
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The kernel Bayes’ rule has been proposed as a nonparametric kernel-based method to realize Bayesian inference in reproducing kernel Hilbert spaces. However, we demonstrate both theoretically and experimentally that the way of incorporating the prior in the kernel Bayes’ rule is unnatural. In particular, we show that under some reasonable conditions, the posterior in the kernel Bayes’ rule is completely unaffected by the prior, which seems to be irrelevant in the context of Bayesian inference. We consider that this phenomenon is in part due to the fact that the assumptions in the kernel Bayes’ rule do not hold in general.
Public interest statement
This paper examines the validity of the kernel Bayes’ rule, a recently proposed nonparametric framework for Bayesian inference. The researchers on the kernel Bayes’ rule are aiming to apply this method to a wide range of Bayesian inference problems. However, as we demonstrate in this paper, the way of incorporating the prior in the kernel Bayes’ rule seems wrong in the context of Bayesian inference. Several theorems of the kernel Bayes’ rule rely on a strong assumption which does not hold in general.
The problems of the kernel Bayes’ rule seem to be nontrivial and difficult, and we have currently no idea to solve them. We hope that this study would trigger reexamination and correction of the basic framework of the kernel Bayes’ rule.
1. Introduction
The kernel Bayes’ rule has recently emerged as a novel framework for Bayesian inference (Fukumizu, Song, & Gretton, Citation2013; Song, Fukumizu, & Gretton, Citation2014; Song, Huang, Smola, & Fukumizu, Citation2009). It is generally agreed that, in this framework, we can estimate the kernel mean of the posterior distribution, given kernel mean expressions of the prior and likelihood distributions. Since the distributions are mapped and nonparametrically manipulated in infinite-dimensional feature spaces called reproducing kernel Hilbert spaces (RKHS), it is believed that the kernel Bayes’ rule can accurately evaluate the statistical features of high-dimensional data and enable Bayesian inference even if there were no appropriate parametric models. To date, several applications of the kernel Bayes’ rule have been reported (Fukumizu et al., Citation2013; Kanagawa et al., Citation2014). However, the basic theory and the algorithm of the kernel Bayes’ rule might need to be modified because of the following reasons:
| (1) | The posterior in the kernel Bayes’ rule is in some cases completely unaffected by the prior. | ||||
| (2) | The posterior in the kernel Bayes’ rule considerably depends upon the choice of the parameters to regularize covariance operators. | ||||
| (3) | It does not hold in general that conditional expectation functions are included in the RKHS, which is an essential assumption of the kernel Bayes’ rule. | ||||
2. Kernel Bayes’ rule
In this section, we briefly review the kernel Bayes’ rule following (Fukumizu et al., Citation2013). Let and
be measurable spaces,
be a random variable with an observed distribution P on
, U be a random variable with the prior distribution
on
, and
be a random variable with the joint distribution Q on
. Note that Q is defined by the prior
and the family
, where
denotes the conditional distribution of Y given
. For each
, let
represent the posterior distribution of Z given
. The aim of the kernel Bayes’ rule is to derive the kernel mean of
.
Definition 1
Let and
be measurable positive definite kernels on
and
such that
and
, respectively, where
denotes the expectation operator. Let
and
be the RKHS defined by
and
, respectively. We consider two bounded linear operators
and
such that
(1)
(1)
for any and
, where
and
denote inner products on
and
, respectively. The integral expressions for
and
are given by
where denotes the marginal distribution of X. Let
be the bounded linear operator defined by
for any and
. Then
is the adjoint of
.
Theorem 1
(Fukumizu et al., Citation2013, Theorem 1) If for
, then
.
Definition 2
Let denote the marginal distribution of W. Assuming that
and
, we can define the kernel means of
and
by
respectively. Due to the reproducing properties of and
, the kernel means satisfy
and
for any
and
.
Theorem 2
(Fukumizu et al., Citation2013, Theorem 2) If is injective,
, and
for any
, then
(2)
(2)
where denotes the range of
.
Here we have, for any (3)
(3)
by replacing in Equation (2) for
. It is noted in Fukumizu et al. (Citation2013) that the assumption
does not hold in general. In order to remove this assumption,
has been suggested to be used instead of
, where
is a regularization constant and I is the identity operator. Thus, the approximations of Equations (2) and (3) are respectively given by
Similarly, for any , the approximation of
is provided by
(4)
(4)
where is a regularization constant and the linear operators
and
will be defined below.
Definition 3
We consider the kernel means and
such that
for any and
, where
denotes the tensor product. Let
and
be bounded linear operators which respectively satisfy
(5)
(5)
for any and
.
From Theorem 2, Fukumizu et al. (Citation2013) proposed that and
can be given by
In case is not included in
, they suggested that
and
could be approximated by
Remark 1
(Fukumizu et al., Citation2013, p. 3760) and
can respectively be identified with
and
.
Here, we introduce the empirical method for estimating the posterior kernel mean following (Fukumizu et al., Citation2013).
Definition 4
Suppose we have an independent and identically distributed (i.i.d.) sample from the observed distribution P on
and a sample
from the prior distribution
on
. The prior kernel mean
is estimated by
(6)
(6)
where are weights. Let us put
,
, and
.
Proposition 1
(Fukumizu et al., Citation2013, Proposition 3, revised) Let denote the identity matrix of size n. The estimates of
and
are given by
respectively, where .
The proof of this revised proposition is given in Section 6.1. It is suggested in Fukumizu et al. (Citation2013) that Equation (4) can be empirically estimated by
Theorem 3
(Fukumizu et al., Citation2013, Proposition 4) Given an observation ,
can be calculated by
where is the diagonal matrix with the elements of
,
, and
.
If we want to know the posterior expectation of a function given an observation
, it is estimated by
where .
3. Theoretical arguments
In this section, we theoretically support the three arguments raised in Section 1. First, we show in Section 3.1 that the posterior kernel mean is completely unaffected by the prior distribution
under the condition that
and
are non-singular. This implies that, at least in some cases,
does not properly affect
. Second, we mention in Section 3.2 that the linear operators
and
are not always surjective, and address the problems associated with the setting of the regularization parameters
and
. Third, we demonstrate in Section 3.3 that conditional expectation functions are not generally contained in the RKHS, which means that Theorems 1, 2, and 5–8 in Fukumizu et al. (Citation2013) do not work in some situations.
3.1. Relations between the posterior  and the prior
and the prior
Let us review Theorem 3. Assume that and
are non-singular matrices. (This assumption is not so strange, as shown in Section 6.2.) The matrix
tends to
as
tends to 0. Furthermore, if we set
from the beginning, we obtain
. This implies that the posterior kernel mean
never depends on the prior distribution
on
, which seems to be a contradiction to the nature of Bayes’ rule.
Some readers may argue that, even in this case, we should not set . Then, however, there is ambiguity about why and how the regularization parameters are introduced in the kernel Bayes’ rule, since Fukumizu et al. originally used the regularization parameters just to solve inverse problems as an analog of ridge regression (Fukumizu et al., Citation2013, p. 3758). They seem to support the validity of the regularization parameters by Theorems 5, 6, 7, and 8 in Fukumizu et al. (Citation2013), however, these theorems do not work without the strong assumption that conditional expectation functions are included in the RKHS, as will be discussed in Section 3.2. In addition, since the theorems work only when
, etc. decay to zero sufficiently slowly, it seems that we have no principled way to choose values for the regularization parameters, except for cross-validation or similar techniques. It is worth mentioning that, in our simple experiments in Section 4.2, we could not obtain a reasonable result with the kernel Bayes’ rule using any combination of values for the regularization parameters.
3.2. The inverse of the operators and
As noted by Fukumizu et al. (Citation2013), the linear operators and
are not surjective in some usual cases, the proof of which is given in Section 6.3. Therefore, they proposed an alternative way of obtaining a solution
of the equation
, that is, a regularized inversion
as an analog of ridge regression, where
is a regularization parameter and I is an identity operator. One of the disadvantages of this method is that the solution
depends upon the choice of
. In Section 4.2, we numerically show that the prediction using the kernel Bayes’ rule considerably depends on the regularization parameters
and
. Theorems 5–8 in Fukumizu et al. (Citation2013) seem to support the appropriateness of the regularized inversion. However, these theorems work under the condition that conditional expectation functions are contained in the RKHS, which does not hold in some cases as proved in Section 3.3. Furthermore, since we need to assume sufficiently slow decay of the regularization constants
and
in these theorems, it is practically difficult to set appropriate values for
and
. A cross-validation procedure seems to be useful for tuning the parameters and we may obtain good experimental results, however, it seems to lack theoretical background.
Instead of the regularized inversion method, we can compute generalized inverse matrices of and
, given a sample
. Below, we briefly introduce a generalization of a matrix inverse. For more details, see Horn and Johnson (Citation2013).
Definition 5
Let A be a matrix of size over the complex number space
. We say that a matrix
of size
is a generalized inverse matrix of A if
. We also say that a matrix
of size
is the Moore-Penrose generalized inverse matrix of A if
and
are Hermitian,
, and
.
Remark 2
In fact, any matrix A has the Moore-Penrose generalized inverse matrix . Note that
is uniquely determined by A. If A is square and non-singular, then
. For a generalized inverse matrix
of size
,
for any vector
if v is contained in the image of A. In particular,
is a vector contained in the preimage of v under A.
In the calculation of , we numerically compare the case
with the original case
in Section 4.2, where
.
3.3. Conditional expectation functions and RKHS
In this subsection, we show that conditional expectation functions are in some cases not contained in the RKHS.
Definition 6
For , we define the spaces
,
, and
as
We also define the norm for
or
as
and the norm for
as
Definition 7
For a function , we define its Fourier transform as
We can uniquely extend the Fourier transform to an isometry . We also define the inverse Fourier transform
as an isometry uniquely determined by
for .
Definition 8
Let us define a Gaussian kernel on
by
As described in Fukumizu (Citation2014), the RKHS of real-valued functions and complex-valued functions corresponding to the positive definite kernel are given by
respectively, and the inner product of or
on the RKHS is calculated by
(7)
(7)
where the overline denotes the complex conjugate. Remark that is a real Hilbert subspace contained in the complex Hilbert space
.
Fukumizu et al. (Citation2013) mentioned that the conditional expectation function is not always included in
. Indeed, if the variables X and Y are independent, then
becomes a constant function on
, the value of which might be non-zero. In the case that
and
, the constant function with non-zero value is not contained in
.
Additionally, in order to prove Theorems 5 and 8 in Fukumizu et al. (Citation2013), they made the assumption that and
, where
and
are independent copies of the random variables
and
on
, respectively. We also see that this assumption does not hold in general. Suppose that X and Y are independent and that so are
and
. Then
is a constant function of
, the value of which might be non-zero. In the case that
and
, the constant function having non-zero value is not contained in
. Note that
is isomorphic to the RKHS corresponding to the kernel
on
, that is,
where the Fourier transform of is defined by
Thus, the assumption that conditional expectation functions are included in the RKHS does not hold in general. Since most of the theorems in Fukumizu et al. (Citation2013) require this assumption, the kernel Bayes’ rule may not work in several cases.
4. Numerical experiments
In this section, we perform numerical experiments to illustrate the theoretical results in Sections 3.1 and 3.2. We first introduce probabilistic classifiers in Section 4.1 based on conventional Bayes’ rule assuming Gaussian distributions (BR), the original kernel Bayes’ rule (KBR1), and the kernel Bayes’ rule using Moore-Penrose generalized inverse matrices (KBR2). In Section 4.2, we apply the three classifiers to a binary classification problem with computer-simulated data sets. Numerical experiments are implemented in version 2.7.6 of the Python software (Python Software Foundation, Wolfeboro Falls, NH, USA).
4.1. Algorithms of the three classifiers, BR, KBR1, and KBR2
Let be a random variable with a distribution P on
, where
is a family of classes and
. Let
and Q be the prior and the joint distributions on
and
, respectively. Suppose we have an i.i.d. training sample
from the distribution P. The aim of this subsection is to derive algorithms of the three classifiers, BR, KBR1, and KBR2, which respectively calculate the posterior probability for each class given an observation
, that is,
.
4.1.1. The algorithm of BR
In BR, we estimate the posterior probability of j-th class given a test value
by
where is the density function of the d-dimensional normal distribution
defined by
The mean vector and the covariance matrix
are calculated from the training data of the class
.
4.1.2. The algorithm of KBR1
Let us define positive definite kernels and
as
for and
, and the corresponding RKHS as
and
, respectively. Here we set
for
. Then, the prior kernel mean is given by
where . Let us put
,
,
,
,
,
,
,
, and
, where
is the identity matrix of size n and
are heuristically set regularization parameters. Note that
stands for the indicator function of a set A described as
Following Theorem 3, the posterior kernel mean given a test value is estimated by
Here, we estimate the posterior probabilities for classes given a test value by
4.1.3. The algorithm of KBR2
Let denote the Moore-Penrose generalized inverse matrix of
. Let us put
,
, and
. Replacing
in Section 4.1.2 for
, the posterior probabilities for classes given a test value
is estimated by
4.2. Probabilistic predictions by the three classifiers
Here, we apply the three classifiers defined in Section 4.1 to a binary classification problem using computer-simulated data-sets, where and
. In the first step, we independently generate 100 sets of training samples with each training sample being
, where
and
if
,
and
if
,
,
, and
. Here,
and
are sampled i.i.d. from
and
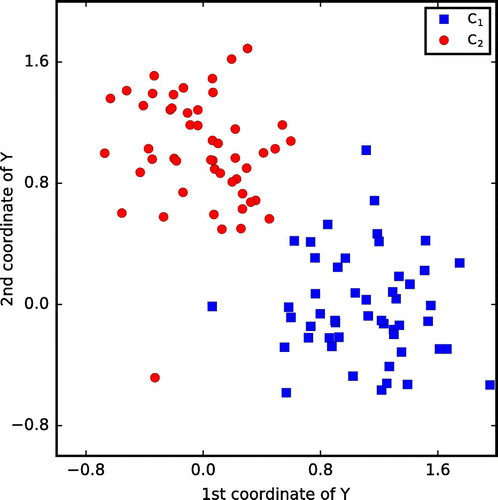
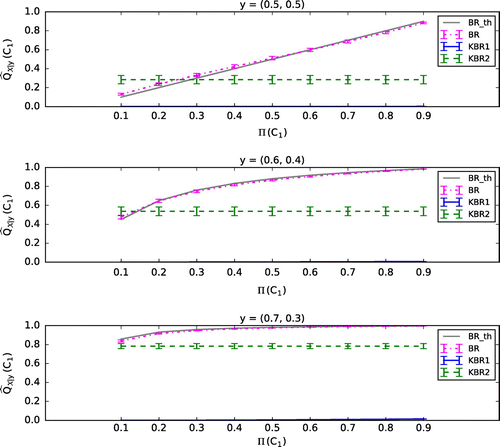
, respectively. Individual Y-values of one of the training samples are plotted in Figure .
Figure 1. Individual Y-values of a training sample.
With each of the 100 training samples and a simulated prior probability of , or
, the classifiers defined in Section 4.1 estimate the posterior probability of
given a test value
, that is,
. Figures – show the mean (plus or minus standard error of the mean, SEM) of the 100 values of
calculated by each of the classifiers, BR, KBR1, and KBR2. Here we show the case where
in KBR1 and KBR2 is fixed to 0.1, and the regularization parameters of KBR1 are set to be
(Figure ),
(Figure ),
(Figure ), and
(Figure ). In Figures –, BR_th represents the theoretical value of BR, which coincides with BR if the parameters
,
,
, and
are set to be
,
,
, and
, respectively.
Figure 2. The case .
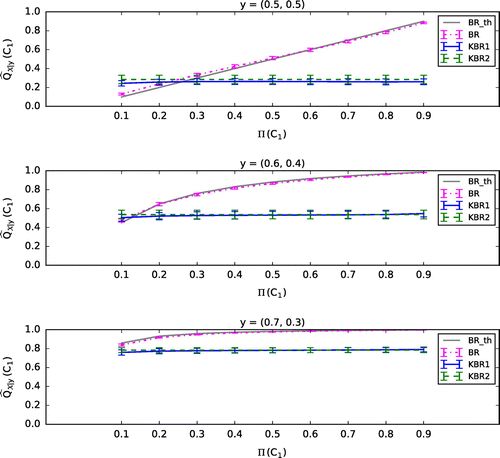
Consistent to Section 3.1, calculated by KBR1 is poorly influenced by
compared with that by BR when
and
are set to be small (see Figures and ). In addition,
calculated by KBR2 also seems to be uninfluenced by
. When
and
are set to be larger, the effect of
on
becomes apparent in KBR1, however, the value of
becomes too small (see Figures and ). These results suggest that in the kernel Bayes’ rule, the posterior does not depend on the prior if
and
are negligible, which might be a contradiction to the nature of Bayes’ theorem. Moreover, even though the prior affects the posterior when
and
become larger, the posterior seems too much dependent on
and
, which are initially defined just for the regularization of matrices.
We have also tested all possible combinations of the following values for the parameters in KBR1 and/or KBR2: ,
, and
. All the experimental results have been evaluated in a similar manner as above, and none of the results are found to be reasonable in the context of Bayesian inference (see Supplementary material).
Figure 3. The case .
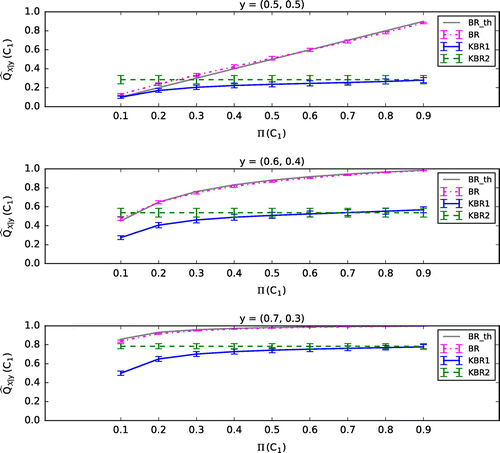
Figure 4. The case .
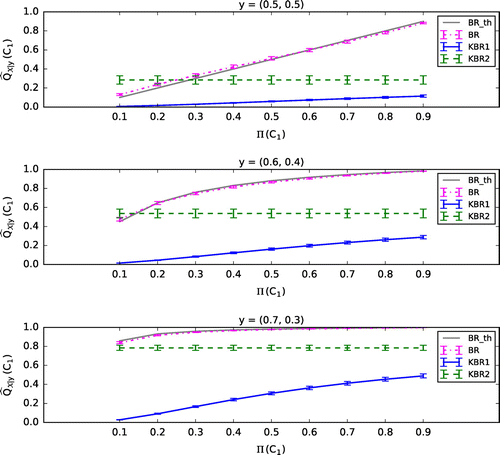
Figure 5. The case .
5. Conclusions
One of the important features of Bayesian inference is that it provides a reasonable way of updating the probability for a hypothesis as additional evidence is acquired. The kernel Bayes’ rule has been expected to enable Bayesian inference in RKHS. In other words, the posterior kernel mean has been considered to be reasonably estimated by the kernel Bayes’ rule, given kernel mean expressions of the prior and likelihood. What is “reasonable" depends on circumstances, however, some of the results in this paper seem to show obviously unreasonable aspects of the kernel Bayes’ rule, at least in the context of Bayesian inference.
First, as shown in Section 3.1, when and
are non-singular matrices and so we set
, the posterior kernel mean
is entirely unaffected by the prior distribution
on
. This means that, in Bayesian inference with the kernel Bayes’ rule, prior beliefs are in some cases completely neglected in calculating the kernel mean of the posterior distribution. Numerical evidence is also presented in Section 4.2. When the regularization parameters
and
are set to be small, the posterior probability calculated by the kernel Bayes’ rule (KBR1) is almost unaffected by the prior probability in comparison with that by conventional Bayes’ rule (BR). Consistently, when the regularized inverse matrices in KBR1 are replaced for the Moore-Penrose generalized inverse matrices (KBR2), the posterior probability is also uninfluenced by the prior probability, which seems to be unsuitable in the context of Bayesian updating of a probability distribution.
Second, as discussed in Sections 3.2 and 4.2, the posterior estimated by the kernel Bayes’ rule considerably depends upon the regularization parameters and
, which are originally introduced just for the regularization of matrices. A cross-validation approach is proposed in Fukumizu et al. (Citation2013) to search for the optimal values of the parameters. However, theoretical foundations seem to be insufficient for the correct tuning of the parameters. Furthermore, in our experimental settings, we are not able to obtain a reasonable result using any combination of the parameter values, suggesting the possibility that there are no appropriate values for the parameters in general. Thus, we consider it difficult to solve the problem that
and
are not surjective by just adding regularization parameters.
Third, as shown in Section 3.3, the assumption that conditional expectation functions are included in the RKHS does not hold in general. Since this assumption is necessary for most of the theorems in Fukumizu et al. (Citation2013), we believe that the assumption itself may need to be reconsidered.
In summary, even though current research efforts are focused on the application of the kernel Bayes’ rule (Fukumizu et al., Citation2013; Kanagawa et al., Citation2014), it might be necessary to reexamine its basic framework of combining new evidence with prior beliefs.
6. Proofs
In this section, we provide some proofs for Sections 2 and 3.
6.1. Estimation of and
Here we give the proof of Proposition 1.
Proof
Let ,
, and
denote the estimates of
,
, and
, respectively. We define the estimates of
and
as
and put . According to Equation (5), for any
and
,
where represents the empirical expectation operator. Thus, from Remark 1,
(8)
(8)
Similarly, for any ,
Thus, from Remark 1,(9)
(9)
Next, we will derive . Since
is a self-adjoint operator,
for any . On the other hand, from Equation (1),
for any . Hence, we have
(10)
(10)
for any . Replacing f in Equation (10) for
, we have
(11)
(11)
Using Equation (6), the left hand side of Equation (11) is given by
Therefore, we have
Replacing for
, Equations (8) and (9) become
respectively.
6.2. Non-singularity of and
Here we show that the assumption in Section 3.1 holds under reasonable conditions.
Definition 9
Let f be a real-valued function defined on a non-empty open domain . We say that f is analytic if f can be described by a Taylor expansion on a neighborhood of each point of
.
Proposition 2
Let k be a positive definite kernel on . Let
be a probability measure on
which is absolutely continuous with respect to Lebesgue measure. Assume that k is an analytic function on
and that the RKHS corresponding to k is infinite dimensional. Then for any i.i.d. random variables
with the same distribution
, the Gram matrix
is non-singular almost surely with respect to
.
Proof
Let us put . Since the RKHS corresponding to k is infinite dimensional, there are
such that
are linearly independent. Then
and hence f is a non-zero analytic function. Note that any non-trivial subvarieties of the euclidean spaces defined by analytic functions have Lebesgue measure zero. By this fact, the subvariety
has Lebesgue measure zero. Since is absolutely continuous,
. This completes the proof.
From Proposition 2, we easily obtain the following corollary.
Corollary 1
Let k be a Gaussian kernel on and let
be i.i.d. random variables with the same normal distribution on
. Then the Gram matrix
is non-singular almost surely.
Proposition 3
Let k be a positive definite kernel on ,
a probability measure on
which is absolutely continuous with respect to Lebesgue measure. Assume that k is an analytic function on
and that the RKHS
corresponding to k is infinite dimensional. Then for any
except Lebesgue measure zero, and for any i.i.d. random variables
with the same distribution
, each
for
is (defined almost surely and) non-zero almost surely, where
,
, and
. Here
denotes the set of positive real numbers.
Proof
Let us put ,
, and
for and
. Since the RKHS corresponding to k is infinite- dimensional, we can obtain
such that
are linearly independent. The Gram matrix
is positive definite, and its eigenvalues are all positive. Hence
for each
, and
is a non-zero analytic function on
for each
.
For , let us define a closed measure-zero set
. Then
is defined on
for each
. Using Cramer’s rule,
where stands for the m-th column vector of
. Here we denote by
the numerator of
, that is,
.
It is easy to see that is a non-zero analytic function of
on
. Indeed, if
,
,
, and
, then
. Hence
is a closed subset of
with Lebesgue measure zero for each
. For any
,
is a closed subset of with Lebesgue measure zero for each
, since
is a non-zero analytic function of
on
. Therefore,
is defined and non-zero for
and for
if
. This completes the proof.
The following corollary directly follows from Proposition 3.
Corollary 2
Let k be a Gaussian kernel on and let
be i.i.d. random variables with the same normal distribution on
. All other notations are as in Proposition 3. Then
is non-singular almost surely for any
except for those in a set of Lebesgue measure zero.
6.3. Non-surjectivity of and
The covariance operators and
are not surjective in general. This can be verified by the fact that they are compact operators. (If the operators are surjective on the corresponding RKHS which is infinite-dimensional, then they cannot be compact because of the open mapping theorem.) Here we present some easy examples where
and
are not surjective. Let us consider for simplicity the case
. Let X be a random variable on
with a normal distribution
. We prove that
is not surjective under the usual assumption that the positive definite kernel on
is Gaussian. In order to demonstrate this, we use the symbols defined in Section 3.3 and several proven results on function spaces and Fourier transforms (see Rudin, Citation1987, for example). Note that the following three propositions are introduced without proofs.
Proposition 4
Let us put for
, where
. Then
Proposition 5
For ,
almost everywhere. In particular, if
, then
almost everywhere.
Proposition 6
For , put
. Then
.
Definition 10
Let denote the density function of the normal distribution
on
, that is,
Let X be a random variable on with
. The linear operator
is defined by
for any
, which is also described as
for any .
Proposition 7
If , then
Proof
From Proposition 5, and
for any
. Then, using Equation (7), we have
Therefore, .
Proposition 8
If , then
.
Proof
From Proposition 5, for
. Then, using Equation (7), we have
Therefore, .
Here, we denote by and
the real part and the imaginary part of a complex number, respectively. We also denote by
the closure of a subset A in a topological space.
Corollary 3
If , then
.
Proof
If , then
by Proposition 8. Hence we see that
This completes the proof.
Remark 3
If , then there uniquely exist
such that
by Corollary 3. This means that
, where
denotes the direct sum.
Proposition 9
For any and for any
, there exists
such that
. In other words,
is dense in
.
Proof
Let denote the space of continuous complex-valued functions with compact support on
. Let us define
by
Note that coincides with the image of
by the Fourier transform. Then,
and
. Hence
. In other words, for any
and for any
, there exists
such that
because
, which implies that there exists
such that
. This completes the proof.
The following corollary has also been shown in Theorem 4.63 in Steinwart and Christmann (Citation2008).
Corollary 4
.
Proof
From Proposition 9, for any and for any
, there exists
such that
. By Remark 3, there exist
such that
. Thus,
Therefore, . This completes the proof.
Definition 11
Let us define as
where and
denote the indicator functions of the intervals
and
, respectively. We also put
and
. Note that
, because
Proposition 10
.
Proof
It is obvious that . Since
, we see that
where . Hence,
. On the other hand,
Therefore .
Let us define for
. Now, we prove that
for any
. This implies that
is not surjective.
Proposition 11
For any ,
.
Proof
Suppose that there exists such that
. Then, for any
,
(12)
(12)
Let us put . From Proposition 4,
. Then, using Equation (7) and Proposition 6, the left hand side of Equation (12) equals
The right hand side of Equation (12) is equal to
Thus, Equation (12) is equivalent to the following equation:(13)
(13)
Let us define and
. Then
. It is easy to see that
as
. Hence
in
. Since
by Proposition 6, we have
which indicates that . Substituting
for f, Equation (13) becomes
(14)
(14)
If n goes to infinity, the left hand side of Equation (14) becomes . On the other hand, the right hand side of Equation (14) becomes
This is a contradiction. Therefore, there exists no such that
. This completes the proof.
7. Supplementary material
Supplementary material for this article can be accessed here http://dx.doi.org/10.1080/23311835.2018.1447220.
Suppl.pdf
Download ()Additional information
Funding
Notes on contributors
Hisashi Johno
Hisashi Johno is a PhD student at the Department of Mathematical Sciences, Faculty of Medicine, University of Yamanashi, Japan. His current research interests include probability theory and interpretable machine learning.
Kazunori Nakamoto
Kazunori Nakamoto is a professor of mathematics at Center for Medical Education and Sciences, Faculty of Medicine, University of Yamanashi, Japan. His main research interests include algebraic geometry, invariant theory, and the moduli of representations.
Tatsuhiko Saigo
Tatsuhiko Saigo is an associate professor of probability and statistics at Center for Medical Education and Sciences, Faculty of Medicine, University of Yamanashi, Japan. His research fields include probability theory, statistics, and applied mathematics.
Related Research Data
References
- Fukumizu, K. (2014). Introduction to kernel methods (in Japanese). Tokyo: Asakura Shoten.
- Fukumizu, K., Song, L., & Gretton, A. (2013). Kernel bayes’ rule: Bayesian inference with positive definite kernels. Journal of Machine Learning Research, 14, 3753–3783.
- Horn, R. A. , & Johnson, C. R. (2013). Matrix analysis (2nd ed.). Cambridge: Cambridge University Press.
- Kanagawa, M., Nishiyama, Y., Gretton, A. , & Fukumizu, K. (2014). Monte carlo filtering using kernel embedding of distributions. Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence (p. 1897-1903).
- Rudin, W. (1987). Real and complex analysis (3rd ed.). New York, NY: McGraw-Hill Book Co..
- Song, L., Fukumizu, K., & Gretton, A. (2014). Kernel embeddings of conditional distributions. IEEE Signal Processing Magazine, 30, 98–111.
- Song, L., Huang, J., Smola, A. , & Fukumizu, K. (2009). Hilbert space embeddings of conditional distributions with applications to dynamical systems. In Proceedings of the 26th Annual International Conference on Machine Learning (p. 961-968).
- Steinwart, I. , & Christmann, A. (2008). Support vector machines. New York, NY: Springer.