
ABSTRACT
The system of axioms for probability theory laid in 1933 by Andrey Nikolaevich Kolmogorov can be extended to encompass the imaginary set of numbers and this by adding to his original five axioms an additional three axioms. Therefore, we create the complex probability set , which is the sum of the real set
with its corresponding real probability, and the imaginary set
with its corresponding imaginary probability. Hence, all stochastic experiments are performed now in the complex set
instead of the real set
. The objective is then to evaluate the complex probabilities by considering supplementary new imaginary dimensions to the event occurring in the ‘real’ laboratory. Consequently, the corresponding probability in the whole set
is always equal to one and the outcome of the random experiments that follow any probability distribution in
is now predicted totally in
. Subsequently, it follows that, chance and luck in
is replaced by total determinism in
. Consequently, by subtracting the chaotic factor from the degree of our knowledge of the stochastic system, we evaluate the probability of any random phenomenon in
. This novel complex probability paradigm will be applied to the established theorem of Pafnuty Chebyshev's inequality and to extend the concepts of expectation and variance to the complex probability set
.
Nomenclature
| = | = real set of events | |
| = | = imaginary set of events | |
| = | = complex set of events | |
| i | = | = the imaginary number where |
| Prob | = | = probability of any event |
| Pr | = | = probability in the real set |
| Pm | = | = probability in the imaginary set |
| Pc | = | = probability of an event in |
| z | = | = complex number = sum of Pr and Pm = complex random vector |
| = | = | |
| Chf | = | = the chaotic factor of z |
| MChf | = | = magnitude of the chaotic factor of z |
| N | = | = number of random variables |
| Z | = | = the resultant complex random vector |
| = | = probability in Z in the real set | |
| = | = probability in Z in the imaginary set | |
| = | = probability in Z in the complex set | |
| = | = | |
| = | = the chaotic factor of Z | |
| = | = magnitude of the chaotic factor of Z | |
| Er | = | = expectation in the real set |
| Em | = | = expectation in the imaginary set |
| Ec | = | = expectation in the complex set |
| Vr | = | = variance in the real set |
| Vm | = | = variance in the imaginary set |
| Vc | = | = variance in the complex set |
1. Introduction
One of the branches of mathematics is the probability theory, which is devoted to probability and to the analysis of random phenomena. Random variables, stochastic processes and events are the fundamental entities of the theory of probability, and which are mathematical abstractions of non-deterministic events or measured quantities that may either be single occurrences or evolve over time in an apparently random fashion (Kuhn, Citation1970; Poincaré, Citation1968; Stewart, Citation1996). According to the classical probability theory, the results of random events cannot be predicted precisely. However, certain patterns which can be studied and predicted are exhibited in a sequence of individual events such as coin flipping or the roll of dice that are influenced by other factors such as friction. The law of large numbers and the central limit theorem are two mathematical results that describe such stochastic patterns (Barrow, Citation1992; Stewart, Citation2012; Warusfel & Ducrocq, Citation2004).
Moreover, probability theory, which is an essential foundation of the field of mathematical statistics, is indispensable to many human activities that involve quantitative analysis of large sets of data. In statistical mechanics, where the descriptions of complex systems are given a partial knowledge of their state, we apply the methods of the classical probability theory. The probabilistic nature of physical phenomena at atomic scales which are described in quantum mechanics is an illustrious discovery of the twentieth century physics (Greene, Citation2003; Hawking, Citation2005; Penrose, Citation1999). Compared to geometry for example, the classical theory of probability as a mathematical subject arose very late, despite the fact that we have prehistoric evidence of man playing with dice from cultures from all over the world. Additionally, Gerolamo Cardano was one of the earliest writers on probability and the earliest known definition of classical probability was perhaps produced by him (Bogdanov & Bogdanov, Citation2010, Citation2012, Citation2013).
Furthermore, in the seventeenth century, precisely in the year 1654, the eminent mathematician and philosopher Blaise Pascal sustained the development of probability when he had some correspondence with his father's friend, Pierre de Fermat, about two problems concerning games of chance that he had heard from the Chevalier de Méré earlier the same year, whom Pascal happened to accompany during a trip. The famous so-called problem of points is one problem which is a classical problem already then treated by Luca Pacioli as early as 1494 and even earlier in an anonymous manuscript in 1400, and deals with the question how to split the money at stake in a fair way when the game at hand is interrupted half-way through. The other problem was one about a mathematical rule of thumb that seemed not to hold when extending a game of dice from using one die to two dice. This last problem, or paradox, was the discovery of Méré himself and showed, according to him, how dangerous it was to apply mathematics to reality. Other mathematical–philosophical issues and paradoxes were discussed, as well during the trip that Méré thought was strengthening his general philosophical view (Bogdanov & Bogdanov, Citation2009; Davies, Citation1993; Wikipedia, Probability Theory). Also, Blaise Pascal disagreed with the Chevalier de Méré who viewed mathematics as something beautiful and flawless but poorly connected to reality, and therefore determined to prove Méré wrong by solving these two problems within pure mathematics. When Pascal learned that Pierre de Fermat, already recognized as a distinguished mathematician, had reached the same conclusions, he was convinced that they had solved the problems conclusively. Other scholars at the time – in particular, Huygens, Roberval and indirectly Caramuel – knew about this circulated correspondence, which marks the starting point for when mathematicians in general began to study problems from games of chance. Knowing that, the correspondence did not mention ‘probability’; it focused on fair prices (Wikipedia, Probability Distribution, Probability Density Function, Probability Space).
In addition, the famous mathematician Bernoulli, half a century later, showed a sophisticated grasp of probability. He showed, in fact, facility with permutations and combinations and discussed the concept of probability with examples beyond the classical definition, such as personal, judicial, and financial decisions, and showed that probabilities could be estimated by repeated trials with uncertainty diminished as the number of trials increased (Wikipedia, Probability Measure, Probability Axioms, Chebyshev’s Inequality).
Also, in the eighteenth century, precisely in 1765, the illustrious classical volume of the ‘Encyclopédie’ of Denis Diderot and Jean le Rond d'Alembert contained a lengthy discussion of probability and a summary of knowledge up to that time. In the encyclopedia, a distinction is made between probabilities ‘drawn from the consideration of nature itself’ (physical) and probabilities ‘founded only on the experience in the past which can make us confidently draw conclusions for the future’ (evidential). Moreover, in 1657, Christiaan Huygens published a book on the subject, and in the nineteenth century a big work was done by Le Marquis Pierre-Simon de Laplace in what can be considered today as the classical probability interpretation (Hawking, Citation2011; Wikipedia, Pafnuty Chebyshev, Markov’s Inequality). As a matter of fact, Laplace provided the source of a clear and lasting definition of probability. As late as 1814 he stated:
The theory of chance consists in reducing all the events of the same kind to a certain number of cases equally possible, that is to say, to such as we may be equally undecided about in regard to their existence, and in determining the number of cases favorable to the event whose probability is sought. The ratio of this number to that of all the cases possible is the measure of this probability, which is thus simply a fraction whose numerator is the number of favorable cases and whose denominator is the number of all the cases possible. [Marquis Pierre-Simon de Laplace, A Philosophical Essay on Probabilities (Wikipedia, Probability Theory)]
This classical definition provides what would be the ultimate description of probability. Several editions of multiple documents were published by Laplace (technical and a popularization) on probability over a half-century span. Many of his predecessors such as Cardano, Bernoulli and Bayes published a single document posthumously (Hawking, Citation2002). Initially, discrete events were mainly considered by probability theory, and its methods were essentially combinatorial. Furthermore, the incorporation of continuous variables into the theory was done due to analytical considerations (Aczel, Citation2000).
Additionally, Andrey Nikolaevich Kolmogorov laid the foundations of probability theory, which culminated in the twentieth century. Precisely, in 1933, Kolmogorov combined the notion of sample space, introduced by Richard von Mises, and measure theory and presented his axiom system for probability theory. Fairly quickly this became the mostly undisputed axiomatic basis for modern probability theory, knowing that alternatives exist, in particular the adoption of finite rather than countable additivity by Bruno de Finetti (Pickover, Citation2008).
Moreover, discrete probability distributions and continuous probability distributions are treated separately in most introductions to probability theory. The more advanced ‘measure theory’, which is based on the treatment of probability, covers both the discrete, the continuous, any mix of these two and more. Since they well describe many natural or physical processes, certain random variables occur very often in probability theory. Therefore, their distributions have gained special importance in the classical theory of probability. We mention here some fundamental discrete distributions, which are the discrete uniform, Bernoulli, binomial, negative binomial, Poisson and geometric distributions. In addition, we mention some important continuous distributions, which include the continuous uniform, normal or Gauss–Laplace, exponential, gamma and beta distributions (Reeves, Citation1988; Ronan, Citation1988).
I conclude the introduction with two very important citations of two eminent mathematicians and philosophers who inspired me greatly when developing the complex probability paradigm (CPP):
An intellect which at any given moment knew all the forces that animate Nature and the mutual positions of the beings that comprise it, if this intellect were vast enough to submit its data to analysis, could condense into a single formula the movement of the greatest bodies of the universe and that of the lightest atom: for such intellect nothing could be uncertain; and the future just like the past would be present before its eyes. (Marquis Pierre-Simon de Laplace)
The Divine Spirit found a sublime outlet in that wonder of analysis, that portent of the ideal world, that amphibian between being and not-being, which we call the imaginary root of negative unity. (Gottfried Wilhelm Von Leibniz)
Finally, this research paper is organized as follows: After the introduction in Section 1, the purpose and the advantages of the present work are presented in Section 2. Then in Section 3, Chebyshev's inequality is explained. Afterward, in Section 4, I explain and illustrate the CPP, and in Section 5, I apply the new paradigm to Chebyshev's inequality. Moreover, in Section 6, I do numerical simulations of some discrete and continuous distributions to support the new model. Additionally, in Section 7, I link the resultant complex random vector Z to Chebyshev's inequality. Furthermore, in Section 8, I define the complex characteristics of the probability distributions such as the expectation and the variance. Finally, I conclude the work by doing a comprehensive summary in Section 9, and then present the list of references cited in the current research work.
2. The purpose and the advantages of the present work
All our work in classical probability theory is to compute probabilities. The original idea in this paper is to add new dimensions to our random experiment, which will make the work deterministic. In fact, the probability theory is a non-deterministic theory by nature; that means that the outcome of the events is due to chance and luck. By adding new dimensions to the event in , we make the work deterministic and hence a random experiment will have a certain outcome in the complex set of probabilities
. It is of great importance that the stochastic system becomes totally predictable since we will be totally knowledgeable to foretell the outcome of chaotic and random events that occur in nature for example in statistical mechanics or in all stochastic processes. Therefore the work that should be done is to add to the real set of probabilities
, the contributions of
which is the imaginary set of probabilities which will make the event in
=
+
deterministic. If this is found to be fruitful, then a new theory in statistical sciences and prognostic is elaborated and this is to understand deterministically those phenomena that used to be random phenomena in
. This is what I called ‘the complex probability paradigm’, which was initiated and elaborated in my six previous papers (Abou Jaoude, El-Tawil, & Kadry, Citation2010; Abou Jaoude, Citation2013a, Citation2013b, Citation2014, Citation2015a, Citation2015b).
Consequently, the purpose and the advantages of the present work are to:
Extend classical probability theory to the set of complex numbers, hence to relate probability theory to the field of complex analysis. This task was initiated and elaborated in my six previous papers and will be more developed in this seventh research work.
Apply the new probability axioms and paradigm to Chebyshev's inequality; hence, extend Chebyshev's inequality beyond the real probability set to encompass the complex probability set.
Prove that all random phenomena can be expressed deterministically in the complex set
.
Quantify both the degree of our knowledge (DOK) and the chaos of the random variables.
Draw and represent graphically the functions and parameters of the novel paradigm associated to Chebyshev's inequality.
Apply the new Chebyshev's theorem to very well-known discrete and continuous probability distributions and thus prove its validity when dealing with any distribution not treated in the current research paper.
Show that the classical concepts of expectation and variance can be extended to
Pave the way to apply the original paradigm to other topics in statistical mechanics, in stochastic processes, to the field of prognostics in engineering. These will be the subjects of my subsequent research papers.
In fact, to summarize and to state the framework of this paper, I will apply throughout this whole research work the novel CPP to the established theorem of Chebyshev's inequality and I will extend the concepts of expectation and variance to the complex probability set . The potential applications of this original theorem are in any field related to stochastic processes whether in applied or pure mathematics, in thermodynamics or statistical mechanics or physics in general, or in any field of engineering or science as a whole, when dealing with probability and random phenomena.
3. Pafnuty Chebyshev’s inequality and contribution
Pafnuty Chebyshev's inequality (also spelled as Tchebysheff's inequality, Russian: ![]() ) in probability theory, guarantees that in any probability distribution, ‘nearly all’ values are close to the mean – the precise statement being that no more than 1/k2 of the distribution's values can be more than k standard deviations away from the mean (or equivalently, at least 1 − 1/k2 of the distribution's values are within k standard deviations of the mean). The rule is often called Chebyshev's theorem, about the range of standard deviations around the mean, in statistics (Wikipedia, Probability Theory, Probability Distribution).
) in probability theory, guarantees that in any probability distribution, ‘nearly all’ values are close to the mean – the precise statement being that no more than 1/k2 of the distribution's values can be more than k standard deviations away from the mean (or equivalently, at least 1 − 1/k2 of the distribution's values are within k standard deviations of the mean). The rule is often called Chebyshev's theorem, about the range of standard deviations around the mean, in statistics (Wikipedia, Probability Theory, Probability Distribution).
Moreover, because it can be applied to completely arbitrary distributions (unknown except for mean and variance), Chebyshev's inequality has great utility. For example, it can be used to prove the weak law of large numbers (Wikipedia, Probability Density Function, Probability Space).
In practical usage, in contrast to the 68-95-99.7% rule (which applies to normal distributions), under Chebyshev's inequality a minimum of just of values must lie within two standard deviations of the mean and
within three standard deviations (Figure ) (Wikipedia, Probability Measure, Probability Axioms).
Figure 1. Chebyshev's inequality applied to the Normal Probability Distribution.
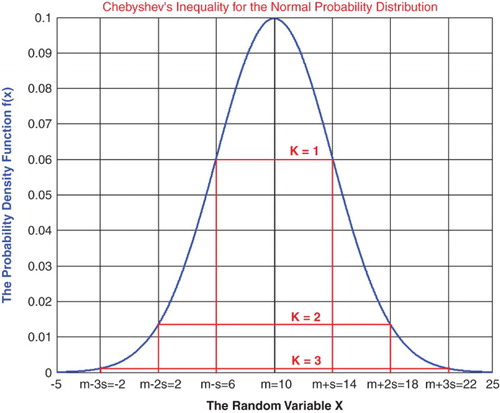
Additionally, the term Chebyshev's inequality may also refer to Markov's inequality, especially in the context of analysis.
It is important to mention here that the theorem is named after the Russian mathematician Pafnuty Chebyshev, although it was first formulated by his friend and colleague Irénée-Jules Bienaymé. The theorem was first stated without proof by Bienaymé in 1853 and later proved by Chebyshev in 1867. His student Andrey Markov provided another proof in his 1884 Ph.D. thesis (Wikipedia, Chebyshev’s Inequality, Pafnuty Chebyshev, Markov’s Inequality).
In addition, Chebyshev's inequality is usually stated for random variables, but can be generalized to a statement about measure spaces (Ferentinos, Citation1982; Katarzyna & Dominik, Citation2010).
Furthermore, let X (integrable) be a random variable with finite expected value μ and finite non-zero variance σ2. Then for any real number , we have
(1)
Only the case where
is useful. When
the right hand:
and the inequality is trivial as all probabilities are
. As an example, using
shows that the probability that values lie outside the interval
does not exceed 1/2 (Baranoski, Rokne, & Xu, Citation2001; Kabán, Citation2012).
Because it can be applied to completely arbitrary distributions (unknown except for mean and variance), the inequality generally gives a poor bound compared to what might be deduced if more aspects are known about the distribution involved (Beasley et al., Citation2004).
To conclude and to summarize, Chebyshev's theorem holds for any distribution of observations and, for this reason, the results are usually weak. The value given by the theorem is a lower bound only. That is, we know that the probability of a random variable falling within two standard deviations of the mean can be no less than 3/4, but we never know how much more it might actually be. Only when the probability distribution is known can we determine exact probabilities. For this reason we call the theorem a distribution-free result. When specific distributions are assumed as in the following sections of this research paper, the results will be less conservative. The use of Chebyshev's theorem is relegated to situations where the form of the distribution is unknown (He, Zhang, & Zhang, Citation2010).
4 The extended set of probability axioms
4.1 The original Andrey N. Kolmogorov set of axioms
The simplicity of Kolmogorov's system of axioms may be surprising. Let E be a collection of elements {E1, E2, … } called elementary events and let F be a set of subsets of E called random events. The five axioms for a finite set E are (Benton, Citation1966a, Citation1966b; Feller, Citation1968; Montgomery & Runger, Citation2003; Walpole, Myers, Myers, & Ye, Citation2002):
Axiom 1: F is a field of sets.
Axiom 2: F contains the set E.
Axiom 3: A non-negative real number Prob(A), called the probability of A, is assigned to each set A in F. We have always 0 ≤ Prob(A) ≤ 1.
Axiom 4: Prob(E) equals 1.
Axiom 5: If A and B have no elements in common, the number assigned to their union is
Hence, we say that A and B are disjoint; otherwise, we have
Moreover, we can generalize and say that for N disjoint (mutually exclusive) event (for
), we have the following additivity rule:
And we say also that for N independent events
(for
), we have the following product rule:
4.2. Adding the imaginary part
Now, we can add to this system of axioms an imaginary part such that:
Axiom 6: Let
Axiom 7: We construct the complex number or vector
Axiom 8: Let Pc denote the probability of an event in the universe
We say that Pc is the probability of an event A in
4.3. The purpose of extending the axioms
It is apparent from the set of axioms that the addition of an imaginary part to the real event makes the probability of the event in always equal to 1. In fact, if we begin to see the set of probabilities as divided into two parts, one real and the other imaginary, understanding will follow directly. The random event that occurs in
(like tossing a coin and getting a head) has a corresponding probability
. Now, let
be the set of imaginary probabilities and let
be the DOK of this phenomenon.
is always, and according to Kolmogorov's axioms, the probability of an event.
A total ignorance of the set makes:
and
in this case is equal to:
. Conversely, a total knowledge of the set in
makes:
and
. Here we have
because the phenomenon is totally known, that is, its laws and variables are completely determined; hence, our DOK of the system is 1 or 100%.
Now, if we can tell for sure that an event will never occur, that is, like ‘getting nothing’ (the empty set), is accordingly equal to 0, that is the event will never occur in
.
will be equal to:
, and
, because we can tell that the event of getting nothing surely will never occur; thus, the DOK of the system is 1 or 100% (Abou Jaoude et al., Citation2010).
We can infer that we have always
(2)
And what is important is that in all cases we have
(3)
In fact, according to an experimenter in
, the game is a game of chance: the experimenter does not know the output of the event. He will assign to each outcome a probability
and he will say that the output is non-deterministic. But in the universe
=
+
, an observer will be able to predict the outcome of the game of chance since he takes into consideration the contribution of
, so we write
Hence
is always equal to 1. In fact, the addition of the imaginary set to our random experiment resulted in the abolition of ignorance and indeterminism. Consequently, the study of this class of phenomena in
is of great usefulness since we will be able to predict with certainty the outcome of experiments conducted. In fact, the study in
leads to unpredictability and uncertainty. So instead of placing ourselves in
, we place ourselves in
then study the phenomena, because in
the contributions of
are taken into consideration and therefore a deterministic study of the phenomena becomes possible. Conversely, by taking into consideration the contribution of the set
, we place ourselves in
and by ignoring
we restrict our study to non-deterministic phenomena in
(Bell, Citation1992; Boursin, Citation1986; Srinivasan & Mehata, Citation1988; Stewart, Citation2002; Van Kampen, Citation2006).
Moreover, it follows from the above definitions and axioms that (Abou Jaoude et al., Citation2010)
(4)
will be called the Chaotic factor in our experiment and will be denoted accordingly by ‘Chf’. We will see why I have called this term the chaotic factor; in fact:
In case
In case
In case
Figure 2. DOK, Chf, and Pc for the uniform probability distribution with .
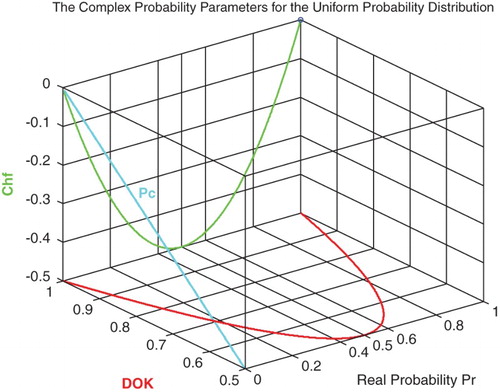
What is interesting here is thus we have quantified both the DOK and the chaotic factor of any random event and hence we write now
(5)
Then we can conclude that
therefore
.
This directly means that if we succeed to subtract and eliminate the chaotic factor in any random experiment, then the output will always be with the probability equal to 1 (Dacunha-Castelle, Citation1996; Dalmedico-Dahan, Chabert, & Chemla, Citation1992; Dalmedico-Dahan & Peiffer, Citation1986; Ekeland, Citation1991; Gleick, Citation1997; Gullberg, Citation1997; Science Et Vie, Citation1999).
Figure shows the linear relation between both DOK and Chf.
Figure 3. Graph of .
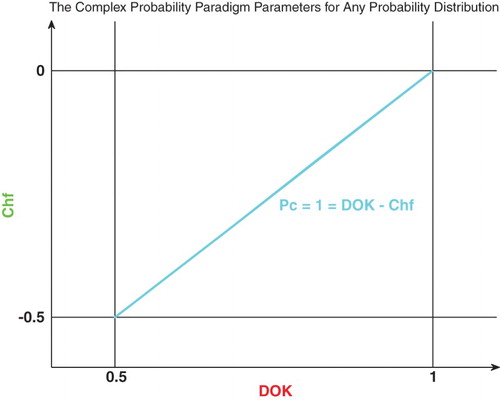
Furthermore, we need in our current study the absolute value of the chaotic factor that will give us the magnitude of the chaotic and random effects on the studied system materialized by the probability density function (PDF), and which leads to an increasing system chaos in . This new term will be denoted accordingly MChf or magnitude of the chaotic factor (Figures –). Hence, we can deduce the following results:
(6)
and
, where
.
Figure 4. Graph of .
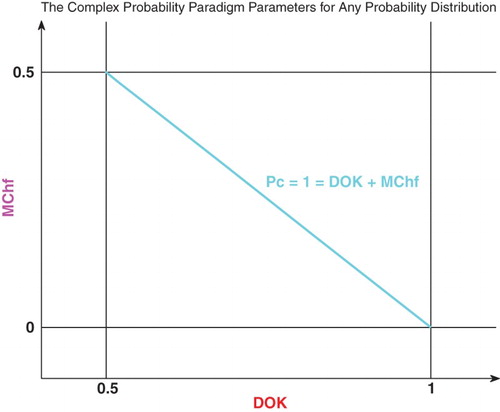
Figure 5. MChf, DOK, and PC for the uniform probability distribution with .
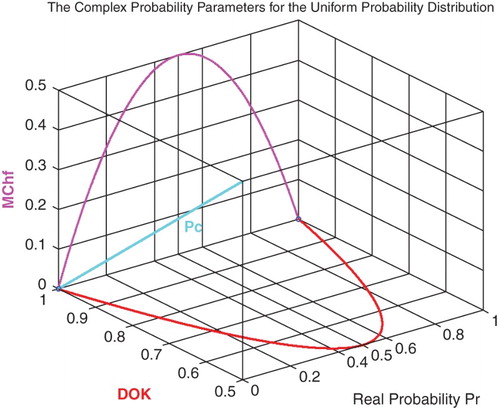
Figure 6. Chf and MChf for the uniform probability distribution with MChf + Chf = 0.
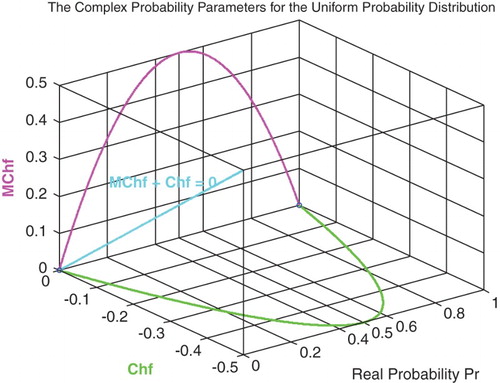
Figure shows the linear relation between both DOK and MChf. Moreover, Figures and show the graphs of Chf, MChf, DOK, and Pc as functions of the real probability Pr for a uniform probability distribution.
To summarize and to conclude, as the Degree of Our certain Knowledge or DOK in the real universe is unfortunately incomplete, the extension to the complex set
includes the contributions of both the real set of probabilities
and the imaginary set of probabilities
. Consequently, this will result in a complete and perfect degree of knowledge in
=
+
(PC = 1). In fact, in order to have a certain prediction of any random event, it is necessary to work in the complex set
in which the chaotic factor is quantified and subtracted from the computed degree of knowledge to lead to a probability in
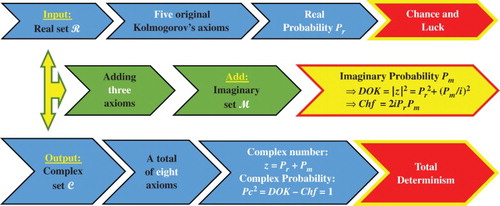
equal to one (Pc2 = DOK − Chf = DOK + MChf = 1). This hypothesis is verified in my six previous research papers by the mean of many examples encompassing both discrete and continuous distributions (Abou Jaoude, Citation2013a, Citation2013b, Citation2014, Citation2015a, Citation2015b; Abou Jaoude et al., Citation2010). The extended Kolmogorov axioms (EKA for short) or the CPP can be illustrated by Figure .
Figure 7. The EKA or the complex probability paradigm (CPP) diagram.
5. The new paradigm and Chebyshev’s inequality (Abou Jaoude, 2004, 2005, 2007; Chan Man Fong, De Kee, & Kaloni, 1997; Stepić & Ognjanović, 2014)
The real probability in the CPP applied to Chebyshev's inequality is
Let
, where we have
.
Therefore we can write using Chebyshev's inequality:
We have from the
; so we can deduce from inequality (2) that
5.1. The DOK
We have from the ; so we can deduce from inequalities (2) and (3) that:
Or
Note that we have from the CPP always:
.
Note that when then inequalities (4) and (5) give:
, which is logical since the real probability is
Hence, we have in this case a certain event and consequently the DOK is perfect and is equal to 1 or 100%.
From inequalities (4) and (5), we can find the Midpoint of DOK denoted by MPDOK, which is equal to (Figures and ):
(7)
Note that:
, then
Figure 8. The midpoint of DOK function of β.
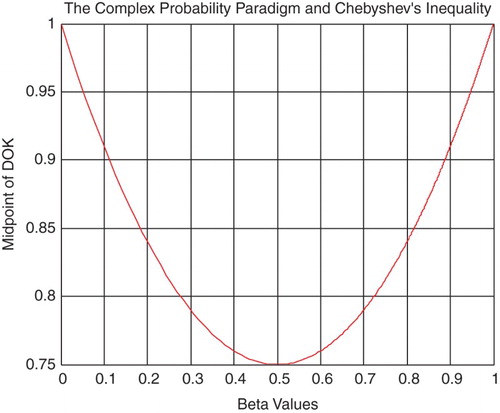
Figure 9. The midpoint of DOK function of k.
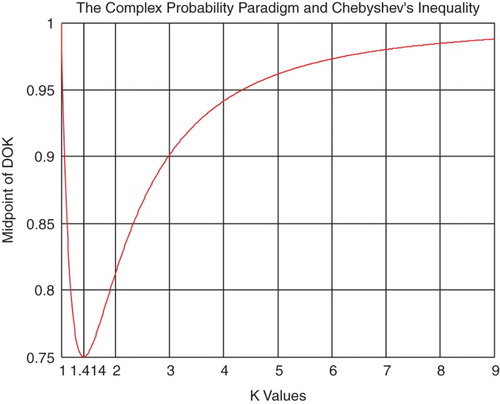
from inequality (1).
At this last point . We have
, hence, MPDOK is a curve concave upward everywhere and its minimum occurs at (0.5, 0.75). This result is very logical since we have from the CPP always:
Note that
If
If from inequality (1)
or for from inequality (1)
5.2. The chaotic factor Chf
We have from the CPP
Then we can deduce from inequality (2) that
Therefore
or
Note that we have from the CPP always:
.
Note that when then inequalities (6) and (7) give
, which is logical since the real probability is
Hence, we have in this case a certain event and consequently the chaotic factor is null and is equal to 0.
From inequalities (6) and (7), we can find the Midpoint of Chf denoted by MPChf (Figures and ), which is equal to
(8)
Figure 10. The midpoint of Chf function of β.
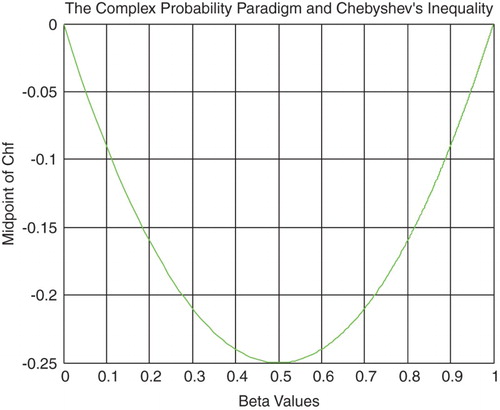
Figure 11. The midpoint of Chf function of k.
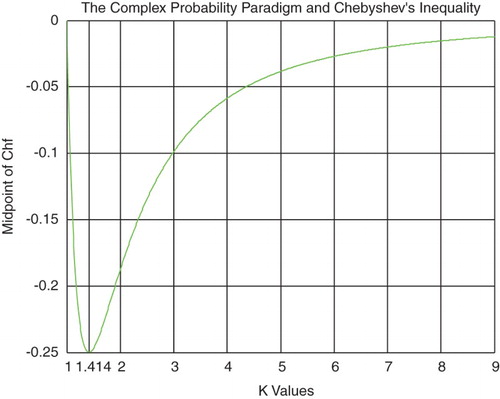
Note that , then
from inequality (1).
At this last point . We have
; hence, the MPChf is a curve concave upward everywhere and its minimum occurs at (0.5, −0.25). This result is very logical since we have from the CPP always
Note that
If then:
for
or for
5.3. The magnitude of the chaotic factor MChf
We have from the CPP
Then we can deduce from inequality (2) that
Therefore,
or
Note that we have from the CPP always:
.
Note that when then inequalities (8) and (9) give:
, which is logical since the real probability is
Hence, we have in this case a certain event and consequently the magnitude of the chaotic factor is null and is equal to 0.
From inequalities (8) and (9), we can find the Midpoint of MChf denoted by , which is equal to (Figures and )
(9)
Note that
, then
Figure 12. The midpoint of MChf function of β.
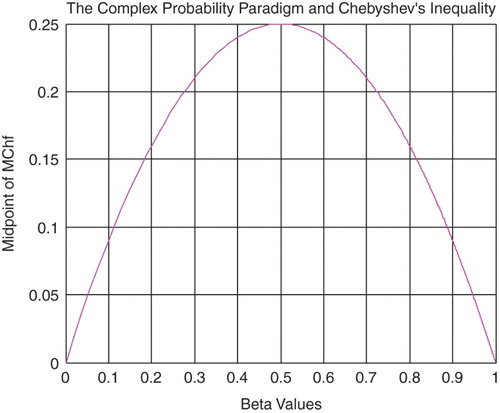
Figure 13. The midpoint of MChf function of k.
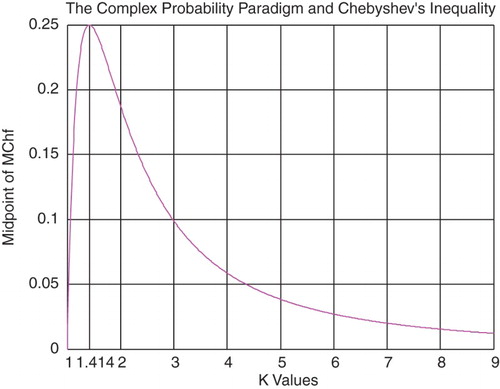
from inequality (1).
At this last point . We have
; hence,
is a curve concave downward everywhere and its maximum occurs at (0.5, 0.25). This result is very logical since we have from the CPP always
Note that
If then:
for from inequality (1)
or for from inequality (1).
5.4. The complex probability Pc
We have from the CPP
and we have
and
Therefore
and
Since we have from the CPP:
and since we have
Therefore, we get the same inequality as inequality (10) just as expected
Note that we have from the CPP always:
In fact, from inequalities (10) and (11), we can find the Midpoint of Pc2 and Pc denoted by
and
, respectively, which are equal to (Figures and )
(10)
and
All the four figures that follow illustrate the relation between the CPP and Chebyshev's inequality (Figures –).
Figure 16 shows the graphs of the midpoints of the CPP parameters in Chebyshev's inequality with the exact , and
, having all of them as functions of
, with
.
Figure 14. The midpoint of Pc function of β.
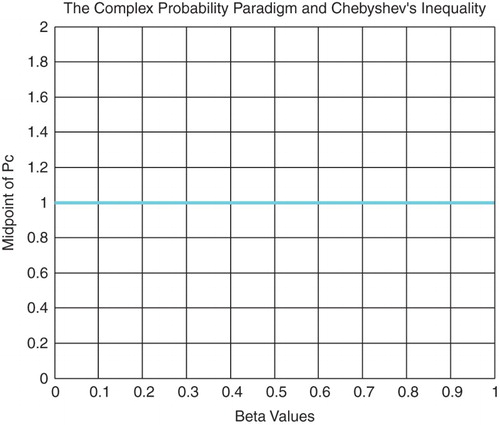
Figure 15. The midpoint of Pc function of k.
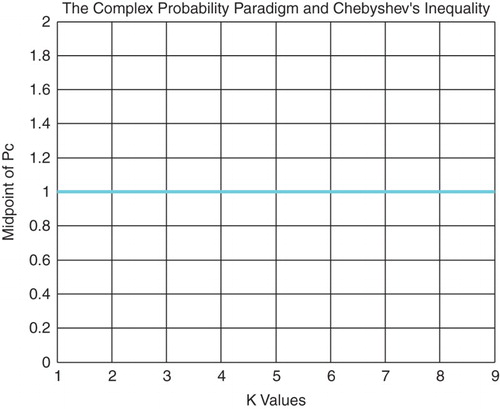
Figure 16. The midpoints of the CPP parameters functions of k.
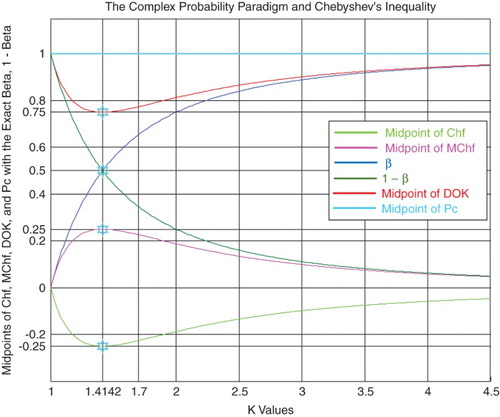
Figure 17. The midpoints and the exact CPP parameters functions of k.
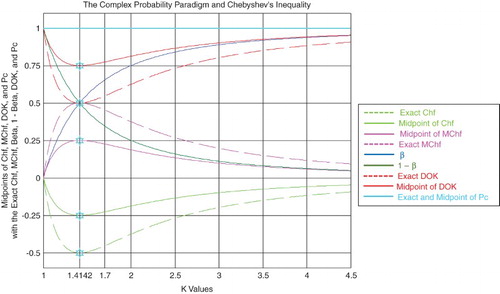
Figure 18. The midpoints of the CPP parameters functions of β.
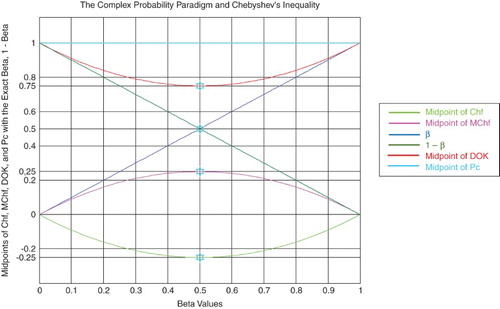
Figure 19. The midpoints and the exact CPP parameters functions of β.
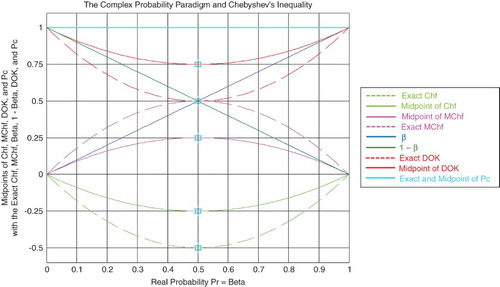
Figure 17 shows the graphs of the midpoints of the CPP parameters in Chebyshev's inequality with the exact , and
, having all of them as functions of k. In addition, I have plotted on the same figure the exact CPP parameters graphs by taking the required simulation's real probability
, with
.
Figure 18 shows the graphs of the midpoints of the CPP parameters in Chebyshev's inequality with the exact , and
, having all of them now as functions of
, with
.
Figure 19 shows the graphs of the midpoints of the CPP parameters in Chebyshev's inequality with the exact , and
, having all of them as functions of
. In addition, I have plotted on the same figure the exact CPP parameters graphs by taking the required simulation's real probability
, with
.
5.5. The complex random vector z
We have from the CPP the complex random vector , then inequality (2) + inequality (3) give
or
Then
and
From inequalities (12) and (13), we can find the Midpoint of the complex random vector z denoted by
, which is equal to
(11)
Note that (Figures and ):
Note that
the slope of the MPz line in the plane whose equation is
(Figure ) (Tables ).
Figure 20. The complex probability vector z midpoint and Chebyshev's inequality function of β.
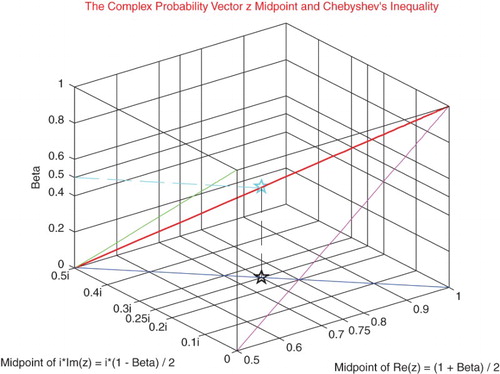
Figure 21. The complex probability vector z midpoint and Chebyshev's inequality function of k.
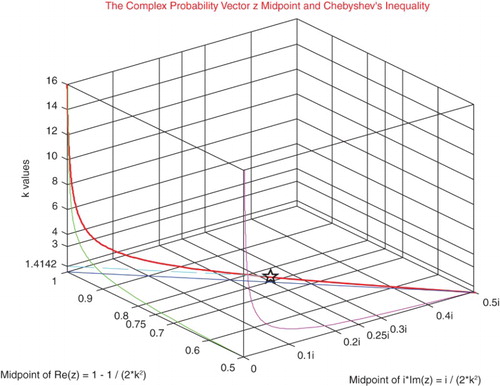
Table 1. The CPP and Chebyshev's inequality for 1 ≤ k ≤ 2.
Table 2. The CPP and Chebyshev's inequality for 3 ≤ k ≤ 100.
Table 3. The CPP and Chebyshev's inequality for k = 1000 and 10,000.
6. Numerical simulations of discrete and continuous distributions and Chebyshev’s inequality (Abou Jaoude, 2013a, 2013b, 2014, 2015a, 2015b; Abou Jaoude et al., 2010; Wikipedia, Probability Theory, Probability Distribution, Probability Density Function, Probability Space, Probability Measure, Probability Axioms, Chebyshev’s Inequality, Pafnuty Chebyshev, Markov’s Inequality)
6.1. The evaluation of the CPP parameters
The cumulative distribution function (CDF) of the discrete or continuous random variable x is denoted by .
Then the CPP parameters are the following:
(12)
(13)
(14)
(15)
The DOK:
(16)
The chaotic factor (Chf):
(17)
The magnitude of the chaotic factor (MChf):
(18)
At any value of the random variable x, the probability expressed in the complex set
is
(19)
Then,
always; hence, the prediction of the outcome of the random variable x in
is permanently certain and absolutely deterministic.
Note that all the numerical values found in the paradigm functions analysis and Chebyshev's inequality for all the values of k and β were computed using the MATLAB version 2016 software.
6.2. Flowchart of the CPP applied to Chebyshev’s inequality
The following flowchart summarizes all the procedures of the proposed complex probability prognostic model:
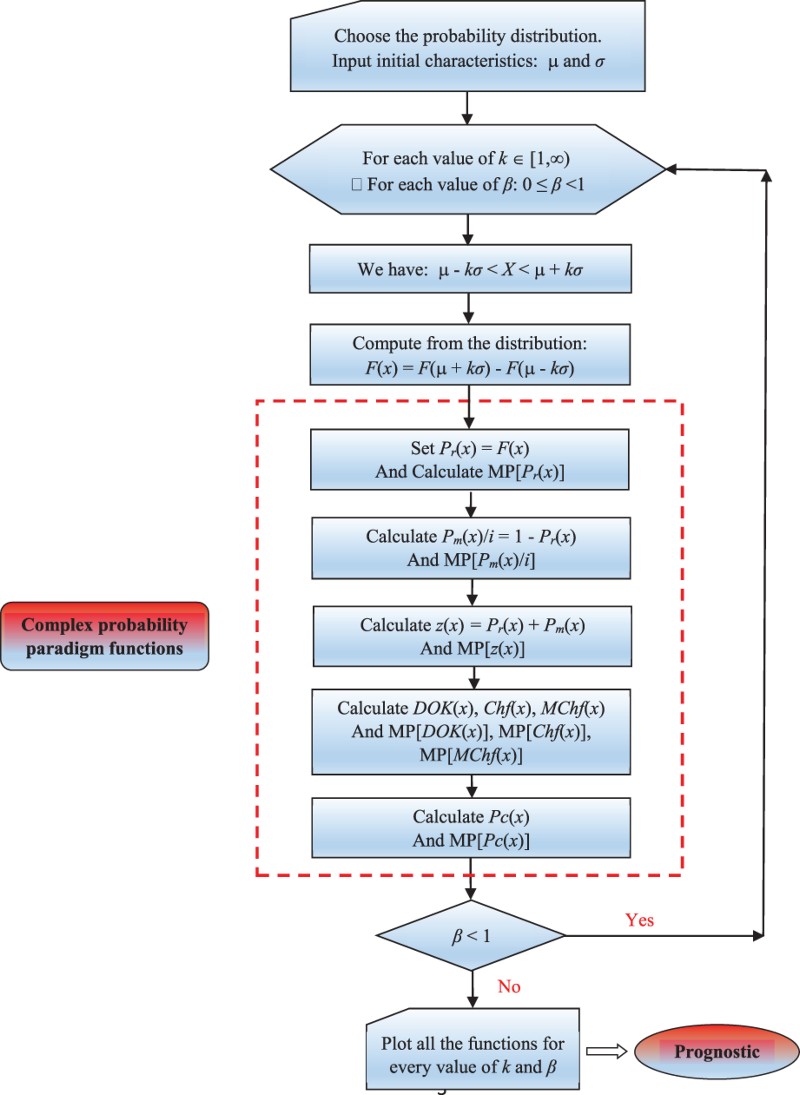
6.3. Numerical simulation of the continuous uniform probability distribution:
The PDF of this continuous distribution is
(20)
and the CDF is
(21)
I have taken the domain for the continuous uniform random variable to be:
and
then
The real probability
is
The complementary probability Pm(x)/i is
The other parameters are calculated from the CPP paradigm (refer to Section 6.1).
The mean of this continuous uniform random distribution is .
The standard deviation is (Figures and ) (Tables and ).
Figure 22. The CPP parameters for the continuous uniform distribution.
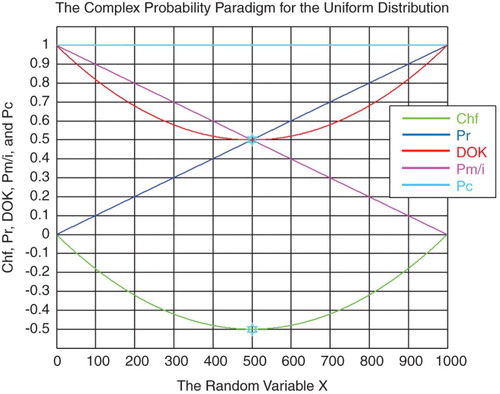
Figure 23. The CPP parameters with MChf for the continuous uniform distribution.
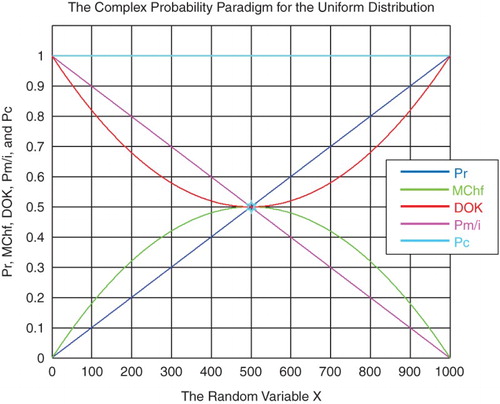
Table 4. The CPP and Chebyshev's inequality for the continuous uniform distribution for k = 1, 1.1, and 1.3.
Table 5. The CPP and Chebyshev's inequality for the continuous uniform distribution for , 1.6, and .
6.4. Numerical simulation of the binomial probability distribution
The PDF of this discrete distribution is
(22)
and the CDF is
(23)
I have taken the domain for the binomial random variable to be:
and
, then:
.
The real probability is
The complementary probability Pm(x)/i is
The other parameters are calculated from the CPP paradigm (refer to Section 6.1).
Taking in our simulation and
, then the mean of this binomial random distribution is
, and the standard deviation is
(Figures and ) (Tables and ).
Figure 24. The CPP parameters for the binomial distribution.
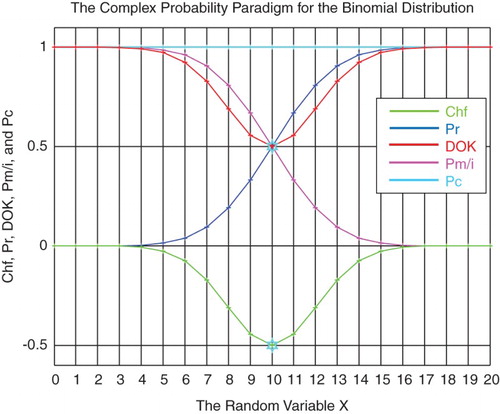
Figure 25. The CPP parameters with MChf for the binomial distribution.
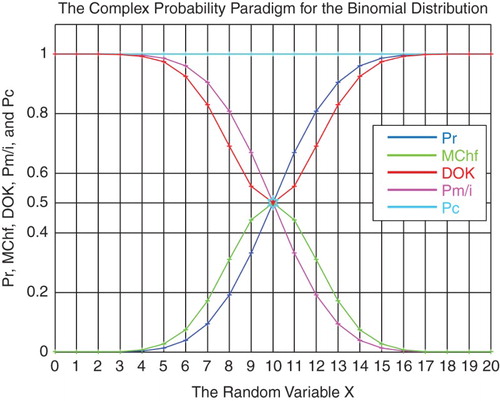
Table 6. The CPP and Chebyshev's inequality for the binomial distribution for k = 1.34, 1.79, and 2.24.
Table 7. The CPP and Chebyshev's inequality for the binomial distribution for k = 2.68, 3.58, and 4.47.
6.5. Numerical simulation of the Poisson probability distribution
The PDF of this discrete distribution is
(24)
and the CDF is
(25)
For the Poisson random variable:
and
, then
.
The real probability is
The complementary probability Pm(x)/i is
The other parameters are calculated from the CPP paradigm (refer to Section 6.1).
Taking in our simulation , then the mean of this Poisson random distribution is
, and the standard deviation is
(Figures and ) (Tables and ).
Figure 26. The CPP parameters for the Poisson distribution.
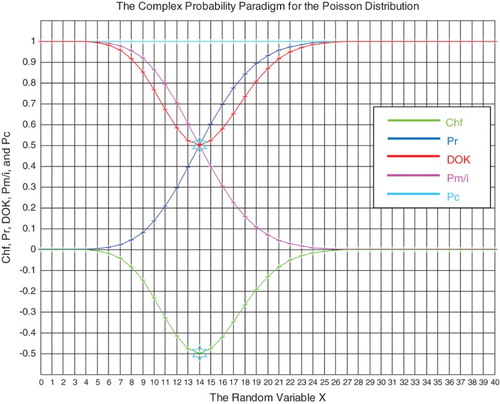
Figure 27. The CPP parameters with MChf for the Poisson distribution.
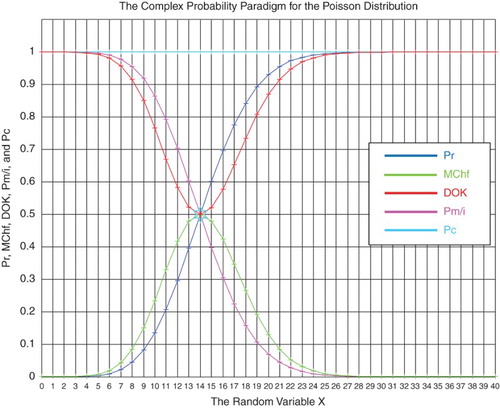
Table 8. The CPP and Chebyshev's inequality for the Poisson distribution for k = 1.22, 1.74, and 2.26.
Table 9. The CPP and Chebyshev's inequality for the Poisson distribution for k = 2.79, 3.31, and 3.83.
6.6. Numerical simulation of the normal Gauss–Laplace probability distribution:
The PDF of this continuous distribution is
(26)
and the CDF is
(27)
The domain for this normal variable is
and I have taken
.
The real probability is
The complementary probability Pm(x)/i is
The other parameters are calculated from the CPP paradigm (refer to Section 6.1).
In the simulation, I have taken the mean of this normal random distribution to be: ,
and the standard deviation is (Figures and ) (Tables ).
Figure 28. The CPP parameters for the normal distribution.
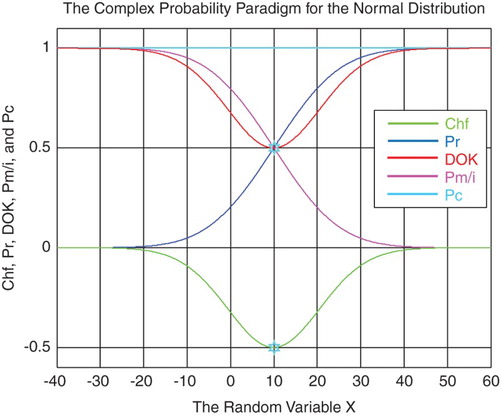
Figure 29. The CPP parameters with MChf for the normal distribution.
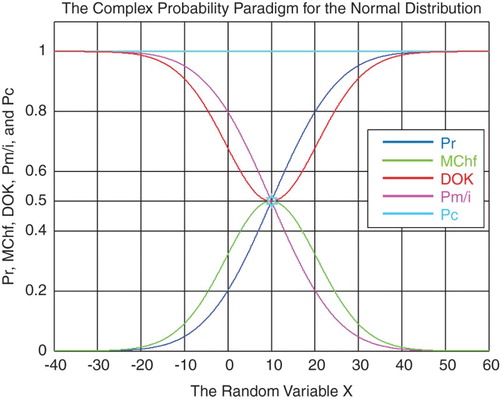
Table 10. The CPP and Chebyshev's inequality for the normal distribution for k = 1, 1.01, and 1.1.
Table 11. The CPP and Chebyshev's inequality for the normal distribution for k = 1.25, 1.5, and 2.
Table 12. The CPP and Chebyshev's inequality for the normal distribution for k = 2.75, 3.5, and 10.
7. The resultant complex random vector Z and Chebyshev’s inequality (Bidabad, 1992; Cox, 1955; Fagin, Halpern, & Megiddo, 1990; Ognjanović, Marković, Rašković, Doder, & Perović, 2012; Weingarten, 2002; Youssef, 1994)
7.1. The resultant complex random vector Z
As a general case, let us consider then this discrete probability distribution with N disjoint and independent random variables (Table ):
Table 13. The discrete probability distribution with N random variables.
We can see that
We have here in
=
+
the complex random vector
corresponding to each random variable
for
:
and the corresponding vector norm of
is
In addition, we have
The resultant complex random vector Z representing the whole random distribution is
(28)
Then we can deduce the following results: the mean of the real probabilities of all the complex random vectors
and
the mean of the imaginary probabilities of all the complex random vectors
; hence,
.
Note that we have for the random vector , which is the mean of the resultant complex random vector Z:
, just like for all the complex random vectors
.
Moreover, we can note that the norm of Z can be computed in the following way:
Having
(29)
Or we can calculate the norm of Z in a different way using
To illustrate the concept of the resultant complex random vector Z, I will use Figure .
Figure 30. The resultant complex random vector for a general distribution with N = 2 (Bernoulli distribution) in the complex probability plane
.
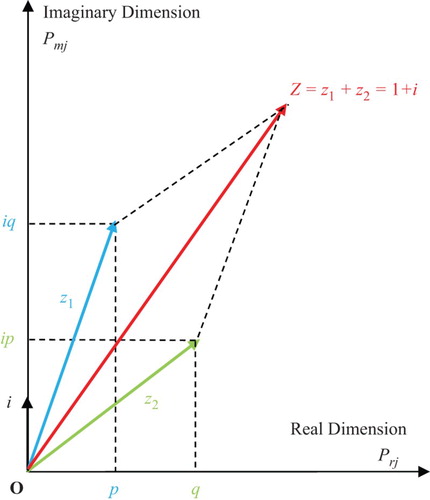
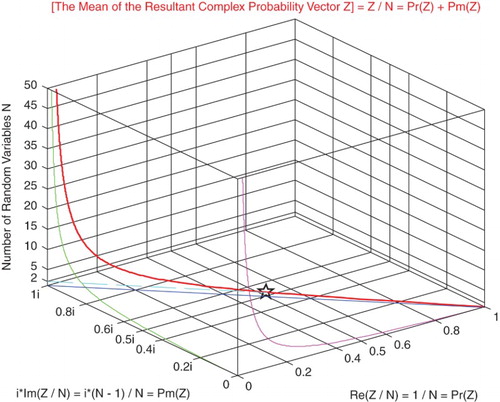
Moreover, to clarify the concept of the resultant complex random vector Z related to Chebyshev's inequality, I will present Figure .
Figure 31. The mean of the resultant complex vector which is Z/N function of the number of random variables N.
7.2. The knowledge and the chaos related to Z
For any complex random vector we have for
:
And .
For the resultant complex random vector we have
(30)
(31)
(32)
(33)
And .
Therefore, the DOK corresponding to the resultant complex vector Z representing the whole distribution of random variables is
(34)
and its relative chaotic factor is
(35)
Similarly, its relative magnitude of the chaotic factor is
(36)
Thus we can verify that we have always
We can deduce mathematically that
(37)
(38)
(39)
From the above, we can also deduce this conclusion:
As much as N increases, as much as the DOK in corresponding to the resultant complex vector is perfect, that is, it is equal to 1, and as much as the chaotic factor that forbids us from predicting exactly the result of the random experiment in
approaches 0. Mathematically we say: If N tends to infinity then the DOK in
tends to 1 and the chaotic factor tends to 0.
Moreover,
This means that for
we have a random experiment with only one outcome, hence, either
or
, which means we have, respectively, either a sure event or an impossible event in
. For this we have surely the DOK is 1 and the chaotic factor is 0 since the experiment is either certain or impossible, which is absolutely logical.
It is important to note that if in addition the outcomes of the random variables are equiprobable, then we get Table :
Table 14. The discrete probability distribution with N equiprobable random variables.
Then,
Therefore
and
for
.
Hence
And
Consequently, these results follow:
(40)
(41)
and
(42)
Therefore
(43)
7.3. Applying Chebyshev’s Inequality to Z
For a probability distribution of N disjoint and independent random variables, we have:
Since then
since
then
and since
Then .
So we can deduce the following results (Figures –):
(44)
Figure 32. |Z|2 with the lower and upper bounds functions of N and k.
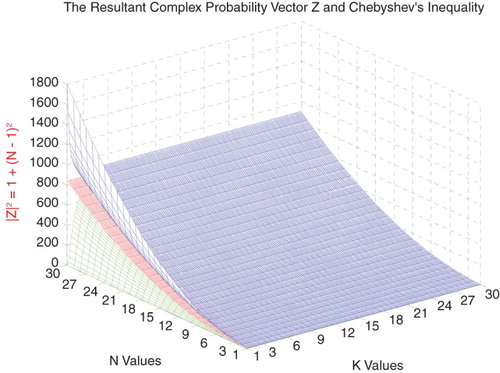
Figure 33. The midpoint of DOK(Z) function of N and k.
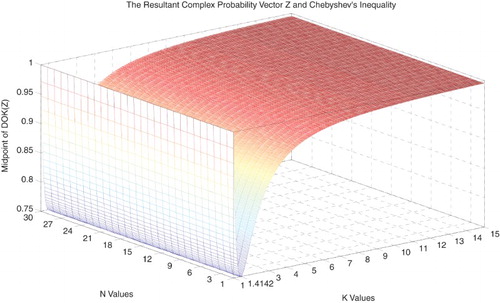
Figure 34. The midpoint of DOK(Z) with the lower and upper bounds functions of N and k.
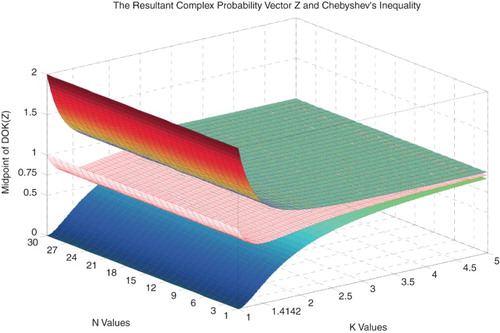
Figure 35. The midpoint of |Z|2 with the lower and upper bounds functions of N and k.
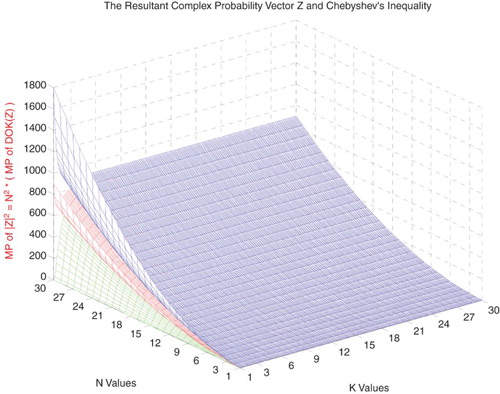
Now since
Then , and
Furthermore, since
Then, and
Therefore, and since then,
Thus, we have reached the same inequality for
in a different way.
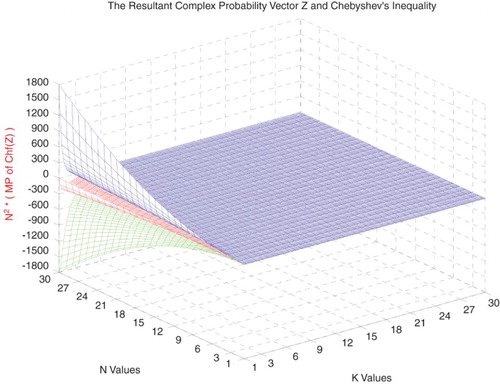
Figure 36. N2 × Chf(Z) with the lower and upper bounds functions of N and k.
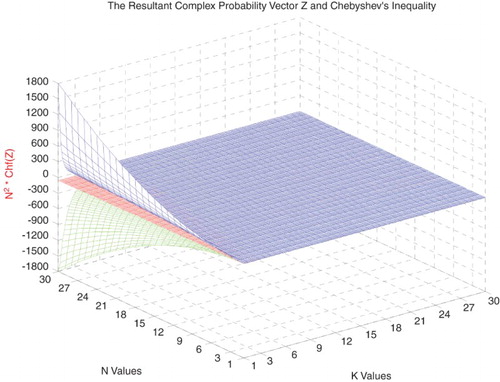
Figure 37. The midpoint of Chf(Z) function of N and k.
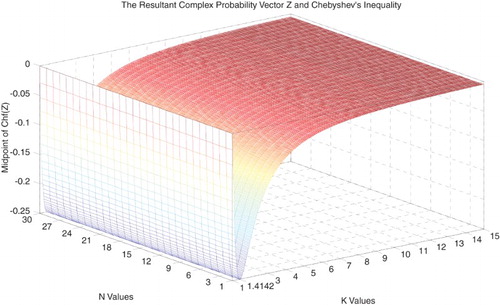
Figure 38. The midpoint of Chf(Z) with the lower and upper bounds functions of N and k.
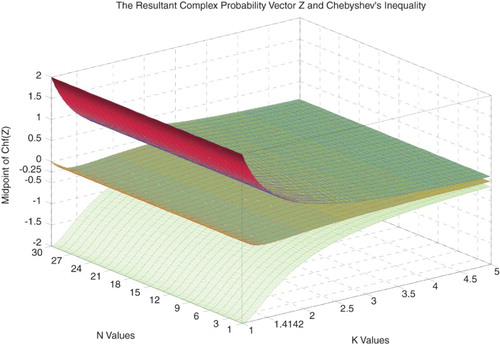
Figure 39. N2 × midpoint of Chf(Z) with the lower and upper bounds functions of N and k.
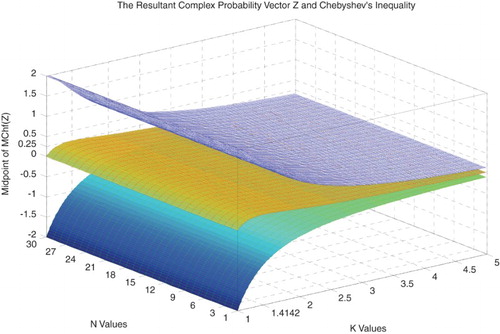
Additionally we can deduce that (Figures –): and
So it follows that:
(45)
Moreover,
Since .
Then (Figures and )
(46)
Figure 40. The midpoint of MChf(Z) function of N and k.
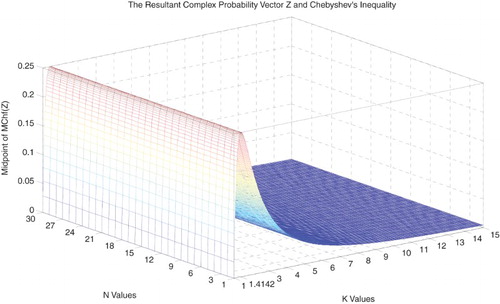
Figure 41. The midpoint of MChf(Z) with the lower and upper bounds functions of N and k.
In addition, we have from the CPP:
Therefore,
And since we have from the CPP:
, therefore, we get the same inequality just as expected:
Note that we have from the CPP always:
Consequently, we can find the Midpoint of
and
denoted by
and
, respectively, and which are equal to:
(47)
and
And
;
.
8. The complex characteristics of the probability distributions (Abou Jaoude, 2013a, 2013b, 2014, 2015a, 2015b; Abou Jaoude et al., 2010; Benton, 1966a, 1966b; Feller, 1968; Montgomery & Runger, 2003; Walpole et al., 2002)
8.1. The expectation in
8.1.1. The general probability distribution case
As a general case, let us consider then this discrete probability distribution with N random variables (Table ):
We can see that
And similarly, we have
We have also
(48)
Moreover,
Furthermore, and
Then,
The conjugate of Z is And let
.
Now, we define the conjugate of by
Therefore, we get the following relations:
And
.
And since
and
8.1.2. The general Bernoulli distribution case
Let us consider then this general Bernoulli discrete probability distribution with N = 2 random variables (Table ):
Table 15. The general Bernoulli distribution with N = 2.
We can see that
With and
Additionally,
And similarly, we have
We have also
Moreover,
With
,
Furthermore,
And the conjugate of Z is
Then and
And let
We can deduce mathematically that for any Bernoulli distribution we have that
(49)
(50)
(51)
(52)
(53)
(54)
(55)
(56)
To illustrate the concept of complex expectation, I will use Figure .
8.2. The variance in
As a general case, let us consider then the discrete probability distribution with N random variables (Table ).
Figure 42. The complex expectation Ec = Er + Em in the complex probability plane .
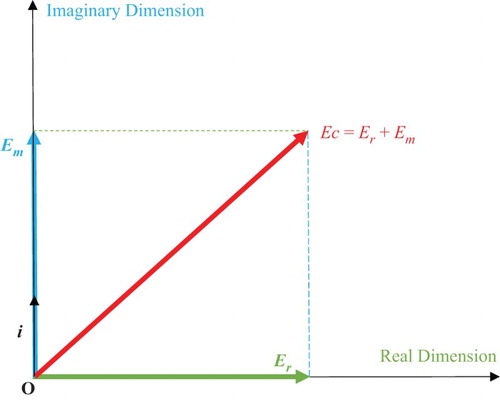
The expectation of the real part of the random variables is defined by
The expectation of the imaginary part of the random variables
is defined by
The expectation of the complex random variables
is defined by
We have also:
The variance of the real part of the random variables is defined by:
(57)
The variance of the imaginary part of the random variables
is defined by:
(58)
The variance of the complex random variables
is defined by:
(59)
But
,
Thus
(60)
8.3. A numerical example of a Bernoulli distribution
Let us consider the following Bernoulli discrete probability distribution with N = 2 random outcomes (Table ):
Table 16. An example of a Bernoulli distribution with N = 2.
We can see that
And similarly, we have
We have also
Moreover
The conjugate of Z is
Then and
And let . We can verify easily the following relations:
And we can verify that
And we have:
, just as expected and proved.
8.4. Numerical simulations (Gentle, 2003)
Numerical simulations verify what has been found earlier. I will use Monte Carlo simulation method with the help of the programming language C++ with its predefined pseudorandom function rand() to generate random numbers with a uniform distribution. To summarize what the seven tables that follow describe:
Tables , are simulations of a Bernoulli distribution where the complex random vectors are chosen randomly by C++.
Tables are simulations of a uniform distribution with three random variables having their complex random vectors also chosen randomly by C++.
Table 17. Computation of for different of values of and which are the complex random vectors of a Bernoulli distribution and which are chosen at random.
Table 18. Computation of the real, imaginary and complex expectations for different of values of and , which are chosen at random and the verification that we have always .
Table 19. Computation of the real, imaginary and complex variances for different of values of and , which are chosen at random and the verification that we have always .
Table 20. Computation of for different of values of , , , which are the complex random vectors of the distribution and which are chosen at random.
Table 21. Computation of the real, imaginary and complex expectations for different of values of , , , which are chosen at random and the verification that we have always .
Table 22. Computation of the real, imaginary and complex variances for different of values of , , , which are chosen at random and the verification that we have always .
Table 23. Computation of the real, imaginary and complex expectations and variances for different of values of , , , which are chosen at random and the verification that we have always and .
They are all in fact numerical simulations that confirm and quantify the results of the concepts of complex probability, expectation and variance that were determined previously.
9. Conclusion and perspectives
In the current paper I applied the Paradigm of Complex Probability to Chebyshev's inequality. Hence, I established a tight link between the new paradigm and this classical probability theorem. Thus, I developed the theory of ‘Complex Probability’ beyond the scope of my previous six papers on this topic.
I applied in this research work the pioneering model related to Chebyshev's theorem to different probability distributions which are: the uniform, the binomial, the Poisson and the normal Gauss–Laplace distributions. Moreover, as it was proved and illustrated in this work, when the CDF tends to 0 or 1 and correspondingly the real probability Pr → 0 or Pr → 1 then the DOK tends to one and the chaotic factor (Chf and MChf) tends to 0 since the state of the system is totally known. Thus, we have always: 0.5 ≤ DOK ≤ 1, −0.5 ≤ Chf ≤ 0, and 0 ≤ MChf ≤ 0.5 during the whole random process. Furthermore, we have permanently Pc2 = DOK − Chf = DOK + MChf = 1 throughout the whole random evolution, which means that the phenomenon which seems to be probabilistic and stochastic in is now deterministic and certain in
=
+
. This is the consequence of adding to
the contributions of
and hence of subtracting the chaotic factor from the DOK. Subsequently, this probability is certainly predicted at each instant in the complex set
with Pc maintained as equal to one through a continuous compensation between DOK and Chf. This compensation is from the instant when the random variable x → −∞ until the instant when x → ∞. Additionally, what is important to note is that throughout the whole paper and using all the illustrated graphs and simulations, we can visualize and quantify both the system chaos (Chf and MChf) and the system certain knowledge (DOK and Pc). Also, I applied this original methodology in the current research paper to some discrete and continuous probability distributions, knowing that this novel paradigm can be applied to any random law or phenomenon not discussed here. In fact, and to summarize, throughout this whole research work I have extended Chebyshev's inequality beyond the real probability set to encompass hence the complex probability set.
In addition, I have used in this paper a new powerful tool, already defined in a personal previous paper, which is the concept of the complex random vector. In fact, it is a vector representing the real and the imaginary probabilities of an outcome, identified in the added axioms as being the term . Then I have defined and expressed the resultant complex random vector Z, which is the sum of all the complex random vectors and representing the whole distribution and system in the complex probability set
. Afterward, I have used this new concept and linked it to the very well-known law of Chebyshev. I have illustrated this methodology by considering a discrete distribution with N random variables as a general case.
After that, I have determined the characteristics (expectation and variance) of discrete distributions corresponding to the imaginary probabilities and to the complex random vectors. Thus, I have showed that there is a correspondence among the real, imaginary and complex expectations as well as among the real, imaginary and complex variances for any Bernoulli distribution or for any probability distribution. Then a numerical example and simulations were considered. Additional development of these new complex paradigm tools will be done in subsequent work.
The benefits of extending Kolmogorov's axioms lead to very interesting and fruitful consequences and results illustrated in this work. Hence, I have called this original and useful new field in applied mathematics and prognostic: ‘The Complex Probability Paradigm’.
It is planned that additional development of this innovative paradigm will be done in subsequent work. It is intended that in future research studies the novel proposed prognostic approach will be elaborated more, and the complex probability paradigm as well as wide and diverse sets of stochastic processes will be applied.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Abou Jaoude, A. (2004, August). Applied mathematics: Numerical methods and algorithms for applied mathematicians (PhD thesis). Bircham International University. Retrieved from http://www.bircham.edu
- Abou Jaoude, A. (2005, October). Computer science: Computer simulation of Monte Carlo methods and random phenomena (Ph.D. thesis). Bircham International University. Retrieved from http://www.bircham.edu
- Abou Jaoude, A. (2007, April). Applied statistics and probability: Analysis and algorithms for the statistical and stochastic paradigm (Ph.D. thesis). Bircham International University. Retrieved from http://www.bircham.edu
- Abou Jaoude, A. (2013a). The complex statistics paradigm and the law of large numbers. Journal of Mathematics and Statistics (JMSS), Science Publications, 9(4), 289–304.
- Abou Jaoude, A. (2013b). The theory of complex probability and the first order reliability method. Journal of Mathematics and Statistics (JMSS), Science Publications, 9(4), 310–324.
- Abou Jaoude, A. (2014). Complex probability theory and prognostic. Journal of Mathematics and Statistics (JMSS), Science Publications, 10(1), 1–24.
- Abou Jaoude, A. (2015a, April). The complex probability paradigm and analytic linear prognostic for vehicle suspension systems. American Journal of Engineering and Applied Sciences, 8(1), 147–175. doi: 10.3844/ajeassp.2015.147.175
- Abou Jaoude, A. (2015b). The paradigm of complex probability and the Brownian motion. Systems Science and Control Engineering, 3(1), 478–503. doi: 10.1080/21642583.2015.1108885
- Abou Jaoude, A., El-Tawil, K., & Kadry, S. (2010). Prediction in complex dimension using Kolmogorov’s set of axioms. Journal of Mathematics and Statistics (JMSS), Science Publications, 6(2), 116–124.
- Aczel, A. (2000). God’s equation. New York, NY: Dell.
- Baranoski, G. V. G., Rokne, J. G., & Xu, G. (2001, May). Applying the exponential Chebyshev inequality to the nondeterministic computation of form factors. Journal of Quantitative Spectroscopy and Radiative Transfer, 69(4), 447–467. Bibcode: 2001JQSRT. 69. 447B. doi:10.1016/S0022-4073(00)00095-9, 15 May 2001.
- Barrow, J. (1992). Pi in the sky. London: Oxford University Press.
- Beasley, T. M., Page, G. P., Brand, J. P. L., Gadbury, G. L., Mountz, J. D., & Allison, D. B. (2004, January). Chebyshev’s inequality for nonparametric testing with small N and α in microarray research. Journal of the Royal Statistical Society: C (Applied Statistics), 53(1), 95–108. doi:10.1111/j.1467-9876.2004.00428.x doi: 10.1111/j.1467-9876.2004.00428.x
- Bell, E. T. (1992). The development of mathematics. New York, NY: Dover.
- Benton, W. (1966a). Probability, encyclopedia Britannica (Vol. 18, pp. 570–574). Chicago: Encyclopedia Britannica.
- Benton, W. (1966b). Mathematical probability, encyclopedia Britannica (Vol. 18, pp. 574–579). Chicago: Encyclopedia Britannica.
- Bidabad, B. (1992). Complex probability and Markov stochastic processes. Proc. First Iranian Statistics Conference. Tehran: Isfahan University of Technology.
- Bogdanov, I., & Bogdanov, G. (2009). Au Commencement du Temps. Paris: Flammarion.
- Bogdanov, I., & Bogdanov, G. (2010). Le Visage de Dieu. Paris: Editions Grasset et Fasquelle.
- Bogdanov, I., & Bogdanov, G. (2012). La Pensée de Dieu. Paris: Editions Grasset et Fasquelle.
- Bogdanov, I., & Bogdanov, G. (2013). La Fin du Hasard. Paris: Editions Grasset et Fasquelle.
- Boursin, J.-L. (1986). Les Structures du Hasard. Paris: Editions du Seuil.
- Chan Man Fong, C. F., De Kee, D., & Kaloni, P. N. (1997). Advanced mathematics for applied and pure sciences. Amsterdam: Gordon and Breach Science.
- Cox, D. R. (1955). A use of complex probabilities in the theory of stochastic processes. Mathematical Proceedings of the Cambridge Philosophical Society, vol. 51, pp. 313–319.
- Dacunha-Castelle, D. (1996). Chemins de l’Aléatoire. Paris: Flammarion.
- Dalmedico-Dahan, A., Chabert, J.-L., & Chemla, K. (1992). Chaos Et Déterminisme. Paris: Edition du Seuil.
- Dalmedico-Dahan, A., & Peiffer, J. (1986). Une Histoire des Mathématiques. Paris: Edition du Seuil.
- Davies, P. (1993). The mind of god. London: Penguin Books.
- Ekeland, I. (1991). Au Hasard. La Chance, la Science et le Monde. Paris: Editions du Seuil.
- Fagin, R., Halpern, J., & Megiddo, N. (1990). A logic for reasoning about probabilities. Information and Computation, 87, 78–128. doi: 10.1016/0890-5401(90)90060-U
- Feller, W. (1968). An introduction to probability theory and its applications (3rd ed.). New York, NY: Wiley.
- Ferentinos, K. (1982). On Tchebycheff’s type inequalities. Trabajos de Estadistica y de Investigacion Operativa, 33, 125–132. doi: 10.1007/BF02888707
- Gentle, J. (2003). Random number generation and Monte Carlo methods (2nd ed.). Sydney: Springer.
- Gleick, J. (1997). Chaos, making a new science. New York, NY: Penguin Books.
- Greene, B. (2003). The elegant universe. New York, NY: Vintage.
- Gullberg, J. (1997). Mathematics from the birth of numbers. New York, NY: W.W. Norton.
- Hawking, S. (2002). On the shoulders of giants. London: Running Press.
- Hawking, S. (2005). God created the integers. London: Penguin Books.
- Hawking, S. (2011). The dreams that stuff is made of. London: Running Press.
- He, S., Zhang, J., & Zhang, S. (2010). Bounding probability of small deviation: A fourth moment approach. Mathematics of Operations Research, 35(1), 208–232. doi:10.1287/moor.1090.0438 doi: 10.1287/moor.1090.0438
- Kabán, A. (2012). Non-parametric detection of meaningless distances in high dimensional data. Statistics and Computing, 22(2), 375–85. doi:10.1007/s11222-011-9229-0
- Katarzyna, S., & Dominik, S. (2010). On Markov-Type inequalities. International Journal of Pure and Applied Mathematics, 58(2), 137–152.
- Kuhn, T. (1970). The structure of scientific revolutions (2nd ed.). Chicago: Chicago Press.
- Montgomery, D. C., & Runger, G. C. (2003). Applied statistics and probability for engineers (3rd ed.). New York, NY: John Wiley & Sons.
- Ognjanović, Z., Marković, Z., Rašković, M., Doder, D., & Perović, A. (2012). A probabilistic temporal logic that can model reasoning about evidence. Annals of Mathematics and Artificial Intelligence, 65, 1–24. doi: 10.1007/s10472-012-9294-x
- Penrose, R. (1999). traduction Française: Les Deux Infinis et L’Esprit Humain. Roland Omnès. Paris: Flammarion.
- Pickover, C. (2008). Archimedes to Hawking. Oxford: Oxford University Press.
- Poincaré, H. (1968). La Science et l’Hypothèse (1st ed.). Paris: Flammarion.
- Reeves, H. (1988). Patience dans L’Azur, L’Evolution Cosmique. Paris: Le Seuil.
- Ronan, C. (1988). traduction Française: Histoire Mondiale des Sciences. Claude Bonnafont. Paris: Le Seuil.
- Science Et Vie. (1999). Le Mystère des Mathématiques. Numéro 984.
- Srinivasan, S. K., & Mehata, K. M. (1988). Stochastic processes (2nd ed.). New Delhi: McGraw-Hill.
- Stepić, A. I., & Ognjanović, Z. (2014). Complex valued probability logics. Publications De L’institut Mathématique, Nouvelle Série, tome, 95(109), 73–86. doi:10.2298/PIM1409073I doi: 10.2298/PIM1409073I
- Stewart, I. (1996). From here to infinity (2nd ed.). Oxford: Oxford University Press.
- Stewart, I. (2002). Does god play dice? (2nd ed.). Oxford: Blackwell.
- Stewart, I. (2012). In pursuit of the unknown. Oxford: Basic Books.
- Van Kampen, N. G. (2006). Stochastic processes in physics and chemistry (Revised and Enlarged Edition). Sydney: Elsevier.
- Walpole, R., Myers, R., Myers, S., & Ye, K. (2002). Probability and statistics for engineers and scientists (7th ed.). Upper Saddle River, NJ: Prentice Hall.
- Warusfel, A., & Ducrocq, A. (2004). Les Mathématiques, Plaisir et Nécessité (1st ed.). Paris: Edition Vuibert.
- Weingarten, D. (2002). Complex probabilities on RN as real probabilities on CN and an application to path integrals. Physical Review Letters, 89, 240201. doi: 10.1103/PhysRevLett.89.240201
- Wikipedia, the free encyclopedia, Probability Theory. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Probability Distribution. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Probability Density Function. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Probability Space. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Probability Measure. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Probability Axioms. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Chebyshev’s Inequality. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Pafnuty Chebyshev. Retrieved from https://en.wikipedia.org/
- Wikipedia, the free encyclopedia, Markov’s Inequality. Retrieved from https://en.wikipedia.org/
- Youssef, S. (1994). Quantum mechanics as Bayesian complex probability theory. Modern Physics Letters A, 9, 2571–2586. doi: 10.1142/S0217732394002422