
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Collecting, archiving, and analyzing handwritten documents are still indispensable acts as people continue to use paper documents. In addition, these archives are an endless source of information. Retrieving information from a handwritten document using automatic text queries as an alternative to manual search in a scanned image requires precise optical character recognition systems. However, properties of the Arabic handwriting such as cursive writing with characters overlapping and touching limit the recognition stages. Inspired by the use of the seam carving algorithm for image resizing and line segmentation, we propose a seam carving algorithm that aims to solve character overlapping and touching. We propose a new energy function for the seam carving algorithm to solve the overlapping problem. Furthermore, we designed a pre-processing stage that avoids generating seams that pass through inappropriate regions. Our proposed segmentation technique reached a 95.66% correct segmentation on IESK-ArDB and IFN/ENIT datasets. Furthermore, our method outperforms state-of-the-art techniques in resolving the overlapping issue.
PUBLIC INTEREST STATEMENT
Today, digital technologies are in a growing their usage, and the world is switching quickly to digitization. Optical character recognition (OCR) is a technique used in the conversion of handwritten scanned documents into editable digital documents. First, text lines are extracted. Then the lines are segmented into words, sub-words, and characters, which need to be recognized. Arabic is a cursive language with different writing styles and various features to complicate character recognition. Overlapping and inappropriate touching by different characters is still a challenging issue in Arabic OCR systems. To improve recognition accuracy, we suggest a method that segments Arabic words into their parts with a focus on solving the sub-word overlapping problem. Our algorithm generates seams that cross the sub-words’ overlapping regions. In testing, more than 95% of the words were segmented correctly.
1. Introduction
With developments in digital methods of information sharing, paper and handwriting-based information increasingly depends on digital means for data retrieval. With the size of processed information growing daily, public service businesses and organizations adopt novel digital technologies as alternatives to paper documents. The transition from paper to digital means requires scalable optical character recognition (OCR) systems that can convert paper documents, whether printed or handwritten, to digital formats.
The recognition of handwritten scripts is more challenging than for printed ones because of the differences in the writing styles among users, paper quality, and so on. Before the recognition stage, a handwritten script undergoes various stages of processing in an OCR system. First, a pre-processing stage prepares the script for the segmentation phase. After that, the segmentation stage is responsible for extracting the text lines from the document and extracting parts of words (sub-words) from the lines. Subsequently, the sub-words are clustered into words and undergo a word recognition stage, or they are subjected to characters or grapheme segmentation followed by a character recognition stage (Alginahi, Citation2013). Either way, the recognition stage depends on the performance of the previous stages, especially the segmentation phase. Incorrect segmentation leads to incorrect recognition.
Arabic is a cursive language with different character shapes and with words composed of one or more sub-words. Additionally, Arabic handwriting can be subject to touching and overlapping characters, which complicates the segmentation and limits its results because two overlapping or touching characters could be considered a single sub-word by mistake (Lawgali, Citation2015), (Alginahi, Citation2013). Scripts’ segmentation techniques have been categorized as dissection, recognition-based, and holistic techniques (Casey & Lecolinet, Citation1996). Dissection-based techniques divide the image into meaningful components such as characters and sub-words. Recognition-based techniques divide the image into its components, which match a dataset of alphabets in holistic techniques. Then the words are recognized directly, bypassing the segmentation stage. Different techniques for Arabic sub-word segmentation have been investigated, such as thresholding (Khan et al., Citation2014), projection profile (Lamsaf et al., Citation2018) (El Mamoun et al., Citation2019), recognition-based (Fazel et al., Citation2016), and connected components-based techniques; In (Alkhateeb et al., Citation2009) (Elzobi et al., Citation2011) (Ghaleb et al., Citation2016) bounding boxes around connected components (CC) are extracted and in (Samoud et al., Citation2012) (Snoussi Maddouri et al., Citation2014) color labels are assigned to CCs. However, the main limitations in previous studies were over-segmentation and under-segmentation, where the number of segmented sub-words is larger than or less than the correct number due to pen-lifting, overlapping, and touching characters. This work proposes a sub-word segmentation algorithm that solves the overlapping problem.
In this paper, we will first present the properties of the Arabic language in Section 2. In Section 3, we will provide a review of Arabic sub-word segmentation. Section 4 describes the seam carving algorithm, and Section 5 explains the proposed methodology. Finally, in Sections 6 and 7, we will present and discuss our results.
2. Arabic handwriting characteristics
There are 28 letters in the Arabic alphabet (Lawgali, Citation2015). Each Arabic letter has more than one shape depending on its position in the word; a single character can have from one to four shapes.
A word may be composed of one or more connected components, which consists of one or more characters. They are called sub-words or parts of Arabic words or pieces of Arabic words (PAW). In Figure , the words صبيح, عنصري, نووي include, respectively, one, two, and three sub-words.
Figure 1. Arabic words with 1, 2 and 3 PAWs.

Arabic letters include dots and vowels that are included as diacritics called harakaat. There are four types of diacritics: dhamma, fatha, kasra, and soukoun. Furthermore, a character may include one, two, or three dots (see Figure ).
Figure 2. Arabic word with diacritics and dots.

Automatic processing of the Arabic language is a difficult task, especially in the field of handwriting recognition, for several reasons (Khan et al., Citation2014), including the cursive nature of Arabic writing, variation in character sizes by the same or different writers, pen lifting, the existence of dots and diacritics that could influence character recognition and segmentation, mainly if they are displaced, and descendant and ascendant characters may overlap or touch neighboring characters. Major difficulties are caused by the following occurrences:
Overlapping: Two characters may overlap horizontally or vertically. A horizontal overlap means that at least two different characters’ pixels appear in the same image row. Such overlapping is generally due to ascendant and descendant characters and may cause lines to overlap. A vertical overlap means that at least two different characters’ pixels appear in the same image column. Such an overlapping may cause sub-words to overlap (see Figure ).
Figure 3. Examples of overlapping and touching characters.

Touching characters can be defined as two characters that cross each other inappropriately in at least one pixel (see Figure ).
Slanting is a result of handwriting style where the strokes are inclined downward. This problem can be rectified before beginning the recognition process (Ziaratban & Faez, Citation2009).
A skew refers to the text’s angular deviation from the horizontal line. It has a major effect on the Arabic recognition system because several systems use baseline estimation algorithms that are not robust against skewing (see Figure ). Skew detection and correction methods can be applied at the pre-processing stage (Boubaker et al., Citation2009), (Atallah et al., Citation2009), and (Boukharouba, Citation2017).
Figure 4. Slant and skew examples.

3. Arabic sub-word segmentation
Contrary to line segmentation and word-to-character segmentation, Arabic sub-word segmentation has not garnered much interest.
In (Samoud et al., Citation2012), the Hough transform and mathematical morphological operators are used to reach a correct line extraction rate of 92% on the Center for Pattern Recognition and Machine Intelligence
(CENPARMI) Arabic check database. The authors also used the same algorithm followed by extractions of labeled CCs for sub-word segmentation, and their segmentation rate was 81% on 1,250 IFN/ENIT database images and 67% only on 200 CENPARMI check database images where sub-words were extracted from a line of words. However, the authors of the paper did not consider the association of diacritics and dots with sub-words, which may limit the use of this method.
In (Snoussi Maddouri et al., Citation2014), Snoussi et al. applied an outer isothetic cover (OIC) of a digital object after a mathematical morphology operator MM-OIC. The mathematical morphological operator was chosen after a learning phase, which led to the choice of a rectangular structural element with dimensions to avoid the line-overlapping problem. They first applied the closing operator to connect the line sub-words and then applied an OIC to extract the line. After extracting the line, they applied the OIC to extract the sub-words. In the second method, they used the Hough transform to extract the lines, followed by an MM and CCs labeling to extract sub-words. The application of the MM just before the CCs labeling avoids pen lifting but may cause two sub-words to connect, which implies an under-segmentation problem. They attained a correct sub-word segmentation of less than 89% for the IFN/ENIT database. They found that the combination of the OIC with the MM outperformed the combination of a Hough transform and an MM.
In (Khan et al., Citation2014), the authors proposed a method for segmenting Arabic handwritten text into constituent sub-words. The concept is based around the global binarization of an image at various thresholding levels. When each sub-word within the image being investigated is processed at multiple threshold levels, a cluster graph is obtained where each cluster represents the individual sub-words of that word. Once the clusters are obtained, the task of segmentation is managed by simply selecting the respective cluster automatically. It was tested on 537 images from the AHTID/MW database and achieved an accuracy of 95.3%. The novelties of the presented method are that (i) it does not depend on the skew of the document or the skew of the line, and (ii) it is very robust in a way that the proposed method is not affected by distortion. The main problem in the proposed method is that the diacritics are ignored, which affects the extraction of some PAWs whose size is similar to the diacritics’.
In (Alkhateeb et al., Citation2009), the authors proposed a word segmentation method for Arabic handwriting at the sub-word level. First, they applied bounding box CCs, then they ignored small CCs and grouped overlapping components are grouped into one sub-word. They then computed the different distances between the sub-words. A threshold of the separating distance between words was then computed and used to group sub-words into separated words. Sub-word segmentation results were not reported. However, their method was also used in (Ghaleb et al., Citation2015) with an improvement in the secondary-component-to-primary-component association step. Their method was evaluated on 400 images from IESK-ArDB, IFN/ENIT, and KHATT and reached 87% correct segmentation. Their main algorithm suffers mainly from secondary components that were considered primary and vice versa because of the bounding box size threshold. In (Ghaleb et al., Citation2016), the same authors proposed a CCs method based on graph modeling. To extract the sub-words, they first extracted CCs and grouped them with their corresponding satellite components, which are the dots and diacritics; a CC fully placed inside another was considered its satellite component, whereas partially overlapping components were separated through a translation to the left of the leftmost one. They conducted their experiments on 150 IFN-ENIT, 150 ArDB, and 25 KHATT images. Before a refinement process was performed, the correct segmentation rate reached 77.63%; 2.7% was over-segmented due to pen lifting, and 16.27% was over-segmented due to hamza and dot displacement; 2.58% were under-segmented words due to touching or totally overlapping characters, and 0.77% had an incorrect association of secondary components. A refinement stage was added to overcome the problem of over-segmentation, in which a satellite component is considered as a separated sub-word. In the refinement stage, each CC height was computed; if less than a certain threshold, it was grouped with the preceding or the next component. Their refinement stage reduced the over-segmentation problem by associating hamza and diacritics to their corresponding principal components. Their results were improved after the refinement, reaching 91.23%; the best results were obtained for the IFN/ENIT with 97.75% and the ArDB with 94.47%.
In (Fazel et al., Citation2016), the authors proposed a recognition-based sub-word segmentation technique for a Farsi handwritten database. Farsi and Arabic are written similarly with the same alphabet. After a pre-processing stage, they applied a sub-word extraction algorithm. Then they applied a sliding window for structural features extraction. For each sub-word, they defined two vectors: a vector that contains the possible positions of the sub-word inside a word and a vector that gives the number of sub-words of a word in which the sub-word appears. They assigned a class for the sub-words based on the previously mentioned vectors. They used a recurrent neural network (RNN) classifier for each class. Their systems segmented 92% of the sub-words correctly.
Table summarizes the previous related works techniques, limitations, and sub-word segmentation accuracy results. However, sub-word segmentation was handled as an intermediate stage in other systems. Accuracy of the sub-word segmentation stage was not reported for these systems.
Table 1. Arabic sub-words segmentation related works
In (Elzobi et al., Citation2011), after applying pre-processing algorithms such as binarization, skew, and slant corrections, the authors segmented the line into sub-words, then segmented the sub-words into characters. In the sub-word segmentation stage, a CC-based method is performed. First, the CCs are classified into main and auxiliary based on whether they cross the baseline. Later, auxiliary components are associated with main components based on whether they are totally or partially overlapping. By the end, the components with their auxiliary ones are shifted to resolve the sub-word overlapping issue. The proposed sub-word segmentation method does not resolve the touching component case and some overlapping cases. An improved method of the later one was investigated in (Humied, Citation2016). In (Atallah & Al-Shatnawi, Citation2014) and (Al Dmour et al., Citation2018), they applied the bounding box sub-word extraction approach to skew detection and correction. In (Makki & Al-Jawad, Citation2017), they used active shape CCs labeling to segment sub-words from lines then they extracted the sub-words’ for the purpose of writers recognition. In (Lamsaf et al., Citation2018) and (El Mamoun et al., Citation2019), they applied the project profile algorithm to extract the sub-words followed by character segmentation. The authors in (El Mamoun et al., Citation2019) reported that characters’ overlapping is the major problem behind the
incorrect segmentation. In (Menasria et al., Citation2018), Arabic literal amounts are recognized through a support vector machine classifier using the words’ statistical features and PAWs’ structural features. The authors showed that touching PAWs limits the classifier’s accuracy.
4. Seam carving
The first introduction of the seam carving algorithm was done by Avidan and Shamir (Avidan & Shamir, Citation2007), who applied it in the field of “content-aware image resizing” to decrease or expand the size of an image. In seam carving, the elements of the image are categorized into important and unimportant. Unimportant pixels form seams that traverse the image; seams are either vertical or horizontal depending on the direction of resizing, where top-to-down-connected pixels represent a vertical seam while left-to-right-connected pixels represent horizontal seams. When an image size reduction is the objective, the unimportant pixels are deleted from the image, or pixels are added. In that way, all important elements in the image will be maintained.
The algorithm consists of three main steps: 1. The energy map of the image is computed; 2. The cumulative energy is generated; 3. A backtracking of the minimum or maximum energy seams is elaborated.
Different image measures such as the image gradient L1 and L2 norm, saliency measure, Harris-Corners measure, the image entropy, and the histogram of gradients are suitable to compute the image energy map depending on the application of seam carving (Avidan & Shamir, Citation2007).
Seam carving was first introduced for line segmentation by Saabni et al. in (Saabni & El-Sana, Citation2011) on binary images and in (Saabni et al., Citation2014) for gray images. The authors started by computing the energy map using the signed distance transform (SDT) such that pixels inside the components have a negative energy map and the pixels outside the components have a positive energy value. Consequently, minimal energies generate seam-crossing components called medial seams. The authors evaluated their algorithm on the Al-Majid dataset and found that 98.9% of lines were correctly extracted. Their proposed approach suffers from seams’ jumping between lines due to the large horizontal space.
In (Arvanitopoulos & Susstrunk, Citation2014), the authors applied the SDT as well. However, before applying the seam carving algorithm, the pre-processing of large components with long ascenders and descenders is performed. The touching parts of ascenders and descenders are removed. The energy is accumulated such that energy from far pixels is weakened. This process avoids the under-segmentation of text lines. In (Daldali & Souhar, 2018), a similar method was applied for Arabic document segmentation into text lines.
The authors of (Zhang & Tan, Citation2014) proposed a constrained seam carving algorithm to extract lines from color and grayscale documents. They first find the medial seam using the smoothed horizontal projection profile algorithm on image slices. Then they computed the separating seams using a modified seam carving algorithm. A separating seam is constrained between two successive medial seams. They generated the energy map using the Gaussian gradient of the grayscale image. Constraining the separating seams to be located between medial seams avoids the problem of jumping seams between successive lines. Their best results for the Al-Majid-A dataset had 93.6% separating seams that were computed correctly. Meanwhile, only 54.4% of the seams were computed correctly in the Thomas Jefferson dataset. The majority of the errors are due to seams that assign punctuation marks or diacritics to the wrong line or to large ascenders or descenders.
5. Methodology
Our proposed method is composed of three steps: pre-processing, segmentation, and association.
5.1. Pre-processing stage
This stage is essential to prepare the image for the subsequent stages; it directly affects the efficiency and reliability of the segmentation and association stages. It includes filling small loops, removing small objects from the binary image, and cropping the edges (see Figure ). Some Arabic characters have loops (ها, ص, ض, ط, ظ ف, ق, م, و), and these loops are responsible for low-energy regions (holes) that, if retained, may be crossed with low-energy seams.
Figure 5. Filling Holes Operation (a) Original image, (b) Image after holes filling.

In this phase, the secondary components, such as diacritics, hamza, and dots, are removed using a morphological operator. However, to associate them correctly after the segmentation stage, their coordinates are subsequently extracted. The steps involved in the removal of secondary components are described in Figure .
Figure 6. Remove diacritics and save coordinates algorithm.

5.2. Segmentation stage
Here, we propose a modified seam carving algorithm to resolve the overlapping problem that will enhance the accuracy of the segmentation stage. This algorithm is composed of three main steps: the computation of the energy map, the computation of the cumulative energy, and the backtracking following the minimum cumulative energy path.
5.2.1. Compute energy map
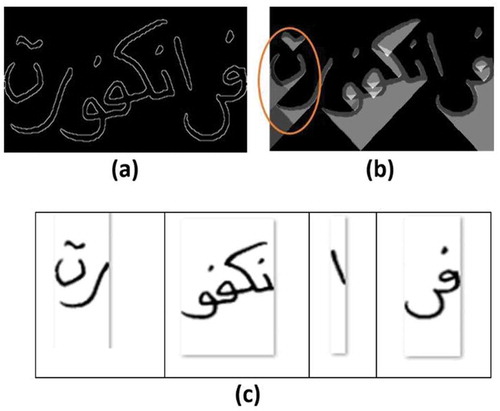
The energy function computation affects the results of the subsequent stages. The energy function presented in image resizing is based on the gradient or the Laplacian to generate seams that avoid the objects’ edges (Avidan & Shamir, Citation2007). The use of the gradient function for the computation of energy was not ideal for text-line segmentation because the energy of some lines may be merged with neighboring ones when computing the cumulative energy, resulting in the under-segmentation of text lines. The authors of (Saabni & El-Sana, Citation2011) and (Saabni et al., Citation2014) proposed the use of the SDT to compute the image energy map, making only minimal energy being assigned to text baselines. In sub-word segmentation, an energy function generated by a gradient energy function produces the cumulation of the energies of overlapping sub-words, which prevents seams from separating them (see Figure ).
Figure 7. Overlapping case energy map (a) cumulative energy map (b) and seam carving result (c) with gradient energy function.
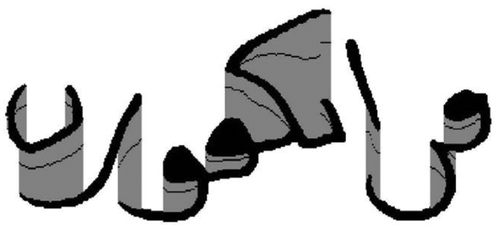
In this paper, we propose an energy function that assigns a minimal value for the pixels located between two overlapping characters. First, the pixels of the image are categorized into three regions: Region 1 contains foreground pixels that are text pixels (black text pixels in Figure ), Region 2 contains background pixels crossing an overlapping region (lines in black in Figure ), and Region 3 contains other background pixels. An overlapping region of pixels is a set of pixels located between two foreground pixels on the same column (see gray regions in Figure ).
Figure 8. Image partitioning.
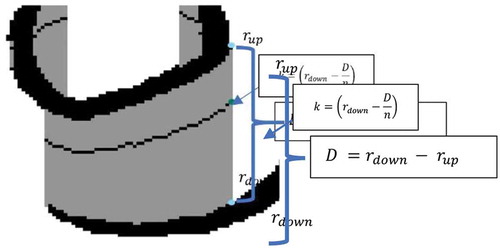
Region 2 pixels are determined in two steps. First, the overlapping regions are extracted, then the height of each overlapping region is computed by EquationEq 1(1)
(1) :
where and
are the row numbers of the closest downward and upward foreground pixels in a specific column of the image. A Region 2 pixel row number is computed by EquationEq 2
(2)
(2) :
where n is an integer determined empirically. See Figure .
Figure 9. Region 2 pixels determination.
The Region 1 pixels are allocated a maximum energy value to force the seam to avoid crossing foreground pixels. Region 3 is a non-restricted area for seams and are thus allocated an energy value of 1. Region 2 pixels are assigned the minimal value of the energy to force the seams to follow them. The energy map computation method is described in Figure .
Figure 10. Compute energy map.

5.2.2. Compute cumulative matrix
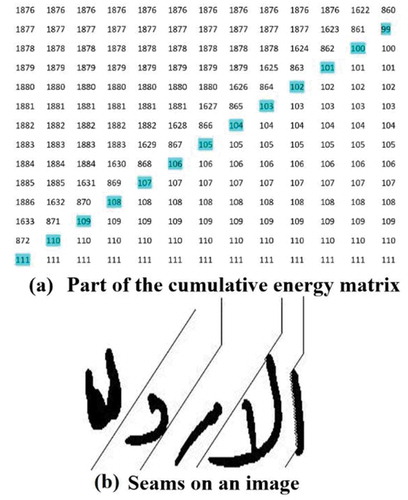
The cumulative energy matrix is computed using a dynamic programming process. For vertical seams, the dynamic programming matrix is filled in a top-down, left-to-right manner. The value of the seam is calculated for each pixel by adding the minimum of the three upper pixels to the current pixel’s energy value (see Equation 3).
Figure illustrates an example of the cumulative energy map of an image using our proposed energy function.
Figure 11. Cumulative energy map of the proposed energy function.

Region 2 pixels will force the cumulative energy to decrease more quickly, which will reduce the possibilities of overlapping between the cumulative energy of the upward character and the overlap of the cumulative energy of the downward character.
5.2.3. Find the optimal path
The cumulative energy M is traversed backward (from the last image row) to find the path of the optimal seam. The seam traverses from bottom to top, forming the minimal energy path as in (Avidan & Shamir, Citation2007). Figure illustrates an example of the seams traversing the image through the lowest cumulative energy path.
Figure 12. Seams on cumulative matrix and on the image.
5.3. Association stage
This stage aims to associate secondary components removed in the pre-processing stage to their main components. In this stage, the handwriting style was taken into consideration because the small components (dots and hamza) are generally not located strictly above or below a character but slightly shifted to the left.
6. Experimental results
In this research, we evaluated the performance of the proposed technique by using handwritten images drawn from two datasets: IESK-ArDB (Elzobi et al., Citation2013) and IFN/ENIT (Pechwitz et al., Citation2002). The IFN/ENIT1 was published by the National School of Engineering of Tunis in Tunisia and the Institute of Communication Technology (IFN) in Germany. There are 26,459 handwritten names, with various qualities of writing included in this dataset of 946 towns and villages by 411 writers. The IESK-ArDB2 database was initially established at Otto-von-Guericke University Magdeburg in the Institute for Electronics, Signal Processing and Communication (IESK). This database includes about 4,000 images of Arabic words and 6,000 images of segmented characters. The IESK-ArDB database samples were collected from 22 writers in many Arabic countries. Both databases contain images with cases of overlapping and touching characters. We selected 300 images with 150 images from each database. Eighty-one images of the IESK-ARDB and 35 images of the IFN/ENIT are included with overlapping between sub-words. After applying the seam carving-based segmentation on our selected set, sub-word segmentation accuracy was computed as the following—there is no standard method for the computation of the accuracy of sub-word segmentation:
As derived from Table , our method reached a correct segmentation rate of 94.67% for the IFN/ENIT and 96.66% for the IESK-ArDB. Our results outperform Snoussi et al. (Snoussi Maddouri et al., Citation2014) and Ghaleb et al. (Ghaleb et al., Citation2016) for the IFN/ENIT database. The thresholding technique proposed in (Khan et al., Citation2014) reached 95.3% on the AHTID/MW database. However, they stated that their detection method may fail in segmenting some non-challenging words. Even though the results of (Ghaleb et al., Citation2016) are promising for sub-word segmentation, the authors provided no indication regarding the selection of the words used in the experiments.
Table 2. Comparison of the results of the proposed approach to state of the art
Our technique’s incorrect segmentations are due to over-segmentation or under-segmentation. Over-segmentation is generally due to pen-lifting or considering diacritics as sub-words, mainly if they are misplaced or large. Under-segmentation can be caused by characters’ overlapping or touching. For the evaluated samples of the two datasets, all the incorrectly segmented cases were over-segmented; the majority of the over-segmented cases were caused by pen lifting (see Table ).
Table 3. Over-segmentation rate per dataset
7. Results discussion
Generally, over-segmentation is caused by pen-lifting or considering hamza, dots, and diacritics as sub-words. Under-segmentation is caused by characters’ touching or overlapping. In the following, we compare our over-segmentation and under-segmentation results to (Ghaleb et al., Citation2016) and explain our strategy toward reducing such a problem. We will also discuss the results of our methods for line-to-sub-word segmentation.
7.1. Over-segmentation results discussion
In (Ghaleb et al., Citation2016), they applied their graph-based CC method on IESK-ARDB, IFN/ENIT, KHATT, and a printed Persian database. They obtained 2.75% pen-lifting over-segmentation and 3.44% under-segmentation caused by hamza and dot displacement. (This occurred with 3.44% obtained after a special refinement stage. Before the refinement, they showed 16.27% hamza and dots displacement). In our technique, the over-segmentation was essentially caused by pen-lifting. We reduced the hamza, dots, and diacritics misplacement with the effective pre-processing and association stages, as we saved the small components’ coordinates in the pre-processing stage and returned them in the association stage. Table shows one case of over-segmentation caused by hamza or dots displacement in (Ghaleb et al., Citation2016) that were solved in our case.
Table 4. Over-segmentation sample of (Ghaleb et al., Citation2016) solved by the proposed method
However, pre-processing still does not overcome all the over-segmentation cases, mainly when the diacritics, dots, or shadda are large. In such cases, the secondary components bypass the pre-processing stage, see Figure .
Figure 13. Failure of segmentation because diacritics are considered as sub-words.

7.2. Under-segmentation results discussion
In (Ghaleb et al., Citation2016), 2.58% of the images were under-segmented, whereas under-segmentation is eliminated in our case. The under-segmentation in (Ghaleb et al., Citation2016) is essentially caused by overlapping and touching. Our technique solved all the cases of overlapping and some touching. Successful segmentations of one case of overlapping and one of touching characters are represented in Table .
Table 5. Successful segmentation for overlapping and touching cases
7.3. Line to sub-word segmentation
We also tested our proposed method to segment a text line into sub-words. The tests conducted on images from the KHATT (Mahmoud et al., Citation2014) database that contains Arabic handwritten lines showed the robustness of the method against line skews. The lines were segmented correctly for the different values of skews (see examples in Figure ). Actually, in our method, the line sub-words’ cumulative energies are separated by low-energy regions, which can be crossed by the seams.
Figure 14. Line to sub-word segmentation.
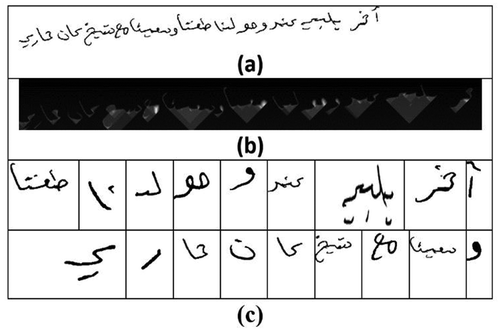
Despite this, some cases of touching sub-words could not be solved, see Figure . Additionally, at the pre-processing stage, small characters could be considered secondary components, which led to their being ignored at the segmentation stage. Such problems can be corrected by categorizing small components into secondary and non-secondary based on their position with respect to the baseline; baseline detection and correction should be done before the detection of secondary components (Boubaker et al., Citation2009).
Figure 15. Non-resolved touching case.

8. Conclusion
Recognition of Arabic handwriting is required in many applications such as keyword spotting, information retrieval, and writer’s recognition. However, Arabic handwriting recognition systems suffer from many limitations due to the characteristics of the language’s handwriting. Among the most common challenges in the recognition of Arabic handwritten documents are overlapping and touching words. In this work, we proposed a new approach to Arabic sub-word segmentation. Our seam carving-based method is designed to read overlapping sub-words correctly.
The proposed method has three main stages. The first stage is the pre-processing stage where the small components, including dots and hamza, were removed and the holes within some characters were filled. The second stage is the segmentation stage; we proposed a new energy function for the seam carving algorithm by designing our distance-based energy function so that it solves the problems of overlapping. We forced the backtracked seams to cross the overlapping region. The final stage was the association stage where the removed dots and hamza were returned to their initial characters.
We tested our proposed method on a set of 300 images of Arabic text drawn from the IESK-ArDB and IFN/ENIT datasets. We showed that our method outperforms the state-of-the-art methods in solving the overlapping problem. Incorrect segmentation was due to over-segmentation principally caused by pen-lifting, which is less harmful for the subsequent stages than under-segmentation. Furthermore, our method showed promising results for the line-to-sub-word segmentation with a robustness against line skews. However, our method needs to be investigated for more cases of touching characters and tested on different datasets with various features such as high slants and other overlapping cases. Seam carving applied for line segmentation showed high segmentation accuracy on historical documents (Arvanitopoulos & Susstrunk, Citation2014). In the future, we intend to extend the proposed approach to sub-word segmentation of Arabic historical documents.
correction
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
Notes on contributors
Lamia Berriche
Lamia Berriche is an assistant professor at Prince Sultan University in Saudi Arabia. She received her PhD in signal and image processing from Telecom Paris Tech in France. Initially, she worked on wireless communication systems and wireless networks. Currently, she is interested in image processing, computer vision steganography, and biometrics domains.
Abeer Al-Mutairy
Abeer Al-Mutairy received her master’s degree in computer science from Al-Imam Mohammad Ibn Saud Islamic University in 2019. Currently, she works as a system analyst at Al-Imam Mohammad Ibn Saud Islamic University.
References
- Al Dmour, A., El Rube, I., & Almazaydeh, L. (2018). A new method for curvilinear text line extraction and straightening of Arabic handwritten text. The International Arab Journal of Information Technology, 15(5), 881–19. https://iajit.org/index.php?option=com_content&task=view&id=1573&Itemid=460
- Alginahi, Y. M. (2013). A survey of Arabic character segmentation. International Journal on Document Analysis and Recognition (IJDAR), 16(2), 105–126. https://doi.org/10.1007/s10032-012-0188-6
- Alkhateeb, J. H., Jiang, J., Ren, J., & Ipson, S. S. (2009). Component-based segmentation of words from handwritten Arabic text. International Journal of Computer Systems Science and Engineering, 5(1), 54–85. http://csse.crlpublishing.com/index.php/csse
- Arvanitopoulos, N., & Susstrunk, S. (2014). Seam carving for text line extraction on color and grayscale historical manuscripts. 14th International Conference on Frontiers in Handwriting Recognition.
- Atallah, A. M., & Al-Shatnawi, M. (2014). A skew detection and correction technique for Arabic script text-line based on subword bounding. IEEE International Conference on Computational Intelligence and Computing Research.
- Atallah, M., Al-Shatnawi, & Khairuddin, O. (2009). Skew detection and correction technique for Arabic document images based on centre of gravity. Journal of Computer Science, 5(5), 363–368. https://doi.org/10.3844/jcssp.2009.363.368
- Avidan, S., & Shamir, A. (2007). Seam carving for content-aware image resizing. ACM Transaction on Graphics, 26(3), 10. https://doi.org/10.1145/1276377.1276390
- Boubaker, H., Kherallah, M., & Alimi, A. (2009). New algorithm of straight or curved baseline detection for short Arabic. 10th International Conference on Document Analysis and Recognition (pp. 778–782).
- Boukharouba, A. (2017). A new algorithm for skew correction and baseline detection based on the randomized hough transform. Journal of King Saud University—Computer and Information Sciences, 29(1), 29–38. https://doi.org/10.1016/j.jksuci.2016.02.002
- Casey, R., & Lecolinet, E. (1996). A survey of methods and strategies in character segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 18(7), 690–706. https://doi.org/10.1109/34.506792
- Daldali, M., & Souhar, A. (2018). Handwritten Arabic documents segmentation into text lines using seam carving. International Journal of Interactive Multimedia and Artificial Intelligence, 5(5), 89–96. https://doi.org/10.9781/ijimai.2018.06.002
- El Mamoun, M., Zennaki, M., & Sadoun, K. (2019). Efficient analysis of vertical projection histogram to segment arabic handwritten characters. Computers, Materials and Continua, 60(1), 55–66. https://doi.org/10.32604/cmc.2019.06444
- Elzobi, M., Al-Hamadi, A., & Al Aghbari, Z. (2011). Off-line handwritten arabic words segmentation based on structural features and connected components analysis. WSCG Communication Papers.
- Elzobi, M., Al-Hamadi, A., Al Aghbari, Z., & Dings, L. (2013). IESK-ArDB: A database for handwritten arabic and an optimized topological segmentation approach. International Journal on Document Analysis and Recognition (IJDAR), 16(3), 295–308. https://doi.org/10.1007/s10032-012-0190-z
- Fazel, M., Ghadikolaie, Y., & Kab, E. (2016). Sub-word based offline handwritten farsi word recognition using recurrent neural network. ETRI Journal, 38(4), 703–713. https://doi.org/10.4218/etrij.16.0115.0542
- Ghaleb, H., Nagabhushan, P., & Pal, U. (2015). Segmentation of overlapped handwritten Arabic sub-words. International Journal of Computer Applications Proceedings on National Conference on Digital Image and Signal Processing,2, 25–29.https://www.ijcaonline.org/proceedings/disp2015/number2/20486-3018
- Ghaleb, H., Nagabhushan, P., & Umapada, P. (2016). Graph modeling sub-words based segmentation of handwritten Arabic text into constituent subwords. International Journal of Image, Graphics & Signal Processing, 8(12), 8–20. https://doi.org/10.5815/ijigsp.2016.12.02
- Humied, I. A. (2016). Segmentation accuracy for offline Arabic handwritten recognition based on bounding box algorithm. Communications on Applied Electronics, 5(9), 21–30. https://doi.org/10.5120/cae2016652364
- Khan, F., Bouridane, A., Khelifi, F., Almotaeryi, R., & Almaadeed, S. (2014). Efficient segmentation of sub-words within handwritten Arabic words. International Conference on Control, Decision and Information Technologies.
- Lamsaf, A., Aitkerroum, M., Boulaknadel, S., & Fakhri, Y. (2018). Lines segmentation and word extraction of arabic handwritten text. Proceedings of the 3rd International Conference on Smart City Applications. Tetouan Morocco.
- Lawgali, A. (2015). A survey of arabic character recognition. International Journal of Signal Processing, Image Processing and Pattern Recognition., 8(2), 401–426. https://doi.org/10.14257/ijsip.2015.8.2.37
- Mahmoud, S. A., Ahmed, I., Al-Khatib, W. G., Alshayeb, M., Parvez, M. T., Margner, V., & Fink, G. A. (2014). KHATT: An open Arabic offline handwritten text database. Pattern Recognition, 47(3), 1096–1112. https://doi.org/10.1016/j.patcog.2013.08.009
- Makki, M., & Al-Jawad, N., (2017). Off line writer identification for Arabic language: Analysis and classification techniques using subwords features. IEEE International Workshop on Arabic Script Analysis and Recognition.
- Menasria, A., Bennia, A., & Nemis, M. (2018). Multiclassifiers system for handwritten Arabic literal amounts recognition based on enhanced feature extraction model. Journal of Electronic Imaging, 27(3), 1. https://doi.org/10.1117/1.JEI.27.3.033024
- Pechwitz, M., Maddouri, S. S., Märgner, V., Ellouze, N., & Ami. (2002). IFN/ENIT—database of handwritten Arabic words. CIFED.
- Saabni, R., Asi, A., & El-Sana, J. (2014). Text line extraction for historical document images. Pattern Recognition Letters, 35(1) 23–33. https://doi.org/10.1016/j.patrec.2013.07.007
- Saabni, R., & El-Sana, J. (2011). Language-independent text lines extraction using seam carving. International Conference on Document Analysis and Recognition (ICDAR).
- Samoud, F. B., Maddouri, S. S., & Ellouze, N. (2012). A hybrid method for three segmentation levels of handwritten Arabic script. Proceedings of the International Workshop on Multilingual OCR.
- Snoussi Maddouri, S., Ghazouani, F., & Bouafif Samoud, F. (2014). Text lines and PAWs segmentation of handwritten arabic document by two hybrid methods. International Conference on Advanced Technologies for Signal and Image Processing.
- Zhang, X., & Tan, C. L. (2014). Text line segmentation for handwritten documents using constrained seam carving. 14th Internation Conference on Frontiers in Handwriting Recognition.
- Ziaratban, M., & Faez, K. (2009). Non-uniform slant estimation and correction for Farsi/Arabic handwritten words. International Journal on Document Analysis and Recognition, 12(4), 249–267. https://doi.org/10.1007/s10032-009-0092-x