
ABSTRACT
Studies on French adults using a written lexical decision task with masked priming, in which targets were more primed by consonant- (jalu-JOLI) than vowel-related (vobi-JOLI) primes, support the proposal that consonants have more weight than vowels in lexical processing. This study examines the phonological and/or lexical nature of this consonant bias (C-bias), using a sandwich priming task in which a brief presentation of the target (pre-prime) precedes the prime-target sequence, a manipulation blocking lexical neighbourhood effects. Results from three experiments (varying pre-prime/prime durations) show consistent C-priming and no significant V-priming at earlier and later processing stages (50 or 66 ms primes). Yet, a joint analysis reveals a small V-priming, while confirming a significant consonant advantage. This demonstrates the contribution of the phonological level to the C-bias. Second, differences in performance comparing the classic versus sandwich priming task also establish a contribution of lexical neighbourhood inhibition effects to the C-bias.
Introduction
Nespor et al. (Citation2003) proposed that consonants and vowels play different roles in language acquisition and lexical processing in adults. More specifically, the proposal is that consonants are more important for word processing (learning and recognition; consonant bias, or C-bias, in lexical processing) while vowels are more important for prosodic and syntactic/structural processing (vowel bias, or V-bias, in prosodic/syntactic processing). This proposal led to many experimental studies being conducted in different languages and modalities, and at different points in development (from birth to adulthood) to evaluate these claims, specify the nature and scope of these biases and their origin (for recent reviews on the C-bias, see Nazzi & Cutler, Citation2019; and Nazzi et al., Citation2016). In the present study, we explore the relative role of consonants and vowels using a masked priming lexical decision task in the written modality, following up some work by New and colleagues on French (New et al., Citation2008; New & Nazzi, Citation2014). Using that task, these previous studies demonstrated a bias for consonants in visual word recognition as target word recognition was facilitated only when the primes preserved consonantal information (C-priming, jalu-JOLI), but not when they preserved vocalic information (vobi-JOLI). By varying the duration of presentation of the prime (33, 50 and 66 ms), they further established that these effects do not generate from the orthographic level, but from the phonological and/or lexical levels. The main goal of the present study was to further specify the relative contributions of the phonological and lexical levels. Secondly, we wanted to re-evaluate the question of whether vocalic information can speed up lexical access, given that previous studies only reported null or inhibition effects.
Many studies conducted on adult speakers of various languages (French, English, Dutch, Spanish) have demonstrated a C-bias in auditory lexical processing (Bonatti et al., Citation2005; Cutler et al., Citation2000; Delle Luche et al., Citation2014; Havy et al., Citation2014; van Ooijen, Citation1996; though no such evidence could yet be found for tone languages such as Mandarin and Cantonese, see Gómez et al., Citation2018; Poltrock et al., Citation2018; and Wiener & Turnbull, Citation2016; for a review, see Nazzi & Cutler, Citation2019; a reversed bias was even found in Mandarin, Wiener, Citation2020). For example, when being asked to transform a nonword into a real word by changing one phoneme, listeners tend to preserve the consonantal over the vocalic structure so that kebra would be changed into cobra rather than into zebra (Cutler et al., Citation2000; van Ooijen, Citation1996). Furthermore, data from brain-damaged individuals provide evidence for a differential processing of consonants and vowels (spelling: Buchwald & Rapp, Citation2006; repeating words: Caramazza et al., Citation2000; reading nonwords: Ferreres et al., Citation2003), suggesting distinct neural loci (see also neuroimaging studies, e.g. Carreiras & Price, Citation2008).
While the above studies establish a C/V asymmetry in lexical access, to the advantage of Cs in most languages, they do not specify at which processing level the observed C-bias originates. While it is difficult to disentangle the different levels using auditory tasks, recent studies suggest that written lexical decision tasks with priming allow such distinctions, and the present study will use such methodology to contribute to a clarification of the levels that are involved in the C/V lexical access asymmetry. Several studies on adults have explored the differential processing of consonants and vowels in the written modality using masked priming. This provides a direct way to study C/V differences in visual word recognition. Furthermore, and more importantly for our research questions, it allows certain experimental manipulations (of the primes, the targets and their timing of presentation) known to influence the processing levels which are mobilised in a given experimental condition (which cannot be done in an auditory task). These manipulations make it possible to specify the relative contribution of the orthographic, phonological and lexical levels. Within the extended interactive activation framework (Grainger & Ferrand, Citation1996; McClelland & Rumelhart, Citation1981), the perception of written nonword primes first activate sublexical orthographic units (letter representations) which, in turn, simultaneously feed forward to the sublexical phonological level (phoneme representations) and the lexical level (word representations). Importantly, this framework assumes that sublexical influences are mainly facilitatory (between-level facilitation), whereas activation of competing words in the lexicon (e.g. observed following longer prime exposure durations) are always inhibitory (within-level inhibition). Previous findings on French (Ferrand & Grainger, Citation1993) show that masked primes presented for 50 ms can activate both the sublexical orthographic and phonological levels (and possibly start activating the lexical level). While sublexical orthographic effects were found following shorter prime presentations (33 ms), only sublexical phonological effects were found following longer prime presentations (>60 ms) and “by 100 msec, both orthographic and phonological effects are absent, having been cancelled by within-level lexical inhibition” (Ferrand & Grainger, Citation1993, p. 122). The manipulation of prime exposure duration has been found to affect the observation of phonological and orthographic level effects in other studies as well. For example, Ziegler et al. (Citation2000) used 4 different prime durations (14, 29, 43, and 57 ms) and different prime-target overlaps (orthographic, phonological, and both) and found that the orthographic code activation precedes the phonological code activation by around 20–30 ms (see also Rastle & Brysbaert, Citation2006, for simulation data, and Grainger & Holcomb, Citation2009, for ERP data).
In using written modality tasks to explore a C/V asymmetry in lexical processing, note that one has to distinguish between tasks that require phonological access (for which a C-bias is predicted according to the Nespor et al., Citation2003, proposal) and tasks that do not. Regarding these non-phonological tasks, note that differences in C/V processing have also been found, for example in a letter search task (Acha & Perea, Citation2010a; whether C- or V-advantage depends on letter position) or a syllable/word length estimation task (Chetail & Content, Citation2012, Citation2014; V-advantage). Importantly, however, these tasks do not target lexical access so that the locus of such effects is presumably at the orthographic level. Additionally, C/V differences have also been found using a masked priming lexical decision task with transposed-letter primes: Testing Spanish-speaking adults, Perea and Lupker (Citation2004) found a facilitative effect when primes, presented for 47 ms, contained transposed nonadjacent consonants (caniso - CASINO), but not when primes contained transposed nonadjacent vowels (anamil - ANIMAL, see also Lupker et al., Citation2008, for English material). If it was at the phonological level, the C-bias hypothesis would predict the inverse pattern, namely faster word recognition in the consonant-preserving condition (like in anamil) than in the vowel-preserving condition. However, this transposed-letter priming effect is very likely orthographic as only transposed-letter primes (caniso) but not pseudohomophone primes (kaniso) speeded up lexical access (Acha & Perea, Citation2010b).
Going back to lexically-related tasks that involve phonological processing (Nazzi & Cutler, Citation2019; New & Nazzi, Citation2014) and for which a C-bias is expected, findings from the above studies leave open the issue of the locus of the C-bias in lexical processing when phonology is involved. Using a different approach, Comesaña et al. (Citation2016) found that the C/V asymmetry in a masked priming lexical decision task was present in skilled readers but not developing readers; since masked phonological priming is not yet in place in developing readers, they concluded that the effects found in skilled readers should originate from the phonological rather than the orthographic level. In a related but distinct line of experiments, using only consonant or vowel skeletons, Duñabeitia and Carreiras (Citation2011) demonstrated that consonant-only (csn - casino) but not vowel-only (aia - animal) primes facilitate target word recognition at both 50 ms and 33 ms prime exposure duration. The authors interpreted this as evidence for the orthographic nature of the C-bias, given the data obtained in lexical decision tasks with masked priming conducted in French, which had found only orthographic effects for shorter prime presentations (33 ms) and only phonological effects for longer prime presentations (>60 ms; Ferrand & Grainger, Citation1993). This inference is, however, questionable given that higher grapheme-phoneme transparency in Spanish than in French might result in an earlier phonological influence in Spanish compared to French.
Hence, the written-modality studies presented in the above section overall support the conclusion that the C/V asymmetry in lexical processing does not originate from the orthographic level. This is congruent with the fact that the C-bias in lexical processing has also been found both in auditory lexical priming tasks in adulthood (Delle Luche et al., Citation2014) and in word learning or word processing tasks in preliterate infants and children (Bouchon et al., Citation2015; Hochmann et al., Citation2011; Nazzi, Citation2005; Nishibayashi & Nazzi, Citation2016; Poltrock & Nazzi, Citation2015). What the previous studies have not done though is to explore whether the non-orthographic locus of the C/V processing asymmetry only relates to phonological processing, or whether it comes from the lexical level or both. Investigations into this issue were started in two studies using replaced-letter primes, which were conducted in French, the language tested in the present experiments (New et al., Citation2008; New & Nazzi, Citation2014). In the first study (New et al., Citation2008), four types of primes were presented for 50 ms; these primes either shared their consonants (e.g. duvo-DIVA) or their vowels (e.g. rifa-DIVA) with the targets, had no letter/phoneme overlap with the targets (e.g. rufo-DIVA), or were identical to the targets (e.g. diva-DIVA). A priming effect was observed for the consonant-related primes but not the vowel-related primes, demonstrating that consonants are more important than vowels in visual word recognition. To explore the level at which this effect originates, and given that the Ferrand and Grainger (Citation1993) findings of only orthographic effects for 33 ms prime presentations and only phonological effects for prime presentations longer than 60 ms had been found for the same language (French), New and Nazzi (Citation2014) reconducted New et al. (Citation2008) study using shorter (33 ms) or longer (66 ms) prime presentation. For the shorter prime condition, no processing difference was observed between consonant- and vowel-related primes, ruling out the interpretation of an orthographically-based bias. For the longer prime conditions (either 66 ms, or 50 ms followed by 16 ms of blank), a processing difference between consonant- and vowel-related primes was found, to the advantage of consonants. It also appeared that compared to the 50 ms condition (New et al., Citation2008), the consonant condition advantage over the vowel condition resulted from the fact that vowels inhibited target word recognition while consonants only had the tendency to facilitate it. In terms of processing levels, New and Nazzi (Citation2014) proposed that their pattern of findings might result from two distinct effects. The first one would correspond to a C-advantage originating from the phonological level, which was the original hypothesis of the authors and is consistent with the original proposal from Nespor et al. (Citation2003). However, they suggested that a second effect might originate from the lexical level (cf. Keidel et al., Citation2007, for a related proposal). This proposal was based on findings that in masked priming procedures, the size of shared neighbourhoods between a target and its prime will determine the size of the priming effect, with smaller facilitation found for larger shared neighbourhoods (for nonword primes in Dutch: Van Heuven et al., Citation2001; for word primes in English: Davis & Lupker, Citation2006). As mentioned above, in the interactive activation model, these effects are thought of as by-products of inhibition mechanisms within the lexicon (McClelland & Rumelhart, Citation1981). Shared phonological neighbourhood analyses of the New and Nazzi (Citation2014) stimuli revealed that on average for all targets, vocalic primes shared their vocalic skeleton with 250 other words besides the target while the consonant primes shared their consonantal skeleton with only 32 neighbours, an asymmetry also reported for the French lexicon in previous studies (Delle Luche et al., Citation2014; Keidel et al., Citation2007; Nazzi & New, Citation2007).Footnote1
The authors proposed that this marked imbalance in shared neighbourhoods might combine with the phonological consonant advantage to explain their results at 50 and 66 ms in the following way. At 50 ms, sublexical phonological activation of consonant units paired with just-emerging lexical inhibitory influences from small-sized neighbourhoods would result in facilitatory priming from consonant-related primes; on the other hand, the lack of priming by vowel-related primes would result either from no or reduced phonological activation of vowels, or because such sublexical facilitation is present but cancelled by inhibitory influences from large-sized neighbourhoods. At 66 ms, changes in the effects observed would be due to increased lexical inhibition, which would have had more time to develop, giving rise to more inhibition in particular for the vowel-related primes. This would explain both the small consonant-related facilitation and the vowel-related inhibition compared to the results at 50 ms.
While the above explanation fits the findings rather well, it leaves several unanswered questions that the present study starts addressing. In particular, while phonologically-based consonant-related priming is needed to explain the pattern of priming at 50 ms, it is unclear whether such an effect is still present at 66 ms. Moreover, no vowel-related priming was ever found in the previous experiments, and it is unclear whether this is due to the fact that vowels have no facilitatory effect at the phonological level, or whether such effects were consistently masked by inhibition from large shared skeleton neighbourhoods, whether the prime was 50 or 66 ms long.
In the present study, we explore these issues by using a “sandwich priming” task, a modification of the masked priming paradigm that has been shown to eliminate or at least considerably minimise the impact of lexical inhibition in the process of activating the target (Lupker & Davis, Citation2009; Stinchcombe et al., Citation2012). Compared to the classic priming technique used by New and colleagues, in the “sandwich priming” technique, the target is briefly presented (for 33 ms) before the prime-target sequence. As a result, the target is therefore pre-activated, which would boost its activation in comparison to other candidates from the shared neighbourhood activated by the prime-target sequence, which would then limit lexical inhibition when recognising the target. Therefore, differences found between different priming conditions (here, the consonant- and vowel-related conditions) would signal effects from the sublexical phonological level and not/less from lexical competition. Note that there are different explanations for the increase of priming in the sandwich technique (see Trifonova & Adelman, Citation2018, who proposed that prelexical processes drive the boost) and regarding whether the two techniques explore identical or slightly different processes, as suggested by Fernández-López et al. (Citation2021). Additional work is clearly needed to specify these issues, although Fernández-López et al. (Citation2021) encourage researchers to continue using the sandwich technique, as we do here.
Experiment 1 assessed phonological effects in determining the C-bias following a 50 ms prime (as done by New et al., Citation2008), and here the prime was preceded by a 33 ms pre-prime corresponding to the target, hence following Lupker and Davis (Citation2009). Since the sandwich paradigm is expected to block lexical effects, we predict that a C-bias should be observed in this condition, as in New et al. (Citation2008), if consonants prime lexical access more than vowels at the phonological level. It will also be of interest to determine whether some vocalic priming is obtained in this condition, contrary to what was found using the classic priming paradigm. This will bear on the issue of whether the lack of vocalic priming previously reported is due to a lack of vocalic priming at the phonological level, or a combination of phonological priming with equally strong inhibition effects from the lexicon.
Experiment 1 (pre-prime: 33- prime: 50 ms)
Method
Participants
Forty-eight students from the Université Savoie Mont-Blanc took part in the experiment. They were all native French speakers and had normal or corrected-to-normal vision.
Stimuli and design
The targets were 60 of the 64 French words used as targets by New et al. (Citation2008): 15 CVCV, 15 VCVC, 15 CVCVCV, and 15 VCVCVC. Targets were presented in uppercase and were preceded by primes in lowercase. Primes had the same orthographic and phonological structure as the target. For each target, three types of primes were selected: 1) Non-word prime sharing all consonants with the target (duvo - DIVA), 2) non-word prime sharing all vowels with the target (rifa - DIVA) and 3) unrelated prime (rufo - DIVA). Primes and targets were chosen so that there was a one-to-one correspondence between letters and phonemes. Moreover, French is relatively transparent from graphemes to phonemes (while the opposite is not true), and there were no grapheme-to-phoneme ambiguities in our stimuli. Compared to New et al. (Citation2008), we did not include the identity condition because in the current experiment, the prime was likely to be more visible (given the presentation of the pre-prime) and this could have attracted the attention of the participants.
We also used 60 fillers from which 12 were 4-letter words, 36 were 5-letter words, and 12 6-letter words, also taken from New et al. (Citation2008). This was done to prevent the participant from guessing the manipulation in the experiment. Without fillers, the participants might have rapidly noticed the repeating syllable structures which could provoke specific reading strategies. Moreover, 120 pseudowords were taken from New et al. (Citation2008), which respected French phonotactics rules and had the same proportion of various orthographic/phonological structures as the words (targets and distractors). Two out of three fillers or pseudowords were preceded by unrelated primes and one out of three were preceded by partially related primes. Three experimental lists were constructed in which prime-target pairs were rotated according to a Latin-square design, so that a given target was primed by one type of prime in each list, and by all the different types of prime across the 3 lists. Each participant was presented with only one list.
Procedure
Participants were tested individually in a quiet room. They were asked to indicate as quickly and accurately as possible whether the presented letter string appearing on the computer screen formed an existing French word or not. They did so by pressing one of two buttons of a response pad. They used their dominant hand to respond “yes”. Each trial began with the presentation of the mask (######) during 500 ms. It was followed by the target presented in uppercase during 33 ms and then, by the prime presented in lowercase during 50 ms. Finally, the prime was followed by the target in uppercase which remained visible until the participant responded (with a maximum presentation of 3s). Between trials, there was a 1300 ms black screen interval. The order of presentation of the stimuli was randomised anew for each participant and presented with the E-Prime 1.2 software (Psychology Software Tools) on a CRT screen having a 60Hz refresh rate. The test items were preceded by twenty practice trials. The participants could take a short break after each block of 80 trials. The experiment lasted approximately 20 min.
Results and discussion
Reaction times (RTs, latency) and response accuracy (proportion of correct responses) were analyzed. Only RTs of correct responses were included in the latency analysis and, additionally, any RTs faster than 300 ms or slower than 1,400 ms were identified as outliers and removed (0.99% of the RTs, all being slower than 1,400 ms). These cutoffs were the same as those used by New et al. (Citation2008) and New and Nazzi (Citation2014). Then, for each subject, RTs of more than two and a half standard deviations above or below the mean were also discarded (2.67% of the RTs). Mean RTs (in ms) and response accuracy (in %) together with their standard deviations for the three priming conditions are shown in for the sandwich (present experiment) and classic (New et al., Citation2008) priming task. We carried out two linear mixed-effects models (lme) on the log-transformed RTs (log10) using the function lmer of the R package lm4, with random intercept effects for participants and items (Bates, Maechler, Bolker, & Walker, Citation2015), and the package languageR (Baayen & Shafaei-Bajestan, Citation2019) to obtain p-values.
Table 1. Mean lexical decision reaction times (in ms; SDs in brackets) and response accuracy (in %, SDs in brackets) for 50 ms primes, in the classic (New et al., Citation2008) versus sandwich priming task (present Exp. 1) and for 66 ms primes, in the classic (New & Nazzi, Citation2014, Exp. 2) versus sandwich priming tasks (present Exp. 2–3).
A first model focused on the sandwich priming task and included, according to the analyses of New et al. (Citation2008) and New and Nazzi (Citation2014), the fixed effects of Prime Type (compared in sliding contrasts: consonant-related vs. unrelated; unrelated vs. vowel-related), Target Type (targets beginning with a consonant or a vowel),Footnote2 and the interaction between Prime Type and Target Type. We specified those two contrasts for Prime Type (consonant- and vowel-related against the unrelated condition, respectively) in order to assess vowel- and consonant-priming separately in the model. Additionally, the vowel- and consonant-related conditions were compared using the emmeans package (Lenth, Citation2021; corrected for multiple comparisons using the Holm–Bonferroni procedure). The model coefficients (β), their estimated standard errors (SE), t-scores and the respective p-values for the fixed effects are provided in . We found a C-priming effect (β = 0.025, SE = 0.003, t = 7.08, p < .001) with shorter reaction times for the consonant-related trials than for unrelated trials (see , left panel). Differences between the vowel-related and the unrelated condition did not reach significance (p = .09). The direct comparison between the consonant- and vowel-related condition revealed significantly faster latencies for C-primes than for V-primes (t(2254) = 5.332, p < .001). Lastly, neither a main effect of Target Type nor an interaction effect with Target Type was found (t < 1).
Figure 1. Effect of consonant and vowel priming as a function of prime duration and paradigm type: 50 ms (classic vs. sandwich, Experiment 1) and 66 ms (classic vs. sandwich 33 ms pre-prime in Experiment 2 vs. sandwich 50 ms pre-prime in Experiment 3). Error bars indicate standard errors of the mean.
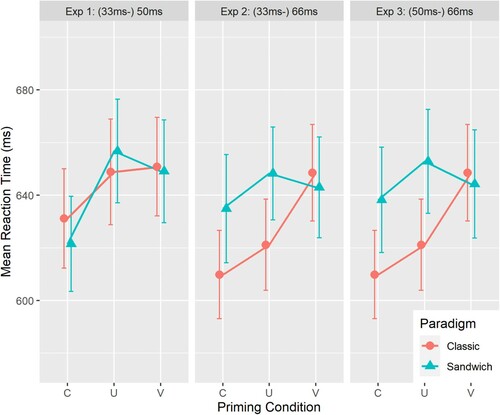
Table 2. Results of model 1 including Prime Type and Target Type as fixed factors (sandwich experiments). The R formula was: log10(RT) ∼ TypeCV * Prime + (1|Subject) + (1|Word).
Although it has been shown that masked priming effects are not modulated by word frequency in behavioural data (e.g. Grainger et al., Citation2012), we decided to add lexical and phonological frequency measures to the model, as suggested by a reviewer, to check whether the relative consonant–vowel priming effect might be affected by those frequency measures. Both lexical frequency (estimated by film subtitles; www.lexique.org) and phonological frequency (calculated as averaged frequency of the word’s phonemes according to their position in the word (initial, middle, final) and by token) were log-transformed (log10), scaled and centred before entering the model. We found a significant main effect for lexical frequency (β = −0.013, SE = 0.004, t = −3.45, p < .01) in the expected direction (the more frequent the target word the faster the RTs), though not for phonological frequency (t < 1). Neither lexical nor phonological frequency interacted with the relative priming effect (both ps > .41), in line with prior data on non-modulation of masked priming effects in behavioural experiments.
For the accuracy analysis, a generalised lme (gmler function in the lme4 package) with binomial variance and logistic link function was used, and the specified contrasts were identical to the ones in the latency analysis (sliding contrasts for Target Type: C- vs. V-initial words; and Prime Type: C-U consonant priming, V-U vowel priming; with by-subjects and by-items intercepts). It revealed a significant interaction effect of Target Type and consonant priming (β = 0.632, SE = 0.305, z = 2.075, p = .04) with higher accuracy rates for C-related primes than for unrelated primes in C-initial words (meanC-related = 92.1%; meanunrelated = 88.1%, z = 2.462, p = .01) but not in V-initial words (meanC-related = 79.8%; meanunrelated = 81.7%, z < 1); no other (main or interaction) effects were found (all ps > .10).
In order to compare our present sandwich priming results with those obtained using the classic priming paradigm (New et al., Citation2008) in which 50 ms primes were also used (reported here in ), a second model on RTs included Prime Type and Paradigm Type and their interaction as fixed effects and again participants and items as random effects. Since no effect on RTs was found for Target Type in neither the sandwich nor the classic priming task, this factor was not included. Prime Type comparisons were again implemented as a sliding contrast (consonant-related vs. unrelated; unrelated vs. vowel-related); the Paradigm Type comparison was implemented as a treatment contrast. As treatment contrasts automatically use the first level as the reference group (here it was set to “Classic Paradigm”), the model output for the factor Prime Type thus refers to the mean of the classic paradigm data. This was done to replicate the results for the Classic Paradigm when analyzing all items, log-transformed RTs and a linear mixed-effects model instead of untransformed RTs and F1/F2 ANOVAs that have been reported by New et al. (Citation2008).
The model coefficients (β), standard errors (SE), t- and p-values are provided in . For the classic priming paradigm, targets preceded by consonant-related primes were responded to faster than targets preceded by unrelated primes (β = 0.011, SE = 0.004, t = 2.85, p = 0.004), whereas no difference was found between vowel-related and unrelated primes (t < 1). The direct comparison between the consonant- and vowel-related condition in the classic paradigm (using the emmeans package, Holm–Bonferroni corrected) revealed significantly faster latencies for C-primes than for V-primes (z = −3.625, p = .004). This confirms the pattern that has been reported in New et al. (Citation2008). There was no main effect of Paradigm Type; yet Paradigm Type interacted significantly with consonant priming (β = 0.014, SE = 0.005, t = 2.82, p = 0.005) and there was a non-significant but marginal interaction with vowel priming (β = −0.009, SE = 0.005, t = −1.88, p = 0.06).
Table 3. Results of model 2 including Prime Type and Paradigm Type as fixed factors (comparing classic and sandwich experiments). The R formula was: log10(RT) ∼ Prime * Experiment + (1|Subject) + (1|Word).
The analyses on the accuracy data first included Target Type, Prime Type (sliding contrasts) and Paradigm Type (treatment contrast) with by-subjects and by-items intercepts. However, this model did not converge, therefore the presented results are from the model excluding the factor Target Type. For the classic paradigm, a main effect of vowel priming was found (β = −0.367, SE = 0.165, z = −2.23, p = .03) with significantly lower accuracy rates for vowel-related primes (82.3%) than unrelated primes (85.7%). Note that this vowel-disadvantage has not been found with the F1/F2 analysis in New et al. (Citation2008). There was again no main effect of Paradigm Type, but there was a non-significant but marginal interaction between Paradigm Type and vowel priming (β = 0.387, SE = 0.220, z = 1.76, p = 0.08).
The present findings using 50 ms primes demonstrate similar priming effects when using a classic priming paradigm and a sandwich priming paradigm blocking lexical inhibition effects. In particular, in both paradigms, we find a C-bias marked by priming from consonant- but not from vowel-related primes. Importantly, however, consonants gave significantly more priming in the sandwich paradigm as compared to the classic paradigm. This pattern of results provides evidence that the sandwich priming technique worked and suggests that this early C/V priming asymmetry comes from a combination of a privileged processing of consonantal information at the phonological level (facilitatory priming in the classic paradigm) which is complemented by effects at the lexical level (boost in lexical access due to lexical preactivation of the target by the pre-prime and blocking of inhibition effects of the lexical neighbourhood in the sandwich paradigm).
Even though vowels show a tendency (p = .06) to also profit from blocking neighbourhood effects, this effect fails to reach significance, and again, no priming effect from vocalic information is found at 50 ms with the sandwich technique. In light of the effects found for consonants, this pattern of results suggests that there is no phonological boost from vowels at 50 ms, even when, as in the sandwich paradigm, neighbourhood inhibition effects are blocked or at least reduced. Yet, because of the marginal interaction, we considered the possibility that a phonological boost from vowels might be observed in the sandwich paradigm at a later processing stage.
Accordingly, Experiment 2 assessed phonological effects in determining the C-bias at a later stage of lexical processing, that is, following a 66 ms prime, again using the sandwich paradigm and a 33 ms pre-prime. Using the classic priming paradigm with 66 ms primes, New and Nazzi (Citation2014) had found a C-bias due to reduced priming by consonants (compared to the finding using 50 ms primes) and strong inhibition by vowels (compared to null effects using 50 ms primes), changes which they had interpreted as resulting from lexical neighbourhood effects, in particular for the vowel-related inhibition. Since the sandwich paradigm blocks lexical neighbourhood effects, we predict that the results in Experiment 2 should differ from those of New and Nazzi (Citation2014), with more priming from consonants, and less inhibition or even facilitation from vowels. If the C-bias found at 66 ms by New and Nazzi (Citation2014) was still at least in part due to phonological effects, then we should replicate a C-bias. Whether some vocalic priming would be found in this condition blocking lexical inhibition will also be evaluated.
Experiment 2 (pre-prime: 33- prime: 66 ms)
Method
Participants
Forty-eight students from the Université Savoie Mont-Blanc took part in the experiment. They did not participate in Experiment 1 and were all native French speakers and had normal or corrected-to-normal vision.
Stimuli and design
The stimuli were the same as in Experiment 1.
Procedure
The procedure was the same as in Experiment 1 except that the targets were presented for 66 ms.
Results and discussion
Reaction times (RTs, latency) and response accuracy (proportion of correct responses) were analyzed. Again, only RTs of correct responses were included in the latency analyses and any RTs faster than 300 ms or slower than 1,400 ms were identified as outliers and removed (0.99% of the RTs, all being slower than 1,400 ms). Then, for each subject, response times of more than two and a half standard deviations above or below the mean were also discarded (2.45% of the RTs).
As for Experiment 1, a first model analyzed the sandwich priming data and included the fixed effects of Prime Type, Target Type and the interaction between Prime Type and Target Type. For the latency analysis, the model coefficients (β), their estimated standard errors (SE), t-scores and the respective p-values for the fixed effects are provided in . We found a C-priming effect (β = 0.011, SE = 0.003, t = 3.25, p = 0.001) with shorter RTs for the consonant-related trials than for unrelated trials (see , middle panel). Differences between the vowel-related and the unrelated condition were not significant. The direct comparison between the consonant- and vowel-related condition (emmeans package, Holm–Bonferroni corrected) revealed non-significant but marginal faster latencies for C-primes than for V-primes (t(2289) = −2.02, p = .09). Neither a main effect of Target Type nor an interaction effect with Target Type was found (t < 1). An additional analysis (conducted as described for Experiment 1) verified that neither lexical nor phonological frequency interacted with relative C-V priming (both ps > .19), again confirming the non-modulation of masked-priming effects by frequency.
The analysis on the accuracy data revealed a main effect of Target Type (β = −0.882, SE = 0.422, z = −2.09, p = .04) with lower accuracy rates for V-initial (80.5%) than C-initial words (91.5%); no other effects were found (all ps > .20).
The second model including Prime Type and Paradigm Type compared the sandwich priming results with those obtained using the classic priming paradigm (New & Nazzi, Citation2014, see for mean RTs and accuracy in both paradigms). For the latency analysis, the output for the fixed effects of model 2 is given in . Within the classic paradigm, targets preceded by consonant-related primes were processed significantly faster than targets preceded by unrelated primes (β = 0.010, SE = 0.004, t = 2.54, p = 0.01). Targets preceded by vowel-related primes were processed significantly slower than those preceded by unrelated primes (β = 0.017, SE = 0.004, t = 4.25, p < 0.001). The direct comparison between the consonant- and vowel-related condition in the classic paradigm (using the emmeans package, Holm–Bonferroni corrected) revealed significantly faster latencies for C-primes than for V-primes (z = −6.75, p < .001). This confirms the basic pattern that has been reported in New and Nazzi (Citation2014, Exp. 2) with the difference that here the marginal C-priming effect from 2014 turned out to be a significant effect using mixed-models and log-transformed RTs. No overall RT differences between the sandwich and the classic paradigm were obtained overall (p = .17), however, Paradigm Type interacted significantly with vowel priming (β = −0.022, SE = 0.005, t = −4.11, p < 0.001), though not with consonant priming (t < 1).
The analysis on the accuracy data revealed a main effect of vowel priming in the classic paradigm (β = −0.598, SE = 0.154, z = −3.89, p < .001) with lower accuracy rates for V-related (77.1%) than unrelated primes (83.7%). The direct C-V comparison (using the emmeans package, Holm–Bonferroni corrected) revealed also significantly lower accuracy rates for V-primes than C-primes (z = −6.75, p < .001). Paradigm Type interacted marginally with vowel-priming (β = 0.406, SE = 0.213, z = 1.91, p = .06), but not with consonant-priming (z < 1). In sum, the sandwich paradigm mainly affected vowel priming at 66 ms primes as reflected in both latency (no inhibition effect anymore) and accuracy data (equal error rates).
The fact that the different types of primes did not have the same effect in the two experimental paradigms suggests, again, that the presentation of the pre-prime did have an effect on processing. However, this effect appears to differ for consonants and vowels. Since the sandwich paradigm reduces lexical neighbourhood inhibitory effects, the interaction results suggest that lexical inhibition was significantly reduced but only for vowel-related primes. The larger effect for vowels could be due to the larger size of the lexical neighbourhoods for the vowel-related primes compared to the consonant-related primes. Why no significant effect of paradigm type could be observed for consonants at 66 ms (while it could be observed at 50 ms, Exp. 1) is unclear, but suggests that the time course of phonological and lexical effects might partly differ for consonants and vowels.
However, since inhibition was particularly strong for vowels at 66 ms in the classic priming paradigm, and since that inhibition was cancelled but did not give rise to priming in the sandwich paradigm (as would be expected if vowels can also provide a phonological boost), we decided to explore the possibility that the 33 ms pre-primes were not of ideal duration for the longer 66 ms primes, and conducted a further experiment, in which we replicated Experiment 2 using a 50 ms pre-prime which should limit even more the potential influence of lexical neighbours.
Experiment 3 (pre-prime: 50 – prime: 66 ms)
Method
Participants
Forty-eight students from the Université Savoie Mont-Blanc took part in the experiment. They did not participate in Experiments 1 and 2, and were all native French speakers and had normal or corrected-to-normal vision.
Stimuli and design
The stimuli were the same as in Experiment 2.
Procedure
The procedure was the same as in Experiment 2 except that the pre-primes were presented for 50 ms.
Results and discussion
Reaction times (RTs, latency) and response accuracy (proportion of correct responses) were analyzed. Again, only response times of correct responses were included in the analyses. In addition, any RTs faster than 300 ms or slower than 1,400 ms were identified as outliers and removed (0.99% of the RTs, all being slower than 1,400 ms). Then, for each subject, RTs of more than two and a half standard deviations above or below the mean were also discarded (2.62% of the RTs).
For the latency analysis, the coefficients (β, SE, t-scores, p-values) for the fixed effects of the first model including Prime Type, Target Type and the interaction between Prime Type and Target Type are provided in . Within the sandwich paradigm, we found a C-priming effect (β = 0.009, SE = 0.003, t = 2.65, p = 0.008) with shorter reaction times for the consonant-related trials than for unrelated trials (see , right panel). Differences between the vowel-related and the unrelated condition were not significant (t = −1,47; p = 0.14). The direct C-V comparison revealed no differences between the consonant- and vowel-related conditions (Holm–Bonferroni corrected, t(2256) = −1.18, p = .28). Neither a main effect of Target Type nor an interaction effect with Target Type was found. An additional analysis (conducted as described for Experiment 1) verified that neither lexical nor phonological frequency interacted with relative C-V priming priming (both ps > .22), again confirming the non-modulation of masked-priming effects by word frequency.
The analysis on the accuracy data did not show any significant main or interaction effect (all ps > .11).
The second model compared the sandwich priming results with those obtained using the classic priming paradigm (New & Nazzi, Citation2014, see for mean RTs and response accuracy and their SDs). The output for the fixed effects of model 2 is given in for the latency analysis. The results within the classic paradigm are identical to what have been reported for Experiment 2 earlier as it is the same data set: significant C-priming and significant V-inhibition. No overall RT differences between the sandwich and the classic paradigm were obtained overall (t = 1.37, p = 0.17). However, Paradigm Type interacted again significantly with vowel priming (β = −0.022, SE = 0.005, t = −4.26, p < 0.001), though not with consonant priming (t < 1).
The accuracy analysis revealed (as for Experiment 2) a main effect of vowel priming in the classic paradigm (β = −0.625, SE = 0.157, z = −3.982, p < .001; with lower accuracy rates for V-related 77.1%, than unrelated primes 83.7% or C-primes 84.0%). Paradigm Type interacted significantly with vowel-priming (β = 0.478, SE = 0.218, z = 2.19, p = .03), but not with consonant-priming (z < 1). In sum, the sandwich paradigm mainly affected vowel priming at 66 ms primes as reflected in both latency (no inhibition effect anymore) and accuracy data (equal error rates).
Like the results of Experiment 2, the present results show that the presentation of the pre-prime had an impact on processing, suggesting that some of the effects found in New and Nazzi (Citation2014) were due to lexical neighbourhood inhibition processes, which are blocked in the present experiment by the sandwich manipulation. Importantly though, confirming the result observed in Experiment 1 and 2, we find here that consonant-related primes facilitate lexical decision. This demonstrates that consonants still provide a phonological boost in lexical access at 66 ms, as found at 50 ms in Experiment 1. Moreover, we again fail to find vowel-related priming, even at this later processing stage (66 ms) and in this condition of reduced lexical neighbourhood inhibition. At the same time, the vowel inhibition found at 66 ms using the classic priming paradigm is not present anymore, confirming the interpretation in terms of lexical neighbourhood effect proposed by New and Nazzi (Citation2014).
Joint analysis
In order to increase statistical power and to compare the results obtained in the current three sandwich experiments using different pre-prime and prime durations (Exp1: 33-50 ms, Exp 2: 33–66 ms, Exp3: 50–66 ms), a joint sandwich analysis was conducted including Prime Type (again, contrasts were defined as C-U and V-U) and experimental version (sliding contrast: Exp1-Exp2; Exp2-Exp3) as fixed effects and by-subjects (N = 144) and by-items intercepts (n = 60). The latency analysis showed a significant overall consonant-priming effect (β = −0.016, SE = 0.002, t = 7.70, p < 0.001) with faster RTs for consonant-related (mean RTs = 631 ms) than for unrelated primes (mean RTs = 653 ms) and a significant overall vowel-priming effect (β = 0.005, SE = 0.002, t = −2.67, p = .008) with faster RTs for vowel-related (mean RTs = 645 ms) than unrelated primes. The difference between consonant- and vowel-related primes (−14 ms) also reached significance (z = −5.00, p < .001, Holm–Bonferroni corrected) confirming an overall consonant over vowel advantage. Experimental version did not show any main effects (ps > .82), but there was a significant interaction of consonant-priming and experimental version (β = 0.014, SE = 0.005, t = −2.80, p = .005) with a greater consonant-priming in Experiment 1 (−36 ms) than in Experiment 2 (−13 ms). No other effects reached significance (ps > .65). Lastly, the accuracy analysis revealed no significant effects (ps > .20). In sum, with increased statistical power, vowel-priming is found when applying the sandwich procedure while the overall consonant-advantage is confirmed.
To compare the results obtained in the sandwich experiments with the results obtained in the two classic experiments, a second model including Paradigm Type (again specified as a treatment contrast with “classic paradigm” defined as reference group) and Prime Type (sliding contrasts: C-U, V-U) as fixed effects and by-subjects (N = 192) and by-items intercepts (n = 64) was conducted. Note that the third sandwich experiment (50–66 ms) was excluded for this analysis in order to evaluate the paradigm effect in a balanced design (2 experiments per paradigm, with 50 and 66 ms primes each). The latency analysis showed for the classic paradigm (merged for the two experimental versions) an overall consonant-priming effect (β = 0.010, SE = 0.003, t = 3.76, p < 0.001) with faster RTs for consonant-related (mean RTs = 620 ms) than for unrelated primes (mean RTs = 635 ms) and a significant overall vowel-inhibition effect (β = 0.010, SE = 0.003, t = 3.60, p < .001) with slower RTs for vowel-related (mean RTs = 650 ms) than unrelated primes. The difference between consonant- and vowel-related primes (−30 ms) also reached significance (z = −7.29, p < .001, Holm–Bonferroni corrected) confirming an overall consonant over vowel advantage in the classic paradigm. The main effect of Paradigm Type was not significant (t = 1.06, p = .29), but Paradigm Type interacted significantly with vowel-related priming (β = −0.016, SE = 0.004, t = −4.25, p < .001) confirming that the vowel-inhibition effect (+15 ms) in the classic paradigm turned into a vowel-facilitation effect (−6 ms) in the sandwich paradigm. The interaction between consonant-related priming and Paradigm Type was also significant (β = 0.008, SE = 0.004, t = 2.23, p = .03) with a bigger consonant priming in the sandwich (−24 ms) as compared to the classic paradigm (−15 ms). Moreover, the C-V difference was significantly bigger in the classic (−30 ms) than in the sandwich (−18 ms) paradigm (β = −0.008, SE = 0.004, t = −2.03, p < .04).
The accuracy analysis revealed for the classic paradigm (again, merged for the two experimental versions) a significant vowel-inhibition effect (β = −0.488, SE = 0.113, z = −4.31, p < .001) with lower response accuracy for vowel-related primes (mean accuracy = 79.7%) than unrelated primes (mean accuracy = 84.7%). The consonant-related condition (mean accuracy = 84.8%) did not differ from the unrelated condition (z < 1), but from the vowel-related condition (z = 4.42, p < .001, Holm–Bonferroni corrected). Both paradigms did not differ in their mean response accuracies (z < 1), but there was a significant interaction of Paradigm Type and vowel-related priming (β = 0.399, SE = 0.154, z = 2.60, p < .01) though not with consonant-related priming (z < 1). This pattern of results confirms that the vowel-disadvantage found in the classic paradigm (−5%) was not there anymore in the sandwich paradigm (−1%). Taking the joint latency and joint accuracy analyses together, the sandwich procedure affected vowel-related priming more than consonant-related priming: Not only do vowels prime lexical recognition in the sandwich paradigm, but participants did also make fewer errors. Importantly, the sandwich effect is not an additive effect but modulated by phoneme category as the consonant over vowel advantage is still observable but decreased when applying the sandwich procedure.
General discussion
Nespor et al. (Citation2003) proposed that consonants and vowels play different roles in language acquisition and lexical processing in adults, with consonants having more weight in lexical processing and vowels in prosodic/syntactic processing. In a recent series of experiments on French-speaking adults, New and colleagues (New et al., Citation2008; New & Nazzi, Citation2014) demonstrated a C-bias using a classic masked priming lexical decision task, both at an earlier (following a 50 ms prime) and later (following a 66 ms prime) processing stage, but not following a 33 ms prime. These studies ruled out that the C-bias resulted from orthographic processing, and together with additional analyses of the lexicon, suggested it might result from either the phonological level or lexical neighbourhood inhibition effects. Our main goal here was to further investigate these proposals and to specify the processing levels implicated. To do so, we used a special written lexical decision task with masked priming, called “sandwich priming” in which the prime-target sequence is preceded by the brief presentation of a pre-prime (corresponding to the target), a procedure that has been established to block lexical neighbourhood inhibition effects (Lupker & Davis, Citation2009; Stinchcombe et al., Citation2012). This procedure was used to go beyond the experiments conducted with the classic paradigm (New et al., Citation2008; New & Nazzi, Citation2014), with a 33 ms pre-prime and a 50 ms prime (Exp. 1, as done in previous “sandwich priming” experiments), and with either a 33 ms (Exp. 2) or 50 ms (Exp. 3) pre-prime and a 66 ms prime.
In Experiment 1, our pattern of findings is similar to what had been found with the classic paradigm, that is, a C-bias due to priming by consonant-related primes and no priming by vowel-related primes. Importantly though, the C-priming is even larger in the sandwich paradigm while the presentation of the pre-prime had not such a strong effect on vowel processing (there was only a non-significant tendency). This pattern of results suggests that at 50 ms, there is phonological activation for consonants that is already influenced by lexical inhibition. Still at 50 ms, there appears to be no phonological activation by vowels although lexical inhibition is found in the classic priming paradigm (leading to inhibition effects) and blocked in the sandwich paradigm (leading to no difference between the unrelated and vowel-related prime conditions). In Experiment 2 and 3, at 66 ms, our pattern of findings again differs between the two paradigms, but differently from what we found at 50 ms: while we find similar C-priming in the classic and the two versions of the sandwich paradigm, the inhibition effect found in the classic paradigm for vowels disappeared in both versions of the sandwich paradigm. However, a facilitatory effect of vowels was found in neither of the sandwich experiments. Yet, a joint analysis of the experiments revealed strong C-priming, weak V-priming, and a significant advantage of Cs over Vs; a comparison with the classic priming experiments further showed that the original V-inhibition turned into V-priming in the sandwich priming experiments. Lastly, analyses investigating whether the relative consonant–vowel effects were modulated by lexical and phonological frequency measures failed to find such modulation, confirming the non-modulation of priming effects reported previously for behavioural data (e.g. Grainger et al., Citation2012).
From a methodological point of view, our results do find an impact of presenting the pre-prime before the prime-target sequence, hence confirming previous reports that the sandwich technique blocks lexical neighbourhood effects (Lupker & Davis, Citation2009; Stinchcombe et al., Citation2012). This is clearly attested by differences in results between classic and sandwich priming at both 50 ms and 66 ms. At 50 ms, the presence of the pre-prime blocking lexical neighbourhood effects affected consonant processing and only marginally vowel processing. At a later processing stage (66 ms), the strong inhibition found from vowel-related primes using classic priming was not found when sandwich priming was used, establishing that the vowel-related primes activated the (shared) neighbourhood of the targets when using classic priming. Lastly, the joint analysis revealed a weakening of consonant priming from classic to the sandwich priming, and a switch from inhibition (in classic priming) to activation (in sandwich priming) for vowels. The fact that the sandwich technique affected vowel-related priming more than consonant-related priming compared to the standard technique suggests partly qualitative, and not just quantitative, differences between both techniques (see also Fernández-López et al., Citation2021) and supports Lupker and Davis (Citation2009) original interpretation that lexical competition is inhibited with the sandwich technique, from which vowels benefit the most. At the methodological level, the differences in findings between classic (New & Nazzi, Citation2014) and sandwich paradigms show that important inhibition effects can occur even when only half of the letters are shared with the target if these letters/phonemes are the consonants (at 50 ms) or vowels (at 66 ms). Hence, sandwich priming could be used to prevent neighbourhood inhibition from prime skeletons sharing only consonants or vowels with the targets. At the theoretical level, our findings are in line with new results (Davis et al., Citation2009; De Moor & Brysbaert, Citation2000) and new neighbourhood measures (Yarkoni et al., Citation2008) showing that orthographic neighbourhoods cannot be limited to the classic neighbourhood definition where only one letter can be changed. Our results suggest that an extended definition of neighbours could also be useful in the phonological domain but future research will be needed to confirm this. Lastly, note that these inhibition effects from phonological neighbourhoods would be compatible with results obtained in French when words have few orthographic neighbours (Grainger et al., Citation2005) and in English when words are highly clustered (Yates, Citation2013).
With respect to the level of processing at which the C-bias originates, the differences in findings between the present series of sandwich priming experiments and the previous classic priming experiments (New et al., Citation2008; New & Nazzi, Citation2014) at both 50 ms and 66 ms suggest that lexical neighbourhood effects are implicated in the C-bias at an earlier and later processing stage, though lexical competition processes seem to influence consonants before (effect at 50 ms) they affect vowel processing (effect at 66 ms). This suggests that consonants are processed faster and more automatically than vowels (cf. Berent & Perfetti, Citation1995, two-cycle model). However, the fact that consonantal priming is found with both paradigms provides evidence that consonants are processed advantageously over vowels at the phonological level given that sublexical influences are always facilitatory and lexical influences always inhibitory (McClelland & Rumelhart, Citation1981). Let us now consider in more detail how consonants and vowels are each processed at the different processing levels, depending on whether lexical neighbourhood effects are playing a role or are blocked.
For consonants, findings at 50 ms show priming by consonant-related primes over unrelated primes with the classic paradigm (+18 ms advantage), and even more so with the sandwich paradigm (+36 ms). This indicates that consonant-related priming is already modulated by lexical neighbourhood effects at this early processing stage, hence that it is the result of phonological and lexical processing. Findings at 66 ms also show some facilitation by consonant-related primes over unrelated primes with no difference between the classic and the two sandwich paradigms (+11 ms and +13/+15 ms advantage respectively), suggesting that only the early phonological effect is carried over at this later processing stage, as suggested by New and Nazzi (Citation2014). This effect, however, appears to be smaller than what is found at the earlier 50 ms processing stage. The replication of this reduced effect with the sandwich priming task thus does not confirm the interpretation that New and Nazzi (Citation2014) had proposed for the reduction of this effect, namely that it might be due to lexical neighbourhood effects, since the sandwich priming task is blocking such effects. This suggests that this early phonological processing advantage of consonants has started to decline by 66 ms in our experiments. This contrasts with findings from Ferrand and Grainger (Citation1993) that had found the highest levels of phonological priming at 66 ms. Given that our primes only shared 50% of phonemes with the targets, while they were identical to targets in Ferrand and Grainger (Citation1993), this difference in timing effects is likely to indicate that the more phonemes are shared between primes and targets, the longer in time is the phonological priming induced.
For vowels, findings at 50 ms fail to show priming by vowel-related primes over unrelated primes with both the classic and the sandwich paradigm (−2 ms and 8 ms respectively). Findings at 66 ms show a negative priming from vowels with the classic paradigm (−27 ms) and no priming with the two sandwich paradigms (5 ms and 9 ms, respectively). While taken individually, the present findings suggest that even when lexical neighbourhood inhibitory effects are cancelled, no facilitatory priming is found for vowels, a small but significant priming by vowels was found in the joint analysis (combining data at 50 and 66 ms), which remained smaller than the priming by consonants. The interaction between V-priming and paradigm type was significant, establishing that blocking lexical neighbourhood effects allowed the emergence of V-priming. While New and Nazzi (Citation2014) had offered two potential explanations to the lack of vowel-related priming in the classic priming paradigm (no phonological priming by vowels versus early phonological priming counterbalanced by small inhibition emerging from the large vowel-related lexical neighbourhoods), the finding of a small effect for vowels in the joint analysis (though not strong enough to emerge in the analysis of each experiment taken separately) supports their second proposal, namely that there is a small phonological priming from vocalic information counterbalanced by inhibition emerging from the large vowel-related lexical neighbourhoods, and getting bigger between 50 and 66 ms. Hence, for the first time, we establish that vowels provide a small phonological boost, priming lexical access at both an earlier and later lexical processing stage, which is found only when using the sandwich technique that blocks lexical neighbourhood effects.
Lastly, when directly comparing the processing advantage of consonants over vowels, we find a clear advantage at the early processing stage (50 ms), demonstrating that there is a clear phonological advantage in consonant processing. However, at the later processing stage (66 ms), we observe that the inhibition resulting from vowel-related primes in the classic masked priming paradigm disappears in the two sandwich masked priming paradigms, with only a marginal advantage of consonants over vowels. However, an advantage of consonants over vowels is significant in the joint analysis, combining data from the 50 and 66 ms primes. This pattern of results suggests that as lexical access gets more advanced, the early phonological advantage for consonants is complemented by a later lexical neighbourhood-related disadvantage for vowels. Such an interpretation echoes current debates in the developmental literature regarding the origin of the C-bias, in which the proposed acoustic/phonetic (Bouchon et al., Citation2015; Floccia et al., Citation2014; linked to the present phonological hypothesis) and the lexical (Keidel et al., Citation2007) hypotheses, first viewed as antagonistic, are now considered as concurring in explaining the emergence of the C-bias in development (Nishibayashi & Nazzi, Citation2016; Poltrock & Nazzi, Citation2015; see also Nazzi et al., Citation2016; and Nazzi & Cutler, Citation2019, for reviews). Moreover, since developmental research has shown variation in the way the C-bias is set into place (C-bias by 8 months in French, Nishibayashi & Nazzi, Citation2016; Poltrock & Nazzi, Citation2015; C-bias emerging between 20 and 30 months in English, Floccia et al., Citation2014; Nazzi et al., Citation2009; V-bias at 20 months in Danish, Højen & Nazzi, Citation2016; V-bias at 30 months in Cantonese, Chen et al., Citation2021), it will be important in the future to extend the current line of studies to more diverse languages having different phonological properties likely to influence the expression of the C-bias, such as Danish or Cantonese.
Because the skeletal structure of our target stimuli, that is the sequencing of consonants (C) and vowels (V) letters/phonemes, consisted of nonadjacent Vs and Cs (CVCV[CV], and VCVC[VC]), it remains unclear whether the same pattern of results would be found for words with different word/syllable structures. There is evidence that adult readers are sensitive to the words’ CV skeletal structure as disruptions to this structure (e.g. C-V transpositions) speed up reaction times in a letter string discrimination task (e.g. Chetail et al., Citation2014) and, furthermore, that it is especially the consonant skeleton that is activated at early lexical processing stages, since substituting a consonant has been found to affect word recognition more than substituting a vowel, the CV structure being preserved in both cases (Perea et al., Citation2018). Although this remains an experimental issue, we expect, based on Perea et al. (Citation2018)’s use of many different (orthographic) consonant–vowel structures (e.g. CVCCVCCV, VCVVCV), our findings to extend to other word/syllable structures as well.
In conclusion, we used the sandwich priming task to tease apart the extent to which our previous results concerning consonant and vowel processing could be explained by phonological biases versus lexical neighbourhood influences. Our results first suggest that both processing levels might be responsible for the C-bias, with an earlier phonological effect followed by a later lexical neighbourhood effect. Second, our results establish that vowel inhibition observed at 66 ms is due to lexical inhibition processes, while providing the first piece of evidence that vowel-related primes do provide a small phonological boost, significantly smaller than the priming found for consonants. The current results are in line with previous studies on consonant/vowel processing differences in lexical access, which had suggested that such effects did not originate from the orthographic level and had suggested that it arose from the phonological level (Acha & Perea, Citation2010b; Comesaña et al., Citation2016; New & Nazzi, Citation2014; Perea & Acha, Citation2009); besides the implication of the phonological level, our findings add new evidence for the implication of the lexical level. These results call for a modified version of the interactive activation model of reading (Grainger & Ferrand, Citation1996; McClelland & Rumelhart, Citation1981) where unit coding for vowels would have weaker or slower links to lexical units than consonants. It remains to be explored if these weaker links are hard-coded in the model or if they are the result of the statistical organisation of phonemes inside a particular language, requiring extensions of the current studies to other languages.
Supplemental Appendix
Download MS Word (15.3 KB)Acknowledgements
Thanks to Marie Bertin, Laurie Costerg, Laurène Baudet and Thomas Sordoillet for having run participants.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 Following the suggestion from a reviewer, Joshua Snell, that entropy might explain the C-bias in French, we calculated a Markov entropy for each consonant and vowel used in French at the orthographic and phonological level, using the formula proposed by Siegelman et al. (Citation2019). If consonants are more informative than vowels they should have a lower entropy on average than vowels. Analyses showed, however, that the distribution of entropy was not significantly different for consonants and vowels, neither at the orthographic nor phonological level. This suggests that entropy alone cannot be the reason why consonants and vowels are differently processed, at least in French.
2 This comparison was also implemented as a sliding contrast. Sliding contrasts use the grand mean as the intercept, therefore the model output for the factors Prime Type and Target Type refers to the mean of all test words.
References
- Acha, J., & Perea, M. (2010a). On the role of consonants and vowels in visual-word processing: Evidence with a letter search paradigm. Language and Cognitive Processes, 25(3), 423–438. https://doi.org/10.1080/01690960903411666
- Acha, J., & Perea, M. (2010b). Does Kaniso Activate CASINO? Experimental Psychology, 57(4), 245–251. https://doi.org/10.1027/1618-3169/a000029
- Baayen, R. H., & Shafaei-Bajestan, E. (2019). R language: Analyzing linguistic data: A practical introduction to statistics (R package version 1.5. 0).
- Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). lme4: Linear mixed-effects models using Eigen and S4. R package version 1.1-8. http://CRAN.R-project.org/package=lme4
- Berent, I., & Perfetti, C. A. (1995). A rose is a REEZ: The two-cycles model of phonology assembly in reading English. Psychological Review, 102(1), 146–184. https://doi.org/10.1037/0033-295X.102.1.146
- Bonatti, L., Peña, M., Nespor, M., & Mehler, J. (2005). Linguistic constraints on statistical computations: The role of consonants and vowels in continuous speech processing. Psychological Science, 16(6), 451–459. https://doi.org/10.1111/j.0956-7976.2005.01556.x
- Bouchon, C., Floccia, C., Fux, T., Adda-Decker, M., & Nazzi, T. (2015). Call me Alix, not Elix: Vowels are more important than consonants in own name recognition at 5 months. Developmental Science, 18(4), 587–598. https://doi.org/10.1111/desc.12242
- Buchwald, A., & Rapp, B. (2006). Consonants and vowels in orthographic representations. Cognitive Neuropsychology, 23(2), 308–337. https://doi.org/10.1080/02643290442000527
- Caramazza, A., Chialant, D., Capasso, R., & Miceli, G. (2000). Separable processing of consonants and vowels. Nature, 403(6768), 428–430. https://doi.org/10.1038/35000206
- Carreiras, M., & Price, C. J. (2008). Brain activation for consonants and vowels. Cerebral Cortex, 18(7), 1727–1735. https://doi.org/10.1093/cercor/bhm202
- Chen, H., Lee, D. T., Luo, Z., Lai, R. Y., Cheung, H., & Nazzi, T. (2021). Variation in phonological bias: Bias for vowels, rather than consonants or tones in lexical processing by cantonese-learning toddlers. Cognition, 213, 104486. ISSN 0010-0277. https://doi.org/10.1016/j.cognition.2020.104486
- Chetail, F., & Content, A. (2012). The internal structure of chaos: Letter category determines visual word perceptual units. Journal of Memory and Language, 67(3), 371–388. https://doi.org/10.1016/j.jml.2012.07.004
- Chetail, F., & Content, A. (2014). What is the difference between OASIS and OPERA? Roughly five pixels orthographic structure biases the perceived length of letter strings. Psychological Science, 25(1), 243–249. https://doi.org/10.1177/0956797613500508
- Chetail, F., Drabs, V., & Content, A. (2014). The role of consonant/vowel organization in perceptual discrimination. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(4), 938–961. https://doi.org/10.1037/a0036166
- Comesaña, M., Soares, A. P., Marcet, A., & Perea, M. (2016). On the nature of consonant/vowel differences in letter position coding: Evidence from developing and adult readers. British Journal of Psychology, 107(4), 651–674. https://doi.org/10.1111/bjop.12179
- Cutler, A., Sebastián-Gallés, N., Soler-Vilageliu, O., & van Ooijen, B. (2000). Constraints of vowels and consonants on lexical selection: Cross-linguistic comparisons. Memory & Cognition, 28(5), 746–755. https://doi.org/10.3758/BF03198409
- Davis, C. J., & Lupker, S. J. (2006). Masked inhibitory priming in English: Evidence for lexical inhibition. Journal of Experimental Psychology: Human Perception and Performance, 32(3), 668–687. https://doi.org/10.1037/0096-1523.32.3.668
- Davis, C. J., Perea, M., & Acha, J. (2009). Re(de)fining the orthographic neighborhood: The role of addition and deletion neighbors in lexical decision and reading. Journal of Experimental Psychology: Human Perception and Performance, 35(5), 1550–1570. https://doi.org/10.1037/a0014253
- Delle Luche, C., Poltrock, S., Goslin, J., New, B., Floccia, C., & Nazzi, T. (2014). Differential processing of consonants and vowels in the auditory modality: A cross-linguistic study. Journal of Memory and Language, 72, 1–15. https://doi.org/10.1016/j.jml.2013.12.001
- De Moor, W., & Brysbaert, M. (2000). Neighborhood-frequency effects when primes and targets are of different lengths. Psychological Research, 63(2), 159–162. https://doi.org/10.1007/PL00008174
- Duñabeitia, J. A., & Carreiras, M. (2011). The relative position priming effect depends on whether letters are vowels or consonants. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37(5), 1143–1163. https://doi.org/10.1037/a0023577
- Fernández-López, M., Davis, C. J., Perea, M., Marcet, A., & Gómez, P. (2021). Unveiling the boost in the sandwich priming technique. Quarterly Journal of Experimental Psychology, https://doi.org/10.1177/17470218211055097
- Ferrand, L., & Grainger, J. (1993). The time-course of phonological and orthographic code activation in the early phases of visual word recognition. Bulletin of the Psychonomic Society, 31(2), 119–122. https://doi.org/10.3758/BF03334157
- Ferreres, A. R., López, C. V., & China, N. N. (2003). Phonological alexia with vowel–consonant dissociation in non-word reading. Brain and Language, 84(3), 399–413. https://doi.org/10.1016/S0093-934X(02)00559-X
- Floccia, C., Nazzi, T., Delle Luche, C., Poltrock, S., & Goslin, J. (2014). English-learning one- to two-year-olds do not show a consonant bias in word learning. Journal of Child Language, 41(5), 1085–1114. https://doi.org/10.1017/S0305000913000287
- Gómez, D. M., Mok, P., Ordin, M., Mehler, J., & Nespor, M. (2018). Statistical speech segmentation in tone languages: The role of lexical tones. Language and Speech, 61(1), 84–96. https://doi.org/10.1177/0023830917706529
- Grainger, J., & Ferrand, L. (1996). Masked orthographic and phonological priming in visual word recognition and naming: Cross-task comparisons. Journal of Memory and Language, 35(5), 623–647. https://doi.org/10.1006/jmla.1996.0033
- Grainger, J., & Holcomb, P. J. (2009). Watching the word go by: On the time-course of component processes in visual word recognition. Language and Linguistics Compass, 3(1), 128–156. http://dx.doi.org/10.1111/j.1749-818X.2008.00121.x
- Grainger, J., Lopez, D., Eddy, M., Dufau, S., & Holcomb, P. J. (2012). How word frequency modulates masked repetition priming: An ERP investigation. Psychophysiology, 49(5), 604–616. https://doi.org/10.1111/j.1469-8986.2011.01337.x
- Grainger, J., Muneaux, M., Farioli, F., & Ziegler, J. C. (2005). Effects of phonological and orthographic neighbourhood density interact in visual word recognition. The Quarterly Journal of Experimental Psychology Section A, 58(6), 981–998. https://doi.org/10.1080/02724980443000386
- Havy, M., Serres, J., & Nazzi, T. (2014). A consonant/vowel asymmetry in word-form processing: Evidence in childhood and in adulthood. Language and Speech, 57(2), 254–281. https://doi.org/10.1177/0023830913507693
- Hochmann, J. R., Benavides-Varela, S., Nespor, M., & Mehler, J. (2011). Consonants and vowels: Different roles in early language acquisition. Developmental Science, 14(6), 1445–1458. https://doi.org/10.1111/j.1467-7687.2011.01089.x
- Højen, A., & Nazzi, T. (2016). Vowel bias in Danish word-learning: processing biases are language-specific. Developmental Science, 19(1), 41–49. https://doi.org/10.1111/desc.12286
- Keidel, J., Jenison, R., Kluender, K., & Seidenberg, M. (2007). Does grammar constrain statistical learning? Commentary on Bonatti, Peña, Nespor, and Mehler (2005). Psychological Science, 18(10), 922–923. https://doi.org/10.1111/j.1467-9280.2007.02001.x
- Lenth, R. V. (2021). Emmeans: Estimated Marginal Means, Aka Least-squares Means. R [R package version 1.6.3]. https://CRAN.R-project.org/package=emmeans
- Lupker, S. J., & Davis, C. J. (2009). Sandwich priming: A method for overcoming the limitations of masked priming by reducing lexical competitor effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35(3), 618–639. https://doi.org/10.1037/a0015278
- Lupker, S. J., Perea, M., & Davis, C. J. (2008). Transposed-letter effects: Consonants, vowels and letter frequency. Language and Cognitive Processes, 23(1), 93–116. https://doi.org/10.1080/01690960701579714
- McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: Part 1. An account of basic findings. Psychological Review, 88(5), 375–407. https://doi.org/10.1037/0033-295X.88.5.375
- Nazzi, T. (2005). Use of phonetic specificity during the acquisition of new words: Differences between consonants and vowels. Cognition, 98(1), 13–30. https://doi.org/10.1016/j.cognition.2004.10.005
- Nazzi, T., & Cutler, A. (2019). How consonants and vowels shape spoken-language recognition. Annual Review of Linguistics, 5(1), 25–47. https://doi.org/10.1146/annurev-linguistics-011718-011919
- Nazzi, T., Floccia, C., Moquet, B., & Butler, J. (2009). Bias for consonantal information over vocalic information in 30-month-olds: Cross-linguistic evidence from French and English. Journal of Experimental Child Psychology, 102(4), 522–537. http://dx.doi.org/10.1016/j.jecp.2008.05.003
- Nazzi, T., & New, B. (2007). Beyond stop consonants: Consonantal specificity in early lexical acquisition. Cognitive Development, 22(2), 271–279. http://dx.doi.org/10.1016/j.cogdev.2006.10.007
- Nazzi, T., Poltrock, S., & Von Holzen, K. (2016). The developmental origins of the consonant bias in lexical processing. Current Directions in Psychological Science, 25(4), 291–296. https://doi.org/10.1177/0963721416655786
- Nespor, M., Peña, M., & Mehler, J. (2003). On the different roles of vowels and consonants in speech processing and language acquisition. Lingue e Linguaggio, 2(2), 203–230. https://doi.org/10.1418/10879
- New, B., Araujo, V., & Nazzi, T. (2008). Differential processing of consonants and vowels in lexical access through reading. Psychological Science, 19(12), 1223–1227. https://doi.org/10.1111/j.1467-9280.2008.02228.x
- New, B., & Nazzi, T. (2014). The time course of consonant and vowel processing during word recognition. Language, Cognition and Neuroscience, 29(2), 147–157. https://doi.org/10.1080/01690965.2012.735678
- Nishibayashi, L. L., & Nazzi, T. (2016). Vowels, then consonants: Early bias switch in recognizing segmented word forms. Cognition, 155, 188–203. https://doi.org/10.1016/j.cognition.2016.07.003
- Perea, M., & Acha, J. (2009). Does letter position coding depend on consonant/vowel status? Evidence with the masked priming technique. Acta Psychologica, 130(2), 127–137. https://doi.org/10.1016/j.actpsy.2008.11.001
- Perea, M., & Lupker, S. J. (2004). Can CANISO activate CASINO? Transposed-letter similarity effects with nonadjacent letter positions. Journal of Memory and Language, 51(2), 231–246. https://doi.org/10.1016/j.jml.2004.05.005
- Perea, M., Marcet, A., & Acha, J. (2018). Does consonant–vowel skeletal structure play a role early in lexical processing? Evidence from masked priming. Applied Psycholinguistics, 39(1), 169–186. https://doi.org/10.1017/S0142716417000431
- Poltrock, S., Chen, H., Kwok, C., Cheung, H., & Nazzi, T. (2018). Adult learning of novel words in a non-native language: Consonants, vowels, and tones. Frontiers in Psychology, 9, 1211. https://doi.org/10.3389/fpsyg.2018.01211
- Poltrock, S., & Nazzi, T. (2015). Consonant/vowel asymmetry in early word form recognition. Journal of Experimental Child Psychology, 131, 135–148. https://doi.org/10.1016/j.jecp.2014.11.011
- Rastle, K., & Brysbaert, M. (2006). Masked phonological priming effects in English: Are they real? Do they matter? Cognitive Psychology, 53(2), 97–145. http://dx.doi.org/10.1016/j.cogpsych.2006.01.002
- Siegelman, N., Bogaerts, L., & Frost, R. (2019). What determines visual statistical learning performance? Insights from information theory. Cognitive Science, 43(12), e12803. https://doi.org/10.1111/cogs.12803
- Stinchcombe, E. J., Lupker, S. J., & Davis, C. J. (2012). Transposed-letter priming effects with masked subset primes: A re-examination of the “relative position priming constraint”. Language and Cognitive Processes, 27(4), 475–499. https://doi.org/10.1080/01690965.2010.550928
- Trifonova, I. V., & Adelman, J. S. (2018). The sandwich priming paradigm does not reduce lexical competitor effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 44(11), 1743–1764. http://dx.doi.org/10.1037/xlm0000542
- Van Heuven, W. J. B., Dijkstra, T., Grainger, J., & Schriefers, H. (2001). Shared neighborhood effects in masked orthographic priming. Psychonomic Bulletin & Review, 8(1), 96–101. https://doi.org/10.3758/BF03196144
- van Ooijen, B. (1996). Vowel mutability and lexical selection in English: Evidence from a word reconstruction task. Memory & Cognition, 24(5), 573–583. https://doi.org/10.3758/BF03201084
- Wiener, S. (2020). Second language learners develop non-native lexical processing biases. Bilingualism: Language and Cognition, 23(1), 119–130. https://doi.org/10.1017/S1366728918001165
- Wiener, S., & Turnbull, R. (2016). Constraints of tones, vowels and consonants on lexical selection in Mandarin Chinese. Language and Speech, 59(1), 59–82. https://doi.org/10.1177/0023830915578000
- Yarkoni, T., Balota, D., & Yap, M. (2008). Moving beyond Coltheart’s N: A new measure of orthographic similarity. Psychonomic Bulletin & Review, 15(5), 971–979. https://doi.org/10.3758/PBR.15.5.971
- Yates, M. (2013). How the clustering of phonological neighbors affects visual word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(5), 1649–1656. https://doi.org/10.1037/a0032422
- Ziegler, J. C., Ferrand, L., Jacobs, A. M., Rey, A., & Grainger, J. (2000). Visual and phonological codes in letter and word recognition: Evidence from incremental priming. The Quarterly Journal of Experimental Psychology Section A, 53(3), 671–692. http://dx.doi.org/10.1080/713755906