
ABSTRACT
Based on web services and the Activiti 5.0 workflow engine, we built a workflow-based web service chain processing flow platform to simplify the operations of complex geospatial information processing applications in the area of high performance geo-computation. The proposed framework includes a web portal and a convenient mode for similar specific applications. We also designed a general service publishing template for high performance commutating (HPC) that can reduce platform differences among different HPC systems and facilitate HPC techniques to improve processing efficiency. Finally, we used a digital elevation model to verify and test the platform. The results indicated that the proposed service chain platform offered convenience and efficiency when processing massive data with HPC.
1. Introduction
In order to accelerate computations and deal with limited computational resources when processing geospatial information, high performance computing (HPC) technologies have been used to improve processing efficiency (Lu, Wang, & Lu et al., Citation2017). As a result, high performance geo-computation (HPGC) (Huang, Tie, & Tao et al., Citation2019; Xue, Liu, Ai, & Wan, Citation2008) is mainly adopted in areas such as geographical information systems, remote sensing (Huang, Liu, Li, Wang, & Xu, Citation2011; Huang et al., Citation2016), petroleum exploration (Plaza, Du, & Chang, Citation2011), environmental protection, and meteorology (Zwieflhofer & Mozdzynski, Citation2005). HPGC is a specific application that utilizes various HPC techniques in the field of geoscience data processing (Xue, Wan, & Ai, Citation2008), which will be beneficial to the research of big Earth data (Guo, Citation2017). HPC systems have evolved from CPU-based homogeneous computing architectures to heterogeneous computing architectures that combine CPUs and coprocessors (Tang, Zhou, Fang, & Shen, Citation2016). Coprocessors are special-purpose processors designed for specific functions that ease the task load of the system processor. A coprocessor has a special instruction set and it usually has low structural redundancy and high energy efficiency. For certain applications, its computing power is generally tens or even hundreds of times that of general-purpose processors. For example, it has many processing cores and powerful floating-point computing capabilities. In particular, coprocessors like graphics processing units (GPUs) excel at data-intensive computing (Lindholm, Nickolls, Oberman, & Montrym, Citation2008), and many integrated core (MIC) architectures are based on the existing x86 architecture. Heterogeneous computing systems mainly refer to systems composed of computing units that use different types of instruction sets and architectures, such as CPUs and coprocessors like GPUs and MIC architectures (Huang, Bu, Tao, & Tan, Citation2016; Huang et al., Citation2017).
The application of HPGC to processing spatial data improves the efficiency of geospatial information processing. However, with the further development of research in the field of spatial information and the refinement of the processing results, every stage in the processing has been refined and expanded. Processing spatial information from the results becomes complex, and the intermediate processes are increasingly complicated. At the same time, a complete set of processes usually involves a variety of geospatial information algorithms. The algorithms themselves are diverse, and it is advisable to use different parallel approaches based on the characteristics of different algorithms. As a result, an optimized parallel algorithm usually inherits heterogeneous characteristics, with strong dependence on the platform. Although the abovementioned problem does not affect the application of a single independent algorithm, for a complete processing process with multiple HPC algorithms, repeated cross-platform processing not only requires system configuration, data transfer, and parameter setting, but also a mastery of HPC technologies and the corresponding HPC platforms. Therefore, it is worth seeking to effectively reduce the tedious operations in the process of spatial information processing while fully integrating existing computing resources.
To address these problems, some researchers have sought to make the usage of HPC platforms more convenient (Grossman & Sarkar, Citation2016). Meanwhile, a workflow can connect individual jobs into a complete execution process. However, for cross-platform integration of computing resources at different geographical locations with a single algorithm, it remains difficult to integrate computing resources based on the workflow with traditional approaches. This is due to the differences between platforms and energy efficiency at different geographical locations. Web services provide a mechanism for integrating computing resources on different platforms and in different geographical regions, owing to features such as loose coupling, modularization, and enhanced integration capability.
To summarize, existing HPC platforms cannot handle a complete process with a single job as the core, and a workflow alone cannot integrate heterogeneous computing resources distributed on different platforms. Therefore, to improve the efficiency and convenience of geospatial information processing with HPC resources, we here considered multiple processes of spatial information processing, along with the diversity of algorithms and the complexity of processing caused by platforms distributed over different geographical locations. Through service publication and discovery, each process was encapsulated into a single independent web service and distributed on different platforms. Meanwhile, by automatically processing the workflow process, all of the related services were linked to form a web service chain. As such, spatial information could be processed automatically and quickly, such that HPGC technologies can be more conveniently and effectively applied to geospatial information processing.
The paper is organized as follows. Section 2 discusses the related works of system or platform constructed with web services and workflow. Section 3 gives a brief introduction to web services and workflow technologies. Section 4 concentrates mainly on the design of the proposed common HPGC platform based on workflow services. Especially, Section 5 focuses on the design of a general algorithm service publishing template for HPGC. Section 6 presents a case study with various experiments performed to verify the correctness and performance of the method and discusses the experimental results. Finally, Section 7 draws some conclusions and points out future research directions.
2. Related works
From above, in the application of geospatial information processing that needs to introduce HPC, there are often existing aforementioned problems, e.g. there are many intermediate processes, the involved HPC platforms are heterogeneous and spatial distributed, cumbersome configuration files and frequent command operations. With easy access to web technology and the thin client technique, many researchers proposed providing computing resources through a combination of web technology and a job management platform (Zhou & Lin, Citation2014). This type of job management system provides a friendly interactive environment for task scheduling and resource allocation for HPC platforms. For instance, the National Energy Research Scientific Computing Center (NERSC) network toolkit (NEWT) created by Cholia et al. brings HPC to networks by making it easy to write web applications and making HPC resources more accessible (Cholia, Skinner, & Boverhof, Citation2010). Thomas et al. developed HotPage, which authenticates users with HPC system accounts and allows them to perform basic computing tasks via a web interface (Thomas, Mock, & Boisseau, Citation2000). Astrocomp, developed by Costa et al., is a web-based user-friendly interface that enables the international community to run parallel code on HPC systems without specific knowledge of UNIX or system commands (Costa et al., Citation2005). Hababeh et al. designed a web-based solution for network data services that monitor and control information authenticity and data dissemination. Their solution also provides HPC services to improve the management of telemedicine data (Hababeh, Khalil, & Khreishah, Citation2015). Liu used WSRF.NET grid middleware and the CONDOR resource scheduler to build a grid-computing platform for a Windows-based system (Liu, Citation2010). Chen et al. leveraged an open and portable batch processing system (PBS XML Accounting Toolkit) and Crond to create a web-based accounting system for HPC platforms (Chen, Yang, Chen, & Wang, Citation2010). Convenient access and thin-client features with web-based systems (known as “portals”) have certainly helped improve the usability of HPC platforms, but such portals are usually based on job management methods, and they focus on tasks consisting of a single independent algorithm. As such, they cannot handle complete task flows that contain applications of multiple algorithms (Liu, Huang, Yang, & Li, Citation2010).
A workflow can connect individual jobs into a complete execution process. There has been research on integrating workflows into a computing platform to solve the problem of process construction and management (Ding, Li, & Zhou, Citation2006). Tracey et al. proposed a workflow management system for developing a contact management system applicable to debt collection (Tracey et al., Citation2004). Du et al. presented a method of executing tasks in a distributed workflow management system. The system runs on one or more computers and is used to control the computer network and execute the workflow (Du, Davis, & Pfeifer, Citation2000). Deelman et al. presented the design and development of the Pegasus workflow management system, which maps abstract workflow descriptions onto a distributed computing infrastructure (Deelman et al., Citation2015). Their system has been used by scientists in a variety of fields, including astronomy, seismology, bioinformatics, and physics. Broomhall et al. proposed a workflow system for remote sensing, providing researchers with a powerful tool that does not require knowledge of remote sensing data processing technology (Broomhall et al., Citation2011). Deng and Yang improved the workflow execution efficiency of a cloud computing environment by adjusting the scheduling strategy of the workflow engine. In their work, the multi-constraint graph partitioning (MCGP) algorithm was applied to a workflow scheduling engine, and an improved multi-constraint graph ratio partitioning (MCGRP) algorithm was proposed (Deng & Wang, Citation2014). From a practical perspective, they analyzed the task workflow design in detail by taking the training system task workflow as an example (Yang & Hu, Citation2015).
However, for cross-platform integration of computing resources at different geographical locations with a single algorithm, it remains difficult to integrate computing resources based on the workflow with traditional approaches. This is due to the differences between platforms and energy efficiency at different geographical locations. Web services provide a mechanism for integrating computing resources on different platforms and in different geographical regions, owing to features such as loose coupling, modularization, and enhanced integration capability. For example, Yu et al. (Citation2006) proposed a method and key technology for spatial data conversion through web services to share and interact with spatial geographic information (Yu, Zhang, Zhang, & Liu, Citation2006). In response to the needs of spatial data sharing, Zhan et al. proposed a spatial data sharing framework based on web services and applied it to a provincial emergency management geographic information system (Zhan, Miao, & Leng, Citation2014). Deng et al. proposed a web service-based method of building a global agricultural drought monitoring and forecasting system that overcomes major limitations in previous global drought information systems and better supports global agricultural drought data and information dissemination and analysis services to help decision-makers (Deng, Di, & Han et al., Citation2015). However, these cases do not fully exploit HPC resources.
3. Web services and workflow technologies
3.1. Web services technologies
The development of computer technologies has resulted in a wide range of programming languages and application platforms. For example, JAVA has a powerful web application development system and is good at server-side development. The .NET. architecture has advantages for client-side development (Zeng, Citation2011). Therefore, for the development of real-world applications, it is a good practice to target different platforms to achieve the best performance with the final application. Because it is difficult or expensive to make an application portable across different platforms, however, the interaction between applications running on different components of a heterogeneous system is a practical challenge. The service-oriented architecture (SOA) was innovatively presented by Gartner in 1996 (Xu & Yao, Citation2008). Its main purpose is to divide tightly coupled systems into business-oriented, coarse-grained, loosely-coupled, and stateless services, which are provided to other application calls after being encapsulated (Barry, Citation2003). A web service is a specific implementation of the SOA. It is a remote calling technology that does not need any internal details. It is used to develop distributed and interoperable applications. By utilizing features such as loose coupling, encapsulation, and integration with other web services technologies, users can easily achieve the mutual communication of heterogeneous architecture applications (Xie, Zhang, & Zhao, Citation2002) while making the final application modular and portable.
3.2. Workflow technologies
3.2.1. Overview of workflows and Activiti 5.0
The definition of a workflow varies depending on the context. Large enterprises such as IBM and research institutions have their own understanding and specific definitions for a workflow. The problem that a workflow solves involves using a computer to automatically transfer information or tasks with the participation of multiple workers in accordance with defined rules, so as to achieve a specific business logic. The original purpose of this technology was to automate office processes (Georgakopoulos, Hornick, & Sheth, Citation1995). Research on workflow technologies has been ongoing since the 1970s. Due to the limitations of developing computing technologies at that time, the potential of workflow technologies was not fully explored. As the Internet was rapidly developing in the 1990s, an international organization called the Workflow Management Coalition (WFMC), committed to standardizing workflow technology, was established in 1993. Since then, workflow technologies have gradually matured (Luo, Fan, & Wu, Citation2000). Due to the wide adoption of workflow technologies, usage is no longer limited to managing documents. Workflows are now used to control and manage business processes.
Due to the popularity of Java EE, many excellent workflow engines have been implemented in Java EE, such as OSWorkflow by OpenSymphony (Diego, Citation2007) and jBPM by JBoss (Salatino, Citation2009). In 2010, a new workflow engine, called Activiti 5.0, was released by a research group led by Tom Baeyens and Joram Barrez at Alfresco. Activiti 5.0 is a lightweight workflow platform for developers and enterprise users. Activiti 5.0 is a fast and stable process engine based on JAVA and the business process model and notation (BPMN) 2.0 specifications, which are compatible with JAVA programs. Because Activiti 5.0 initially chose to adopt the open-source protocol Apache license 2.0, it has received ample attention from the open-source community. The project also attracted contributions from a large number of experts in the field of workflows, facilitating the development of Activiti 5.0 workflow technology.
3.2.2. Activiti and BPMN 2.0 specifications
BPMN decouples the underlying technology and business logic and fills the gap between process design and implementation through its defined process technology with a graphical model for process manipulation. The version of the BPMN specification has been upgraded from 1.x to 2.0. Version 2.0 focuses on execution semantics and the establishment of a universal exchange format widely adopted by the industry. This is significant because the process model established by BPMN 2.0 is not only commonly used for process design, although it is applicable to all process engines that use BPMN 2.0 as the description specification. Because of the advantages of BPMN, it stands out in many business process specifications and has been widely adopted by the industry. After the release of BPMN 2.0 in 2011, the major providers of workflow engines supported it. The workflow engine Activiti 5.0 used in our study is based on the BPMN 2.0 specification.
Currently, Activiti 5.0 supports a variety of common models of the BPMN 2.0 specification. Because there are many models in the BPMN 2.0 specification, this section focuses exclusively on models that are relevant to the content of this article.
(1) Start Event and End Event
The start event is the entry point of the process and it is represented by a circle drawn with thin lines in BPMN 2.0, as shown in ). It cannot be started by itself. Rather, it must be triggered by a third party. Generally, the start event element is represented by a start event element tag in the generated extensible markup language (XML) description file of the BPMN 2.0 specification. Similar to the start event, when the process executes to the end event, this signals that the whole process has been executed. This event is usually identified by a thick-lined circle, as shown in ).
Figure 1. Start and end events (a) Start event (b) End event
(2) Sequence Flow
As each model is independent, a connector is required to connect two models and establish a certain relationship. This is exactly the role of a sequence flow. Usually, a directed arrow is used to represent a sequence flow, and the direction of the arrow is the direction in which the process is executed, as shown in ). In the XML description file, sequenceFlow is usually used to identify the sequence flow. The source of the sequence flow is identified by the sourceRef attribute of the sequenceFlow element, and the targetRef attribute is used to identify the destination model (i.e. the model that is pointed to by the arrow) of the sequence flow.
Figure 2. Sequence flow and task (a) Sequence flow (b) Task
(3) Tasks
Tasks are a vital component of the process. A task model represents an individual business. In the BPMN 2.0 specification, the task model is denoted by a rectangle, as shown in ). For different types of business, there are different types of tasks. Among them, there is a type of task related to the research topic of this article, namely, a web service task. Web service tasks are used to call external web services and are represented in the XML description file as serviceTask elements.
4. System design of a common HPCG platform based on workflow services
4.1. Overview of the platform’s architecture design
To reduce the complexity of the system design and separate concerns during the process of code development, the system is divided into four main layers: the presentation layer, application layer, data layer, and hardware layer. In this way, each layer has a specific task, and at the same time reduces the coupling between the codes. This makes the system design more organized and convenient for subsequent maintenance. An overview of the system architecture is shown in .
Figure 3. Layered diagram of the common HPCG platform based on workflow services
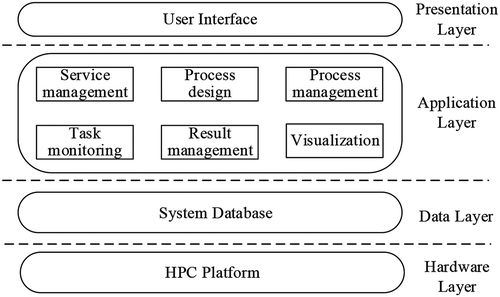
The presentation layer is a channel for users to interact with the platform directly. By providing the web-based interface, the platform processes information and related business functions, presenting the processed results to users. The presentation layer enables users to build models and process tasks with a user-friendly interface.
The application layer is a combination of various system function modules. It is the functional core of the system. It interacts with the presentation layer and the data layer, and it is responsible for the processing of all the system’s business. In the application layer, to decouple each function, a single independent function is designed as an independent module.
The data layer is responsible for storing all system-related data, including registered web service information, process definition files deployed in the workflow engine, and data from old tasks.
The hardware layer contains the HPC platform resources and spatial information algorithms deployed on the platforms. The main task of this layer is to provide a hardware platform for data processing.
As mentioned above, the application layer is the core layer of the entire system. The application layer is mainly divided into the following modules: process management, process modeling, service management, task monitoring, result management, and visualization. The dependency relationship among the modules is shown in .
Figure 4. Dependency graph of the modules in the application layer
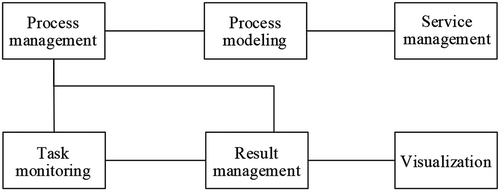
The specific function of each module shown in is as follows:
(1) Process management module: its main function is to manage web services. Since the services presented in this article are for internal usage, a local registration center is provided for local users to construct subsequent processes easily.
(2) Process modeling module: this module is used for intuitive and simple workflow-based web service chain modeling, for establishing business process description files, and for deploying to the Activiti 5.0 workflow engine. In this module, a user can drag the corresponding active node, select the required web servers on this node, and set its parameters.
(3) Service management module: this module is used to manage the process definition file deployed in the workflow engine, for example by viewing the BPMN 2.0 definition file and diagram of the process, or starting or deleting the established process. At the same time, the module also provides an interface for adding external process definition files.
(4) Task monitoring module: this module is responsible for checking the running status of the tasks, for example, the status of file uploading, task execution, and error labeling of each subtask.
(5) Result management module: this module manages the results of the processes that have ended, such as viewing and downloading the results and information (e.g. the time spent) of all subtasks of historical tasks. In addition, the platform’s visualization module interacts through the interface provided by the module.
(6) Visualization module: for most of the tasks related to image processing, this module visualizes the results.
A complete task execution sequence diagram for the proposed platform is shown in . The specific operation proceeds as follows.
(1) First, the user logs in to the platform page through a browser, and checks whether the algorithm service to be processed exists in the service management interface. If it does not exist, the published algorithm service can be registered locally.
(2) Then, the user enters the interface for the process designer to model the process, and proceeds to the process management interface to view the established process information and start the process.
(3) After the process enters the running state, the user can view the current task processing status information in the task monitoring module.
(4) After the entire process is completed, the user can view the task processing results on the result information interface and download the results.
Figure 5. Diagram of the operation sequence
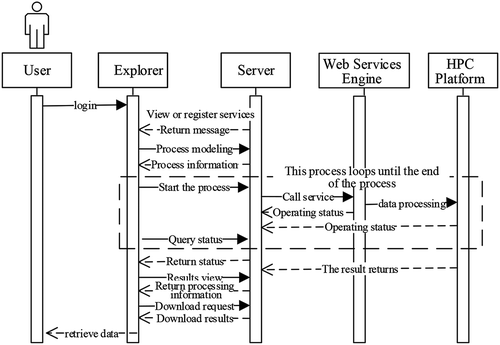
shows the complete process from scratch. If the user sees that there is a process definition in the process management interface, the process of modeling can be skipped and the process can be started directly.
4.2. Overall architecture of the platform
Following the layered structure of the system, the overall architecture of the system can be divided into several parts: HPGC service resources, application implementation, and the database. The overall system architecture is shown in .
Figure 6. Overall architecture of the system
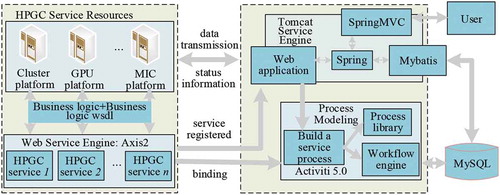
As shown in , complete task processing goes through the following stages:
(1) The user sends a request through a web browser to obtain the webpage of the system, and the request is sent to the background and processed by Spring MVC, a Spring framework that provides a full-featured model, view, and controller (MVC) module to build web applications conveniently.
(2) The system checks whether there is already a web service that is related to the request. If not, the service is added and registered, and the related data is stored in a MySQL database through the persistence tool, Mybatis.
(3) Process modeling: the user establishes a business process model through the process designer we developed. The model is submitted to generate a process description file in the background, and it is deployed to the Activiti 5.0 workflow engine.
(4) The process calls the web service deployed in the Axis2 engine during the automatic execution process. The web service interacts with the HPC platform internally through a remote access protocol. Meanwhile, the HPC platform exchanges data and information with the web service to deliver the results.
(5) After the task processing ends, all the results are saved in the MySQL database, and the user obtains the results through a web-based user interface.
5. Design and implementation of the general HPGC algorithm service publishing template
According to the above, the key to realizing such a platform is to provide and build a general HPGC service, and to drive these services running with other different modules on the platform. This section introduces the design of the general publishing mode of a geospatial information processing algorithm based on the popular web service engine, Apache Axis2, to facilitate the service publishing of the geospatial information algorithm applicable to this platform.
5.1. Design of general algorithm service publishing template for high-performance geo-computation
5.1.1. Characteristics of a HPGC algorithm service publishing template
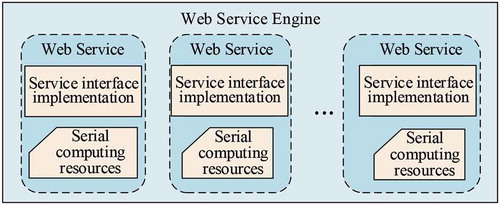
Due to the maturity of web service technology, there are many ways to publish web services. This is the most common way is to publish services based on a web service engine provided by major manufacturers. Because of its low platform dependence, the common serial algorithm can directly call the coding implementation class of the algorithm in the interface implementation of the service to complete the encapsulation of the service function. In addition, this kind of situation can be directly implemented on the machine that publishes the service, as shown in . However, the HPGC algorithm differs in important ways from the serial algorithm, so there are also many differences in the web service encapsulation and publishing of these algorithms.
Figure 7. General serial algorithm service encapsulation and publishing mode
First, HPC platforms are diverse and heterogeneous. The architecture based on a CPU cluster, GPU, and MIC coprocessor platform is widely used. In the research, the detailed information of the involved HPC platforms are listed in .
Table 1. Detailed configurations of the experimental platforms
At the same time, their programming mode is also diversified. (1) The message passing interface (MPI) is widely used in the CPU cluster area. It is a message passing programming model for inter-process communication. It provides a set of programming interfaces with high portability and can easily transplant other parallel codes. In addition, the MPI function library supports C/C++ and FORTRAN programming, and abides by the call rules of library functions. Programmers can write MPI programs without mastering other new concepts. (2) Due to the advantages of GPU processing power and memory bandwidth, with intensive and highly parallel characteristics, GPU computing platforms are booming. GPU platform-based programming methods include NVIDIA’s parallel compute unified device architecture (CUDA) and the non-profit OpenCL heterogeneous programming framework. These provide CUDA with the ability to develop programs in C language, which is convenient for developers using GPUs in parallel. However, because this programming mode can only run on an NVIDIA GPU card, the GPU platform is incompatible. In contrast, OpenCL is compatible with a variety of hardware devices from GPU manufacturers. It adopts a highly abstract mode of mapping application programs with the host, processing unit, and memory area, and offers two programming modes, task parallel and data parallel, which are convenient and flexible for developers. (3) Based on Intel’s integrated multi-core architecture, the MIC coprocessor is used for data parallel processing. The OpenMP programming model based on the MIC platform provides three programming elements: compilation guidance, API functions, and environment variables. Parallel programming mode shares the main memory, which simplifies programming details and makes programming more efficient. Most of the parallel algorithms based on MIC are based on the OpenMP program, which is implemented by adding the specific compiling guidance statements of the MIC platform.
Second, HPC platforms are distributed in different geographical locations, while parallel algorithms have strong platform dependence. In our framework, for example, the MPI parallel algorithm is based on the CPU cluster, whereas the OpenMP parallel algorithm is based on the MIC platform. As such, parallel algorithms must be deployed on the computing platform on which they depend.
For the above characteristics of the HPGC algorithm, unlike publishing with the common serial algorithm, service publishing with the HPGC parallel algorithm has the following characteristics:
(1) Due to the diversity of HPC platforms and different programming models, an appropriate method should be used to shield the differences among parallel algorithms based on heterogeneous computing platforms and the different programming methods, such that any parallel algorithm can adopt the same service publishing method.
(2) If the parallel algorithm is directly encapsulated in the implementation interface of the service in the manner of serial algorithm publishing, it is necessary to deploy the web service engine configuration environment in each computing platform to publish these services, owing to the strong platform dependence of the parallel algorithm. This will inevitably lead to repeated and tedious operations during the publishing process.
Based on this, the parallel algorithm service publishing template implemented in this paper separates the service implementation interface and computing resources, so as to avoid the repeated deployment of the web service engine and to decouple the interface from the computing resources. The proposed general parallel algorithm service encapsulation mode is shown in . It can be seen from the figure that algorithms and services are not directly connected, effectively shielding the differences of the HPC platform and reducing the dependence of the platforms. A detailed description of this design is introduced in the following subsection. In this way, it provides a general implementation mode for HPGC algorithm service encapsulation and release, without considering differences between the platforms.
Figure 8. General parallel algorithm encapsulation and publishing mode
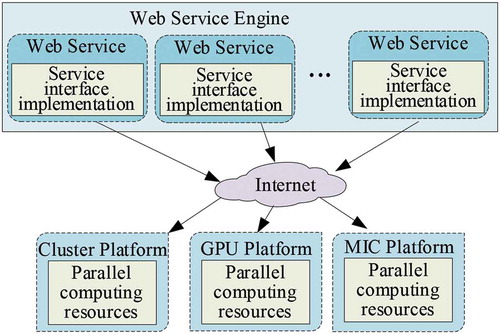
5.1.2. Design of a HPGC parallel algorithm service publishing template based on Axis2
Generally, geospatial information processing algorithms are written in different programming languages. For example, Axis2 uses JAVA to write service code. Different programming languages have different platform dependencies. Under this circumstance, the services encapsulation for geospatial processing algorithms will have strong platform dependence, and this is unsuitable when directly encapsulating the relevant geospatial information parallel algorithm in the interface of the service. The service publishing method based on the proposed framework separates the geospatial information parallel algorithm from the service specific logic. Because of the strong platform dependence of the algorithm, it is suitable to deploy the algorithm in the remote computing platform on which it depends. Through the interface of the service, the transmission of the control data in the class and the execution of the task of the remote HPC are realized. The structure of service publishing is shown in .
Figure 9. Publishing structure of spatial information algorithm service
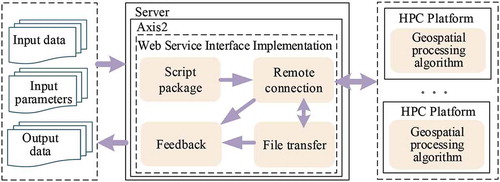
The details of the specific design are given as follows:
(1) Service operation parameter setting: When the geospatial information algorithm runs through the command line, it needs to know not only the command to run the algorithm, but also the input data and output data path information of the algorithm. If the algorithm has parameter settings, it should also provide this information. Therefore, three variables, input data, output data, and algorithm parameters, are provided in the service interface implementation as the input parameters when invoking the service.
(2) Script encapsulation: In order to achieve the automatic operation of the program without human intervention, the implementation logic of the service interface adopts a way of creating a running script, which encapsulates the commands related to the algorithm processing into script execution. Because HPC computing platforms usually run and manage the running program through portable batch system (PBS) job management software, we used a PBS script as the remote computing platform to execute the script. The specific program running instructions are encapsulated in this script.
(3) Remote connection: Because the geospatial information algorithm associated with the service is deployed in the remote HPC computing platform, the communication between the service interface and the remote computing platform must be realized when the service is invoked to realize data processing. When the computing platform uses Linux as the operating system, the remote connection classes that realize the functions of remote login, remote file copy, and remote command execution are written based on the SSH2 (secure Shell) protocol. With the Windows operating system, the remote interaction is based on the Telnet service component and Telnet protocol.
(4) Data transmission. After communication with the remote computing platform is established through remote login, the input file processed by the subtask is uploaded to the computing platform as the input data. After processing the program, the results are downloaded to the file path associated with the application server for subsequent processing.
Finally, after the remote platform finishes executing the program, the executed result parameters are sent to the user.
5.2. Implementation of general HPGC algorithm service encapsulation and publishing template
The web service for the proposed framework is published on the Apache Axis2 web service engine. Based on this, the web service construction adopts the “.aar” package publishing method recommended by Axis2. That is, after creating a common JAVA project and writing the business class and file configuration of the service implementation, the whole project is exported as a package file with the “.arr” suffix, and deployed in the Axis2 container for publishing. A related class diagram for web service publishing is shown in .
Figure 10. Class diagram of geospatial information algorithm web service publishing
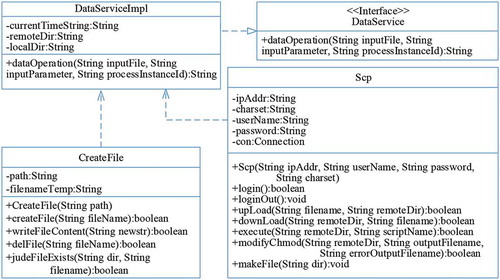
In the above class diagram, DataService is the interface class for web service publishing, and dataserviceimpl is the implementation class of the DataService interface, which is responsible for the main business logic implementation of service publishing. Class Scp is a class written based on the communication between the SSH2 protocol and the remote connection computing platform, and class CreateFile is used to realize the operation of files involved in service processing, such as script files, input and output files, etc. The profile code of the publishing service is as follows.
<?xml version = “1.0” encoding = “UTF-8”?>
<service name = “DataService”> //Interface name
<description>
Data Service Example //Description
</description>
<parameter name = “ServiceClass”>
com.qzhu.service.DataServiceImpl //Interface implantation class
</parameter>
<parameter name = “useOriginalwsdl”>
false
</parameter>
<operation name = “dataOperation”> //Dependent resources
<messageReceiver class = “org.apache.axis2.rpc.receivers.RPCMessageReceiver”/>
</operation>
</service>
6. Case study: a workflow-based HPGC DEM application
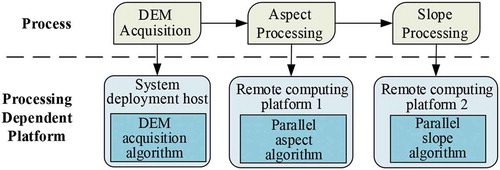
In order to validate the proposed workflow-based platform for HPGC, a large-scale application of a digital elevation model (DEM) product production was used. DEM data is important in the field of spatial information. It is moreover widely used in many research fields, such as mapping, engineering, geographical information systems, and Digital Earth. For this application, we needed to automatically obtain a large amount of DEM data from the Internet. The data was then transferred to HPC platforms for slope and aspect calculations in parallel. The overall block diagram of the data product production is shown in .
Figure 11. General steps for the experimental DEM application
Based on the techniques described above, a diagram of the specific technical implementation is shown in .
Figure 12. Technical implementation of the experimental DEM processing application
In the above applications, the generation of many products is not realized by the one-step processing of the DEM data, but rather through the generation of many intermediate products. It is not until the last step that the desired results or products can be obtained. Here, for DEM processing, we adopted the generation of aspect and slope data from the DEM data as the sub-process. Note that in the above processes of the experimental application, the ArcToolbox tool provided by ArcGIS offers many processing modules, while providing a model builder and Python-compatible components to integrate various intermediate processes and to simplify the operations. However, ArcGIS software is usually installed on a single general computer. With an increase in data volume and processing, the processing efficiency will undoubtedly be affected. Thus, the proposed framework is based on the spatial information data processing algorithm designed in the HPC platform, to process such DEM data quickly.
Therefore, in , the whole process of the experimental DEM application is divided into three steps: (1) DEM data acquisition, (2) aspect generation, and (3) slope generation. The following introduces the implementation of each step according to the general workflow-based framework.
6.1. DEM data acquisition and service encapsulation and publishing
It is common to obtain DEM data through existing DEM data and other channels. At present, there are many websites, mainly government agencies, which provide free DEM data, such as ASTER (advanced spaceborne thermal emission and reflection radiometer) and GDEM (the generalized digital environment model) provided by the United States Geological Survey (USGS) (Essic, Citation2008).
Generally, if we want to obtain DEM data for a region of interest, we enter the website to register and log in, and then obtain the data through search criteria. To obtain such data more quickly and conveniently, we designed a quick data acquisition method for DEM data based on a Python crawler. To select the data area of interest, a method of obtaining longitude and latitude was used. For the proposed platform, the component of acquiring the longitude and latitude of an area of interest was based on “Baidu” map control. This component mainly delineates the area of interest by drawing polygons, and then obtains the longitude and latitude of the vertices of the polygon.
The area covered by each image of DEM data provided by USGS is a grid calibrated by latitude and longitude units. For example, the grid area from latitude 30°N to latitude 31°N and from longitude 115°E to longitude 116°E is an image of DEM data. Therefore, the polygon of the region of interest can be abstracted into a rectangle containing the region, and multiple vertices of the polygon can be abstracted into four vertices of the rectangle to simplify the input parameters. The abstraction process is shown in .
Figure 13. Sketch map for obtaining longitude and latitude by polygon abstraction
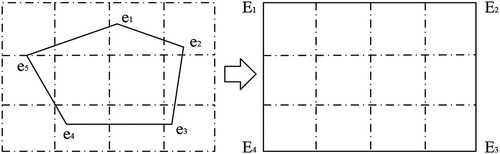
As shown in , the polygon region composed of vertices e1 to e5 can be abstracted into a rectangular region that absolutely contains the polygon region, so as to locate the DEM data of the polygon region according to the longitude and latitude information of the four corners of the rectangle.
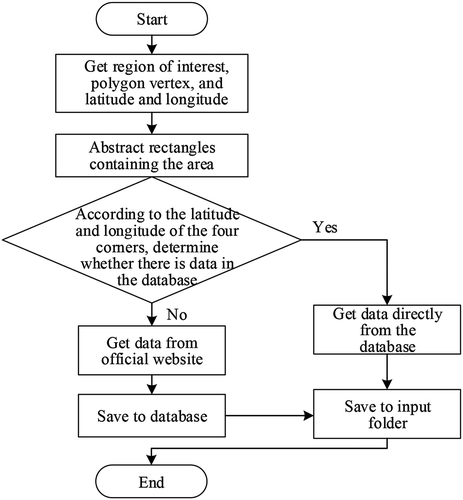
To avoid repeatedly downloading previously obtained data, the data downloaded each time is stored in the database. Before each data acquisition, it is first determined whether this data is saved in the database. If it is, the data can be used directly without crawling from the website. The specific implementation flow for data acquisition is shown in .
Figure 14. Flow chart of GDEM data acquisition
6.2. Parallel algorithm implementation of slope and aspect
For processing multiple tasks simultaneously, a process with a single serial algorithm is bound to affect the efficiency, and using a parallel serial algorithm can effectively speed up processing. In this section, to generate the slope data, all data processing is independent of each other without any correlation, and the MPI parallel programming mode based on the cluster can be adopted. The task-level parallel strategy can be adopted to distribute all the data to be processed to each calculation process equally in a single data unit, without too much consideration of the communication between nodes. The parallel algorithm design of serial slope algorithm based on MPI is shown in .
Figure 15. Structure chart of the parallel slope algorithm
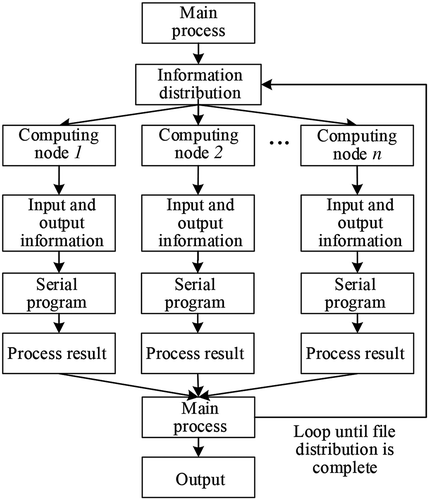
In , the main node reads the data to be processed, integrates the input information of the serial algorithm through the data, and defines the corresponding output information according to the input information. Then, the main process distributes the information to each computing node. The strategy of information distribution is as follows. The amount of DEM data is taken as the unit, which is distributed to each computing node in turn. After distributing the information, each node finds the corresponding data to process and obtains the results and defines the data output according to the information obtained from the distribution. This process is repeated until all of the data is processed and ends in parallel after the output.
After analyzing the implementation code of the serial aspect algorithm, we found that when moving a 3 × 3 window to traverse each pixel, there were multiple for-loops, occupying most of the running time of the algorithm. At the same time, each pixel was independent during the process of pixel traversal and there was no data dependence before and after the for-loop. It can be seen that when processing a single DEM data, it is necessary to traverse the whole image and carry out the same processing operation, so a multi-cores method is more suitable for parallel aspect algorithm. Thus, we opted to use the method of OpenMP, based on the MIC platform, to carry out parallel aspect algorithm. When processing a piece of DEM data each time, the data will be distributed to multiple computing units for simultaneous processing, and the final result will be obtained.
We first implemented the corresponding OpenMP parallel slope computing algorithm on a multi-core CPU, before migrating and deploying it to the MIC platform. In the MIC platform, the commonly used offload mode of OpenMP was used to migrate the parallel part of the algorithm to the MIC coprocessor, whereas the original serial part was still executed on the CPU. The structure of the slope parallel algorithm is shown in .
Figure 16. Parallel structure of the aspect algorithm based on OpenMP
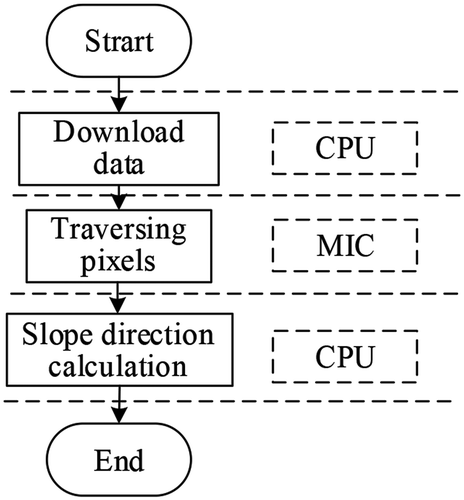
As shown in , when the program is executed to the pixel reading, it calls the offload statement to transmit the data to the MIC coprocessor for parallel execution, and then returns to the CPU for subsequent serial processing.
6.3. Workflow-based DEM application experiments
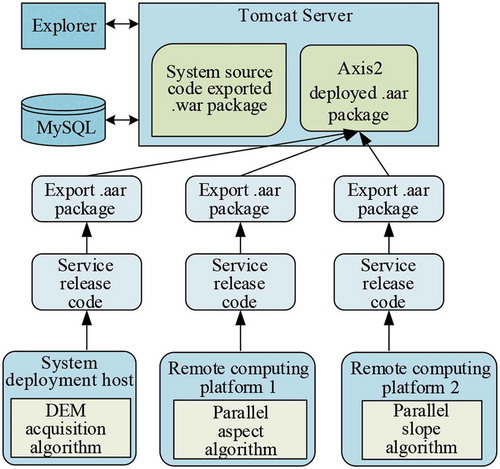
Before the platform function test, based on our web service publishing method, the algorithms involved in processing were published as web services and deployed on Axis2. The specific implementation of the algorithm service was described in the previous section. When deploying the algorithm services, to consider the different geographical distribution of the computing platform and to compute resources called from different geographical locations, we deployed the data acquisition service on a PC machine. Furthermore, we deployed the parallel slope algorithm based on MPI on our college’s CPU cluster, and we deployed the parallel aspect algorithm based on MIC on a remote supercomputing platform, located in different geographical places. The deployment of the platform is illustrated in .
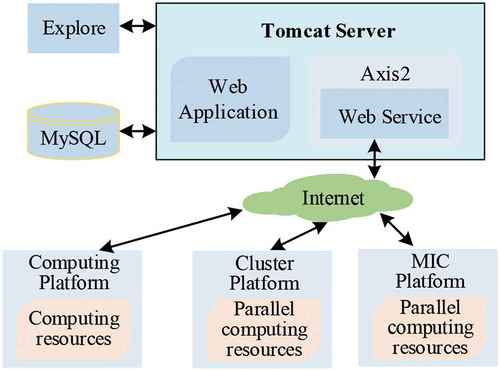
Figure 17. Platform deployment diagram
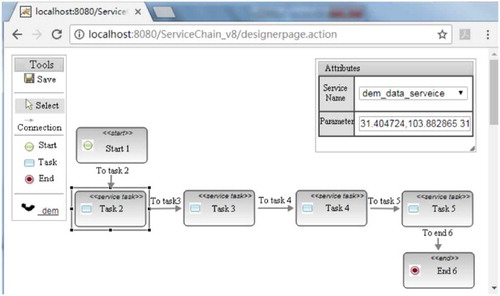
Thus, we opened the process designer, dragged to select the activity node, set the parameters of the node, and generated the business process. When setting parameters, the first task is the data acquisition service, and the input parameters are the longitude and latitude coordinates for the top of the area of interest. The second task is the slope generation service, and the third is the aspect generation service. Finally, the fourth task is the ridge generation service, as shown in .
Figure 18. Process modeling diagram
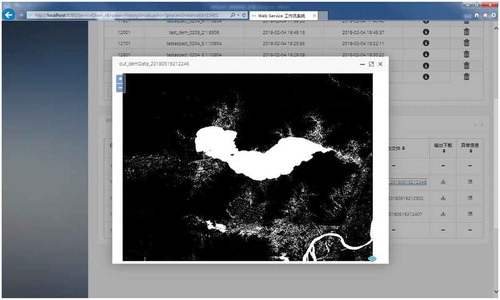
A preview of the processing results of the visual implementation is shown in . Users can preview the results by clicking the output file name of the subtask information list.
Figure 19. Preview of the processing results with workflow-based platform
To validate the algorithm service chain deployed on different HPC computing platforms and to evaluate the performance of the corresponding parallel computing service, we systematically tested the specific application of the DEM to extract the slope direction. In the test, different DEM datasets were used, and the processing time of each step was obtained. The processing time of the parallel algorithm service was compared in the standard way.
The processes based on the HPC service chain and the platform information it depends on are shown in . For parallel processing, the MPI slope parallel algorithm based on the cluster was deployed on the CPU cluster of the School of Resources and Environment, University of Electronic Science and Technology (HPC Platform 1 in ). The OpenMP aspect parallel algorithm based on the MIC was deployed on the supercomputing platform of the Chinese Academy of Sciences (HPC Platform 2 in ). The detailed hardware environment of the platforms are shown in . It is worth pointing out that in the experiments, due to the limitation of data size and algorithm itself, a CPU computing node (12 cores) can make the parallel slope algorithm achieve its theoretical maximum acceleration ratio. At the same time, the parallel aspect algorithm on MIC, 60 cores can also meet the actual needs.
From the experiments, we found that:
(1) All processing results were identical with those from serial processing.
(2) All processes were automatic; and they did not require human operation and had a high degree of automation. Once a job was submitted, the follow-up was automatically completed, and the services could be flexibly combined (in the case of satisfying the processing logic), such that the entire operation was very flexible.
(3) In fact, it was relatively difficult to measure the efficiency of the application in the workflow-driven platform compared that with serial processing, e.g. with the traditional ArcGIS processing method. This was because the processing time of the platform included the transmission time of all data, and the transmission of the data was affected by the network speed and other factors (especially the general Internet network environment). Further, there were interactive reasons for the serial processing, and the hardware configurations differed depending on the particular processing platforms. However, we can evaluate the acceleration ratio of parallel algorithms. When the number of DEM involved exceeds 36 (each data near to 50 M), the best acceleration ratio of parallel aspect algorithm can reach 3 ~ 5X; the best acceleration ratio of parallel slope algorithm can reach to 4 ~ 5x. Meanwhile, for the comparison, in the whole process (excluding data acquisition), the method of workflow can achieve 16–20% performance improvement compared with the method of ArcGIS on personal PC (with the popular PC, all processing ArcGIS components are linked in series with python).
In addition, we also deployed the PMODTRAN application (Huang et al., Citation2016) on the platform. Overall, the experiment demonstrates that the proposed platform avoids tedious operations, simplifies processing, and uses the resources deployed on HPC platforms easily and flexibly.
7. Conclusions and future directions
Aiming at problems associated with multiple intermediate processes, many operations, and long processing times for spatial information processing, we proposed a high performance geoscience computing service platform based on workflows. A DEM for generating slope and aspect data was successfully applied to the proposed platform as an example. The test results showed that the platform avoided tedious operations and improved data flow with HPC platforms for data processing by simplifying this process, and easily and flexibly used the resources deployed in high performance computing platforms to process the relevant data and improve processing efficiency. Moreover, the types and scale of involved HPC computing resources can be added to the system conveniently according to the method proposed in this paper.
However, there is still room for optimization in the involved parallel algorithms and for further improvements to the acceleration effect. Such optimization efforts include parallelization of the OpenMP aspect algorithm on MIC with asynchronous offload mode, MPI slope algorithm with more nodes etc. Meanwhile, in the future work, we can further increase the amount of data acquisition and processed in the experiments, and bring more other applications that are suitable for running with workflow into the system platform.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Additional information
Funding
References
- Barry, D. K. (2003). Service-oriented architecture overview. Web Services and Service-Oriented Architectures, 3–4. San Francisco: Morgan Kaufmann.
- Broomhall, M., Chedzey, H., Garcia, R., Lynch, M., Fearns, P., King, E., & Wang, Z. (2011). Ensemble dust detection techniques utilizing a web-based workflow environment linked to a high performance computing system. Proceedings of the 34th International Symposium on Remote Sensing of Environment, 713–716.
- Chen, Z. Y., Yang, Y., Chen, L. J., & Wang, C. X. (2010). Design and realization of high-performance computing platform accounting system. Proceedings of the International Conference on Future Computer and Communication, Shanghai, China, V2-702-V2-705.
- Cholia, S., Skinner, D., & Boverhof, J. (2010). NEWT: A RESTful service for building high performance computing web applications. Proceedings of the Gateway Computing Environments Workshop (GCE), 1–11.
- Costa, A., Becciani, U., Miocchi, P., Antonuccio, V., Capuzzo Dolcetta, R., Di Matteo, P., & Rosato, V. (2005). Astrocomp: Web technologies for high performance computing on a network of supercomputers. Computer Physics Communications, 166(1), 17–25.
- Deelman, E., Vahi, K., Juve, G., Rynge, M., Callaghan, S., Maechling, P. J., … Wenger, K. (2015). Pegasus, a workflow management system for science automation. Future Generation Computer Systems, 46, 17–35.
- Deng, B. L., & Wang, Y. L. (2014). An improved algorithm for workflow scheduling in Cloud environment based on graph cut. Computer & Modernization, 2014(2), 55–58.
- Deng, M., Di, L., Han, W., Yagci, A. L., Peng, C., & Heo, G. (2015). Web-service-based monitoring and analysis of global agricultural drought. Photogrammetric Engineering and Remote Sensing, 79(10), 929–943.
- Diego, A. N. L. (2007). OSWorkflow: A guide for java developers and architects to integrating open-source business process management. Birmingham: Packt Publishing.
- Ding, J. Y., Li, Q., & Zhou, M. L. (2006). A model for grid resource management and workflow scheduling based on virtual organization. Computer Applications & Software, 23(2), 22–24.
- Du, W., Davis, J. W., & Pfeifer, C. (2000). System and method for performing flexible workflow process execution in a distributed workflow management system. Google Patents. U.S. Patent No. 6,041,306. Washington, DC: U.S. Patent and Trademark Office.
- Essic, J. (2008). Digital elevation models (DEMs). Alphascript Publishing, 89(7), 240–240.
- Georgakopoulos, D., Hornick, M., & Sheth, A. (1995). An overview of workflow management: From process modeling to workflow automation infrastructure. Distributed and Parallel Databases, 3(2), 119–153.
- Grossman, M., & Sarkar, V. (2016). SWAT: A programmable, in-memory, distributed, high-performance computing platform. Proceedings of the ACM International Symposium on High-Performance Parallel and Distributed Computing, Kyoto, Japan, 81–92.
- Guo, H. (2017). Big Earth data: A new frontier in Earth and information sciences. Big Earth Data, 1(1–2), 4–20.
- Hababeh, I., Khalil, I., & Khreishah, A. (2015). Designing high performance Web-based computing services to promote telemedicine database management system. IEEE Transactions on Services Computing, 8(1), 47–64.
- Huang, F., Bu, S. S., Tao, J., & Tan, X. C. (2016). OpenCL implementation of a parallel universal Kriging algorithm for massive spatial data interpolation on heterogeneous systems. International Journal of Geo-Information, 5(6), 96.
- Huang, F., Liu, D. S., Li, X. W., Wang, L. Z., & Xu, W. B. (2011). Preliminary study of a cluster-based open-source parallel GIS based on the GRASS GIS. International Journal of Digital Earth, 4(5), 402–420.
- Huang, F., Tao, J., Xiang, Y., Liu, P., Dong, L., & Wang, L. Z. (2017). Parallel compressive sampling matching pursuit algorithm for compressed sensing signal reconstruction with OpenCL. Journal of Systems Architecture, 72, 51–60.
- Huang, F., Tie, B., Tao, J., Tan, X., & Ma, Y. 2019. Methodology and optimization for implementing cluster-based parallel geospatial algorithms with a case study. Cluster Computing. doi:10.1007/s10586-019-02944-y.
- Huang, F., Zhou, J., Tao, J., Tan, X., Liang, S., & Cheng, J. (2016). PMODTRAN: A parallel implementation based on MODTRAN for massive remote sensing data processing. International Journal of Digital Earth, 9(9), 819–834.
- Lindholm, E., Nickolls, J., Oberman, S., & Montrym, J. (2008). NVIDIA Tesla: A unified graphics and computing architecture. IEEE Micro, 28(2), 39–55.
- Liu, F. (2010). Research on Grid computing platform and resource scheduling algorithm based on WSRF.NET and CONDOR [Master dissertation]. Beijing Normal University.
- Liu, J. C., Huang, R. F., Yang, B., & Li, J. (2010). Workflow-based meteorological user environment for high performance computing. Computer Engineering, 36(8), 278–280.
- Lu, M., Wang, J. Y., Lu, G., Tao W. D., & Wang, J. C. (2017). Research of raster data spatial analysis under CPU/GPU heterogeneous hybrid parallel environment——Take terrain factors analysis as an example. Computer Engineering & Applications, 53(1), 172–177.
- Luo, H., Fan, Y., & Wu, C. (2000). Overview of workflow technology. Journal of Software, 11(7), 899–907.
- Plaza, A., Du, Q., & Chang, Y. L. (2011). High performance computing for hyperspectral remote sensing. IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing, 4(3), 528–544.
- Salatino, M. (2009). jBPM developer guide. Cleveland Clinic Journal of Medicine, 70(2), 141–146.
- Tang, Y. Y., Zhou, H. F., Fang, M. Q., & Shen, X. L. (2016). Hyperspectral remote sensing image data processing research and realization based on CPU/GPU heterogeneous model. Computer Science, 43(2), 47–50+77.
- Thomas, M., Mock, S., & Boisseau, J. (2000). Development of Web toolkits for computational science portals: The NPACI hotpage. Proceedings of the High-Performance Distributed Computing, Proceedings of the Ninth International Symposium on, Pittsburgh, PA, USA, 308–309.
- Tracey, J. B., Mackinlay, B., Tagupa, J., Lauffenburger, P., Exline, I. D., & LeachJr, H. T. (2004). Workflow management system. Google Patents. U.S. Patent No. 6,798,413. Washington, DC: U.S. Patent and Trademark Office.
- Xie, S., Zhang, H. W., & Zhao, L. (2002). Basic features of web service and its application to supply chain management system. Journal of Chengdu Institute of Meteorology, 02, 82–87.
- Xu, L. M., & Yao, Y. W. (2008). Research and implementation of SOA developing framework. Journal of Computer Applications, 28(S1), 307–309.
- Xue, Y., Liu, D., Ai, J., & Wan, W. (2008). High performance geocomputation—Preface, Proceedings in: ICCS 2008, 8th International Conference of Computational Science, Kraków, Poland, June 23-25, 2008. Part II, pp. 603–604. Springer.
- Xue, Y., Wan, W., & Ai, J. W. (2008). High performance geocomputation developments. World Scientific Research and Development, 30(3), 314–319.
- Yang, S. L., & Hu, J. P. (2015). Design of task workflow based on Activiti technology. Applied Mechanics & Materials, 740, 802–805.
- Yu, X. Q., Zhang, W. C., Zhang, T., & Liu, X. (2006). Web service technique and its application to the conversion of spatial data. Journal of Jilin Architectural & Civil Engineering Institute, 23(3), 51–53.
- Zeng, H. (2011). The comparative analysis between Java frame and .NET frame. Science Education Article Collects, 9, 106–109.
- Zhan, L., Miao, F., & Leng, X. P. (2014). Research of sharing spatial data in WebGIS with spatial information web services. Geomatics & Spatial Information Technology, 37(3), 65–68.
- Zhou, K., & Lin, M. (2014). Research on a new job scheduling policy based on Torque. Microcomputer & Its Applications, 33(22), 63–66.
- Zwieflhofer, W., & Mozdzynski, G. (2005). Realizing teracomputing, Proceedings of the Tenth ECMWF Workshop on the Use of High Performance Computers in Meteorology. World Scientific, Reading, UK.