Abstract
The classification of remote sensing data based on the exploitation of spatial features extracted with morphological and attribute profiles has been recently gaining importance. With the development of efficient algorithms to construct the profiles for large datasets, such methods are becoming even more relevant. When dealing with hyperspectral imagery, the profiles are traditionally built on the first few principal components computed from the data. However, it needs to be determined if other feature reduction approaches are better suited to create base images for the profiles. In this article, we explore the use of profiles based on features derived from three supervised feature extraction techniques (i.e. Discriminant Analysis Feature Extraction, Decision Boundary Feature Extraction and Non-parametric Weighted Feature Extraction) and two unsupervised feature-extraction techniques (i.e. Principal Component Analysis (PCA) and Kernel PCA) in classification and compare the classification accuracies obtained by using different techniques for two different classification methods. The obtained results indicate significant improvements in the accuracies using the supervised feature extraction methods. However, the choice of the method affects the quality of the results for different datasets depending on the availability of the training samples.
1. Introduction
When dealing with remote sensing images, especially with those of metre or even sub-metre spatial resolution, the spatial information (e.g. contextual relations, geometrical and structural features) is an informative source of fundamental importance for the data analysis (Datcu et al. Citation1998, Daya Sagar and Serra Citation2010). For a review on the use of mathematical morphology tools for the modelling of spatial information for the analysis of remote sensing images, the reader can refer to Soille and Pesaresi (Citation2002) and Daya Sagar and Serra (Citation2010). Morphological profiles (MPs) and attribute profiles (APs) have been successfully exploited as tools for fusing spectral and spatial information for the classification of remote sensing data (Pesaresi and Benediktsson Citation2001, Benediktsson et al. Citation2003, Citation2005, Dalla Mura et al. 2010a, Citation2010b, Citation2011a). Also, with the development of computationally efficient algorithms to construct profiles of large datasets, the relevance of using them as standard tools for efficient classification of remote sensing data is manifold (Ouzounis and Soille Citation2009, Wilkinson et al. 2008, Citation2010, Citation2011). As defined in Pesaresi and Benediktsson (Citation2001), an MP of an image is built using a sequence of geodesic closing and opening transformations (Soille Citation2003) computed with a window of fixed shape and increasing size, called structuring element (SE). When multidimensional images are considered (i.e. multi- and hyperspectral imagery), a direct application of the concept of the MP to the data is not possible (Benediktsson et al. Citation2005, Dalla Mura et al. Citation2010b). Thus, in Benediktsson et al. (Citation2005), it was proposed to reduce the high dimensionality of a hyperspectral image with the Principal Component Analysis (PCA) and to generate an MP to each of the extracted features associated to the largest eigenvalues. The computed profiles stacked together, namely an extended morphological profile (EMP), were considered as features for classification. An extension of the MP is the more versatile morphological AP (Dalla Mura et al. Citation2010b), which is built on a sequence of increasingly severe attribute filters (Breen and Jones Citation1996). The use of attribute filters permits to extract features that are not only related to the scale of the regions in the image (as by using the geodesic operators in the MPs), but also to any measure (e.g. geometrical, textural and spectral) that can be computed on the regions. Analogous to the EMP, the corresponding stack of APs computed on features extracted from hyperspectral data is called the extended attribute profile (EAP) (Dalla Mura et al. Citation2010b). When multiple EAPs are computed considering different attributes and stacked together in the same data structure, an extended multi-attribute profile (EMAP) is obtained (Dalla Mura et al. Citation2010b). By considering multiple attributes, especially for measures as less correlated as possible (e.g. spatial and spectral characteristics), it is possible to extract a richer description of the regions in the image. This provides a more complete modelling of the spatial information of the investigated scene (Dalla Mura et al. Citation2010c).
When dealing with hyperspectral images, which have huge dimensionality (e.g. about 100 of spectral channels), the profiles are computed on a set of reduced number of features extracted from the data. Traditionally, the EMP (Benediktsson et al. Citation2005) and EAP (Dalla Mura et al. Citation2010b) are computed on the first few principal components (PCs) extracted from the images of full dimensionality. The main reason for this selection was due to the fact that the PCA is optimal for representation in the mean square sense. An open question is whether the feature reduction mechanism to create base images further considered by the EMP and EAP can be improved by using supervised dimensionality reduction approaches for a classification task. The feature reduction operation applied to the data is of fundamental importance, since the modelling of the spatial information is performed by computing the profiles that are based on the extracted features. This is also very important while handling large datasets. There have been earlier attempts to study the classification results with profiles using various feature reduction algorithms independently (e.g. Fauvel et al. Citation2009, Castaings et al. Citation2010, Licciardi et al. Citation2011, Peeters et al. Citation2011, Dalla Mura et al. Citation2011b). However, no attempt has been made to study the classification results with the profiles generated using the various supervised feature reduction algorithms in comparison to unsupervised feature reduction algorithms. The aim of this work is to study the effect of feature reduction on the EMAPs for the purpose of classification.
In greater detail, we aim at assessing the robustness of the EMAP approach considering different feature extraction techniques in relation with the availability of the training samples. Such analysis is of interest, since in many practical scenarios (especially when dealing with large datasets), the labelled samples might not be enough for properly and completely modelling the heterogeneity of the data, hence influencing the classification results. The analysis of the effect of different feature reduction techniques on the profile and the related validation results for efficient classification can become the base for extending the application of the approaches to large datasets using available efficient implementations. For this reason, in this work, we focus on the effectiveness of the profiles built with different feature reduction methods considering different processing architectures. This study thus provides guidelines to effectively utilise the concept of APs while classifying high spatial resolution hyperspectral data.
The performance of the profiles built with kernel-based unsupervised feature reduction using kernel-PCA (KPCA) (Schölkopf et al. Citation1998) is also studied. The supervised feature reduction techniques used in this work are the Discriminant Analysis Feature Extraction (DAFE), Decision Boundary Feature Extraction (DBFE) and Non-parametric Weighted Feature Extraction (NWFE) (Landgrebe Citation2003). The aim of this article is not only to compare the results statistically, according to the available ground truth information, but also to visually verify the geometric stability of the classification maps. This helps in understanding the bias of the resulting maps towards the corresponding training samples of the classes of interest. While EMP and EAP are both considered as effective tools for combining spectral and spatial information, we only use the EAP in this work as it is found to consistently provide more accurate classification results than EMP (Dalla Mura et al. Citation2010b). Thus, in this work we consider different feature reduction techniques while using only the APs.
This article is organised into five sections. The next section is devoted to the presentation of the concept of the EAP. Section 3 illustrates the proposed classification technique. Section 4 presents the two hyperspectral dataset considered and Section 5 reports the results obtained in the experimental analysis. Finally, conclusions are drawn in Section 6.
2. Extended attribute profiles
EAPs are a generalisation of the APs for hyperspetral images. We recall that the APs are an extension of the MPs based on morphological APs (Breen and Jones Citation1996). In the following, we briefly review the concepts of attribute filters and APs prior to introducing the EAPs.
Attribute filters are connected operators (Salembier and Wilkinson Citation2009), so they process an image only by merging its connected components (i.e. regions of iso-intensity spatially connected pixels). When considering binary images, the connected components are simply the foreground and background regions present in the image. When dealing with greyscale images, the set of connected components can be extracted by considering the image as composed by a stack of binary images generated by thresholding the image at all its grey-level values (Maragos and Ziff Citation1990). Since connected operators cannot create new or distort existing borders of the regions, they are particularly suitable for the analysis of remote sensing images, especially for high spatial resolution data.
The two main operators in the attribute filters family are attribute thinning and attribute thickening (Breen and Jones Citation1996) that, roughly speaking, process bright and dark connected components (with respect to their surrounding regions), respectively. Attribute filters process an image according to a given criterion. A criterion is a logical predicate that compares the value of an arbitrary attribute, attr (e.g. area, volume, standard deviation) measured on a connected component C against a given reference value λ, e.g. T(C) = attr(C) > λ. The criterion is then evaluated on all the connected components of the image and the output of the filter is obtained by considering whether the criterion is fulfilled or not. If the predicate is verified on a connected component, then the corresponding region is kept unaffected; otherwise, the region is merged to the connected component with the closer greater or lower value, accordingly a thickening or thinning transformation is considered, respectively. When the considered criterion is increasing (i.e. if it is verified for a given connected component, it will be also verified for all those regions including the considered component), the thinning and thickening transformations become also increasing leading to attribute opening and attribute closing, respectively. Increasing criteria are usually associated to increasing attributes (e.g. area and volume). When the criterion is not increasing, we recall that the output of the filter is obtained according to a filtering rule (Salembier et al. Citation1998, Salembier and Wilkinson Citation2009).
An AP is obtained by considering a sequence of attribute thinning and thickening transformations defined with a sequence of progressively stricter criteria. The sequence of criteria has to be ordered in order to achieve the fulfilment of the absorption property on the profile (i.e. each image is point-wise lower or equal than its previous one). The AP computed on a greyscale image f with the set of n criteria T = {T 1, T 2 , … , Tn } can be formalised as (Dalla Mura et al. Citation2010c):
Analogous to the definition of the EMP (Benediktsson et al. Citation2005), the EAP is simply obtained by the concatenation of the APs computed on each feature extracted by a multivalue image (e.g. a hyperspectral image) (Dalla Mura et al. Citation2010b). In Dalla Mura et al. (Citation2010b), the reduction of the dimensionality of the original data was performed by PCA, whereas in Dalla Mura et al. (Citation2011b) by independent component analysis. The EAP derived from m features extracted by a generic feature reduction transformation are defined as
Dalla Mura et al. (Citation2010b) proposed to consider the EAPs, obtained by using different attributes, in the same data structure (in order to provide a more complete modelling of the spatial information). The structure composed by k EAPs (each one computed with a different attribute) stacked in sequence was named EMAP:
By considering multiple attributes, an improved capability in extracting the spatial characteristics of the structures in the scene is gained (especially if the attributes describe different characteristics of the regions). However, a significant increase of the dimensionality of the data is also obtained.
When considering the application of the profiles to large volumes of data, the computational burden associated with the computation of the profile becomes an essential issue. The application of conventional MPs to large datasets (e.g. giga-pixel images) has already been proved to be feasible, thanks to efficient implementations (Wilkinson et al. Citation2010, Citation2011). Efficient implementations of attribute filters have been proposed in the literature (Salembier and Wilkinson Citation2009), taking advantage of representations of the set of connected components of an image as a hierarchical structure called Max-tree (Salembier et al. Citation1998). The computation of Max-tree structures can also be performed exploiting parallel architectures, since an efficient concurrent implementation exists (Salembier and Wilkinson Citation2009). Furthermore, when the attribute filters are applied multiple times to the same image as for APs and EAPs, it is possible to further exploit the efficiency of the attribute filters implementation. In fact, an image can be converted to the correspondent Max-tree structure only once since the filtered versions of the image, obtained with the different criteria, can be easily generated from the direct analysis of the computed Max-tree (Dalla Mura et al. Citation2010b, c).
3. Methodology
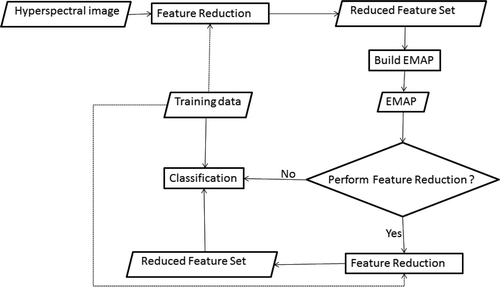
The general overview of the work flow for the classification of hyperspectral images using the EMAP is shown in . Feature reduction is performed on the hyperspectral image and the resulting features are used to build the EMAP. The feature reduction can either be supervised or unsupervised. A further feature reduction operation applied to the EMAP can both reduce the effect of the Hughes phenomenon and the redundancy in the profiles for classification. The classification is usually performed using non-linear classifiers due to the fact that the resulting EMAP is characterised by highly non-linear class distributions.
Figure 1. The work flow of spectral-spatial classification with EMAP. The dotted lines indicate the possibility of switching between supervised and unsupervised feature reduction. An optional feature reduction step can be used to reduce the dimensionality of EMAP before classification.
In this work, two unsupervised (i.e. PCA and KPCA) and three supervised feature reduction methods (i.e. DAFE, DBFE and NWFE) are considered. In the case of unsupervised methods, PCA is a linear method while KPCA is a non-linear method. More details on these techniques can be found in Fukunaga (Citation1990) and Schölkopf et al. (Citation1998). The selection of the kernel parameters for KPCA is sometimes done by a supervised way using the training samples, but in this work a fixed value is used for the kernel parameter. It is calculated as two times the mean of all the pairwise distances of all the samples. For supervised methods, DAFE aims at identifying linear features that increase the separability between classes. On the other hand, DBFE uses the training samples to imply a decision boundary between the classes and uses this to extract the optimal features. NWFE can be seen as a method which combines the advantages of both DAFE and DBFE. NWFE exploits different weights for different samples focusing on samples close to the decision boundary. DAFE only produces k − 1 features for k classes and is less effective when the class means are similar, which is often the case with impervious classes. DBFE is computationally expensive as it depends on the training samples. Furthermore, the DBFE may give sub-optimal features for a small number of training samples when it may not be possible to get the best approximation of decision boundary. Therefore, NWFE might perform better in the case where there are a limited number of samples. We refer the reader to Landgrebe (Citation2003) for a more complete presentation of these latter supervised feature extraction techniques.
The Random Forest™ (RF) (Breiman Citation2001) and support vector machines (SVM) (Schölkopf and Smola Citation2002) are used in this work for classifying the EMAP. While both methods are shown to be effective non-linear classifiers, SVM requires an exhaustive (computationally intensive) parameter tuning (e.g. model selection performed on a grid) for optimal results, whereas RF does not require any such tuning and is found to be more robust. The comparison of the theoretical aspects of these classifiers is out of scope of this article and is not presented here.
4. Experimental setup
4.1 Dataset description
The two standard datasets, namely AVIRIS Indian Pines dataset and the ROSIS University of Pavia dataset, which are frequently used in the literature, are used in this work.
(1) Indian Pines dataset: The Indian Pines dataset is a standard dataset acquired in 1992 using the Airborne Visible Infrared Imaging Spectrometer (AVIRIS) sensor. It is an image with a spatial resolution of 20 m, consisting of 220 bands in the 400–2500 nm wavelength range. This dataset is one of the most widely used datasets in the literature for testing various methodologies corresponding to the hyperspectral data analysis. A false colour composite of the data is shown in . shows the ground truth classes and the number of available test pixels.
Figure 2. Indian Pine dataset. (a) False colour representation of the Indian Pines image, (b) test and (c) training sets.

Table 1. Number of training and test pixels used for the Indian Pines image.
2) University of Pavia dataset: The image is a standard dataset acquired within the framework of the European Union HySens project using a ROSIS-3 instrument on the flight operated by the German Aerospace Center (DLR) over the University of Pavia in Pavia, Italy. It consists of 115 bands in the range of 0.43–0.86 µm at a spatial resolution of 1.3 m. Twelve noisy channels were removed leading finally to 103 bands. A false colour composite of the images is shown in . shows the ground reference classes and the number of available training and test pixels for every class.
Figure 3. Pavia University dataset. (a) False-colour representation of the University of Pavia image, (b) test and (c) training set.
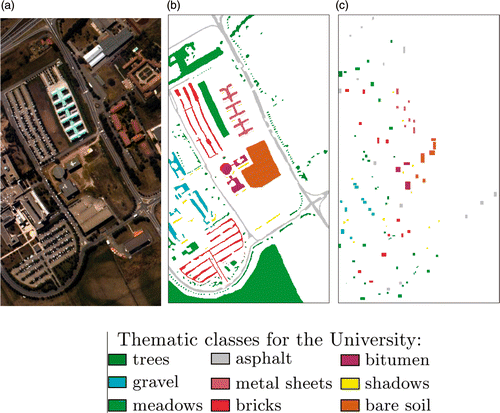
Table 2. Number of training and test pixels used for the Pavia image.
4.2 Setup
Several experiments are carried out to observe the effectiveness of EMAPs and various feature reduction methods. Furthermore, the effect of feature reduction of the EMAPs is also studied. While the APs can be built using a large number of attributes, only area and standard deviation attributes are considered in this work as they can be more easily calculated and are well-related to the object hierarchy in the images. Area is an increasing attribute (thus leading to have attribute opening and closing operators), whereas the standard deviation of the pixels values is non-increasing. The subtractive rule (Salembier and Wilkinson Citation2009) has been considered as filtering strategy when considering this latter attribute.
In all the cases but for NWFE, the features corresponding to the top few eigenvalues which account for 99% of the total sum of the eigenvalues were selected. For NWFE, 90% was chosen as it requires many more features to cover 99%. KPCA is done with 2000 samples selected uniformly over the entire image. The kernel parameter is chosen as twice the mean distance of all the sample pairs. Therefore, it needs to be noted that the number of features differs for each feature reduction method considered. The estimation of the covariance of the data, which especially for problems dealing with high-dimensional patterns can lead to singularity problems, is performed using the leave one out covariance estimate (Hoffbeck and Landgrebe Citation1996) for all the supervised feature reduction techniques.
The experiments are done with RF and SVM classifiers. The SVM classifier is tuned once the parameters of its model (e.g. the parameters defining the kernel) are defined. It is well known that the performances of an SVM strongly rely on the model selection procedure. In all the experiments with the SVM classifier, a radial basis function (RBF) was considered as kernel. An RF classifier is defined by setting the number of trees and the number of variables used in the classification process. Five-fold cross-validation is used to set the parameters of SVM. According to previous experiments, it was seen that the RF classifier is more robust than SVM to variations of the values of the model parameters. Thus, in all the experiments the number of trees was set to 200 and the cardinality of the subset of features considered for each split of the classification tree was equal to the square root of the total number of features (as suggested in Breiman Citation2001). The classification results are compared using the class-specific accuracies, overall accuracy (OA), average accuracy (AA) and κ coefficient.
The results of classification using the spectral information only are indicated using the names of the feature reduction methods as PCA, KPCA, DBFE, DAFE and NWFE. The classification results using the corresponding EMAPs are indicated with a prefix p (e.g. DAFE p ). The additional experiments where a feature reduction is performed on the EMAP are denoted using the first two initials of the corresponding methods (e.g. NW-NW for NWFE feature reduction applied to the EMAP of NWFE features; KP-DB for the DBFE feature reduction applied to the EMAP of KPCA features).
5. Experimental results and discussion
5.1 Indian Pines data
As can be seen in , this dataset has a limited number of training samples for some classes. The classifications are done using the EMAP built with various features of reduction methods. Threshold values in the range of 2.5–10% with respect to the mean of the individual features with a step of 2.5% are chosen for the standard deviation attribute and thresholds of 200, 500 and 1000 are selected for the area attribute. The threshold values for standard deviation are adaptively chosen according to the automatic technique presented in Marpu et al. (Citation2012), unlike previous works published in the literature, in which fixed values were considered. The thresholds of area are chosen based on both the resolution of the data and the fact that it is an agricultural area and the individual fields are slightly larger in size compared to urban areas.
Table 3. Accuracies (%) for classification of Indian Pines image. The best results in terms of accuracy are marked in bold.
Table 4. Accuracies in percentage for classification of the University of Pavia image. The best results in terms of accuracy are marked in bold.
The results of the classification of the Indian Pines image are shown in and the corresponding classification maps resulting from RF and SVM classifiers are shown in and , respectively, for classification using spectral information only and in and for classification using EMAPs. The experiments are carried out with the mentioned feature reduction techniques.
Figure 4. Classification maps for Indian Pines data with RF classifier using (a) Original data (b) PCA, (c) KPCA, (d) DAFE, (e) DBFE and (f) NWFE.
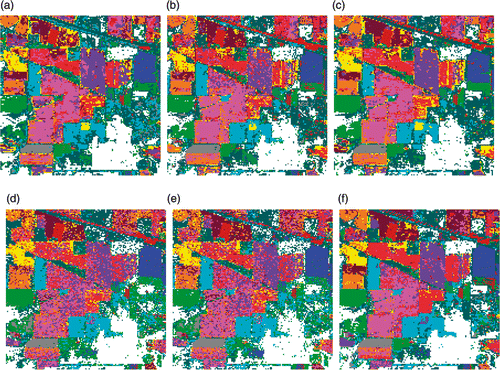
Figure 5. Classification maps for Indian Pines data with SVM classifier using (a) Original data (b) PCA, (c) KPCA, (d) DAFE, (e) DBFE and (f) NWFE.

Figure 6. Classification maps for Indian Pines data with RF classifier using EMAPs of (a) PCA, (b) KPCA, (c) DAFE, (d) DBFE and (e) NWFE, and feature reduction applied on EMAP using (f) NW-NW and (g) KP-NW.
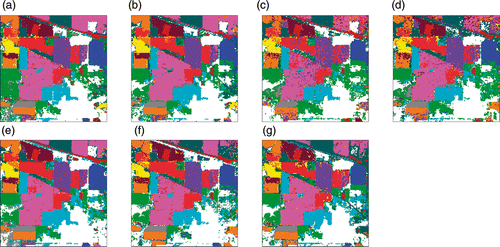
Figure 7. Classification maps of Indian Pines data with SVM classifier using EMAPs of (a) PCA, (b) KPCA, (c) DAFE, (d) DBFE and (e) NWFE, and feature reduction applied on EMAP using (f) NW-NW and (g) KP-NW.
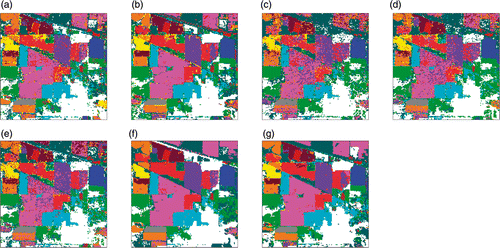
It can be observed from the results that the RF consistently provides higher accuracies compared to SVM when directly using the EMAP, but SVM performs better in terms of accuracies when a feature reduction is applied to the EMAP. This shows the effectiveness of the RF classifier in dealing with the high-dimensionality space in input to the classifier. On the other hand, feature reduction of the EMAP degrades the accuracy of the RF classifier. This may depend on the fact that the RF classifier is based on a tree of weak classifiers, which can statistically take advantage from a large set of redundant features. On the contrary, the SVM classifier is expected to be more effective in designing the discriminant function when a subset of non-redundant features defines a highly non-linear problem.
The best results in terms of accuracies are obtained by using EMAPs built with NWFE and KPCA. NWFE with RF classifier provides the highest overall accuracy. SVM provides slightly lower, yet comparable, accuracies when a further feature reduction is applied to the EMAP. With the SVM, supervised feature reduction of the EMAP defined with both NWFE and KPCA using NWFE provides very similar performances in terms of accuracies. It is interesting to note that the classification of the EMAP of NWFE provides high accuracy, while the classification of EMAPS of DAFE and DBFE do not exhibit good accuracy. This shows that NWFE is more suitable for supervised feature reduction when a limited number of training samples are available.
Some interesting observations can be made while comparing the results when only spectral information derived from various feature reduction methods is used and the corresponding results when spatial information with EMAPs is used. The first observation is that significantly higher accuracies are achieved when profiles are used as was outlined in the literature. The second observation is that the results of classifying the EMAPs do not necessarily correlate with the performance of the classifiers when only spectral information is used. When the RF classifier is used, the accuracy of the result of classifying the KPCA features is much lower compared to the NWFE features, but the accuracies of the corresponding results using EMAPs are very similar. The obtained accuracies of SVM using NW-NW and KP-NW are similar, while the EMAP classification of KPCA produces higher accuracy in comparison to the EMAP classification of NWFE. At the same time, the results using DAFE and DBFE show that enough spectral information could not be captured in the feature reduction process to be able to discriminate the classes by exploiting the spatial information. While RF produces similar accuracies for DAFE and DBFE features and the corresponding EMAPs, the SVM produces higher accuracies for DBFE when compared to DAFE.
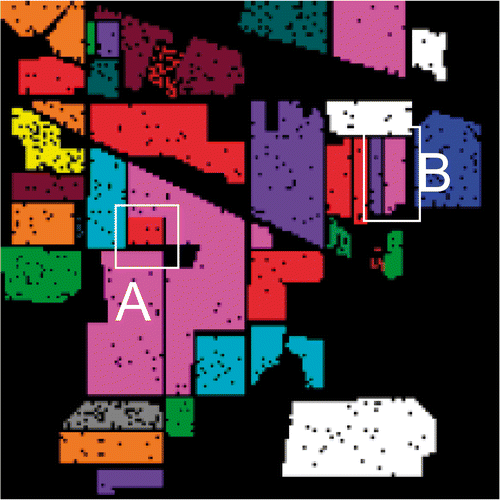
By visually comparing the classification maps, the results seem to be spatially more homogeneous when EMAP of KPCA is used, which is an indication that the spatial information is used effectively. However, a closer look at the ground truth shown in reveals that the unsupervised feature reduction carried out by PCA and KPCA could not correctly classify the object in the area denoted by A in . Only the supervised feature reduction methods could discriminate that object from the local background. This is due to the fact that the object has similar spectrum as the background, and thus is difficult to separate using unsupervised methods. However, given the training samples, it is possible to extract better features to discriminate it from the background. None of the feature reduction methods provided features that could correctly classify the area denoted by B in , even if EMAPs of PCA and KPCA performed slightly better than the others. A visual comparison of the classification maps points out that this area is highly non-homogenous and the selected training pixels probably do not fully represent the spectral variability of the class, thus resulting in a sub-optimal representation in the EMAP. Overall, on the one hand, it can be concluded that the supervised feature reduction is biased towards the training samples considered and their capability to properly represent the different classes of interest. On the other hand, the unsupervised methods could not effectively distinguish between similar spectra. The utilisation of spatial information too could not completely resolve the problem.
Figure 8. The ground reference data for the Indian Pines image. The segments shown in white boxes are found to be difficult to classify.
5.2 University of Pavia Data
As one can see in , a large number of training pixels are available for the experiments. The threshold values of 2.5–10% with respect to the mean of the individual features with a step of 2.5% are chosen for the definition of the criteria based on the standard deviation attribute (Marpu et al. Citation2012). Values of 100, 200, 500 and 1000 are selected as references for the attribute area. The threshold values considered for the area attribute are chosen according to the resolution of the data and, thus, the size of the objects present in the scene.
The results of the classification of the Pavia image are shown in , Figures . The experiments are carried out with the mentioned feature reduction methods and feature reduction on EMAPs was carried out using DA-DB, DB-DB and KP-DB.
Figure 9. Classification maps for University of Pavia data with RF classifier using (a) Original data (b) PCA, (c) KPCA, (d) DAFE, (e) DBFE and (f) NWFE.

Figure 10. Classification maps for University of Pavia data with SVM classifier using (a) Original data (b) PCA, (c) KPCA, (d) DAFE, (e) DBFE and (f) NWFE.

Figure 11. Classification results of University of Pavia data with RF classifier using EMAPS of (a) KPCA, (b) DBFE, (c) NWFE and feature reduction applied on EMAP using (d) DB-DB.

Figure 12. Classification maps of University of Pavia data with SVM classifier using EMAPS of (a) KPCA, (b) DBFE, (c) NWFE and feature reduction applied on EMAP using (d) DB-DB.

As expected, the classification based on EMAP and supervised feature reduction techniques performs well in this case due to the availability of sufficient training samples. The highest accuracy is obtained with DBFE feature reduction applied to the EMAP features computed on the DBFE components and using the SVM classifier. Conversely, when considering the RF classifier, the Gravel class was not correctly classified. Whereas, when the EMAP is used for classification, only the EMAP of KPCA could correctly classify the Gravel class. However, it could not effectively distinguish between Meadows and Bare Soil, which are the main contributors of the relatively low accuracy of the classification with the EMAP of KPCA. This can be easily understood as both these classes are characterised by high intra-class variability and have very similar spectra (i.e. low inter-class variability).
While using only the spectral information, NWFE, DAFE and DBFE all seem to produce similar accuracies, but when the corresponding EMAPs are used for classification, the accuracies are quite different indicating that the classification with EMAPs do not necessarily follow the trend of classification with spectral information only. It depends on how well the class objects are discriminated from the background region using different feature reduction methods.
Surprisingly, the DAFE p and DBFE p both outperform NWFE p in terms of classification accuracies except for the Trees class. Accordingly, in the case of a sufficient set of available training samples, it can be stated that both DAFE and DBFE obtain more discriminant features compared to those obtained by NWFE. This effect of considering a reduced number of training samples can be verified by the results reported in and . It is also interesting to note that SVM, in this scenario, provides similar or better accuracies compared to those obtained by RF (unlike as the results of Indian Pines dataset). This shows that the number of samples and the dimensionality of the data have a clear influence on the relative accuracies on the classification results of both the RF and SVM classifiers.
Table 5. Accuracies in percentage for classification of Pavia image with 30 training pixels per class. The best results in terms of accuracy are marked in bold.
Table 6. Accuracies in percentage for classification of Pavia image with 100 training pixels per class. The best results in terms of accuracy are marked in bold.
In order to evaluate the geometrical precision of the classification maps, nine objects are considered as shown in , which shows a snapshot of a recent very high resolution image from Google maps.Footnote1 It can be noted that all the selected objects have not changed from the time of the acquisition of the ROSIS data used in the experiments. Among all the considered objects, only the objects C and I contain pixels that are part of the original reference set of labelled samples used for the accuracy assessment. The spectra of some of the objects like A, D, E, F, G and H probably cannot be related to the classes of interest identified in the given reference data. The presence of such objects in the scene means that we can investigate the bias of the supervised feature reduction towards the classes of interest. The following observations can be made with respect to the classification results of various experiments for the considered objects.
Figure 13. A snapshot of University of Pavia region from Google Maps (accessed 02 November 2011). A big part of the image remains unchanged from the date of acquisition of the ROSIS image. The boxes delineates specific areas considered in the discussion to visually compare the geometric stability of the classification results. Imagery ©2011 DigitalGlobe, GeoEye.
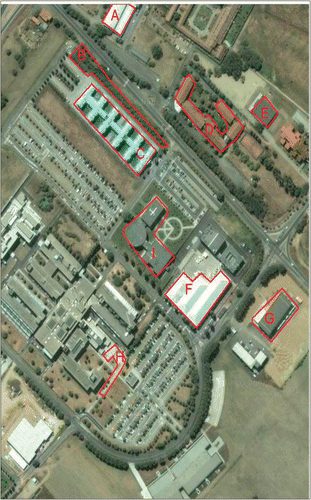
Object A is a building with metallic roof and hence should have a relatively similar spectrum compared to Object C, which forms a part of the training and reference data. However, an observation of the classification maps indicates that only EMAP of KPCA with RF classifier could correctly detect this object. It was misclassified as tree class using SVM. None of the other results show any consistent classification and the shape of the object is also not well preserved.
Object B is made up of bushes, thus, it should be spectrally similar to the tree and meadows classes in the reference data. This confusion is clearly seen in the results. While considering EMAPs based on KPCA and DBFE classify it as trees, the other classifiers associate this object as Meadows. Only the results with KPCA seem to maintain the geometric characteristics of this object.
Object C is a student dormitory with metal sheets on the roof. The bright area just above the object C, which is a parking area, should be ideally classified as the bricks class in the reference data. However, the spectrum of the pixels belonging to this object seems to be a bit different to the spectra of the pixels belonging to the bricks class in reference data. The area of the parking lots merges in the classification maps with the roof of the adjacent building when KPCA is used. However, this issue does not occur when supervised feature reduction is used. The geometric characteristics of the object are preserved only when considering EMAP of DBFE and RF.
Object D is another student dormitory where the roof is covered with clay tiles. This class is not represented in the reference data and there is no stability of this object in any classification results. However, according to some classification maps, the spectra of the pixels belonging to the roof are more similar to the Bare soil class. However, the shapes of the objects seem to remain stable in most of the classification maps.
Object E and G have similar spectra, but again they are not related to any classes in the reference data. They are classified as bitumen in all the cases, and hence are merged with road objects. Although they are not correctly represented in the thematic maps, their external boundaries are precisely extracted.
Object F is a building with metallic roof, but its spectral signature seems to be different to those of the objects used in reference data. Only by using KPCA it was possible to correctly extract the shape of the object.
Object H is a pathway made of cement blocks and is not represented in the reference data. Among all the feature extraction techniques, only when considering KPCA it is possible to represent precisely the shape of this object in the classification maps.
According to the observations reported above, it is clear that there is a significant difference between the results when considering different feature extraction methods. The profiles built with unsupervised feature reduction seem to maintain the geometric features of objects with spectra different to that of their background, but the capability of distinguishing between structures with slightly similar spectra becomes low as is evident when looking at object C. This effect is in accordance with the conclusions drawn on the results of the Indian Pines dataset. The EMAPs built with supervised feature reduction has a high bias towards the classes of interest and the training data. In this latter case, it is also observed that the geometric shapes of the objects which are not represented in the reference data are not preserved well.
5.3 Experiments using reduced training samples
Two additional experiments were done using the University of Pavia dataset with a reduced number of training samples, in order to confirm the observed behaviour in the above experiments on the effect of the number of samples on the different supervised feature reduction algorithms and their EMAPs. The first experiment was done with 30 training pixels per class sampled randomly using a uniform random number generator from the training samples shown in . The second experiment was done with 100 samples per class sampled in the same way. The EMAPs were constructed with 5%, 7.5% and 10% of the feature mean as thresholds for the standard deviation attribute and sizes of 100, 200, 500 and 1000 are selected as references for the area attribute.
The classification accuracies obtained when using 30 samples per class are shown in , and the corresponding classification maps are shown in and using RF and SVM classifiers, respectively. The best accuracies in this case were obtained using EMAPS of NWFE and KPCA, as was observed in the case of Indian Pines data. The classification map obtained with EMAP of KPCA is composed of more homogeneous regions as there is less influence of noise, which would be present in supervised feature reduction due to inadequate number of samples. Again the major problem with KPCA is the confusion between Meadows and Bare soil classes.
Figure 14. Classification maps of University of Pavia data using 30 training samples per class with RF classifier using (a) KPCA, (b) DAFE, (c) DBFE, (d) NWFE, (e) KPCA p , (f) DAFE p , (g) DBFE p and (h) NWFE p .
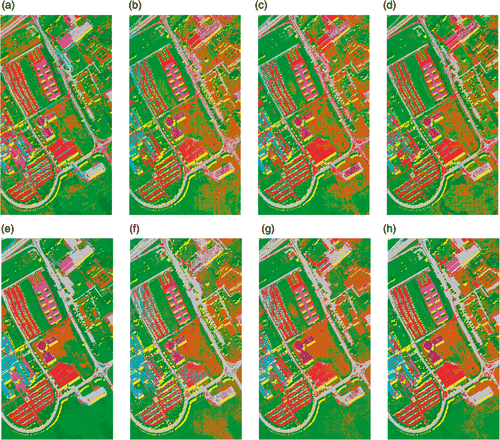
Figure 15. Classification maps of University of Pavia data using 30 training samples per class with SVM classifier (a) KPCA, (b) DAFE, (c) DBFE (d) NWFE, (e) KPCA p , (f) DAFE p , (g) DBFE p and (h) NWFE p .

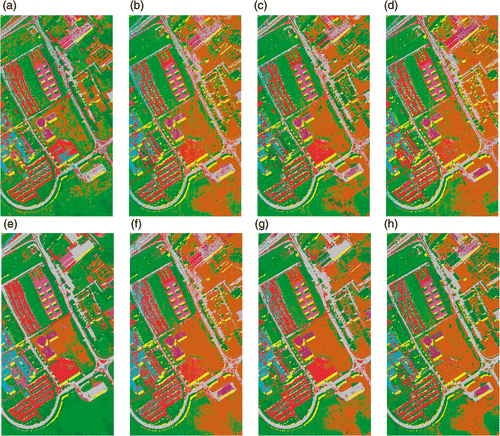
The classification accuracies and maps using 100 training samples per class are shown in (Panel A) and in for RF and in (Panel B) and for SVM. The results show that EMAP of DBFE now has the highest accuracy, indicating that sufficient training samples are available to obtain more optimal features which can discriminate the class objects from the background. This is similar to what is observed in the experiments with full training data. EMAP of KPCA also performs well, barring the Meadows class. Again the results of KPCA are spatially more homogeneous compared to those generated by the supervised methods.
Figure 16. Classification maps of University of Pavia data using 100 training samples per class with RF classifier using (a) KPCA, (b) DAFE, (c) DBFE, (d) NWFE, (e) KPCA p , (f) DAFE p , (g) DBFE p and (h) NWFE p.

Figure 17. Classification maps of University of Pavia data using 100 training samples per class with SVM classifier using (a) KPCA, (b) DAFE, (c) DBFE, (d) NWFE, (e) KPCA p , (f) DAFE p , (g) DBFE p and (h) NWFE p .
6. Conclusions
The aim of this article is to explore the suitability of various feature reduction algorithms to create base images for EAPs when used in spectral-spatial classification. Five supervised and unsupervised feature reduction methods were considered as two classifiers. Experiments were conducted using two standard datasets, namely AVIRIS Indian Pines and ROSIS University of Pavia. Further experiments were carried out using reduced training data in the case of Pavia data to see the effect of the number of training samples. The following conclusions can be made.
| 1. | The accuracies of spectral-spatial classification with APs of features from various feature reduction methods do not necessarily follow the same trend as using the spectral information only. | ||||
| 2. | The EMAP based on KPCA produces more accurate classification, but there can be problems when the classes are difficult to separate. Moreover, neighbouring objects with similar spectra can be merged together in the classification maps, as observed in the experiments with both the datasets. KPCA preserves the shapes of the objects which are not represented by any training sample. | ||||
| 3. | In terms of the classification accuracies obtained in the experiments, NWFE was the best supervised feature reduction algorithm when the size of the training data was small, whereas DBFE provided the best results when sufficient training data were available. | ||||
| 4. | The shapes of the objects that are not represented by the training data may not be preserved when using supervised feature reduction methods even while using the profiles. | ||||
| 5. | The dimensionality of the input data has an influence on the accuracy provided by the different classifiers considered in this study. RF seems to be more suitable to work in the high-dimensional feature space which contains redundant features in comparison to the SVM classifier. | ||||
In general, EMAP based on KPCA was found to be more consistent even if it produces slightly inferior accuracies compared to the supervised feature reduction methods. However, it is difficult to determine which supervised feature reduction can be better suited as it depends on the training samples. So, it might be interesting to find a way to fuse the results of classifying EMAPs from different feature reduction methods. As future developments of this work, we aim at extending the experimental analysis considering other hyperspectral datasets with high spatial resolution and a wide range of feature reduction algorithms. Moreover, motivated by the promising results obtained on the considered datasets, we plan to test the proposed approach on large-scale images in order to assess computational issues and to provide insights for an optimisation and complete automation of the classification process.
Notes
References
- Benediktsson , JA , Palmason , JA and Sveinsson , JR . 2005 . Classification of hyperspectral data from urban areas based on extended morphological profiles . IEEE Transactions on Geoscience and Remote Sensing , 43 ( 3 ) : 480 – 491 .
- Benediktsson , JA , Pesaresi , M and Arnason , K . 2003 . Classification and feature extraction for remote sensing images from urban areas based on morphological transformations . IEEE Transactions on Geoscience and Remote Sensing , 41 ( 9 ) : 1940 – 1949 .
- Breen , EJ and Jones , R . 1996 . Attribute openings, thinnings, and granulometries . Computer Vision and Image Understanding , 64 ( 3 ) : 377 – 389 .
- Breiman , L . 2001 . Random forests . Machine Learning , 45 ( 1 ) : 5 – 32 .
- Castaings , T . 2010 . On the influence of feature reduction for the classification of hyperspectral images based on the extended morphological profile . International Journal of Remote Sensing , 31 ( 22 ) : 5921 – 5939 .
- Dalla Mura , M , Benediktsson , JA and Bruzzone , L . 2010a. Classification of hyperspectral images with extended attribute profiles and feature extraction techniques. In: International geoscience and remote sensing symposium (IGARSS), Honolulu, HI, 76–79
- Dalla Mura , M . et al., 2011a. The evolution of the morphological profile: from panchromatic to hyperspectral images. In: S. Prasad, L. Mann Bruce and J. Chanussot, eds. Optical remote sensing – advances in signal processing and exploitation techniques. Springer Verlag, 123–146
- Dalla Mura , M . 2010b . Extended profiles with morphological attribute filters for the analysis of hyperspectral data . International Journal of Remote Sensing , 31 ( 22 ) : 5975 – 5991 .
- Dalla Mura , M . 2010c . Morphological attribute profiles for the analysis of very high resolution images . IEEE Transactions on Geoscience and Remote Sensing , 48 ( 10 ) : 3747 – 3762 .
- Dalla Mura , M . 2011b . Classification of hyperspectral images by using extended morphological attribute profiles and independent component analysis . IEEE Geoscience and Remote Sensing Letters , : 541 – 545 .
- Datcu , M , Seidel , K and Walessa , M . 1998 . Spatial information retrieval from remote-sensing images – part I: information theoretical perspective . IEEE Transactions on Geoscience and Remote Sensing , 36 ( 5 ) : 1431 – 1445 .
- Daya Sagar , BS and Serra , J . 2010 . Spatial information retrieval, analysis, reasoning and modelling . International Journal of Remote Sensing , 31 ( 22 ) : 5747 – 5750, 2010 .
- Fauvel , M . Chanussot, J., and Benediktsson, J. A., 2009. Kernel principal component analysis for the classification of hyperspectral remote sensing data over urban areas. EURASIP Journal on Advances in Signal Processing, 2009, 14
- Fukunaga , K . 1990 . Introduction to statistical pattern recognition , 2nd , London , , UK : Academic Press .
- Hoffbeck , J and Landgrebe , DA . 1996 . Covariance matrix estimation and classification with limited training data . IEEE Transactions on Pattern Analysis and Machine Intelligence , 18 ( 7 ) : 763 – 767 .
- Landgrebe , DA . 2003 . Signal theory methods in multispectral remote sensing , London : Wiley-Inter Science .
- Licciardi , G . et al., 2012. Linear versus non-linear PCA for the classification of hyperspectral data based on the extended morphological profiles. IEEE Geoscience and Remote Sensing Letters, 9 (3), 447–451
- Maragos , P and Ziff , R . 1990 . Threshold superposition in morphological image analysis systems . IEEE Transactions on Pattern Analysis and Machine Intelligence , 12 ( 5 ) : 498 – 504 .
- Marpu , PR . et al., 2012. Automatic generation of standard deviation attribute profiles for spectral-spatial classification of remote sensing data. IEEE Geoscience and Remote Sensing Letters, accepted for publication
- Ouzounis G.K., and Soille, P., 2009. Differential area profiles. In: 20th International conference on pattern recognition, 23–26 August 2009, Istanbul, Turkey, 4085–4089
- Peeters , S . et al., 2011. Classification using Extended Morphological Attribute Profiles based on different feature extraction techniques. In: IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 24–29 July 2011, Vancouver, Canada, 4453–4456
- Pesaresi , M and Benediktsson , JA . 2001 . A new approach for the morphological segmentation of high-resolution satellite imagery . IEEE Transactions on Geoscience and Remote Sensing , 39 ( 2 ) : 309 – 320 .
- Salembier , P , Oliveras , A and Garrido , L . 1998 . Anti-extensive connected operators for image and sequence processing . IEEE Transactions on Image Processing , 7 ( 4 ) : 555 – 570 .
- Salembier , P and Wilkinson , MHF . 2009 . Connected operators . IEEE Signal Processing Magazine , 26 ( 6 ) : 136 – 157 .
- Schölkopf B., and Smola A.J., 2002. Learning with kernels: support vector machines, regularization, optimization, and beyond. Cambridge, MA, USA: MIT Press
- Schölkopf , B , Smola , AJ and Müller , K-R . 1998 . Nonlinear component analysis as a kernel eigenvalue problem . Neural Computation , 10 : 1299 – 1319 .
- Soille , P . 2003 . Morphological image analysis. Principles and applications , 2nd , Berlin , , Germany : Springer Verlag .
- Soille , P and Pesaresi , M . 2002 . Advances in mathematical morphology applied to geosciences and remote sensing . IEEE Transactions on Geoscience and Remote Sensing , 40 : 2042 – 2055 .
- Wilkinson , MHF . 2008 . Concurrent computation of attribute filters on shared memory parallel machines . IEEE Transactions on Pattern Analysis and Machine Intelligence , 30 ( 10 ) : 1800 – 1813 .
- Wilkinson M.H.F., Soille P., and Ouzounis, G.K., 2010. Concurrent computation of differential morphological profiles for remote sensing. In: Workshop on Applications of Digital Geometry and Mathematical Morphology, 26–29 September, Istanbul, Turkey
- Wilkinson , MH . 2011 . “ Concurrent computation of differential morphological profiles on giga-pixel images ” . In Mathematical morphology and its applications to image and signal processing , Edited by: Soille , P , Pesaresi , M and Ouzounis , G . 331 – 342 . Berlin, Heidelberg : Springer .