Abstract
The effect of variation in genes coding for drug targets and for the enzymes involved in drug metabolism has highlighted the genetic component of drug response. Drug response can be likened to a complex, multifactorial genetic trait, and the study of its genetic variation, termed pharmacogenetics, is analogous to the study of complex genetic disease in terms of the questions posed and the analytical possibilities. Just as DNA variants are associated with specific disease predispositions, so will they be associated with individual response to certain drugs. The testing for drug response is following the same route as the genetic testing for inherited disorders, and has reached the stage where genome-wide analysis, as opposed to the analysis of single genes, is a reality. In this article, we will discuss some of the technical advances that facilitate such analyses, leading to faster and more extensive diagnostic capabilities.
El efecto de la variación en los genes que codifican blancos de fármacos y las enzimas que participan en el metabolisme de los medicamentos ha aclarado el componente genético de la respuesta a los fármacos. La respuesta a un medicamento puede asimilarse a un complejo rasgo genético, multifactorial, y el estudio de su variación genética - llamada farmacogenética - es análogo al estudio de una enfermedad genética compleja en términos de las preguntas que surgen y de las posibilidades de análisis. Así como las variantes del DNA están asociadas con predísposiciones a enfermedades específicas, así también estarán asociadas con la respuesta individual a ciertos fármacos. La evaluación de la respuesta a medicamentos sigue el mismo camino que la evaluación genética de las enfermedades hereditarias, y ha alcanzado un estado en que el análisis del genoma compléto, opuesto al análisis de genes únicos, es una realidad. En este articulo se discuten algunos de los avances técnicos que facilitan esos análisis, lo que se traduce en capacidades diagnóstics más rápidas y más completas.
L'effet de la variation des gènes codant les cibles médicamenteuses et les enzymes impliquées dans le métabolisme des médicaments a souligné la composante génétique de la réponse au médicament Celle-ci peut être comparée à un caractère génétique complexe et multifactorial, et l'étude de sa variation génétique, appelée pharmacogénétique, est analogue à l'étude d'une maladie génétique complexe en termes de questions posées et de possibilités analytiques. Tout comme les variantes de l'ADN sont associées à des prédispositions spécifiques à une maladie, elles seront aussi associées à une réponse individuelle à certains médicaments. L'analyse de la réponse au médicament suit le même chemin que l'analyse génétique pour les maladies héréditaires et a atteint le stade auquel l'analyse du génome dans sa globalité, par opposition à celle des gènes individuels, est une réalité. Dans cet article, nous discuterons quelques-unes des avancées techniques qui facilitent de telles analyses, conduisant à des possibilités de diagnostic plus rapides et plus approfondies.
Biomedical research and practice is in the midst of a profound transformation that is being driven by two primary factors: the massive increase in the amount of DNA sequence information; and the development of technologies to apply the new information. The principal aim of the Human Genome Project, namely the elucidation of the approximately 3 billion base pairs (bps) of the entire genome, has almost, been achieved. In February 2001, the analysis of the first, draft of the sequence was published,Citation1 and this analysis provided the first great, surprise: the total number of protein-coding genes was nearer to 35 000 than the previously estimated 100 000.Citation2 The finished sequence of five entire human chromosomes (chromosomes 22, 21, 20, 14, and Y) has been published,Citation3-Citation7 and for the 50th anniversary of the publication of the structure of DNA by Watson and CrickCitation8 in April 2003, the finished DNA sequence of the entire genome was made available to the public by the International Human Genome Sequencing Consortium (IHGSC) on the internet. Over the past few years, more than 30 organisms have had their genomes completely sequenced, with another 100 in progressCitation9,Citation10 and an at least partial DNA sequence has been obtained for thousands of mouse and rat genes. Consequently, we find ourselves at a time at which new types of experiments are possible, and observations, analyses, and discoveries are being made on an unprecedented scale. It, can be expected that genetic considerations will become important, in all aspects of disease, be they diagnosis, treatment, or prevention.
Unfortunately, the billions of bases of DNA sequence do not tell us what all the genes do, how cells work, how we age, how to develop a drug, or - more pertinent, to this paper - how a particular subject will respond to a particular drug. The latter forms the stuff of the future, and this rather broad field has been given the name “functional genomics.” This review attempts to describe the application of genomics to the problem of drug response, and examine future possibilities for effective genetic testing for drug response. The overall incidence of adverse drug reactions (ADRs), at least in American hospitals, is about 6.7%; fatal ADRs occur with an incidence of about 0.3%.Citation11 These unanticipated reactions to medications are largely, if not entirely, genetically determined. By definition, pharmacogenetics is the study of variability in drug responses attributed to genetic factors in different populations.Citation12 In its narrowest, sense, pharmacogenetics can be restricted to those genetic variations that alter the ability of the body to absorb, transport, metabolize, or excrete drugs or their metabolites. In broader and more useful terms, pharmacogenetics encompasses any genetically determined variation in response to drugs. This type of variation includes, for instance, the effect, of barbiturates in precipitating clinical disease in persons with acute intermittent porphyria, an autosomal dominant inherited disease associated with intermittent neurological dysfunction, as well as the effect, of alcohol use by pregnant women on the incidence of fetal alcohol syndrome. Pharmacogenomics is the determination and analysis of the genome (DNA) and its products (RNA and proteins) as they relate to drug response.Citation12
Medicine would surely be revolutionized if one could predict, a response before medication and provide a statistical probability of a good or bad response. Current, drug therapy is very much ”one size fits all,“ and the costs of the administration of ineffective drugs and the compensation for serious ADRs of unsuitable medication are immense, not to mention the high number of deaths caused by severe ADRs. The long-term goal of pharmacogenetics is to one day offer personalized medicine, so that clinicians can choose the best treatment for each individual patient.
Genetic variation and current testing for monogenic disorders
It has been well known for many years that DNA sequence is highly variable, even within populations. DNA variation can be in the form of single nucleotide substitutions, the deletion or insertion of one or more nucleotides, or the variable repetition of a number of nucleotides (small tandem repeats [STRs] or longer variable number of tandem repeats [VNTRs]). Neutral DNA changes or “variants” (with respect to selective pressures) are referred to as polymorphisms when their rarest allele is present, in more than 1 % of chromosomes in a particular population. Mutations, on the other hand, are rare differences that occur in less than 1 % of the population (usually much less than 1%) and have typically been discovered in the coding sequences of genes causing rare inherited diseases. How neutral the so-called polymorphisms really arc is merely assumed on the basis of their lack of direct association with a particular phenotype. However, it is feasible to assume that a particular variant may produce a particular phenotype when in combination with particular alleles of other such variants.
The ability to screen particular genes for mutations has developed into an important diagnostic tool, and genetic testing for disorders that, are inherited in a mendelian fashion (primarily single-gene disorders, so-called monogenic) is already well established in medical practice. This is relatively easily performed for monogenic disorders when the causative gene is known, eg, cystic fibrosis, hemophilia, various forms of muscular dystrophy, mental retardation, and late-onset neurological disorders. Testing for mutations in specific disease genes can help diagnose the disease, determine the carrier status of an individual, and predict, the occurrence of the disease. Thus, predictive or presymptomatic testing for late-onset neurological disorders, such as Huntington's disease or cerebellar ataxia in younger relatives of patients, is well established. Moreover, kits for the diagnosis of several human disorders (via mutation detection) including cystic fibrosis, β-thalassemia, and Tay-Sachs disease, among others, are commercially available.
The problem of genetic heterogeneity
Even from these single-gene disorders, we have indications that the situation is not that simple. Geneticists are familiar with terms such as “epigenetics,” ie, genetic phenomena that cannot be explained by traditional genetics.
One example of this is disease transmission and severity being affected by the sex of the transmitting parent and “modifying factors” (probably other genes that affect, disease severity); this is the case for cystic fibrosisCitation13 and hemochromatosis.Citation14 We increasingly observe that, even if the gene causing the disorder is known, the phenotype-genotype relationship is not clear.
This genetic heterogeneity poses a real problem for diagnostic testing. The connection between a patient's symptoms, diagnosis, and the underlying mechanism of disease is often obscure. For example, patients with mutations in different, genes may present as clinically identical, while patients with the same mutation may present, clinically disparate.
Alzheimer's disease (AD) is an oft-quoted example of a disorder with different forms of inheritance and illustrates the problem that genetic heterogeneity creates for diagnostic testing. Early-onset AD is strongly familial, whereas late-onset AD is considered a complex disease with strong environmental influences. Mutations in the y4PP,presenilin 1 (PS1), and presenilin 2 (PS2) genes can cause clinically indistinguishable forms of early AD.Citation15-Citation17 On the other hand, different mutations in the same gene, eg, APP, can lead to two distinct diseases, early-onset AD and recurrent, intracerebral hemorrhage.Citation18
The more disease genes that are discovered, the more apparent this phenomenon becomes. Another example is mutations in the androgen receptor gene (AR) in which the expansion of the trinucleotide triplet repeat CAG in the first exon of the gene leads to adult-onset motor neuron diseaseCitation19 (spinal and bulbar muscular atrophy [SB MA] or Kennedy disease), whereas different types of mutations in the other exons of the same gene lead to androgen insensitivityCitation20; these are two completely different, pathologies.
Thus, it is not hard to imagine that the situation is even more complex for polygenic disorders, which are caused by many different, genes and have an environmental component. For most, common diseases, such as schizophrenia, severe depression, diabetes, asthma, and psoriasis, which affect a much more significant, percentage of the population than the single-gene disorders mentioned above, the situation is apparently far more complicated, hence the name “complex disorders.” Some examples of single-gene and polygenic disorders are provided in Table I. Citation21-Citation32
Table I. Examples of single-gene and polygenic disorders and their mutations or susceptibility loci.
Current testing for drug response: metabolizing enzymes
Until very recently, the genetic testing for drug response could be likened to the testing for the monogenic inherited disorders described above. Differences between the rates of drug metabolism among people, associated with particular polymorphic forms of enzymes involved in drug catabolism, have been known for decades. GarrodCitation33 first suggested that genetically controlled enzymes responsible for the detoxification of foreign compounds may be lacking in some individuals. KalowCitation34 succeeded in associating enzyme abnormality (serum cholinesterase) with drug sensitivity (succinylcholine). During the 1960s and 1970s, HarrisCitation35 matched structural gene mutations with physiological and pathological data in hemoglobinopathies and enzymopathies. Since then, a large number of polymorphisms in metabolizing enzymes have been described, which are known to contribute to interindividual differences in the pharmacokinetics of many drugs. The origin of polymorphisms for drug response, and the mechanisms by which they are maintained, pose an interesting problem. They obviously have not, developed in response to drugs, because they antedate the drugs concerned. It, has been suggested that these polymorphisms arose as the result, of different dietary selective pressures in different, populations.Citation36
External compounds have to follow a succession of oxidations reactions (phase I) and conjugations (phase II) by metabolizing and transporting enzymes to be assimilated and then secreted by an organism. Mutations in the genes coding for metabolizing enzymes can affect the incorporation or elimination of foreign compounds, resulting in their toxic accumulation or rapid elimination from the organism. Polymorphic DNA variants within genes have been found to have the same effect. Although these polymorphisms may not directly influence the drug's therapeutic value, the metabolizing rate will be affected and the therapeutic dose will have to be adjusted to the patient's phenotype to achieve maximum efficacy and minimal ADRs.
Interindividual response variation could not be explained on the basis of metabolizing polymorphisms only, and the research field was extended to include the drugs' site of action. Mutations altering the neurotransmitter receptor and transporter systems targeted by antipsychotics and antidepressants (for example, mutations in dopamine and serotonin receptor and transporter genes) may also play an important, role in treatment, outcome. This topic has been extensively researched and reviewed in the psychiatric genetics literature (see, for example, references 37 and 38) and therefore will not be described in detail here. The analysis of the cytochrome P450 (CYP) genes will be summarized, as they have retained their relevance for drug response testing using current, methodologies.
Drug treatment of psychiatric disorders is troubled by severe adverse effects, low compliance, and a lack of efficacy in about 30% of patients. Consequently, much research has been performed on metabolizing enzymes, such as the CYP enzymes and the effect, of their variation on the efficacy and tolerability of commonly used antipsychotic and antidepressant, drugs. Twelve families of CYP enzymes have been described, of which four (CYP1 to CYP4) are directly involved in drug metabolism.Citation39 They constitute the best-studied family of xenobiotic-metabolizing enzymes. Mutations in the genes CYP2D6, CYP2C9, and CYP2C19 have already been shown to be the cause of altered drug pharmacokinetics:Citation40-Citation42 Possibly the most-studied drug-metabolizing enzyme is CYP2D6, which may be involved in the metabolism of up to 25% of commonly used drugs.Citation43 Mutations in the CYP2D6 gene have been found to be responsible for phenotypic variation in the metabolism of debrisoquine, and individuals can be classified as poor metabolizers (PMs), intermediate metabolizers (IMs), extensive metabolizers (EMs), or ultrarapid metabolizers (UMs). Ninety-five percent of the PMs are generally homozygous for two of the mutations or the deletion of the entire CYP2D6 gene. Polymerase chain reaction (PCR) methods are available for the rapid detection of these mutations as well as mutations in other drugmetabolizing enzyme genes, such as CYP2C9, CYP2C19, and cytosolic N-acetyltransferase 2 gene (NAT2), in order to facilitate the prediction of an individual's metabolizing rates.
Due to the high frequency of mutations in metabolizing enzymes in the general population, they will probably remain important in the success of therapeutic treatment. It, has been proposed that, variation in metabolizing enzymes, and variation in drug targets or receptors, combine to fully explain the heterogeneity in response to psychiatric treatment. DNA chips (see below) for the detection of CYP2D6 and CYP2C19 mutations have already been developed for the identification of PMsCitation44-Citation45 and these will be combined with the pharmacogenetic single nucleotide polymorphism (SNP) profiles described in the next section to predict, with a high degree of accuracy, individuals who are likely to have an ADR to a medication, even without specific knowledge of the metabolism of the drug or of the specific alleles that modulate responses to it.
SNPs and the testing for common complex disorders
If a region of the human genome is sequenced from two randomly chosen individuals, 99% of the examined DNA will be identical. Of the 0.1 % that differs, more than 80% will be SNPs.Citation46 SNPs represent a single bp variation (for example, a C to T transition) between individuals in the population, where each version of the variant, (in the above example, C or T) is observed in the general population at a frequency of more than 1%.Citation47,Citation48 This type of variation, has been known and applied to genetic analysis for the last, two decades,Citation49 but was originally detected using the rather laborious method of Southern blotting.Citation50 The recent technological development of quick, high-throughput methods for genotyping has projected SNPs into the limelight, over the last few years.Citation51 Added to this is the fact that SNPs are abundant, and occur throughout the human genome, in regulatory, coding, and noncoding regions, with an average frequency of approximately 1 per 1000 bp.Citation48 When it falls within coding regions, the variant may actually result, in an amino acid change, which in turn may be of medical significance.
A major interest among research groups concentrating on SNPs is the identification of the genetic variation that underlies common, complex traits. It, is no coincidence that these are the ailments for which the pharmaceutical companies are most, interested in developing new drugs and being able to test for the efficacy of their drugs. The SNP Consortium (TSC), which comprises pharmaceutical and bioinformational companies, five academic centers, and a charitable trust, is currently producing an ordered high-density SNP map of the human genome. Mapped SNPs are regularly being placed on public domain websites. TSC's mission was to develop up to 300 000 SNPs distributed evenly throughout the human genome and, at the beginning of 2001, they published a map containing 1.4 million SNPs.Citation53 More recently, a high-resolution human SNP linkage map with a resolution of 3.9 centimorgans, and an SNP screening set was published.Citation54
Since SNPs constitute the bulk of human genetic variation, they can be used to track the inheritance of genes in traditional family-based linkage studies. On a larger scale, though, they can be used to track associations to disease, without necessarily finding each functionally important SNP, due to a phenomenon called linkage disequilibrium (LD). LD occurs when combinations of alleles at different, loci occur more frequently together than would be expected from random association. LD fades with time (in successive generations), at, a rate depending on the amount, of recombination that, occurs during meiosis between the loci. The closer two SNP loci are together on a chromosome, the more likely they are to be inherited together than those that are further apart. Therefore, SNPs that, are close to or within a particular gene are likely to be inherited together with the gene when they are in LD, and the variation of particular SNPs can act as markers for particular forms of the gene.
Combinations of alleles are referred to as haplotypes, and the study of haplotypes has been instrumental in analyzing the link between genetic variation and disease predisposition. A haplotype block can be defined by a set of SNPs on a chromosome and ranges from 3 to 150 kb. The National Human Genome Research Institute (Bethesda, Md) is sponsoring research to construct, a human haplotype map to help find those chromosome regions that are associated with diseases, and the success of this approach has been verified experimentally by reidentifying the APOE4 allele as a susceptibility factor for earlier age-of onset AD, using a high-density SNP mapping analysis across the 4 million base region that, contained the APOE gene.Citation55,Citation56 Similarly, a susceptibility locus for schizophrenia on chromosomal region 6p22, which was first, identified by linkage analysis in families, was recently confirmed by SNP haplotype analysis.Citation57 Although results have been slow in coming, in practice, LD association mapping has identified susceptibility loci for both psoriasis and migraine.Citation29,Citation58 The hypothesis is that, in a similar way, haplotypes will be associated with particular drug responses. The concept, of using SNPs to develop an SNP profile is illustrated in .
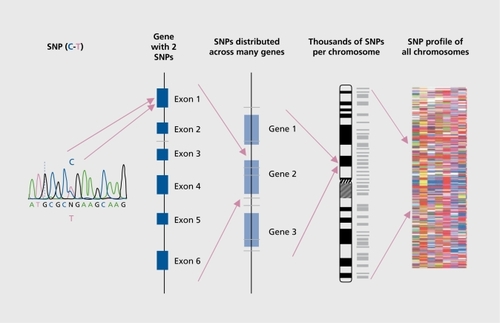
Genetic testing in the future: new technology
There is a general tendency in human genetics to move away from studies of single genes to genome-wide approaches. The genetic testing for inherited disorders is following the same trend and, similarly, the emphasis in testing for drug response will move from the analysis of single genes affecting drug metabolism, to the large-scale analysis of genetic variation in relation to drug response. Instead of investigating polymorphisms close to candidate genes, thousands of variants (SNPs) across the genome will be typed and organized into an individual “fingerprint,” also referred to as an SNP printCitation12 or, for the sake of this review, an SNP pharmacogenetic profile. Multiple, closely ordered polymorphisms, which are inherited together over many generations and are therefore in LD, will distinguish particular regions of the genome. The objective will be to rapidly identify a genetic profile that characterizes patients who are more likely to suffer an ADR, compared with other patients who are likely to respond to the drug safely.
There are various factors that can confound such analyses, one very important, consideration being ethnic differences between patients. The allele frequencies of DNA polymorphisms such as SNPs are highly variable between populations, so that population admixture may mask, blur, or alter the LD patterns.Citation59 Secondly, ethnic variation in drug response is well known: in World War II it was discovered that. African-American soldiers who were treated with the antimalarial drug primaquine developed hemolytic anemia crises at high altitudes, due to glucose-6-phosphate dehydrogenase deficiency.Citation36 Hence, different SNP profiles relating to drug response can be expected in different populations. This concept, is not new to genetic testing, for example, mutation analysis for cystic fibrosis is already tailored to patients with different, ethnic backgrounds.Citation60
Essential to this progress is a scaling up of the applied technology, and this is happening rapidly. The diagnostic methods that are currently available in small molecular genetic laboratories will be scaled up to test hundreds of individuals simultaneously for hundreds of mutations or DNA variants. Methods for the detection of SNPs on a large scale have already been developed by several companiesCitation44,Citation46 and arc high on the agenda of most, companies involved in molecular biological research and development. The industrial aim is to develop high-throughput, accurate, sensitive, and cost-effective genetic diagnoses, which in turn could lead to accurate, sensitive, and cost-effective medication.
DNA arrays and chip technology
Most, of the hope is placed on DNA arrays and chip technology, which have been developed over the last 5 years. High-density DNA arrays allow complex mixtures of RNA and DNA to be interrogated in a parallel and quantitative fashion. While the making of arrays with more than several hundred elements was until recently a significant technical achievement, arrays with more than 250 000 different oligonucleotide probes or 10 000 different cDNAs (transcribed DNAs) per square centimeter can now be produced in significant, numbers.Citation61,Citation62 DNA chips are simply glass surfaces bearing arrays of DNA fragments at discrete addresses, at which the fragments are available for hybridization. There are many variations on the chip theme, but the general approach is as follows:
- To immobilize multiple DNA samples on a solid support, which are then interrogated (hybridized) with a pool of oligonucleotide probes (a selected singlestranded string of nucleotides) that are specific for particular mutations or DNA variants (allele-specific oligonucleotides, ASOs).
- To immobilize oligonucleotides on a solid support, which are then interrogated by individual DNA samples.
Either way, the sequence of the oligonucleotides that hybridize to the DNA samples is determined, thus revealing the nature of the mutation or variant, present in the DNA sample. DNA chips are commonly used either to monitor the expression of arrayed genes in mRNA samples from living cells or tissues, or to detect DNA sequence polymorphisms or mutations in genomic DNA. DNA chip technologies are distinguished by the sizes of the arrayed DNA fragments, the methods of arraying, the chemistries and linkers for attaching DNA to the chip, and the hybridization and detection methods. The production of a DNA chip for the analysis of DNA variants or SNPs is shown in .
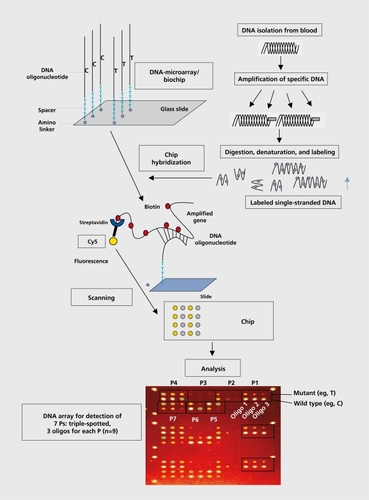
One of the most prevalent uses of DNA arrays is to measure levels of gene expression (messenger RNA abundance) for tens of thousands of genes simultaneously. Such cDNA arrays consist, of either thousands of inserts of cDNA clones (transcribed DNA) by robotic deposition onto a glass surface, representing up to 10 000 genes on an area of 3.6 cm, or cDNA representing up to 30 000 human genes, that are synthesized on a chip. These arrays allow the comparison of fluorescently labeled cDNA populations from control and experimental tissues (eg, disease- or drugtreated tissue) in two colors. By scanning each color separately, differential gene expression can be assessed in an internally controlled manner. This method of gene expression analysis is a convenient way to compare the efficacy and side effects of drug candidates: cultured cells or animals are treated with several drug candidates that, share a common mechanism. A comparison of gene expression changes often reveals changes that are mechanism-related and are shared by such compounds, as well as changes that are peculiar to one compound and suggest, that the compound has side effects. Such analyses can help clarify the therapeutic mechanism of action of drugs.
Oligonucleotide arrays, upon which sets of oligonucleotides represent different alleles of an SNP, are used for the analysis of DNA variation. In this way, thousands of SNPs can be read out automatically and rapidlyCitation63,Citation64 By applying whole-genome SNP LD mapping to patients during phase 2 clinical trials of a drug, it may be possible to select multiple small regions from the whole-genome SNP map where SNPs are in LD and associated with efficacy and common adverse event, phenotypes. Selecting only these small regions of SNP LD into abbreviated SNP LD profiles will enable more rapid and inexpensive screening of patients who are likely to experience efficacy or ADRs in response to that drug.Citation65 Thus, whereas the phase 2 SNP scan might, genotype up to 200 000 SNPs for each patient,Citation66 the critical data, used for identifying markers for efficacy for subsequent, phase 3 clinical trials may use only several hundred SNPs from multiple small regions in LD associated with efficacy or ADRs.
The cost of chips as a platform for drug response profiling is likely to be reduced when analyses of hundreds of thousands of patients are performed once the medicine is marketed. In fact, each chip could contain a panel of abbreviated SNP LD profiles for several drugs with the same clinical indications, so that the most appropriate medicine with that indication for that patient can be determined from a single blood sample. Competition in the biotechnology sector to develop industrial genotyping capacity has reduced the retail price of genotyping some SNPs from US1 to US0.10 per SNP within 1 year,Citation12 and the prediction is a continued decrease in price to less than US$0.01. There are ongoing technological developments, eg, the extraction of DNA from a few cells, from a buccal swab, and for the amplification of human DNA and RNA, in order to produce sufficient, quantities from minute samples (eg, GenomiPhi®, Amersham). This will circumvent, the need for a blood sample and make individual sampling even easier. One can predict that, in the future, metabolic screens of genetic variants will be standardized so that automated read-outs of each person's predicted response to each medicine can be generated. One possible scenario is the rapid testing of a salvia sample within minutes in the doctor's office or the pharmacy, before prescribing or delivering drugs. These DNA-based screens will not provide disease-specific diagnosis, but useful information to aid in individual dosing of medications or avoidance of ADRs. The information gained will produce a drug-response genotype profile and finally more personalized medicine, to ensure that the majority of people obtain the drug with the highest efficacy and lowest adverse effects.
Ethical considerations
One of the biggest, challenges of the advances described in this review will be to design tests to provide only information relevant to the testing of response to a particular drug, without additional prognostic value. It will be essential to exclude polymorphisms known to be associated with specific diseases; however, this cannot, exclude the possibility that the diagnostic value of some of the polymorphisms used will only be exposed at, a later stage. Data management, protection, and privacy will be of paramount importance, so that data are only used for the purpose at hand. These problems already exist, for the testing of inherited disorders, and legal and ethical guidelines are continually being drawn up and revised to accompany new developments. It will be vital to pass on, adjust, and apply the experience from the testing for genetic disorders to the practice of testing for drug response.
Conclusions
Technical advances now allow faster and more reliable diagnostic capabilities and in the future will make more extensive screening programs a feasible option in both practical and economic terms. Despite the rapid pace of change in medical science, it seems certain that the identification of DNA alterations will remain a central part of medicine in the future. Diagnostics and pharmacogenomics are destined to a communal future. The transition from the study of single genes or variants to multiples thereof has been relatively slow; however, it, is likely that the benefits of the efforts of the last, few years will soon be reaped.
With the advancement of high throughput, of genetic data and the realization of the potential of pharmacogenomics by the pharmaceutical companies, an explosion of data leading to the individualization of treatment can be expected. However, the day when each of us will have our genotypes determined on a microchip in the doctor's consulting room before a drug is prescribed is far off. These technologies arc still in their infancy, with plenty of room for further development, technical improvements, widespread acceptance, and accessibility before they can be routinely applied. The pattern of development, and use of arrays and other parallel genomic methodologies will probably be similar to that seen for computers and other high-technology electronic devices, which started out as the exotic and expensive tools in the hands of a few developers and then quickly became easier to use, less expensive, and more accessible. Probably most, of the work lies in developing computer models and software to extract relevance from the mass of data produced from the testing. It will be necessary to extract and identify complex patterns embedded in the data via data mining.
All these advances will lead to the rapid development, of new diagnostic methods and therapeutic products using genomic information and, hopefully, to the improvement of patient care. Although pharmacogenetics is aimed at improving patient care rather than acquiring knowledge about, disease genes, the latter may well be a spin-off of the former. The initial impetus for pharmacogenetics came from the search for disease genes and the establishment of molecular genetic diagnosis; however, in the future the opposite can be expected. The subdivision of the population into responders and nonresponders to a particular drug may provide an invaluable starting point for the association of genetic variation with particular phenotypes. When performed in an ethical way with a laudable and healthy aim, pharmacogenetics and the effective testing for drug response can provide hope for a future of genetic testing in the best, interests of patients and their relatives.
Selected abbreviations and acronyms
| ADR | = | adverse drug reaction |
| AD | = | Alzheimer's disease |
| bp | = | base pair |
| CYP | = | cytochrome P450 |
| LD | = | linkage disequilibrium |
| PM | = | poor metabolizer |
| SNP | = | single nucleotide polymorphism |
REFERENCES
- VenterJC.AdamsMD.MyersEW.et al.The sequence of the human genome.Science.20012911304135111181995
- ClaverieJM.What if there are only 30 000 human genes?Science.20012911255125711233450
- DeloukasP.MatthewsLH.AshurstJ.et al.The DNA sequence and comparative analysis of human chromosome 20.Nature.200141486587111780052
- DunhamI.ShimizuN.RoeBA.et al.The DNA sequence of human chromosome 22.Nature.199940248949510591208
- HattoriM.FujiyamaA.TaylorTD.et al.The DNA sequence of human chromosome 21.Nature.200040531131910830953
- HeiligR.EckenbergR.PetitJL.et al.The DNA sequence and analysis of human chromosome 14.Nature.200342160160712508121
- SkaletskyÄH.Kuroda-KawaguchiT.MinxPJ.et al.The male-specific region of the human Y chromosome is a mosaic of discrete sequence classes.Nature.200342382583712815422
- WatsonJD.CrickFH.Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid.Nature.195317173773813054692
- The Institute for Genomic Research (TIGR). Available at: http://www.tigr.org. Accessed November 25, 2003
- National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, Md. Available at: http://www.ncbi.nlm.nih.gov:80/Genomes/index. html. Accessed November 25, 2003
- NussbaumRL.MclnnesRR.WillardHF.Thompson and Thompson Genetics in Medicine.6th ed. Philadelphia, Pa: WB Saunders Company;2001
- RosesAD.Pharmacogenetics.Hum Mol Genet.2001102261226711673409
- ZielenskiJ.CoreyM.RozmahelR.et al.Detection of a cystic fibrosis modifier locus for meconium ileus on human chromsome 19q13.Nat Genet.19992212812910369249
- Merryweather-ClarkeAT.CadetE.BomfordA.et al.Digenic inheritance of mutations in HAMP and HFE results in different types of haemochromatosis.Hum Mol Genet.2003122241224712915468
- GoateA.Chartier-HarlinMC.MullanM.et al.Segregation of a missense mutation in the amyloid precursor protein gene with familial Alzheimer's disease.Nature.19913497047061671712
- Levy-LehadE.WascoW.PoorkajP.et al.Candidate gene for the chromosome 1 familial Alzheimer's disease locus.Science.19952699739777638622
- SherringtonR.RogaevEl.LiangY.et al.Cloning of a gene bearing missense mutations in early-onset familial Alzheimer's disease.Nature.19953757547607596406
- Van NostrandWE.WagnerSL.HaanJ.BakkerE.RoosRA.Alzheimer's disease and hereditary cerebral hemorrhage with amyloidosis-Dutch type share a decrease in cerebrospinal fluid levels of amyloid p-protein precursor.Ann Neurol.1992322152181510361
- La SpadaAR.WilsonEM.LubahnDB.HardingAE.FischbeckKH.Androgen receptor gene mutations in X-linked spinal and bulbar muscular atrophy.Nature.199135277792062380
- JakubiczkaS.NedelS.WerderEA.et al.Mutations of the androgen receptor gene in patients with complete androgen insensitivity.Hum Mutation.199795761
- Huntington's Disease Collaborative Research Group. A novel gene containing a trinucleotide repeat that is expanded and unstable on Huntington's disease chromosomes.Cell.1993729719838458085
- Cystic Fibrosis Mutation Database. The Hospital for Sick Children, Toronto, Canada. Available at: http://www.genet.sickkids.on.ca. Accessed November 25. 2003
- RoesslerE.MuenkeM.How hedgehog might see holoprosencephaly.Hum Mol Genet.200312R1 5R2512668591
- StrittmatterWJ.SaundersAM.SchmechelD.et al.Apolipoprotein E: high-avidity binding to (3-amyloid and increased frequency of type 4 allele in late-onset familial Alzheimer disease.Proc Natl Acad Sci USA.199390197719818446617
- ZubenkoGS.HughesHB 3rd.StifflerJS.Neurobiological correlates of a putative risk allele for Alzheimer's disease on chromosome 12q.Neurology.19995272573210078717
- VaxillaireM.BoccioV.PhilippiA.et al.A gene for maturity onset diabetes of the young (MODY) maps to chromosome 12q.Nat Genet.199594184237795649
- McCarthyMl.Growing evidence for diabetes susceptibility genes from genome scan data.Curr Diabetes Rep.20033159167
- RabyBA.SilvermanEK.LazarusR.LangeC.KwiatkowskiDJ.WeissST.Chromosome 12q harbors multiple genetic loci related to asthma and asthma-related phenotypes.Hum Mol Genet.2003121973197912913068
- McCarthyLC.HosfordDA.RileyJH.et al.Single nucleotide polymorphism (SNP) alleles in the insulin receptor (INSR) gene are associated with typical migraine.Genomics.20017813514911735220
- EnlundF.SamuelssonL.EnerbackC.et al.Psoriasis susceptibility locus in chromosome region 3q21 identified in patients from southwest Sweden.Eur J Hum Genet.1999778379010573011
- Veal.CD.CaponF.AllenMH.et al.Family-based analysis using a dense single-nucleotide polymorphism-based map defines genetic variation at PSORS1, the major psoriasis-susceptibility locus.Am J Hum Genet.20027155456412148091
- BowcockAM.BarkerJN.Genetics of psoriasis: the potential impact on new therapies.J Am Acad Dermatol.200349S51S5612894126
- GarrodAE.Inborn Factors in Disease: An Essay. New York, NY: Oxford University Press;1931
- KalowW.Pharmacogenetics - Heredity and the Response to Drugs. Philadelphia, Pa: WB Saunders;1962
- HarrisH.Enzyme variants in human populations.Johns Hopkins Med J.19761382452521065781
- NebertDW.Polymorphisms in drug-metabolizing enzymes: what is their clinical relevance and why do they exist?Am J Hum Genet.1997602652719012398
- SachseC.BrockmoellerJ.BauerS.RootsI.Cytochrome P450 2D6 variants in a Caucasian population: allele frequencies and phenotypic consequences.Am J Hum Genet.1997602842959012401
- KerwinRW.ArranzMJ.Psychopharmacogenetics. In: Mcguffin P, Owen MJ, Gottesman II, eds. In:Psychiatric Genetics and Genomics. Oxford, UK: Oxford University Press;2002397413
- BertilssonL.DahlML.Polymorphic drug oxidation.CMS Drugs.19965200223
- LinKM.PolandRE.WanYJ.et al.The evolving science of pharmacogenetics: clinical and ethnic perspectives.Psychopharmacol Bull.1996322052178783890
- CaracoY.Genetic determinants of drug responsiveness and drug interactions.Therap Drug Monit.1998205175249780128
- KiddRS.StraughnAB.MeyerMC.et al.Pharmokinetics of chlorpheniramine, phenytoin, glipizide and nifedipine in an indiviual homozygous for the CYP2C9*3 allele.Pharmacogenetics.19999718010208645
- BenetLZ.KroetzDL.SheinerLB.Pharmacokinetics. In: Hardman JG, Goodman Gilman A, Limbird LE, eds.Goodman and Gilman's The Pharmacological Basis of Therapeutics. 9th ed. New York, NY: McGraw-H ill;1996327
- MarshallA.HodgsonJ.DNA chips: an array of possibilities.Nature Biotechnol.19981627319447589
- PfeiferD.KaufmanM.FiebichB.SpleissO.Pharmacogenetic profiling with biochips: an innovative concept to improve the efficiency of clinical trials. Proceedings of the Joint Annual Fall Meeting of the German Society for Biochemistry and Molecular Biology (GBM) and the German Society for Experimental and Clinical Pharmacology and Toxicology. 2002. Available at: http://www.gbm-online.de. Accessed November 25, 2003
- LanderES.The new genomics: global views of biology.Science.19962745365398928008
- ZhaoLP.AragakiC.HsuL.QuiaoitE.Mapping of complex traits by single-nucleotide polymorphisms.Am J Hum Genet.1998632252409634510
- BrookesAJ.The essence of SNPs.Gene.199923417718610395891
- BotsteinD.WhiteRL.SkolnickM.DavisRW.Construction of a genetic linkage map in man using restriction fragment length polymorphisms.Am J Hum Genet.1980323143316247908
- SouthernEM.Detection of specific sequences among DNA fragments separated by gel electrophoresis.J Mol Biol.1975985035171195397
- HaciaJG.Resequencing and mutational analysis using oligonucleotide microarrays.Nat Genet.19992142479915500
- The SNP Consortium Ltd. Single nucleotide polymorphisms for biochemical research. Available at: http://snp.cshl.org. Accessed November 25, 2003
- The International SNP Map Working Group. A map of human genome sequence variation containing 1.4 million SNPs.Nature.200140992893311237013
- MatiseTC.SachidanandamR.ClarkAG.et al.A 3.9-centimorgan-resolution human single-nucleotide polymorphism linkage map and screening set.Am J Hum Genet.20037327128412844283
- LaiE.RileyJ.PurvisI.RosesAD.A 4-Mb high-density single nucleotide polymorphism-based map around human APOE.Genomics.19985431389806827
- MartinER.LaiEH.GilbertJR.et al. SNPing away at complex diseases: analysis of single nucleotide polymorphisms around APOE in Alzheimer's disease.Am J Hum Genet.20006738339410869235
- SchwabSG.KnappM.MondabonS.et al.Support for association of schizophrenia with genetic variation in the 6p22.3 gene, dysbindin, in sibpair families with linkage and in an additional sample of triad families.Am J Hum Genet.20037218519012474144
- HewettD.SamuelssonL.FoldingJ.et al.Identification of a psoriasis susceptibility candidate gene by linkage disequilibrium mapping with a localized single nucleotide polymorphism map.Genomics.20027930531411863360
- DengHW.Population admixture may appear to mask, change or reverse genetic effects of genes underlying complex traits.Genetics.20011591319132311729172
- TsuiLC.The spectrum of cystic fibrosis mutations.Trends Genet.199283923981279852
- LipschutzRJ.FodorSP.GingerasTR.LockhartDJ.High density synthetic oligonucleotide arrays.Nat Genet.19992120249915496
- BowtellDD.Options available - from start to finish - for obtaining expression data by microarray.Nat Genet.19992125329915497
- HaciaJG.FanJB.Ryder0.et al.Determination of ancestral alleles for human single-nucleotide polymorphisms using high-density oligonucleotide arrays.Nat Genet.19992216416710369258
- ChenJ.lannoneMA.LiMS.et al.A microsphere-based assay for multiplexed single-nucleotide polymorphism analysis using single base chain extension.Genome Res.20001054955710779497
- RosesAD.Pharmacogenetics and the future of drug development and delivery.Lancet.20003551358136110776762
- RosesAD.Pharmacogenetics and the practice of medicine.Nature.200040585786510866212