
Abstract
This paper investigates a scheduling combined manpower-vehicle routing problem with a central depot in and a set of multi-skilled manpower for serving to customers. Teams are in different range of competencies that it will affect the service time duration. Vehicles are in different moving speeds and costs and not all the vehicles are capable to move toward all the customers’ sites. The objective is to minimize the total cost of servicing, routing, and lateness penalties. This paper presents a mixed integer programming model and two meta-heuristic approaches of genetic algorithm (GA) and artificial bee colony algorithm (ABC) are developed to solve the generated problems. Furthermore, Taguchi experimental design method is applied to set the proper values of parameters. The available results show the higher performance of proposed GA compared with ABC, in quality of solutions.
1. Introduction
The vehicle routing problem (VRP) was introduced by Dantzig and Ramser in 1959 (Dantzig & Ramser, Citation1959). It is a fundamental planning problem in the field of transportation, distribution, and logistics. This combinatorial optimization problem consists in seeking routes for a set of vehicles, to perform a set of tasks in a network. The VRP can be defined as finding optimal routes for a fleet of vehicles to serve some geographically scattered customers in order to minimize the total operation cost, with each route starting and ending at the depot. Collection of household waste, gasoline delivery trucks, goods distribution, snow plough, and mail delivery are the most used applications of the VRP. The VRP plays a vital role in distribution and logistics. In the traditional VRP, the vehicles are the servers for the customer locations and a customer requires only one task (or visit) by one vehicle. Problems associated with determining optimal routes for vehicles from one or several depots to a set of locations/customers, subject to various constraints, such as vehicle capacity, route length, time windows, etc. are known as VRPs. These problems have a significant economic importance due to the many practical applications in the field of distribution, collection, logistics, etc. In the combined manpower-vehicle routing problem (CMVRP) that is presented in this paper, a central depot is considered in which a set of vehicles and a set of multi-skilled teams originate from it to move toward each customer’s site for servicing tasks. The problem is different from traditional VRP in which the tasks are not done by vehicles but by the teams. Although it is hard to find literature in this problem, it arises in areas like allocation of technicians to service jobs, in hospitals where teams of doctors and nurses are needed for different surgeries, and in the problems of home care sector.
In the previous studies, Lim, Rodrigues, and Song (Citation2004) proposed a manpower allocation model with time windows in which each customer is served by multiple servicemen. However, in their model the servicemen are assumed to be all the same that can move by them and they did not consider vehicles for the movements. Li, Lim, and Rodrigues (Citation2005) extended the model of Lim et al. (Citation2004) by introducing job-teaming constraints while a job is satisfied if the required composite team can be brought together at the job’s location. Hollis, Forbes, and Douglas (Citation2006) are the first to consider a problem with multiple depots, where vehicles and teams may be stationed and interchanged. They describe a simultaneous vehicle and crew routing and scheduling application for urban letter mail distribution at Australia Post, and presented a path-based mixed integer programming model and solved it by heuristic column generation. Zäpfel and Bögl (Citation2008) consider an application of local letter mail distribution for Pickup and delivery routes. Schedules are planned for both teams and vehicles, taking into account European Union social legislation. The problem is solved heuristically, by decomposing it into a generalized VRP with time windows and a ‘personnel assignment problem’. Laurent and Hao (Citation2008) consider the problem of simultaneously scheduling vehicles and teams for a limousine rental company. The required transports are pickup-and-delivery trips with given time windows. The authors use a two-stage solution approach which aims to find a feasible crew and vehicle schedule by assigning a team-limousine pair to each trip. Dohn, Kolind, and Clausen (Citation2009) studied the scheduling problem of ground handling tasks in some European airports. The problem requires manpower allocation with the consideration of time windows, job-teaming constraints, and a limited number of teams in order to maximize the total number of assigned tasks. Kim, Koo, and Park (Citation2010) presented a combined vehicle routing and staff scheduling problem where a certain number of tasks has to be performed in a fixed sequence by a set of teams. The teams should be moved by a set of vehicles and the objective is to find an efficient schedule for the teams. They developed a mixed integer programming model for the problem that could not be solved optimally due to out of memory errors. Hence, they developed a dispatching-based heuristic algorithm to find feasible solutions for the generated problems. Ho and Leung (Citation2010) studied a manpower scheduling problem with job time windows and job-skills constraints. They considered an airline servicing operations before the flights take-off. Given the jobs to be serviced and the roster of workers for each shift, the problem is to form teams and assign them to the jobs, to service as many flights as possible.
Drexl, Rieck, and Berning (Citation2011) study a simultaneous vehicle and crew routing and scheduling problem arising in long-distance road transport. In their study, they abandon the assumption of fixed assignment of teams to vehicles and allow for vehicle/driver changes at some relay stations. Although their work did not contain a mathematical model, they developed a solution heuristic based on two-stage decomposition for the problem.
In home care sector, Rasmussen, Justesen, Dohn, and Larsen (Citation2012) studied a crew scheduling problem with Preference-based visit clustering and temporal dependencies. A home caring staff has to be assigned to a number of visits to patients’ homes, such that the overall service level is maximized. In their model, the challenge lies within assigning visits to crews, in the existence of soft preference constraints, and temporal dependencies between the start times of visits. Pureza, Morabito, and Reimann (Citation2012) considered a vehicle routing with multiple deliverymen for which, besides routing and scheduling decisions, a number of extra deliverymen can be assigned to each route in order to reduce service times. They presented a model based on the assumptions that each vehicle performs only one route, the deliverymen skills are not different, and the number of the deliverymen that are dedicated to each route affects the related service times. Goel and Meisel (Citation2013) investigated a combined routing and scheduling problem for the maintenance of electricity networks. Each maintenance job therefore consists of multiple tasks which must be performed at different locations in the network. The goal is to assign each task to a worker and to determine a schedule such that the downtimes of power lines and the travel effort of workers are minimized. To solve the problem, they combine a Large Neighborhood Search meta-heuristic with mathematical programming techniques.
Talarico, Meisel, and Sorensen (Citation2015) considered a routing problem for ambulances in a disaster response scenario, in which a large number of injured people require medical aid at the same time. Each ambulance carries medical personnel that can provide first aid to slightly injured people in the field. Seriously injured individuals are accompanied by the medical staff on their way to the hospital where skilled doctors are available. The authors presented two mathematical formulations for their problem of minimizing the latest service completion time and proposed a Large Neighborhood Search meta-heuristic. For a comprehensive and relevant review of the literature, the readers may refer to the taxonomy provided by Lahyani, Khemakhem, and Semet (Citation2015).
This paper addresses a problem integrating vehicle routing and crew scheduling. In this problem, a number of geographically scattered customers demand a specific task with a predefined due date. A number of multi-skilled teams, located at depot, are ready to do the tasks. Each task should be serviced by exactly one team. However, the teams are in different range of competencies which affects the service time. Furthermore, a fleet of vehicles are used to move the teams. The vehicles are in different range of moving speed and not all the vehicles are capable to move toward all the customers. Hence, there is no fixed assignment of a vehicle to a team. Indeed, after visiting a customer, the corresponding vehicle may either continue the route with the companion team or return to the depot to exchange the companion team and then, leave the depot to visit another customer. The objective is to find an efficient schedule for the teams and vehicles movement in order to minimize the total cost of servicing, routing, and lateness penalties. To our knowledge, there is no study related to CMVRP with crew scheduling that considered exchanging teams in depot.
The remainder of the paper is organized as follows. Section 2 presents the problem definition and model formulation. The solution methodologies of proposed Genetic Algorithm (GA) and Artificial Bee Colony Algorithm (ABC) are described in Section 3. The parameter tuning and experimental design is conducted in Section 4. Section 5 provides comparisons between the Cplex software and the meta-heuristic algorithms and discusses the superiority of the proposed GA. Finally, conclusions and future frameworks are drawn in Section 6.
2. Problem definition and modeling
This paper investigates the vehicle routing and crew scheduling problem. There are a number of customers locating in known points. The travel distance between two points is calculated using the Euclidean distance. Each customer demands a specific task and in a predefined due date which is serviced by only one team. The teams are multi-skilled and can perform some, but not all the tasks of customers. The available teams to perform a task are in different competencies, that it will affect the servicing time. The vehicles are in the charge of moving and exchanging the teams in the depot. The vehicles are different from one another in their moving speed and the capability to move toward each customer’s site, which is known in literature as a site-dependent problem. There is no fixed assignment of a vehicle to a team, but teams and vehicles should be synchronized.
After completing one task of a customer by a team, the vehicle in a tour may exchange the companion team with another appropriate team in the depot to perform the next customer’s tasks. If the services to the customers are done after the due date, some penalties of lateness are considered for the problem. The goal is to service all the customers with appropriate teams, in order to minimize all the costs of routing, servicing, and the costs of penalties for lateness. Basic notations are introduced as follows:
Indices
i, j, h Index of nodes i, j, h = 0,1,2,…,N,
k Index of vehicles k = 1,2,…,V,
m Index of teams m = 1,2,…,R.
Parameters
D(i,j): Distance between nodes i, j(i ≠ j),
CV (k): Cost of vehicle k incurred for performing a route,
V (k): Movement speed of vehicle k,
ST(j): Standard duration of the task of customer j,
CT (m): Cost of team m to perform a task,
A (m, i): Matrix of competency of team m to perform the task of customer i,
G (k, i): Matrix of capability of vehicle k to visit the customer i,
D D (i): Due date of servicing for the customer i,
W (i): Penalty of lateness of servicing for the customer i,
M: A big number.
Decision variables
T(i): Finishing time of servicing to customer i,
L(i): Tardiness time of servicing to customer i,
S(i): variable for elimination of sub tour.
Mathematical model
(1)
s.t.(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
The objective function is to minimize total costs of servicing by the teams, routing by the vehicles, and the penalties of lateness. Restrictions (Equation2(2) ) and (Equation3
(3) ) ensure that every vehicle should start its tour from the depot and comeback to it at the end of the tour. Restrictions (Equation4
(4) ), (Equation5
(5) ) and (Equation6
(6) ) state that each customer is visited by exactly one vehicle and one team, and the same vehicle and team will leave the visited customer. Restrictions (Equation7
(7) ) are subtour elimination constraint set. Constraints (Equation8
(8) ) and (Equation9
(9) ) show the time connection between two consequent customers in a tour of a vehicle. Constraints (Equation10
(10) ) and (Equation11
(11) ) are the compatibility constraints for the teams and vehicles to visit the customers. They guarantee that the inappropriate vehicles and teams are not sending to each customer. Equations (Equation12
(12) ) and (Equation13
(13) ) are to know which teams go over the traveling distance and to define lateness for the customer. Constraints (Equation14
(14) ) provide limits on the decision variables.
The number of variables and constraints in the model are presented in Tables and , respectively, based on the variable indices.
Table 1. The number of variables in the model.
Table 2. The number of constraints in the model.
3. Solution methodologies
3.1. Genetic algorithm
The basic concept of GA was introduced by Holland (Citation1962), this algorithm is inspired by the natural evolution mechanism, devises a guided random approach to seek the solution space. GAs are stochastic search techniques based on the natural mechanism and genetic rules of the crossover and mutation.
GA starts with a population which consists of population size (PS) of individuals and it is suitable for encoding or representation of the solution to a problem. Each individual has a fitness value that measures the quality of the solution associated with the chromosome. These are the most generation’s numbers in a simple GA in order to evolve current population to the new one for each iteration. There are basic operations which include: Selection, Crossover, Mutation, and Elitisms.
By selecting parents from the population, in a crossover operation, the parents are combined by crossover operator to produce one or more offsprings based on crossover probability (Pc); the mutation operator alters offspring according to the mutation rules to offset convergence effect and guarantees the population diversity based on mutation probability (Pm); and sometimes, in a GA, a number of fitter individuals are copied directly from current to the new population which is called elitisms The proposed GA steps are as follows:
Step 1. Initial of population
In this step, initial feasible population is randomly produced. To represent a solution, a chromosome is included by an array with (N + V − 1) columns and two rows in which N is equal to the number of customers and V is equal to the number of vehicles. The first row represents the customers, while the second row shows the team’s number. To split the tours of vehicles from each other, the sign star (*) is inserted. A typical chromosome of a solution is shown in Figure .
Figure 1. A chromosome representation of a solution.
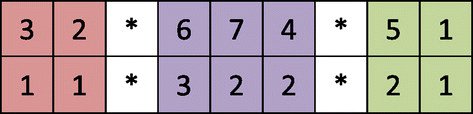
In Figure , customers 3 and 2 are in the tour of vehicle 1 which is serviced consequently by the team 1. The customers 6, 7, and 4 are in the tour of second vehicle. Vehicle 2, after visiting customer 6 should exchange the team 3 by the team 2 at the depot and then move to customers 7 and 4 consequently. Also, Vehicle 3 after visiting customer 5 exchanges the team 2 and 1 at the depot and then moves to customer 1 by the team 1.
Step 2. Objective function
After generating the initial population, objective function should be calculated.
Step 3. Selection strategy
The roulette wheel strategy is used for crossover operation and the random selection strategy is employed for mutation operation. Then, after computing fitness values, better solutions have more chances to be selected using the roulette wheel mechanism as a selection approach.
Step 4. Crossover operator
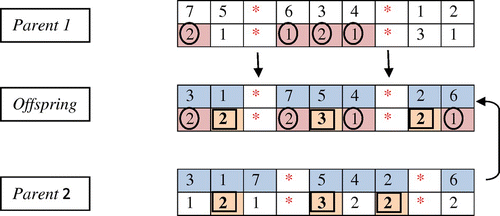
Crossover starts with chromosomes which are selected from the selection mechanism as parents, and mixes them to produce children. Proposed crossover produces offspring by taking the stars position from parent1 and the combination of customers from parent 2, while the teams are copied from the related customer’s number of both parents. The steps of the crossover operator are as follows:
| (1) | Select two parents by roulette wheel strategy. | ||||
| (2) | Copy the stars positions from parent 1 into same positions of the child’s array. | ||||
| (3) | Insert the sequence of customers from parent 2 into the remaining positions of the offspring’s array. | ||||
| (4) | Insert the related team number of parents 1 and 2 in alternate order into every other position of second row of the offspring. The proposed crossover operator is shown graphically in Figure 2. | ||||
Figure 2. Crossover operator.
Step 5. Mutation operator
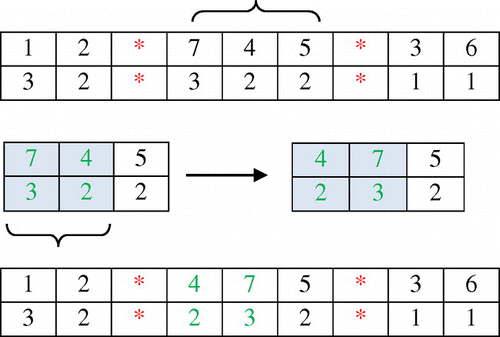
The mutation operator changes the structure of some chromosomes in the generation in order to guarantee diversification in solutions. It also helps to prevent from falling into local optimum trap. The steps of the crossover operator are as follows (Figure ):
| (1) | Select a chromosome randomly from the mating pool. | ||||
| (2) | Pick up a sequence of genes (one route of one vehicle) from the selected chromosome. | ||||
| (3) | Reverse the sequence of some of the genes and return them back to the same positions. | ||||
Figure 3. Mutation operator.
Step 6. Stopping criterion
Stopping criterion is the number of generations and the algorithm will terminate if it meets the given number of generations.
3.2. Artificial bee colony
ABC algorithm was introduced by D. Karboga and it is based on concept of swarm intelligence, which inspired intelligent foraging behavior of honey bee swarm.
ABC is proposed for global optimization problem because it has many advantages such as memory, multi-character, local search, and solution improvement mechanism. Also, it is applied successfully in neural network (Karaboga & Akay, Citation2007), scheduling problem (Pan, Fatih Tasgetiren, Suganthan, & Chua, Citation2011), reliability redundancy allocation problem (Yeh & Hsieh, Citation2011), and function optimization (Kang, Li, & Xu, Citation2009; Sonmez, Citation2011).
Three groups of honey bees are in a natural bee swarm namely: employed bees, onlooker, and scouts. Each solution to the problem is called a food source and is represented by n dimension vector. The title ‘Employed bees’ is called to a bee that currently exploiting for a food source. A bee waiting in the hive area for choosing a food source is named as an onlooker and a bee carrying out random search to find a new food source is called a scout. The process of search that is done by the artificial bees is summarized as follows (Pan et al., Citation2011):
| • | A food source in the neighborhood of the food source in their memory is determined by employed bees. | ||||
| • | The information obtained by employed bees is shared with onlookers within the hive and the onlookers choose one of the food sources. | ||||
| • | A food source within the neighborhood of food sources chosen by themselves. | ||||
| • | An employed bee of which the source has been abounded becomes a scout and starts to search a new food source randomly. | ||||
ABC is an iterative process similar to other evolutionary algorithms, such as GA, particle swarm optimization, and imperialist competitive algorithm which starts with population of solutions(food sources).Then, the following steps are looped to meet a termination criterion:
| Step 1. | The employed bees are sent to the food sources and measure their nectar amounts. | ||||
| Step 2. | Select the food sources by onlookers after sharing the information of employed bees and determine the nectar amount of the food sources. | ||||
| Step 3. | Choose the scout bees and send them to possible food sources. | ||||
In a robust search, exploration and exploitation must be done together. In ABC algorithm, onlookers and employed bees carry out the exploitation process in the search space and scouts carry out the exploration process.
The main sections of the basic ABC algorithm are described in detail as follows:
3.2.1. Initialization of the parameter
In the basic ABC algorithm, the parameters are the number of food sources (SN) that is equal to the number of the employed bees, the number of trials for releasing a food source (limit), and termination criterion.
The number of employed colony is set to the number of food sources in the population. Therefore, there is only one employed bee for every food source.
3.2.2. Initialization of the population
The initial population of food sources is generated with SN number randomly. Let represent the ith food source in the population of solutions and each ones is produced as follows:
(15)
where i = 1, 2, …, SN and j = 1, 2, …, n; r is a uniform random number in the range [0,1]; UBj and LBj are the upper and lower bounds for the dimension j, respectively.
3.2.3. Initialization of the bee phase
In this phase, each employed bee determines a new neighborhood source using the food source that is associated with them as follows:(16)
where k = 1, 2, …,SN and j = 1, 2, …, n are randomly generated indexes, but k must be different from i. R is a uniformly distributed number in [−1,1].
3.2.4. Onlooker bee phase
The nectar amount that is taken from all employed bees is calculated and a food source is selected based on its probability value by onlooker bee. The probability is computed by the following expression:(17)
where fiti is the fitness value for food source i, which is proportional to nectar amount of the food source i. the fitness function is defined as where fi is the objective function value of solution i.
After each solution is generated and then evaluated by artificial bee, it is compared with the old one. If the new food source has an equal or bigger nectar amount food source, it is replaced with the old one. Otherwise, the old one is retained. In other words, a greedy selection mechanism is applied between these solutions.
3.2.5. Scout bee phase
The corresponding employed bee becomes a scout when a food source cannot improve through a number of trials limit. In this phase, the food source is abounded and scout produces a food source randomly. It assumes that the abandoned source is xi and j = 1,2,…,n, n is the solution vector, the scout discovers a new food source which will be replaced with xi.(18)
where j is determined randomly and it must be different from i.
3.2.6. Stopping criterion
There are two basic stopping criterions in this algorithm. One is the maximum number of iterations, and the other is maximum elapsed time. In this study, both the criterions are considered. In other words, the stopping criterion is the maximum number of iterations or maximum elapsed time.
The structure of encoding method in ABC is similar to GA.
The steps of ABC algorithm are described as follows:
Algorithm 2: ABC algorithm
Step 1: Initialize the population of solutions and evaluate them.
Step 2: Generate new solutions for the employed bees and evaluate them.
Step 3: Use the greedy selection process.
Step 4: Calculate the probability for each solution.
Step 5: Produce the new solutions for onlooker bees and evaluate them.
Step 6: Use the greedy selection process.
Step 7: Determine the abandoned solution for the scout.
Step 8: If a termination is not met, go to Step 2; otherwise stop the process of ABC.
4. Experimental design
4.1. Data generation
To evaluate the effectiveness of the proposed algorithm, some test problem instances are generated. The instances must be comprehensive and representative. So, some parameters such as: location of customers (X, Y), The team’s competency, The team’s wages, Travelling cost of vehicles, The moving speed of vehicles, and Penalty of lateness for the teams are determined experimentally and are given in Table .
Table 3. Levels of problem parameters.
4.2. Parameter setting
In this study, Taguchi experimental design is applied for tuning parameters of proposed algorithms. The Parameter Design was developed by Dr. Taguchi in early 1960s and can be applied to process design. Goal of this method is to minimize the effect of noise factors and determine optimal level of important controllable factors based on the concept of robustness. The signal-to-noise (S/N) ratio denotes the amount of variation in the response variable that must be maximized. The formula is:(19)
where E(OFi) is mean of objective function in round of i . Also, k is number of loop that each meta-heuristic algorithm should be repeated. The level of the parameters of GA and ABC are presented in Tables and .
Table 4. Factors and their levels in GA.
Table 5. Factors and their levels in ABC.
The appropriate orthogonal array in GA and ABC is that is shown in Table .
Table 6. The orthogonal array  .
.
The experiments on the GA and ABC algorithms were created on the orthogonal array distribution method, and nine different combinations of factors were considered. Each trial is calculated five times and the mean S/N ratio of the objective value for GA and ABC is shown in Figures and . As demonstrated in Figure , better performance and robustness of the GA is when the parameters are set on the following levels: PC; 0.6, PM; 0.25 and (PS, Iteration1); (120,100). And robust parameters for ABC are on below levels: (Population of food, Iteration); (80,150), Random number; 0.25 and PE; 0.15.
Figure 4. The average S/N ratio plot at each level for GA.
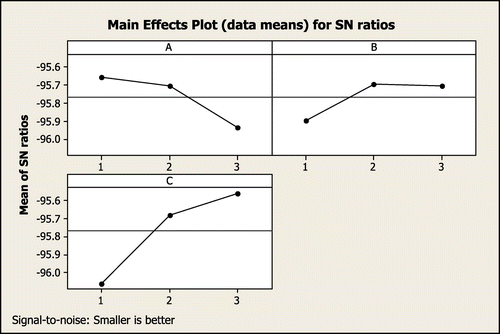
Figure 5. The average S/N ratio plot at each level for ABC.
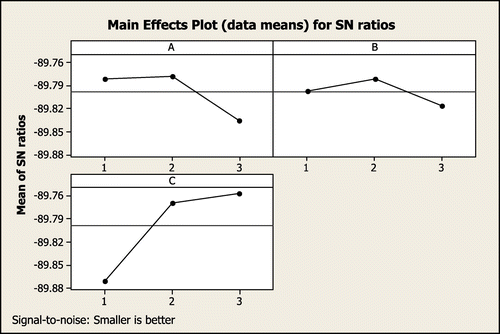
The goal of analysis of variance (ANOVA) is to inspect the relevant implication of individual parameters based on the objective value. In other words, by means of ANOVA, the parameters that are more effective in problem will be identified. Tables and illustrated ANOVA in GA and ABC algorithms. Results obtained from ANOVA indicate PC in GA and PE in ABC, showing significant impact on the robustness of the algorithms.
Table 7. ANOVA for S/N ratio in GA.
Table 8. ANOVA for S/N ratio in ABC.
5. Computational results
To evaluate the quality of the proposed procedures, mathematical model was encoded in Cplex11 to solve the test problems exactly when it is possible, and the meta-heuristic procedures were encoded in Matlab7. There are 20 combinations for the different values of Number of nodes; Number of vehicles, Number of teams, and the characteristics of each test problem are illustrated in Table .
Table 9. The characteristics of the generated test problems.
The test problems were run 10 times on an HP 4520s laptop with 4 GB RAM and a 3 GHz processor running in Windows 7. In Table , the results of test problem instances are reported under measures of: best solution and computational time for those instances where the exact solutions are available; and under measures of mean solution and computational time of ABC and GA for the large-sized problems.
Table 10. Comparison of results of the model solved by Lingo 9 and GA with ABC
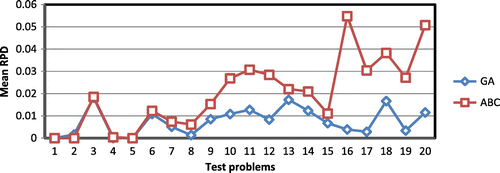
The data show that GA and ABC are not so different based on their objective value in small size problems and both of them perform well for this scale. The mean deviation from the best solutions for the first 12 instances for the GA and ABC are 0.006461 and 0.012177. For the instances 13–19, the local optimum solutions of the Cplex11 are available for comparing purposes.
In large-scale problems, Cplex11 cannot obtain optimum solutions even after the implied computational time. Therefore, we emphasize to compare the performance of the proposed algorithm of GA and ABC in large size problem, to determine the better procedure.
The mean deviation of best solutions from the mean for the GA and ABC are 0.0076083 and 0.0208088. For evaluating the proposed algorithms, relative percentage deviation (RPD) is calculated as Equation (Equation20(20) ):
(20)
Figure represents and compares the mean RPD of the proposed GA and ABC for the problem instances. It is clear that for the almost of the instances, GA takes much less amount of RPD.
Figure 6. Comparing the RPD for the GA and ABC.
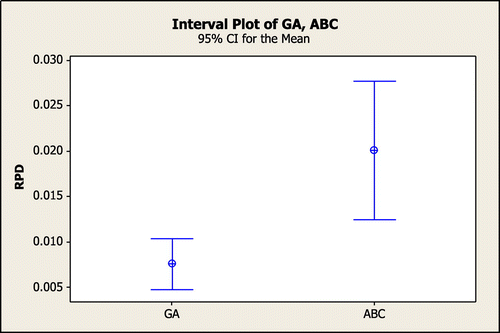
The results of this experiment are shown in Figure and it is clear that GA has better performance than ABC.
Figure 7. Means plot and LSD interval for the algorithms.
For testing these results obtained by the proposed algorithm, the t-test is chosen as a method for statistical testing. Hypothesis testing is as follows:
in which after conducting the statistical tests, the null hypothesis is rejected for all combinations of parameters at 95% significance level. Thus, GA performs better than ABC in almost of the problems.
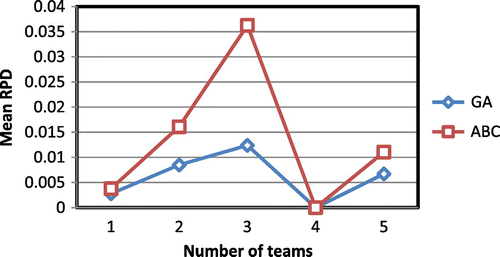
Figures represent the available results of the performance of the proposed GA and ABC for the test problems divided by the number of nodes, vehicles, and teams, respectively.
Figure 8. Average relative percent deviation for different value of number of depots.
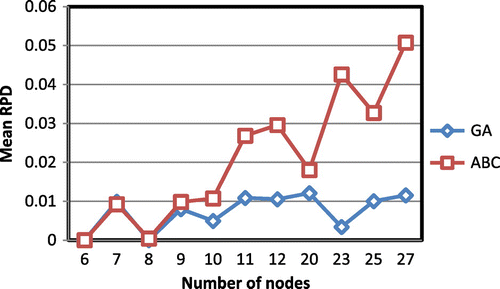
Figure 9. Average relative percent deviation for different value of number of vehicles.
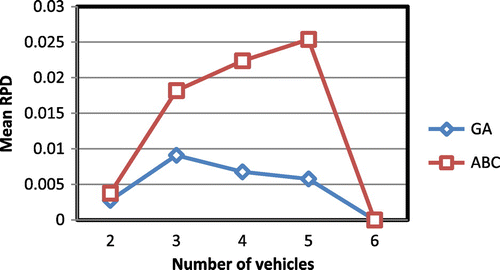
Figure 10. Average relative percent deviation for different value of number of teams.
6. Conclusions and future works
This paper considered CMVRP with multi-skill teams. We presented a new mathematical model in order to deal with the simultaneous planning of multi-skilled teams and transporting vehicles. For solving the generated test problems, two meta-heuristic algorithms, namely GA and ABC algorithm, are proposed to achieve best solutions for the problem. To compare their quality in achieving best solutions RPD measure is used and many instances are generated. Also, the parameters of the proposed algorithms are tuned by Taguchi method. Computational results of 20 standard tests problems and 200 instances revealed that GA is statistically performing better than ABC according to RPD measure. For future research, it is worthwhile to seek a dynamic model of the problem where the teams and vehicles are not gathered in a depot, but in scattered places, and the replacements may happen in every node. Also, it is worthwhile to consider ordering relations or priorities between the services of teams to the customers. Hence, the customers may have some preferences for specials teams to receive their services. It is also possible to think of a step forward heuristic for the problem to reach for feasible and optimum solutions.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Dantzig, G., & Ramser, J. H. (1959). The truck dispatching problem. Management Science, 6, 80–91.10.1287/mnsc.6.1.80
- Dohn, A., Kolind, E., & Clausen, J. (2009). The manpower allocation problem with time windows and job-teaming constraints: A branch-and-price approach. Computers and Operations Research, 36, 1145–1157.10.1016/j.cor.2007.12.011
- Drexl, J., Rieck, T., & Berning, B. (2011). Simultaneous vehicle and crew routing and scheduling for partial and full load long-distance road transport. Technical Report, 2, 242–264.
- Goel, A., & Meisel, F. (2013). Workforce routing and scheduling for electricity network maintenance with downtime minimization. European Journal of Operational Research, 231, 210–228.10.1016/j.ejor.2013.05.021
- Ho, S. C. & Leung, J. M. (2010). Solving a manpower scheduling problem for airline catering using metaheuristics. European Journal of Operational Research, 202, 903–921.10.1016/j.ejor.2009.06.030
- Holland, J. H. (1962). Outline for logical theory of adaptive systems. Journal of the Association of Computing Machinery, 4, 279–297.
- Hollis, B., Forbes, M., & Douglas, B. (2006). Vehicle routing and crew scheduling for metropolitan mail distribution at Australia post. European Journal of Operational Research, 150, 123–133.
- Kang, F., Li, J., & Xu, Q. (2009). Structural inverse analysis by hybrid simplex artificial bee colony algorithms. Computers and Structures, 87, 861–870.10.1016/j.compstruc.2009.03.001
- Karaboga, D., & Akay, B. (2007). Artificial bee colony (ABC) algorithm on training artificial neural networks. In IEEE 15th Signal Processing and Communications Applications, SIU 2007 (pp. 1–4), Eskisehir.
- Kim, B. I., Koo, J., & Park, J. (2010). The combined manpower-vehicle routing problem for multi-staged services. Expert Systems with Applications, 37, 8424–8431.10.1016/j.eswa.2010.05.036
- Lahyani, R., Khemakhem, M., & Semet, S. (2015). Rich vehicle routing problems: From a taxonomy to a definition. European Journal of Operational Research, 241(1), 1–14. doi:10.1016/j.ejor.2014.07.048
- Laurent, B., & Hao, J. K. (2008). Simultaneous vehicle and crew scheduling for extra urban transports (Vol. 5027, pp. 466–475). Berlin Heidelberg: Springer-Verlag.
- Li, Y., Lim, A., & Rodrigues, B. (2005). Manpower allocation with time windows and job-teaming constraints. Naval Research Logistics, 52, 302–311.10.1002/(ISSN)1520-6750
- Lim, A., Rodrigues, B., & Song, L. (2004). Manpower allocation with time windows. Journal of the Operational Research Society, 55, 1178–1186.10.1057/palgrave.jors.2601782
- Pan, Q.-K., Fatih Tasgetiren, M., Suganthan, P. N., & Chua, T. J. (2011). A discrete artificial bee colony algorithm for the lot-streaming flow shop scheduling problem. Information Sciences, 181, 2455–2468.10.1016/j.ins.2009.12.025
- Pureza, V., Morabito, R., & Reimann, M. (2012). Vehicle routing with multiple deliverymen: Modeling and heuristic approaches for the VRPTW. European Journal of Operational Research, 218, 636–647.10.1016/j.ejor.2011.12.005
- Rasmussen, M. S., Justesen, T., Dohn, A., & Larsen, J. (2012). The home care crew scheduling problem: Preference-based visit clustering and temporal dependencies. European Journal of Operational Research, 219, 598–610.10.1016/j.ejor.2011.10.048
- Sonmez, M. (2011). Discrete optimum design of truss structures using artificial bee colony algorithm. Structural and Multidisciplinary Optimization, 43, 85–97.10.1007/s00158-010-0551-5
- Talarico, L., Meisel, F., & Sorensen, K. (2015). Ambulance routing for disaster response with patient groups. Computers and Operations Research, 56, 120–133. doi:10.1016/j.cor.2014.11.006
- Yeh, W., & Hsieh, T. (2011). Solving reliability redundancy allocation problems using an artificial bee colony algorithm. Computers & Operations Research, 38, 1465–1473.10.1016/j.cor.2010.10.028
- Zäpfel, G., & Bögl, M. (2008). Multi-period vehicle routing and crew scheduling with outsourcing options. International Journal of Production Economics, 113, 980–996.10.1016/j.ijpe.2007.11.011