
Abstract
The aim of this study is to develop a material selection framework structured around a knowledge-based system (KBS). Specifically, a hybrid data mining technique is employed to extract knowledge from large datasets using cluster analysis techniques; the mined knowledge then serves as the inference logic within the KBS designed for material selection purposes. Cluster analysis results are used as a basis for the tree-based structure of the KBS where if–then rules are developed based on the general cluster properties; that is, inference logic is structured in a way such that it can predict general sustainability characteristics of the material as well as its exact mechanical, cost and physical properties. To develop the structure of the KBS, the selection structure employs sustainable material indices. Additionally, the proposed material selection model of the KBS is purposefully composed of material sustainability, functionality and cost indices. The constructed knowledge is then demonstrated for selecting automobile structural panels.
1. Introduction
Knowledge is the most valuable asset of a manufacturing enterprise. This makes a firm to differentiate itself from competitors and enables to deal with all suppliers, competitors and customers in the market. Knowledge exists in almost all stages of the manufacturing processes, starting from purchasing materials, marketing, design, production, maintenance and distribution; however, knowledge can be notoriously difficult to identify, capture and manage (Harding et al. Citation2006).
Knowledge-based systems (KBSs) are composed of several approaches and algorithms from database management, machine learning, statistics and artificial intelligence. The accelerated development of the KBS motivates its deployment to process data in different fields such as banking, finance, marketing, insurance, science and engineering. Particularly in the field of manufacturing, KBSs are gaining wide acceptance and importance, as they can provide a significant competitive advantage over traditional analysis methods (Halevi and Wang Citation2007; Shehab and Abdalla Citation2002).
The complexity of KBSs is mainly dependent on the manufacturing process itself because it decides on the parameters used in building the database. Spiegler (Citation2003) differentiated between two models of knowledge: the first model is based on a conventional hierarchy and the transformation of data into information and knowledge with a spiral and a recursive way of knowledge generation, whereas the second model uses a reverse hierarchy where knowledge can be discovered in early stages, i.e. before data and information processing. Database, knowledge management and knowledge-based engineering are potential tools from which knowledge discovery can be built to accommodate manufacturing-borne data. From the perspective of end-users, their specific benefits can include the following aspects:
A speed-up of human professional or semi-professional work.
Major internal cost savings within companies. These cost savings could be either direct such as the cost saving in assembling a remote team, or indirect as a result of quality improvement.
Improving the quality and speed of decision-making. Using the KBS enhances the quality of decision-making and reduces the time required to implement the correctness of decisions.
Facilitating the new product development process. Some good examples of new product development that use the KBS and the benefits drawn from the KBS are given in this review.
Hence, this paper attempts to provide a framework for developing a KBS designed for selecting materials while taking the sustainability factor – through sustainability indices – into consideration. In this study, the specific implementation is focused on eco-material selection for automobile body structures (panels). The study also discusses the challenges associated with processing large datasets into meaningful knowledge using data mining techniques. Such data mining methods will serve as a basis for building the system's inference logic. Therefore, this study integrates data mining techniques and the KBS into one comprehensive intelligent model that can aid designers in the automotive industry in decision-making and investigating different alternative materials. The practical implications of this hybrid data mining (H-DM)–KBS can help designers and engineers in early design stages to select best materials for automobile structural panels; in addition, the proposed KBS can be used by non-expert people to gather more information related to sustainability in order to facilitate their understanding in this field. It can be said that such a KBS is a good example of user-friendly, graphical user interface system that can help both expert and non-expert people in selecting sustainable materials for autobodies.
2. KBSs in engineering design and material selection
Material selection is an important discipline in engineering design. The selection process is usually carried out by designers and material engineers who are tasked with selecting the best material that fits the application in terms of function, shape and cost.
Sapuan et al. (2002) emphasised the importance of the KBS within the context of concurrent engineering, while discussing the role of the materials database in helping designers in rigorous material selection scenarios. Employing a KBS framework equipped with a material database has been reported by several researchers (Sapuan et al. Citation2002; Sapuan and Abdalla Citation1998; Mohamed and Celik Citation1998; Cherian, Smith, and Midha, Citation2000). These studies focused on tabulating the materials and their mechanical, thermal and electrical properties in a database, while creating logical and graphical user interfaces to facilitate the access to such information. Currently, the use of the KBS in material selection is receiving more acceptance due to its efficient operation especially in early design stages.
Mok, Chin, and Ho (Citation2001) showed how KBS and graphic modules could be integrated to develop a useful tool for selecting mould designs for an injection moulding process. Tang (Citation2004) used a collaborative design environment, during the product development phase, to facilitate active die-maker involvement in developing a sheet-metal stamping die. The author has reported that the die-maker should be involved in new product development processes as early as possible to integrate concurrent engineering practices in metal stamping development. Also, the author has suggested that an agent-based approach consists of part design agent, die-maker involvement agent and coordination agent, which integrates the die-maker's activities into the customer's product development process within a collaborative concurrent environment. The author further illustrated an example where the agent-based system was used to involve the die-maker with the part designer to achieve an optimal part design.
In order to use the available data effectively, it should be formulated and stored in a knowledge base, which can be used along with an inference logic engine to form an intelligent search and inference algorithm because the ‘Selection’ implies ‘Making Decision’. Hence a KBS computer system attempts to represent human knowledge or engineers' expertise to provide relatively quick and accessible educated decisions. Additionally, the KBS has the ability to accomplish cognitive tasks that currently still require a human expert by automating data mining and decision-making processes (Sapuan Citation2001; Madhusudan, Zhao, and Marshall Citation2004).
As an emerging field, design for sustainability for automotive applications is considered as a multi-interdisciplinary approach and needs a wide spectrum of expertise that ranges between economic, environment and manufacturing.
This paper presents the H-DM–KBS approach in which data mining results were used to develop case-based reasoning inference logic for KBSs in order to develop effective and eco-material selection for autobodies. The motivation for this study track is to fill the gap in eco-material selection, which is currently structured around the general, mechanical and environmental characteristics of each individual material rather than the class of this material, for example current KBSs are structured based on stored examples on the inference engine, hence they usually reveal stored knowledge without having the ability to predict or analyse new examples. The main concern comes from the large amounts of information necessary to undertake in the eco-material selection process. In addition, the strong interdisciplinary nature of sustainability information can be organised in a better way using data mining methods [mainly cluster analysis (CA)] to discover hidden knowledge and patterns in data prior to performing any KBS activities. This discovered knowledge can then be used as a basis for developing a user-friendly KBS. The key goal of the KBS is to develop an organisational template that can be used to represent eco-material selection knowledge in one simple module. This integrated approach can be considered as a new method that not only considers the properties of engineering materials, but also takes into consideration the sustainability characteristics of any candidate material before making any selection decisions.
The study structure starts by addressing the KBS architecture through the proposed sustainability model for material selection, the methodology used for data mining and CA. The results from data mining and CA are presented in Section 5, while Section 5.1 explains the inner workings of the KBS and Section 5.2 gives an example for sustainable material selection for car doors. Section 6 summarises the study and presents future work directions.
3. Models for sustainable material selection for automotive applications
Several methodologies exist for incorporating environmental concerns in the material selection process. Some methods emphasise selecting materials based on a single portion of a product's life cycle (e.g. end-of-life material recovery), while others attempt to consider the entire life cycle, either qualitatively or quantitatively. For example, Graedel and Allenby (Citation1994) as well as Davies (Citation2004) provided a set of material selection guidelines as a set of qualitative selection methodologies. Material selection guidelines are simply rules-of-thumb such as ‘Choose abundant, non-toxic, non-regulated materials, if possible’. Although using qualitative methods can help to classify materials as desirable or not desirable, still the prioritisation of certain materials is difficult.
Alternatively, quantitative approaches for environmental material selection rate the materials using specific indicators, such as: (1) single environmental indicator such as the eco-indicator used by Wegst and Ashby (Citation1998) or the energy content proposed and used by Ashby (Citation2008, Citation2009) or a set of environmental indicators (e.g. CO2, SOx, NOx, a measure of grade of recyclability) and resource scarcity as suggested by Coulter et al. (Citation1996); (2) an economic indicator such as the environmental cost used by Ermolaeva, Castro, and Kandachar (Citation2004).
Ashby (Citation2008) demonstrated that performance index methodology may also be used to evaluate materials based on individual environmental parameters (e.g. energy consumption) in conjunction with other material factors. Another important study by Kampe (Citation2001) aimed at developing a model where a lifetime environmental load associated with the selection of a specific material can be routinely assessed as part of the overall decision-making process. This model first uses classical mass-based material selection indices developed by Ashby and then it introduces some modifications to include total energy consumption prior to, and during, service.
Therefore, it can be said that there is still a need for a systematic method or procedure to model sustainable material selection using a holistic approach that covers the economic, environmental and societal aspects. Design for sustainability for automobile bodies should consider all of these aspects as well as design functional and aesthetic requirements especially for load bearing and structural panels. The following major sustainability metrics have been chosen to represent the different aspects of sustainability: environmental, economical, societal and technical factors (Mayyas and Omar Citation2012; Mayyas, Qattawi, Mayyas, et al. Citation2012; CitationMayyas, Shen, et al.). Figure shows the structure of the proposed sustainability model and identifies its sub-model factors. This model is pivoted around material selection for a sustainable lightweight design rather than a traditional lightweight design (Mayyas and Omar Citation2012). Factors that are used to construct the sustainability model and their importance are tabulated in Table . More details about the design for a sustainability model can be found in Mayyas and Omar (Citation2012), Mayyas, Qattawi, Mayyas, et al. (Citation2012), Mayyas, Shen, et al. Citation2012 and Mayyas, Qattawi, Omar, et al. (Citation2012).
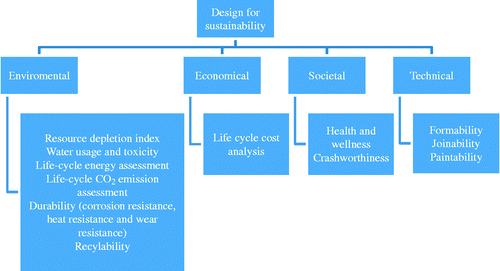
Table 1 Sustainability factors and their importance.
4. Approach
4.1 Data mining and CA methods
In this study, the sustainability attributes are represented as points (vectors) in a multidimensional space, where each dimension represents a distinct attribute (variable, measurement) describing the object. Thus, a set of objects is represented as an m × n matrix, where there are m rows, one for each object, and n columns, one for each attribute. One quantitative measure of similarity is the distance between cases. The Euclidean distance measures the length of a straight line between any two cases, where the numeric distance value depends on the measurement scale. The data are sometimes transformed before being used for many reasons such as when the dataset has different ranges or different measures for different attributes. In cases where the range of values differs widely from an attribute to another, this difference in attributes' scales can dominate or bias the findings from the CA, so it is common to standardise these data so that all its attributes are following only one scale. Additionally, to avoid the issue of having one attribute dominating others, the following data standardisation method is proposed to normalise all the attributes on a scale from 0 to 1. Normalisation of any attribute can be done using the following normalisation methods, depending on the direction of improvement of that specific attribute. For example, if the expectancy is the-larger-the-better (e.g. recycle fraction), then the original attribute performance value can be normalised as follows:
If the expectancy is the-smaller-the-better (e.g. density), then the original attribute performance value can be normalised as
In this study, 21 different candidate engineering materials were considered ranging between form grade steels, high-strength steels, stainless steels, aluminium alloys, magnesium alloys, titanium alloys and different plastic composite materials. Table shows these candidate materials and their normalised values for all sustainability attributes used in this study.
Table 2 Normalised values for all material properties used to establish the sustainability model.
4.1.1 Cluster analysis
CA is an exploratory data analysis tool that is usually used to solve classification problems (Freitas Citation2003; Naik Citation2012). Its objective is to sort cases – either quantitative or qualitative – into groups, or clusters, so that the degree of interrelationship is high between the members of the same cluster and minimal between the members of different clusters or groups. Each cluster thus describes, in terms of the data collected, the class to which its members belong.
Therefore, CA can be considered as a tool of data mining (Abonyi and Feil Citation2007), because it has the ability to reveal associations and structures in large datasets where knowledge is not evident in their original shape. The advantage of using CA comes from the fact that a user does not have to make any assumptions about the underlying distribution of the data prior to its analysis (Sharma 1996).
There are numerous ways in which clusters can be formed. Hierarchical clustering is one of the most straightforward methods (Harding et al. Citation2006). Most common statistical packages use one of the following hierarchal clustering approaches to determine the distance between observations in the cluster and between different clusters: single linkage (nearest-neighbour approach), complete linkage (furthest neighbour), average linkage, Ward's method and centroid method (Sclove Citation2012). All of these approaches differ in the method used to calculate the distance and what defines the distance as being statistically significant or insignificant. Usually, the distance is based on the Euclidean distance in the sample axes. However, in this study, the single linkage approach was used to discover hidden knowledge in the data. Some of the important issues to be considered before performing hierarchal CA are as follows: the user must select a criterion to determine the similarity or the distance between the different cases; also it is important to select a criterion to decide on the number of clusters that are needed to represent the data. However, there is not a generally accepted procedure for determining the number of clusters. This decision should be guided by theory and practicality of the results, along with the use of inter-cluster distances at successive steps. When using a criterion such as the between-group sum of squares or likelihood, this can be plotted against the number k of clusters in a scree diagram (Sclove 2012). In multivariate data analysis, principal component analysis (PCA) is usually used as a precursor to determine the appropriate number of clusters to be extracted. PCA is considered as a variable reduction procedure, which makes it an efficient statistical method in reducing a complex dataset to a lower dimension, thus revealing knowledge or patterns that are often hidden in the data. Because the goal of PCA is to reduce the dimension of the dataset, focusing on a few principal components (PCs) versus many variables, several rules have been proposed for determining how many PCs should be considered and how many can be ignored. One common rule is to ignore PCs at the point at which the next PC offers a very small increase in the total variance explained. A second rule is to only consider all PCs up to a pre-determined total percentage of variance explained, usually 90% is used. A third rule is to ignore components whose variance explained is less than 1 when a correlation matrix is used or that is less than the average variance explained when a covariance matrix is used, with the idea being that such a PC offers less than one variable's worth of information. A fourth standard is to ignore the last PCs whose variance explained is all approximately equal (Holand Citation2008; Sharma Citation1996; Hair et al. Citation2007). Then, the CA can be performed accordingly. In this study, the hierarchical clustering algorithm was used, as shown in Figure (adopted from Naik 2012).

5. Results and discussion
The basic approach used to build the KBS in this study starts from reducing the dimension of the dataset into meaningful, smaller components or groups, hence using the CA in association with PCA to extract the hidden knowledge prior to translating this knowledge into the usable if–then rules; such rules can then be used as a basis for the KBS. The PCA attempts to reduce both the amount of information and its complexity; therefore, the PCA is used as a precursor to obtain the right number of clusters or groups that can be extracted from the CA. Upon performing the CA, it is found that five clusters would be enough to capture most of the data variability as well as their ability to reflect the sustainability characteristics into usable classes. Figure displays the hierarchical tree diagram (dendrogram) of these clusters, showing a convenient graphical display of the entire sequence of merging (or splitting). The CA statistics are tabulated in Table , while Table shows the distances between the different clusters. The interpretation of these clusters into meaningful sustainability aspects is presented in Table . For example, cluster 1 has a high density, very good technical factors (i.e. formability, joinability and paintability), good environmental characteristics [medium life-cycle impacts (energy and CO2) and high recycle fraction], low life-cycle cost impacts and good mechanical properties for autobody applications. Similar conclusions can be drawn from the other clusters. Remarkably, it is found that a high-strength carbon fibre (0° unidirectional lamina) composite occupies a single cluster by itself; however, knowing the fact that this material has a modulus of elasticity of 140 GPa and a yield strength of 1850 MPa (the same value for ultimate tensile strength) makes it a possible candidate for replacing load-bearing structural panels, exceeding other materials such as stainless steel.
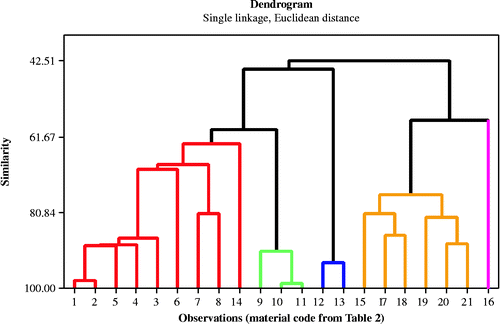
Table 3 CA statistics.
Table 4 Distances between cluster centroids.
Table 5 Clusters and their interpretations.
Rule-based reasoning based on CA results is then used to construct the KBS framework. However, a basic KBS comprises a knowledge base expressed by the if–then rules along with an inference mechanism or rule interpreter. Hence, the rule-based reasoning based on the cluster's interpretations is used as a basis for building the inference engine of the KBS according to the following structure:
If (conditions: A1, A2, …, Am)
Then (conclusions: X1, X2, …, Xn)
ElseIf (conditions: B1, B2, …, Bm)
Then (conclusions: Y1, Y2, …, Yn)
ElseIf (conditions: C1, C2, …, Cm)
Then (conclusions: Z1, Z2, …, Zn)
ElseIf (conditions: D1, D2, …, Dm)
Then (conclusions: U1, U2, …, Un)
Else (conclusions: V1, V2, …,Vn)
EndIf
5.1 KBS description
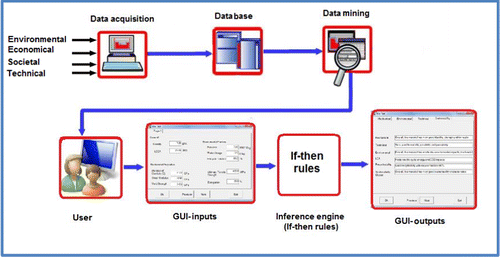
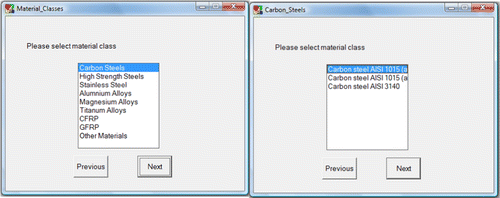
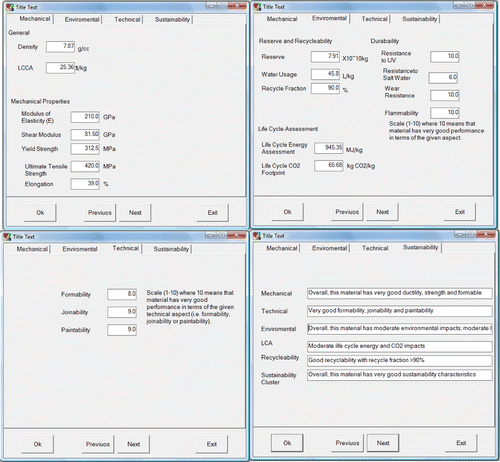
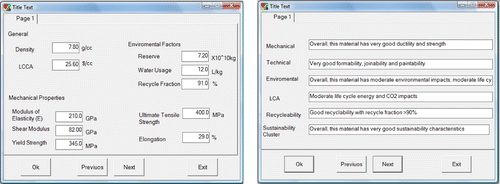
The proposed eco-material selection of the KBS for automobile body-in-white panels consists of a user interface, knowledge acquisition, inference engine, and knowledge base and database. Figure details the proposed system structure, while Figure displays the internal structure of the KBS where the logic flow takes place upon entering the inputs. The database consists of the materials and their properties. The inference engine communicates between the user and the knowledge base, reasons the facts and makes appropriate decisions, and finally recommends a solution. A rule-based technique is used for developing the inference engine; these rules describe the conditions and attributes at which the selection procedure is to be made. A user-friendly interface is created to enable non-expert users to interact with the system with a minimal effort; this interface incorporates and organises the user inputs. In order to use the proposed KBS effectively, the user has to select one of the material's classes that are stored within the database, and then he/she has to select the material type under that selected class. An example of such a selection is illustrated in Figure . The code interface is designed in such a way that when the material of interest is being selected, it invokes the necessary mechanical, economical, environmental and technical characteristics and starts running the inference process to provide a final sustainability classification, as shown in Figure . The output of this KBS is composed of multi-tabs to inform the user about the selected material characteristics in terms of its mechanical, environmental, technical and sustainability aspects. However, if the user needs to assess a new material that is not stored in the database, then he/she has to input that material properties, i.e. mechanical properties, environmental characteristics and some other general aspects (i.e. density and cost), as shown in Figure . Then, the KBS is able to accommodate the new material and provide the general sustainability assessment of this material.
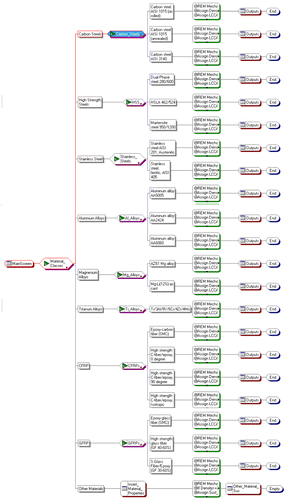
Some of the limitations of the current KBS are:
The KBS works well only within a narrow domain of knowledge. In fact, the KBS can be used efficiently in selecting any material from its database, but it has limited predictability and cannot be used for other materials that are not stored in its database.
In addition to a large complexity of technical knowledge of engineering materials, human experts have common sense when compared with the KBS which has a limited degree of adaptation and ability to discover new knowledge; however, the KBS needs more effort (time and programming) to be able to mimic human brain and reach its level of dealing with complex knowledge systems (material universe). In addition, human experts automatically adapt to changing environments, whereas KBSs must be explicitly updated to deal with any new rules or examples.
The current KBS is structured around the eco-material selection process. Future work should be directed towards integrating eco-material selection along with sustainable manufacturing into one comprehensive KBS.
5.2 Case study for eco-material selection for autobodies
Suppose that the design team is looking for a lightweight material to replace steel in a vehicle's doors, knowing that the main design function of the outer doors is dent resistant, then any new candidate material should have at least the same or larger level of dent resistance. Some examples of candidate materials are as follows: aluminium alloys, magnesium alloys, titanium alloys, stainless steels and plastic composite materials (carbon fiber reinforced plastic (CFRP) and glass fiber reinforced plastic (GFRP)). However, the material selection index is derived by the material engineer and was found to be (), where σy is the yield strength (MPa) and ρ is the material density (kg/m3), so any material that has a value of (
) and that exceeds the steel value could be a potential candidate material to replace steel. However, the design team believes that some materials have some concerns; for example, some plastic composite materials have (
) values that exceed steel values, but they also have a high material cost, a high manufacturing cost and a low recycle fraction. Other members of this design team believe that aluminium alloys should be considered as best candidate materials to replace steel, as they have a relatively low cost, a moderate manufacturing cost, low environmental impacts (low CO2 emission and low manufacturing energy). The third party believes that magnesium should also be considered. However, the current KBS can be used as a basis for both qualitative and quantitative comparisons and can aid the design team in this regard. Table summarises KBS outputs that can be used to easily judge all of these candidate materials from the perspective of sustainability.
Table 6 Summary of KBS outputs for sustainable material selection for a vehicle's door.
KBS outputs suggest the use of aluminium or magnesium rather than the use of CFRP or even GFRP because they have better sustainability characteristics such as good recyclability, good formability, low environmental impacts and good durability. By eliminating plastic composite materials, the design team will focus more on the narrow comparative window (aluminium vs. magnesium) and they can decide on which they want to use. Other important factors, such as the material cost and manufacturability of aluminium, may make it more preferable if the team decided on replacing current steel on the vehicle's door.
6. Conclusions
This study proposed a new design for a sustainability model that is further packaged within the framework of an eco-material selection of KBS for automobile panels. The KBS output ranks materials so that it meets a set of sustainability indices without compromising its functional or technical requirements such as the material's structural load-bearing characteristics. The study has also discussed the use of CA to group a multi-attribute dataset of material properties into meaningful groups, thereby affording rules for building the KBS. These clusters form the basis for a rule-based reasoning and inference logic engine. Additionally, the study illustrated the use of the PCA as a pre-processing step for data mining, to help improve the data content while reducing its repetitions and covariance. The study exhibited the integration of the PCA along with the CA tools within the KBS framework using an automobile body as a case study. From the sustainability assessment of the KBS, one can see that the different steel grades are still the best choice for automobile load-bearing panels, which explains the growing trends of alloying, even stronger steel grades including the ultra-strong, high-strength steels such as dual-phase, transformation-induced plasticity and complex-phase steels. Future work should focus on including further sustainability assessment indices and more material classes and types, in addition to demonstrating the developed methodology in other case studies.
References
- Abonyi, J., and B.Feil. 2007. Cluster Analysis for Data Mining and System Identification. Basel: BirkhauserVerlag AG.
- Ashby, M.2008. Materials Selection in Mechanical Design. 3rd ed.Oxford, UK: Butterworth-Heinemann.
- Ashby, M.2009. Materials and the Environment. 1st ed.Oxford, UK: Butterworth-Heinemann.
- Cherian, R. P., L. N.Smith, and P. S.Midha. 2000. “A Neural Network Approach for Selection of Powder Metallurgy Materials and Process Parameters.” Artificial Intelligence in Engineering14: 39–44. 10.1016/S0954-1810(99)00026-6.
- Coulter, S., B.Bras, G.Winslow, and S.Yester. 1996. “Designing for Material Separation: Lessons from Automotive Recycling.” In Proceedings of the 1996 ASME Design Engineering Technical Conferences and Computers in Engineering Conference, August 18–22, 1996, Irvine, CA. doi:https://doi.org/10.1115/1.2829179.
- Davies, G.2004. Materials for Automobile Bodies. 1st ed.Oxford, UK: Butterworth-Heinemann.
- Ermolaeva, N. S., M.Castro, and P. V.Kandachar. 2004. “Materials Selection for an Automotive Structure by Integrating Structural Optimization with Environmental Impact Assessment.” Materials & Design, 25: 689–698. 10.1016/j.matdes.2004.02.021.
- Freitas, A. A.2003. “A Survey of Evolutionary Algorithms for Data Mining and Knowledge Discovery.” In Advances in Evolutionary Computing, 819–845. Berlin: Springer.
- Graedel, T. E., and B. R.Allenby. 1994. Industrial Ecology and the Automobile. Upper Saddle River, NJ, USA: Prentice Hall International.
- Hair, J. F., W. C.Black, B. J.Babin, and R. E.Anderson. 2007. Multivariate Data Analysis. 7th ed.Upper Saddle River, NJ, USA: Prentice Hall.
- Halevi, G., and K.Wang. 2007. “Knowledge Based Manufacturing System (KBMS).” Journal of Intelligent Manufacturing18: 467–474. 10.1007/s10845-007-0049-1.
- Harding, J. A., M.Shahbaz, S.Srinivas, and A.Kusiak. 2006. “Data Mining in Manufacturing: A Review.” Journal of Manufacturing Science and Engineering128: 969–976. 10.1115/1.2194554.
- Holand, S. M.2008. “Principal Components Analysis (PCA).” Accessed December 27, 2011. http://strata.uga.edu/software/pdf/pcaTutorial.pdf.
- Kampe, S. L.2001. “Incorporating Green Engineering in Materials Selection and Design.” In Proceedings of the 2001 Green Engineering Conference: Sustainable and Environmentally-Conscious Engineering. Roanoke, VA: Virginia Tech's College of Engineering and the U.S. Environmental Protection Agency.
- Madhusudan, T., J. L.Zhao, and B.Marshall. 2004. “A Case-based Reasoning Framework for Workflow Model Management.” Data & Knowledge Engineering50: 87–115. 10.1016/j.datak.2004.01.005.
- Mayyas, A. T., and M.Omar. 2012. “Eco-material Selection Assisted with Decision Making Tools, Guided by Product's Attributes; Functionality and Manufacturability.” International Journal of Materials and Structural Integrity6 (2–4): 190–219. 10.1504/IJMSI.2012.049955.
- Mayyas, A. T., A.Qattawi, A. R.Mayyas, and M. A.Omar. 2012. “Life Cycle Assessment-based Selection for a Sustainable Lightweight Body-in-White Design.” Energy39 (1): 412–425. 10.1016/j.energy.2011.12.033.
- Mayyas, A. T., A.Qattawi, M. A.Omar, and D.Shan. 2012. “Design for Sustainability in Automotive Industry: A Comprehensive Review.” Renewable and Sustainable Energy Reviews16 (4): 1845–1862. 10.1016/j.rser.2012.01.012.
- Mayyas, A., Q.Shen, A. T.Mayyas, M.Abdelhamid, D.Shan, A.Qattawi, and M.Omar. 2012. “Using Quality Function Deployment and Analytical Hierarchy Process for Material Selection of Body-In-White.” Materials & Design32: 2771–2782. 10.1016/j.matdes.2011.01.001.
- Mohamed, A., and T.Celik. 1998. “An Integrated Knowledge-based System for Alternative Design and Materials Selection and Cost Estimating.” Expert Systems with Applications14: 329–339. 10.1016/S0957-4174(97)00086-9.
- Mok, C. K., K. S.Chin, and K. L.Ho. 2001. “An Interactive Knowledge-based CAD System for Mould Design in Injection Moulding Processes.” International Journal of Advanced Manufacturing Technologies17: 27–38. 10.1007/s001700170207.
- Naik, A.2012. “Hierarchical Clustering Algorithm.”, Accessed February 2, 2012. https://sites.google.com/site/dataclusteringalgorithms/hierarchical-clustering-algorithm.
- Sapuan, S. M.2001. “A Knowledge-based System for Materials Selection in Mechanical Engineering Design.” Materials & Design22: 687–695. 10.1016/j.compind.2003.11.001.
- Sapuan, S. M., and H. S.Abdalla. 1998. “A Prototype Knowledge-based System for the Material Selection of Polymeric-based Composites for Automotive Components.” Composites Part A: Applied Science and Manufacturing29: 731–742. 10.1016/S1359-835X(98)00049-9.
- Sapuan, S. M., M. S. D.Jacob, F.Mustapha, and N.Ismail. 2002. “A Prototype Knowledge-based System for Material Selection of Ceramic Matrix Composites of Automotive Engine Components.” Materials & Design23: 701–708. 10.1016/S0261-3069(02)00074-2.
- Sclove, S. L.2012. “Statistics for Information Systems and Data Mining.” January 13, 2012. http://www.uic.edu/classes/idsc/ids472/clustering.htm.
- Sharma, S.1996. Applied Multivariate Techniques. 1st ed.New York, USA: Wiley.
- Shehab, E., and H. S.Abdalla. 2002. “An Intelligent Knowledge-based System for Product Cost Modelling.” International Journal of Advanced Manufacturing Technology19: 49–65. 10.1007/PL00003967.
- Spiegler, I.2003. “Technology and Knowledge: Bridging a ‘Generating’ Gap.” Information & Management40 (6): 533–539. 10.1016/S0378-7206(02)00069-1.
- Tang, D.2004. “An Agent-based Collaborative Design System to Facilitate Active Die-maker Involvement in Stamping Part Design.” Computers in Industry54: 253–271.
- Wegst, G. K., and M. F.Ashby. 1998. “The Development and Use of a Methodology for the Environmentally-Conscious Selection of Materials.” Proceedings of the Third World Conference on Integrated Design and Process Technology (IDPT)5: 88–93.