
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
A year following the initial COVID-19 outbreak in China, many countries have approved emergency vaccines. Public-health practitioners and policymakers must understand the predicted populational willingness for vaccines and implement relevant stimulation measures. This study developed a framework for predicting vaccination uptake rate based on traditional clinical data – involving an autoregressive model with autoregressive integrated moving average (ARIMA) – and innovative web search queries – involving a linear regression with ordinary least squares/least absolute shrinkage and selection operator, and machine-learning with boost and random forest. For accuracy, we implemented a stacking regression for the clinical data and web search queries. The stacked regression of ARIMA (1,0,8) for clinical data and boost with support vector machine for web data formed the best model for forecasting vaccination speed in the US. The stacked regression provided a more accurate forecast. These results can help governments and policymakers predict vaccine demand and finance relevant programs.
Introduction
Approximately one year following the initial COVID-19 outbreak in Wuhan, China, two vaccines were approved for emergency distribution in the US: Pfizer-BioNTech (BNT162b2) and Moderna (mRNA-1273).Citation1 Recent real-world and clinical trials showed these vaccines as safe and effective against symptomatic infection, hospitalization, intensive care unit admission, and death even during the rising prevalence of the Delta variant.Citation2,Citation3 As there is currently no fully approved treatment against SARS-CoV-2 implemented on a large scale, the use of vaccines is currently the only global public-health strategy stopping infection spread and appearance of potentially dangerous virus mutations.Citation4,Citation5 Therefore, public-health policymakers and practitioners must understand and predict the future progress of vaccination.
Although the US Centers for Disease Control (CDC) publishes daily statistics on vaccines administered across the US, there is usually a 1–3-week delay for veracious data;Citation6 thus, traditional forecasting methods on vaccination based on clinical data lack accuracy. This adverse impact on decision-making processes results in further deaths and expiration of vaccine validity. Specifically, nations with surplus vaccines due to insufficient forecast on the vaccine demand were difficult to donate or swap vaccines with other nations and faced the risks of vaccine waste. So, the expiry date of many vaccines that were due to expire in a short time was extended without concrete empirical evidence.Citation7 To improve the forecast, researchers developed a new method: infodemiology, defined as the science of abstracting health-related content generated by internet users to improve public health.Citation8 Although online user-generated information is updated quickly, it is unpredictable compared with traditional statistical methods, and machine-learning is proving reliable with high predictive power, enabling the assessment of the future vaccination progress.Citation9 It will provide more information to public health practitioners and policymakers to ensure more optimal distribution while facilitating the implementation of interventions based on infodemiological approaches to reduce vaccine hesitancy.Citation10 Optimized management of vaccine distribution may further assist governmental decision-making on potential allotment of predicted vaccine excess supplies, such as for developing nations, which are now facing vaccine shortages.Citation11 Furthermore, the practice of monitoring vaccinations using both clinical and non-clinical web data can result in more accurate predictions on future vaccination rates in real-time while better elucidating any infodemiological nuances germane to vaccination behaviors behind the statistics. The analysis using Google Trends search interest in anti-vaccine terms revealed a concerning trend, and the burden of COVID-19 did not dissuade much vaccine hesitancy.Citation12 Therefore, our study provides evidence facilitating the development of prompter and more accurate public-health policies.Citation13,Citation14 Importantly, public-health interventions to increase vaccination rates can be improved through a more accurate understanding of vaccination speed; this is a critical area of consideration to stop infection spread and the appearance of potentially dangerous virus mutations.
Previously, the autoregressive model (AR) and autoregressive integrated moving average (ARIMA) were widely applied for infection prediction and analysis of associated vaccination uptake,Citation15–17 including confirmed cases of COVID-19.Citation18 During COVID-19 vaccination, it was applied to fully vaccinated people’s clinical data to predict future global vaccination rate.Citation19 Importantly, ARX, a similar model, can also be applied to non-clinical web data, in addition to clinical data, which may contain measurement errors. Non-clinical web data are the infodemiological data using user-generated information from electronic media such as statistics on online public-health-related interactions by individuals, including Tweets, comments, and search queriesCitation20,Citation21 to inform public-health policymaking.Citation22,Citation23 While previous studiesCitation24,Citation25 applied the practice of selecting search queries for web data based on expert judgments in Sycinska-Dziarnowska et al.,Citation26 heavy reliance on human judgment is costly and difficult to justify quantitatively. Alternatively, researchers proposed using real-time correlations between query term frequencies and clinical reports to automatically select terms for future prediction.Citation27 Still, dynamic changes in future health events may render historically predictive terms unreliable for later contemporary predictions due to concept drift in machine learning. Müller and SalathéCitation28 showed that the use of pre-COVID-19 social media data to predict vaccine sentiments would systematically misclassify data for prediction during the pandemic. Our study develops another approach extracting query keywords based on their frequency of mention in individual Tweets related to vaccinations.
Recently, infodemiological studies and machine-learning algorithms were also implemented with non-clinical data to better predict vaccinations. One study used a supervised machine-learning algorithm with multivariate ordinary least squares (OLS) regression to explore the predictive power of both non-clinical personal attitudes toward scientific information and the clinical experience of severe respiratory disease on the influenza vaccination rate; accordingly, the area under the receiver operating characteristic curve (AUC) for this mixed clinical and non-clinical prediction method was 85%.Citation29 Carrieri et al.Citation30 implemented the supervised random-forest machine-learning algorithm on area-level indicators of institutional and socioeconomic backgrounds to predict the vaccine hesitancy rate for Italian local authorities, thus helping public-health practitioners run targeted awareness campaigns. Their findings suggested that non-clinical features had the highest predictive powers in the random-forest algorithm, with an AUC of 0.836. Besides these algorithms, Gothai et al.Citation31 proposed supervised machine-learning via the Holt-Winter model to obtain a prediction that captured seasonal variations in vaccination across the year to improve accuracy. While web data had similar strong predictive powers when monitoring the Middle East respiratory syndrome outbreak in South Korea, Shin et al.Citation32 noted statistically significant lag correlation coefficients higher than 0.8 between non-clinical variables of Google query keywords and Tweets from Twitter. This emphasizes the importance of using pertinent and accurate non-clinical web variables in conjunction with clinical data. Building upon the use of a single model for clinical and non-clinical data, Santillana et al.’sCitation33 evolved method used ensemble methods of stacking regression that combine separate outcomes from each model of different statistical classifiers based on labeled Tweets to predict vaccinations; they achieved considerable testing accuracy of 85.71% in the 10-fold cross-validation. Besides using a clinical or non-clinical data method solely, Hansen et al.Citation14 proposed a mixture method using two methods’ predictions to attain higher prediction accuracy.
However, no relevant studies have implemented statistical and machine-learning predictions using both clinical and infodemiological web data on national-level COVID-19 vaccinations. Thus, we focused on finding more accurate ways of predicting COVID-19 vaccination rates by innovatively using both clinical and web information. This is a method-comparison study where not only the compared methods varied, but also the dataset used with each method. We innovate through an infodemiological approach, that is, in the use of non-clinical web data in addition to clinical data so far used in this field of research. Specifically, this study proposes to forecast COVID-19 vaccination rates using the AR/ARIMA model with clinical data and the OLS/least absolute shrinkage and selection operator (LASSO)/machine-learning methods with web data. Then stacked regressions are used to combine both to generate new predictions. This study uses the root-mean-squared error (RMSE) across all statistical and machine-learning methods to determine the best model. Eventually, more accurate predictions are anticipated to better explain vaccination behaviors.
Materials and methods
Data sources
We obtained study data from January 2 to July 27, 2021. The study data, collected from CDC, is the daily first-dose vaccination in the United States. Regarding the outcome variable, Hansen et al.Citation14 proposed that the vaccination-to-expectation ratio is a more accurate measurement than the simple daily vaccination rate. It is defined as , where people expected to be vaccinated are all individuals in the US who have not received relevant vaccinations.
We considered daily records of the first COVID vaccine dose published by the CDC as clinical data, while the relative interest as searched using selected words from Google Trends was considered as web data.
We initially downloaded the “Covid Vaccine Tweets” dataset from Kaggle, which consisted of the texts of all the tweets related to COVID-19 vaccines. We then converted the Tweet texts into a corpus file to select words for the web data, which was preprocessed to remove irrelevant numbers, punctuations, symbols, and stop words. We extracted 68,409 features mentioned more than once and created a table of features ranked by their frequency of occurrence. Next, we qualitatively assessed the top 1,000 most frequent words and checked such queries’ availability on Google Trends to select 12 words for each category of attitude (positive, negative, and neutral). To ensure that the added words were relevant to vaccination, we used the relative search volume of queries with the word “vaccine” before each identified keyword. Finally, to convert web searches into quantitatively analyzable “web data,” we searched the relative interest in Google Trends from December 21, 2020, to July 27, 2021, in the US. As Google Trends allows up to five words per search, the reference word “Joker” was used to standardize the index of relative search volume across each search. We then added all standardized indices into three categories ().
Table 1. Web data (search categories and related words)
The outcome variable is represented as Daily_0, and the altitude variables (positive, neutral, and negative) are represented as pt_0, nt_0, ng_0 ().
Table 2. Summary of raw data
Overview of forecasting methods
Previously, statistical models with clinical data are widely used to predict vaccine uptake rate. The performance of forecasts is hypothesized to be improved when they are incorporated into infodemiological datasets. Herein, we generated our predictions through three stages. The first stage is repeating the most common statistical model AR/ARIMA with clinical data. The second stage is implementing machine-learning approaches on infodemiological datasets where OLS is the reference of the machine learning algorithms. The third stage is to “stack” different combinations of predictions from the first two stages, similar to the forecasting averaging method in traditional statistics.
Forecast with clinical data
AR/ARIMA models are widely applied to forecast future vaccine uptake rates solely using clinical data, and the reliability of applying AR/ARIMA on clinical data had been proven in history. This requires stationarity of time-series data; a given sequence is stationary if the joint probability distribution remains constant over time. The Dickey-Fuller (dfuller) and unit-root tests can be applied to confirm stationarity, and the dfuller test’s null hypothesis is the existence of a unit root. If the null hypothesis is rejected, stationarity is satisfied.
As shows, stationarity holds so that AR/ARIMA can be implemented without further differencing. Autocorrelation and partial correlation are necessary to identify our AR/ARIMA model. To estimate AR(p), we needed to choose the number of AR lags (p) as follows:
Table 3. Dickey-Fuller test
In clinical data analysis, is the expected value of daily vaccination-to-expectation ratio on day t,
is the intercept,
is the value of daily vaccination-to-expectation ratio on day (t-i), and
is the weight of the ith lag term. According to the principle of parsimony, we chose lags 1, 3, 5, 6, and 7 due to their positive partial autocorrelation out of the 95% confidence intervalCitation34 (). The ARIMA model is required to further ensure accurate predictions. A non-seasonal ARIMA model is presented as ARIMA(p,d,q), where p represents AR lags, d represents differencing (I) lags, and q represents moving average (MA) lags. The first two symbols are identified as ARIMA(p,0,q), as stationarity holds without differencing, and AR(p) is identified earlier. Autocorrelation is required to identify MA lags.
Figure 1. Partial autocorrelation plots.
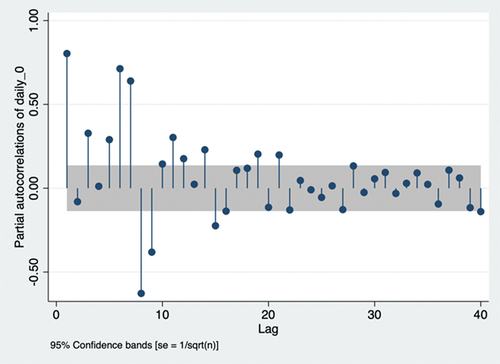
According to the principle of parsimony, we chose lags 8, 15, 21, and 28 due to their autocorrelation out of the 95% confidence interval ().Citation34 Therefore, ARIMA (p,0,q) estimates
Figure 2. Autocorrelation plots. MA(q): moving average model of order q.
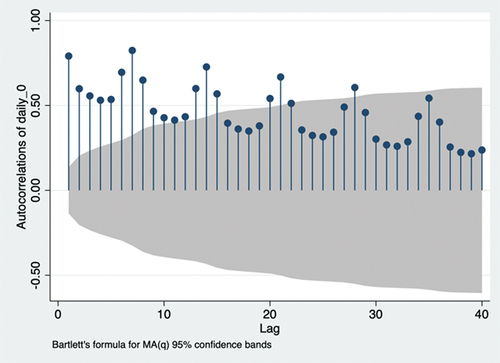
where is the forecast error on day (t-k) and
is the weight of the forecast error. Further, ARIMA(p,0,q) uses q MA lags to smooth the data. Hence, ARIMA(1,0,8), ARIMA(1,0,15), ARIMA(1,0,21), ARIMA(1,0,28), ARIMA(3,0,8), ARIMA(3,0,15), ARIMA(3,0,21), ARIMA(3,0,28), ARIMA(5,0,8), ARIMA(5,0,15), ARIMA(5,0,21), and ARIMA(5,0,28) have been identified. The Akaike information criterion (AIC) and Bayesian information criterion (BIC) can be applied to determine the best-fit parameters of p and q.
As shows, ARIMA(7,0,28) had the smallest AIC, while ARIMA(7,0,8) had the smallest BIC and second smallest AIC. As the AIC of ARIMA(7,0,8) showed a very small difference compared with ARIMA(7,0,28) (according to the principle of parsimony), ARIMA(7,0,8) was identified as the best fit to our ARIMA model. Therefore, ARIMA(7,0,8) estimates
Table 4. Results of Akaike information criterion (AIC) and Bayesian information criterion (BIC)
Briefly, the forecast for vaccination-to-expectation ratio on day t involves the weighted sum of vaccination-to-expectation ratios for the last seven days and the weighted sum of the forecast errors for the last eight days.
Forecast with web data
We applied linear regressions with OLS/LASSO, and machine-learning with boost and the random-forest algorithm to analyze comparably unpredictable web data. Machine-learning methods were implemented due to irregularity (e.g. outliers) of search frequencies.
Linear regression with OLS
Linear regression with OLS simply estimates
In non-clinical web data analysis, represents the altitude, and its weight is given by
. Our independent variables were three altitudes and their one-period lags in the web data, so there were six independent variables. The one-period lag was decided because of a strong partial correlation between the two periods.
LASSO regression
The LASSO regression is very similar to linear regression but is more accurate for predictions. It aims to fit the best-fitting model of least bias by minimizing the squared errors whilst avoids overfitting irrelevant features by selecting a reduced set of known covariates and reducing the size of coefficients. In this study, we used the same variables as in “Linear regression with OLS” to make predictions via LASSO.
Boost classification
Machine-learning was used to further ensure accurate prediction. In this process, we implemented the STATA module r_ml_STATA.Citation35 For all classifications, we used 10-fold cross-validation as the rule of thumb. We also used the first 212 days as training data and the last 7 days as testing data for all methods. The boost classification is an ensemble method that reduces errors by introducing a strong classifier from several weak classifiers, which is done by building an initial model for training data and then building models to minimize variance. A single robust model is based on many smaller models. The final prediction is a weighted sum of sequenced models known as weak classifiers.
Random-forest classification
Similarly, random-forest classification is also a machine-learning algorithm. It is another ensemble method referred to as the bagging algorithm together with featured randomness. It reduces the variance of individual classification trees by randomly selecting from the dataset. Averaging these uncorrelated predictors produces a final prediction using this algorithm.
Forecast with mixed clinical and non-clinical web data model
To combine clinical and non-clinical web data models, we use stacking regression. Specifically, we regress the actual vaccination-to-expectation ratio on predictions from the AR/ARIMA clinical model and predictions from one of four non-clinical web data models. Since there are two clinical models and four non-clinical web data models, eight combinations are available for each stacking method.
Stacking with linear regression
Linear regression is first used to “stack” predictions from the clinical data analysis and web data analysis
. The model estimates
is the expected value of daily vaccination-to-expectation ratio in day t,
is the constant term, and
and
are weights of predictions based on clinical and non-clinical web data, respectively. Then, we used OLS to minimize the residual:
where is the actual value of daily vaccination-to-expectation ratio on day t. We minimize differences between the actual and predicted daily vaccination-to-expectation ratios on day t.
Stacking with support vector regression (SVR)
We continued to “stack” predictions from clinical data analysis and web data analysis
, but with a different regression: SVR. SVR classification is a supervised machine-learning model that splits the dataset into two categories. We applied it to the continuous variable here using SVR, which generates a regression similar to the linear regression model. In contrast with the OLS method, we find the coefficients of SVR by minimizing the coefficient vector’s norm:
where controls the penalty for large weights of clinical and non-clinical web data predictions. We defined
, where
is represented by r, and
is a hyperparameter that controls the maximum error of predictions allowed. Both
and λ allow us to define the tolerance level of error in our model. Unless
, V(r) = 0.
To find the model with the least prediction error, RMSE is used to compare among traditional clinical, innovative infodemiological, and stacked models by calculating differences between predictions and actual values
:
A model with smaller RMSE has less prediction error and higher accuracy.
Results
As shows, both clinical models have smaller RMSE than non-clinical models. Besides, ARIMA(7,0,8) had a smaller RMSE than AR(7). So, ARIMA(7,0,8) performed better than AR(7), and models with only clinical data performed better than models with only web data. Further, linear regression with OLS performed best across all web data methods.
Table 5. Root-mean-square error of forecast models based on single clinical or web data
As shows, under stacking with both OLS and SVR, the combination of ARIMA(7,0,8) and boost performed the best, and stacking with SVR outperformed stacking with OLS. Further, the regression using SVR to stack ARIMA(7,0,8) and boost together has smaller RMSE than the traditional clinical data model ARIMA(7,0,8). So, stacked regression improves prediction accuracy.
Table 6. Root-mean-square error of forecast models based on ensemble models
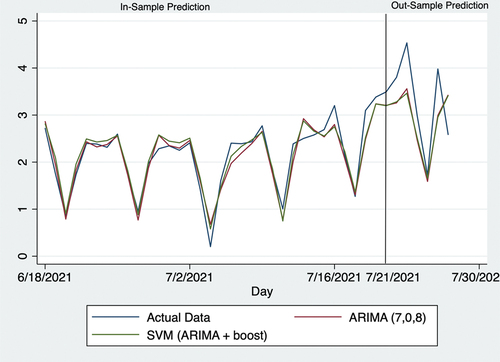
shows 7-day predictions of the vaccination-to-expectation ratio. During the forecasting process, we removed actual vaccination-to-expectation ratios from July 21 to 27, 2021, so that this 1-week forecast was the “out-sample.”
Table 7. Seven-day forecast of the best model compared with the actual data and traditional clinical model
shows the forecast for the last 40 days. Prior to July 21, 2021, predictions were made based on all available data; beginning with July 21, 2021, actual data of the daily vaccination-to-expectation ratio were removed when forecasting.
Figure 3. Actual data and predictions. SVR: support vector regression; ARIMA: autoregressive integrated moving average.
Discussion
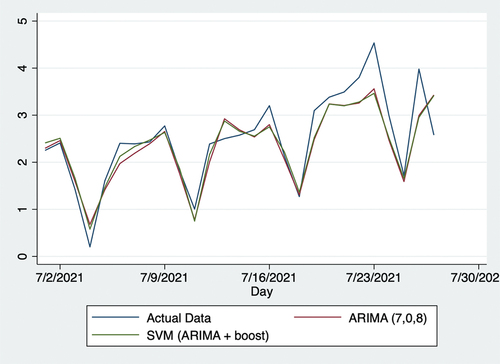
Using web data, this study produced more accurate forecasts than traditional forecasting methods with solely clinical data, as reflected by RMSE, proving the function of online networks in predicting populational willingness to receive vaccinations. Specifically, compared with the traditional ARIMA model with clinical data, SVR with the predictions of both clinical data using ARIMA (7,0,8) and web data using Boost algorithm reduced RMSE by 9.1%. shows the vaccination uptake rate from December 21, 2020, to April 5, 2021. Over this period, the vaccination rate steadily increased, likely attributed to both the initial supply shortages and growing efficiency in vaccination facilities as rollout progressed. As shows, the vaccination-to-expectation ratio remained steady at approximately 2.2 from April 6, 2021, to June 30, 2021, likely attributed to two factors. First, on April 26, 2021, US President Joseph Biden announced that the US would begin donating vaccines to other countries.Citation36 This implied that the US was very likely to have sufficient vaccines for its whole population. Two, the number of new COVID-19 cases steadily declined over this period,Citation37 which alleviated populational concerns over the possibility of a more serious pandemic. As shows, the vaccination-to-expectation rate rose slowly and steadily from July 2 to 30, 2021. In this regard, the number of new COVID-19 infections rose sharply on July 1, 2021, which increased concerns that the pandemic would worsen. It might potentially be the factor leading populational willingness to receive vaccinations to increase. As shows, these trends are also mathematically evident through Kendall’s . In sum, policymakers must understand daily vaccine demands in relation to vaccine supply and other factors when making relevant decisions.
Table 8. Kendall’s
Figure 4. Actual data and predictions from December 21, 2020, to April 5, 2021. SVR: support vector regression; ARIMA: autoregressive integrated moving average.
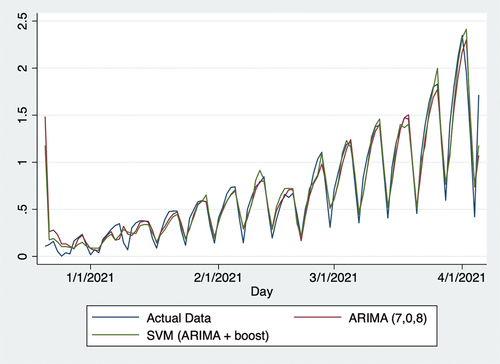
Figure 5. Actual data and predictions from April 6, 2021, to June 30, 2021. SVR: support vector regression; ARIMA: autoregressive integrated moving average.
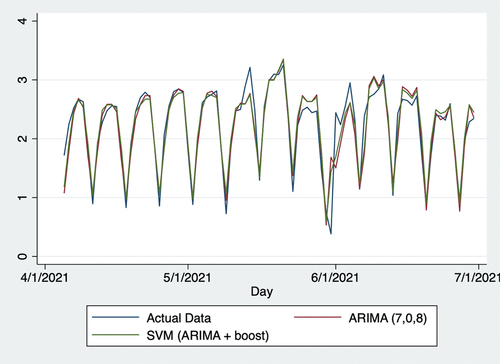
Figure 6. Actual data and predictions from July 1, 2020, to July 27, 2021. SVR: support vector regression; ARIMA: autoregressive integrated moving average.
On July 27, 2021 (the last day considered in this study), it initially seemed that forecasts of the vaccination-to-expectation ratio were quite different from actual data in numbers and trends. Thus, forecasts appeared to overestimate this day and were higher than those from the previous day, whereas actual data showed a decline here. Despite this seemingly large error, forecasts may have provided some information based on potentially existing measurement errors by the CDC. In this regard, data gathered by the CDC are rarely of sufficient accuracy in the daily real-time context. Many such organizations and agencies globally implement the standard protocol of checking and adjusting data on later dates. The authors initially began this research in June but repeated the procedures multiple times until July 27, 2021. As the data provided by the CDC were adjusted several times over this period, it was observed that CDC also made measurement errors. Herein, the increased predictions from July 27, 2021 may signify that the CDC made positive measurement errors. This point may also help public-health practitioners and policymakers improve the accuracy of their policies.
Unfortunately, this research had a few unavoidable limitations. First, the US provides vaccinations to all individuals living in the country, regardless of citizenship status or permanent residency. Thus, temporary residents such as students also expected vaccinations. As these data were not available, adjustment based on the US population was made according to the Migration Policy Institute;Citation38 foreign nationals on temporary visas comprise around 7.1% of the total population, including citizens and permanent residents. Second, there was a slight error in the collected web data. As the relative interests of a few variables for a few days were too small to be illustrated, they were censored as “<1.” To fix this, we simply adjusted them to 0.5, owing to the assumption of probability distribution. However, this adjustment should not have significantly impacted the forecasts, as the relative interests were very small and only affected a few days.
Despite unavoidable errors of no consequence, the forecasts in this study should help public-health practitioners and policymakers better foresee vaccine uptake behaviors and therefore develop more appropriate policies. Specifically, many sites such as Google currently collect personal information such as age and race when their users access the contents. Within the law, public-health practitioners and policymakers may predict vaccine uptake rate for different age, cultural and other groups more accurately with the help of those sensitive data. Further, relevant forecast models can also be applied to other countries and epidemic events in future settings. In addition, a new potential approach to encourage vaccination is appeared in this study: censoring negative social media contents. This study is based in US, so all contents are visible within the law. In the future, we aim to discover the impact of censoring negative social media contents through further studies in places where censoring negative social media contents exists.
Data availability
Data that support the findings of this study are openly available in Covid Vaccine Tweets at https://www.kaggle.com/kaushiksuresh147/covidvaccine-tweets.
Acknowledgments
The co-authors apprecite Dennnis Kristensen, Dylan Kneale and editors from Taylor and Francis Editing Service for helpful suggestions and comments, Xingyou Zhou and Xiyan Shi for assembling data for the study.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Mahase E. Covid-19: Pfizer and BioNTech submit vaccine for US authorisation. BMJ. 2020;371:m4552. PMID: 33219049. doi:10.1136/bmj.m4552.
- Puranik A, Lenehan PJ, Silvert E, Niesen MJM, Corchado-Garcia J, O’Horo JC, Virk A, Swift MD, Halamka J, Badley AD, et al. Comparison of two highly-effective mRNA vaccines for COVID-19 during periods of Alpha and Delta variant prevalence. medRxiv. 2021 Aug 21 [accessed 2021 Aug 25]:34. PMID: 34401884. doi:10.1101/2021.08.06.21261707.
- Thompson MG, Burgess JL, Naleway AL, Tyner H, Yoon SK, Meece J, Olsho LEW, Caban-Martinez AJ, Fowlkes AL, Lutrick K, et al. Prevention and attenuation of COVID-19 by BNT162b2 and mRNA-1273 vaccines. N Engl J Med. 2021;385(4):320–8. PMID: 34192428. doi:10.1056/NEJMoa2107058.
- Calina D, Docea AO, Petrakis D, Egorov AM, Ishmukhametov AA, Gabibov AG, Shtilman MI, Kostoff R, Carvalho F, Vinceti M, et al. Towards effective COVID-19 vaccines: updates, perspectives and challenges. Int J Mol Med. 2020;46(1):3–16. PMID: 32377694. doi:10.3892/ijmm.2020.4596.
- Koff WC, Berkley SF. A universal coronavirus vaccine. Science. 2021;371(6531):759. PMID: 33602830. doi:10.1126/science.abh0447.
- Yang S, Santillana M, Kou SC. Accurate estimation of influenza epidemics using Google search data via ARGO. Proc Natl Acad Sci USA. 2015;112(47):14473–78. PMID: 26553980. doi:10.1073/pnas.1515373112.
- Feinmann J. How the world is (not) handling surplus doses and expiring vaccines. BMJ. 2021;374:n2062. doi:10.1136/bmj.n2062.
- Eysenbach G. Infodemiology: the epidemiology of (mis) information. Am J Med. 2002;113(9):763–65. doi:10.1016/S0002-9343(02)01473-0.
- Xue J, Chen J, Hu R, Chen C, Zheng C, Su Y, Zhu T. Twitter discussions and emotions about the COVID-19 pandemic: machine learning approach. J Med Internet Res. 2020;22(11):e20550. PMID: 33119535. doi:10.2196/20550.
- Ashrafian H, Darzi A. Transforming health policy through machine learning. PLoS Med. 2018;15(11):e1002692. PMID: 30422977. doi:10.1371/journal.pmed.1002692.
- Mahase E. Covid-19: freedom won’t last if UK doesn’t share excess vaccine doses, aid agencies warn. BMJ. 2021;373:n1444. PMID: 34088730. doi:10.1136/bmj.n1444.
- Pullan S, Dey M. Vaccine hesitancy and anti-vaccination in the time of COVID-19: a Google Trends analysis. Vaccine. 2021;39(14):1877–81. PMID: 33715904. doi:10.1016/j.vaccine.2021.03.019.
- Finney Rutten LJ, Zhu X, Leppin AL, Ridgeway JL, Swift MD, Griffin JM, St Sauver JL, Virk A, Jacobson RM. Evidence-based strategies for clinical organizations to address COVID-19 vaccine hesitancy. Mayo Clin Proc. 2021;96(3):699–707. PMID: 33673921. doi:10.1016/j.mayocp.2020.12.024.
- Hansen ND, Lioma C, Mølbak K. Ensemble learned vaccination uptake prediction using web search queries. CKIM ’16; Proceedings of the 25th ACM International on Conference on Information and Knowledge Management; 2016 Oct 24–26; Indianapolis (IN): Association for Computing Machinery. p. 1953–56. doi:10.1145/2983323.2983882.
- Bragazzi NL, Barberis I, Rosselli R, Gianfredi V, Nucci D, Moretti M, Salvatori T, Martucci G, Martini M. How often people Google for vaccination: qualitative and quantitative insights from a systematic search of the web-based activities using Google Trends. Hum Vaccin Immunother. 2017;13(2):464–69. PMID: 27983896. doi:10.1080/21645515.2017.1264742.
- He Z, Tao H. Epidemiology and ARIMA model of positive-rate of influenza viruses among children in Wuhan, China: a nine-year retrospective study. Int J Infect Dis. 2018;74:61–70. PMID: 29990540. doi:10.1016/j.ijid.2018.07.003.
- Sahisnu JS, Natalia F, Ferdinand FV, Sudirman S, Ko CS. Vaccine prediction system using ARIMA method. ICIC Express Lett B. 2020;11(6):567–75. doi:10.24507/icicelb.11.06.567.
- Kim M. Prediction of COVID-19 confirmed cases after vaccination: based on statistical and deep learning models. SciMedicine J. 2021;3(2):153–65. doi:10.28991/SciMedJ-2021-0302-7.
- Cihan P. Forecasting fully vaccinated people against COVID-19 and examining future vaccination rate for herd immunity in the US, Asia, Europe, Africa, South America, and the world. Appl Soft Comput. 2021;111:107708. PMID: 34305491. doi:10.1016/j.asoc.2021.107708.
- Çimke S, Yıldırım Gürkan D. Determination of interest in vitamin use during COVID-19 pandemic using Google Trends data: infodemiology study. Nutrition. 2021;85:111138. PMID: 33578243. doi:10.1016/j.nut.2020.111138.
- Tangherlini TR, Roychowdhury V, Glenn B, Crespi CM, Bandari R, Wadia A, Falahi M, Ebrahimzadeh E, Bastani R. “Mommy blogs” and the vaccination exemption narrative: results from a machine-learning approach for story aggregation on parenting social media sites. JMIR Public Health Surveill. 2016;2(2):e166. PMID: 27876690. doi:10.2196/publichealth.6586.
- Eysenbach G. Infodemiology and infoveillance: framework for an emerging set of public health informatics methods to analyze search, communication and publication behavior on the Internet. J Med Internet Res. 2009;11(1):e11. PMID: 19329408. doi:10.2196/jmir.1157.
- Mavragani A, Ochoa G. Google Trends in infodemiology and infoveillance: methodology framework. JMIR Public Health Surveill. 2019;5(2):e13439. PMID: 31144671. doi:10.2196/13439.
- Suppli CH, Hansen ND, Rasmussen M, Valentiner-Branth P, Krause TG, Mølbak K. Decline in HPV-vaccination uptake in Denmark—The association between HPV-related media coverage and HPV-vaccination. BMC Public Health. 2018;18(1):1360. PMID: 30526589. doi:10.1186/s12889-018-6268-x.
- Yuan Q, Nsoesie EO, Lv B, Peng G, Chunara R, Brownstein JS. Monitoring influenza epidemics in China with search query from Baidu. PLoS One. 2013;8(5):e64323. PMID: 23750192. doi:10.1371/journal.pone.0064323.
- Sycinska-Dziarnowska M, Paradowska-Stankiewicz I, Woźniak K. The global interest in vaccines and its prediction and perspectives in the era of COVID-19. Real-time surveillance using Google Trends. Int J Environ Res Public Health. 2021;18(15):7841. PMID: 34360134. doi:10.3390/ijerph18157841.
- Santillana M, Zhang DW, Althouse BM, Ayers JW. What can digital disease detection learn from (an external revision to) Google flu trends? Am J Prev Med. 2014;47(3):341–47. PMID: 24997572. doi:10.1016/j.amepre.2014.05.020.
- Müller M, Salathé M. Addressing machine learning concept drift reveals declining vaccine sentiment during the COVID-19 pandemic. arXiv.org. 2020 Dec 7 [accessed 2021 Aug 25]:12. doi:arXiv: 2012.02197.
- Keske Ş, Mutters NT, Tsioutis C, Ergönül Ö. Influenza vaccination among infection control teams: a EUCIC survey prior to COVID-19 pandemic. Vaccine. 2020;38(52):8357–61. PMID: 33183855. doi:10.1016/j.vaccine.2020.11.003.
- Carrieri V, Lagravinese R, Resce G. Predicting vaccine hesitancy from area-level indicators: a machine learning approach. medRxiv. 2021 Mar 9 [accessed 2021 Aug 25]:11. doi:10.1101/2021.03.08.21253109.
- Gothai E, Thamilselvan R, Rajalaxmi RR, Sadana RM, Ragavi A, Sakthivel R. Prediction of COVID-19 growth and trend using machine learning approach. Mater Today Proc. 2021 Apr 15 [accessed 2021 Aug 25]:6. PMID: 33880331. doi:10.1016/j.matpr.2021.04.051.
- Shin S-Y, Seo D-W, An J, Kwak H, Kim S-H, Gwack J, Jo M-W. High correlation of Middle East respiratory syndrome spread with Google search and Twitter trends in Korea. Sci Rep. 2016;6:32930. PMID: 27595921. doi:10.1038/srep32920.
- Santillana M, Nguyen AT, Dredze M, Paul MJ, Nsoesie EO, Brownstein JS. Combining search, social media, and traditional data sources to improve influenza surveillance. PLOS Comput Biol. 2015;11(10):e1004513. PMID: 26513245. doi:10.1371/journal.pcbi.1004513.
- Nau R. Identifying the numbers of AR or MA terms in an ARIMA model. Statistical Forecasting: Notes on Regression and Time Series Analysis. Durham (NC): Fuqua School of Business, Duke University; 2020 Aug 18 [accessed 2021 Aug 25]. https://people.duke.edu/~rnau/411arim3.htm.
- Cerulli G. Machine learning using Stata/Python. arXiv.org. 2021 Mar 3 [accessed 2021 Aug 25]:22. doi:arXiv: 2103.03122.
- Widakuswara P. Biden says US will donate 500 million COVID vaccines to world. Voice of America. 2021 June 10 [accessed 2021 Aug 25]. https://www.voanews.com/usa/biden-says-us-will-donate-500-million-covid-vaccines-world.
- Centers for Disease Control and Prevention, COVID Data Tracker. Trends in number of COVID-19 cases and deaths in the US reported to CDC, by state/territory. Atlanta (GA): Centers for Disease Control and Prevention, US Department of Health and Human Services; 2021 [accessed 2021 July 28]. https://covid.cdc.gov/covid-data-tracker/#trends_dailytrendscases.
- Batalova J, Hanna M, Levesque C. Frequently requested statistics on immigrants and immigration in the United States. Washington (DC): Migration Policy Institute; 2021 Feb 11 [accessed 2021 Aug 25]. https://www.migrationpolicy.org/article/frequently-requested-statistics-immigrants-and-immigration-united-states-2020.