
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper explores a variety of density and kernel-based techniques that can smoothly connect (crossfade or “morph” between) two functions. When the functions represent audio spectra, this provides a concrete way of adjusting the partials of a sound while smoothly interpolating between existing sounds. The approach can be applied to both interpolation crossfades (where the crossfade connects two different sounds over a specified duration) and to repetitive crossfades (where a series of sounds are generated, each containing progressively more features of one sound and fewer of the other). The interpolation surface can be thought of as the two dimensions (time and frequency) of a spectrogram, and the kernels can be chosen so as to constrain the surface in a number of desirable ways. When successful, the timbre of the sounds is changed dynamically in a plausible way. A series of sound examples demonstrate the strengths and weaknesses of the approach.
Public Interest Statement
A common cinematic effect is the morphing of one image to another: a person transforms smoothly into a werewolf or the features of one person change fluidly into those of another. The analogous effect in audition is sometimes called a crossfade, and this paper examines two kinds of generalized crossfades that allow one sound to smoothly transform into another. Using ideas from differential equations and probability theory, the “kernel” of the crossfade is defined, and its structure helps to determine the behavior of the resulting sound in terms of audible ridges. A number of sound examples present the uses and limitations of the method.
1. Introduction
Crossfading between two sounds can be simple: one sound decreases in volume as the second sound increases in volume. More interesting crossfades may attempt to maintain common aspects of the sounds while smoothly changing dissimilar aspects. For example, it may be desirable to gradually transform one sound into another while requiring that nearby partials sweep between nearby partials or it may be advantageous to require that the sound retains its harmonic integrity over the duration of the crossfade. Sometimes called audio morphing, such generalized crossfades are an area of investigation in the computer music field (Hatch, Citation2004; Slaney, Covell, & Lassiter, Citation1996; Tellman, Haken, & Holloway, Citation1995) and the techniques may also find use in speech synthesis, where smoothly connecting speech sounds is not a trivial operation (Farnetani & Recasens, Citation2010).
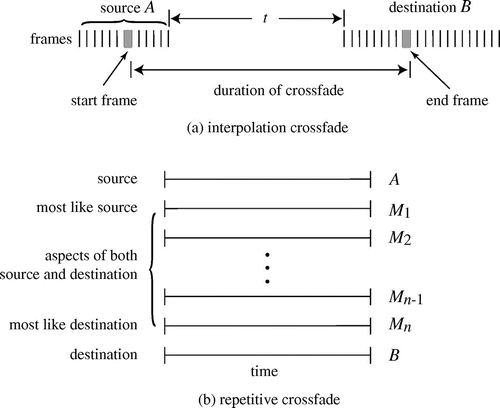
Two kinds of crossfades may be distinguished based on the information used and the desired time over which the fade is to be conducted. In interpolation crossfades, two sounds A and B are separated in time by some interval t. The goal of the fade is to smoothly and continuously change from A (the source) to B (the destination) over the time t. The fade “fills in” the time between a single (starting) frame in A and a single (ending) frame in B. Figure (a) shows this schematically. In a repetitive crossfade, the goal is to create a series of intermediate sounds each of which exhibits progressively more aspects of B and fewer aspects of A, as shown in Figure (b). Observe that repetitive crossfading is formally analogous to image morphing since it creates a series of intermediaries between the specified start and end points. Interpolation crossfades, by filling in a silence between two sounds, can be thought of as a time-stretching procedure where the start and end sounds may be chosen arbitrarily. In both cases, kernel-based techniques can be used to place constraints on and guide the crossfade.
Figure 1. Audio crossfades generate sounds that change smoothly between a source and a destination sound. Notes: In interpolation crossfades (a), the sound begins as A and over time smoothly becomes like B. The total duration of the output sound is independent of the duration of A and B and the cross only depends on the sound in the starting and ending frames. The overall effect is one of stretching time under the constraint that the sound must emerge continuously from A and merge continuously into B. In repetitive crossfades (b), a series of intermediate sounds merge aspects of A and B, analogous to the intermediary photographs of an image morph that merges various aspects of the starting and ending photographs. The duration of each output sound
is equal to the common duration of A and B. Thus, interpolation crosses begin as one sound and end as another, while in a repetitive cross, each
contains features of both of the original sounds. For instance, an interpolation crossfade might start with the attack portion of a cymbal and end with the final moments of a lion’s roar. The interpolation crossfade is the transition that occurs over a user specified time. In contrast, each intermediate sound in a repetitive crossfade merges aspects of both the complete lion sound (from start to end) with those of the complete cymbal (from attack to decay).
Perhaps the most common strategy for creating audio morphings is to:
| (1) | derive sets of features | ||||
| (2) | create a correspondence where features in sound A are assigned to features in sound B, | ||||
| (3) | interpolate between the corresponding features over the specified time of the morph, and | ||||
| (4) | synthesize the morphed sound from the interpolated features. | ||||
This paper suggests an alternative procedure for the construction of smooth audio connections that generalizes to any sensible kernel function. An advantage of this method is that two of the common problems in the general scheme (1–4) are avoided. First, no choice of specific features is made and there is no need to locate significant partials or features in the sound. Hence, there can be no mistakes made in identifying such features. Second, since the crossfade is defined by a PDE or, in a probabilistic sense, as a density or kernel function, no correspondence of features is required, and hence there is no possibility of error in the assignment of such correspondences.
Section 2 presents the conceptual and analytical foundations of the method, which reside in the specification of a pair of density-like functions and
that describe how the left and right spectra of the sound are propagated and a pair of mixing functions
and
that describe how the spectra are combined. Section 3 presents a number of crossfades between sinusoids that are simple enough to approach analytically, and the idea of a ridge able to connect nearby partials is introduced and analyzed. Section 4 then presents several sound examples that demonstrate the basic functioning of the generalized crossfading process and a selection of examples are conducted between both instrumental and environmental sounds, including a set of fades between clarinet multiphonics. Section 4.2 then provides details on the repetitive crossfades along with corresponding sound demonstrations.
2. Crossfading, potentials, and probability theory
Given two functions of a real variable, and
, the solution to the mathematical crossfade problem may be defined to be a real-valued function of two real variables
with domain
and such that
and
. The domain D is an infinite strip of width
in the
plane, with the strip extending from
to
and extending infinitely in the positive and negative y directions. The two functions
and
act as boundary conditions on the left and right margins (respectively) of the infinite strip. A solution to the crossfade problem is then any real-valued function over the strip that when restricted to the left (right) margin is
(
). We often impose additional conditions in order to avoid useless and/or trivial answers. For example, in this paper, we always require that
have some sort of smoothness or differentiability on the interior of D to ensure that the surface
is smooth.
This is analogous in many ways to the Dirichlet problem which consists of finding a solution to Laplace’s equation on some domain D where the solution on the boundary of D is equal to a given function. Perhaps the simplest field equation is Laplace’s equation, which is the linear, second-order, steady-state elliptic PDE(1)
(1)
where is the Laplacian operator. For 2-D rectangular coordinates,
(2)
(2)
Problems of great physical diversity can be studied using this equation. For example, in the thermal case, the field potential function represents the temperature; in gravitational problems, it is the gravitational potential; in hydrodynamics, it is the velocity potential; and in electrostatics, it is the voltage.
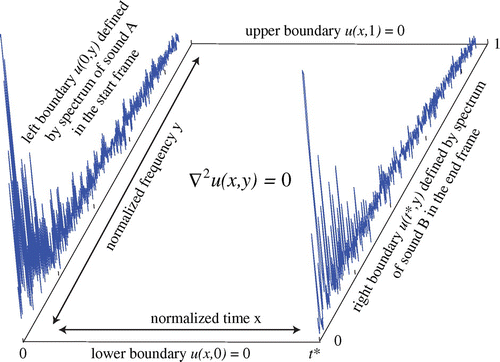
Laplace’s equation is the condition required from a variational analysis for minimizing the field energy of a surface “stretched across” the boundaries (Gustafson, Citation1980). Imagine a rectangular wire frame where the contour of the left-hand side is specified by the spectrum of the sound A (given by the function ), the contour of the right-hand side is given by the spectrum of the sound B (given by
), and where the top and bottom are set to zero as depicted in Figure . This is tantamount to an assumption that there is no sound energy at DC and none at high frequencies, for instance, those outside the normal range of hearing. If this wire frame is dipped into a pool of soapy water and carefully retracted, a smooth sheet forms that is characterized as the surface that minimizes the surface energy where the height of the sheet at each point is
. Mathematically, this can be stated as the PDE (1) with the specified boundary conditions. Reinterpreting the contour of the soap film (i.e. the field values) as sound provides the audio output, which can be heard to smoothly interpolate from the left-hand spectrum to the right-hand spectrum. This views the crossfade function as the solution to a boundary value problem over a two-dimensional domain defined by the spectrum of the sound in the y dimension and the duration of the crossfade in the x direction. The soapy film is, in essence, reinterpreted as a spectrogram.
Figure 2. A crossfade surface can be defined by Laplace’s equation with boundary conditions given by the spectra of two sounds A and B. Notes: The x-axis (representing time) proceeds from time 0 to time
, while the y-axis (representing frequency) covers the range from DC (at 0) to the Nyquist rate (at 1). The surface is formally analogous to a spectrogram and can be inverted back into the time domain using a variety of standard techniques.
Close connections exist between potential theory and the theory of Markov processes (Doob, Citation1984); most famously, the solution to the Dirichlet problem can be expressed as a functional of the mean hitting time of a standard Brownian motion. Suppose that is a standard two-dimensional Brownian motion whose value at time zero is
. Let
denote the expectation operator with respect to this Brownian motion and let
denote the time that the Brownian motion first hits the boundary of the strip
=
. The value of
at this time is
. Defining the “initial condition” function over
as
, the solution to the Dirichlet problem can be rewritten
A Brownian motion that begins at the point z in the interior of D wanders about in D until (with probability one) it hits either the left or the right
boundary. It is true (and intuitive) that areas on the boundary closer to z have a greater chance of being hit than areas further away, and the probability distribution of the points hit on the boundary (the so-called hitting distribution) is
(3)
(3)
where is called the kernel. Making the specific choice of the Poisson kernel
(4)
(4)
allows a complete analogy with the heat equation. The indicator functions keep track of the hitting distributions on the left and right boundaries. if A is true and is zero if A is false. Since
it can be shown that starting from the point , the Brownian motion will hit the left boundary with a probability
and the right boundary with a probability
. Thus, the hitting distribution conditioned on the event that the left boundary is hit first is
(5)
(5)
and the hitting distribution conditioned on the event that the right boundary is hit first is(6)
(6)
Observe that converges to the Dirac delta function
as
approaches zero and
converges to
as
approaches
. Thus, the Dirichlet problem can be restated as
(7)
(7)
We call the functions and
crossover functions because they control the relative hitting probabilities in the x direction. Making the specific choice that
and
where
(8)
(8)
allows a complete analogy with the heat equation, that is, is equal to the field potential function
given by the heat Equation (2).
In the crossfade setting, there is no compelling reason that the kernel function must have exactly the form of the Poisson kernel (4) or that the crossover function
must have the form (8). The essence of the audio morphing design problem is encapsulated in (7), which exists independently of the heat equation or reference to Brownian motions. The crucial factors (for audio morphing) are that
converges to
,
, and
as
converges to zero, and similarly that
converges to
,
, and
as
converges to
. Together, these allow
to converge to the desired boundary conditions (as z approaches the boundaries), and to smoothly connect the left-hand initial condition with the right-hand initial condition. Thus, the role of the hitting distributions may be played by any kernel that smoothly connects the boundaries, which, in the audio morphing application, are given by the spectra of the starting and ending sounds. By choosing kernel and crossover functions judiciously, fades with a variety of different (audible) properties may be selected.
Example 1
(Simple Linear Crossfade) Let ,
, and
. Then,
.
This crossfade is the standard audio crossfade in which the volume of the first sound is lowered proportionally as the volume of the second is raised. Fortunately, there are more interesting forms of crossfades.
Example 2
(Heat Equation) With and
chosen as in (5) and (6) with kernel (4) and with
, this is the standard heat equation corresponding to the solution given by (Equation 2) (and the intuition of Figure ).
The heat equation formulation is used in several of the sound examples as it gives a smooth fade that connects nearby partials at the two endpoints. For instance, a frequency at the left boundary sweeps smoothly upwards to meet another frequency
at the right boundary. By its nature, the heat equation diffuses energy as it moves away from the boundaries, and this can sometimes be heard as a lowering of the volume of the sound toward the middle of the crossfade surface.
Example 3
(Harmonic Integrity) Since the human auditory apparatus perceives pitches (roughly) on a log scale, it makes sense to allow the hitting distribution to scale so that it is wider at higher frequencies. Let be an arbitrary probability density function and choose a reference frequency
. For a point
, define the left hitting density
and the right hitting density
Note that as approaches either zero or
, these hitting distributions collapse to the required boundary Dirac delta functions. This strategy tends to maintain the perceptual integrity of a harmonic collection. A number of other choices for the functional forms of
,
,
, and
are investigated in the following sections.
3. Crossfades between sinusoids
The simplest setting is where the starting and ending sounds both consist of a small number of sinusoids. In the first example, a pair of sinusoids with normalized frequencies and
at the left boundary are crossed with a pair of sinusoids with normalized frequencies
and
at the right boundary. Accordingly, the left boundary function is the (one-sided) Fourier transform
and the right boundary function is
. For simplicity, the duration of the crossfade is scaled to be
and the two boundary functions only consider positive frequencies (the negative frequencies proceed analogously). Because the boundary functions have a simple form (as a sum of
functions), the crossfade surface (7) can be integrated exactly as
when the kernels are chosen to mimic the heat equation as in Example 2 (with given by (4) and
by (8)).
This is plotted in Figure (a). The boundaries at the left and right show the two sinusoids (as delta functions at their respective frequencies) while the surface gradually descends to the middle where they meet. Observe that there are two shapes that connect the nearby frequencies, to
and
to
. These are local maxima (in the y direction) which form a connected set as x varies over its range; call these ridges. Observe that there is a significant loss of height in the ridges of Figure (a). Since the magnitude of the surface corresponds to the amplitude of the spectral components, this may be perceptible as a drop in the volume toward the middle of the crossfade region.
Figure 3. Sinusoids of frequencies and
are crossed with frequencies
and
using the Poisson kernel and three different crossover functions (see text for details). Notes: Though the ridges connecting the nearby frequencies appear in all three figures, the drop in (a) is likely to be heard as a drop in volume over the course of the first half of the crossfade.
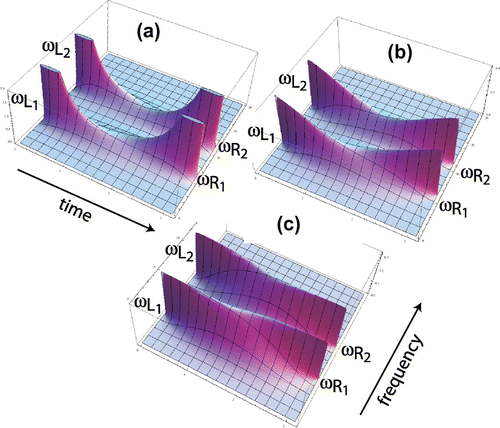
Figure (b) also uses the Poisson kernel (4) but chooses crossover functions and
. This tends to increase the total mass in the middle of the crossfade, and the ridge sags less than in (a). Figure (c) shows the results when using crossover functions
(9)
(9)
This boosts the ridge to a (near) constant height as it spans the duration to connect the sinusoidal pairs on the two boundaries. Observe that in all three cases, the sinusoids sweep smoothly from their starting to ending frequencies. In contrast, a linear combination of the two sounds (as in the crossfade of Example 1) has no ridges: the amplitudes of the two starting frequencies die away to zero over the duration of the fade while the amplitudes of the two ending frequencies slowly increase.
The kernels used in Figure have the same width at all frequencies y, which may not be desirable when attempting to cross more complex sounds. Consider a source sound with partials at (relative) frequencies 8, 16, 32, and 64 and a destination sound with partials at 9, 18, 36, and 72. If these sounds are to be spectrally crossed, it is desirable to have ,
,
, and
. With an equal width between all pairs, this is impossible since the distance between 9 and 16 (two partials which should not be connected by a ridge) is less than 8, while the distance between 64 and 72 (two partials which should be connected by a ridge) is 8. This is shown in the left side of Figure . While the lower ridges appear as expected, the upper two pairs are not joined together by a ridge. Once again, the freedom to modify the kernels allows a solution. The right-hand side of Figure shows a kernel, as suggested by Example 3, that is narrow at lower frequencies and wider at higher frequencies, allowing ridges to form for all the pairs. The specific kernel used is
(10)
(10)
With , the
values stretch more for larger y, mimicking the sensitivity of the auditory system. In subsequent examples,
is chosen as a compromise. If c is chosen much larger, the desired ridges fail to exist; if chosen much smaller, the ridges in the low frequencies tend to merge together.
Figure 4. The ridges in the crossfade surface on the left are equally wide, irrespective of the absolute frequency. In some situations, it may be advantageous to allow the width of the ridges to become wider at higher frequencies, as shown on the right. This can be accomplished by defining the kernels as in (10).
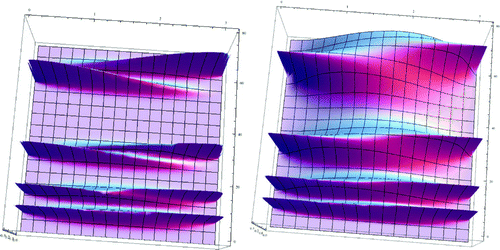
The above discussion emphasizes the importance of the ridges, and it is crucial to be able to make good choices of kernels that lead to desirable ridges. While it is difficult to prove in general when ridges will occur and how wide they are, in the simple case where the kernel is a rectangle function, the existence and behavior of ridges can be described analytically. Viewing the smooth kernels as having a support that can be approximated by an appropriate set of rectangle functions suggests that insights gained from studying the rectangle kernels may be useful in more general situations.
The rectangle function is defined as one for
and zero otherwise. For
, let
and define the kernel as in Example 3. The support of the left boundary hitting density is
and the support of the right boundary hitting density is
. The support of the left density varies linearly in x (if y is held constant) from zero at
to a maximum of
at
(and similarly for the support of the right density). Consider the crossfade between a pure frequency
on the left boundary to a pure frequency
on the right boundary. Thus,
and
. The crossfade surface is
A ridge is said to exist whenever there is a trajectory such that both terms in the above expression are nonzero }.
Theorem 1
(The Ridge Theorem) Suppose that and that
. A ridge exists if and only if
(11)
(11)
A proof is given in Appendix A.1.
4. Audio crossfades
This section presents a series of experiments that carry out generalized crossfades between a variety of sounds, including sinusoids, instrumental, and environmental sounds. The experiments demonstrate the ridge theorem concretely by showing the interaction between the width of the kernel and the frequencies joined by the ridges. To be practical, it is desirable to have ridges that connect partials of the starting and ending sounds when the frequencies are close and to not have ridges when the frequencies of the partials are distant.
In order to implement the crossfade procedure, it is necessary to discretize the two dimensions, to choose the size of the FFTs that will be used to specify the boundary spectra, and to select a window that will extract the
samples from the sound waveforms. These choices are familiar from short-time Fourier transform (STFT) modeling (Oppenheim & Schafer, Citation2009), and the same trade-offs apply. In addition,
must be equal to the number of points in the vertical y direction. We have found
,
, and
to be convenient and have used a standard Hann window. In the horizontal x direction, we have typically used between
and
points.
The inversion of the two-dimensional surface of (7) into a sound waveform can be accomplished using any of the techniques that would invert an STFT image into sound. The sound examples of this section implement a “phase vocoder” strategy that is well known in applications such as time scaling and pitch transposition (Dolson, Citation1986; Laroche & Dolson, Citation1999; Sethares, Citation2007). This method synthesizes phase values for a given set of magnitude values, effectively choosing phase values that guarantee continuity across successive frames. To be explicit, suppose that the frequency
is to be mapped to some value
. Let
be the closest frequency bin in the FFT vector, i.e. the integer
that minimizes
where
is the sampling rate. Then, the
th bin of the output spectrum at time index
has magnitude equal to the magnitude of the
th bin of the input spectrum with corresponding phase
(12)
(12)
where is the time separation between consecutive frames. The phase values in (12) guarantee that the resynthesized partials are continuous across frame boundaries, reducing the likelihood of discontinuities and clicks. An advantage of this approach is that it allows the duration of the fade to be freely chosen after the solution to the crossfade surface has been obtained. Thus, the relationship between
in Figure and real time can be freely adjusted even after the calculation of the surface
.
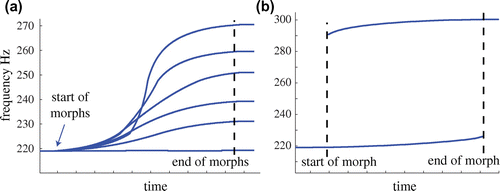
A series of generalized crossfades demonstrate that the ridges of Figures and are perceived as pitch glides. Sound examples 220to230.wav, 220to240.wav, through 220to270.wav are available at the website (http://sethares.engr.wisc.edu/papers/audioMorph.html, date last viewed 27 September 2015, as are all other sound files discussed throughout the paper). All examples use the kernel in (10) and the crossover function
of (9). In each case, the crossfade starts at the pitch corresponding to the first frequency and rises smoothly to the pitch corresponding to the second frequency, as shown graphically in Figure (a). The frequency values are calculated from the output of the phase vocoder using an analysis that interpolates three frequency bins in each FFT frame. In these graphs, the method is accurate to about 2 Hz (far better than the
Hz resolution of the FFT bins).
When the frequencies of the sinusoids at the start and end are far apart, there is less interaction. The sound example in 220to300.wav begins as a sine wave at 220 Hz and ends as a sine wave at 300 Hz. What happens is that the starting sinusoid decreases in amplitude and the ending sinusoid increases in amplitude throughout the process. Essentially, the kernel is no longer wide enough to form ridges and the connecting sound has become a simple crossfade. The instantaneous frequencies of the two sines are shown in Figure (b), which show that both sines are individually identifiable throughout the process. The pitches are not completely fixed at 220 and 300, but bend slightly toward each other. The final sinusoidal example shows how superposition applies to the crossfade process when the sine waves are far apart in frequency. In the example 220to260+440to400.wav, a sine at 220 glides smoothly to 260, while a sine at 440 glides smoothly to 400. The two are effectively independent. Indeed, the output to the two crossfaded pairs is (almost exactly) the sum of outputs to the two pairs crossfaded separately. Observe that the goal of this method is not to connect every frequency with every other but to gain control over the spreading of the kernel. Indeed, this is exactly what the ridge theorem quantifies: how to trade off the spreading of the energy to nearby frequencies vs. the continuity over the course of the crossfade.
Figure 5. (a) Six different crossfades begin at 220 Hz and proceed to 220, 230, 240, 250, 260, and 270 Hz. Each sounds like a single sine wave that slowly increases in pitch up to the specified frequency. (b) A sinusoid at 220 Hz is crossfaded with a sinusoid at 300 Hz. Because the pitches only bend slightly, the process is almost indistinguishable from a simple amplitude crossfade.
4.1. Instrumental and environmental crossfades
The crossfades in this section are conducted as interpolation crossfades, which stretch time proportional to the x-width of the surface . Again, the kernel used is
of (10) and the crossover function
is (9). The first two examples cross between single-tone instrumental sounds. In morph-PianoClarinet.wav, an
attack on the piano changes slowly into a sustained
on the clarinet. Similarly, in morph-ViolinTrumpet.wav, both instruments play a
as the attack of the violin crossfades into the sustained portion of the trumpet. Two spectrally rich sounds, a chinese gong and a low C on a minimoog synth, are crossed in morph-GongMinimoog.wav. Several nonobvious effects can be heard including the rising and falling pitch contours, and the slow swelling of the low C toward the end. Then, in morph-GongLion.wav, the same gong recording is crossed with the roar of a lion. Spectrally rich sounds seem to crossfade particularly well.
Multiphonics occur in wind instruments when the coupling between the driver (the reed or lips) and the resonant tube evokes more than a single fundamental pitch. The sounds tend to be inharmonic and spectrally rich; the timbres range from soft and mellow to noisy and harsh. We recorded Paris-based instrumentalist Carol Robinson playing a large number (about 80) of multiphonics. These ranged in duration from brief (a few hundred milliseconds) to fully sustained (several seconds). The timbres ranged from soft and mellow to noisy and harsh. For the present application, a number of these were selected, and sustained crossfades were calculated between a variety of starting and ending multiphonics. These are
where (X,Y) take on values (13, 23), (29, 66), (32, 14), (39, 28), (48, 64), and (74, 53). All of these can be heard (along with the original recordings of the multiphonics) on the website for the paper (http://sethares.engr.wisc.edu/papers/audioMorph.html, date last viewed 27 September 2015). Despite the variety of starting and ending timbres, the crossfades connect smoothly. There are partials that move in frequency (as suggested by the experiments of Section 3) and the basic level of noisiness in some of the samples also changes smoothly throughout the process.
4.2. Repetitive crossfades
Interpolation crossfades tend to change the timbre of the sounds in proportion to the amount time is stretched. Repetitive crossfades more closely parallel visual morphing since the output is a collection of sounds that are each the same duration as the sounds A and B. In this case, the sounds are not partitioned into frames and the boundaries of the crossfade surface are the complete spectra of the sounds. Each column of the solution represents the spectrum of a different intermediate sound.
This distinction has several implications. First, the sounds cannot be too long since they must be analyzed (and inverted) all at once; at the normal CD sampling rate, this limits the duration to a few seconds. Second, the horizontal axis needs only as many points as the desired number of output (intermediate) sounds (recall that for the interpolation crossfades, there needs to be as many mesh points as there are frames in the duration t). Thus, while the frequency y dimension is significantly larger, the time dimension x is significantly smaller. It is possible to be clever. Appendix A.2 shows how, when using the Poisson kernel (4), it is possible to calculate the crossed signal at the midpoint without calculating the complete surface, that is, to calculate
in isolation. This can reduce the numerical complexity significantly. The method of the Appendix can also be iterated to yield the solutions for
,
, etc.
Perhaps the greatest difference is in the reinterpretation of the into sound. In the interpolation crossfade, it is necessary to reconstruct the phases of the spectra in some way (for instance, using the phase vocoder strategy as in (12)). In the repetitive crossfade, it is possible to use the complete complex-valued spectra as the boundary conditions; the surface
becomes complex valued and each column represents the complete spectrum of the sound.
The first two examples of the repetitive crossfade are between single-tone instrumental sounds. In repmorph-PianoClarinet.wav, an attack on the piano is crossed with an
on the clarinet. Each of the sounds was truncated to about 2.5 seconds, and nine different intermediate sounds were generated. In the soundfile, each of the nine sounds is separated by about 0.25 seconds of silence. The first sound is the trumpet (sound A), the last is the clarinet (sound B), and the others are the intermediaries. Similarly, in repmorph-TrumpetViolin.wav, both instruments play a
as the attack of the trumpet is crossed into the violin.
Two spectrally rich sounds, a chinese gong and a low C on a minimoog synth, are crossed in repmorph-MinimoogGong.wav. The first 2.5-second sound is the minimoog note, and the next several slowly incorporate increasing amount of gong noise. The final segment is the pure gong sound. Observe that this is quite a different set of effects from the interpolation crossfades of the same sounds. In repmorph-Gong1Gong2.wav, two different gong sounds are faded together, creating a variety of “new” intermediate gong-like sounds. Finally, in repmorph-LionGong.wav, the same gong recording is crossed with the roar of a lion. Spectrally rich sounds cross easily, and the middle sounds are plausible hybrids.
5. Conclusion
By formalizing the idea of a crossfade function as one which smoothly connects two signals, this paper provides a basis for studying processes that underlie sound transitions. The use of a variety of kernels is key, as this specification connects a family of uninteresting transitions (such as simple crossfades) with more interesting transitions (such as spectral crossfades). The ridge theorem delineates in a simple setting when spectral peaks in one signal connect to those in another. The methodology (of regarding the spectrogram as a surface defined by hitting points of a stochastic process) provides some hope that similar questions can also be handled analytically. The mathematics is applied concretely to the problems of interpolation and repetitive crossfades, and each is demonstrated in a handful of sound examples where the strengths and weaknesses of the approach become apparent. In many of the examples, it is possible to clearly hear the ridges, indicating that these plausibly correspond (in an audio sense) to the smooth ridges that appear in Figures and . Using this setup, interpolation crossfades appear to be more convincing (as spectrally rich audio morphs) than the repetitive crossfades, which tend to sound more like simple amplitude crossfades. There are two competing factors in the choice of the kernels and the crossover functions: the desire to have a level ridge and the desire to not have the energy spread out in the middle. We suspect it may be possible to find better functions using some kind of optimization procedure that trades off these two features, but we have been unable to formulate and solve this in a concrete way.
Acknowledgements
The authors would like to thank Howard Sharpe for extensive discussions during the early phases of this project.
Additional information
Funding
Notes on contributors
William A. Sethares
William A Sethares and James A Bucklew are both with the Department of Electrical and Computer Engineering at the University of Wisconsin-Madison. Their research interests include signal processing as applied to audio, images, and telecommunications.
References
- Boccardi, F., & Drioli, C. (2001). Sound morphing with Gaussian mixture models. In Proceedings on 4th COST-G6 Conference on Digital Audio Effects. Limerick.
- Dolson, M. (1986). The phase vocoder: A tutorial. Computer Music Journal, 10, 14–27.
- Doob, J. L. (1984). Classical potential theory and its probabilistic counterpart. Berlin: Springer-Verlag.
- Erbe, T. (1994). Soundhack manual (pp. 7–40). Lebanon, NH: Frog Peak Music.
- Farnetani, E., & Recasens, D. (2010). Coarticulation and connected speech processes. In W. J. Hardcastle, J. Laver, & F. E. Gibbon (Eds.), Handbook of phonetic sciences (2nd ed., pp. 316–352). Chichester: Blackwell.
- Fitz, K., Haken, L., Lefvert, S., & O’Donnell, M. (2002). Sound morphing using Loris and the reassigned bandwidth-enhanced additive sound model: Practice and applications. In International Computer Music Conference. Gotenborg.
- Gustafson, K. E. (1980). Introduction to partial differential equations and Hilbert space methods (pp. 1–35). Hoboken, NJ: Wiley.
- Hatch, W. (2004). High-level audio morphing strategies (MS thesis). McGill University, Montreal.
- Laroche, J., & Dolson, M. (1999). Improved phase vocoder time-scale modification of audio. IEEE Transactions on Audio, Speech and Language Processing, 7, 323–332.
- McAulay, R. J., & Quatieri, T. F. (1986). Speech analysis/synthesis based on a sinusoidal representation. IEEE Transactions on Acoustics, Speech, and Signal Processing, ASSP, 34, 744–754.
- Oberhettinger, F. (1973). Fourier transforms of distributions and their inverses (pp. 15–17). New York, NY: Academic Press.
- Oppenheim, A. V., & Schafer, R. W. (2009). Discrete-time signal processing (3rd ed., pp. 730–742).Upper Saddle River, NJ: Prentice-Hall .
- Polansky, L., & McKinney, M. (1991). Morphological mutation functions: Applications to motivic transformations and to a new class of cross-synthesis techniques. Proceedings of the International Computer Music Conference. Montreal.
- Serra, X. (1994). Sound hybridization based on a deterministic plus stochastic decomposition model. In Proceedings of the International Computer Music Conference (pp. 348–351). Aarhus.
- Sethares, W. A. (2007). Rhythm and transforms (pp. 111–145). London: Springer-Verlag.
- Sethares, W. A., Milne, A., Tiedje, S., Prechtl, A., & Plamondon, J. (2009). Spectral tools for dynamic tonality and audio morphing. Computer Music Journal, 33, 71–84.
- Slaney, M., Covell, M., & Lassiter, B. (1996). Automatic audio morphing. In Procceedings of the 1996 International Conference on Acoustics, Speech, and Signal Processing. Atlanta, GA.
- Tellman, E., Haken, L., & Holloway, B. (1995). Timbre morphing of sounds with unequal numbers of features. Journal of the Audio Engineering Society, 43, 678–689.
Appendix 1
Proof of the Ridge Theorem
Fix a value of x in the interval . There is a nonzero contribution from both terms as long as the upper part of the rectangle for the first term extends further than the lower part of the rectangle for the second term. The y value for where the upper part of the rectangle for the first term terminates satisfies
Similarly, the y value for where the lower part of the rectangle for the second term terminates satisfies
Thus, the condition for overlap is
It is easy to verify that the right-hand side of the above inequality is increasing in x and thus takes on its minimum value at . This gives the theorem statement.
A computational simplification
Let be the Poisson kernel (Equation4
(4)
(4) ). The line where
represents the center strip of the crossfade surface. A Brownian motion started on this center strip has the hitting distribution
To find the characteristic function or Fourier transform of this probability density,
The following transform pair can be found in Oberhettinger (Citation1973), Table 1A, Even Functions, # 201:
where . Letting
,
, and
gives the transform relation
Hence,
where is the characteristic function (and Fourier transform since we are dealing with even functions) of
.