
Abstract
Through a mixed methods research design, we address normative aspects of news recommendation engines by examining whether search personalisation and news diversity are evident on Google News in the UK. First, in a quasi-experimental design, we asked a diverse set of participants (N = 78) to search Google News using four search terms and report the first five articles recommended for each term. We found little evidence of news personalisation, which challenges the claim that news search algorithms contribute to weakened viewpoint diversity. We also found a high degree of homogeneity in news search results, with legacy media brands dominating. Second, we conducted a manual content analysis of the articles recommended by Google News for our search terms (N = 192), focusing on favourability towards each term. We found that while there was little relationship between the favourability slant of the articles and political leanings of participants, there were two exceptions: self-identified right-wing participants were more likely to see unfavourable stories about 1) immigration, and 2) a left-wing politician. This reopens the question of news search engines’ contributions to polarisation and viewpoint diversity for certain news consumers.
Whenever we consume news online, we are subject to various algorithms that sort, organise, and recommend news based on information that websites and apps collect from us. For many reasons, we might welcome the efficiency, consistency, speed and scale which machines can bring to the distribution and organisation of news. However, the algorithms underpinning search results and recommendations – the cornerstone of navigating the Web – raise fundamental normative questions over the role of machines as news gatekeepers (Napoli Citation2015; Nechushtai and Lewis Citation2019). For instance, what kinds of news gatekeepers do we want machines to be? Do we want them to personalise news search recommendations based on information they collect about us? If so, what aspects of personalisation – such as our location, age, news consumption habits or political preferences – should prevail? Should these news recommendations confirm our pre-existing political beliefs, or challenge them? And what might the democratic consequences of these decisions be?
These questions come at a time when algorithms are an increasingly influential factor in the selection and distribution of news. More than half of news users worldwide (55%) prefer to access news through search engines, social media, or news aggregators, which rely on algorithms rather than editors to select and rank stories (Newman et al. Citation2019). The preference for news aggregators (websites or apps that aggregate syndicated news content in one location) has grown significantly in recent years, with young people particularly likely to rely on them as their primary source of news (Newman et al. Citation2019). Internationally, Google News (which combines news aggregation with Google search functionality) has the largest share of the news aggregation market, with 17% of North American and EU news consumers having used it in the last week, rising to 28% in Asia and 41% in Latin America (Newman et al. Citation2019).
Google introduced personalisation to its PageRank algorithm in 2009 to solve the issue of sorting through the massive amount of information that passes through it (Google Citation2009). However, concerns have proliferated on how its algorithms filter information, shape news consumption and potentially manipulate public knowledge. Although there is an established body of knowledge about personalisation and news content diversity on social media, we know less about news search. This is compounded by the frequency of Google algorithm changes (Moz Citation2018), making it harder to build a reliable base of evidence on news search and content diversity (Ørmen Citation2016). Responding to this need for further research, our paper addresses normative aspects of the algorithms that underpin news search recommendations. This study contributes to current debates on the extent of algorithmic news personalisation and its consequences for news diversity in three ways. First, through an experimental study design it expands the search terms used to examine personalisation and news diversity in news aggregators beyond politicians to also include political issues. Second, combining experiments with content analysis, it considers news diversity at two levels: 1) the news brand (source diversity), and 2) the article (viewpoint diversity). Third, it is the first study to concurrently examine both news personalisation and news diversity in one research design, thus providing a more complete picture of the diversity of news sources and perspectives that users of news aggregators are exposed to.
News Diversity and Algorithmic Personalisation
A fundamental function of news media systems in democratic contexts is to provide citizens with a diversity and balance of news outlets and content to choose from, thereby ensuring the circulation of a range of perspectives in the public sphere (Norris Citation2000). News diversity can facilitate an informed and engaged electorate and is a key indicator of a news media system’s health and performance (Hallin and Mancini Citation2012). News diversity is typically conceptualised and operationalised at three levels (see McDonald and Dimmick Citation2003). First, source diversity considers a news outlet’s inclusion of multiple informational sources as the building blocks of a story (Voakes et al. Citation1996). The diversity of such sources – much critiqued in journalism studies literature – can tell us about the nature of societal power and journalism’s relationships to it (Thorsen and Jackson Citation2018). However, from a citizen’s perspective, source diversity can also be understood as the array of news outlets one regularly consumes as part of one’s news diet (Haim, Graefe, and Brosius Citation2018; Thurman Citation2011). This can be influenced by, amongst other things, the algorithms of news aggregators – the focus of this article. Second, content diversity can refer to the topics that a news consumer experiences through news consumption (either through a single news outlet or multiple news outlets). Third, viewpoint diversity considers the plurality of perspectives that a news outlet includes as part of its coverage of an issue (Haim, Graefe, and Brosius Citation2018).
As news consumption has increasingly moved online, so has scholarly attention shifted to the role of algorithms in the process of managing and filtering news diversity. After all, algorithms are now central to the process of assisting news consumers to navigate through the potentially overwhelming amount of available information online (Thurman, Lewis, and Kunert Citation2019). In many news contexts, algorithms are utilised to recommend (potentially personalised) content to users based on information held about them, such as their location, stated preferences and previous online behaviour. These recommendations can be drawn from explicit or implicit personalisation preferences. The former are preferences the user has actively volunteered and the latter those the platform has observed from users’ behaviour – although, as with Google News, these are often in combination (see Zuiderveen Borgesius et al. Citation2016).
A key question, then, is whether the consumption of a diverse news diet is aided or hindered in online news environments where algorithms are most prevalent. Arguing the latter, some research has advanced the idea that algorithmic personalisation can systematically filter counter-attitudinal news and information akin to “invisible auto-propaganda indoctrinating us with our own ideas” (Pariser Citation2011, p. 15), a process typically known as “filter bubbles.” A related claim is that “echo chambers” occur when people with the same interests or political worldviews interact primarily within their group (Dubois and Blank Citation2018). While echo chambers pre-date the Internet, algorithms can facilitate the process of both seeking and sharing information online that conforms to the norms of an in-group and tends to reinforce existing beliefs (Jamieson and Cappella Citation2008; Sunstein Citation2009). Both filter bubbles and echo chambers can have potentially deleterious consequences for democracy by, for example, weakening viewpoint diversity, undermining the normal functioning of group deliberation and public debate, and contributing to political polarisation (Milano, Mariarosaria, and Luciano Citation2020).
Such theories assume that algorithms make personalised recommendations exactly in line with information people are interested in and viewpoints they hold. But this does not have to be the case. After all, algorithmic design is a technological process that can be altered to suit the demands of both commercial and democratic imperatives. Algorithms can be designed to expose citizens to more diverse content and to politically cross-cutting information, while simultaneously maintaining audience engagement and monetising long-tail content (Bakshy, Messing, and Adamic Citation2015; Bodó et al. Citation2019; Heitz et al. Citation2022). Indeed, there is a growing body of evidence that algorithms can equally engender forms of political heterogeneity and diversity as they do political homogeneity and uniformity (Barberá et al. Citation2015; Bruns Citation2019; Dubois and Blank Citation2018; Møller Citation2022). This can be, for example, through incidental exposure to a greater range of news outlets (Bakshy, Messing, and Adamic Citation2015; Fletcher and Nielsen Citation2018a) and discordant news on social media (Kim, Chen, and Gil De Zúñiga Citation2013) than would otherwise be encountered; the formation and strengthening of weak ties able to accommodate more political diversity (Barberá et al. Citation2015); or consumption of news shared by friends that counters existing belief structures (Messing and Westwood Citation2014).
Personalisation and News Diversity in News Search Engines
While there is a growing body of evidence that either contradicts or adds nuance to some of the more dystopian claims about the consequences of algorithmic personalisation on social media, we know much less about the role of news search engines (or aggregators) in this process. Given the widespread popularity and growth of news search around the world, this is a significant deficiency. Existing research has examined the relationship between news consumption through search engines and news diversity. Comparing four countries, Fletcher and Nielsen (Citation2018b) asked survey participants about their news consumption and whether they used search engines for news. They found that news search users on average utilised more sources of online news, were more likely to utilise both left-leaning and right-leaning online news outlets, and were exposed to a greater balance of news coverage in terms of similar numbers of left-leaning and right-leaning sources. Finding little evidence to support filter bubble theory, they instead advanced the concept of “automated serendipity” where people were led to sources of news they would not otherwise encounter. Similarly, in a seven-country survey, Dutton et al. (Citation2017) found that news search was key among an array of media consulted by those interested in politics, and that internet users were not trapped in a bubble on a single platform.
A second strand of research – typically drawing on experimental research designs – examines the nature of personalisation itself, which users might experience through searching for news. In one of the earliest pieces of research on personalisation of search results, Hannak et al. (2017) found that personalisation occurred based on whether the person was signed in and geo-location. Their experiment also found that politics was the most personalised category of search on the US version of Google, and 11.7% of search results contained personalisation. A two-pronged study focused on the German version of Google News analysed “the effects of personalization on news diversity for news aggregators” (Haim, Graefe, and Brosius Citation2018, p. 333) and tested “the effect of both implicit and explicit personalization on the content and source diversity” (p. 330). It produced two primary findings. First, there was no evidence to substantiate the filter-bubble hypothesis beyond “small effects of implicit personalization on content diversity”; and second, there was a political bias through over-representation of particular news outlets such as Focus Online and Die Welt and therefore under-representation of “other, highly frequented, news outlets” (p. 330) such as Bild.de, T-Online, RTL and orStern.de. “Given the overrepresented outlets’ conservative nature,” the researchers commented, “this bias can be troubling, especially in terms of viewpoint diversity” (p. 339).
Conversely, Nechushtai and Lewis (Citation2018), explaining their findings from research conducted shortly before the 2016 US presidential election (Nechushtai and Lewis Citation2019), stated that Google News “does not deliver different news to users based on their position on the political spectrum, despite accusations from conservative commentators and even President Trump.” They found that Google News “algorithms recommended virtually identical news sources to both liberals and conservatives” and that Google News was in fact “designed to avoid personalized search results, intentionally constructing a shared public conversation based on traditional criteria of journalistic values.” However, an inherent bias was identified as arising from criteria “which don’t directly have anything to do with a news organization’s political bent” (Nechushtai and Lewis Citation2018). The results were dominated by mainstream, legacy news organisations which tended to be viewed as centre-left. Nearly half of search results encompassed just five national news organisations: The New York Times, CNN, Politico, The Washington Post, and HuffPost (Nechushtai and Lewis Citation2018). This mirrors the findings of an experiment in Dutch-speaking Belgium (Courtois, Slechten, and Coenen Citation2018) that found Google search results favoured online versions of traditional legacy media.
While this emerging body of literature on news search and personalisation has found little evidence of reduced news diversity, there is still a need to examine this important issue in different national and temporal settings, and to ask new questions that advance our understanding. In the following section, we outline our study and the four research questions that hold it together.
Research Focus and Questions
Since the publication of the aforementioned research, Google launched a new Publisher Centre (in December 2019) where it provided more information on its search ranking process. It claimed that Google News “aims to promote original journalism and expose users to diverse perspectives” (Google News 2020). A number of factors underpinning the algorithmic ranking of news were listed, namely: relevance of content, prominence, authoritativeness, freshness, location, and language. In the academic literature, there is a wide-ranging hypothesised group of items, which often differs between researchers and experiments, thus making “personalisation… the great ‘known unknown’ of search engines” (Ørmen Citation2016, p.110). Previous research has found personalisation in news search results might also likely be influenced by political leaning, time stamps, language settings, geo-location and whether the participant is signed in to a Google account (Hannak et al. Citation2017; Ørmen Citation2016). Other studies find little evidence of personalisation in Google News search results (Nechushtai and Lewis Citation2019). We therefore need more research to understand which factors prevail in various settings. Our first research question therefore asks:
RQ1: What factors influence personalisation in search results on Google News in the UK?
RQ2: Are Google News search results from a diverse set of news sources?
RQ3: Are Google News search results diverse at story level (viewpoint diversity)?
RQ4: Does previous online news consumption determine the news sources that Google News recommends?
Method
Developing a method to measure black-boxed algorithms is a significant problem (Ørmen Citation2016). As Haim et al. (2018) state, “we can only analyse the effects of personalization on news diversity based on input-output analyses, for example, by varying a user’s surf behaviour or preferences (i.e., input) and comparing the resulting news offer (i.e., output)” (p. 333). Aside from the fact that scholars and journalists alike are uncertain what factors influence algorithms, causing obvious issues when studying them, there are also differences in how personalisation can be defined. For example, is the presence of different news sources and rank orders enough to claim personalisation is present (Courtois, Slechten, and Coenen Citation2018)? Nechushtai and Lewis (Citation2019) respond to this issue by measuring personalisation in their results based on the (news outlet) source of each article, similar to Fletcher and Nielsen (Citation2018b). However, they conclude that looking at personalisation on a source level omits the fact that most news sources self-regulate by showing multiple perspectives. They say research should consider looking at a story level (i.e., viewpoint diversity).
Owing to the issues outlined above, and because accommodating these ideas in a single piece of research has not been done before, this study applies a unique, mixed methods design. The experimental stage was carried out first, followed by the content analysis stage, with the former taking logistical and time-sensitive precedence.
Experimental Design
Following Nechushtai and Lewis (Citation2019), we conducted a quasi-experiment to examine the news recommendations to users when conducting searches in real time from their personal accounts. The experiment was hosted online, and asked participants to copy and paste links to the top five articles recommended for each term searched through news.google.com. Participants were asked to apply four search terms: “Theresa May,” “Jeremy Corbyn,” “People’s Vote” and “Immigration.” These search terms encompassed the-then leaders of the two major political parties and two hotly contested topics in the UK at the time of the survey and were chosen as opinions can often be split along party lines (Walker Citation2019).
Past research has used differing ways to define and measure personalisation (RQ1). Therefore, this study combined the methods of two relevant studies. Hannak et al. (2017) measured the number of differences between a control and experimental group, looking at the line-up of stories recommended. Adapting Nechushtai and Lewis (Citation2019) methods, the most common five articles for each search term were calculated, and the number of differences for each participant computed, in order to calculate personalisation for each person dependent on each search term. A number of variables, including self-identified political leaningFootnote1 (M = 3.89, SD = 1.18), age (M = 34.05, SD = 16.17) and education levelFootnote2 (M = 3.16, SD = 0.79), were then plotted against the number of differences, creating a correlational analysis for whether personalisation was evident.
In order to determine the political slant of each news outlet, this research used an audience-based approach developed by previous research (Flaxman, Goel, and Rao Citation2016; Fletcher and Nielsen Citation2018b) where participants were asked to rate each news outlet’s political slant on a seven-point scaleFootnote3. We also looked at the favourability of participants towards each search term (May, Corbyn, People’s Vote, Immigration) on a seven-point scale, following the conclusion of Fletcher and Nielsen (Citation2018b) that one single measure of the traditional left-right divide may be less important for personalisation.
To understand news source diversity (RQ2), the sources (news outlets) of recommendations were analysed alongside other indicators of diversity mentioned above. To ascertain whether previous online news consumption influenced what Google News recommended to them (RQ4), this study looked at six news sources. The criteria used to decide these were a) previous news consumptionFootnote4, b) the news that was recommended to participants in the experiment, and c) the self-identified political leanings of our participants. The process of cross-referencing a) and b) led to approximately 10 most common news sources, which were then reduced to six to reflect a balance across the political spectrum. The six sources chosen were: The Guardian, The Independent, BBC News, Sky News, Daily Mail and The Sun.
Research Procedure and Participants
Ethical approval for the study was granted by X University in advance of data collection commencing (Ethics ID: 25787), which included informed consent of all participants. All participants were asked to complete the study in the same period which, after several trial periods, was set between 2.45 pm and midnight on 20 March 2019. This was done to control for shifts in the news agenda (Nechushtai and Lewis Citation2019) and changes in the Google algorithm (Moz Citation2018). The main political news story during the period of study was the ongoing Brexit process, with UK Prime Minister Theresa May attempting to move Parliament in favour of her withdrawal deal. To ensure no particular story affected the results, the time of search and number of search result differences were correlated, with significance values for Spearman’s Correlation coefficient coming back not significant for three of the search terms (TM = 0.923, JC = 0.88, PV = 0, IM = 0.306). However, the correlation between People’s Vote and time was significant. To account for this, no conclusions were made from the results from the People’s Vote searches. Therefore, this did not affect the study’s measure of personalisation.
The link to the experiment was distributed via social media, as well as on Call for Participants, a research recruitment website. Because of the necessarily tight time window (around nine hours) in which the experiment could be conducted, recruiting large samples of participants was a challenge. In total, 86 participants were recruited, via self-selecting sampling. However, three participants completed the study after midnight, two participants had submitted links to the same story for multiple categories, and links from two participants reflected that they had accidentally searched google.co.uk rather than news.google.com. Data from these seven participants was removed. Furthermore, in the case of one participant, links submitted for the Theresa May search were in order, but other links reflected that google.co.uk had been searched for the remaining three search terms. Hence the results for the Theresa May search were retained (N = 79) whilst the data from the remaining three search terms were deleted (N = 78).
As part of the experimental survey, we took participants’ personal characteristics. While our sample makes no claims to representativeness of the UK population, it makes for respectable comparisons, with slightly under 30% of participants self-identifying as right-wing in their political leaning and around another 35% identifying, in each instance, as left-wing or politically central (measured on a seven point scale, with 1 = very left wing [M: 3.88, SD= 1.17]). Furthermore, a 55–45% split of females to males was achieved, and whilst there was a slight skew towards younger participants [M = 34.05, SD= 16.17] this was consistent with research that shows younger people are more likely to use search engines to find news (Ofcom Citation2017). Finally, education was measured on a four-point scale, ranging from no qualifications to degree-level or above (M: 3.16, SD= 0.79). 35% of participants’ highest qualification was a university degree while 51% had a post-secondary education qualification, making our participants slightly more educated than average for the UK.
Each unique search result was then given a four-digit code. It was evident that, on several occasions, the same link was entered more than once from the same participant. When this happened, the replicated links were deleted and calculations adjusted. In all, 19 links were deleted in this manner, meaning a total of 1546 links were gathered. Taking into account duplication of results, this represented 192 unique articles from 57 publications, which formed the basis of our content analysis.
Content Analysis
To record the viewpoint diversity of recommendations (RQ3), all 192 unique articles from the experimental survey were content analysed for their favourability towards the search term. This method was chosen because Flaxman, Goel, and Rao (Citation2016) say that by labelling each story based on its publication’s overall political slant, contrasting views evident in the same publication are mis-labelled and neutral coverage of breaking news is incorrectly labelled as having a slant. Our unit of analysis was the news article. Our method allowed each article to be analysed and coded for its favourability towards the search term it was recommended forFootnote5 (e.g., Theresa May, Immigration, etc.) on a 3-point scale (−1 = unfavourable, 0 = balanced, 1 = favourable), based on how the article as a whole portrayed the search term and taking into account journalistic approach as well as leaning of any sources used. Each participant was then given an average favourability slant for each search term based on the actual articles they saw. We also coded for the type of article (news, feature, opinion, etc.) and the country the article primarily concerned. Two coders performed the content analysis. Intercoder reliability tests were conducted on 50 of the articles (26% of total sample). Cohen’s kappa scores demonstrate high levels of agreement for the type of article (k = 0.96), the country (k = 0.94), and favourability slant towards the search term (k = 0.9).
Findings
Factors Influencing Personalisation on Google News (RQ1)
Google News recommendations from all four searches were analysed, and the most popular five articles were calculated for each search term. This was then compared to each individual’s recommendations, and the number of differences per participant per search term was calculated. The combined mean was 2.16, with Theresa May having the most [3.24] and People’s Vote the least [0.91].
As illustrates, personalisation is seen but varies dramatically based on the search term. For Theresa May, more than three out of five search results were different, on average, compared to less than one in five for the People’s Vote search.
Table 1. Mean number of differences in the top five search results for each term.
Turning to the variables that might influence personalisation, as shows, even if personalisation can be seen it does not on the whole correlate with any of the variables tested. There is one exception, with a positive correlation between self-identified political leaning and the number of differences in search results for Jeremy Corbyn [rs = 0.286, p < 0.05]. The more right-wing the participant was, the more personalised were the results after searching for Jeremy Corbyn, a politician who sits on the left of the political spectrum.
Table 2. Relationships between personal characteristics and diversity of search results for each search term.
News Source Diversity in Google News Results (RQ2)
RQ2 concerned the news outlets that were recommended for the Theresa May and Jeremy Corbyn searches. These two searches yielded recommendations from 22 and 21 news outlets respectively [see and ]. This was only slightly less than the findings of Nechushtai and Lewis (Citation2019) – an average of 23.25. Despite this large number of news sources, the top five represented 55% of recommendations for Theresa May and 66% of sources for Jeremy Corbyn. Across the two searches, nine news sources ranked inside the top five. They are listed in , along with the number and percentage of recommendations they accounted for.
Figure 1. News recommendations in Google News searches for "Theresa May."
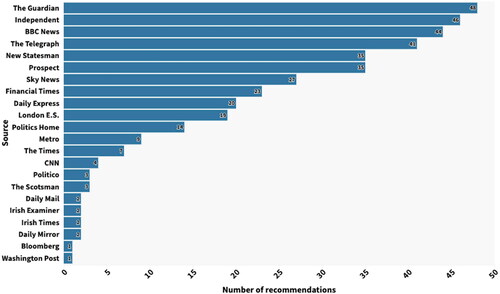
Figure 2. News recommendations in Google News searches for "Jeremy Corbyn."
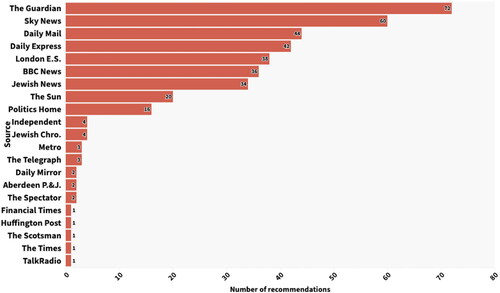
Table 3. News outlets that ranked amongst the top five most popular stories across Theresa May and Jeremy Corbyn searches.
These nine outlets made up 75% of all links seen by participants, compared with Nechushtai and Lewis (Citation2019) figure of 79% for the top 14 sources. Findings also showed that the vast majority (97%) of recommended news sources were the same for people of all political persuasions. As other studies found (Nechushtai and Lewis Citation2019), the number of recommendations was unevenly distributed amongst these top news sources. The top five – The Guardian, Sky News, BBC News, Daily Express, and London Evening Standard – made up more than half [52%] of the 775 recommendations. This means that when a politically diverse set of UK residents searched for either of the main party leaders, they had a greater than one in two chance of being directed to one of these five outlets for each search result. Whilst BBC News and The Guardian are the two most popular online news sources, and Sky News comes in fourth, the Daily Express and London Evening Standard are not amongst the top read news outlets online in the UK (Newman et al. Citation2018). So, despite other sources being more widely read online, these two news brands are being seemingly over-rewarded by the Google algorithm. One potential explanation is their relative investments in search engine optimisation (Dick Citation2011), and in the case of the Express, their aggressive use of clickbait headlines.
By most measures, there was little diversity of these most recommended news sources. All are legacy media: six of the nine outlets were originally print newspapers, two are broadcasters and one is a magazine. All are based in London. This contrasts with a US study which looked at Google News search results for health queries (Lin and Rosenkrantz Citation2017), where half of all results were from local news outlets, something barely seen in this study. Our results generally support the conclusions of Courtois, Slechten, and Coenen (Citation2018) who found that the distribution of Google search results favoured the “primary and secondary definers that for long have been dominating the public debate” (p. 2013): the mainstream media.
However, beyond the nine news outlets that dominate searches, there was still small space for smaller and alternative news outlets. For the Jeremy Corbyn searches, Jewish News was recommended 34 times, representing almost 9% of links for that search. Similar results were found for Politics Home across both searches, representing a total of almost 4% of links. Neither are household names, and whilst Jewish News is a legacy media brand, Politics Home is a specialist, digital-native site.
Search Results and Viewpoint Diversity at the Article Level (RQ3)
Looking solely at the sources of recommendations is only part of the issue of diversity in online searches (Hannak et al. Citation2017; Flaxman, Goel, and Rao Citation2016; Fletcher and Nielsen, Citation2018b). To make an assessment of viewpoint diversity, each article recommended to and seen by participants was content analysed for its favourability towards the search term. represents the average favourability slant for each search term.
Table 4. Average favourability slant for each search term in Google News results.
Immediately evident is the fact that the coverage of the two main party leaders was negative, with Theresa May marginally more so than Jeremy Corbyn. In addition, there was much more favourable content for People’s Vote than any of the other search terms. The campaign for a People’s Vote – a second referendum on the UK’s membership of the EU – had people across the political spectrum divided (Walker Citation2019). While it is surprising that search results were so favourable, it may have been owing in part to news outlets unfavourable towards the topic simply not covering it.
Findings were analysed in relation to favourability of the search term for, as well as stated political leaning of, each participant. Similar to RQ1, on the whole very little significant correlation was found ().
Table 5. Correlations between search terms, favourability and political leaning.
However, there was one significant negative correlation between immigration and political leaning [rs = −0.227, p < 0.05], where the more right-wing a participant was, the more likely it was for the participant to see unfavourable stories about immigration. The finding was despite, on the whole, there being a greater number of recommended stories that were favourable towards immigration [M = 0.24]. This couples with the finding from RQ1 that right-wing participants see more personalised recommendations for certain searches.
Looking below news outlet level when measuring personalisation has not been done before, despite calls to do so from scholars (Hannak et al. 2017; Flaxman, Goel, and Rao Citation2016; Fletcher and Nielsen Citation2018b). These results support previous suggestions that coding each recommendation by news source can cause results to miss certain aspects of personalisation. It also supports the call for further research on a deeper level looking at whether other semantic factors are evident in personalisation.
Previous Online News Consumption and Google News Recommendations (RQ4)
The final research question refers to the popular, although as yet unproven, theory that news consumption history has an effect on personalisation. We performed this analysis on six news sources, taking into account previous news consumption, the news that was recommended to participants in the experiment, and the stated political leanings of participants.
We then compared the total number of, for example, Guardian links seen in the results for Guardian readers and non-readers. This was then repeated for the remaining five sources. If personalisation based on previous online news consumption in this instance was present, it would be expected that Guardian readers would have a higher percentage of recommendations than non-Guardian readers. As seen in , there are no meaningful differences between groups, with Mann-Whitney U tests confirming the non-significant relationshipsFootnote6.
Table 6. Percentage of recommendations for six news sources, based on whether participants are readers or non-readers of that source.
In addition to looking at individual publications, we calculated whether participants who read left-wing news sources were more likely to see left-wing news sources in their search results (see ). This was then applied to centre and right-wing news sources, using the same six publications. Again, there were no significant differences in search resultsFootnote7, suggesting that personalisation based on users’ previous online news consumption was not seen.
Table 7. Percentage of recommendations for the six news sources, grouped by political leaning, based on whether participants are readers or non-readers of a source of that political leaning.
Discussion and Conclusion
The ambition of this article was to bring together multiple aspects of the debate surrounding news search personalisation and news source diversity into one piece of research. Our results show that personalisation is evident on Google News in the UK. However, this did not appear to correlate significantly with any of the variables tested, including previous online news-searching behaviour. Our findings therefore support previous research that claims the list of personalisation factors is, on the whole, unknown (Ørmen Citation2016).
Overall, our results provide little evidence to support claims that the personalising algorithms of news search engines reduce news diversity. Based on our four search terms, users were exposed to quite a large range of news brands and individual articles that encompassed different sides of the political spectrum. Beyond just rejecting the filter bubble hypothesis, our findings add weight to the positive effects of using news search in exposing news consumers to a greater balance of news sources and political viewpoints than other forms of news consumption (e.g., Fletcher and Nielsen, Citation2018b). There were two exceptions to this overall finding, however, both of which may have normative implications. First, we found that right-wing participants were significantly more likely to find negative articles about a left-wing politician (Jeremy Corbyn) in contrast to those participants on the left. Second, when considering viewpoint diversity on an article level, very little significant correlation was found between the slant of articles seen and political leaning or favourability of the search term. However, participants who self-identified as right-wing were recommended more negative stories about immigration. When we consider the greater propensity of right-leaning voters to be anti-immigration (Kaufmann Citation2017), this may hint towards a personalising effect akin to a filter bubble. It may also suggest that algorithmic personalisation can occur around other similarly divisive political issues – an empirical question that warrants further research given its potential democratic consequences.
Significantly, a high degree of news source homogeneity was observed, similar to U.S. findings (Nechushtai and Lewis Citation2019). This links to concerns over the way search engines recommend news. Our study shows that the Google algorithm mainly directs users to traditional, legacy media that gained prominence before the Internet. Normatively, we need to reflect on whether such homogeneity is good or bad. Given concerns about “fake news,” and the quality of news and information circulating on the Internet, we may find reassurance in the fact that the top nine recommended news sources were all relatively “trusted” brands (Newman et al. Citation2018) that together, provide a reasonable cross-section of the ideological spectrum. But this also needs to be weighed against the question of diversity and balance. As the news landscape fragments there are, for instance, flourishing digital-only news brands alongside an influential alternative news sector often set up explicitly as a counterweight to the political consensus of the mainstream media (Cushion Citation2021). With two exceptions, these news outlets barely registered in Google News search results. Hardly any local news was offered to people relevant to their location, despite most of the search terms having local alongside national relevance. These findings support Nechushtai and Lewis’s (2019) argument that “digital distribution of news might narrow the conversation around a small set of national outlets” (p.302). Still, while our study shows the dominance of a handful of news sources, we are reminded that, generally, people do not have particularly diverse news repertoires, and that use of search engines is typically related to a more diverse diet of news (Fletcher and Nielsen, Citation2018b).
Beyond the empirical findings of this research, the results connect to ongoing questions about the normative role of algorithms in news and journalism. The ability of algorithms to affect what users see – via search and elsewhere online – has been well established (Bruns Citation2019; Fletcher and Nielsen Citation2018c; Ørmen Citation2016). However, as Nechushtai and Lewis (Citation2019) discuss, there has been little debate on what is expected from algorithmic editors. There is hope that algorithms will perform as well as, or even better than, humans when selecting news content. But there is such wide interpretation of what performing “well” means that it is almost impossible to determine whether algorithms are performing these functions as expected (Nechushtai and Lewis Citation2019). In this context, consideration of the different models of democracy that news organisations can serve in the implementation of recommender technology is of utmost importance, because such technology can offer both threats and opportunities for the democratic role of the media (Helberger Citation2019). Here, important theoretical and empirical progress is being made that is driven by socially responsible designs in news recommendations (Bernstein et al. Citation2021; Helberger Citation2019; Helberger, Karppinen, and D’Acunto Citation2018; Heitz et al. Citation2022; Milano, Mariarosaria, and Luciano Citation2020; Thurman, Lewis, and Kunert Citation2019). Such studies are finding that news recommenders can be designed to enhance the public service function of the news media rather than dilute it (Møller Citation2022). This can be done through, for example, incorporating diversity, serendipity and editorial input into the algorithmic design that nudges users towards preferring news with differing or even opposing views. Not only does this offer a potentially depolarising effect in increasingly divided democracies, it also seems that users are more positive towards personalisation if recommender systems provide them with diverse news (Bodó et al. Citation2019).
Together, these new directions in research – alongside our empirical findings – paint a more optimistic picture of algorithms in the news than that offered by the filter bubble hypothesis. First, however, this does not mean that in practice, news organisations are always designing them with public service principles in mind. As Helberger (Citation2019, p.1009) argues: “Too often news recommenders are developed as part of an R&D project, or with purely commercial objectives in mind.” Second, the democratic promise of algorithms has been largely developed through a focus on the recommender algorithms of news websites, not news aggregators such as Google News. Without the same public service ethos as news organisations, it should not be assumed that Google will take the same journey as their journalistic counterparts. For now, we can perhaps be reassured that most news consumers view both algorithmic and human editorial selection processes with some suspicion (Fletcher and Nielsen Citation2018c).
Because these are formative times for the integration of machines into news production and circulation, the landscape we are studying is changing faster than researchers can reasonably capture and make sense of. It is therefore crucial for further research to examine – both empirically and theoretically – the impact of machines on the news ecology. To advance understanding of algorithmic personalisation in news search and building on some of the limitations of this study, we would recommend several directions for future research. Our study expanded the range of search terms that experimental studies have utilised, to include policy issues in addition to party leaders. Still, examining only two policy issues limits the conclusions we can make about the influence of algorithms in shaping public debate. Given our findings, it is important for future research to explore a range of policy issues that have differing degrees of polarisation and party ownership. Existing studies – including our own – have also typically used only one or two experimental windows. To understand algorithmic personalisation more fully, we should expand this towards longitudinal research designs that can monitor search results over a longer period. The experimental part of our study – like others in this fledgling field – was based on a small sample of participants. While generalisability is not the goal of such exploratory quasi-experimental study designs, the field would nevertheless benefit from larger-scale experimental studies that draw from a larger geographical spread than our study was capable of. Then, for example, we could better understand the influence of individual demographic factors, including geo-location, on news personalisation. At the same time, our study demonstrated the value of combining content analysis with experiments to examine different levels of source diversity in news search results. Given that news outlets do not always speak with one voice; it would be prudent to combine methods in future research. Finally, this research tested only one way that an algorithm could exploit a user’s news consumption behaviour to influence search results. Future research should look to include more search history data points, as we know that search engines use data to build profiles of users to aid news search personalisation (Bai et al. Citation2017).
Disclosure Statement
No potential conflict of interest was reported by the authors.
Notes
1 Participants were asked to position themselves on a seven-point scale, with 1 being “far left wing” and 7 being “far right wing”.
2 Measured on a 4 point scale ranging from 1 (Didn’t finish secondary education) to 4 (Degree level or higher).
3 “What, in your opinion, is the political inclination of the AUDIENCE of each of these media organisations?”
4 Following Fletcher and Nielsen (Citation2018a), we asked: “Which of the following brands have you used to access news online THREE days or more in the last week (via websites, apps, social media, and other forms of Internet access)? Please select all that apply.”
5 For example, if the article was returned from a search for ‘Theresa May’ and was highly critical of the National Health Service but favourable towards Theresa May, then it would be coded as ‘favourable’.
6 p values ranged from 0.438 to 0.945.
7 For the Mann-Whitney U tests, p values ranged from 0.443 to 0.516.
References
- Bai, Xiao., B. Barla Cambazoglu, Francesco. Gullo, Amin. Mantrach, and Fabrizio. Silvestri. 2017. “Exploiting Search History of Users for News Personalization.” Information Sciences 385–386: 125–137.
- Bakshy, Eytan., Solomon. Messing, and Lada. Adamic. 2015. “Exposure to Ideologically Diverse News and Opinion on Facebook.” Science 348 (6239): 1130–1132.
- Barberá, Pablo., John T. Jost, Jonathan. Nagler, Joshua A. Tucker, and Richard. Bonneau. 2015. “Tweeting from Left to Right: Is Online Political Communication More than an Echo Chamber?” Psychological Science 26 (10): 1531–1542.
- Bernstein, Abraham., Claes. de Vreese, Natali. Helberger, Wolfgang. Schulz, Katharina. Zweig, Christian. Baden, and Michael A. Beam., 2021. “Diversity in News Recommendation.” Dagstuhl Manifestos 9 (1): 43–61.
- Bodó, Balázs., Natali. Helberger, Sarah. Eskens, and Judith. Möller. 2019. “Interested in Iiversity. The Role of User Attitudes, Algorithmic Feedback Loops, and Policy in News Personalization.” Digital Journalism 7 (2): 206–229.
- Bruns, Axel. 2019. Are Filter Bubbles Real? London: Polity.
- Courtois, Cédric., Laura. Slechten, and Lennert. Coenen. 2018. “Challenging Google Search Filter Bubbles in Social and Political Information: Disconforming Evidence from a Digital Methods Case Study.” Telematics and Informatics 35 (7): 2006–2015.
- Cushion, Stephen. 2021. “UK Alternative Left Media and Their Criticism of Mainstream News: Analysing the Canary and Evolve Politics.” Journalism Practice. doi:10.1080/17512786.2021.1882875.
- Dick, Murray. 2011. “Search Engine Optimisation in UK News Production.” Journalism Practice 5 (4): 462–477. doi:10.1080/17512786.2010.551020.
- Dubois, Elizabeth, and Grant. Blank. 2018. “The Echo Chamber is Overstated: The Moderating Effect of Political Interest and Diverse Media.” Information, Communication & Society 21 (5): 729–745.
- Dutton, William H. Bianca. Residorf, Elizabeth. Dubois, and Grant. Blank. 2017. “Social Shaping of the Politics of Internet Search and Networking: Moving Beyond Filter Bubbles, Echo Chambers, and Fake News,” Quello Centre Working Paper No. 2944191. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2944191.
- Flaxman, Seth., Sharad. Goel, and Justin M. Rao. 2016. “Filter Bubbles, Echo Chambers, and Online News Consumption.” Public Opinion Quarterly 80 (S1): 298–320.
- Fletcher, Richard, and Rasmus Kleis. Nielsen. 2018b. “Automated Serendipity.” Digital Journalism 6 (8): 976–989.
- Fletcher, Richard, and Rasmus Kleis. Nielsen. 2018c. “Generalised Scepticism: How People Navigate News on Social Media.” Information, Communication & Society 22 (12): 1751–1769.
- Fletcher, Richard, and Rasmus Kleis. Nielsen. 2018a. “Are People Incidentally Exposed to News on Social Media? A Comparative Analysis.” New Media & Society 20 (7): 2450–2468.
- Google. 2005. Accessed 4 April 2019. http://googlepress.blogspot.com/2005/11/personalized-search-graduates-from_10.html.
- Google. 2009. Accessed 7 May 2019. https://googleblog.blogspot.com/2009/12/personalized-search-for-everyone.html.
- Haim, Mario., Andreas. Graefe, and Hans-Bernd. Brosius. 2018. “Burst of the Filter Bubble? Effects of Personalization on the Diversity of Google News.” Digital Journalism 6 (3): 330–343.
- Hallin, Daniel C, and Paolo. Mancini. 2012. Comparing Media Systems. Cambridge: Cambridge University Press.
- Hannak, Aniko, Piotr Sapieżyński, Arash Molavi Kakhki, Balachander Krishnamurthy, David Lazer, Alan Mislove, and Christo Wilson. 2017. “Measuring Personalization of Web Search.” arXiv:1706.05011. doi:10.48550/arXiv.1706.05011.
- Heitz, Lucien., Juliane A. Lischka, Alena. Birrer, Bibek. Paudel, Suzanne. Tolmeijer, Laura. Laugwitz, and Abraham. Bernstein. 2022. “Benefits of Diverse News Recommendations for Democracy: A User Study.” Digital Journalism. doi:10.1080/21670811.2021.2021804.
- Helberger, Natali. 2019. “On the Democratic Role of News Recommenders.” Digital Journalism 7 (8): 993–1012.
- Helberger, Natali., Karl. Karppinen, and Lucia. D’Acunto. 2018. “Exposure Diversity as a Design Principle for Recommender Systems.” Information, Communication and Society 21 (2): 191–207.
- Jamieson, Kathleen Hall, and Joseph. Cappella. 2008. Echo Chamber: Rush Limbaugh and the Conservative Media Establishment. London: Oxford University Press.
- Kaufmann, Eric. 2017. “Levels or Changes? Ethnic Context, Immigration and the UK Independence Party Vote.” Electoral Studies 48: 57–69.
- Kim, Yonghwan., Hsuan-Ting. Chen, and Homero. Gil De Zúñiga. 2013. “Stumbling upon News on the Internet: Effects of Incidental News Exposure and Relative Entertainment Use on Political Engagement.” Computers in Human Behavior 29 (6): 2607–2614.
- Lin, Leng Leng Young, and Andrew B. Rosenkrantz. 2017. “The U.S. Online News Coverage of Mammography Based on a Google News Search.” Academic Radiology 24 (12): 1612–1615.
- McDonald, Daniel G, and John. Dimmick. 2003. “The Conceptualization and Measurement of Diversity.” Communication Research 30 (1): 60–79.
- Messing, Solomon, and Sean J. Westwood. 2014. “Selective Exposure in the Age of Social Media: Endorsements Trump Partisan Source Affiliation When Selecting News Online.” Communication Research 41 (8): 1042–1063.
- Milano, Silvia., Taddeo. Mariarosaria, and Floridi. Luciano. 2020. “Recommender Systems and Their Ethical Challenges.” AI & SOCIETY 35 (4): 957–967.
- Möller, Judith., Damian. Trilling, Natali. Helberger, and Bram. van Es. 2018. “Do Not Blame It on the Algorithm: An Empirical Assessment of Multiple Recommender Systems and Their Impact on Content Diversity.” Information, Communication and Society 21 (7): 959–977.
- Møller, Lynge Asbjørn. 2022. “Between Personal and Public Interest: How Algorithmic News Recommendation Reconciles with Journalism as an Ideology.” Digital Journalism. doi:10.1080/21670811.2022.2032782.
- Moz. 2018. “Moz - Google Algorithm Change History,” Accessed 4 November 2018. https://moz.com/google-algorithm-change.
- Napoli, Philip M. 2015. “Social Media and the Public Interest: Governance of News Platforms in the Realm of Individual and Algorithmic Gatekeepers.” Telecommunications Policy 39 (9): 751–760.
- Nechushtai, Efrat, and Seth C. Lewis. 2019. “What Kind of News Gatekeepers Do we Want Machines to Be? Filter Bubbles, Fragmentation, and the Normative Dimensions of Algorithmic Recommendations.” Computers in Human Behavior 90: 298–307.
- Nechushtai, Efrat, and Seth C. Lewis. 2018. “Google News serves Conservatives and Liberals Similar Results, but Favors Mainstream Media.” The Conversation [online], 31 August 2018. Accessed 26 February 2020. https://theconversation.com/google-news-serves-conservatives-and-liberals-similar-results-but-favors-mainstream-media-102389
- Newman, Nic., Richard. Fletcher, Antonis. Kalogeropoulos, David A. L. Levy, Rasmus, and Kleis. Nielsen. 2018. “Reuters Institute Digital News Report 2018,” Accessed 14 February 2019. https://reutersinstitute.politics.ox.ac.uk/sites/default/files/digital-news-report-2018.pdf.
- Newman, Nic, Richard. Fletcher, Antonis. Kalogeropoulos, David A. L. Levy, Rasmus, and Kleis. Nielsen. 2019. “Reuters Institute Digital News Report 2019,” Accessed 29 April 2019. https://reutersinstitute.politics.ox.ac.uk/sites/default/files/2019-06/DNR_2019_FINAL_0.pdf.
- Norris, Pippa. 2000. A Virtuous Circle: Political Communications in Postindustrial Societies. Cambridge: Cambridge University Press.
- Ofcom. 2017. “News Consumption in the UK: 2016,” Accessed 2 February 2019. https://www.ofcom.org.uk/__data/assets/pdf_file/0016/103570/news-consumption-uk-2016.pdf.
- Ørmen, Jacob. 2016. “Googling the News.” Digital Journalism 4 (1): 107–124.
- Pariser, Eli. 2011. The Filter Bubble: What the Internet is Hiding from You. London: Penguin.
- Sunstein, Cass R. 2009. Republic. Com 2.0. Princeton, NJ: Princeton University Press
- Thorsen, Einar, and, Daniel Jackson. 2018. “Seven Characteristics Defining Online News Formats.” Digital Journalism 6 (7): 847–868. doi:10.1080/21670811.2018.1468722.
- Thurman, Neil. 2011. “Making ‘the Daily Me’: Technology, Economics and Habit in the Mainstream Assimilation of Personalized News.” Journalism 12 (4): 395–415.
- Thurman, Neil., Seth C. Lewis, and Jessica. Kunert. 2019. “Algorithms, Automation, and News.” Digital Journalism 7 (8): 980–992.
- Voakes, Paul S., Jack. Kapfer, David. Kurpius, and David. Shano-yeon Chern. 1996. “Diversity in the News: A Conceptual and Methodological Framework.” Journalism & Mass Communication Quarterly 73 (3): 582–593.
- Walker, Peter. 2019. “Most Labour Members Believe Corbyn Should Back Second Brexit Vote,” Accessed 24 February 2019. www.theguardian.com/politics/2019/jan/02/most-labour-members-believe-corbyn-should-back-second-brexit-vote.
- Zuiderveen Borgesius, J. Frederick., Damian. Trilling, Judith. Möller, Balázs. Bodó, Claes. de Vreese, and Natali. Helberger. 2016. “Should We Worry about Filter Bubbles?” Internet Policy Review 5 (1). doi:10.14763/2016.1.401.