
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Though convolutional neural networks (CNN) exhibit promise in image semantic segmentation, they have limitations in capturing global context information, resulting in inaccuracies in segmenting small object features and object boundaries. This study introduces a hybrid network, ICTANet, which incorporate convolutional and Transformer architectures to improve the segmentation performance of fine-resolution remote sensing urban imagery. The ICTANet model is essentially a Transformer-based encoder-decoder structure. The dual-encoder architecture, which combines CNN and Swin Transformer modules, is designed to extract both global and local detail information. The feature information at various stages is collected by the Feature Extraction and Fusion modules (FEF), enabling multi-scale contextual information fusion. In addition, an Auxiliary Boundary Detection (ABD) module is introduced at the end of the decoder to enhance the model’s ability to capture object boundary information. Numerous ablation experiments have been conducted to demonstrate the efficacy of various components within the network. The testing results have proven that the proposed model can achieve satisfactory performance on the ISPRS Vaihingen and Potsdam dataset, with overall accuracies of 91.9% and 92.0%, respectively. Simultaneously, the proposed model is also compared to the current state-of-the-art methods, exhibiting competitive performance, particularly in the segmentation of diminutive objects like cars and trees.
Introduction
With the advancement of science and technology, satellite remote sensing has been providing comprehensive earth observations at various spatial resolutions. Notably, fine-resolution optical imagery captures a wealth of spatial details that find extensive applications in change detection (M. Wang et al., Citation2019; Xing et al., Citation2018), road and building extraction (Griffiths & Boehm, Citation2019; Shamsolmoali et al., Citation2021), environmental protection (Samie et al., Citation2020), and various other practical domains (Ding et al., Citation2024; Shen et al., Citation2019; Tang & Werner, Citation2023). In particular, semantic segmentation of urban scenes serves as an essential descriptor for the development of urbanization (T. Li et al., Citation2020). Traditionally, the extraction of these terrestrial features from large remote sensing images can be performed manually by human experts. However, this approach is time-consuming and inefficient, primarily due to the vast quantity of satellite data and the subjectivity and variability among different observers in identifying urban features (Vobecky et al., Citation2022; J. Wang et al., Citation2015). As a consequence, there is an urgent community need to automatically, effectively, and accurately segment complex urban scenes that consist of numerous objects.
In the early days, numerous efforts were made to automatically extract urban features using various methods, including spectral analysis (F. Chen et al., Citation2017; Clark & Kilham, Citation2016), morphological index techniques (Huang & Zhang, Citation2012; Huang et al., Citation2017), and multi-information fusion methods (Mezaal et al., Citation2017; L. Yang et al., Citation2003). These methods primarily differentiate the urban objects from the background by analyzing the differences in reflected spectral characteristics among various ground objects and incorporating geometrical and contextual information (Ok, Citation2013). However, they rely heavily on prior knowledge of specific data and can be influenced by intra-class spectral discrepancies and inter-class similarities, making them inadequate for images with complex features (Abdollahi & Pradhan, Citation2021; Yuan & Mohd Shafri, Citation2022). In recent years, machine learning-based methods have garnered significant attention due to their potential in semantic segmentation, which have been widely used in remote sensing fields. For example, Ünsalan and Boyer (Citation2005) simultaneously detected houses and streets using IKONOS-2 data by introducing a k-means clustering process that considers spatial information. F. Chen et al. (Citation2018) employed a support vector machine (SVM) method to derive land cover maps of urban environments from high-resolution hyperspectral data. These simple machine learning methods do not fully leverage the rich spatial-spectral information in satellite imagery, resulting in relatively poor overall accuracy and necessitating adjustments for different scenarios (Coseo & Larsen, Citation2019; X. Ma et al., Citation2023; Ok, Citation2013).
Convolutional neural network (CNN) methods have emerged as a pivotal framework in semantic segmentation tasks using high-resolution satellite imagery (Kemker et al., Citation2018; Kotaridis & Lazaridou, Citation2021; L. Ma et al., Citation2019; Tong et al., Citation2020). This type of method has the capability to automatically and adaptively capture hierarchical context information, resulting in significant capabilities for feature extraction and representation (Griffiths & Boehm, Citation2019). The fully convolutional network (FCN), as proposed by Long et al. (Citation2015), has been widely acknowledge as an effective architecture for semantic segmentation (Caye Daudt et al., Citation2018; Mou & Zhu, Citation2018; B. Zhang et al., Citation2019). While multiple convolutions and pooling operations can extract information and expand the receptive fields, they may also lead to the loss of global context information (R. Liu et al., Citation2022). Addressing this limitation, L.-C. Chen et al. (Citation2014) introduced atrous convolutions that enlarge receptive fields without reducing spatial resolution. To maximize the utilization of contextual information in the encoder-decoder FCN architecture, Ronneberger et al. (Citation2015) introduced skip connections, integrating high-level and low-level features to facilitate more precise predictions. Furthermore, several studies have explored the use of the spatial pyramid pooling (SPP) module to capture multi-level contextual features and enhance performance in complex environments (He et al., Citation2015; Yu et al., Citation2018; Zhao et al., Citation2017). Meanwhile, Fu et al. (Citation2019) integrated spatial path attention and channel path attention modules into a dilated FCN, allowing dynamic integration of local features with their global dependencies. Objects in urban scenes often display diverse shapes and scale variability. Despite significant progress, challenges remain in processing images of varying sizes or objects at different scales. This is particularly evident in the inadequate segmentation of small-scale objects and imprecise delineation of image boundaries (Audebert et al., Citation2018; Kampffmeyer et al., Citation2016; Yuan & Mohd Shafri, Citation2022; Yuan et al., Citation2021).
Compared to CNN-based methods, Transformer-based methods typically use self-attention mechanisms to enhance global information extraction and sequence-to-sequence modeling capabilities, yielding superior segmentation results (Vaswani et al., Citation2017; Z. Zhang et al., Citation2023). Moreover, this method integrates broader contextual information to capture extended dependencies across larger image areas, enhancing semantic segmentation capabilities (Ding et al., Citation2022). Most existing Transformers for semantic segmentation still follow the encoder-decoder structure, which can be roughly categorized into three groups. The first category is the encoder-decoder-based Transformers, known as pure Transformer, including models such as Segmenter (Strudel et al., Citation2021) and SwinUNet (Cao et al., Citation2023). These models capitalize on the transformer’s ability to enhance global contextual understanding, thereby improving segmentation precision (Carion et al., Citation2020). However, their deployment is hindered by substantial computational demands and a dependency on extensive annotated datasets, which pose significant challenges in resource-limited settings (Vaswani et al., Citation2017). Moreover, they struggle with segmenting small-objects and delineating image boundaries (Hou et al., Citation2019). The second category typically involves a combination of a Transformer-based encoder and a CNN-based decoder (J. Chen et al., Citation2021). For instance, DC-Swin is an architecture that combines a Swin Transformer-based encoder (Z. Liu et al., Citation2021) with a decoder utilizing a densely connected convolutional architecture for segmenting fine-resolution remote sensing images (L. Wang, Li, Duan, et al., Citation2022). These architectures enhance segmentation accuracy through contextual awareness and adaptability across different scales. However, they face challenges due to high computational demands and reliance on extensive training datasets (Z. Wang et al., Citation2021). In contrast, the third category consists of a CNN-based encoder and a Transformer-based decoder, as seen in Unetformer (L. Wang, Li, Zhang, et al., Citation2022). While numerous achievements, Transformer-based models have limitations in remote sensing tasks that involve multi-objective segmentation (Z. Zhang et al., Citation2023). These models not only lack the inductive biases found in CNN, potentially leading to decreased performance on small datasets, but also require improvements in extracting complex and small target features, as well as capturing boundary feature information (Dosovitskiy et al., Citation2021; Lin et al., Citation2021). Additionally, the computational complexity of these models is higher compared to CNN-based models, which can impact their suitability for urban-related applications (L. Wang, Li, Zhang, et al., Citation2022; Xie et al., Citation2021).
In this paper, the ICTANet model is proposed, which integrates convolution and transformer architectures. This design enhances multi-scale feature extraction and fusion, improving the segmentation of small and medium-sized targets in urban scenes and addressing issues of inaccurate boundary segmentation. Hybrid CNN-transformer models combine the strengths of CNNs and transformers to effectively leverage both local and global information. However, the wide variety of natural and man-made features at various scales presents challenges in segmenting fine-resolution remote sensing images, especially when features overlap or when the boundaries between different features are not well-defined. In this study, the ICTANet model focuses on two key components: the Feature Extraction and Fusion (FEF) model and the Auxiliary Boundary Detection (ABD) module. These components are integrated within the main structure of the hybrid CNN-transformer to effectively process multi-scale information and enhance boundary detection in urban remote sensing images. Our study makes the following key contributions: (1) ICTANet adopts a hybrid architecture with a dual encoder and a symmetric Transformer-based decoder, enabling competitive results in semantic segmentation of fine-resolution remote sensing urban images. (2) the FEF module, incorporated into the encoder, employs a global-local attention mechanism to effectively integrate local features with global representations and fuse multi-scale information. (3) To enhance the extraction of target boundary feature information, the ABD module is introduced at the end of the decoder, effectively improving the model’s performance. (4) The performance of ICTANet is evaluated using numerical indices and visualization inspections. The results demonstrate that ICTANet achieves competitive performance on the ISPRS Vaihingen and Potsdam dataset, with overall accuracy of 91.9%, and 92.0%, respectively.
The remainder of this paper is organized as follows: the data source and preprocessing is presented in Section 2. Materials and the details of the proposed ICTANet model are introduced in Section 3. Section 4 describes the experiential results and discussions. The conclusions of this study are drawn in Section 5.
Data source and preprocessing
To analyze the performance of the proposed model for urban scene classification quantitatively and qualitatively, we utilized the Vaihingen and Potsdam datasets from the International Society for Photogrammetry and Remote Sensing (ISPRS) Test Project in our experiments. Both of these public datasets are freely accessible at https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx. The details of datasets are presented in SI (Table S1).
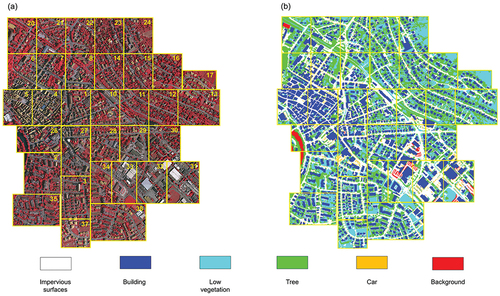
The Vaihingen dataset consists of 33 patches with varying sizes, covering the Vaihingen region of Germany (as shown in ). For each patch, a true orthophoto and a digital surface model (DSM) are provided, both with a ground sampling distance of 9 cm. In our experiments, the model input exclusively consists of true orthophotos, with their RGB bands corresponding to the near infrared (NIR), red, and green channels of the camera. The high-quality labeled ground truths for these patches, which serve as the true labels in model building, can also be obtained (as shown in ). In this dataset, it contains five foreground classes, namely impervious surface, building, low vegetation, tree, and car, along with a background class referred to as “clutter”. Therefore, its complex environments, multiscale objects, and diverse distributions provide an opportunity to evaluate the capability for automatic segmentation and generalization of the proposed model.
Figure 1. Overview of the ISPRS Vaihingen 2D dataset. There are consists of 33 tiles of true orthophotos (TOP) tiles and their corresponding digital surface models (DSMs). The numbers in each tile represents the ID number of the tile. The figure source from: (https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/). (a) represents the original image (IRRG), (b) shows the ground truth of image.
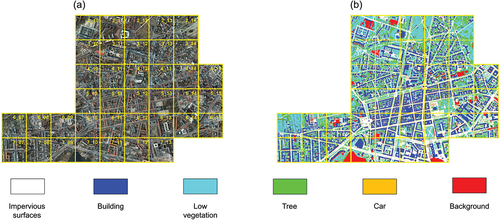
Similarly, the Potsdam dataset is named after the region it covers and consists of 38 patches, all with the same size of 6000 × 6000. As depicted in , the true orthophotos with four channels (red, green, blue and NIR) and their corresponding labeled ground truths are picked to further verify the performance or accuracy of the developed model. In this region, it contains the same six urban categories as the Vaihingen dataset. However, compared to Vaihingen, Potsdam exhibits larger building blocks, narrow streets, and a denser settlement structure. Additionally, the Potsdam dataset offers a greater number of training samples.
Figure 2. Overview of the ISPRS Potsdam 2D dataset. There are 38 tiles of true orthophotos. The numbers in each tile represents the ID number of the tile. The figure source from: (https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/). (a) represents the original image (IRRG), (b) shows the ground truth of image.
Prior to training, it is necessary to preprocess these datasets due to the large size of the high-resolution images and the constraints imposed by GPU memory. In this study, patches with IDs 1, 3, 5, 7, 11, 13, 15, 17, 21, 23, 26, 28, 32, 34, and 37 (2_11, 2_12, 3_10, 3_11, 3_12, 4_10, 4_11, 4_12, 5_10, 5_11, 5_12, 6_07, 6_08, 6_09, 6_10, 6_11, 6_12, 7_07, 7_08, 7_09, 7_10, 7_11, 7_12) from the Vaihingen (Potsdam) dataset are used to generate the training dataset. Patch ID 30 (2_10) from the Vaihingen (Potsdam) dataset is utilized to construct the validation dataset, while the remaining 17 (14) patches from the Vaihingen (Potsdam) dataset are used to build the testing dataset. Notably, only red, green and blue channels in Potsdam images are used in our experiments. The training and validation patches are randomly cropped into 512 × 512 batches using a sliding window approach. As noted by Y. Liu et al. (Citation2017), the segmentation accuracy tends to be highest when the overlap size of the sliding window reaches 75%, while there are less gains for further increases. Therefore, the overlap rate of the crop is set at 75% to preserve the spatial structure of the objects and enhance segmentation accuracy. In addition, a strategy incorporating random horizontal and vertical flipping, rotation, and scaling is employed to augment the dataset and enhance the generalization ability of the proposed model. The details of the training, validation, and testing datasets in this study are listed in Table S1.
All models in the experiments were implemented with the Pytorch framework on a single NVDIA GeForce RTX 2080 Ti GPU, 11GB graphics memory, running on the Ubuntu 18.04.6 LTS operating system and Python 3.8 environment. The AdamW optimizer is used to train and optimize the model, accelerating its convergence speed. The initial value of the learning rate is set to 0.001, the momentum coefficient and weight attenuation are set to 0.9 and 0.01, respectively. The proposed model is retrained on the Vaihingen and Potsdam datasets for semantic segmentation, maintaining the same hyperparameters and training process.
Methodology and materials
Overall architecture
The overall structure of the ICTANet model, mainly consisting of a dual encoder and a Transformer-based decoder, is depicted in . It is evident that this backbone is primarily based on the Swin Transformer, which employs spatial-wise self-attention mechanisms to capture spatial dependencies and facilitate long-range interactions across the entire image. As illustrated in , each Swin Transformer block consists of several components, including multi-head self-attention, Multi-Layer Perceptron (MLP) layers, residual connections, and layer normalization.
Figure 3. The flowchart of the ICTANet.
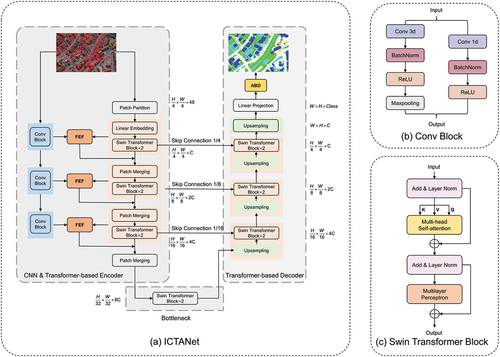
Since the CNN has the capability to capture spatially local features and extract hierarchical representations of image data, we combine a CNN module and a Swin Transformer module as a dual encoder to effectively capture fine-grained local features and achieve a comprehensive global contextual understanding. In this study, the input images with dimensions of H×W×C (where H, W, and C represent the height, width, and number of channels for the image, respectively) are simultaneously processed by both the convolutional and Swin Transformer modules. Three convolutional blocks are stacked in the CNN module to progressively capture informative features from the input images. As shown in , each convolutional block contains a 3 × 3 convolutional layer for extracting local features, followed by batch normalization, a ReLU activation function for introducing non-linearity, a pooling layer for reducing spatial dimensionality, and a 1 × 1convolution layer for adjusting channel dimensions and fusing multi-scale information. The spatial size of the output feature maps from each convolutional block is halved, while the depth is doubled.
Similarly, the Transformer module also consists of three blocks. Initially, the input images are transformed into smaller one-dimensional sequences by a Patch Partition operation. These sequences are then projected into a lower-dimensional space using Linear Embedding, facilitating effective processing by subsequent Transformer operations. Furthermore, two stacked Swin Transformer blocks are employed to enable efficient attention-based modeling of spatial dependencies and to efficiently process high-resolution image data. The output of the Swin Transformer block and the integrated feature maps from the FEF module are subsequently aggregated in the Patch Merging process. Lastly, the most important features of the input data are captured by the bottleneck, which encompasses two successive Swin Transformer modules.
In the decoder section, the encoding feature maps are reconstructed and transformed into the final outputs using a symmetric Transformer-based module. As illustrated in the right part of , the feature maps from the decoder are concatenated with the corresponding feature maps from the encoder at the same depth using skip connection. This process aims to preserve spatial details and integrate multi-scale information. Prior to this integration, the feature maps from the decoder are upsampled to ensure seamless integration. Subsequently, these feature maps are then passed to the two stacked Swin Transformer blocks, which play a vital role in generating meaningful and contextually relevant output sequences. After three iterations, the reconstructed features are directed to a Linear Projection layer to generate pixel-level segmentation predictions. At the final stage of this model, the Auxiliary boundary detection module is incorporated to enhance boundary detection or segmentation performance by producing sharper boundaries.
Feature extraction and fusion module (FEF)
Both global contextual information and local details are crucial for the semantic segmentation of complex urban scenes. In the encoder section, the FEF is introduced to efficiently integrate local and global information to enhance the representation learning capabilities of the model. As shown in , the FEF consists of local global integration branches and fusion stages. Within the local extraction branch, 1 × 1 convolutions and 3 × 3 convolutions are utilized to integrate local information in a multi-scale manner. In addition, a batch normalization layer is added before the cascaded summation operation to expedite the convergence of the model. In the global extraction branch, the multi-head self-attention mechanism plays a significant role in integrating global information. The one-dimensional sequence from the Swin Transformer block is split into query (Q), key (K), and value (V) matrices through linear projection. These matrices are then divided into multiple heads to attend to different positions and aspects of the input. For each head, the Q and K metrics are subjected to dot product operation and normalized by the softmax function to quantify the importance of each position in the input. This process is defined as follows:
Figure 4. Illustration of the feature extraction and fusion module (FEF).
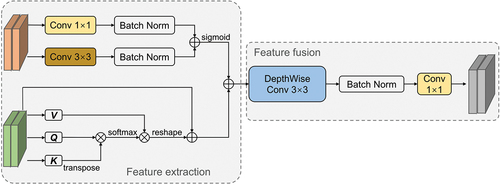
Where Fji represents the attention scores between the ith and jth elements of Q and K, respectively. N represents the number of elements in the K. Then, they are multiplied with V to determine the contribution of each value, with greater attention placed on positions that are more informative for capturing global dependencies. The reshaped results are then scaled by α and subjected to element-wise addition with the input features Ej, resulting in the attended representation Gj (Equation 2).
Finally, the feature maps obtained from the global and local branches are concatenated along the channel dimension, which may result in an increase in the output channels. To address this, a convolutional module consisting of a 3 × 3 deep convolutional layer, batch normalization, and a standard 1 × 1 convolutional layer is employed to combine the global and local contextual features and fused the features.
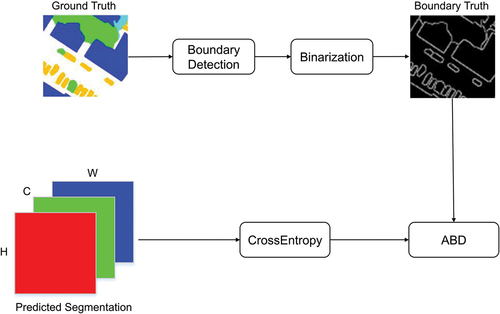
Auxiliary boundary detection module (ABD)
The diversity and complexity of objects in remote sensing images present challenges in accurately identifying object boundaries, frequently resulting in the common problem of pixel confusion around the boundaries and making it challenging to differentiate between similar categories. To address this issue, an auxiliary boundary detection module is devised to improve the generation of thin and accurate boundaries in image segmentation tasks. Its function is to provide a loss that guides the model to generate sharper and more precise boundaries. As shown in , ABD consists of a segmentation prediction and a boundary extraction section. As shown in EquationEquation (3)(3)
(3) , the pixel-based cross entropy loss (i.e. lossce) is used to process each pixel individually in the semantic segmentation result, without considering the semantic relationship between adjacent pixels and different objects. Consequently, this approach fails to capture the overall geometric boundaries of the objects.
Figure 5. Illustration of the auxiliary boundary detection (ABD) module.
where xi is the ith value of the label, and x’i represents the corresponding prediction.
In the boundary detection process, a boundary detector is employed to accurately locate the object boundary from the ground truth, resulting in the acquisition of the corresponding boundary truth values. Subsequently, the boundary prediction errors are calculated using the boundary perception loss, effectively enhancing the features surrounding the boundaries and suppressing noise features in the background. This process proves beneficial for improving the accuracy of boundary pixel classification. The boundary detection involves a binary classification task, with the loss function described by EquationEquation (4)(4)
(4) . Then, points in the boundary regions can obtain larger loss weight coefficients, indicating that the model will focus more on learning the boundary regions (EquationEquation 5
(5)
(5) ).
where p(xi) represents the probability of pixel xi being classified as a boundary pixel. H(xi) and H(yj) denote the cross-entropy loss for boundary and non-boundary pixels, respectively. numEP and numNP represent the number of boundary and non-boundary pixels, with numNP typically being much larger than numEP. Consequently, points in the boundary regions can obtain larger loss weight coefficients, indicating that the model will focus more on learning the boundary regions. Finally, the overall loss function is calculated as the sum of the segmentation prediction loss and the boundary detection loss:
Evaluation metrics
In this study, the overall accuracy (OA), F1-Score, and mean intersection over union (mIoU) are selected as evaluation metrics to assess the accuracy of the proposed model. These metrics are computed based on the accumulated confusion matrix as follows:
Where TPk, FPk, TNk, and FNk represent the true positive, false positive, true negative, and false negatives of class k, respectively. OA is computed for all categories including the background. In addition, the frames per second (FPS) was used to evaluate how many frames (images) the segmentation algorithm processes in one second. Meanwhile, the memory footprint (MB) and the number of model parameters (M) were used to assess the memory requirements.
Experimental results and discussions
In this study, the proposed model is retrained six times on both the Vaihingen and Potsdam datasets, respectively. From the , it can be found the proposed model performs relatively stable, as evidenced by the low variability in the evaluation outcomes. Consequently, the experiments with the best performance have been selected for showcasing, specifically Experiment 4 for the Vaihingen dataset and Experiment 6 for the Potsdam dataset.
Table 1. Quantitative evaluation results of six experiments on the Vaihingen and Potsdam datasets.
Ablation study
Each component of ICTANet
To assess the individual performance of the modules within the ICTANet model, a series of ablation experiments are conducted using testing datasets. Specifically, the relative importance of the FEF module and the ABD module is evaluated by removing certain components and analyzing the impact on the overall performance of the system. In the experiments, four variations of the ICTANet model incorporating different modules are tested: (a) without the FEF and ABD modules, (b) with only the FEF module, (c) with only the ABD module, and (d) with both the FEF and ABD modules. During these ablation experiments, it is important to note that the model, when lacking a specific component, is retrained using the same hyperparameters as the original ICTANet model, with all other aspects of the model and training process remaining unchanged. For a fair comparison, the segmentation accuracy of each class, F1-Score, OA, and mIoU are calculated. report the experiment results for the Vaihingen and Potsdam datasets, respectively. Significantly, an FCN-32s model (Long et al., Citation2015), which set the backbone as the ResNet18 model, is employed as the baseline to evaluate the improvements of the proposed model.
Table 2. Ablation study on the effects of various components in ICTANet architecture, evaluated on the Vaihingen dataset. (“–” indicates without FEF and ABD modules).
Table 3. Same as , but on the Potsdam dataset.
It is evident that the model without the FEF and ABD modules performs similarly on the Vaihingen dataset to the baseline model (i.e. FCN-32s). The performance gradually improves when equipped with the FEF and ABD modules, achieving the best results with both modules incorporated into the ICTANet model. The model reaches a peak F1-Score of 91.71%, an OA of 91.9%, and a mIoU of 84.2%. Specifically, when only the FEF module is incorporated, the proposed model achieves improvements of 1.95% in F1-Score, 1.37% in OA, and 3.2% in mIoU compared to the baseline model. It also reveals an increase of 5.31% in the segmentation accuracy for small targets (i.e. car). This demonstrates that the FEF module, integrating features with varying semantic information, can effectively enhance the model performance through context and local feature extraction, and improve the segmentation accuracy of small objects. In addition, incorporating the ABD module, which reduces the impact of fuzzy boundaries, results in an F1-Score of 90.45% and an OA of 90.39%. These figures mark improvements of 1.97% and 1.24%, respectively, over the baseline model. In addition, the model that incorporates both the FEF and ABD modules outperforms configurations that include only one of these modules. As shown in , the results on the Potsdam dataset demonstrate similar performance. The results of the ablation experiments highlight the effective enhancement in fine-resolution remote sensing image semantic segmentation by incorporating the FEF and ABD modules.
Encoder-decoder combination
To demonstrate the effectiveness of the hybrid structure, the ablation experiments are conducted on the Vaihingen and Potsdam datasets, which are also compared with the ERFNet, SwinUNet, and TransUNet model results (shown in ). We report the training time for each epoch, inference time. In terms of mIoU on the Vaihingen and Potsdam datasets, the ICTANet model maintains competitive accuracy. Notably, when compared to the pure CNN structure (i.e. ERFNet), the ICTANet model shows improvements with an increase of 15.1% and 12.2% on the Vaihingen and Potsdam datasets, respectively. Compared to pure Transformer networks like SwinUNet, the ICTANet model achieves a 50% reduction in computational complexity. Although it has more parameters than Transformer-based encoder-decoder architectures, the ICTANet model can still achieve higher mIoU on both datasets. Additionally, the ICTANet model has fewer parameters than the models consisting of a Transformer-based encoder and a CNN-based decoder (TransUNet) (J. Chen et al., Citation2021). Therefore, the hybrid structure of the ICTANet model, consisting of a CNN & Transformer-based encoder and a Transformer-based decoder, offers both high execution speed and superior accuracy in remote sensing segmentation.
Table 4. Ablation study on the effects of various encoder-decoder combinations, evaluated on the Vaihingen and Potsdam datasets. The complexity and speed are measured by a 512 × 512 input image and give the inference speed measured in frames per second (FPS) on a single NVIDIA RTX 2080 Ti GPU. The last column mIoU is divided two types, where the first number is the mIoU on the Vaihingen dataset and the second one is the Potsdam dataset.
Assessment of network efficiency
Due to the importance of complexity and speed in fine-resolution remote sensing image segmentation, evaluating the efficiency of the neural network becomes essential. To evaluate the efficiency of the encoder-decoder architecture with different components, metrics such as complexity, parameters, FPS, training time per epoch, inference time, and mIoU are reported in . While the ICTANet model does not offer the lowest computational cost (FPS = 60.21), it still achieves a competitive computational cost compared to other networks. In addition, the mIoU values on the ISPRS Vaihingen and Potsdam datasets demonstrate that the proposed model outperforms other models in semantic segmentation. These comparisons underscore the suitability of ICTANet for fine-resolution urban image segmentation.
In addition, the ICTANet model is compared with other networks on the Vaihingen and Potsdam testing datasets in terms of complexity, parameter counts, FPS, and mIoU. As demonstrated in , the ICTANet model has comparable complexity and size to other ResNet18-based networks. Although the ICTANet model has greater complexity and a higher parameter count compared to lightweight networks such as UNetFormer and DANet, it maintains relatively high operational efficiency. Specifically, the ICTANet model achieves a competitive inference speed of 60.21 FPS. Its complexity and parameter counts are comparable to models with similar architectures, yet it achieves notably higher segmentation accuracy. This is evidenced by its performance, surpassing other networks by over 15.6% and 12.5% in mIoU on the Vaihingen and Potsdam datasets, respectively. The relatively high accuracy and speed of the ICTANet model demonstrate the efficiency of its hybrid structure and the effectiveness of the newly introduced FEF and ABD modules. This not only highlights the competitive performance of the ICTANet model but also shows that it can achieve satisfactory segmentation outcomes within limited computational resources.
Table 5. The evaluation results of the ICTANet model compared with other networks. “G” means Gillion (i.e. units for the number of floating point operation), and “M” indicates Million (i.e. units for the number of parameters). The speed is measured by a 512 × 512 input image and give the inference speed measured in frames per second (FPS) on a single NVIDIA RTX 2080 Ti GPU. The mIoU is divided into two types: the first number represents the mIoU on the Vaihingen dataset, and the second one represents the Potsdam dataset.
Assessment of performance on the Vaihingen dataset
The performance of the ICTANet model is further evaluated using the Vaihingen dataset and compared with some leading networks. From the evaluation results presented in , it can be found that the ICTANet model exhibits strong performance relative to other networks. Based on evaluation results, the ICTANet model achieves the highest segmentation accuracy in terms of F1-Score (91.7%), OA (91.9%), and mIoU (84.2%). Specifically, the ICTANet model effectively identifies buildings with an impressive 96.3% segmentation accuracy. This is due to the larger size and greater data volume of the buildings in the dataset, which enable the accurate capture of boundaries and enhance the stability of the proposed model. Additionally, the ICTANet model has achieved optimal segmentation accuracies for tree and car objects, underscoring its effectiveness in extracting irregular and small-scale ground objects. While the segmentation accuracy of impervious surfaces and low vegetation is relatively low compared with SwinB-CNN-BD (X. Zhang et al., Citation2022) and MFNet (Su et al., Citation2022), attributed to the challenges of distinguishing them from building or trees, the proposed model still achieved competitive performance compared to other networks. illustrates two cases (i.e. ID 11 and 2 in Vaihingen Dataset) to demonstrate that the ICTANet model can effectively segment fine-resolution remote sensing images with relatively high accuracy. In summary, ICTANet shows great potential for urban scene segmentation.
Figure 6. Segmentation results for ID 11 and 2 in the Vaihingen dataset. The first column represents the input RGB images. The second and third columns display the ground truth and the segmentation outcomes generated by the ICTANet model, respectively.
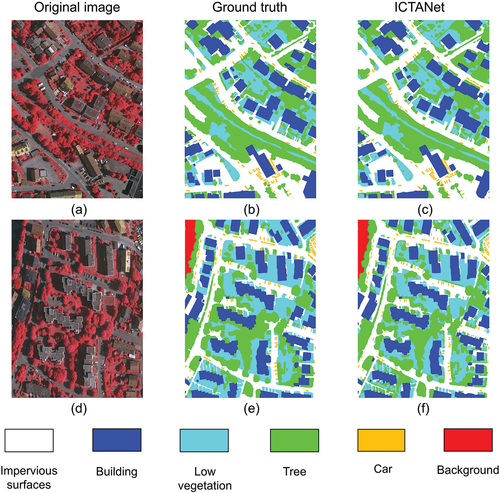
Table 6. Quantitative evaluation results on the Vaihingen testing dataset.
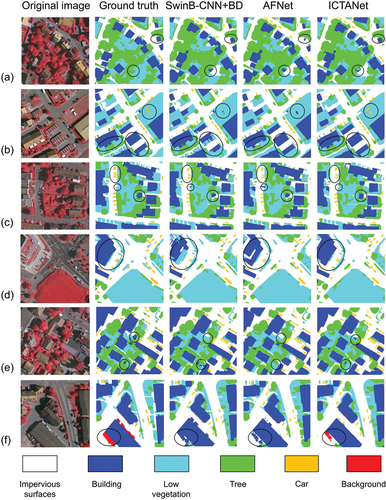
In , the segmentation details of the ICTANet model and other networks on the Vaihingen dataset are compared. The enlarged partial regions of the original remote sensing images and their corresponding ground truth labels are shown in the first and second columns, respectively. The third to fifth columns display the segmentation results from the Swin-B+BD model, the AFNet model (X. Yang et al., Citation2021), and the ICTANet model, respectively. As shown in the original images in , the tops of buildings and impervious surfaces exhibit similar texture characteristics due to their similar materials and the absence of height information in remote sensing images. Despite their similar features, the ICTANet model shows a relatively accurate ability to distinguish cement roads from low buildings with cement roofs. This can be attributed to the incorporation of the FEF module, which enables the learning and extracting of more comprehensive features from global and local contexts. As illustrated in rows (a) and (e) of , tree segmentation presents a significant challenge due to limited contextual and spatial information available to the network. The introduced ABD module in this study enhances the capability to capture relevant information, partially addressing challenges related to shadow occlusion in tree segmentation. The ICTANet model also achieves improved segmentation performance for small objects like cars partially occluded by tree and low vegetation shadows, as shown in . Even in scenes with dense car arrangements, the ICTANet model can effectively capture car boundaries under various conditions, thanks to the enhanced ability provide by the FEF and ABD modules. Additionally, the complex and compact ground features can be accurately distinguished by the ICTANet model to a certain degree (), resulting in closer alignment with the ground truths.
Figure 7. Comparison of segmentation results on the Vaihingen test dataset. The first column displays the enlarged original image. The second column represents the corresponding ground truth, with impervious surfaces, buildings, low vegetation, trees, cars, and the background denoted as white, blue, cyan, green, orange and red, respectively. The third, fourth, and fifth columns showcase instance segmentation results obtained through various methods.
Assessment of performance on the Potsdam dataset
The comparison of the segmentation accuracy between the ICTANet and other methods on the Potsdam dataset are listed in . The Potsdam dataset is characterized by its large size and diversity, enabling the proposed model to leverage the advantages of large-scale data and mitigate the risk of overfitting. It’s evident that the ICTANet model outperforms other methods, achieving optimal segmentation results. Due to their similar color characteristics, low vegetation and trees pose challenges in segmentation. Moreover, sparse low vegetation plants can be easily confused with the impervious surface category, potentially resulting in incorrect segmentation. Significantly, the segmentation accuracy of the ICTANet model for impervious surfaces is slightly inferior to that of AFNet, UPerNet (Y. Li et al., Citation2023) and MFNet, which excel in capturing and processing fine-scale textural in complex urban environments. Nevertheless, the ICTANet model excels in low vegetation and tree segmentations, demonstrating its capability to distinguish complex features. Compared to other objects, cars constitute a relatively small proportion in the image and are often obscured by shadows cast, buildings, and trees, posing a challenge to effective feature extraction. The segmentation accuracy of cars of the ICTANet model reaches 97.2%, demonstrating its capability to effectively discern subtle differences between classes. Despite a slight reduction in building segmentation accuracy (97.4%) compared to the UperNet model, the ICTANet model still achieves comparable performance with other methods. The slight decline in building segmentation may be caused by excessive recognition of uniform textures, resulting in over-segmentation. In contrast, the sensitivity of the UPerNet model to subtle texture variations enhances its building segmentation accuracy. In addition, the ICTANet model achieves a high accuracy of F1-Score (93.4%) and mIoU (88.4%), demonstrating the effectiveness of the dual encoder structure and FEF module proposed in this study. The ICTANet model accurately extracts and fuses available feature information from various objects, thereby enhancing the overall model segmentation performance to 92.0%. illustrates the prediction results for ID 3_12 and 4_11, further affirming the effectiveness of the ICTANet model in capturing intricate object details.
Figure 8. Visualization results of ID 3_12 and 4_11 from the Potsdam test set. The first column represents the input RGB images. The second column shows the ground truth, and the third column denotes the segmentation results of the ICTANet.
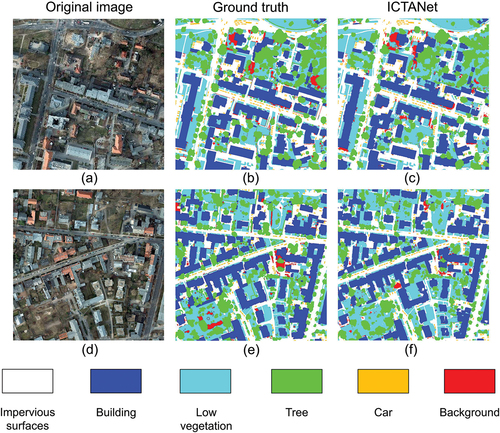
Table 7. Quantitative evaluation results on the Potsdam testing dataset.
illustrates the comparison of image segmentation details between the proposed model and other methods on the Potsdam dataset. The ICTANet model has demonstrated overall good accuracy in segmenting fine-resolution remote sensing urban images. As shown in rows (a) to (c) of , the ICTANet model performs relatively high accuracy in segmenting large-scale ground features, such as buildings and low vegetation. In addition, the ICTANet model enhances boundary detail recognition and reduces false segmentation issues caused by the background. Though distinguishing low vegetation from low buildings with rooftop lawns and impervious surfaces with lawns remains challenging, the ICTANet model achieves commendable segmentation results in these cases (rows (a) and (b)). This can be attributed to the self-attention mechanism’s capacity to extract global context information and the ability of Transformer module to capture long-term dependencies. Furthermore, in rows , the network demonstrates improved car segmentation. It successfully distinguishes various car types and demonstrates improved boundary accuracy for densely arranged small ground objects. The dual encoder structure of the ICTANet model facilitates the simultaneous learning and integration of both overall and detailed information. shows that the ICTANet model accurately identifies thin and long ground objects. The high inter-class similarity between low vegetation and trees often poses challenges in accurately identifying and distinguishing their boundaries. Nonetheless, the ICTANet model overcomes this challenge by employing the ABD module, which enhances boundary information and improves internal pixel object classification.
Figure 9. Comparison of segmentation results on the Potsdam test dataset. The first column displays the enlarged original image. The second column represents the corresponding ground truth, with impervious surfaces, buildings, low vegetation, trees, cars, and the background denoted as white, blue, cyan, green, orange, and red, respectively. The third, fourth, and fifth columns showcase instance segmentation results obtained through various methods.

Conclusions
In this study, Transformer-based network that combines convolutional operations and a self-attention mechanism is proposed for fine-resolution remote sensing urban image segmentation. A dual encoder structure is designed to extract both global context and local detail information from remote sensing images. Compared to typical hybrid CNN-transformer models, our approach introduces a Feature Extraction and Fusion module (FEF) to enhance network feature representation by optimizing and fusing local features and global representations at different stages. Additionally, an auxiliary boundary detection (ABD) module is added at the end of the model to enhance the extraction of object boundary information. As a result, the ICTANet model is not only effective in segmenting fine-resolution remote sensing urban images but also improve the performance for small objects.
Based on two publicly available fine-resolution remote sensing image datasets, namely, the ISPRS Vaihingen and Potsdam datasets, the ICTANet model effectively segments fine-resolution remote sensing urban images with relatively high accuracy. It achieves 91.9% (92.0%), 91.7% (93.4%), and 84.2% (88.4%) in terms of overall accuracy, F1-Score, and mean intersection over union on the Vaihingen (Potsdam) dataset. Compared to various other methods, the proposed model demonstrates competitive performance for large objects like buildings and low vegetation. The ICTANet model excels in accurately capturing the distribution and boundary details of small objects like cars and sparse trees, outperforming other methods. Comprehensive benchmark and ablation experiments further demonstrate the effectiveness and efficiency of the proposed method for fine-resolution remote sensing urban images.
However, balancing computational efficiency with performance remains crucial. There is potential to reduce the model size and improve inference speed in future studies. Future efforts should focus on reducing consumption cost while maintaining the efficiency and accuracy of the proposed model.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The datasets supporting this study’s findings are available on the website (https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/; https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/).
Additional information
Funding
References
- Abdollahi, A., & Pradhan, B. (2021). Integrated technique of segmentation and classification methods with connected components analysis for road extraction from orthophoto images. Expert Systems with Applications, 176, 114908. https://doi.org/10.1016/j.eswa.2021.114908
- Audebert, N., Le Saux, B., & Lefèvre, S. (2018). Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS Journal of Photogrammetry and Remote Sensing, Geospatial Computer Vision, 140, 20–18. https://doi.org/10.1016/j.isprsjprs.2017.11.011
- Cao, H., Wang, Y., Chen, J., Jiang, D., Zhang, X., Tian, Q., & Wang, M. (2023). Swin-Unet: Unet-like pure transformer for medical image segmentation. In L. Karlinsky, T. Michaeli, & K. Nishino (Eds.), Computer vision – ECCV 2022 workshops, lecture notes in computer science (pp. 205–218). Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-25066-8_9
- Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-end object detection with transformers. https://doi.org/10.48550/arXiv.2005.12872
- Caye Daudt, R., Le Saux, B., & Boulch, A. (2018). Fully convolutional siamese networks for change detection. 2018 25th IEEE International Conference on Image Processing (ICIP) Presented at the 2018 25th IEEE International Conference on Image Processing (ICIP) (pp. 4063–4067). https://doi.org/10.1109/ICIP.2018.8451652
- Chen, F., Jiang, H., Van de Voorde, T., Lu, S., Xu, W., & Zhou, Y. (2018). Land cover mapping in urban environments using hyperspectral APEX data: A study case in Baden, Switzerland. International Journal of Applied Earth Observation and Geoinformation, 71, 70–82. https://doi.org/10.1016/j.jag.2018.04.011
- Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., Lu, L., Yuille, A., & Zhou, Y. (2021). TransUnet: Transformers make strong encoders for medical image segmentation. arXiv. org. Retrieved May 11, 2021, from https://arxiv.org/abs/2102.04306v1
- Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2014). Semantic image segmentation with deep convolutional nets and fully connected CRFs [WWW document]. arXiv.org. Retrieved April 24, 2023, from https://arxiv.org/abs/1412.7062v4
- Chen, F., Wang, K., Van de Voorde, T., & Tang, T. F. (2017). Mapping urban land cover from high spatial resolution hyperspectral data: An approach based on simultaneously unmixing similar pixels with jointly sparse spectral mixture analysis. Remote Sensing of Environment, 196, 324–342. https://doi.org/10.1016/j.rse.2017.05.014
- Clark, M. L., & Kilham, N. E. (2016). Mapping of land cover in northern California with simulated hyperspectral satellite imagery. ISPRS Journal of Photogrammetry and Remote Sensing, 119, 228–245. https://doi.org/10.1016/j.isprsjprs.2016.06.007
- Coseo, P., & Larsen, L. (2019). Accurate characterization of land cover in urban environments: Determining the importance of including obscured impervious surfaces in urban heat island models. Atmosphere, 10(6), 347. https://doi.org/10.3390/atmos10060347
- Ding, L., Lin, D., Lin, S., Zhang, J., Cui, X., Wang, Y., Tang, H., & Bruzzone, L. (2022). Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 60, 1–13. https://doi.org/10.1109/TGRS.2022.3168697
- Ding, L., Zhu, K., Peng, D., Tang, H., Yang, K., & Bruzzone, L. (2024). Adapting segment anything model for change detection in VHR remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 62, 1–11. https://doi.org/10.1109/TGRS.2024.3368168
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2021). An image is worth 16x16 words: Transformers for image recognition at scale. https://doi.org/10.48550/arXiv.2010.11929
- Fu, J., Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z., & Lu, H. (2019). Dual attention network for scene segmentation. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3141–3149). https://doi.org/10.1109/CVPR.2019.00326
- Gao, L., Liu, H., Yang, M., Chen, L., Wan, Y., Xiao, Z., & Qian, Y. (2021). STransFuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14, 10990–11003. https://doi.org/10.1109/JSTARS.2021.3119654
- Griffiths, D., & Boehm, J. (2019). Improving public data for building segmentation from convolutional neural networks (CNNs) for fused airborne lidar and image data using active contours. ISPRS Journal of Photogrammetry and Remote Sensing, 154, 70–83. https://doi.org/10.1016/j.isprsjprs.2019.05.013
- He, K., Zhang, X., Ren, S., & Sun, J. (2015). Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(9), 1904–1916. https://doi.org/10.1109/TPAMI.2015.2389824
- Hou, Q., Cheng, M. M., Hu, X. W., Borji, A., Tu, Z., & Torr, P. (2019). Deeply supervised salient object detection with short connections. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(4), 815–828. https://doi.org/10.1109/TPAMI.2018.2815688
- Huang, X., Yuan, W., Li, J., & Zhang, L. (2017). A new building extraction postprocessing framework for high-spatial-resolution remote-sensing imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 10(2), 654–668. https://doi.org/10.1109/JSTARS.2016.2587324
- Huang, X., & Zhang, L. (2012). Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 5(1), 161–172. https://doi.org/10.1109/JSTARS.2011.2168195
- Hu, P., Perazzi, F., Heilbron, F. C., Wang, O., Lin, Z., Saenko, K., & Sclaroff, S. (2021). Real-time semantic segmentation with fast attention. IEEE Robotics and Automation Letters, 6(1), 263–270. https://doi.org/10.1109/LRA.2020.3039744
- Kampffmeyer, M., Salberg, A. B., & Jenssen, R. (2016). Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Presented at the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (pp. 680–688). https://doi.org/10.1109/CVPRW.2016.90
- Kemker, R., Salvaggio, C., & Kanan, C. (2018). Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS Journal of Photogrammetry and Remote Sensing, Deep Learning RS Data, 145, 60–77. https://doi.org/10.1016/j.isprsjprs.2018.04.014
- Kotaridis, I., & Lazaridou, M. (2021). Remote sensing image segmentation advances: A meta-analysis. ISPRS Journal of Photogrammetry and Remote Sensing, 173, 309–322. https://doi.org/10.1016/j.isprsjprs.2021.01.020
- Li, T., Jiang, C., Bian, Z., Wang, M., & Niu, X. (2020). Semantic segmentation of urban street scene based on convolutional neural network. Journal of Physics Conference Series, 1682(1), 012077. https://doi.org/10.1088/1742-6596/1682/1/012077
- Li, Y., Liu, Z., Yang, J., & Zhang, H. (2023). Wavelet transform feature enhancement for semantic segmentation of remote sensing images. Remote Sensing, 15(24), 5644. https://doi.org/10.3390/rs15245644
- Lin, T., Wang, Y., Liu, X., & Qiu, X. (2021). A survey of transformers [WWW document]. arXiv.org. Retrieved June 16, 2023, from https://arxiv.org/abs/2106.04554v2
- Liu, Q., Kampffmeyer, M., Jenssen, R., & Salberg, A. B. (2020). Dense dilated convolutions’ merging network for land cover classification. IEEE Transactions on Geoscience and Remote Sensing, 58(9), 6309–6320. https://doi.org/10.1109/TGRS.2020.2976658
- Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., & Guo, B. (2021). Swin transformer: Hierarchical vision transformer using shifted windows. 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Presented at the 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (pp. 9992–10002). https://doi.org/10.1109/ICCV48922.2021.00986
- Liu, Y., Minh Nguyen, D., Deligiannis, N., Ding, W., & Munteanu, A. (2017). Hourglass-ShapeNetwork based semantic segmentation for high resolution aerial imagery. Remote Sensing, 9(6), 522. https://doi.org/10.3390/rs9060522
- Liu, R., Tao, F., Liu, X., Na, J., Leng, H., Wu, J., & Zhou, T. (2022). RAANet: A residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images. Remote Sensing, 14(13), 3109. https://doi.org/10.3390/rs14133109
- Li, X., Xu, F., Xia, R., Lyu, X., Gao, H., & Tong, Y. (2021). Hybridizing cross-level contextual and attentive representations for remote sensing imagery semantic segmentation. Remote Sensing, 13(15), 2986. https://doi.org/10.3390/rs13152986
- Li, R., Zheng, S., Duan, C., Su, J., & Zhang, C. (2022). Multistage attention ResU-net for semantic segmentation of fine-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters, 19, 1–5. https://doi.org/10.1109/LGRS.2021.3063381
- Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3431–3440). https://doi.org/10.1109/CVPR.2015.7298965
- Ma, L., Liu, Y., Zhang, X., Ye, Y., Yin, G., & Johnson, B. A. (2019). Deep learning in remote sensing applications: A meta-analysis and review. ISPRS Journal of Photogrammetry and Remote Sensing, 152, 166–177. https://doi.org/10.1016/j.isprsjprs.2019.04.015
- Ma, X., Man, Q., Yang, X., Dong, P., Yang, Z., Wu, J., & Liu, C. (2023). Urban feature extraction within a complex urban area with an improved 3D-CNN using airborne hyperspectral data. Remote Sensing, 15(4), 992. https://doi.org/10.3390/rs15040992
- Mezaal, M. R., Pradhan, B., Shafri, H. Z. M., & Yusoff, Z. M. (2017). Automatic landslide detection using Dempster–Shafer theory from LiDAR-derived data and orthophotos. Geomatics, Natural Hazards and Risk, 8(2), 1935–1954. https://doi.org/10.1080/19475705.2017.1401013
- Mou, L., & Zhu, X. X. (2018). RiFCN: Recurrent network in fully convolutional network for semantic segmentation of high resolution remote sensing images. arXiv.org. Retrieved May 5, 2018, from https://doi.org/10.48550/arXiv.1805.0209
- Nogueira, K., Dalla Mura, M., Chanussot, J., Schwartz, W. R., & dos Santos, J. A. (2019). Dynamic multicontext segmentation of remote sensing images based on convolutional networks. IEEE Transactions on Geoscience and Remote Sensing, 57(10), 7503–7520. https://doi.org/10.1109/TGRS.2019.2913861
- Ok, A. O. (2013). Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS Journal of Photogrammetry and Remote Sensing, 86, 21–40. https://doi.org/10.1016/j.isprsjprs.2013.09.004
- Oršić, M., & Šegvić, S. (2021). Efficient semantic segmentation with pyramidal fusion. Pattern Recognition, 110, 107611. https://doi.org/10.1016/j.patcog.2020.107611
- Pan, X., Gao, L., Marinoni, A., Zhang, B., Yang, F., & Gamba, P. (2018). Semantic labeling of high resolution aerial imagery and LiDAR data with fine segmentation network. Remote Sensing, 10(5), 743. https://doi.org/10.3390/rs10050743
- Romera, E., Álvarez, J. M., Bergasa, L. M., & Arroyo, R. (2018). ERFNet: Efficient residual factorized ConvNet for real-time semantic segmentation. IEEE Transactions on Intelligent Transportation Systems, 19(1), 263–272. https://doi.org/10.1109/TITS.2017.2750080
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. In N. Navab, J. Hornegger, W.M. Wells, & A.F. Frangi (Eds.), Medical image computing and computer-assisted intervention – MICCAI 2015, lecture notes in computer science (pp. 234–241). Springer International Publishing. https://doi.org/10.1007/978-3-319-24574-4_28
- Samie, A., Abbas, A., Azeem, M. M., Hamid, S., Iqbal, M. A., Hasan, S. S., & Deng, X. (2020). Examining the impacts of future land use/land cover changes on climate in Punjab province, Pakistan: Implications for environmental sustainability and economic growth. Environmental Science and Pollution Research, 27(20), 25415–25433. https://doi.org/10.1007/s11356-020-08984-x
- Shamsolmoali, P., Zareapoor, M., Zhou, H., Wang, R., & Yang, J. (2021). Road segmentation for remote sensing images using adversarial spatial pyramid networks. IEEE Transactions on Geoscience and Remote Sensing, 59(6), 4673–4688. https://doi.org/10.1109/TGRS.2020.3016086
- Shen, Y., Chen, J., Xiao, L., & Pan, D. (2019). Optimizing multiscale segmentation with local spectral heterogeneity measure for high resolution remote sensing images. ISPRS Journal of Photogrammetry and Remote Sensing, 157, 13–25. https://doi.org/10.1016/j.isprsjprs.2019.08.014
- Strudel, R., Garcia, R., Laptev, I., & Schmid, C. (2021). Segmenter: Transformer for semantic segmentation. arXiv.org. Retrieved May 11, 2021, from https://doi.org/10.48550/arXiv.2105.05633
- Su, Y., Cheng, J., Bai, H., Liu, H., & He, C. (2022). Semantic segmentation of very-high-resolution remote sensing images via deep multi-feature learning. Remote Sensing, 14(3), 533. https://doi.org/10.3390/rs14030533
- Sun, Y., Tian, Y., & Xu, Y. (2019). Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning. Neurocomputing, 330, 297–304. https://doi.org/10.1016/j.neucom.2018.11.051
- Tang, L., & Werner, T. T. (2023). Global mining footprint mapped from high-resolution satellite imagery. Communications Earth & Environment, 4(1), 1–12. https://doi.org/10.1038/s43247-023-00805-6
- Tong, X. Y., Xia, G. S., Lu, Q., Shen, H., Li, S., You, S., & Zhang, L. (2020). Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sensing of Environment, 237, 111322. https://doi.org/10.1016/j.rse.2019.111322
- Ünsalan, C., & Boyer, K. L. (2005). A system to detect houses and residential street networks in multispectral satellite images. Computer Vision and Image Understanding, 98(3), 423–461. https://doi.org/10.1016/j.cviu.2004.10.006
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need [WWW document]. arXiv.org. Retrieved April 25, 2023, from https://arxiv.org/abs/1706.03762v5
- Vobecky, A., Hurych, D., Siméoni, O., Gidaris, S., Bursuc, A., Pérez, P., & Sivic, J. (2022). Drive & segment: Unsupervised semantic segmentation of urban scenes via cross-modal distillation. Proceedings of the European Conference on Computer Vision (ECCV), 13679, 478–495. https://doi.org/10.48550/arXiv.2203.11160
- Wang, Z., Chen, J., & Hoi, S. C. H. (2021). Deep learning for image super-resolution: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(10), 3365–3387. https://doi.org/10.1109/TPAMI.2020.2982166
- Wang, L., Li, R., Duan, C., Zhang, C., Meng, X., & Fang, S. (2022). A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters, 19, 1–5. https://doi.org/10.1109/LGRS.2022.3143368
- Wang, L., Li, R., Zhang, C., Fang, S., Duan, C., Meng, X., & Atkinson, P. M. (2022). UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS Journal of Photogrammetry and Remote Sensing, 190, 196–214. https://doi.org/10.1016/j.isprsjprs.2022.06.008
- Wang, J., Song, J., Chen, M., & Yang, Z. (2015). Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. International Journal of Remote Sensing, 36(12), 3144–3169. https://doi.org/10.1080/01431161.2015.1054049
- Wang, M., Zhang, X., Niu, X., Wang, F., & Zhang, X. (2019). Scene classification of high-resolution remotely sensed image based on ResNet. Journal of Geovisualization and Spatial Analysis, 3(2), 16. https://doi.org/10.1007/s41651-019-0039-9
- Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo, P. (2021). SegFormer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems (NeurIPS), 34, 12077–12090. https://doi.org/10.48550/arXiv.2105.15203
- Xing, J., Sieber, R., & Caelli, T. (2018). A scale-invariant change detection method for land use/cover change research. ISPRS Journal of Photogrammetry and Remote Sensing, 141, 252–264. https://doi.org/10.1016/j.isprsjprs.2018.04.013
- Yang, L., Huang, C., Homer, C. G., Wylie, B. K., & Coan, M. J. (2003). An approach for mapping large-area impervious surfaces: Synergistic use of Landsat-7 ETM+ and high spatial resolution imagery. Canadian Journal of Remote Sensing, 29(2), 230–240. https://doi.org/10.5589/m02-098
- Yang, X., Li, S., Chen, Z., Chanussot, J., Jia, X., Zhang, B., Li, B., & Chen, P. (2021). An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS Journal of Photogrammetry and Remote Sensing, 177, 238–262. https://doi.org/10.1016/j.isprsjprs.2021.05.004
- Yuan, Q., & Mohd Shafri, H. Z. (2022). Multi-modal feature fusion network with adaptive center point detector for building instance extraction. Remote Sensing, 14(19), 4920. https://doi.org/10.3390/rs14194920
- Yuan, Q., Shafri, H. Z. M., Alias, A. H., & Hashim, S. J. B. (2021). Multiscale semantic feature optimization and fusion network for building extraction using high-resolution aerial images and LiDAR data. Remote Sensing, 13(13), 2473. https://doi.org/10.3390/rs13132473
- Yu, B., Yang, L., & Chen, F. (2018). Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 11(9), 3252–3261. https://doi.org/10.1109/JSTARS.2018.2860989
- Zhang, B., Kong, Y., Leung, H., & Xing, S. (2019). Urban UAV images semantic segmentation based on fully convolutional networks with digital surface models. 2019 Tenth International Conference on Intelligent Control and Information Processing (ICICIP). Presented at the 2019 Tenth International Conference on Intelligent Control and Information Processing (ICICIP) (pp. 1–6). https://doi.org/10.1109/ICICIP47338.2019.9012207
- Zhang, X., Li, L., Di, D., Wang, J., Chen, G., Jing, W., & Emam, M. (2022). SERNet: Squeeze and excitation residual network for semantic segmentation of high-resolution remote sensing images. Remote Sensing, 14(19), 4770. https://doi.org/10.3390/rs14194770
- Zhang, Z., Liu, F., Liu, C., Tian, Q., & Qu, H. (2023). ACTNet: A dual-attention adapter with a CNN-transformer network for the semantic segmentation of remote sensing imagery. Remote Sensing, 15(9), 2363. https://doi.org/10.3390/rs15092363
- Zhao, H., Shi, J., Qi, X., Wang, X., & Jia, J. (2017). Pyramid scene parsing network. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 6230–6239). https://doi.org/10.1109/CVPR.2017.660