 salt lakes, and 96 freshwater lakes. For highlighting the extracted lake features better, the predicted results were cut into 256 × 256 pixel sizes in this paper.
4.2.1.1. Performance comparison in small lake regions
For different spatial and spectral features, different types, and different states of small lakes, our proposed method MSCANet could define the contour shape of the lake more accurately. As shown in , the extraction results of deep learning comparison methods on three different small lakes all had the problem of lake omission or false alarms, especially U-Net, ResNet, ResUNet, and HR-Seg. In the meantime, owing to the unique spatial and temporal variability of the spectral features of lakes on the Tibetan Plateau, it was difficult for the traditional methods NDWI and MNDWI to determine suitable thresholds to effectively distinguish lakes from other features, such as mountains and snow. Additionally, as marked in red #1, our method MSCANet misclassified mountain with similar spectral features to lakes as lakes. Like #2 labeled, frozen lake with similar appearance as well as spectral features to the snow of the surrounding mountains was not predicted. However, our method was able to extract the spatial features of small lakes with complex texture features accurately. While observing the quantitative results in , we found that MSCANet had the highest average accuracy.
Figure 11. Performance comparison of different models for small lakes extraction.

Table 2. Experimental results of the small lakes dataset.
4.2.1.2. Performance comparison in frozen lake regions
gave a subset of the lake extraction results in the frozen lake dataset of the Tibetan Plateau. The first column showed three remote sensing images of frozen lakes with different scales, contextual environments, and spectral features. The visualization results showed that our proposed MSCANet generated the expected lake extraction maps, which were relatively close to the mountain facts. For the case of the first glacier adjacent to a frozen lake, the comparison methods had more or less the problem of misclassifying the glacier as a lake. In the second area, comparison methods had incomplete frozen lake surface extraction. Especially NDWI, no suitable threshold value was selected causing large frozen lake surface not to be identified. In the third area, frozen lake surfaces were not predicted. And yet, as shown in #1, for glaciers with similar appearance and spectral features to the lake, MSCANet could have misjudgment. In addition, as shown in #2, no accurate predictions were made for regions with extremely similar spectral features to the mountain. This is because MSCANet is a highland lake extraction model. A piece of previous knowledge about the geometric properties of frozen lakes is less considered, which leads to wrong lake extraction ().
Figure 12. Performance comparison of different models for frozen lakes extraction.
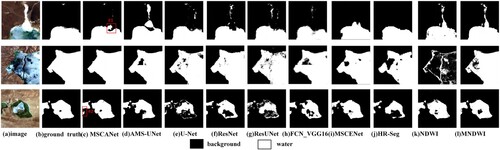
Table 3. Experimental results of the frozen lakes dataset.
4.2.1.3. Performance comparison in background-disturbed lake regions
A subset of the extraction results from the Tibetan Plateau lake dataset under snow, glacier, and cloud cover were given in . For the first area disturbed by snow, most comparison methods were interfered by snow and misclassified the snow as lakes. After comparison, we found that the more accurate the lake extraction was, the easier it was for NDWI to misclassify snow on mountain ranges as lakes when different thresholds were chosen, due to the similarity of snow and lake features. For the second glacier-disturbed lake, AMS_UNet, ResUNet, MSCANet, NDWI, and MNDWI clearly misjudged the glacier as a lake. In the third region, we mainly used the spatial proximity relationship and the spatial continuity based on its proximity to perform the identification of cloud-covered pixels (Qiu et al. Citation2019), and then judged that the region was obscured by clouds. With the qualitative representation in and the quantitative representation in , our method MSCANet showed good results under the interference of snow, glacier, and cloud backgrounds. This is with the advantage that the IBCE module can accurately distinguish the target lakes even under the interference of complex background noise and filter out irrelevant information.
Figure 13. Performance comparison of different models for background-disturbed lakes extraction.
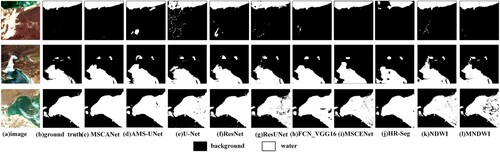
Table 4. Experimental results of the background-disturbed lakes dataset.
4.2.1.4. Performance comparison in freshwater lake regions
We selected some of the freshwater lakes in the Tibet Plateau endorheic basin and they were in the spectral characteristics of the black color is dominant. As shown in , contrast networks did not accurately predicted the spectral features of black lakes. On the contrary, the continuity and accuracy of the spatial features of freshwater lakes extracted by our proposed MSCANet was much stronger. This proved that our proposed network can maintain good prediction performance even under different spectral features and texture structures. At the same time, other comparison network models suffered from the problem of destroying the spatial structure of the feature maps, which led to spatial information loss. Finally, as shown in , the traditional water body index method NDWI predicted good performance of freshwater lakes, and the threshold value could capture the dividing line between freshwater lakes and the mountain more successfully. On the other hand, the results extracted by MNDWI were not satisfactory, which indicated that the threshold value was not applicable to partitioning freshwater lakes.
Figure 14. Performance comparison of different models for freshwater lakes extraction.

Table 5. Experimental results of the freshwater lakes dataset.
4.2.1.5. Performance comparison in salt lake regions
As in , where we showed the extraction effect of some salt lake areas. In the first area, U-Net, ResUNet, HR-Seg, NDWI, and MNDWI were not accurate enough for lakes outline extraction. The second area in which AMS_UNet, ResNet, MSCENet, and HR-Seg misclassified the salt zone next to the lake as a lake, AMS_UNet was the most obvious. All remaining comparison methods had missed detection and false detection. In the third area, in the process of extracting salt lakes, there were cases of misjudgment influenced by the background information. In conclusion, both quantitatively and qualitatively, our method had good results ().
Figure 15. Performance comparison of different models for salt lakes extraction.

Table 6. Experimental results of the salt lakes dataset.
4.2.2. Sentinel-2A dataset
We verified the robustness of our proposed model in depth using Sentinel-2A satellite remote sensing image data with a resolution of 10 m in 2020; and easily observed the detailed parts of the lake in the Tibetan Plateau. The label data were annotated by Labelme software. According to different lake features, we chose different pixel sizes for the images: 512 × 512, 1536 × 1536, 1024 × 1024, 512 × 512, and 2048 × 2048. illustrated the extraction results of eight neural network methods for five different regions, different types, and different spatial and spectral features. Regarding the first frozen lake region, the conflicting methods all had the issue of incomplete lakes surface prediction, and the U-Net network had the most serious problem. The second area was part of the freshwater Lake, and the comparison network had some defects in obtaining the spatial boundary features of the freshwater lake. Meanwhile, there were discontinuities as well as multiple judgments. For example, it misidentified the mountain background area as lakes. In the third area, MSCANet could more effectively extract the spatial extent of small lakes and lakes with diverse spectral features. For the fourth cloud-covered lake, from the quantitative results, as shown in , MSCANet was less influenced by the cloud cover. However, other comparison methods could not catch the lakes under the cloud cover accurately on the one hand; on the other hand, the lakes with black spectral texture features could not be predicted automatically. The fifth area was the salt lake, and the comparison methods had incomplete prediction of the surrounding small lakes and interference of background information.
Figure 16. Performance comparison of different models for Sentinel-2A dataset extraction.

Table 7. Experimental results of the Sentinel-2A dataset.
In summary, by qualitative and quantitative judgments, although our method MSCANet was also subject to judgment errors and background interference on five regions, the spatial continuity as well as accuracy of the lake results extracted by MSCANet was higher compared to other networks. At the same time, the comparison method had better extraction results for a certain region, but could not guarantee good effects for all five regions. For example, MSCENet had the highest F1 value in region 3 and region 5, while the prediction results in other regions were not as satisfactory as our method, especially for the fourth region, where the lake extraction accuracy was at the bottom of all methods. Whereas MSCANet showed promising performance in the five regions.
4.2.3. Google earth dataset
To verify the robustness of the optimal model, this study obtained brand new regions of lakes on the Qinghai-Tibet Plateau from Google Earth, generates binary classification images of corresponding lakes based on OSM vector water data (Liu et al. Citation2021), and used the MSCANet model to obtain the lake parts. We selected five lakes with different states, types and textural spectral features distributed in Tibet Autonomous Region and Qinghai Province, whose pixel sizes were 1024 × 1024, 1536 × 1536, 768 × 768, 1536 × 1536, 768��× 768, respectively. The images of five lake areas with different textures and spectral features as well as the extraction results are shown in . The specific accuracy results are shown in .
Figure 17. Lake prediction results for different textures and spectral characteristics of the Tibetan Plateau.
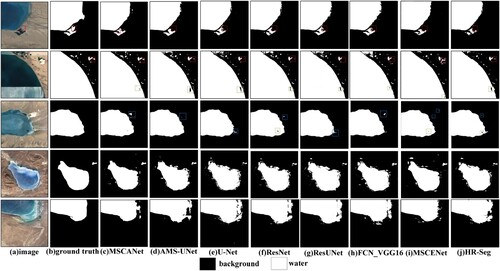
Table 8. Experimental results of the Google Earth Dataset.
As in , region 1, for small lakes with similar spectral features to the ground, all neural network methods did not predict accurately. In addition, all comparison methods had different degrees of empty cases. In contrast, the extraction results of MSCANet retain its morphological features while accurately capturing the small lakes separated from it (red box). For the same lake with different texture features as in region 2, there was an obvious texture gap between the upper and lower parts of the large lake and the middle part, yet the extraction results were not affected by the texture difference. It was observed that the comparison network would have obvious lake missing cases (green box) when predicting lakes with complex texture features through . In addition, The MSCANet was less affected by low clouds and could extract the whole lake area covered by clouds (green box). Specifically, it was accurate in predicting numerous tiny lakes with fragmented shores (red boxes). The region 3 is a salt lake, our model could completely extract the frozen lake surface as well as the continuous lake boundary; however, there was a minor part of disturbing factors divided into lakes due to the influence of surrounding white shadows (blue boxes). In the fourth and fifth regions, the comparison method was disturbed to vary by background information, such as the surrounding mountains of the frozen lakes, and thus misclassified them as lakes. Although the MSCANet model was also subject to the error of starring and classifying land shadows, etc., as lakes. However, from the overall lake extraction results, small lakes, lakes with different textural spectral features, and frozen lakes can be correctly predicted. Compared with the comparison network, The MSCANet had some advantages in extracting the area obscured by clouds.
Through the above extraction of different types of lakes, such as small lakes, frozen lakes, background-disturbed Lakes, freshwater lakes, and salt lakes. We found that, in general, our proposed method has higher accuracy requirements than the existing traditional water extraction methods NDWI and MNDWI, and had stronger robustness for different types of lake extraction in highland environments. The traditional methods were less effective for lake extraction in the complex environment around the lakes on the Tibetan plateau, which was easy to misjudge. Meanwhile, the existence of icing and the sophisticated spectral texture features on the surface of some lakes was unfavorable to the lake extraction by traditional methods. As a comparative experiment, NDWI, and MNDWI could also be achieved with higher accuracy by adjusting the threshold value. However, this required a strong sense of subjectivity, considerable experience, and plenty of time. It was difficult to adapt it to large-scale automated applications. Compared with the deep learning methods proposed by related experts, our method could extract not only from Google remote sensing images, but also from Landsat-8, Sentinel-2 across scales and data sources to extract the contour boundaries of the Tibetan Plateau lakes. In other words, we could achieve the extraction of different types of Tibetan Plateau lakes from remote sensing images of different data sources using only one dataset. This saved time and experience to a great extent. Meanwhile, this indicated that our model had good generalization and stability. Therefore, given the advantages of MSCANet in extracting multi-scale and unique features of Tibetan Plateau lakes, our MSCANet achieved the expected extraction performance in dealing with lakes rich in variations with different scales, freezing, spectral and complex texture features.
4.3. Ablation experiments results
The ablation experiments were conducted on the Tibetan Plateau lake semantic dataset to analyze the effect of having a Multiscale Feature Integration module (MSFI), Inverted Bottleneck Channel Attention module (IBCE), Channel Attention Mechanism, and Multicore Pyramid Pooling Module (MPPM) to verify the effectiveness of each module structure on improving the accuracy of lake extraction results. (1) CANet model: There is no MSFI module for MSCANet. In this paper, we improved the robustness of lake features extraction by embedding multi-scale image features to refine the segmentation mapping. showed that the proposed encoder-decoder model in this paper improved the F1 value by 2.09% on the Tibetan Plateau lake semantic dataset, which confirmed the effectiveness of the MSFI module. (2) MSANet model: The MSCANet without IBCE module. We designed the IBCE module to enhance the expression of the spatial features of lake spectra while deepening the number of network layers and improving the capture of lake details on the Tibetan Plateau. showed that the module was effective in enhancing the accuracy of extracting lakes on the Tibetan Plateau, with an F1 value increase of 2.03%, confirming the effectiveness of the IBCE module.(3) MSIRNet model: MSCANet without channel attention mechanism was utilized to verify the effectiveness of the channel attention mechanism, which can ignore distractors such as shadow glaciers, mountains, and snow that are not related to the lake and focus only on important lake semantic information. (b) As shown in , this channel attention mechanism improved the F1 value by 1.42% in the dataset. (4) MSCNet model: MSCANet without MPPM module, used to verify the effectiveness of MPPM. Using MPPM to increase the perceptual field of the neural network to integrate global and local contextual information. Thus contributing to the decoder to recover a clearer lake profile. The use of this module in improved the final accuracy by 0.23%. Although the improvement in accuracy is small, it is sufficient to prove the validity of the MPPM.
Table 9. Ablation experiment results.
The results of the above ablation experiments showed that the MSCANet outperforms CANet, MSANet, MSIRNet, MSCNet, and MSCNet on the Tibetan Plateau lake semantic dataset, which indicated that MSFI, IBCE, channel attention mechanism, and MPPM all had a positive contribution to the improvement of MSCANet model accuracy.
5. Conclusion
In this study, we have proposed an MSCANet model for lake extraction on the Qinghai-Tibetan Plateau from different remote sensing images, which was based on an encoder-decoder network. The model used multiscale lake feature encoders to increase the depth of the network without causing model degradation, extracted a large amount of useful multiscale contextual spectral-spatial information of Tibetan Plateau lakes, enhanced the sensitivity of the network to information features, and suppressed interference noise by weakening useless information from a global perspective. Additionally, a multicore pyramid pooling module was introduced to use the pyramid structure to expand the receptive field and extract robust features of lake objects with different scales (Liu et al. Citation2022). Our research targets the lake region of the Tibetan Plateau in remote sensing images, which were extracted using the designed MSCANet model and compared with the results of AMS-UNet and classical U-Net, ResNet, ResUNet, and FCN_VGG16 network segmentation algorithms. The results showed that the proposed method can extract small target lake areas more accurately and ensure the integrity of the extraction results, more accurately distinguishing the boundaries between backgrounds such as glaciers, snow, mountains, ridges, and lakes. It also has advantages in improving the accuracy of lakes with different textures and spectral features. Finally, we transferred the pre-trained optimal model to the Landsat-8 and Sentinel-2A datasets to verify the robustness of the MSCANet. Meanwhile, this study acquired new lake images from Google Earth of the Tibetan Plateau and uses pre-trained weights to predict lake areas. By applying our proposed model MSCANet to lake extraction from remote sensing images with different data sources, we successfully verified the effectiveness of the MSCANet model in extracting lakes on the Tibetan Plateau.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The Tibetan Plateau lake semantic dataset is provided by National Cryosphere Desert Data Center. (http://www.ncdc.ac.cn). The code used in this study are available by contacting the corresponding author.
Additional information
Funding
References
- Badrinarayanan, V., A. Kendall, and R. Cipolla. 2017. “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (12): 2481–2495. doi:10.1109/TPAMI.2016.2644615.
- Chen, Y., L. Tang, Z. Kan, M. Bilal, and Q. Li. 2020. “A Novel Water Body Extraction Neural Network (WBE-NN) for Optical High-Resolution Multispectral Imagery.” Journal of Hydrology 588: 125092. doi:10.1016/j.jhydrol.2020.125092.
- Dong, Z., G. Wang, S. Amankwah, X. Wei, Y. Hu, and A. Feng. 2021. “Monitoring the Summer Flooding in the Poyang Lake Area of China in 2020 Based on Sentinel-1 Data and Multiple Convolutional Neural Networks.” International Journal of Applied Earth Observation and Geoinformation 102 (13): 102400. doi:10.1016/j.jag.2021.102400.
- Duan, L., and X. Hu. 2019. “Multiscale Refinement Network for Water-Body Segmentation in High-Resolution Satellite Imagery.” IEEE Geoscience and Remote Sensing Letters PP 99: 1–5. doi: 10.1109/LGRS.2019.2926412.
- Feng, W., H. Sui, W. Huang, C. Xu, and K. An. 2019. “Water Body Extraction from Very High-Resolution Remote Sensing Imagery Using Deep U-Net and a Superpixel-Based Conditional Random Field Model.” IEEE Geoscience and Remote Sensing Letters 16 (4): 618–622. doi:10.1109/LGRS.2018.2879492.
- Gao, L., W. Song, J. Dai, and Y. Chen. 2019. “Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network.” Remote Sensing 11 (5): 552. doi:10.3390/rs11050552.
- Ge, C., W. Xie, and L. Meng. 2022. “Extracting Lakes and Reservoirs from GF-1 Satellite Imagery Over China Using Improved U-Net.” IEEE Geoscience and Remote Sensing Letters 19: 1–5. doi:10.1109/lgrs.2022.3155653.
- He, K., X. Zhang, S. Ren, and J. Sun. 2016. “Deep Residual Learning for Image Recognition.” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778. doi:10.1109/CVPR.2016.90.
- Huang, J., X. Zhang, Q. Xin, Y. Sun, and P. Zhang. 2019. “Automatic Building Extraction from High-Resolution Aerial Images and LiDAR Data Using Gated Residual Refinement Network.” ISPRS Journal of Photogrammetry and Remote Sensing 151 (5): 91–105. doi:10.1016/j.isprsjprs.2019.02.019.
- Kang, J., H. Guan, D. Peng, and Z. Chen. 2021. “Multi-scale Context Extractor Network for Water-Body Extraction from High-Resolution Optical Remotely Sensed Images.” International Journal of Applied Earth Observation and Geoinformation 103: 102499. doi:10.1016/j.jag.2021.102499.
- Kingma, D., and J. Ba. 2014. “Adam: A Method for Stochastic Optimization.” Computer Science, doi:10.48550/arXiv.1412.6980.
- Kulkarni, U., M. S, S. Gurlahosur, and G. Bhogar. 2021. “Quantization Friendly MobileNet (QF-MobileNet) Architecture for Vision Based Applications on Embedded Platforms.” Neural Networks 136: 28–39. doi:10.1016/j.neunet.2020.12.022.
- Li, Y., B. Dang, Y. Zhang, and Z. Du. 2022. “Water Body Classification from High-Resolution Optical Remote Sensing Imagery: Achievements and Perspectives.” ISPRS Journal of Photogrammetry and Remote Sensing 187: 306–327. doi:10.1016/j.isprsjprs.2022.03.013.
- Li, P., X. He, M. Qiao, D. Miao, X. Cheng, D. Song, M. Chen, et al. 2021. “Exploring Multiple Crowdsourced Data to Learn Deep Convolutional Neural Networks for Road Extraction.” International Journal of Applied Earth Observation and Geoinformation 104: 102544. doi:10.1016/j.jag.2021.102544.
- Li, R., W. Liu, L. Yang, S. Sun, W. Hu, F. Zhang, and W. Li. 2018. “DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 11: 3954–3962. doi:10.1109/JSTARS.2018.2833382.
- Li, L., Z. Yan, Q. Shen, G. Cheng, L. Gao, and B. Zhang. 2019a. “Water Body Extraction from Very High Spatial Resolution Remote Sensing Data Based on Fully Convolutional Networks.” Remote Sensing 11 (10): 1162. doi:10.3390/rs11101162.
- Li, Y., D. Zhang, and D. Lee. 2019b. “IIRNet: A Lightweight Deep Neural Network Using Intensely Inverted Residuals for Image Recognition.” Image and Vision Computing 92: 103819.1–103819.8. doi:10.1016/j.imavis.2019.10.005.
- Liu, W., X. Chen, Jiangjun Ran, Lin Liu, Qiang Wang, Linyang Xin, and Gang Li. 2021. “LaeNet: A Novel Lightweight Multitask CNN for Automatically Extracting Lake Area and Shoreline from Remote Sensing Images.” Remote Sensing 13 (1): 56. doi:10.3390/rs13010056.
- Liu, T., M. Gong, D. Lu, Q. Zhang, H. Zheng, F. Jiang, and M. Zhang. 2022. “Building Change Detection for VHR Remote Sensing Images via Local–Global Pyramid Network and Cross-Task Transfer Learning Strategy.” IEEE Transactions on Geoscience and Remote Sensing 60: 1–17. doi:10.1109/tgrs.2021.3130940.
- Lu, J., Y. Qiu, X. Wang, W. Liang, P. Xie, L. Shi, M. Menenti, and D. Zhang. 2020. “Constructing dataset of classified drainage areas based on surface water-supply patterns in High Mountain Asia.” Big Earth Data 4 (3): 225–241. doi: 10.1080/20964471.2020.1766180.
- Lu, X., Y. Zhong, Z. Zheng, Y. Liu, J. Zhao, A. Ma, and J. Yang. 2019. “Multi-Scale and Multi-Task Deep Learning Framework for Automatic Road Extraction.” IEEE Transactions on Geoscience and Remote Sensing 57 (11): 9362–9377. doi:10.1109/TGRS.2019.2926397.
- Ma, L., Y. Liu, X. Zhang, Y. Ye, G. Yin, and B. Johnson. 2019. “Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review.” ISPRS Journal of Photogrammetry and Remote Sensing 152: 166–177. doi:10.1016/j.isprsjprs.2019.04.015.
- Mayer, T., A. Poortinga, B. Bhandari, Andrea P. Nicolau, K. Markert, N. Thwal, A. Markert, et al. 2021. “Deep Learning Approach for Sentinel-1 Surface Water Mapping Leveraging Google Earth Engine.” ISPRS Open Journal of Photogrammetry and Remote Sensing 2: 100005. doi:10.1016/j.ophoto.2021.100005.
- McFeeters, S. 1996. “The use of the Normalized Difference Water Index (NDWI) in the Delineation of Open Water Features.” International Journal of Remote Sensing 17 (7): 1425–1432. doi:10.1080/01431169608948714.
- Qin, M., L. Hu, Z. Du, Y. Gao, L. Qin, F. Zhang, and R. Liu. 2020. “Achieving Higher Resolution Lake Area from Remote Sensing Images Through an Unsupervised Deep Learning Super-Resolution Method.” Remote Sensing 12 (12): 1937. doi:10.3390/rs12121937.
- Qiu, Y., P. Xie, M. Leppäranta, X. Wang, J. Lemmetyinen, H. Lin, and L. Shi. 2019. “MODIS-based Daily Lake Ice Extent and Coverage dataset for Tibetan Plateau.” Big Earth Data 3 (2): 170–185. doi: 10.1080/20964471.2019.1631729.
- Ronneberger, O., P. Fischer, and T. Brox. 2015. “Lecture Notes in Computer Science.” International Conference on Medical Image Computing and Computer-Assisted Intervention, doi:10.1007/978-3-319-24574-4_28.
- Sandler, M., A. Howard, M. Zhu, A. Zhmoginov, and L. C. Chen. 2018. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 4510–4520. doi:10.1109/CVPR.2018.00474.
- Shelhamer, E., J. Long, and T. Darrell. 2017. “Fully Convolutional Networks for Semantic Segmentation.” IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (4): 640–651. doi:10.1109/TPAMI.2016.2572683.
- Sun, G., H. Huang, A. Zhang, F. Li, H. Zhao, and H. Fu. 2019. “Fusion of Multiscale Convolutional Neural Networks for Building Extraction in Very High-Resolution Images.” Remote Sensing 11 (3): 227. doi:10.3390/rs11030227.
- Wang, J., F. Chen, M. Zhang, and B. Yu. 2022. “NAU-Net: A New Deep Learning Framework in Glacial Lake Detection.” IEEE Geoscience and Remote Sensing Letters 19: 1–5. doi:10.1109/lgrs.2022.3165045.
- Wang, Z., X. Gao, and Y. Zhang. 2021. “HA-Net: A Lake Water Body Extraction Network Based on Hybrid-Scale Attention and Transfer Learning.” Remote Sensing 13 (20): 4121. doi:10.3390/rs13204121.
- Wang, Z., X. Gao, Y. Zhang, and G. Zhao. 2020a. “MSLWENet: A Novel Deep Learning Network for Lake Water Body Extraction of Google Remote Sensing Images.” Remote Sensing 12 (24): 4140. doi:10.3390/rs12244140.
- Wang, Y., Z. Li, C. Zeng, G. Xia, and H. Shen. 2020b. “An Urban Water Extraction Method Combining Deep Learning and Google Earth Engine.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 13: 769–782. doi:10.1109/Jstars.2020.2971783.
- Wang, G., M. Wu, X. Wei, and H. Song. 2020c. “Water Identification from High-Resolution Remote Sensing Images Based on Multidimensional Densely Connected Convolutional Neural Networks.” Remote sensing 12 (5): 795. doi:10.3390/rs12050795.
- Wang, Q., B. Wu, P. Zhu, P. Li, and Q. Hu. 2020d. “ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11531–11539. doi:10.1109/CVPR42600.2020.01155.
- Weng, L., Y. Xu, M. Xia, Y. Zhang, J. Liu, and Y. Xu. 2020. “Water Areas Segmentation from Remote Sensing Images Using a Separable Residual SegNet Network.” Isprs International Journal of Geo-Information 9 (4), doi:10.3390/ijgi9040256.
- Xia, M., Y. Cui, Y. Zhang, Y. Xu, J. Liu, and Y. Xu. 2021. “DAU-Net: A Novel Water Areas Segmentation Structure for Remote Sensing Image.” International Journal of Remote Sensing 42 (7): 2594–2621. doi:10.1080/01431161.2020.1856964.
- Xu, H. 2006. “Modification of Normalised Difference Water Index (NDWI) to Enhance Open Water Features in Remotely Sensed Imagery.” International Journal of Remote Sensing 27 (14): 3025–3033. doi:10.1080/01431160600589179.
- Yu, Y., Y. Yao, H. Guan, D. Li, Z. Liu, L. Wang, C. Yu, S. Xiao, W. Wang, and L. Chang. 2021. “A Self-Attention Capsule Feature Pyramid Network for Water Body Extraction from Remote Sensing Imagery.” International Journal of Remote Sensing 42 (5): 1801–1822. doi:10.1080/01431161.2020.1842544.
- Zhang, J., S. Lin, L. Ding, and L. Bruzzone. 2020. “Multi-Scale Context Aggregation for Semantic Segmentation of Remote Sensing Images.” Remote Sensing 12 (4): 701. doi:10.3390/rs12040701. 2.24.
- Zhang, X., L. Liu, X. Chen, Y. Gao, S. Xie, and Mi. 2021a. “GLC_FCS30: Global Land-Cover Product with Fine Classification System at 30 m Using Time-Series Landsat Imagery.” Earth System Science Data 13 (6): 2753–2776. doi:10.5194/essd-13-2753-2021.
- Zhang, F., X. Qian, L. Han, and Y. Shen. 2021b. “Inverted Residual Siamese Visual Tracking With Feature Crossing Network.” IEEE Access 9: 27158–27166. doi:10.1109/ACCESS.2021.3056194.
- Zhang, T., C. Shi, D. Liao, and L. Wang. 2021c. “Deep Spectral Spatial Inverted Residual Network for Hyperspectral Image Classification.” Remote Sensing 13 (21): 4472. doi:10.3390/rs13214472.
- Zhang, J., M. Xing, G. Sun, J. Chen, M. Li, Y. Hu, and Z. Bao. 2021d. “Water Body Detection in High-Resolution SAR Images With Cascaded Fully-Convolutional Network and Variable Focal Loss.” IEEE Transactions on Geoscience and Remote Sensing 59 (1): 316–332. doi:10.1109/TGRS.2020.2999405.
- Zhao, H., J. Shi, X. Qi, X. Wang, and J. Jia. 2017. “Pyramid Scene Parsing Network.” 2017IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6230–6239. doi:10.1109/CVPR.2017.660