
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Teaching quality is the lifeline of the higher education. Many universities have made some effective achievement about evaluating the teaching quality. In this paper, we establish the Students’ evaluation of teaching (SET) discriminant analysis model and algorithm based on principal component clustering analysis. Additionally, we classify the SET by clustering the result of extracting the indexes through the principal component analysis (PCA), then we also test the rationality of the rating using Fisher’s discriminant function. Finally, the model and algorithm are proved to be effective and objective according to the empirical analysis.
Public Interest Statement
The quality of teaching, which affected honor of major colleges and universities in all over the world, was a significant ingredient in personnel training term. This perspective article describes the way of evaluating the teaching quality, based on data gathered via analyzing index system related with the teaching quality, which was used to illustrate impacts of the teaching. It was found that the way is not only the primary part of the teaching quality evaluation, but also a suitable solution to evaluate. Clearly, teaching and studying are the key factor to decide the teaching quality, and the course is the important link of teaching and studying. Evaluating these effects can improve education in colleges. Exploration of the quality of teaching issues can also help universities to enhance their competitiveness and the teaching level.
1. Introduction
The teaching quality is the general trend of higher education nowadays. Correspondingly, how to improve the teaching quality in colleges or universities, is being regarded as an innovation of the instruction system. On the one hand, the college which try to structure the reasonable culture knowledge and skill system is helpful for cultivating the undergraduate with the ability of innovation; on the other hand, the students studying the relevant course could learn much knowledge to satisfy the requirements of personal development. So, the course teaching which is the core link in the higher education teaching can directly affect the accomplishment of the personnel training and teaching goal.
The course teaching quality evaluation is the vane of the teaching quality evaluation in college. Many colleges generally regard the teaching evaluation as a way to improve the teaching quality. The teaching quality evaluation, first coming into being in Harvard University in 1920s and blooming in the later period in the popularization of the higher education (Li, Citation2012), has its main principal: the school serve the students and the goal of it is to realize the personal expectation. Importantly, evaluating the teaching must mainly consider whether the teaching can satisfy the students’ demand, so the students are suitable to make evaluation. From 1960s, the teaching evaluation is in a wide use in college, middle school, and primary school in many developed countries(Chen, Citation2001; Fernandez & Mateo, Citation1992). It has become a unique feature in education evaluation and improved the teaching quality effectively (Fernandez & Mateo, Citation1992; Luo, Citation2013; Zhou, Zhang, & Chen, Citation2013).
In late 1980s, SET began to be introduced in China and applied in some colleges. With the start of the quality project of the higher education, the domestic colleges pay more attention to the monitoring system of teaching quality evaluation by using the SET. And there are five kinds of SET, which are as follows. The first one is the students’ teaching evaluation group system represented by Nanjing University; the second is the student messenger system represented by Wuhan University. In addition, the student questionnaire partly checked system represented by Tsinghua University and the all students evaluating the teaching system represented by North China Electric Power University are also part of SET; the last is the student teaching messenger and total students directly evaluating mixed system represented by Chongqing University of Posts and Telecommunications. Additionally, many scholars have studied the SET both qualitatively and quantitatively. For example, Chen and Zhao (Citation2004) propose to study the SET from four aspects relevant to teaching, namely teaching method, content of courses, teaching idea, and teaching style. Chen and Zhou (Citation2008) referenced the existent SET system and using the fuzzy hierarchy analysis to compound the total hierarchy weight, get the weight of each hierarchy of general objective, and put forward the SET model. Because of the SET information’s limited, incomplete, and characterized by random uncertainty, Xu (Citation2006)using the grey system theory (Deng, Citation1982,Citation1989) and defining the whitenization weight function of the index, gets the SET grey clustering model and rates different courses.
Nowadays, SET is concerned with two questions: one is whether the system of SET is measurable or scientific; the other is that the index system often has the multicollinearity which few models and algorithm can overcome. Si (Citation2006) use the PCA to transfer the multi-index problem to fewer indexes problem. Though it can overcome the multicollinearity of the indexes to some extent, new indexes using PCA directly for evaluating it will cause some situation inconsistent with the real condition. In order to solve this problem, in this paper, PCA and clustering algorithm are employed to establish the SET model based on principal component and clustering, then used Fisher’s discriminate function to test the reliability of the evaluation. Consequently, given/based on the scientific criterion for college instruction, the SET system may better display its function in instruction management and quality evaluation.
2. Measurement to the SET and its index system
A scientific SET index system should investigate the teaching quality from multiple perspectives. In order to evaluate the teaching quality accurately and effectively, both of the evaluation system and method are importance. SET is affected by many factors. It not only involves teaching attitude, teaching content, teaching method and the teachers’ personal qualities, but also including the studying attitude of the students, school spirit, teaching conditions, social morality, and some relevant policy. It will also be related with the variety of many other factors. In order to fit the evaluation demand in different periods for people, it is very important to set the evaluation index scientifically. After having referenced many SET index systems, according to the principal of scientific, orientation, and operability, we establish the evaluation index system (see Table ) based on the data of course standards, teachers’ performance, and students’ experience. We also give some explanation for them as follows. The course standards are instructional documents of teaching in defining the course quality, course goal, content goal, and implementing recommendations of a specific course. In these parts of the basic conception, course goal and implementing recommendations, it elaborates in detail, especially making some requirements about the basic study for all students. At the same time, defining the course standards and grasping the teaching rules are helpful for improving the teaching quality (Yiannis & Sotierios, Citation2014). Teaching is a science, also an art.
Table 1. The index system of SET
Using various kinds of teaching methods flexibly, finishing the teaching task students’ and getting good teaching results are the basic skills of a teacher. The teachers’ teaching performance not only affects the teaching quality, but also has an impact on the students’ learning interests deeply. Such good classroom performance is necessary for a good teacher. Student is the object of the teaching work service, and the students’ experience during study is the fundamental basis in evaluating a course. So keeping the students’ interest can make the evaluation results better, and it can also improve the teaching quality.
3. SET discriminate model based on PCA and clustering
Composing the PCA correlation matrix through the teaching quality index variables, we calculate the score of each PC according to the linear combination of the principal component decided by the PCA. Then we cluster the PC score of each course and establish the discriminate function based on principal component score (Julian & Mauro, Citation2014). Using the discriminate function classifies the course and verify the results (Ye & Wei, Citation2009; Zhang, Citation2007; Chen & Hou, Citation2007; Ding & He, Citation2004).
3.1. Architecture of PCA
Principal components analysis(PCA)(Yeung & Ruzzo, Citation2001) is a well-known technique for extracting the main tendencies of data on reduced dimension space, which is projected space from original high-dimensional data space.
Suppose we are given a set of n samples and its p index variables. We can transfer the original variables to the factor variables which are the linear combination of the original variables. That is to say,
are synthesized to
variables
, and these m uncorrelated variables are called the principal component
, respectively. The expression is as follow:
(1)
(1)
In the analysis of the practical problems, we often choose the biggest principal components to decrease the number of the variables, grasp the main contradiction and simplify the relationships between variables. Choosing the principal component is to confirm the load of the original variable
in each principal component.
According to the theory of principal components analysis, the steps of principal components analysis are follow:
Firstly, to calculate the index mean value and standard deviation of each sample, then calculate the correlation coefficient matrix R.
where ,
,
,
,
.
Secondly, extract the principal component of the R. Namely calculate eigenvalue and eigenvector
of the correlation coefficient matrix R. And rank the eigenvalue in order. Then we calculate the contribution rate and the cumulative contribution rate as follow.
(2)
(2)
We choose the number of principal component when .
At last, calculate the load of each variable in principal component and get the expression as (1).(3)
(3)
3.2. Clustering analysis
Clustering is the method to study the mutual relationship between data logically and physically, and its analysis results can not only reveal the intrinsic relations and differences between data, but also provide the important foundation for the further data analysis and knowledge discovery. The essence of clustering analysis is to classify the data into several clusters according to the distance until the difference between the data in the same cluster is as tiny as possible and the difference between the data in the different clusters is as big as possible. The key of clustering is to cluster the similar things into the same cluster. According to the Euclidean distance of two sets during clustering, the modeling is as follows.(4)
(4)
Where is the index i in sample k , n is the number of sample.
is the distance between sample i and sample j. We combine the clusters of the minimum distance until the number of cluster can meet the requirement.
According to the theory of cluster analysis, the steps of hierarchical clustering algorithm are as follows:
Step 1. Initially classify. Let , and each mode is a cluster, namely
.
Step 2. Calculate the distance between each cluster, and get a symmetrical distance matrix , where m is the number of cluster.
Step 3. Find the minimum elements in Step 2, and let it be the distance between and
. Then we combine the cluster
and
to one cluster, and we can get the new cluster
.
Step 4. Check the result of cluster whether satisfy the objection, if not, then return to Step 2.
3.3. Fisher’s discriminate analysis
Discriminate analysis (Sun & Li, Citation2014) can judge which cluster the new sample belongs to when studying the classification in accordance. Its basic principal is to determine the undetermined coefficient of the discriminate function through analyzing the mass data of the objects and calculating the recognition indexes. When the mean vector of population is high in multicollinearity, the Fisher’s discriminate method is simple, and we can judge through a few discriminate functions. It also doesn’t have any special requests about the distribution of the population, so it has a wide use.
Suppose there are k populations , and we extract
samples. Let
, and
is the observation vector of sample
in population i . We suppose the discriminate function is
, where
is the mean value of sample in
and sample variance is
, where
is the sample mean vector and sample covariance matrix, respectively. In order to make coefficient vector C to be the biggest, we need to let
be the biggest, where
is the positive weighting coefficient set by ourselves, and it is usually chosen as the prior probability. Let
, and substitute
to get:
,where
is the dispersion matrix of group, and A is the sample covariance matrix between populations. After these calculating, we can get the model :
. Let
, we can get
and C is the generalized eigenvalue and the corresponding eigenvector of A, E . Let
to express all the non zero eigenvalue, and
is the corresponding eigenvector. Then we can structure m discrimination functions:
(5)
(5)
and we can get belong to the cluster i, if
.
According to the theory of discriminate analysis, the calculating steps of discriminate analysis are as follow:
Step 1.Use the selected training sample to calculate the cluster mean value and the mean difference
. Calculate the coefficient matrix by
. Then we can get the discrimination function through:
(6)
(6)
Step 2. Use the data of the training sample to substitute into the discrimination function, calculate the center of gravity of each cluster. According to , we can calculate the critical point of discriminate
, and then we can judge through the discriminate criterion.
Step 3. Check the result of discrimination whether satisfy the objection, then calculate the misjudgment rate and discriminant accuracy; if not, then return to Step 1.
3.4. A new discriminate model based on principal component clustering and its algorithm
3.4.1. Discriminate model based on principal component and clustering for teaching quality grading
According to the SET index system combined with PCA model, clustering model and discriminate analysis model, we can establish the discriminate model based on principal component clustering (DPCC) for teaching quality grading shown as follow.(7)
(7)
where ( k is the number of the principal component),
.
3.4.2. An algorithm of the DPCC
Based on the above analysis and model (7), an algorithm of the New Discriminate Model based on Principal Component Clustering (DPCC) was developed as follow.
Procedure DPCC:
Input: A: data of the students’ evaluation of teaching(SET).
Output: D: an update classification model and result
1. Initialization phase.
2. While not end of the SET do
2.1 Once a new labeled data SET in, store its elements and class information, increase the size of the class by one which the new data belongs to.
2.2 According to formula 2, we can get the cumulative contribution rate, and we choose the principal component by the rate over 0.90. We can get the score of principal component factor through the load of each index in the principal component, and the principal component expression as formula 1.
2.3 According to the score of principal component factor of each course solved by formula (1), we can cluster them by agglomerative hierarchy clustering method through formula (7a). According to the mean principal component score in each cluster, we can rate each cluster by the size of the score, from high to low. The rating result is also the same.
2.4 According to the results by formula (1) and formula (7a),we can use formula (7b) to get the discriminate function of each cluster, and substitute the data of training sample back into discriminate functions and calculate the center of gravity of each cluster. And we can judge them by discriminate criterion.
3. Endwhile
4. Return D.
3.5. Case study
The authors have recently observed the SET of the Chongqing University of Post and Telecommunications (CQUPT), which has 13 major departments, 47 undergraduate programs, 38 postgraduate programs, and 2 PhD programs. CQUPT, founded in 1950, is one of the few universities that has been blue-printed and given priority to develop by the State. It has also grown into a prominent university and is acknowledged by its excellence in the field of information industry both within and outside China. The university has built many well-established relationships with over 50 universities from other countries such as USA, Canada, UK, Germany, and Korea, etc.
Firstly, we set the questionnaire and obtain the data from all students in fall semester in 2012. Then, we normalize the data every variable, and get the correlation matrix, choose the principal component by formula 2. At last, we compute the value of evaluation of every course use the DPCC by the algorithm of the DPCC, and analyze the synthetical score situation with SPSS and get the eigenvalue of the correlation matrix shown as Table and factor score matrix shown as Table .
Table 2. Eigenvalue of the correlation matrix
Table 3. Factor score matrix
According to Table , we can get(8)
(8)
The score of each course is shown in Table solved by the corresponding PC.
Table 4. Score of the course
Table is the score of PC solved by each PC factor matrix. Now, we can cluster the score of PC of each course, and the clustering dendrograms are shown as Figures and .
Figure 1. The clustering dendrogram based on 1 PC.
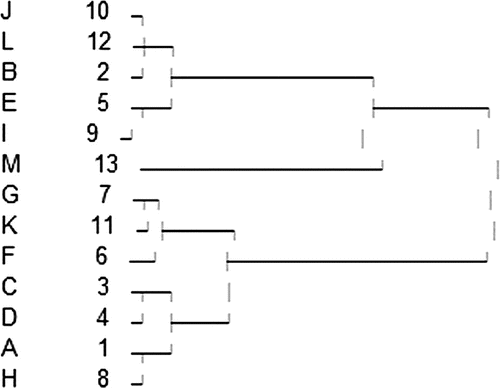
Figure 2. The clustering dendrogram based on original dat.
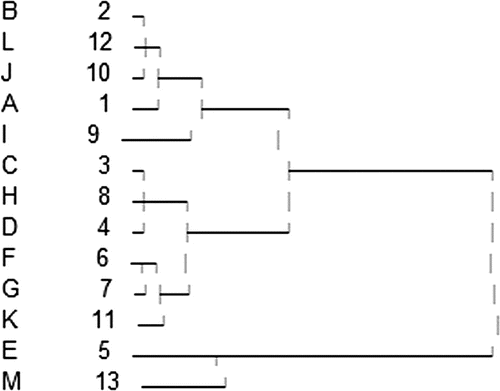
According to the 2 dendrograms, we can find choosing 1PC or 3 PCs, the results have no difference when we classify these courses into 3 clusters. So, only one PC has reflected the information of the original variables basically. Then we can classify the courses according to the clustering results. On the basis of the dendrogram, we can classify A, C, D, F, G, H, K into a cluster,B, E, I, J, L into a cluster, and M is a cluster.
We can calculate the mean value of each samples score in each cluster, and rank the 3 clusters. According to the score high to low, we rate them “good,” “medium,” and “bad,” expressing by “1, 2, 3,” respectively. The clustering result is shown as Table , and we can see there are six in first cluster, six in the second cluster, and one in the third cluster.
Table 5. The classification results after the clustering analysis
According to the score of PC factors of each course and the clustering results in Table , we can discriminate the 13 courses and determine the reliability of each clustering analysis result. The coefficient of the Fisher’s discriminate function is shown in Table .
Table 6. The coefficient of the Fisher’s discriminate function
Table 7. The classification result after the Fisher’s discriminate analysis
So, the Fisher’s discriminate function of the first cluster is the second cluster is
and the third cluster is
. According to the model established before, we can substitute the PC score of each course into the three Fisher’s discriminate functions. we judge the cluster of the sample by the discriminate criterion. If
, we can get
belong to the cluster i. The discriminate results can be seen in Table , and there are six in the first cluster, six in the second cluster, and one in the third cluster. In Table , the data in the diagonal is the number of the course classified correctly and there are 12 courses are classified correctly. Compared with the clustering results, we can find 0.923 of the classification and rating in clustering analysis result is correct, and, that is to say, the clustering analysis and the discriminate function analysis have comparatively good agreement.
4. Conclusions
Being the primary part of the teaching quality evaluation, SET is a complex problem including multilayer and multi-index. In this paper, according to the new SET index system, we establish discriminate model based on the PCA and clustering. Firstly, PCA is used to simplify the complex data of the instruction quality and reduce the quantities of synthetic indexes to substitute the more primitive variables. Then, we rate the courses rationally through clustering analysis. Lastly, we structure the Fisher’s discriminate function evaluation model. The model has not only overcome the multicollinearity phenomena in the index system, but also tested the result by comparing the clustering analysis with discriminate analysis. It renders the SET model more objective and pave the way for students teaching quality evaluation.
In the future, we are willing to continue studying on the extension of the case. Such as the more possibility of robust can be obtained with using the different method. We can also apply the DPCC to other universities.
Acknowledgements
The authors express their gratitude to the editor and the anonymous reviewers for their valuable and constructive comments.
Additional information
Funding
Notes on contributors
Sidong Xian
Sidong Xian is currently a professor with the school of Science, Chongqing University of Posts and Telecommunications, Chongqing, China. He is presiding over the Graduate Teaching Reform Research Program of Chongqing Municipal Education Commission (No. YJG143010) and the Teaching Reform Research Program of Chongqing University of Posts and Telecommunications(No. XJG201328). And he directed his students Haibo Xia, Yubo Yin, Zhansheng Zhai and Yan Shang to study the problem of teaching evaluation in the project. Yubo Yin and Zhansheng Zhai have participated in data collection and processing, Haibo Xia and Yan Shang have analyzed and modeled the data.
References
- Chen, Q. Y. (2001). Evaluation of classroom teaching of information technology in primary and middle schools. China Educational Technology, 3, 28–30.
- Chen, Q. B., & Hou, X. L. (2007). Clustering and principal component analysis of germplasm resources of onion. Jiangsu Journal of Agricultural Sciences, 23, 376–378.
- Chen, F. H., & Zhao, X. Y. (2004). The teaching evaluation in college internal. Modern Information, 2, 12–15.
- Chen, Y. H., & Zhou, S. M. (2008). The application of fuzzy analytical hierarchy process in the college teaching evaluation. Pioneering with Science & Technology Monthly, 8, 115–116.
- Deng, J. L. (1982). Control problems of grey system. Systems & Control Letters, 1, 288–294.
- Deng, J. L. (1989). Introduction to grey system theory. The Journal of Grey System, 1, 1–24.
- Ding, C., & He, X. (2004). K-means clustering via principal component analysis. In Proceedings of the 21st International Conference on Machine Learning (pp. 225–232). Banff.
- Fernandez, J., & Mateo, M. A. (1992). Student evaluation of university teaching quality: Analysis of a questionnaire for a sample of university students in Spain. Educational & Psychological Measurement, 52, 675–686.
- Julian, E. W., & Mauro, Z. (2014). Main difference between volatiles of sparkling and base wines accessed through comprehensive two dimensional gas chromatography with time-of-flight mass spectrometric detection and chemometric tools. Food Chemistry, 164, 427–437.
- Luo, M. (2013). Application of AHP-DEA-FCE model in college English teaching quality evaluation. International Journal of Applied Mathematics & Statistics, 51, 101–108.
- Li, X. F. (2012). The ideal and reality of students’ evaluation: The study based on the fourth generation evaluation theory[D]. Beijing: Beijing Normal University.
- Si, F. J. (2006). The application of principal component analysis in teaching evaluation. Intelligence, 26, 78–79.
- Sun, Z., & Li, J. (2014). Kernel inverse fisher discriminate analysis for face recognition. Neurocomputing, 134, 46–52.
- Xu, Q. (2006). The grey cluster model of classroom teaching evaluation. Journal of Jilin Normal University, 5, 51–53.
- Ye, X. F., & Wei, Y. W. (2009). Model of the quality evaluation of flue-cured tobacco based on principal component analysis and cluster analysis. System Science and Comprehensive Studied in Agriculture, 25, 268–270.
- Yeung, K. Y., & MRuzzo, W. L. (2001). Principal component analysis for clustering gene expression data. Bioinformatics, 17, 763–774.
- Yiannis, N., & Sotierios, G. D. (2014). On the student evaluation of university course and faculty member’s teaching performance. European Journal of Operational Reaserch, 238, 199–207.
- Zhang, H. (2007). The case teaching method of the principal component and clustering analysis. Statistics and Decision, 20, 163–164.
- Zhou, L., Zhang, N., & Chen, Q. (2013). Principal component model for comparative evaluation of e-Learning system: An empirical investigation. International Journal of Applied Mathematics & Statistics, 42, 330–336.