
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Given observations of selected concentrations one wishes to determine unknown intensities and locations of the sources for a hazard. The concentration of the hazard is governed by a steady-state nonlinear diffusion–advection partial differential equation and the best fit of the data. The discretized version leads to a coupled nonlinear algebraic system and a nonlinear least squares problem. The coefficient matrix is a nonsingular M-matrix and is not symmetric. Iterative methods are compositions of nonnegative least squares and Picard/Newton methods, and a convergence proof is given. The singular values of the associated least squares matrix are important in the convergence proof, the sensitivity to the parameters of the model, and the location of the observation sites.
Public Interest Statement
Chemical or biological hazards can move by diffusion or fluid flow. The goal of the research is to make predictions about the location and intensities of the hazards based on the down stream location of observations sites. Mathematical models of the diffusion and flow are used to extrapolate from the observations data sites to unknown upstream locations and intensities of the hazards. The convergence of the iterative process for these extrapolations is studied. The sensitivities of the calculations, because of variations of the model parameters, observation data, and location of the observation sites, are also studied.
1. Introduction
The paper is a continuation of the work in White (Citation2011). The first new result is a convergence proof of the algorithm to approximate a solution to a nonlinear least square problem. A second new result is a sensitivity analysis of the solution as a function of the model parameters, measured data, and observation sites. Here, the singular value decomposition of the least squares matrix plays an important role.
A convergence proof is given for the algorithm to approximate the solution of a coupled nonlinear algebraic system and a nonnegative least squares problem, see lines (9–11) in this paper and in White (Citation2011). These discrete models evolve from the continuous models using the advection–diffusion PDE in Equation (1) (see Pao, Citation1992). In contrast to the continuous models in Andrle and El Badia (Citation2015), Hamdi (Citation2007), and Mahar and Datta (Citation1997), this analysis focuses on the linear and semilinear algebraic systems. In Hamdi (Citation2007), the steady-state continuous linear model requires observations at all of the down stream portions of the boundary. In Andrle and El Badia (Citation2015), the continuous linear velocity free model where the intensities of the source term are time dependent requires observations at the boundary over a given time interval. In both these papers, the Kohn–Vogelius objective function is used for the symmetric models in the identification problems.
Here and in White (Citation2011) we assume the coefficient matrix associated with the steady-state discretized partial differential equation in Equation (1) is an M-matrix and may not be symmetric, which includes coefficient matrices from upwind finite difference schemes for the advection–diffusion PDE. The least squares matrix C( : , ssites), see Equations (6–8), is an matrix where
and k and l are the number of observation and source sites, respectively. The rank and singular values (see Meyer, Citation2000, section 5.12), of C( : , ssites) determines whether of not the observation and source sites are located so that the intensities can be accurately computed.
Four examples illustrate these methods. The first two examples in Section 3 are for and
unknowns, and they show some of the difficulties associated with the nonlinear problem. Sections 4 and 5 contain the convergence proof. Examples three and four in Section 6 are applications of the 1D and 2D versions of the steady-state advection–diffusion PDE. Sensitivity of the computed solutions due to variation of the model parameters, the data and the relative location of the source and observation sites is illustrated. The connection with the sensitivity and the singular values of the least squares matrix is established.
2. Problem formulation
Consider a hazardous substance with sources from a finite number of locations. The sources are typically located at points in a plane and can be modeled by delta functionals. The hazard is described as concentration or density by a function of space and time, u(x, y, t). This is governed by the advection–diffusion PDE(1)
(1)
where S is a source term, D is the diffusion, v is the velocity of the medium, is the decay rate, and f(u) is the nonlinear term such as in logistic growth models. The source term will be a finite linear combination of delta functionals
(2)
(2)
where the coefficients are the intensities and the locations
are possibly unknown points in the line or plane. The source coefficients should be nonnegative, which is in contrast with impulsive culling where the coefficient of the delta functionals are negative and have the form
(see White, Citation2009).
We will assume the source sites and the observation sites do not intersect. The reason for this is the ability to measure concentrations most likely allows one to measure the intensities at the same site.
Identification problem: Given data for u(osites) at a number of given observation sites, osites, determine the intensities () and locations (
) at source sites, ssites, so that
2.1. Linear least squares
Since the governing PDE is to be discretized, we first consider the corresponding linear discrete problem
The coefficient matrix A is derived using finite differences with upwind finite differences on the velocity term. Therefore, we assume A is a nonsingular M-matrix (see Berman & Plemmons, Citation1994, chapter 6 or Meyer, Citation2000, section 7.10). The following approach finds the solution in one least squares step. The coefficient matrix is and nodes are partitioned into three ordered sets, whose order represents a reordering of the nodes:
The discrete identification problem is given data data at osites, find d(ssites) such that
In general, the reordered matrix has the following block structure with
(3)
(3)
where ,
,
and
.
Assumptions of this paper:
| (1) | A is an M-matrix so that A and a have inverses. | ||||
| (2) |
| ||||
| (3) |
| ||||
where . Solve Equation (5) for
and then
. Define
(6)
(6)
The computed approximations of the observed data are in and the source data are in
. This gives a least squares problem for z
(7)
(7)
Since a is , e is
, and
is
, the matrix C is
and the least squares matrix C( : , ssites) is
where
. The least squares problem in (7) has a unique solution if the columns of C( : , ssites) are linearly independent (
implies
.
Impose the nonnegative condition on the components of the least squares solution. That is, consider finding such that
(8)
(8)
If the matrix C( : , ssites) has full column rank, then the nonnegative least squares problem (8) has a unique solution (see Bjorck, Citation1996, section 5.2). The nonnegative least squares solution can be computed using the MATLAB command lsqnonneg.m (see MathWorks Inc., Citation2015).
2.2. Least squares and nonlinear term
Consider a nonlinear variation of (9)
(9)
where (as in assumption 3) and
.
Use the reordering in (3) and repeat the block elementary matrix transformation in (4) and (5) applied to the above. Using the notation one gets
Solve for and then for
where and
.
This leads to a nonlinear least squares problem for nonnegative z (10)
(10)
The solution of the nonnegative least squares problem is input to the nonzero components in d, that is, . The coupled problem from (9) and (10) is to find
and u so that
(11)
(11)
3. Two algorithms for the coupled problem
If the nonnegative least squares problem has a unique solution given a suitable u, then we can write (11) as
or as a fixed point
The following algorithm is a composition of nonnegative least squares and a Picard update to form one iteration step. Using additional assumptions we will show this is contractive and illustrate linear convergence. Example 3.2 is a simple implementation with , and in Section 6 Example 6.1 uses the 1D steady-state version of the model in (1) and Example 6.2 uses the 2D steady-state model in (1).
Algorithm 1. NLS-Picard Method for (11) choose nonnegative for
, mmax solve the nonnegative least squares problem
solve the linear problem
test for convergence end for-loop
The following algorithm uses a combination of nonnegative least squares and Newton like updates. Define F(z, u) and as
where is the diagonal matrix with components
.
The matrix is not the full derivative matrix of F(z, u) because it ignores the dependence of z on u. Choose
so that
has an inverse.
Algorithm 2. NLS-Newton Method for (11) choose nonnegative and
for
, mmax solve the nonnegative least squares problem
solve the linear problem
compute
compute
solve the linear problem
test for convergence end for-loop
Variations of the NLS-Newton algorithm include using over relaxation, , at the first linear solve and using damping,
, on the second linear solve in the Newton update:
Appropriate choices of and
can accelerate convergence.
The calculations recorded in Table 4 and Figure 4 in White (Citation2011), illustrate the NLS-Newton algorithm for the 1D steady-state problem with logistic growth term and variable growth rate c. The larger the c parameter resulted in larger concentrations. The intensities at the three source sites were identified. However, the number of iterations of the NLS-Newton algorithm increased as the c parameter increased. The algorithm did start to fail for c larger than 0.0100.
The lack of convergence is either because the associated fixed point problem does not have a contractive mapping or because the solutions become negative. The following example with , nonzero source term and nonsymmetric A illustrates the difficulty of solving a semilinear algebraic problem where the solution is required to be positive.
Example 3.1
Let and use
. Equation (9) has the form
The first equation is whose solution is either
or
. Put the nonzero solution into the second equation
and solve for
. If
, then the second equation is
and will have a positive solution.
The next example with , given data at the first and second nodes and a source term at the third node illustrates the coupled problem in (11). This simple example can be solved both by-hand calculations and the NLS-Picard algorithm, and more details are given in Appendix 1.
Example 3.2
Let the data be given at the first and second nodes
Let the matrix A and nonlinear terms be given by system
The submatrices of A are
Then one easily computes
The g(u) in the nonlinear least square Equation (11) is
The calculation with the NLS-Picard algorithm for this example with in White (Citation2015, testlsnonlc.m) confirms both the exact solution for
and convergence for
, which are given in Appendix 1. The number of iterations needed for convergence increases as c increases, and convergence fails for
. Both the exact and NLS-Picard calculations show
for
and
for
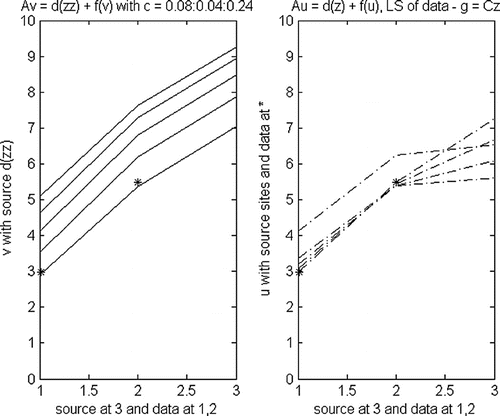
. The outputs for five values of
are given in Figure . The left graphs indicate the five solutions of (10) for fixed
and increasing c. The two “*” are the given data, which are from the solution of (10) with
and 5% error. The right graphs are the converged solutions of (11) for
.
4. Nonnegative least squares problem
The nonnegative least squares problem in (10) for has several forms
This may be written as(12)
(12)
where
Figure 1. NLS-Picard algorithm for n = 3.
If C( : , ssites) has full column rank, then the matrix is symmetric positive definite (SPD). J(z) is the quadratic functional associated with the linear system (normal equations)
When the nonnegative condition is imposed on and the matrix is SPD, then the following are equivalent (see Cryer, Citation1971):
Any solution of a variational inequality is unique and depends continuously on the right-hand side. The next theorem is a special case of this.
Theorem 4.1
Consider the nonnegative least squares problem in (10). If C( : , ssites) has full column rank, then there is only one nonnegative solution for each u. Let be the solution for each u in S where S is a bounded set of nonnegative n-vectors. Moreover, if
, then there is a constant
such that
Proof
Let z and w be solutions of (10). The variational inequalities for z with , and for w with
are
Add these to get a contradiction for the case is not a zero vector
In order to show the continuity, use the above with and
Add these to obtain for
Use the Cauchy inequality
By the definition of g and the assumption on d we have for some
The solution of the variational problem for fixed u has the form H(u). The assumption that C( : , ssites) has full column rank implies there is a positive constant
such that
. This and the above theorem give the following
(13)
(13)
Although in Example 3.2 with one can estimate
and
, generally these constants are not easily approximated. However,
can be estimated by the smallest singular value of the least squares matrix.
5. Convergence proof of the NLS-Picard algorithm
Let the assumptions in the previous theorem hold so that (12) is true for all . The mapping
may not give
This appears to be dependent on the particular problem and properties of
. If the bound is chosen so that
is also nonnegative, then assumption (1) implies
and hence
. The least squares condition requires the solution to be “close” to the given data at the osites, which suggests the G(u) should remain bounded. The following theorem gives general conditions on the problem.
Theorem 5.1
Let the assumptions of Theorem 4.1 hold for . Assume there is a solution to the coupled problem (11),
. Let
and
be from (12). If
then the NLS-Picard algorithm will converge to this solution of (11).
Proof
Let and
.
Since , this implies convergence
6. Applications and sensitivity analysis
Both the NLS-Picard and NLS-Newton methods converge linearly, that is, the errors at the next iteration are bounded by a contractive constant, , times the error from the current iteration. However, the contractive constant for the NLS-Newton algorithm is significantly smaller than the contractive constant for the NLS-Picard algorithm, and this results in fewer iterations steps for the NLS-Newton algorithm. The calculations in the next two examples can be done by either algorithm. The relevance of the singular values of the least squares matrix to the sensitivity of the calculations with variations in the data and the source and observation sites is demonstrated.
Figure 2. NLS-Newton algorithm with variable c.
Example 6.1
Consider the steady-state 1D model in (1). The following calculations were done by the MATLAB code in White (Citation2015, poll1dlsnonla2.m) and with seven observation sites, three source sites, and . The differential Equation (1) was discretized by the upwind finite difference approximations, and the sources terms were the intensities times the approximation of the delta functionals
where initially . In order to check the accuracy of the finite difference model, calculations were done with
and 480, which gave similar results as reported below for
. The condition number (ratio of the largest and smallest singular values) of the least squares matrix controls the relative errors in the computed least squares problem. The condition numbers for the
, and 480 are about the same at 17.0170, 16.5666, and 16.4146, respectively.
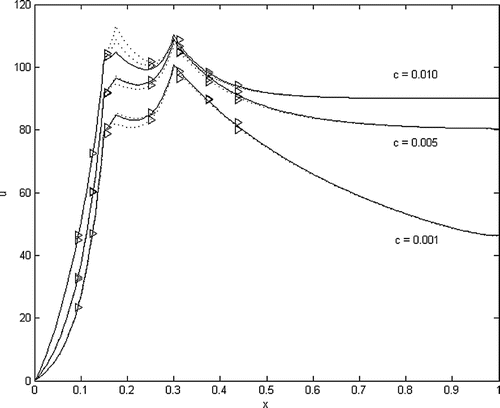
For the NLS-Picard algorithm did not converge, but the NLS-Newton algorithm converged in 92 steps. The solid lines in Figure are with no random error in the data, and the dotted lines are from data with 5% random error. For
the NLS-Picard algorithm converged in 100 steps with
, and the NLS-Newton algorithm converged in 19 steps with
. If w is changed from 1.0 to 1.1, then the NLS-Newton algorithm converges in 16 steps with
. As c decreases, the iterations required for convergence and
decrease.
The dotted lines indicate some uncertainty in the numerical solutions, which can be a function of the physical parameters and the location of the observation sites relative to the source sites. If there is no error in the data, the intensities of the sources are in the vector
Use 100 computations with the and 5% random errors. The means and standard deviations of the computed intensities at the three source sites are
The standard deviation of the intensities at the center source in Figure is large relative to its mean value. The large computed least squares errors are a result of some relatively small singular values in the singular value decomposition of the least squares matrix
where the singular values are the diagonal components of
; U is
,
is
and V is
.
In this example, the third singular value is small
The least square solution of (10) is given by the pseudo inverse of the least squares matrix times
Because is relatively small, any errors in
will be amplified as well as the components of
This suggests the second component, the center source, of least squares solution will have significant errors. The errors can be decreased if the percentage random error is smaller or by alternative location of the observation sites. In the 1D model this is not too difficult to remedy. However, in the 2D model this is more challenging.
Example 6.2
Consider the steady-state 2D model in (1) with boundary conditions equal to zero up stream and zero normal derivative down stream. The calculations in Figure were done by the MATLAB code in White (Citation2015, testlsnonlf2da3.m) using NLS-Picard and with four variable observation sites and three fixed source sites. The three fixed sources are to the left near , and the four observation sites are indicated by the symbol “*” above the site. The intensities times the approximation of the delta functionals is
where initially and
. If there is no random error in the data, then the computed source will be
The numerical experiments involve varying the location of the observation site at (x, 16) where and varying the y-component of the velocity, vely. The velocity term in (1) is
. The base calculation in Figure uses
and
along with 5% random error in the data and
growth coefficient in the nonlinear term. The singular values of the least squares matrix and the mean and standard deviations of the intensities of the three computed sources are recorded for 100 computations.
and
Changing the y-component of the velocity can cause the concentration to be moved away from the observation sites and cause more uncertainty in the calculations, which is indicated by larger standard deviations and smaller singular values of the least squares matrix. Change to
and
.
and
Here, the third singular value has significantly decreased and can cause failure of the NLS-Picard algorithm or increased computation errors because of the variation in the data.
and
In this case the second and third singular values of the least squares matrix decreased, and the standard deviation of the second source increased.
Changing the location of the third observation site can also cause more uncertainty in the calculations, which is indicated by larger standard deviations and smaller singular values of the least squares matrix. Change to
and
and keep
.
and
Here, the third singular value has significantly decreased and can cause failure of the NLS-Picard algorithm or increased computation errors because of the variation in the data. The standard deviation of the third source has significantly increased.
and
In this case the third singular values of the least squares matrix have dramatically decreased, and the standard deviation of the third source is very large relative to the mean.
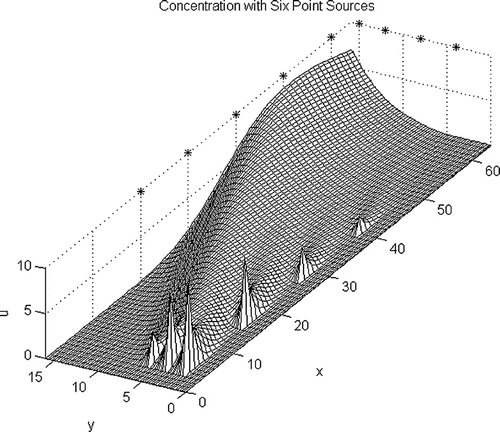
The calculation in Figure has six source sites (near the axes) and nine observation sites (down stream and below the “*”) (White, Citation2015, testlsnonlf2da6.m) uses NLS-Picard. Here the vely is larger with velocity the equal to (1.00, 0.30), and the random error in the data is smaller and equal to 1%:
The source closest to the origin is the most difficult to identify; with one percent error in the data the standard deviation is 0.8512 and with five percent error this goes up to 4.2348. This happens despite the relatively close distribution of the singular values from 0.0782 to 0.0047 for a condition number equal to 16.7658.
7. Summary
In order to determine locations and intensities of the source sites from data at the observation sites, there must more observations sites than source sites and the observation sites must be more chosen so that the least squares matrix C( : , ssites) has full column rank. Furthermore, the singular values in the singular value decomposition of the least squares matrix are important in the convergence proof and the location of the observation sites.
Figure 3. Three sources and four observations.
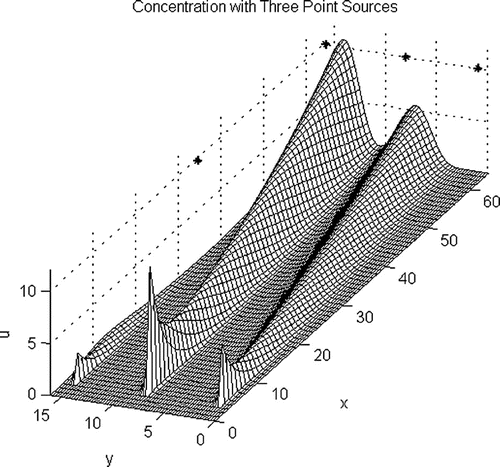
Figure 4. Six sources and nine observations.
Measurement errors in the observations as well as uncertain physical parameters can contribute to significant variation in the computed intensities of the sources. Multiple computations with varying these should be done, and the means and standard deviations should be noted. Large standard deviations from the mean indicate a lack of confidence in the computations. In this case, one must adjust the observation sites, which can be suggested by inspection of the smaller singular values for the least squares matrix and the corresponding columns in V of the singular value decomposition.
Additional information
Funding
Notes on contributors
Robert E. White
Professor Robert E. White has published numerous articles on numerical analysis including approximate solutions of partial differential equations, numerical linear algebra, and parallel algorithms. The most recent work is on hazard identification given observation data. He has authored three textbooks. The second edition of Computational Mathematics: Models, Methods and Analysis with MATLAB and MPI will be published in the fall of 2015 by CRC Press/Taylor and Francis.
References
- Andrle, M., & El Badia, A. (2015). On an inverse problem. Application to a pollution detection problem, II. Inverse Problems in Science and Engineering, 23, 389–412.
- Berman, A., & Plemmons, R. J. (1994). Nonnegative matrices in the mathematical sciences. Philadelphia, PA: SIAM.
- Bjorck, A. (1996). Numerical methods for least squares problems. Philadelphia, PA: SIAM.
- Cryer, C. W. (1971). The solution of a quadratic programming problem using systematic over ralaxation. SIAM Journal on Control and Optimization, 9, 385–392.
- Hamdi, A. (2007). Identification of point sources in two-dimensional advection-diffusion-reaction equations: Application to pollution sources in a river. Stationary case, Inverse Problems in Science and Engineering, 15, 855–870.
- Mahar, P. S., & Datta, B. (1997). Optimal monitoring network and ground-water-pollution source identification. Journal of Water Resources Planning and Management, 199, 199–2007.
- MathWorks Inc. (2015). (123, pp. 199–207). Retrieved from http://www.mathworks.com
- Meyer, C. D. (2000). Matrix analysis and applied linear algebra. Philadelphia, PA: SIAM.
- Pao, C. V. (1992). Nonlinear parabolic and elliptic equations. New York, NY: Plenum Press.
- White, R. E. (2009). Populations with impulsive culling: Identification and control. International Journal of Computer Mathematics, 86, 2143–2164.
- White, R. E. (2011). Identification of hazards with impulsive sources. International Journal of Computer Mathematics, 88, 762–780.
- White, R. E. (2015). MATLAB codes for hazard identification. Retrieved from http://www4.ncsu.edu/eos/users/w/white/www/white/hazardid/hazardid.htm
Appendix 1
Details for Example 3.2 with 
The least square problem in (11) can be solved for nonnegative
Next, consider the system in (11). The first two equations give the first and second unknowns in terms of the third unknown
Insert the formulas for , and
into the third equation in the system to get a nonlinear problem for a single unknown
and the single equation
When , this can be solved by Newton’s method to give
. Then solve for the first two unknowns and finally solve for z
In the above example, we were able to explicitly solve for nonnegative z in terms of the components of u. The problem is
where
The equivalent fixed point problem is
Expand the matrix-vector product to get
Assume u, v are nonnegative and bounded and in
Then and since
. If
, then
and G aps S into S.
The contraction mapping theorem requires G(u) to be contractive, that is,
One can approximate the differences
Then it is possible to estimate r as a function of c
Let and require
.