
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Diabetic retinopathy is a common complication of diabetes, that affects blood vessels in the light-sensitive tissue called the retina. It is the most common cause of vision loss among people with diabetes and the leading cause of vision impairment and blindness among working-age adults. Recent progress in the use of automated systems for diabetic retinopathy diagnostics has offered new challenges for the industry, namely the search for a less resource-intensive architecture, e.g., for the development of low-cost embedded software. This paper proposes a comparison between two widely used conventional architectures (DenseNet, ResNet) with the new optimized one (EfficientNet). The proposed methods classify the retinal image as one of 5 class cases based on the dataset obtained from the 4th Asia Pacific Tele-Ophthalmology Society (APTOS) Symposium.
PUBLIC INTEREST STATEMENT
Imagine that we can stop blindness before it becomes irreversible, with the help of simple hardware and common cell phone. The problem of blindness is closely related to the disease of diabetic retinopathy (DR) - a vascular complication of diabetes mellitus (DM). DR takes one of the first places as the cause of blindness and visual impairment in the age group from 20 to 70 years. In this study, we offer testing results of various state-of-the-art neural network architectures applied to DR diagnosis, in terms of accuracy and performance. The purpose of such work is the hardware-software complex in the form of a service that can be used by a non-specialized medical worker (paramedic and nurse), this is especially important for the rural and regional population, where there are not enough doctors (ophthalmologists and endocrinologists). And moreover, not everywhere there is access to the Internet.
1. Introduction
Diabetic retinopathy (DR) is one of the significant causes of blindness. Since DR is a progressive process, medical experts suggest that patients with diabetes must be screened at least twice a year to diagnose the signs of the disease promptly. With the current clinical diagnosis, detection is mainly based on the fact that the ophthalmologist examines the color image of the fundus. This detection is laborious and time-consuming, which leads to a more significant error. Also, due to a large number of patients with diabetes and the lack of medical resources in some areas, many patients with DR cannot diagnose and treat promptly, thus losing the best treatment options and ultimately leading to irreversible loss of vision. Especially for those patients at an early stage, if DR can be detected and treated immediately, the process can be well controlled and delayed. At the same time, the effect of manual interpretation is exceptionally dependent on the experience of the clinician. Misdiagnosis often occurs due to a lack of experience with doctors. (Aljawadi & Shaya, Citation2007; Kaleeva & Libman, Citation2010; Lisochkina et al., Citation2004).
In connection with the problem of an erroneous diagnosis, the development of intelligent systems to support decision-making by ophthalmologists has aroused the interest of the scientific community in several works (Gadekallu et al. Citation2020; Gulshan et al., Citation2016; Mateen et al., Citation2018; Reddy et al., Citation2020).
We should note the pioneering work (Gulshan et al., Citation2016), the main idea is dedicated to telemedicine issues, namely the ability to diagnose retinopathy remotely based on images obtained using a cell phone. The study shows a methodological approach for obtaining fundus images with subsequent diagnosis by neurocomputing algorithms and comparing the results with the opinion of ophthalmologists. The mentioned above neurocomputing algorithms are Convolutional Neural Networks (CNN). The base hardware is the smartphone iPhone 4. The sample size of patients was small, only 55 people, 110 eye shots. In general, remote diagnostics showed high values of sensitivity and specificity.
CNN have made remarkable achievements in a large number of computer vision and image classification, significantly exceeding all previous image analysis methodologies.
(Russakovsky et al., Citation2012) described new CNN architecture—AlexNet. It showed significant performance improvements at the 2012 LSVRC competition, achieving top-5 error 15,31 %. For comparison, a method that does not use convolutional neural networks received an error of 26.1%. The network contains 62.3 million parameters and spends 1.1 billion calculations in a direct pass. Convolutional layers, which account for 6% of all parameters, perform 95% of the calculations.
VGG Net is a convolutional neural network model proposed in (Simonyan and Zisserman (Citation2014). At the 2014 ILSVRC competition, an ensemble of two VGG Net received a top-5 error of 7.3%. Due to the depth and number of fully connected nodes, the VGG16 weighs over 533 MB and contains 138 million parameters. The enormous size of VGG makes the deployment process of the model a tedious task.
The next step in the development of CNN model was the winner of ILSVRC 2015 with a top-5 error of 3.57%—an ensemble of six ResNet type (Residual Network) networks developed by Microsoft Research (K. He et al., Citation2016). The ResNet-50 has over 23 million trainable parameters.
The next architecture, in which it was possible to significantly reduce the number of parameters without significant loss of quality, was published in (Huang et al., Citation2017) and called DenseNet (Dense Convolutional Network). The main idea of the architecture is to shorten the connection at CNN, which allowed to train deeper and more accurate models. With dense connection, fewer parameters and high accuracy are achieved compared with ResNet and Pre-Activation ResNet. DenseNet121 number of model parameters was 7 million.
Recent work (Real et al., Citation2019) presented a new artificially discovered architecture—AmoebaNet-A. The architecture sets a new state-of-the-art 83.9% top-1/96.6% top-5 ImageNet accuracy. The results are comparable to the current state-of-the-art ImageNet models.
There is a modern EfficientNet architecture that achieve much better accuracy and efficiency than AmoebaNet-C. EfficientNet-B7 achieves state-of-the-art 84.4% top-1/97.1% top-5 accuracy on ImageNet while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet (Tan & Le, Citation2019). Thus, one of the important areas of research was the issue of reducing the computational complexity of neural network architectures while maintaining an acceptable level of accuracy. Indeed, the modern requirements for diagnostic software imply working offline, since not all settlements have high-quality high-speed Internet. This paper explores the use of low resource CNN architectures for the diagnosis of diabetic retinopathy.
2. Related work
The task of the early detection of DR is a hard problem in the field of computer vision area. The goal of detection is to find clinical features of retinopathy due to diagnostic transparency requirements. In retinal color fundus images, there are various clinical features of DR, such as microaneurysms, hemorrhages, exudates, and others. The extraction of these signs are an essential matter for the precise diagnostics; they help to determine the actual status of DR.
(Hann et. al., Citation2009) states a conventional approach based on the morphology of digital images that extracts the number such features from fundus images. The advantages of the approach are transparency and simplicity. The presence of exudates next to macular on fundus image are an important diagnostical sign of diabetic macular edema.
The work of (Walter et al., Citation2002) presented efficient algorithms for the extraction of the retinal exudates and optic disc. The main idea of the paper that exudates can be extracted with the help of high grey level variations, and their contour can be detected with morphological reconstruction techniques.
Another work of (Agurto et al., Citation2010) proposed an approach based on multiscale amplitude-modulation frequency-modulation (AM-FM) methods to discriminate between normal and pathological retinal images. The modulations were applied to the set of different small regions of fundus images with different types of lesions. After that, the feature vector of a small region was derived from the amplitude-frequency response. The authors claimed that there is a statistical differentiation of normal retinal structures and pathological lesions based on AM-FM features. (Kazakh-British et al., Citation2018) conducted numerical experiments with the following processing pipeline; first of all, Frangi & Sato filters were applied to fundus images for blood vessels extraction; after that, the CNN classifier was trained to detect lesions.
(Abràmoff et al., Citation2010) tested wavelet detectors and k Nearest Neighbors for clinical feature extraction from fundus images. The results of the extraction are AUC 0.86 and Standard Error 0.0084. It worth noting that the dataset was produced with the help of “non-mydriatic” digital retinal cameras. The size of a fundus image varied from 0.15 to 0.5MB.
(Gulshan et al., Citation2016) tested the deep learning algorithm of diabetic retinopathy on the dataset that was produced with the help of a smartphone. This paper shows the opportunity of access to diagnostical methods of diabetic retinopathy for a broad audience.
(Pratt et al., Citation2016) developed and tested CNN with 13 layers to detect the stage of DR. Their CNN was trained and tested on NVIDIA K40c. Also, the authors stated that image with size 512 × 512 could be processed in 0.04 seconds, which makes possible real-time feedback.
(Tan et al., Citation2017) proposed another CNN with 10 layers to simultaneously segment and discriminate exudates, hemorrhages, and micro-aneurisms. The results of exudates detection are sensitivity 0,87 and 0,71. The sensitivities of hemorrhages and micro-aneurisms are 0,62 and 0,46.
(Choi et al., Citation2017) tested VGG-19 architecture on STructured Analysis of the REtina (STARE) database. The results achieved an accuracy of 30.5%, relative classifier information (RCI) of 0.052, and Cohen’s kappa of 0.224 on 10 categories as the target variable. In the case of 3 categories, results are showed an accuracy of 72.8%, 0.283 RCI, and 0.577 kappa.
(Mateen et al., Citation2018) proposed a symmetrically optimized solution through the combination of a Gaussian mixture model (GMM), visual geometry group network (VGGNet), singular value decomposition (SVD) and principal component analysis (PCA), and softmax, for region segmentation, high dimensional feature extraction, feature selection, and fundus image classification, respectively. The authors claimed that the VGG-19 model outperformed the AlexNet and spatial invariant feature transform (SIFT) in terms of classification accuracy and computational time.
(Khalifa et al., Citation2019) presented deep transfer learning models for medical DR detection were investigated. The numerical experiments were conducted on the Asia Pacific Tele-Ophthalmology Society (APTOS) 2019 dataset. The models in this research were AlexNet, Res-Net18, SqueezeNet, GoogleNet, VGG16, and VGG19. These models were selected, as they consist of a small number of layers when compared to larger models, such as DenseNet and InceptionResNet. Data augmentation techniques were used to render the models more robust and to overcome the overfitting problem.
We are working on the classification of fundus images according to the severity of DR so that we can perform end-to-end classification in real-time from the fundus image to the state of patients. For this task, we use pixel normalization techniques to highlight various clinical features (blood vessels, exudates, microaneurysms, and others) and then classify the retinal image into the appropriate stage of the disease. We adopt the CNN architecture for DR discovery in the “APTOS 2019 Blindness Detection” Dataset. The contribution of this article is summarized as follows:
We test the latest CNN model (DenseNet121, ResNet50, ResNet101, EfficientNet-b4) to recognize small differences between classes of images for DR detection (F. He et al., Citation2019; Hu et al., Citation2017; Tan & Le, Citation2019)
Hand-held training and tuning of hyper-parameters are adopted, and the experimental results have demonstrated better accuracy than the non-transmitting training method for classifying DR images.
3. Dataset
Aravind Eye Hospital collected the dataset of fundus images of high quality in India, information about the dataset can be found at https://www.kaggle.com/c/aptos2019-blindness-detection/. It consists of 10 GB of data across 5,590 RGB-images of the fundus(approximately). The data owners divided the dataset into two parts, in particular, the training dataset consists of 3662 images with target labels and 1928 of the testing dataset without labels. Like any real-world data set, there is a noise in both the images and labels. Images may contain artifacts, be out of focus, underexposed, or overexposed. The images were gathered from multiple clinics using a variety of cameras over an extended period, which affects further variation.
There are five classes in data; from Table , one can see that classes are not uniformly represented.
Table 1. Distribution of images across classes
4. Preprocessing
There is a first step of preprocessing of all images before augmentation and training. All images were normalized to keep the efficiency of models pre-trained on ImageNet. Preprocessing involved several steps:
1. Balancing image sizes: images were rescaled to have the same radius and cropped to avoid uninformative black pixels around the edges of the fundus.
2. Reducing lighting-condition effects: images come with many different lighting conditions: some images are very dark. That was fixed by subtracting the local average color from each pixel.
3. CLAHE: Contrast adjustment was performed using the contrast limited adaptive histogram equalization (CLAHE) filtering algorithm (Reza, Citation2004).
We applied augmentation on images in real-time to reduce overfitting. During each epoch, a random augmentation of images that preserve collinearity and distance ratios was performed.
The training was started from no augmentation applied, retrained with light, mid, substantial augmentation:
1. Light: randomly rotate an image 90 degrees, randomly flip an image horizontally.
2. Mid: randomly rotate an image 90 degrees, randomly flip an image horizontally and transpose an image by swapping rows and columns. Apply median blur with randomly picked parameters. Randomly apply CLAHE, Sharpening or Randomize Contrast and Brightness.
3. Strong: randomly rotate image 90 degrees, randomly flip the image horizontally, transpose the image by swapping rows and columns. Apply median blur with randomly picked parameters. Randomly apply CLAHE, sharpening filter or randomized contrast and brightness adjustments, distortion and hue shift.
All steps of preprocessing presented in Table . There is a visual result of preprocessing in Figure .
Figure 1. Examples of fundus images before(left) and after(right) preprocessing.
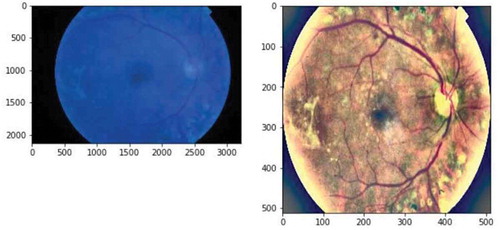
Table 2. Preprocessing flowchart
5. EfficientNet model
It is common practice to develop convolutional neural networks (CNNs) at a lower resource cost, and then if more resources are available, scaled it up to achieve better performance. There are several options to scale a model, namely, there is arbitrarily increasing of the CNN depth or width, or to use high-resolution input images during the training phase to grab data dependencies in detail.
While such an approach is good at improving model accuracy, it usually requires manual tuning, and still often yield suboptimal performance.
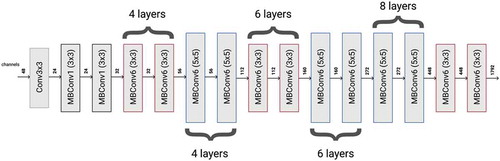
For comparative analysis, we chose the EfficientNet-B4 model that is ahead of the results, remaining significantly less in the number of model parameters. Its architecture is presented in Figure .
Figure 2. Architecture of efficientNet-B4 model.
In general, one can define a convolutional layer as tensor function, namely , where Fi is tensor operator, Yi is output tensor, Xi is input tensor. The input tensor shape
, Hi and Wi are spatial dimensions and Ci is a color dimension. One should define the model of convolutional networks as a sequence of embedded functions (Tan & Le, Citation2019), where
is a layer repeated L times at stage i,
is the shape of the input tensor of the particular layer;
is the operator of a Hadamard product. The complexity and performance of a CNN model depend on width, height, depth parameters. There is a method to scale up a CNN to obtain better accuracy and efficiency based on compound scaling method with the following coefficient Φ to uniformly scales network width, height, and resolution (Tan & Le, Citation2019), where α, β, γ are constants that can be defined by grid search. Briefly, Φ is a user-defined parameter that controls the number of free resources for model scaling, while α, β, γ specify the scaled aspect of a model (Tan & Le, Citation2019). On the mentioned above principles EfficientNet-b4 was generated and used at the presented work.
6. Numerical experiments
To compare the quality and performance of various models, we conducted experiments with preprocessed and not preprocessed images. The dataset is divided into training and validation data and also compared the variants with 5 classes. The assessment value of the classification is the Κ-statistic, which is used to control only those instances that may have been correctly classified by chance. The Κ can be calculated using both the observed (total) accuracy and random accuracy, where total accuracy;
—random accuracy. Non-preprocessed images obtained a Κ below 0.656 with various models. The error was calculated using cross-entropy for discrete values. Accuracy was calculated using a conventional formula. At the Table there are the results of the numerical experiments of various models. The preprocessed photos have a Κ below 0.690, as you can see at Table , the accuracy had significantly increased when strong augmentation was added to the pipeline of the models. The best model we obtained through the encoding of network output with the help of ordinal regression, the K coefficient below 0.790. On another hand, the best results were obtained on contemporary model EfficientNet-b4 with respect to familiar models such as DenseNet and ResNet, which explains the good convergence of EfficientNet-b4 and complete applicability in the task of DR diagnosis. The estimation of computational complexities presented at Table .
Table 3. Comparative analysis of classification models
Table 4. Numbers of parameters of classification models
7. Conclusion
The task of early detection of diabetic retinopathy is an actual problem of predictive medicine. Diabetic retinopathy is the most common cause of blindness among the old aged group of people. Due to the development of technologies the diagnostics methods become available for all segments of the population. The most advanced techniques that help detect the stage of diabetic retinopathy resides in a field of neurocomputing. The open problem of the area is computational complexity because there is a demand of smartphone embedded software with low computational requirements. In the paper, we show the possibility of the various pixel normalization techniques to highlight various clinical features (blood vessels, exudates, microaneurysms, and others) and then classify the retinal image into the appropriate stage of the disease. Also, we show the possibility of the development of such a diagnosis method with the help of EfficentNet in comparison with other neural network architectures. EfficientNet is an optimal model in terms of accuracy and number of parameters. The numerical experiments were conducted on the Asia Pacific Tele-Ophthalmology Society (APTOS) 2019 dataset. Further work assumes the augmentation of the algorithm with preprocessing in order to reveal clinical-pathological features and performance upgrades.
Acknowledgements
We gratefully acknowledge the financial support of the Ministry of Education and Sciences, Republic of Kazakhstan (Grant AP05132760).
Additional information
Funding
Notes on contributors
Alexandr Pak
Our team comprises of 5 people. We specialize in artificial neural networks, natural language processing, digital signal and image processing. The goals and objectives of the research are the development and testing of methods, algorithms, and architectures of applied neural networks to medical data, in particular to diabetic retinopathy.
Pak Aleхandr Aleхandrovich - Candidate of Technical Sciences, Assistant Professor at FIT KBTU, Scientific Leader of the Doctoral Candidate, Project Manager: No. AP05132760 “The development of methods for deep learning of semantic probability inference” of the Institute of Information and Computational Technologies.
Atabay Ziyaden- software engineer in (IICT), Big data mining laboratory.
Tukeshev Kuanysh – Medical Doctor at Institute of Eye Diseases.
Jaxylykova Assel- PhD student from KazNU, IICT in specialty: «Information Systems».
Abdullina Dana – Medical Doctor at Institute of Eye Diseases.
References
- Abramoff, M. D., Garvin, M. K., & Sonka, M. (2010). Retinal Imaging and Image Analysis. IEEE Reviews in Biomedical Engineering, 3, 169–9. doi:10.1109/RBME.2010.2084567
- Agurto, C., Murray, V., Barriga, E., Murillo, S., Pattichis, M., Davis, H., … Soliz, P. (2010). Multiscale AM-FM methods for diabetic retinopathy lesion detection. IEEE Transactions on Medical Imaging, 29(2), 502–512. https://doi.org/10.1109/TMI.2009.2037146
- Aljawadi, M., & Shaya, F. T. (2007). Diabetic retinopathy. Clinical Ophthalmology, 3(1), 259–265. https://pubmed.ncbi.nlm.nih.gov/19668479/
- Choi, J. Y., Yoo, T. K., Seo, J. G., Kwak, J., Um, T. T., & Rim, T. H. (2017). Multi-categorical deep learning neural network to classify retinal images: A pilot study employing small database. PloS One, 12(11), e0187336. https://doi.org/10.1371/journal.pone.0187336
- Gadekallu, T. R., Khare, N., Bhattacharya, S., Singh, S., Reddy Maddikunta, P. K., Ra, I. H., & Alazab, M. (2020). Early detection of diabetic retinopathy using PCA-firefly based deep learning model. Electronics, 9(2), 274. https://doi.org/10.3390/electronics9020274
- Gulshan, V., Peng, L., Coram, M., Stumpe, M. C., Wu, D., Narayanaswamy, A., … Kim, R. (2016). Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. Jama, 316(22), 2402–2410. https://doi.org/10.1001/jama.2016.17216
- Hann, C. E., Revie, J. A., Hewett, D., Chase, J. G., & Shaw, G. M. (2009). Screening for Diabetic Retinopathy Using Computer Vision and Physiological Markers. Journal of Diabetes Science and Technology, 3(4),819–834. doi:10.1177/193229680900300431
- He, F., Liu, T., & Tao, D. (2019). Why resnet works? residuals generalize. arXiv Preprint arXiv:1904.01367. https://doi.org/10.1109/tnnls.2020.2966319
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778). https://www.computer.org/csdl/proceedings-article/cvpr/2016/8851a770/12OmNxvwoXv
- Hu, H., Dey, D., Del Giorno, A., Hebert, M., & Bagnell, J. A. (2017). Log-DenseNet: How to sparsify a DenseNet. arXiv Preprint arXiv:1711.00002. https://ui.adsabs.harvard.edu/abs/2017arXiv171100002H/abstract
- Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700–4708), Los Alamitos, CA, USA.
- Kaleeva, E. V., & Libman, E. S. (2010). The state and dynamics of disability due to visual impairment in Russia. In Materials of the IX Congress of Ophthalmologists.
- Kazakh-British, N. S., Pak, A. A., & Abdullina, D. (2018, October). Automatic detection of blood vessels and classification in retinal images for diabetic retinopathy diagnosis with application of convolution neural network. In Proceedings of the 2018 international conference on sensors, signal and image processing (pp. 60–63), International Conference on Sensors, Signal and Image Processing, Prague. ACM.
- Khalifa, N. E. M., Loey, M., Taha, M. H. N., & Mohamed, H. N. E. T. (2019). Deep transfer learning models for medical diabetic retinopathy detection. Acta Informatica Medica, 27(5), 327. https://doi.org/10.5455/aim.2019.27.327-332
- Krizhevsky, A., Ilya Sutskever, & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Neural Information Processing Systems Conference, 25, 1097–1105. https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
- Lisochkina, S. B., Astakhov, Y. S., & Shadrichev, F. E. (2004). Diabetic retinopathy (tactics of patient management). Clinical Ophthalmology, 5(2), 85–92. https://www.rmj.ru/articles/oftalmologiya/Diabeticheskaya_retinopatiya_taktika_vedeniya_pacientov/
- Mateen, M., Wen, J., Song, S., & Huang, Z. (2018). Fundus image classification using VGG-19 architecture with PCA and SVD. Symmetry, 11(1), 1. https://doi.org/10.3390/sym11010001
- Pratt, H., Coenen, F., Broadbent, D. M., Harding, S. P., & Zheng, Y. (2016). Convolutional neural networks for diabetic retinopathy. Procedia Computer Science, 90, 200–205. https://doi.org/10.1016/j.procs.2016.07.014
- Real, E., Aggarwal, A., Huang, Y., & Le, Q. V. (2019, July). Regularized evolution for image classifier architecture search. In Proceedings of the aaai conference on artificial intelligence (Vol. 33, pp. 4780–4789), Honolulu, Hawaii, USA.
- Reddy, G. T., Reddy, M. P. K., Lakshmanna, K., Kaluri, R., Rajput, D. S., Srivastava, G., & Baker, T. (2020). Analysis of dimensionality reduction techniques on big data. IEEE Access, 8, 54776–54788. https://doi.org/10.1109/ACCESS.2020.2980942
- Reza, A. M. (2004). Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. Journal of VLSI signal processing systems for signal. Image and Video Technology, 38(1), 35–44. https://doi.org/10.1023/B:VLSI.0000028532.53893.82
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv Preprint arXiv:1409.1556. https://arxiv.org/pdf/1409.1556.pdf
- Tan, J. H., Fujita, H., Sivaprasad, S., Bhandary, S. V., Rao, A. K., Chua, K. C., & Acharya, U. R. (2017). Automated segmentation of exudates, haemorrhages, microaneurysms using single convolutional neural network. Information Sciences, 420, 66–76. https://doi.org/10.1016/j.ins.2017.08.050
- Tan, M., & Le, Q. V. (2019). EfficientNet: rethinking model scaling for convolutional neural networks. arXiv Preprint, arXiv:1905.11946. http://proceedings.mlr.press/v97/tan19a/tan19a.pdf
- Walter, T., Klein, J.-C., Massin, P., & Erginay, A. (2002). A contribution of image processing to the diagnosis of diabetic retinopathy-detection of exudates in color fundus images of the human retina. IEEE Transactions on Medical Imaging, 21(10),1236–1243. doi:10.1109/TMI.2002.806290