
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Early stage breast cancer detection can reduce death rates in long term. Mammography is the current standard screening tool available for breast cancer detection, but it is found to have high false-positive and false-negative rates. This may be due to poor quality of mammograms, subtle nature of malignancies and limitations in human/brain visual system. The aim of this research work is to develop an efficient classification tool with improved breast screening accuracy to distinguish between healthy, benign and malignant breast parenchyma in digital mammograms. This paper presents a computer aided diagnosis system for automated detection and diagnosis of breast cancer in digital mammograms. The proposed system can be used as a reference reader for double reading the mammograms and thus assisting the radiologists in clinical diagnosis by indicating suspicious abnormalities. This can improve the diagnostic performance of the radiologists. In the proposed methodology, the regions of interest (ROI) are automatically detected and segmented from mammograms using global thresholding, Otsu’s method and morphological operations. Shape, texture and grey-level features are extracted from the ROIs. Optimal features are selected using Classifier and Regression Tree (CART). Classification is performed with Feed forward artificial neural networks using back propagation. Performance is evaluated using Receiver Operating Characteristic (ROC) analysis and confusion matrix. Experimental results show that the proposed method achieved an accuracy of 96% with 83% sensitivity and 98% specificity. The proposed methodology has been compared with several other classification models and is found to have a good performance in terms of accuracy, sensitivity and specificity.
Public Interest Statement
Space occupying lesions are important signs of breast cancer in mammograms. As there is only a small difference in the X-ray attenuation between the lesions and the normal tissues in mammograms, it is not easy to detect abnormalities using naked eye and thus some of the malignancies may be overlooked. Other factors that affect mammogram interpretation include the poor quality of the mammograms and lack of experience of the radiologists in the field. The aim of the research is to develop a Computer Aided Diagnosis (CAD) system for automated detection and diagnosis of breast cancer in digital mammograms. This system can be used as a reference reader for double reading the mammograms and thus can assist the radiologists in clinical diagnosis by indicating suspicious abnormalities. The decision of the CAD system when combined with the expert’s knowledge can greatly improve the diagnostic performance of the radiologists.
1. Introduction
Breast cancer is the most common cancer affecting women across the world. It is the second most common cancer in the world and there is a steady increase in breast cancer cases among young women (Siegel, Naishadham, & Jeimal, Citation2013). Statistics reveal that India has the largest breast cancer mortality in the world (Statistics of Breast Cancer in India, Citation2013).
Several screening modalities for breast cancer are available like mammography, PET, MRI, Ultrasonography etc. of which mammography is considered to be the most reliable and economical (World Cancer Research Fund International, Citation2013–2014). Space occupying lesions are most common symptoms of breast cancer in mammograms (American Cancer Society, Citation2016). Lesions can be of three types-masses, architectural distortion and bilateral asymmetry of the breast (Homer, Citation2004). Masses can either be benign or malignant depending on their shape, margin and density properties. In terms of shape, masses that are round, oval and slightly lobular shaped are benign. An irregular, multi lobular mass may suggest malignancy. In terms of margin, masses with well-defined or circumscribed margins are considered benign. Masses with spiculated, indistinct or micro lobulated margins are highly suspicious of malignancy. In terms of density, a low density mass is probably benign where as a hard immobile mass is a sign of malignancy. Isodense masses with lobular shape and microlobulated margins are moderately suspicious (Mammographic Mass Characteristics, Citation2017). Second type of space occupying lesions, architectural distortion, is the tethering or indentation of breast tissue region with radiating spiculations. Architectural distortion belongs to the benign category if it is caused due to post-surgical scars or soft tissue damage. It is highly suspicious of malignancy if it is accompanied with palpable breast mass (Banik, Rangaraj, & Desautals, Citation2013). The third type of space occupying lesions in mammograms, bilateral asymmetry, reveals an area of high density in one of the breast as compared to the same area in the other. Breast cancer can present itself as an area of focal asymmetry or when in advanced stage can present itself as a new asymmetry (Rangayyan, Ferrari, & Frère, Citation2007). Hence, it requires detailed evaluation.
Mammography is found to be less effective for small lesions or tumors as it is difficult to detect them using naked eye and also for subjects less than 40 years of age with dense breasts (Wang, Citation2017). Some of the lesions in mammograms may go undetected or may be diagnosed incorrectly due to poor quality of mammograms, inexperience of the radiologists or due to the limitation in human/brain visual system (Sheba & Gladston Raj, Citation2016). To overcome the above limitations, computer aided detection and diagnosis systems are used by radiologists for breast cancer detection and diagnosis. Currently, the accuracy of CAD systems is not very high. Improving the accuracy of CAD system can lead to an improvement in detection accuracy and this can result in higher survival rate and treatment options.
The proposed system presents a methodology with improved accuracy for automatic classification of mammograms as normal, benign or malignant. Furthermore, it aids in detecting lesions in abnormal mammograms which may indicate the presence of malignancies.
The paper is organized as follows. Section 2 presents the recent work done in this field. Section 3 explains the proposed methodology. Section 4 discusses the experimental results and Section 5 concludes the paper.
2. Related work
Recent research has laid stress on the development of computer aided detection and diagnosis system for breast cancer.
Wang, Yu, Kang, Zhao, and Qu (Citation2014) in their paper proposed a method for breast tumor detection and classification based on ELM classifier. Here, modified wavelet transformation of the local modulus maxima algorithm is applied for segmentation. Five textural and five morphological features have been extracted from the ROIs for classification purpose. This method is found to have improved training speed and better classification accuracy than SVM. de Lima, da Silva-Filho, and Dos Santos (Citation2016) extracted Zirinke moments from the region of interests of the images. They combined them with texture and shape features. A classification accuracy of 94.11% was obtained. The proposed method however obtained high accuracy when classifying fatty glandular and fatty breasts. A novel weight optimized multi-layer perception (MLP) based classifier with genetic algorithm is proposed for classification of lesions in mammograms by authors Valarmathi and Robinson (Citation2016). Classification accuracy is claimed to have significantly improved by 10.53% as compared to traditional MLP neural networks. Gedik (Citation2015) presents a CAD system which makes use of new contourlet transform algorithm (SFLCT) and least square SVM classifier to classify mammogram images. They have obtained an accuracy of 98.467%. Sensitivity is not mentioned. Hu, Gao, and Li (Citation2011) developed a novel algorithm which utilizes a combination of adaptive global thresholding segmentation and adaptive local thresholding segmentation on multi resolution representation of original mammograms. The algorithm has a sensitivity of 91.3% with 0.71 false positives per image. Only texture features have been used. The detection results may have greatly improved if shape features and grey level intensity features had been included. Surinderan and Vadivel (Citation2012) made use of CART classifier for classifying mammogram masses. Only shape features have been used for classification. They obtained a classification accuracy of 93.62%. The ROIs have been manually extracted. Also shape features are good at classifying one type of lesions especially circumscribed lesions. A new approach for classification of mass is proposed by Minavathi and Dinesh (Citation2012) which make use of active contour method and measurement of the angle of curvature of each pixel at the boundary of the mass for segmentation of ROIs. This method obtains 92.7% sensitivity with 0.88 area under the ROC curve. Talha (Citation2016) in his paper presented a fully computerized classification scheme to identify normal and abnormal mammograms using newly proposed GP filter. It obtained an accuracy of 96.97 with 98.39% sensitivity and 94.59% specificity. But, the scheme does not differentiate between benign and malignant mammograms. The authors Mehdy, Ng, Shair, Saleh, and Gomes (Citation2017) in their paper have discussed the usage of artificial neural networks in breast cancer detection. They have discussed different variations of neural network especially the recent trend of hybrid neural networks like SOM model and have concluded that neural networks when combined with other methods can achieve better accuracy, sensitivity and positive predictive value. Wang, Nishikawa, and Yang (Citation2017) developed a convolutional neural network (CNN) to which the input consisted of large image window for computerized detection of clustered microcalcifications. They conducted the experiment on digital and film mammograms and evaluated the detection performance using receiver characteristic analysis. CNN classifier achieved 0.971 in the area under the ROC curve. Abdel-Zaher and Eldeib (Citation2016) in their paper developed a CAD scheme for detection of breast cancer using deep belief network unsupervised path followed by back propagation supervised path. The technique was tested on Wincosin Breast cancer data-set and was found to have high success rate in breast cancer detection. Wang, Li, and Gao (Citation2014) developed a new classification scheme using LDA model with spatial pyramid extension incorporating spatial and marginal statistical characteristics. This classification scheme was found to be more robust compared to general feature based classification with accuracy of 92.74%
3. The proposed system
The proposed system involves the following phases- Image pre-processing, image segmentation, feature extraction, feature selection and classification. Normal mammograms do not contain lesions. But for the purpose of classification, they are also subjected to pre-processing, segmentation, feature extraction and feature selection prior to classification.
3.1. Image pre-processing
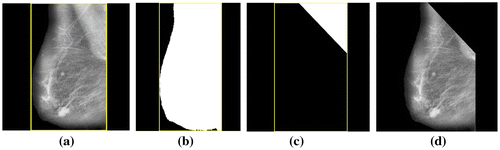
The aim of pre-processing in mammograms is to enhance the breast profile from the background and to remove artifacts, labels and noise that may appear in the mammograms. Also, unrelated parts like pectoral muscles appear in the mammograms. This also needs to be eliminated to help in correct interpretation of images (Sheba & Gladston Raj, Citation2016). In this work, pre- processing has been carried out in two stages. The first stage consists of noise filtering, artifact and label removal and image enhancement. Median filter (Huang & Zhu, Citation2012) has been used for noise filtering, global thresholding (Chaubey, Citation2016) for artifact and label removal and adaptive fuzzy logic based bi-histogram equalization (Sheba & Gladston Raj, Citation2017) for controlled enhancement. Adaptive fuzzy logic based bi-histogram equalization (Sheba & Gladston Raj, Citation2017) is an efficient algorithm proposed in our previous paper to improve the quality of the mammograms for better perception. The algorithm combines fuzzy logic with brightness preserving bi-histogram equalization (BBHE). The merit of the proposed method is that it is fully adaptive in nature where all the parameters are computed based on the characteristics of the mammographic images and this aids in providing controlled contrast enhancement. Algorithm 1 describes the process. Figure shows the results. The second stage consists of elimination of pectoral muscles. The pectoral muscles is nearly triangular in shape and appears in the upper left corner or the upper right corner of the breast contour depending on whether it is the left or right breast. In this work, the Bounding Box (Chang, Citation2006) has been used for the removal of pectoral muscles. Bounding Box of any image contains the coordinates of the rectangular border that fully contains the image. Bounding Box for the breast contour in the mammogram is calculated. The pectoral muscles is contained in the upper left or right corner in one third the width of the bounding box and hence an upper triangle is created with one third the width of the bounding box. All the pixels in the upper triangle are changed to binary zeros. This process has been used for the removal of pectoral muscles. Algorithm 2 describes the process and Figure shows the results. All the algorithms have been implemented using MATLAB 15.0.
Figure 1. (a) Mammogram image mdb005. (b) Image obtained after noise filtering (c) Binary masks obtained after global thresholding and (d) Final enhanced image with artefacts and labels removed.
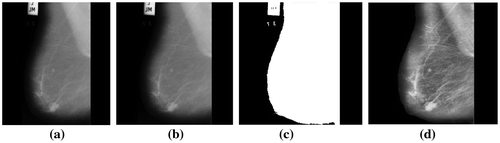
Figure 2. (a) Bounding box of the breast contour of the enhanced mammogram image mdb005 (b) The binary mask of the breast contour (c) Binary mask of the upper triangle of the bounding box and (d) Final image with pectoral muscles removed.
Algorithm 1
Aim: To enhance the mammogram image I and to remove noises, labels, artifacts.
Input: A two dimensional mammogram image I.
Output: An enhanced, noise free image with pectoral muscles removed.
Step 1: Read the mammogram I.
Step 2: Apply median filter to filter noises
I2 = medfilt2 (I)
Step 3: Scale up every pixel by constant
I3 = I2.*10.
Step 4: Apply global thresholding to the image. This finds a threshold value and generates a binary image with all pixel values below the threshold being converted to 0s and those above to binary ones.
mask = im2bw(I3, graythresh(I3)).
Step 5: Fill the tiny holes in the binary mask.
mask = imfill(mask,’holes’)
Step 6: Select the largest object with binary 1’s in the binary image. The largest object is the breast contour.
mask = bwpropfilt(mask,’area’,1).
Step 7: Apply mask to the filtered image // Image is logically ANDed with the largest object
masked = I2, masked (~mask)=0.
Step 8: Apply adaptive fuzzy logic based HE to enhance the final image.
preprocessed = adaptfuzzyhisteq(masked).
Step 9: Stop.
Algorithm 2
Aim: To eliminate pectoral muscles.
Input: An enhanced noise free two dimensional mammogram image I.
Output: An image with pectoral muscles removed.
Step 1: Find the size of the pre-processed image.
[r, c]=size (preprocessed) // r and c represents the number of rows and columns
Step 2: Get the Bounding Box of the breast contour of the pre-processed mammogram. It contains the coordinates of the rectangular border that encloses the breast contour.
Bbox (x, y, width, height).
Here, Bbox(1) = x- coordinate of the origin of the bounding box
Bbox(2) = y- coordinate of the origin of the bounding box
Bbox(3) = width of the Bbox
Bbox(4) = height of the Bbox
Step 3: Create a binary mask (mask2) of the region enclosed by the bounding box with each pixel within the breast contour being binary ones and the remaining binary zeros.
mask 2 = ones (r-Bbox(2), Bbox (3)) //r-Bbox(2) and Bbox(3) represents the // height and width of mask2
Step 4: Find the upper triangle of the mask located within one third of the width of the bounding box and assign binary zeros to the region in the mask other than the upper triangle
k = Bbox(3)/3 // k represents one third the width of the mask
mask2 = triu (mask2, k) // triu function calculates the upper triangle and // automatically assigns binary 0’s to the surrounding region of the triangle.
Step 5: Create two more binary masks (mask1 and mask3) which are of the same size as the regions to the left and right of the bounding box. As these regions are unwanted regions, not required for pectoral muscle elimination, all the pixels in these masks are changed to binary zeros.
mask 1 = zeros (r-Bbox (2), Bbox (1)) // r-Bbox(2) and Bbox(1) represents the // height and width of mask1.
mask 3 = zeros (r-Bbox (2), c-(Bbox (1) + Bbox(3))) // The parameters represent // height and width respectively of mask3
Step 6: Concatenate all masks
mask = [ mask1, mask2, mask3]
Step 7: Apply the mask to the preprocessed image such that the region in the image enclosed by the upper triangle of the bounding box becomes zero keeping the remaining portion of the image intact.
preprocessed (mask) = 0
Step 8: Stop.
3.2. Segmentation of lesions
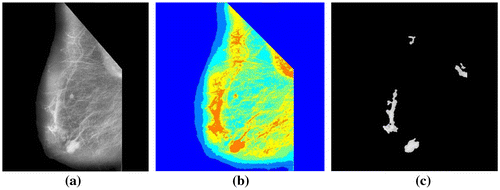
Suspicious space occupying lesions are automatically segmented from the mammograms for further processing. Lesions tend to be brighter than the surrounding area, therefore they have higher intensity values. Multithresholding based on Otsu’s method (Chen et al., Citation2012) is applied on the mammograms. Mutithreshold values are generated. Based on these threshold values, the image is quantized to create a label matrix. Pixels regions containing highest label values of size varying from 400 to 21,000 pixels are chosen. The contours of the pixel regions are smoothened using morphological operations open and close (Zhang, Ji, Li, & Wu, Citation2016). Cancerous and non-cancerous lesions are found to have a size ranging from less than 2 cm to greater than 5 cm at its widest points. From experimentation, we have found that all lesions whether cancerous or non-cancerous have an area with pixel regions ranging from 400 to 21,000 pixels in mammograms. Algorithm 3 gives the algorithm for the segmentation of lesions and Figure shows the results.
Figure 3. (a) Preprocessed image mdb005 with pectoral muscles removed (b) After applying multithresholding based on Otsu’s method and (c) Segmented ROIs.
Algorithm 3
Aim: To detect suspicious lesions in mammograms.
Input: Preprocessed mammogram image.
Output: Segmented lesions
Step 1: Read the preprocessed image I.
Step 2: Assign the number of grey levels (NL) to be used in multithresholding (NL) 5
Step 3: Multithresholding based on Otsu’s method is applied to the image
thresh = multithresh (I, NL)
Step 4: Breast image is quantized to create a label matrix of the same size containing pixel values ranging from 1 to NL + 1
seg = imquantize (I, thresh);
Step 5: Choose the pixel regions having values greater than ‘NL’.
mask = seg > NL
Step 6: Smoothen the edges of the mask using morphological operations open and close
mask = imopen (mask, se); // se is a structuring element of disk shape. se = 5
mask = imclose (mask,se);
Step 7: Select objects having area between 400 to 21,000 pixels.
mask = bwpropfilt (mask, ‘area’, [400, 21,000]);
Step 8: Apply mask to the input image
I (~mask)=0
Step 9: Stop.
Figures shows the preprocessing and segmentation of the normal, malignant and benign mammograms using the algorithm 1 and algorithm 2.
Figure 4. (a) Benign image mdb013 (b) Its preprocessed image with abnormalities recorded (c) With pectoral muscles removed and (d) Segmented ROIs.
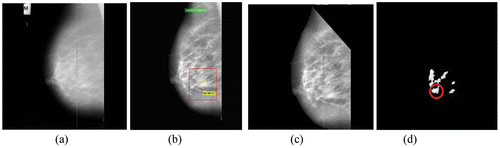
Figure 5. (a) Malignant image mdb028 (b) Its preprocessed image with abnormalities recorded (c) With pectoral muscles removed and (d) Segmented ROIs.
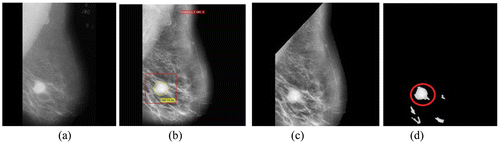
Figure 6. (a) Normal image mdb008 (b) Its preprocessed image (c) With pectoral muscles removed and (d) Segmented ROIs.
3.3. Feature extraction
The three different types of space occupying lesions- masses, architectural distortion of the breast and asymmetric breast tissues can be characterized as benign or malignant based on their shape, texture and grey level intensity values. Hence, it is important to extract texture, shape and grey level features from the segmented ROIs to classify them as normal, benign or malignant. In order to extract grey level intensity features, first order statistical feature analysis method (Nurhayati, Susanto, Thomas, & Maesadji, Citation2011) has been used. To extract texture features two methods namely, grey level co-occurrence method (Eichkitz, John, Amtmann, Marcellus, & de Paul, Citation2015) and grey level run length method (Bharathi & Subashini, Citation2013) has been used. Shape feature analysis method has been used to extract shape features.
3.3.1. First order statistical feature analysis method
First order statistical feature analysis method (Nurhayati et al., Citation2011) is the simplest of all feature analysis method. This method makes use of intensity level histogram of the image to compute the grey level intensity features. Six statistical features are extracted from the ROIs- mean, variance, skewness, kurtosis, energy and entropy. These features are useful in measuring the brightness, the contrast and intensity variation of the ROIs. In mammograms, as lesions tend to be brighter and have higher contrast as compared to normal tissues, the statistical features are useful in detecting suspicious lesions.
3.3.2. Grey level co-occurrence matrix (GLCM) method
GLCM method (Eichkitz et al., Citation2015) is a statistical texture analysis method which characterizes the ROIs based on texture properties. GLCM method derives a large set of second order texture features from the normalized grey-level co-occurrence matrix of the image. 13 texture features are derived from the GLCM matrix each at angles 0°, 45°, 90° and 135° at distance d = 1. Hence, a total of 52 texture features values are obtained. They include- energy, contrast, correlation, variance, homogeneity, entropy, sum average, sum entropy, sum variance, difference variance, difference entropy, first correlation measure and second correlation measure. GLCM features are useful in differentiating smooth, soft texture from hard, rough textures. Benign lesions in mammograms tend to be soft & smooth whereas malignant lesions are hard and immobile. Hence, GLCM features help in distinguishing benign lesions from malignant ones.
3.3.3. Grey-level run length matrix (GLRLM) method
GLRLM method (Bharathi & Subashini, Citation2013) is a statistical texture analysis method which searches the image for the runs of pixels having same grey level values in a particular direction θ using the grey level run length matrix(GLRLM) derived from the image. 11 texture features are derived from the GLRLM of the image at angles 0°, 45°, 135° and 90°. Hence a total of 44 GLRLM texture features are obtained. The GLRLM features include short run emphasis (SRE), long run emphasis (LRE), grey level non-uniformity (GLN), run percentage (RP), run length non-uniformity (RLN), low grey level run emphasis (LGRE), high grey level run emphasis (HGRE), short run low grey level emphasis (SRLGE), short run high grey level emphasis (SRHGE), low run low grey level emphasis (LRLGE) and low run high grey level emphasis (LRHGE). GLRLM features play an important role in differentiating benign lesions which have smooth soft texture from malignant lesions which have coarse hard texture.
3.3.4. Shape feature analysis
Shape and margin of lesions are useful in distinguishing them as benign or malignant. 15 shape and margin features (Surinderan & Vadivel, Citation2012) have been extracted from the ROIs. These features help in measuring the circularity of the lesions, their irregularity and their margin characteristics. Shape and margin features include area, perimeter, eccentricity, equidiameter, compactness, thinness ratio, circularity1, circularity2, elongatedness, dispersion, shape index, Euler number, maximum radius, minimum radius and S.D of the edge.
3.4. Feature selection
Altogether, 117 features are extracted from the ROIs of the mammograms (6 histogram features, 52 GLCM features, 44 GLRLM features and 15 shape features). It has been found that the large set of features do not necessarily lead to high classification accuracy as some of the features may be redundant, irrelevant, noisy or misleading. This can actually have a negative impact on the classification process in terms of classifier efficiency and computational time complexity. Feature selection is inevitable to select an optimal subset of significant features which not only improves classification but also leads to lower data collection. In this paper, classifier and regression tree (CART) (Hayes, Usami, Ross, & John, Citation2015) has been used for feature selection. CART is a decision tree induction algorithm which constructs a flow chart like structure where each internal node denotes a test on an attribute and each external node denotes a class prediction. At each internal node, the CART algorithm chooses the best feature to partition the data into individual classes using the Gini index. Hence, the features that appear on the decision tree are the relevant features. These features form the reduced subset of attributes. Figures shows the decision trees constructed using CART algorithm for selection of optimal subset of histogram features, GLCM features, GLRLM features and shape features. Here, Class 1 = Normal class, Class 2 = Benign class and Class 3 = Malignant class.
Figure 7. Optimal histogram features using CART.
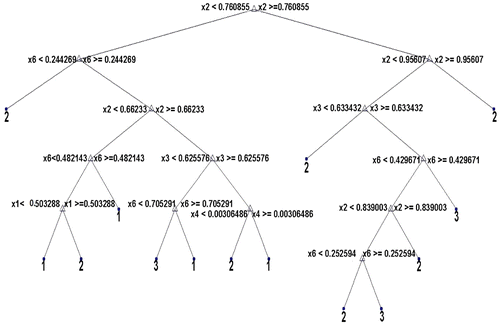
Figure 8. Optimal GLCM features using CART.
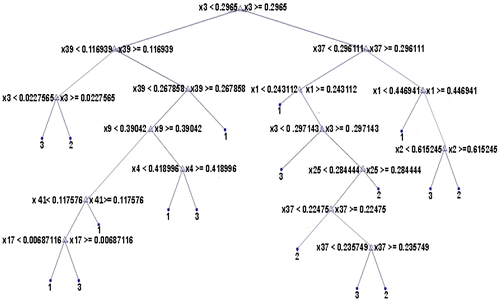
Figure 9. Optimal GLRLM features using CART.
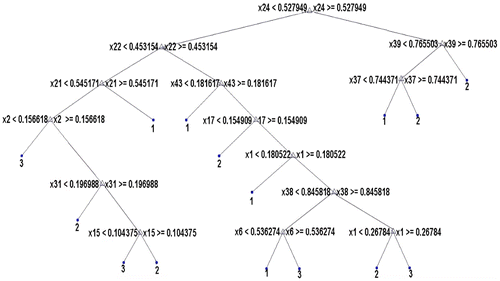
Figure 10. Optimal shape features using CART.
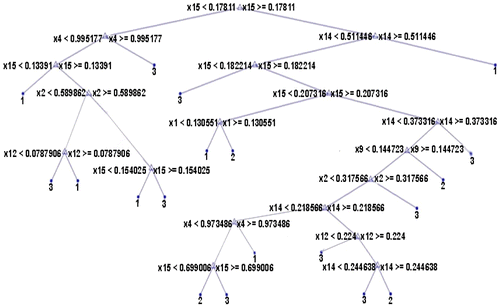
In Figure , x1, x2, x3, x4, x5 and x6 represents features mean, variance, skewness, kurtosis, energy and entropy. Only four features namely, x1, x2, x3 and x6 appear on the decision tree and hence are the relevant features.
In Figure , x1-x4 represents contrast in four different angles, x5-x8 represents homogeneity, x9-x12 represents energy, x13-x16 represents correlation, x17-x20 represents variance, x21-x24 represents entropy, x25-x28 represents sum average, x29-x32 represents sum entropy, x33-x36 represents sum variance, x37-x40 represents difference entropy, x41-x44 represents difference variance, x45-x48 represents correlation1 and x49-x52 represents correlation2 in directions 0°, 45°, 135° and 90° respectively. But, only 9 GLCM features appear on the decision tree namely, x1, x2, x3, x9, x17, x25, x37 x39 and x41.
In Figure , x1-x4 represent SRE in four direction, x5-x8 represents LRE, x9-x12 represents GLN, x13-x16 represents RLN, x17-x20 represents RP, x21-x24 represents LGRE, x25-x28 represent HGRE, x29-x32 represents SGLGE, x33-x36 represents SRHGE, x37-x40 represents LRLGE and x41-x44 represents LRHGE in four directions. Out of these, 13 GLRLM features appear on the decision tree and hence are relevant. They are x1, x2, x6, x15, x17, x21, x22, x24, x31, x337, x38, x39, and x43.
In Figure , x1 to x15 represents shape features area, perimeter, max radius, min radius, Euler number, eccentricity, equidiameter, elogatedness, circularity1, circularity2, compactness, dispersion, thinness ratio, shape index and standard deviation of edge. There are only 7 relevant features appearing on the decision tree namely, x1, x2, x4, x9, x12, x14 and x15.
From Figures , it is clear that 4 out of 6 histogram features, 9 out of total 52 GLCM features, 13 out of 44 GLRLM features and 7 out of 15 shape features appear as internal nodes on the decision trees which means that out of 117 features, there are only 33 features which are relevant and significant features for classification. All the remaining features are eliminated from further consideration.
3.5. Classification
Feed forward artificial neural networks with back propagation (FFANN) (Mehdy et al., Citation2017) has been used as the classifier for the classification phase. CART has not been used to classify mammograms after feature selection because it has been found by experiment that FFANN has better classification accuracy than CART. FFANN is one of the most popular techniques for classification as it is simple, robust and has fast training speed.
FFANN is a network of three layers- an input layer with number of neurons equal to the number of selected features i.e., 33, a hidden layer and an output layer with three neurons each representing a target class- normal, benign and malignant. The sample data-set is divided into three sets- training set, test set and validation set. Initial weights and bias are randomly selected for FFANN usually between −1.0 to 1.0 and −0.5 to 0.5.To propagate the inputs forward, an activation function is used. The log sigmoid function is used as the activation function.
FFANN processes the data-set of training tuples comparing the network prediction of each tuple with the actual known class label. FFANN learns by using the gradient descent method in the backward direction to iteratively search for a set of weights and bias to minimize the mean square distance between networks class prediction and the known target value of the tuples. In order to avoid over fitting by the FFANN, the validation set is used during the training process. After the necessary accuracy is obtained, the weights are frozen. The test data is then fed to the FFANN and the classification accuracy is measured.
3.6. Performance evaluation
There are several evaluation measures available to evaluate the performance of the classification model. Two such measures, confusion matrix and receiver operating characteristics (ROC) analysis have been used in this paper to evaluate the performance of the classification tool.
3.6.1. Confusion matrix
Confusion matrix (Prabusankarlal, Thirumoorthy, & Manavalan, Citation2017) is a useful tool for analyzing how accurately the classifier recognizes tuples of different classes. Performance of a classification algorithm can be summarized in the form of a confusion matrix. Figure shows a confusion matrix where the row of the matrix represents the predicted class and the columns represent the actual class.TP and TN denote the number of positive tuples and number of negative tuples that are classified correctly as positives and negatives respectively. FP and FN represents the tuples that are wrongly misclassified as positives and negatives. Several evaluation metrics like accuracy, sensitivity and specificity can be generated from the confusion matrix.
Figure 11. Confusion matrix.
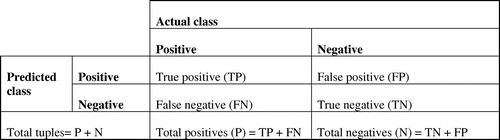
Accuracy is the proportion of true results - both true positives and true negatives. Accuracy measures how well the classifier predicts all classes correctly. Accuracy results can be misleading if there exists a class imbalance problem where tuples in the data-set are not uniformly distributed in all classes i.e. majority of all tuples belong to one class with only very few belonging to the remaining classes. In such cases, sometimes, it can so happen that even when the accuracy rate is high it may not be acceptable because the classifier may only be correctly labeling tuples belonging to the majority class while misclassifying tuples belonging to the minority class. This is especially true in case of breast cancer. This is because breast cancer is rare and breast cancer data-set consists of tuples mostly belonging to the negative class. In such cases, evaluation metrics like sensitivity and specificity gives better evaluation than the overall accuracy as sensitivity is the proportion of true positives and specificity is the proportion of true negatives correctly identified by the classifier.
3.6.2. Receiver operating characteristic (ROC) analysis
ROC curves (Wang et al., Citation2017) are useful tools for visualizing and evaluating classifiers. ROC graphs are two dimensional graphs in which sensitivity (TP rate) is plotted on Y axis and FP rate (1- specificity) is plotted on the X axis and it represents the trade-off between the rate at which the model can accurately identify positive tuples versus the rate at which it misclassifies negative cases as positive. For each tuple, a point is plotted in the ROC space by using its TP rate against its FP rate. A ROC curve is plotted using these ROC points. An ROC curve of a good classifier moves steeply from center (0, 0) towards the top left corner and then the curve eases off and becomes more horizontal. The area under the curve is a good measurement of accuracy. Higher the area, higher is the accuracy of the model. A model with higher accuracy will have an area closer to 1.0 and that with less accuracy will have an area closer to 0.5.
4. Experimental results
The proposed system was tested using mammograms obtained from mini-MIAS database (Suckling et al., Citation1994). The database includes 322 breast images of 161 patients which have been carefully selected, expertly diagnosed and positions of abnormalities have been recorded in case of malignant and benign mammograms. Only normal mammograms and those cases from mini-MIAS database containing space occupying lesions are considered in this work. They are selected based on the appropriate description provided for each image. 251 mammograms are selected of which 178 are normal, 44 are with benign lesions and 29 are with malignant space occupying lesions.
All the mammograms are preprocessed and ROIs are detected. Histogram, GLCM, GLRLM and shape features are extracted from the ROIs. 33 optimal features are selected using the decision trees. Normal mammograms do not contain lesions. But for the purpose of classification, they also undergo all the steps mentioned above. For training purpose, a total of 171 mammograms containing 124 normal mammograms, 24 mammograms with benign lesions and 23 mammograms with malignant lesions are used. Hence, a matrix of size 33 × 171 is given as input to the input layer which is made up of 33 neutrons. Each row of the matrix contains the value of a particular feature for 171 mammograms. Using this feature matrix, FFANN is trained and once the necessary accuracy is obtained, it is saved as an object file. Finally, FFANN containing 33 neurons in the input layer, 50 neurons in the hidden layer and 3 neurons in the output layer is obtained as the most accurate FFANN in the training stage. During the testing phase, for each test mammogram, matrix of size 33 × 1 is created where each row represents one of the 33 features for the respective mammogram. The class of the mammogram is then decided by the FFANN based on the training results. Figure (a)–(c) provides the FFANN design and demonstrates the classification performance using the ROC curve and all confusion matrix. From Figure (b), the all confusion matrix can be interpreted as follows.
| (1) | From 178 normal cases, 177 have been classified as normal and 1 has been misclassified as malignant. | ||||
| (2) | From 44 benign cases, 40 have been truly classified as benign and 4 has been misclassified as malignant. | ||||
| (3) | Out of 29 malignant cases, 24 have been classified as malignant whereas 1 has been misclassified as normal and 4 as benign. | ||||
Figure 12. (a) FFANN design (b) All confusion matrix and (c) All ROC curve.
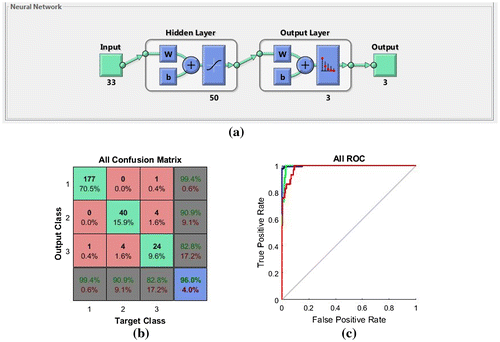
Table 1. An accuracy comparison
The types of features extracted, the selection of optimal subset of features and the segmentation process greatly contribute to classifier performance. A better classification accuracy rate can be obtained only if the region of interest is segmented in such a manner that it is restricted to contain only tumour and delineates the enormous unwanted region surrounding it. The ground truth data in mini- MIAS database provides the location of the abnormalities. By comparing with the ground truth data, it has been found that the segmentation process which consisted of multithresholding using Otsu’s method, morphological operations open and close and a constraint value for choosing pixel regions yielded good segmentation results. The types of features extracted from the ROIs are also important in enhancing the classifier performance. Besides the histogram features, texture and shape features have also been extracted as texture and shape are two important characteristics that distinguish benign lesions from malignant lesions. Also, the optimal subset of features selected using CART classifier has also contributed to the efficiency of the classifier.
5. Conclusion and future work
The use of computer aided detection and diagnosis system for breast cancer has received widespread acceptance among the radiologists in the recent years. They contribute as second readers in the early detection and diagnosis of breast cancer. The proposed methodology in this paper can be used in the development of CAD system for breast cancer as it achieves high accuracy rate. In our future work, we would like to make the following enhancements.
| (1) | Though accuracy and specificity are high, sensitivity needs to be improved. The experiment needs to be conducted on larger number of malignant mammograms as this can avoid class imbalance problem and lead to higher sensitivity results. | ||||
| (2) | Optimal features play an important role in improving the classifier performance. In future, we would like to compare different feature selection methods and choose the best method | ||||
| (3) | The technique for pectoral muscles removal has to be improved, as in some cases, lesions occurring very close to the pectoral muscles have been partially removed leading to misclassifications. | ||||
| (4) | Segmentation process does not yield good results with masses having obscure margins. This needs to be addressed. | ||||
Funding
The authors received no direct funding for this research.
Additional information
Notes on contributors
K.U. Sheba
K.U. Sheba, received her Master of Computer Applications (MCA) from the Department of Studies in Computer Science, University of Mysore and M.Phil. in Computer Science from Bharathidasan Univeristy, Trichy. She is currently working as Associate Professor in the Department of Computer Applications, BPC College, Piravom, Kerala. Her research interest include Image Processing, Soft Computing, Machine Learning and Theory of Computation.
S. Gladston Raj
S. Gladston Raj, took his Master of Science (MSc.), Master of Technology (M.Tech.), Doctor of Philosophy (PhD.) all in Computer Science and from University of Kerala. He is presently serving as Head, Department of Computer Science, Government College, Nedumangad, Kerala. His research interest include Image Processing, Pattern Recognition, Machine Learning and Data Mining.
Related Research Data
References
- Abdel-Zaher, A. M. , & Eldeib, A. M. (2016). Breast cancer classification using deep belief networks. Expert Systems with Applications , 2016 (46), 139–147.10.1016/j.eswa.2015.10.015
- American Cancer Society . (2016). Breast cancer signs and symptoms . Retrieved from http:///www.cancer.org
- Banik, S. , Rangaraj, M. , & Desautals, J. E. L. (2013). Measures of angular spread and entropy for detection of architectural distortion in prior mammograms. International Journal of Computer Assisted Radiology and Surgery , 8 (1), 121–134.10.1007/s11548-012-0681-x
- Bharathi, P. T. , & Subashini, P. (2013). Texture feature extraction of infrared river ice images using second order spatial statistics. International Journal of Computer, Electrical, Automation and Information Engineering , 7 (2), 195–204.
- Buciu, I. , & Gacsadi, A. (2011). Directional features for automatic tumor classification of mammogram images. Biomedical Signal Processing and Control , 6 (4), 370–378.10.1016/j.bspc.2010.10.003
- Chang, C. M. (2006). Detecting ellipses via bounding boxes. Asian Journal of Health and Information Sciences , 1 , 73–84.
- Chaubey, A. K. (2016). Comparison of the local and global thresholding methods in image segmentation. World Journal of Research and Review , 2 (1), 1–4.
- Chen, Q. , Zhao, L. , Lu, J. , Kuang, G. , Wang, N. , & Jiang, Y. (2012). Modified two-dimensional Otsu image segmentation algorithm and fast realization. IET Image Processing , 6 (4), 426–433.10.1049/iet-ipr.2010.0078
- de Lima, S. M. , da Silva-Filho, A. G. , & Dos Santos, W. P. (2016). Detection and classification of masses in mammographic images in a multi kernel approach. Computer Methods and Programs in Biomedicine , 134 , 11–29.10.1016/j.cmpb.2016.04.029
- Eichkitz, C. G. , John, D. , Amtmann, J. , Marcellus, G. S. , & de Paul, G. (2015). Grey level co-occurrence matrix and its applications to seismic data. Modelling/Interpretation , 33 , 71–77.
- Gedik, N. (2015). Breast cancer diagnosis system via contourlet transform with sharp frequency localization and least squares support vector machine. Journal of Medical Imaging and Health Informatics , 5 (3), 497–505.10.1166/jmihi.2015.1422
- Hayes, T. , Usami, S. , Ross, J. , & John, J. M. (2015). Using classification and regression Trees-(CART) and random forest to analyze attrition: Results from two simulations. Psychology and Aging , 30 (4), 911–929.10.1037/pag0000046
- Homer, M. J. (2004). Breast imaging, standard of care and expert. Radiologic Clinics in North America , 42 (5), 963–974.10.1016/j.rcl.2004.03.012
- Hu, K. , Gao, X. , & Li, T. (2011). Detection of suspicious lesions by adaptive thresholding based on multi resolution analysis in mammograms. IEEE Transaction on Instrumentation and Measurement , 6 (2), 462–472.10.1109/TIM.2010.2051060
- Huang, C. , & Zhu, Y. (2012). An improved median filtering algorithm for image noise reduction. Physics Procedia , 25 , 609–616.
- Liu X , Liu J , Feng Z , Xu X , Tang J. (2014, January). Mass classification in mammograms with semi-supervised relief based feature selection. Proceedings of SPIE 9069: fifth International Congress on Graphics and Image processing (ICGIP 2013) , Hong Kong, China. doi:10.1117/12.2051006
- Mammographic Mass Characteristics . (2017). Mass shape, margin and density as found with screening mammography . Retrieved from http://breast-cancer.ca/mass-chars/
- Mehdy, M. M. , Ng, P. Y. , Shair, E. F. , Saleh, N. I. M. , & Gomes, C. (2017). Artificial neural networks in image processing for early detection of breast cancer. Computational and Mathematical Methods in Medicine , 2017 , 2610628. doi:10.1155/2017/2610628
- Minavathi, M. S. , & Dinesh, M. S. (2012). Classification of mass in breast ultra sound images using image processing techniques. International Journal of Computer Applications , 42 (10), 29–36.10.5120/5730-7801
- Nurhayati, O. D. , Susanto, A. , Thomas, S. W. , & Maesadji, T. (2011). Principal component analysis combined with first order statistical method for breast thermal images. International Journal of Computer Science and Technology , 2 (2), 12–18.
- Prabusankarlal, K. M. , Thirumoorthy, P. , & Manavalan, R. (2017). Classification of breast masses in ultrasound images using self-adaptive differential evolution extreme learning machine and rough set feature selection. Journal of Medical Imaging , 4 (2), 024507. doi:10.1117/1.JMI.4.2.024507
- Rangayyan, R. M. , Ferrari, R. J. , & Frère, A. F. (2007). Analysis of bilateral asymmetry in mammograms using directional, morphological and density features. Journal of Electronic Imaging , 16 (1), 1–12.
- Saki, F. , Tahmasbi, A. , Soltaman-Zadenn, H. , & Shahriar, B. S. (2013). Fast opposite weight learning rules with application in breast cancer diagnosis. Computers in Biology and Medicine , 43 (1), 32–41.10.1016/j.compbiomed.2012.10.006
- Sheba, K. U. , & Gladston Raj, S. (2016). Objective quality assessment of image enhancement methods in digital mammography – a comparative study. Signal & Image processing: An International Journal , 7 (4), 1–13.
- Sheba K. U. , & Gladston Raj S. (2017). Adaptive fuzzy logic based bi-histogram equalization for contrast enhancement of mammograms. Proceedings of IEEE International Conference on Intelligent Computing, Instrumentation and Control Technologies (ICICICT-2017) , Kerala, India, June 6–7 ( in press).
- Siegel, R. , Naishadham, D. , & Jeimal, A. (2013). Cancer statistics 2013. CA: A Cancer Journal for Clinicians , 63 , 11–30.
- Statistics of Breast Cancer in India . (2013). Global comparison . Retrieved from http://www.breastcancerindia.net
- Suckling, J. , Parker, J. , Dance, D. , Astley, S. , Hutt, I. , Boggis, C. , … Taylor, P. (1994). The mammographic image analysis society digital mammogram database. Exerpta Medica. International Congress Series , 1069 , 375–378.
- Surinderan, B. , & Vadivel, A. (2012). Mammogram mass classification using various geometric shape and margin features for early detection of breast cancer. International Journal of Medical Engineering and Informatics , 4 (1), 36–54.10.1504/IJMEI.2012.045302
- Talha, M. (2016). Classification of mammograms for breast cancer detection using fusion of discrete cosine transform and discrete wavelet transform features. Biomedical Research , 27 (2), 322–327.
- Valarmathi, P. , & Robinson, S. (2016). An improved neural networks for mammogram classification using genetic optimization. Journal of Medical Imaging and Health Informatics , 6 (7), 1631–1635.10.1166/jmihi.2016.1862
- Wang, J. , Nishikawa, R. M. , & Yang, Y. (2017). Global detection approach for clustered microcalcifications in mammograms using a deep learning network . Journal of Medical Imaging , 4 (2):024501. https://doi.org/10.1117/1.JMI.4.2.024501
- Wang, L. (2017). Early diagnosis of breast cancer. Sensors , 17 (7), 1–20. doi:10.3390/s17071572
- Wang, Y. , Li, J. , & Gao, X. (2014). Latent feature mining of spatial and marginal characteristics for mammographic mass classification. Neurocomputing , 144 , 107–118.
- Wang, Z. , Yu, G. , Kang, Y. , Zhao, Y. , & Qu, Q. (2014). Breast tumor detection in digital mammography based on extreme learning machine. Neurocomputing , 128 , 175–184.10.1016/j.neucom.2013.05.053
- World Cancer Research Fund International . (2013–2014). Cancer facts and figures . Retrieved from http://www.werf.org
- Zhang, Y. , Ji, T. Y. , Li, M. S. , & Wu, Q. H. (2016). Identification of power disturbances using generalized morphological open-closing and close-opening undecimated wavelet. IEEE Transactions on Industrial Electronics , 63 (4), 2330–2339.