
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
As a novel type of automotive signal light, the running light is gradually being used in automobiles. To address the problem that there are few methods dedicated to detecting defects in automotive running lights and existing methods are inefficient, this paper proposes a YOLOv7-based method for detecting defects in automotive running lights. The accurate recognition of running light defects with different features is achieved by training a single model. Moreover, some improvements are made on the basis of the original network to improve the accuracy of recognition. To enhance the overall feature extraction capability and detail information retention capability of the algorithm, recursive gated convolution (gnconv) and global attention mechanism (GAM) are added to the network. Ghost convolution and parameter-free attention mechanism (SimAM) are introduced to reduce information redundancy and avoid the drastic increase in the number of parameters. In addition, a parallel structure ELAN module incorporating the attention mechanism is proposed. The experimental results show that the recognition accuracy of the method in this paper reaches 89.7% on the self-built dataset, while the image inference speed is maintained at 61 frames per second, which can meet the demand for efficient detection.
1. Introduction
Automobiles bring many conveniences to people's lives. As automobiles become more and more indispensable in the daily travel, the production of automobiles worldwide has gradually increased (Yang et al., Citation2022). As one of the important components of automobiles, the production and inspection of headlights have been gradually scaled up and standardized with the growth of automobile production. In recent years, as a novel form of turn signal light, running lights are used by more and more automobile companies as part of the headlight components to play the role of the turn signal. Therefore, the quality of automotive running lights has a direct impact on road safety. However, the wide variety of automobile running lights leads to more complex features of the defect in the running lights. In traditional defect detection methods, it is difficult to detect running light defects with different features using just a single model.
With the improvement of graphics processing unit performance, deep learning algorithms have been widely used in the field of defect inspection (Tabernik et al., Citation2020; Zheng et al., Citation2021). Benefiting from the powerful feature extraction ability of convolutional neural networks and the capability of characterizing high-dimensional data, deep learning-based methods can not only learn features that are difficult to extract by traditional methods but also significantly improve detection accuracy and speed (Fan et al., Citation2020; Li et al., Citation2022; Lu et al., Citation2021, August). The current object recognition algorithms in the field of deep learning can be divided into two categories: two-stage methods based on the regional proposal, such as R-CNN (Sun et al., Citation2021; Zhang et al., Citation2020, August; Zhang, Yu, et al., Citation2022), Fast R-CNN (Hsu et al., Citation2018, January), Faster R-CNN (He & Zhang, Citation2020, August), and Mask R-CNN (Cheng et al., Citation2020); and one-stage methods based on regression analysis, such as SSD detectors and YOLO (Chen et al., Citation2021; Wang et al., Citation2021; Wang, Liu, et al., Citation2022; Zhang, Wang, et al., Citation2022) series of detectors. The two-stage algorithm has an advantage in terms of accuracy, but the one-stage algorithm has an advantage in terms of speed. The YOLO algorithm uses a single convolutional neural network to implement detection, and its training and prediction are both end-to-end (Diwan et al., Citation2022). Therefore, the YOLO algorithm is relatively simple and fast. At the same time, the YOLO algorithm is more suitable for industrial defect detection (Liu et al., Citation2022).
In the quality monitoring of headlights, traditional image processing methods are more frequently applied, but a small number of scholars have also applied deep learning to automotive headlight inspection. Moon et al. (Citation2021) proposed inspection system for vehicle headlight defects based on a convolutional neural network, which can detect the defects in the region of interest (ROI) After position and angle calibration. Automotive running light defects have complex and variable characteristics, and the types of defects are gradually becoming more complex with the increase of running light styles. Accurately identifying different types of running light defects with a single model has become a practical problem that needs to be solved. Industrial defect inspection methods based on deep learning can improve the accuracy and efficiency of detection (Chen et al., Citation2023; Song et al., Citation2022). However, there is little research on the use of deep learning algorithms to detect automotive running light defects.
Many scholars have used existing modules to improve the performance of CNNs. Zheng et al. (Citation2022) added recursive gated convolution to the network of yolov7 for enhancing the network's ability to extract image features and improving the network's detection accuracy for small defective targets. Wu et al. (Citation2022) added ghost convolution to the yolov5 network, and then proposed a lightweight defect detection method. The attention mechanism is one of the core techniques in deep learning. Recently, attention modules have been widely used in various types of deep learning tasks. Ju et al. (Citation2021) proposed adaptive feature fusion with attention mechanism (AFFAM) for multi-scale target detection. AFFAM uses a global attention mechanism to learn correlations between different channels and can perform adaptive fusion of features at different scales. In this paper (You et al., Citation2023), the no-parameter attention SimAM is integrated into EfficientNet, and the improved SimAM-EfficientNet has the advantages of smaller parameters and shorter training time.
In response to the dilemma that there are few high-efficiency algorithms applicable to automotive running light defects and that it is difficult to identify multiple types of defects with a single model by traditional methods, we applied the current YOLOv7 (Wang, Bochkovskiy, et al., Citation2022) algorithm of the YOLO series to running light inspection and proposed a YOLOv7-based defect detection method for automotive running lights. The proposed method incorporates the recursive gated convolution, global attention mechanism, Ghost convolution, and parameter-free attention mechanism, which can effectively improve the feature extraction capability of the network without adding too many parameters. The main contributions of our work are as follows:
There are few publicly available automotive running light defect datasets. We collected a variety of automotive running light components and took a large number of running light images with defects. The automotive running light defect dataset was created.
Traditional methods make it difficult to detect defects with different features simultaneously with one model. Deep learning is introduced to the defect detection task of automotive running lights, and a YOLOv7-based defect detection method for automotive running lights is proposed. Detection of different feature defects can be achieved by training a model.
The feature extraction capability of the original network for running light defects needs to be enhanced, and the model parameters need to be further compressed. Decursive gated convolution and global attention mechanism are introduced to enhance the feature extraction capability. Ghost convolution and SimAM are introduced for reducing redundant features and model parameters. Directly inserting multiple modules into the network tends to weaken the original feature extraction ability, therefore the parallel structured ELAN modules incorporating attention mechanisms are proposed.
2. Basic method
YOLO was first proposed in 2016, and the full name is You Only Look Once. The YOLO algorithm considers the object detection problem as a regression problem and uses a single neural network to directly predict the object bounding box and classification probability, enabling end-to-end object detection. YOLOv7 was proposed in July 2022. The paper claims that in the frame-per-second range of 5FPS to 160FPS, YOLOv7 outperforms other currently known target detectors in terms of accuracy and speed.
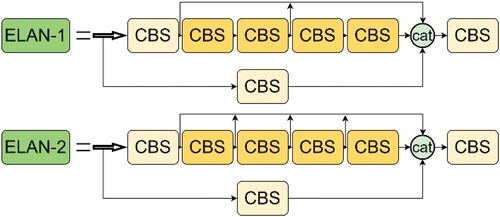
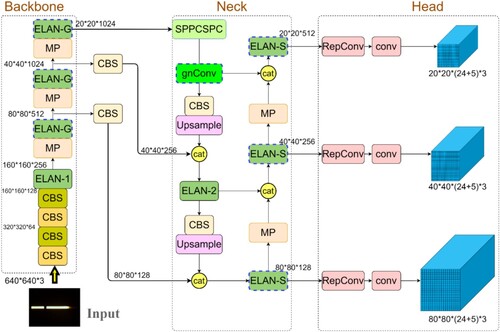
As with most target detectors, the network structure of YOLOv7 can be divided into Backbone, Neck, and Head. The network structure is shown in Figure . YOLOv7 constructs the whole network in different modules, where the CBS module consists of convolution operation, regularization, and SiLU activation. the SiLU activation function is formulated in Formula 1. The MP module consists of the CBS module and the maximum pooling. The ELAN-1 and ELAN-2 modules are the main computational modules of YOLOv7, which are responsible for extracting features, and the structure diagram is shown in Figure .
Figure 1. Original YOLOv7 network structure.
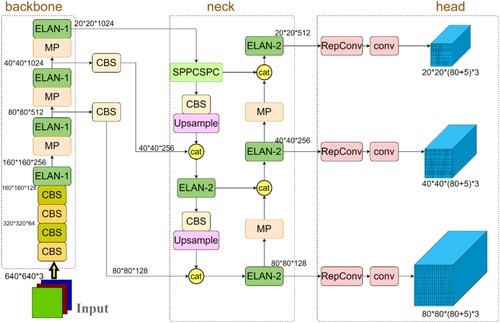
Figure 2. Original ELAN module structure.
In the input part, the size of the three-channel colour image will be uniformly cropped to 640×640. In the Backbone part, unlike other algorithms that directly apply the existing backbone network structure design, YOLOv7 uses four ELAN-1 modules to complete the main feature extraction task. Among them, three ELAN-1 modules are output to the Neck part after modifying the number of channels. In the Neck part, the feature pyramid structure is used in YOLOv7, using 1 SPPCSPC module and 4 ELAN-2 modules to implement the feature extraction function. Among them, the 3 ELAN-2 modules on the right side are directly output to the Head part. Finally, the network performs feature output through three detection heads. Three different sizes of 2020, 40
40, and 80
80 feature maps are output. The output feature maps become in the form of a one-dimensional vector after convolution, called the Fully Connected Layer. With the one-dimensional vector output by the convolutional neural network, the targets in the image can be predicted.
(1)
(1)
The loss function of the YOLOv7 model consists of three parts: confidence loss(Lobj), classification loss(Lcls), and localization loss(Lbox). The total loss is the sum of the three losses with different weights. The total loss function is expressed as Formula 2.
(2)
(2) where a, b, and c are the weighting factors corresponding to the three partial losses. Binary cross-entropy loss is used for classification loss and confidence loss, and CIoU loss is used for localization loss.
(3)
(3)
The binary cross-entropy loss can be defined as Formula 3. Where represents the real sample label, and p(y) is the predicted probability of the point being positive for all N points.
(4)
(4) CIoU can be expressed as Formula 4. Where
represents the Euclidean distance between the centre points of the prediction frame and the real frame, and c represents the diagonal distance of the smallest area that can contain the predicted and real boxes. The IoU represents the intersection area of the prediction box and the real box.
3. The proposed method
3.1. Related theories
3.1.1. Recursive Gated Convolution (gnConv)
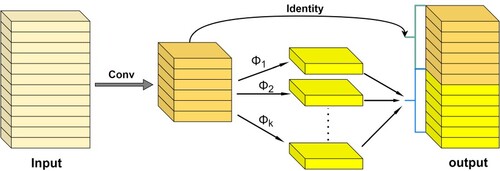
Recursive Gated Convolution (Rao et al., Citation2022) implements high-order spatial interactions by gated convolution and recursive structural design, which is efficient, extendable, and translation-equivariant. It also extends the two-order interactions in self-attention to arbitrary orders without introducing a large amount of extra computation. The accuracy increases with the increase of spatial order. The structure is shown in Figure .
Figure 3. Recursive Gated Convolution structure.
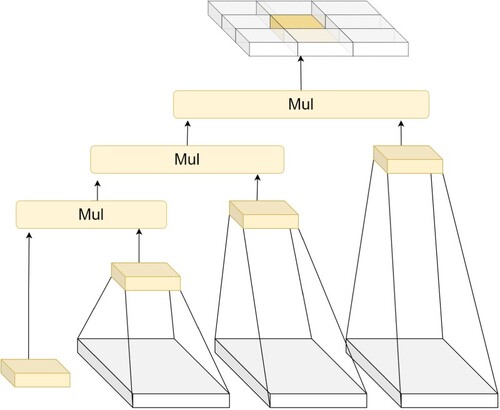
The gnConv proposed by the original authors includes two important concepts: (1) Gated convolution. Formula 5 represents the process of 1-order gated convolution, where and
are the linear projection layers to perform channel mixing. The input feature map (x) is separated into two equal parts by
. The f is the depth-separable convolution, and the symbol
indicates the element-wise multiplication.
adjusts the channel dimension of P1. (2) Recursive structure design. The recursive design of multiple gated convolutions is the order-by-order multiplication operation of the features. By extending the 1-order operation of Formula 5 to higher orders according to the recursive design of Figure , a recursive gated convolution of arbitrary order can be achieved. More higher-order information can be retained by such recursively designed features.
(5)
(5)
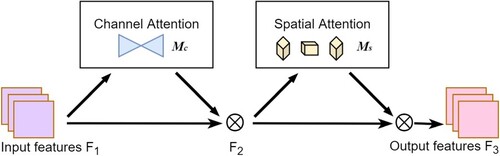
3.1.2. Global Attention Mechanism (GAM)
Most attention mechanisms ignore the significance of preserving information in both channel and space to enhance cross-dimensional interactions. The paper (Liu et al., Citation2021) proposes a global attention mechanism to improve the performance of deep neural networks by reducing information dispersion and amplifying the global interaction representation. The original authors follow the sequential design of CBAM for channel attention and spatial attention and redesign the submodules. The overall structural design of GAM can be shown in Figure . And the principle can be briefly expressed as Formula 6, where and
denote the channel and spatial attention modules, respectively, and
denotes the corresponding element multiplication.
(6)
(6)
Figure 4. Global attention mechanism structure.
3.1.3. Ghostconv
Deep convolutional neural networks usually require a large number of convolutional operations, which leads to huge computational costs. Successive ordinary convolution operations produce many similar feature maps, which leads to information redundancy. The Ghost convolution is proposed in the paper (Han et al., Citation2020), which can generate more features using fewer parameters. The structure is shown in Figure . In the Ghost convolution, an original convolutional layer will be split into two parts. The first part is an ordinary convolution operation, and the dimensions of the extracted feature maps will be strictly controlled. The input feature maps are convolved first, but the number of convolution filters is only half of the dimension of the input feature maps. Based on the feature maps obtained in the first part, more feature maps are generated by a series of simple linear operations. The in Figure indicates a linear operation, which requires only a convolution filter. Compared with the ordinary convolutional neural network, the parameters and computational complexity of the Ghost convolution are reduced without changing the size of the output feature maps.
Figure 5. GhostConv.
3.1.4. Parameter-Free Attention (SimAM)
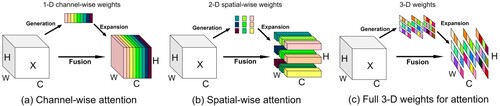
In response to the fact that most of the currently existing attention modules generate 1-dimensional or 2-dimensional parameter weights from the input, the paper (Yang et al., Citation2021, July) proposes an attention mechanism, which can generate 3-dimensional parameter weights directly and without generating redundant parameters. The structure is shown in Figure . Among them, Figure (a) shows channel attention, and each parameter corresponds to a different channel; Figure (b) shows spatial attention, and each parameter corresponds to the same position of all channels respectively; Figure (c) shows the SimAM principle. In contrast to the simple 1-dimensional or 2-dimensional parameter structure, the refined features between different feature maps and different elements of the same feature map are taken into account by the 3-dimensional parameter weights at the same time.
Figure 6. Comparisons of different dimensions of attention.
3.2. Improvements
The defect features of automotive running lights are more complex and difficult to identify. To solve this problem, our method adds recursive gated convolution modules to the original network, as well as replaces several original ELAN modules with improved ELAN modules. These modifications aim to further improve the accuracy of YOLOv7 in running light defect recognition, making the improved network more adaptable to different styles of running lights. The improved network structure is shown in Figure .
Figure 7. Improved YOLOv7 network structure.
The ELAN-G module is proposed in this paper. In the Backbone part, the ELAN-G modules are used to replace the three ELAN-1 modules that output directly to the Neck part. And we keep the first ELAN-1 module to retain the feature extraction effect of ordinary convolution on images. As shown in Figure , the GAM and Ghost convolution are used in the ELAN-G module. Among them, the GAM is more capable of feature extraction and also has more parameters. Most automotive running lights light up sequentially in the same direction. For more running lights with different lighting directions, the global attention mechanism can take into account the defective characteristics of running lights at different locations and retain more valuable parameters. As with the ELAN-1 module, a convolution operation is required at the end of the ELAN-G module to adjust the dimension. However, the ELAN-G module includes more convolution operations, which generate a large amount of duplicate feature information when fully extracting defective features. Unlike the ELAN-1 module, Ghost convolution is used to replace the CBS module in the ELAN-G module. Ghost convolution is placed at the end of the ELAN-G module. Initial feature extraction is first performed by ordinary convolution with dimensional control and then continues to generate more feature maps by a series of simple linear operations. It can effectively eliminate redundant defective features and avoid adding unnecessary parameters due to too much similar feature information. For the structure of ELAN-G, we adopted the design of parallel structure. Compared with the original ELAN-1 module structure, the design of parallel structure can make the 4 branches of the cat module not affect each other. It can get the features after ordinary convolution and the features extracted by the global attention mechanism respectively, and also retain the original input features.
Figure 8. Improved ELAN module.
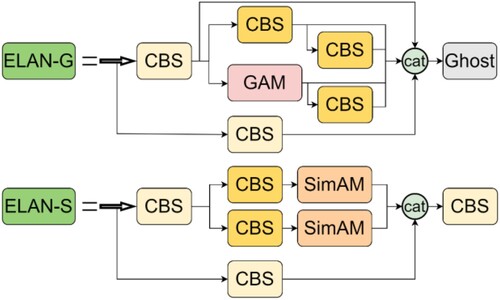
The ELAN-S module is proposed in this paper. In the Neck part, the ELAN-S modules are used to replace the three ELAN-2 modules that output directly to the Head part. To retain the feature extraction effect of the successive ordinary convolution operations, this ELAN-2 module on the left side of the feature pyramid structure is kept. As shown in Figure , the SimAM is used in the ELAN-S module. SimAM was introduced without any additional parameters, which resulted in a significant reduction in the parameters of the ELAN-S module compared to the original ELAN-2 module. At the same time, SimAM can focus on both channel and spatial features, reducing the possibility of defective feature information loss. For the structure of ELAN-S, we also adopted a parallel structure design. The CBS module and SimAM module are used to form two main pathways for feature extraction, and the original input features are retained.
In addition, the recursive gated convolution module (gnconv) is added behind the SPPCSPC module, and output to the CBS module and the cat module. The addition of the recursive gated convolution module helps to further enhance the feature extraction capability for running light defects. The higher the order of the recursive design, the more gated convolution operations are performed.
4. Experiments and discussions
4.1. Experiment environment and settings
The experiments were conducted in the Windows 10 system environment, and the details of the experimental environment are shown in Table .
Table 1. Experimental environment.
Since there are few publicly available automotive running light defect datasets, we built an automotive running light defect dataset. The collected images of automotive running light defects were captured from real running lights. We used twelve styles of automotive running lights, and the camera was a Hikvision MV-CA004-10UC industrial aerial camera. Some of the lamps and image capture devices are shown in Figure .
Figure 9. Headlights and camera equipment.

For the annotation of the dataset, we defined two kinds of annotation objects. For running light defects due to lamp bead damage, we annotated the defective part of the running lights as the target. For sequence problems with running lamps, we labelled the first bead part of the running light, which can be used to check the timing. Therefore, the defective part of the running light and the first light bead will be the target for identification in the experiment. Labelimg was chosen as the image labelling software. In the self-built dataset used in this paper, most of the defects of the running lights are due to damage to the LED beads. The appearance of defective parts is in the form of single LED beads that do not light up, broken parts of the running light strip, and defective modules of the running light. An example of a defective running light is shown in Figure .
Figure 10. Example of running light defect.

We used Recall, Precision, Mean Average Precision (mAP), and Frame Per Second (FPS) as evaluation indexes for this experiment. The Recall cares only about how the positive samples are classified. The Precision reflects how reliable the model is in classifying samples as positive. The mAP reflects the accuracy of the model. FPS indicates the number of images that are processed in one second. In addition, the weights of different models are used as auxiliary indexes. ‘Recall’ and ‘Precision’ are denoted as ‘R’ and ‘P’ in Formula 7.
(7)
(7)
In the formula mentioned above, TP is the number of positive samples predicted to be positive. FP is the number of negative samples predicted to be positive. FN is the number of positive samples predicted to be negative.
4.2. Experimental results and discussions
The following experiments are designed to demonstrate the performance of our method. To compare the effectiveness of the proposed method with other methods on the self-built running light dataset, the contrast experiment is conducted. To analyze the contribution of different modules to the performance of the proposed method, the ablation experiment is conducted. For the applicability of our method on other object detection tasks, we conducted a contrast experiment using the metal casting dataset. In addition, different sizes of input images produce different effects on the model during the training process, therefore we experimented with different image input sizes as variables. The specific analysis of the experiment is as follows.
4.2.1. Contrast experimental analysis of different methods with the automotive running light dataset
Based on the self-built automotive running light defect dataset, we compared the improved YOLOv7 network with other object detectors for experiments, including YOLOv3, YOLOv4, YOLOv5, and the original YOLOv7. As shown by the contrast analysis in Table , the improved YOLOv7 has the highest mAP of 89.7%. The mAP improved by 4% relative to the original YOLOv7, and by 16.2%, 9.5%, and 8.9% relative to YOLOv3, YOLOv4, and YOLOv5, respectively. The original YOLOv7 is the fastest at 72.46 fps, while the original YOLOv7 has the smallest weight at 71.5 MB. However, the improved YOLOv7 still has significant advantages over other methods in the YOLO family in terms of speed and less weight, making it more suitable for deployment on embedded platforms. From the above discussion, the improved YOLOv7 can have a higher accuracy while maintaining the detection speed compared to the other three YOLO target detectors. Compared to the original YOLOv7, the improved model is not competitive in terms of detection speed but has higher recognition accuracy. Therefore, our method improves detection accuracy while ensuring real-time inspection in the process of running light defect detection, achieving a balance between detection speed and accuracy.
Table 2. Contrast experiment.
4.2.2. Ablation experiment
To investigate the contribution of different modules to the model, the ablation experiment based on a self-built dataset of running light defects is conducted. The main investigation is on the effect of adding ELAN-G, ELAN-S, and gnconv modules separately on the model performance. The ELAN-G module incorporates the Ghost module and the global attention mechanism, and the ELAN-S module incorporates the SimAM. From the analysis in Table , it can be seen that the number of model parameters is significantly increased and more valid information is retained after adding the gnconv module. Then the weight size increases by 5.8M, and the picture inference slows down. But there is a small improvement of 0.2% in accuracy. After adding the ELAN-S module, the weight of the model is reduced by 2.8M due to the parameter-free feature of SimAM. At this time, the speed of picture inference is significantly improved, but the accuracy is reduced. After adding the ELAN-G module, the feature extraction ability of the model is enhanced due to the global attention mechanism, and the improvement of recognition accuracy is more obvious. At the same time, the image inference speed is reduced due to the deepening of the network layers. However, because the Ghost module can effectively reduce the parameters, the weights of the model parameters at this point are still smaller than those of the original model. After incorporating all modules, the weight of the improved YOLOv7 model becomes larger and the speed of picture inference decreases, but there is a significant improvement in accuracy.
Table 3. Ablation experiments.
4.2.3. Versatility experiment with metal casting dataset
To validate the effectiveness of our method on other detection tasks, we conducted a further experiment using the metal casting dataset. The metal casting dataset contains 1084 images with six types of castings to be inspected. The six types of castings have different shapes and sizes, which can verify the adaptability of the proposed method to different characteristics of the detection target. Model training is performed without the use of pre-trained weights. The experimental results of the different methods on the metal casting dataset are shown in Table . The proposed method has a 1.3% improvement over the original YOLOv7 algorithm on the casting dataset and is also better than YOLOv3, YOLOv4, and YOLOv5. This proves that the proposed method is effective not only for running light defects but also for other targets. However, the contribution to accuracy is not obvious, presumably because our method has a stronger focus on the defect features of automotive running lights.
Table 4. Versatility experiments with metal casting dataset.
4.2.4. The effect of different image input-sizes on the model
Images of different sizes are uniformly cropped to the same size before being fed into the network for training. Different input-sizes correspond to different output-sizes feature maps. To compare the effect of different image input-sizes on the detection accuracy and speed of the model, the contrast experiment is designed for the model effect with different image input-sizes. The original input size of YOLOv7 is 640×640, and two input-sizes of 512×512 and 800×800 are added as a comparison. The corresponding feature map output-sizes for the three different input-sizes are shown in Table .
Table 5. Relationship between input-sizes and output-sizes.
The analysis of the experimental results in Table shows that the inference of the pictures is fastest when the input size is 512×512. Because the smaller the size of the input picture, the fewer convolution operations the picture has to perform in the computer. Picture inference is much faster. However, in terms of accuracy, the 640×640 image input size has the highest accuracy. Usually, the larger size of the input image means that the three output feature maps are larger and can retain more detailed information. Most of the time large size has a positive effect on the improvement of recognition accuracy. In our experiments, the larger input size led to a decrease in accuracy, reasoning that the output size of the feature map obtained from the 640×640 image input size was more suitable for the defect size of the self-built automotive running light dataset.
Table 6. Performance of different image input-sizes.
4.2.5. Recognition results
The defect detection results for six different styles of automotive running lights are shown in Figure . For many different characteristics of running light defects, our method is capable of accurately identifying them and distinguishing the categories. It also enables the first light tracking recognition, as shown in Figure . In summary, our method can accurately identify many different characteristics of automotive running light defects and the first lamp bead simultaneously, by training a single deep-learning model. Thus high-efficiency automobile running light defect detection is realized.
Figure 11. Identification results of different types of defects.

Figure 12. Tracking of the first light beads.

5. Conclusion
This paper proposes an improved YOLOv7 model based on the original YOLOv7 network for the accurate detection of automotive running light defects. We made improvements to the original network and used the self-built running light dataset for model training. Then the defective part and the first light part of the running light can be accurately detected. To enhance feature extraction and retain more valid information, recursive gated convolution, and global attention mechanism are added to the model. To reduce information redundancy and avoid information loss, the Ghost convolution module and SimAM are added to the model. The parallel structure ELAN module incorporating the attention mechanism is proposed. The experimental results show that the improved YOLOv7 achieves an accuracy of 89.7% on the automotive running light defect detection task, which can meet the accuracy requirements of actual industrialized inspection. In the future, we will further investigate the lightweight design of the model and the deployment of the embedded system, to further research the approach of real-time detection of automotive running lights in the operating state.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Chen, K., Cai, N., Wu, Z., Xia, H., Zhou, S., & Wang, H. (2023). Multi-scale GAN with transformer for surface defect inspection of IC metal packages. Expert Systems with Applications, 212, 118788. https://doi.org/10.1016/j.eswa.2022.118788
- Chen, Q., Wang, Y., Yang, T., Zhang, X., Cheng, J., & Sun, J. (2021, June 21–24). You only look one-level feature. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13039–13048). https://doi.org/10.1109/CVPR46437.2021.01284
- Cheng, T., Wang, X., Huang, L., & Liu, W. (2020, August 23–28). Boundary-preserving mask r-cnn. European Conference on Computer Vision (pp. 660–676), Springer, Cham. https://doi.org/10.48550/arXiv.2007.08921
- Diwan, T., Anirudh, G., & Tembhurne, J. V. (2022). Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimedia Tools and Applications, 82(6), 9243–9275. https://doi.org/10.1007/s11042-022-13644-y
- Fan, B., Chen, W., Cong, Y., & Tian, J. (2020, August 23–28). Dual refinement underwater object detection network. European Conference on Computer Vision (pp. 275–291), Springer, Cham. https://doi.org/10.1007/978-3-030-58565-5_17
- Han, K., Wang, Y., Tian, Q., Guo, J., Xu, C., & Xu, C. (2020). Ghostnet: More features from cheap operations. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1580–1589). June 13-19.
- He, Z., & Zhang, L. (2020, August 23–28). Domain adaptive object detection via asymmetric tri-way faster-rcnn. European Conference on Computer Vision (pp. 309–324), Springer, Cham. https://doi.org/10.48550/arXiv.2007.01571
- Hsu, S. C., Huang, C. L., & Chuang, C. H. (2018, January). Vehicle detection using simplified fast R-CNN. In 2018 International Workshop on Advanced Image Technology (IWAIT) (pp. 1–3). IEEE.
- Ju, M., Luo, J., Wang, Z., & Luo, H. (2021). Adaptive feature fusion with attention mechanism for multi-scale target detection. Neural Computing and Applications, 33(7), 2769–2781. https://doi.org/10.1007/s00521-020-05150-9
- Li, R., Wu, J., & Cao, L. (2022). Ship target detection of unmanned surface vehicle base on efficientdet. Systems Science & Control Engineering, 10(1), 264–271. https://doi.org/10.1080/21642583.2021.1990159
- Liu, J., Zhu, X., Zhou, X., Qian, S., & Yu, J. (2022). Defect detection for metal base of TO-Can packaged laser diode based on improved YOLO algorithm. Electronics, 11(10), 1561. https://doi.org/10.3390/electronics11101561
- Liu, Y., Shao, Z., & Hoffmann, N. (2021). Global attention mechanism: Retain information to enhance Channel-Spatial Interactions. arXiv preprint arXiv:2112.05561.
- Lu, P., Song, B., & Xu, L. (2021). Human face recognition based on convolutional neural network and augmented dataset. Systems Science & Control Engineering, 9(sup2), 29–37. https://doi.org/10.1080/21642583.2020.1836526
- Moon, C. B., Lee, J. Y., Kim, D. S., & Kim, B. M. (2021). Inspection system for vehicle headlight defects based on convolutional neural network. Applied Sciences, 11(10), 4402. https://doi.org/10.3390/app11104402
- Rao, Y., Zhao, W., Tang, Y., Zhou, J., Lim, S. N., & Lu, J. (2022). Hornet: Efficient high-order spatial interactions with recursive gated convolutions. arXiv preprint arXiv:2207.14284.
- Song, K., Yang, H., & Yin, Z. (2022). Anomaly composition and decomposition network for accurate visual inspection of texture defects. IEEE Transactions on Instrumentation and Measurement, 71, 1–14. https://doi.org/10.1109/TIM.2022.3196133
- Sun, P., Zhang, R., Jiang, Y., Kong, T., Xu, C., Zhan, W., & Luo, P. (2021, June 19–25). Sparse r-cnn: End-to-end object detection with learnable proposals. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14454–14463). https://doi.org/10.1109/CVPR46437.2021.01422
- Tabernik, D., Šela, S., Skvarč, J., & Skočaj, D. (2020). Segmentation-based deep-learning approach for surface-defect detection. Journal of Intelligent Manufacturing, 31(3), 759–776. https://doi.org/10.1007/s10845-019-01476-x
- Wang, C., Liu, Y. S., Chang, F. X., & Lu, M. (2022). Pedestrian detection based on YOLOv3 multimodal data fusion. Systems Science & Control Engineering, 10(1), 832–845. https://doi.org/10.1080/21642583.2022.2129507
- Wang, C. Y., Bochkovskiy, A., & Liao, H. Y. M. (2021, June 19–25). Scaled-yolov4: Scaling cross stage partial network. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13029–13038). https://doi.org/10.1109/CVPR46437.2021.01283
- Wang, C. Y., Bochkovskiy, A., & Liao, H. Y. M. (2022). YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696.
- Wu, L., Zhang, L., Shi, J., Zhang, Y., & Wan, J. (2022). Damage detection of grotto murals based on lightweight neural network. Computers and Electrical Engineering, 102, 108237. https://doi.org/10.1016/j.compeleceng.2022.108237
- Yang, L., Zhang, R. Y., Li, L., & Xie, X. (2021, July 18–24). Simam: A simple, parameter-free attention module for convolutional neural networks. International Conference on Machine Learning (pp. 11863–11874). PMLR.
- Yang, X., Zheng, Q., Hu, Y., Chen, R., Wang, X., & Liu, Y. (2022). Research on high-quality development of auto parts manufacturing industry based on machine learning model. Scientific Programming, 2022. https://doi.org/10.1155/2022/3659742
- You, H., Lu, Y., & Tang, H. (2023). Plant disease classification and adversarial attack using SimAM-EfficientNet and GP-MI-FGSM. Sustainability, 15(2), 1233. https://doi.org/10.3390/su15021233
- Zhang, H., Chang, H., Ma, B., Wang, N., & Chen, X. (2020, August 23–28). Dynamic R-CNN: Towards high quality object detection via dynamic training. European Conference on Computer Vision (pp. 260–275), Springer, Cham. https://doi.org/10.48550/arXiv.2004.06002
- Zhang, K., Wang, C., Yu, X., Zheng, A., Gao, M., Pan, Z., & Shen, Z. (2022). Research on mine vehicle tracking and detection technology based on YOLOv5. Systems Science & Control Engineering, 10(1), 347–366. https://doi.org/10.1080/21642583.2022.2057370
- Zhang, S., Yu, Z., Liu, L., Wang, X., Zhou, A., & Chen, K. (2022, June 21–24). Group R-CNN for weakly semi-supervised object detection with points. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9417–9426). https://doi.org/10.48550/arXiv.2205.05920
- Zheng, J., Wu, H., Zhang, H., Wang, Z., & Xu, W. (2022). Insulator-Defect Detection Algorithm based on improved YOLOv7. Sensors, 22(22), 8801. https://doi.org/10.3390/s22228801
- Zheng, X., Zheng, S., Kong, Y., & Chen, J. (2021). Recent advances in surface defect inspection of industrial products using deep learning techniques. The International Journal of Advanced Manufacturing Technology, 113(1), 35–58. https://doi.org/10.1007/s00170-021-06592-8