
ABSTRACT
Language comprehension proceeds at a very fast pace. It is argued that context influences the speed of language comprehension by providing informative cues. How syntactic contextual information influences the processing of incoming words is, however, less known. Here we employed a masked syntactic priming paradigm in four behavioural experiments in the German language to test whether masked primes automatically influence the categorisation of nouns and verbs. We found robust syntactic priming effects with masked primes but only when verbs were morpho-syntactically marked. Furthermore, we found that, compared to baseline, primes slow down target categorisation when the relationship between prime and target is syntactically incorrect, rather than speeding it up when the relationship is syntactically correct. This argues in favour of an inhibitory nature of syntactic priming. Overall, the data indicate that humans automatically extract syntactic features from the context to guide the analysis of incoming words during online language processing.
1. Introduction
The rapid pace of language comprehension is thought to lie in the human ability to quickly extract features from the linguistic context – i.e. syntactic, semantic, morphological, and word form information – which influence the processing of incoming words (Dikker et al., Citation2009; Lau et al., Citation2006; MacGregor et al., Citation2012; Mancini et al., Citation2014; Marslen-Wilson, Citation1973; Shtyrov & Lenzen, Citation2017; Shtyrov & Macgregor, Citation2016; Staub & Clifton, Citation2006). Early production studies for example showed that semantic and syntactic contextual information can induce speakers to produce specific errors in speech shadowing tasks (Marslen-Wilson, Citation1973). In language comprehension, a well-known way to study the role of context on word processing is to induce priming effects in highly controlled experimental settings. Priming refers to the influence of a prime word on the following target word, with which it shares some linguistic dimension, such as the word “web” being recognised faster when it follows “spider” than when it follows “coffee”. Previous priming studies suggest that different levels of contextual linguistic information – morphological, semantic, syntactic, orthographic, and phonological – affect the processing of upcoming words (Ferrand & New, Citation2004; Goodman et al., Citation1981; Humphreys et al., Citation1982; Kiefer, Citation2019; Longtin et al., Citation2003; Marslen-Wilson et al., Citation2008; Naccache & Dehaene, Citation2001; Perea & Rosa, Citation2002b; Rastle et al., Citation2004; Segui & Grainger, Citation1990).
In the present study we specifically focus on how incoming words are affected by syntactic context, which is known to be accessed very early during the most automatic processing stage of sentence comprehension (Friederici, Citation2002, Citation2011). In particular, we use a two-word syntactic priming paradigmFootnote1 to address the influence of minimal syntactic context (e.g. the determiner EIN (“the”) or the pronoun ER (“he”)) on the processing of upcoming nouns or verbs in German. A central aspect of this paradigm is that, by orthogonally manipulating the grammatical relationship between prime and target, it is possible to highlight syntactic processing while minimising semantic confounds and working memory demands (Goodman et al., Citation1981; Maran, Friederici, et al., Citation2022). Previous syntactic priming manipulations focused either on the morpho-syntactic level, i.e. gender, number, and case agreement like “she sings” versus “*she sing”Footnote2 (Carello et al., Citation1988; Gurjanov, Lukatela, Lukatela, et al., Citation1985; Gurjanov, Lukatela, Moskovljević, et al., Citation1985; Katz et al., Citation1987; Lukatela et al., Citation1982, Citation1983, Citation1987) or on the word-category level like “she sings” versus “*she apple” (Goodman et al., Citation1981; Seidenberg et al., Citation1984). At the morpho-syntactic level, it has been shown that target verbs are processed faster when they correctly agree in person features with pronouns presented as primes compared to when they do not (Lukatela et al., Citation1982). Similar syntactic priming effects were reported in studies using prepositions, adjectives or possessive pronouns as primes, and nouns as target words (Gurjanov, Lukatela, Lukatela, et al., Citation1985; Gurjanov, Lukatela, Moskovljević, et al., Citation1985; Lukatela et al., Citation1983, Citation1987). At the word-category level, reduced response latencies to nouns and verbs primed by syntactically correct functional elements were reported in two studies conducted in English (Goodman et al., Citation1981; Seidenberg et al., Citation1984) and one study in French (Berkovitch & Dehaene, Citation2019). Together, these findings suggest that previous syntactic context, as short as single function words, can affect the processing of upcoming words (see also Maran, Friederici, et al., Citation2022, for a recent review). However, despite the extensive application of the paradigm to study syntactic contextual effects in the psycholinguistic literature, three main research questions remain open: the extent to which syntactic priming stems from automatic linguistic processes (§1.1.); its facilitatory or inhibitory nature (driven, respectively, by grammatical or ungrammatical prime-target relationship, §1.2.); and the role of morphological marking in driving the reported effects (§1.3.).
1.1. Automaticity of syntactic priming
The first major research question in focus here concerns the automatic extraction of syntactic information during language processing at the behavioural level. Neurophysiological data suggest that the extraction of syntactic information to build up syntactic structures is a highly speeded automatic process, as reflected in the earliness and task-independent nature of Event-Related Potential (ERP) components such as the (Early) Left Anterior Negativity ((E)LAN) and the syntactic Mismatch Negativity (sMMN) (Batterink & Neville, Citation2013; Hahne & Friederici, Citation1999; Hanna et al., Citation2014; Hasting et al., Citation2007; Herrmann et al., Citation2009; Jiménez-Ortega et al., Citation2014, Citation2021; Lucchese et al., Citation2017; Pulvermüller & Assadollahi, Citation2007; Pulvermüller & Shtyrov, Citation2003). One way to test behaviourally the automaticity of syntactic processing is to use priming paradigms in combination with masking techniques or very short stimulus-onset asynchronies (SOA) (Maran, Friederici, et al., Citation2022). The common rationale behind these two approaches is that, if the prime is presented for a very short amount of time (Colé & Segui, Citation1994; Katz et al., Citation1987; Lukatela et al., Citation1982) or perceived unconsciously (Ansorge et al., Citation2013; Berkovitch & Dehaene, Citation2019), participants will not be able to initiate strategic behaviour, therefore automatic processes will be highlighted.
Masked priming has been widely used to identify a range of automatic linguistic processes by ensuring the unconscious perception of primes (Berkovitch & Dehaene, Citation2019; Dehaene et al., Citation1998; Iijima & Sakai, Citation2014; Kiefer, Citation2002; Kiefer et al., Citation2019; Kouider & Dehaene, Citation2007; Lehtonen et al., Citation2011; Marslen-Wilson et al., Citation2008; Naccache & Dehaene, Citation2001; Van den Bussche et al., Citation2009). In a typical masked priming paradigm, primes are presented below the threshold of conscious perception (∼33 ms), followed by visible targets on which participants perform a specific task. Although the primes are shown so briefly that they do not reach consciousness, previous studies repeatedly revealed prime-driven contextual effects (Ansorge et al., Citation2013; Berkovitch & Dehaene, Citation2019; Iijima & Sakai, Citation2014; Kiefer, Citation2002; Lehtonen et al., Citation2011; Naccache & Dehaene, Citation2001; Nakamura et al., Citation2018). To the best of our knowledge, there are only five studies in the literature on masked syntactic and morpho-syntactic priming: a behavioural study in German by Ansorge et al. (Citation2013), a behavioural study in French by Berkovitch and Dehaene (Citation2019), a magnetoencephalography (MEG) study in Japanese by Iijima and Sakai (Citation2014), and two electroencephalography (EEG) studies in Spanish by Jiménez-Ortega et al. (Citation2014, Citation2021). Among these five studies, at the behavioural level morpho-syntactic priming was observed under masked conditions in one study only, albeit employing primes which were ambiguous regarding the grammatical feature of interest (Ansorge et al., Citation2013). Two further studies (Jiménez-Ortega et al., Citation2014, Citation2021) showed an early anterior negativity(-like) modulation followed by a posterior positivity elicited by masked agreement violations, without any behavioural effects in the masked condition. The MEG study by Iijima and Sakai (Citation2014) tested the effect of subliminal transitive verbs in two-word sentences formed by object/subject NPs and transitive/intransitive verbs in the Japanese language. The authors found an increased response in the left inferior frontal gyrus (IFG) for object-verb sentences when subliminal and supraliminal verbs were both transitive. Behaviourally, object-verb sentences enhanced subliminal verb transitivity – compared to subject-verb sentences – although there was no RT difference between congruent and incongruent verbs. Masked syntactic priming at the word-category level – the topic of our study – was conversely only addressed in one behavioural study by Berkovitch and Dehaene (Citation2019) who reported faster processing of French nouns and verbs preceded by syntactically congruent masked primes (determiners and pronouns, respectively) compared to incongruent primes. The ERP study by Batterink and Neville (Citation2013) and the MMN study by Lucchese et al. (Citation2017) share the rationale of the masked priming paradigm as they tested the automaticity of syntactic and morpho-syntactic processing in the absence of awareness and attention, respectively. The former study revealed that undetected masked syntactic violations elicited an early negativity and delayed the behavioural response to an auditory tone presented 200 ms prior to the violation. The latter study found an interaction between lexico-semantic and morpho-syntactic processing in the early time-window (70–210 ms), though no behavioural measures were collected.
Previous studies used the terms subliminal or unconscious when referring to priming effects under very brief presentation of masked primes (Berkovitch & Dehaene, Citation2019; Dehaene et al., Citation1998; Iijima & Sakai, Citation2014; Kiefer, Citation2002; Kiefer et al., Citation2019; Kouider & Dehaene, Citation2007; Naccache & Dehaene, Citation2001; Van den Bussche et al., Citation2009). However, we here refrain from using the terms subliminal and unconscious when addressing syntactic priming in the masked setting, and rather suggest a distinction between automatic (i.e. masked) and more-controlled (i.e. unmasked) syntactic priming. Indeed, the brief (33 ms, SOA = 49 ms) and masked presentation of the primes in our study prevents strategic control (Dehaene & Changeux, Citation2011), highlighting a highly automatic processing stage (see also Katz et al., Citation1987; Lukatela et al., Citation1982; Maran, Friederici, et al., Citation2022, for a discussion of the SOA manipulation in studies testing automatic priming effects).
1.2. Directionality of automatic syntactic priming: inhibition and facilitation
The second research question concerns the directionality of the automatic syntactic priming effect at the word-category level. At present, it remains unclear whether automatic syntactic priming is facilitatory (i.e. a syntactically grammatical relationship between prime and target facilitates performance) and/or inhibitory (i.e. a syntactically ungrammatical relationship slows down performance). Addressing this issue requires careful baseline conditions, in which a target word follows a prime which does not establish a constraining context. Strong inhibition seems the most reliable finding reported in the literature on less automatic processing under unmasked conditions, while weak facilitation seems to be rather language-specific or task-dependent (Friederici & Jacobsen, Citation1999). However, it remains unclear whether the same mechanism accounts for the contextual effects observed at the word-category level (Goodman et al., Citation1981; Seidenberg et al., Citation1984) and under conditions of automatic processing (i.e. masked priming), since no baseline condition has ever been used in the previous masked syntactic priming studies (Berkovitch & Dehaene, Citation2019).
1.3. Linguistic mechanisms behind syntactic priming
A final research question relates to the mechanism of syntactic priming. Previous studies point towards a central role of morphological markers in driving syntactic priming effects (Gurjanov, Lukatela, Moskovljević, et al., Citation1985; Lukatela et al., Citation1982, Citation1983, Citation1987). It is worth noting that these studies were conducted in Serbo-Croatian, a morphologically rich language where morpho-syntactic features are expressed via suffixes attached to function and content words (e.g. “mojoj sestri”, “my.DAT.FEM.SG sister.DAT.FEM.SG”, where the suffix “oj” on the possessive adjective and the suffix “i” on the noun mark feminine singular words in the dative case). Thus, syntactic priming effects in these studies might have emerged due to a link between the agreeing morphemes of the prime and the target word (Lukatela et al., Citation1987). As a matter of fact, studies on syntactic agreement employing pseudo-word conditions support this hypothesis: pseudo-word targets bearing morphological markers that agree with the prime were rejected more slowly (Lukatela et al., Citation1982, Citation1983, Citation1987). However, it remains unknown whether morphological markers have a central role in driving the syntactic priming effects also at the word-category level, where for example nouns and verbs can be either morphologically overtly marked like “he sing-s” or unmarked like “the apple-Ø”. Indeed, a link between agreeing morphemes seems to only partially account for the syntactic priming effects at the word-category level in English (Goodman et al., Citation1981; Seidenberg et al., Citation1984), since in these studies stimuli bearing overt morphological cues like “she kiss-ed” were mixed with stimuli lacking such cues like “a thing-Ø”. Importantly, the link between overt marking and syntactic priming has not been tested yet in conditions of automatic processing (i.e. masked presentation of the primes). This also holds for the automatic syntactic priming at the word-category level (Berkovitch & Dehaene, Citation2019), where a dissociation of contextual effects on morphologically unmarked nouns such as “le sport” (“the sport”) and morphologically marked verbs such as “il dor-t” (“he sleep-s”) was not tested. Notably, at a broader theoretical level, a relationship between syntactic priming and overt morphological marking would converge on neurophysiological data (e.g. Sensory hypothesis: Dikker et al., Citation2009, Citation2010; Herrmann et al., Citation2009). Behavioural evidence for this claim is however still missing, though essential for identifying the underlying cognitive mechanisms (Krakauer et al., Citation2017) and ultimately understanding the architecture of the human language faculty.
1.4. Overview of the present study
Following the discussion above, our study pursued three major goals ().
First, we aimed at verifying the degree of automaticity of syntactic processing at the word-category level, using the masked syntactic priming paradigm (Pilot and Experiment 1). We expected to observe automatic syntactic effects of the primes (determiner: EIN, “a”; pronoun: ER, “he”) on the grammatical categorisation of nouns and verbs employed as targets.
Second, we aimed at clarifying whether the nature of the automatic syntactic priming effect at the word-category level is facilitatory and/or inhibitory (Experiment 2). Three scenarios are here possible: the processing of the target category can be facilitated or inhibited by grammatical and ungrammatical contexts respectively, or both effects can be observed.
Finally, we explored the role of overt morphology in automatic syntactic priming. In Experiments 1 and 2, we hypothesised that masked pronouns would prime verbs by preactivating or facilitating the integration of a morphological marker (the German inflectional suffix “t”), whereas masked determiners would not prime nouns given the absence of a closed-class morphological marker on nouns (zero forms). In Experiment 3, we further tested the role of overt morphology in syntactic priming by employing morphologically unmarked verbs.
Figure 1. Prime-target syntactic relationship. A: Morpho-syntactic inflection on verbs (V) is overt in Experiments 1 and 2 and absent in Experiment 3. Nouns (N) have no overt morphological markers. Crucially, in Experiments 1 and 2, the last letter on nouns perceptually resembles the morphological marker (“t”) used for the verbs. PRO = pronoun; DET = determiner; infl = inflection; ER = “he”; EIN = “a/an”; KAUT = “chews”; BLIEB = “stayed”; BART = “beard”; TEICH = “pond”. The cross indicates an ungrammatical prime-target relationship. B: The three research questions addressed in our study and corresponding experiments.
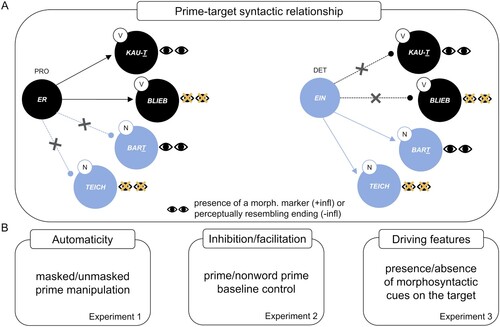
We addressed these research questions in a Pilot study (N = 19) and three main behavioural experiments (Experiment 1, N = 43; Experiment 2, N = 50; Experiment 3, N = 40) in the German language. The Pilot experiment (see the supplemental data) served to test our paradigm using three different prime pairs to select the perceptually most similar ones. Experiment 1 tested masked and unmasked syntactic priming effects, by manipulating the grammatical relationship at the word-category level between primes (determiners vs. pronouns) and targets (nouns vs. marked verbs). This allowed us to observe the magnitude of the syntactic priming effect when morphological marking is available. In Experiment 2, we included a baseline condition – nonword primes – to test noun and verb processing in the absence of context. The inclusion of a baseline condition enabled us to investigate the directionality of the priming effect (i.e. facilitation or inhibition), and to control for potential categorical confounds (i.e. processing differences between nouns and verbs per se). Finally, in Experiment 3 we used irregular verbs requiring no overt inflectional morphology, to further test syntactic priming effects in the absence of integrative processing between a prime and morphological markers.
2. General procedure
Each of our experiments consisted of three tests, following the design of Berkovitch and Dehaene (Citation2019): syntactic priming, prime visibility, and repetition priming test. We here only focus on the syntactic priming and prime visibility tests, which are central to our research questions.
2.1. Tests and timing of events
The syntactic priming test consisted of a speeded grammatical categorisation over target words, which were shown after the masked or unmasked presentation of a prime. Thus, it examined the influence of syntactic context on the target word processing and the degree of automaticity of this effect (i.e. presence of priming effects in the masked setting). The determiner EIN (“a”) and the pronoun ER (“he”) served as primes (see the supplemental data, Figure S.1 and Table S.8 for the selection procedure), while nouns and verbs were employed as targets. Accordingly, the prime-target pairs formed syntactically grammatical or ungrammatical sequences ((A)). The categorisation task ensured that the response was orthogonal to the grammaticality of the prime-target relation (e.g. DET+N and PRO+N both required a “noun” response). In the Pilot and in the three main experiments, the following factors were included (): Prime (determiner EIN; pronoun ER), Target’s Category (noun; verb), and Masking (masked; unmasked presentation of the prime). In Experiment 2, an additional factor was included, namely Prime Lexicality, which allowed to establish a neutral baseline for syntactic priming effects (see §4.1.4. for details).
Table 1. Experimental design. The asterisks indicate ungrammaticality. DET = determiner, PRO = pronoun.
The timing of events of the syntactic priming test was common to all experiments () and follows the procedure of Berkovitch and Dehaene (Citation2019). Prime duration (33 ms) was held constant for both masked and unmasked settings. Participants performed a speeded grammatical categorisation task: they were asked to indicate as quickly and accurately as possible whether the presented word was a noun or a verb by pressing the correspondent button (the response code was counterbalanced across participants). In the syntactic priming test, participants were not informed about the presence of the primes.
Figure 2. Time-course of stimuli presentation in all experiments. In both tests, each trial started with a fixation cross (734 ms), with an inter-trial-interval (ITI) jittered between 960 and 1440 ms. In the prime visibility test, the sequence of events was identical to the syntactic priming test except that the target word remained on the screen for 500 ms. After the target, a response cue assigning the response code of the trial appeared on the screen until a response was given on the response box, indicating whether the prime was a determiner or a pronoun. In this example, participants would press the left button to indicate that the prime was the pronoun (“Pronomen”) ER and the right button to indicate that the prime was the determiner (“Artikel”) EIN. Participants could either see PRON(ER) on the left side and ART(EIN) on the right side of the screen, or the other way round, in a pseudo-randomized order across the trials.
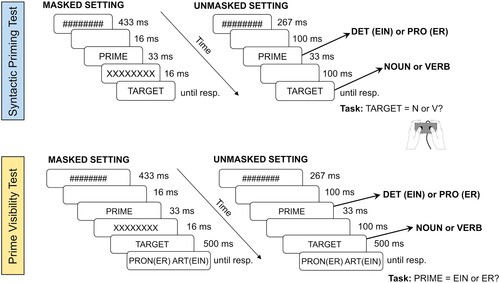
The prime visibility test, which always followed the syntactic priming test, consisted of a two-alternative forced-choice prime recognition task (Berkovitch & Dehaene, Citation2019; Iijima & Sakai, Citation2014; Kiefer et al., Citation2019) to ensure that in the masked setting participants were not aware of the prime that had been shown (see for more details). In the prime visibility test, participants were instructed to pay attention to the primes and to respond as accurately as possible (response speed was not important).
2.2. Data analysis
Common analyses across experiments (Experiments 1, 2, and 3) are summarised in . Data from the syntactic priming test were analysed with Linear Mixed-Effects Models (LMM) for RTs and with Generalized Linear Mixed-Effects Models (GLMM) for the accuracy. We included the following factors: Prime, Target’s Category, and Masking, using the sum coding scheme. LMMs were estimated for the whole data set as well as for the masked and the unmasked setting separately to investigate whether syntactic priming could be observed in both levels of Masking. The LMM and GLMM analyses were performed in R (R core team, Citation2021) using the package lme4 (Bates et al., Citation2015). LMMs were fit with the Maximum Likelihood Estimation method. GLMMs with the binomial family distribution were fit with the Laplace approximation. Model selection was performed via Likelihood Ratio Tests that estimate the goodness of fit. The interactions of interest were further analysed via post-hoc comparisons using the function emmeans() from the emmeans package in R. P values were adjusted for multiple comparisons with the Benjamini-Hochberg procedure (False Discovery Rate) (Benjamini & Hochberg, Citation1995). For more details, see the supplemental data (§S.2.2.1.). The random effects structures included in LMMs and GLMMs in each of the experiments are reported in the respective sections below.
Figure 3. Exclusion criteria and analyses presented in the main text. For the additional analyses and the Pilot experiment, see the supplemental data.
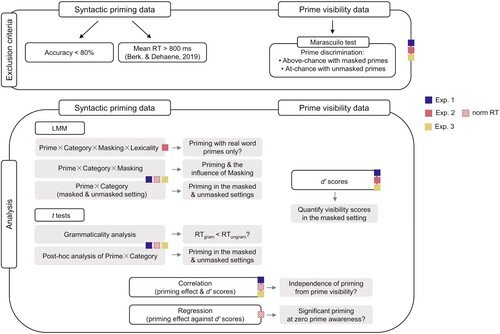
Additionally, we conducted a “Grammaticality analysis” (in compliance with Berkovitch & Dehaene, Citation2019), in which we compared the average RTs of grammatical (DET+N, PRO+V) and ungrammatical (*DET+V, *PRO+N) constructions. This additional analysis allows to quantify the effect size (Cohen’s d) and the strength of evidence in favour of one hypothesis over the other (the Bayes Factor, BF). The descriptive statistics for each cell of the experimental design and for the grammaticality analyses can be found in the supplemental data, §S.3.1.5.
We further complemented all analyses with a within-subject repeated measures Analysis of Variance (ANOVA) for comparability with previous studies using masked priming manipulations (Ansorge et al., Citation2013; Berkovitch & Dehaene, Citation2019; Iijima & Sakai, Citation2014; Kiefer, Citation2002; Lehtonen et al., Citation2011; Naccache & Dehaene, Citation2001; Nakamura et al., Citation2018). To lessen data burden in the main text, the ANOVA results, which essentially replicate the LMM results, are reported in the supplemental data (§S.3.1.1.).
Data from the prime visibility test were used to exclude participants who showed awareness of the masked primes using the Marascuilo test (Marascuilo, Citation1970) (see the supplemental data for more details, §S.2.2.2.). We furthermore calculated the sensitivity index d′ (Green & Swets, Citation1966) for each participant in the masked setting to quantify the prime visibility scores. We also ran one-sample t tests on d′ values against the mean d′ value reported earlier in the literature for the syntactic priming test (Berkovitch & Dehaene, Citation2019; Experiment 3; d′ = 0.12) to ensure comparability across studies (supplemental data, §S.3.2.1.). To further provide evidence for the independence of the priming effect from participants’ visibility scores in the masked setting, we performed simple correlations between the priming effects and d′ values (Kiefer et al., Citation2019; Ortells et al., Citation2016).
2.3. Sample size
Consistent syntactic priming effects were found for sample sizes ranging between 16 and 24 participants with a similar experimental paradigm and the same task (Berkovitch & Dehaene, Citation2019). We recruited 43 and 40 participants for the experiments including three factors (Experiments 1 and 3, respectively). For the experiment including four factors (Experiment 2), we recruited 50 participants, which was deemed sufficient to match and possibly exceed the ones included in previous studies. Indeed, Bayesian sequential analysis provides strong evidence for the presence of an automatic syntactic priming effect already with 25 participants (supplemental data, Figure S.5). No participant took part in more than one experiment.
3. Experiment 1: automaticity of syntactic contextual effects
The goal of Experiment 1 was to test masked and unmasked syntactic priming effects in German. The syntactic priming test involved a speeded grammatical categorisation task with a 2 × 2 × 2 factorial within-subject design with the factors Prime (determiner EIN; pronoun ER), Target’s Category (noun; verb), and Masking (masked; unmasked).
3.1. Methods
3.1.1. Participants
Data of 36 participants (25 females, 11 males, Mage = 24.7, age range: 18–34) from the 43 recruited native German speakers (29 females, 14 males, Mage = 25.2, age range: 18–35) entered the final analysis. In particular, seven participants were removed for the following reasons: four participants had mean response times longer than 800 ms in at least one condition across the combination of the factors’ levels (Berkovitch & Dehaene, Citation2019), one participant’s accuracy was below 80% in at least one condition; one further participant was removed due to above-chance performance in the masked setting of the prime visibility test; and one participant showed at-chance performance in the unmasked setting of the prime visibility test, possibly due to misunderstood instructions. All participants included in the analysis were right-handed according to the Edinburgh Handedness Inventory (Oldfield, Citation1971) (average laterality quotient = 90.4, SD = 14.1, range = 50–100). All of them had normal or corrected-to-normal vision. Approval for the experiments was obtained from the Ethics Committee of the University of Leipzig (approval number: 299/19-ek). The participants gave written consent and were reimbursed 9 Euro per 1 h for participating in the study.
3.1.2. Stimuli
The stimulus set included 40 mono- and disyllabic countable masculine nouns in the singular form as well as 40 mono- and disyllabic verbs in the third person, singular, present tense form (supplemental data, Table S.9). Importantly, all verbs and nouns selected ended with the letter “t”, which is an inflectional suffix for verbs (“er kau-t”, “he chew-s”) but part of the stem for nouns (“ein Bart”, “a beard”). As participants were asked to perform a grammatical categorisation task, indicating if the target was a noun or a verb, our stimulus selection procedure ensured that the factor Category was not confounded by the presence or absence of the letter “t” in the target.
From nouns (N = 581) and verbs (N = 5987) extracted from the morpho-syntactically annotated CELEX database for German (Baayen et al., Citation1995), we excluded direct transitive verbs as they require two arguments (a subject and an object) to form a syntactic constituent; nouns and verbs that can take either the prefix “ein” or the prefix “er”; nouns and verbs with missing bigram frequencies for grammatical prime-target pairs (EIN+N or ER+V); and homophones or homographs of words from other grammatical categories (for a detailed description of the stimulus selection procedure see §S.1.1.2. in the supplemental data). The stimulus set was slightly adjusted in accordance with participants’ feedback from the Pilot experiment. We further excluded all nouns sharing the stem with verbs because they can be easily mistaken for a related verb. After the exclusion of stem-sharing nouns and verbs, exactly 40 nouns and 44 verbs remained. To select nouns and verbs matched along the psycholinguistic variables of interest, we randomly extracted 40 nouns and 40 verbs from the remaining pool over 2000 iterations, running statistical tests on each iteration (for details see §S.1.1.2. in the supplemental data). The final sets of nouns and verbs were matched along the psycholinguistic variables of interest ().
Table 2. Experiment 1: nouns and verbs matched for the psycholinguistic variables. Log frequency = logarithmic SUBTLEX word frequency; phon length = phonological length; ortho length = orthographic length; OLD20 = the neighbourhood measure Orthographic Levenshtein Distance 20.
3.1.3. Procedure
The experimental session of Experiment 1 lasted approximately 1 h. Participants remained at a fixed distance to the screen during the whole experiment as ensured by a chin rest placed 50 cm from the screen. Stimuli were presented with the Presentation® software (Neurobehavioral Systems, Inc., Berkeley, CA, www.neurobs.com) on an LCD screen (17 in.) with a refresh rate of 60 Hz (16.67 ms for one video frame) in black Arial font in capital letters on white background, subtending 1.15 degree of the vertical visual angle. During the practice part (one block, 20 trials: 10 masked and 10 unmasked), participants received feedback on each trial indicating whether the response was correct or not. The syntactic priming test consisted of four blocks (80 trials in each block: 40 masked and 40 unmasked; 320 trials in total) with a break within each block after 40 trials as well as between the blocks. Participants saw all the possible combinations of the factors Prime, Target’s Category, and Masking across four blocks (counterbalanced with a Latin Square design [Grant, Citation1948])). Each noun/verb appeared only once within a block and four times in total across blocks (each time in a different condition across Prime × Masking). The trial order was pseudo-randomized for each participant. The prime visibility test, which was presented after the syntactic priming test, included one block (80 trials: 40 masked and 40 unmasked) with a break after 40 trials.
3.1.4. Data analysis
Accuracy scores and RTs (correct responses, log-transformed) were analysed using GLMMs and LMMs, respectively, with factors Prime (determiner EIN; pronoun ER), Target’s Category (noun; verb), and Masking (masked; unmasked) for the syntactic priming test. In LMMs, the random effects structure included varying intercepts for subjects (1|subject), target words (1|target), trial (1|trial number), and block (1|block number) numbers. In GLMMs, the random effects structure included varying intercepts for subjects (1|subject) and target words (1|target) (see Appendix for more details). Models with more complex random effects structures failed to converge or resulted in a singular fit. Correct responses above and below 3 standard deviations from an individual RT mean calculated across Prime, Target’s Category, and Masking were excluded from the analysis. For the grammaticality analyses, we ran frequentist and Bayesian (JASP Team, Citation2020) paired-samples t tests on average log RTs in grammatical versus ungrammatical conditions in the masked and unmasked settings.
3.2. Results
3.2.1. Syntactic priming
The performance of the 36 participants included in the analysis following the application of the exclusion criteria was at ceiling [error rate: M = 2%, SD = 1.2%, range = 0.3% – 5%; GLMMs on accuracy scores revealed the following significant main effects and interactions: Masking (χ2(1) = 10.85, p < .001) with higher accuracy in the masked setting (masked: M = 98.4%, SD = 1.2%; unmasked: M = 97.6%, SD = 1.6%), Prime × Target’s Category (χ2(1) = 6.77, p = .009), and Prime × Target’s Category × Masking (χ2(1) = 6.43, p = .01), see Table S.18 and Figure S.2 in the supplemental data]. The LMMs run on the log-transformed RT data revealed three significant effects (). Responses were on average 23.5 ms slower in the masked setting (masked: M = 625 ms, SD = 64.3 ms; unmasked: M = 601.5 ms, SD = 62.5 ms). A significant Prime × Target’s Category interaction points to a syntactic priming effect. A significant three-way Prime × Target’s Category × Masking interaction suggests a difference in the priming pattern between the masked and the unmasked setting.
Table 3. Experiment 1: results of LMMs run on the log-transformed RT data. Significant main effects and interactions are reported in bold.
To explore the Prime × Target’s Category × Masking interaction, we estimated LMMs in the masked and unmasked settings separately. A significant Prime × Target’s Category interaction was found in both masked (χ2(1) = 4.88, p = .03) and unmasked (χ2(1) = 131.48, p < .001) settings (Table S.21 in the supplemental data). We further analysed the Prime × Target’s Category interaction in the masked and the unmasked settings by running post-hoc comparisons (; Table S.22 in the supplemental data). In the unmasked setting all comparisons were significant. In the masked setting, there was no processing advantage for the grammatical phrase PRO+V compared to the ungrammatical phrase PRO+N (PRO+N – PRO+V: −1.2 ms, t = −0.08, p = .94), and no processing advantage for the grammatical determiner phrase (DET+V – DET+N: 14.1 ms, t = 1.43, p = .46). Furthermore, there was a trend towards an automatic syntactic priming effect with nouns (PRO+N – DET+N: 11.3 ms, t = 2.45, p = .09), but not with verbs (DET+V – PRO+V: 1.6 ms, t = 0.67, p = .75).
Figure 4. Experiment 1: results of the grammaticality analysis and post-hoc analysis of the Prime × Target’s Category interaction in the masked (left panel) and unmasked (right panel) settings. The dots correspond to the individual raw observations. The median values are displayed within the boxplots. The mean values and the error bars indicating ±1 standard error of the mean are shown to the right of the boxplot. For the visualisation purpose we show non-log-transformed RTs. The FDR approach (Benjamini & Hochberg, Citation1995) was used to correct p values for the Type I error. (***p < .001. **p<.01. *p < .05. n.s. = non-significant).
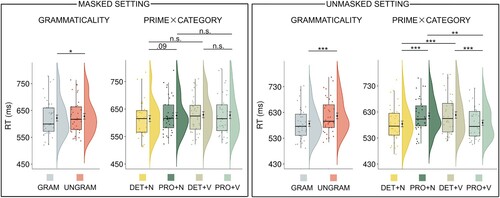
According to the grammaticality analysis run on mean log-transformed RTs to grammatical (DET+N, PRO+V) vs. ungrammatical (DET+V, PRO+N) prime-target phrases, ungrammatical phrases were processed slower than grammatical phrases in the masked and unmasked settings (average RT difference in the masked setting: 6.5 ms, t(35) = 2.35, p = .02, Cohen’s d = 0.39, 95% Confidence Interval (CI) = [0.05, 0.73], BF10 = 2, Median posterior δ = 0.36, 95% Credible Interval (CI) = [0.04, 0.70]; average RT difference in the unmasked setting: 30.2 ms, t(35) = 7.91, p < .001, Cohen’s d = 1.32, 95% CI = [0.86, 1.76], BF10 = 4.48e+6, Median posterior δ = 1.26, 95% CI = [0.82, 1.72]).
3.2.2. Prime visibility
Using the Marascuilo test (Marascuilo, Citation1970), we excluded two participants: one subject showed above-chance performance in the masked setting of the prime visibility test and one subject showed at-chance performance in the unmasked setting, possibly due to misunderstood instructions. For the 36 participants included in the analysis of the syntactic priming test, the mean d′ in the masked setting was equal to 0.16 (55% correct). A correlation test between d′ values and priming effects in the masked setting revealed no reliable correlation (r = .19, t(34) = 1.14, p = .26, 95% CI = [−0.15, 0.49], BF01 = 2.62, 95% CI = [−0.14, 0.47]).
3.3. Discussion
The results from Experiment 1, and specifically the grammaticality analysis, support the conclusion that automatically processed (masked) determiners and pronouns facilitate the processing of categories with which they form grammatical syntactic sequences compared to ungrammatical sequences. Two issues deserve closer attention. First, in the masked setting comparable RTs are found for grammatical and ungrammatical conditions starting with a pronoun (PRO+V and PRO+N, respectively). A similar pattern seems to be visually present in the French study by Berkovitch and Dehaene (Citation2019). From a theoretical point of view, verbs might require more processing time than nouns, because of case, tense, and thematic role assignment (e.g. the verb “sings” assigns an agent role to the subject “he”; Chomsky, Citation1995; Pollock, Citation1989). The comparable RTs for grammatical (PRO+V) and ungrammatical (PRO+N) phrases might be the result of two concomitant different mechanisms, acting in opposite directions. On the one hand, verbs may be primed by the syntactic context. On the other hand, nouns independently might be processed faster due to a category effect. Therefore, differences between the two conditions might disappear. Hence a careful manipulation is required to ensure that categorical differences between nouns and verbs do not confound syntactic priming effects. The second issue concerns the directionality of the priming effect. Although the results suggest that a grammatical prime-target relationship facilitates the categorisation of nouns and verbs compared to an ungrammatical prime-target relationship, it remains unclear whether the priming effect is facilitatory and/or inhibitory with respect to a baseline – i.e. when nouns and verbs are preceded by meaningless context. To shed light on this aspect, in Experiment 2 we included nonword primes as a baseline condition.
4. Experiment 2: inhibition vs. facilitation
The aim of Experiment 2 was twofold. First, we wanted to test whether categorical differences between nouns and verbs might have biased the grammaticality effect in Experiment 1. Second, we aimed at identifying the directionality of the syntactic priming effect. Three different scenarios are possible: the automatic syntactic priming effect might be (i) facilitatory, (ii) inhibitory, or (iii) facilitatory and inhibitory. A facilitatory effect means that the categorisation of nouns and verbs is facilitated by a grammatical relationship between the target and the prime. An inhibitory effect means that an ungrammatical relationship between the prime and the target produces the opposite effect, slowing down the categorisation of nouns and verbs. Finally, the presence of both effects would implicate the possibility of both grammatical and ungrammatical relationships to affect categorical processing. To provide answers to these questions, we included two nonword primes – FTN (nonword determiner) and FR (nonword pronoun) – as meaningless context in Experiment 2, in addition to the real word primes – EIN and ER. The presence of nonword primes allowed us to eliminate confounding differences between nouns and verbs via a category-normalisation procedure, such that RTs for nouns and verbs preceded by nonword primes (FTN, FR) were subtracted from RTs for nouns and verbs preceded by corresponding real word primes (EIN, ER) on each trial for each subject.
4.1. Methods
4.1.1. Participants
Data of 39 participants (25 females, 14 males, Mage = 26.1, age range: 20–35) from the 50 recruited native German speakers (32 females, 18 males, Mage = 26, age range: 19–35) entered the final analysis. In particular, eleven participants were excluded from the analysis: seven participants had mean response times longer than 800 ms in at least one condition across the combination of the factors’ levels, and four participants were excluded due to a discrimination bias in the masked setting of the prime visibility tests. All participants included in the analysis were right-handed according to the Edinburgh Handedness Inventory (Oldfield, Citation1971) (average laterality quotient = 90.1, SD = 13.5, range = 60–100). All of them had normal or corrected-to-normal vision by self-report. Approval for the experiments was obtained from the Ethics Committee of the University of Leipzig (approval number: 299/19-ek). The participants gave written consent and were reimbursed 13.5 Euro for 1 h and 15 min.
4.1.2. Stimuli
We used the same nouns and verbs as well as the same real word primes (EIN and ER) as in the previous experiment (supplemental data, Table S.9). Each of the two nonword primes – FTN (nonword determiner) and FR (nonword pronoun) – was matched in letter similarity and length to one of the real word primes ( and Table S.10). This allowed us to create nonword primes, FTN and FR, sharing perceptual similarity with the real word primes EIN and ER, respectively. provides an example of the stimuli used in the present experiment.
Figure 5. Letter similarity matrix. Letter similarity was computed by creating binary images for each letter of the Latin alphabet (capitalised, Arial font) and calculating the area overlap for each combination of letters. The area overlap was obtained by dividing the area of overlap in pixels between letter1 and letter2 by the total summated area of two letters. The matrix shows the percentage of the area (in pixels) shared by the letters of the Latin alphabet. The yellow diagonal line illustrates a 100% overlap between identical letters.
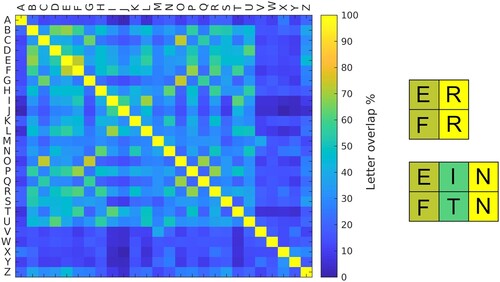
Table 4. Experiment 2: example of the stimuli including real word and nonword primes. DET = determiner, PRO = pronoun, REAL = real word prime, NON = nonword prime. The asterisks indicate ungrammaticality.
4.1.3. Procedure
The experimental session lasted approximately 1 h and 15 min. The masking technique and the order of the tests were identical to the previous experiment, with the exception that the prime visibility test consisted of two blocks: one block (80 trials) with real word primes (EIN; ER) and one block (80 trials) with nonword primes (FTN; FR). Due to the inclusion of nonword primes, the syntactic priming test consisted of eight blocks (four blocks with real word primes and four blocks with nonword primes), including 80 trials in each block (640 trials in total). Each block contained either real word or nonword primes, i.e. the prime types were not mixed within a block. Blocks with real word and nonword primes were alternated, with the order counterbalanced across participants. Each noun/verb appeared only once within a block and eight times in total across blocks (each time in a different condition across Prime × Prime Lexicality × Masking). The factors were counterbalanced across blocks with a Latin Square design (Grant, Citation1948). A short break was included within each block as well as between the blocks.
4.1.4. Data analysis
Accuracy scores and RTs (correct responses, log-transformed) were analysed as in Experiment 1 using GLMMs and LMMs, respectively. Correct responses above and below 3 standard deviations from an individual RT mean calculated across Prime, Target’s Category, Masking, and Prime Lexicality were excluded from the analysis. For each subject, on each trial we subtracted the log RTs of the nouns and verbs preceded by nonword primes from the log RTs of the nouns and verbs preceded by their respective real word primes to remove the confounding Category effect (e.g. log RT EIN+Nnormalised = log RT EIN+N – log RT FTN+N).Footnote3 Note that this subtraction also allows to control for the difference in length between the two real word primes. Following this procedure, category-normalised RTs were analysed using LMMs including the same factors as Experiment 1: Prime (determiner EIN; pronoun ER), normalised Target’s Category (noun; verb), and Masking (masked; unmasked). In LMMs, we excluded the varying intercept for target words from the random effects structure since the category-normalisation procedure removed the processing differences between nouns and verbs. Accordingly, the random effects structure included varying intercepts for subjects (1|subject), block (1|block number), and trial (1|trial number) numbers in the LMM analysis, and varying intercepts for subjects (1|subject) and target words (1|target) in the GLMM analysis. Models with more complex random effects structures failed to converge or resulted in singular fit (see Appendix for more details on the random effects structures).
Since the nonword primes provide a neutral baseline, we could examine whether syntactic context facilitates or slows down target processing, compared to the absence of syntactic context. To analyse the directionality of syntactic priming, eight one-sample t tests against log(1)Footnote4 (=zero, i.e. baseline) were run on category-normalised RTs for all Prime × Target’s Category × Masking conditions.
Prime visibility was analysed as described in §2.2. For the prime visibility test, we additionally performed a simple regression analysis with d′ values as an independent variable and corresponding masked priming effects as a dependent variable.Footnote5 Previous studies employed this regression analysis to test whether the priming effect is significant at zero prime awareness (d′ = 0) (Berkovitch & Dehaene, Citation2019; Greenwald et al., Citation1995; Kiefer, Citation2002; Ortells et al., Citation2016).
4.2. Results
4.2.1. Syntactic priming (normalised data)
The performance of the 39 participants included in the analysis following the application of the exclusion criteria was at ceiling (error rate: M = 2.4%, SD = 2.1%, range = 0.2%–10%; GLMMs on accuracy scores revealed the following significant main effects and interactions: Prime (χ2(1) = 7.94, p = .005) with higher accuracy with real word and nonword pronouns (pronoun (ER, FR): M = 97.8%, SD = 2%; determiner (EIN, FTN): M = 97.3%, SD = 2.3%); Prime Lexicality (χ2(1) = 4.20, p = .04) with higher accuracy with nonword primes (nonword primes: M = 97.7%, SD = 1.8%; real word primes: M = 97.4%, SD = 2.5%); Masking × Target’s Category (χ2(1) = 8.87, p = .003); Prime × Target’s Category (χ2(1) = 11.93, p < .001); and Prime × Target’s Category × Lexicality (χ2(1) = 17.97, p < .001); see Table S.19 and Figure S.3 in the supplemental data).
Before estimating LMMs based on the category-normalised RT data, we analysed unnormalised RT data, (see §S.3.1.3. in the supplemental data) including the factors: Prime (determiner; pronoun), Prime Lexicality (real word; nonword), Target’s Category (noun; verb), and Masking (masked; unmasked). We found a significant Prime × Prime Lexicality × Target’s Category × Masking interaction, pointing towards the presence of a syntactic priming effect, modulated by Masking, only when real word primes were presented. We furthermore found no significant Prime × Target’s Category interaction with nonword primes, suggesting that the two nonword primes (in none of the masking settings) were not interpreted as a real pronoun or a determiner, but rather provided a neutral baseline. Crucially, in line with the hypothesis discussed above, a significant Masking × Target’s Category interaction (χ2(1) = 46.36, p < .001) was observed with nonword primes driven by longer processing of verbs compared to nouns in the masked setting (t = 2.71, p = .02), longer processing of verbs in the masked compared to the unmasked setting (t = 12.02, p < .001), and of nouns in the masked compared to the unmasked setting (t = 2.39, p = .03) (see the supplemental data, Tables S.27 and S.28).
The results of LMMs performed on category-normalised RTs (correct responses, log-transformed) are shown in . As expected, the main effect of Target’s Category was not significant given the normalisation procedure. A significant Target’s Category × Masking interaction was observed, driven by the Prime × Target’s Category × Masking interaction (specifically, by slower processing of verbs compared to nouns in the ungrammatical conditions (DET+V > PRO+N) in the unmasked setting, see ). The significant Prime × Target’s Category interaction indicates a syntactic priming effect, which due to the normalisation procedure is not confounded by processing differences between nouns and verbs. The significant Prime × Target’s Category × Masking interaction indicates that syntactic priming differs between the masked and unmasked settings.
Figure 6. Experiment 2: results of the post-hoc analysis of the Prime × Target’s Category interaction and the inhibition/facilitation analysis (one-sample t tests against log(1) = 0) in the masked and unmasked setting after the category-normalisation procedure. The dotted line displays the baseline. The dots correspond to the individual raw observations. The median values are displayed within the boxplots. The mean values and the error bars indicating ± 1 standard error of the mean are shown to the right of the boxplots. For the visualisation purpose we show non-log-transformed RTs. The FDR approach (Benjamini & Hochberg, Citation1995) was used to correct p values for the Type I error. (***p < .001. **p < .01. *p < .05. n.s. = nonsignificant).
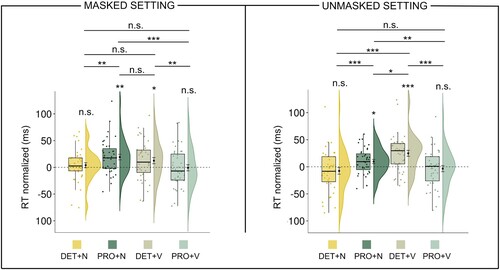
Table 5. Experiment 2: results of LMMs run on the category-normalised log-transformed RT data (real word primes). Significant interactions are reported in bold.
To explore the Prime × Target’s Category × Masking interaction, we estimated LMMs in the masked and unmasked settings. The Prime × Target’s Category interaction was found in both settings [masked (χ2(1) = 20.71, p < .001), unmasked (χ2(1) = 52.85, p < .001); Table S.29 in the supplemental data].
The results of the post-hoc comparisons addressing the Prime × Target’s Category interaction in the masked and unmasked settings are shown in (for more details see Table S.30 in the supplemental data). In the masked setting, the post-hoc comparisons revealed a processing advantage for verbs compared to nouns when preceded by a pronoun (20 ms, t = 4.42, p < .001). This finding suggests that in the Pilot and Experiment 1 the processing advantage for the grammatical phrase PRO+V was hidden by the Category effect. We found, however, no processing advantage for nouns compared to verbs when preceded by a determiner (8.5 ms t = 1.92, p = .08). We further observed an automatic syntactic priming effect for nouns (PRO+Nnormalised – DET+Nnormalised: 15.2 ms, t = 3.33, p = .003) as well as for verbs (DET+Vnormalised – PRO+Vnormalised: 13.4 ms, t = 3.11, p = .004). In the unmasked setting, all four comparisons were significant.
According to the grammaticality analysis run on mean normalised log-transformed RTs to grammatical (DET+N, PRO+V) vs. ungrammatical (DET+V, PRO+N) prime-target phrases, ungrammatical phrases were processed slower than grammatical phrases in the masked and unmasked settings (average RT difference in the masked setting: 14.3 ms, t(38) = 3.95, p < .001, Cohen’s d = 0.63, 95% CI = [0.28, 0.97], BF10 = 83, Median posterior δ = 0.59, 95% CI = [0.26, 0.94]; in the unmasked setting: 23 ms, t(38) = 6.27, p < .001, Cohen’s d = 1.00, 95% CI = [0.61, 1.39], BF10 = 64,109, Median posterior δ = 0.96, 95% CI = [0.58, 1.35]).
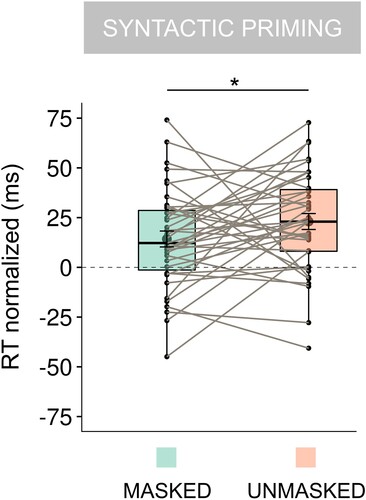
A paired-samples t test on normalised log RTs revealed a larger syntactic priming effect with real word primes in the unmasked setting compared to the masked setting (t(38) = 2.21, p = .03, Cohen’s d = 0.35, 95% CI = [0.03, 0.68], BF10 = 1.52, with median posterior δ = 0.33, 95% CI = [0.02, 0.65]; ).
Figure 7. Experiment 2. Syntactic priming effects in the masked and unmasked settings, calculated by subtracting mean normalised RTs to grammatical conditions (DET+N; PRO+V) from mean normalised RTs to ungrammatical conditions (PRO+N; DET+V) in the masked and unmasked settings. A paired-samples t test was run on normalised log-transformed RTs. For visualisation purpose we show normalised non-log-transformed RTs. The dots reflect individual syntactic priming effects. The median, the mean (the large dot), and the error bars indicating ± 1 standard error of the mean are shown within the boxplots. (*p < .05).
4.2.2. Facilitatory and inhibitory processing
In the masked setting, the pronoun exerted a significant inhibitory effect on noun categorisation (M (SD) = 19.2 ms (32.7 ms), t = 3.75, p = .002). Determiner processing also showed a significant inhibitory effect on verb categorisation (M (SD) = 12.5 ms (36.6 ms), t = 2.40, p = .04). In the unmasked setting, both primes slowed down the processing in the syntactically ungrammatical conditions (PRO+N against baseline: M (SD) = 9.7 ms (24.2 ms), t = 2.57, p = .04; DET+V against baseline: M (SD) = 24.9 ms (34.4 ms), t = 4.66, p < .001). We found no facilitation effect in any of the masking settings (; Table S.31 in the supplemental data).
4.2.3. Prime visibility
Using the Marascuilo test (Marascuilo, Citation1970), we excluded three participants who showed above-chance performance with masked real word primes and one subject who showed above-chance performance with masked nonword primes. For the 39 participants included in the analysis of the syntactic priming test, the mean d′ was 0.17 (55% correct) with masked real word primes and 0.13 (54% correct) with masked nonword primes. A correlation test between d′ values and the priming effects (normalised log RTs) with real word primes in the masked setting revealed no reliable correlation (r = .16, t(37) = 0.97, p = .34, 95% CI = [−0.17, 0.45], BF01 = 3.22, 95% CI = [−0.16, 0.44]). Regression of the priming effect (normalised log RTs) against d′ values in the masked setting revealed a syntactic priming effect at zero prime awareness (intercept was significantly larger than zero: 12.5 ms, t(37) = 2.90, p = .006; Figure S.6. in the supplemental data).
4.3. Discussion
Experiment 2 replicated the automatic syntactic priming effect found in our previous experiment: nouns were processed faster when preceded by a masked determiner compared to a masked pronoun (DET+N < PRO+N), while verbs were processed faster when preceded by a pronoun compared to a determiner (PRO+V < DET+V). The category-normalisation procedure confirmed the hypothesis that the absence of processing differences between the grammatical phrase PRO+V and the ungrammatical phrase PRO+N in the masked setting of Experiment 1 might have been hidden by a category effect, i.e. participants spent more time on the processing of verbs. The removal of categorical confounds left the pure effect of syntactic context on grammatical categorisation. The post-hoc comparisons run on category-normalised RTs of the masked setting revealed faster responses to grammatical phrases with the pronoun – PRO+Vnormalised < PRO+Nnormalised. Conversely, we found no processing advantage for the determiner in grammatical phrases – DET+Nnormalised = DET+Vnormalised. We propose that these diverging findings might be explained assuming the existence of two routes for word category access: a rapid morphological and a slow lexical route (Berkovitch & Dehaene, Citation2019). The determiner EIN which is followed by zero-marked nouns strongly suggests the lexical route for word category access. The pronoun ER suggests the morphological route for word category access since ER is associated with an inflectional suffix “t” on verbs. The general discussion section elaborates on this proposal in greater detail (§6.2.).
Regarding the directionality of syntactic priming, the results suggest an inhibitory nature of masked and unmasked syntactic priming: the primes slow down and do not facilitate the grammatical categorisation of subsequent words. The inhibitory nature of syntactic priming will be addressed in more detail in the general discussion (§6.2.1.).
Overall, the present experiment confirmed the automaticity of syntactic priming and revealed its inhibitory nature. Our third major question concerning the underlying computational mechanism motivated the last experiment. In Experiment 3, we removed the morphological marker on verbs by including irregular past tense verbs lacking overt morphology to test whether the relevance of syntactic context relies on perceptually salient morpho-syntactic features (“t”) during automatic processing in the masked setting.
5. Experiment 3: the role of morphology in automatic syntactic priming
The goal of the last experiment was to test whether the automatic syntactic priming effect for verbs (PRO+V < DET+V) would disappear in the absence of morphological cues on them. For this purpose, we used German irregular past tense verbs, which in contrast to regular past tense verbs ending with “te” do not show overt morphological marking (e.g. “blieb”, “stayed”). The syntactic priming test involved again a speeded grammatical categorisation task with a 2 × 2 × 2 within-subject design including the factors Prime (determiner: EIN; pronoun: ER), Target’s Category (noun; verb), and Masking (masked; unmasked).
5.1. Methods
5.1.1. Participants
Data of 31 participants (21 females, 10 males, Mage = 25.6, age range: 20–34) from the 40 recruited native German speakers (26 females, 14 males, Mage = 25, age range: 19–34) entered the final analysis. In particular, nine participants were excluded: three participants performed above chance in the masked setting of the prime visibility test, four participants had mean RTs longer than 800 ms (Berkovitch & Dehaene, Citation2019) in at least one condition across the combination of the factors’ levels, and two participants’ accuracy rate was below 80% in at least one condition. All participants included in the analysis were right-handed according to the Edinburgh Handedness Inventory (Oldfield, Citation1971) (average laterality quotient = 88.9, SD = 13.1, range = 52–100). All of them had normal or corrected-to-normal vision by self-report. Approval for the experiments was obtained from the Ethics Committee of the University of Leipzig (approval number: 299/19-ek). The participants gave written consent and were reimbursed 9 Euro for 1 h.
5.1.2. Stimuli
From nouns (N = 5285) and verbs (N = 3657) extracted from the CELEX database for German (Baayen et al., Citation1995), we excluded (i) verbs with the regular past tense suffix “te”; (ii) verbs with prefixes because in the sentences with a finite verb in the second position certain verbal prefixes are separated from the verb and occupy the sentence-final position (e.g. “Sie zieht ihre Jacke an.”, “She puts on her jacket.”); and (iii) verbs with missing bigram frequencies for the grammatical phrase ER+V. Due to a small number of remaining verbs (N = 16), the stimulus set of the present experiment included both intransitive and transitive verbs. Among nouns, we removed (i) nouns ending with “t”; (ii) prefixed nouns; and (iii) nouns with missing bigram frequencies for the grammatical phrase EIN+N. For all exclusion criteria see the supplemental data (§S.2.1.2.). After the exclusion procedure, 41 countable masculine singular nouns remained. We performed the same procedure as in the previous experiments to select nouns and verbs matched for the psycholinguistic variables (). The final stimulus set included 16 masculine singular countable nouns and 16 third person singular, irregular past tense verbs (supplemental data, Table S.11). An example of the stimulus material is shown in .
Table 6. Experiment 3: nouns and verbs matched for the psycholinguistic variables. log frequency = logarithmic SUBTLEX word frequency; ortho length = orthographic length; OLD20 = Orthographic Levenshtein Distance 20.
Table 7. Experiment 3: example of the stimuli. Primes: determiner EIN (“a”) and pronoun ER (“he”); targets: masculine singular countable nouns with various endings and past tense irregular verbs in the third person singular form without overt morphological markers. In the present example, the past tense (“blieb”) of the verb “bleiben” (“to stay”) is expressed by a vowel change within the stem without addition of any overt suffixes.
5.1.3. Procedure
The procedure and the masking technique were identical to the previous experiments. The experimental session lasted approximately 45 min. The syntactic priming test consisted of eight blocks with 32 trials per block (16 masked and 16 unmasked; 256 trials in total). Nouns and verbs were presented in all conditions (across Prime × Target’s Category × Masking) across four blocks and repeated in the subsequent four blocks to compensate for a small stimulus set. Thus, each noun/verb appeared only once within a block and eight times in total across blocks. Each combination of the factors was presented two times (i.e. each noun/verb appeared twice in the same condition across Prime × Masking). The factors were counterbalanced across blocks with a Latin Square design (Grant, Citation1948). In the prime visibility test, given a small stimulus set (N = 32), we included three blocks to have the number of trials comparable with previous experiments (three blocks, 32 trials each, 96 trials in total).
5.1.4. Data analysis
Accuracy and RT (correct responses, log-transformed) data of the syntactic priming test were analysed as for the previous experiments, using GLMMs and LMMs, respectively, with factors Prime (determiner EIN; pronoun ER), Target’s Category (noun; verb), and Masking (masked; unmasked). In LMMs, the random effects structure included varying intercepts for subjects (1|subject), target words (1|target), trial (1|trial number), and block (1|block number) numbers. In GLMMs, the random effects structure included varying intercepts for subjects (1|subject) and target words (1|target). Models with more complex random effects structures failed to converge or resulted in a singular fit (see Appendix for more details). Correct responses above and below 3 standard deviations from an individual RT mean calculated across Prime, Target’s Category, and Masking were excluded from the analysis. Prime visibility was analysed as in §2.2.
5.2. Results
5.2.1. Syntactic priming
The performance of the 31 participants included in the analysis following the application of the exclusion criteria was at ceiling (error rate: M = 3.1%, SD = 1.8%, range = 0% – 6.6%; GLMMs on accuracy scores revealed the following significant main effects and interactions: Prime × Target’s Category (χ2(1) = 14.29, p < .001), Masking × Target’s Category (χ2(1) = 5.68, p = .02), and Prime × Target’s Category × Masking (χ2(1) = 5.91, p = .02), see Table S.20 and Figure S.4 in the supplemental data).
LMMs performed on log RTs revealed the main effects and interactions shown in . Responses in the masked setting were on average 24.7 ms slower than in the unmasked setting (masked: M = 595.1 ms, SD = 59.7 ms; unmasked: M = 570.4 ms, SD = 58.5 ms); responses to verbs were on average 31.6 ms slower than to nouns (verbs: M = 598.8 ms, SD = 61.9 ms; nouns: M = 567.2 ms, SD = 60.1 ms); a significant Prime × Target’s Category interaction points to a syntactic priming effect, and a significant Prime × Target’s Category × Masking interaction indicates differences in the priming between the masked and the unmasked settings.
Table 8. Experiment 3: results of LMMs run on the log-transformed RT data. Significant main effects and interactions are reported in bold.
To further explore the Prime × Taget’s Category × Masking interaction, we estimated LMMs for the masked and unmasked settings separately: the Prime × Target’s Category interaction was significant in the unmasked setting only (χ2(1) = 62.92, p < .001). In the masked setting, we found only a Category effect (χ2(1) = 13.23, p < .001) (Table S.32 in the supplemental data). To explore the Prime × Target’s Category interaction in the unmasked setting, we performed post-hoc comparisons (; Table S.33 in the supplemental data) that revealed priming effects for nouns (PRO+N – DET+N: 24.9 ms, t = 5.06, p < .001) and verbs (DET+V – PRO+V: 28.1 ms, t = 6.20, p < .001). Furthermore, responses were faster with the determiner in the grammatical condition compared to the ungrammatical condition (DET+V – DET+N: 51 ms, t = 4.25, p < .001). Though, with the pronoun the RTs did not differ between the grammatical and the ungrammatical condition (PRO+N – PRO+V: 2 ms, t = 0.34, p = .74).
Figure 8. Experiment 3: results of the grammaticality analysis and the post-hoc analysis of the Prime × Target’s Category interaction in the masked (left panel) and unmasked (right panel) settings. The dots correspond to the individual raw observations. The median values are displayed within the boxplots. The mean values and the error bars indicating ± 1 standard error of the mean are shown to the right of the boxplot. For the visualisation purpose we show non-log-transformed RTs. The FDR approach (Benjamini & Hochberg, Citation1995) was used to correct p values for the Type I error. (***p < .001. **p<.01. n.s. = non-significant).
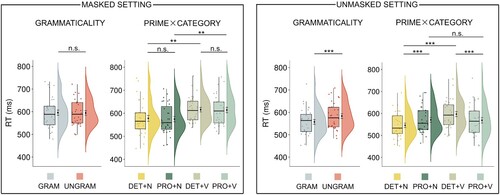
According to the grammaticality analysis run on mean log RTs to grammatical (DET+N, PRO+V) vs. ungrammatical (DET+V, PRO+N) prime-target phrases, no RT differences between grammatical and ungrammatical phrases were found in the masked setting (t(30) = −0.05, p = .96, Cohen’s d = −0.01, 95% CI = [−0.36, 0.34], BF10 = 0.19, Median posterior δ = −0.01, 95% CI = [−0.34, 0.33]). In the unmasked setting, participants responded 26.3 ms faster to grammatical phrases (t(30) = 5.67, p < .001, Cohen’s d = 1.02, 95% CI = [0.58, 1.45], BF10 = 5504, Median posterior δ = 0.96, 95% CI = [0.53, 1.40]).
5.2.2. Prime visibility
Using the Marascuilo test (Marascuilo, Citation1970), we excluded three participants who showed above-chance performance in the masked setting of the prime visibility test. For the 31 participants included in the analysis of the syntactic priming test, in the masked setting the mean d′ was equal to 0.16 (55% correct). A correlation test between d′ values and the priming effects in the masked setting revealed no reliable correlation (r = −.06, t(29) = −0.34, p = .74, 95% CI = [−0.43, 0.31], BF01 = 4.24, 95% CI = [−0.39, 0.29]).
5.3. Discussion
The experiment provided preliminary insights into the interaction between syntactic context and covert morphological marking of the category. The syntactic priming effect in the masked setting was absent when verbs lacked an overt morphological marker and nouns lacked a perceptual ending resembling it. In the unmasked setting, the analysis revealed a syntactic priming effect. We elaborate on the mechanism at the basis of this pattern of results in the general discussion (§6.2.).
6. General discussion
In the present study, we addressed three major research questions. The first question concerned the automaticity of syntactic contextual processing at the behavioural level. In Experiment 1 and Experiment 2 we tested the automaticity of syntactic priming effects under the masked presentation of syntactic context. The second question concerned the directionality of the automatic syntactic priming effect, which we addressed in Experiment 2 using nonword primes. The third question concerned the linguistic mechanism underlying automatic syntactic priming. In Experiment 3, we tested one specific hypothesis that overt morphological cues and perceptual endings resembling them drive automatic syntactic priming effects.
Overall, we found evidence for the existence of automatic syntactic priming effects (Experiments 1 and 2). We furthermore provided evidence for an inhibitory nature of syntactic priming: primes slow down the processing of nouns and verbs in syntactically ungrammatical prime-target relationships (Experiment 2). We finally found no automatic syntactic priming effect with irregular verb forms without overt morphological markers (Experiment 3). This result points towards a central role of a rapid analysis between a function word (e.g. a pronoun) and morphological markers. The findings are discussed in turn below.
6.1. Automaticity of syntactic priming
The syntactic priming effect we found for the masked setting supports the notion that syntactic features are extracted from the context in a highly automatic fashion (Berkovitch & Dehaene, Citation2019). This converges with neurophysiological data indicating that the initial stage of syntactic structure building is very fast and processed in the absence of attention, as suggested by sMMN and (E)LAN studies, and independent of participants’ strategies and expectations (Batterink & Neville, Citation2013; Hahne & Friederici, Citation1999; Hasting et al., Citation2007; Herrmann et al., Citation2009; Jiménez-Ortega et al., Citation2014, Citation2021; Kaan et al., Citation2016; Pulvermüller & Assadollahi, Citation2007; Pulvermüller & Shtyrov, Citation2003). Extending previous sMMN studies (Hanna et al., Citation2014; Hasting et al., Citation2007; Herrmann et al., Citation2009; Lucchese et al., Citation2017; Pulvermüller & Assadollahi, Citation2007; Pulvermüller & Shtyrov, Citation2003), we showed that automatic analysis of a grammatical relationship can be observed including a wider range of stimuli and with visually masked syntactic context. The present results question previous studies on masked (morpho-)syntactic processing that provided evidence for syntactic automaticity at the neural but not at the behavioural level (Iijima & Sakai, Citation2014; Jiménez-Ortega et al., Citation2014, Citation2021). Similarly, they reinforce the behavioural results of the ERP study by Batterink and Neville (Citation2013) who found that visual undetected syntactic violations masked by an auditory tone interfered with the behavioural response. As such, they support the conclusion that the detection of syntactic errors is automatic. Most importantly, our findings add two novel aspects to our current knowledge of syntactic computations: the inhibitory nature of automatic syntactic priming (§6.2.1.) and the existence of a dual route to word category access (§6.2.).
We found that the magnitude of the syntactic priming effect was larger in the unmasked setting compared to the masked setting, as already previously observed (Berkovitch & Dehaene, Citation2019). As discussed by Dehaene and Changeux (Citation2011) in a comprehensive review of (un)conscious processing, masked priming effects negatively correlate with cognitive level/processing depth. Given that language and specifically syntactic analysis are higher-order cognitive skills (Everaert et al., Citation2015; Friederici et al., Citation2017; Zaccarella et al., Citation2021), syntactic priming is expected to decline in the masked setting – a pattern observed in our data. A further crucial distinction between masked and unmasked priming is the involvement of executive control: unmasked priming induces conscious processing, and thus is susceptible to executive control, including task-related strategic processing (Dehaene & Changeux, Citation2011). For example, some studies on masked priming demonstrated that the relatedness proportion (i.e. the proportion of prime-target pairs related on a certain dimension) modulates priming effects under conscious (unmasked) but not under unconscious (masked) conditions (Grossi, Citation2006; Hutchison, Citation2007; Perea & Rosa, Citation2002a), supporting the idea that processing under masked conditions is automatic. In light of these considerations, syntactic processing under unmasked but not under masked conditions might be influenced by strategies, expectations and other extra-syntactic factors, resulting in larger priming effects. Note that a similar distinction between early automatic and late controlled syntactic processes exists in the EEG literature, with the distinct functional profile of the ELAN and the P600 components (Hahne & Friederici, Citation1999).
As discussed in the introduction, we refrain from using the terms subliminal or unconscious and from relying on the sensitivity index d′ to prove prime unawareness for several reasons. First, as noted by Seth et al. (Citation2008), the research on (un)conscious processing faces the problem of the appropriate measurement, whereby the choice of the awareness measure is dictated by the theory of consciousness. The sensitivity index d′ raises at least three problems (Dehaene & Changeux, Citation2011): first, often there is a discrepancy between objective (d′) and subjective measures of prime awareness; second, at chance performance might be dependent on the task and other choices such as the number of experimental trials; and, finally, the null hypothesis of zero prime awareness is nearly impossible. Thus, if a bias was present during the syntactic priming test, it logically follows that an (unconscious) bias should be also present when participants engage in a forced-choice prime recognition task during the prime visibility test. In other words, if we expect that masked primes unconsciously influence performance during the syntactic priming test, this unconscious influence might as well affect performance in the prime visibility test. As discussed in the introduction, syntactic information is computed in a highly automatic fashion in the masked setting given a very brief prime duration (33 ms) and SOA (49 ms), which leave insufficient time for an initiation of any strategic process. Nonetheless, the presentation of a minimal syntactic context already triggers the analysis of the prime-target syntactic relationship, despite the fact that this relationship is not required to perform grammatical categorisation of the target word (see Faussart et al. [Citation1999] and Maran, Friederici, et al. [Citation2022], for a similar argumentation).
6.2. Routes to syntactic priming
Our findings point towards a central role of morphological cues to syntactic priming effects. Language comprehension relies on the ability to access the lexical representation of incoming words, which can be morphologically decomposable or not (e.g. zero or irregular forms). Dual-route theories of morphology (Baayen et al., Citation1997; Leminen et al., Citation2019; Marcus et al., Citation1995; Marslen-Wilson & Tyler, Citation1998; Pinker, Citation1991) account for this aspect by postulating that regular word forms are rapidly decomposed into morphological constituents (Leminen et al., Citation2013; Longtin & Meunier, Citation2005; Marslen-Wilson et al., Citation2008; Neophytou et al., Citation2018; Rastle et al., Citation2004) while irregular forms are retrieved as a whole from the mental lexicon (Penke et al., Citation1997; Sonnenstuhl et al., Citation1999; Ullman et al., Citation1997). Such a distinction has also been grounded onto separate neuro-cognitive systems (Ullman, Citation2001). In line with dual-route theories of word recognition, the existence of two routes leading to word category access has been suggested – a lexical and a (pseudo-)morphological route (Berkovitch & Dehaene, Citation2019). While the morphological route allows recognising word category via morphological markers or via a rapid morphological decomposition process, the lexical route proceeds via direct extraction of word category information from the mental syntactic lexicon. These two routes are proposed to operate in parallel, whereby the morphological route is rapid and occasionally leads to wrong encodings (e.g. based on the verbal suffix “ing”, the noun “sibling” would be wrongly categorised as a verb), the lexical route is slower but more accurate. A third component influencing word category access is syntactic context, involving application of structural grammatical principles.
We here propose that the mechanism by which syntactic context influences category access is by increasing or decreasing the relevance of the two routes (). Accordingly, function words building phrases with morphologically unmarked forms (e.g. determiners in the nominative case and singular form: “ein Bart-Ø”, “a beard”) might lead to a stronger reliance on the lexical route for word category access. Since both nouns and verbs are in the lexicon, this route can in principle be used to access both. Function words requiring an inflected formFootnote6 might point towards a morphological decomposition of the upcoming word as long as a morphological marker or an ending perceptually resembling it (e.g. “t” on nouns in Experiments 1 and 2) is present.
Figure 9. A dual-route mechanism of automatic syntactic priming. Word category information can be accessed via two routes: a rapid morphological and a slow lexical route (Berkovitch & Dehaene, Citation2019). The pronoun suggests the morphological route for word category access given the presence of overt morpho-syntactic inflection (eyes open, +infl) on the target word. If the target word lacks overt morpho-syntactic inflection but has an ending perceptually resembling it (eyes open, –infl), the morphological route is attempted but rapidly dismissed (the red exclamation mark sign). If the target word has neither overt inflection nor an ending resembling it (eyes closed, ±infl), the target word category is accessed via the lexical route. The determiner which is followed by zero-marked target words always suggests the lexical route for word category access.
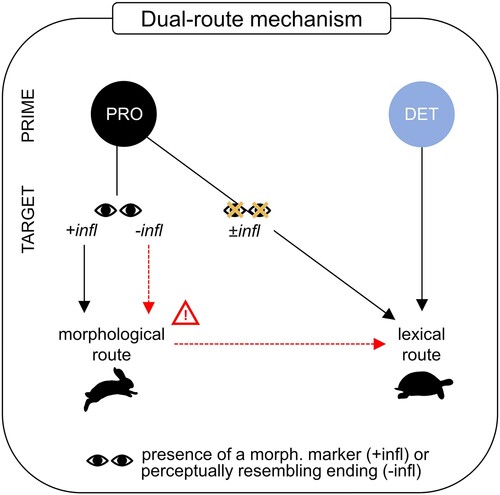
We propose that slower processing of the target words in ungrammatical sequences stems from wrong or suboptimal routes suggested by the context for word category access. Let us first consider the patterns found in the masked setting of Experiment 2 after the confounding category effect was removed:
PRO+N > DET+N: the pronoun suggests a morphological decomposition analysis that can be wrongly applied to nouns given the ending “t” as a possible morphological marker. However, since the decomposed stem is not part of the lexicon, the rapid morphological route is overridden by a slower lexical route leading to slower processing of PRO+N phrases.
DET+V > PRO+V: the determiner triggers a lemma search via the lexical route, leading to the extraction of a verb category from the lexicon. However, the slow lexical route proves as suboptimal compared to the fast morphological route suggested by the pronoun in PRO+V.
PRO+N > PRO+V: the mechanism is similar to the PRO+N > DET+N comparison. The pronoun suggests a morphological decomposition analysis which is overridden by the lexical route because the noun stem stripped of the “t” is not part of the lexicon. This double analysis – first, via the morphological route, followed by a lemma search in the lexicon – slows down the processing of PRO+N phrases.
DET+V = DET+N: the determiner initiates a word category search in the mental lexicon; since the morphological structure of a word does not matter for the lemma search via the lexical route, nouns and verbs are similarly extracted from the lexicon. Therefore, no differences in speed for word category access are expected, as the retrieval route is the same.
Notably, we found no automatic syntactic priming effects in Experiment 3. Here, the irregular verbs lack morphological markers – they need to be retrieved as full forms (Marcus et al., Citation1995; Marslen-Wilson & Tyler, Citation1998; Pinker, Citation1991; Weyerts et al., Citation1996). Similarly, nouns in the nominative case do not require morphological decomposition – they are retrieved via the lexicon. In both cases, no interference between the two routes arises, since the lexical route appears to be the most efficient way to access the target categories, given the lack of morphological markers or any resembling elements on the target words.Footnote7
6.2.1. Inhibitory nature of syntactic priming
A major contribution of our study is the characterisation of the inhibitory nature of automatic syntactic priming at the categorical level. While ungrammatical syntactic context slowed down the processing of nouns and verbs, correct syntactic context showed no facilitatory effect compared to the baseline condition.
The lack of facilitation with grammatical syntactic context might reflect the effortless nature of basic syntactic structure building. In particular, contrary to the semantic domain in which pre-activation might efficiently facilitate processing, the syntactic domain deals with a limited number of categories and constructions, rendering any predictive facilitative processing costly and inefficient especially when building simple two-word constructions (Maran, Friederici, et al., Citation2022; Maran, Numssen, et al., Citation2022; Matchin et al., Citation2017). Supporting evidence comes from previous EEG and MEG studies showing that the early stage of syntactic structure building is not affected by the frequency of a construction or expectations (Herrmann et al., Citation2009; Kaan et al., Citation2016; Kroczek & Gunter, Citation2021; Pulvermüller & Assadollahi, Citation2007). In this regard, evidence in favour of an ELAN modulation by predictive processes (Lau et al., Citation2006) has been challenged from a methodological point of view (Nieuwland, Citation2019) and not replicated in a more recent follow-up study (Kaan et al., Citation2016).
If syntactic context generated predictions about upcoming words, this would require a mental pre-activation of an extremely large set of words within a specific word category in the lexicon (Seidenberg et al., Citation1984), leading to lateral inhibition among word candidates and no processing advantage for any entry in particular (Maran, Friederici, et al., Citation2022). The probabilistic Bayesian computational framework underlying predictive processing provides a supporting argument. Within this framework, the language user aims at maximising the utility of a prediction (Kuperberg & Jaeger, Citation2016), which would be extremely low in the syntactic domain. In German, the article EIN (“a”) can be followed by over 22,700 potential masculine and neuter noun candidates. Since the sum of all probabilities adds up to 1, the probability of each noun candidate would be approximately equal to 0.00004 (1/22,700). Consequently, the increase in belief for the encountered noun and the decrease in belief for the remaining nouns would be too negligible to bring any processing advantage. The fact that we observed no processing differences between the grammatical and the baseline conditions in the masked setting (DET+N = FTN+N; PRO+V = FR+V, Table S.24 in the supplemental data) conforms to this prediction. In contrast to the inhibitory nature of syntactic priming, Lukatela et al. (Citation1988) showed facilitation but no inhibition in semantic priming with a lexical decision task. Importantly, a key aspect to consider is that in the semantic domain predictions can lead to the pre-activation of a limited number of entries in the lexicon (e.g. “building”, “tower”, “skyscraper” after the adjective “tall”), therefore affecting performance (Maran, Friederici, et al., Citation2022). This distinction suggests that semantic/associative and syntactic priming operate at different stages in the process of word recognition: semantic/associative priming arises via the spreading activation within the lexicon, while syntactic priming might reflect a post-lexical integration process and feature checking (Carello et al., Citation1988; Faussart et al., Citation1999; Maran, Friederici, et al., Citation2022; Seidenberg et al., Citation1984).
6.3. Limitations & directions for future research
A remaining open issue in the model we put forward in the present study concerns the possibility that categorical knowledge is accessed based on statistical principles like co-occurrence probabilities (McClelland & Rogers, Citation2003), rather than based on abstract syntactic relationships between words (Chomsky, Citation1957; Culbertson & Adger, Citation2014; Goucha et al., Citation2017; Zaccarella et al., Citation2017). Although our study did not directly examine the role of statistical probabilities in syntactic priming, previous findings showed that the syntactic priming effect is also observed when the transitional probability between prime and target is zero – namely, when the prime and the target form a sequence which is syntactically correct but which contains unattested agreement violations such as “des reptile” (“some reptile”) where a plural determiner “des” disagrees in number with a singular noun “reptile” (Berkovitch & Dehaene, Citation2019). Similarly, contextual effects have also been observed in studies employing morphologically inflected pseudo-words as targets (Lukatela et al., Citation1982, Citation1983). This converges on neurophysiological studies showing no effect of transitional probabilities in the early and automatic stages of syntactic analysis (Friederici et al., Citation1996; Herrmann et al., Citation2009; Pulvermüller & Assadollahi, Citation2007). One further open issue concerns the locus of syntactic contextual effects: the design of our study does not allow to disentangle whether syntactic context affects target processing at the pre- or the post-lexical stage. To the best of our knowledge, the studies that found post-lexical effects in syntactic priming (Carello et al., Citation1988; Seidenberg et al., Citation1984) did not test the effect of priming under masked settings. Therefore, further investigation is required to answer the question whether automatically processed syntactic context induces pre- and/or post-lexical effects.
A limitation of the present study is that, as in the previous application of subliminal syntactic priming (Berkovitch & Dehaene, Citation2019), masked and unmasked settings are characterised by different SOAs between primes and targets. Notably, the reduction of the SOA between prime and target is a manipulation commonly used in the literature to test automatic syntactic processing (Lukatela et al., Citation1982, Citation1988). Since in our and previous (Berkovitch & Dehaene, Citation2019) studies this difference is orthogonal to the grammatical relationships tested (i.e. it affects both grammatical and ungrammatical structures), it might not represent a confounding factor when investigating the automaticity of syntactic priming. However, future studies investigating the main effect of Masking in this paradigm might need to equate SOAs between masked and unmasked settings.
7. Conclusion
Our study investigated the automaticity of syntactic processing in German by employing a masked syntactic priming paradigm. We found evidence for automatic syntactic priming effects between primes (determiner and pronoun) and targets (nouns and verbs) during flashed visual word stimulation. We furthermore reported an inhibitory nature of syntactic priming that is independent of automaticity as it was observed in both masked and unmasked settings, pointing towards a strong influence of syntactic context over the access to grammatical categories. We finally found that automatic syntactic priming disappears when overt morphological markers are removed from the targets. A dual-route model of categorical access is proposed involving interfering effects between lexical and morphological processing. On a final note, syntactic priming has mostly been addressed in morphologically rich languages such as Serbo-Croatian, French, English, and German. Hence, an empirical hypothesis yet to be tested is whether the lexical route to category access becomes more prominent in isolating languages with no overt morphology, as suggested by the tight interplay between contextual syntactic and semantic factors during sentence comprehension (Ye et al., Citation2006).
Supplemental Material
Download PDF (3.1 MB)Acknowledgements
Elena Pyatigorskaya and Matteo Maran have contributed equally to this work and share first authorship. The authors would like to thank Ulrike Barth, Heike Boethel, Kristiane Klein, the Department of Neuropsychology (Max Planck Institute for Human Cognitive and Brain Sciences), and in particular Prof. Angela D. Friederici for her continuous support throughout the study and for her constructive feedback on earlier versions of the manuscript, as well as Patrick C. Trettenbrein and Dr. Constantijn van der Burght for the valuable input provided when discussing the present study.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1 The term syntactic priming is used to describe two distinct phenomena in the psycholinguistic literature. According to the first interpretation, syntactic priming is understood as structural priming, i.e. a tendency to reuse syntactic structures. According to the second interpretation, which we address in the present work, syntactic priming refers to the influence of syntactic context (a prime) on the processing of the following word (a target). Response latencies are faster when the prime word forms a correct construction with the target word than when the prime and the target word form an incorrect one.
2 Following the convention adopted from theoretical linguistics, we use the symbol * to denote an ungrammatical construction.
3 To perform the category-normalisation procedure on a trial-wise basis, we removed from the final data frame those trials on which the normalisation was not possible due to missing trials (incorrect responses and excluded trials according to the mean and SD criterion). For example, if the trial “FTN BART” (masked setting) was missing for subject 1, we removed the trial “EIN BART” (masked setting) from the final data frame of this subject because the normalisation of RTs (RT EIN+BART – RT FTN+BART) was not possible.
4 Since the t tests were run on log-transformed RTs, we decided to use log(1) instead of a zero as a baseline given that log(0) does not exist.
5 The regression analysis was run only for Experiment 2 as, compared to other experiments, due to the normalisation procedure in Experiment 2 the syntactic priming effects were not confounded by processing differences between nouns and verbs.
6 In addition to pronouns, other case-inflected function words such as determiners (“wegen ein-es Zwischenfall-s”, “because of an incident”) would rely on the word category access via the morphological route.
7 As Experiment 3 did not include a baseline condition, given the possibility of categorical differences between nouns and verbs as well as the inclusion of both transitive and intransitive verbs, we, here, refrain from interpreting the comparisons PRO+V vs. PRO+N and DET+V vs. DET+N.
References
- Ansorge, U., Reynvoet, B., Hendler, J., Oettl, L., & Evert, S. (2013). Conditional automaticity in subliminal morphosyntactic priming. Psychological Research, 77(4), 399–421. https://doi.org/10.1007/s00426-012-0442-z
- Baayen, R. H., Dijkstra, T., & Schreuder, R. (1997). Singulars and plurals in Dutch: Evidence for a parallel dual-route model. Journal of Memory and Language, 37(1), 94–117. https://doi.org/10.1006/jmla.1997.2509
- Baayen, R. H., Gulikers, L., & Piepenbrock, R. (1995). The CELEX lexical database (WebCelex). University of Pennsylvania, Linguistic Data Consortium.
- Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1). https://doi.org/10.18637/jss.v067.i01
- Batterink, L., & Neville, H. J. (2013). The human brain processes syntax in the absence of conscious awareness. Journal of Neuroscience, 33(19), 8528–8533. https://doi.org/10.1523/JNEUROSCI.0618-13.2013
- Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B (Methodological), 57(1), 289–300. https://doi.org/10.1111/j.2517-6161.1995.tb02031.x
- Berkovitch, L., & Dehaene, S. (2019). Subliminal syntactic priming. Cognitive Psychology, 109, 26–46. https://doi.org/10.1016/j.cogpsych.2018.12.001
- Carello, C., Lukatela, G., & Turvey, M. T. (1988). Rapid naming is affected by association but not by syntax. Memory & Cognition, 16(3), 187–195. https://doi.org/10.3758/BF03197751
- Chomsky, N. (1957). Syntactic structures. Mouton.
- Chomsky, N. (1995). The minimalist program. MIT Press.
- Colé, P., & Segui, J. (1994). Grammatical incongruency and vocabulary types. Memory & Cognition, 22(4), 387–394. https://doi.org/10.3758/BF03200865
- Culbertson, J., & Adger, D. (2014). Language learners privilege structured meaning over surface frequency. Proceedings of the National Academy of Sciences, 111(16), 5842–5847. https://doi.org/10.1073/pnas.1320525111
- Dehaene, S., & Changeux, J.-P. (2011). Experimental and theoretical approaches to conscious processing. Neuron, 70(2), 200–227. https://doi.org/10.1016/j.neuron.2011.03.018
- Dehaene, S., Naccache, L., Le Clec’H, G., Koechlin, E., Mueller, M., Dehaene-Lambertz, G., van de Moortele, P. F., & Le Bihan, D. (1998). Imaging unconscious semantic priming. Nature, 395(6702), 597–600. https://doi.org/10.1038/26967
- Dikker, S., Rabagliati, H., Farmer, T. A., & Pylkkänen, L. (2010). Early occipital sensitivity to syntactic category is based on form typicality. Psychological Science, 21(5), 629–634. https://doi.org/10.1177/0956797610367751
- Dikker, S., Rabagliati, H., & Pylkkänen, L. (2009). Sensitivity to syntax in visual cortex. Cognition, 110(3), 293–321. https://doi.org/10.1016/j.cognition.2008.09.008
- Everaert, M. B. H., Huybregts, M. A. C., Chomsky, N., Berwick, R. C., & Bolhuis, J. J. (2015). Structures, not strings: Linguistics as part of the cognitive sciences. Trends in Cognitive Sciences, 19(12), 729–743. https://doi.org/10.1016/j.tics.2015.09.008
- Faussart, C., Jakubowicz, C., & Costes, M. (1999). Gender and number processing in spoken French and Spanish. The Italian Journal of Linguistics, 11, 75–101.
- Ferrand, L., & New, B. (2004). Semantic and associative priming in the mental lexicon. In P. Bonin (Ed.), Mental lexicon: “Some words to talk about words” (pp. 25–43). Nova Science Publishers.
- Friederici, A. D. (2002). Towards a neural basis of auditory sentence processing. Trends in Cognitive Sciences, 6(2), 78–84. https://doi.org/10.1016/S1364-6613(00)01839-8
- Friederici, A. D. (2011). The brain basis of language processing: From structure to function. Physiological Reviews, 91(4), 1357–1392. https://doi.org/10.1152/physrev.00006.2011
- Friederici, A. D., Chomsky, N., Berwick, R. C., Moro, A., & Bolhuis, J. J. (2017). Language, mind and brain. Nature Human Behaviour, 1(10), 713–722. https://doi.org/10.1038/s41562-017-0184-4
- Friederici, A. D., Hahne, A., & Mecklinger, A. (1996). Temporal structure of syntactic parsing: Early and late event-related brain potential effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22(5), 1219–1248. https://doi.org/10.1037/0278-7393.22.5.1219
- Friederici, A. D., & Jacobsen, T. (1999). Processing grammatical gender during language comprehension. Journal of Psycholinguistic Research, 28(5), 467–484. https://doi.org/10.1023/A:1023264209610
- Goodman, G. O., McClelland, J. L., & Gibbs, R. W. (1981). The role of syntactic context in word recognition. Memory & Cognition, 9(6), 580–586. https://doi.org/10.3758/BF03202352
- Goucha, T., Zaccarella, E., & Friederici, A. D. (2017). A revival of Homo loquens as a builder of labeled structures: Neurocognitive considerations. Neuroscience & Biobehavioral Reviews, 81(Pt B), 213–224. https://doi.org/10.1016/j.neubiorev.2017.01.036
- Grant, D. A. (1948). The latin square principle in the design and analysis of psychological experiments. Psychological Bulletin, 45(5), 427–442. https://doi.org/10.1037/h0053912
- Green, D. M., & Swets, J. A. (1966). Signal detection theory and psychophysics. Wiley.
- Greenwald, A. G., Klinger, M. R., & Schuh, E. S. (1995). Activation by marginally perceptible (“subliminal”) stimuli: Dissociation of unconscious from conscious cognition. Journal of Experimental Psychology: General 124(1), 22–42. https://doi.org/10.1037/0096-3445.124.1.22
- Grossi, G. (2006). Relatedness proportion effects on masked associative priming: An ERP study. Psychophysiology, 43(1), 21–30. https://doi.org/10.1111/j.1469-8986.2006.00383.x
- Gurjanov, M., Lukatela, G., Lukatela, K., Savić, M., & Turvey, M. T. (1985). Grammatical priming of inflected nouns by the gender of possessive adjectives. Journal of Experimental Psychology: Learning, Memory, and Cognition, 11(4), 692–701. https://doi.org/10.1037/0278-7393.11.1-4.692
- Gurjanov, M., Lukatela, G., Moskovljević, J., Savić, M., & Turvey, M. T. (1985). Grammatical priming of inflected nouns by inflected adjectives. Cognition, 19(1), 55–71. https://doi.org/10.1016/0010-0277(85)90031-9
- Hahne, A., & Friederici, A. D. (1999). Electrophysiological evidence for two steps in syntactic analysis: Early automatic and late controlled processes. Journal of Cognitive Neuroscience, 11(2), 194–205. https://doi.org/10.1162/089892999563328
- Hanna, J., Mejias, S., Schelstraete, M. A., Pulvermüller, F., Shtyrov, Y., & van der Lely, H. K. J. (2014). Early activation of Broca’s area in grammar processing as revealed by the syntactic mismatch negativity and distributed source analysis. Cognitive Neuroscience, 5(2), 66–76. https://doi.org/10.1080/17588928.2013.860087
- Hasting, A. S., Kotz, S. A., & Friederici, A. D. (2007). Setting the stage for automatic syntax processing: The mismatch negativity as an indicator of syntactic priming. Journal of Cognitive Neuroscience, 19(3), 386–400. https://doi.org/10.1162/jocn.2007.19.3.386
- Herrmann, B., Maess, B., Hasting, A. S., & Friederici, A. D. (2009). Localization of the syntactic mismatch negativity in the temporal cortex: An MEG study. NeuroImage, 48(3), 590–600. https://doi.org/10.1016/j.neuroimage.2009.06.082
- Humphreys, G. W., Evett, L. J., & Taylor, D. E. (1982). Automatic phonological priming in visual word recognition. Memory & Cognition, 10(6), 576–590. https://doi.org/10.3758/BF03202440
- Hutchison, K. A. (2007). Attentional control and the relatedness proportion effect in semantic priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(4), 645–662. https://doi.org/10.1037/0278-7393.33.4.645
- Iijima, K., & Sakai, K. L. (2014). Subliminal enhancement of predictive effects during syntactic processing in the left inferior frontal gyrus: An MEG study. Frontiers in Systems Neuroscience, 8, 217. https://doi.org/10.3389/fnsys.2014.00217
- JASP Team. (2020). JASP (0.13.0).
- Jiménez-Ortega, L., Badaya, E., Casado, P., Fondevila, S., Hernández-Gutiérrez, D., Muñoz, F., Sánchez-García, J., & Martín-Loeches, M. (2021). The automatic but flexible and content-dependent nature of syntax. Frontiers in Human Neuroscience, 15. https://doi.org/10.3389/fnhum.2021.651158
- Jiménez-Ortega, L., García-Milla, M., Fondevila, S., Casado, P., Hernández-Gutiérrez, D., & Martín-Loeches, M. (2014). Automaticity of higher cognitive functions: Neurophysiological evidence for unconscious syntactic processing of masked words. Biological Psychology, 103, 83–91. https://doi.org/10.1016/j.biopsycho.2014.08.011
- Kaan, E., Kirkham, J., & Wijnen, F. (2016). Prediction and integration in native and second-language processing of elliptical structures. Bilingualism: Language and Cognition, 19(1), 1–18. https://doi.org/10.1017/S1366728914000844
- Katz, L., Boyce, S., Goldstein, L., & Lukatela, G. (1987). Grammatical information effects in auditory word recognition. Cognition, 25(3), 235–263. https://doi.org/10.1016/S0010-0277(87)80005-7
- Kiefer, M. (2002). The N400 is modulated by unconsciously perceived masked words: Further evidence for an automatic spreading activation account of N400 priming effects. Cognitive Brain Research, 13(1), 27–39. https://doi.org/10.1016/S0926-6410(01)00085-4
- Kiefer, M. (2019). Cognitive control over unconscious cognition: Flexibility and generalizability of task set influences on subsequent masked semantic priming. Psychological Research, 83(7), 1556–1570. https://doi.org/10.1007/s00426-018-1011-x
- Kiefer, M., Trumpp, N. M., Schaitz, C., Reuss, H., & Kunde, W. (2019). Attentional modulation of masked semantic priming by visible and masked task cues. Cognition, 187, 62–77. https://doi.org/10.1016/j.cognition.2019.02.013
- Kouider, S., & Dehaene, S. (2007). Levels of processing during non-conscious perception: A critical review of visual masking. Philosophical Transactions of the Royal Society B: Biological Sciences, 362(1481), 857–875. https://doi.org/10.1098/rstb.2007.2093
- Krakauer, J. W., Ghazanfar, A. A., Gomez-Marin, A., MacIver, M. A., & Poeppel, D. (2017). Neuroscience needs behavior: Correcting a reductionist bias. Neuron, 93(3), 480–490. https://doi.org/10.1016/j.neuron.2016.12.041
- Kroczek, L. O. H., & Gunter, T. C. (2021). The time course of speaker-specific language processing. Cortex, 141, 311–321. https://doi.org/10.1016/j.cortex.2021.04.017
- Kuperberg, G. R., & Jaeger, T. F. (2016). What do we mean by prediction in language comprehension? Language, Cognition and Neuroscience, 31(1), 32–59. https://doi.org/10.1080/23273798.2015.1102299
- Lau, E., Stroud, C., Plesch, S., & Phillips, C. (2006). The role of structural prediction in rapid syntactic analysis. Brain and Language, 98(1), 74–88. https://doi.org/10.1016/j.bandl.2006.02.003
- Lehtonen, M., Monahan, P. J., & Poeppel, D. (2011). Evidence for early morphological decomposition: Combining masked priming with magnetoencephalography. Journal of Cognitive Neuroscience, 23(11), 3366–3379. https://doi.org/10.1162/jocn_a_00035
- Leminen, A., Leminen, M., Kujala, T., & Shtyrov, Y. (2013). Neural dynamics of inflectional and derivational morphology processing in the human brain. Cortex, 49(10), 2758–2771. https://doi.org/10.1016/j.cortex.2013.08.007
- Leminen, A., Smolka, E., Duñabeitia, J. A., & Pliatsikas, C. (2019). Morphological processing in the brain: The good (inflection), the bad (derivation) and the ugly (compounding). Cortex, 116, 4–44. https://doi.org/10.1016/j.cortex.2018.08.016
- Longtin, C.-M., & Meunier, F. (2005). Morphological decomposition in early visual word processing. Journal of Memory and Language, 53(1), 26–41. https://doi.org/10.1016/j.jml.2005.02.008
- Longtin, C.-M., Segui, J., & Hallé, P. A. (2003). Morphological priming without morphological relationship. Language and Cognitive Processes, 18(3), 313–334. https://doi.org/10.1080/01690960244000036
- Lucchese, G., Hanna, J., Autenrieb, A., Miller, T. M. C., & Pulvermüller, F. (2017). Electrophysiological evidence for early and interactive symbol access and rule processing in retrieving and combining language constructions. Journal of Cognitive Neuroscience, 29(2), 254–266. https://doi.org/10.1162/jocn_a_01038
- Lukatela, G., Carello, C., Kostić, A., & Turvey, M. T. (1988). Low-constraint facilitation in lexical decision with single-word contexts. The American Journal of Psychology, 101(1), 15–29. https://doi.org/10.2307/1422790
- Lukatela, G., Kostić, A., Feldman, L. B., & Turvey, M. T. (1983). Grammatical priming of inflected nouns. Memory & Cognition, 11(1), 59–63. https://doi.org/10.3758/BF03197662
- Lukatela, G., Kostić, A., Todorović, D., Carello, C., & Turvey, M. T. (1987). Type and number of violations and the grammatical congruency effect in lexical decision. Psychological Research, 49(1), 37–43. https://doi.org/10.1007/BF00309201
- Lukatela, G., Moraca, J., Stojnov, D., Savic, M. D., Katz, L., & Turvey, M. T. (1982). Grammatical priming effects between pronouns and inflected verb forms. Psychological Research, 44(4), 297–311. https://doi.org/10.1007/BF00309326
- MacGregor, L. J., Pulvermüller, F., Van Casteren, M., & Shtyrov, Y. (2012). Ultra-rapid access to words in the brain. Nature Communications, 3(1), 711. https://doi.org/10.1038/ncomms1715
- Mancini, S., Molinaro, N., Davidson, D. J., Avilés, A., & Carreiras, M. (2014). Person and the syntax–discourse interface: An eye-tracking study of agreement. Journal of Memory and Language, 76, 141–157. https://doi.org/10.1016/j.jml.2014.06.010
- Maran, M., Friederici, A. D., & Zaccarella, E. (2022). Syntax through the looking glass: A review on two-word linguistic processing across behavioral, neuroimaging and neurostimulation studies. Neuroscience & Biobehavioral Reviews, 142, 104881. https://doi.org/10.1016/j.neubiorev.2022.104881
- Maran, M., Numssen, O., Hartwigsen, G., & Zaccarella, E. (2022). Online neurostimulation of Broca’s area does not interfere with syntactic predictions: A combined TMS-EEG approach to basic linguistic combination. Frontiers in Psychology, 13. https://doi.org/10.3389/fpsyg.2022.968836
- Marascuilo, L. A. (1970). Extensions of the significance test for one-parameter signal detection hypotheses. Psychometrika, 35(2), 237–243. https://doi.org/10.1007/BF02291265
- Marcus, G. F., Brinkmann, U., Clahsen, H., Wiese, R., & Pinker, S. (1995). German inflection: The exception that proves the rule. Cognitive Psychology, 29(3), 189–256. https://doi.org/10.1006/cogp.1995.1015
- Marslen-Wilson, W. D. (1973). Linguistic structure and speech shadowing at very short latencies. Nature, 244(5417), 522–523. https://doi.org/10.1038/244522a0
- Marslen-Wilson, W. D., Bozic, M., & Randall, B. (2008). Early decomposition in visual word recognition: Dissociating morphology, form, and meaning. Language and Cognitive Processes, 23(3), 394–421. https://doi.org/10.1080/01690960701588004
- Marslen-Wilson, W. D., & Tyler, L. K. (1998). Rules, representations, and the English past tense. Trends in Cognitive Sciences, 2(11), 428–435. https://doi.org/10.1016/S1364-6613(98)01239-X
- Matchin, W., Hammerly, C., & Lau, E. (2017). The role of the IFG and pSTS in syntactic prediction: Evidence from a parametric study of hierarchical structure in fMRI. Cortex, 88, 106–123. https://doi.org/10.1016/j.cortex.2016.12.010
- McClelland, J. L., & Rogers, T. T. (2003). The parallel distributed processing approach to semantic cognition. Nature Reviews Neuroscience, 4(4), 310–322. https://doi.org/10.1038/nrn1076
- Naccache, L., & Dehaene, S. (2001). Unconscious semantic priming extends to novel unseen stimuli. Cognition, 80(3), 215–229. https://doi.org/10.1016/S0010-0277(00)00139-6
- Nakamura, K., Makuuchi, M., Oga, T., Mizuochi-Endo, T., Iwabuchi, T., Nakajima, Y., & Dehaene, S. (2018). Neural capacity limits during unconscious semantic processing. European Journal of Neuroscience, 47(8), 929–937. https://doi.org/10.1111/ejn.13890
- Neophytou, K., Manouilidou, C., Stockall, L., & Marantz, A. (2018). Syntactic and semantic restrictions on morphological recomposition: MEG evidence from Greek. Brain and Language, 183, 11–20. https://doi.org/10.1016/j.bandl.2018.05.003
- Nieuwland, M. S. (2019). Do ‘early’ brain responses reveal word form prediction during language comprehension? A critical review. Neuroscience & Biobehavioral Reviews, 96, 367–400. https://doi.org/10.1016/j.neubiorev.2018.11.019
- Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia, 9(1), 97–113. https://doi.org/10.1016/0028-3932(71)90067-4
- Ortells, J. J., Kiefer, M., Castillo, A., Megías, M., & Morillas, A. (2016). The semantic origin of unconscious priming: Behavioral and event-related potential evidence during category congruency priming from strongly and weakly related masked words. Cognition, 146, 143–157. https://doi.org/10.1016/j.cognition.2015.09.012
- Penke, M., Weyerts, H., Gross, M., Zander, E., Münte, T. F., & Clahsen, H. (1997). How the brain processes complex words: An event-related potential study of German verb inflections. Cognitive Brain Research, 6(1), 37–52. https://doi.org/10.1016/S0926-6410(97)00012-8
- Perea, M., & Rosa, E. (2002a). Does the proportion of associatively related pairs modulate the associative priming effect at very brief stimulus-onset asynchronies? Acta Psychologica, 110(1), 103–124. https://doi.org/10.1016/S0001-6918(01)00074-9
- Perea, M., & Rosa, E. (2002b). The effects of associative and semantic priming in the lexical decision task. Psychological Research, 66(3), 180–194. https://doi.org/10.1007/s00426-002-0086-5
- Pinker, S. (1991). Rules of language. Science, 253(5019), 530–535. https://doi.org/10.1126/science.1857983
- Pollock, J.-Y. (1989). Verb movement, Universal Grammar and the structure of IP. Linguistic Inquiry, 20(3), 365–424.
- Pulvermüller, F., & Assadollahi, R. (2007). Grammar or serial order?: Discrete combinatorial brain mechanisms reflected by the syntactic mismatch negativity. Journal of Cognitive Neuroscience, 19(6), 971–980. https://doi.org/10.1162/jocn.2007.19.6.971
- Pulvermüller, F., & Shtyrov, Y. (2003). Automatic processing of grammar in the human brain as revealed by the mismatch negativity. NeuroImage, 20(1), 159–172. https://doi.org/10.1016/S1053-8119(03)00261-1
- Rastle, K., Davis, M. H., & New, B. (2004). The broth in my brother’s brothel: Morpho-orthographic segmentation in visual word recognition. Psychonomic Bulletin & Review, 11(6), 1090–1098. https://doi.org/10.3758/BF03196742
- R core team. (2021). R: A language and environment for statistical computing (4.1.1.). R Foundation for Statistical Computing.
- Segui, J., & Grainger, J. (1990). Priming word recognition with orthographic neighbors: Effects of relative prime-target frequency. Journal of Experimental Psychology: Human Perception and Performance, 16(1), 65–76. https://doi.org/10.1037/0096-1523.16.1.65
- Seidenberg, M. S., Waters, G. S., Sanders, M., & Langer, P. (1984). Pre- and postlexical loci of contextual effects on word recognition. Memory & Cognition, 12(4), 315–328. https://doi.org/10.3758/BF03198291
- Seth, A. K., Dienes, Z., Cleeremans, A., Overgaard, M., & Pessoa, L. (2008). Measuring consciousness: Relating behavioural and neurophysiological approaches. Trends in Cognitive Sciences, 12(8), 314–321. https://doi.org/10.1016/j.tics.2008.04.008
- Shtyrov, Y., & Lenzen, M. (2017). First-pass neocortical processing of spoken language takes only 30 msec: Electrophysiological evidence. Cognitive Neuroscience, 8(1), 24–38. https://doi.org/10.1080/17588928.2016.1156663
- Shtyrov, Y., & Macgregor, L. J. (2016). Near-instant automatic access to visually presented words in the human neocortex: Neuromagnetic evidence. Scientific Reports, 6(1), 1–9. https://doi.org/10.1038/srep26558
- Sonnenstuhl, I., Eisenbeiss, S., & Clahsen, H. (1999). Morphological priming in the German mental lexicon. Cognition, 72(3), 203–236. https://doi.org/10.1016/S0010-0277(99)00033-5
- Staub, A., & Clifton, C. (2006). Syntactic prediction in language comprehension: Evidence from either … or. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32(2), 425–436. https://doi.org/10.1037/0278-7393.32.2.425
- Ullman, M. T. (2001). A neurocognitive perspective on language: The declarative/procedural model. Nature Reviews Neuroscience, 2(10), 717–726. https://doi.org/10.1038/35094573
- Ullman, M. T., Corkin, S., Coppola, M., Hickok, G., Growdon, J. H., Koroshetz, W. J., & Pinker, S. (1997). A neural dissociation within language: Evidence that the mental dictionary is part of declarative memory, and that grammatical rules are processed by the procedural system. Journal of Cognitive Neuroscience, 9(2), 266–276. https://doi.org/10.1162/jocn.1997.9.2.266
- Van den Bussche, E., Van den Noortgate, W., & Reynvoet, B. (2009). Mechanisms of masked priming: A meta-analysis. Psychological Bulletin, 135(3), 452–477. https://doi.org/10.1037/a0015329
- Weyerts, H., Münte, T. F., Smid, H. G. O. M., & Heinze, H.-J. (1996). Mental representations of morphologically complex words: An event-related potential study with adult humans. Neuroscience Letters, 206(2-3), 125–128. https://doi.org/10.1016/S0304-3940(96)12442-3
- Ye, Z., Luo, Y., Friederici, A. D., & Zhou, X. (2006). Semantic and syntactic processing in Chinese sentence comprehension: Evidence from event-related potentials. Brain Research, 1071(1), 186–196. https://doi.org/10.1016/j.brainres.2005.11.085
- Zaccarella, E., Meyer, L., Makuuchi, M., & Friederici, A. D. (2017). Building by syntax: The neural basis of minimal linguistic structures. Cerebral Cortex, 27(1), 411–421. https://doi.org/10.1093/cercor/bhv234
- Zaccarella, E., Papitto, G., & Friederici, A. D. (2021). Language and action in Broca’s area: Computational differentiation and cortical segregation. Brain and Cognition, 147, 105651. https://doi.org/10.1016/j.bandc.2020.105651