
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Rapid and accurate landslide inventory mapping is significant for emergency rescue and post-disaster reconstruction. Nowadays, deep learning methods exhibit excellent performance in supervised landslide detection. However, due to differences between cross-scene images, the performance of existing methods is significantly degraded when directly applied to another scene, which limits the application of rapid landslide inventory mapping. In this study, we propose a novel Domain Style and Feature Adaptation (DSFA) method for cross-scene landslide detection from high spatial resolution images, which can leverage labeled source domain images and unlabeled target domain images to mine robust landslide representations for different scenes. Specifically, we mitigate the large discrepancy between domains at the dataset level and feature level. At the dataset level, we introduce a domain style adaptation strategy to shift landslide styles, which not only bridges the domain gap, but also increases the diversity of landslide samples. At the feature level, adversarial learning and domain distance minimization are integrated to narrow large feature distribution discrepancies for learning domain-invariant information. In addition, to avoid information omission, we improve the U-Net3+ model. Extensive experimental results demonstrate that DSFA has superior detection capability and outperforms other methods, showing its great application potential in unsupervised landslide domain detection.
1. Introduction
Landslides are a catastrophic natural disaster that causes significant damage to human safety, property, and the natural environment (Azarafza et al. Citation2021; Nikoobakht et al. Citation2022; Taalab, Cheng, and Zhang Citation2018; Trinh et al. Citation2022). Effective and accurate landslide detection is critical to support post-disaster rescue and reconstruction efforts (Fang et al. Citation2020, Citation2021; Lissak et al. Citation2020; Lu, Bai, et al. Citation2019; Lu, Qin, et al. Citation2019; Wang, Fang, and Hong Citation2019). Initial landslide identification methods mainly depend on field surveys, which are not only time-consuming and laborious, but also do not adequately satisfy the requirements of large-scale landslide mapping. Remote sensing technology offers significant advantages in terms of efficiency, objectivity, and timeliness (Scaioni et al. Citation2014). Therefore, landslide detection based on remote sensing images has been investigated extensively (Chen et al. Citation2007; Yang et al. Citation2023).
Many landslide detection methods are proposed to complete the target identification task. In general, they can be classified into two categories: traditional and deep learning methods. To distinguish landslides using traditional methods, researchers propose a pixel-based strategy. However, this strategy does not consider adjacent region connections and results in many isolated landslide points (Ghorbanzadeh et al. Citation2019; Vohora and Donoghue Citation2004; Yi and Zhang Citation2020). Hence, object-based methods are devised to construct subregion pieces as clauses to detect landslides, which reduces isolated points and eliminates spectral variations within the objects (Amatya et al. Citation2021; Ghorbanzadeh, Gholamnia, and Ghamisi Citation2022; Hölbling et al. Citation2012). However, object-based methods require extensive experiments to define the input parameters as well as sophisticated expertise.
Recently, deep learning methods allow feature information to be analyzed automatically without human–computer interaction and thus receive widespread attention from the computer vision community (Ding et al. Citation2016; Ghorbanzadeh et al. Citation2022; Si et al. Citation2023; Si, He, Wu, et al. Citation2022; Si, He, Zhang, et al. Citation2022; Zhang, Wang, et al. Citation2022). Deep learning has been applied for the landslide detection field, and the results demonstrate the superiority of deep learning techniques over traditional methods (Ghorbanzadeh et al. Citation2019; Prakash, Manconi, and Loew Citation2020; Yi and Zhang Citation2020). Effective network frameworks such as matrix semantic segmentation network (SegNet), pyramid scene parseing network (PSPNet), visual geometry group (VGG), Residual network (ResNet), dense network (DenseNet), and U-Net are utilized to detect landslides (Hacıefendioğlu, Demir, and Başağa Citation2021; Li et al. Citation2021; Li and Guo Citation2020; Yu et al. Citation2021). Among them, the U-Net model is a well-known encoder-decoder architecture that yields superior results (Ghorbanzadeh et al. Citation2021; Meena et al. Citation2022; Shahabi and Ghorbanzadeh Citation2022; Soares, Dias, and Grohmann Citation2020). Researchers develop U-Net variants to learn deep semantic information and capture multi-scale features (Ghorbanzadeh, Gholamnia, and Ghamisi Citation2022; Li et al. Citation2023; Liu et al. Citation2020; Qi et al. Citation2020). For example, U-Net3+ is a typical upgraded version of U-Net that can better fit fine-granularity information and exhibits significant potential for landslide detection (Huang et al. Citation2020).
However, the superior performance of deep learning techniques is driven by a large number of annotations, where the training and test datasets have the same feature distribution (Ghorbanzadeh et al. Citation2022; Zou et al. Citation2018). These models do not perform well for cases involving new landslide detection scenes because the information from new scenes is inconsistent with the knowledge learned using previous methods (Zou et al. Citation2018). Therefore, they often suffer significant performance degradation when faced with new landslide detection scenes (Qin et al. Citation2021; Xu et al. Citation2022). Labeling significant amounts of data for each scene is time-consuming and impractical for real-world applications. Hence, transferring landslide detection models from one scene to another is essential and has become a widely investigated research topic.
Unsupervised domain adaptation (UDA) focuses on addressing domain shifts and avoiding expensive laborious annotations (Wang et al. Citation2021). UDA utilizes labeled source data and unknown target data to complete the knowledge transfer process such that advanced results in target domains that do not participate in the training process can be generated (Song et al. Citation2019; Toldo et al. Citation2020). The existing UDA methods can be classified into three categories: consistency regularization, adversarial learning, and self-learning. Consistency regularization aims to learn an appropriate feature transformation that projects the source and target domains into similar feature representation spaces (Long et al. Citation2015; Sun and Saenko Citation2016). For example, in Tzeng et al. (Citation2014), the authors construct a maximum average discrepancy constraint to address the domain-shift problem by projecting the source and target domains into a similar feature space. Adversarial learning employs adversarial loss driven by an additional discriminator to minimize domain shifts (Dong et al. Citation2017; Zhang, Lemoine, and Mitchell Citation2018). Typically, the process contains an adversarial network G and a discriminative model D. G attempts to extract various target information, whereas D attempts to distinguish different types of features. After iterative games between G and D, G is stimulated to mine meaningful domain-invariant representations (Shamsolmoali et al. Citation2021). In addition, self-learning typically involves the generation of pseudo-label for the target domain. Subsequently, the segmentation network is fine-tuned based on the generated pseudo-label and labeled source domain data (Zou et al. Citation2018). Hence, the performance of self-learning methods primarily depends on the quality of the generated pseudo-label.
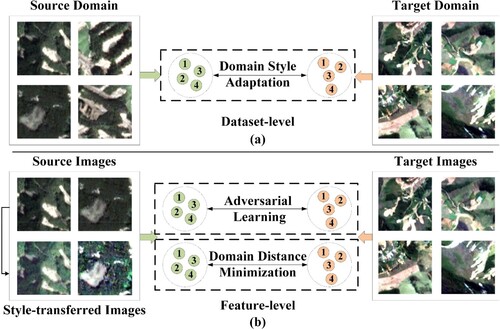
Although domain adaptation strategies receive considerable attention in other fields, only a few related studies propose suitable technologies for cross-scene landslide detection. Hence, unsupervised deep learning models for landslide detection are still in the early development stages. Cross-scene landslide detection is affected by many factors, such as significant differences in the environment, shape, and complex spatial structure. Thus far, researchers consider feature distributions and ignore dataset level landslide domain discrepancies; as such, cross-scene information cannot be fully utilized to mine landslide features. Therefore, we propose the domain style and feature adaptation (DSFA) method for cross-scene landslide detection to transfer landslide features from the source domain to the target domain for alleviating the significant domain bias from different scenarios at the dataset and feature levels. As shown in , style discrepancies and visual differences result in significant domain bias between the source and target domain images. We propose a domain style adaptation strategy that shifts the landslide style from the source domain to the target domain at the dataset level. Concretely, we randomly select a source domain sample and a target domain sample as the input sample pair to optimize the style-transferred model, which generates the corresponding style-transferred landslide samples. These style-transferred landslide samples preserve content information and alter the landslide style, which not only enhances the diversity of landslide images, but also reduces the distance between domains. Owing to the promotion of style-transfer samples, deep models can perceive different types of landslide information. Subsequently, we combine actual and style-transferred landslide samples to optimize our model for analyzing domain-invariant features.
Figure 1. Cross-scene domain adaptation from two different levels. (a) Domain style adaptation method bridges the gap between source and target domain images at the dataset level, (b) adversarial learning and domain distance minimization are integrated to explore domain-invariant information by narrowing the domain discrepancy at the feature level.
Considering the complex spatial structure of different domains, we propose a response feature alignment scheme to further mine domain knowledge based on the feature structure similarity at the feature level. Specifically, we leverage domain distance minimization and adversarial loss to guide the feature extractor in learning global domain-invariant feature representations. For adversarial learning, a general adversarial model comprising a segmentation network and a domain discriminator is established to reduce the data distribution discrepancy between different domains. The segmentation network focuses on extracting beneficial and invariant landslide representations to confuse the discriminators. Considering that U-Net3+ may cause information omission in the max-pooling operation, we use the tokenized multilayer perceptron (MLP) instead of the max-pooling operation in the original U-Net3+ to learn better representations because the tokenized MLP can use appropriate parameters and computations to encode meaningful feature information (Valanarasu and Patel Citation2022). The improved U-Net3+ is regarded as a segmentation network. The discriminator aims to distinguish the domains from their source or target domains. By performing consecutive games, the segmentation model can exploit domain-invariant feature presentations. Additionally, we introduce a domain distance minimization method to project different domain features into a close feature space to alleviate the domain gap. Finally, adversarial learning, domain distance minimization, and domain style adaptation strategy are seamlessly integrated to mine the domain invariance features for cross-scene landslide identification. We evaluate the effectiveness of the proposed method in three independent landslide areas to demonstrate that the DSFA achieves state-of-the-art performance and outperforms other competitive approaches.
The main contribution of this study can be summarized as follows:
At the dataset level, we propose a domain style adaptation strategy by transferring landslide styles from one domain to another. These style-transferred landslide images preserve the content information and alter the landslide style, which not only enhances the diversity of landslide images, but also reduces the distance between domains.
At the feature level, owing to the complexity of landslide shapes, spatial structures, and environments, we propose a corresponding feature alignment scheme for mining different domain knowledge based on domain distance minimization and adversarial constraints.
As for the segmentation network, to avoid information omission during down sampling, we improve U-Net 3+ by embedding a tokenized MLP module into U-Net3+ to explore detailed landslide representations.
Finally, we perform a comprehensive analysis of the cross-scene landslide detection and demonstrate the effectiveness of each component in DSFA. Results of extensive experiments show that DSFA performs better than other state-of-the-art methods, thus demonstrating its potential for future cross-scene landslide detection.
2. Study area
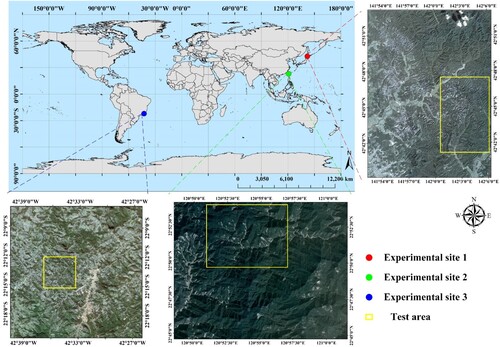
Numerous experiments are conducted in three typical independent areas with different environmental contexts to validate the performance of the proposed method. In , some landslide samples are presented, and a significant domain shift caused by different landslide surfaces, illumination conditions, vegetation recoveries, background context, spatial resolution, etc. is indicated among the three experimental sites. As the three study areas belong to different scenes and possess completely different properties, they indicate significant feature distribution discrepancies. Hence, the three study areas offer adequate complementary advantages for verifying the cross-scene landslide identification effect of our unsupervised method.
Figure 2. Optical images of landslide samples from three study areas. The first column indicates landslides in Experimental site 1 (Earthquake-induced in Japan). The second column denotes landslides in Experimental site 2 (Rainfall-induced in China). The third column represents landslides in Experimental site 3 (Rainfall-induced in Brazil).

2.1. Experimental site 1: earthquake-induced in Japan
Japan is located on the border of the Eurasian Plate, which is susceptible to natural disasters. Hokkaido belongs to the temperate monsoon climate, with annual precipitation ranging from 800 to 1200 mm. In September 2018, a magnitude Mw 6.6 earthquake hit the Iburi-Tobu area of Hokkaido, Japan, with the epicenter located at 42.72° North and 142.0° East at a depth of approximately 37.0 km. This event resulted in numerous landslides over an area measuring 700 km2, as well as resulted in more than 40 fatalities and 600 injuries, most of which are caused by landslides. In this study, we select a severely affected location in this region, as indicated by the red rectangle in . The ground truth of the experimental site has been obtained by other researchers and utilized to complete some study works (Shahabi and Ghorbanzadeh Citation2022; Xu et al. Citation2022). The earthquake caused 6287 landslides that affected areas ranging from 81.64 m2 to 1798397.26 m2. We download remote sensing images with a spatial resolution of 3 m from PlanetScope.
Figure 3. Geographic location of three typical experimental sites. The red dot area represents the location of experimental site 1, the green dot area represents the location of experimental site 2, and the blue dot area represents the location of experimental site 3.
2.2. Experimental site 2: rainfall-induced in China
According to the Carpens Climate Classification Standard, the region belongs to the subtropical monsoon climate. The average annual precipitation is 1585.62 mm, and most of the precipitation occurs in June, July, and August. The unique geography of Taiwan renders it extremely susceptible to natural disasters such as earthquakes, floods, and landslides. The Forestry Bureau of Taiwan launched a project to generate an island-wide landslide inventory map for the period 2004–2018. This landslide inventory has been used extensively for various applications (Chen et al. Citation2019; Lin, Ke, and Lo Citation2017). Because planet satellites have been launched in recent years, we download PlanetScope satellite images with a spatial resolution of 3 m in 2017. We randomly select a region in Taiwan as our experimental site, as indicated by the green rectangle in . It has 3021 landslides, which encompass an area measuring 61.89–665124.79 m2.
2.3. Experimental site 3: rainfall-induced in Brazil
Experimental site 3 locates in the Nova Friburgo Mountainous Area of Rio de Janeiro, Brazil. Based on the criterion of the Carpens climate classification, the region belongs to the subtropical plateau climate. The average annual precipitation is 1585.62 mm, and most of the rainfall occurs in November, December, and January. In January 2011, Rio de Janeiro, Brazil, experienced its most treacherous rainfall, which featured a precipitation rate of 350 mm/ 48 h and resulted in more than 3500 translational landslides. The incident killed at least 1500 people and damaged most city facilities. We select one of the most severely affected regions as our third experimental site (blue rectangle in ). The landslide inventory mapping of this region has been manually generated using high-resolution satellite images by other scholars (Netto et al. Citation2013). The study area measured 625 km2, and heavy rainfall resulted in 832 landslides encompassing an area measuring 200.32–78117.35 m2. Remote sensing images are downloaded from RapidEye with a spatial resolution of 5 m.
3. Methodology
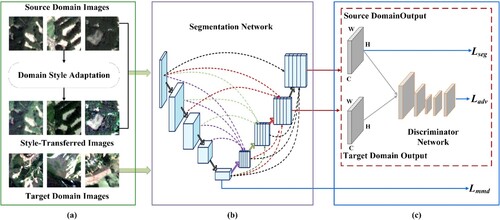
For a labeled source domain image S and an unlabeled target domain image T, the proposed DSFA method aims to analyze domain-invariant representations of landslides by implementing dataset and feature level constraints for unsupervised landslide domain adaptation. The overall framework of the DSFA is shown in , and comprises three components: landslide domain style adaptation, segmentation network, and feature alignment.
Figure 4. Domain Style and Feature Adaptation (DSFA) framework for cross-scene landslide detection. (a) Style-transferred samples are generated for domain style adaptation to bridge domain discrepancy at the dataset level, (b) a tokenized MLP is embedded into U-Net3+ to avoid information damage in the segmentation network, and (c) adversarial learning and domain distance minimization are integrated to mitigate the large feature discrepancy between source and target domains at the feature level.
3.1. Landslide domain style adaptation
Because of the different types of landslide surfaces, illumination conditions, vegetation recoveries, background contexts, and spatial resolutions, the source and target domain images differ significantly, as shown in , which further complicates unsupervised landslide domain adaptation. Reducing the significant discrepancy between different domains is an effective method for solving problems associated with unsupervised domain adaptations. Thus far, researchers merely implement feature constraints to minimize the feature distribution discrepancy at the feature level, which renders it difficult to eliminate the considerable visual effects between the source and target domain images. Researchers of computer vision propose image-generation methods for generating new images to solve specific unsupervised adaptation tasks. Early conventional methods focus on texture synthesis but require complex formulation computations (Bruckner and Gröller Citation2007). The rapid development of convolutional neural networks has enabled the adoption of convolutional operations to construct generative adversarial networks for transferring image styles, thereby resulting in better performance (Wang, Li, et al. Citation2020; Zhu et al. Citation2017).
However, the application of deep learning operations to cross-scene landslide detection has not been discussed. In this study, our goal is to generate new landslide samples that preserve the full content of the source domain images and possess the landslide style of the target domain images to reduce the domain distance at the dataset level. Hence, we propose a novel landslide domain style adaptation scheme that not only smooths image-style disparities, but also enhances the diversity of landslide images.
Because of the limited receptive field of the convolution operation, long-distance dependency cannot be captured; hence, semantic information is omitted. Recently, transformers demonstrate significant potential in capturing long-range dependencies and achieving superior performance (Paul and Chen Citation2022). Therefore, we extend a state-of-the-art transformer-based network, StyTr2, using a domain style adaptation strategy to reduce the distance between the two domains (Deng et al. Citation2022). Leveraging the ability of the transformer to capture long-term dependencies, StyTr2 constructs two different transformer-based encoders to generate feature sequences for modeling the content and style features, separately. Additionally, the model uses a transformer-based decoder to stylize the content sequence based on the style sequence. Therefore, StyTr2 can simultaneously maintain fine content structures and rich style patterns. To complete model optimization, we randomly select a source domain sample and a target domain sample as the input sample pair to train the deep model. After training, a content image from the source domain and a style image from the target domain is selected to generate new style-transfer landslide samples, which not only store innate contextual information, but also exhibit styles similar to other scenes. Finally, we combine the actual and style-transferred images to optimize the segmentation network, which can improve the generalization performance of cross-scene landslide detection.
3.2. Segmentation network
As U-Net3+ combines low-level details and high-level representations from multiple scales, we employ U-Net3+ as the baseline network to detect landslides. Four max-pooling operations in the U-Net3+ encoder block cause information omission during the down sampling process. Tokenized MLP modules show excellent capabilities for building models (Valanarasu and Patel Citation2022). To reduce feature omission, we replace max pooling with an MLP-based tokenization module in each encoder block of U-Net3+ and named it the ‘improved U-Net3+’.
Tokenized MLPs aim to project convolutional landslide features into abstract objects and then employ the MLP to learn valuable information, thus requiring fewer computations and enabling the modeling of high-level representations (Valanarasu and Patel Citation2022). Specifically, the feature maps from each encoder block are projected onto the tokens via convolutional operations. These generated tokens are transmitted to a shifted MLP (across the width), which is suitable for analyzing local features corresponding to specified axial shifts. Subsequently, the output is fed in a depth-wise manner to promote encoder features without requiring excessive computation time. Subsequently, these features are fed into another shifted MLP (across the height) to obtain the feature maps. Finally, residual connections are employed to add the original tokens as residuals. Therefore, the tokenized MLP blocks perform better than standard positional encoding techniques. Thus, the improved U-Net3+ can exploit more detailed landslide representations.
3.3. Feature alignment
On the other side of the feature level, we design a feature alignment process to constrain the feature distribution and eliminate significant feature discrepancies. Adversarial learning can be used to learn domain-invariant feature representations, and domain distance minimization can be directly used to reduce feature distances across different domains. Hence, we seamlessly integrate adversarial learning and perform distance minimization to complete feature alignment, which results in an effective mapping of different features to a similar distribution space.
Adversarial learning is performed to search for domain-invariant features between source and target domains that are competent in domain adaptation tasks (Tsai et al. Citation2018). To reduce the significant feature distribution discrepancy, we implement an adversarial learning scheme to learn robust landslide features and improve the generalization ability of the segmentation model. In particular, we design an adversarial model comprising a segmentation network G and a domain discriminator D. In this study, the improved U-Net3+ is termed the segmentation network G. D is composed of five convolutional layers with 4 × 4 kernels, where the numbers of channels are e {64, 128, 256, 512, 2}. G explores domain-invariant landslide representations to confuse D, whereas D distinguishes whether the information originated from the source or target domain. After a continuous game between G and D, landslide features from different domains are projected onto a similar spatial distribution.
The decoder of our segmentation model contains five blocks. To fully analyze the domain-invariant information, we impose adversarial constraints on two types of predicted probability from different blocks, i.e. the fourth and fifth blocks. For the constraint of the fifth block, we extract the predicted probabilities of the source and target domain images. Subsequently, we feed them into the discriminator to ascertain the domain to which they belong. In the adversarial optimization phase, we utilize the binary cross-entropy loss to optimize the domain discriminator.
(1)
(1) where
and
denote the predicted landslide probabilities of the source and target domains, respectively;
and
indicate the distributions of predicted probability from the source and the target domains, respectively;
and
represent the probabilities that the discriminator distinguishes
and
as the source and target domains, respectively.
For the target domain images, we feed the predicted landslide probabilities into the discriminator to discriminate the inputs belonging to the source or target domains. To mine the domain-invariant features and complete the adversarial process, we force the discriminator to identify the target domain information as the source domain by optimizing the segmentation model to project different domains into similar feature spaces. Therefore, the adversarial loss for the segmentation network can be written as:
(2)
(2) where
denotes the probability of the discriminator distinguishing
from the source domain.
For adversarial learning, the optimization process of the fourth block is the same as that of the fifth block. Therefore, we extract the predictions from the fourth block and fed the results to the discriminator. The constraint function for optimizing the discriminator and segmentation network is expressed as:
(3)
(3)
(4)
(4) We combine these two scales to implement the adversarial process and calculate the overall adversarial loss as follows:
(5)
(5) where
and
control the importance of different scales to optimize the segmentation model. We empirically set
and
to 0.01 and 0.001, respectively.
Domain distance minimization directly reduces the feature distribution discrepancy between the source and target domains. As a practical constraint function, the maximum mean discrepancy can be used to learn feature representations by minimizing the feature distribution discrepancy (Tzeng et al. Citation2014). Therefore, at the feature level, we employ a maximum mean discrepancy constraint function to reduce the distance between the landslide representation and the first block of the decoder. The discrepancy between the two domains is formulated as:
(6)
(6) where k indicates the Gaussian radial basis function kernel for computing the feature distribution; and a and b denote the source and target features, respectively.
3.4. Final optimization objective
Because the source domain possesses label information, we use labeled source data to optimize the segmentation model. Considering the imbalance between landslide positive and negative samples, we exploit the Dice function to analyze the landslide features of the source domain at two scales from the fourth and fifth decoder blocks (Milletari, Navab, and Ahmadi Citation2016). The constraint function is expressed as:
(7)
(7) where d denotes the ground truth; and
represents the weight of the dice loss in the fourth block, which is set to 0.1.
We employ source domain label information to learn the landslide features. Meanwhile, we reduce the domain discrepancy at both the dataset and feature levels. Therefore, the overall objective of the proposed method can be expressed as follows:
(8)
(8) where γ indicates the importance of Lmmd, and its value is set to 0.01 in this study.
During the training operation, we alternately optimize the segmentation and discriminator networks. When the parameters of one component are updated, those of the other components are fixed. After training, we use only the optimized segmentation model to predict landslides in the target domain images during testing.
3.5. Data preprocessing
Understanding the environmental conditions in which landslides occur is essential for landslide detection. Researchers discover that adopting a combination of optical and digital elevation model (DEM)-related factors can yield better results compared with using a single optical image, thus demonstrating the effectiveness of multiple-source data (Liu et al. Citation2020). Therefore, we employ the NDVI, DEM, and six related topographic influencing factors, slope, aspect, hill shade, curvature, profile curvature, plan curvature, and combine them with optical images to identify landslides.
In terms of data preprocessing, to match the spatial resolution of the optical image to that of the DEM of the Alaska Satellite Facility (i.e. 12.5 m), we use the QGIS to resample the DEM data through bilinear interpolation. To facilitate model optimization, we conduct experiments using only four typical spectral channels (blue, green, red, and near-infrared) of the RapidEye and PlanetScope data, excluding the red edge band in the RapidEye data. Subsequently, we incorporate these spectral channels with the aforementioned predisposing factors into a single merged file and utilize the Z-scores for image normalization. Finally, we partition the remote sensing image into 128 × 128 patches with a 20% overlap to preserve contextual information. The proposed model is comprehensively validated in three independent test areas, as shown in .
3.6. Experimental settings
All experiments are implemented on the PyTorch framework on a Linux platform equipped with NVIDIA RTX 3090 GPUs with 24 G memory. During the training phase, we employ the Glorot normal initializer to initialize the network weights. We utilize stochastic gradient descent to optimize the model with a momentum of 0.9 and a weight decay of 10−4. The batch size, initial learning rate, and number of iterations are set to 8, 0.01, and 20k, respectively. During the testing phase, we utilize only the trained segmentation network to detect landslides. In our experiments, we use six standard evaluation metrics to demonstrate the effectiveness of the proposed DSFA, i.e. accuracy, precision, recall, F1-score, kappa, and mean intersection over union (mIoU).
We refer to experimental sites 1, 2, and 3 as target domains. For the source domain, six ranking combinations are established, among which three (i.e. Groups A, B, and C) are randomly selected for cross-scene landslide detection experiments. The three experimental groups are described in .
Table 1. Description of three groups.
4. Experimental results
4.1. Comparison with state-of-the-art methods
To demonstrate the superiority of the DSFA method, we compare it with five other competitive unsupervised methods: MCD (Tzeng et al. Citation2014), FADA (Wang, Shen, et al. Citation2020), PyCDA (Lian et al. Citation2019), DAFormer (Hoyer, Dai, and Van Gool Citation2022b), and HRDA (Hoyer, Dai, and Van Gool Citation2022a). The predicted results and landslide inventory mappings are qualitatively shown in , , and . The orange regions indicate the predicted results derived from the deep learning models, and the blue regions indicate landslide inventory mapping. Therefore, the overlapping area between the reference and automatic inventories is the intersection of both sets, which indicates the correctly predicted area.
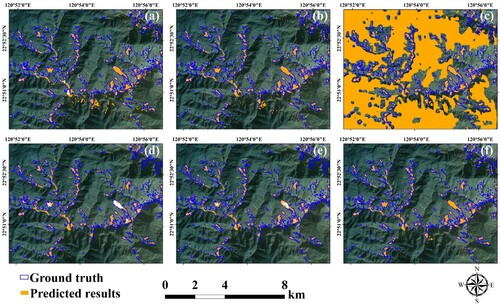
Figure 5. Qualitative comparison of methods on Experimental site 1. (a) MCD, (b) FADA, (c) PyCDA, (d) DAFormer, (e) HRDA, and (f) DSFA.
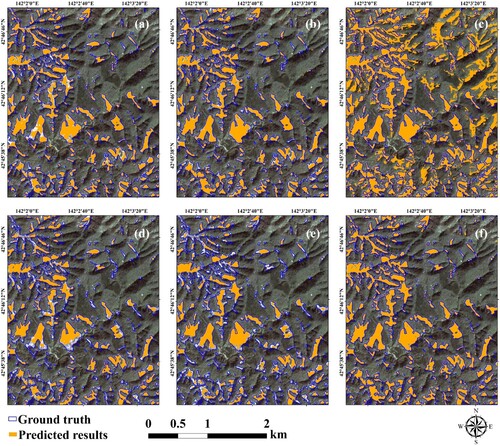
Figure 6. Qualitative comparison of different methods on Experimental site 2. (a) MCD, (b) FADA, (c) PyCDA, (d) DAFormer,(e) HRDA, and (f) DSFA.
4.1.1. Results of Group A
For a qualitative comparison, we randomly select a sub-region for better visualization. As shown in , most large landslides are correctly identified. Unlike other UDA models, the DSFA can yield correct and fine-grained detailed segmentation results. Among the compared approaches, PyCDA yields the worst results for cross-scene landslide detection. During the training process, PyCDA defines high-confidence prediction regions as pseudo-label to optimize the deep model. However, the generated pseudo-label inevitably contains considerable noise, which can easily mislead model optimization (Zhang, Jing, et al. Citation2021).
For a quantitative comparison, the evaluation results are listed in . DAFormer achieves a maximum precision of 88.35%, which is higher than that of the proposed DSFA. However, the values of the other metrics derived from DAFormer are much lower than those derived from the DSFA, which demonstrates the weak landslide detection ability of DAFormer. As for the recall value, PyCDA achieves a maximum value of 80.24% but indicates the lowest precision, which implies that most of the predicted landslides are incorrect. In terms of the other metrics, the DSFA indicates values exceeding 70%, which implies that is more reliable than the other UDA methods. Additionally, the DSFA results in more detailed boundaries and a label that is highly similar to the actual landslide label. In conclusion, the DSFA can be successfully applied to cross-scene landslide detection at experimental site 1 and exhibits accurate and reliable capabilities for landslide identification.
Table 2. Evaluation indices (%) of the six UDA methods in Group A. The highest accuracy for each index is highlighted in bold.
4.1.2. Results of Group B
Qualitative detection results are shown in . Similarly, PyCDA yields numerous over detections. MCD, FADA, DAFormer, and HRDA exhibit better detection capabilities than PyCDA. However, many regions are not successfully recognized by these methods, unlike our method. In addition, coarse landslide segmentation boundaries are generated. The proposed DSFA generates fine-grained landslide location boundaries with less over-detection compared with the other methods.
The results are summarized in . As shown, the DSFA yields the highest value among the methods compared, and its evaluation metrics show values exceeding 80%, except for precision, which confirms the stable and superior performance of the DSFA. PyCDA yields the highest recall of 87.75% and the lowest precision of 9.35%, thus indicating that a significant percentage of regions are incorrectly classified as landslides. Therefore, PyCDA is unsuitable for UDA landslide detection.
Table 3. Evaluation indices (%) of the six UDA methods in Group B. The highest accuracy for each index is highlighted in bold.
4.1.3. Results of Group C
For a qualitative comparison, the detection results by different methods are shown in . The source and target domain images have different spatial resolutions of 3 and 5 m, respectively. Furthermore, they are subjected to different landslide types, such as earthquakes and rainfall events. As shown in , the DSFA indicates better accuracy than the other methods. In terms of quantitative comparison, shows that the DSFA offers the highest accuracy, precision, F1-socre, kappa, and mIoU, thus further corroborating the superiority of the DSFA.
Figure 7. Qualitative comparison of different methods on Experimental site 3. (a) MCD, (b) FADA, (c) PyCDA, (d) DAFormer, (e) HRDA, and (f) DSFA.
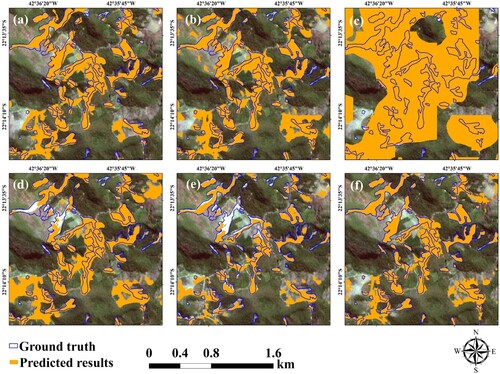
Table 4. Evaluation indices (%) of the six UDA methods in Group C. The highest accuracy for each index is highlighted in bold.
4.2. Ablation experiments
To comprehensively evaluate the advantages of each component in the proposed DSFA method, we randomly select three groups (i.e. Groups A, B, and C) for cross-scene landslide detection experiments to conduct a series of ablation experiments. The evaluation results for the three databases are listed in Tables , , and , respectively.
Table 5. Evaluation indices on Group A (%). The highest accuracy of each index is highlighted in bold.
Table 6. Evaluation indices on Group B (%). The highest accuracy of each index is highlighted in bold.
Table 7. Evaluation indices on Group C (%). The highest accuracy of each index is highlighted in bold.
U-Net3+ is a baseline model trained using only source domain data. We test the model performance on the target domain and obtain unsatisfactory performance. Lseg indicates that the improved U-Net3+ is employed to optimize the segmentation network, which is better than the original U-Net3+. The experimental results confirm the effectiveness of employing a tokenized MLP instead of max pooling to avoid information omission.
We incorporate adversarial learning into unsupervised domain adaptation, which can be expressed as Lseg + Ladv. Based on Tables 5, 6, and 7, Lseg + Ladv performs better than Lseg, which proves that adversarial learning allows domain-invariant features to be analyzed such that cross-scene landslide detection can be performed more effectively.
In addition, we further integrate domain distance minimization into the optimization process, which can be expressed as Lseg + Ladv + Lmmd. We discover that Lseg + Ladv + Lmmd results in better performance than Lseg + Ladv, which implies that Lmmd successfully reduces the domain distance between the source and target domains, thereby improving the generalization performance. As shown in , the accuracy and precision values of Lseg + Ladv exceed those of Lseg + Ladv + Lmmd, whereas its recall, F1-score, kappa, and mIoU values are much lower than those of Lseg + Ladv + Lmmd. This indicates that Lseg + Ladv only detects regions with significant landslides, whereas Lseg + Ladv + Lmmd detects more regions with landslides. The results presented in the three tables indicate above show that we successfully integrate adversarial learning and domain distance minimization to learn domain-invariant landslide information at the feature level.
Finally, we add style-transferred images to train the proposed model, which we named Lseg + Ladv + Lmmd +DSA. Compared with the results of Lseg + Ladv + Lmmd, the recall, F1-score, kappa, and mIoU of Lseg + Ladv + Lmmd +DSA are 0.37%, 5.32%, 2.93%, 3.10%, and 2.09% higher, respectively, whereas its precision decreases by 0.95% in Group A. Although Lseg + Ladv + Lmmd +DSA indicates a precision value lower than those of the other methods, its values for the other metrics are significantly higher. In Group B, although Lseg + Ladv + Lmmd indicates a recall value higher than that of Lseg + Ladv + Lmmd +DSA, its values for the other evaluation metrics are lower. Lseg + Ladv + Lmmd + DSA demonstrates stable and advanced performance, with precision, recall, F1-score, kappa, and mIoU values of 97.85%, 83.69%, 83.16%, 83.42%, 82.27%, and 84.64%, respectively. In Group C, Lseg + Ladv + Lmmd + DSA outperforms Lseg + Ladv + Lmmd in all metrics, thus indicating the extraordinary ability of the DSFA in solving problems related to landslide domain adaptation. These results verify the effectiveness and practicability of the domain style adaptation strategy in the UDA for landslide detection.
5. Discussion
5.1. Effectiveness of domain style adaptation
We propose a domain style adaptation strategy to bridge the gap between source and target domains. shows the visual effects of domain style adaptation. We refer to experimental sites 1 and 2 as source domain and the target domain, respectively. As shown in (a,b), the source and target domain images have different image styles and visual effects, which is the main challenge that hinders the identification of cross-scene landslide detection.
Figure 8. Visualization of different types of landslide samples. (a) Source domain images, (b) target domain images, (c) style-transferred images, and (d) frequency histograms.
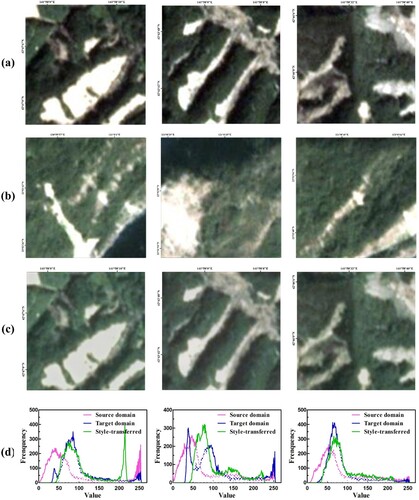
After domain style adaption, we convert source domain landslides to have a similar style to the target domain, as shown in (c). The style transfer images possess both the original content of the source domain and the style of the target domain, which not only bridges the domain gap, but also increases the diversity of landslide images. It is well-known that domain style adaptation methods can decrease the brightness of source domain images and generate similar style features to target domain images.
Furthermore, we compute the frequency histogram in (d) to further analyze the effect of domain style adaptation. We can observe that the statistical curve of the source domain image tends to the left with low values, while the statistical curve of the target domain image tends to the right side with higher values. After domain style adaptation, the statistical curves of style-transferred images are shifted to the middle, thus bridging the modality gap. We combine style-transferred images with real images to optimize the segmentation model, which helps the model effectively explore robust landslide representations. From Tables 5, 6, and 7, it can be concluded that using style-transferred images produces better accuracy than using only real images, which proves that the domain style adaptation strategies are meaningful for landslide detection.
5.2. Advantages of the proposed DSFA
Deep learning has been applied to landslide detection and achieves promising performance (Song et al. Citation2021). However, the superior performance is driven by the large amounts of labeled data in specific scenes (Hacıefendioğlu, Demir, and Başağa Citation2021; Li et al. Citation2021; Li and Guo Citation2020). When transferred to a different landslide scene, they tend to generate poor identification results, greatly hindering the development of the landslide detection community. In practice, it is difficult to label a large number of landslide samples for each specific scene (Madadi et al. Citation2020; Pinheiro Citation2018). To address this problem, Xu et al. (Citation2022) propose an adversarial learning method to explore shared domain landslide features and demonstrated the effectiveness of adversarial learning. However, they ignore the domain discrepancy at the dataset level, which makes it difficult to mine robust landslide features.
Considering the large discrepancy between the source and target domains, we propose DSFA to solve the domain shift problem from the dataset level and feature level. At the dataset level, we introduce a domain style adaption strategy to bridge the domain gap by converting the style of the source domain image to a style similar to the target domain. With the domain style adaption scheme, the landslide segmentation model has made great progress, as listed in Tables 5, 6, and 7.
At the feature level, we improve the original U-Net3+ to avoid representation omissions. Moreover, we integrate adversarial learning and domain distance minimization to align feature distributions from different domains. The effectiveness of each component has been verified in ablation experiments. Extensive experiments demonstrate that DSFA yields fine-grained landslide segmentation boundaries and better results than other UDA methods. DSFA can successfully integrate dataset level and feature level constraints to solve the domain shift problem, showing the potential for future cross-scene landslide detection.
5.3. Observations from comparison models
Based on these sufficient experiments and comparison results, we have the following new observations:
Among the comparison methods, PyCDA aims to generate pseudo labels for model optimization. Due to the complexity and diversity of landslides, the pseudo-label generated by PyCDA is of poor quality, affecting the model optimization process. DAFormer and HRDA also achieve better performance than PyCDA by integrating multiple information from different levels to produce pseudo labels. However, their performance is still poor compared to our method, which illustrates that the proposed DSFA is valuable for landslide identification and also proves that the pseudo-label has a vital impact on the final result.
As for the comparison methods, MCD and FADA focus on feature alignment, and the proposed DSFA achieves the highest performance. These comparative experiments demonstrate that feature alignment alone is not sufficient for the landslide domain adaption task. In addition, the domain style adaptation strategy significantly bridges the domain gap between source and target domain images. Experiment results demonstrate that it is valuable for narrowing large domain differences from the dataset level.
For comparison, the original structures of MCD, FADA, and PyCDA are all deeplabv2, which is not suitable for landslide detection. Therefore, we set MCD, FADA, and PyCDA, to have the same modified structure in the proposed DSFA. As for DAFormer and HRDA, they utilize different model structures to learn effective information. Extensive experiments demonstrate that MCD, FADA, and DSFA have better accuracy than the DAFormer and HRDA, which shows that our baseline is important for landslide identification.
Previous segmentation models usually simply fuse contextual information from adjacent scales, ignoring the problem of dense connections from different network layers. U-Net3+ merges feature maps of different scales through full-scale skip connections that promote the landslide detection community (Huang et al. Citation2020). However, there are four down-sampling operations from max-pooling in U-Net3+, which may destroy some landslide information. To avoid information loss in the down-sampling step and learn detailed landslide representations, we replace the max-pooling operation with a tokenized MLP module in each encoder block of U-Net3+. By integrating full landslide features of different scales, the improved U-Net3+ shows excellent performance in landslide detection. The ablation results show that the modified U-Net3+ can avoid information corruption in the down sampling operation.
5.4. Limitations and future work
Although extensive experimental results show that DSFA has a great ability in solving the problem of cross-scene landslide detection, there is still a large improvement room. To address landslide identification in a wider range of real-world scenes, more variable datasets are required. For Group C, we combine source domain images with a spatial resolution of 3 m and target domain images with a spatial resolution of 5 m to implement cross-scene landslide detection. They are characterized by different landslide types and resolutions. As a result, the identification accuracy is relatively lower than that of Group A and Group B. This means that the source domain is important and affects the whole optimization process, which is a universal consensus problem throughout the field of unsupervised domain adaption. To this end, we further consider valuable solutions. We believe that the synthesis, generation, and realism evaluation of landslide datasets will be meaningful for cross-scene landslide detection. In the future, we will further explore multi-scene landslide detection techniques by acquiring new large-scale or creating meaningful synthesis landslide samples.
6. Conclusion
In this study, a novel DSFA method for unsupervised landslide domain adaptation is proposed. DSFA innovatively resolves the large domain differences at the dataset level and the feature level, thereby greatly improving the transferable accuracy of cross-scene landslide detection. At the dataset level, a domain style adaptation scheme is introduced to transfer the style of source domain images to similar target domain images, bridging domain gaps and increasing the diversity of datasets. Meanwhile, adversarial learning and domain distance minimization are integrated to exploit domain-invariant landslide information at the feature level. To this end, we develop an adversarial model consisting of a segmentation network and a discriminator network. In addition, to avoid representation omission, we improve the original U-Net3+ by importing a tokenized MLP module, and call it a segmentation network. Finally, these modules are seamlessly concatenated to enable the landslide domain adaption task. We conduct extensive experiments on three different scene datasets and compare them with several popular methods, fully demonstrating the superior performance of DSFA. Also, ablation experiments demonstrate that each component improves detection accuracy and they complement each other. This indicates that DSFA is an effective procedure that can facilitate the development of large-scale landslide inventory mapping.
Acknowledgment
The authors would like to thank the handling editors and four anonymous reviewers for their valuable comments and suggestions, which significantly improved the quality of this paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Additional information
Funding
References
- Amatya, Pukar, Dalia Kirschbaum, Thomas Stanley, and Hakan Tanyas. 2021. “Landslide Mapping Using Object-Based Image Analysis and Open Source Tools.” Engineering Geology 282:106000. https://doi.org/10.1016/j.enggeo.2021.106000.
- Azarafza, Mohammad, Mehdi Azarafza, Haluk Akgün, Peter M. Atkinson, and Reza Derakhshani. 2021. “Deep Learning-Based Landslide Susceptibility Mapping.” Scientific Reports 11 (1): 24112. https://doi.org/10.1038/s41598-021-03585-1.
- Bruckner, Stefan, and M. Eduard Gröller. 2007. “Style Transfer Functions for Illustrative Volume Rendering.” Paper presented at the Computer Graphics Forum.
- Chen, Kun Shan, Melba M. Crawford, Paolo Gamba, and James S. Smith. 2007. “Introduction for the Special Issue on Remote Sensing for Major Disaster Prevention, Monitoring, and Assessment.” IEEE Transactions on Geoscience and Remote Sensing 45 (6): 1515–1518. https://doi.org/10.1109/TGRS.2007.899144.
- Chen, Chi Wen, Yu Shiang Tung, Jun Jih Liou, Hsin Chi Li, Chao Tzuen Cheng, Yung Ming Chen, and Takashi Oguchi. 2019. “Assessing Landslide Characteristics in a Changing Climate in Northern Taiwan.” Catena 175:263–277. https://doi.org/10.1016/j.catena.2018.12.023.
- Deng, Yingying, Fan Tang, Weiming Dong, Chongyang Ma, Xingjia Pan, Lei Wang, and Changsheng Xu. 2022. “Stytr2: Image Style Transfer with Transformers.” Paper presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Ding, Anzi, Qingyong Zhang, Xinmin Zhou, and Bicheng Dai. 2016. “Automatic Recognition of Landslide Based on CNN and Texture Change Detection.” Paper presented at the Youth Academic Annual Conference of Chinese Association of Automation.
- Dong, Hao, Simiao Yu, Chao Wu, and Yike Guo. 2017. “Semantic Image Synthesis via Adversarial Learning.” Paper presented at the Proceedings of the IEEE international Conference on Computer Vision.
- Fang, Zhice, Yi Wang, Ling Peng, and Haoyuan Hong. 2020. “Integration of Convolutional Neural Network and Conventional Machine Learning Classifiers for Landslide Susceptibility Mapping.” Computers & Geosciences 139:104470. https://doi.org/10.1016/j.cageo.2020.104470.
- Fang, Zhice, Yi Wang, Ling Peng, and Haoyuan Hong. 2021. “A Comparative Study of Heterogeneous Ensemble-Learning Techniques for Landslide Susceptibility Mapping.” International Journal of Geographical Information Science 35 (2): 321–347. https://doi.org/10.1080/13658816.2020.1808897.
- Ghorbanzadeh, Omid, Thomas Blaschke, Khalil Gholamnia, Sansar Raj Meena, Dirk Tiede, and Jagannath Aryal. 2019. “Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection.” Remote Sensing 11 (2): 196. https://doi.org/10.3390/rs11020196.
- Ghorbanzadeh, Omid, Alessandro Crivellari, Pedram Ghamisi, Hejar Shahabi, and Thomas Blaschke. 2021. “A Comprehensive Transferability Evaluation of U-Net and ResU-Net for Landslide Detection from Sentinel-2 Data (Case Study Areas from Taiwan, China, and Japan).” Scientific Reports 11 (1): 1–20. https://doi.org/10.1038/s41598-021-94190-9.
- Ghorbanzadeh, Omid, Khalil Gholamnia, and Pedram Ghamisi. 2022. “The Application of ResU-Net and OBIA for Landslide Detection from Multi-Temporal Sentinel-2 Images.” Big Earth Data, 1–26. https://doi.org/10.1080/20964471.2022.2031544.
- Ghorbanzadeh, Omid, Yonghao Xu, Pedram Ghamis, Michael Kopp, and David Kreil. 2022. “Landslide4sense: Reference Benchmark Data and Deep Learning Models for Landslide Detection.” arXiv preprint arXiv:2206.00515.
- Hacıefendioğlu, Kemal, Gökhan Demir, and Hasan Basri Başağa. 2021. “Landslide Detection Using Visualization Techniques for Deep Convolutional Neural Network Models.” Natural Hazards 109 (1): 329–350. https://doi.org/10.1007/s11069-021-04838-y.
- Hölbling, Daniel, Petra Füreder, Francesco Antolini, Francesca Cigna, Nicola Casagli, and Stefan Lang. 2012. “A Semi-Automated Object-Based Approach for Landslide Detection Validated by Persistent Scatterer Interferometry Measures and Landslide Inventories.” Remote Sensing 4 (5): 1310–1336. https://doi.org/10.3390/rs4051310.
- Hoyer, Lukas, Dengxin Dai, and Luc Van Gool. 2022a. “HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation.” Paper presented at the Proceedings of the European Conference on Computer Vision.
- Hoyer, Lukas, Dengxin Dai, and Luc Van Gool. 2022b. “Daformer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation.” Paper presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Huang, Huimin, Lanfen Lin, Ruofeng Tong, Hongjie Hu, Qiaowei Zhang, Yutaro Iwamoto, Xianhua Han, Yen Wei Chen, and Jian Wu. 2020. “UNet 3+: A Full-Scale Connected Unet for Medical Image Segmentation.” Paper presented at the IEEE International Conference on Acoustics, Speech and Signal Processing.
- Li, Zhun, and Yonggang Guo. 2020. “Semantic Segmentation of Landslide Images in Nyingchi Region Based on PSPNet Network.” Paper presented at the International Conference on Information Science and Control Engineering.
- Li, Penglei, Yi Wang, Guosen Xu, and Lizhe Wang. 2023. “LandslideCL: Towards Robust Landslide Analysis Guided by Contrastive Learning.” Landslides 20 (2): 461–474. https://doi.org/10.1007/s10346-022-01981-w.
- Li, Chang, Bangjin Yi, Peng Gao, Hui Li, Jixing Sun, Xueye Chen, and Cheng Zhong. 2021. “Valuable Clues for DCNN-Based Landslide Detection from a Comparative Assessment in the Wenchuan Earthquake Area.” Sensors 21 (15): 5191. https://doi.org/10.3390/s21155191.
- Lian, Qing, Fengmao Lv, Lixin Duan, and Boqing Gong. 2019. “Constructing Self-Motivated Pyramid Curriculums for Cross-Domain Semantic Segmentation: A Non-Adversarial Approach.” Paper presented at the Proceedings of the IEEE International Conference on Computer Vision.
- Lin, S. C., M. C. Ke, and C. M. Lo. 2017. “Evolution of Landslide Hotspots in Taiwan.” Landslides 14 (4): 1491–1501. https://doi.org/10.1007/s10346-017-0816-9.
- Lissak, Candide, Annett Bartsch, Marcello De Michele, Christopher Gomez, Olivier Maquaire, Daniel Raucoules, and Thomas Roulland. 2020. “Remote Sensing for Assessing Landslides and Associated Hazards.” Surveys in Geophysics 41 (6): 1391–1435. https://doi.org/10.1007/s10712-020-09609-1.
- Liu, Peng, Yongming Wei, Qinjun Wang, Yu Chen, and Jingjing Xie. 2020. “Research on Post-Earthquake Landslide Extraction Algorithm Based on Improved U-Net Model.” Remote Sensing 12 (5): 894. https://doi.org/10.3390/rs12050894.
- Long, Mingsheng, Yue Cao, Jianmin Wang, and Michael Jordan. 2015. “Learning Transferable Features with Deep Adaptation Networks.” Paper presented at the International Conference on Machine Learning.
- Lu, Ping, Shibiao Bai, Veronica Tofani, and Nicola Casagli. 2019. “Landslides Detection through Optimized Hot Spot Analysis on Persistent Scatterers and Distributed Scatterers.” ISPRS Journal of Photogrammetry and Remote Sensing 156:147–159. https://doi.org/10.1016/j.isprsjprs.2019.08.004.
- Lu, Ping, Yuanyuan Qin, Zhongbin Li, Alessandro C. Mondini, and Nicola Casagli. 2019. “Landslide Mapping from Multi-Sensor Data through Improved Change Detection-Based Markov Random Field.” Remote Sensing of Environment 231:111235. https://doi.org/10.1016/j.rse.2019.111235.
- Madadi, Yeganeh, Vahid Seydi, Kamal Nasrollahi, Reshad Hosseini, and Thomas B. Moeslund. 2020. “Deep Visual Unsupervised Domain Adaptation for Classification Tasks: A Survey.” IET Image Processing 14 (14): 3283–3299. https://doi.org/10.1049/iet-ipr.2020.0087.
- Meena, Sansar Raj, Lucas Pedrosa Soares, Carlos H. Grohmann, Cees Van Westen, Kushanav Bhuyan, Ramesh P. Singh, Mario Floris, and Filippo Catani. 2022. “Landslide Detection in the Himalayas Using Machine Learning Algorithms and U-Net.” Landslides 19 (5): 1209–1229. https://doi.org/10.1007/s10346-022-01861-3.
- Milletari, Fausto, Nassir Navab, and Seyed-Ahmad Ahmadi. 2016. “V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation.” Paper presented at the International Conference on 3D Vision.
- Netto, Ana Luiza Coelho, Anderson Mululo Sato, André de Souza Avelar, Lílian Gabriela G. Vianna, Ingrid S. Araújo, David L. C. Ferreira, Pedro H. Lima, Ana Paula A. Silva, and Roberta P. Silva. 2013. “January 2011: The Extreme Landslide Disaster in Brazil.” In Landslide Science and Practice: Volume 6: Risk Assessment, Management and Mitigation, 377–384. https://doi.org/10.1007/978-3-642-31319-6-51.
- Nikoobakht, Shahrzad, Mohammad Azarafza, Haluk Akgün, and Reza Derakhshani. 2022. “Landslide Susceptibility Assessment by Using Convolutional Neural Network.” Applied Sciences 12 (12): 5992. https://doi.org/10.3390/app12125992.
- Paul, Sayak, and Pin-Yu Chen. 2022. “Vision Transformers Are Robust Learners.” Paper presented at the Proceedings of the AAAI Conference on Artificial Intelligence.
- Pinheiro, Pedro O. 2018. “Unsupervised Domain Adaptation with Similarity Learning.” Paper presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Prakash, Nikhil, Andrea Manconi, and Simon Loew. 2020. “Mapping Landslides on EO Data: Performance of Deep Learning Models vs. Traditional Machine Learning Models.” Remote Sensing 12 (3): 346. https://doi.org/10.3390/rs12030346.
- Qi, Wenwen, Mengfei Wei, Wentao Yang, Chong Xu, and Chao Ma. 2020. “Automatic Mapping of Landslides by the ResU-Net.” Remote Sensing 12 (15): 2487. https://doi.org/10.3390/rs12152487.
- Qin, Shengwu, Xu Guo, Jingbo Sun, Shuangshuang Qiao, Lingshuai Zhang, Jingyu Yao, Qiushi Cheng, and Yanqing Zhang. 2021. “Landslide Detection from Open Satellite Imagery Using Distant Domain Transfer Learning.” Remote Sensing 13 (17): 3383. https://doi.org/10.3390/rs13173383.
- Scaioni, Marco, Laura Longoni, Valentina Melillo, and Monica Papini. 2014. “Remote Sensing for Landslide Investigations: An Overview of Recent Achievements and Perspectives.” Remote Sensing 6 (10): 9600–9652. https://doi.org/10.3390/rs6109600.
- Shahabi, Hejar, and Omid Ghorbanzadeh. 2022. “Model-Centric vs Data-Centric Deep Learning Approaches for Landslide Detection.” 1–6. CDCEO 2022: 2nd Workshop on Complex Data Challenges in Earth Observation, July 25, Vienna, Austria.
- Shamsolmoali, Pourya, Masoumeh Zareapoor, Huiyu Zhou, Ruili Wang, and Jie Yang. 2021. “Road Segmentation for Remote Sensing Images Using Adversarial Spatial Pyramid Networks.” IEEE Transactions on Geoscience and Remote Sensing 59 (6): 4673–4688. https://doi.org/10.1109/TGRS.2020.3016086.
- Si, Tongzhen, Fazhi He, Penglei Li, and Xiaoxin Gao. 2023. “Tri-Modality Consistency Optimization with Heterogeneous Augmented Images for Visible-Infrared Person Re-Identification.” Neurocomputing 523:170–181. https://doi.org/10.1016/j.neucom.2022.12.042.
- Si, Tongzhen, Fazhi He, Haoran Wu, and Yansong Duan. 2022. “Spatial-Driven Features Based on Image Dependencies for Person Re-Identification.” Pattern Recognition 124:108462. https://doi.org/10.1016/j.patcog.2021.108462.
- Si, Tongzhen, Fazhi He, Zhong Zhang, and Yansong Duan. 2022. “Hybrid Contrastive Learning for Unsupervised Person Re-Identification.” IEEE Transactions on Multimedia. https://doi.org/10.1109/TMM.2022.3174414.
- Soares, Lucas P., Helen C. Dias, and Carlos H. Grohmann. 2020. “Landslide Segmentation with U-Net: Evaluating Different Sampling Methods and Patch Sizes.” arXiv preprint arXiv:2007.06672.
- Song, Lei, Min Xia, Junlan Jin, Ming Qian, and Yonghong Zhang. 2021. “SUACDNet: Attentional Change Detection Network Based on Siamese U-Shaped Structure.” International Journal of Applied Earth Observation and Geoinformation 105:102597. https://doi.org/10.1016/j.jag.2021.102597.
- Song, Shaoyue, Hongkai Yu, Zhenjiang Miao, Qiang Zhang, Yuewei Lin, and Song Wang. 2019. “Domain Adaptation for Convolutional Neural Networks-Based Remote Sensing Scene Classification.” IEEE Geoscience and Remote Sensing Letters 16 (8): 1324–1328. https://doi.org/10.1109/LGRS.2019.2896411.
- Sun, Baochen, and Kate Saenko. 2016. “Deep Coral: Correlation Alignment for Deep Domain Adaptation.” Paper presented at the Proceedings of the European Conference on Computer Vision.
- Taalab, Khaled, Tao Cheng, and Yang Zhang. 2018. “Mapping Landslide Susceptibility and Types Using Random Forest.” Big Earth Data 2 (2): 159–178. https://doi.org/10.1080/20964471.2018.1472392.
- Toldo, Marco, Andrea Maracani, Umberto Michieli, and Pietro Zanuttigh. 2020. “Unsupervised Domain Adaptation in Semantic Segmentation: A Review.” Technologies 8 (2): 35. https://doi.org/10.3390/technologies8020035.
- Trinh, Thanh, Binh Thanh Luu, Trang Ha Thi Le, Duong Huy Nguyen, Trong Van Tran, Thi Hai Van Nguyen, Khanh Quoc Nguyen, and Lien Thi Nguyen. 2022. “A Comparative Analysis of Weight-Based Machine Learning Methods for Landslide Susceptibility Mapping in Ha Giang Area.” Big Earth Data, 1–30. https://doi.org/10.1080/20964471.2022.2043520.
- Tsai, Yi Hsuan, Wei Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming Hsuan Yang, and Manmohan Chandraker. 2018. “Learning to Adapt Structured Output Space for Semantic Segmentation.” Paper presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Tzeng, Eric, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. 2014. “Deep Domain Confusion: Maximizing for Domain Invariance.” arXiv preprint arXiv:1412.3474.
- Valanarasu, Jeya Maria Jose, and Vishal M. Patel. 2022. “UNeXt: MLP-Based Rapid Medical Image Segmentation Network.” Paper presented at the Medical Image Computing and Computer Assisted Intervention.
- Vohora, V. K., and S. L. Donoghue. 2004. “Application of Remote Sensing Data to Landslide Mapping in Hong Kong.” International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences.
- Wang, Yi, Zhice Fang, and Haoyuan Hong. 2019. “Comparison of Convolutional Neural Networks for Landslide Susceptibility Mapping in Yanshan County, China.” Science of the Total Environment 666:975–993. https://doi.org/10.1016/j.scitotenv.2019.02.263.
- Wang, Huan, Yijun Li, Yuehai Wang, Haoji Hu, and Ming-Hsuan Yang. 2020. “Collaborative Distillation for Ultra-Resolution Universal Style Transfer.” Paper presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Wang, Haoran, Tong Shen, Wei Zhang, Ling-Yu Duan, and Tao Mei. 2020. “Classes Matter: A Fine-Grained Adversarial Approach to Cross-Domain Semantic Segmentation.” Paper presented at the Proceedings of the European Conference on Computer Vision.
- Wang, Junjue, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zhong. 2021. “LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation.” arXiv preprint arXiv:2110.08733.
- Xu, Qingsong, Chaojun Ouyang, Tianhai Jiang, Xin Yuan, Xuanmei Fan, and Duoxiang Cheng. 2022. “MFFENet and ADANet: A Robust Deep Transfer Learning Method and Its Application in High Precision and Fast Cross-Scene Recognition of Earthquake-Induced Landslides.” Landslides 19 (7): 1617–1647. https://doi.org/10.1007/s10346-022-01847-1.
- Yang, Zhiyuan, Jing Li, Juha Hyyppä, Jianhua Gong, Jingbin Liu, and Banghui Yang. 2023. “A Comprehensive and Up-to-Date Web-Based Interactive 3D Emergency Response and Visualization System Using Cesium Digital Earth: Taking Landslide Disaster as an Example.” Big Earth Data, 1–23. https://doi.org/10.1080/20964471.2023.2172823.
- Yi, Yaning, and Wanchang Zhang. 2020. “A New Deep-Learning-Based Approach for Earthquake-Triggered Landslide Detection from Single-Temporal RapidEye Satellite Imagery.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 13:6166–6176. https://doi.org/10.1109/JSTARS.2020.3028855.
- Yu, Bo, Fang Chen, Chong Xu, Lei Wang, and Ning Wang. 2021. “Matrix SegNet: A Practical Deep Learning Framework for Landslide Mapping from Images of Different Areas with Different Spatial Resolutions.” Remote Sensing 13 (16): 3158. https://doi.org/10.3390/rs13163158.
- Zhang, Yunlong, Changxing Jing, Huangxing Lin, Chaoqi Chen, Yue Huang, Xinghao Ding, and Yang Zou. 2021. “Hard Class Rectification for Domain Adaptation.” Knowledge-Based Systems 222:107011. https://doi.org/10.1016/j.knosys.2021.107011.
- Zhang, Brian Hu, Blake Lemoine, and Margaret Mitchell. 2018. “Mitigating Unwanted Biases with Adversarial Learning.” Paper presented at the Proceedings of the AAAI Conference on AI, Ethics, and Society.
- Zhang, Zhong, Yanan Wang, Shuang Liu, Baihua Xiao, and Tariq S. Durrani. 2022. “Cross-Domain Person Re-Identification Using Heterogeneous Convolutional Network.” IEEE Transactions on Circuits and Systems for Video Technology 32 (3): 1160–1171. https://doi.org/10.1109/TCSVT.2021.3074745.
- Zhu, Jun Yan, Taesung Park, Phillip Isola, and Alexei A. Efros. 2017. “Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks.” Paper presented at the Proceedings of the IEEE International Conference on Computer Vision.
- Zou, Yang, Zhiding Yu, B. V. K. Kumar, and Jinsong Wang. 2018. “Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training.” Paper presented at the Proceedings of the European Conference on Computer Vision.