
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
River sedimentation is an important indicator for ecological and geomorphological assessments of soil erosion within any watershed region. Sediment transport in a river basin is therefore a multifaceted field yet being a dynamic task in nature. It is characterized by high stochasticity, non-linearity, non-stationarity, and feature redundancy. Various artificial intelligence (AI) modeling frameworks have been introduced to solve river sediment problems. The present survey is designed to provide an updated account of the latest and most relevant AI-based applications for modeling the sediment transport in river basin systems. The review is established to capture the subsequent developments in the advanced AI models applied for river sediment transport prediction. Also, several hydrological and environmental aspects are identified and analyzed according to the results produced in those studies. The merits and constraints of the well-established AI models are further discussed in much detail, particularly considering state-of-the art, modeling frameworks and their application-specific appraisal, and some of the key proposed future research directions. Together with the synthesis of such information to drive a new understanding of models and methodologies related to suspended river sediment prediction, this review provides a future research vision for hydrologists, water scientists, water resource engineers, oceanography and environmental planners.
1. Introduction
River systems are often regulated for multipurpose usage, such as, but not limited to, water supply, irrigation, navigation, flood control, and hydropower generation (Evaristo & McDonnell, Citation2019). In addition, river systems are used for wastewater disposal platforms. For instance, the drain water from textiles, pharmaceutical, mills and other factories (Bhagat & Tiyasha, Citation2013; Bhagat et al., Citation2018; Yaseen, Zigale, et al., Citation2019). Effective utilization of a river system’s resources and the mitigation of risk posed to this system usually requires water treatments with different forms of civil structures and hydrological control systems (Kisi et al., Citation2019; Yaseen, Mohtar, et al., Citation2019). Furthermore, altering the watershed runoff conditions by increasing the land use intensity for agricultural or recreation activities, and by removing the vegetation cover for urbanization, building roads and highways constructions, or mining operations can significantly affect the dynamics and the morphology of a river system (Heathcote, Citation2009). When a river system’s equilibrium is disturbed by human-induced activity, it often tends to adjust to a new equilibrium state by scouring the bed, depositing the sediments, or changing its overall planform. Such changes may be localized or may also extend over a long reach. The issues of aggradation and degradation, siltation of reservoirs, channel scours during a flood event, local scour around the structures, and river bend migration, are the examples of such changes to a natural river system. Excessive amount of sediment in water creates problems for the operation of hydraulic machinery (Betrie et al., Citation2011; Walling & Collins, Citation2008). Large concentration of sediment also affects the overall quality of water. Therefore, addressing such problems requires an prediction of suspended loads, which represent about 95% of the total sediment loads (Simons & Şentürk, Citation1992). Development of a reliable suspended sediment transport model still remains a challenge due to the complex character of a river system’s geometry that governs the water velocity, and the turbulence structure of flow, which in turn, control the sediment-carrying capacity of the water flowing through the river system (Armanini et al., Citation2015).
Despite the importance of sediment transport in environmental pollution, its pattern understanding from the engineering point of view is less than satisfactory, perhaps due to the complex interrelations of a large number of variables that influence the transport process (Shojaeezadeh et al., Citation2018). Traditionally, hydrologic studies have relied on similitude analysis through experiments, because there appear to be no reliable and comprehensive theoretical formulae that can describe the two-phase phenomenon of fluid and sediment transport. Numerous analytical and experimental methods were developed to compute sediment transport variables. Some of these methods describe the geometric boundary and its resistance to water flow, sediment transport rate, and mass conservation of sediment. This article aims to review some of the useful and practical artificial intelligence (AI) models that have been applied to model suspended sediment in a river system. The AI-based models are described in the next section after reviewing the relevant literature related to suspended sediment transport.
Accurate prediction of the amount of suspended sediment in rivers and streams is critically important for the operation of canals, diversions, and dams (i.e. hydraulic structures) (Cigizoglu, Citation2004; Liu, Zhou, et al., Citation2019; Sharafati et al., Citation2019; Suif et al., Citation2016). In watershed systems, sediment transport and erosion are a complex hydrological and environmental problems so the impact of sediments present in a river in terms of the global utilization of surface water resources has become a major research area (Greig et al., Citation2005; Malagó et al., Citation2017; Sinha et al., Citation2019). Several natural processes influence sediment dynamics in river basins, including deforestation, overgrazing, and agricultural activities that erode the soil surface and contribute much of the sediment input. Given the difficulty faced by physical-deterministic models (e.g. issues associated with initial or boundary conditions, stochasticity of river flow, and non-stationarity of the flow), the prediction of sediment load in a river is more likely to be achieved using AI-based modeling frameworks that are capable of handling nonlinear relationships between water flow and environmental factors.
It is of prime interest to the present discussion that we consider suspended sediment prediction as a complex and nonlinear process, given the several influencing factors (Bhagat, Tung, and Yaseen, Citation2020). In general, these factors, which are likely to drive our understanding of the causal inference that exists between sediment transport and its related predictor variables, could be classified into four primary categories as Afan et al. (Citation2016):
(i) Meteorological origin (such as precipitation characteristics and erosive effect of rainfall).
(ii) Hydrological origin (such as base flow, runoff amount, and floodwater rates).
(iii) Geological origin (such as river basins’ soil characteristics).
(iv) Watershed geomorphology (drainage pattern, topography, and hypsometry).
Due to its interdisciplinary nature, sediment transport remains a widely explored research area, spanning across several methods that have been developed for the prediction (estimation) and the forecasting of suspended sediment in rivers (Williams & Berndt, Citation1976). However, the adoption of purely physical or deterministic methods can be inaccurate or rather time-consuming (particularly incorporating the initial or boundary conditions into the physical-based models that differ significantly for different watersheds). Furthermore, such methods can be over-parameterized due to the nonlinear and complicated nature of suspended sediment transport in river bodies. Even though such spatial data can be obtained from satellite or other remotely sensed sources, they are difficult to obtain at the precise level of initial condition for different watersheds and also, they may need calibration before they are ready to be used as a physical model input (Akay et al., Citation2008).
The determination of physical processes involved in the transportation of suspended sediment to water bodies is important for the practical implementation and putting in place the necessary measures to mitigate sediment deposition (Adams et al., Citation2018; Sadeghi & Singh, Citation2017). Several studies have recently reported the issues associated with active storage and estimation of a reservoir’s lifespan (De Vente et al., Citation2005). The issue of reservoir sedimentation is thus a universal problem, which, if solved, can be of universal value. Another issue is the progression of reservoir sedimentation that is generally is a complex transport mechanism (Verstraeten et al., Citation2003).
Various studies have been shown that the complexity of physical processes related to the current-flow density can contribute to the difficulty in predicting the concentration of suspended sediment (Leisenring & Moradkhani, Citation2012; Wu et al., Citation2018). The density current-flow refers to the specific flow pattern experienced. This can happen when the water-specific gravity of the inflow turbidity is greater than that of water in the reservoir (Wang et al., Citation2019). The water of high relative density settles at the base of the reservoir and maintains its flow under relatively clean water. However, there is a clear demarcation between the two fluids of varying densities. A conceptual model’s capability to represent reality is a function of its conceptual background; hence, it is necessary to ensure that such models are built using out-of-range data. Thus, the dynamics of density current flow can be established using a conceptual model developed with reliable data in the first stage.
Water pollution is another sedimentation-related problem of interest to the present study (Tiyasha & Yaseen, Citation2020). Soil degradation by water erosion causes the transportation of pollutants from the soil surfaces into the river bodies (Halecki et al., Citation2018; Zhao et al., Citation2017). Numerous models and empirical equations have been developed for soil losses estimation, especially to estimate the size distribution of sediments leaving the field, e.g. empirical equations and physically based models (Rice & Church, Citation1996). The physically-based models usually operate with a high quality, and huge data volume, which sometimes may be greater than the actual available amount of data in the study area. These data are often required to develop the empirical relationship(s) between the watershed and relevant predictors, and they must be fed as initial conditions, or empirical constants into the physics-based equations for model validation purposes. On the other hand, the composition of sediment-associated with individual events cannot be predicted by such empirical equations, prompting the need for the often unavailable data (Cigizoglu & Alp, Citation2006).
Suspended sediment load (SSL) has been modeled using several methods like empirical or AI models (such as those using data-driven approaches), hydraulic/numerical methods (such as sediment transport or physics-based models), statistics-based models (such as copula function or joint distribution models), as well as physical/mathematical models (such as distributed physically-based and lumped conceptual models) (Ab Ghani & Azamathulla, Citation2014; Merkhali et al., Citation2015). In this respect, some studies have attempted to analyze the pattern of SSL in stream flow by using one factor such as high flow and a flood event during individual hydrologic events, and these have been achieved mainly by the use of mathematical models (Duy Vinh et al., Citation2016; Fang & Wang, Citation2000; Huang et al., Citation2015; Lenzi & Marchi, Citation2000). These studies have reported that the relationship between SSL and the flow rate is not so robust, and that it is likely to follow a non-constant (i.e. non-linear) trend. Furthermore, most of these studies have pointed out a lag between the peak of SSL and that of the flow rate. Regarding the hydraulic/numerical models, these tend to be time-consuming and rather complicated because they involve solving a set of differential equations in 2-phase stream flow discharge and sediment transport (Demirci & Baltaci, Citation2013; Jha & Bombardelli, Citation2011). Mathematical models may not work favorably, unless the true spatial distribution of the data for most of the important variables e.g. evaporation and precipitation are provided and are of relatively high quality. They also require data on the spatial changes in watershed properties; hence, such models involve a prolonged modeling process. Owing to the unavailability of required data in most developing countries, the results deduced from physical and mathematical models are often uncertain and can be impractical for diverse watershed regions (Afan et al., Citation2016).
Traditionally, either simple statistical models (e.g. sediment rating curves (SRC)) or numerical models (e.g. finite difference methods) have been employed to simulate the behavior of SSL in rivers or streams (Nguyen et al., Citation2009; Walling, Citation1977). Recently, the emergence of artificial intelligence (AI) or machine learning (ML) models, that operate by the integration of soft computing methods and data mining approaches, have led to many promising results, especially in simulating nonlinear systems related to hydrological procedures to solve water resources problems (Qin et al., Citation2019; Yaseen, Ebtehaj, et al., Citation2019; Zounemat-Kermani et al., Citation2009). Considering recent developments in artificial intelligence models and their implementations in modeling sediment transport in river basins, it is necessary to therefore create new grounds that can advance the past and current progress on AI-based models.
The diverse nature of independent parameters required to model sediment problems as well as the complicated nonlinear process of SSL have provided motivation to explore the capability and efficiency of AI-based techniques for SSL modeling (Francke et al., Citation2008; Olyaie et al., Citation2015; Shamaei & Kaedi, Citation2016). To date, several supervised learning, AI-approaches have been developed for the modeling of SSL. The frequently used keywords on river sediment prediction that employed AI-models and the countries where these works were undertaken are reported in Figure . Determined from the literature, these are based on the works reported in Scopus database with Figure presenting the implemented models as being:
(i) Network-based AI models include algorithms, such as:
Artificial Neural Network (ANN) (Alp & Cigizoglu, Citation2007).
Adaptive neuro-fuzzy inference system (ANFIS) (Kisi & Zounemat-Kermani, Citation2016).
Wavelet transformation (Rajaee, Citation2011).
Bayesian network (Mount & Stott, Citation2008).
(ii) Tree-based AI models include algorithms, such as:
Classification and regression trees (CART) (Choubin et al., Citation2018).
Multivariate adaptive regression splines (MARS) (Yilmaz et al., Citation2018).
M5 model tree (Senthil Kumar et al., Citation2012).
(iii) Support vector-based AI models include algorithms, such as:
Support vector machines (SVM)
Support vector regression models (SVR) (Zounemat-Kermani et al., Citation2016).
(iv) Evolutionary AI models include algorithms, such as
• Gene expression programming (GEP) (Azamathulla et al., Citation2012).
• Genetic programming (GP) (Kisi et al., Citation2012).
• Evolutionary fuzzy inference system (Kişi, Citation2009).
Figure 1. Frequently used keywords on river sediment prediction employing artificial intelligence models and major countries undertaking the works.
Figure 2. Artificial intelligence models applied for sediment concentration prediction.
The current study is aimed to survey the recent literature on the applicability of AI methods for sediment transport modeling, particularly over the past four years, with the primary aim of providing a best practice, summarized guideline on the application and enhanced capability of AI models. The survey also highlights the progress made in terms of AI methods and related advanced computer-aided methodologies for modeling river sediment transport. The review also discusses each of the AI model’s merits and constraints, the necessity for additional exploration of various river types, their unresolved issues related to data collection, and recommendations for future research. Since previous studies embarked on an extensive review of the AI models (Afan et al., Citation2016), this study serves as an extension recognizing recent advancements in the deployment of AI models as prediction tools. We also aim to make recommendations for novel approaches that demonstrate the versatility of AI models in river systems engineering, water resources management and sustainability.
2. Classical (standalone) artificial intelligence models
2.1. Introduction of classical AI models
2.1.1. Artificial neural network
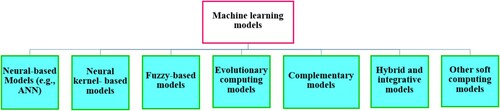
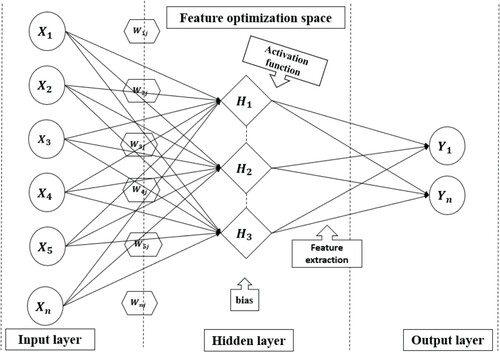
Artificial neural network is a powerful computation technique that can handle non-linear relationships and complex problems (Qin, Wang, Lin, Zhang, Xia, et al., Citation2018). ANN models have been applied in many areas, such as speech and image recognition, chemical research, medicinal and molecular biology research, and ecological and environmental studies (Lek & Guégan, Citation1999). ANN models were developed, considering the problem at hand and the solution to achieve the goal (Qin, Wang, Lin, Zhang, and Bilal, Citation2018). An ANN architecture consists of three layers, the first one is called the input layer where computation of weighted sum is performed, the second layer is used for data processing i.e. hidden layer, which can be converted to multiple layers depending on the complexity of the problem, and lastly, the final result is produced in the output layer. Each layer is made up of neurons which unite to form the architectural framework (Singh et al., Citation2009). Conventional ANN models typically consist of multi-layer feed-forward neural network with application of backpropagation algorithm (BPNN) (Rumelhart et al., Citation1988); similarly, radial basis function neural network (RBFNN) applies feed-forward neural network and one hidden layer for model execution (Chen & Cowan, Citation1991), multi-layer perceptron (MLP) network using feedforward neural network (Rosenblatt, Citation1961), recurrent neural network (RNN) using backpropagation and additional layer connected to hidden layer (Du & Swamy, Citation2019), Levenberg-Marquart (LM), Bayesian regularization (BR), and gradient descent and adaptive learning (Maier & Dandy, Citation1999; Samarasinghe, Citation2006). The general architecture of three layers is presented in Figure .
Figure 3. Typical ANN architecture for SSL modeling where w: weight and bias are justified by the training process. Most common transfer functions are sigmoid, Gaussian and tangent sigmoid (i.e. tansig).
2.1.2. Support vector machine
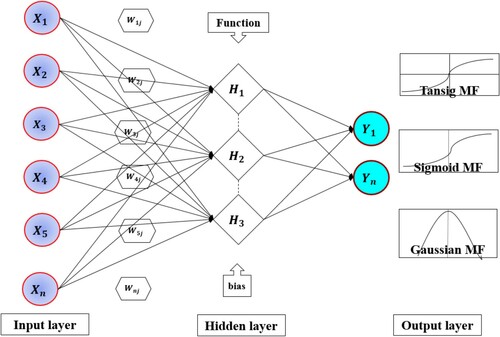
SVM, based on statistical learning theory, has a resilient conjectural statistical arrangement which makes it a robust model. SVM has been successful in handling classification, regression and other kinds of forecasting or predictive modeling. The SVM model is based on statistical learning theory and structural risk minimization hypothesis. It was developed by (Cortes & Vapnik, Citation1995) and since it is a kernel-based model, it is able to reduce model’s complexity and prediction error. Usually, kernel type models have good adaptability, can achieve great results in global optimization and generalization, and are capable of managing small samples and minimizing empirical risk (Raghavendra & Deka, Citation2014). Kernels are special nonlinear functions created by non-linear mapping and allow the model to separate complicated hyperplanes. The correct selection of a kernel function is the key to produce excellent model performance. The most applied kernel functions are linear, polynomial, radial basis function, and sigmoid. The modified versions popularly applied are least-square SVM (Suykens & Vandewalle, Citation1999), linear programming SVM (Zhou et al., Citation2002), and Nu-SVM (Schölkopf et al., Citation2000). The general architecture of the SVM model is presented in Figure .
Figure 4. (a) Typical SVM architecture for SSL modeling where = weight and b = bias. Most common transfer functions are linear, polynomial, radial basis, and sigmoidal, K = support vector, m = number of support vectors, φ(x) = non-linear function. (b). Non-linear SVR vapnik’s ϵ-insensitivity loss function.
2.1.3. Adaptive neuro-fuzzy inference system
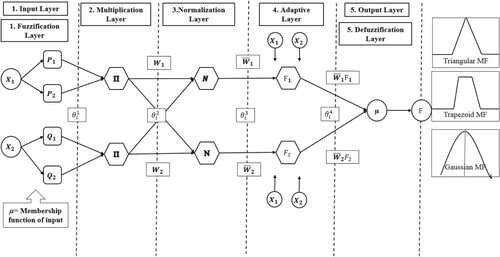
Fuzzy logic models are a powerful tool for dealing with difficult computational problems (Wang, Kisi, Zounemat-Kermani, Zhu, et al., Citation2017), and can deal with non-linearity, uncertainty, and subjective data. These models overcome the shortcomings of numerical modeling. The most popularly applied model is ANFIS, whose architecture consists of a multilayer feed-forward network that utilizes a neural network learning algorithm and can identify non-linear boundaries and fuzzy logic to distinguish non-linear equations and together can map the input-output space (Takagi & Hayashi, Citation1988) which allows it to achieve high non-linear mapping for non-linear time series data. The stages of ANFIS consist of choosing the type of interference system, such as Mamdani, Sugeno and Tsumoto (Mamdani & Assilian, Citation1975; Takagi & Sugeno, Citation1985), aggregation, and defuzzification. The general five-layer design of ANFIS is presented in Figure .
Figure 5. Five layers ANFIS model design with most common MFs, where, = Node Output, i = node, F = final output, X1 and X2 = Input variable, P1, P2, Q1, Q2 = Fuzzy rules.
2.1.4. Bayesian networks (BNs)
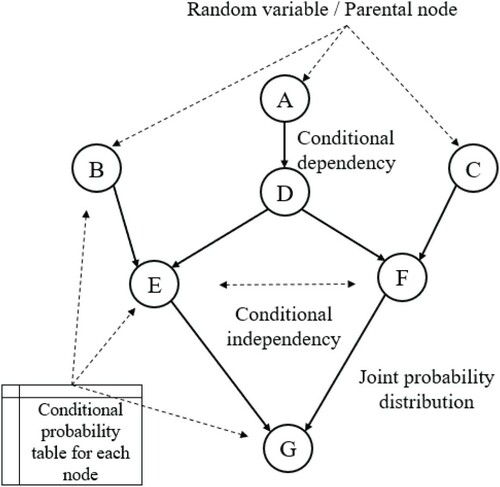
Bayesian methods provide conformity for reasoning in terms of the fractional beliefs under the condition of uncertainty. Various numerical parameters imply the degree of belief and later they parameters are combined and manipulated as per the rules of probability theory, considering conditional probabilities, absolute certainty, and conditionally independent variables (Pearl, Citation2014). They give rise to the conjugate form of Bayesian theorem and graphical theory, which adhere to probability rules for conducting interference. Thus, in a simple form, BNs are probabilistic, directed acyclic graphical models (Gregory, Citation2005). For experimental data analysis, a conditional distribution is computed using the rearrangement of the chain rule which allows for the computation of conditional probability of the discrete state of any variable with any number of parents. Additionally, nodes stipulate no parents, indicating that random variables are not conditionally dependent, and the joint nodes are conditionally dependent which can be calculated by a joint probability distribution which is the product of nodes and parents. States of nodes and their conditional probability can be allotted as per a qualitative or quantitative procedure. The efficient BNs are as good as the proximity of dependencies, thus only the most relative number of variables and their association with the problem should be used for construction (Mount & Stott, Citation2008). Consequently, the computational cost and complexity can increase exponentially, if the number of nodes is not controlled which may happen in real-life problems. A schematic representation of a basic Bayesian network design is shown in Figure .
Figure 6. Basic Bayesian network design that satisfies the local Markov property which states that a node conditionally independent of its non-descendants’ parent (e.g. E & F). Joint probability (e.g. P(G|F), product of P (node|parental node)) is calculated using the chain rule of probability.
2.2. Bibliography
Three AI models, including SVR, ANFIS and ANN models, were employed for SSL simulation at Coruh River, Turkey (Buyukyildiz & Kumcu, Citation2017). The models were built using a daily scale of discharge (Q) and SSL hydrological data, and the accuracy of prediction by the SVM model over other implemented AI models was confirmed.
Kaveh et al. (Citation2017) examined different trained ANFIS models with parametric algorithms, such as Levenberg-Marquardt and back-propagation. They used the daily scale of Q and SSL dataset gathered from Schuylkill River, United States and results showed the capability of the applied AI models for modeling suspended sediment load.
Bharti et al. (Citation2017) developed an ANN, least support vector regression (LSSVR), reduced error pruning tree (REPT), and M5 Tree model for the modeling of Q and SSL at the Pokhariys watershed, India. Using climatological variables with monthly scale, including rainfall, air temperature (AT), relative humidity (RH), pan evaporation (ETo), solar radiation, sunshine duration, and wind speed, they showed the influence of climatological variables on the modeled Q and SSL. However, the performance of AI models was related to the variance results.
Pektas and Cigizoglu (Citation2017a) presented a traditional perdition investigation for daily scale sediment transport in Yadkin River using the feasibility of ANN and MLR models. The ANN model reported an acceptable prediction performance. The same case study was investigated for ANN internal tuning (Pektas & Cigizoglu, Citation2017a, Citation2017b). On the same trend, ANFIS and ANN models were implemented for sediment prediction (Riahi-Madvar & Seifi, Citation2018). Predictive models constructed, based on hydraulic parameters, including hydraulic radius, water surface slope, sediment particle dimensions, sediment shear, river discharge, and water depth. From statistical results and uncertainty analysis, the ANFIS model showed better results than the ANN model. The ANFIS and ANN models were developed for simulating suspended sediment concentration for Thames River, London, Ontario, using daily water temperature, river discharge, and electrical conductivity, and results evidenced the potential of ANN in modeling SSC.
Moeeni and Bonakdari (Citation2018) combined the integrated autoregressive moving average exogenous (ARMAX) model with ANN to predict SSL based on river Q and SSL using daily time scale. Normalizing the data using the exponential and Box–Cox transformations, they found the combined model to have an excellent predictive performance. Hamaamin et al. (Citation2018) designed two AI models, including ANFIS and Bayesian regression (BR), to predict SSL for Saginaw River, United States, with daily data of air temperature, rainfall, and SSL as input variables. The models were validated against the soil and water assessment tool (SWAT) and both models provided a reliable alternative for SWAT to predict SSL.
Gholami et al. (Citation2018) applied the ANN model to evaluate soil erosion from Kaslilian watershed, Iran. The Geographic information system (GIS) was used for data pre-processing of the spatial variation of soil erosion, where the predictors were rainfall intensity and amount, soil moisture, vegetation cover, slope, air, and soil temperature. The ANN model performed well for the watershed.
The classification and regression tree (CART), adaptive neuro-fuzzy inference system, multi-layer perceptron, and two support vector regression models were compared for simulating SSL of Haraz watershed in the northern region of Iran (Choubin et al., Citation2018). These models were constructed, based on several hydro-meteorological data (e.g. river water level, river discharge, rainfall, and SSL). The CART model was found to be superior, especially for one-month lead time.
Samet et al. (Citation2019) predicted SSL in Gizlarchay River, Maku Dam, Iran, using ANFIS, ANN, and GP using water temperature, river discharge, and three-section sediment sampling (CM) and found ANFIS to be far better than ANN and GP.
Khan et al. (Citation2019) predicted SSC of the Ramaganga River, India, using the ANN model and with daily river discharge and suspended sediment concentration. The SSC prediction was promising for the watershed.
Emamgholizadeh and Demneh (Citation2019) used daily data of Q and SSL from Telar and Kasilian Rivers, Iran, to construct several AI models (i.e. GEP, ANN and ANFIS) which were validated against the SRC approach. The evolutionary GEP model showed potential for modeling SSL.
Bisoyi et al. (Citation2019) employed the ANN model to predict SSL for Narmada River, India, using daily rainfall, Q and SSL data. Considering various hydrological variables and focusing on one peak event based on monsoon season, it was necessary to use rainfall and Q datasets.
Proper input selection is essential for predictive models (Noori et al., Citation2011). Kumar et al. (Citation2019) used ANN and ANFIS along with Gamma Test (GT) for input selection for modeling river sediment and discharge. Daily antecedent Q and SSL from Pathagudem and Polavaram watersheds in India for the period 1996–2010 were used. Results showed the suitability of GT as a prior stage for the learning process.
Singh et al. (Citation2018) integrated GT and correlation function (CF) with AI models, including multi-layer perceptron (MLP), co-active adaptive inference system (CANFIS), self-organization map (SOM), and radial basis function (RBF), and two regression models (e.g. SRC and MLR). Models were constructed for hydrological data obtained from Burhabalang basin, Orissa, India. Both GT and CF were used to select the appropriate input variables as a prior modeling procedure. The MLP model with one lead time of SSL and Q was the best prediction model among all other models.
Malik et al. (Citation2019) used the RBF, SOM, least square support vector regression, and MARS models with GT for input selection to predict SSC from the Ashti, Tekra and Bamini stations located at Godavari River basin, India. They found the RBF model to be the best model.
3. Complementary artificial intelligence models
3.1. Wavelet transform
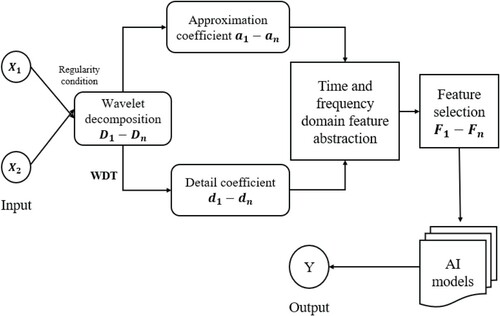
The limitation of various AI models to handle non-stationary data has led to incorporate wavelet transform, developed by (Grossmann Jean, Citation1984), as s signal preprocessing method to provide insights into time-scaling and its relationship through numerical analysis and manipulation of multi-dimensional signals. This technique can be used for diagnostic classification and forecasting (Nourani et al., Citation2014). The hybrid model applies the wavelet transform, however, its performance is based on the selection of a suitable mother wavelet and decomposition level. Frequently used mother wavelets are Daubechies-1, Daubechies-2, Daubechies-4, Haar, db2 and db4. The two common forms of wavelet analysis are discrete wavelet analysis which deals with discrete signals and decomposes the series into sub-signals at a specific wavelet and decomposition level (Daubechies, Citation1988). The other is continuous wavelet transform which deals with continuous signals and is useful for disclosing series features under multi-temporal scales (Percival & Walden, Citation2000). Wavelet transform is applied for wavelet decomposition, wavelet de-noising, wavelet aided complexity explanation, and wavelet aided predicting (Sang, Citation2013). A schematic diagram of hybrid wavelet-AI model is shown in Figure .
Figure 7. Schematic diagram of hybrid wavelet-AI model: regularity condition with order N decides the choice of wavelet. Wavelet de-noising (WDT) is applied to adjust detail coefficient. X1 and X2 = Input variables, D1-Dn = decomposition level, Y = Output variable.
3.2. Bibliography
A complementary predictive model, based on the integration of data-mining M5 decision tree (M5Tree) with wavelet data pre-processing technique, was developed for SSL prediction for the upper Rio Grande and Lighvanchai Rivers (Nourani et al., Citation2019). Discharge and sediment data with daily and monthly time scales were used to build the predictive models, and Standalone M5Tree and ANN models were used for comparison. The complementary WA-M5Tree was found to be a robust prediction model for both rivers and time scales. (Sharghi, Nourani, Najafi, and Soleimani, Citation2019) coupled complementary wavelet exponential smoothing (WES) with ANN model to enhance predictive performance based on time series data pre-processing as a prior stage to prediction. WES-ANN was validated against autoregressive integrated moving average (ARIMA), seasonal ARIMA (SARIMA), and ANN models. The Upper Rio Grande and Lighvanchai Rivers daily SSL data were used to build the complementary predictive and benchmark models. The proposed model exhibited improved prediction.
Himanshu et al. (Citation2017) evaluated the wavelet SVM (W-SVM) and SVM models for daily SSL prediction for different lead times (1, 3, and 6 days), using the Tropical Rainfall Measuring Mission (TRMM) Multi-satellite Precipitation Analysis (TMPA). The WSVM model was found to be applicable for the prediction of SSL over all targeted leads, and results showed the bias of TMPA precipitation on SSL modeling for data-sparse regions.
Alizadeh et al. (Citation2017) equated the W-ANN model and classical ANN model for predicting multiple scale ahead of SSC at Skagit River, United States. Daily Q and SSC data were used for initiating the models based on the correlated lead times. Results indicated that the W-ANN model was superior to the classical ANN model.
Sharghi, Nourani, Najafi, and Gokcekus (Citation2019a) developed a complementary model based on wavelet-emotional neural network (W-ENN) for predicting daily and monthly SSL in Rio Grande and Lighvanchai Rivers. The motivation of the wavelet preprocessing approach application to establish the fact that sediment transport is related with stochasticity, seasonality, and non-linearity. The proposed W-ENN model was validated against standalone ENN and ANN models and was found to be having potential for modeling SSL.
Himanshu et al. (Citation2016) used an ensemble WA-SVR model with hydrometeorological variables for the prediction of SSL, including the peak values of sediment and accumulated sediment for reservoir operation, at multiple steps ahead daily scales, including (1-, 3-, 6- and 9-days). Daily Q, rainfall, and SSL data over 40-years from two watersheds (i.e. Muneru and Marol) in India were used.
Liu, Zhang, et al. (Citation2019) used the Hilbert-Huang transform (HHT) to identify the time scale of daily horizon Q, RF, SSC and normalized difference vegetation index (NDVI) of Kuye River, China. Several predictive models, including ANN, MLR, and their complementary version integrated with ensemble empirical mode decomposition (EEMD), were employed. The intrinsic mode function (IMF) was used to detect the correlation between RF, Q, NDVI, and SSC. The integrated EEMD-ANN model was more accurate than MLR, ANN and EEMD-MLR. The non-linear IMF provided antecedent values of the predictors.
4. Nature-inspired hybrid artificial intelligence models
4.1. Introduction to nature-inspired optimization algorithm
Nature-inspired meta-heuristic algorithms have gained popularity in engineering applications because of their ability to solve optimization problems. They mimic biological incidents, attend local optima, and are flexible. They can be divided into evolutionary-based, physically-based, and swarm-based. Evolutionary-based methods are inspired by the laws of evolution. They allow optimizing by selecting the best individual which leads to the better next generation. Some of the popular evolutionary algorithms are genetic algorithm (Goldberg & Holland, Citation1988), evolutionary strategies (Rechenberg, Citation1994), genetic programming (Koza, Citation1994), and gene expression programming (Ferreira, Citation2001). The swarm-based method is based on the social behavior of groups of animals and insects. The most popular optimizers are (i) Particle Swarm Optimization (PSO) found in the social behavior of flocking birds where particles fly in the search space to find the best result (Kennedy & Eberhart, Citation1995); (ii) ant colony optimization centered around the social behavior of ants in the ant colony to find the shortest path to home and food (Dorigo et al., Citation1996); and Artificial Bee Colony (ABC) inspired by the behavior of honey bee swarms (Karaboga & Basturk, Citation2007). In general, the nature-inspired/heuristic algorithms can be combined with AI models to serve as efficient optimization algorithms with the potential to improve their accuracy and precision (Cicek & Ozturk, Citation2021; Fadaee et al., Citation2020). The combined models may be called integrative or hybrid AI models. In this study, we use the term hybrid for an embedded AI model with a nature-inspired or heuristic algorithm that improves the performance of a standalone AI model.
4.2. Bibliography
Adib and Mahmoodi (Citation2017) used the hybrid (integrative) ANN-GA model to predict annual SSL in Marun River, Iran. Zounemat-Kermani (Citation2017) tested several AI models (i.e. ANN, ANN-PSO, ANFIS and GEP) for modeling SSC in highly dynamic river discharge, and sufficient lead times were computed using mutual information. Daily sediment data was gathered from San Joaquin River, United States. The hybrid ANN-PSO was more efficient and robust for SSC prediction than ANN, ANFIS and GEP.
A new AI model, integrating genetic algorithm with SVR model, was developed for modeling daily scale SSL at two earth dams located in Iran (Rahgoshay et al., Citation2018). Two AI models, including multivariate adaptive regression spline (MARS) and M5Tree, were developed. Results concluded the superiority of MARS and M5Tree models. The river discharge with three-day antecedent values had a major correlation to predict one day ahead SSL.
Integrating the continuity equation and fuzzy pattern-recognition into a structure of double artificial neural networks, (Chen & Chau, Citation2016) developed a hybrid double feedforward neural network model for daily SSL estimation, by integrating continuity equation and fuzzy pattern-recognition into a structure of double ANNs. The results showed that the hybrid model outperformed other three benchmarking conventional ML models.
A fuzzy C-means clustering (FCM) approach was hybridized with an SVR model for internal parameter optimization and the hybrid model was implemented for predicting SSL of Sistan River, Iran (Hassanpour et al., Citation2019). The proposed hybrid FCM-SVR model was developed using univariate modeling scheme where only daily SSL data were used. Several benchmark models were developed, including SRC, ANN, ANFIS and SVR, and results demonstrated the hybrid FCM-SVR model accurately predicted SSL.
A new hybrid AI model was developed based on a binary nature-inspired optimization algorithm with feed-forward neural network model to quantify the monthly sediment load of Narmada River, one of India’s largest rivers (Meshram et al., Citation2019). Using ten years of Q, RF and SSL historical data, the model was validated against the ANFIS model and was found superior to the ANFIS model and accurately modeled SSL.
Rahgoshay et al. (Citation2019) hybridized SVR model with two nature inspired optimization algorithms, including GA and particle swarm optimization (PSO) for SSL prediction. M5 Tree and MARS were used for validation purposes. For two case studies (i.e. Veynakeh and Royan), located in Iran, the hybridization of PSO with SVR model was promising for modeling sediment transport.
Yadav et al. (Citation2018) developed two hybrid predictive models by tuning ANN and SVR models using genetic algorithm (GA) for modeling SSL using RF, Q, T and SSL data from Mahanadi River, India. Two predictive models, including MLR and sediment rating curve (SRC), were used for model assessment. The hybrid models exhibited a noticeable prediction accuracy.
5. Ensemble artificial intelligence models
5.1. Introduction to ensemble artificial intelligence methods
In contrast to the conventional or stand-alone AI models, in the ensemble learning, multiple base algorithms are trained. In other words, ensemble learning attempts to improve the performance of conventional AI models by combining multiple hypotheses for the same dataset. Alternatively, ensemble learning can also be accomplished for conjoining the results of different models (e.g. SVM and ANN) for the same dataset (Wang et al., Citation2011). Ensemble methods are learning algorithms that create classifiers and categorize new data points by considering weighted and unweighted voting of predictions. The basic method is Bayesian average but newer methods have been developed, such as error-correction output coding, bagging, and boosting (Dietterich, Citation2000). Ensemble classifiers are more accurate than any individual member, and two classifiers producing different errors are considered as diverse classifiers. Additionally, diverse classifiers are judged good since one classifier result is unrelated to the other, giving a better voting advantage when error rates below 0.5 are chosen. There are three advantages over other models like ANN or decision tree: (i) It can produce good accuracy without sufficient data; (ii) it is constructed by running local search from many different starting points which provide better approximation resulting in a better computational technique; and (iii) it has better representation by using effective space of hypothesis search (Zhang & Ma, Citation2012).
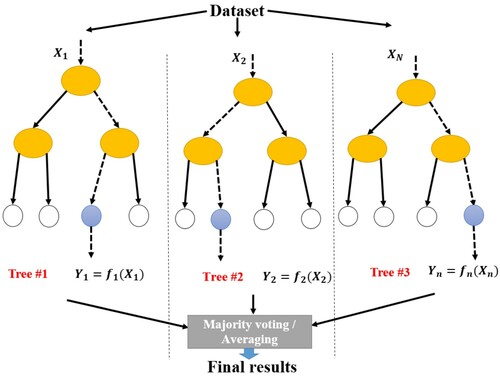
Random forest (RF) is a bagging type ensemble learning method which has an additional layer of randomness. It is the combination of predictors creating a distribution pattern of trees in forest and generalizes the error of tree power of individual trees and correlation among them. Inputs are selected randomly so that the node can grow (Bhagat, Pyrgaki, et al., Citation2021). Its accuracy is good; it is robust to outliers and noise, faster than bagging and boosting, and provides good internal assessment of the error, strength, correlation and variable importance (Breiman, Citation2001). The basic architecture RF is presented in Figure .
Figure 8. Random forest (RF).
5.2. Bibliography
Shamaei and Kaedi (Citation2016) applied the ensemble stacking method to predict SSL based on the results of two different AI techniques, including genetic programming and neuro-fuzzy models. It was found that the ensemble technique drastically improved the prediction accuracy of the single soft computing models.
6. Other applied artificial intelligence models
6.1. Overview of other artificial intelligence models
6.1.1. Classification and regression tree (CART)
Sequential binary splits, applied for explanatory variables using a decision rule for allocating items to a group, are the basic concept of a classification tree. CART was initially developed to handle clinical data due to its ability to simultaneously manage combinations of categorical variables and continuous information and search for the best way to split the range of continuous variables into two groups (Breiman et al., Citation1984). The tree was able to split at different points or nodes till the end or leaf node. The CART addresses linear and regression problems and helps in linear logistic and additive logistic models for classification problems. Binary recursive portioning is used for splitting the sequential data into homogeneous subsets until the condition is fulfilled. Each split depends on the definite variable value and divides into two subsets generating a binary tree structure. The construction features include: selection of binary splits of the measurement space, decision of creating a node or continuous splitting and assigning each terminal node to a class (Crichton et al., Citation1997). Classification components are dependent variables, independent variables, learning dataset and future dataset. Regression components are prior probabilities from each outcome and cost matrix. The progress of CART models has been fairly slow due to the complexity of analysis in some cases. These models are effective to understand multifaceted interactions between predictors in respect of traditional multi-variate techniques. They can handle highly skewed data and categorical data, deal with missing data by using surrogate variables, need little amount of input for analysis, and are relatively simple to interpret (Lewis et al., Citation2000).
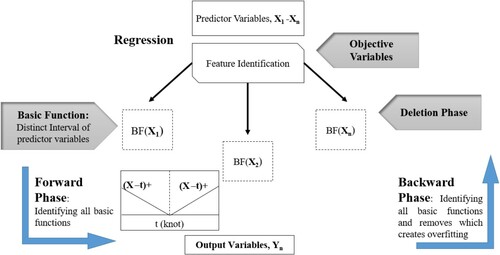
6.1.2. Multivariate adaptive regression splines (MARS)
Multivariate adaptive regression spline is a flexible regression non-parametric modeling approach which can work with high dimensional non-linear data and is the form of expansion of spline basis function (Wang, Kisi, Zounemat-Kermani, and Li, Citation2017). It utilizes the technique of recursive partitioning approach and regression analysis (Bhagat, Paramasivan, et al., Citation2021; Friedman, Citation1991), is flexible and accurate, and can forecast continuous and binary output. It has been applied in the fields of energy, and environmental and ecological studies and can interpret complex and nonlinear relationships between predictors and response variable and does not make any assumption between input and output variables (Bhagat, Paramasivan, et al., Citation2021). It consists of knots which are breaks between regions, basic functions for distinct intervals of predictors with two phases known as forward and backward phases. The forward phase generates all possible basis functions and the backward phase eliminates basis functions which create overfitting which in turn improves prediction accuracy (Yilmaz et al., Citation2018). The general schematic of the MARS model is shown in Figure .
Figure 9. Multivariate adaptive regression splines (MARS).
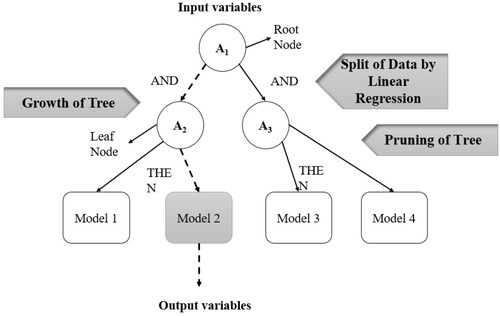
6.1.3. M5 model tree
M5 model tree is a piecewise linear model proposed by Quinlan (Citation1992). It maps the inputs and the output, constructed in two different stages i.e. the tree growth and tree pruning. The first stage splits the input into subsets using a linear regression model and diminishes the error between measured observations and predicted values and instantaneously creates decision tree. The second stage consists of the pruning of tress from each leaf (Heddam & Kisi, Citation2018). The basic architecture of M5 model tree is shown in Figure .
Figure 10. M5 model tree.
6.1.4. Regression model
The regression method is a baseline statistical modeling technique which takes account of the relationship between variables and finds a meaningful relation and differences. A regression model can be linear, non-linear, or parametric and non-parametric, depending on the type of analysis. The basic models consist of predictor variables and response variables. The response variables are assumed continuous, whereas predictors can be discrete or continuous with various assumptions on correlation. There are many frequently applied regression models, such as simple linear regression (Younger, Citation1979), multiple linear regression (Andrews, Citation1974), logistic regression (Hosmer et al., Citation2013), ordinal regression (Harrell, Citation2015), multinomial regression, and discriminant analysis (Klecka et al., Citation1980).
6.2. Bibliography
Khosravi et al. (Citation2018) developed several data mining predictive models to quantify hourly scale SSL measured at Andean Catchment, Chile. Their models were standalone reduced error pruning tree (REPT), instance-based learning (IBK), M5P, hybrid models (i.e. bagging-M5P, random sub-space-REPT (RS-REPT), and random committee-REPT (RC-REPT)). The input combinations were constructed based on Q, water temperature (WT), and electrical conductively (EC) in addition to SSL. The hybrid bagging-M5P data mining model accurately predicted hourly SSL in comparison with other models.
Ulke et al. (Citation2017) inspected five different empirical models, including models of Einstein, Lane and Kalinske, Chang-Simons-Richardson, and Brooks, for predicting SSL of three major rivers in Turkey. The models were formulated using Q, SSL, river cross-section area, material size of the transported material, and Manning coefficient (n). Among the empirical formulations, the Brooks model attained the best prediction results. However, when genetic algorithm was integrated with the Brooks model for internal parameters tuning, the GA-Brooks model showed results comparable to those attained from classical ANN and ANFIS models. The empirical model revealed that the particles size influenced the SSL transport. Overall, the GA-Brooks model exhibited an ability for modeling SSL of this particular region.
Afan et al. (Citation2017) employed three AI models, including ANN, response surface method (RSM), and RSM basis global harmony search (GHS), for modeling SSL. The RSM model is integrated as an input selection method prior to prediction. Daily Q and SSL over a decade from Johor River were used to construct the models. Results showed the viability of integrating RSM with GHS to select the optimal antecedent records for prediction.
Kisi and Ozkan (Citation2016) developed a local weighted linear regression (LWLR) model for SSC prediction based on daily discharge and suspended sediment concentration data in Eel River, United States. LSSVR, ANN and SRC models were used for validation, and the LWLR model showed a superior prediction performance.
Using rainfall, river flow discharge, and sediment yield, Sudhishri et al. (Citation2016) employed a non-linear dynamic (NLD) model for modeling daily sediment transport in a large mountainous watershed, Bino Watershed, India. Modeling was done using rainfall, river flow discharge, and sediment yield. The NLD model showed superior prediction results over ANN and W-ANN models. However, under-estimation was experienced during the events of high land-sliding and flash floods.
7. Appraisal of the literature
The exploration of related studies leaves little room for uncertainty as to the superiority of mathematical data-driven models (viz. regression-based) and soft computing data-driven models (viz. artificial intelligence or machine learning methods) over traditional sediment rating curve (SRC) method in simulating SSL (Singh et al., Citation2018; Zounemat-Kermani et al., Citation2016). In a recent review, Zounemat-Kermani, Matta, et al. (Citation2020) acknowledged the absolute superiority of neuro-computing AI models over the traditional and statistical methods, such as SRC, MLR or ARIMA. The findings of studies show that AI models performed better than standard mathematical data-driven models. However, the question is which category (network-based, tree-based, support vector-based or evolutionary-based) or what type of AI model can be chosen as the best AI model for SSL simulation, is still ongoing. Further research in this particular area and related hydrological areas would lead to an answer but would also make it more indistinguishable and open-ended. Even though the majority of studies affirm the promising results from AI models in SSL simulation over traditional methods (e.g. Buyukyildiz & Kumcu, Citation2017; Choubin et al., Citation2018; Singh et al., Citation2018; Zounemat-Kermani et al., Citation2016). Different reasons might be associated with dissimilarities in announcing the best AI model by various studies. Indeed, existing contrasts in the datasets applied (e.g. length of dataset, input vector, and lead time), feature selection methods (e.g. auto-correlation, average mutual information, Gamma Test), data preparation techniques (e.g. hold-out method, cross-validation method), and model tuning techniques (e.g. learning algorithms, model architecture, and termination factors) could be pointed out as some of the leading causes. In such studies (AI application to SSL), all the details related to modeling (e.g. data division strategy, used algorithm or method and calibration of its control parameters) should be provided by the modeler. In this way, the same methodology can be repeated and more robust conclusions about the implemented method may be derived from the results. Wu et al. (Citation2014) suggested a protocol for ANN implementation and evaluated it using drinking water quality data. They examined 81 journal papers since 2000 and reported that there was no systematic protocol for the development of ANN models. The proposed protocol included the reasons why a specific method was selected, methods used and details of implementation, data collection and pre-processing, input selection, data splitting, model architecture selection, and model calibration and validation (replicative, predictive and structural). The study emphasized that similar protocols should be developed for other AI methods to better follow the implemented methodology for other case studies.
The literature suggests that the development of most AI models is based on a multivariate modeling strategy. The suspended sediment is modeled, based on various hydro-meteorological variables, possibly because AI models can establish the non-linear relationship that describes the physical progression between the predictand and the predictors by exploiting the advantages of the randomized learning process. Sediment transport modeling was conducted, using various hydrological and geophysical variables as causally related predictors (Tao et al., Citation2019). For modeling, it is assumed that the predictor-predictand relationship is stationary, but this assumption does not hold in real cases, as it depends on the actual data. When there is a non-stationary predictor-predictand relationship, the model results can be uncertain. Hence, the reasons for the non-stationary predictor-predictand relationship must be identified, and the selection of predictors must be carefully done to prevent the presence of any non-stationarity.
Different statistical methods have been used to select the most suitable input combinations to develop sediment load prediction models. These methods are the gamma test, correlation analysis, intrinsic mode function, auto-correlation, average mutual information, neighborhood component analysis, Boruta feature selection, and iterative input selection, to name a few (Ahmed, Deo, Raj et al., Citation2021; Ahmed, Deo, Ghahramani et al., Citation2021; Kumar et al., Citation2019; Liu, Zhang, et al., Citation2019; Singh et al., Citation2018). These methods first evaluate each candidate input’s relation with the output separately and rank them, and then the higher-ranked inputs are selected for model development. However, individually highly correlated inputs do not guarantee good performance when working together due to collinearity. Recursive Feature Elimination (RFE), a wrapper feature selection algorithm, has shown prominence in selecting ML models’ inputs. The RFE has been recently used to select inputs for a sediment heavy metal prediction model (Bhagat, Tiyasha, Awadh, et al., Citation2020; Bhagat, Tiyasha, Tung, et al., Citation2020) and a sediment chemical prediction model (Sakizadeh, Citation2020). The advantage of RFE is its ability to select the most suitable input combination by iteratively removing the less influencing inputs. However, the use of different kinds of wrappers, including RFE, is still limited in the AI sediment prediction model development.
Despite the excellent performance of AI models in modeling sediment transport and abstracting non-linearities that characterize the physical process via multivariate modeling strategies, it is often necessary to build new univariate models, which will serve as ‘time-series prediction models.' Such models utilize the patterns and magnitudes of the study variables to predict their potential value in the future. This is important for most developing countries where there are limited or unavailable hydro-meteorological data at the metrological monitoring stations. Therefore, there is a need to develop such a univariate modeling strategy for implementation using the feasibility of soft computing models. It should be noted that the predictive ability of AI models for univariate input data applications has been verified for sediment simulation.
The present review also points to the significant improvement of AI models in their integration with data pre-processing approaches to achieve a ‘complementary modeling approach.' Such studies point to the dependence of integrative models on the input space decomposition with several frequency-based information levels used to enhance performance. However, according to a recent study by Quilty and Adamowski (Citation2018), some of the current research studies inaccurately developed wavelet-based AI models and thus they could not be properly applied for practical purposes, mainly related to forecasting applications. The issues in these research studies are related to: (i) the potential use of future data as an input in the development of selected models, (ii) an inappropriate choice of the decomposition level and wavelet filters, and (ii) the imprudent partitioning of training and testing data. Because of not addressing the reflection boundary conditions in applying the wavelet decomposition, the researchers have incorrectly implemented wavelet-based AI models, resulting in much better accuracy (with a relative positive bias) than what is normally achievable. To resolve this issue, the subsequent study of Quilty and Adamowski (Citation2018) reported a new strategy to avoid such errors and to adequately using wavelet decomposition method. The strategic recommendation mentioned in the study should be considered in future research studies related to wavelet-based complementary modeling approach. To demonstrate the newly proposed approach, a few other research studies (e.g. (Al-Musaylh et al., Citation2020; Ghimire et al., Citation2019; Prasad et al., Citation2017)) have already adopted maximum overlap discrete wavelet transform for water resources, solar radiation and energy prediction studies.
In the recent decade, the ensemble machine learning (EML) models, like stacking, bagging, and boosting methods, have been used dramatically in hydrologic modeling; and simulating sediment transport in water bodies has followed the same trend (Oehler et al., Citation2012; Sharafati et al., Citation2020). Literature shows that the prevalent approaches in generating ensemble models aim to enhance the general capability and accuracy of individual AI models in simulating/predicting/forecasting suspended sediment. This claim can be supported, based on the results of: (i) stacking EML models (Alizadeh et al., Citation2017; Shamaei & Kaedi, Citation2016), (ii) model averaging (Wang et al., Citation2015), (iii) bagging EMLs (Nhu et al., Citation2020), (iv) boosting EMLs (Shadkani et al., Citation2020) and (v) ensemble empirical model decomposition with adaptive noise algorithm for multi-scale river flow prediction (Wen et al., Citation2019).
There is no universal AI model that can capture the global watershed features, mainly because each model presents its own limitations based on the algorithm and watershed input features. This is evidenced by the nature of various patterns due to the ‘regionalization effect of the model accuracy in terms of hydrological alterations.' Meanwhile, the results of AI models have proven the sophisticated nature of these predictive tools or the predictive algorithms when implemented in various types of watershed areas with diverse features, while modeling and applying the non-linear hydrological parameters.
Optimization in engineering, specifically in hydrological and water management engineering, has been a challenge for many decades. Additionally, optimization methods play a vital role in the training of AI models. As an illustration, standard types of AI using mathematical techniques, such as traditional gradient-based optimization methods, were used to solve problems of interest. Some studies reported the successful practice of certain types of gradient-based optimization methods like the Levenberg-Marquardt algorithm in hydrological modeling (Qanza et al., Citation2019; Zounemat-Kermani, Citation2012). Nonetheless, due to their intrinsic shortcomings in addressing complexities in non-linear, chaotic, and stochastic hydrological systems, effective and reliable nature-inspired optimization techniques, called meta-heuristic algorithms, have been under development. Due to their robustness and efficiency in coping with the complexities of noisy environment, they are superior to traditional mathematical algorithms for exploring the problem search space (Gomes et al., Citation2018). Recent literature shows that several attempts have been made to enhance the efficiency of meta-heuristic optimizers in training ordinary AI models (Kisi & Yaseen, Citation2019).
Comparing different versions of AI models, it is clear that the integrated meta-heuristic AI models are the most appropriate for utilization as a potential alternative to the existing models for modeling river suspended sediment over diverse hydrological regions. Integrated meta-heuristic AI models represent a hybridization between nature-inspired optimization algorithms and classical AI models, such as ANFIS, SVR, ANN, etc (Sharafati et al., Citation2021). In this regard, Fadaee et al. (Citation2020) assessed the capability of using integrative (hybrid) AI models in improving the suspended sediment predictions based on two types of meta-heuristic algorithms, namely the butterfly optimization algorithm (BOA) and the genetic algorithm (GA). In general, the meta-heuristic algorithm increased the accuracy of AI models (ANFIS and ANN) by almost eight per cent. In such studies, however, limited data were used, and therefore, their generalization was also limited. More comprehensive studies related to the implementation of AI techniques with nature-inspired algorithms, considering that various stations have distinct geographical characteristics or climate, are needed.
Different optimization algorithms have been found to work better with different AI algorithms for suspended sediment modeling. Rahgoshay et al. (Citation2019) showed that the SVR model performed better in modeling the sediment transport amount when it was hybridized with PSO than with the GA method. However, Darabi et al. (Citation2021) showed that ANFIS performed better when hybridized with sine-cosine algorithm (SCA) than certain nature-inspired optimization algorithms, such as PSO. There are no guidelines on which optimizer should be hybridized with which AI algorithm for better prediction of sediment load. Different AI algorithms were individually optimized in previous studies using different optimizers to find the best AI-optimizer combination. However, only a few AI and optimization algorithms have been evaluated. Darabi et al. (Citation2021) examined the performance of three AI models, namely ANN, ANFIS and RBRNN models, with four optimization algorithms, namely sine-cosine algorithm (SCA), PSO, firefly algorithm, and bat algorithm, for sediment load prediction. Experiments can be conducted using more AI and optimization algorithms for comparative performance evaluation of different AI-optimizer combinations.
It is evident from the literature that linear regression and sediment rating curves are generally used and compared with AI methods for modeling SSL, and these methods produce inferior results compared to the latter methods. The MLR and SRC methods cannot adequately map the hysteresis behavior of the Q-SSL relationship. Therefore, it seems that comparison of highly non-linear AI methods with MLR and/or SRC in modeling SSL is not reasonable.
The other important issue in modeling SSL is that in most studies, previous SSL values were used as model inputs, which is hard to apply in practice because of the difficulty in measuring SSL data especially in the case of extreme events. On the other hand, the use of only water level data instead of discharge carries much more importance in modeling SSL, especially for the developing countries where effective variables are not available or missing for most of the stations.
It is worth noting some of the limitations to the use of AI approaches in modeling the SSL data series. It is known that two variables, SSL and streamflow, are generally used for modeling SSL and these variables have high spatial and temporal variability and mostly having highly skewed distributions. The main limitations of the implemented AI models are their low applicability to other basins which may have different morphological and climatic characteristics. The other limitation is their black box nature and their physical interpretation is a challenge and requires further analysis in quantifying the relationship between the independent and dependent parameters in a more reasonable way. Although the AI methods have some advantages in local modeling of SSLs, their limitations need to be addressed.
8. Insights for future research direction
Although several studies have endorsed ensemble learning as a more robust and effective artificial intelligence paradigm, there still exists a significant gap in utilizing ensemble learning in constructing AI models for suspended sediment concentration (Baskin et al., Citation2017; Wang et al., Citation2011). In this sense, further research is encouraged to explore the capability of different types of ensemble learning, particularly novel methodologies such as, AdaBoost and bagging techniques. Another topic that should be pursued in the area of suspended sediment modeling is the importance of bedload transportation in river systems and its influence on the variations of SSL. Although some studies consider both bedload and SSL modeling using AI methods (Pektaş & Doğan, Citation2015; Zounemat-Kermani, Mahdavi-Meymand, et al., Citation2020), the vast majority of the published studies have focused solely on the SSL as the target variable. Since employing AI models facilitates the process of encountering and embedding different input parameters, it is suggested to examine the effect of adding the bedload variable to the input vector in improving the final accuracy.
There is a need to channel more effort towards extending the current scope of research in this area. Considering these outcomes and the extensive state-of-the-art, the following recommendations can be considered for future studies:
This review provides interesting findings on AI models, especially in the area of their practical applicability. For instance, ELM, advanced version of ANN model has shown fast-computational learning capability, which has been qualified as an online expert predictive system with great real-time application potential. It has been recommended for the monitoring of sediment transport, which contributes to the operation of reservoir systems and development of dependable irrigation systems and water pollution control. Another benefit of SSL prediction is its importance to river engineering sustainability from hydrological, environmental, and ecological perspectives. The general architecture of ELM is shown in Figure .
Figure 11. Extreme learning machine general architecture.
In the single hidden layer ELM model, the random initialization of weight of internal network throughout the learning process can determine its efficiency. However, this framework can be an issue from the soft computing viewpoint, since the learning performance of the network can be affected by the single hidden layer which can lead to inaccurate predictions. Therefore, the extension of ELM to a deep learning NN model is needed, where recurrent hidden layers are hosted in the feature space, thereby ensuring a better determination of the internal weight. The presence of deep-learning-based AI models to solve hydrological related problems is yet to be explored; however, their high accuracy and fast training/testing times have rendered them desirable for modeling sediment transport.
Future applications of ELM as a hydrological prediction tool in areas with prominent hydrological feature memories could hinge on the use of advanced versions of the deep learning (DL) process which utilizes gradient-based Long Short-term Memory Network (LSTM) along with recurrent (or convolutional) layers (Hochreiter & Schmidhuber, Citation1997) as a predictive tool. The LSTM-based recurrent ELM can be applied in a way that LSTM can learn to bridge the marginal time lags in the case of discrete steps in order to enforce a constant error flow through error carousels, thereby permitting multiplicative gate units to learn the open/close access to the constant error flow. Such a model can implement input data time-series lagged behavior, and the result can be promising (Hochreiter & Schmidhuber, Citation1997; Sak et al., Citation2014; Tian & Pan, Citation2015). The local features in space and time can also be searched using LSTM-based ELM, since it has a generally little computational complexity, which can facilitate the extensive extraction of features with a low latency of the hydrological related variable output.
Another possible future direction is the assessment of prediction uncertainty, which has become a requirement for most modeling within the hydrology and water quality studies (Bayram et al., Citation2013; Wan Mohtar et al., Citation2019). Using the Lower Upper Bound Estimation method, Chen and Chau (Citation2019) attempted to address uncertainty analysis on a novel hybrid double feedforward neural network model for producing the sediment load prediction interval with promising results. This provides a preparatory work and other uncertainty methods can be further explored.
Beven (Citation2016) suggested that the development of hydrological science was being threatened by scarce resources. Hence, the use of cost-effective soft computing models should be considered rather than embarking on costly experimental investigations. Therefore, this advantage must be exploited to build expert systems, which can help solve real-world problems.
Suspended sediment flow is a complex non-linear process that AI algorithms try to map by establishing a relationship between inputs and output. It is often suggested that AI models’ inputs should be selected based on the non-linear relationship between inputs and output, rather than using conventional linear statistical approaches like correlation and auto-regression. In recent years, RFE method has been integrated with AI algorithms like SVM and ANN to use the RFE-SVM and RFE-ANN to select input features based on non-linear inputs-output relationships. For example, Pour et al. (Citation2020) used RFE-SVM to select inputs for a rainfall prediction model of peninsular Malaysia using AI. Such non-linear feature selection methods can be employed to improve AI models’ sediment prediction accuracy.
The relationship between suspended sediment and its driving factors may change with time. This is more likely due to changes in rainfall and other drivers of river sedimentation in the contexts of climate and other environmental changes. Therefore, the predictive model developed using historical data becomes obsolete within a short period. In recent years, the forward rolling method has been used to make the AI prediction model adaptable to changes in the input-output relationship. For example, Khan et al. (Citation2021) used a forward rolling AI algorithm to develop a climate change resilient heatwave prediction model for Pakistan. Such approach can be used in modeling suspended sediment to make them robust to environmental changes.
Sediment data is unavailable in most of the rivers, even in developed countries. Transformation of basin information from one gauged catchment to another nearby ungauged catchment is often suggested to model the ungauged catchment’s hydrological process. Recently, AI models have been used to predict streamflow of one catchment using rainfall and streamflow data of nearby gauged catchment. For example, Kim and Song (Citation2020) trained a convolution neural network with data of a gauged catchment and used it for streamflow prediction of a nearby catchment. Kratzert et al. (Citation2019) conducted a review on predictions in ungauged basins using AI and its potential. A similar study can be conducted to predict sediment flow in ungauged or poorly gauged catchments using nearby catchment data.
Big data is considered as the future solution to complex prediction problem. An extensive amount of data from different sources, including satellite, dense observational network and governmental statistics, are used. AI models can be used to integrate satellite high-resolution precipitation, land use, soil, and digital elevation model data for real-time prediction of river sedimentation’s spatial distribution. Such models have more potential to provide the required information for river sedimentation management.
Obviously, the efficiency of AI models must not only be based on its numerical accuracy, rather, but its practical implementation for water resources management must be considered, especially, knowledge-based expert systems. The physically-based modeling approaches, for instance, have been proven useful and as excellent hydrological methodologies. Therefore, hybridization of the AI modeling technique with the current decision-making outline is still a difficult task, especially when considering the complicated nature of the system physics and availability of information.
The impact of human activity on modeling has been noted as a significant factor missing in the extensive review. It is certain that human activities can significantly affect the behavior of a basin of a multi-criteria catchment; therefore, such a constructive factor must not be neglected as it can influence model performance.
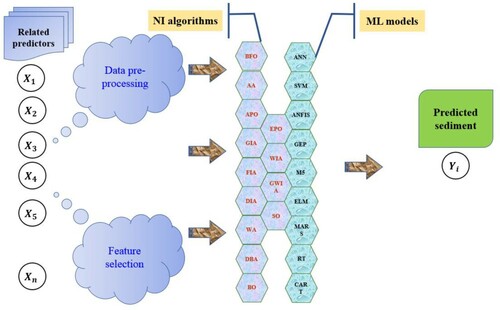
Hybrid AI models have succeeded in handling non-stationary, random, and complex data (Tahani et al., Citation2019). Consequently, these efforts should be encouraged for the proposition of more coupled models in forthcoming research possibilities. Various nature-inspired (NI) optimizers have been established over the years among which many are still unmapped in the field of river suspended sediment modeling. Such optimizers are bacterial foraging optimization (Das et al., Citation2009), amoeba based algorithm (Zhang et al., Citation2013), artificial plant optimization (Cui et al., Citation2012), flower pollination algorithms (Yang, Citation2012), grasshopper-insect based algorithm (Saremi et al., Citation2017), wasp-insect based algorithm (Theraulaz, Citation1991), fruitfly-insect based algorithm (Xing & Gao, Citation2014), glow- worm-insect based algorithm (Krishnanand & Ghose, Citation2009), dragonfly-insect based algorithm (Mirjalili, Citation2016), shark optimization (Hersovici et al., Citation1998), whale optimization (Mirjalili & Lewis, Citation2016), bean optimization (Zhang et al., Citation2010), doves-bird based algorithms (Su et al., Citation2009), eagle-bird based algorithms (Yang & Deb, Citation2010), cuckoo search (Yang & Deb, Citation2009), bird mating (Askarzadeh & Rezazadeh, Citation2012), monkey-animal based algorithms (Mucherino & Seref, Citation2007), wolf-animal based algorithms (Liu et al., Citation2011), lion-animal based algorithms (Yazdani & Jolai, Citation2016), and artificial fish-swarm algorithm (Li, Citation2003). A possible design of NI algorithm coupled with AI models applied to river sediment modeling is shown in Figure .
Figure 12. Proposed scheme of hybrid predictive models based on the hybridization of nature inspired optimization algorithms with standard artificial intelligence models.
Based on an experimental study (Juez et al., Citation2018) concluded that the dynamics of fine sediment jointly observed with discharge found in nature was different in different reaches of the same river system. The morphological evolution of the riverbed within a reach (degradation or aggradation) is controlled by the importance of the sediment available at that location relative to the incoming sediment. The type of hysteretical loop modulated by the interaction of both the distal and proximal supply is intrinsically related with these two types of morphological processes of the riverbed. Consequently, sediment processes as sediment hysteresis are difficult to model adequately. This shows that adequately modeling of SSL needs new modeling strategies considering the inputs including the morphological changes in the riverbed (Juez et al., Citation2018).
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Ab Ghani, A., & Azamathulla, H. M. (2014). Development of GEP-based functional relationship for sediment transport in tropical rivers. Neural Computing and Applications. https://doi.org/https://doi.org/10.1007/s00521-012-1222-9
- Adams, M. P., Ghisalberti, M., Lowe, R. J., Callaghan, D. P., Baird, M. E., Infantes, E., & O’Brien, K. R. (2018). Water residence time controls the feedback between seagrass, sediment and light: Implications for restoration. Advances in Water Resources, 117, 14–26. https://doi.org/https://doi.org/10.1016/j.advwatres.2018.04.004
- Adib, A., & Mahmoodi, A. (2017). Prediction of suspended sediment load using ANN GA conjunction model with Markov chain approach at flood conditions. KSCE Journal of Civil Engineering, 21(1), 447–457. https://doi.org/https://doi.org/10.1007/s12205-016-0444-2
- Afan, H. A., El-shafie, A., Mohtar, W. H. M. W., & Yaseen, Z. M. (2016). Past, present and prospect of an Artificial Intelligence (AI) based model for sediment transport prediction. Journal of Hydrology, https://doi.org/https://doi.org/10.1016/j.jhydrol.2016.07.048
- Afan, H. A., Keshtegar, B., Mohtar, W. H. M. W., & El-Shafie, A. (2017). Harmonize input selection for sediment transport prediction. Journal of Hydrology, 552, 366–375. https://doi.org/https://doi.org/10.1016/j.jhydrol.2017.07.008
- Ahmed, A. A., Deo, R. C., Raj, N., Ghahramani, A., Feng, Q., Yin, Z., & Yang, L. (2021a). Deep learning forecasts of soil moisture: Convolutional neural network and gated recurrent unit models coupled with satellite-derived MODIS, observations and synoptic-scale climate index data. Remote Sensing, 13(4), 554. https://doi.org/https://doi.org/10.3390/rs13040554
- Ahmed, A. A. M., Deo, R. C., Ghahramani, A., Raj, N., Feng, Q., Yin, Z., & Yang, L. (2021b). LSTM integrated with Boruta-random forest optimiser for soil moisture estimation under RCP4. 5 and RCP8. 5 Global warming scenarios. Stochastic Environmental Research and Risk Assessment, 1–31. https://doi.org/https://doi.org/10.1007/s00477-021-01969-3
- Akay, A. E., Erdas, O., Reis, M., & Yuksel, A. (2008). Estimating sediment yield from a forest road network by using a sediment prediction model and GIS techniques. Building and Environment, 43(5), 687–695. https://doi.org/https://doi.org/10.1016/j.buildenv.2007.01.047
- Al-Musaylh, M. S., Deo, R. C., & Li, Y. (2020). Electrical energy demand forecasting model development and evaluation with maximum overlap discrete wavelet transform-online sequential extreme learning machines algorithms. Energies, 13(9), 2307. https://doi.org/https://doi.org/10.3390/en13092307
- Alizadeh, M. J., Jafari Nodoushan, E., Kalarestaghi, N., & Chau, K. W. (2017). Toward multi-day-ahead forecasting of suspended sediment concentration using ensemble models. Environmental Science and Pollution Research, 24(36), 28017–28025. https://doi.org/https://doi.org/10.1007/s11356-017-0405-4
- Alp, M., & Cigizoglu, H. K. (2007). Suspended sediment load simulation by two artificial neural network methods using hydrometeorological data. Environmental Modelling & Software, 22(1), 2–13. https://doi.org/https://doi.org/10.1016/j.envsoft.2005.09.009
- Andrews, D. F. (1974). A robust method for multiple linear regression. Technometrics, 16(4), 523–531. https://doi.org/https://doi.org/10.1080/00401706.1974.10489233
- Armanini, A., Cavedon, V., & Righetti, M. (2015). A probabilistic/deterministic approach for the prediction of the sediment transport rate. Advances in Water Resources, 81, 10–18. https://doi.org/https://doi.org/10.1016/j.advwatres.2014.09.008
- Askarzadeh, A., & Rezazadeh, A. (2012). A new heuristic optimization algorithm for modeling of proton exchange membrane fuel cell: Bird mating optimizer. International Journal of Energy Research, 37(10), 1196–1204. https://doi.org/https://doi.org/10.1002/er.2915
- Azamathulla, H. M., Cuan, Y. C., Ghani, A. A., & Chang, C. K. (2012). Suspended sediment load prediction of river systems: GEP approach. Arabian Journal of Geosciences, 6(9), 3469–3480. https://doi.org/https://doi.org/10.1007/s12517-012-0608-4
- Baskin, I. I., Marcou, G., Horvath, D., & Varnek, A. (2017). Bagging and boosting of regression models. Tutorials in chemoinformatics. John Wiley & Sons. https://doi.org/https://doi.org/10.1002/9781119161110.ch16
- Bayram, A., Kankal, M., Tayfur, G., & Önsoy, H. (2013). Prediction of suspended sediment concentration from water quality variables. Neural Computing and Applications, 24(5), 1079–1087. https://doi.org/https://doi.org/10.1007/s00521-012-1333-3
- Betrie, G. D., Mohamed, Y. A., Griensven, A., & Srinivasan, R. (2011). Sediment management modelling in the Blue Nile Basin using SWAT model. Hydrology and Earth System Sciences, 15(3), 807–818. https://doi.org/https://doi.org/10.5194/hess-15-807-2011
- Beven, K. (2016). Advice to a young hydrologist. Hydrological Processes, 30(20), 3578–3582. https://doi.org/https://doi.org/10.1002/hyp.10879
- Bhagat, S. K., Paramasivan, M., Al-Mukhtar, M., Tiyasha, T., Pyrgaki, K., Tung, T. M., & Yaseen, Z. M. (2021). Prediction of lead (Pb) adsorption on attapulgite clay using the feasibility of data intelligence models. Environmental Science and Pollution Research. https://doi.org/https://doi.org/10.1007/s11356-021-12836-7
- Bhagat, S. K., Pyrgaki, K., Salih, S. Q., Tiyasha, T., Beyaztas, U., Shahid, S., & Yaseen, Z. M. (2021). Prediction of copper ions adsorption by attapulgite adsorbent using tuned-artificial intelligence model. Chemosphere, 276, 130162. https://doi.org/https://doi.org/10.1016/j.chemosphere.2021.130162
- Bhagat, S. K., & Tiyasha, T. (2013). Impact of millions of tones of effluent of textile industries: Analysis of textile industries effluents in Bhilwara and an approach with bioremediation. International Journal of ChemTech Research, 5(3), 1289–1298.
- Bhagat, S. K., Tiyasha, T., Awadh, S. M., Tung, T. M., Jawad, A. H., & Yaseen, Z. M. (2020). Prediction of sediment heavy metal at the Australian Bays using newly developed hybrid artificial intelligence models. Environmental Pollution, 115663. https://doi.org/https://doi.org/10.1016/j.envpol.2020.115663
- Bhagat, S. K., Tiyasha, T., & Bekele, D. N. (2018). Economical approaches for the treatment and reutilization of Laundry wastewater – A review. Journal of Industrial Pollution Control, 34(2), 2164–2178.
- Bhagat, S. K., Tiyasha, T., Tung, T. M., Mostafa, R. R., & Yaseen, Z. M. (2020). Manganese (Mn) removal prediction using extreme gradient model. Ecotoxicology and Environmental Safety, 204(August), 111059. https://doi.org/https://doi.org/10.1016/j.ecoenv.2020.111059
- Bhagat, S. K., Tung, T. M., & Yaseen, Z. M. (2020). Heavy metal contamination prediction using ensemble model: Case study of Bay sedimentation, Australia. Journal of Hazardous Materials, 403, 123492. https://doi.org/https://doi.org/10.1016/j.jhazmat.2020.123492
- Bharti, B., Pandey, A., Tripathi, S. K., & Kumar, D. (2017). Modelling of runoff and sediment yield using ANN, LS-SVR, REPTree and M5 models. Hydrology Research, 48(6), 1489–1507. https://doi.org/https://doi.org/10.2166/nh.2017.153
- Bisoyi, N., Gupta, H., Padhy, N. P., & Chakrapani, G. J. (2019). Prediction of daily sediment discharge using a back propagation neural network training algorithm: A case study of the Narmada River, India. International Journal of Sediment Research, 34(2), 125–135. https://doi.org/https://doi.org/10.1016/j.ijsrc.2018.10.010
- Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/https://doi.org/10.1023/A:1010933404324
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and regression trees. Wadsworth.
- Buyukyildiz, M., & Kumcu, S. Y. (2017). An estimation of the suspended sediment load using adaptive network based fuzzy inference system, support vector machine and artificial neural network models. Water Resources Management, 31(4), 1343–1359. https://doi.org/https://doi.org/10.1007/s11269-017-1581-1
- Chen, S., & Cowan, F. N. (1991). Orthogonal least squares learning algorithm for radial basis function networks. IEEE Transactions on Neural Networks, 2(2), 302–309. https://doi.org/https://doi.org/10.1109/72.80341
- Chen, X., & Chau, K. (2019). Uncertainty analysis on hybrid double feedforward neural network model for sediment load estimation with LUBE method.
- Chen, X. Y., & Chau, K. W. (2016). A hybrid double feedforward neural network for suspended sediment load estimation. Water Resources Management, 30(7), 2179–2194. https://doi.org/https://doi.org/10.1007/s11269-016-1281-2
- Choubin, B., Darabi, H., Rahmati, O., Sajedi-Hosseini, F., & Kløve, B. (2018). River suspended sediment modelling using the CART model: A comparative study of machine learning techniques. Science of the Total Environment, 615, 272–281. https://doi.org/https://doi.org/10.1016/j.scitotenv.2017.09.293
- Cicek, Z. I. E., & Ozturk, Z. K. (2021). Optimizing the artificial neural network parameters using a biased random key genetic algorithm for time series forecasting. Applied Soft Computing, 102, 107091. https://doi.org/https://doi.org/10.1016/j.asoc.2021.107091
- Cigizoglu, H. K. (2004). Estimation and forecasting of daily suspended sediment data by multi-layer perceptrons. Advances in Water Resources, 27(2), 185–195. https://doi.org/https://doi.org/10.1016/j.advwatres.2003.10.003
- Cigizoglu, H. K., & Alp, M. (2006). Generalized regression neural network in modelling river sediment yield. Advances in Engineering Software, 37(2), 63–68. https://doi.org/https://doi.org/10.1016/j.advengsoft.2005.05.002
- Cortes, C., & Vapnik, V. (1995). Support vector machine. Machine Learning, 20(3), 273–297.
- Crichton, N. J., Hinde, J. P., & Marchini, J. (1997). Models for diagnosing chest pain: Is CART helpful? Statistics in Medicine, 16(7), 717–727. https://doi.org/https://doi.org/10.1002/(SICI)1097-0258(19970415)16:7<717::AID-SIM504>3.0.CO;2-E
- Cui, Z., Yang, C., & Sanyal, S. (2012). Training artificial neural networks using APPM. International Journal of Wireless and Mobile Computing, 5(2), 168–174. https://doi.org/https://doi.org/10.1504/IJWMC.2012.046787
- Darabi, H., Mohamadi, S., Karimidastenaei, Z., Kisi, O., Ehteram, M., ELShafie, A., & Haghighi, A. T. (2021). Prediction of daily suspended sediment load (SSL) using new optimization algorithms and soft computing models. Soft Computing, 1–18. https://doi.org/https://doi.org/10.1007/s00500-021-05721-5
- Das, S., Dasgupta, S., Biswas, A., Abraham, A., & Konar, A. (2009). On stability of the chemotactic dynamics in bacterial-foraging optimization algorithm. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, 39(3), 670–679. https://doi.org/https://doi.org/10.1109/TSMCA.2008.2011474
- Daubechies, I. (1988). Orthonormal bases of compactly supported wavelets. Communications on Pure and Applied Mathematics, 41(7), 909–996. https://doi.org/https://doi.org/10.1002/cpa.3160410705
- De Vente, J., Poesen, J., & Verstraeten, G. (2005). The application of semi-quantitative methods and reservoir sedimentation rates for the prediction of basin sediment yield in Spain. Journal of Hydrology. https://doi.org/https://doi.org/10.1016/j.jhydrol.2004.08.030
- Demirci, M., & Baltaci, A. (2013). Prediction of suspended sediment in river using fuzzy logic and multilinear regression approaches. Neural Computing and Applications, 23(Suppl. 1), 145–151. https://doi.org/https://doi.org/10.1007/s00521-012-1280-z
- Dietterich, T. G. (2000). Ensemble methods in machine learning. In Oncogene (Vol. 12, pp. 1–15). https://doi.org/https://doi.org/10.1007/3-540-45014-9_1.
- Dorigo, M., Maniezzo, V., & Colorni, A. (1996). Ant system: Optimization by a colony of cooperating agents. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, https://doi.org/https://doi.org/10.1109/3477.484436
- Du, K.-L., & Swamy, M. N. S. (2019). Recurrent neural networks. In Neural networks and statistical learning (pp. 351–371). Springer.
- Duy Vinh, V., Ouillon, S., Van Thao, N., & Ngoc Tien, N. (2016). Numerical simulations of suspended sediment dynamics due to seasonal forcing in the Mekong coastal area. Water, 8(6), 255. https://doi.org/https://doi.org/10.3390/w8060255
- Emamgholizadeh, S., & Demneh, R. K. (2019). A comparison of artificial intelligence models for the estimation of daily suspended sediment load: A case study on the Telar and Kasilian rivers in Iran. Water Science and Technology: Water Supply, 19(1), 165–178. https://doi.org/https://doi.org/10.2166/ws.2018.062
- Evaristo, J., & McDonnell, J. J. (2019). Global analysis of streamflow response to forest management. Nature. https://doi.org/https://doi.org/10.1038/s41586-019-1306-0
- Fadaee, M., Mahdavi-Meymand, A., & Zounemat-Kermani, M. (2020). Suspended sediment prediction using integrative soft computing models: On the analogy between the butterfly optimization and genetic algorithms. Geocarto International. 1–14. https://doi.org/https://doi.org/10.1080/10106049.2020.1753821
- Fang, H.-W., & Wang, G.-Q. (2000). Three-dimensional mathematical model of suspended-sediment transport. Journal of Hydraulic Engineering, 126(8), 578–592. https://doi.org/https://doi.org/10.1061/(asce)0733-9429(2000)126:8(578)
- Ferreira, C. (2001). Gene expression programming: A new adaptive algorithm for solving problems. Complex Systems, 13(2), 87–129. arXiv preprint cs/0102027.
- Francke, T., López-Tarazón, J. A., & Schröder, B. (2008). Estimation of suspended sediment concentration and yield using linear models, random forests and quantile regression forests. Hydrological Processes: An International Journal, 22(25), 4892–4904. https://doi.org/https://doi.org/10.1002/hyp.7110
- Friedman, J. H. (1991). Multivariate adaptive regression splines. The Annals of Statistics, 19(1), 1–67. https://doi.org/https://doi.org/10.1214/aos/1176347963
- Ghimire, S., Deo, R. C., Raj, N., & Mi, J. (2019). Wavelet-based 3-phase hybrid SVR model trained with satellite-derived predictors, particle swarm optimization and maximum overlap discrete wavelet transform for solar radiation prediction. Renewable and Sustainable Energy Reviews, 113, 109247. https://doi.org/https://doi.org/10.1016/j.rser.2019.109247
- Gholami, V., Booij, M. J., Nikzad Tehrani, E., & Hadian, M. A. (2018). Spatial soil erosion estimation using an artificial neural network (ANN) and field plot data. Catena, 163(April), 210–218. https://doi.org/https://doi.org/10.1016/j.catena.2017.12.027
- Goldberg, D. E., & Holland, J. H. (1988). Genetic algorithms and machine learning. Machine Learning, 3(2), 95–99. https://doi.org/https://doi.org/10.1023/A:1022602019183
- Gomes, W. J. S., Beck, A. T., Lopez, R. H., & Miguel, L. F. F. (2018). A probabilistic metric for comparing metaheuristic optimization algorithms. Structural Safety, 70, 59–70. https://doi.org/https://doi.org/10.1016/j.strusafe.2017.10.006
- Gregory, P. (2005). Bayesian logical data analysis for the physical sciences: A comparative approach with mathematica® support. Cambridge University Press.
- Greig, S. M., Sear, D. A., & Carling, P. A. (2005). The impact of fine sediment accumulation on the survival of incubating salmon progeny: Implications for sediment management. Science of the Total Environment. https://doi.org/https://doi.org/10.1016/j.scitotenv.2005.02.010
- Grossmann Jean, A. (1984). Decomposition of hardy functions into square integrable wavelets of constant shape. SIAM Journal on Mathematical Analysis, 15(4), 723–736. https://doi.org/https://doi.org/10.1137/0515056
- Halecki, W., Kruk, E., & Ryczek, M. (2018). Estimations of nitrate nitrogen, total phosphorus flux and suspended sediment concentration (SSC) as indicators of surface-erosion processes using an ANN (Artificial Neural Network) based on geomorphological parameters in mountainous catchments. Ecological Indicators, 91(March), 461–469. https://doi.org/https://doi.org/10.1016/j.ecolind.2018.03.072
- Hamaamin, Y. A., Nejadhashemi, A. P., Zhang, Z., Giri, S., Adhikari, U., & Herman, M. R. (2018). Evaluation of neuro-fuzzy and Bayesian techniques in estimating suspended sediment loads. Sustainable Water Resources Management. https://doi.org/https://doi.org/10.1007/s40899-018-0225-9
- Harrell, F. E. (2015). Regression modeling strategies: with applications to linear models, logistic and ordinal regression, and survival analysis. Springer.
- Hassanpour, F., Sharifazari, S., Ahmadaali, K., Mohammadi, S., & Sheikhalipour, Z. (2019). Development of the FCM-SVR hybrid model for estimating the suspended sediment load. KSCE Journal of Civil Engineering, 23(6), 2514–2523. https://doi.org/https://doi.org/10.1007/s12205-019-1693-7
- Heathcote, I. W. (2009). Integrated watershed management: Principles and practice. John Wiley & Sons.
- Heddam, S., & Kisi, O. (2018). Modelling daily dissolved oxygen concentration using least square support vector machine, multivariate adaptive regression splines and M5 model tree. Journal of Hydrology. https://doi.org/https://doi.org/10.1016/j.jhydrol.2018.02.061
- Hersovici, M., Jacovi, M., Maarek, Y. S., Pelleg, D., Shtalhaim, M., & Ur, S. (1998). The shark-search algorithm. An application: Tailored web site mapping. Computer Networks and ISDN Systems, 30(1–7), 317–326. https://doi.org/https://doi.org/10.1016/S0169-7552(98)00038-5
- Himanshu, S. K., Asce, S. M., Pandey, A., & Yadav, B. (2016). Ensemble wavelet-support vector machine approach for prediction of suspended sediment load using hydrometeorological data. Journal of Hydrologic Engineering, 22(3), 1–14. https://doi.org/https://doi.org/10.1061/(ASCE)HE.1943-5584.0001516
- Himanshu, S. K., Pandey, A., & Yadav, B. (2017). Assessing the applicability of TMPA-3B42V7 precipitation dataset in wavelet-support vector machine approach for suspended sediment load prediction. Journal of Hydrology, 550, 103–117. https://doi.org/https://doi.org/10.1016/j.jhydrol.2017.04.051
- Hochreiter, S., & Schmidhuber, J. J. (1997). Long short-term memory. Neural Computation, 9(8), 1–32. https://doi.org/https://doi.org/10.1162/neco.1997.9.8.1735
- Hosmer, D. W., Lemeshow, S., & Sturdivant, R. X. (2013). Applied logistic regression. John Wiley & Sons.
- Huang, L., Fang, H., & Reible, D. (2015). Mathematical model for interactions and transport of phosphorus and sediment in the Three Gorges Reservoir. Water Research, 85, 393–403. https://doi.org/https://doi.org/10.1016/j.watres.2015.08.049
- Jha, S. K., & Bombardelli, F. A. (2011). Theoretical/numerical model for the transport of non-uniform suspended sediment in open channels. Advances in Water Resources, 34(5), 577–591. https://doi.org/https://doi.org/10.1016/j.advwatres.2011.02.001
- Juez, C., Hassan, M. A., & Franca, M. J. (2018). The origin of fine sediment determines the observations of suspended sediment fluxes under unsteady flow conditions. Water Resources Research, 54(8), 5654–5669. https://doi.org/https://doi.org/10.1029/2018WR022982
- Karaboga, D., & Basturk, B. (2007). A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. Journal of Global Optimization, 39(3), 459–471. https://doi.org/https://doi.org/10.1007/s10898-007-9149-x
- Kaveh, K., Duc Bui, M., & Rutschmann, P. (2017). A comparative study of three different learning algorithms applied to ANFIS for predicting daily suspended sediment concentration. International Journal of Sediment Research, 32(3), 340–350. https://doi.org/https://doi.org/10.1016/j.ijsrc.2017.03.007
- Kennedy, J., & Eberhart, R. (1995). Particle swarm optimization, 1942–1948.
- Khan, M. Y. A., Tian, F., Hasan, F., & Chakrapani, G. J. (2019). Artificial neural network simulation for prediction of suspended sediment concentration in the River Ramganga, Ganges Basin, India. International Journal of Sediment Research, 34(2), 95–107. https://doi.org/https://doi.org/10.1016/j.ijsrc.2018.09.001
- Khan, N., Shahid, S., Ismail, T. B., & Behlil, F. (2021). Prediction of heat waves over Pakistan using support vector machine algorithm in the context of climate change. Stochastic Environmental Research and Risk Assessment, 1–19. https://doi.org/https://doi.org/10.1007/s00477-020-01963-1
- Khosravi, K., Mao, L., Kisi, O., Yaseen, Z. M., & Shahid, S. (2018). Quantifying hourly suspended sediment load using data mining models: Case study of a glacierized Andean catchment in Chile. Journal of Hydrology, 567(June), 165–179. https://doi.org/https://doi.org/10.1016/j.jhydrol.2018.10.015
- Kim, D. Y., & Song, C. M. (2020). Developing a discharge estimation model for ungauged watershed using CNN and hydrological image. Water, 12(12), 3534. https://doi.org/https://doi.org/10.3390/w12123534
- Kişi, Ö. (2009). Evolutionary fuzzy models for river suspended sediment concentration estimation. Journal of Hydrology. https://doi.org/https://doi.org/10.1016/j.jhydrol.2009.03.036
- Kisi, O., Choubin, B., Deo, R. C., & Yaseen, Z. M. (2019). Incorporating synoptic-scale climate signals for streamflow modelling over the Mediterranean region using machine learning models. Hydrological Sciences Journal. https://doi.org/https://doi.org/10.1080/02626667.2019.1632460
- Kisi, O., Dailr, A. H., Cimen, M., & Shiri, J. (2012). Suspended sediment modeling using genetic programming and soft computing techniques. Journal of Hydrology, 450–451, 48–58. https://doi.org/https://doi.org/10.1016/j.jhydrol.2012.05.031
- Kisi, O., & Ozkan, C. (2016). A new approach for modeling sediment-discharge relationship: Local weighted linear regression. Water Resources Management, 31(1), 1–23. https://doi.org/https://doi.org/10.1007/s11269-016-1481-9
- Kisi, O., & Yaseen, Z. M. (2019). The potential of hybrid evolutionary fuzzy intelligence model for suspended sediment concentration prediction. Catena, 174(May 2018), 11–23. https://doi.org/https://doi.org/10.1016/j.catena.2018.10.047
- Kisi, O., & Zounemat-Kermani, M. (2016). Suspended sediment modeling using neuro-fuzzy embedded fuzzy c-means clustering technique. Water Resources Management, 30(11), 3979–3994. https://doi.org/https://doi.org/10.1007/s11269-016-1405-8
- Klecka, W. R., Iversen, G. R., & Klecka, W. R. (1980). Discriminant analysis (Vol. 19). Sage.
- Koza, J. R. (1994). Genetic programming as a means for programming computers by natural selection. Statistics and Computing, 4(2), 87–112. https://doi.org/https://doi.org/10.1007/BF00175355
- Kratzert, F., Klotz, D., Herrnegger, M., Sampson, A. K., Hochreiter, S., & Nearing, G. S. (2019). Toward improved predictions in ungauged basins: Exploiting the power of machine learning. Water Resources Research, 55(12), 11344–11354. https://doi.org/https://doi.org/10.1029/2019WR026065
- Krishnanand, K. N., & Ghose, D. (2009). Glowworm swarm optimization for simultaneous capture of multiple local optima of multimodal functions. Swarm Intelligence, 3(2), 87–124. https://doi.org/https://doi.org/10.1007/s11721-008-0021-5
- Kumar, A., Kumar, P., & Singh, V. K. (2019). Evaluating different machine learning models for runoff and suspended sediment simulation. Water Resources Management, 33(3), 1217–1231. https://doi.org/https://doi.org/10.1007/s11269-018-2178-z
- Leisenring, M., & Moradkhani, H. (2012). Analyzing the uncertainty of suspended sediment load prediction using sequential data assimilation. Journal of Hydrology, 468, 268–282. https://doi.org/https://doi.org/10.1016/j.jhydrol.2012.08.049
- Lek, S., & Guégan, J. F. (1999). Artificial neural networks as a tool in ecological modelling, an introduction. Ecological Modelling, 120(2–3), 65–73. https://doi.org/https://doi.org/10.1016/S0304-3800(99)00092-7
- Lenzi, M. A., & Marchi, L. (2000). Suspended sediment load during floods in a small stream of the Dolomites (northeastern Italy). CATENA, 39(4), 267–282. https://doi.org/https://doi.org/10.1016/s0341-8162(00)00079-5
- Lewis, R. J., Ph, D., & Street, W. C. (2000). An introduction to classification and regression tree (CART) analysis. 2000 Annual Meeting of the Society for Academic Emergency Medicine, (310), 14 p. https://10.1.1.95.4103.
- Li, X. L. (2003). A new intelligent optimization-artificial fish swarm algorithm. Doctor Thesis, Zhejiang University of Zhejiang.
- Liu, C., Yan, X., Liu, C., & Wu, H. (2011). The wolf colony algorithm and its application. Chinese Journal of Electronics, 20(2), 212–216.
- Liu, J., Zhou, Z., & Zhang, X. J. (2019). Impacts of sediment load and size on rill detachment under low flow discharges. Journal of Hydrology, 570, 719–725. https://doi.org/https://doi.org/10.1016/j.jhydrol.2019.01.033
- Liu, Q. J., Zhang, H. Y., Gao, K. T., Xu, B., Wu, J. Z., & Fang, N. F. (2019). Time-frequency analysis and simulation of the watershed suspended sediment concentration based on the Hilbert-Huang transform (HHT) and artificial neural network (ANN) methods: A case study in the Loess Plateau of China. Catena, 179(April 2018), 107–118. https://doi.org/https://doi.org/10.1016/j.catena.2019.03.042
- Maier, H. R., & Dandy, G. C. (1999). Empirical comparison of various methods for training feed-forward neural networks for salinity forecasting. Water Resources Research,35(8), 2591–2596. https://doi.org/https://doi.org/10.1029/1999WR900-150
- Malagó, A., Bouraoui, F., Vigiak, O., Grizzetti, B., & Pastori, M. (2017). Modelling water and nutrient fluxes in the Danube River Basin with SWAT. Science of the Total Environment. https://doi.org/https://doi.org/10.1016/j.scitotenv.2017.05.242
- Malik, A., Kumar, A., Kisi, O., & Shiri, J. (2019). Evaluating the performance of four different heuristic approaches with Gamma test for daily suspended sediment concentration modeling. Environmental Science and Pollution Research. https://doi.org/https://doi.org/10.1007/s11356-019-05553-9
- Mamdani, E. H., & Assilian, S. (1975). An experiment in linguistic synthesis with a fuzzy logic controller. International Journal of Man-Machine Studies, 7(1), 1–13. https://doi.org/https://doi.org/10.1016/S0020-7373(75)80002-2
- Merkhali, S. P., Ehteshami, M., & Sadrnejad, S. A. (2015). Assessment quality of a nonuniform suspended sediment transport model under unsteady flow condition (case study: Aras River). Water and Environment Journal. https://doi.org/https://doi.org/10.1111/wej.12137
- Meshram, S. G., Ghorbani, M. A., Deo, R. C., Kashani, M. H., Meshram, C., & Karimi, V. (2019). New approach for sediment yield forecasting with a two-phase feedforward neuron network-particle swarm optimization model integrated with the gravitational search algorithm. Water Resources Management, 33(7), 2335–2356. https://doi.org/https://doi.org/10.1007/s11269-019-02265-0
- Mirjalili, S. (2016). Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Computing and Applications, 27(4), 1053–1073. https://doi.org/https://doi.org/10.1007/s00521-015-1920-1
- Mirjalili, S., & Lewis, A. (2016). The whale optimization algorithm. Advances in Engineering Software, 95, 51–67. https://doi.org/https://doi.org/10.1016/j.advengsoft.2016.01.008
- Moeeni, H., & Bonakdari, H. (2018). Impact of normalization and input on ARMAX-ANN model performance in suspended sediment load prediction. Water Resources Management, 32(3), 845–863. https://doi.org/https://doi.org/10.1007/s11269-017-1842-z
- Mount, N., & Stott, T. (2008). A discrete Bayesian network to investigate suspended sediment concentrations in an Alpine proglacial zone. Hydrological Processes, 22(18), 3772–3784. https://doi.org/https://doi.org/10.1002/hyp.6981
- Mucherino, A., & Seref, O. (2007). Monkey search: a novel metaheuristic search for global optimization. In AIP conference proceedings (Vol. 953, pp. 162–173). AIP.
- Nguyen, K. D., Guillou, S., Chauchat, J., & Barbry, N. (2009). A two-phase numerical model for suspended-sediment transport in estuaries. Advances in Water Resources, 32(8), 1187–1196. https://doi.org/https://doi.org/10.1016/j.advwatres.2009.04.001
- Nhu, V.-H., Rahmati, O., Falah, F., Shojaei, S., Al-Ansari, N., Shahabi, H., & Ahmad, B. (2020). Mapping of groundwater spring potential in karst aquifer system using novel ensemble bivariate and multivariate models. Water, 12(4), 985. https://doi.org/https://doi.org/10.3390/w12040985
- Noori, R., Karbassi, A. R., Moghaddamnia, A., Han, D., Zokaei-Ashtiani, M. H., Farokhnia, A., & Gousheh, M. G. (2011). Assessment of input variables determination on the SVM model performance using PCA, Gamma test, and forward selection techniques for monthly stream flow prediction. Journal of Hydrology, 401(3–4), 177–189. https://doi.org/https://doi.org/10.1016/j.jhydrol.2011.02.021
- Nourani, V., Hosseini Baghanam, A., Adamowski, J., & Kisi, O. (2014). Applications of hybrid wavelet–artificial intelligence models in hydrology: A review. Journal of Hydrology, 514, 358–377. https://doi.org/https://doi.org/10.1016/j.jhydrol.2014.03.057
- Nourani, V., Molajou, A., Tajbakhsh, A. D., & Najafi, H. (2019). A wavelet based data mining technique for suspended sediment load modeling. Water Resources Management, 33(5), 1769–1784. https://doi.org/https://doi.org/10.1007/s11269-019-02216-9
- Oehler, F., Coco, G., Green, M. O., & Bryan, K. R. (2012). A data-driven approach to predict suspended-sediment reference concentration under non-breaking waves. Continental Shelf Research, 46, 96–106. https://doi.org/https://doi.org/10.1016/j.csr.2011.01.015
- Olyaie, E., Banejad, H., Chau, K.-W., & Melesse, A. M. (2015). A comparison of various artificial intelligence approaches performance for estimating suspended sediment load of river systems: A case study in United States. Environmental Monitoring and Assessment, 187(4), 189. https://doi.org/https://doi.org/10.1007/s10661-015-4381-1
- Pearl, J. (2014). Probabilistic reasoning in intelligent systems: Networks of plausible inference. Elsevier.
- Pektas, A. O., & Cigizoglu, H. K. (2017a). Investigating the extrapolation performance of neural network models in suspended sediment data. Hydrological Sciences Journal, 62(10), 1694–1703. https://doi.org/https://doi.org/10.1080/02626667.2017.1349316
- Pektas, A. O., & Cigizoglu, H. K. (2017b). Long-range forecasting of suspended sediment. Hydrological Sciences Journal, 62(14), 2415–2425. https://doi.org/https://doi.org/10.1080/02626667.2017.1383607
- Pektaş, A. O., & Doğan, E. (2015). Prediction of bed load via suspended sediment load using soft computing methods. Geofizika, 32(1), 27–46. https://doi.org/https://doi.org/10.15233/gfz.2015.32.2
- Percival, D., & Walden, B. (2000). Wavelet methods for time series analysis. Cambridge Univ. Press.
- Pour, S. H., Wahab, A. K. A., & Shahid, S. (2020). Physical-empirical models for prediction of seasonal rainfall extremes of Peninsular Malaysia. Atmospheric Research, 233, 104720. https://doi.org/https://doi.org/10.1016/j.atmosres.2019.104720
- Prasad, R., Deo, R. C., Li, Y., & Maraseni, T. (2017). Input selection and performance optimization of ANN-based streamflow forecasts in the drought-prone Murray Darling Basin region using IIS and MODWT algorithm. Atmospheric Research, 197, 42–63. https://doi.org/https://doi.org/10.1016/j.atmosres.2017.06.014
- Qanza, H., Maslouhi, A., Hachimi, M., & Hmimou, A. (2019). Simultaneous estimation of hydro-dipersive parameters using a new modified levenberg-marquardt algorithm. MATEC Web of Conferences, 286, 6001. https://doi.org/https://doi.org/10.1051/matecconf/201928606001
- Qin, W., Wang, L., Lin, A., Zhang, M., & Bilal, M. (2018). Improving the estimation of daily aerosol optical depth and aerosol radiative effect using an optimized artificial neural network. Remote Sensing. https://doi.org/https://doi.org/10.3390/rs10071022
- Qin, W., Wang, L., Lin, A., Zhang, M., Xia, X., Hu, B., & Niu, Z. (2018). Comparison of deterministic and data-driven models for solar radiation estimation in China. Renewable and Sustainable Energy Reviews, 81(May 2017), 579–594. https://doi.org/https://doi.org/10.1016/j.rser.2017.08.037
- Qin, W., Wang, L., Zhang, M., Niu, Z., Luo, M., Lin, A., & Hu, B. (2019). First effort at constructing a high-density photosynthetically active radiation dataset during 1961–2014 in China. Journal of Climate. https://doi.org/https://doi.org/10.1175/JCLI-D-18-0590.1
- Quilty, J., & Adamowski, J. (2018). Addressing the incorrect usage of wavelet-based hydrological and water resources forecasting models for real-world applications with best practices and a new forecasting framework. Journal of Hydrology, https://doi.org/https://doi.org/10.1016/j.jhydrol.2018.05.003
- Quinlan, J. R. (1992). Learning with continuous classes. In 5th Australian joint conference on artificial intelligence (Vol. 92, pp. 343–348). Singapore.
- Raghavendra, S., & Deka, P. C. (2014). Support vector machine applications in the field of hydrology: A review. Applied Soft Computing Journal, 19, 372–386. https://doi.org/https://doi.org/10.1016/j.asoc.2014.02.002
- Rahgoshay, M., Feiznia, S., Arian, M., Ali, S., & Hashemi, A. (2018). Modeling daily suspended sediment load using improved support vector machine model and genetic algorithm.
- Rahgoshay, M., Feiznia, S., Arian, M., & Hashemi, S. A. A. (2019). Simulation of daily suspended sediment load using an improved model of support vector machine and genetic algorithms and particle swarm. Arabian Journal of Geosciences, 12(9), https://doi.org/https://doi.org/10.1007/s12517-019-4444-7
- Rajaee, T. (2011). Wavelet and ANN combination model for prediction of daily suspended sediment load in rivers. Science of the Total Environment, 409(15), 2917–2928. https://doi.org/https://doi.org/10.1016/j.scitotenv.2010.11.028
- Rechenberg, I. (1994). Evolutionsstrategie. frommann-holzboog.
- Riahi-Madvar, H., & Seifi, A. (2018). Uncertainty analysis in bed load transport prediction of gravel Bed Rivers by ANN and ANFIS. Arabian Journal of Geosciences, 11(21), 21. https://doi.org/https://doi.org/10.1007/s12517-018-3968-6
- Rice, S., & Church, M. (1996). Sampling surficial fluvial gravels; the precision of size distribution percentile sediments. Journal of Sedimentary Research, 66(3), 654–665. https://doi.org/https://doi.org/10.2110/jsr.66.654
- Rosenblatt, F. (1961). Principles of neurodynamics. Perceptrons and the theory of brain mechanisms. Cornell Aeronautical Lab Inc Buffalo NY.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1988). Learning representations by back-propagating errors. Cognitive Modeling, 5(3), 1.
- Sadeghi, S. H., & Singh, V. P. (2017). Dynamics of suspended sediment concentration, flow discharge and sediment particle size interdependency to identify sediment source. Journal of Hydrology, 554, 100–110. https://doi.org/https://doi.org/10.1016/j.jhydrol.2017.09.006
- Sak, H., Senior, A., & Beaufays, F. (2014). Long short-term memory recurrent neural network architectures for large scale acoustic modeling. Interspeech, 2014(September), 338–342. https://1402.1128
- Sakizadeh, M. (2020). Spatial distribution and source identification together with environmental health risk assessment of PAHs along the coastal zones of the USA. Environmental Geochemistry and Health, 42(10), 3333–3350. https://doi.org/https://doi.org/10.1007/s10653-020-00578-3
- Samarasinghe, S. (2006). Neural networks for applied Sciences and engineering. Taylor & Francis Group, LLC.
- Samet, K., Hoseini, K., Karami, H., & Mohammadi, M. (2019). Comparison between soft computing methods for prediction of sediment load in rivers: Maku Dam case study. Iranian Journal of Science and Technology – Transactions of Civil Engineering, 43(1), 93–103. https://doi.org/https://doi.org/10.1007/s40996-018-0121-4
- Sang, Y.-F. (2013). A review on the applications of wavelet transform in hydrology time series analysis. Atmospheric Research, 122, 8–15. https://doi.org/https://doi.org/10.1016/j.atmosres.2012.11.003
- Saremi, S., Mirjalili, S., & Lewis, A. (2017). Grasshopper optimisation algorithm: Theory and application. Advances in Engineering Software, 105, 30–47. https://doi.org/https://doi.org/10.1016/j.advengsoft.2017.01.004
- Schölkopf, B., Smola, A. J., Williamson, R. C., & Bartlett, P. L. (2000). New support vector algorithms. Neural Computation, 12(5), 1207–1245. https://doi.org/https://doi.org/10.1162/089976600300015565
- Senthil Kumar, A. R., Ojha, C. S. P., Goyal, M. K., Singh, R. D., & Swamee, P. K. (2012). Modeling of suspended sediment concentration at Kasol in India using ANN, fuzzy logic, and decision tree algorithms. Journal of Hydrologic Engineering, 17(3), 394–404. https://doi.org/https://doi.org/10.1061/(ASCE)HE.1943-5584.0000445
- Shadkani, S., Abbaspour, A., Samadianfard, S., Hashemi, S., Mosavi, A., & Band, S. S. (2020). Comparative study of multilayer perceptron-stochastic gradient descent and gradient boosted trees for predicting daily suspended sediment load: The case study of the Mississippi River, US. International Journal of Sediment Research. https://doi.org/https://doi.org/10.1016/j.ijsrc.2020.10.001
- Shamaei, E., & Kaedi, M. (2016). Suspended sediment concentration estimation by stacking the genetic programming and neuro-fuzzy predictions. Applied Soft Computing Journal, 45, 187–196. https://doi.org/https://doi.org/10.1016/j.asoc.2016.03.009
- Sharafati, A., Haghbin, M., Motta, D., & Yaseen, Z. M. (2019). The application of soft computing models and empirical formulations for hydraulic structure scouring depth simulation: A comprehensive review, assessment and possible future research direction. Archives of Computational Methods in Engineering, 1–25. https://doi.org/https://doi.org/10.1007/s11831-019-09382-4
- Sharafati, A., Haji Seyed Asadollah, S. B., Motta, D., & Yaseen, Z. M. (2020). Application of newly developed ensemble machine learning models for daily suspended sediment load prediction and related uncertainty analysis. Hydrological Sciences Journal, https://doi.org/https://doi.org/10.1080/02626667.2020.1786571
- Sharafati, A., Masoud, H., Tiwari, N. K., Bhagat, S. K., Al-Ansari, N., Chau, K.-W., & Yaseen, Z. M. (2021). Performance evaluation of sediment ejector efficiency using hybrid neuro-fuzzy models. Engineering Applications of Computational Fluid Mechanics, 15(1), 627–643. https://doi.org/https://doi.org/10.1080/19942060.2021.1893224
- Sharghi, E., Nourani, V., Najafi, H., & Gokcekus, H. (2019). Conjunction of a newly proposed emotional ANN (EANN) and wavelet transform for suspended sediment load modeling. Water Supply, 1–9. https://doi.org/https://doi.org/10.2166/ws.2019.044
- Sharghi, E., Nourani, V., Najafi, H., & Soleimani, S. (2019). Wavelet-exponential smoothing: A new hybrid method for suspended sediment load modeling. Environmental Processes. 6(1), 191–218. https://doi.org/https://doi.org/10.1007/s40710-019-00363-0
- Shojaeezadeh, S. A., Nikoo, M. R., McNamara, J. P., AghaKouchak, A., & Sadegh, M. (2018). Stochastic modeling of suspended sediment load in alluvial rivers. Advances in Water Resources. https://doi.org/https://doi.org/10.1016/j.advwatres.2018.06.006
- Simons, D. B., & Şentürk, F. (1992). Sediment transport technology: Water and sediment dynamics. Water Resources Publication.
- Singh, K. P., Basant, A., Malik, A., & Jain, G. (2009). Artificial neural network modeling of the river water quality – A case study. Ecological Modelling, 220(6), 888–895. https://doi.org/https://doi.org/10.1016/j.ecolmodel.2009.01.004
- Sinha, R., Gupta, A., Mishra, K., Tripathi, S., Nepal, S., Wahid, S. M., & Swarnkar, S. (2019). Basin-scale hydrology and sediment dynamics of the Kosi river in the Himalayan foreland. Journal of Hydrology, 570, 156–166. https://doi.org/https://doi.org/10.1016/j.jhydrol.2018.12.051
- Singh, V. K., Kumar, D., Kashyap, P. S., & Kisi, O. (2018). Simulation of suspended sediment based on gamma test, heuristic, and regression-based techniques. Environmental Earth Sciences, 77(19). https://doi.org/https://doi.org/10.1007/s12665-018-7892-6
- Su, M. C., Su, S. Y., & Zhao, Y. X. (2009). A swarm-inspired projection algorithm. Pattern Recognition, 42(11), 2764–2786. https://doi.org/https://doi.org/10.1016/j.patcog.2009.03.020
- Sudhishri, S., Kumar, A., & Singh, J. K. (2016). Comparative evaluation of neural network and regression based models to simulate runoff and sediment yield in an outer Himalayan Watershed. Journal of Agricultural Science and Technology, 18(3), 681–694.
- Suif, Z., Fleifle, A., Yoshimura, C., & Saavedra, O. (2016). Spatio-temporal patterns of soil erosion and suspended sediment dynamics in the Mekong River Basin. Science of the Total Environment, 568, 933–945. https://doi.org/https://doi.org/10.1016/j.scitotenv.2015.12.134
- Suykens, J. A. K., & Vandewalle, J. (1999). Least squares support vector machine classifiers. Neural Processing Letters, 9(3), 293–300. https://doi.org/https://doi.org/10.1023/A:1018628609742
- Tahani, M., Yousefi, H., Noorollahi, Y., & Fahimi, R. (2019). Application of nature inspired optimization algorithms in optimum positioning of pump-as-turbines in water distribution networks. Neural Computing and Applications. https://doi.org/https://doi.org/10.1007/s00521-018-3566-2
- Takagi, H., & Hayashi, I. (1988). Artificial-neural-network-driven fuzzy reasoning. In Workshop on fuzzy system application (pp. 217–218).
- Takagi, T., & Sugeno, M. (1985). Fuzzy identification of systems and its applications to modeling and control. IEEE Transactions on Systems, Man and Cybernetics, 15(1), 116–132. https://doi.org/https://doi.org/10.1109/TSMC.1985.6313399
- Tao, H., Keshtegar, B., & Yaseen, Z. M. (2019). The feasibility of integrative radial basis M5Tree predictive model for river suspended sediment load simulation. Water Resources Management, 33(13), 4471–4490. https://doi.org/https://doi.org/10.1007/s11269-019-02378-6
- Theraulaz, G. (1991). Task differentiation in Polistes wasp colonies: a model for self-organizing groups of robots. In Proceedings of the First International Conference on Simulation of Adaptive Behavior: From Animals to Animates, 1991 (pp. 346–355). The MIT Press.
- Tian, Y., & Pan, L. (2015). Predicting short-term traffic flow by long short-term memory recurrent neural network. In 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity) (pp. 153–158). https://doi.org/https://doi.org/10.1109/SmartCity.2015.63.
- Tiyasha, T., & Yaseen, Z. M. (2020). A survey on river water quality modelling using artificial intelligence models: 2000–2020. Journal of Hydrology. https://doi.org/https://doi.org/10.1016/j.jhydrol.2020.124670
- Ulke, A., Tayfur, G., & Ozkul, S. (2017). Investigating a suitable empirical model and performing regional analysis for the suspended sediment load prediction in major rivers of the Aegean region, Turkey. Water Resources Management. https://doi.org/https://doi.org/10.1007/s11269-016-1357-z
- Verstraeten, G., Poesen, J., de Vente, J., & Koninckx, X. (2003). Sediment yield variability in Spain: A quantitative and semiqualitative analysis using reservoir sedimentation rates. Geomorphology, 50(4), 327–348. https://doi.org/https://doi.org/10.1016/S0169-555X(02)00220-9
- Walling, D. E. (1977). Assessing the accuracy of suspended sediment rating curves for a small basin. Water Resources Research, 13(3), 531–538. https://doi.org/https://doi.org/10.1029/wr013i003p00531
- Walling, D. E., & Collins, A. L. (2008). The catchment sediment budget as a management tool. Environmental Science & Policy, 11(2), 136–143. https://doi.org/https://doi.org/10.1016/j.envsci.2007.10.004
- Wan Mohtar, W. H. M., Abdul Maulud, K. N., Muhammad, N. S., Sharil, S., & Yaseen, Z. M. (2019). Spatial and temporal risk quotient based river assessment for water resources management. Environmental Pollution, 248, 133–144. https://doi.org/https://doi.org/10.1016/j.envpol.2019.02.011
- Wang, G., Hao, J., Ma, J., & Jiang, H. (2011). A comparative assessment of ensemble learning for credit scoring. Expert Systems with Applications, 38(1), 223–230. https://doi.org/https://doi.org/10.1016/j.eswa.2010.06.048
- Wang, L., Kisi, O., Zounemat-Kermani, M., & Li, H. (2017). Pan evaporation modeling using six different heuristic computing methods in different climates of China. Journal of Hydrology, 544, 407–427. https://doi.org/https://doi.org/10.1016/j.jhydrol.2016.11.059
- Wang, L., Kisi, O., Zounemat-Kermani, M., Zhu, Z., Gong, W., Niu, Z., & Liu, Z. (2017). Prediction of solar radiation in China using different adaptive neuro-fuzzy methods and M5 model tree. International Journal of Climatology. https://doi.org/https://doi.org/10.1002/joc.4762
- Wang, S., Flanagan, D. C., & Engel, B. A. (2019). Estimating sediment transport capacity for overland flow. Journal of Hydrology, 123985. https://doi.org/https://doi.org/10.1016/j.jhydrol.2019.123985
- Wang, X., Yen, H., Jeong, J., & Williams, J. R. (2015). Accounting for conceptual soil erosion and sediment yield modeling uncertainty in the APEX model using Bayesian model averaging. Journal of Hydrologic Engineering, 20(6), C4014010. https://doi.org/https://doi.org/10.1061/(ASCE)HE.1943-5584.0001119
- Wen, X., Feng, Q., Deo, R. C., Wu, M., Yin, Z., Yang, L., & Singh, V. P. (2019). Two-phase extreme learning machines integrated with the complete ensemble empirical mode decomposition with adaptive noise algorithm for multi-scale runoff prediction problems. Journal of Hydrology, 570, 167–184. https://doi.org/https://doi.org/10.1016/j.jhydrol.2018.12.060
- Williams, J. R., & Berndt, H. D. (1976). Sediment yield prediction based on watershed hydrology. American Society of Agricultural Engineering.
- Wu, L., Yao, W., & Ma, X. (2018). Using the comprehensive governance degree to calibrate a piecewise sediment delivery ratio algorithm for dynamic sediment predictions: A case study in an ecological restoration watershed of northwest China. Journal of Hydrology, 564, 888–899. https://doi.org/https://doi.org/10.1016/j.jhydrol.2018.07.072
- Wu, W., Dandy, G. C., & Maier, H. R. (2014). Protocol for developing ANN models and its application to the assessment of the quality of the ANN model development process in drinking water quality modelling. Environmental Modelling and Software, 54, 108–127. http://www.scopus.com/inward/record.url?eid=2-s2.0-84892886293&partnerID=40&md5=d674e77b09b399ef7aeca582f4ab94f6. https://doi.org/https://doi.org/10.1016/j.envsoft.2013.12.016
- Xing, B., & Gao, W.-J. (2014). Fruit fly optimization algorithm. In Innovative computational intelligence: A rough guide to 134 clever algorithms (pp. 167–170). Springer.
- Yadav, A., Chatterjee, S., & Equeenuddin, S. M. (2018). Suspended sediment yield estimation using genetic algorithm-based artificial intelligence models: Case study of Mahanadi River, India. Hydrological Sciences Journal, 63(8), 1162–1182. https://doi.org/https://doi.org/10.1080/02626667.2018.1483581
- Yang, X.-S., & Deb, S. (2009). Cuckoo search via Lévy flights. In 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC) (pp. 210–214). IEEE.
- Yang, X.-S., & Deb, S. (2010). Eagle strategy using Lévy walk and firefly algorithms for stochastic optimization. In Nature inspired cooperative strategies for optimization (NICSO 2010) (pp. 101–111). Springer.
- Yang, X. S. (2012, September). Flower pollination algorithm for global optimization. In International conference on unconventional computing and natural computation (pp. 240–249). Springer.
- Yaseen, Z. M., Ebtehaj, I., Kim, S., Sanikhani, H., Asadi, H., Ghareb, M. I., & Al-Ansari, N. (2019). Novel hybrid data-intelligence model for forecasting monthly rainfall with uncertainty analysis. Water, 11(3), 502. https://doi.org/https://doi.org/10.3390/w11030502
- Yaseen, Z. M., Mohtar, W. H. M. W., Ameen, A. M. S., Ebtehaj, I., Razali, S. F. M., Bonakdari, H., & Shahid, S. (2019). Implementation of univariate paradigm for streamflow simulation using hybrid data-driven model: Case study in tropical region. IEEE Access, 7, 74471–74481. https://doi.org/https://doi.org/10.1109/ACCESS.2019.2920916
- Yaseen, Z. M., Zigale, T. T., Kumar, R., Salih, S. Q., Awasthi, S., Tung, T. M., & Bhagat, S. K. (2019). Laundry wastewater treatment using a combination of sand filter, bio-char and teff straw media. Scientific Reports, 9(1), 1–11. https://doi.org/https://doi.org/10.1038/s41598-019-54888-3
- Yazdani, M., & Jolai, F. (2016). Lion optimization algorithm (LOA): a nature-inspired metaheuristic algorithm. Journal of Computational Design and Engineering, 3(1), 24–36. https://doi.org/https://doi.org/10.1016/j.jcde.2015.06.003
- Yilmaz, B., Aras, E., Nacar, S., & Kankal, M. (2018). Estimating suspended sediment load with multivariate adaptive regression spline, teaching-learning based optimization, and artificial bee colony models. Science of the Total Environment, 639, 826–840. https://doi.org/https://doi.org/10.1016/j.scitotenv.2018.05.153
- Younger, M. S. (1979). Handbook for linear regression (Vol. 1). Duxbury Press North Scituate.
- Zhang, C., & Ma, Y. (2012). Ensemble machine learning: Methods and applications. Springer.
- Zhang, X., Sun, B., Mei, T., & Wang, R. (2010). Post-disaster restoration based on fuzzy preference relation and bean optimization algorithm. In 2010 IEEE Youth Conference on Information, Computing and Telecommunications (pp. 271–274). IEEE.
- Zhang, X., Zhang, Y., Hu, Y., Deng, Y., & Mahadevan, S. (2013). An adaptive amoeba algorithm for constrained shortest paths. Expert Systems with Applications, 40(18), 7607–7616. https://doi.org/https://doi.org/10.1016/j.eswa.2013.07.054
- Zhao, H., Yang, S., Yang, B., & Huang, Y. (2017). Quantifying anthropogenic and climatic impacts on sediment load in the sediment-rich region of the Chinese Loess Plateau by coupling a hydrological model and ANN. Stochastic Environmental Research and Risk Assessment, 31(8), 2057–2073. https://doi.org/https://doi.org/10.1007/s00477-017-1381-4
- Zhou, W., Zhang, L., & Jiao, L. (2002). Linear programming support vector machines. Pattern Recognition, 35(12), 2927–2936. https://doi.org/https://doi.org/10.1016/S0031-3203(01)00210-2
- Zounemat-Kermani, M. (2012). Hourly predictive Levenberg–Marquardt ANN and multi linear regression models for predicting of dew point temperature. Meteorology and Atmospheric Physics, 117(3–4), 181–192. https://doi.org/https://doi.org/10.1007/s00703-012-0192-x
- Zounemat-Kermani, M. (2017). Assessment of several nonlinear methods in forecasting suspended sediment concentration in streams. Hydrology Research, 48(5), 1240–1252. https://doi.org/https://doi.org/10.2166/nh.2016.219
- Zounemat-Kermani, M., Beheshti, A.-A., Ataie-Ashtiani, B., & Sabbagh-Yazdi, S.-R. (2009). Estimation of current-induced scour depth around pile groups using neural network and adaptive neuro-fuzzy inference system. Applied Soft Computing, 9(2), 746–755. https://doi.org/https://doi.org/10.1016/j.asoc.2008.09.006
- Zounemat-Kermani, M., Kişi, Ö, Adamowski, J., & Ramezani-Charmahineh, A. (2016). Evaluation of data driven models for river suspended sediment concentration modeling. Journal of Hydrology, 535, 457–472. https://doi.org/https://doi.org/10.1016/j.jhydrol.2016.02.012
- Zounemat-Kermani, M., Mahdavi-Meymand, A., Alizamir, M., Adarsh, S., & MundherYaseen, Z. (2020). On the complexities of sediment load modeling using integrative machine learning: An application to the great river of loíza in Puerto Rico. Journal of Hydrology, 124759. https://doi.org/https://doi.org/10.1016/j.jhydrol.2020.124759
- Zounemat-Kermani, M., Matta, E., Cominola, A., Xia, X., Zhang, Q., Liang, Q., & Hinkelmann, R. (2020). Neurocomputing in surface water hydrology and hydraulics: A review of two decades retrospective, current status and future prospects. Journal of Hydrology. https://doi.org/https://doi.org/10.1016/j.jhydrol.2020.125085