
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Recent deep-learning successes have led to a new wave of semantic segmentation in remote sensing (RS) applications. However, most approaches rarely distinguish the role of the body and edge of RS ground objects; thus, our understanding of these semantic parts has been frustrated by the lack of detailed geometry and appearance. Here we present a multiscale decoupled supervision network for RS semantic segmentation. Our proposed framework extends a densely supervised encoder-decoder network with a feature decoupling module that can decouple semantic features with different scales into distinct body and edge components. We further conduct multiscale supervision of the original and decoupled body and edge features to enhance inner consistency and spatial boundaries in remote sensing image (RSI) ground objects, enabling new segmentation designs and semantic components that can learn to perform multiscale geometry and appearance. Our results outperform the previous algorithm and are robust to different datasets. These results demonstrate that decoupled supervision is an effective solution to semantic segmentation tasks of RS images.
1. Introduction
Semantic segmentation plays an important role in RSI applications, such as resource exploration (Shirmard et al. Citation2022), environmental monitoring (Li et al. Citation2020b), natural disaster prediction (Munawar, Hammad, and Waller Citation2022), etc. Prior to the advent of semantic segmentation, manual visual interpretation was the primary technique employed for segmenting RSI (Xu et al. Citation2019). However, this method has limitations in processing large volumes of RS data, and it is unable to achieve efficient and fast extraction of semantic information. With the increasing volume of RS data being collected, manual segmentation methods must be reconsidered to meet the demands of the era of big data. As a result, the need for automated segmentation techniques, such as semantic segmentation, is crucial for overcoming these limitations and maximizing the potential of RS data.
Recent advancements in deep learning have revolutionized the field of computer vision and enabled us to accurately allocate every pixel within an image to a specific class. Semantic segmentation has emerged as a prominent research focus in this field, particularly in the context of RSI. RS semantic segmentation involves segmenting satellite images at the pixel level based on various factors, including color, morphology, and texture features. These segmented image features, such as buildings, vegetation, rivers, and roads, are labeled appropriately. The inception of fully convolutional networks (FCNs) (Long, Shelhamer, and Darrell Citation2015) marked a significant milestone in integrating deep learning-based approaches for semantic segmentation, leading to many promising advancements since then.
Numerous studies have explored the potential of FCN-based approaches in semantic segmentation and have shown promising results (Yuan, Shi, and Gu Citation2021). However, these approaches still face some limitations. One key limitation is that the receptive field (RF) of FCNs increases linearly with depth, which can hinder their ability to capture long-range semantic correlations among image pixels (Luo et al. Citation2016). This, in turn, makes pixel classification difficult, particularly when there is ambiguity and noise in object boundaries. Another shortcoming of FCNs is that they use downsampling operations, which can lead to blurry predictions due to the loss of edge details at low resolution. This can result in segmented objects that look blobby with inadequate boundary details, leading to a decrease in performance, particularly for smaller objects. These issues are particularly significant when working with remotely sensed images, which often involve complex scenes with a high level of heterogeneity and variability. To overcome the limitations of RF in FCNs, researchers have proposed various methods, including dilation convolution (Yu and Koltun Citation2015) and pyramidal pooling modules (Zhao et al. Citation2017). Some approaches incorporate low-level features that contain edge information with high-level features (Zhang et al. Citation2018), while others refine the output directly (Bertasius, Shi, and Torresani Citation2016). However, these methods may not fully consider the intricate interplay between the contours of objects and their interior regions.
Recently, Li et al. (Citation2020) introduced an innovative semantic segmentation approach, DecoupleSegNet. This method divides the feature map into body and edge features. The goal is to obtain smooth representations of the interior areas of objects with low frequencies using body features while capturing high-frequency details along object boundaries with edge features. DecoupleSegNet employs separate supervised signals for each subtask, helping tackle body consistency and edge preservation issues in semantic segmentation. However, implementing DecoupleSegNet in high-resolution RSIs poses challenges. First, it necessitates improving the intricate texture features of high-resolution RSIs, which contain a wealth of texture information. Second, pixel stacking is common in RSIs, leading to pixels with the same label displaying varied characteristics. Since DecoupleSegNet solely focuses on segmenting low-resolution features, its effectiveness in this task needs enhancement. Consequently, there is a requirement to integrate detailed information from multiple scales to identify better subtle structural differences between classes in high-resolution RSIs.
In this study, we present an RSI semantic segmentation model utilizing a multiscale decoupled supervision framework. Inspired by the DecoupleSegNet architecture, our framework separates semantic features into body and edge components across different scales, which are then supervised independently. Unlike the DecoupleSegNet approach, our framework effectively captures both local and global background information by considering body and edge features at various scales. To further improve the performance of our model, we designed a novel hybrid loss function for edge supervision, which combines Binary Cross Entropy (BCE) and Intersection over Union (IOU) at both the pixel and map levels. This hybrid loss function enhances the network’s sensitivity to edge pixels, preserves edge details, and ultimately boosts segmentation accuracy. In summary, our contributions are as follows:
We propose MDSNet, an RSI semantic segmentation framework with multiscale decoupled supervision, which can effectively capture local and global features in complex backgrounds. Specifically, MDSNet utilizes the characteristics of RS objects to extract more differences between different classes based on supervising the body and edge features of RSIs at different scales.
To enhance the performance of edge segmentation, we introduce a novel joint loss function for edge supervision that merges BCE and IOU at both pixel and map levels. Considering the significant imbalance between classes (with the edge features being sparse), it calculates the posterior probability ratio between the edge class and the body classes, thereby further magnifying the probability distinction between the edge and body classes. Moreover, this innovative approach can be implemented in all semantic segmentation techniques incorporating nested edge detection.
Extensive experimental results on the Beijing Land Use (BLU) and the Potsdam datasets demonstrate the effectiveness of our model. Our findings are in remarkable alignment with theoretical predictions, further solidifying the validity and reliability of our approach.
2. Related work
Semantic segmentation has gained significant attention due to its wide range of applications. With the introduction of Fully Convolutional Networks (FCNs) for semantic segmentation, deep learning-based methods have gradually taken the lead in this field. Subsequently, a series of encoder-decoder based network architectures have been proposed, including U-Net (Ronneberger, Fischer, and Brox Citation2015), SegNet (Badrinarayanan, Kendall, and Cipolla Citation2017), PSPNet (Zhao et al. Citation2017), and the Deeplab series (Chen et al. Citation2018). These methods extract features progressively through the encoder part and perform upsampling and feature fusion through the decoder part, effectively capturing the contextual information in images. However, they still face challenges in achieving high segmentation accuracy for small or complex textured objects. In recent years, there has been a growing trend of using Transformer-based methods for semantic segmentation, such as BANet (Wang et al. Citation2021a), SegFormer (Xie et al. Citation2021), TransUNet (Chen et al. Citation2021), DC-Swin (Wang et al. Citation2022) and so on. These methods fully leverage the advantages of Transformers in capturing global context and modeling long-range dependencies, enabling the networks to better handle image semantic segmentation tasks. In addition, WiCoNet (Ding et al. Citation2022) addresses the context modeling issue in high-resolution RSI semantic segmentation by employing a wide-context Transformer. However, due to the locality of the self-attention mechanism in Transformers, it struggles to effectively capture edge information far from the center pixel, presenting challenges in accurately identifying edge pixels and preserving fine details.
Several recent approaches have recognized the importance of edge information in semantic segmentation, as demonstrated by GSCNN (Takikawa et al. Citation2019) and Zhen et al. (Citation2020). These methods consider the ability to perceive object shapes as a priority and aim to improve the accuracy of semantic segmentation and the capture of fine-grained edges through edge supervision. However, these networks may tend to overlook the sparse nature of edge pixels, which can limit the effectiveness of edge supervision in improving segmentation performance. Further research is needed to address these limitations and develop more sophisticated approaches that can better leverage edge information to enhance segmentations while also overcoming the challenges of sparsity in edge pixels.
Meanwhile, other innovative methods for semantic segmentation are also emerging continuously. PWC-Net (Sun et al. Citation2018) employs a pyramid optical flow estimation approach, leveraging multiple-scale feature maps and a pyramid-based flow estimation process for multiscale flow estimation. Zhou et al.(Citation2021) utilize flow learning between two features to align the positions of high-level and low-level feature mappings. Different from these methods, we utilize a flow field to warp the features toward the interior of the object. Moreover, RSS-PV (Zhou et al. Citation2022) enhances the ability to capture unique features and changes within each semantic class by defining prototype samples for each class, resulting in more accurate and accurate semantic segmentation results. Wang et al. (Citation2021) enhance segmentation performance by leveraging the cross-image pixel contrast in a collection of images. Zhou et al. (Citation2021a) improve weakly supervised semantic segmentation through group-wise learning. These methods offer new insights and directions for semantic segmentation but still face challenges in handling complex boundary details in RSIs. Recently, Segmenting Anything (SAM) (Kirillov et al. Citation2023) has achieved promising results in general segmentation tasks. However, SAM only performs segmentation on visual objects and lacks detailed semantic information.
Although these studies have improved the accuracy of semantic segmentation to some extent, none of them has fully considered the relationship between the object's interior and its surrounding boundary. In light of this, DecoupleSegNet proposes an innovative decoupling method to separate the feature maps of semantic segmentation into body and edge features and designs a specialized supervisory framework. However, in the DecoupleSegNet method, the feature map may lose some detailed information after multiple downsampling operations. This limitation poses significant challenges in segmenting RSIs, which often contain abundant texture information, complex land boundaries, and objects of various scales. Furthermore, DecoupleSegNet also fails to fully address the sparsity problem of edge pixels, which may be disregarded due to insufficient saliency. Consequently, developing of a network suitable for RSI semantic segmentation remains a challenging issue within the field of semantic segmentation.
3. Methods
Compared to prior semantic segmentation methods for RSIs, our approach employs a unique approach by separating the problem into two fundamental components: the low-frequency spatial component, which accounts for more gradual changes, and the high-frequency details component, which accounts for more abrupt changes. By supervising both components, we have achieved superior performance in semantic segmentation for RSIs. Additionally, we have devised a multiscale output structure that captures object details across differing scales within RSI. A detailed overview of our network architecture and supervision framework is presented below.
3.1. Decoupling module
As shown in , given a feature map , where
is the channel dimensions, and
represents the spatial resolution, the decoupling module outputs body features and boundary features of the same size. To achieve this, we use a body feature generation module that aggregates detailed characterization of the ground objects to create a distinct body part for each object. We first generate the body feature using this module and then obtain the edge features by subtracting the body features from the original feature map. In other words,
,
, where
is the body generation module.
Figure 1. Illustration of our decoupling module. The decoupling module consists of two steps: first, the body feature generation module generates body features, and then edge features are obtained through explicit subtraction.
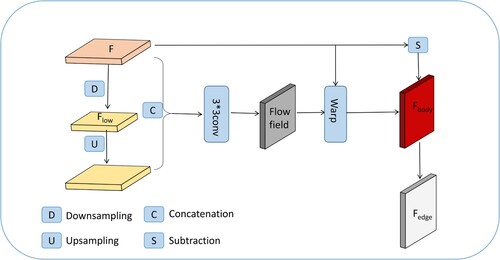
Our body feature generation module is inspired by DecoupleSegNet (Li et al. Citation2020). We consider the low-resolution feature corresponding to the feature
as representing the central part of the object's interior, which we view as a collection of seed points. Specifically, We utilize two consecutive convolutional layers with a kernel size of 3 × 3 and a stride of 2 to compress
into a low-frequency
, and then upsampled it to the original size by bilinear interpolation. Then, we concatenate
and
, and utilize a convolutional layer with a kernel size of 3 × 3 to predict the flow field
. The expression for flow field generation can be represented as follows:
(1)
(1) where
represents upsampling with bilinear interpolation,
represents the convolutional layer.
In the feature warping part, the point at each position can be mapped to a new point
on a standard spatial grid
through
(p) in which
represents the point at the same position in the flow field. This results in a warped spatial grid
, which is then used to approximate each point
in
by using differentiable bilinear sampling. The sampling mechanism was introduced in the spatial transformer networks (Jaderberg et al. Citation2015). This mechanism allows for linear interpolation of the values of the four pixels closest to the target pixels. The interpolation formula is as follows:
(2)
(2) where
denotes the weights assigned to the bilinear kernel on the deformed spatial grid
,
refers to the neighboring pixels that are associated with the point
,
indicates the value of the point
in the feature map
.
Our edge feature generation module obtains edge features by subtracting the body features from the original feature map . This approach differs from DecoupleSegNet, which fuses edge features with low-level features. We believe that merging edge features with low-level features may introduce non-edge information, which can impact edge supervision. In contrast, direct display subtraction offers a straightforward and effective approach to obtaining edge features.
3.2. Network architecture
As shown in , our proposed model is composed of a densely supervised encoder-decoder network with U-Net-like architecture, as well as six feature decoupling modules. By utilizing skip connections across different layers, this network is able to capture both broad contextual information and detailed low-level features, which addresses the problem of losing detailed information that was associated with decoupled edge features in DecoupleSegNet.
Figure 2. An illustration of the complete structure of our proposed network, which incorporates a decoupling module targeting specific features.
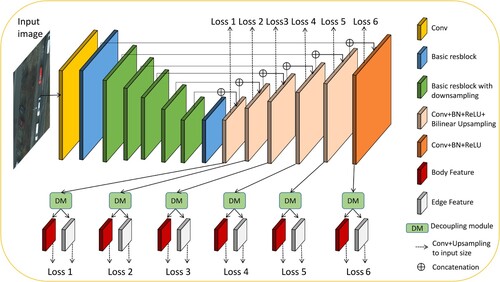
In our model, the encoder is comprised of an input convolutional layer and six basic res-blocks. The input convolutional layer has 64 filters with a 3 × 3 kernel size and a stride of 1. The following four levels of the input convolutional layer use ResNet-34 to extract features. However, we don't utilize pooling operations after the input layer, unlike ResNet-34, which enables our network to acquire higher-resolution feature maps in the early layers while reducing the overall perceptual domain. To match the same perceptual field as ResNet-34, we added two extra stages following the fourth stage of ResNet-34, consisting of three basic res-blocks each and employing 512 filters after a non-overlapping maximum pooling layer of size 2.
To augment the global contextual information, we introduced an intermediate stage between the encoder and decoder. This stage includes three convolutional layers with 512 dilated 3 × 3 filters. After every convolutional layer, we applied batch normalization and ReLU activation functions.
The decoder's architecture is symmetrical to that of the encoder comprising three convolutional layers in each stage. Each layer is followed by a batch normalization layer and ReLU activation function. At the input of each stage, a concatenated feature map is formed by upsampling the output of the previous stage and the corresponding stage in the encoder. In our model, the last layer of each decoder is partitioned into two separate components, namely, and
, by the decoupling module.
Taking inspiration from the HED approach proposed by Xie and Tu (Citation2015), we adopt a multiscale supervision framework to enhance our network’s ability to effectively learn multilevel and multiscale features. As discussed by Lee et al. (Citation2015), this approach can boost the learning efficiency and generalization performance of neural networks by providing extra and more immediate training signals to the preceding layers through intermediate network outputs during training. By incorporating supervision at multiple scales, our model can effectively capture larger structures and utilize the RF by encoding significant features in the deeper layers.
Specifically, we provide supervision for each decoder-level feature as well as the decoupled body and edge features. To generate the side output, each feature at the decoder level, along with separate body and edge features, undergoes a 3 × 3 convolutional operation and is then upsampled to the input image size using bilinear interpolation. Furthermore, we process the edge features through the sigmoid function. This process results in our model generating corresponding probability maps for the features and their decoupled body and edge features at six scales. The specific supervisory framework for the probability maps is described in detail in Section 3.3 of the paper.
3.3. Supervision module
Our proposed supervisory framework consists of three parallel branches, ,
and
. The
branch is dedicated to supervising the segmentation probability map at each decoder level, the
branch supervises the body features at each decoder level and the
branch supervises the edge features at each decoder level. The total loss is calculated as:
(3)
(3) where
represents ground truth (GT),
is the GT binary mask which is generated by
.
,
and
represent segmentation i-th map prediction from
,
and
respectively.
,
, and
represent the three hyperparameters associated with these tasks. Since all three tasks involve CE loss, we set them to the default value of 1.
is a cross-entropy loss in the segmentation task. Then, we discuss the losses of
and
in detail as follows.
For supervision of the part, we relaxed the object boundaries during the training process and utilized a boundary relaxation loss that only samples pixels within the object (Zhu et al. Citation2017). Specifically, we defined boundary pixels as any pixel with neighbors by different labels. For simplicity, we consider the scenario where a pixel is being classified on the boundary between two classes,
and
. Rather than optimizing for the likelihood of the target label given by the annotations, we suggest optimizing for the likelihood of the combination of
and
. As they are mutually exclusive, our objective is to maximize the union of both classes:
(4)
(4) where
refers to the probability distribution obtained through the softmax function for each category. Then, we define the loss of
as follows:
(5)
(5)
In which, represents the collection of classes inside a 3 × 3 neighborhood surrounding pixel
.
represents the complete set of classes inside a 3 × 3 region centered at pixel
.
In the edge supervision portion, we observed that many semantic segmentation methods utilizing nested edge supervision employ Binary Cross Entropy (BCE) loss for guiding the edge prediction maps. Unfortunately, this method neglects the inherent sparsity of edge pixels, which often results in insignificant edge losses. Our experiments showed that merely increasing the weight of BCE loss was insufficient for enhancing the network's accuracy. To tackle this challenge, we propose a hybrid loss function that fuses BCE and Intersection over Union (IOU) loss for effectively supervising edge pixels. The IOU loss, when supervising data with a limited number of positive samples (such as those found in edge pixels), causes the network to prioritize segmentation boundary accuracy more. Consequently, the IOU loss allows the network to better capture the shape and boundary information of objects. Our combined loss function facilitates pixel-level and map-level supervision of boundaries in remote sensing images (RSI), ultimately improving the network’s sensitivity to edge pixels. Furthermore, we adopt a comprehensive loss function encompassing boundary priors deduced from edge features. Since the boundary pixels of objects in RSI tend to be particularly challenging to classify, our approach is centered on these pixels and implements online hard example mining using a predetermined edge threshold during the training process. Therefore, includes
and
, which respectively refer to the categorization of edge pixels and the depiction of object contours.
mines the edge parts of objects in RSI through online hard example mining. The expression of
is shown as follows:
(6)
(6) where
,
, and
are three hyper-parameters, and we set them to default values of 1. The calculation of
and
is as follows in the equation:
(7)
(7)
(8)
(8) To
, it merges the edge prior from
with the weighted bootstrap cross-entropy. The calculation of
is as follows:
(9)
(9) where
, in which
represents the number of pixels in the RSI,
represents the target class of pixel
,
is the predicted posterior probability that pixel
belongs to class
,
is the weight value of the corresponding class of pixel
.
if
is true or
if x is false.
is the sigmoid function to determine if pixel
falls on the object boundary. We use a threshold
to select the pixel-matching probability and a threshold
to determine whether pixel
is on the boundary.
We achieve separate supervision of the object body and boundary by measuring sampled pixels from different parts of the RSI separately. By doing those, we can improve the performance of the prediction results.
4. Experiments
4.1. Datasets
To assess the effectiveness of the proposed approach, we conducted tests on two datasets, including the Beijing Land-Use dataset (Ding et al. Citation2022) and the Potsdam dataset. The Beijing Land-Use dataset was obtained in June 2018 using the Beijing-2 satellite, which twenty-first Century Space Technology Co provided. The dataset consists of RGB optical images with a ground sampling distance (GSD) of 0.8 m, acquired over the region of Beijing. The Potsdam dataset comprises 38 UAV images of 6000 × 6000 pixels collected from urban scenes with six categories. The dataset was split into training and test sets, with 24 and 14 images, respectively. The images were then cropped into non-overlapping patches of size 512 × 512. The training set comprises 2904 patches, while the test set contains 1694 patches.
4.2. Experimental setup and evaluation metrics
This experiment is implemented based on PyTorch. Our hardware environment for the experiments is a workstation equipped with an I9 10920 K CPU, 64 GB of RAM, and an RTX3090 GPU. For the BLU and Potsdam datasets, we set the hyperparameters of the training process to fixed values, including 80 epochs, a batch size of 4, an initial learning rate of 0.002, a momentum of 0.9, and a weight decay of 1e-4. The data enhancement contains techniques such as random level flipping.
In this study, we used evaluation metrics widely adopted in semantic segmentation, including recall, precision, overall accuracy (OA), F1 score, and overall and individual MIOU for each class. The equations for these evaluation measures can be formulated based on the counts of true positive (TP), true negative (TN), false positive (FP), and false negative (FN) pixels, which are calculated as:
(10)
(10)
(11)
(11)
(12)
(12)
(13)
(13)
4.3. Experimental results
4.3.1. Comparison with existing deep learning-based methods
To assess the effectiveness of our proposed model, we will contrast it with other approaches for deep learning based on the BLU dataset and Potsdam dataset, including FCN (Long, Shelhamer, and Darrell Citation2015), DeepLabv3+ (Chen et al. Citation2018), DecoupleSegNet (Li et al. Citation2020), BANet (Wang et al. Citation2021a), SegFormer (Xie et al. Citation2021), TransUNet (Chen et al. Citation2021), DC-Swin (Wang et al. Citation2022), WiCoNet (Ding et al. Citation2022) and SAM (Kirillov et al. Citation2023). As the segmentation produced by SAM lacks semantic information, we solely visualize the segmentation results of SAM.
Using the BLU dataset, we conducted five repeated experiments on various semantic segmentation models. presents the performance evaluation and corresponding standard deviations on multiple metrics, including recall, precision, overall accuracy (OA), and F1 score. The experimental results demonstrate the superiority of our MDSNet model, outperforming other models in nearly all metrics. It achieves the highest recall rate, OA, and F1 score, with slightly lower precision than DC-Swin.
Table 1. Performance comparison of existing methods on the BLU dataset using Recall (%), Precision (%), OA (%), and F1 (%) metrics.
shows that our proposed MDSNet achieved a higher mIoU score than other models. Furthermore, MDSNet outperformed other models in terms of IoU for most classes, notably for water bodies and roads. This superior performance can be attributed to MDSNet’s ability to model spatial continuity using contextual information from neighboring pixels at multiple scales. Instead of relying solely on the characteristics of individual pixels, MDSNet captures contextual information from different scales by using multiscale supervision, leading to better recognition of continuous features. However, further studies are required to improve the inference speed.
Table 2. Performance comparison of existing methods on the BLU dataset using IoU (%), mIoU (%), and FPS (Hz) scores for each category.
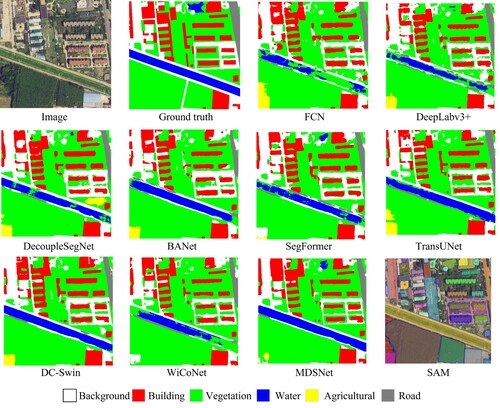
The visualized results in showcase the segmentation performance of all compared methods. Our proposed MDSNet accurately segmented different objects with less internal noise and more accurate spatial boundaries compared to other models. Compared with DecoupleSegNet, our model performs better in segmentation performance. Although DecoupleSegNet also supervises the body and edge regions of the object, it only supervises low-resolution features, leading to the loss of some fine-grained information and a decrease in performance. Compared to other Transformer-based semantic segmentation methods, MDSNet achieves more accurate edge segmentation. This is because Transformer-based methods typically focus more on modeling global context and semantic information, while edge information may not be explicitly modeled sufficiently. This can lead to certain difficulties in pixel-level edge recognition. Additionally, while SAM achieves precise segmentation of objects, it falls short in recognizing the semantic information of ground objects in RSI and may misclassify objects of the same category as different ones. Based on the visualization results, it is apparent that MDSNet demonstrates enhanced continuity and superior edge segmentation when recognizing the water class. This finding aligns with our experimental results and analysis.
Figure 3. Comparison of visualization results on BLU dataset with different semantic segmentation methods.
We also conducted five repeated experiments using these semantic segmentation models on the Potsdam dataset. The specific evaluation metrics and standard deviations are shown in . The experimental results indicate that our MDSNet model performs exceptionally well on most metrics.
Table 3. Performance comparison of existing methods on the Potsdam dataset using Recall (%), Precision (%), OA (%), and F1 (%) metrics.
shows that our proposed MDSNet achieves higher mIoU scores compared to other state-of-the-art semantic segmentation models on the Potsdam dataset. Additionally, in the Potsdam dataset, the Cluster category refers to clustered buildings in urban areas, which are often more densely packed, complex, and prone to overlapping than other building classes such as Residential and Industrial. This makes it challenging to distinguish the Cluster category from other categories. Compared to other models, our proposed MDSNet shows significantly more accurate classification results for the Cluster class. This is because our network learns through multiscale side outputs and can better adapt to the shape and size of Cluster buildings. This demonstrates that our network is better suited for identifying complex RS objects. However, in terms of inference speed, MDSNet only achieved a frame rate of 12.8 FPS, indicating the need for further improvements in the future.
Table 4. Performance comparison of existing methods on the Potsdam dataset using IoU (%), mIoU (%), and FPS (Hz) scores for each category.
presents the visualized results of various semantic segmentation models on the Potsdam dataset. The results demonstrate that our proposed approach can accurately segment diverse objects with high precision and outperform other models regarding spatial boundaries and internal consistency. This highlights the efficacy of our decoupled supervision framework. Notably, MDSNet performs significantly better than several other models in edge pixel segmentation. An important reason, MDSNet can capture edge information at various scales, and its hybrid loss function is better at achieving the supervised effect on edge pixels. While SAM also performs well in edge segmentation, its lack of semantic information makes it unsuitable for the semantic segmentation of remote sensing objects. Clearly, our MDSNet network significantly outperforms other networks in segmenting edge pixels, incredibly complex edge pixels. This further highlights the efficacy of our proposed hybrid loss function in enhancing the supervised effect on edge pixels and establishes the superiority of the MDSNet network in RSI segmentation.
Figure 4. Comparison of visualization results on Potsdam dataset with different semantic segmentation methods.

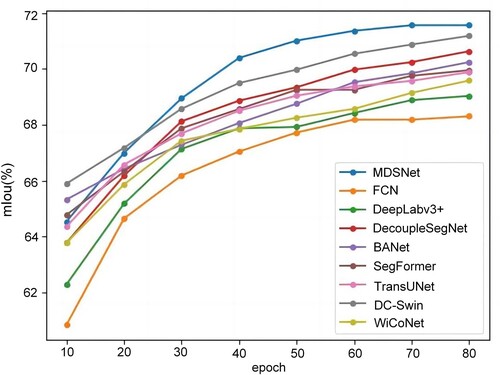
To gain a more intuitive understanding of the differences between our method and other approaches, we present in the variations of mIoU during the training process for different methods on the BLU dataset. The results in demonstrate that in the early stages of training, our network does not outperform some Transformer-based segmentation methods. This is because Transformer models have strong modeling capabilities and a better understanding of global context, enabling the network to quickly learn key features and semantic information from the data. However, as the number of epochs increases, MDSNet exhibits better performance. We believe that this is due to the training strategy of multiscale decoupled supervision, which allows better focus on the features at each level of the decoder and independently optimize them. This training approach enables the network to adjust the parameters of each layer more quickly in the later stages, thereby improving the accuracy of segmentation.
Figure 5. The variation of mIoU during the training process on the BLU dataset.
Our model exhibits higher segmentation accuracy and better segmentation results in conducting experiments on BLU and Potsdam datasets. In particular, the problems of inconsistent object interiors and unsmooth segmentation edges have been important problems plaguing the field in semantic segmentation tasks. Our model makes substantial improvements in this area, resulting in more accurate and smoother segmentation results. These experimental results further demonstrate the effectiveness and practicality of our proposed method and provide new ideas and methods for further research and applications in the semantic segmentation of RSI.
4.3.2. Ablation studies
showcases the ablation experiments conducted on the baseline model. In these experiments, we maintain consistency with other conditions while utilizing ResNet-34 as the encoder structure for our UNet baseline. We compare this baseline model with an extended version that incorporates two extra stages, corresponding to the last two steps of our encoder structure. Lastly, we introduce an intermediate stage between the encoder and decoder to achieve a comprehensive network architecture. The results of the experiments demonstrate that the inclusion of the ‘two extra stages’ significantly expands the receptive field, allowing for the capture of a broader range of contextual information and resulting in improved performance. Furthermore, the introduction of the intermediate stage further enhances the overall network performance.
Table 5. Ablation experiment on the baseline model.
To show the efficacy of our decoupled supervision framework, we systematically investigated its performance through a series of ablation experiments presented in . In these experiments, we progressively added loss functions for supervising the body and edge parts of the network, denoted as and
respectively, to assess their impact on segmentation performance. The results demonstrate that adding
alone improved our mean Intersection over Union (mIoU) by 0.66% and 0.95% on BLU and Potsdam datasets, respectively, and the supervision from
effectively reduced uncertain noise along boundaries. Similarly, adding
alone improved our mIoU by 0.97% and 1.43% on BLU and Potsdam datasets, respectively. Finally, combining
and
yielded significant improvements of 1.85% and 2.39% on the respective datasets, thus providing robust evidence for the efficacy of our decoupled supervision approach for the body and edge components.
Table 6. Ablation experiments on decoupling module.
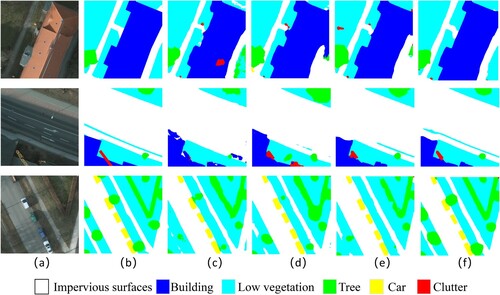
For a more intuitive presentation, we display the visualization results based on the BLU dataset (see ) and the Potsdam dataset (see ). From the visualization results in and , we observe inconsistencies in the interior of objects and inaccurate edge pixel partitioning in both and (c). By adding , we found that the noise inside the objects decreased, as shown in and (d). This indicates that we achieved better internal consistency by supervising the body features. Similarly, with the addition of
we achieved more accurate segmentation boundaries, as shown in and (e). This demonstrates the effectiveness of our edge supervision module. Finally, by combining
and
, we achieved better internal consistency and spatial boundaries.
Figure 6. Visualization results on BLU dataset. (a) Images, (b) GT, (c) MDSNet without and
, (d) MDSNet without
, (e) MDSNet without
, and (f) MDSNet.
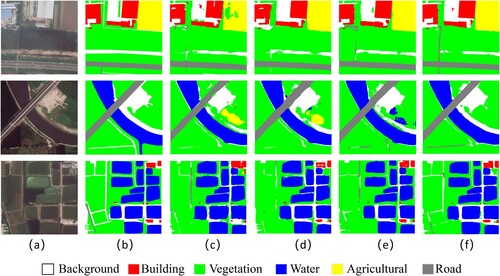
Figure 7. Visualization results on the Potsdam dataset. (a) Images, (b) GT, (c) MDSNet without and
, (d) MDSNet without
, (e) MDSNet without
, and (f) MDSNet.
To show the effectiveness of our hybrid loss for the edge, we conducted a series of experiments by utilizing our loss combination. The experimental results presented in demonstrate that the performance is significantly improved by our proposed hybrid loss, which combines IOU and BCE. To further illustrate the qualitative impact of the loss, we trained the model with different losses, as shown in . When we used only BCE loss for edge supervision, there was slight performance improvement, likely due to the sparsity of edge pixels. We attempted to increase the coefficient of the BCE loss but found that it did not lead to significant performance improvement. However, when we used the hybrid IOU and BCE loss, the performance improved significantly, demonstrating the effectiveness of our hybrid loss. In addition, by incorporating hard pixel mining on Ledge, we observed a performance improvement of around 0.47% and 0.65% on the BLU and Potsdam datasets, respectively, indicating the effectiveness of our adopted boundary comprehensive loss.
Table 7. Ablation experiment of edge loss.
To evaluate the effectiveness of our multiscale supervision network, we conducted a series of experiments and summarized the results in . In these experiments, we examined the impact of different supervision scenarios, including the absence of supervision at a particular scale and supervision of only the prediction with the highest accuracy. It's important to note that our loss function encompasses features at different scales, including body and edge features. The results of our experiments reveal that the absence of supervision at any scale leads to a slight decrease in the mIoU index. Additionally, we observed that supervising only the prediction with the highest accuracy caused a reduction in the mIoU index of BLU and Potsdam datasets by 1.27% and 1.50%, respectively. This can be attributed to the lack of supervision in the middle layer, which limits the network's ability to receive direct feedback during training. These findings indirectly demonstrate the efficacy of our multiscale supervision. They suggest that each supervision scale plays a significant role in the final semantic segmentation result, thereby strengthening the viability and effectiveness of our proposed MDSNet.
Table 8. Ablation experiment of multiscale supervision.
5. Conclusion
In this study, we propose an RSI segmentation model called MDSNet, which utilizes a multiscale decoupled supervised framework to improve segmentation performance. By supervising decoupled body and edge features, our approach can significantly enhance the internal consistency of RS objects and learn spatial boundaries. Moreover, the multiscale output enables our model to learn objects at different scales, which makes our model more adaptable to RS semantic segmentation. Notably, we propose a novel edge hybrid loss, which effectively improves the network's ability to recognize edge pixels and further enhances the segmentation performance of our model. We validate the effectiveness of the proposed multiscale decoupled supervision framework and edge hybrid loss through ablation experiments on BLU and Potsdam datasets. Our proposed model's superior performance in RSI segmentation is demonstrated by the experimental results on the BLU and Potsdam datasets, highlighting its robustness across various datasets and scenarios in comparison to other existing methods.
Despite our proposed model's strengths, it still has limitations. The multiscale output strategy we employed has augmented the network's intricacy, resulting in an expanded model size. As a result, we plan to investigate ways to decrease network resource consumption in future research while enhancing or retaining the model's efficiency.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The BLU dataset and Potsdam dataset in this study are downloaded at https://rslab.disi.unitn.it/dataset/BLU/ and https://www.isprs.org/
Additional information
Funding
References
- Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla. 2017. “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (12): 2481–2495. https://doi.org/10.1109/tpami.2016.2644615.
- Bertasius, Gedas, Jianbo Shi, and Lorenzo Torresani. 2016. “Semantic Segmentation with Boundary Neural Fields.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2016.392.
- Chen, Jieneng, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Le Lu Yan Wang, Alan L. Yuille, and Yuyin Zhou. 2021. “TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation.” ArXiv:2102.04306.
- Chen, Liang-Chieh, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. 2018. “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.” In Computer Vision – ECCV 2018, Lecture Notes in Computer Science, 833–851. https://doi.org/10.1007/978-3-030-01234-2_49.
- Ding, Lei, Lin Dong, Lin Shaofu, Zhang Jing, Cui Xiaojie, Wang Yuebin, Tang Hao, and Bruzzone Lorenzo. 2022. “Looking Outside the Window: Wide-Context Transformer for the Semantic Segmentation of High-Resolution Remote Sensing Images.” IEEE Transactions on Geoscience and Remote Sensing 60: 1–13 https://doi.org/10.1109/TGRS.2022.3168697.
- Jaderberg, Max, Karen Simonyan, Andrew Zisserman, and Koray Kavukcuoglu. 2015. “Spatial Transformer Networks.” ArXiv:1506.02025.
- Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, et al. 2023. “Segment Anything.” ArXiv:2304.02643.
- Lee, Chen-Yu, Saining Xie, Patrick Gallagher, Zhengyou Zhang, and Zhuowen Tu. 2015. “Deeply-Supervised Nets.” ArXiv:1409.5185.
- Li, Xiangtai, Xia Li, Li Zhang, Guangliang Cheng, Jianping Shi, Zhouchen Lin, Shaohua Tan, and Yunhai Tong. 2020a. Improving Semantic Segmentation Via Decoupled Body and Edge Supervision.” In Computer Vision – ECCV 2020,Lecture Notes in Computer Science, 435–452. https://doi.org/10.1007/978-3-030-58520-4_26.
- Li, Jun, Yanqiu Pei, Shaohua Zhao, Rulin Xiao, Xiao Sang, and Chengye Zhang. 2020b. “A Review of Remote Sensing for Environmental Monitoring in China.” Remote Sensing 12 (7): 1130. https://doi.org/10.3390/rs12071130.
- Long, Jonathan, Evan Shelhamer, and Trevor Darrell. 2015. “Fully Convolutional Networks for Semantic Segmentation.” In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), https://doi.org/10.1109/cvpr.2015.7298965.
- Luo, Wenjie, Yujia Li, Raquel Urtasun, and Richard Zemel. 2016. “Understanding the Effective Receptive Field in Deep Convolutional Neural Networks.” ArXiv:1701.04128v2.
- Munawar, Hafiz Suliman, Ahmed WA Hammad, and S. Travis Waller. 2022. “Remote Sensing Methods for Flood Prediction: A Review.” Sensors 22 (3): 960. https://doi.org/10.3390/s22030960.
- Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” In Lecture Notes in Computer Science,Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, 234–241. https://doi.org/10.1007/978-3-319-24574-4_28.
- Shirmard, Hojat, Ehsan Farahbakhsh, R. Dietmar Müller, and Rohitash Chandra. 2022. “A Review of Machine Learning in Processing Remote Sensing Data for Mineral Exploration.” Remote Sensing of Environment, January 268: 112750. https://doi.org/10.1016/j.rse.2021.112750.
- Sun, Deqing, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. 2018. “PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume.” In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, https://doi.org/10.1109/cvpr.2018.00931.
- Takikawa, Towaki, David Acuna, Varun Jampani, and Sanja Fidler. 2019. “Gated-SCNN: Gated Shape CNNs for Semantic Segmentation.” In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), https://doi.org/10.1109/iccv.2019.00533.
- Wang, Libo, Rui Li, Chenxi Duan, Ce Zhang, Xiaoliang Meng, and Shenghui Fang. 2022. “A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images.” IEEE Geoscience and Remote Sensing Letters 19: 1–5. https://doi.org/10.1109/LGRS.2022.3143368.
- Wang, Libo, Rui Li, Dongzhi Wang, Chenxi Duan, Teng Wang, and Xiaoliang Meng. 2021a. “Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images.” Remote Sensing 13 (16): 3065. https://doi.org/10.3390/rs13163065.
- Wang, Wenguan, Tianfei Zhou, Fisher Yu, Jifeng Dai, Ender Konukoglu, and Luc Van Gool. 2021b. “Exploring Cross-Image Pixel Contrast for Semantic Segmentation.” In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), https://doi.org/10.1109/iccv48922.2021.00721.
- Xie, Saining, and Zhuowen Tu. 2015. “Holistically-Nested Edge Detection.” In Proceedings of the IEEE International Conference on Computer Vision, 1395–1403. https://doi.org/10.48550/arXiv.1504.06375.
- Xie, Enze, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. 2021. “SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers.” Advances in Neural Information Processing Systems 34: 12077–12090. https://doi.org/10.48550/arXiv.2105.15203.
- Xu, Yue, Feng Mengru, P. I. Jiatian, and Chen Yong. 2019. “Remote Sensing Image Segmentation Method Based on Deep Learning Model.” Journal of Computer Applications 39 (10): 2905. http://www.joca.cn/EN/Y2019/V39/I10/2905.
- Yu, Fisher, and Vladlen Koltun. 2015. “Multiscale Context Aggregation by Dilated Convolutions.” ArXiv:1511.07122.
- Yuan, Xiaohui, Jianfang Shi, and Lichuan Gu. 2021. “A Review of Deep Learning Methods for Semantic Segmentation of Remote Sensing Imagery.” Expert Systems with Applications 169: 114417. https://doi.org/10.1016/j.eswa.2020.114417.
- Zhang, Zhenli, Xiangyu Zhang, Chao Peng, Xiangyang Xue, and Jian Sun. 2018. ExFuse: Enhancing Feature Fusion for Semantic Segmentation.” In Computer Vision – ECCV 2018,Lecture Notes in Computer Science, 273–88. https://doi.org/10.1007/978-3-030-01249-6_17.
- Zhao, Hengshuang, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. 2017. “Pyramid Scene Parsing Network.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), https://doi.org/10.1109/cvpr.2017.660.
- Zhen, Mingmin, Jinglu Wang, Lei Zhou, Shiwei Li, Tianwei Shen, Jiaxiang Shang, Tian Fang, and Long Quan. 2020. “Joint Semantic Segmentation and Boundary Detection Using Iterative Pyramid Contexts.” In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), https://doi.org/10.1109/cvpr42600.2020.01368.
- Zhou, Tianfei, Liulei Li, Xueyi Li, Chun-Mei Feng, Jianwu Li, and Ling Shao. 2021a. “Group-Wise Learning for Weakly Supervised Semantic Segmentation.” IEEE Transactions on Image Processing 31: 799–811. https://doi.org/10.1109/TIP.2021.3132834.
- Zhou, Tianfei, Wenguan Wang, Ender Konukoglu, and Luc Van Gool. 2022. “Rethinking Semantic Segmentation: A Prototype View.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2582–2593. https://arxiv.org/abs/2203.15102.
- Zhou, Tianfei, Wenguan Wang, Si Liu, Yi Yang, and Luc Van Gool. 2021b. “Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing.” In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), https://doi.org/10.1109/cvpr46437.2021.00167.
- Zhu, Xizhou, Yuwen Xiong, Jifeng Dai, Lu Yuan, and Yichen Wei. 2017. “Deep Feature Flow for Video Recognition.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2017.441.