
Abstract
Prompted by the ongoing development of content personalization by social networks and mainstream news brands, and recent debates about balancing algorithmic and editorial selection, this study explores what audiences think about news selection mechanisms and why. Analysing data from a 26-country survey (N = 53,314), we report the extent to which audiences believe story selection by editors and story selection by algorithms are good ways to get news online and, using multi-level models, explore the relationships that exist between individuals’ characteristics and those beliefs. The results show that, collectively, audiences believe algorithmic selection guided by a user’s past consumption behaviour is a better way to get news than editorial curation. There are, however, significant variations in these beliefs at the individual level. Age, trust in news, concerns about privacy, mobile news access, paying for news, and six other variables had effects. Our results are partly in line with current general theory on algorithmic appreciation, but diverge in our findings on the relative appreciation of algorithms and experts, and in how the appreciation of algorithms can differ according to the data that drive them. We believe this divergence is partly due to our study’s focus on news, showing algorithmic appreciation has context-specific characteristics.
Introduction
Algorithmic recommendations have become central to how consumers interact with some media outlets. Netflix estimates that its recommender system influences choices responsible for 80 per cent of the video streamed on its platform and saves the company more than $1 billion per year by increasing customer retention (Gomez-Uribe and Hunt Citation2015, 5).
While recommender systems may not become as central to the business of journalism, news publishers continue to experiment with, and extend the provision of, personalized news (see e.g. Kunert and Thurman, in press), as evidenced by recent announcements from Reuters (Citation2017) and the New York Times, with the Times beginning an “ambitious new effort to customize the delivery of news online” (Spayd Citation2017).
The use of algorithms in organizations’ interactions with their clients and customers is not, of course, confined to the media industry. Crunchbase lists over 650 firms in its “personalization” category; these operate in sectors including healthcare, education, and financial and government services (Crunchbase Citationn.d.).
As algorithmic recommendations become more prevalent, consumers’ opinions about them are of interest to academics, regulators, and media professionals. Analyses of such opinions can help inform decisions about how these technologies are developed, including who they are designed for; whether they should be regulated; and the need for educational curricula and public information campaigns to address their existence, use, and consequences. For example, the European Commission has commissioned work—to be informed by “robust scientific insights”—on algorithmic transparency in decision-making and online information mediation, with objectives that include “raising public awareness” and the development of “policy options” (European Commission Citation2018).
Such “robust scientific insights” might come from investigations into:
The extent to which consumers appreciate algorithmic recommendations against recommendations from peers or professionals.
Whether context makes a difference to algorithmic appreciation; for example, whether the recommendations relate to products—like music, books, or films—where tastes vary from person to person; or concern something where the answer is more clear cut, such as the fastest route to a destination.
Differences in algorithmic appreciation between particular classes of individuals, such as the young, or those with more formal education.
Although researchers have begun to address these questions, there is still much to learn, which is why, in this article, we try to contribute to the body of work on algorithmic appreciation by conducting a secondary analysis of a large-scale international survey (N = 53,314) that included questions about the different ways news can be recommended, including by algorithms. Although the focus is on a single context—news—the size of the survey, and its representativeness in each of the 26 countries1 surveyed, means that the results have a degree of generalizability not found in some other work on the topic. The availability of data, from the same survey, on respondents’ online news consumption behaviour, on other opinions they hold, and on their demographics also enables us to analyse the effects of a number of individual characteristics.
Some of our results are in line with one state-of-the-art model (Logg, Minson, and Moore Citation2018; Logg Citation2017) which holds that people en masse have higher levels of appreciation for algorithmic recommendations than for recommendations from humans. However, our findings also contradict a part of this model by showing that this preference can persist even when the (alternative) human recommendations come from experts rather than laypeople. Furthermore, we show how appreciation of algorithmic recommendations can vary depending on the source of the data driving them. We find that where the source is stated as being (the past behaviour of) respondents themselves, algorithmic recommendations are evaluated as having more utility than where the source is stated as being (the past behaviour of) respondents’ friends.
The specific context of our study, news, helps to explain these general findings. We explore these contextual issues as well as a number of specific findings about the individual drivers of opinions about news selection, such as particular news consumption practices.
In the Literature Review that follows we:
Briefly introduce the context for our study, focusing on some key current debates and practices concerning the mechanisms of news selection.
Summarize some of the general literature on attitudes to algorithmic recommendations, focusing on Logg, Minson, and Moore’s state-of-the-art model.
Highlight research evidence that provides pointers to how individuals’ personal characteristics and opinions may affect their attitudes to different types of news selection, including algorithmic.
Literature Review
News Selection Mechanisms: Contemporary Context
Over the last few years, there has been widespread public discussion about the mechanisms of news selection, in part prompted by the increasing reach of social networks, in particular Facebook, which has made extensive use of both automated personalization and human moderation. These discussions have been further fuelled by the Brexit vote and the election of Donald Trump, events that some have linked to algorithms usurping journalists and editors as “gatekeepers to the news” (see e.g. Solon Citation2016).
With this focus on social networks as sources of—and gateways to—news, we must not forget that traditional news brands are still important destinations for audiences (see e.g. Newman et al. Citation2017). Although the news they offer online is, predominantly, still selected and prioritized by editors and journalists, such brands have made use of automated personalization since before Facebook existed. For example, three years before Facebook’s launch, the Washington Post was allowing audiences to customize their own personal page at MyWashingtonPost.com (Business Wire Citation2001). Over the years, many types of personalization have been deployed by the likes of the Post (see e.g. Thurman Citation2011). Furthermore, established news brands are continuing to develop and deploy personalization, especially on their mobile channels. For example, Alex Watson, head of product at BBC News, said that “personalization is very much a focus for us over the next 2–5 years … particularly for younger audiences [and for mobile apps]” (personal communication, 14 December 2016).
Although established news brands such as BBC News are continuing to deploy technologies that outsource gatekeeping functions to audiences and algorithms, there is no sense that these organizations want to dispense with human editors altogether. In common with other editors we have spoken to, Alex Watson said that BBC News will continue to show a “common set of top stories” selected by editors (ibid.).
Debates about achieving the right balance between algorithmic and human selection are also taking place with regard to social networks. When it was revealed that editors at Facebook had a high degree of influence over trending topics appearing in its desktop version (Thielman Citation2016a) and that those editors were, allegedly, filtering out politically right-leaning sources (Bowles and Thielman Citation2016), the company made the editorial team largely redundant and “left the algorithm to do its job” (Thielman Citation2016b; also see Carlson Citation2018). Facebook has, however, also been expanding its team of human moderators. After criticism of the “hate speech, child abuse and self-harm” (BBC News Citation2017) that the platform was publishing, the CEO, Mark Zuckerberg, announced that his company would be adding 3000 staff to its “community operations team” in order that Facebook could “get better at removing things” from the platform (Zuckerberg Citation2017).
Research into how audiences perceive the relative merits of algorithmic and editorial news selection is largely non-existent. There is, however, a range of literature on the relative appreciation of algorithmic and human recommendations in other contexts. It is this literature to which we turn next in order to develop our hypotheses and research questions.
Attitudes to Algorithmic Recommendations
Algorithmic recommendations are not new, and neither are observations about what people think of them, if, indeed, they think of them at all. Back in the mid-twentieth century, Meehl (Citation1954) cited some of the scepticism that medical practitioners had towards the use of algorithms in diagnosis. Substantive empirical research did not follow for decades, perhaps because algorithmic recommendations were not widely available or utilized, making the measurement and analysis of opinions about them a low priority for researchers. However, the twenty-first century has seen the publication of a number of studies, the results of which paint a mixed picture, with some showing that participants prefer human recommendations (see e.g. Dietvorst, Simmons, and Massey Citation2015; Promberger and Baron Citation2006; Sinha and Swearingen Citation2001; Yeomans et al. Citation2018) and others showing that people prefer recommendations from algorithms (see e.g. Dijkstra, Liebrand, and Timminga Citation1998; Dijkstra Citation1999). These contradictory results might be explained, in part, by the different contexts covered by the studies. For example, people may be more comfortable relying on other people than on algorithms when receiving recommendations about matters—such as jokes they might find funny—where personal taste is involved (see e.g. Yeomans et al. Citation2018). Conversely, if the recommendation is derived from known rules (as with medical diagnosis or legal counsel) people might rather follow the advice of an algorithm (see e.g. Dijkstra, Liebrand, and Timminga Citation1998).
Logg, Minson, and Moore’s (2018; Logg Citation2017) state-of-the-art model, based on rich experimental evidence, has removed some of the uncertainty around algorithmic appreciation. They found that people gave greater weight to advice when they thought it came from an algorithm than when they thought it came from a person, and that this held true across different contexts, from the more subjective to the more objective. The contexts tested ranged from those where recommendations were about how to answer questions that had absolute answers (e.g. estimating the weight or age of a person) to those where recommendations were about how to answer questions where there was a great deal of uncertainty about the outcomes and where personal subjectivity came into play (e.g. predicting the popularity of songs or the likelihood that two people would become romantically involved).
Although context appeared to make no significant difference to the results of Logg, Minson, and Moore’s experiments, the source of the human advice, where it was varied, did. In most of their experiments, the human advice that participants were presented with (as an alternative to the algorithmic advice) came from other experimental participants rather than experts. However, when subjects were presented with 12 decision-making scenarios, and asked to consider the utility of advice from an algorithm, another person, or a specific expert (for example, a book critic, a clothing stylist, or a real-estate agent), participants said they would rely more on the experts than the algorithms (Logg Citation2017). We might, therefore, expect to find news recommendations by experts—editors and journalists—to be preferred over news recommendations by algorithms.
In Logg, Minson, and Moore’s experiments, the sources of the algorithmic recommendations were given simply as “an algorithm” or as an algorithm driven by data about decisions taken by other study participants (i.e. laypeople). In the survey that we analyse, two forms of algorithmic news selection were presented, the first described as being driven by data on respondents’ friends’ consumption behaviour (hereon in referred to as “peer filtering”) and the second described as being driven by data on respondents’ own consumption behaviour (hereon in referred to as “user tracking”). A range of research (see e.g. Nisbett and Ross Citation1980) has shown that people regularly demonstrate overconfidence in their own reasoning in relation to advice from others. People’s self-reliance, and our survey’s description of one form of algorithmic news selection as driven by an individual’s past behaviour, could mean that survey participants will rate user tracking higher than peer filtering.
In order to test these hypotheses, our first research question asks:
RQ1: To what extent do online news consumers in 26 countries agree that (1) story selection by algorithms (guided by their or their friends’ past consumption) and (2) story selection by editors and journalists are good ways to get news online?
The Effects of Personal Characteristics
Having considered what one state-of-the-art model leads us to expect about the attitudes of consumers en masse to different types of news selection, including algorithmic, we now turn our attention to differences between individuals. Logg and colleagues say little about individual differences, except that “neither age nor gender have a relationship with reliance on algorithmic advice” (Logg Citation2017, 12) and “appreciation of algorithms was … lower among less numerate participants” (Logg, Minson, and Moore Citation2018, 35). In the following sections, we consider a range of literature that provides potentially useful pointers to how opinions about news selection may differ on an individual basis. We address both people’s news consumption behaviour and concerns—regarding privacy and missing important information and challenging viewpoints—that people may have about algorithmic news recommendations.
Concerns related to privacy
Algorithmic news personalization makes extensive use of data to identify which stories may be relevant to a user (Zuiderveen Borgesius et al. Citation2016). Such data may include the items a user has viewed in the past as well as other personal information. The fact that news personalization technology collects personal data could mean that those with stronger concerns about their own privacy view such technology less positively. For example, a nationally representative survey of English-speaking US residents (N = 1000) found that although 45 per cent said they would, or may, want websites to show news tailored to their interests, this proportion fell to between 17 and 29 per cent if that tailoring was based on their web browsing behaviour being tracked (Turow et al. Citation2009).
Concerns related to missing important information
The principle of personalization implies that news and information of relevance to specific users may be favoured over other news items, including news that has wide general appeal. As a result, users may fear that they will miss out on important information when using personalized news services. While there is currently no consensus in the literature to support this fear (see e.g. Beam and Kosicki Citation2014), these concerns may play an important role in the acceptance of news personalization technologies. For example, a representative study in the Netherlands found the fear of missing out on important information was the third most important argument for or against accepting personalization, almost twice as important as privacy concerns (Bodó, Moeller, and Helberger Citation2017).
Concerns related to missing challenging viewpoints
A prominent concern in popular and academic discourse about algorithmic news selection is that it may lead to a reduction in exposure to challenging viewpoints (see e.g. Pariser Citation2011; Sunstein Citation2001). Because personalization can favour news stories that match the political preferences of users, some have suggested that there will be a reduction in the ideological diversity of users’ news diet. There is some evidence from the USA (see e.g. Dylko et al. Citation2017) to support this concern, although less so in the European context (see e.g. Zuiderveen Borgesius et al. Citation2016). Nevertheless, due to public debate about echo chambers and filter bubbles and their possible effects on democracy, it is possible that concerns about missing challenging viewpoints will influence attitudes towards algorithmic news personalization.
News consumption behaviour
The range of devices and platforms on which people consume news has never been so diverse; nor have the revenue models of news providers. It is, therefore, reasonable to assume that how people access news, and the amount of time and money they invest in the activity, may have an influence on their attitudes to the utility of different types of news selection.
Consumers’ interest in news varies considerably. In a study of consumers in 34 European countries, Elvestad, Blekesaune, and Aalberg (Citation2014) classified 18 per cent of citizens as “news avoiders” and 13 per cent as intense “news seekers”. Those with high levels of interest in news may look favourably on algorithmic news selection as a means by which they can be efficiently alerted to stories of interest, but their expectations are also likely to be high. For example, subscribers to FT.com “expect high relevance” in the personalized news they receive on the platform, because “they expect [the FT] to know lots about them” (James Webb, product manager for personalization at FT.com, personal communication, 8 February 2017).
A second consideration is the significant growth in the use of social networking platforms and mobile devices to access news (see e.g. Newman et al. Citation2017). It may be that automated personalization is seen as a particularly good way to get news by those who frequently access news via mobile devices. Firstly, the fact that mobile devices can transmit data on their whereabouts means that information can be personalized to a smartphone user’s particular location as well as to other characteristics of theirs. Indeed, BBC News’s head of product thinks that younger mobile audiences “expect” to be able to give their location and be shown news relating to it (Alex Watson, personal communication, 14 December 2016). Secondly, by bringing information to the user, personalization may circumvent the difficulties—caused by user-interface issues—of browsing or searching for news via smartphones.
The rapid growth in the use of social networking platforms is exposing more and more people around the world to personalized information spaces. Facebook introduced its News Feed in 2006, which it described as a “personalized list of news stories” (Sanghvi Citation2006). In 2011 it announced that users' News Feeds would become even more personal, taking into account when they last logged on to the platform (Tonkelowitz Citation2011). Facebook users are highly engaged with the platform, with a report from comScore (Citation2016) showing that US users spend around 15 hours a month using the social network. It may be, then, that there is a relationship between more frequent use of social media as a source of news and higher levels of agreement that algorithmic personalization is a good way to get news.
Finally, although only a small minority of consumers pay for news online, those that do may value particular functionalities or editorial approaches. Qualitative research into attitudes to paying for online news has shown that consumers “appreciate providers that allow them to customise the interface [and] prioritise content of interest” (Kantar Citation2017, 8). On the other hand, the same Kantar study also suggested that consumers are more likely to pay for a “plurality of views and perspectives” (4) and for “variety, which allows serendipitous content discovery” (12)—something that algorithmic news selection is not always optimized to deliver. Another attribute those who pay for news may value is a strong editorial voice. James Webb, product manager for personalization at FT.com, said that consumer research conducted by the Financial Times had told them that their “users [who have to pay for access to the FT’s print and online editions] really want the FT view” (personal communication, 8 February 2017). There are, therefore, mixed signals from the literature about how willingness to pay for online news may influence consumers’ evaluations of different types of news selection.
In order to investigate the effects of the individual characteristics discussed in the above sub-section, we ask this second research question:
RQ2: What relationships exist between the individual characteristics of news consumers (such as their concerns about personalization and their news consumption behaviour) and the beliefs they expressed in RQ1?
Methodology
Sample
We conducted a secondary analysis of data from the 2016 Reuters Institute for the Study of Journalism’s Digital News Report survey, an online survey2 (N = 53,314) that was conducted in 26 countries in January and February 2016. Respondents were drawn from YouGov’s panel of five million internet users and are broadly representative of the populations of the countries in question. Because the survey concerned news consumption, respondents who had not consumed news in the previous month were excluded. Across all countries, an average of 3.5 per cent of responses were excluded for this reason, although in some countries that number was higher, for example Canada (12 per cent). Once collected, the data were weighted to targets based on census/industry-accepted data, such as age, gender, and region. The samples in Brazil and Turkey are representative of those countries’ urban rather than national populations, which should be taken into account when interpreting the results.
Questionnaire
The survey question at the heart of this study asked respondents to think about how stories are selected by news websites, mobile apps, and social networks. It made a distinction between news selected by editors and journalists and news selected by computer algorithms. It made a further distinction between two forms of algorithmic selection, the first based on what we call peer filtering and the second based on what we call user tracking. We define peer filtering as automated story selection based on what a user’s friends have consumed. We define user tracking as automated story selection based on what the user themselves has consumed in the past. The question asked respondents to say how much they agreed or disagreed (on a 5-point scale from “Strongly Disagree” to “Strongly Agree”) that each of these three methods was a good way to get news. This is the question in full:
Every news website, mobile app, or social network makes decisions about what content to show to you. These decisions can be made by editors and journalists or by computer algorithms analysing information about what other content you have used, or on the basis of what you and your friends share and interact with on social media. With this in mind, please indicate your level of agreement with the following statements:
Having stories automatically selected for me on the basis of what I have consumed in the past is a good way to get the news.
Having stories selected for me by editors and journalists is a good way to get news.
Having stories automatically selected for me on the basis of what my friends have consumed is a good way to get news.
The survey contained a number of other questions,3 which we were able to use as independent or control variables in our analysis. Those variables and associated questions and possible responses are summarized in Table 1 in online Supplemental Data, along with the means and standard errors.
TABLE 1 Effects of individual characteristics of news consumers (in 26 countries) on their opinions about the utility of algorithmic and editorial news selection
Analysis
In order to answer RQ2, we used multi-level regression modelling and maximum likelihood estimation (Hox Citation2010). Specifically, we added a random intercept to the model to account for the nested structure of the data (individuals nested in countries). A multi-level model was needed because opinions about news selection, as well as many of the predictors of those opinions, vary between countries. Before entering the independent variables into the regression model, we transformed them into z-scores, which allowed us to compare and plot their effect sizes. These comparisons form the core of our analysis and are discussed in detail in the Results section. It is out of the scope of this article to compare the effects of the predictors within the models in detail. Further detail on the formula used in our models is provided in the online Supplemental Data.
Results
RQ1: To what extent do online news consumers in 26 countries agree that (1) story selection by algorithms (guided by their or their friends’ past consumption) and (2) story selection by editors and journalists are good ways to get news online?
The results show that across the entire sample, algorithmic news selection based on a user’s past consumption behaviour was considered a slightly better way to get news than selection by editors and journalists. Selection by editors and journalists was, in turn, considered a slightly better way to get news than algorithmic selection based on a user’s friends’ past consumption (see ).4
Figure 1 Belief among news consumers in 26 countries that having news stories selected either automatically (on the basis of own past consumption [“user tracking”] or friends’ news consumption [“peer filtering”]) or by editors and journalists (“journalistic curation”) is a good way to get news (N = 53,314)
![Figure 1 Belief among news consumers in 26 countries that having news stories selected either automatically (on the basis of own past consumption [“user tracking”] or friends’ news consumption [“peer filtering”]) or by editors and journalists (“journalistic curation”) is a good way to get news (N = 53,314)](/cms/asset/af8a71ae-c990-46f7-9552-a8bfe0d0fa2a/rdij_a_1493936_f0001_b.jpg)
Looking at the results across all of the 26 countries surveyed5 reveals some intriguing differences. Although algorithmic news selection based on a user’s past consumption behaviour was considered the best way to get news in 19 countries, in six countries (Brazil, Denmark, France, Germany, the Netherlands, and Switzerland) selection by editors and journalists was considered best. Uniquely, in the Republic of Korea algorithmic news selection based on a user’s friends’ past consumption behaviour was considered the best form of news selection. In all countries bar the Republic of Korea and Greece, peer filtering was the least favourite form of selection (see Table 2 in online Supplemental Data).
RQ2: What relationships exist between the individual characteristics of news consumers (such as their concerns about personalization and their news consumption behaviour) and the beliefs they expressed in RQ1?
Trust in, and Opinions about the Independence of, the News Media
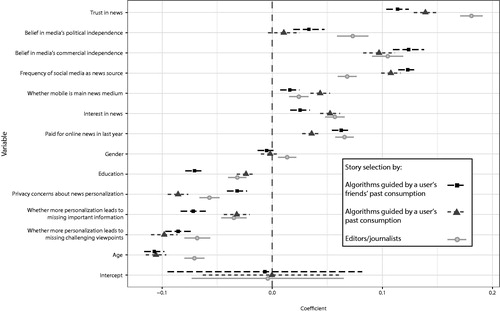
As trust in news organizations falls, people are less likely to agree that selection by editors is a good way to get news. This effect is also seen for automated personalization, but to a lesser degree. Similarly, as their trust in the media’s political independence falls, people are less likely to agree that selection by editors is a good way to get news. However, we see no, or only a minor, change in participants’ opinion about whether automated personalization is a good way to get news. As trust in the media’s commercial independence falls, people are less likely to agree that any form of news selection is a good thing, but there are no significant differences between the three forms of news selection (see and ).
Figure 2 Effect sizes of the individual characteristics of news consumers (N = 53,314) in 26 countries on their opinions about the utility of algorithmic and editorial news selection
Demographics
With increasing age we see lower levels of agreement that any sort of news selection (by editors or algorithms) is a good thing. However, older people are more likely to agree that editors are a good way to get news than agree that algorithmic personalization is a good way to get news. As levels of educational attainment fall, so does agreement that any sort of news selection is a good thing. However, this effect is significantly stronger for automated peer-based personalization. Gender effects do not differ significantly between the three different types of news selection (see and ).
News Consumption Behaviour
As the likelihood that a mobile device is used as people’s main way of accessing news online increases, we see higher levels of agreement that any sort of news selection is a good thing. However, this effect is stronger for automated personalization based on a user’s own behaviour than for editorial selection or automated peer-based personalization. As interest in news rises, we see higher levels of agreement that any sort of news selection is a good thing. However, this effect is weakest for automated peer-based personalization. The more frequently people access news via social media the higher their agreement that any sort of news selection is a good thing. This effect is significantly stronger for automated personalization than for selection by editors. Having paid for online news in the last year is a positive predictor for increased belief that any form of news selection is a good thing, but this effect is stronger for selection by editors and automated peer-based personalization than for automated personalization based on a user’s own behaviour (see and ).
Concerns about More Personalized News
The more people are concerned about the privacy risks associated with more personalized news, the less they agree that any form of news selection is a good way to get news. However, this effect is strongest for automated personalization based on a user’s own behaviour. As concerns about missing important information as a result of more personalized news rise, agreement that any form of news selection is a good thing falls. However, this effect is significantly stronger for peer-based personalization. As concerns about missing challenging viewpoints rise, there is less agreement that any form of news selection is a good thing. There are no significant differences between the three types of news selection (see and ).
It should be noted that the results for the three forms of news selection (user tracking, journalistic curation, and peer filtering) do not—in relation to the dependent variables—vary wildly from each other, often being in the same range and almost always being in the same direction (see ). This covariance might be explained by two factors, one methodological and one conceptual. The methodological factor relates to the fact that respondents were asked about the three forms of news selection in the same battery of questions. There is some, albeit weak, evidence that correlations between answers to questions grouped on the same screen are higher than correlations between answers to questions presented across separate screens (see e.g. Tourangeau, Couper, and Conrad Citation2004). Conceptually, it may be that there is an underlying factor that influences acceptance of any form of news selection. Adopting, for a moment, Kohring and Matthes’s (2007, 239) contention that trust in the news media is actually about trust in their selectivity, we might speculate that those with lower levels of trust in general are less prepared than others to delegate news selection to any entity—human or computational.
Discussion
Relative Appreciation of Recommendations from Algorithms and Experts
Some of our results are in line with Logg, Minson, and Moore’s (2018; Logg Citation2017) state-of-the-art model which holds that people en masse have higher levels of appreciation for algorithmic recommendations than for recommendations from humans. However, our findings contradict an element of this model by showing that this preference can persist even when the human recommendations come from experts—in our case editors and journalists—rather than laypeople.
When thinking about this contradiction, it is important to consider how journalists’ and editors’ expertise in news selection might be perceived. Although research into consumers’ appreciation of editors and journalists’ selectivity is uncommon, there is plenty of research into the trust—or confidence—consumers have in the news and those who produce it. Such research may be a good proxy: as we have previously mentioned, Kohring and Matthes (Citation2007) define trust in news media as meaning “trust in their specific selectivity rather than in objectivity or truth” (239).
In international surveys of the public, trust—or confidence—is mostly measured as a single item, applied to related, but not identical, objects such as news, the press, television, traditional media, and online-only media. Looking at the results of such surveys in the countries in our sample in the period (2010–2014) just before the collection of our own data in 2016 shows that confidence in the press and television was rather low compared with other civic institutions such as the police, the armed forces, and universities, but higher than in political institutions and labour unions (World Values Survey Citation2016).
Our own survey also measured confidence (operationalized as “trust”) in news organizations (and belief in the news media’s political and commercial independence). The results, en masse, are ambiguous, with respondents, on average, neither agreeing nor disagreeing that news organizations are trustworthy most of the time, or free of political or commercial influence (see Table 1 in online Supplemental Data). As with the results of the World Values Survey there was considerable variability between countries. For example, while 62 per cent of Finns had some trust in news organizations, just 16 per cent of Greeks did.
Our inferential analyses show that there is a link between respondents’ trust in news organizations and their assessment of the relative utility of algorithmic and editorial news selection. As trust in news organizations, and in the political independence of the news media, falls, people are less likely to agree that selection by editors and journalists is a good way to get news. This is no surprise. Editors and journalists are key actors in the operation of news organizations. Trust in an institution and trust in its functionaries are clearly closely linked. By contrast, agreement that automated personalization is a good way to receive news is affected less by distrust in the media and its perceived political independence. It appears, therefore, that users are, to an extent, divorcing the operation of automated news personalization from the operation of news organizations, believing the technology has a degree of immunity from contamination by a politically compromised or untrustworthy news media.
Are such beliefs justified?
Our survey question related to decisions made by news websites, mobile apps, and social networks. Most of those social networks, and some of the aggregating websites and mobile apps that users are likely to associate with news (e.g. Google News and Flipboard), are owned by supranational companies that our respondents may consider to have relatively benevolent personalization algorithms that are not subject to the influence of governments or of untrustworthy national or local news media. Indeed, there have been instances where such companies have sought to resist political influence in national markets. For example, in 2010 Google effectively withdrew from the Chinese market when it stopped censoring search results on the Chinese version of its search engine (Drummond Citation2010). However, Google and other providers of personalized news and information services do alter their algorithms in response to local legislation and government requests. Facebook revealed that between July and December 2016 it had restricted access to 6944 pieces of content in 21 countries as a result of government requests (Facebook Citation2017), and it is reported that Facebook has “developed software to suppress posts from appearing in people’s news feeds in specific geographic areas” to help it, claimed the New York Times, “get into China” (Issac 2016).
Furthermore, the operation of social networks’ and aggregators’ algorithms clearly has a commercial motive, to keep users engaged as long as possible (see e.g. DeVito Citation2017) and target them with advertising. Other motives have also come into play. Evidence has emerged that Facebook has conducted experiments with tens of millions of its users, selectively changing what information those users receive, with effects on their voting behaviour (Bond et al. Citation2012) and emotional states (Kramer, Guillory, and Hancock Citation2014). In other words, while users may believe news selection algorithms are more benevolent than editors and primarily serve their informational needs, the reality may be very different, at least for social networks.
As we have established, algorithms are also being used by traditional news brands to personalize content for consumers. Are the algorithms at these institutions deserving of audiences’ apparent belief in their utility, even when they have been deployed by untrustworthy or politically dependent news organizations? On the one hand, given algorithms’ relatively opaque modus operandi and voluminous output, they may be more difficult for an editor or proprietor to monitor and modify than, for example, a print newspaper. On the other hand, news organizations have various degrees of control over whether and how such algorithms operate. At the most basic level, they are able to turn off any form of algorithmic selection whose output does not meet editorial policy. However, such a step is unlikely to be necessary because news organizations have finer control over how these technologies operate. If, as is sometimes the case, they have developed the system themselves (see e.g. Spangher Citation2015), then they are able to design or amend the logic to suit their needs. If—as is also often the case (see e.g. Thurman and Schifferes Citation2012)—the personalization technology has been provided by a third party, it is likely to come with a dashboard offering control over its operation. For example, one of the most frequently used third-party content recommendation technology providers, Outbrain,6 says its platform “is fully customizable and flexible to meet all your business needs” (Outbrain Citationn.d.).
Appreciation for Algorithms Differs According to the Source of Their Data
Our results add a new layer to Logg, Minson, and Moore’s (2018; Logg Citation2017) model by showing how appreciation of algorithms can vary depending on the source of the data driving the recommendations they make. Across almost all of the countries in our survey, respondents considered automated personalization based on their friends’ past consumption behaviour to be a less good way to get news than selection by either editors and journalists or by automated personalization based on their own past consumption behaviour (see Table 2 in online Supplemental Data).
This finding may, in part, be explained with reference to the literature on self-confidence, which has shown that people regularly demonstrate overconfidence in their own reasoning in relation to advice from others (see e.g. Nisbett and Ross Citation1980). People’s self-reliance, and our survey’s description of one form of algorithmic news selection as driven by an individual’s past behaviour, may help explain why respondents en masse rated user tracking higher than peer filtering. However, there may be other explanations to do with the particular context of our study, news. One of the drivers for the perceived low utility of peer-based personalization seems to be a concern that more of it would result in users missing out on important information (see and ).
Peer-based news personalization (as described by our survey question) relies on the assumption that it is possible to infer which stories a user will find relevant or interesting by reference to the stories consumed by that user’s online social network. Personalization in this form has been deployed by a number of mainstream news publishers. For example, Thurman (Citation2011) reported that in late 2009 users of the Wall Street Journal’s website could “choose to receive recommendations based on the behaviour of other WSJ.com users or of ‘friends’ in their Facebook network”. Approximately one year later the NYTimes.com, Telegraph.co.uk, and WashingtonPost.com were offering similar functionality via the Facebook Activity Feed plug-in (Thurman and Schifferes Citation2012). However, by 2016 this form of personalization was absent from the websites and apps of a sample of 15 mainstream news outlets in the UK, US and Germany (Kunert and Thurman, in press).
The reason is likely to be simply that it does not work very well. As Thurman and Schifferes (Citation2012) explain:
limited evidence of overlapping interests can make recommendations difficult—the so-called “sparse matrix problem”—and it “may take some time for stories to receive enough user feedback to lead to accurate recommendations” (Billsus and Pazzani Citation2007), by which time the news agenda is likely to have moved on—the so-called “latency problem”.
Although the Facebook Activity Feed plug-in sidestepped the “sparse matrix” and “latency” problems by requiring a recommendation from only a single friend in a user’s network, by doing so it relied on the—considerable—assumption that there was sufficient overlap between the interests of readers and their Facebook friends (Thurman and Schifferes Citation2012). There was also a problem with the frequency with which sites’ Facebook Activity Feeds updated. Thurman and Schifferes (Citation2012) noted that recommendations could be months old.
There are limitations, then, in trying to use data about an individual’s online social network to drive news selection, and it may be that those with high levels of interest in the news, and those who do not want to miss out on important information, are particularly aware of those limitations.
Effects of Individual Characteristics
Like Logg (Citation2017, 12), we found no correlation between gender and algorithmic appreciation. Analogous with Logg, Minson, and Moore’s (2018, 35) findings, we found lower algorithmic appreciation amongst respondents with lower levels of educational achievement (their finding related to a specific educational ability, numeracy). Our results differ, however, as they relate to age. While Logg (Citation2017, 12) did not find a relationship between age and reliance on algorithmic advice, our results show that older people are more likely to agree that editors are a good way to get news than agree algorithmic personalization is a good way to get news. As such, our results support Hoff and Bashir’s (Citation2014, 414) contention that, regarding trust in automation, “the specific effect of age likely varies in distinct contexts”. More research is required to determine the reasons for the age effects we observed, but they may relate to the fact that older people are heavier users of traditional media products (see e.g. Thurman and Fletcher Citation2017), such as printed newspapers, which are not personalized.
Due to space limitations we are unable to discuss all the effects of individual characteristics. It is worth mentioning, however, that, as expected, we found correlations between the consumption of news via mobile devices and via social media and higher levels of appreciation for a form of algorithmic news selection. Also as expected, we found lower levels of appreciation for a form of algorithmic news selection as concerns about privacy rose.
We also found that having paid for online news in the last year is a positive predictor for increased belief that any form of news selection is a good thing. Interestingly, this effect is stronger for selection by editors and automated peer-based personalization than for automated personalization based on a user’s own behaviour. It appears, therefore, that people value aspects of editorial curation including, as suggested by some of the findings highlighted in our Literature Review, the variety that editors and journalists have long felt they should provide. Pete Picton, speaking when he was editorial director of Mirror Online, said it was part of his job to get his audience to “read things outside their favourite subject areas”, and believed that a long-held objective of newspaper editors, to surprise their (stereotypically male) readers to the extent that they exclaimed “Hey Martha” or “Hey Doris” to their wives when confronted with an unexpected story, was still important in an online environment (personal communication, 10 February 2017). Ensuring such diverse exposure is not just of value to the individual but also to society more widely, helping to foster tolerance and open-mindedness and enabling informed deliberation and societal inclusion.
It is more difficult to explain why paying for news is a positive predictor of agreement that peer-based personalization is a good way to get news. One possible explanation is that those who pay for news feel part of a privileged network or “club” and value the opinions of their fellow subscribers.
Conclusion
This study’s methods and focus mean its results and analysis have a degree of generalizability at the same time as exploring how, and why, algorithms are appreciated in a particular context, news. As a result, we hope it can contribute to efforts to understand algorithmic appreciation in general terms, as well as providing specific evidence and explanation about audiences’ appreciation of different forms of news selection, including algorithmic.
By analysing data from a large-scale (N = 53,314) international survey we have—at least in the context of news—been able to replicate Logg, Minson, and Moore’s finding that people en masse have higher levels of appreciation for (a form of) algorithmic recommendation than for recommendation by humans.
However, our findings contradict part of Logg, Minson, and Moore’s model by showing that the preference for algorithmic recommendation can persist even when the (alternative) human recommendations come from experts rather than laypeople. We explain this contradiction with reference to the ambivalence shown towards journalists’ and editors’ expertise in news selection. This contradiction, and its explanation, shows that algorithmic appreciation has context-specific characteristics.
We have also explored algorithmic appreciation—among general populations and, again, in the context of news—in a way that distinguishes between two different types: peer filtering and user tracking. By making this distinction we have been able to show that appreciation of algorithms can differ according to the source of their data, with user tracking preferred over peer filtering. Although this preference was observed in all but one of the 26 countries surveyed, the particular focus of our study limits the generalizability of this finding to other contexts. As we have discussed, although pure peer filtering has been used by mainstream providers to personalize news, it did not work very well. Our results may reflect those failures.
The availability of data from our survey on respondents’ behaviours and demographics, and on other opinions they hold, enabled us to probe the effects of individual characteristics on the appreciation of different types of news selection, including algorithmic. Our exploratory analyses replicated Logg’s (Citation2017) finding that algorithmic appreciation does not vary by gender. However, we did find that 11 independent variables in our model had significant effects, including age, paying for news, mobile news access, concerns over privacy, and trust in news. We explored one of these findings in particular detail: how respondents appear to divorce the operation of automated news personalization from the operation of news organizations, and seem to believe the technology has a degree of immunity from contamination by untrustworthy news media. We challenged this belief, pointing out how, while users may believe news selection algorithms are more benevolent than editors, and primarily serve their information needs, the reality may be very different, in particular at social networks.
Although, on the surface, our findings make discouraging reading for editors and journalists, dig a little deeper and the picture is not so gloomy. Publishers can find support in our results for their development of personalization for the young and for mobile users. Our findings should also encourage them to challenge audiences’ belief in the neutrality of the algorithms used by the likes of Facebook, to stand apart in their commitment to readers’ privacy, and to emphasize the value of their curated content and the communities of readers they cultivate.
Limitations and Further Research
It should be noted that most of the evidence that informed Logg, Minson, and Moore’s (2018; Logg Citation2017) model comes from experiments in which the actions of participants were analysed. By contrast our survey asked respondents about their opinions rather than analysing their actions. As is well known, the opinions people state frequently differ from related actions they take. Research indicates that while relatively high proportions of news consumers say they would like to receive personalized news (see e.g. Business Wire Citation2005), in practice smaller proportions invest the time in setting up personal preferences or use the sections of news websites and apps where stories have been tailored to their implicitly determined interests (see e.g. Thurman Citation2011). It might be, then, that our results overestimate algorithmic appreciation. Furthermore, Jennifer Logg and colleagues’ experiments were mostly about algorithmic advice being used in specific estimation and prediction tasks. While news may be used by people in decision-making, including estimation and predictions tasks, it also fulfils other functions, for example escapism (see e.g. Berelson Citation1949). Further work is required to understand the influence, if any, of the uses made of algorithmic recommendations on how they are appreciated.
As we conducted a secondary analysis of a data set collected by the Reuters Institute for the Study of Journalism, we were constrained in the operationalization of our dependent variables. We would prefer to have used multi-item measures to gauge respondents’ attitudes towards story selection. Consequently, our measurement error may be higher than if multi-item measures had been used. Future research could test the conclusions of our exploratory analyses by developing attributes that measure story selection preferences more precisely, and fielding them in further surveys.
SUPPLEMENTARY MATERIAL
Supplementary material is available for this article at: https://www.tandfonline.com/doi/suppl/10.1080/21670811.2018.1493936?scroll=top
Supplementary Material
Download MS Word (24.4 KB)ACKNOWLEDGEMENTS
The authors thank Reuters Institute for the Study of Journalism and YouGov for permission to use data from the 2016 Digital News Report survey and Jessica Kunert for conducting the interviews from which this article quotes
DISCLOSURE STATEMENT
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors
Neil Thurman
Neil Thurman Department of Communication Studies and Media Research, LMU Munich, Germany and Department of Journalism, City, University of London. Email: [email protected]. Web: http://www.neilthurman.com. Twitter: @neilthurman.
Judith Moeller
Judith Moeller (author to whom correspondence should be addressed), Amsterdam School of Communication Research, Department of Communication, University of Amsterdam, Netherlands. Email: [email protected].
Natali Helberger
Natali Helberger Institute for Information Law, University of Amsterdam, Netherlands. Email: [email protected].
Damian Trilling
Damian Trilling Amsterdam School of Communication Research, Department of Communication, University of Amsterdam, Netherlands. Email: [email protected]. Twitter: @damian0604
Notes
1 Australia, Austria, Belgium, Brazil, Canada, Czech Republic, Denmark, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Japan, Netherlands, Norway, Poland, Portugal, Republic of Korea, Spain, Sweden, Switzerland, Turkey, United Kingdom and the United States.
3 In total, the survey contained 45 core questions, which were asked in all 26 countries. About 20 supplementary questions were asked in a sub-set of countries. To allow maximization of the sample size, this study only uses data from questions asked in every country.
4 Although these results were partially reported in Nielsen (Citation2016), only the percentages of respondents who “Tend to agree” and “Strongly agree” were given.
5 The results from only six countries were reported in Nielsen (Citation2016).
6 Used by publishers and marketers in “more than 55 countries” (https://www.outbrain.com/about/company/).
REFERENCES
- BBC News. 2017. “Facebook Hires 3,000 to Review Content.” BBC News online, 3 May. http://www.bbc.com/news/technology-39793175.
- Beam, Michael A., and Gerald M. Kosicki. 2014. “Personalized News Portals: Filtering Systems and Increased News Exposure.” Journalism & Mass Communication Quarterly 91 (1): 59–77.
- Berelson, Bernard. 1949. “What ‘Missing the Newspaper’ Means.” In Communications Research: 1948–1949, edited by Paul Lazarsfeld, and Frank Stanton, 111–129. Oxford, England: Harper.
- Billsus, Daniel, and Michael J. Pazzani. 2007. “Adaptive News Access.” In The Adaptive Web: Methods and Strategies of Web Personalization, edited by Peter Brusilovsky, Alfred Kobsa, and Wolfgang Nejdl, 550–570. Berlin: Springer-Verlag.
- Bodó, Balázs, Judith Moeller, and Natali Helberger. 2017. “Piercing the Filter Bubble Bubble – Factors and Conditions of Acceptance of News Personalization.” Paper presented at TILTing Perspectives 2017: Regulating a Connected World, Tilburg, The Netherlands, 19 May.
- Bond, Robert M., Christopher J. Fariss, Jason J. Jones, Adam D. I. Kramer, Cameron Marlow, Jaime E. Settle, and James H. Fowler. 2012. “A 61-million-person Experiment in Social Influence and Political Mobilization.” Nature 489: 295–298. doi:10.1038/nature11421.
- Bowles, Nellie, and Sam Thielman. 2016. “Facebook Accused of Censoring Conservatives, Report Says.” Guardian.com, 9 May. https://www.theguardian.com/technology/2016/may/09/facebook-newsfeed-censor-conservative-news.
- Business Wire. 2001. “Washingtonpost.com Introduces New Personalization Service, Giving Users News and Info the Way They Want It.” 5 June. Retrieved from Nexis database, 9 October 2017.
- Business Wire. 2005. “National Survey Finds Consumers Want a Personalized Online Experience, But Fear the Loss of Personal Information; 80% Express Strong Interest in Personalized Content; 63% Concerned about the Security of their Personal Information.” 15 August. Retrieved from Nexis database, 13 October 2017.
- Carlson, Matt. 2018. “Facebook in the News: Social Media, Journalism, and Public Responsibility Following the 2016 Trending Topics Controversy.” Digital Journalism 6 (1): 4–20. doi: 10.1080/21670811.2017.1298044.
- comScore. 2016. “2016 U.S. Cross-platform Future in Focus.” comScore. http://www.comscore.com/Insights/Presentations-and-Whitepapers/2016/2016-US-Cross-Platform-Future-in-Focus.
- Crunchbase. n.d. https://www.crunchbase.com/search/organization.companies/74d5bac197e29e6aeccb8812e25e3f611025b0f5
- DeVito, Michael A. 2017. “From Editors to Algorithms: A Values-based Approach to Understanding Story Selection in the Facebook News Feed.” Digital Journalism 5 (6): 753–773.
- Dietvorst, Berkeley, Joseph Simmons, and Cade Massey. 2015. “Algorithm Aversion: People Erroneously Avoid Algorithms after Seeing Them Err.” Journal of Experimental Psychology: General 144 (1): 114–126.
- Dijkstra, Jaap. 1999. “User Agreement with Incorrect Expert System Advice.” Behaviour & Information Technology 18 (6): 399–411.
- Dijkstra, Jaap, Wim Liebrand, and Ellen Timminga. 1998. “Persuasiveness of Expert Systems.” Behaviour & Information Technology 17 (3): 155–163.
- Drummond, David. 2010. “A New Approach to China: An Update.” Google blog, 22 March. https://googleblog.blogspot.de/2010/03/new-approach-to-china-update.html.
- Dylko, Ivan, Ivor Dolgov, William Hoffman, Nicholas Eckhart, Maria Molina, and Omar Aaziz. 2017. “The Dark Side of Technology: An Experimental Investigation of the Influence of Customizability Technology on Online Political Selective Exposure.” Computers in Human Behavior 73: 181–190.
- Elvestad, Eiri, Arild Blekesaune, and Toril Aalberg. 2014. “The Polarized News Audience? A Longitudinal Study of News-seekers and News-avoiders in Europe.” Available at SSRN: https://ssrn.com/abstract=2469713.
- European Commission. 2018. “Algorithmic Awareness-building.” 25 April. https://ec.europa.eu/digital-single-market/en/algorithmic-awareness-building
- Facebook. 2017. “Government Requests Report.” https://govtrequests.facebook.com/.
- Gomez-Uribe, Carlos A., and Neil Hunt. 2015. “The Netflix Recommender System: Algorithms, Business Value, and Innovation.” ACM Transactions on Management Information Systems 6 (4): 1–19.
- Hoff, Kevin, and Masooda Bashir. 2014. “Trust in Automation: Integrating Empirical Evidence on Factors that Influence Trust.” Human Factors 57 (3): 407–434.
- Hox, Joop J. 2010. Multilevel Analysis: Techniques and Applications. 2nd ed. New York: Routledge.
- Isaac, Mike. 2016. “Facebook Said to Create Censorship Tool to Get Back into China.” New York Times, 22 November. https://www.nytimes.com/2016/11/22/technology/facebook-censorship-tool-china.html.
- Kantar. 2017. “Attitudes to Paying for Online News.” Kantar Media, August. http://reutersinstitute.politics.ox.ac.uk/sites/default/files/2017-09/KM%20RISJ%20Paying%20for%20 online%20news%20-%20report%20230817_0.pdf.
- Kohring, Matthias, and Jörg Matthes. 2007. “Trust in News Media: Development and Validation of a Multidimensional Scale.” Communication Research 34 (2): 231–252.
- Kramer, Adam D. I., Jamie E. Guillory, and Jeffrey T. Hancock. 2014. “Experimental Evidence of Massive-scale Emotional Contagion through Social Networks.” Proceedings of the National Academy of Sciences 111 (24): 8788–8790.
- Kunert, Jessica, and Neil Thurman. In press. “The Form of Content Personalisation at Mainstream Transatlantic News Outlets: 2010–2016.” Journalism Practice.
- Logg, Jennifer. 2017. “Theory of Machine: When Do People Rely on Algorithms?” Harvard Business School Working Paper, No. 17-086. https://dash.harvard.edu/handle/1/31677474
- Logg, Jennifer, Julia Minson, and Don A. Moore. 2018. “Algorithm Appreciation: People Prefer Algorithmic to Human Judgment.” Harvard Business School NOM Unit Working Paper No. 17–086. Available at SSRN: https://ssrn.com/abstract=2941774.
- Meehl, Paul E. 1954. Clinical versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence. Minneapolis, MN: University of Minnesota Press.
- Newman, Nic, Richard Fletcher, Antonis Kalogeropoulos, David A. L. Levy, and Rasmus Kleis Nielsen. 2017. Reuters Institute Digital News Report 2017. Oxford: Reuters Institute for the Study of Journalism.
- Nielsen, Rasmus Kleis. 2016. “People Want Personalised Recommendations (Even as They Worry about the Consequences).” In Reuters Institute Digital News Report 2016, edited by Nic Newman, Richard Fletcher, David A. L. Levy and Rasmus Kleis Nielsen, 111–113. Oxford: Reuters Institute for the Study of Journalism.
- Nisbett, Richard, and Lee Ross. 1980. Human Inference: Strategies and Shortcomings of Social Judgment. Englewood Cliffs, New Jersey: Prentice-Hall.
- Outbrain. n.d. https://www.outbrain.com/engage/. Accessed 13 October 2017.
- Pariser, Eli. 2011. The Filter Bubble: What the Internet Is Hiding from You. London: Penguin.
- Promberger, Marianne, and Jonathan Baron. 2006. “Do Patients Trust Computers?” Journal of Behavioral Decision Making 19 (5): 455–468.
- Reuters. 2017. “Reuters.com Upgrades Reading Experience with Debut of New Article Pages and Introduction of New Advertising Units.” https://plus.reuters.com/en/news/reuters_upgrades_reading_experience.html
- Sanghvi, Ruchi. 2006. “Facebook Gets a Facelift.” Facebook.com, 5 September. https://www.facebook.com/notes/facebook/facebook-gets-a-facelift/2207967130.
- Sinha, Rashmi, and Kirsten Swearingen. 2001. “Comparing Recommendations Made by Online Systems and Friends.” In Proceedings of the DELOS-NSF Workshop on Personalization and Recommender Systems in Digital Libraries Dublin: Dublin City University, June 18–20.
- Solon, Olivia. 2016. “Facebook’s Failure: Did Fake News and Polarized Politics Get Trump Elected?” Guardian.com, 10 November. https://www.theguardian.com/technology/2016/nov/10/facebook-fake-news-election-conspiracy-theories.
- Spangher, Alexander. 2015. “Building the Next New York Times Recommendation Engine.” New York Times blog post, 11 August. https://open.blogs.nytimes.com/2015/08/11/building-the-next-new-york-times-recommendation-engine/.
- Spayd, Liz. 2017. “A ‘Community’ of One: The Times Gets Tailored.” New York Times, 18 March. https://www.nytimes.com/2017/03/18/public-editor/a-community-of-one-the-times-gets-tailored.html
- Sunstein, Cass R. 2001. Republic.com. Princeton, NJ: Princeton University Press.
- Thielman, Sam. 2016a. “Facebook News Selection Is in Hands of Editors Not Algorithms, Documents Show.” Guardian.com, 12 May. https://www.theguardian.com/technology/2016/may/12/facebook-trending-news-leaked-documents-editor-guidelines.
- Thielman, Sam. 2016b. “Facebook Fires Trending Team, and Algorithm without Humans Goes Crazy.” Guardian.com, 29 August. https://www.theguardian.com/technology/2016/aug/29/facebook-fires-trending-topics-team-algorithm.
- Thurman, Neil. 2011. “Making ‘The Daily Me’: Technology, Economics and Habit in the Mainstream Assimilation of Personalized News.” Journalism: Theory, Practice & Criticism 12 (4): 395–415.
- Thurman, Neil, and Richard Fletcher. 2017. “Has Digital Distribution Rejuvenated Readership? Revisiting the Age Demographics of Newspaper Consumption.” Journalism Studies. doi:10.1080/1461670X.2017.1397532.
- Thurman, Neil, and Steve Schifferes. 2012. “The Future of Personalization at News Websites: Lessons from a Longitudinal Study.” Journalism Studies 13 (5–6): 775–790.
- Tonkelowitz, Mark. 2011. “Interesting News, Any Time You Visit.” Facebook.com, 20 September. https://newsroom.fb.com/news/2011/09/interesting-news-any-time-you-visit.
- Tourangeau, Roger, Mick P. Couper, and Frederick Conrad. 2004. “Spacing, Position, and Order: Interpretive Heuristics for Visual Features of Survey Questions.” Public Opinion Quarterly 68 (3): 368–393.
- Turow, Joseph, Jennifer King, Chris Jay Hoofnagle, Amy Bleakley, and Michael Hennessy. 2009. “Americans Reject Tailored Advertising and Three Activities that Enable It.” Available at SSRN: http://dx.doi.org/10.2139/ssrn.1478214.
- World Values Survey. 2016. WORLD VALUES SURVEY Wave 6 2010–2014 OFFICIAL AGGREGATE v.20150418. World Values Survey Association (www.worldvaluessurvey.org). Aggregate File Producer: Asep/JDS, Madrid SPAIN.
- Yeomans, Mike, Anuj Shah, Sendhil Mullainathan, and Jon Kleinberg. 2018. “Making Sense of Recommendations.” Unpublished manuscript. http://scholar.harvard.edu/files/sendhil/files/recommenders55.pdf
- Zuckerberg, Mark. 2017. Untitled Post. Facebook, 3 May. https://www.facebook.com/zuck/posts/10103695315624661.
- Zuiderveen Borgesius, Frederik J., Damian Trilling, Judith Moeller, Balázs Bodó, Claes H. De Vreese, and Natali Helberger. 2016. “Should We Worry about Filter Bubbles?” Internet Policy Review 5 (1):1–16.