
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
For a linear stochastic vibration model in state-space form, with system matrix A and white noise excitation
, under certain conditions, the solution
is a random vector that can be completely described by its mean vector,
, and its covariance matrix,
. If matrix
is asymptotically stable, then
and
, where
is a positive (semi-)definite matrix. As the main new points, in this paper, we derive two-sided bounds on
and
as well as formulas for the right norm derivatives
, and apply these results to the computation of the best constants in the two-sided bounds. The obtained results are of special interest to applied mathematicians and engineers.
Public Interest Statement
In recent years, the author has developed a differential calculus for norms of vector and matrix functions. More precisely, differentiability properties of these quantities were derived for various vector and matrix norms, and formulas for the pertinent (right-hand, resp. left-hand) derivatives were obtained. These results have been applied to a number of linear and non-linear problems by computing the best constants in two-sided bounds on the solution of the pertinent initial value problems. In the present paper, the application area is extended to stochastically excited vibration systems. Specifically, new two-sided estimates on the mean vector and the co-variance matrix are derived, and the optimal constants in these bounds are computed in a numerical example employing the differential calculus of norms.
1. Introduction
In this paper, linear stochastic vibration models of the form with real system matrix
and white noise excitation
are investigated, in which the initial vector
can be completely characterized by its mean vector
and its covariance matrix
. Likewise, the solution
, also called response, is a random vector that can be described by its mean vector
, and its covariance matrix,
. For asymptotically stable matrices
, it is known that
and
, where
is a positive (semi-)definite matrix. This leads to the question of the asymptotic behavior of
and
. As appropriate norms for the investigation of this problem, the Euclidean norm for
and the spectral norm for
is the respective natural choice; both norms are denoted by
.
The main new points of the paper are
the determination of two-sided bounds on
and
the derivation of formulas for the right norm derivatives
the application of these results to the computation of the best constants in the two-sided bounds.
In Section 2, the linear stochastically excited vibration model in state-space form is presented. Then, in Section 3, new two-sided bounds on are determined. In Section 4, preliminary work for two-sided bounds on
is made that is employed in Section 5 to derive new two-sided bounds on
itself. In Section 6, the local regularity of
is studied. In Section 7, as the new result, formulas for the right norm derivatives
are obtained. In Section 8, for the specified data in the stochastically exited model, the differential calculus of norms is applied to compute the best constants in the new two-sided bounds on
and
. In Section 9, conclusions are drawn. Finally, in Appendix 1 , more details on some items are given.
2. The linear stochastically excited vibration system
In order to make the paper as far as possible self-contained, we summarize the known facts on linear stochastically excited systems. In the presentation, we follow closely the line of Müller (Citation1976, Sections 9.1 and 9.2).
So, let us depart from the deterministic model in state-space form(1)
(1)
with system matrix , the state vector
and the excitation vector
.
Now, we replace the deterministic excitation by a stochastic excitation in the form of white noise. Thus,
can be completely described by the mean vector
and the central correlation matrix
with
(2)
(2)
where is the
intensity matrix of the excitation and
the
-function (more precisely, the
-functional).
From the central correlation matrix, one obtains for the positive semi-definite covariance matrix
(3)
(3)
At this point, we mention that the definition of a real positive semi-definite matrix includes its symmetry.
When the excitation is white noise, the deterministic initial value problem (1) can be formally maintained as the theory of linear stochastic differential equations shows. However, the initial state must be introduced as Gaussian random vector,
(4)
(4)
which is to be independent of the excitation (2); here, the sign means that the initial state
is completely described by its mean vector
and its covariance matrix
. More precisely:
is a Gaussian random vector whose density function is completely determined by
and
alone.
The stochastic response of the system (1) is formally given by(5)
(5)
where besides the fundamental matrix and the initial vector
a stochastic integral occurs.
It can be shown that the stochastic response is a non-stationary Gauss-Markov process that can be described by the mean vector
and the correlation matrix
. For
, we get the covariance matrix
.
If the system is asymptotically stable, the properties of first and second order for the stochastic response we need are given by
(6)
(6)
where the positive semi-definite matrix
satisfies the Lyapunov matrix equation
This is a special case of the matrix equation , whose solution can be obtained by a method of Ma (Citation1966). For the special case of diagonalizable matrices
and
, this is shortly described in Appendix A.1.
For asymptotically stable matrix , one has
and thus from (6),
(7)
(7)
and(8)
(8)
Therefore, it is of interest to investigate the asymptotic behavior of and
. This investigation will be done in the next sections by giving two-sided bounds on both quantities in appropriate norms.
Even though the two-sided bounds on can be obtained by just applying known estimates, they will be stated for the sake of completeness in Section 3.
As opposed to this, the determination of two-sided bounds on leads to a new interesting problem and will be solved in two steps described in Sections 4 and 5.
3. Two-sided bounds on
According to Equation , we have
From Kohaupt (Citation2006, Theorem 8), one obtains two-sided bounds on .
To see this, let and
the Euclidean norm in
. Then, there exists a constant
and for every
an constant
such that
(9)
(9)
where is the spectral abscissa of matrix
with respect to the vector
(see Kohaupt Citation2006, Section 7, p. 146). We mention that often
, cf. (Kohaupt, Citation2006, p. 154).
4. Preliminary work for two-sided bounds on
In this section, we derive two-sided bounds that are of general interest beyond their application in Section 5. Therefore, more general assumptions than needed there will be made. We obtain the following lemma.
Lemma 1
(Two-sided bounds on )Let
with
, where
is the adjoint of
. Further, let
be the spectral norm of a matrix.
Then, the two-sided bound(10)
(10)
is valid where(11)
(11)
(12)
(12)
Proof
(i) Decisive tool is the fact that for with
one has the two representations
In the following, this will be applied to .
(ii) Lower bound:
One has
For , this upper bound remains valid.
(iii) Upper bound
Similarly, one obtains
For , this lower bound remains valid.
Remark
In Lemma 1, it is known that(13)
(13)
where for
.
Similarly, one can derive a chain of relations for , as the next lemma shows.
Lemma 2
(Chain of relations for )
Let with
.
Then,(14)
(14)
Now, let be additionally regular, let
denote any vector norm as well as the associated sub norm.
Then,(15)
(15)
this is especially valid also for the spectral norm .
The proof will be given in Appendix A.2.
5. Two-sided bounds on
In this section, the results of Section 4 are employed to estimate above and below by
as well as by
resp.
where
is the spectral abscissa of matrix
. New will be the quadratic asymptotic behavior of
.
We show the following lemma.
Theorem 3
(Two-sided bounds on based on
)
Let , let
be the associated fundamental matrix with
where
is the identity matrix. Further, let
be the covariance matrices from Section 2.
Then,(16)
(16)
where(17)
(17)
and(18)
(18)
If , then
. If
is regular, then
(19)
(19)
Proof
We obtain Theorem 3 by applying Lemmas 1 and 2 with ,
and
.
Further, two-sided bounds can be derived by using Kohaupt (Citation2006, Theorem 8). Thus, there is a constant and for every
a constant
such that
(20)
(20)
This leads to the following corollary.
Corollary 4
(Two-sided bounds on based on
)
Let , let
be the associated fundamental matrix with
where
is the identity matrix. Further, let
be the covariance matrices from Section 2.
Then, there exists a constant and for every
a constant
such that
(21)
(21)
If , then
. If
is regular, then also
.
Remark
Due to the equivalence of norms in finite-dimensional spaces, corresponding bounds as in Theorem 3 and Corollary 4 are valid also in all other (not necessarily multiplicative) matrix norms. Of course, besides the spectral norm , also the Frobenius norm
(cf. Kohaupt, bib15) is of special interest in the context of stochastically excited systems.
6. Local regularity of the function
We have the following lemma which states loosely speaking
that for every
, the function
is real analytic in some right neighborhood
.
Lemma 5
(Real analyticity of on
)
Let . Then, there exists a number
and a function
, which is real analytic on
such that
.
Proof
Based on , the proof is similar to that of Kohaupt (Citation2001, Lemma 1). The details are left to the reader.
7. Formulas for the norm derivatives
In this section, in a first step, for complex matrices and
with
, we define a matrix function
and derive formulas for the right norm derivatives
based on the representation
instead of
. Even though the last one is also valid for
, the first one leads to simpler formulas. In a second step, the obtained formulas are employed for
and
to deliver the formulas for
.
Let with
. Then, the eigenvalues
of
are real, and for the spectral norm of
, one has the formula
and thus
Now, let ,
its fundamental matrix, and define
Then, with
and thus
cf. (Achieser & Glasman, Citation1968, Chapter II.2, p. 62) or (Kantorowitsch & Akilow, Citation1964, p. 255).
We mention that without , one would have the formula
Of course, this formula remains valid for , but is more complicated and probably numerically less good than the first representation of
. The computation of
by the last formula would be similar as in Kohaupt (Citation2001) for
.
In order to get a formula for in terms of the given matrices
and
, at the beginning, we follow a similar line as in Kohaupt (Citation2001, Section 3, pp. 6–7), however.
Starting point is the series expansion
with. Thus, e.g.
Consequently,
with
Then, due to Kato (Citation1966, Theorem 5.11, Chapter II, pp. 115–116) and Kohaupt (Citation1999, Lemma 2.1),
where the quantities are given by the formulas for
in Kohaupt (Citation2001, pp. 6–7) with the operators
defined above. This is shortly recapitulated in Appendix A.3.
The series expansion
is obtained via the formula
Now, define
Then,
with
and
Hence, for fixed ,
where the norm derivatives are obtained by the formulas of Kohaupt (Citation2002, Theorem 6). This is shortly recapitulated in Appendix A.4.
If one replaces by
, then one gets the functions
.
The norm derivatives are obtained as the special case
with
and
.
These formulas are needed in Section 8.
8. Applications
In this section, we apply the new two-sided bounds on obtained in Section 5 as well as the differential calculus of norms developed in Sections 6 and 7 to a linear stochastic vibration model with asymptotically stable system matrix and white noise excitation vector.
In Section 8.1, the stochastic vibration model as well as its state-space form is given, and in Section 8.2 the data are chosen. In Section 8.3, computations with the specified data are carried out, such as the computation of and
as well as the computation of the curves
and of the curve
along with its best upper and lower bounds. In Section 8.4, computational aspects are shortly discussed.
8.1. The stochastic vibration model and its state-space form
Consider the multi-mass vibration model in Figure .
Figure 1. Multi-mass vibration model.
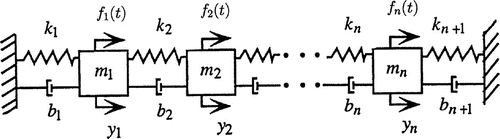
The associated initial-value problem is given by
where and
as well as
Here, is the displacement vector,
the applied force, and
,
, and
are the mass, damping, and stiffness matrices, as the case may be. Matrix
is regular.
In the state-space description, one obtains
with , and
,
where the initial vector is characterized by the mean vector
and the covariance matrix
.
The system matrix and the excitation vector
are given by
respectively. The vector
is called state vector.
The (symmetric positive semi-definite) intensity matrix is obtained from the (symmetric positive semi-definite) intensity matrix
by
(see Müller, Citation1976, Formulas (9.65)) and the derivation of this relation in Appendix A.5 .
8.2. Data for the model
As of now, we specify the values as
Then,(if
is even), and
We choose n=5 in this paper so that the state-space vector has the dimension
.
Remark
In Sections 2–7, we have denoted the dimension of by
. From the context, the actual dimension should be clear.
For , we take
with
and
similarly as in Kohaupt (Citation2002) for and
. For the
matrix
, we choose
The white-noise force vector is specified as
so that its intensity matrix with
has the form
We choose
With , this leads to (see Appendix A.5)
In the Lyapunov equation
of Section 2, we employ the replacements
to obtain the limiting covariance matrix .
8.3. Computations with the specified data
(i) Bounds on in the vector norm
Upper bounds on in the vector norm
for the two cases (I) and (II) of
are already given in Kohaupt (Citation2002, Figures 2 and 3). There, we had a deterministic problem with
and the solution vector
, where
there had the same data as
here. We mention that for the specified data,
in both cases (cf. Kohaupt, Citation2006, p. 154) for a method to prove this. For the sake of brevity, we do not compute or plot the lower bounds and thus the two-sided bounds, but leave this to the reader.
(ii) Computation of and
as well as of their associated eigenproblems
With the data of Section 2, we obtainThe column vector of eigenvalues
and the modal matrix
, that is, the matrix whose columns are made up of the eigenvectors, are computed as
and
showing that
is positive definite. Correspondingly,
and
showing that
is symmetric and regular (but not positive definite). Matrix
is needed to compute the curve
.
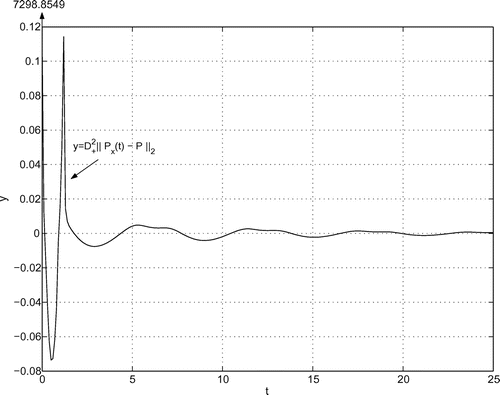
(iii) Computation of the curves ,
The computation of ,
for the given data is done according to Section 7 with
. The pertinent curves are illustrated in Figures –. By inspection, there are no kinks (like in the curve
at
) so that
,
. For some details on the computation of
, see Appendix A.6
We have checked the results numerically by difference quotients. More precisely, setting
and
we have investigated the approximations
and
as well as
For
we obtain
as well as
and
so that the computational results for ,
with
are well underpinned by the difference quotients. As we see, the approximation of
by
is much better than by
, which was to be expected, of course.
Figure 2. Curve .
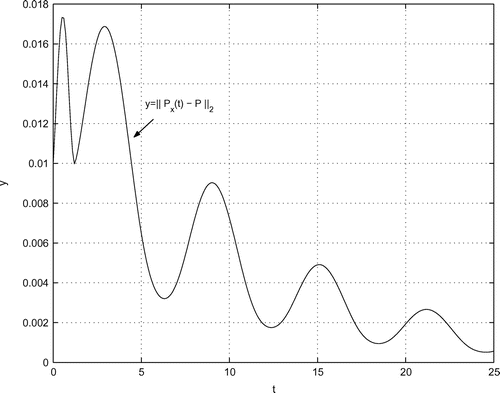
Figure 3. Right norm derivative .
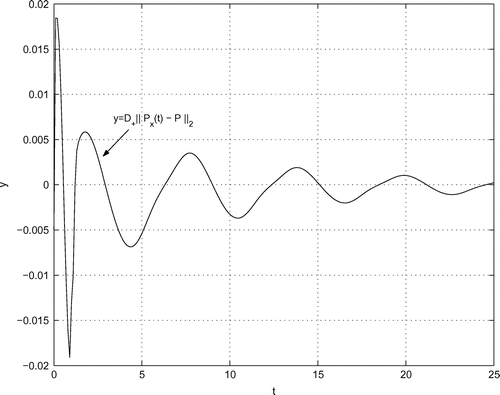
Figure 4. Second right norm derivative .
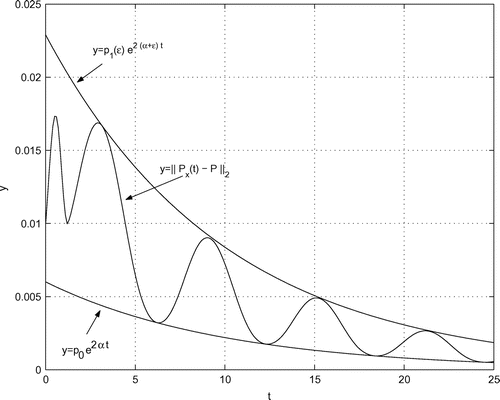
(iv) Bounds on in the spectral norm
Let be the spectral abscissa of the system matrix
. With the given data, we obtain
so that the system matrix is asymptotically stable.
The upper bound on is given by
,
. Here,
can be chosen since matrix
is diagonalizable. But, in the programs, we have chosen the machine precision
of MATLAB in order not to be bothered by this question.
With , the optimal constant
in the upper bound is obtained by the two conditions
where is the place of contact between the curves.
This is a system of two non-linear equations in the two unknowns and
. By eliminating
, this system is reduced to the determination of the zero of
which is a single non-linear equation in the single unknown . For this, MATLAB routine fsolve was used.
After has been computed from the above equation, the best constant
is obtained from
From the initial guess , the computations deliver the values
In a similar way, in the lower bound , we compute the best constant
and the place of contact
. For the initial guess
, the results are
The curve along with the best upper and lower bounds is illustrated in Figure .
Figure 5. along with the best upper and lower bounds.
(v) Applicability of the second norm derivative
The first norm derivative was employed in Point (iv). Apart from this, it can be applied to determine the relative extrema of the curve
.
The second norm derivative can be used to compute the inflexion points. The details are left to the reader.
8.4. Computational aspects
In this subsection, we say something about the computer equipment and the computation time for some operations.
(i) As to the computer equipment, the following hardware was available: an Intel Pentium D(3.20 GHz, 800 MHz Front-Side-Bus, 2x2MB DDR2-SDRAM with 533 MHz high-speed memories). As software package, we used MATLAB, Version 6.5.
(ii) The computation time of an operation was determined by the command sequence
; it is put out in seconds rounded to two decimal places by Matlab. For the computation of the eigenvalues of matrix
, we used the command
; the pertinent computation time is less than
. To determine
, we employed Matlab routine
. For the computation of the
values
in Figure , it took
Table for Figure )
s. Here,
stands for the time value running from
to
with stepsize
;
stands for the value of
,
for the value of the best upper bound
and
for the value of the best lower bound
.
9. Conclusion
In the present paper, linear stochastic vibration systems of the form are investigated driven by white noise
. If the system matrix
is asymptotically stable, then the mean vector
and the covariance matrix
both converge with
and
for some symmetric positive (semi-)definite matrix
. This raises the question of the asymptotic behavior of both quantities. The pertinent investigations are made in the Euclidean norm
for
and in the spectral norm, also denoted by
, for
. The main new points are the derivation of two-sided bounds on both quantities, the derivation of the right norm derivatives
and, as application, the computation of the best constants in the bounds. Since we have used a new way to determine the norm derivatives
, we have checked the obtained formulas by various difference quotients. They underpin the correctness of the numerical values for the specified data.
It is reminded that the original system consists of a multi-mass vibration model with damping and white noise force excitation. By a standard method, it is cast into state-space form.
As illustration of the results, the curves are plotted as well as the curve
together with the best two-sided bounds.
The computation time to generate the last figure with a matrix
is less than a second. Of course, in engineering practice, much larger models occur. As in earlier papers, we mention that in this case engineers usually employ a method called condensation to reduce the size of the matrices.
We have added an Appendix to exhibit more details on some items in order to make the paper easier to comprehend.
The numerical values were given in order that the reader can check the results.
Altogether, the results of the paper should be of interest to applied mathematicians and particularly to engineers.
Additional information
Funding
Notes on contributors
Ludwig Kohaupt
Ludwig Kohaupt received the equivalent to the Master Degree (Diplom-Mathematiker) in Mathematics in 1971 and the equivalent to the PhD (Dr phil nat) in 1973 from the University of Frankfurt/Main.
From 1974 until 1979, he was a teacher in Mathematics and Physics at a Secondary School. During that time (from 1977 until 1979), he was also an auditor at the Technical University of Darmstadt in Engineering Subjects, such as Mechanics, and especially Dynamics.
From 1979 until 1990, he joined the Mercedes-Benz car company in Stuttgart as a Computational Engineer, where he worked in areas such as Dynamics (vibration of car models), Cam Design, Gearing, and Engine Design. Some of the results were published in scientific journals (on the whole, 12 papers and 1 monograph).
Then, in 1990, he combined his preceding experiences by taking over a professorship at the Beuth University of Technology Berlin. He retired on 01 April 2014.
References
- Achieser, N. I., & Glasman, I. M. (1968). Theorie der linearen Operatoren im Hilbert-Raum [Theory of linear operators in Hilbert space]. Berlin: Akademie-Verlag.
- Heuser, H. (1975). Funktionalanalysis [Functional analysis]. Stuttgart: B.G. Teubner.
- Kantorowitsch, L. W., & Akilow, G. P. (1964). Funktionalanalysis in normierten Räumen [Functional analysis in normed linear spaces]. Berlin: Akademie-Verlag. (German translation of the Russian Original).
- Kato, T. (1966). Perturbation theory for linear operators. New York: Springer.
- Kohaupt, L. (1999). Second logarithmic derivative of a complex matrix in the Chebyshev norm. SIAM Journal on Matrix Analysis and Applications, 21, 382–389.
- Kohaupt, L. (2001). Differential calculus for some p-norms of the fundamental matrix with applications. Journal of Computational and Applied Mathematics, 135, 1–21.
- Kohaupt, L. (2002). Differential calculus for p-norms of complex-valued vector functions with applications. Journal of Computational and Applied Mathematics, 145, 425–457.
- Kohaupt, L. (2006). Computation of optimal two-sided bounds for the asymptotic behavior of free linear dynamical systems with application of the differential calculus of norms. Journal of Computational Mathematics and Optimization, 2, 127–173.
- Ma, E.-Ch. (1966). A finite series solution of the matrix equation AX ₋ XB ₌ C. SIAM Journal on Applied Mathematics, 14, 490–495.
- Müller, P. C., & Schiehlen, W. O. (1976). Lineare Schwingungen [Linear Vibrations]. Wiesbaden: Akademische Verlagsgesellschaft.
- Niemeyer, H., & Wermuth, E. (1987). Lineare algebra [Linear algebra]. Braunschweig Wiesbaden: Vieweg.
- Stummel, F., & Hainer, K. (1982). Praktische Mathematik [Introduction to numerical analysis]. Stuttgart: B.G. Teubner.
- Taylor, A. E. (1958). Introduction to functional analysis. New York, NY: Wiley.
Appendix 1
In this Appendix, we show more details on some items in order to make this paper more easily understandable especially for engineers and generally for a broader readership.
Solution of the Lyapunov matrix equation by a method of Ma
In this section, we restrict ourselves to the case of diagonalizable matrices and
since we need only this case in Section 8. The treatment of the general case can be found in Ma (Citation1966).
Let ,
, and
. The problem is to find the solution matrix
such that
We suppose that matrices and
both be diagonalizable and that the eigenvalues
and
satisfy the condition
Then, the solution of the equation can be obtained as follows.
Since and
are diagonalizable, there exist regular matrices
and
such that
where
Define
Then, can be written as
or
Its solution is given by
From this, we obtain the solution of the original matrix equation by the relation
Remarks
| (i) | The solution | ||||
| (ii) | If | ||||
| (iii) | If | ||||
Proof of Lemma 2
In this section, we follow closely the line of Heuser to carry over the proof of to derive a corresponding relation for
for
with
(see Heuser, Citation1975, pp. 277–278 resp. Theorem 6.8.5).
So, let be the common vector norm resp. the spectral matrix norm.
Let be chosen arbitrarily. Then,
which is proven by simplifying the right member of the equation. This entails
if and
,
. Thus,
with and
, if
and
.
Using the parallelogram identity, we obtain
Let and
. Then,
or
Now,
This leads to if
and
,
.
Special cases (S1)–(S3):
(S1) This implies
. Therefore,
Let
Then,
and therefore
Thus,
so that
Thus, relation is also proven in the special case (S1).
(S2) This case is treated similarly as (S1).
(S3) This leads to
for an with
. Therefore,
so that inequality (22) is also valid in the special case (S3).
Relation (22) with instead of
is trivial. On the whole, the chain of Equation (14) is proven.
Now, let be regular, let
denote any vector norm and the associated sub matrix norm. Because for the range of
one has
, then
thus showing relation (15). On the whole, the proof of Lemma 2 is completed.
Remark
We have seen that the method described by Heuser (Citation1975) to derive the relation
for with
can be carried over to prove the relation
As opposed to this, using Taylor’s method in Taylor (Citation1958, pp. 322–323), it seems to be impossible to prove the inf relations in a similar way as the sup relations.
Since Heuser’s book is written in German, we think that it is worthwhile to make Heuser’s proof idea accessible to a broad readership. Of course, the author cannot rule out that the above inf formulas have been derived before. But, he has not found such a derivation in literature.
Series expansion of
We determine the coefficients in the series expansion of Section 7, where we have set
. The derivation follows a line similar to that of Kohaupt (Citation2001, pp. 6–7). We note that the operators
and
,
,
are defined in a way different from that in Kohaupt (Citation2001), however. This is the first difference.
Let be the largest eigenvalue of
. Then, due to
Kato (Citation1966, Theorem 5.11, Chapter II, pp. 115–116] and Kohaupt (Citation1999, Lemma 2.1)
where the quantities ,
, and
are derived now.
Let and
be the eigenvalues of
. Then,
Further, define
Let
be the matrix formed by the orthonormal set of eigenvectors associated with
, and let
be the orthogonal projection on the algebraic eigenspace
(which is here identical with the geometric eigenspace). Then,
with
. Further,
can be calculated by
(cf. Niemeyer & Wermuth, Citation1987, pp. 234–238). Let
and
be the eigenvalues of . Then,
Let
be the matrix formed by the orthonormal set of eigenvectors associated with
, and let
be the orthogonal projection on the algebraic eigenspace
Then, with
. As above,
can be calculated by
Let
with(for
cf. Kato, Citation1966, p. 40, Problem 5.10, Formula (5.32)) and for
(cf. Kato, Citation1966, p. 116). Let
be the eigenvalues of . Then,
Remark
In the formula for , exactly those eigenvectors
lie in
for which
. (In Kohaupt (Citation2001, p. 7, Remark), instead of
it reads
there, which is a typo.) Similarly one proceeds in the formula for
.
The second difference to Kohaupt (Citation2001) is that the formulas of Kohaupt (Citation2001, Theorem 4) are not applied. Instead, one may use the relations .
Formulas for
For these formulas, we refer to Kohaupt (Citation2002, pp. 433–434). Let and
, and define the following sign functionals for
:
;
. With these sign functionals, define the further functionals
(A1)
(A1)
Then, the right derivatives for real vector functions read as follows.
Theorem 6
(, real vector function) Let
be an n-dimensional real-valued vector function that is m times continuously differentiable, and let
. Suppose additionally that each two components of
are either identical or intersect each other at most finitely often near
. Further, let
and
be the set of all indices
where
from (23) attains its maximum, i.e.
. Then, the right derivatives of
at
are given by
Remark
In our case, in Section 7, one has and
. Further,
is analytic so that the additional condition is automatically fulfilled.
Determination of symmetric positive semi-definite intensity matrix from
Since with
one obtains, using
, the relation
and thus
Thus, according to Müller (Citation1976, Formula (9.7)) with , one has
Now, Since
is white noise, one has
, leading to
This implies
giving
with
Some details on the computation of
According to Section 7 and Appendix A.3, the computation of is based on
and
as well as
and
where the quantities and
depend on
.
For all , the constraint “
" resp. “
" was fulfilled with the only exception of that for
and
with
. The reason for this could not be clarified, however. In this exceptional case, we have set the quantities equal to zero. Since for
we have
, the norm derivatives are given by
and
, and thus do not depend on
or
for
, however.
Remark
It is interesting to note that for all without exception, only one of the eigenvalues
and
was different from zero, and further that the above-mentioned constraints can be dropped for the given data without changing the results.
Remark
Finally, we want to remind the reader that, since the operator is different from zero as well as finite dimensional, it is self-adjoint and completely continuous. Therefore, according to Achieser and Glasman (Citation1968, no. 60, p. 158) or Kantorowitsch and Akilow (Citation1964, Chapter IX, §4.3, p. 255),
has at least one eigenvalue different from zero for all
.
Simplification of the computation of
In the case of , one can simplify the computation as follows. Let
Then,
Further, according to the last Remark above, and therefore
, so that in Appendix A.4 with
and
, we obtain the signs
Thus, from Appendix A.3, we get
With the given data in Section 8, we had and
for all
. This means
.