
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper proposes a novel approach to utilizing open-source legal databases in academic education, especially in the fields of law and police investigations. Our framework provides a way to organize and analyze this data and extract reports that are associated with crime scenes, addressing the challenge of classifying unstructured legal documents by using text mining, natural language processing, and machine learning techniques. We developed a supervised machine learning model capable of accurately classifying court documents based on two classifiers: one identifies the documents containing crime scenes, and the other classifies them into five types of crimes. The experimental results were promising, as the random forest algorithm achieved an accuracy of 91.07% for the first classifier and support vector machines achieved an accuracy of 82.46% for the second classifier. What distinguishes our work is the creation of a crime dictionary that includes 70 crime tools and 151 related terms extracted from various forensic sources. It is considered relatively small, but it contributed to giving good classification results. The proposed crime dictionary can be generalized, developed, used in advanced searches, and integrated with police databases to improve crime scene analysis. Overall, the research highlights the use of court databases in police academic education and attempts to utilize them in a more effective manner.
REVIEWING EDITOR:
1. Introduction
Police officers often spend a substantial amount of their time writing reports, which are required for recording different situations. These reports, often known as police reports, comprise all relevant paperwork and narratives that document the events, persons involved, and officers’ activities. Accuracy in reporting a broad variety of scenarios, from small occurrences to major crimes, is critical. These reports act as a replacement for officers in court, assisting the judicial system in understanding their findings. Despite the importance of report writing, many police schools provide little instruction in this area. While police are trained in many parts of law enforcement, report writing is sometimes overlooked and should be included in a more comprehensive curriculum that covers all aspects of the criminal justice system (Yu & Monas, Citation2020).
Studies have shown that there is a link between reading and writing abilities, since reading is an effective source of writing that helps pupils overcome language and topic knowledge issues. Reading may help to create writing models by composing and organizing phrases, paragraphs, and essays. It also improves critical thinking skills by requiring students to evaluate and analyze the content they encounter, which is necessary for writing compelling and logical arguments (Bai & Wang, Citation2023; Graham & Hebert, Citation2010; Shanahan & Shanahan, Citation2008). According to these studies, reading actual reports can help forensics and law enforcement students improve their writing skills and gain practical knowledge, such as crime scene analysis, hypothesis development, legal terminology, and identifying court-worthy points of interest. Academics can also use these cases as teaching tools, presenting them to students as case studies and leading in-depth discussions about various aspects of the cases, such as flaws in the investigations, improper evidence presentation, and the possibility of overturning the ruling. However, the public is often unable to access police reports due to legal restrictions on data use agreements, concerns about victims’ privacy information, and the need for permission from the relevant authorities. As a result, despite the educational value of these reports, their distribution is a challenge. To address this issue, we reviewed existing research (HeinOnline, Citation2022; Lage-Freitas et al., Citation2022; Novotná & Harašta, Citation2019; The Caselaw Access Project (CAP), Citation2022; Zhang, Citation2021) and discovered projects from various countries that make legal and court documents available online as a ‘case law dataset’. However, they have the disadvantage of including reports that are not appropriate for our work, whether they are brief or cover topics unrelated to our field.
The main goal of this study is to prepare the criminal documents found in these databases by processing and classifying them using text mining and Machine Learning (ML) techniques and building an educational tool. This tool contains a large group of criminal cases that provide details about the crime and help investigators, whether professionals or trainees, access criminal documents easily. Homicide cases were selected as a case study for our research because they are one of the most popular criminal cases among students due to the many factors and hypotheses requiring logical thinking and analysis. In addition, the Caselaw Access Project (CAP) (Citation2022), a database made available by the Harvard Law School Collection, served as the adopted database for our experiments. The contributions are as follows:
Propose an educational tool for real-life cases using court reports to improve education at police academies. This is the first study of its kind that suggests the utilization of court reports in this field.Build a crime dictionary from different external resources in criminal field.Design a two-phase ML model with a small number of features from the proposed crime dictionary to classify court documents based on homicide crime types.
The rest of the paper is organized as follows: Section 2 presents the related works, and Section 3 describes the materials and method of the proposed framework. In Section 4, the experimental results of the model are illustrated by tables, statistics, and graphs with discussion. Finally, Section 5 concludes the paper and offers suggestions for future investigation.
2. Related works
Crime classification is a complex and multifaceted field that involves categorizing criminal activities using various criteria. There are various systems for classifying crimes, which often differ by jurisdiction and legal framework. Studies on the classification of crimes using crime tools will be reviewed, as we searched for the following keywords: ‘crime classification’, ‘narrative reports’, ‘text mining’, and ‘machine learning’. All studies using statistical police reports to classify crimes were excluded. This is because our topic is about providing crime details to students as an educational resource, preferably narrative police reports. Then we conducted another search, with the goal of finding a suitable open-source database. Because we could not find open-source narrative reports from the police, we turned to alternative sources: ‘legal court documents’ published as databases in various countries. We reviewed studies that used these databases in various fields in general, as well as the CAP database, which we utilized in our research. We also reviewed the methods and machine learning algorithms used in these studies to get a general idea of effective approaches to crime classification and legal document analysis.
2.1. Crime classification
This section explores recent applications and contributions in crime classification using narrative records across various contexts from diverse sources, such as police reports, child welfare records, and social media content, with text mining, natural language processing (NLP), and ML techniques. The literature reviewed demonstrates the potential of these techniques for automating crime analysis tasks and extracting valuable insights from free-text data routinely collected by law enforcement agencies. However, there are limitations and challenges that have been identified in the research.
Some studies have used open-source datasets derived from news websites (Carnaz et al., Citation2021; Thaipisutikul et al., Citation2021), a legal website (Li & Qi, Citation2019), and social media platforms like Twitter (Lal et al., Citation2020) and YouTube (Ashraf et al., Citation2020). These datasets are not suitable for our study because they lack details about crimes in the reports, and some of them use datasets in languages other than English. In contrast, several studies were acquired which classify crimes according to unstructured narrative police reports and for various objectives. The systems implemented in the studies (Birks et al., Citation2020; Kuang et al., Citation2017; Mohemad et al., Citation2020; Percy et al., Citation2018) aimed to identify and prevent crime patterns such as burglaries, housebreakings, and murder. Domestic violence has also been the subject of research, including that of Karystianis et al. (Citation2022). It emphasizes the various forms of abuse and the injuries sustained by victims to offer distinctive perspectives on domestic violence patterns that can be utilized to monitor and regulate. To reduce violent deaths, Arseniev-Koehler et al. (Citation2022) identified patterns surrounding suicides, homicides, and other violent fatalities. Furthermore, in an effort to formulate social service initiatives, Victor et al. (Citation2021) identified instances of violence in the writings of abused children. In addition, Geurts et al. (Citation2023) and Baek et al. (Citation2021) each conducted research that resulted in the development of a risk assessment tool and an early identification of risk situations, respectively. The mentioned studies utilize various ML algorithms for different crime-related tasks like analysis, classification, crime detection, and prevention. A summary of these studies is presented in .
Table 1. Summary of related studies to the crime classification.
One of the constraints of these studies is their reliance on private or restricted data sets, which could hinder the progress of the research and prevent external validation of the findings. Online-published and open-source court databases were proposed as a potential solution to this problem. A potential analytical bias is introduced because these investigations mine and extract features for classification from the same dataset, which is the second limitation. The presence of bias in text mining and ML models with respect to groups of individuals or categories of crimes can result in inaccurate or unjust outcomes. Furthermore, the functionality of the classifier cannot be applied to different datasets that fall under the same domain. As a result, a proposition was made to establish a crime dictionary, comprising terms gathered from reliable external sources within the domain of crime, with the intention of incorporating them into various datasets.
2.2. Legal documents
Legal document analysis has become an increasingly important area of research in recent years, with a growing need for automated methods to process and analyze legal documents. Many studies have focused on developing ML and NLP techniques using different datasets that include a variety of legal documents, reflecting the complexity and variety of legal contexts. The dataset comprises legal judgments, court case documents, and other legal texts, providing a rich source of unstructured data for analysis. The studies have utilized datasets from various legal domains, including Indian Supreme Court judgments, US state court decisions, European Court of Human Rights cases, and more, as listed in .
Table 2. Summary of studies using legal documents.
The dataset has been employed for a multitude of tasks, such as legal judgment prediction in many studies (Habernal et al., Citation2023; Nuranti et al., Citation2022; Prasad et al., Citation2022; Petrova et al., Citation2020; Tyss et al., Citation2023), sentiment analysis to assess public sentiments on legal issues (Gupta et al., Citation2023), document classification (Prasad et al., Citation2022; Song et al., Citation2022; Tyss et al., Citation2023; Vatsal et al., Citation2023), and information extraction (Chang et al., Citation2020; Castano et al., Citation2020; Savelka et al., Citation2019; Savelka & Ashley, Citation2020; Tang et al., Citation2020). The studies have also explored the use of the dataset for building semantic annotation systems and knowledge graphs to represent legal knowledge in a structured format (Tang et al., Citation2020). It is important to note that the dataset has been instrumental in advancing research in the field of legal document analysis, enabling the development and evaluation of ML and NLP techniques tailored to the legal domain. The utilization of this dataset across multiple studies underscores its significance as a valuable resource for training and testing models, as well as for gaining insights into legal decision-making processes and public perceptions of legal issues.
We concluded, therefore, that we could utilize one of the databases in a new domain, namely academic police education, given that most of them are freely available, open source, and readily accessible. The CAB database, which contains numerous court decisions published in the Harvard Law School Library, was selected because it is one of the most comprehensive legal databases available. Ideal for big data initiatives and streamlining the data mining procedure, the CAP dataset is presented in a pristine, machine-readable format. Previous research in the field of legal document classification and analysis using CAP datasets has not specifically addressed the classification of legal documents based on crime scenes or crime types, which is the primary focus of our intended study. The results of our work seek to assist in educating investigators and helping them organize crime-related materials and information so they can study crime patterns more abstractly.
3. Proposed framework
This section presents our novel framework aimed at classifying legal documents into five criminal types: beating, shooting, stabbing, strangulation, and multiclass. The overall architecture presented in this research is depicted in . The key challenge in achieving our goal relates to the unstructured nature of the documents, which contain narrative information that is not related to the crime scene. To get an overview of its topics and understand its contents, the usual solution is to utilize clustering algorithms. Thus, a Term Frequency-Inverse Document Frequency (TF-IDF) technique with the K-means clustering algorithm was applied as an initial experiment. TF-IDF is a simple technique for converting text into a feature vector based on the Bag-of-Words (BoW) model (Kim & Gil, Citation2019). Different topics were created depending on the word frequency in the document and the importance of the word in the dataset. However, the results were not suitable for our study, as the outcome topics and their keywords were far from what was required. The reason is that the CAP database is primarily for court decisions and not police reports. Most of the documents consist of trial and appeal procedures with other information like the offender’s life history, while the details of the crime scene and scenario are mentioned as background in the document, and their length varies from document to document. For example, the document contains 150 pages, and the important part is about one and a half pages. Therefore, the important keywords in our research may be neglected or of little significance. To solve this problem, a framework was proposed, as shown in , that takes advantage of text mining to explore a big database rapidly and efficiently by using the prior definition of topics with their own keywords as well as ML techniques for analyzing court documents to achieve our objectives. Our primary contribution consists of compiling terms from various sources in the fields of crime and forensics into a crime dictionary. This enables us to extract features from the database that are not restricted to the terms found in the database under investigation, thereby enhancing its generalizability and applicability to other databases. According to the proposed framework, the following main steps are involved in building ML models:
Figure 1. The proposed framework architecture.
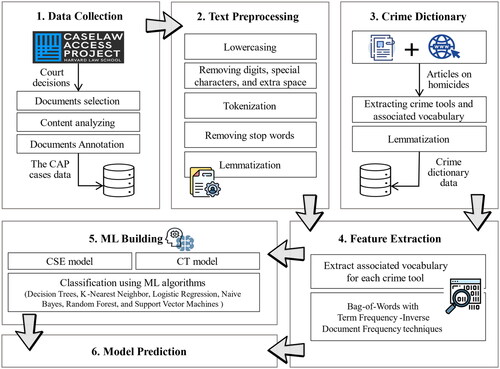
Collect and filter the court decisions from the CAP dataset and label some of them for the ML models. Then, save the filtered documents with labels in the database.
Get the labeled documents from the database to be preprocessed and converted to word tokens.
Create a crime dictionary manually using some websites and research articles on homicides. It will be lemmatized and then stored in the database.
Next, based on the dictionary and BoW with TF-IDF techniques, the text tokens will be embedded and turned into appropriate vectors that can be used as features for the ML models.
Build a two-phase ML model that consists of two models: Crime Scene Existence (CSE) to find out if the document has information about the crime scene or not (binary classification). The second model is Crime Type (CT), which determines the type of crime committed based on the context of the words (multiclass classification). These models apply an appropriate ML algorithm to the TF-IDF vectors with their labels and create the classifiers. For the CT model, TF-IDF vectors of documents with only positive CSE will be used.
The resultant two classifiers from the system can help predict the classification of new court documents automatically.
The proposed model was programmed using the Python language with different libraries like Panda, Natural Language Toolkit (NLTK), and Scikit-Learn (sklearn). It consists of different modules, and the details of each are as follows.
3.1. Data collection
As mentioned previously, our work requires a publicly accessible database containing crime-related information. This does not apply to police reports, as they are subject to privacy laws due to the sensitivity of their details. Therefore, the CAP database was chosen, as it was collected by Harvard University and it is a comprehensive legal database with much information that contains 6,920,596 documents, which represent everything published in the last three hundred years. Although it was not designed specifically to analyze crime scenes or types of crime, the opinions, legal data, and information it provides are valuable sources for educational and research purposes, including the study of cases-related to the crime. After reviewing some cases, we found that the CAP dataset can provide details about crimes that can be used in our work. In addition, it is characterized by the presence of a special website that contains search and retrieval tools, as well as metadata and tagging, to make it easier for users to find specific legal cases or concepts, which is the main reason for choosing it, as it has benefited us in the process of selecting the reports we need to classify and organize cases related to crime scenes and types of crimes. This section outlines the processes used to collect the data and select the legal documents in the CAP dataset. The documents were downloaded as bulk data from the CAP website (The Caselaw Access Project (CAP), Citation2022). The summary of our data collection processes is displayed in .
Figure 2. Flowchart of data collection from CAP website.
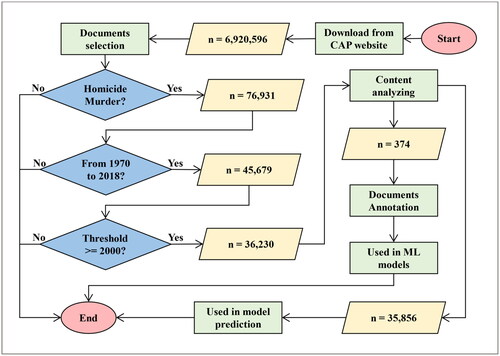
3.1.1. Documents selection
According to the latest statistics, the database contains 6,920,596 documents. For our experiment, 36,230 documents were selected using three filter stages. Firstly, 6,920,596 documents were filtered down to n = 76,931 by using the phrase ‘homicide murder’ to meet the case study for our research. Secondly, the rest of these documents were filtered to n = 45,679 according to their publication date. As all the documents over the past three hundred years are represented in the CAP dataset, the documents for the last fifty years, from 1970 to 2018, were the only ones considered. Lastly, a minimum threshold of 2,000 words was set to eliminate any document that may contain very modest information or lack details. As a result, the final total was n = 36,230 documents. Statistics for the CAP dataset depending on words are shown in .
Table 3. Statistics of the CAP dataset used for experimentation.
3.1.2. Content analyzing
Each document in the CAP dataset has a range of metadata, such as the case name, citation, court, date, etc. Some cases were read randomly to find the important details of the case, which were found in the ‘head_matter’ and ‘Opinions’ under the case body section. It is noted that the documents vary, whether in length as stated in , writing style, or content, as it depends on the writer. Content may include court decisions, general regulations, the constitution, and court proceedings. In addition, some documents contain a crime scene description, witness statements, and the crime scenario, which is relevant to our study and often found under the headings ‘Facts’ and ‘Background’. An example of a document from the CAP dataset with different content is shown in . This information helped facilitate the identification of documents for the annotation process.
Table 4. An example of the different information contained in the court document.
3.1.3. Documents annotation
For classification purposes, some documents from the CAP dataset need to be tagged. Due to the huge number of documents in the dataset, previous information was used to guide our document selection. A subset of metadata was obtained from documents that met our requirements, and two other features were extracted, namely word count and the terms ‘Facts’ and ‘Background’. Accordingly, the documents were sorted and divided into various groups based on these new features. Then, 374 documents were selected in a random fashion from each group and labeled manually for the suggested ML models: CSE and CT.
3.2. Text preprocessing
As the CAP dataset documents are row data, the data must be prepared and cleaned before being analyzed to get higher quality results. This step is important to emphasize features that are used as inputs to our ML model (Joshi, Citation2020; Torfi et al., Citation2020). Basic techniques were implemented as follows:
Convert text to lowercase.
Remove digits, special characters, and extra space from the text.
Through the tokenization of the text into small parts called tokens, word tokens were chosen, and all tokens that had fewer than two letters were dropped.
Remove stop words that have no significant effect in the text, such as conjunctions, determiners, and helping verbs. The predefined stop words from the NLTK package were used.
Lemmatization of the word is an improved method of stemming. This process will return the word forms to their root, which exists in the language’s dictionary. The one that exists in the NLTK package was applied to nouns, verbs, and adjectives. The term ‘wound’ is an important term in our work. An exception was made for it because it was returned to ‘wind’ as the root, which is an inappropriate word in the context.
3.3. Crime dictionary
As previously stated, the CAP dataset includes mixed information in an unstructured format. Thus, the output text from the preprocessing remains inadequate. To improve the performance of the ML classifiers, a dictionary of the topic and its keywords was built, and it contained only the most distinguished keywords. Our field is homicide crimes, and the evidence collected from crime scenes plays an essential role, such as fingerprints, blood, saliva, drugs, and others. The most important is the crime tool, as the investigator can find the weapon at the crime scene or infer it from the marks that exist on the scene and the wounds on the body. All this information is recorded in police reports. In our experiment, the proposed crime dictionary was focused on the associated vocabulary of the crime tool to demonstrate the presence of the crime scene description in the documents. Further, the methods of murder were classified into four types: beating, shooting, stabbing, and strangulation. A crime dictionary was manually gathered, which includes crime types, tools, and associated vocabulary that is repeated in the context. It depends on a site that reviews physical evidence and some articles on homicides (Amita et al., Citation2021; Bohnert et al., Citation2006; Papi et al., Citation2020). The suggested keywords in the dictionary were shown in . In fact, there are eight different lists of topics. It is noticeable that the keywords vary in terms of usage, from common to rare. As the dictionary’s terms are hand-picked, no preprocessing procedures are required. However, it is best to perform only one procedure, lemmatization, to guarantee that the terms are in the root forms and can be compatible with the CAP database after preprocessing the documents.
Table 5. Crime dictionary (list of crime tools and associated vocabulary).
3.4. Feature extraction
The BoW and TF-DF models are the main techniques in our feature extraction process. The classic BoW model extracts words from all the contents of the document. This causes computational complexity, especially if the data volume is huge (Kim & Gil, Citation2019). TF-IDF helps encode words in documents by retrieving words with numerical statistics. For a particular document, TF calculates the ratio of the frequency of a keyword in the document. In contrast, the IDF denotes the dataset’s significance for the keyword (Thaipisutikul et al., Citation2021). Here, only associated vocabulary terms that exist in the crime dictionary were extracted from the documents, and the rest of the words were filtered out, which makes it more specific to what is required and allows faster analysis by reducing the BoW dimension to 151 keywords only. The ‘TfidfVectorizer’ function from sklearn was adopted for this task. The following equations were used to find the value for each document (Borcan, Citation2020; Kim & Gil, Citation2019):
(1)
(1)
(2)
(2)
(3)
(3)
Where is the frequency of word
in document
is the number of documents in the dataset, and
is the frequency of word
in the whole dataset
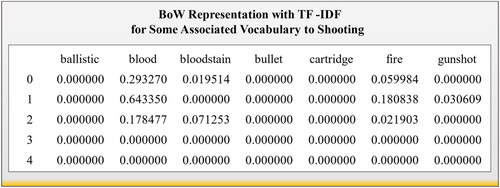
An example of a portion of a BoW representation with TF-IDF is presented in , which shows a
value for some vocabulary associated with a shooting-type crime.
Figure 3. An example of BoW representation with TF-IDF for five documents from the CAP dataset.
3.5. ML building
This phase contains two phases: training and testing with two-stage classification using CSE and CT models, as indicated in . Different functions and methods from the sklearn library were applied to execute our experiment. Several supervised classification algorithms have been implemented (Sen et al., Citation2020; scikit-learn: Machine Learning in Python, Citation2023): Decision Trees (DT), K-Nearest Neighbor (KNN), Logistic Regression (LR), Naive Bayes (NB), Random Forest (RF), and Support Vector Machines (SVM). The CSE model is a binary classification that is responsible for checking if a document contains a crime description. It has two classes: ‘Not Exist’ labeled with 0, and ‘Exist’ labeled with 1. In the next stage, the CT model will work only on documents that have an ‘Exist’ class resulting from the first model. It is a multiclass classification labeled from one to five that is responsible for classifying documents according to crime types.
3.6. Model prediction
The purpose of this step is to apply the CSE and CT classifiers that were acquired from the previous step to new data. The remaining unlabeled documents from the CAP dataset were utilized as inputs to the prediction process. To perform this step, the ‘predict’ function in the sklearn library was used to get the finding, which will be saved in the dataset later.
3.7. Experimental setup
3.7.1. Dataset division
The CAP dataset was divided into 70% for the training set and 30% for the testing set using the ‘train_test_split’ function. It corresponds to 262 and 112 documents in the CSE model, respectively. Further, the CT model was trained on 130 documents and tested against 57 documents. Details of the data division are shown in .
Table 6. Statistics of the dataset splitting for the experiment.
3.7.2. Performance metrics
To evaluate our work, commonly applied metrics were compared between ML algorithms. The first metric is the accuracy score, which was calculated by the equation:
(4)
(4)
where
is the number of correct predictions and
is the total number of all predictions. In addition, the k-fold cross-validation method was applied with 10 folds to validate the model effectiveness and to avoid the underfitting problem because of the small dataset. With this method, the training set is partitioned into k equal-sized folds (groups), where
is the total number of partitions. If
for instance, the dataset will be divided into ten subsets. In this scenario, nine divisions were employed for training purposes and one for evaluation. Iteratively, the system was trained ten times, each time with a new partition serving as the test set and the remaining nine partitions serving as the training set. The findings are then summarized by averaging them to get the validation accuracy (Ramezan et al., Citation2019). To choose the best value of the random state (
) parameter in the ‘train_test_split’ function that splits the dataset into an appropriate distribution, different experiments with the value of
were implemented, and then the difference between the validation accuracy and the model accuracy was calculated.
(5)
(5)
(6)
(6)
where
is the selected random state parameter and
is the threshold used to determine the suitable difference between the two accuracies, which in our experiment was 0.6. The ML algorithm that gives the best
will be deployed, and the trained classifier will be saved in the database for use in future prediction. For the CT model, only documents that contain a crime scene will be used. The selected
that was adopted in our experiment for different algorithms and models is listed in .
Table 7. The selected value of the Random State parameter () used in our experiment.
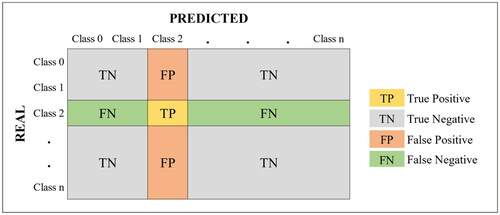
In contrast, the evaluation metrics for each class in the model will be calculated using the parameters from the confusion matrix (Krüger, Citation2016), as illustrated in . The following equations can be used to find the metrics:
(7)
(7)
(8)
(8)
(9)
(9)
(10)
(10)
where
indicates the number of the class was predicted while it is real,
indicates the number of the class was not predicted and it is not real,
indicates the number of the class was predicted but it is not real, and
indicates the number of the class was not predicted but is real.
is used to measure all positive predictive values.
also known as recall represents the true positive rate while
represents the true negative rate. Finally,
is the harmonic mean of precision and recall. For all these metrics, the higher the value, the better.
Figure 4. Confusion matrix for the classification model.
4. Results and discussion
This work is research on an increasingly important academic area of research on the utilization of published court reports in the police academy for educational purposes, classifying court reports that contain murders using the crime dictionary, and predicting the class from the description of the crime scene even if the crime instrument is not declared in the document. All that is done using advanced computer techniques such as text mining and supervised ML methods.
4.1. Crime dictionary evaluation
In this section, the statistical data of the keywords that were extracted from all documents in the CAP will be presented and illustrated, which totaled 36,230 documents as mentioned in . Different statistics were generated depending on the suggested crime dictionary, which presented in . Our goal in providing this overview of the documents’ contents is to figure out whether the CAP dataset and crime dictionary are appropriate for our work. These statistics will be obtained using the BoW model based on the presence of the keyword in the document without regard to its frequency. A document that contains the keyword once is equal to a document in which the keyword is repeated.
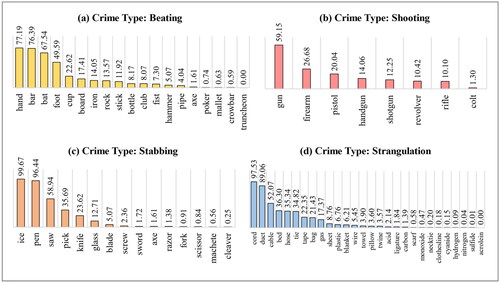
The initial stage was to identify crime tools that were directly mentioned in the documents; the results of this analysis are shown in . According to the statistical data, the most common criminal tools from each type stated in the documents are hands, guns, ice from an ice pick, and cords. However, several instruments are never mentioned in the documents at all, like the truncheon and acrolein. Tools such as poker, mallet, fork, scissor, necktie, and scarf were also cited by fewer than 1.0% of respondents. That means many of the documents in the dataset are written in common terms, with only a few references to scientific terminology. In other words, they are lacking in fine details. Additionally, terms including hand, bar, foot, ice, pen, cord, etc. are frequently used in public life and are not categorized as well-known criminal tools such as guns, pistols, knives, and others. Therefore, the number of documents for these terms is high. For example, the terms ‘ice’ and ‘cord’ appear in 99.67% and 97.53% of the documents, respectively, but the words ‘gun’ and ‘knife’ appear in 59.15% and 23.62%, respectively. Since the CAP dataset is comprised of legal documents as opposed to police reports, it should not be assumed that every given document containing these instruments is necessarily associated with criminal activity. These tools may be stated in the report but have little to do with the incident itself, and not all crime reports include a description of the crime scene.
Figure 5. Statistics of crime documents (%) in the CAP dataset by crime tools. (a) Crime type: Beating. (b) Crime type: Shooting. (c) Crime type: Stabbing. (d) Crime type: Strangulation.
A crime dictionary heatmap was also presented, as shown in . It shows the number of documents that include the crime tool and its associated vocabulary in the same document, to explore the correlation between them. Dark cells indicate a larger number of documents. From the examples that illustrate the relationship, in more than 20% of the documents with multiple associated vocabulary, in a beating-type crime, there is a relationship between ‘hand’ and the associated vocabulary like ‘throw’, ‘strike’, ‘lip’, ‘hit’, ‘head’, ‘fall’, ‘eye’, ‘blood’, ‘beat’, and ‘abuse’. The term ‘gun’ is used in the shooting crime and is related to terms such as ‘wound’, ‘shoot’, ‘injury’, ‘hole’, ‘hit’, ‘head’, ‘gunshot’, ‘fire’, ‘bullet’, and ‘blood’. Also, it is noticeable that the association of ‘pen’ in stabbing crime with the following terms: ‘wound’, ‘stab’, ‘size’, ‘neck’, ‘length’, ‘injury’, ‘hit’, ‘hand’, ‘force’, ‘finger’, ‘edge’, ‘cut’, ‘chest’, ‘blood’, ‘attack’, and ‘arm’. In strangulation crime, a term like ‘cord’ is associated with terms like ‘white’, ‘pull’, ‘neck’, ‘mark’, ‘head’, ‘hand’, and ‘bind’. Therefore, when manually classifying the reports, most of them fell under the following crimes: beating, shooting, stabbing, and strangulation.
Figure 6. Heatmap of crime documents (%) in the CAP dataset. (a) Crime type: Beating. (b) Crime type: Shooting. (c) Crime type: Stabbing. (d) Crime type: Strangulation.
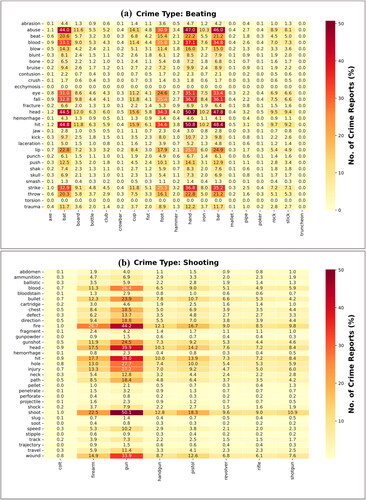
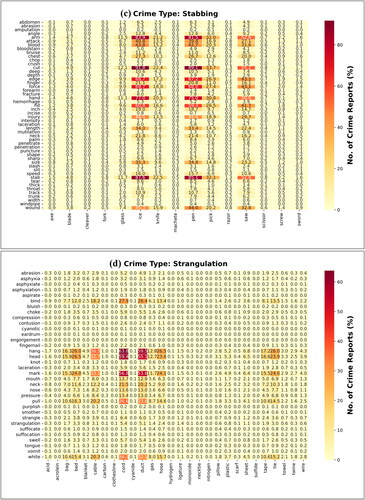
Some cases have more than one body or more than one way to kill, like beating with stabbing, or stabbing with strangulation. Because of this, they were put in the ‘multiclass’ category, as shown in . Additionally, the heat map proves what was mentioned earlier, from . The term ‘cord’ from strangulation is in about 97.53% of the documents as present in , and after filtering using the associated vocabulary ‘hang’ in , it becomes 63.8%. Also, the crime of hitting is typically committed with the hand, so there is a relationship between them in the heatmap; however, the hand is not typically considered a crime tool; thus, the percentage decreased from 77.19% to 50% with the terms ‘head’ and ‘hit’. In contrast, the well-known methods of murder, such as shooting with a gun and stabbing with a knife, showed similar results before and after, as they were 59.15% and 23.62%, which then became 50.1% with the term ‘shoot’ and 22.5% with the term ‘stab’, respectively. This makes it more likely that they are crime tools, even if they do not have the associated vocabularies.
In general, heatmaps show a connection between crime tools and their associated vocabulary. Therefore, descriptive data is often helpful at crime scenes. Even if the name of the crime instrument was not mentioned in the report, this clue can be used to infer it from the context of the text. These findings are also useful in our work, as the documents in the CAP dataset are unstructured court reports, and not all of them relate to homicides. Therefore, the dictionary was used to identify the important features that distinguish each type of crime to use it in the classification and organization of documents, thereby facilitating its application as a reference in academic education, which is our goal in this work.
4.2. Evaluation of ML models
To evaluate the performance of CSE and CT models, six different algorithms were compared based on different evaluation metrics. The metrics are confusion matrix, precision, sensitivity, specificity, F1-score, and accuracy scores.
4.2.1. Evaluation of CSE model
The results of the CSE model were displayed in and , which is a binary classification. The accuracy scores indicated in were between 82.46% and 91.07%. As mentioned earlier, several tests were run to determine the optimal value of (), shown in , for the distribution of the dataset so that the values of the two scores are relatively close. Among different algorithms, RF gave the best test accuracy with 91.07% and validation with 90.85%. Therefore, the results of the RF algorithm will be discussed in detail. As noted, the ‘not exist’ class had scores of 88.33%, 94.64%, 87.5%, and 91.28% for precision, sensitivity, specificity, and the F1-score, respectively. In contrast, the second class obtained the following scores: 94.23%, 87.5%, 94.64%, and 90.74%. Notably, the F1-score is relatively close for both classes in each algorithm, suggesting that the classifier is balanced in recognizing the correct class regardless of the error percentage. According to the confusion matrix in , three documents out of 56 were misclassified as not containing a crime scene, while another seven were misclassified as containing a crime scene. The error rate may be due to the difference in the length of the documents, as there is a wide variation in the size of the reports as stated in .
Figure 7. Confusion matrix of ML models using different algorithms. (a) CSE model; (b) CT model.
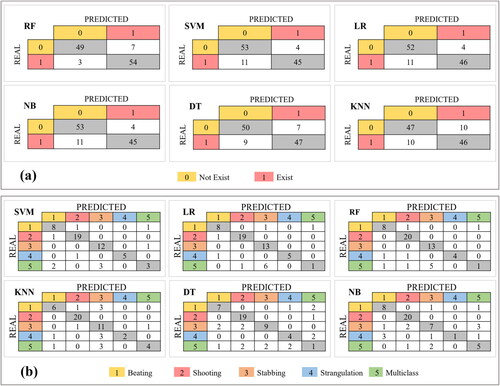
Table 8. Results of CSE model using different algorithms.
Similar search to ours, as presented in , utilizes Twitter tweets. Our analysis reveals that the accuracy rate is 98.10%, since the tweets contain limited words, and they used these words as features of the classification model. On the other hand, the accuracy rate in our work is also considered high, about 91.07%, despite the discrepancy in the length of the reports and the fact that they are mixed with a lot of information, as the features extracted from the crime dictionary helped classify the documents well by highlighting the important words in the document and eliminating distractions.
Table 9. Comparing result of CSE model with previous study.
4.2.2. Evaluation of CT model
The findings for the second model, a multiclass classification model based on crime type, are significantly different, as presented in and . The KNN, DT, and NB algorithms had an accuracy of less than 76% based on . The reason is that the training set is small with imbalanced data and needs to increase the number of labeled documents in each class. However, the SVM, RF, and LR algorithms had good accuracy scores of over 80%. The SVM algorithm provides the best score for the CT model, and therefore its classifier will be adopted in the discussion of the results. Its test accuracy is about 82.46%, and the validation score is around 82.31%. For the other metrics in , the strangulation class achieved the best levels of precision and specificity with 100%, while the shooting class had the highest levels of sensitivity with 95% and the highest F1-score with 92.68%. Conversely, the crime of multiclass type obtained the lowest percentage in all metrics except specificity, as follows: precision (60%), sensitivity (37.5%), and F1-score (46.15%). The lowest specificity is in the stabbing class at 93.18%. From the confusion matrix in , there were two misclassified in the beating class, five misclassified in multiclass, and one misclassified in the rest of the classes, for a total of 10 misclassified out of 57 reports. The most crimes were confused in the multiclass crimes in all algorithms. This is because some crime documents include a detailed description of one method but not the other, and hence the classifier prefers the detailed method. For example, in a stabbing crime, the offender may also hit or strangle the victim, and the report includes facts about these events.
Table 10. Results of CT model using different algorithms.
In relation to the comparison with prior research, illustrates that the first study (Petrova et al., Citation2020) classified documents based on legal outcomes utilizing deep learning (LSTM) and the CAB database. However, due to the limited number of documents examined, the accuracy score was approximately 81%. The second study (Thaipisutikul et al., Citation2021), which utilized the same algorithms with pre-labeled Thai news articles, attempted to categorize crimes. In doing so, it was extremely like our research. Despite the experiment utilizing a substantial number of articles, the obtained accuracy score of approximately 79.41% appears to be indicative of a lack of feature extraction customization, as evidenced by the fact that the whole article was utilized. The accuracy rate of the model proposed in this study, on the other hand, was approximately 82.46%, despite the experiment utilizing a smaller number of documents. This indicates that the crime dictionary had a positive impact on the results, particularly since the terms for this dictionary were collected from forensic reports and websites and not from the same documents used in the experiment.
Table 11. Comparing result of CT model with previous studies.
Although conducting further comparative experiments would enhance the quality of the work, direct comparisons are not possible due to the distinctive characteristics of our research design and dataset. To guarantee a rigorous assessment of our proposed method, we have undertaken thorough experimentation with a multitude of algorithms. Furthermore, these experiments function as an indirect comparison, showcasing the efficacy of our methodology in relation to the array of machine learning techniques presently accessible.
4.3. Results of ML prediction
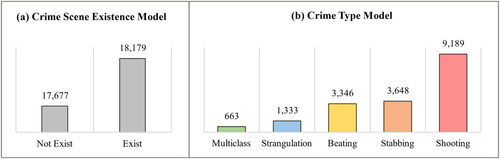
As we mentioned earlier in the data collection section, the number of documents in the database after the filtering process is about 35,856 unclassified documents. The outcome classifiers from the proposed models will be applied to annotate these cases. The first classifier used to predict CSE, and 18,179 documents that describe the crime scene have been found, as displayed in . These documents are classified by crime type using the CT classifier. From , we find that crimes committed by shooting are the highest, at about 9,189 crimes. The crimes of stabbing and beating are close to each other with 3,648 and 3,346, respectively. There are also 1,333 strangulation offenses, with the multiclass type being the least at 663 crimes.
Figure 8. Classification of documents from the CAP dataset according to our experience. (a) Crime scene existence model. (b) Crime type model.
Our proposed method for classifying crime types in legal documents is a big step forward, but it’s important to look at where it might fall short. One potential drawback is that our technique strongly relies on the crime dictionary, which, while extensive, may be limited. Unusual or unique criminal instruments and tactics may be underrepresented in classification results. Furthermore, categorization performance is influenced by the quality and detail of the narrative in crime reports, which can vary. In addition, while the accuracy rates seem promising, they could be more flawless, and misclassifications may compromise the system’s trustworthiness in real-world applications. Another limitation is the possibility of bias in the crime vocabulary compiled from existing forensic reports and websites. If the sources of these terms contain inherent biases, the classification results may reflect them.
In summary, while our method is highly accurate and offers a novel approach to classifying crime types in unstructured texts, we are constantly working to enhance and improve the model. Future studies will try to expand the criminal dictionary, investigate the integration of other contextual aspects, and solve the observed flaws to improve the approach’s robustness and application.
5. Conclusions
Our work is just the first step toward activating and bringing attention to the legal databases in academic education. We presented a novel framework to assist students studying law and police procedures in effectively organizing and analyzing crime scene data. This framework involves classifying unstructured crime scene documents and making predictions about the types of crimes that occurred. Therefore, legal and case-law documents in this study were collected to study crime scenes through criminal investigations. We have successfully built a machine learning model using a limited number of features, which yields highly accurate outcomes in the classification of court documents according to crime scenes and types of crimes. These legal documents have been categorized to make it easier for people who are interested to find the information they need. Finally, we tested various classification algorithms to determine the best classifier for correctly predicting new crimes classes.
In NLP applications, it is difficult to classify huge, unlabeled texts with a narrative writing style. Therefore, the present work proposes text mining with NLP and supervised ML techniques to build a framework model that utilizes two classifiers: one that identifies documents that contain crime scenes, and another that labels them as one of five crime types: beating, shooting, stabbing, strangulation, and multiclass. This work has led to the development of a substantial crime dictionary that includes 70 criminal instruments and 151 words for terminology related to them, so that crime types, tools, and associated vocabulary are easily understood and can thus be utilized by other researchers in the future. The experimental test shows that the results obtained are promising. The random forest algorithm was adopted for the first classifier with an accuracy score of 91.07%, while the second classifier achieved an accuracy score of 82.46% with support vector machines.
As an initial exploration of text mining court documents in the field of crime scene investigation, our work has some limitations. One limitation of our research is the small size of the dataset for each class, which is also unbalanced. This issue can be addressed by increasing the number of classified documents used to train and test ML classifiers. Additional information from forensic reports can be incorporated to enhance the crime dictionary. Utilizing the dictionary in conjunction with the police database is anticipated to yield superior outcomes compared to the court database. We propose extracting large portions of the court database rather than simply categorizing it by crime type and focusing on the data that police students require.
Future work in this paper may investigate a variety of approaches to improve and extend the research findings. Our efforts can be expanded by implementing and testing this educational tool in police academies, as well as conducting research on its educational and practical implications. Deep learning techniques can also be used to analyze and classify these documents, allowing for a better understanding of the crimes in question. Another promising research area for improving analysis is predicting the exact crime instrument used by expanding the crime vocabulary with wound description terms from forensics. Finally, we suggest evaluating the system using real police reports and comparing the outcomes to verify the suitability of the crime dictionary for analyzing descriptive police reports.
Authors’ contributions
The authors confirm contribution to the paper as follows: study conception and design: E. Bifari and W. Alhalabi; data collection: E. Bifari; analysis and interpretation of results: E. Bifari and S. Albaradei; original draft manuscript preparation: E. Bifari; writing, review, and editing: E. Bifari, A. Basabrin, R. Mirza, A. Bafail and S. Albaradei. All authors reviewed the results and approved the final version of the manuscript.
Availability of data and materials
The dataset supporting the conclusions of this article is available in the [Harvard Law School Collection] repository, [https://case.law/about/].
Disclosure statement
The authors declare that they have no conflicts of interest to report regarding the present study.
Correction Statement
This article has been corrected with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
Notes on contributors
Ezdihar Bifari
Ezdihar Bifari, Department of Computer Science, King Abdulaziz University, Jeddah, Saudi Arabia, [email protected]
Arwa Basbrain
Arwa Mohmmed Basbrain, Department of Computer Science, King Abdulaziz University, Jeddah, Saudi Arabia, [email protected]
Rsha Mirza
Rsha Mirza, Department of Computer Science, King Abdulaziz University, Jeddah, Saudi Arabia, [email protected]
Alaa Bafail
Alaa Bafail, Artificial intelligence, Department of Computer Science, King Abdulaziz University, Jeddah, Saudi Arabia, [email protected]
Somayah Albaradei
Somayah Albaradei, Department of Computer Science, King Abdulaziz University, Jeddah, Saudi Arabia, [email protected]
Wadee Alhalabi
Wadee Alhalabi, Virtual Reality Research Group, Department of Computer Science, King Abdulaziz University, Jeddah, Saudi Arabia, [email protected]
References
- Amita, R., Arunkumar, P., Avedschmidt, S., Banerjee, P., French, K., Ghandili, M. (2021). Autopsy & forensics. https://www.pathologyoutlines.com/autopsy.html
- Arseniev-Koehler, A., Cochran, S. D., Mays, V. M., Chang, K.-W., & Foster, J. G. (2022). Integrating topic modeling and word embedding to characterize violent deaths. Proceedings of the National Academy of Sciences, 119(10), e2108801119. https://doi.org/10.1073/pnas.2108801119
- Ashraf, N., Mustafa, R., Sidorov, G., & Gelbukh, A. (2020) Individual vs. group violent threats classification in online discussions [Paper presentation]. 29th World Wide Web Conference (WWW) (pp. 629–633), Taipei, Taiwan. https://doi.org/10.1145/3366424.3385778
- Baek, M. S., Park, W., Park, J., Jang, K. H., & Lee, Y. T. (2021). Smart policing technique with crime type and risk score prediction based on machine learning for early awareness of risk situation. IEEE Access, 9, 131906–131915. https://doi.org/10.1109/ACCESS.2021.3112682
- Bai, B., & Wang, J. (2023). Conceptualizing self-regulated reading-to-write in ESL/EFL writing and investigating its relationships to motivation and writing competence. Language Teaching Research, 27(5), 1193–1216. https://doi.org/10.1177/1362168820971740
- Birks, D., Coleman, A., & Jackson, D. (2020). Unsupervised identification of crime problems from police free-text data. Crime Science, 9(1), 18. https://doi.org/10.1186/s40163-020-00127-4
- Bohnert, M., Hüttemann, H., & Schmidt, U. (2006). Homicides by sharp force. In M. Tsokos (Ed.), Forensic pathology reviews (Vol. 4, pp. 65–89). Humana Press.
- Borcan, M. (2020). TF-IDF explained and Python Sklearn implementation. https://towardsdatascience.com/tf-idf-explained-and-python-sklearn-implementation-b020c5e83275
- Carnaz, G., Antunes, M., & Nogueira, V. B. (2021). An annotated corpus of crime-related Portuguese documents for NLP and machine learning processing. Data, 6(7), 71. https://doi.org/10.3390/data6070071
- Castano, S., Falduti, M., Ferrara, A., & Montanelli, S. (2020). The LATO knowledge model for automated knowledge extraction and enrichment from court decisions corpora [Paper presentation]. First International Workshop "CAiSE for Legal Documents", co-Located with the 32nd International Conference on Advanced Information Systems Engineering, CAiSE (2020) (Vol. 2690, pp. 15–26), Grenoble, France.
- Chang, F., McCabe, E., & Lee, J. (2020). Mining the Harvard Caselaw Access Project. Available at SSRN 3529257.
- De Oliveira, R. S., & Nascimento, E. G. S. (2022). Brazilian court documents clustered by similarity together using natural language processing approaches with transformers. arXiv Preprint, arXiv 220407182.
- Garat, D., & Wonsever, D. (2022). Automatic curation of court documents: Anonymizing personal data. Information, 13(1), 27. https://doi.org/10.3390/info13010027
- Geurts, R., Raaijmakers, N., Delsing, M. J. M. H., Spapens, T., Wientjes, J., Willems, D., & Scholte, R. H. J. (2023). Assessing the risk of repeat victimization using structured and unstructured police information. Crime & Delinquency, 69(9), 1736–1757. https://doi.org/10.1177/00111287211047533
- Graham, S., & Hebert, M. (2010). Writing to read: Evidence for how writing can improve reading: A report from Carnegie Corporation of New York.
- Gupta, I., Chatterjee, I., & Gupta, N. (2023). A two-staged NLP-based framework for assessing the sentiments on Indian supreme court judgments. International Journal of Information Technology, 15(4), 2273–2282. https://doi.org/10.1007/s41870-023-01273-z
- Habernal, I., Faber, D., Recchia, N., Bretthauer, S., Gurevych, I., Spiecker Genannt Döhmann, I., & Burchard, C. (2023). Mining legal arguments in court decisions. Artificial Intelligence and Law, 1–38. https://doi.org/10.1007/s10506-023-09361-y
- HeinOnline. (2022). HeinOnline databases – Case law. https://home.heinonline.org/content/case-law/
- Joshi, Y. (2020). A quick guide to text cleaning using the nltk library. https://www.analyticsvidhya.com/blog/2020/11/text-cleaning-nltk-library/#h2_2
- Karystianis, G., Adily, A., Schofield, P. W., Wand, H., Lukmanjaya, W., Buchan, I., Nenadic, G., & Butler, T. (2022). Surveillance of domestic violence using text mining outputs from Australian police records. Frontiers in Psychiatry, 12, 787792. https://doi.org/10.3389/fpsyt.2021.787792
- Kim, S.-W., & Gil, J.-M. (2019). Research paper classification systems based on TF-IDF and LDA schemes. Human-Centric Computing and Information Sciences, 9(1), 30. https://doi.org/10.1186/s13673-019-0192-7
- Krüger, F. (2016). Activity, context, and plan recognition with computational causal behaviour models [PhD Thesis]. Computer Science and Electrical Engineering, Rostock University.
- Kuang, D., Brantingham, P. J., & Bertozzi, A. L. (2017). Crime topic modeling. Crime Science, 6(1), 12. https://doi.org/10.1186/s40163-017-0074-0
- Lage-Freitas, A., Allende-Cid, H., Santana, O., & de Oliveira-Lage, L. (2022). Predicting Brazilian court decisions. Peer Journal of Computer Science, 8, e904. https://doi.org/10.7717/peerj-cs.904
- Lal, S., Tiwari, L., Ranjan, R., Verma, A., Sardana, N., & Mourya, R. (2020). Analysis and classification of crime tweets. In International conference on computational intelligence and data science (ICCIDS) (vol. 167, pp. 1911–1919). NorthCap University.
- Li, Y.-S., & Qi, M.-L. (2019). An approach for understanding offender modus operandi to detect serial robbery crimes. Journal of Computational Science, 36, 101024. https://doi.org/10.1016/j.jocs.2019.101024
- Mandal, A., Chaki, R., Saha, S., Ghosh, K., Pal, A., & Ghosh, S. (2017). Measuring similarity among legal court case documents [Paper presentation]. Proceedings of the 10th Annual ACM India Compute Conference (pp. 1–9), Bhopal, India. https://doi.org/10.1145/3140107.3140119
- Mohemad, R., Naziah Mohd Muhait, N., Maizura Mohamad Noor, N., & Ali Othman, Z. (2020). Unstructured Malay text analytics model in crime. IOP Conference Series: Materials Science and Engineering, 769(1), 012015. https://doi.org/10.1088/1757-899X/769/1/012015
- Novotná, T., & Harašta, J. (2019). The Czech Court Decisions Corpus (CzCDC): Availability as the First Step. arXiv preprint arXiv:1910.09513.
- Nuranti, E. Q., Yulianti, E., & Husin, H. S. (2022). Predicting the category and the length of punishment in Indonesian courts based on previous court decision documents. Computers, 11(6), 88. https://doi.org/10.3390/computers11060088
- Papi, L., Gori, F., & Spinetti, I. (2020). Homicide by stabbing committed with a Fantasy Knife. Forensic Science International: Reports, 2, 100068. https://doi.org/10.1016/j.fsir.2020.100068
- Percy, I., Balinsky, A., Balinsky, H., & Simske, S. (2018). Text mining and recommender systems for predictive policing" [Paper presentation]. 18th ACM Symposium on Document Engineering (DocEng), HalifaxCANADA (pp. 1–4). https://doi.org/10.1145/3209280.3229112
- Petrova, A., Armour, J., & Lukasiewicz, T. (2020). Extracting outcomes from appellate decisions in US state courts. Proceedings of the 33rd International Conference on Legal Knowledge and Information Systems, JURIX 2020 (vol. 334, pp. 133–142).
- Prasad, N., Boughanem, M., & Dkaki, T. (2022). Effect of hierarchical domain-specific language models and attention in the classification of decisions for legal cases [Paper presentation]. Proceedings of the CIRCLE (Joint Conference of the Information Retrieval Communities in Europe) (pp. 4–7), Samatan, Gers, France.
- Purnomo, E. P., Zahra, A. A., Malawani, A. D., & Anand, P. (2021). The Kalimantan forest fires: An actor analysis based on Supreme Court documents in Indonesia. Sustainability, 13(4), 2342. https://doi.org/10.3390/su13042342
- Ramezan, C. A., Warner, T. A., & Maxwell, A. E. (2019). Evaluation of sampling and cross-validation tuning strategies for regional-scale machine learning classification. Remote Sensing, 11(2), 185. https://doi.org/10.3390/rs11020185
- Savelka, J., & Ashley, K. D. (2020). Learning to rank sentences for explaining statutory terms. Proceedings of the 2020 Workshop on Automated Semantic Analysis of Information in Legal Text (ASAIL).
- Savelka, J., Xu, H., & Ashley, K. D. (2019). Improving sentence retrieval from case law for statutory interpretation [Paper presentation]. Proceedings of the Seventeenth International Conference on Artificial Intelligence and Law, Montreal, QC, Canada. pp. 113–122. https://doi.org/10.1145/3322640.3326736
- scikit-learn: Machine Learning in Python. (2023). https://scikit-learn.org/
- Sen, P. C., Hajra, M., & Ghosh, M. (2020). Supervised classification algorithms in machine learning: A survey and review. In Emerging technology in modelling and graphics (pp. 99–111). Springer Singapore.
- Shanahan, T., & Shanahan, C. (2008). Teaching disciplinary literacy to adolescents: Rethinking content-area literacy. Harvard Educational Review, 78(1), 40–59. https://doi.org/10.17763/haer.78.1.v62444321p602101
- Sokol, D. D., Bensley, S., & Crook, M. (2020). Measuring the antitrust revolution. Antitrust Bulletin, 65(4), 499–514. https://doi.org/10.1177/0003603X20950230
- Song, D., Vold, A., Madan, K., & Schilder, F. (2022). Multi-label legal document classification: A deep learning-based approach with label-attention and domain-specific pre-training. Information Systems, 106, 101718. https://doi.org/10.1016/j.is.2021.101718
- Tang, M., Su, C., Chen, H., Qu, J., & Ding, J. (2020). SALKG: A semantic annotation system for building a high-quality legal knowledge graph [Paper presentation]. 2020 IEEE International Conference on Big Data (Big Data) (pp. 2153–2159), Atlanta, GA, USA. https://doi.org/10.1109/BigData50022.2020.9378107
- Thaipisutikul, T., Tuarob, S., Pongpaichet, S., Amornvatcharapong, A., & Shih, T. K. (2021). Automated classification of criminal and violent activities in Thailand from online news articles. 13th International Conference on Knowledge and Smart Technology (KST) (pp. 170–175).
- The Caselaw Access Project (CAP). (2022). https://case.law/about/
- Torfi, A., Shirvani, R. A., Keneshloo, Y., Tavvaf, N., & Fox, E. (2020). Natural language processing advancements by deep learning: A survey. ArXiv, vol. abs/2003.01200.
- Tyss, S., Ichim, O., & Grabmair, M. (2023). Zero-shot transfer of article-aware legal outcome classification for European court of human rights cases. Findings of the association for computational linguistics: EACL 2023 (pp. 593–605). Association for Computational Linguistics.
- Vatsal, S., Meyers, A., & Ortega, J. (2023). Classification of US Supreme Court cases using BERT-based techniques. arXiv preprint arXiv:2304.08649.
- Victor, B. G., Perron, B. E., Sokol, R. L., Fedina, L., & Ryan, J. P. (2021). Automated identification of domestic violence in written child welfare records: Leveraging text mining and machine learning to enhance social work research and evaluation. Journal of the Society for Social Work and Research, 12(4), 631–655. https://doi.org/10.1086/712734
- Yu, H., & Monas, N. (2020). Recreating the scene: An investigation of police report writing. Journal of Technical Writing and Communication, 50(1), 35–55. https://doi.org/10.1177/0047281618812441
- Zhang, Y. (2021). Exploration of cross-modal text generation methods in smart justice. Scientific Programming, 2021, 14.