
Abstract
In this research a closed loop supply chain is designed which incorporates reverse logistics and forward logistic system simultaneously. In the design of reverse logistic system, recovery options are embedded in traditional supply chain for treating returned products. The recovery system includes collection centres, remanufacturing plants and disposal centres. Since the product return is supply driven, there is an uncertainty about it. In the proposed configuration for closed loop supply chain, the optimised configuration for supply chain in terms of locating recovery plants is developed. Accordingly, a fuzzy mixed integer linear programming model develops to deal with the uncertainty of returning products by customers. A general-purpose solver (LINGO 8.0) and a Meta heuristic approach (genetics algorithm) are implemented to solve the proposed model. The answers are compared by defining indexes and then the optimal answer, configuration and variables are identified. This solution will suggest a new design of supply chain network in which waste of materials is minimised and the new raw materials are necessary only when the used products may not be recovered by recovery options.
1. Introduction
During the last decades, supply chains have evolved from the simple traditional arrangements to more complicated environmental consciousness configurations. This new configuration incorporates the forward flow of materials to satisfy customer's demands with reverse flow of used products from customer zones back to supply chain tiers in order to reduce the necessity of new raw materials. Actually, the fundamental reasons for supply chain network design modifications are customer's consciousness about wasted products and government regulations for manufacturers to take back their products after the end of the life cycle. Beyond these reasons, the crucial effecting factor to change the traditional supply chain to new network design is successive search of manufacturers to find ways to tackle manufacturing costs. Amongst these ways, redesign of supply chain in an effective and efficient configuration is a sophisticated effort, where all tiers in supply chain attempt to eliminate wastes of used products as much as possible meanwhile reducing new raw material consumptions. In addition to traditional tiers in forward flow including raw material suppliers, manufacturers, warehouses and distribution centres, and finally customer's zones, the concepts of recovery operations are embedded into network design to constitute a closed loop supply chain. In fact a closed loop supply chain, in addition to forward and reverse logistics systems, should implement the basic concepts of recovery operations. These options mainly include reuse, recycle and repair operations. These operations are accomplished by remanufacturing facility, collection centres and disposal centres. The resulting system, which is called recovery system, is designed to extend product life cycles and recover materials by recycling the products at the end of their life cycle.
By implementing the concepts of recovery system in a closed loop supply chain, procurement of new raw materials is necessary only for substitution of disposed parts or components. The final stage of the remanufacturing system deals with the management of the remanufactured product flow. This flow of products directs repairable products to products manufactured, reusable parts to component manufacturers and recyclable materials to raw material suppliers. To design the closed loop supply chain, it should be considered that customers are the source of input materials to the recovery system and new materials are necessary to substitute those materials that cannot be recovered by recovery options (such as remanufacturing, repair, cannibalisation, recycling and refurbishing). Also in the material recovery system, collection centres are concerned with managing the flow of returned products from consumers to remanufacturing plants. In these centres, inspections, cleaning and sorting of returning product are accomplished and then the returned products (cores) will be transported to the remanufacturing plants to transform them into products with acceptable quality and standards equivalent to original new products. Actually, the design of this network is a crucial challenge for both researchers and practitioners in supply chain network design, considering all effecting factors and interaction of the tiers. Locating new facilities to minimise total cost of the whole system is one of the decisive considerations in supply chain design that brings effectiveness and efficiency for all tiers, while there are uncertainties about some parameters in closed loop supply chain. Some of these uncertainties are concerned with the closed loop supply chain characteristics, particularly in reverse logistics system design where it is supply driven not demand driven. The source of this uncertainty is customers' unclear willingness for returning the used products to reverse logistics system for recovery operations.
In this paper, a hybrid model is developed in order to deal with uncertainties of returned products by customers and locate new collection centres, remanufacturing plant and disposal centres to form a closed loop supply chain. The proposed model will be solved by two approaches: genetics algorithm (GA) and then LINGO 8.0. The values of the objective function are compared with both approaches. Then the optimised answers and configurations are provided. After a concise introduction, the remainder of this paper is structured as follows: a literature review related to papers in facility location problem is investigated in Section 2, and then conceptual model development is presented in Section 3 and data generation is discussed in Section 4. Prior to Section 6 that deals with further suggestions, the findings and conclusions are presented in Section 5.
2. Literature review
The fundamental concepts of closed loop supply chain are a combination of both forward and reverse logistics systems. This emerging system should include all aspects and interactions of tiers in the supply chain. The American Reverse Logistics Executive Council has defined reverse logistics as
The process of planning, implementing, and controlling the efficient, cost effective flow of raw materials, in-process inventory, finished goods and related information from the point of consumption to the point of origin for the purpose of recapturing value or proper disposal. (Alimoradia, Yussufa, and Zulkiflia Citation2011)
Kodali and Routroy (Citation2006) consider facility location decision as a strategic decision and confirm that for minimisation of the objective function, many traits of supply chain should be considered. Based on them, the objective of the closed loop supply chain is to minimise total costs of facility location or plant selection. They classify modelling approaches as integer programming, dynamic programming, nonlinear programming, goal and analytical hierarchy programming, non-convex programming, quadratic programming, analogue approach, multi-attribute utility method and multiple regression analysis. Considering these classifications, Kuo and Han (Citation2011) developed an integer programming model for upper and lower levels of supply chain. The proposed model considers the supply chain as a decentralised network and finds the answers to distribution problems. They implement GA and particle swarm optimisation as the efficient method in finding the optimised answers for the proposed bi-level programming model. The results of these algorithms are retrieved for four problems from other studies. Then the performance of the suggested solution algorithms is determined by comparison of the provided answers by each approach. Another modelling class is the mixed integer linear programming performed in supply chain design by Pinto-Varela, Barbosa-Póvoa, and Novais (Citation2011). They develop the proposed model in two sections. The first section balances annual profits and environmental impacts by symmetric fuzzy linear programming, while the second section models the supply chain by mixed integer linear programming. Finally they validate the model by a solution of a set of supply chain problems. In contrast to their model that splits the modelling into two sections, Tabrizi and Razmi (Citation2013) consider a mixed integer nonlinear model for presenting the uncertainties of the supply chain variables. They use a Bender decomposition method to transform the model to a mixed integer one. Since their model is simple in terms of considered variables, they use sensitivity analysis to check the model performance.
In order to design an effective reverse logistics, three key issues should be considered: structure of network, material planning, and classification and routing of materials. Supply-driven flow is another key aspect in reverse logistics which means that the demand and collection of goods are outside of direct control of the company. This trait of reverse flow has a great deal of uncertainty regarding quantity and timing of returned products because predicting of returned goods is very hard since it depends on willingness of customers to return their used goods (Jayaraman, Guide, and Srivastava Citation1999). There are a few researches in this field to develop a model for closed loop supply chain that can incorporate both forward and reverse flow of materials simultaneously. Lu and Bostel (Citation2007) suggest a 0-1 mixed integer programming model for reverse and forward logistics and their mutual interactions. They present a two-level location problem with three types of facilities to be located in a specific reverse logistics system. An algorithm based on Lagrangian heuristics method is developed and the model is tested on data adapted from classical test problems. These data are considered as crisp numbers and the uncertainty of returned goods are neglected.
Meng, Huang, and Cheu (Citation2009) developed a generic mathematical program for the facility location decision to maximise the objective function and find location of new firms in the supply chain and production level of each firm simultaneously. It first proposes a variation inequality for the supply chain network equilibrium model with production capacity constraints, and then employs the logarithmic–quadratic proximal prediction–correction method as a solution algorithm. Subsequently, a hybrid GA that incorporates with the logarithmic–quadratic proximal prediction–correction method is developed for solving the proposed mathematical program with an equilibrium constraint. Their research only shows that a reformed supply chain could be beneficiary, but they consider neither the closed loop design of supply chain nor the uncertainty in product return.
Tzeng and Chen (Citation1999) developed a fuzzy multi-objective location model for optimal number of location and site selection at an international airport. Their model also provides site selection and optimal number of fire stations at an airport. This model is not related to supply chain design but implements a fuzzy concept in facility location decision. Xu, Liu, and Wang (Citation2008) developed a random fuzzy multi-objective mixed integer nonlinear programming model for a supply chain network problem. The suggested model deals with cost minimisation for the supply chain including fixed costs of plants and distribution centres, distribution costs and delivery time. They tested their proposed multi-objective model in Chinese liquor industry using spanning tree-based genetic algorithms (st-GAs). In order to demonstrate the performance of the approach, results of a numerical experiment of the st-GAs are compared with those of traditional matrix-based GA. On the other hand Wang and Hsu (Citation2010) implemented the concept of st-GA for a suggested non deterministic polynominal model solution. By numerical experiment, they showed the efficiency and accuracy of their proposed model and algorithm to support the logistics decisions in closed loop supply chain with huge quantity of parameters. Demirel and Gökçen (Citation2008) presented an integrated model which provides the optimal values of production and transportation quantities of the manufactured and remanufactured products and solved the model to find the location of three types of remanufacturing facilities. Since locating new facilities is an important factor for maximising efficiency and effectiveness of all tiers in the closed loop supply chain, Alimoradia, Yussufa, and Zulkiflia (Citation2011) suggested the problem as a fuzzy multi-criteria decision-making problem. Their proposed approach aims to find the best place to locate remanufacturing and collection centres in a reverse logistics system as to minimise the total costs of location decision. In this research, they only emphasise on site selection based on management decision in a decentralised supply chain network for reverse logistics system without considering forward flow in closed loop design.
In order to deal with uncertainty during practical implementation of product recovery, two methods were applied in researches. Qin and Ji (Citation2010) employed a fuzzy programming tool to design product recovery network. They suggested three types of optimisation models and they designed a hybrid intelligent algorithm for solution which integrates fuzzy simulation and GA. Their focus was on management of returned products to recovery centres with minimum costs in an effective and efficient manner. Their proposed model accomplishes two main tasks including choosing collection centres among the potential sites and quantity of returned products accepted by each collection sites from customer zones. The other method implemented by Aardal and Larsson (Citation1990) and Schultmann, Engels, and Rentz (Citation2003) is based on two scenarios derived from assumptions for simplicity of data achievement. Since data for network structure were not available or very limited, they used some basic assumptions based on data from existing facilities in traditional reverse logistics and then two scenarios were suggested and solved to find the best solutions for a capacitated two-level facility location problem to determinate the optimal design of the closed-loop supply chain under different conditions. The proposed model was modified for the facility location problem network design such that the depots represent the sorting facilities, the customers represent the recycling facilities and the plants represent the collection points for returned products. They also implement the Bender decomposition method to transform the model. Kim, Saghafian, and Van Oyen (Citation2013) formulate the closed loop supply chain as Markov decision process to control production, remanufacturing and disposal decisions. They consider average profit maximisation as the decision criterion for answers selection. By implementing numerical comparisons, they show the benefits of utilising the recovery options in design of closed loop supply chain.
Literature review reveals that all the previous researches in design of the supply chain have focused on design of reverse logistics only while the forward logistic system is unchanged. Since the closed loop supply chain is an integrated identity comprising both forward and reverse logistics systems, its network should include all interactions of tiers. Furthermore, to minimise total cost of the whole supply chain, some tiers in forward logistics should be redesigned. These gaps considered in the literature review emphasise that the network design should include design of forward and reverse logistics tiers simultaneously. By the resultant system, the performance of the designed closed loop supply chain considerably increases. These developments, based on the model, can be achieved for various variables such as flow of material among tiers, the number of open facilities in all stages of the supply chain, fixed costs of the network and so on.
In this research, based on the mentioned gap, a hybrid model develops which incorporates both fuzzy and crisp variables in modelling the closed loop supply chain. Then the model is solved by two different approaches, a general-purpose solver package and a Meta heuristic approach. In order to find the best configuration for the closed loop supply chain, the provided answers are compared in terms of minimised objective functions, solution times and defined index for measuring performance of approaches. Then, based on the results, the optimised configuration for the suggested numerical problem is presented which shows the optimised closed loop supply chain. This closed loop supply chain also embodies both forward and reverse logistics simultaneously which is the best form of supply chain network design. It means that in this research, redesign of all tiers is concurrently considered: from distribution centres in forward logistics to reverse tiers such as collection centres, remanufacturing facilities and disposal centres.
3. Proposed model
A reverse logistics system comprises a series of activities, which form a continuous process to treat return products until they are properly recovered or disposed of. These activities include collection, cleaning, disassembly, test and sorting, storage, transport and recovery operations. The latter can also be represented as one or a combination of several main recovery options, such as reuse, repair, refurbishing, remanufacturing, cannibalisation and recycling. In our model, we suggest a system which uses collection centres for collecting, cleaning, testing and sorting, disassembly and storage of returned products and then remanufacturing plants for recovery operations such as reuse, repair, recycle and disposal of waste. Based on the classification of returned products, since remanufactured products are used as new parts and components, this configuration design will be a remanufacturing network design. Here, remanufacturing is defined as one of the recovery methods by which used/defective products or parts can be recovered in a state of the same quality as ‘new’ ones and can be included as new products to be resold in the same market as new products or parts.
3.1 Conceptual framework for model
In the conceptual framework for closed loop supply chain configuration, we consider a logistic system that incorporates forward flow along with reverse flow of materials. In this system, based on definition of reverse logistics, all activities that return used products from point of use to disposition point should be included. These activities include flow of materials from supplier to manufacturer, from manufacturer to its storage facility and distribution centres, from distribution centres to customers, from customers to collection centres, from collection centres to remanufacturing facility and from remanufacturer to disposal, suppliers and manufacturing facility. An important aspect in closed loop supply chain is locating new facilities for collecting, remanufacturing and disposal of the returned products. The conceptual framework for the model, based on the discussed flow of materials and products, is sketched as in Figure .
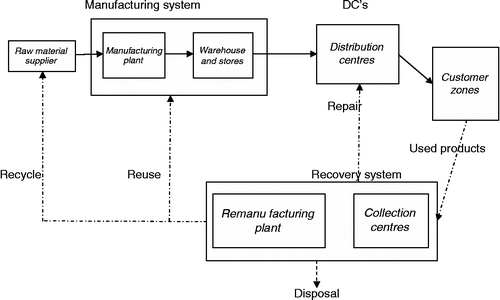
Based on the conceptual configuration for closed loop supply chain, we consider some assumptions which are implemented as the basis for modelling. These assumptions include the following:
The model is considered as single period multi-products.
The model is a single and discrete objective function.
The facilities are capacitated.
Suppliers, manufacturers, distribution centres and customer places are known and determined (Alimoradia, Yussufa, and Zulkiflia Citation2011).
Recovery facilities opening costs are fuzzy numbers.
Number of facilities are not pre-defined.
The supply chain is considered as supplies driven, then the capacity of recovery facilities is considered as fuzzy numbers.
Returned rate of used products is uncertain, considered as fuzzy numbers.
All the returned products are collected which means that all the customers and rules are satisfied.
Since a closed loop supply chain will be designed, we consider all logistics costs as a percent of raw material.
Storage facilities are considered inside manufacturing plants, so distribution centres serve as dispatch points without any storage capacity for products in forward flow.
Collection centres collect, cleanse, test and sort the returned products from customer zones, so wastes take place only at these centres.
Remanufacturing facilities send recovered products to corresponding partners.
3.2 Objective function, indexes, parameters and variables
The objective function proposed for this closed loop supply chain configuration will minimise the total costs. These costs include transportation costs, holding costs and fixed costs of opening facilities. The objective function conceptually would be such as to:
Subject to:
Based on the details of conceptual supply chain given in Section 3.1, the indices for introducing all tiers in supply chain modelling are:
| I | = | Fixed places for suppliers i ∈ I |
| J | = | Fixed places for manufacturers j ∈ J |
| K | = | Fixed places for distribution k ∈ K |
| L | = | Customer zones l ∈ L |
| M | = | Places for collection centres m ∈ M |
| N | = | Places for rubbish centre n ∈ N |
| P | = | Set of remanufacturing facilities p ∈ P |
| S | = | Product sets s ∈ S |
Parameters for the model are:
| = | Return rate of product s from remanufacturing facility p to manufacturer j | |
| = | Return rate of product s from remanufacturing facility p to rubbish centre n | |
| = | Return rate of product s from remanufacturing facility p to distribution centre k | |
| = | Return rate of product s from remanufacturing facility p to supplier i | |
| = | Fixed cost of locating and opening distribution centre k | |
| = | Fuzzy demand of returned product s by customer l | |
| = | Return rate of product s by customer l | |
| = | Fuzzy cost for locating collection centre m | |
| = | Fuzzy cost for locating remanufacturing plant p | |
| = | Fuzzy cost for locating waste centre n | |
| = | Transportation cost of product s from supplier i to manufacturer j | |
| = | Transportation cost of product s from manufacturer j directly to distribution centre k | |
| = | Transportation cost of product s in manufacturer j to its own storage facility | |
| = | Transportation cost of product s via manufacturer store j to distribution centre k | |
| = | Transportation cost of product s from distribution centre k to customer zone l | |
| = | Transportation cost of core s from customer zone l to collection centre m | |
| = | Transportation cost of core s from collection centre m to remanufacturing centre p | |
| = | Transportation cost of core s from collection centre m to rubbish n | |
| = | Transportation cost of reusable products s from remanufacturing facility p to manufacturer j | |
| = | Transportation cost of repairable products s from remanufacturer p to distribution centre k | |
| = | Transportation cost of recycled cores s from remanufacturing plant p to supplier i | |
| = | Supplier capacity at i | |
| = | Manufacturer capacity at j | |
| = | Manufacturer storage capacity at j | |
| = | Remanufacturing capacity for manufacturer at j | |
| = | Capacity of distribution centre at k | |
| = | Remanufactured products distribution capacity at distribution centre k | |
| = | Fuzzy capacity of collection centre m | |
| = | Fuzzy capacity of remanufacturing centre p | |
| = | Fuzzy capacity of rubbish at n | |
| = | Holding cost of product s at manufacturer j |
Variables for the model are:
| = | Quantity of product s from supplier i to manufacturer m | |
| = | Quantity of product s from manufacturer j to distribution centre k | |
| = | Flow of product s from manufacturer j to its storage facility j | |
| = | Quantity of product s from distribution centre k to customer zone l | |
| = | Flow of product s from manufacturer warehouse j to distribution centre k | |
| = | Quantity of returned product s from customer l to collection centre m | |
| = | Quantity of reused product s from remanufacturing plant p to manufacturer j | |
| = | Quantity of repaired product s from remanufacturing facility p to distributor k | |
| = | Quantity of returned product s from collection centre m to remanufacturing facility p | |
| = | Quantity of waste product s from remanufacturing centre p to rubbish n | |
| = | Quantity of recycled core s from remanufacturing facility p to supplier i | |
| = | Quantity of product s stored in manufacturer warehouse j |
Correspondingly, we formulate the objective function for the model as to minimise total cost of facility location, transportation costs in both forward and reverse logistic systems, and holding costs. These costs include:
Transportation costs including:
Transportation cost from supplier to manufacturer:
Transportation cost from manufacturer to distribution centres and to the storage facility:
Transportation cost from the distribution centre to the customer:
Transportation cost for returned products from customer to the collection centre:
Transportation cost from collection centre to remanufacturer:
Transportation cost from remanufacturer to supplier, to disposal centre, to manufacture and to distribution centre:
Fixed cost:
Fixed cost of opening a distribution centre:
Fuzzy fixed cost of opening collection centre:
Fuzzy fixed cost of opening remanufacturing facility:
Fuzzy fixed cost of opening disposal centre:
Holding cost for manufacturer:
The objective function will be the sum of all above costs incurred in network and minimises total costs of the closed loop supply chain as below:
Subject to:
Restrictions numbers (1) to (8) show the flow of materials from distribution centres to customer, collection centres, remanufacturers and disposal centres. In these restrictions, β is rate of returning products among facilities in the recovery system. These restrictions also show that some products returned by customers cannot be recovered, so the total recovered products are less than total input products to the recovery system. Restriction numbers (9) to (12) show the flow of materials for tiers and storage facility of the manufacturer.
Restrictions (13) to (23) ensure that flow exists in nodes where a facility is located, and in these facilities sum of the flows do not exceed facility capacity. In fact in these restrictions, capacities are limited by input not by throughput.
Restrictions (24) to (27) guarantee that at least one facility is active in the supply chain.
Statement (28) guarantees that returned products coefficients are smaller than 1.
Restrictions (29) and (30) are logical and actual limitations of decision variables in the proposed problem.
3.3 Model transformation and solution method
3.3.1 Model transformation
The proposed model and restrictions are in fuzzy format and in order to solve it, we should first transform it to deterministic model. There are many methods implemented by other studies to transform the model such as Kuo and Han (Citation2011) and Tabrizi and Razmi (Citation2013). Since some of the proposed parameters are selected randomly, many of the mathematical approaches to transform the model are not valid for this research. Therefore, in this research fundamental concepts developed by Zimmermann (Citation1996) and approaches implemented by Alimoradia, Yussufa, and Zulkiflia (Citation2011) and Jimenez et al. (Citation2007) are used as methodology for solution. These approaches allow using expected values for random and fuzzy parameters and also further necessary mathematical operations. Jimenez et al. (Citation2007) presented a ranking method for fuzzy numbers which is based on comparison of their expected values. In this approach, is a trapezoidal fuzzy number, membership function of which will be as follows:
Let and
be linear functions and
a trapezoidal fuzzy number, then their expected integer range will be:
Also expected, value for fuzzy number is:
This expected value of the trapezoidal fuzzy number is:
By implementing all relations and definitions mentioned from (31) to (34), the developed fuzzy model converts to the deterministic one as the function as follows:
And the constraints change as follows:
The above relations convert the fuzzy model to deterministic one which is ready for validation by the proposed approach.
3.3.2 Solution method
Since the facility location modelling categorises as Np-Hard problems, ordinary solution methods are not applicable to find answers for it (Daskin Citation1995; ReVelle, Eiselt, and Daskin Citation2008). Basically solution methods include traditional methods (such as fundamental formulation and stochastic programming), simulation-based methods or general-purpose solver, and heuristics (Chen et al. Citation2012). In this research, two approaches, one Meta heuristic (GA) and one general-purpose solver (LINGO 8.0), are implemented to find the optimum answers for locating facilities, flow of materials and minimising total costs.
The first approach is a GA which is a special kind of evolutionary algorithms which benefits from biological techniques such as mutation and inheritance. Many scholars believe that performance of GA in finding approximate optimal answers for Np-Hard problems such as facility location compares with that of other search algorithms such as Tabu search, ant colony optimisation and simulated annealing. This algorithm was first introduced in the twentieth century and is a Meta heuristic algorithm based on the population, which in each iterate has a set of population of answers(Min, Ko, and Ko Citation2006). Each individual answer in this algorithm is called a chromosome and starts with a population of answers and produces new answers using mutation, crossover and reproduction operators. These operators are defined as follows.
Producing initial population: GA is a population-based algorithm in which each individual iterate or generation has constituted from a chromosome population and this population should be equal in all the algorithm iterates. At the beginning of the process, this algorithm should also produce an initial population of answers in which their numbers are identified as algorithm parameters.
Mutation: In each iteration of the algorithm, some answers are selected and a neighbouring operator is executed on them which is called a mutation operator. The selected number of answers for applying this operation depends on the mutation pace. This rate is a number between 0 and 1 and is considered as a parameter for algorithm input. For instance, if the mutation rate is 0.2, then 20% of the existing answers in the population are selected for applying the mutation operator.
Crossover: Another GA operator which executes on two selected answers or parents and produces two children is the crossover operator. The number of the answers that are selected for an operator depends on the crossover rate. This crossover rate is a number between 0 and 1 and is considered as an input parameter for the algorithm. Let the crossover rate be 0.6, then 60% of all answers in the population which any operators have been executed on them selects for the crossover operator.
Reproduction: Some of the existing answers in the population which crossover and mutation operators do not execute on them will be passed to the next generation without any changes. A number of these answers depend on the reproduction rate which is calculated as:
The above definition means that the sum of the all three operators is 1 (or 100%).Parent selection: As discussed in crossover operator, in order to execute this operator, two answers are selected as parents and implemented by this operator. There are many different parent selection patterns for this operator. In this research, roulette wheel selection is preferred to other methods that randomly discard or change all the parents' chromosomes.
Fitness function: This function is determined for each individual answer and is a criterion for comparison of the answers. By this criterion, the best answer among a set of answers is selected.
Most of the Meta heuristic algorithms implement a random method for producing initial answers (Wang, Sun, and Fang Citation2008). But the produced random initial answers are not optimum or are near optimum answers which require many iterates to reach the optimised initial sets of answers in a long time. So this method has a long solution time, meanwhile near optimised answers are not achieved. These facts make global optimal answers far inaccessible and then the whole model will not be optimised. Since the quality of the derived optimum answers directly depends on the quality of initial produced sets of answers, in this research for producing initial answers of GA, a local search parallel construction is implemented. The main purpose of implementing this method is producing initial answers with an acceptable level of quality for producing global optimal answers by the algorithm. This construction commences with a feasible random answer as the starting point and implements four local search operators. All these operators are executed on existing initial answers evenly and each time the best answer among the five answers (existing+produced answers) is selected based on the objective function and identified as input for the next parallel construction. After the end of parallel construction, the output answer, if it is not already repeated in the population, will be added to the answer population. This procedure continues until producing all N non-repeated answers as initial populations of answers for the algorithm. Based on the defined fitness function for the algorithm and at the end of each iterate, among the iterate answers and new produced answers, N answers that have higher fitness values are selected. These answers are considered as optimised answers for the problem and are tabulated. Finally these answers are compared with answers provided by the general-purpose solver software. Here LINGO 8.0 is the selected software as the second method for model validation and finding optimum answers.
4. Data generation
There are a few simulation and case study test problems with different sizes in the literature regarding concurrent network design for forward and reverse logistics (Zanjirani Farahani, Drezner, and Asgari Citation2009). In this research in order to validate the model, some cases from other studies are selected and modified. Some of these cases used as the basis for test problem simulation are mentioned in Table .
Table 1 Different sizes of test problems in the literature.
Based on these cases in the literature, two test problems sets with different sizes for the proposed model validation are designed: a small size and a medium size test problem. The term size refers to the number of manufacturers, collection centres and remanufacturing centres designed to be located in the supply chain. The proposed test problems also include disposal centres and suppliers simultaneously which others have neglected. Since actual supply chains have more suppliers than manufactures in their networks, this fact is also embedded in the test problem design. Tables and are the result of these assumptions for test problem design.
Table 2 Designed small size test problems.
Table 3 Designed medium size test problems.
These test problems are designed based on variations in the number of tiers in forward logistics, reverse tiers and finally number of products on supply chain network. These problems are used as the basic configurations for the supply chain network design. The first part of the problem design was concerned with design of the supply chain network configuration. The second part deals with adjustment of the parameters for the GA. In order to adjust some parameters such as population, mutation rate and crossover rate, MINITAB software was used. For GA parameter adjustment, mutation rate and crossover rate were considered at three levels. Population size was also considered in three different levels as given in Table .
Table 4 Levels of parameters for GA.
For an analysis of the answers, an index is defined to measure the performance of the algorithm in providing answers. In fact, the designed index measures the gap between the least achieved value by each solution method and the least existing value among answers of methods; meanwhile the least index value confirms closer quantity and optimised performance of the methods in providing answers.
This index, which is named as ‘Real Performance Difference’ or RPD is measured as follows:
Based on the definitions, Figures and show analysis of crossover rate and mutation rate, and effective number for population size derived from MINITAB software. In Figure , three labels can be seen on the horizontal axis and each label illustrates a combination of two operator rates that are defined as:
| a1 | = | 0.7 for crossover and 0.1 for mutation 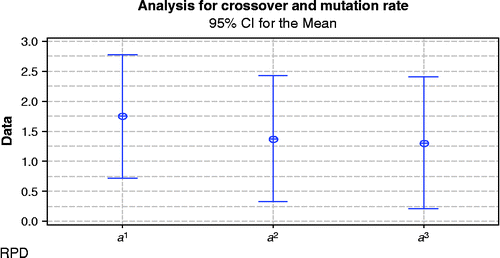 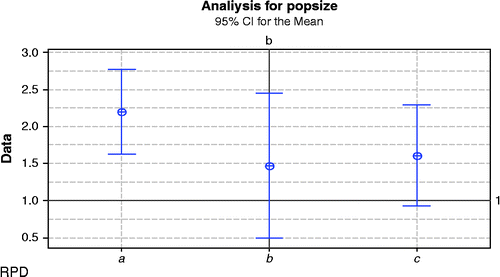 |
| a2 | = | 0.7 for crossover and 0.2 for mutation |
| a3 | = | 0.8 for crossover and 0.1 for mutation |
Based on Figure , the best combination is the third one with 0.8 for crossover rate and 0.1 for mutation rate. In fact a3 covers more data levels than the other two. Therefore, in this research corresponding quantities for a3 are considered as crossover and mutation rates in GA.
Based on previous literature, population sizes are considered from 50 to 200. In this research three different population sizes are considered. These sizes include 70, 150 and 200. The second figure illustrates the population size adjustment in three levels in the horizontal axis as:
| a | = | Population size is 70 |
| b | = | Population size is 150 |
| c | = | Population size is 200 |
As Figure illustrates, the effective level, which covers more data from the vertical axis, is the second one with population size 150.
The other parameters for problem solution are considered as follows:
Fixed costs for locating facilities such as disposal, collection and remanufacturing are
= (20,000,40,000,60,000,80,000).
Return rate produced randomly from range [60,100].
Transportation costs are randomly produced from range [1,100].
Capacity of manufacturers, suppliers and distribution centres is produced randomly from [500,1000].
5. Findings
In Section 4, two different test problems were designed based on the literature for problem solution. In order to understand and compare the effectiveness and efficiency of the proposed GA, the results are compared with LINGO software outputs for the designed test problems.
In order to determine the gap between the answers of LINGO software and the proposed GA answers, and index is defined as follows:
The error function (66) defines the difference of the answers of the proposed algorithm solution and optimum answers of LINGO software. This index is a comparative index and will be used as a criterion for effectiveness and performance measurements of algorithms.
Based on these definitions and other considerations in Section 4, the proposed problems in Tables and are solved in MATLAB software package by a Pentium® 4, 3.06 GHz 512 MB of RAM, and the results for the small and medium size problems solutions in both approaches are given in Tables and respectively.
Table 5 Results for small size test problem.
Table 6 Results for medium size test problem.
Table shows that for the first problem, the error is 0.06 which is very small and ignorable. In this problem the performance of LINGO software for minimising total cost is better than the performance of the GA approach; in both solutions time and objective function minimisation. In problems 2 and 3, the increase in error shows that LINGO is performing better in finding an optimum answer than GA. But in problems 4 and 5 while the error increases steadily, solution times for both approaches are growing closely. Table emphasises on these findings and shows that as the number of problems increases, the solution times and objective functions for the GA approach optimise. In these cases, LINGO software is not applicable in finding optimum answers anymore. In fact, since in the proposed model the number of restrictions, parameters and variables are numerous problem solution by LINGO, even in small sizes in global solver, is too much time consuming. In these situations, sometimes local answers are provided by these general-purpose solvers which are misinterpreted as global optimal answers. Figures illustrate all these findings for the objective function values derived from GA and LINGO approaches and also the corresponding solution times.
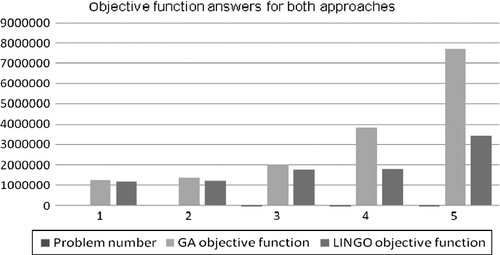
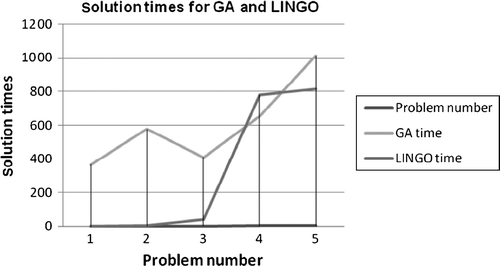
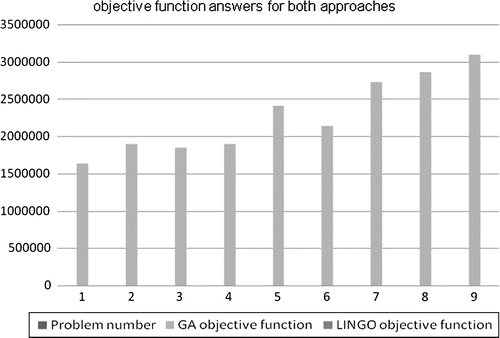
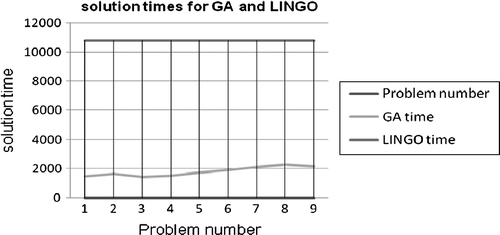
The findings show that GA has general properties of an optimisation algorithm and can optimise the proposed model effectively compared with LINGO as a general-purpose solver. The findings also emphasise that the GA approach is more accurate and effective for problems in medium or large sizes than LINGO. This approach can be used to locate new facilities to constitute optimised closed loop supply chain. In order to configure optimised network, from Table , three problems are selected. These problems are numbers 3, 6 and 9 which are shown in Table . This selection is based on the least solution time and minimum objective function. These problems also possess all details of the other problems such as product variety, the number of distribution centers (DCs) and different number of facilities for reverse logistics system meanwhile different tiers in their network. Table shows the optimised number of these facilities, based on the defined variables in Section 3, for both forward and reverse logistics by GA executed in MATLAB.
Table 7 Selected problems for design of optimised configuration.
Table 8 Optimised configuration for selected problems.
6. Further suggestions and future researches
In this research, we designed a complete closed loop supply chain from supplier to customer in forward flow and then from the customer back to a recovery system in reverse flow. In other researches, up to today, the design of the supply chain was not performed in both flows. It means that interactions of forward and reverse flow with each other were neither considered nor included in the network design. In order to design a perfect, effective and efficient supply chain that minimises total cost, it is vital to consider all the tiers and their roles in both forward and reverse logistics. Since for this research simulation methods were implemented, answers and some boundaries, maybe, do not clearly match those of the real world. We suggest designers to add real world factors, such as tax and labour effects on fixed costs, effects of technology in recovery systems and their cost and availability, and actual number of suppliers, manufacturers and DCs and even customers in the supply chain design and also implementation of other artificial intelligence algorithms for deriving the optimum answers. All these efforts by designers of the supply chain will result in less consumption of raw material, less prices for customers and finally more effective and efficient supply chain for all tiers in both forward and reverse logistics.
References
- AardalK., and T.Larsson. 1990. “A Bender Decomposition Based Heuristic for the Hierarchical Production Planning Problem.” European Journal of Operational Research45: 4–14.
- AlimoradiA., R. M.Yussufa, and N.Zulkifli. 2011. “A hybrid model for remanufacturing facility location problem in a closed loop supply chain.” International Journal of Sustainable Engineering4 (1): 16–23.
- ArasN., D.Aksen, and A. G.Karaarslan. 2008. “Locating Collection Centers for Incentive-Dependent Returns Under a Pick-Up Policy with Capacitated Vehicles.” European Journal of Operational Research191 (3): 1223–1240.
- ChenS., Y.Zheng, C.Cattani, and W.Wang.2012. “Modeling of Biological Intelligence for SCM System Optimization.” Computational and Mathematical Methods in Medicine2012: article ID769702,10 p
- DaskinM. S.1995. Network and Discrete Location: Models, Algorithms, and Applications. New York: John Wiley.
- DemirelN. O., and H.Gökçen. 2008. “A Mixed Integer Programming Model for Remanufacturing in Reverse Logistics Environment.” International Journal of Advanced Manufacturing Technology39 (11–12): 1197–1206.
- GenM., F.Altiparmak, and L.Lin. 2006. “A Genetic Algorithm for Two-Stage Transportation Problem Using Priority-Based Encoding.” OR Spectrum28: 337–354.
- IlginM. A., and S. M.Gupta. 2010. “Environmentally Conscious Manufacturing and Product Recovery (ECMPRO): A Review of the State of the Art.” Journal of Environmental Management91 (3): 563–591.
- JayaramanV., V.GuideJr, and RSrivastava. 1999. “A Closed-Loop Logistics Model for Remanufacturing.” Journal of the Operational Research Society50 (5): 497–508.
- JayaramanV., R. A.Patterson, and E.Rolland. 2003. “The Design of Reverse Distribution Networks: Models and Solution Procedures.” European Journal of Operational Research150 (1): 128–149.
- JimenezM., M.Arenas, ABilbao, and M.Victoria Rodríguez. 2007. “Linear Programming with Fuzzy Parameters: An Interactive Method Resolution.” European Journal of Operational Research177: 1599–1609.
- KimE., S.Saghafian, and M. P.Van Oyen. 2013. “Joint Control of Production, Remanufacturing, and Disposal Activities in a Hybrid Manufacturing–Remanufacturing System.” European Journal of Operational Research231 (2): 337–348.
- KodaliR., and S.Routroy. 2006. “Decision Framework for Selection of Facilities Location in Competitive Supply Chain.” Journal of Advanced Manufacturing Systems5 (1). 10.1142/S021968670600073X.
- KuoR. J., and Y. S.Han. 2011. “A Hybrid of Genetic Algorithm and Particle Swarm Optimization for Solving Bi-Level Linear Programming Problem – A Case Study on Supply Chain Model.” Applied Mathematical Modelling35 (8): 3905–3917.
- LuZ., and N.Bostel. 2007. “A Facility Location Model for Logistics Systems Including Reverse Flows: The Case of Remanufacturing Activities.” Computers and Operations Research34 (2): 299–323.
- MengQ., Y.Huang, and R. L.Cheu. 2009. “Competitive Facility Location on Decentralized Supply Chains.” European Journal of Operational Research196 (2): 487–499.
- MinH., H. J.Ko, and C. S.Ko. 2006. “A Genetic Algorithm Approach to Developing the Multi-Echelon Reverse Logistics Network for Product Returns.” Omega34 (1): 56–69.
- Pinto-VarelaT., A. P. F. D.Barbosa-Póvoa, and A. Q.Novais. 2011. “Bi-Objective Optimization Approach to the Design and Planning of Supply Chains: Economic Versus Environmental Performances.” Computers & Chemical Engineering35 (8): 1454–1468.
- QinZ., and X.Ji. 2010. “Logistics Network Design for Product Recovery in Fuzzy Environment.” European Journal of Operational Research202 (2): 479–490.
- ReVelleC. S., H. A.Eiselt, and M. S.Daskin. 2008. “A Bibliography for Some Fundamental Problem Categories in Discrete Location Science.” European Journal of Operational Research148: 817–848.
- SchultmannF., B.Engels, and ORentz. 2003. “Closed-Loop Supply Chains for Spent Batteries.” Interfaces33 (6): 57–71.
- TabriziB. H., and J.Razmi. 2013. “Introducing a Mixed-Integer Non-Linear Fuzzy Model for Risk Management in Designing Supply Chain Networks.” Journal of Manufacturing Systems32 (2): 295–307.
- TzengG. H., and Y. W.Chen. 1999. “The Optimal Location of Airport Fire Stations: A Fuzzy Multi-Objective Programming and Revised Genetic Algorithm Approach.” Transportation Planning and Technology23 (1): 37–55.
- WangH. F., and H. W.Hsu. 2010. “A Closed-Loop Logistic Model with a Spanning-Tree Based Genetic Algorithm.” Computers and Operations Research37 (2): 376–389.
- WangX. F., X. M.Sun, and Y.Fang. 2008. “Genetic Algorithm Solution for Multi-Period Two-Echelon Integrated Competitive/Uncompetitive Facility Location Problem.” Asia-Pacific Journal of Operational Research25 (1): 33–56.
- XuJ., Q.Liu, and R.Wang. 2008. “A Class of Multi-Objective Supply Chain Networks Optimal Model Under Random Fuzzy Environment and Its Application to the Industry of Chinese Liquor.” Information Sciences178 (8): 2022–2043.
- YehW. C.2005. “A Hybrid Heuristic Algorithm for the Multistage Supply Chain Network Problem.” International Journal of Advanced Manufacturing Technology26: 675–685.
- Zanjirani FarahaniR., Z.Drezner, and N.Asgari. 2009. “Single Facility Location and Relocation Problem with Time Dependent Weights and Discrete Planning Horizon.” Annals of Operations Research167: 353–368.
- Zimmermann, H. J., ed. 1996. Fuzzy Set Theory and Its Applications. Boston, MA: Kluwer Academic Publishers.