
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this study, a three-parameter lifetime distribution namely generalized weighted Lindley (GLW) distribution is proposed. The GLW distribution is an useful generalization of the weighted Lindley distribution which accommodates increasing, decreasing, decreasing-increasing-decreasing, bathtub, and unimodal hazard rate making it a flexible model for reliable data. A significant account of mathematical properties for this distribution is presented. Different estimation procedures are discussed such as maximum likelihood estimators, method of moments, ordinary and weighted least-squares, percentile, maximum product of spacings, and minimum distance estimators. The estimators are compared by extensive numerical simulations. Finally, two data-sets are analyzed for illustrative purposes proving that the GWL outperforms several other three-parameter lifetime distributions.
Public Interest Statement
We have proposed and presented a probability distribution called generalized weighted Lindley (WL) distribution. This distribution is an useful generalization of the WL distribution which accommodates increasing, decreasing, decreasing-increasing-decreasing, bathtub, and unimodal hazard rate. A significant account of mathematical properties for this distribution was presented. Different estimation procedures were proposed and compared by extensive numerical simulations. We believe that new distribution will allow the users to describe different data-sets obtaining a better predictive performance in comparison with other usual distributions.
1. Introduction
In recent years, several new extensions of the exponential distribution have been introduced in the literature for describing real problems. Ghitany, Atieh, and Nadarajah (Citation2008) investigated different properties of the Lindley distribution and outlined that in many cases the Lindley distribution outperforms exponential distribution. Since then, many generalizations of the Lindley distribution have been introduced such as generalized Lindley (Zakerzadeh & Dolati, Citation2009), extended Lindley (Bakouch, Al-Zahrani, Al-Shomrani, Marchi, & Louzada, Citation2012), exponential Poisson Lindley (Barreto-Souza & Bakouch, Citation2013), and Power Lindley (Ghitany, Al-Mutairi, Balakrishnan, & Al-Enezi, Citation2013) distribution.
Ghitany, Alqallaf, Al-Mutairi, and Husain (Citation2011) introduced a new class of weighted Lindley (WL) distribution adding more flexibility to the Lindley distribution. Let T be a random variable with a WL distribution. Then probability density function (p.d.f) is given by(1)
(1)
for all ,
and
and
is the gamma function. One of its peculiarities is that the hazard function can have an increasing
or bathtub
shape. Different properties and estimation methods for this model were presented by Mazucheli, Louzada, and Ghitany (Citation2013), Ali (Citation2015), Wang and Wang (Citationin press), Al-Mutairi, Ghitany, and Kundu (Citation2015).
In this study, a new lifetime distribution family is proposed which is a direct generalization of the WL distribution. The p.d.f is given by(2)
(2)
for all ,
and
. Important probability distributions can be obtained from the GWL distribution as the WL distribution (
) , Power Lindley distribution (
) and the Lindley distribution (
and
). Due to this relationship, such model could also be named as weighted power Lindley or generalized power Lindley distribution.
Torabi, Falahati-Naeini, and Montazeri (Citation2014) discussed a class of distribution with four parameters which is a generalization of the proposed model. Such distribution includes the generalized WL, generalized gamma (GG) distribution, gamma and Weibull, among others. The main difference of this study lies in the fact that the proposed three-parameter distribution has a simple structure with less computational issues. In this way, the behavior of the p.d.f and the hazard function can be studied. This model has different forms of hazard function such as increasing, decreasing, bathtub, unimodal, or decreasing-increasing-decreasing shape making the GWL distribution a flexible model for reliable data. Moreover, a significant account of mathematical properties for the new distribution is provided.
The inferential procedures for the parameters of GLW distribution are presented considering different methods such as maximum likelihood estimators (MLE), methods of moments (ME), ordinary least-squares estimation (OLSE), weighted least-squares estimation (WLSE), maximum product of spacings (MPS), Cramer-von Mises type minimum distance (CME), Anderson–Darling (ADE) and right-tail Anderson–Darling (RADE). The performance of these estimation procedures are compared using extensive numerical simulations. Finally, two data-sets are analyzed for illustrative purposes proving that the GWL outperforms several usual three-parameter lifetime distributions such as the GG distribution (Stacy, Citation1962), the generalized Weibull (GW) distribution (Mudholkar, Srivastava, & Kollia, Citation1996), the generalized exponential-Poisson (GEP) distribution (Barreto-Souza & Cribari-Neto, Citation2009), and the exponentiated Weibull (EW) distribution (Mudholkar, Srivastava, & Freimer, Citation1995).
The results of this paper are organized as follows. Section 2 provides a significant account of mathematical properties for the new distribution. Section 3 presents the eight estimation methods which are considered. In the Section 4, a simulation study is presented in order to identify the most efficient procedure. Section 5 illustrates the proposed methodology in two real data-sets. Section 6 summarizes the present work.
2. Generalized weighted Lindley distribution
The generalized WL distribution (2) can be expressed as a two-component mixture
where and
, for
, i.e.
has GG distribution, given by
(3)
(3)
The behavior of the p.d.f. (2) when and
are, respectively, given by
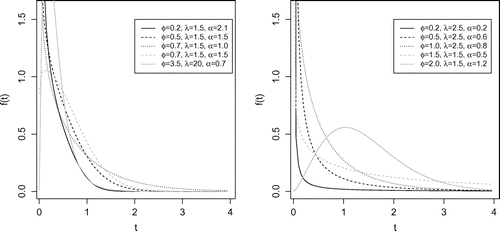
Figure gives examples of the shapes of the density function for different values of and
.
Figure 1. Density function shapes for GWL distribution considering different values of and
.
The cumulative distribution function from the GWL distribution is given by(4)
(4)
where is the lower incomplete gamma function.
2.1. Moments
Many important features and properties of a distribution can be obtained through its moments such as mean, variance, kurtosis, and skewness. In this section, important moment functions such as the moment-generating function, r-th moment, r-th central moment, among others are presented.
Theorem 2.1
For the random variable T with GWL distribution, the moment-generating function is given by(5)
(5)
Proof
Note that, the moment-generating function from GG distribution (3) is given by
Since the GWL distribution (2) can be expressed as a two-component mixture, we have
Corollary 2.2
For the random variable T with GWL distribution, the r-th moment is given by(6)
(6)
Proof
Note that, and the result follows.
Corollary 2.3
For the random variable T with GWL distribution, the r-th central moment is given by(7)
(7)
Corollary 2.4
A random variable T with GWL distribution has the mean and variance respectively given by(8)
(8)
(9)
(9)
Proof
From (6) and considering we have
. The second result follows from (7) considering
with some algebraic manipulations.
Another moment function that can be easily achieved for GWL distribution and plays an important role in information theory is given by(10)
(10)
2.2. Survival properties
In this section, we present the survival, hazard, and mean residual life (MRL) function for the GWL distribution. The survival function of T is given by(11)
(11)
where is called upper incomplete gamma. The hazard function is given as
(12)
(12)
The behavior of the hazard function (12) when and
are, respectively, given by
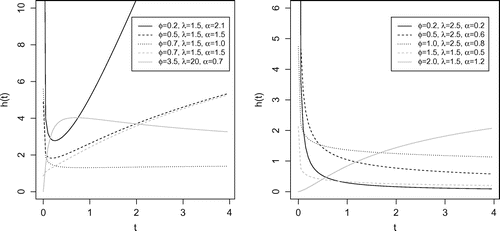
Theorem 2.5
The hazard rate function h(t) of the GWL distribution is increasing, decreasing, bathtub, unimodal, or decreasing-increasing-decreasing shaped.
Proof
The theorem proposed by Glaser (Citation1980) is not easily applied in the GLW distribution. Since the hazard rate function (12) is complex, we considered the following cases:
| (1) | Let | ||||
| (2) | Let | ||||
increasing when
;
decreasing when
decreasing-increasing-decreasing if
| (3) | Let | ||||
These properties make the GWL distribution a flexible model for reliable data. Figure gives examples of the shapes of the hazard function for different values of and
.
Figure 2. Hazard function shapes for GWL distribution and considering different values of and
.
The MRL has been widely used in survival analysis and represents the expected additional lifetime given that a component has survived until time t.
Proposition 2.6
The MRL function of the GWL distribution is given by
(13)
(13)
Proof
Note that
The behavior of the MRL function when and
are, respectively, given by
2.3. Entropy
In information theory, entropy has played a central role as a measure of uncertainty associated with a random variable. Shannon’s entropy is one of the most important metrics in information theory. For the GWL distribution, Shannon’s entropy can be obtained by solving(14)
(14)
Proposition 2.7
A random variable T with GWL distribution has Shannon’s entropy given by(15)
(15)
where
Proof
From the Equation (14), we have(16)
(16)
Note that
using the change of variable and after some algebra
From Equations (6) and (10), we can easily find the solution of and
and the result as follows.
Another popular entropy measure is proposed by Renyi (Citation1961). Some recent applications of the Renyi entropy can be seen in Popescu and Aiordachioaie (Citation2013). If T has the probability density function (1) then Renyi entropy is defined by(17)
(17)
Proposition 2.8
A random variable T with GWL distribution, has the Renyi entropy given by(18)
(18)
where .
Proof
The Renyi entropy is given by
and with some algebra the proof is completed.
2.4. Lorenz curves
The Lorenz curve (Bonferroni, Citation1930) is a well-known measure used in reliability, income inequality, life testing and renewal theory. The Lorenz curve for a non-negative T random variable is given through the consecutive plot of
Proposition 2.9
The Lorenz curve for the GWL distribution is
where .
3. Methods of estimation
In this section, we present eight different estimation methods for the parameters and
of the GWL distribution.
3.1. Maximum likelihood estimation
The maximum likelihood method has been widely used due to its better asymptotic properties. The estimates are obtained by maximizing the likelihood function. Let be a random sample where
, the likelihood function is given by
(19)
(19)
The log-likelihood function is given by
(20)
(20)
From the expressions ,
,
, the likelihood equations are
(21)
(21)
(22)
(22)
and(23)
(23)
where . Numerical methods such as Newton-Rapshon are required to find the solution of the nonlinear system. Note that from (21) and (23) and after some algebra we have
(24)
(24)
(25)
(25)
Under mild conditions, the maximum likelihood estimates (MLEs) are asymptotically normal distributed with a joint multivariate normal distribution given by
where is the Fisher information matrix is given as
(26)
(26)
and the elements of the matrix are given in Appendix 2.
3.2. Moments estimators
The method of moments is one of the oldest methods used for estimating parameters in statistical models. The moments estimators (MEs) of the GLW distribution can be obtained by equating the first three sample moments ,
and
with the theoretical moments
Therefore, the ME ,
and
, can be obtained by solving the non-linear equations
3.3. Ordinary and weighted least-square estimate
Let be the order statistics (the same notation is assumed for the next subsections) of the random sample of size n from
. The least square estimators
,
and
can be obtained by minimizing
with respect to and
. Equivalently, the estimates can be obtained by solving the non-linear equations
where(27)
(27)
Note that the solution of for
involves partial derivatives of the lower incomplete gamma function. However, this can be easily achieved numerically with high precision.
The weighted least-squares estimates (WLSEs), ,
and
, can be obtained by minimizing
These estimates can also be obtained by solving the non-linear equations
where ,
and
are given in (27).
3.4. Method of maximum product of spacings
The MPS method is a powerful alternative to MLE for the estimation of unknown parameters of continuous univariate distributions. Proposed by Cheng and Amin (Citation1979,Citation1983), this method was also independently developed by Ranneby (Citation1984) as an approximation to the Kullback–Leibler information measure. Cheng and Amin (Citation1983) proved desirable properties of the MPS such as asymptotic efficiency, invariance, and more importantly, the consistency of maximum product of spacing estimators holds under more general conditions than for MLEs.
Let , for
be the uniform spacings of a random sample from the GWL distribution, where
and
Clearly
. The MPS estimates
,
and
are obtained by maximizing the geometric mean of the spacings
(28)
(28)
with respect to ,
and
, or, equivalently, by maximizing the logarithm of the geometric mean of sample spacings
(29)
(29)
The estimates ,
and
of the parameters
,
and
can be obtained by solving the nonlinear equations
(30)
(30)
where ,
and
are given respectively in (27). Note that if
then
. Therefore, the MPS estimators are sensitive to closely spaced observations, especially ties. When the ties are due to multiple observations,
should be replaced by the corresponding likelihood
since
.
Under mild conditions for the GWL distribution, the MPS estimators are asymptotically normal distributed with a joint trivariate normal distribution given by
3.5. The Cramer-von Mises minimum distance estimators
The Cramer-von Mises estimator is a type of minimum distance estimators (also called maximum goodness-of-fit estimators) and is based on the difference between the estimate of the cumulative distribution function and the empirical distribution function (Luceño, Citation2006).
Macdonald (Citation1971) motivated the choice of the CME estimators providing empirical evidence that the bias of the estimator is smaller than the other minimum distance estimators. The Cramer-von Mises estimates ,
and
of the parameters
,
and
are obtained by minimizing
(31)
(31)
with respect to ,
and
. These estimates can also be obtained by solving the nonlinear equations:
where ,
and
are given respectively in (27).
3.6. The Anderson–Darling and Right-tail Anderson–Darling estimators
Another type of minimum distance estimator is based on ADE statistic and is known as ADE estimator. The ADE estimates and
of the parameters
and
are obtained by minimizing, with respect to
,
and
, the function
(32)
(32)
These estimates can also be obtained by solving the nonlinear equations
The Right-tail ADE estimates and
of the parameters
and
are obtained by minimizing the function
(33)
(33)
with respect to ,
and
. These estimates can also be obtained by solving the nonlinear equations:
where ,
and
are given respectively in (27).
4. Simulation study
In this section, an intensive simulation study is presented to compare the efficiency of the estimation procedures for parameters of the GWL distribution. The following procedure was adopted:
| (1) | Generate pseudo-random values from the | ||||
| (2) | Using the values obtained in step 1, calculate | ||||
| (3) | Repeat the steps 1 and 2 N times. | ||||
| (4) | Using | ||||
Figure 3. Proportion of failure from N simulated samples, considering different values of n using the following estimation method 1-MLE, 2-MPS, 3-ADE, 4-RTADE, 5-LSE, 6-WLSE, 7-ME, 8-CME.
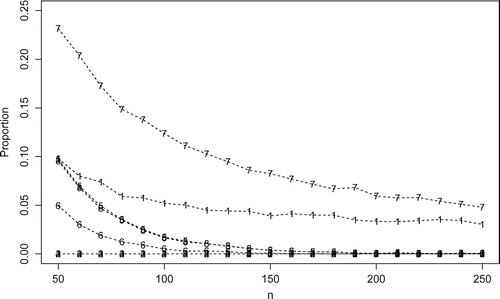
Figure 4. MREs, MSEs related from the estimates of and
for N simulated samples, considering different values of n obtained using the following estimation method 1-MLE, 2-MPS, 3-ADE, 4-RTADE.
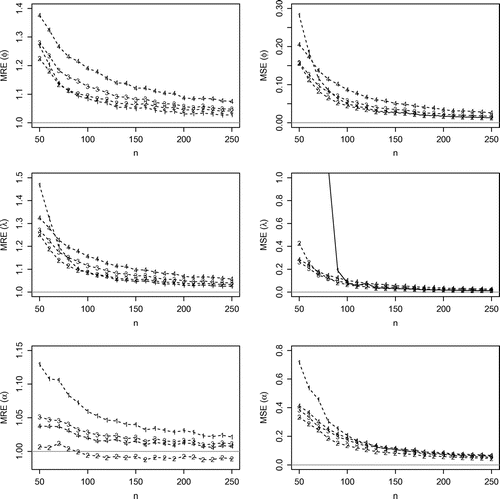
Figure 5. (left panel) the TTT-plot, (middle panel) the fitted survival superimposed to the empirical survival function and (right panels) the hazard function adjusted by GWL distribution.
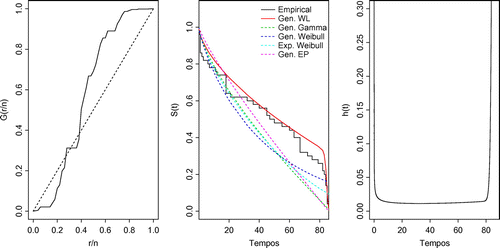
Figure 6. (left panel) the TTT-plot, (middle panel) the fitted survival superimposed to the empirical survival function and (right panels) the hazard function adjusted by GWL distribution.
For this comparison to be meaningful, the estimation procedures need to be performed under same conditions. However, for some particular samples and estimation methods, the numerical techniques do not work well in finding the parameter estimates. Therefore, a rate study is presented to verify the frequency of convergence of the numerical solutions. This procedure is carried out by counting the number of times each estimation fails in finding the numerical solution. In Figure we present the proportion of failure from each method.
From Figure , the MLE, LSE, WLSE, ME, and the CME estimators fail in finding the parameter estimates for a significant number of samples. Therefore, such methods are not recommended for estimation of the GLW parameters. Hereafter, we consider the MPS, ADE, RADE estimators due to their better computational stability. The MLE is considered only for illustrative purposes since it is the most used estimation method. Figure presents the MREs, MSEs for the estimates of and
using the MLE, MPS, ADE, RADE with N simulated samples and different values of
and n. The horizontal lines in both figures correspond to MREs and MSEs being one and zero, respectively.
From these results, the MSE of the MLE, MPS, ADE, and RADE estimators tend to zero for large n and also, as expected, the values of MREs tend to one, i.e. the estimates are consistent and asymptotically unbiased for the parameters. For small sample sizes, the MLE has the largest MSEs. The MPS has smaller MSEs with MREs closer to one for almost all values of n. Additionally, the MPS, ADE, and RADE estimators were the only methods that were able to find and
for all the
generated samples. Therefore, combining all results with the good properties of the MPS method such as consistency, asymptotic efficiency, normality and invariance, we conclude that the MPS estimators are a highly competitive method compared to the maximum likelihood for estimating the parameters of the GWL distribution.
5. Application
In this section, we compare the GWL distribution with other three-parameter lifetime distributions considering two data-sets, the first with bathtub hazard rate and the other with the increasing hazard function. The following lifetime distributions were considered. The GG distribution with p.d.f given by
where and
. The GW distribution where the p.d.f is
where and
. The GEP distribution with p.d.f given by
where and
The EW distribution with p.d.f
where and
.
The TTT-plot (total time on test) is considered in order to verify the behavior of the empirical hazard function (Barlow & Campo, Citation1975). The TTT-plot is obtained through the plot of [r / n, G(r / n)] where
and is the statistical order. If the curve is concave (convex), the hazard function is increasing (decreasing). On the other hand, when it starts convex and then becomes concave (concave and then convex) the hazard function has bathtub (inverse bathtub) shape.
The goodness of fit is checked considering the Kolmogorov–Smirnov (KS) test. This procedure is based on the KS statistic , where
is the supremum of the set of distances,
is the empirical distribution function and
is c.d.f. A hypothesis test is conducted at the
level of significance to test whether or not the data come from
. In this case, the null hypothesis is rejected if the returned p-value is smaller than 0.05.
To carry out the model selection, the following discrimination criterion methods are adopted: AIC (Akaike information criteria) and AICc (Corrected Akaike information criterion) computed, respectively, by and
, where k is the number of parameters to be fitted and
is estimation of
. For a set of candidate models for
, the best one provides the minimum values.
5.1. Lifetimes data
Aarset (Citation1987) presents the data-set (see Table ) related to the lifetime in hours of 50 devices on test
Table 1. Lifetimes data (in hours) related to a device on test
Figure shows (left panel) the TTT-plot, (middle panel) the fitted survival superimposed to the empirical survival function and (right panels) the hazard function adjusted by GWL distribution. Table presents the AIC and AICc criteria and the p-value from the KS test for all fitted distributions considering the Aarset dataset.
Table 2. Results of AIC and AICc criteria and the p-value from the KS test for all fitted distributions considering the Aarset dataset
Table 3. MPS estimates, standard-error and CI for
and
Table 4. January average flows (m/s) of the Cantareira system
Table 5. Results of AIC and AICc criteria and the p-value from the KS test for all fitted distributions considering the data-set related to the january average flows (m/s) of the Cantareira system
Table 6. ML estimates, standard-error and CI for
and
Comparing the empirical survival function with the adjusted distributions, it can be observed that the GWL distribution is as a better fit. This result is also confirmed from the AIC and AICC (see Table ) since GWL distribution has the minimum values and also the p-values returned from the KS test are greater than 0.05. It should be emphasized that considering a significance level of , the others models are not able to fit the proposed data. Table displays the MPS estimates, standard errors, and the confidence intervals (CI) for
and
of the GWL distribution.
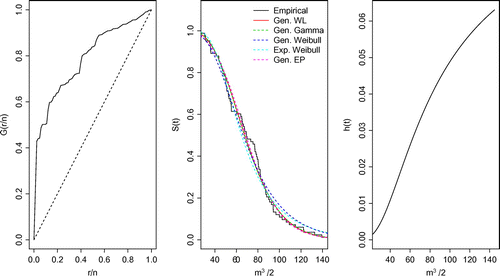
In this section, we consider the ML estimator showing that both MPS or MLE could be used successfully in applications. Figure shows (left panel) the TTT-plot, (middle panel) the fitted survival superimposed to the empirical survival function and (right panels) the hazard function adjusted by GWL distribution. Table presents the AIC and AICc criteria and the p-value from the KS test for all fitted distributions considering the data-set related to the January average flows (m/s) of the Cantareira system.
From the empirical survival function and the adjusted distributions, it can be observed that the GWL distribution is better. This result is also confirmed from AIC and AICC since GWL distribution has the minimum values and the p-values returned from the KS test are greater than 0.05. Table displays the ML estimates, standard errors, and the CI for and
of the GWL distribution.
5.2. Average flows data
The study of average flows has been proved to be of high importance to protect and maintain aquatic resources in streams and rivers (Reiser, Wesche, & Estes, Citation1989). In this section, we consider a real data-set related to the average flows (m/s) of the Cantareira system during January at São Paulo city in Brazil. It is worth mentioning that the Cantareira system provides water to 9 million people in the São Paulo metropolitan area. The data-set available in Table was obtained from the National Water Agency from 1930 to 2012.
6. Concluding remarks
To summarize, we have proposed a three-parameter lifetime distribution. The GLW distribution is a straightforward generalization of the WL distribution proposed by Ghitany et al. (Citation2011), which accommodates increasing, decreasing, decreasing-increasing-decreasing, bathtub, and unimodal hazard rate making the GWL distribution a flexible model for reliable data. The mathematical properties of this distribution are also discussed.
The estimation procedures for the parameters of GWL distribution are also derived considering eight estimation methods. Since it is not feasible to compare these methods theoretically, we have presented an extensive simulation study in order to identify the most efficient procedure. We observed that the MLE, ME, LSE, WLSE, and the CME estimators fail in finding the parameter estimates for a significant number of samples. The simulations showed that the MPS (maximum product of spacing) is the most efficient method for estimating the parameters of the GWL distribution in comparison to its competitors. Finally, two data-sets were analyzed for illustrative purposes proving that the GWL distribution outperforms several usual three parameter lifetime distributions.
Acknowledgements
We are grateful to the Editorial Board and the reviewers for their valuable comments and suggestions which has improved the manuscript.
Additional information
Funding
Notes on contributors
P.L. Ramos
P.L. Ramos holds a BSc degree in Statistics and an MSc in Applied and Computational Mathematics from the São Paulo State University, Brazil. He is currently reading for his PhD in Statistics at the Institute for Mathematical Science and Computing, University of São Paulo (USP), Brazil. His main research interests are in survival analysis, Bayesian inference, classical inference, and probability distribution theory.
F. Louzada
F. Louzada is a professor of Statistics at the Institute for Mathematical Science and Computing, University of So Paulo (USP), Brazil. He received his PhD degree in Statistics from the University of Oxford, UK, his MSc degree in Computational Mathematics from USP, Brazil, and his BSc degree in Statistics from UFSCar, Brazil. His main research interests are in survival analysis, data mining, Bayesian inference, classical inference, and probability distribution theory.
Related Research Data
References
- Aarset, M. V. (1987). How to identify a bathtub hazard rate. IEEE Transactions on Reliability, 36, 106–108.
- Ali, S. (2015). On the bayesian estimation of the weighted lindley distribution. Journal of Statistical Computation and Simulation, 85, 855–880.
- Al-Mutairi, D., Ghitany, M., & Kundu, D. (2015). Inferences on stress-strength reliability from weighted lindley distributions. Communications in Statistics-Theory and Methods, 44, 4096–4113.
- Bakouch, H. S., Al-Zahrani, B. M., Al-Shomrani, A. A., Marchi, V. A., & Louzada, F. (2012). An extended lindley distribution. Journal of the Korean Statistical Society, 41, 75–85.
- Barlow, R. E., & Campo, R. A. (1975). Total time on test processes and applications to failure data analysis (Technical report). Berkeley, CA: DTIC Document.
- Barreto-Souza, W., & Bakouch, H. S. (2013). A new lifetime model with decreasing failure rate. Statistics, 47, 465–476.
- Barreto-Souza, W., & Cribari-Neto, F. (2009). A generalization of the exponential-poisson distribution. Statistics & Probability Letters, 79, 2493–2500.
- Bonferroni, C. (1930). Elementi di statistica generale. Firenze: Seeber.
- Cheng, R. & Amin, N. (1979). Maximum product of spacings estimation with application to the lognormal distribution (Mathematical Report 79-1). Cardiff: University of Wales IST.
- Cheng, R., & Amin, N. (1983). Estimating parameters in continuous univariate distributions with a shifted origin. Journal of the Royal Statistical Society. Series B (Methodological), 45, 394–403.
- Ghitany, M., Al-Mutairi, D., Balakrishnan, N., & Al-Enezi, L. (2013). Power lindley distribution and associated inference. Computational Statistics & Data Analysis, 64, 20–33.
- Ghitany, M., Alqallaf, F., Al-Mutairi, D., & Husain, H. (2011). A two-parameter weighted lindley distribution and its applications to survival data. Mathematics and Computers in Simulation, 81, 1190–1201.
- Ghitany, M., Atieh, B., & Nadarajah, S. (2008). Lindley distribution and its application. Mathematics and Computers in Simulation, 78, 493–506.
- Glaser, R. E. (1980). Bathtub and related failure rate characterizations. Journal of the American Statistical Association, 75, 667–672.
- Luceño, A. (2006). Fitting the generalized pareto distribution to data using maximum goodness-of-fit estimators. Computational Statistics & Data Analysis, 51, 904–917.
- Macdonald, P. (1971). An estimation procedure for mixtures of distribution. Journal of the Royal Statistical Society. Series B (Methodological), 33, 326–329.
- Mazucheli, J., Louzada, F., & Ghitany, M. (2013). Comparison of estimation methods for the parameters of the weighted lindley distribution. Applied Mathematics and Computation, 220, 463–471.
- Mudholkar, G. S., Srivastava, D. K., & Freimer, M. (1995). The exponentiated weibull family: A reanalysis of the bus-motor-failure data. Technometrics, 37, 436–445.
- Mudholkar, G. S., Srivastava, D. K., & Kollia, G. D. (1996). A generalization of the weibull distribution with application to the analysis of survival data. Journal of the American Statistical Association, 91, 1575–1583.
- Popescu, T. D., & Aiordachioaie, D. (2013). Signal segmentation in time-frequency plane using renyi entropy-application in seismic signal processing. In 2013 Conference on Control and Fault-Tolerant Systems (SysTol) (pp. 312–317). Nice: IEEE.
- Ranneby, B. (1984). The maximum spacing method. An estimation method related to the maximum likelihood method. Scandinavian Journal of Statistics, 11, 93–112.
- Reiser, D. W., Wesche, T. A., & Estes, C. (1989). Status of instream flow legislation and practices in north america. Fisheries, 14, 22–29.
- Renyi, A. (1961). On measures of entropy and information. In Fourth Berkeley Symposium on Mathematical Statistics and Probability, 1, 47–561.
- Stacy, E. W. (1962). A generalization of the gamma distribution. The Annals of Mathematical Statistics, 33, 1187–1192.
- Torabi, H., Falahati-Naeini, M., & Montazeri, N. (2014). An extended generalized lindley distribution and its applications to lifetime data. Journal of Statistical Research of Iran, 11, 203–222.
- Wang, M., & Wang, W. (in press). Bias-corrected maximum likelihood estimation of the parameters of the weighted lindley distribution. Communications in Statistics-Simulation and Computation, 46, 530–545.
- Zakerzadeh, H., & Dolati, A. (2009). Generalized lindley distribution. Journal of Mathe-matical Extension, 3, 1–17
Appendix 1
Appendix
The elements of the Fisher information matrix are