
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The semantic segmentation of informal urban settlements represents an essential contribution towards renovation strategies and reconstruction plans. In this context, however, a big challenge remains unsolved when dealing with incomplete data acquisitions from multiple sensing devices, especially when study areas are depicted by images of different resolutions. In practice, traditional methodologies are directed to downgrade the higher-resolution data to the lowest-resolution measure, to define an overall homogeneous dataset, which is however ineffective in downstream segmentation activities of such crowded unplanned urban environments. To this purpose, we hereby tackle the problem in the opposite direction, namely upscaling the lower-resolution data to the highest-resolution measure, contributing to assess the use of cutting-edge super-resolution generative adversarial network (SR-GAN) architectures. The experimental novelty targets the particular case involving the automatic detection of ‘urban villages’, sign of the quick transformation of Chinese urban environments. By aligning image resolutions from two different data sources (Gaofen-2 and Sentinel-2 data), we evaluated the degree of improvement with regard to pixel-based landcover segmentation, achieving, on a 1 m resolution target, classification accuracies up to 83%, 67% and 56% for 4x, 8x, and 10x resolution upgrades respectively, disclosing the advantages of artificially-upscaled images for segmenting detailed characteristics of informal settlements.
1. Introduction
Remote sensing imagery has a consolidated role in extracting and revealing locations, boundaries, and spatial extents, allowing for data acquisitions of wide geographic areas (Cheng and Han Citation2016; Zhu et al. Citation2017). Despite traditional cartography of unplanned buildings, which has been based on costly and labor-intensive field surveys by land management departments (Mahabir et al. Citation2018), remote sensing technologies have recently started to stand out as a supplementary approach for quickly updating base map data (Li, Huang, and Liu Citation2017), providing more convenient characteristics in terms of large coverage and relatively low cost. Indeed, in many cases, information about informal settlements is unavailable, inaccurate, and often obsolete (Hofmann Citation2001), which prevents from a proper mapping of cadastral areas and their transformations over time (Amado et al. Citation2018). Following the rapid technological advance, high-resolution satellite imagery ( resolution) has become more and more available, offering the potential for more accurate land cover classifications and pattern analyses, allowing for extracting and highlighting characteristic urban shapes (Niebergall, Loew, and Mauser Citation2008; Rüther, Martine, and Mtalo Citation2002). Usually outperforming medium- and low-resolution data in capturing spectral and textural information of small habitat patches, it has especially boosted analytical capabilities on the detection and quantification of land cover changes (Lv et al. Citation2022).
The literature on identifying and mapping informal settlements comprise a variety of methodologies, such as object-oriented, contour models, and radial casting (Kuffer and Barrosb Citation2011; Mayunga, Coleman, and Zhang Citation2007; Stow et al. Citation2007). The common trait is based on detecting unknown settlements and determining their location (Huang, Lu, and Sellers Citation2007). Recently, remote sensing studies have further pushed towards extensive developments on the exploration of morphological features of unplanned settlements, in the form of automatic classifications from satellite images (Mboga et al. Citation2017; Williams, Quincey, and Stillwell Citation2016). In this sense, beyond the traditional use of object-based image analysis (OBIA) (Fallatah et al. Citation2019; Kuffer, Pfeffer, and Sliuzas Citation2016), the role of machine learning has emerged as a very effective tool for advancing the automatization capabilities of informal settlement detection (Fallatah, Jones, and Mitchell Citation2020; Gram-Hansen et al. Citation2019), contributing to the strong endeavor of a fully automatic global mapping of urban forms.
In particular, the leading driving factor has been represented by the integration of high-resolution images and modern deep-learning-based semantic segmentation methodologies, specifically involving fully convolutional network (FCN) architectures (Fu et al. Citation2017; Sherrah Citation2016). By strictly enforcing a specific output labeling for each single pixel, they have generally allowed for more accurate localizations of built-up areas, not incorporating the bounding box simplification of traditional OBIA methods. Presenting the advantage of automatically learning feature representations from nearly raw data, without need for field expertise in manually predefining feature extractions (Zhu et al. Citation2017), FCN-based semantic segmentation has been applied to several urban-related tasks, such as road mapping, land-use classification, and vehicle detection (Bai, Mas, and Koshimura Citation2018; Li et al. Citation2019; Peng, Zhang, and Guan Citation2019; Wagner et al. Citation2019; Yi et al. Citation2019).
In this context, high-resolution remote sensing imagery and FCN-based semantic segmentation represent a valuable option for helping map unplanned urban settlements in large cities. However, monitoring considerable amounts of such informal settlements faces several challenges. First, an informal settlement is characterized by atypical morphological characteristics such as poor infrastructures, dense low-rise buildings, small roof sizes, limited green spaces, and irregular patterns within urban territories. Manually creating multiple large sets of tagged informal settlement images by remote sensing interpretation experts is usually very time-consuming and labor-intensive. Moreover, the current costs and restricted availability of very-high-resolution data make the large-scale analysis of high-quality images for unplanned settlement monitoring particularly troublesome. As a consequence, most of research studies on informal settlement identification are limited to a certain geographic area and a distinctive data source, resulting in unclear generalization capabilities across places and, especially, across different sensing acquisition modalities.
Specifically, the major inherent issue is represented by study areas depicted by images of different resolutions, therefore determining an overall inconsistent dataset, which causes the impossibility for a global training process or a direct transfer of model architectures and parameters from a data source to another one. In practice, traditional methodological solutions are directed to downgrade the higher-resolution data to the lowest-resolution measure (Zhang et al. Citation2011), to define an overall homogeneous dataset. However, this way is ineffective when associated to downstream segmentation activities of sharp and detailed objects and contours, particularly present in such crowded informal urban environments. To this purpose, we hereby tackle the problem in the opposite direction, namely upscaling the lower-resolution data to the highest-resolution measure (Park, Park, and Kang Citation2003; Wang, Chen, and Hoi Citation2021), aiming to improve the transfer learning ability across different locations and different satellite sensors. Specifically, we contribute to assess the use of state-of-the-art super-resolution generative adversarial network (SR-GAN) architectures (Ledig et al. Citation2017) to the domain of remote sensing imagery for informal settlement detection, intentionally enlarging the view to solving unaligned resolution problems among multiple data sources. By artificially increasing image resolution, we intend to depict finer spatial details than those captured by the original lower-resolution sensors, enabling the harmonization of size and details of urban structural features among different acquired data, and consequently facilitating potential identifications of unplanned urban settlements in contexts of multi-source remote sensing imagery.
The proposed experimental novelty is intended to integrate the super-resolution framework into the background of semantic segmentation of chengzhongcun, namely ‘urban villages’, primary sign of the quick transformation of Chinese urban environments (Wang, Wang, and Wu Citation2009), testing the feasibility of SR-GANs on high-density informal settlements in multi-resolution satellite data. In very recent years, advanced super-resolution techniques have started to be increasingly utilized in remote sensing applications (Chen, Li, and Jin Citation2021; Sdraka et al. Citation2022; Sedona et al. Citation2021); however, the specific target on unplanned settlements in cities, especially in the case of Chinese urban environments, has not been properly investigated. The benefits of a meaningful upgrade on the quality of such distinctive areas, presenting atypical morphological characteristics, define an essential step towards their correct identification and monitoring over time. We, therefore, intend to expand the super-resolution research wave in remote sensing into the analysis of informal settings and unplanned urban zones, investigating the feasibility and resulting potential advantages of a targeted quality upgrade from related satellite image acquisitions.
Our experiment particularly focuses on generative models for aligning pairs of image resolutions, in terms of both single-source upscaling (4x, 8x) and multi-source alignment (10x). We specifically leverage high-resolution Gaofen-2 data (1-meter resolution), and lower-resolution Sentinel-2 data (10-meter resolution). Following the assumption that an artificially-augmented resolution leads to better downstream outcomes, we evaluate the degree of improvement with regard to pixel-based landcover segmentation, testing a high-performance ResU-Net segmentation model on an urban environment potentially classified into one of four possible categories: urban village, other built-up areas, vegetation and water. The experimental results over the case study area of Dongguan, China, demonstrate the remarkable capabilities of the proposed super-resolution approach, determining a significant performance improvement with respect to the original low-resolution data sources.
Standing out as a feasibility study on image resolution alignments prior to semantic segmentation operations in dense urban environments, our work contributes to the expanding wave of artificial intelligence solutions for geographic applications, disclosing further insights on the potential of deep neural network advancements within the remote sensing domain. Inserted in the big picture of unplanned settlement redevelopment, as part of an active urban management plan and effort to improve the living conditions of citizens, the effective identification and characterization of urban villages represents an essential contribution towards renovation strategies and reconstruction planning (Li, Huang, and Liu Citation2017; Mahabir et al. Citation2018). By acquiring reliable and timely information on the characteristics and extensions of these areas, city managers can design effective policies for promoting sustainable urban development. In the wake of the United Nations’ Sustainable Development Goal (SDG) number 11 (sustainable cities and communities), our objective is to provide an advanced technological tool for supporting the gathering of detailed information on informal urban structures that are supposed to undergo specific reconstruction/renovation processes, to meet adequate housing requirements for urban equity and inclusion, health and safety, and livelihood opportunities.
2. Study area and data collection
The super-resolution framework is evaluated in the study area of the city of Dongguan, China, whose fast urbanization and land-use conversion has led to the rise of skyscrapers and modern buildings side by side high-density urban villages (Huang, Xue, and Huang Citation2021). Typical situation in many Chinese cities, such unplanned settlements have been often subjected to an ever-expanding process of urban redevelopment, aimed at eliminating or reconstructing them (Zhaohui Citation2011). Consequence of the high demand for low-cost residencies since 1980s, urban villages still mainly serve the purpose of providing housing opportunities to low-income citizens and immigrants from rural areas, often presenting unsanitary environments, limited open space and green areas, poorly managed facilities, and general safety-related issues (Li et al. Citation2014, Pan et al. Citation2019b), therefore missing the requirements of formal urban planning strategies. Their redevelopment has gradually become significant, within active plans of urban management and livelihood improvement of citizens (Pan, Hu, and Wang Citation2019). Visual information on the study area is reported in .
Figure 1. Visual information on the study area: (A) Geographic location in Dongguan; (B) Urban village view from Google Maps; (C) Related street view image; (D) Visual interpretation of land cover; (E) Gaofen-2 data in true color; (F) Sentinel-2 data in true color.

The overall experimental data refer to two original data sources, namely the lower-resolution (publicly available) Sentinel-2 satellite data, and the higher-resolution (privately obtained) Gaofen-2 satellite data. Covering the same urban territory, the datasets were both acquired on the same day (2019-03-11), to avoid issues with seasonal effects and environmental changes. Gaofen-2 presents a resolution of 1 meter, Sentinel-2 resolution is instead 10 meters; both of them are made of four imaging bands, RBG plus infrared. The whole depicted area features a size of 8 km2, comprising a multitude of urban villages. The segmentation masks were manually labeled into one of four pre-defined classification categories (i.e. urban villages, other built-up areas, vegetation, and water) according to the landscape in the high-resolution data, presenting a strict spatial alignment with the satellite images.
3. Methodology
The methodological process is directed to aligning images of different resolutions by upgrading the lower-resolution measure to the corresponding higher-resolution version. Specifically, given an original (low) resolution and a target (high) resolution
, the system is intended to upgrade
into
, generating an artificial high-resolution output from a real low-resolution input, ideally reconstructing small details and contours that are heavily blurred (or not even present) in the original input image. The procedure follows a fully automatic processing, without requiring any manual feature extraction or human knowledge assistance. Such generated super-resolution images are supposed to benefit downstream analytical tasks, particularly involving image semantic segmentation, namely correctly labeling each pixel to a certain specific class (Garcia-Garcia et al. Citation2017).
The overall processing details are organized into four subsections, illustrating corresponding structural steps:
Input data preparation, describing the image format and input data modeling set-up;
SR-GAN model training, reporting the generative architecture and adversarial training process at the base of the automatic learning of the underlying semantics for image resolution upgrades;
Super-resolution inference, characterizing the automatic generation of artificial high-resolution data as a consequence of real low-resolution input images;
Downstream segmentation evaluation, comparing semantic segmentation performances on high-resolution data, low-resolution data, and variants of generated super-resolution data.
3.1. Input data preparation
Input data are intended to support the actual adversarial training process for learning resolution upgrades, therefore involving the pairing of low-resolution images with their corresponding high-resolution version. The original satellite data undergo a slicing process for creating smaller image patches, whereby corresponding high-resolution and low-resolution formats need to present a precise geospatial overlap. Specifically, inputs are represented by images of source
and
images of source
, describing the same portions of the territory under study. In practice, the model receives pairs of images
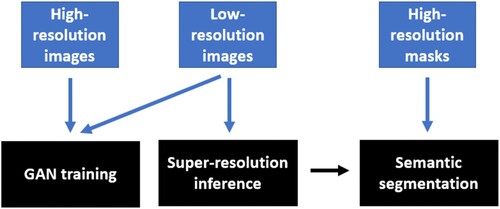
in order to learn how to transform the first data source into the second one. Regarding the image characteristics, we isolate and rescale the RGB format within the super-resolution generation framework, whereas potentially considering additional channels (e.g. infrared) in the segmentation-based downstream evaluation stage. Whereas the GAN training does not involve the use of any labeling procedure, standing out as a purely mapping process between low- and high-resolution image formats, the segmentation task leverages corresponding ground-truth masks annotated at the level of the highest image resolution, following the purpose of assessing the feasibility of automatically learning the most detailed segmentation as possible. The overall input data strategy is summarized in , indicating the corresponding input types to each step of the methodological workflow.
Figure 2. Input data strategy of the overall methodological workflow.
3.2. SR-GAN model training
The scope of super-resolution models is directed to recover high-resolution information from corresponding low-resolution imagery. In recent years, deep learning has been intensively exploited for super-resolution solutions, achieving state-of-the-art performances in a variety of applications (Yang et al. Citation2019). Our case aims to attempt on leveraging super-resolution processes to transform an acquired remote sensing data source into a different and higher-quality one. Specifically, we adopt a GAN-based training process to increase the resolution of a low-resolution data source to ideally match the one of a destination high-resolution source. In practice, given a low-resolution input image, the model is intended to estimate a super-resolved image, artificially-generated version of an ideal original high-resolution image, differing from the input one by a scale factor .
The GAN architecture consists of two competing neural networks: a generator and a discriminator
. The generator
is fed with real low-resolution images, and tries to generate corresponding synthetic images that look similar to real high-resolution images; the discriminator
tries to discriminate real high-resolution images from fake generated images. While
is prompt to learn the distribution and underlying patterns of real high-resolution data,
learns to discern real samples in the original training set from synthetic images produced by
.
More specifically, given real high-resolution data ,
is designed to maximize
for images from
, and minimize
for images from
. On the other side, given a low-resolution input
, sampled from
,
produces synthetic images
to trick
; consequently,
is trained to maximize the probability
of
mistaking, equivalently minimizing
. The training of
and
can be finally summarized as the adversarial min–max problem:
In this way,
is optimized for generating more and more realistic images, while
is optimized for distinguishing real high-resolution images from generated super-resolved ones. The intended purpose is to make
learn to create artificial data that are highly similar to real data and therefore difficult to be distinguished by
.
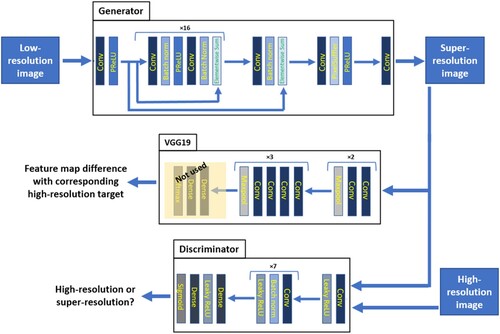
To capture image characteristics, we rely on the deep convolutional-neural-network-based architecture reported in (Ledig et al. Citation2017), defining as made of 16 stacked residual blocks of two convolutional layers with 3 × 3 kernels and 64 feature maps, followed by batch-normalization layers (Ioffe and Szegedy Citation2015) and ParametricReLU activation function (He et al. Citation2015); the input resolution is finally increased by means of trained sub-pixel convolution layers.
is instead composed of eight convolutional layers with a number of 3 × 3 filter kernels increasing by a factor of two, whereby strided convolutions progressively reduce the image resolution; the last feature maps are followed by two dense layers and a sigmoid activation function for providing image classification probabilities.
A prominent importance is attributed to the loss function used for the adversarial training optimization. Whereas super-resolution solutions traditionally rely on minimizing pixel-wise error measurements, e.g. mean squared error (MSE) (Dong et al. Citation2016; Shi et al. Citation2016), SR-GAN introduced the use of loss functions that better grasp perceptually relevant characteristics, leading to perceptually superior solutions residing in the subspace of natural images (Ledig et al. Citation2017). In our case study, we stick to the perceptual loss intended as a weighted sum of a content and an adversarial component:
The adversarial loss measures, over all training samples
, the attempt of the generative component
, parametrized by
, on fooling the discriminator network
, parametrized by
, whereby
represents the probability that a generated image
, output of an input low-resolution image
, is mistaken for a real high-resolution image:
On the other hand, the content loss is based on the 19-layer VGG network (Simonyan and Zisserman Citation2014) pre-trained with the ImageNet dataset (1.3 million images belonging to 1000 categories) (Russakovsky et al. Citation2015), intended as the Euclidean distance between the feature representations of a generated image
and its reference real image
in correspondence of the ReLU activation layers, with
indicating the feature map of the
-th convolution before the
-th maxpooling layer, and
and
representing its width and height respectively:
The high-level workflow representing the GAN training process is summarized in .
Figure 3. Visual summary of the GAN training process.
3.3. Super-resolution inference
At the end of the training phase, is expected to have successfully learned to produce realistic synthetic high-resolution images (i.e. super-resolution samples). Thus,
is not needed anymore during inference time, and only the trained
is extracted and used among the GAN architecture framework. Therefore, no real high-resolution images are utilized; only low-resolution images are employed as an input to
. The artificial super-resolution images are solely generated based on an initial low-resolution input, successively processed along
’s layer blocks.
Outputting a super-resolved image as a function of an input low-resolution sample only relies on the model parameter configuration achieved at end of the training process, as no parameters are updated in during the testing inference procedure. Intuitively, the final generated super-resolution image is intended to depict a plausible (non-existent) high-resolution version that reasonably corresponds to a specific given real low-resolution patch.
3.4. Downstream segmentation evaluation
To quantitatively evaluate the advantages of the proposed framework, we setup a comparison analysis among high-resolution, low-resolution, and various degrees of super-resolution samples with the goal of assessing potential improvements in downstream performances. In particular, we refer to a semantic segmentation task, involving four different classes, namely urban villages, other-built-up areas, vegetation and water. The idea is to train a segmentation model on high-resolution data and assess the transferability performances on different areas covered only by low-resolution acquisitions and their derived generated super-resolution upgrades.
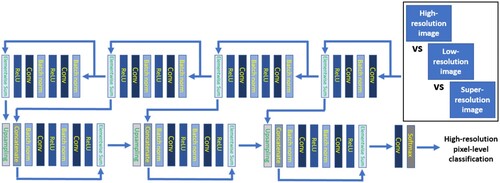
The model was chosen to be defined in the form of a Res-UNet architecture, popular representative state-of-the-art neural network, successfully applied to a variety of remote-sensing-based segmentation tasks with remarkable effectiveness (Diakogiannis et al. Citation2020; Ghorbanzadeh et al. Citation2021), leading to precise objects’ localizations through pixel-to-pixel and end-to-end mapping from input to output.
The ResU-Net design is conceived as a variant of the U-Net algorithm, leveraging the use of residual learning blocks. The network architecture comprises two parts: a contracting path and a symmetric expansive path. The first one includes five consecutive blocks for feature extraction and downsampling, each of them made of two 3 × 3 unpadded convolutions with a convolution stride of 2. The second one consists instead of four blocks, each performing an upsampling of the feature map followed by a 2 × 2 convolution. Along the two processing paths, batch normalization is applied before each convolutional layer, and the number of feature channels is doubled and halved after each downsampling and upsampling, respectively. To define the final segmentation output, a 1 × 1 convolutional layer with a softmax activation function is added on top of the ResU-Net architecture, in order to produce output probabilities for each pixel to belong to each of the four pre-defined segmentation categories. A visual summary of the semantic segmentation model is reported in .
Figure 4. Visual summary of the downstream semantic segmentation process.
4. Experiment and result analysis
4.1. Experimental settings
The experimental training and evaluation procedures were carried out on distinctively separated urban areas, by means of a six-fold cross-validation process defining training and testing input data roughly representing 80% and 20% of the overall dataset, respectively. The study area was divided into almost three thousand non-overlapping images of size pixels, and the low-resolution samples for single-source upscaling were obtained by downsampling the high-resolution images using bicubic kernel with a downsampling factor
and
.
The super-resolution image generation framework leveraged the adversarial learning process on the training data to subsequently be able to automatically generate synthetic high-resolution images on the test set, which are expected, ideally, to realistically replace unavailable real high-resolution data. A few GAN variants were explored in this sense, investigating different optimization modalities based on various choices of the loss function to minimize. Specifically, different layers of the pre-trained VGG19 network were employed for calculating the Euclidean distance between label and prediction representations, particularly referring to error differences at layers 2, 3, and 5; moreover, the traditional MSE minimization was used for performance comparisons. For weight optimization, we opted for the Adam optimizer (Kingma and Ba Citation2014), with and a learning rate of
.
Regarding the downstream segmentation task, training and testing data followed the same splits as the super-resolution framework, and comparison analyses involved distinctive segmentation results on high-resolution images, low-resolution images, and super-resolution images (VGG loss and MSE loss). The parameter optimization of the Res-UNet model, through mini-batch stochastic training, relied on the cross-entropy loss function and Adam optimizer.
The whole framework, comprising model implementations, training and evaluations, was implemented in Python through the TensorFlow library, running on Nvidia Quadro RTX 3000 GPU.
4.2. Results
The resulting findings are organized on two levels: a visual qualitative evaluation of the generated super-resolution images, and a quantitative evaluation with regards to downstream segmentation performances. The underlying idea is directed to assess a visual realistic character of the synthetic data and evaluate their potential feasible use in further analytical tasks.
4.2.1. Visual evaluation
A first evaluation criterion is focused on assessing the realistic visual character of the generated super-resolution data. We proceeded to explore and visualize perceptual differences among low-resolution and super-resolution images, investigating the preferable configuration that leads to produce high-quality synthetic data. This follows the assumption that the GAN model is expected to properly process input low-resolution images and convert them into visually-acceptable higher-resolution data. We carried out the resolution upgrade task on single-source and cross-source upscaling, namely 4x-upscaling and 8x-upscaling on the same (manually downgraded) Gaofen-2 data source, and 10x-upscaling from low-resolution Sentinel-2 images into higher-resolution Gaofen-2 images.
reports a number of examples of super-resolution images generated from low-resolution data. The results refer to the SR-GAN model optimized with a VGG-loss calculated in correspondence of the last VGG19 layer (VGG_5.4). The visual performance exhibits satisfying outcomes, effectively demonstrating a clear valuable increase of image resolution on the generated artificial samples. From an overall perspective, the GAN model is presumed to have correctly grasped the real underlying visual patterns and subsequently learn to generate synthetic data holding such realistic characteristics.
Figure 5. Examples of super-resolution images generated by SR-GAN (VGG_5.4 loss) from low-resolution data.

To have a broader view on SR-GAN parameter configurations, we explored different levels of VGG loss definition, namely defining a training setup following loss function calculations at the level of the second layer (VGG_2.2) and the third layer (VGG_3.4) of the VGG19 network. However, as shown in , visual results are not satisfactory, leading to generating images affected by a variety of artifacts. We, therefore, assumed the last VGG layer as the one providing the best optimization performances in terms of super-resolution data quality.
Figure 6. Examples of super-resolution images obtained by minimizing VGG_2.2 and VGG_3.4 losses on a 4x upscaling.

Moreover, we explored the parameter optimization according to the traditional MSE minimization, therefore not using the pre-trained VGG19 network to define the loss function values (in terms of internal feature map differences), but directly calculating the final MSE between real targets and generated images at each training step. As shown in , results present a lower upscaling capability, producing blurred super-resolution images unable to reconstruct sharp details and contours in small objects, therefore implying a much worse effectiveness in generating good-quality higher-resolution synthetic data. We deduced that the VGG19 network, although pre-trained with the ImageNet dataset (1.3 million images belonging to 1000 generic classes, therefore not with including satellite images) still provides a remarkable advantage over pixel-based optimizations on the GAN learning procedure, leading to a substantially better parameter configuration and realistic image resolution upgrades.
Figure 7. Examples of super-resolution images obtained by minimizing MSE loss.

Whereas the VGG_5.4 loss was revealed to produce the overall best-quality synthetic images, it is worth noticing a peculiar issue affecting the correct generation of a few images. Specifically, by visually investigating the super-resolution results, we encountered the presence of some artifacts on uniform water backgrounds, as reported in the examples of . Such artifacts stand out in the form of round and ‘heart’ light shapes or overlapping mixtures of colors, which, although not frequently present across images, sporadically occurred in more than a case.
Figure 8. Examples of visual artifacts in generated super-resolution images.

To sum up, in an overall perspective, SR-GAN, when designed under a proper configuration, is able to generate realistic synthetic images that successfully increase the resolution of an input low-resolution image in the context of urban village environments and urban areas in general. The visual results clearly indicate a substantial benefit over original low-resolution conditions.
In accordance with the visual evaluation, the peak signal-to-noise ratio (PSNR) reports an improvement in correspondence of the VGG19-based SR-GAN, with a particular increment in regard to cross-source upscaling measures, as shown in . However, being an index that only relies on a pixel-wise image difference, its ability to capture high texture details and perceptually relevant differences is limited (Ledig et al. Citation2017). To quantify the meaningfulness and effective usability of the generated images, we therefore proceeded to test the super-resolution results in the context of automatic semantic segmentation setups.
Table 1. PSNR scores in correspondence of 4x upscaling, 8x upscaling and 10x cross-source upscaling.
4.2.2. Downstream segmentation evaluation
To quantitatively assess the performances (and the consequent usability) of the generated super-resolution images, we evaluated the characteristics of synthetic data in the context of semantic segmentation of urban villages, more precisely referring to the task of classifying pixels into one of four different categories: urban villages, other built-up areas, vegetation and water.
The problem is arranged as a comparison setup of a ResUnet-based model trained on real high-resolution data (therefore leveraging detailed segmentation masks during the learning process), assessing the transferability capabilities over real low-resolution data and synthetic super-resolution data, with the hypothesis that artificial resolution upgrades lead to a substantial improvement when compared to original low-resolution images, ideally reaching segmentation performances that are as close as possible to the high-resolution data.
We first explored the results on 4x upscaling. reports the pixel-based accuracy scores and intersection-over-union (IoU) scores (in brackets) of high-resolution, low-resolution, VGG-based SR-GAN and MSE-based SR-GAN. The main evidence is represented by the remarkable improvement achieved on the urban village category, which is badly detected in low-resolution data (49.4% accuracy, with 48.2% of pixels specifically misclassified as ‘other built-up areas’), but reaches similar performances to the high-resolution case when it comes to super-resolution data (75.8% accuracy, with only 16.2% of pixels misclassified as ‘other built-up areas’). Also, it is worth noticing that the effect of MSE optimization leads to substantially worse performances, especially regarding ‘urban village’ and ‘vegetation’ categories. Finally, a further mention is necessary on the low GAN performance in detecting the ‘water’ class. That is related to the artifacts appearing in water backgrounds, leading to a corresponding number of pixels to be wrongly classified (specifically, 6.9% misclassified as ‘vegetation’, 1.1% as ‘other built-up areas’).
Table 2. Pixel-based accuracy and IoU (in brackets) of downstream land-cover segmentation for 4x upscaling.
displays instead the accuracy and IoU scores related to the 8x upscaling. The results reinforce the reported observations on the SR-GAN performance characteristics, further stretching the previous statements. In particular, the increment on urban village detection is even more remarkable: whereas, in the low-resolution case, the accuracy equals 22.5%, with 53.3% of pixels specifically misclassified as ‘other built-up areas’ and 23.5% misclassified as ‘vegetation’, super-resolution images lead to an accuracy of 61.9%, with only 36.6% of pixels misclassified as ‘other built-up areas’ and a minimal amount of 1.4% misclassified as ‘vegetation’. The issue on water detection, due to the artifacts, is still present in a comparable measure (85.1% accuracy, with 10.1% misclassified as ‘vegetation’, and 7.1% as ‘other built-up areas’).
Table 3. Pixel-based accuracy and IoU (in brackets) of downstream land-cover segmentation for 8x upscaling.
Finally, reports the results in terms of 10x upscaling across two different data sources, leading the previous observations to the extremes. In particular, low-resolution performance drops dramatically, not being able to correctly detect any ‘urban village’-related pixel (specifically, with 97.8% of pixels misclassified as ‘other built-up areas’), and even presenting a substantial decrease in terms of vegetation and water detection. On the other hand, VGG-based super-resolution results exhibit a noteworthy improvement compared to low-resolution ones, successfully detecting half of urban villages (51.9% accuracy, with 46.3% of pixels misclassified as ‘other built-up areas’) and achieving better performances on the ‘water’ category, though still presenting a substantial drop in terms of ‘vegetation’ detection (68.5% accuracy, with 29.4% of pixels misclassified as ‘other built-up areas’) with respect to high-resolution. Finally, a last note on the MSE optimization performance, leading, as in the low-resolution case, to not detecting any urban village, therefore not presenting any improvement in this sense.
Table 4. Pixel-based accuracy and IoU (in brackets) of downstream land-cover segmentation for cross-source 10x upscaling.
In addition to the segmentation results obtained on the RGB image format, we proceeded to attempt on exploring potential improvements when adding the supplementary near infrared (NIR) channel to the RGB layers. Due to the fact that the super-resolution images are generated in the plain RGB format, we manually added the real low-resolution NIR layer on the back of the produced super-resolution RGB image. Real high-resolution and low-resolution images are instead tested with their original NIR layer attached. The results are reported in , referring to 4x upscaling, 8x upscaling and cross-source 10x upscaling, respectively. The improvement is particularly prominent with regards to the ‘urban village’ category, likely due to the different construction materials used in urban villages compared to modern buildings, reflected in the values of the infrared signal. Moreover, another considerable aspect relates to the substantially better detection capability at the level of ‘water’ pixels in the generated super-resolution data. This is because the attached infrared layer partially solved the problem derived from the generated artifacts, as the confused model predictions on the areas characterized by shapes of light and artificial color mixtures are moved towards the water classification as a consequence of the clear water-defining signal at the level of infrared values.
Table 5. Pixel-based accuracy and IoU (in brackets) of downstream land-cover segmentation for 4x upscaling on four-band input images.
Table 6. Pixel-based accuracy and IoU (in brackets) of downstream land-cover segmentation for 8x upscaling on four-band input images.
Table 7. Pixel-based accuracy and IoU (in brackets) of downstream land-cover segmentation for cross-source 10x upscaling on four-band input images.
The overall segmentation results depict an effective benefit of artificial resolution upgrades in the context of urban village detection, clearly disclosing the advantages of an upscaled (although synthetic) image for segmenting detailed objects and characteristics such as crowded informal settlements.
4.3. Discussion
We proposed an extensive investigation of a generative deep learning framework, in the context of remote sensing imagery, for artificially upgrading low-resolution images into corresponding synthetic high-resolution data. The methodology relied on a SR-GAN architecture trained on satellite images of crowded urban environments, examining the potential of addressing resolution upgrades among single-source and cross-source set-ups, in the characteristic use case of unplanned urban settlements.
In particular, the experiments tackled the problem of Chinese urban villages, a peculiar environmental structure and critical social condition widely spread in Chinese big cities. We focused on 4x and 8x upscaling of an original data source, but also investigated cross-source transferability capabilities from an initial dataset into a 10x-upgraded different satellite imagery, whereby trivial generalization solutions are highly ineffective. Instead of manually downgrading high-resolution samples to the low-resolution values, we adopted the opposite perspective, generating super-resolution data as upscaled synthetic versions of original low-resolution images, targeting substantial performance improvements on downstream segmentation problems involving fine details and sharp objects.
The comparative evaluation highlighted indeed the necessity of a solution that helps reconstruct clear visual features, as the detection of urban villages, negatively affected by issues of resolution difference, is often misinterpreted as the general ‘other built-up areas’ category. Specifically, the segmentation performance of the ‘urban village’ class was experienced to substantially decrease by increasing the downscaling factor, reaching the maximum drop in the cross-source trial, together with a marked detection decrease of the ‘vegetation’ and ‘water’ categories as well. The advantage of the GAN approach was proved to represent a valuable step for a correct downstream automatic segmentation, especially leading to remarkable improvements on a proper identification of urban villages. In this sense, reports some exemplifying visual cases of segmentation results in terms of high-resolution, low-resolution, and super-resolution testing data.
Figure 9. Exemplifying visual cases of semantic segmentation results in terms of high-resolution, low-resolution, and super-resolution data, highlighting the remarkable performance improvement on urban village detection after the super-resolution upscaling.

Within the vision of providing increased segmentation performances, our method does not directly aim to optimize classification results by means of an improved internal (black-box oriented) processing for mining original input data in a more effective way (e.g. Mosinska et al. Citation2018), but inserts an explicit processing step in between, which is the generation of explicit super-resolution data that are supposed to replace the original lower-quality images along the segmentation pipeline. The explicit generation of super-resolution images represents an ‘explainable’ tool for assessing the goodness of the framework, as this additional processing step allows undergoing manual and automatic visual inspections on the quality of such artificially upgraded images, which hold the same format of the original input data but improve their original characteristics. Moreover, since we are dealing with a proper image format (although artificially produced), its use is not only limited to automatic semantic segmentation, but can even be potentially directed towards other downstream tasks that may benefit from a substantial resolution upgrade of lower-quality inputs.
Furthermore, we explored the visual effects of different GAN variants, assessing the best configuration for the desired upgrading task. In particular, we investigated the impact of the pre-trained VGG19 network as a methodological tool for defining the loss function to be minimized during training. Visual results reported the most realistic character in correspondence of a loss minimization at the level of the last layer of the last VGG block, whereas choices on preceding blocks give rise to prominent artifacts in the form of vertical strips across the generated images, disclosing a trend of obtaining clearer reconstructions as deeper we go in the VGG architecture to select the layer to insert in the loss minimization process. In addition, we proceeded to compare the VGG loss with the traditional pixel-based optimization leveraging MSE calculation, registering a clear tendency of the latter to elicit more blurred outputs and undefined details. This also reflects to the downstream segmentation performances, where the MSE optimization was reported to lead to a substantial drop with regards to a correct classification of the ‘urban village’ category. Overall, the VGG_5.4 loss presents an adequate outcome both in terms of visual image characteristics and quantitative segmentation results, therefore demonstrating that, whereas pre-trained with images that are not satellite-based, its pre-defined convolutional layers provide high-level features that still carry meaningful information for image reconstruction.
However, despite the promising behavior of the SR-GAN’s VGG-based optimization, it is due to mention its seldom generation of visual artifacts occurring in the form of round and ‘heart’ shapes in plain water backgrounds, possible consequence of the over-mentioned pre-trained VGG configuration, whose big variety of training images range from animals to people, to objects, to daily life representations, therefore not directly relevant to strict remote sensing backgrounds. The lack of detailed information in broad water bodies may favor the internal VGG layers to present some fake patterns as a result of the original pre-trained weights in the network. This may have an influence in artificially adding some visual representations that are not present in the input images. In this sense, future works may investigate the possibility of replacing the ImageNet-based VGG19 with networks specifically pre-trained on satellite images, even if such step is definitely not trivial. Still, the number of images affected by unreal patterns is very limited, and primarily concerns backgrounds made of expanses of water, therefore not closely related to urban village environments.
Beyond the generated RGB image format, we investigated the potential benefits that may derive on downstream segmentation performances by stacking a further NIR channel on top of the synthetic 3-channel image. Results presented a substantial improvement, particularly including urban village detection, possibly because of the additional information on the differences of building materials between unplanned settlements and higher-quality constructions. The cross-source trial also highlighted a prominent increment of correct vegetation detection, solving its classification overlapping conflict with the ‘other built-up areas’ class. Finally, of great importance is the effect on artifact-driven misclassifications in water backgrounds, which are solved by adding the infrared information, orienting the segmentation model towards a water matter when confused by the artificial mixture of RGB colors.
A final point to discuss refers to the overall view of the category misclassifications, providing an insight on the segmentation mistakes of the four land covers. In particular, misclassifications are coherent among the 4x, 8x, and 10x upscaling, presenting similar trends. Urban villages are mainly misclassified as ‘other built-up areas’; ‘other built-up areas’ tend to be easily predictable; vegetation drops its accuracy in the cross-source trial, mainly misclassified as ‘other built-up areas’; and water is mainly mistaken as ‘vegetation’ and ‘other built-up areas’, due to its artifacts.
To conclude, our feasibility assessment on generative deep learning frameworks for upscaling remote sensing images opens to significant perspectives within the identification of informal settlements in cities. By leveraging the conceptual view of generating synthetic upscaled images rather than downgrading original imagery acquisitions in multi-source environments, we aimed to automatically learn the underlying patterns of the available original high-resolution data portion in order to subsequently generate realistic super-resolution images in areas covered only by low-resolution acquisitions. Our contribution is inserted into the wave of methodological integration of artificial neural networks and remote sensing research, extending the exploration of deep learning adaptations on satellite data and identifying a prominent path for future analytical investigations within the critically evolving domain of geospatial image processing.
5. Conclusion
Inspired by developments in super-resolution research, this paper explored the adaptation of cutting-edge super-resolution modeling into remote sensing and urban studies. We presented a generative method for upscaling urban-village-related satellite images within single-source and multi-source settings, demonstrating the potential for solving problems caused by spatial resolution unalignments among different data acquisitions. In particular, we generated RGB synthetic images with a resolution upgrade of 4x, 8x and 10x. Subjected to an adversarial training process based on the VGG loss minimization, the model automatically detects image patterns in a purely data-driven manner, learning to reconstruct sharp details and small shapes depicting the unplanned chaotic environments that naturally characterize Chinese urban villages, whereby the specific unique traits are a consequence of the distinctive social situation. Our findings stand out as a significant starting point for further examinations on quality upgrading techniques for remote sensing image acquisitions of unplanned urban settlements.
It is important to point out that the detection of informal settlements carries relevant ethical consequences, as its use in real-world contexts leads to decisions that impact society, and may negatively affect marginalized communities (Kuffer et al. Citation2018). Accountability and transparency should be guaranteed in the process of disseminating information (Owusu et al. Citation2021), which inevitably creates an asymmetry between the people owning the mapping technologies and the people being mapped, who are not involved in the acquisition and analysis of the data. Moreover, especially when dealing with high-resolution images, there may be relevant concerns on the privacy of individuals (Gevaert et al. Citation2018). Whereas our case refers only to the segmentation of settlement boundaries, individual privacy is not a major issue, but matters of group privacy and security should be still taken into account (Taylor Citation2017). The automatic detection of unplanned urban areas is intended to represent a key source of information for urban planning and management, and its adoption is meant to be directed towards the development of initiatives for supporting citizens’ wellbeing, not misused as a weapon for stigmatization.
Extensions of our work may be directed towards multiple different efforts. A more in-depth analysis on the causes and influences of high-quality reconstruction in multi-source settings, and its effect for enhancing the segmentation performance to a maximum extent, is needed, together with a theoretical clarification on the inherent choices of the model with regard to different objects, digging into the reasons behind a specific way of upgrading particular pieces of landscape. Another examination may focus on carefully quantifying the robustness of the super-resolution methodology, even exploring its effectiveness in other study areas covered with different building types. Moreover, further generative architecture variants can be tested, investigating more elaborated set-ups such as ways of optimizing GANs with multiple channels, beyond the common RGB format, making them adaptable to the wide variety of satellite data types. In this sense, other additional modifications may refer to the exploration of possible combinations among different input data, leveraging additional social-environmental input information beside the initial remote sensing data source. Finally, a more futuristic perspective may lead to attempt on adapting SR-GANs for predicting environment transformations over time, not only dealing with resolution upgrades but also grasping the time-dependent environmental changes in the context of cross-source alignment from different acquisition dates (e.g. ongoing construction sites, post-disaster environmental recovery).
In conclusion, this study has enhanced the potential effectiveness of super-resolution deep learning methodologies in reconstructing high-resolution details from low-resolution images of crowded urban environments, tackling the resolution unalignment problem derived from different acquired data sources. Within the context of Chinese urban villages, our paper actively contributes towards the expansion of artificial intelligence for geospatial analysis, taking a primary spot among the recent trends on smart strategies for urban redevelopment solutions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
Sentinel-2 data are publicly available in the Copernicus Open Access Hub (https://scihub.copernicus.eu/dhus). Gaofen-2 data were privately acquired and are available on request from the corresponding author.
Additional information
Funding
References
- Amado, Miguel, Francesca Poggi, Adriana Martins, Nuno Vieira, and Antonio Ribeiro Amado. 2018. “Transforming Cape Vert Informal Settlements.” Sustainability 10 (7): 2571. https://doi.org/10.3390/su10072571.
- Bai, Yanbing, Erick Mas, and Shunichi Koshimura. 2018. “Towards Operational Satellite-Based Damage-Mapping Using u-net Convolutional Network: A Case Study of 2011 Tohoku Earthquake-Tsunami.” Remote Sensing 10 (10): 1626. https://doi.org/10.3390/rs10101626.
- Chen, Bin, Jing Li, and Yufang Jin. 2021. “Deep Learning for Feature-Level Data Fusion: Higher Resolution Reconstruction of Historical Landsat Archive.” Remote Sensing 13 (2): 167. https://doi.org/10.3390/rs13020167.
- Cheng, Gong, and Junwei Han. 2016. “A Survey on Object Detection in Optical Remote Sensing Images.” ISPRS Journal of Photogrammetry and Remote Sensing 117: 11–28. https://doi.org/10.1016/j.isprsjprs.2016.03.014.
- Diakogiannis, Foivos I., François Waldner, Peter Caccetta, and Chen Wu. 2020. “ResUNet-a: A Deep Learning Framework for Semantic Segmentation of Remotely Sensed Data.” ISPRS Journal of Photogrammetry and Remote Sensing 162: 94–114. https://doi.org/10.1016/j.isprsjprs.2020.01.013.
- Dong, Chao, Chen Change Loy, Kaiming He, and Xiaoou Tang. 2016. “Image Super-Resolution Using Deep Convolutional Networks.” IEEE Transactions on Pattern Analysis and Machine Intelligence 38 (2): 295–307. https://doi.org/10.1109/TPAMI.2015.2439281.
- Fallatah, Ahmad, Simon Jones, and David Mitchell. 2020. “Object-based Random Forest Classification for Informal Settlements Identification in the Middle East: Jeddah a Case Study.” International Journal of Remote Sensing 41 (11): 4421–4445. https://doi.org/10.1080/01431161.2020.1718237.
- Fallatah, Ahmad, Simon Jones, David Mitchell, and Divyani Kohli. 2019. “Mapping Informal Settlement Indicators Using Object-Oriented Analysis in the Middle East.” International Journal of Digital Earth 12 (7): 802–824. https://doi.org/10.1080/17538947.2018.1485753.
- Fu, Gang, Changjun Liu, Rong Zhou, Tao Sun, and Qijian Zhang. 2017. “Classification for High Resolution Remote Sensing Imagery Using a Fully Convolutional Network.” Remote Sensing 9 (5): 498. https://doi.org/10.3390/rs9050498.
- Garcia-Garcia, Alberto, Sergio Orts-Escolano, Sergiu Oprea, Victor Villena-Martinez, and Jose Garcia-Rodriguez. 2017. “A Review on Deep Learning Techniques Applied to Semantic Segmentation.” arXiv preprint arXiv:1704.06857. https://doi.org/10.48550/arXiv.1704.06857
- Gevaert, Caroline M., Richard Sliuzas, Claudio Persello, and George Vosselman. 2018. “Evaluating the Societal Impact of Using Drones to Support Urban Upgrading Projects.” ISPRS International Journal of geo-Information 7 (3): 91. https://doi.org/10.3390/ijgi7030091.
- Ghorbanzadeh, Omid, Alessandro Crivellari, Pedram Ghamisi, Hejar Shahabi, and Thomas Blaschke. 2021. “A Comprehensive Transferability Evaluation of U-Net and ResU-Net for Landslide Detection from Sentinel-2 Data (Case Study Areas from Taiwan, China, and Japan).” Scientific Reports 11 (1): 1–20. doi:10.1038/s41598-021-94190-9.
- Gram-Hansen, Bradley J., Patrick Helber, Indhu Varatharajan, Faiza Azam, Alejandro Coca-Castro, Veronika Kopackova, and Piotr Bilinski. 2019. “Mapping Informal Settlements in Developing Countries Using Machine Learning and Low Resolution Multi-Spectral Data.” In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pp. 361-368. https://doi.org/10.1145/3306618.3314253
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. “Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification.” In Proceedings of the IEEE international conference on computer vision, 1026–1034. https://doi.org/10.1109/ICCV.2015.123.
- Hofmann, Peter. 2001. Detecting Informal Settlements from IKONOS Image Data Using Methods of Object Oriented Image Analysis—An Example from Cape Town (South Africa).” In Proceedings of the 2nd international symposium remote sensing of urban areas, 107–118.
- Huang, Jingnan, Xi Xi Lu, and Jefferey M. Sellers. 2007. “A Global Comparative Analysis of Urban Form: Applying Spatial Metrics and Remote Sensing.” Landscape and Urban Planning 82 (4): 184–197. https://doi.org/10.1016/j.landurbplan.2007.02.010.
- Huang, Yingmin, Desheng Xue, and Gengzhi Huang. 2021. “Economic Development, Informal Land-use Practices and Institutional Change in Dongguan, China.” Sustainability 13 (4): 2249. https://doi.org/10.3390/su13042249.
- Ioffe, Sergey, and Christian Szegedy. 2015. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.” In International conference on machine learning, 448–456.
- Kingma, Diederik P., and Jimmy Ba. 2014. “Adam: A Method for Stochastic Optimization.” arXiv preprint arXiv:1412.6980. https://doi.org/10.48550/arXiv.1412.6980
- Kuffer, Monika, and Joana Barrosb. 2011. “Urban Morphology of Unplanned Settlements: The use of Spatial Metrics in VHR Remotely Sensed Images.” Procedia Environmental Sciences 7: 152–157. https://doi.org/10.1016/j.proenv.2011.07.027.
- Kuffer, Monika, Karin Pfeffer, and Richard Sliuzas. 2016. “Slums from Space—15 Years of Slum Mapping Using Remote Sensing.” Remote Sensing 8 (6): 455. https://doi.org/10.3390/rs8060455.
- Kuffer, Monika, Jiong Wang, Michael Nagenborg, Karin Pfeffer, Divyani Kohli, Richard Sliuzas, and Claudio Persello. 2018. “The Scope of Earth-Observation to Improve the Consistency of the SDG Slum Indicator.” ISPRS International Journal of geo-Information 7 (11): 428. https://doi.org/10.3390/ijgi7110428.
- Ledig, Christian, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, et al. 2017. “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network.” In Proceedings of the IEEE conference on computer vision and pattern recognition, 4681–4690. https://doi.org/10.1109/CVPR.2017.19.
- Li, Weijia, Conghui He, Jiarui Fang, Juepeng Zheng, Haohuan Fu, and Le Yu. 2019. “Semantic Segmentation-Based Building Footprint Extraction Using Very High-Resolution Satellite Images and Multi-Source GIS Data.” Remote Sensing 11 (4): 403. https://doi.org/10.3390/rs11040403.
- Li, Yansheng, Xin Huang, and Hui Liu. 2017. “Unsupervised Deep Feature Learning for Urban Village Detection from High-Resolution Remote Sensing Images.” Photogrammetric Engineering & Remote Sensing 83 (8): 567–579. https://doi.org/10.14358/PERS.83.8.567.
- Li, Ling Hin, Jie Lin, Xin Li, and Fan Wu. 2014. “Redevelopment of Urban Village in China–A Step Towards an Effective Urban Policy? A Case Study of Liede Village in Guangzhou.” Habitat International 43: 299–308. https://doi.org/10.1016/j.habitatint.2014.03.009.
- Lv, Zhiyong, Tongfei Liu, Jón Atli Benediktsson, and Nicola Falco. 2022. “Land Cover Change Detection Techniques: Very-High-Resolution Optical Images: A Review.” IEEE Geoscience and Remote Sensing Magazine 10 (1): 44–63. https://doi.org/10.1109/MGRS.2021.3088865.
- Mahabir, Ron, Arie Croitoru, Andrew T. Crooks, Peggy Agouris, and Anthony Stefanidis. 2018. “A Critical Review of High and Very High-Resolution Remote Sensing Approaches for Detecting and Mapping Slums: Trends, Challenges and Emerging Opportunities.” Urban Science 2 (1): 8. https://doi.org/10.3390/urbansci2010008.
- Mayunga, S. D., D. J. Coleman, and Y. Zhang. 2007. “A Semi-Automated Approach for Extracting Buildings from QuickBird Imagery Applied to Informal Settlement Mapping.” International Journal of Remote Sensing 28 (10): 2343–2357. https://doi.org/10.1080/01431160600868474.
- Mboga, Nicholus, Claudio Persello, John Ray Bergado, and Alfred Stein. 2017. “Detection of Informal Settlements from VHR Images Using Convolutional Neural Networks.” Remote Sensing 9 (11): 1106. https://doi.org/10.3390/rs9111106.
- Mosinska, Agata, Pablo Marquez-Neila, Mateusz Koziński, and Pascal Fua. 2018. “Beyond the Pixel-Wise Loss for Topology-Aware Delineation.” In Proceedings of the IEEE conference on computer vision and pattern recognition, 3136–3145. https://doi.org/10.1109/CVPR.2018.00331.
- Niebergall, Susan, Alexander Loew, and Wolfram Mauser. 2008. “Integrative Assessment of Informal Settlements Using VHR Remote Sensing Data—The Delhi Case Study.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 1 (3): 193–205. https://doi.org/10.1109/JSTARS.2008.2007513.
- Owusu, Maxwell, Monika Kuffer, Mariana Belgiu, Tais Grippa, Moritz Lennert, Stefanos Georganos, and Sabine Vanhuysse. 2021. “Towards User-Driven Earth Observation-Based Slum Mapping.” Computers, Environment and Urban Systems 89: 101681. https://doi.org/10.1016/j.compenvurbsys.2021.101681.
- Pan, Zhuokun, Yueming Hu, and Guangxing Wang. 2019a. “Detection of Short-Term Urban Land use Changes by Combining SAR Time Series Images and Spectral Angle Mapping.” Frontiers of Earth Science 13 (3): 495–509. https://doi.org/10.1007/s11707-018-0744-6.
- Pan, Zhuokun, Guangxing Wang, Yueming Hu, and Bin Cao. 2019b. “Characterizing Urban Redevelopment Process by Quantifying Thermal Dynamic and Landscape Analysis.” Habitat International 86: 61–70. https://doi.org/10.1016/j.habitatint.2019.03.004.
- Park, Sung Cheol, Min Kyu Park, and Moon Gi Kang. 2003. “Super-resolution Image Reconstruction: A Technical Overview.” IEEE Signal Processing Magazine 20 (3): 21–36. https://doi.org/10.1109/MSP.2003.1203207.
- Peng, Daifeng, Yongjun Zhang, and Haiyan Guan. 2019. “End-to-end Change Detection for High Resolution Satellite Images Using Improved UNet++.” Remote Sensing 11 (11): 1382. https://doi.org/10.3390/rs11111382.
- Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, et al. 2015. “Imagenet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision 115 (3): 211–252. https://doi.org/10.1007/s11263-015-0816-y.
- Rüther, Heinz, Hagai M. Martine, and E. G. Mtalo. 2002. “Application of Snakes and Dynamic Programming Optimisation Technique in Modeling of Buildings in Informal Settlement Areas.” ISPRS Journal of Photogrammetry and Remote Sensing 56 (4): 269–282. https://doi.org/10.1016/S0924-2716(02)00062-X.
- Sdraka, Maria, Ioannis Papoutsis, Bill Psomas, Konstantinos Vlachos, Konstantinos Ioannidis, Konstantinos Karantzalos, Ilias Gialampoukidis, and Stefanos Vrochidis. 2022. “Deep Learning for Downscaling Remote Sensing Images: Fusion and Super-Resolution.” IEEE Geoscience and Remote Sensing Magazine 10 (3): 202–255. https://doi.org/10.1109/MGRS.2022.3171836.
- Sedona, Rocco, Claudia Paris, Gabriele Cavallaro, Lorenzo Bruzzone, and Morris Riedel. 2021. “A High-Performance Multispectral Adaptation GAN for Harmonizing Dense Time Series of Landsat-8 and Sentinel-2 Images.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 14: 10134–10146. https://doi.org/10.1109/JSTARS.2021.3115604.
- Sherrah, Jamie. 2016. “Fully Convolutional Networks for Dense Semantic Labelling of High-Resolution Aerial Imagery.” arXiv preprint arXiv:1606.02585. https://doi.org/10.48550/arXiv.1606.02585
- Shi, Wenzhe, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. 2016. “Real-time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network.” In Proceedings of the IEEE conference on computer vision and pattern recognition, 1874–1883. https://doi.org/10.1109/CVPR.2016.207.
- Simonyan, Karen, and Andrew Zisserman. 2014. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/arXiv.1409.1556
- Stow, D., A. Lopez, C. Lippitt, S. Hinton, and J. Weeks. 2007. “Object-Based Classification of Residential Land use Within Accra, Ghana Based on QuickBird Satellite Data.” International Journal of Remote Sensing 28 (22): 5167–5173. https://doi.org/10.1080/01431160701604703.
- Taylor, Linnet. 2017. “Safety in Numbers? Group Privacy and big Data Analytics in the Developing World.” Group Privacy: New Challenges of Data Technologies, 13–36. https://doi.org/10.1007/978-3-319-46608-8_2.
- Wagner, Fabien H., Alber Sanchez, Yuliya Tarabalka, Rodolfo G. Lotte, Matheus P. Ferreira, Marcos PM Aidar, Emanuel Gloor, Oliver L. Phillips, and Luiz EOC Aragao. 2019. “Using the U-net Convolutional Network to map Forest Types and Disturbance in the Atlantic Rainforest with Very High Resolution Images.” Remote Sensing in Ecology and Conservation 5 (4): 360–375. https://doi.org/10.1002/rse2.111.
- Wang, Zhihao, Jian Chen, and Steven CH Hoi. 2021. “Deep Learning for Image Super-Resolution: A Survey.” IEEE Transactions on Pattern Analysis and Machine Intelligence 43 (10): 3365–3387. https://doi.org/10.1109/TPAMI.2020.2982166.
- Wang, Ya Ping, Yanglin Wang, and Jiansheng Wu. 2009. “Urbanization and Informal Development in China: Urban Villages in Shenzhen.” International Journal of Urban and Regional Research 33 (4): 957–973. https://doi.org/10.1111/j.1468-2427.2009.00891.x.
- Williams, Nathaniel, Duncan Quincey, and John Stillwell. 2016. “Automatic Classification of Roof Objects from Aerial Imagery of Informal Settlements in Johannesburg.” Applied Spatial Analysis and Policy 9 (2): 269–281. https://doi.org/10.1007/s12061-015-9158-y.
- Yang, Wenming, Xuechen Zhang, Yapeng Tian, Wei Wang, Jing-Hao Xue, and Qingmin Liao. 2019. “Deep Learning for Single Image Super-Resolution: A Brief Review.” IEEE Transactions on Multimedia 21 (12): 3106–3121. https://doi.org/10.1109/TMM.2019.2919431.
- Yi, Yaning, Zhijie Zhang, Wanchang Zhang, Chuanrong Zhang, Weidong Li, and Tian Zhao. 2019. “Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network.” Remote Sensing 11 (15): 1774. https://doi.org/10.3390/rs11151774.
- Zhang, Yongbing, Debin Zhao, Jian Zhang, Ruiqin Xiong, and Wen Gao. 2011. “Interpolation-dependent Image Downsampling.” IEEE Transactions on Image Processing 20 (11): 3291–3296. https://doi.org/10.1109/TIP.2011.2158226.
- Zhaohui, Liu. 2011. “An Empirical Analysis of the Community Life of New Urban Migrants: Guangzhou, Dongguan, Hangzhou, Chengdu, Zhengzhou, and Shenyang.” Chinese Sociology & Anthropology 43 (3): 5–37. https://doi.org/10.2753/CSA0009-4625430301.
- Zhu, Xiao Xiang, Devis Tuia, Lichao Mou, Gui-Song Xia, Liangpei Zhang, Feng Xu, and Friedrich Fraundorfer. 2017. “Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources.” IEEE Geoscience and Remote Sensing Magazine 5 (4): 8–36. doi:10.1109/MGRS.2017.2762307.